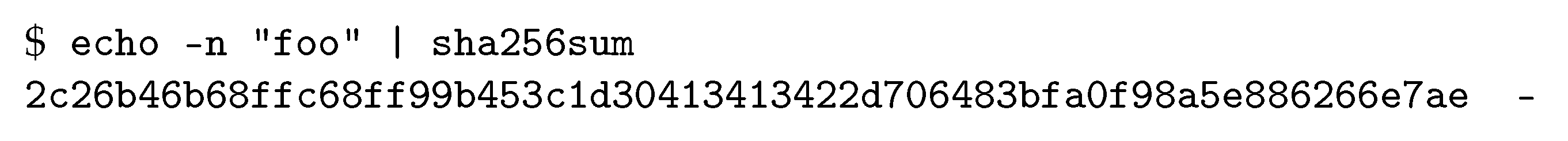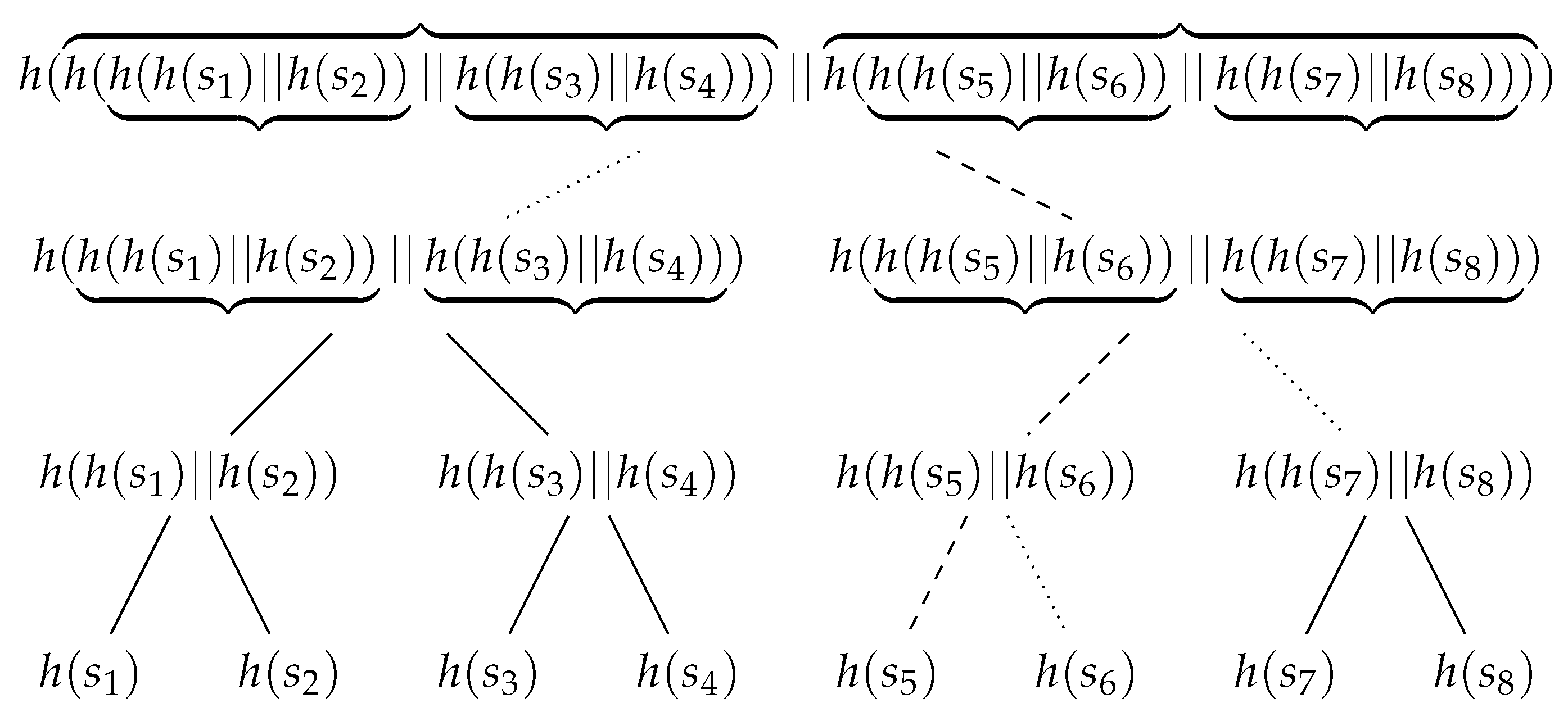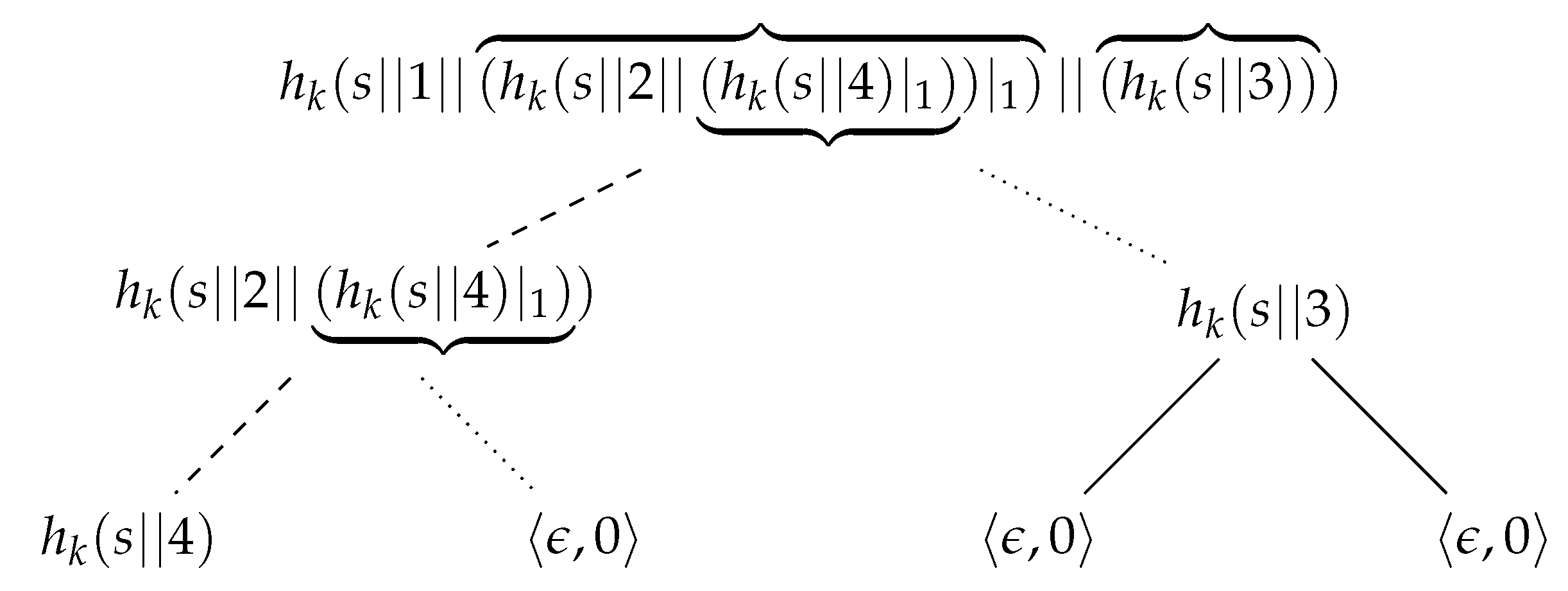1. Introduction
Denial-of-service (DoS) attacks are focused on making a resource (site, application, server) unavailable for the purpose it was designed for and represent a severe threat to the current Internet community [
1]. DoS attacks cause significant losses [
2,
3] and motivate the research of sophisticated detection techniques [
4,
5,
6,
7,
8]. Dwork and Noar [
9] suggested the use of proof-of-work (PoW) schema to mitigate the proliferation of spam emails: a computation stamp is required to obtain a service; in the context of emails, the service can be the forwarding of a message. In general, PoW is a form of cryptographic proof in which one party (the prover) proves to others (the verifiers) that a certain amount of a specific computational effort has been expended; verifiers can subsequently confirm this expenditure with minimal effort on their part [
10]. PoW schema are dissymmetric in favor of the verifier: the computation is moderately hard for the prover, while it is easy for a verifier to check a given solution. When PoW is applied to DoS mitigation, the prover role is played by a client aiming at accessing a service, and the verifier role is played by the server providing the required service.
PoW is often implemented by solving a cryptographic puzzle. The puzzle can be chosen by the sever, leading to
challenge–response protocols, or self-imposed by the request of the client, leading to
solution–verification protocols. In this article, protocols of these kinds are collectively called
client puzzle protocols.
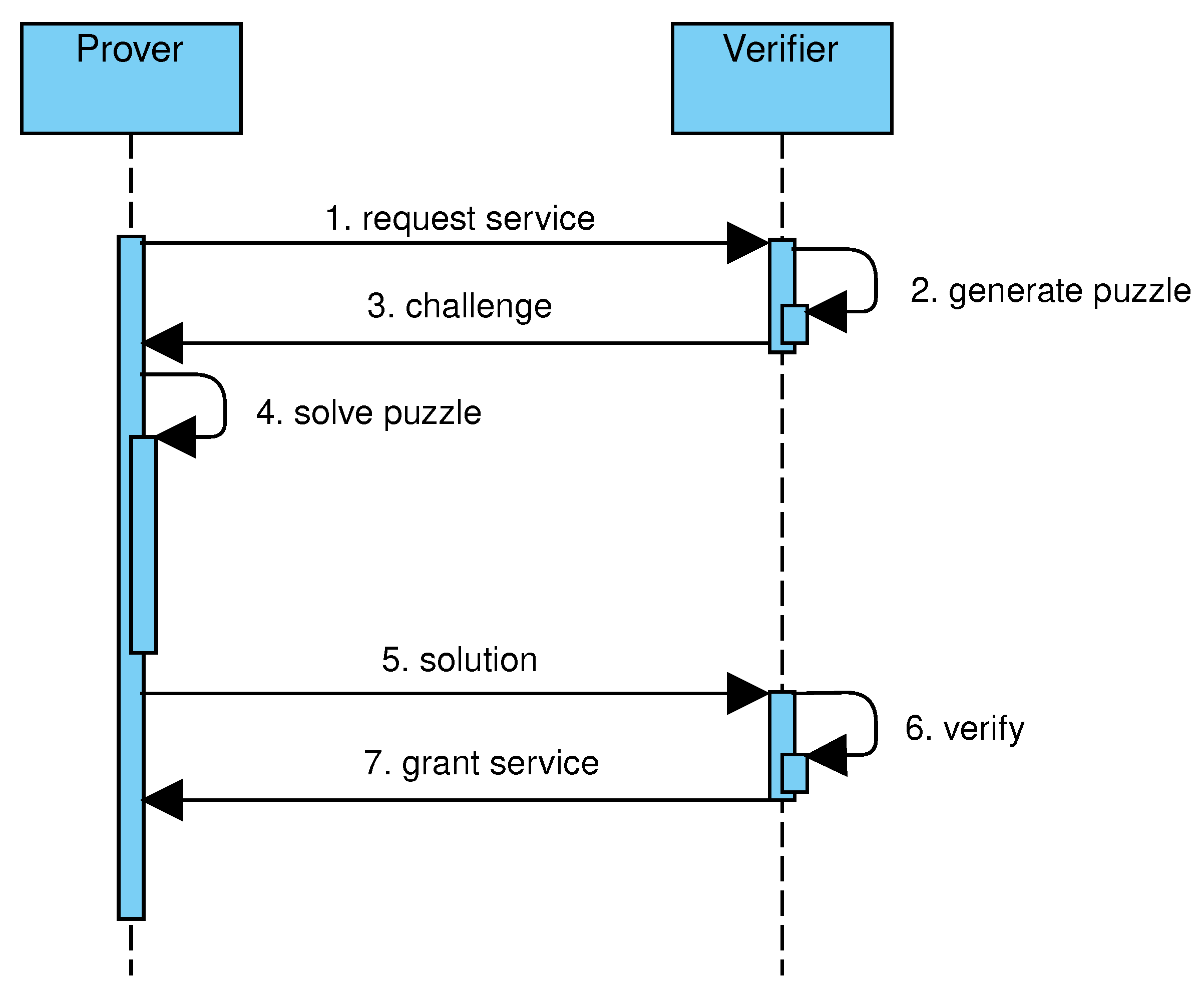
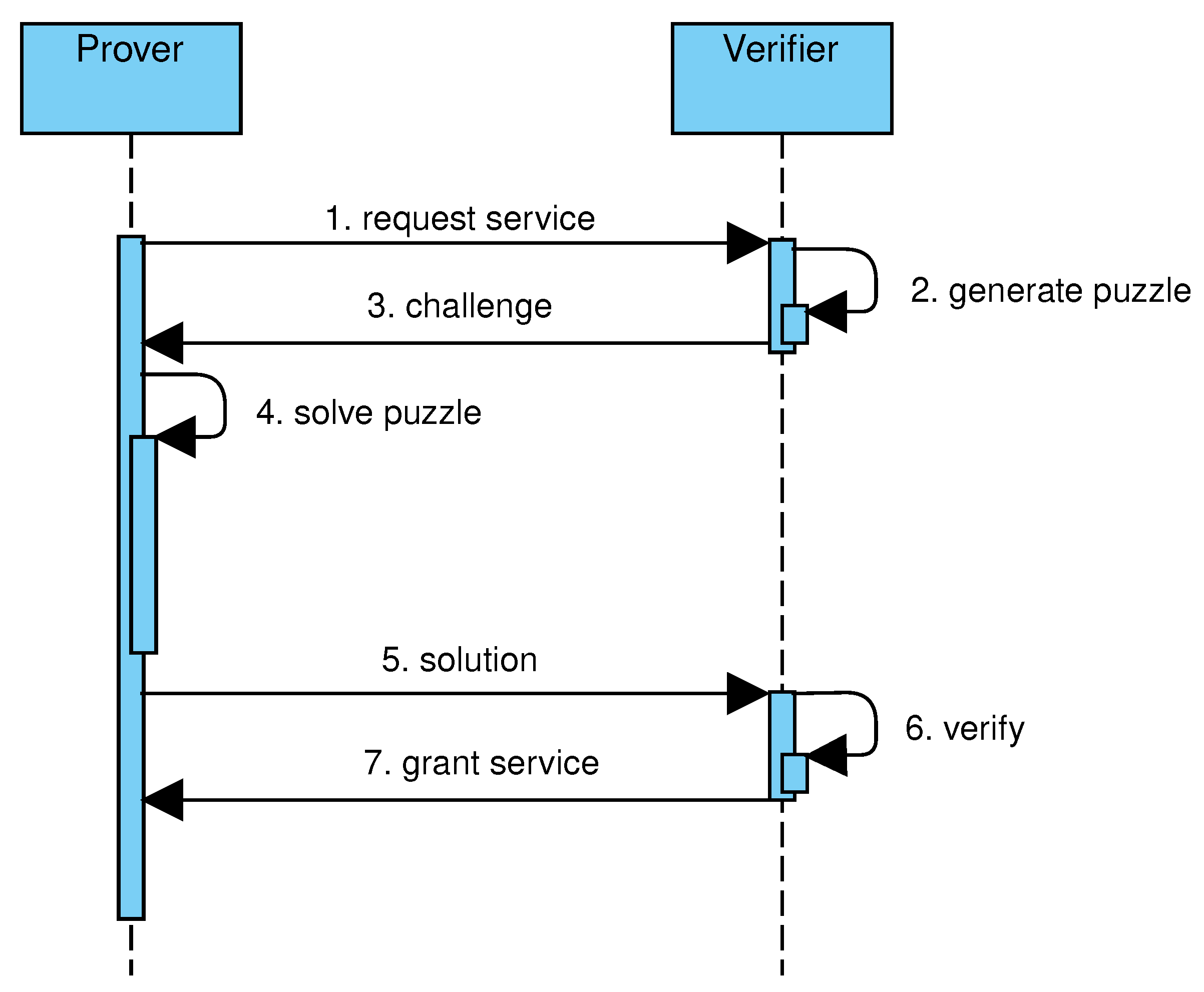
Figure 1 shows the main steps of challenge–response protocols. A client, acting as prover, needs a service provided by a server, acting as verifier (step 1). The verifier generates a puzzle, with negligible effort, and challenges the client (steps 2–3). The client affords a moderately hard computation to solve the puzzle, and sends the solution to the server (steps 4–5). The server verifies the solution, again with negligible effort, and grants access to the requested service (steps 6–7).
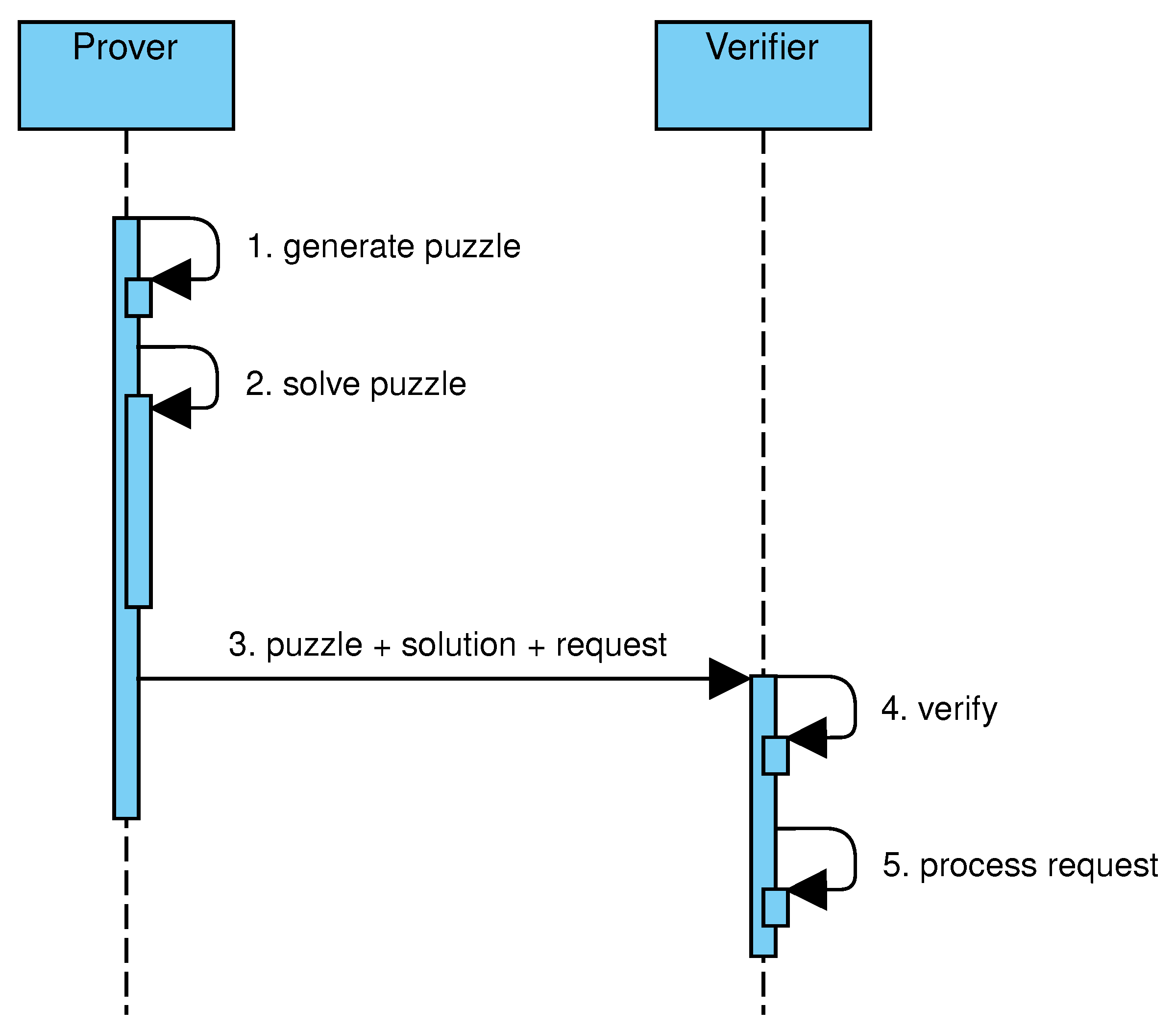
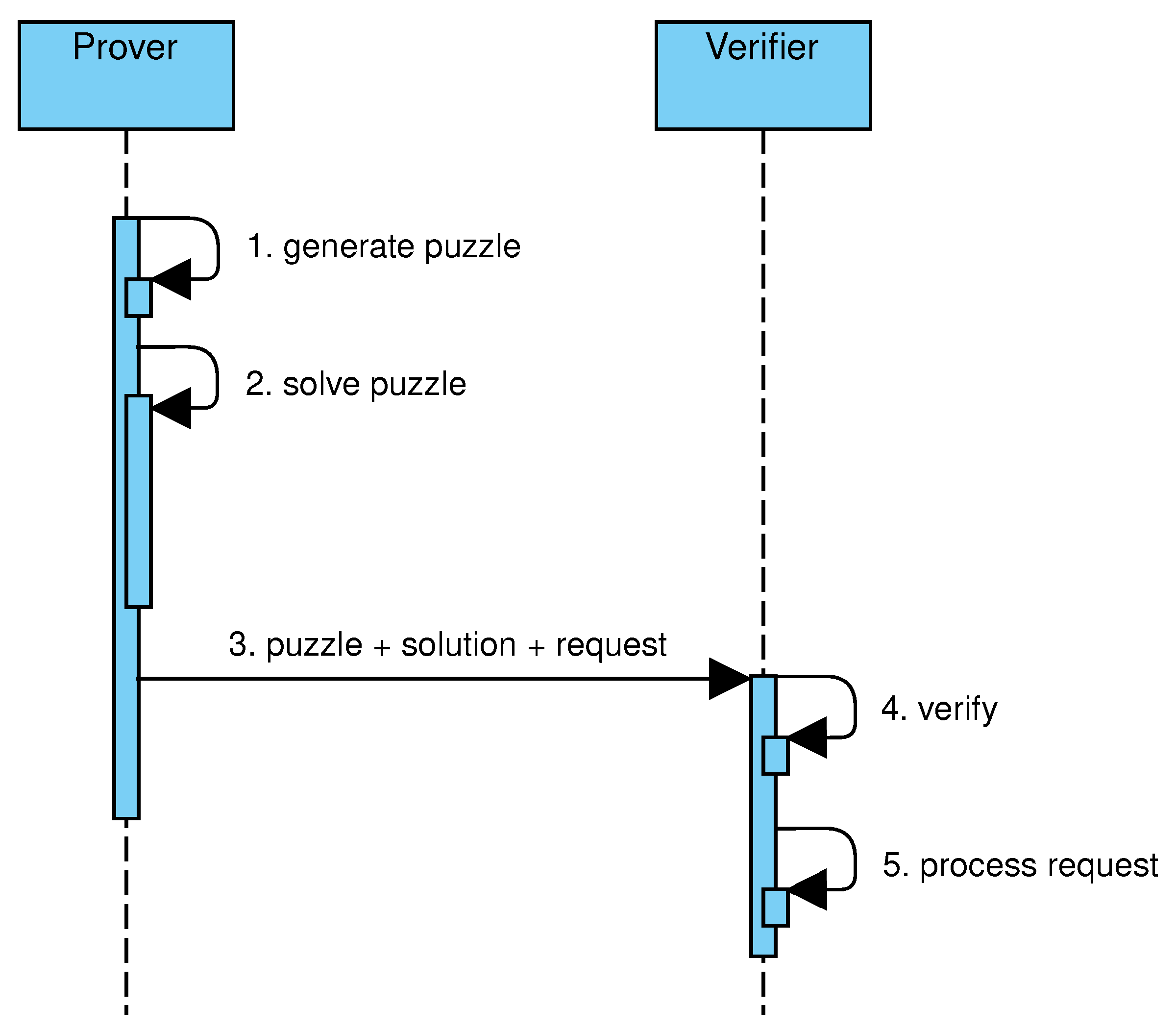
Figure 2 shows the main steps of solution–verification protocols. The client generates a puzzle based on the requested service and computes a solution (steps 1–2). After that, the client sends the puzzle, its solution, and the request to the server (step 3). The server verifies that the puzzle was correctly generated and that the solution is valid (step 4). If both tests succeed, the request is processed (step 5).
Hashcash [
11] is a cryptographic hash-based PoW algorithm that can be used for defining both challenge–response protocols and solution–verification protocols. In a challenge–response protocol based on hashcash, the verifier challenges the prover to find an extension of a given string whose hash value starts with a given number of zeros. As a PoW, the prover sends the extended string and its hash value, that is, the output of the hashcash algorithm. In a solution–verification protocol, the hashcash algorithm is applied to the service description, with a prefix length fixed in the protocol. Dissymmetry is given by the fact that the prover must try several extensions of the given string to find one with the required prefix, while the verifier needs only one hash value computation to verify the provided solution.
The main downside of hashcash is that the difficulty of the puzzle only depends on the length of the required all-zeros prefix. Adding a single zero to the prefix doubles the number of attempts that the prover must afford, and also the variance increases exponentially. A much better control on the difficulty of the puzzle was obtained by Coelho [
12], who proposed a
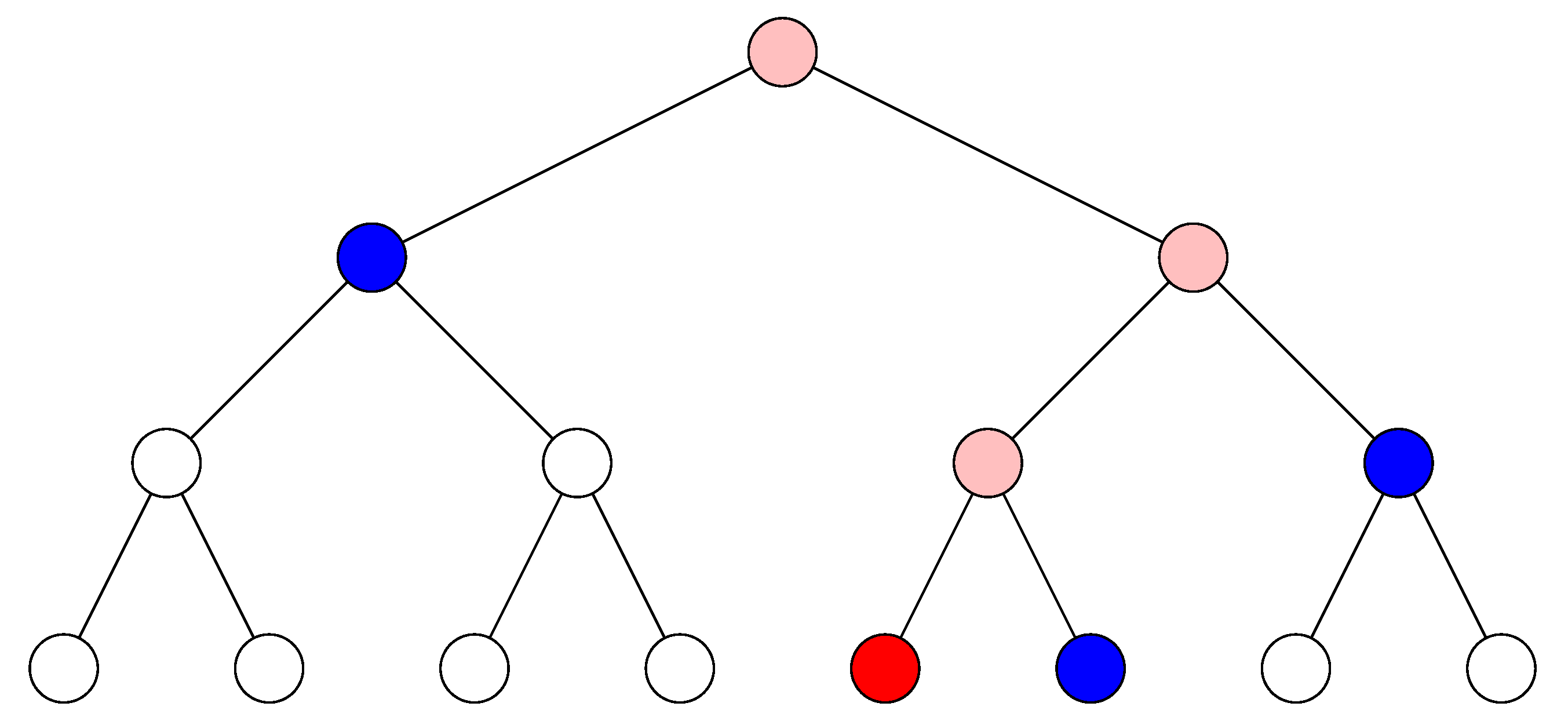
solution–verification protocol based on hash trees. In such trees, every leaf is labeled by the hash value of the leaf index concatenated with the service description. Every internal node is labeled by the hash value of the string obtained by concatenating child labels. Finally, some leaves are selected based on the hash value of the root. The prover constructs the tree and sends to the verifier the nodes in the paths from the selected nodes and their children (actually, the set of nodes is shrunk by removing nodes whose children belongs to the set; see
Figure 3). This way, the verifier has sufficient data to verify that the puzzle was generated and solved correctly. While such a protocol succeeds in controlling the growth of the prover’s effort, in practice it needs very large hash trees that must be either stored for the full computation or recomputed after the root hash is determined.
In a nutshell, this article addresses the following research questions:
- RQ1
Is it possible to define a client puzzle protocol based on hashcash but with more controllable difficulty of puzzles?
- RQ2
Is it possible to define a client puzzle protocol based on hash trees but requiring smaller trees than those used by Coelho [
12]?
- RQ3
How resistant to parallel computation is the proposed client puzzle protocol?
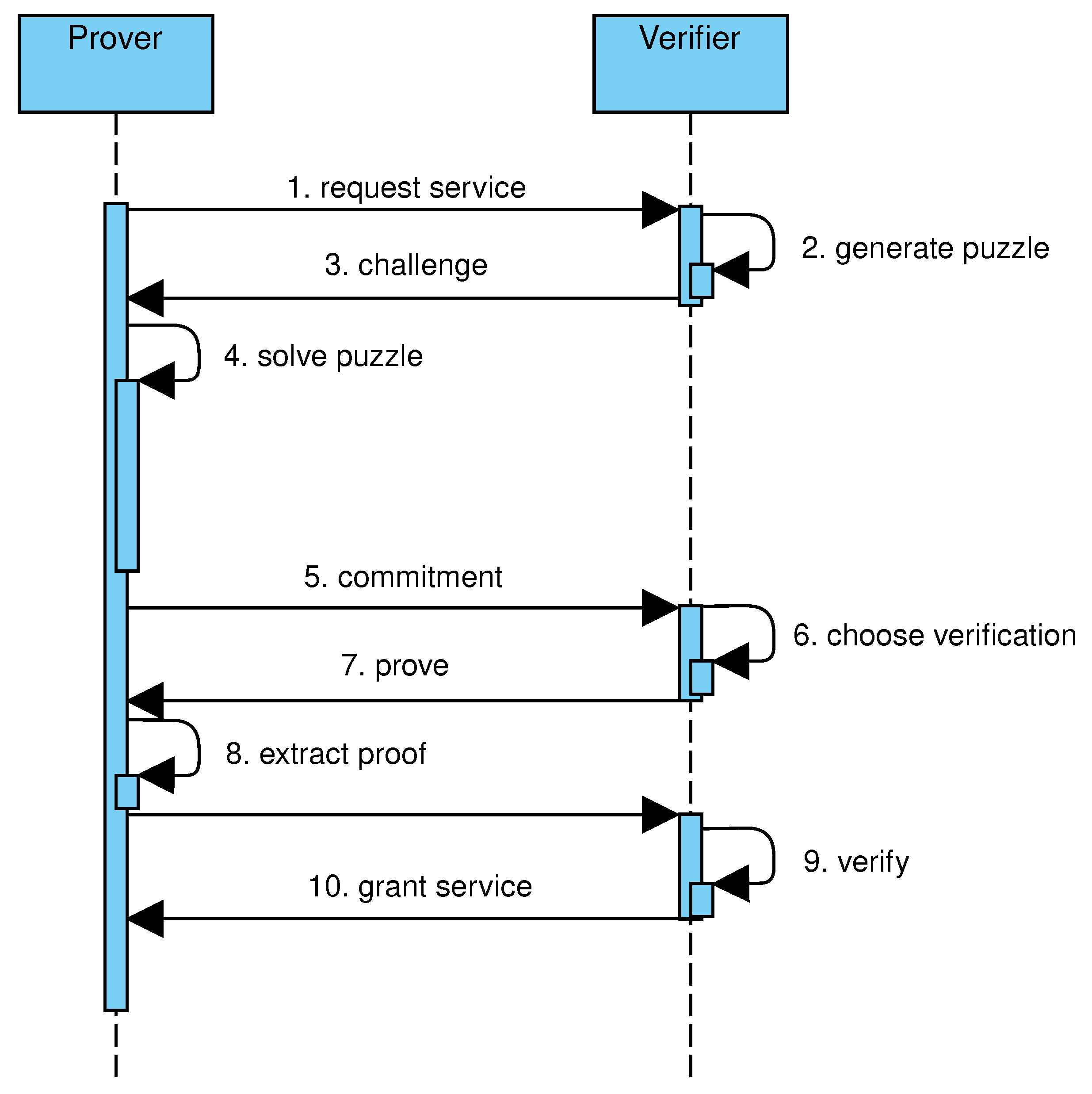
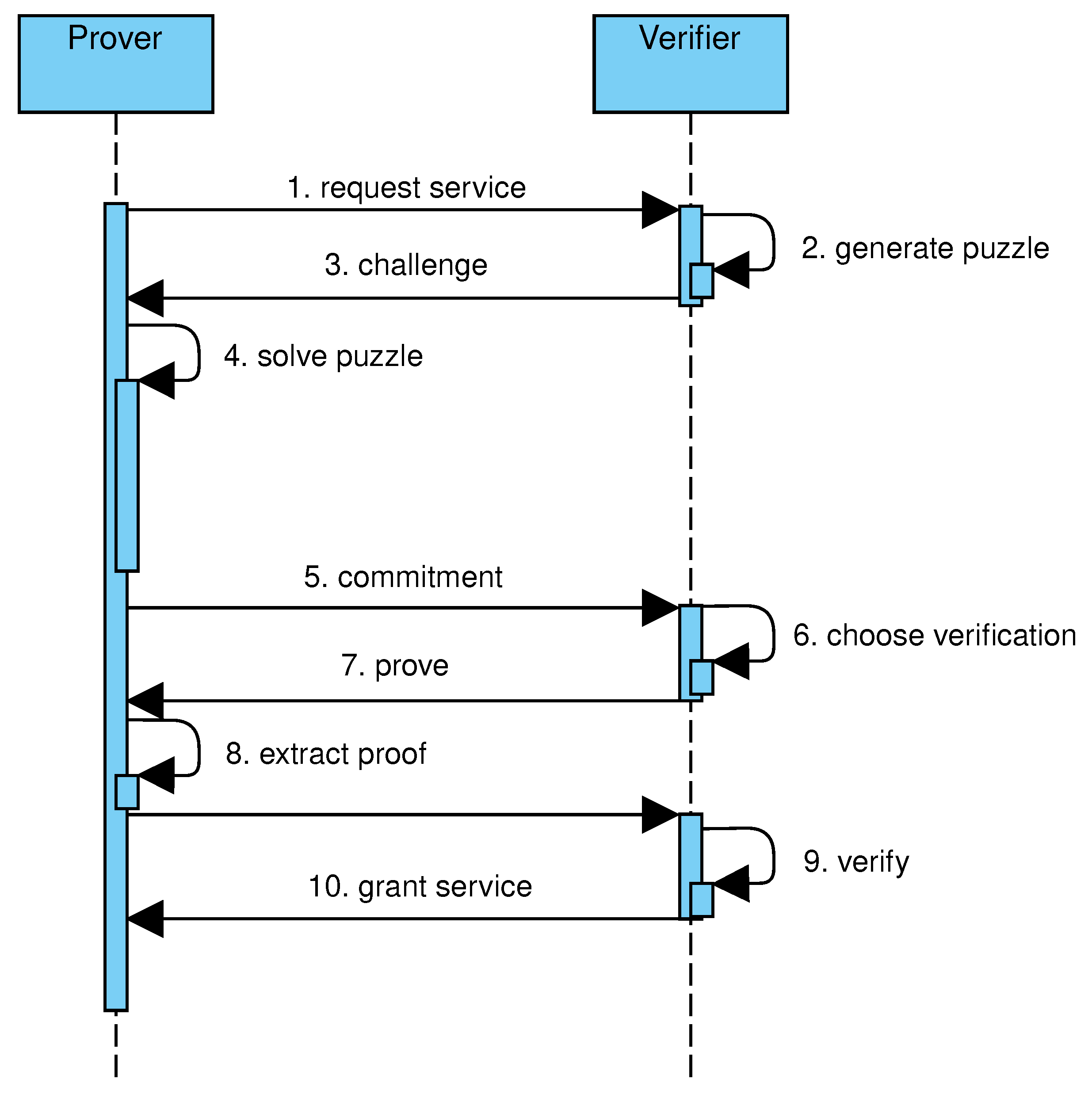
To answer the above questions, the challenge–response protocol is modified by splitting the challenge in two phases, as shown in
Figure 4. In the first phase, the prover is challenged to solve a puzzle generated by the verifier (steps 2–3). After solving the puzzle (step 4), the prover sends to the verifier a
commitment to conclude the first phase (step 5). In the second phase, the prover is asked to provide a proof of the solution, that is, sufficient data to verify that the prover has computed the committed solution (steps 6–9). In the proposed protocol, the puzzle consists of building a tree satisfying the following conditions: every leaf is labeled by the output of the hashcash algorithm applied on a verifier-provided string concatenated to the leaf index; every internal node is labeled by the output of the hashcash algorithm applied on the verifier-provided string concatenated to the node index and the hash values of child nodes. This way, the difficulty of the construction of the tree can be controlled by varying the length of the all-zeros prefix and the number of nodes in the tree. Similarly to hash trees, the verification of a solution involves the selected node, those in the path from the selected node to the root, and their children. Given the combination of features from hashcash and hash trees, the proposed data structure is named
hashcash tree.
Hashcash trees and the two-phases challenge–response protocol relying on them are presented in
Section 3, after introducing the required background in
Section 2. Properties of the proposed client puzzle protocol are discussed in
Section 4. In particular, the computational complexity is analyzed in terms of computed hash values for both the construction of hashcash trees and their verification. As for generating hashcash trees, the average number of computed hash values grows exponentially on the length of the all-zeros prefix and linearly on the number of nodes. Variance has a similar trend. It turns out that the grow can be controlled by fixing a relatively small length for the prefix and varying only the number of nodes depending on the workload of the verifier. As for the verification phase, the effort only depends (logarithmically) on the number of nodes. The construction of hashcash trees can be only partially parallelized, as the computation of a node label depends on the label of child nodes. An empirical evaluation of a proof-of-concept implementation of the protocol is reported in
Section 5. The results confirm that the client puzzle protocol based on hashcash trees can be used in practice to challenge the prover in generating trees whose construction effort in terms of the number of computed hash values is controllable. Finally, related work is discussed in
Section 6, and the article conclusion is summarized in
Section 7.
In summary, the article answers RQ1 and RQ2 by introducing a new data structure combining hashcash and hash trees, namely hashcash trees. The computation of a single node of a hashcash tree is more expensive than a node in a hash tree because it requires solving a hashcash challenge. Thanks to such a more expensive computation, hashcash trees of relatively small size can be adopted by the proposed client puzzle protocol (RQ2). At the same time, solving several hashcash challenges of modest difficulty enables a fine-grained control on the difficulty of puzzles, which is not possible to achieve with a single hashcash challenge (RQ1). Finally, the fact that a node in a hashcash tree can be computed only after knowing the labels of child nodes provides a restricted form of parallel resistance (RQ3).
2. Background
This section introduces preliminary notions such as strings and hash functions (
Section 2.1). Moreover, a client puzzle protocol based on the hashcash nondeterministic function is defined in
Section 2.2. Finally, the main notation used for trees and the notion for hash trees are given in
Section 2.3.
2.1. Hash Functions
The term string is used to refer binary strings, that is, elements in ; strings are also seen as sequences of bits. The empty string is denoted by . The prefix of length of a string s is the string consisting of the first n bits of s and is denoted by . The concatenation of two strings is denoted by . For a string s and a non-negative integer x, the notation is abused to denote the concatenation of s with the binary string representation of x. The concatenation of a string s with itself times is denoted by and defined inductively as follows: ; for . The i-th element of a string s, and in general of a sequence or tuple, is denoted by .
Example 1. The concatenation , assuming an 8-bit representation of the integer 237, is 1010100011101101. The string is 101101101.
A
hash function is any function mapping strings of arbitrary length to strings of fixed length. If
is the fixed length, the signature of the hash function is
For a string , the value returned by the hash function h is called the hash value of s; the string s is called message. Cryptographic hash functions additionally ensure the following properties:
- (i)
The probability of a particular hash value for a message is ;
- (ii)
Finding a message that matches a given hash value is unfeasible (preimage resistance);
- (iii)
Finding a second message that matches the hash value of a given message is unfeasible (second-preimage resistance);
- (iv)
Finding two different messages that yield the same hash value is unfeasible (collision resistance).
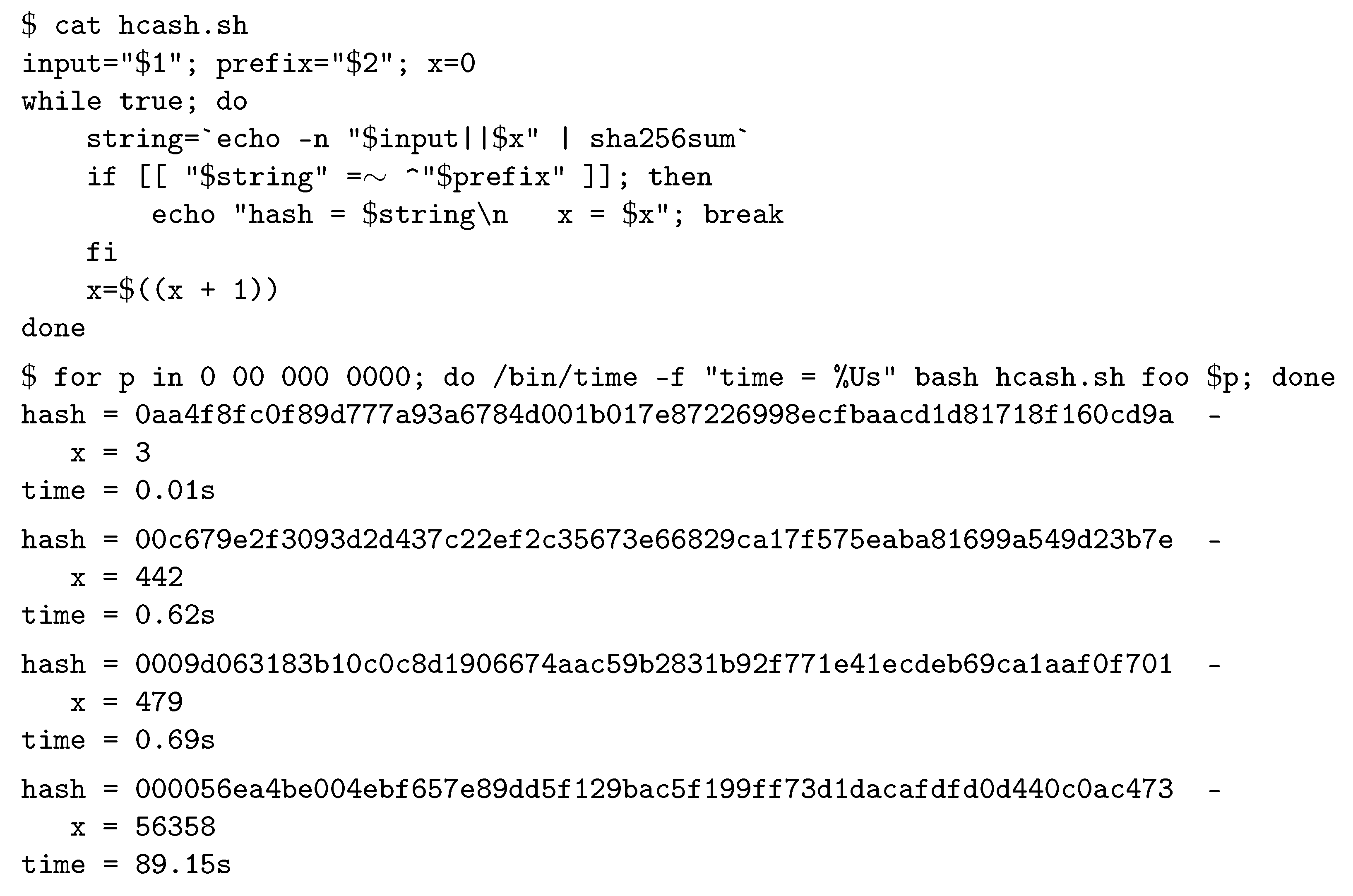
Example 2. SHA-256 is a popular cryptographic hash function. It produces hash values of length 256. In Unix systems, the hexadecimal representation of the SHA-256 hash value of the string foo can be obtained as shown in Figure 5. Note that the produced hash value starts with 0x2c = 00111100, that is, has an all-zero prefix of length 2. 2.2. A Client Puzzle Protocol Based on Hashcash
Hashcash is a (nondeterministic) function parameterized by a hash function
h and a positive integer
k; it associates every input string
with any pair
such that
and
. Let
denote any valid output
of the hashcash function parameterized by
h and
k. Hashcash essentially asks for finding partial hash collisions on the all-zeros prefix of length
k, and the fastest algorithm for computing partial collisions is brute force [
13]; see Algorithm 1. Assuming that the brute force algorithm increments
x starting from
, finding a valid
output value requires the computation of
hash values. In general, hashcash has
unbounded probability cost, in the sense that theoretically the brute force algorithm can run forever, though the probability that a solution is not found decreases rapidly towards zero. On the other hand, verifying that
is a valid output requires the computation of one hash value, as shown in Algorithm 2.
| Algorithm 1: Hashcash(s, h, k) |
![Algorithms 16 00462 i001]() |
| Algorithm 2: HashcashVerify(〈hhash_value〉, s, h, k) |
| 1 return prefix(hash_value, k) = 0k and hash_value = h(s||x); |
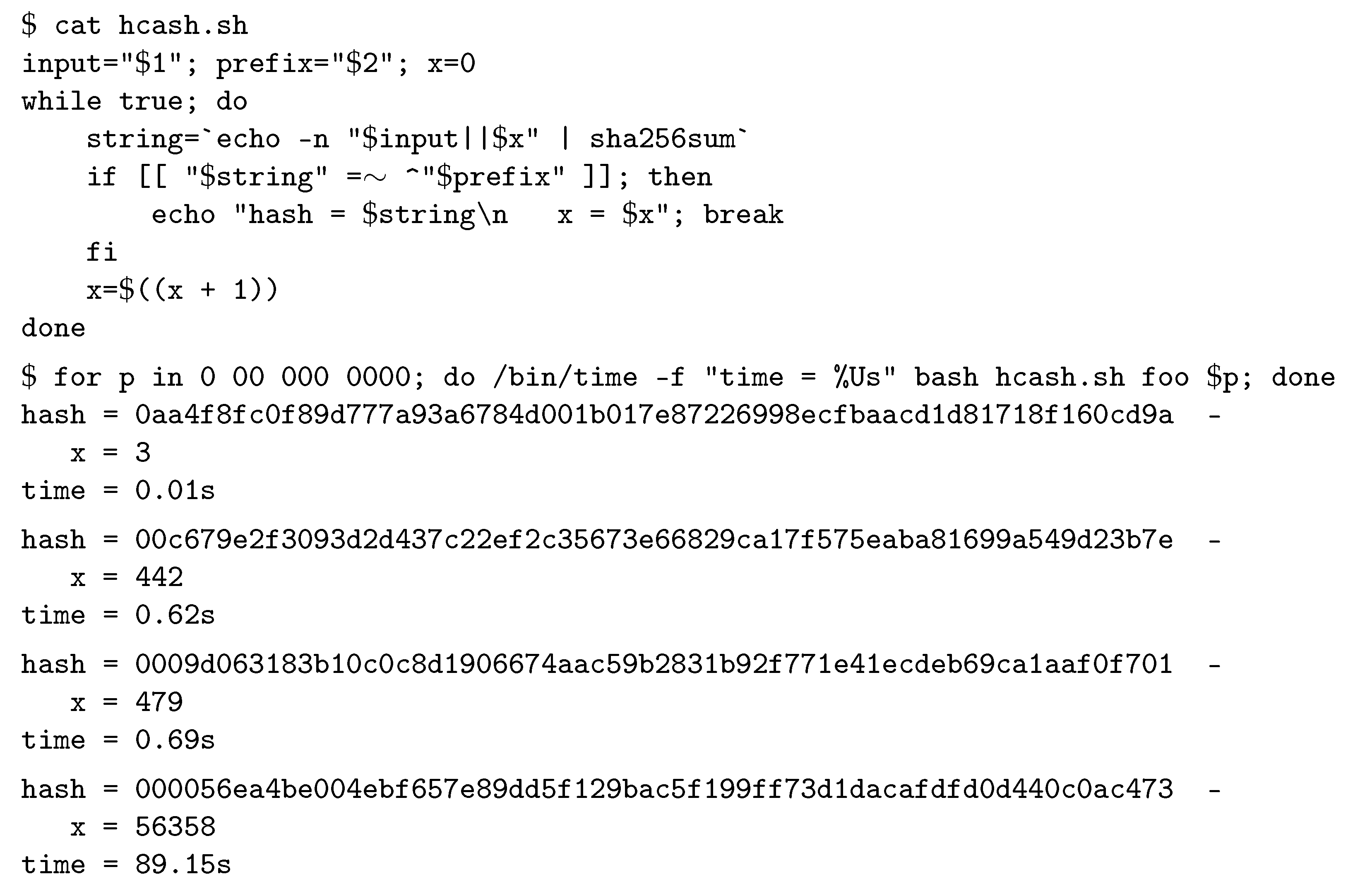
Example 3. Figure 6 shows a Bash script implementing Algorithm 1 and its execution for different lengths of the all-zeros prefix. Time measured on an Intel(R) Core(TM) i7-7600U CPU @ 2.80GHz. It can be observed that the difficulty of the problem does not increase linearly with the number of zeros in the demanded prefix. A client puzzle protocol (CPP) involves two entities, namely a verifier V and a prover P. P needs to access some (computationally expensive) resource of V. V challenges P to solve a puzzle before processing its request. A simple CPP based on hashcash comprises the following steps:
The setup consists in V generating and storing a master key . The master key is used to sign data so that V can complete the protocol without storing any further data. (No signed data is extended in the protocol; no need for HMAC.)
P needs to send a request to V. To this aim, P sends to V. (Here is considered unique. For example, can include a nonce chosen by P and a timestamp, and V can track for all completed within the allotted time window. To simplify the presentation, such details are omitted from the discussion.)
V determines the difficulty parameter based on its current workload, generates a timestamp t by which the protocol must be completed, computes , and sends to P. (Note that the hash value of the request is signed, not the request, so that the signed message has fixed length.)
P computes and sends to V.
V checks all the following conditions: ; t is in the future; S is valid, i.e., and ; . If all conditions are met, is processed.
The idea of a CPP is that a legit user is willing to waste a small amount of its computational resources in order to access a resource of V, while an attacker requires an unaffordable amount of computational resources to exhaust V capabilities. The main downside of the above simple protocol is that the difficulty parameter k does not give a fine-grained control on the amount of resources needed to solve the puzzle (no determinable difficulty). Moreover, the brute-force algorithm for hashcash has linear speedup (weak parallel computation resistance).
Example 4. As shown in Example 3, for the message foo there is essentially no difference in increasing the prefix from to , while increasing the prefix to makes the problem much more difficult. Also note that Algorithm 1 can be easily parallelized, and a GPU with 384 cores would solve the prefix by computing around 150 hash values per core in around 0.25 s.
2.3. Trees
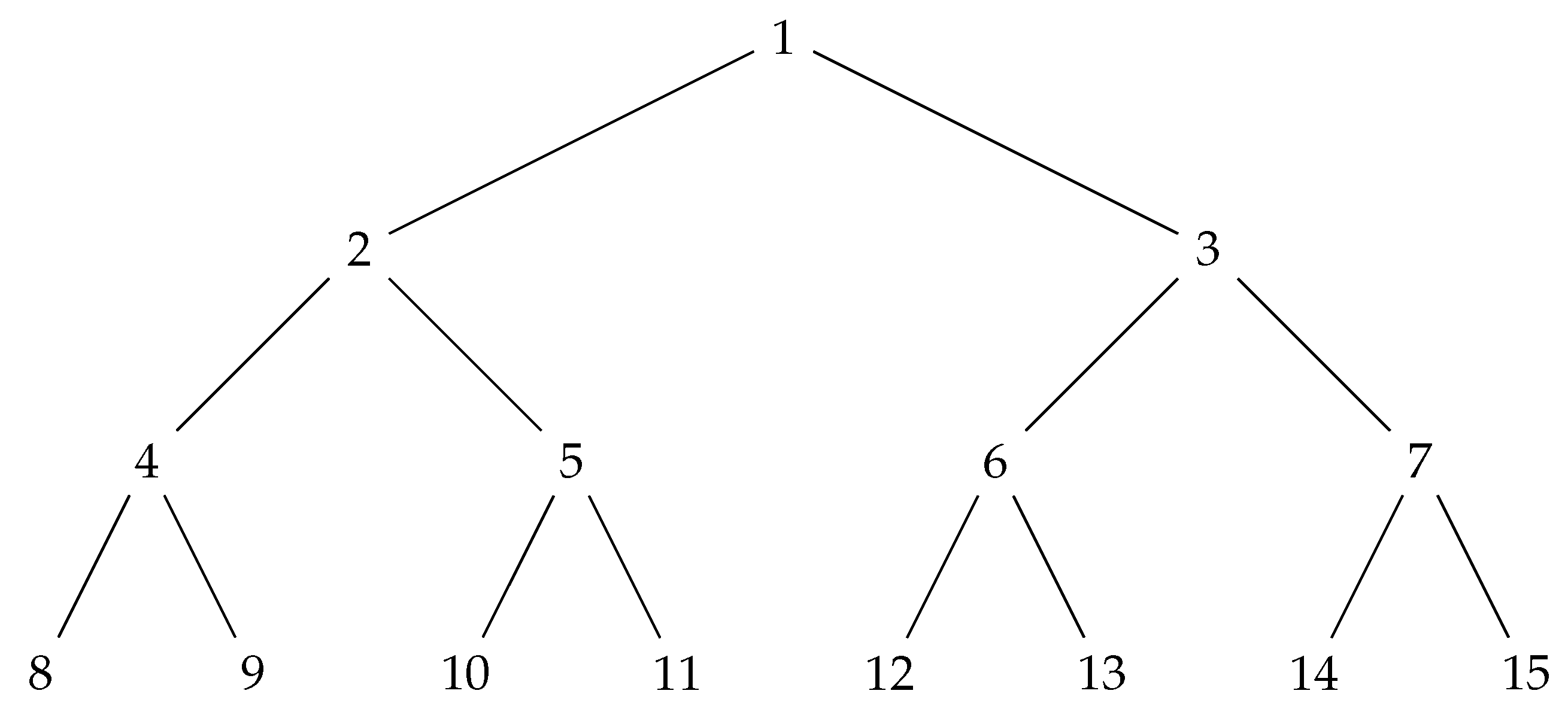
A labeled binary tree T is either the empty set ∅ or a quadruple , where r is the root node (of T), ℓ is the label (of r), and are labeled binary trees referred to as the left child and the right child (of both T and r); and R are respectively denoted by , and . (In the following, the term tree is used to refer labeled binary trees.) Nodes of a tree are defined inductively: ; . When , node r is also called a leaf. Leaves of a tree are defined inductively: ; ; , if or . An internal node of T is any non-leaf node of T, that is, .
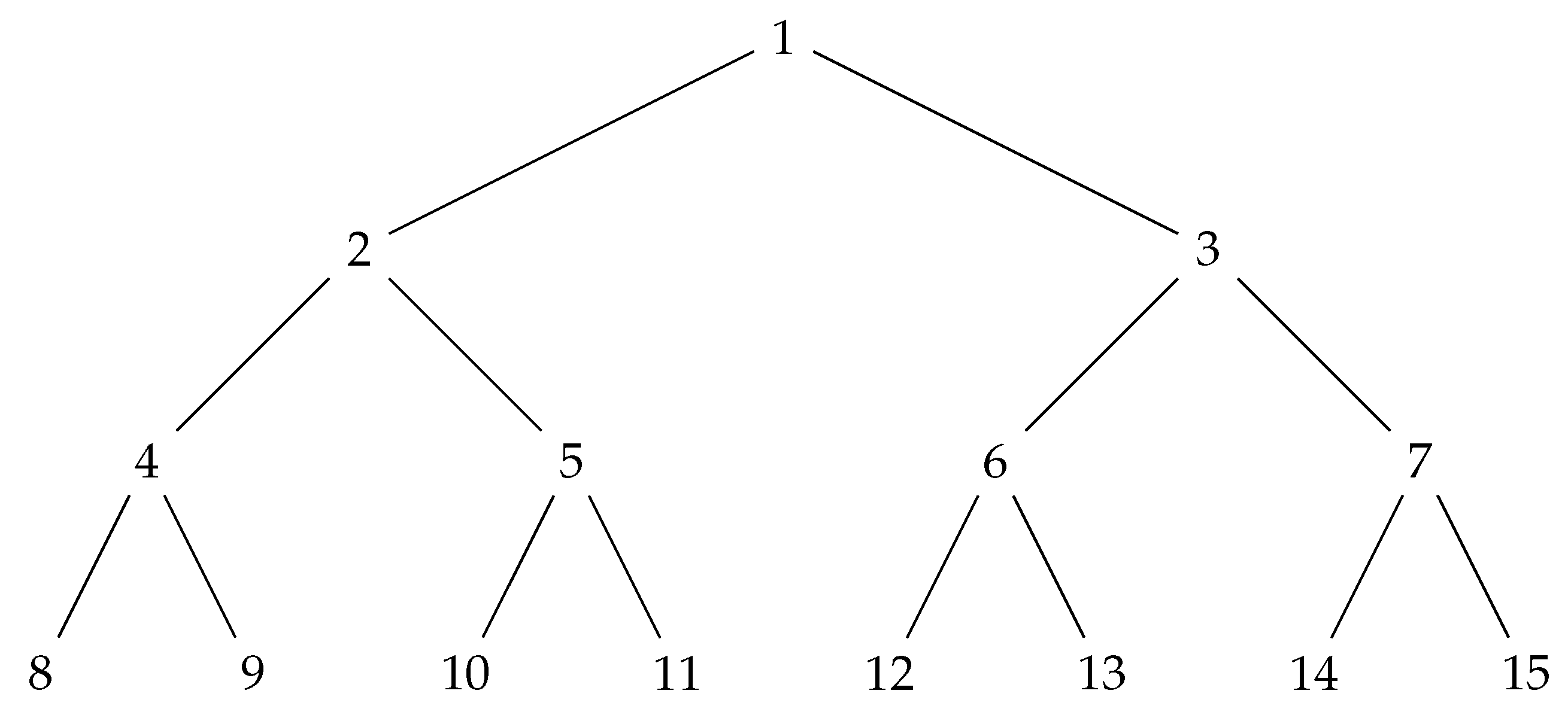
Let be a node of . The label of v in T is defined inductively: ; if ; if ; if . The level of v in T is defined inductively: if ; if ; if . A tree is perfect if all interior nodes have nonempty children and all leaves have the same level. (In the following, only perfect trees are considered.) The height of a tree is the level of its leaves. The order of v in T is defined via breadth-first search (BFS) or level-order search: ; for every occurring in T, and . Note that T can be compactly represented by a one-based array of size , having whenever .
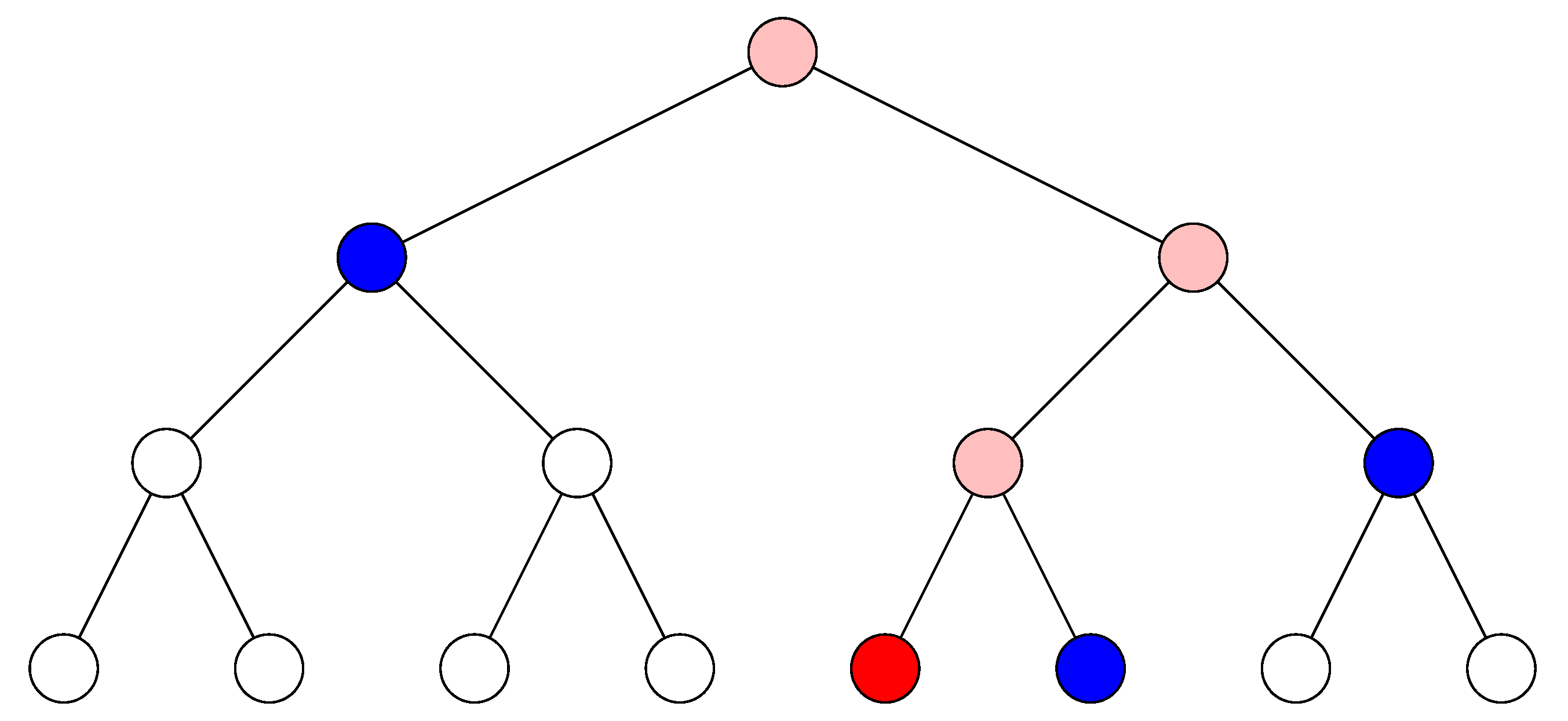
Example 5. Let T be the tree of height 4 shown in Figure 7. T is such that for all . Its array representation is . The leaves have level 4 and are the nodes with label from 8 to 15. Inner nodes have label from 1 to 7. The root has label 1. A hash tree, or Merkle tree, is a tree in which every leaf is labeled with the hash value of a data block, and every internal node is labeled with the hash value of the labels of its child nodes. Here a data block is any piece of information in a commitment scheme, that is, hidden data that cannot be changed. In fact, sharing the hash value associated with the root is sufficient to guarantee that no label of the hash tree is modified. If T is the hash tree associated with a sequence of data blocks (, in order to verify that some () was not modified, it is sufficient to check nodes in the path from the leaf with label to the root. The check involves the labels of these nodes and their children; in formulas, if denotes the node of T such that , the labels involved in the verification of are and , for .
Example 6. Let T be the hash tree shown in Figure 8. Let denote the node of T such that . To verify that was not modified, the nodes involved are . In particular, the hash values that are recomputed are those associated with nodes from the leaf with label to the root, i.e., those of , , and . Essentially, to modify without changing the label of requires violating second-preimage resistance of h at each level of T: find new labels for and matching the hash value in ; find new labels for and matching the new hash value in ; find a new label ℓ for such that matches the new hash value in . 3. Hashcash Trees and Their Application to Client Puzzle Protocols
The definition of hashcash tree is parameterized with respect to a hash function
h and a positive integer
k, which are assumed fixed in this section. Recall that
denotes any pair
such that
and
. For a string
s and an integer
, let
be the (nondeterministic) sequence of labels defined as follows:
The
hashcash tree of size
n for the string
s is the perfect tree
T of height
such that, for each
, if
, then
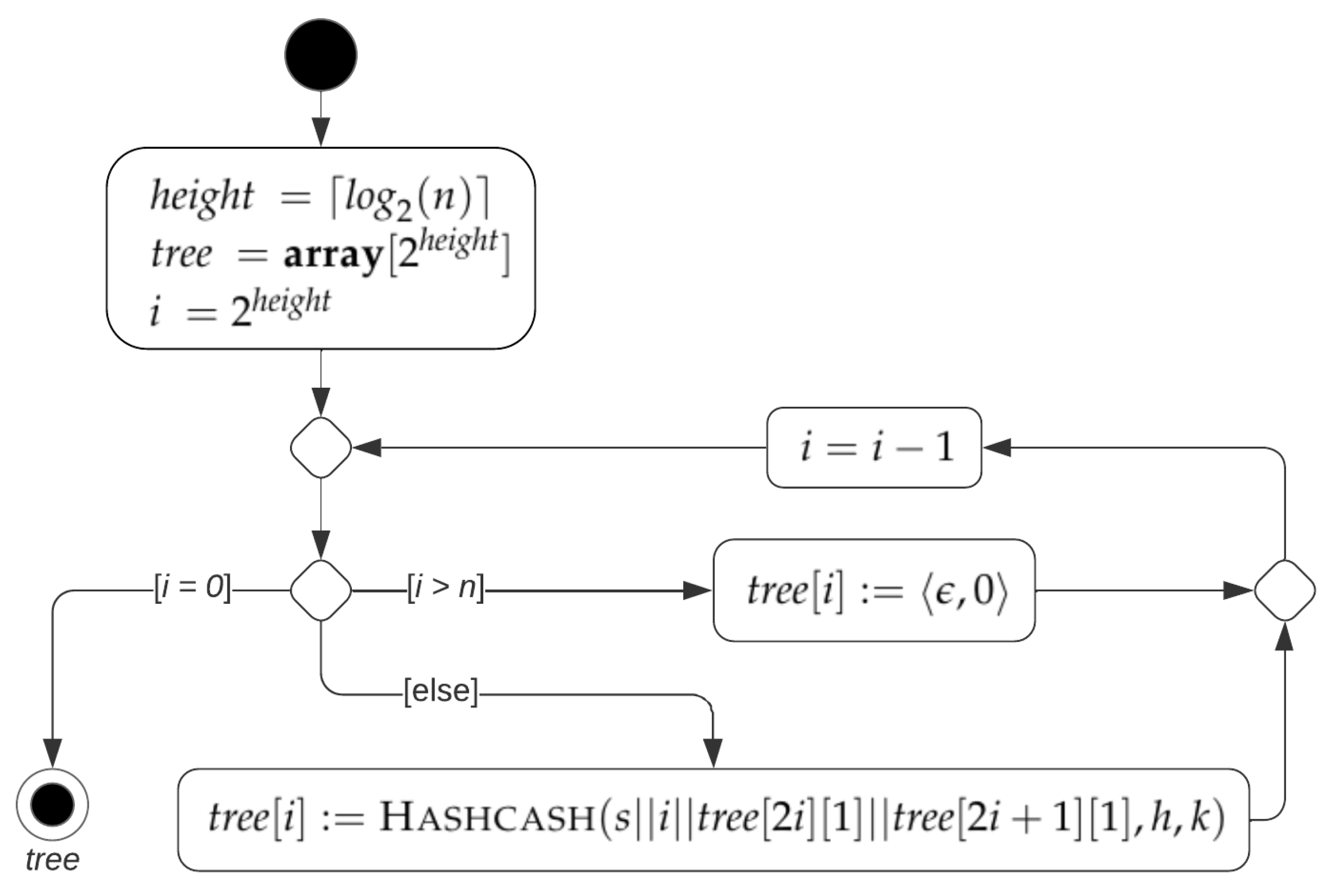
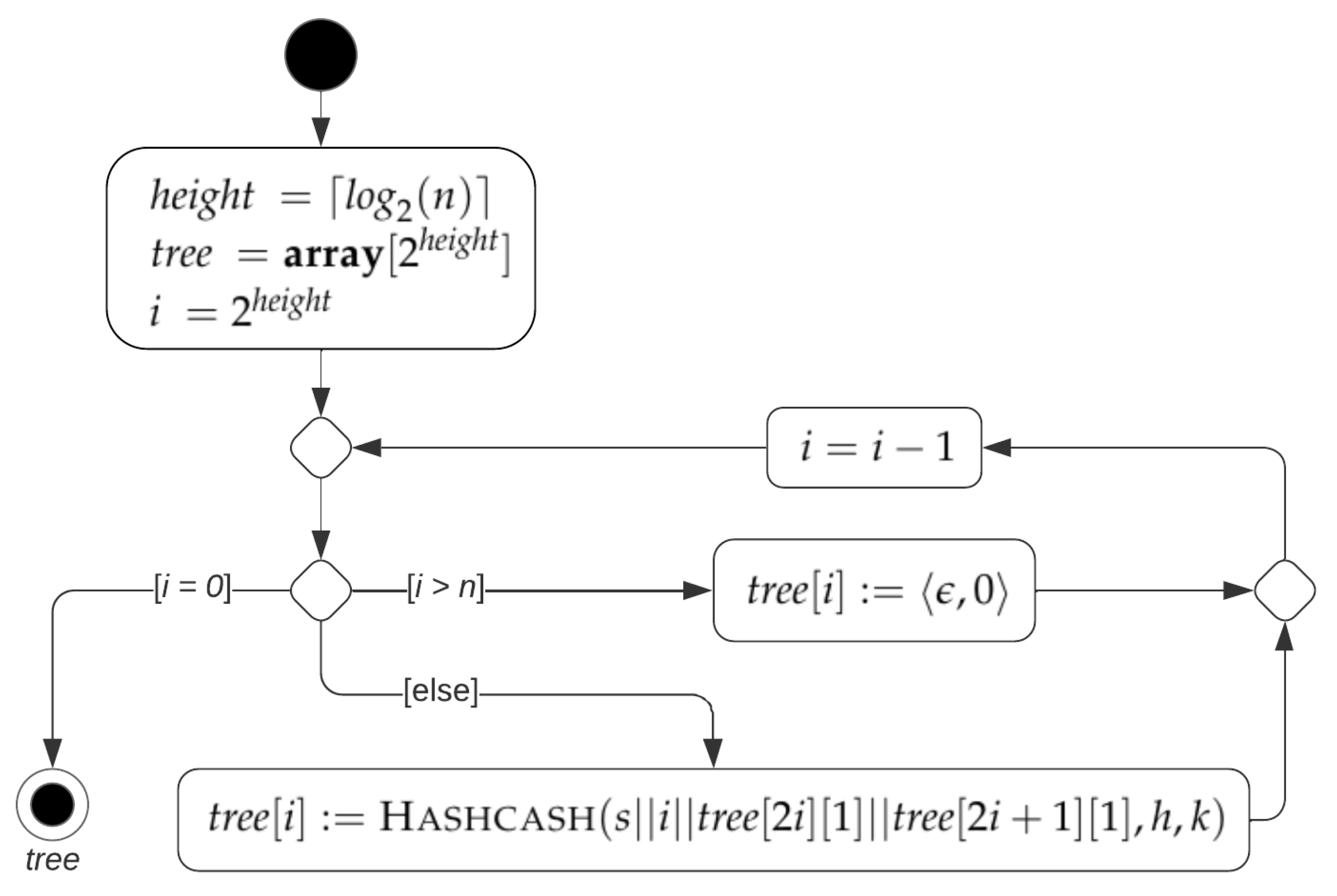
. As shown by Algorithm 3 and
Figure 9, a hashcash tree of size
n is constructed by first computing the labels of the nodes of level
(i.e., leaves) and then iteratively computing the labels of nodes of previous levels until the label of the root is obtained. In total, the algorithm performs
n hashcash computations.
| Algorithm 3: HashcashTree(s, n, h, k) |
![Algorithms 16 00462 i002]() |
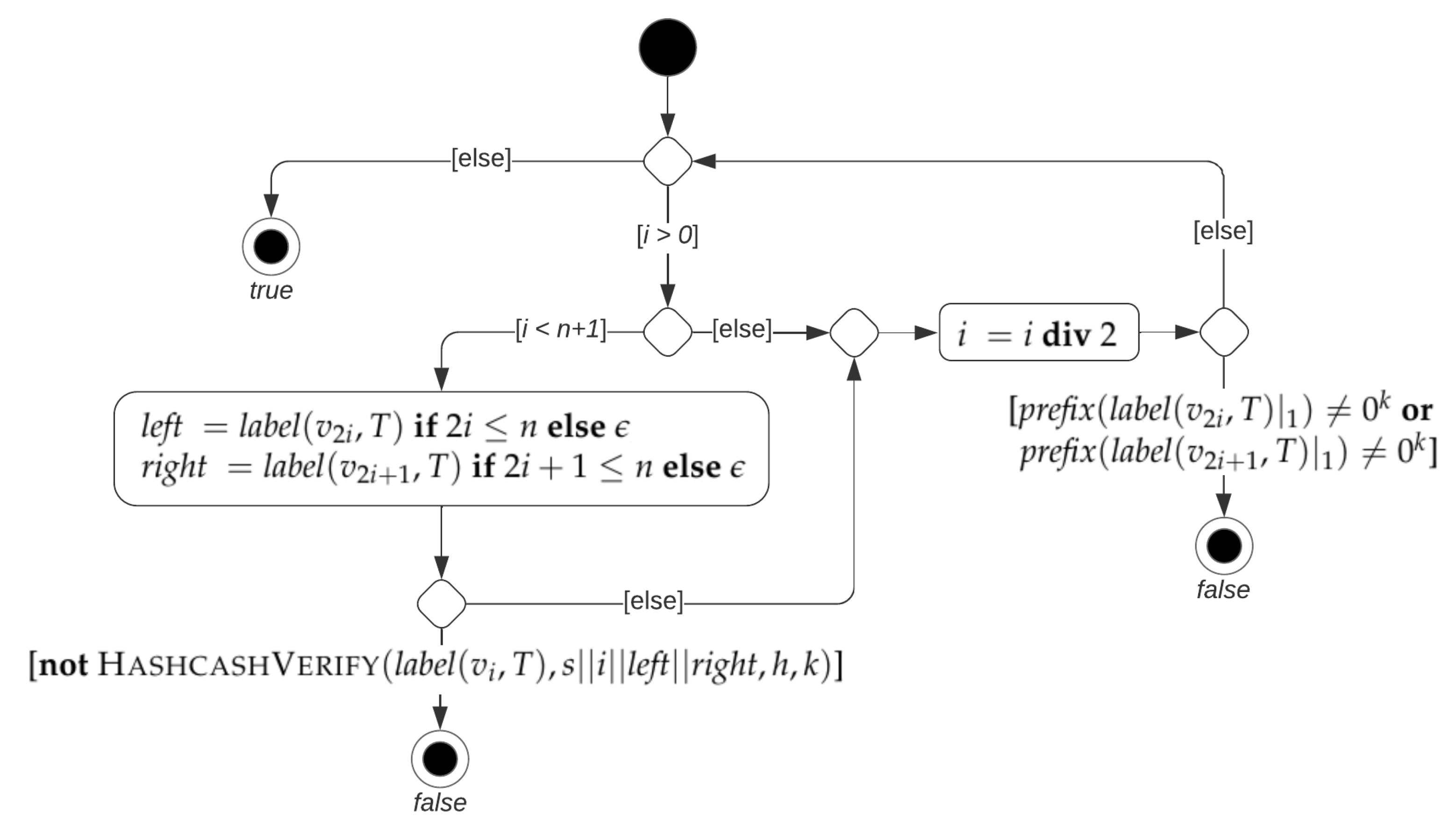
Example 7. Let T be the hashcash tree shown in Figure 10. Let denote the node of T such that . Once the label of the root is disclosed, changing any label in the tree is computationally unfeasible. In particular, changing the label of a leaf, say , requires violating second-preimage resistance of h at each level of T, with the additional difficulty that the new hash values must also be a valid output of the hashcash algorithm. | Algorithm 4: HashcashTreeVerify (T, i, s, n, h, k) |
![Algorithms 16 00462 i003]() |
Similarly to a hash tree, the validation of a leaf
i of a hashcash tree
T involves nodes in the path from
i to the root of
T and their children; see Algorithm 4 and
Figure 11. Specifically, the prefix of all hash values associated with these nodes is validated (lines 8–9), while hash values are recomputed only for nodes in the path from
i to the root of
T (lines 2–6). On the basis of Algorithms 3–4, the proposed CPP comprises the following steps:
The setup consists in the verifier V generating and storing a master key .
The prover P needs to send a request to V. To this aim, P sends to V.
V determines the difficulty parameter based on its current workload, generates a timestamp t by which the protocol must be completed, computes , and sends to P.
P computes and stores the hashcash tree T of size n for s using Algorithm 3 and sends to V, where is .
V checks , verifies that t is in the future, randomly selects a number (a leaf), and sends to P, where .
P sends to V, where S consists of labels associated with nodes in the path from i to the root and their children; in formulas, S is the sequence comprising and , for . (As an optimization, witness integers of labels not in the path from i to the root can be discarded.)
V checks all the following conditions: ; t is in the future; , where is in S (i.e., the hash value associated with the root of the partial hashcash tree sent by P); S is valid; . If all conditions are met, is processed.
The validation of
S at step 7 amounts to check that each label
in the path from
i to the root is actually obtained according to (
2); Algorithm 4 is used.
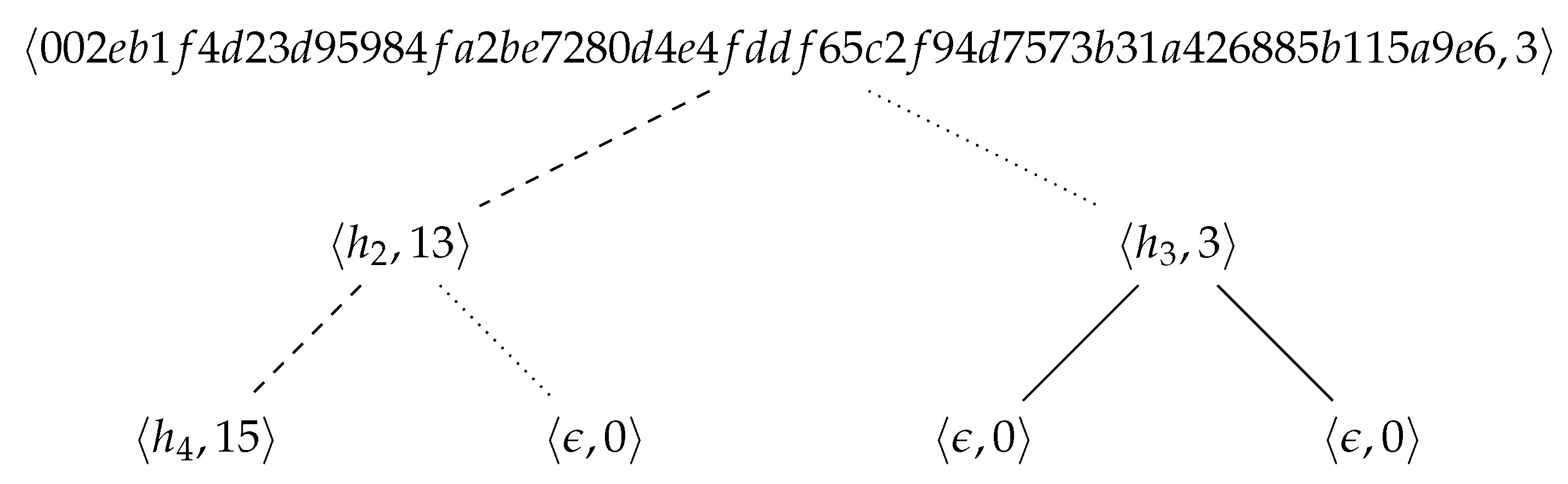
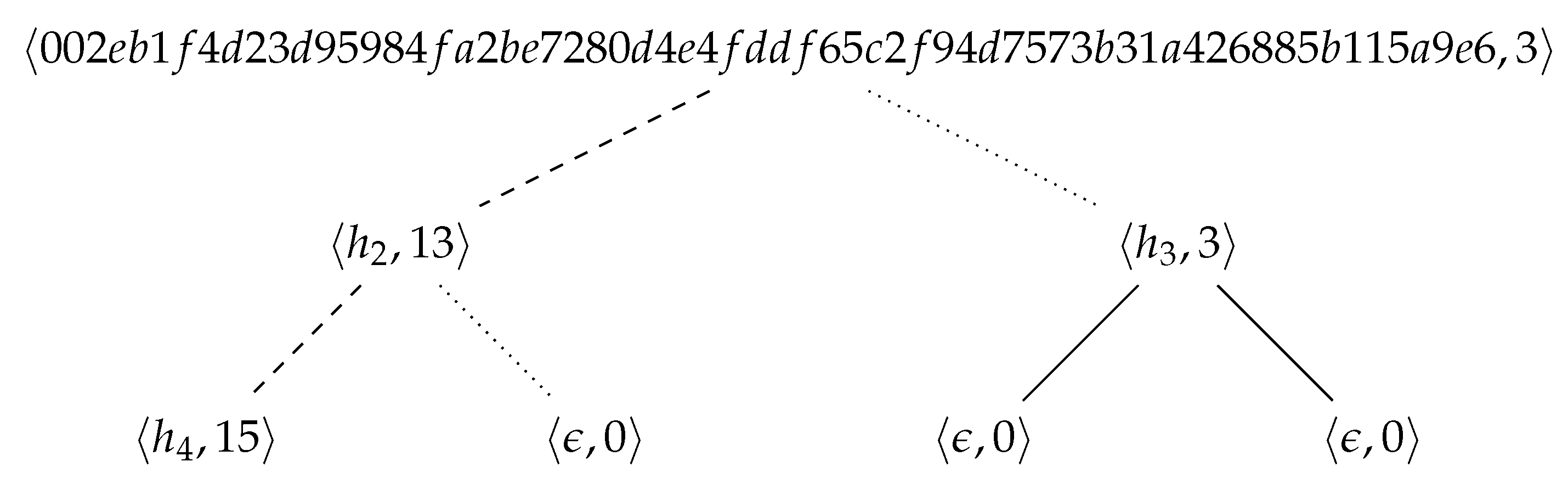
Example 8. Let us run the CPP for , using the hash function SHA-256 and a prefix length . V generates the master key . P sends to V. V determines (encoded as 0400), (10 s in the future, encoded as ), , and sends to P. P computes the hashcash tree shown in Figure 12, and sends (with and ) to V. V checks that s and t are valid, randomly selects (the first leaf), computes , and sends to P. P sends the labels , , , and to V (with the other required data). V runs Algorithm 4 on a tree T constructed with the received labels (other labels are irrelevant). Since the algorithm returns , and all other conditions are met, the request is processed. 5. Implementation and Experiment
A proof-of-concept implementation of the algorithm presented in
Section 3 is available at
https://github.com/alviano/hashcash-tree (accessed on 28 September 2023). It is written in Python 3.11 and uses the SHA-256 function from the
hashlib package (even if other hash functions can be easily added). Numeric computation is powered by NumPy, and witnesses are represented as unsigned 16-bits integers. The CPP is implemented in a REST server powered by the FastAPI framework. Master keys are
universally unique identifier (UUID) v4, i.e., 36-character alphanumeric strings. Timestamps are represented as double precision floating-point numbers. An example client for consuming the REST API is also provided. It performs 1000 (one thousand) requests, possibly using multiple threads or processes. Requests themselves are not of particular importance for the example client, which is designed so that all the computation is focused on solving the CPP provided by the REST server. Note that fixing
in the implemented CPP essentially results into the CPP defined in
Section 2.2; the prover is challenged to solve a single hashcash computation, for some prefix length
k. On the other hand, fixing
in the implemented CPP essentially results in a CPP using hash trees because hashcash is disabled.
In order to empirically verify the theoretical analysis carried out in
Section 4, the REST server and the example client were run with several configurations. The difficulty of the generated puzzles was varied by modifying both the prefix length (parameter
k) and the size of the hashcash tree (parameter
n); within this respect,
k was tested with all values from 0 to 8, and
n was tested with value
for
. As for the client, since the experiment was run on a quad-core Intel(R) Xeon(R) CPU X3430 @ 2.40 GHz with 16 GB of RAM, the number of workers was fixed to 4 (i.e., the 1000 requests were processed in parallel by 4 processes). Measured values include the total CPU usage of the REST server, and the CPU usage of the example client for each request (from starting the interaction with the REST server to the submission of the validation data). Computed values include the average CPU usage for completing the 1000 requests, the standard deviation, and the minimum and maximum CPU usage.
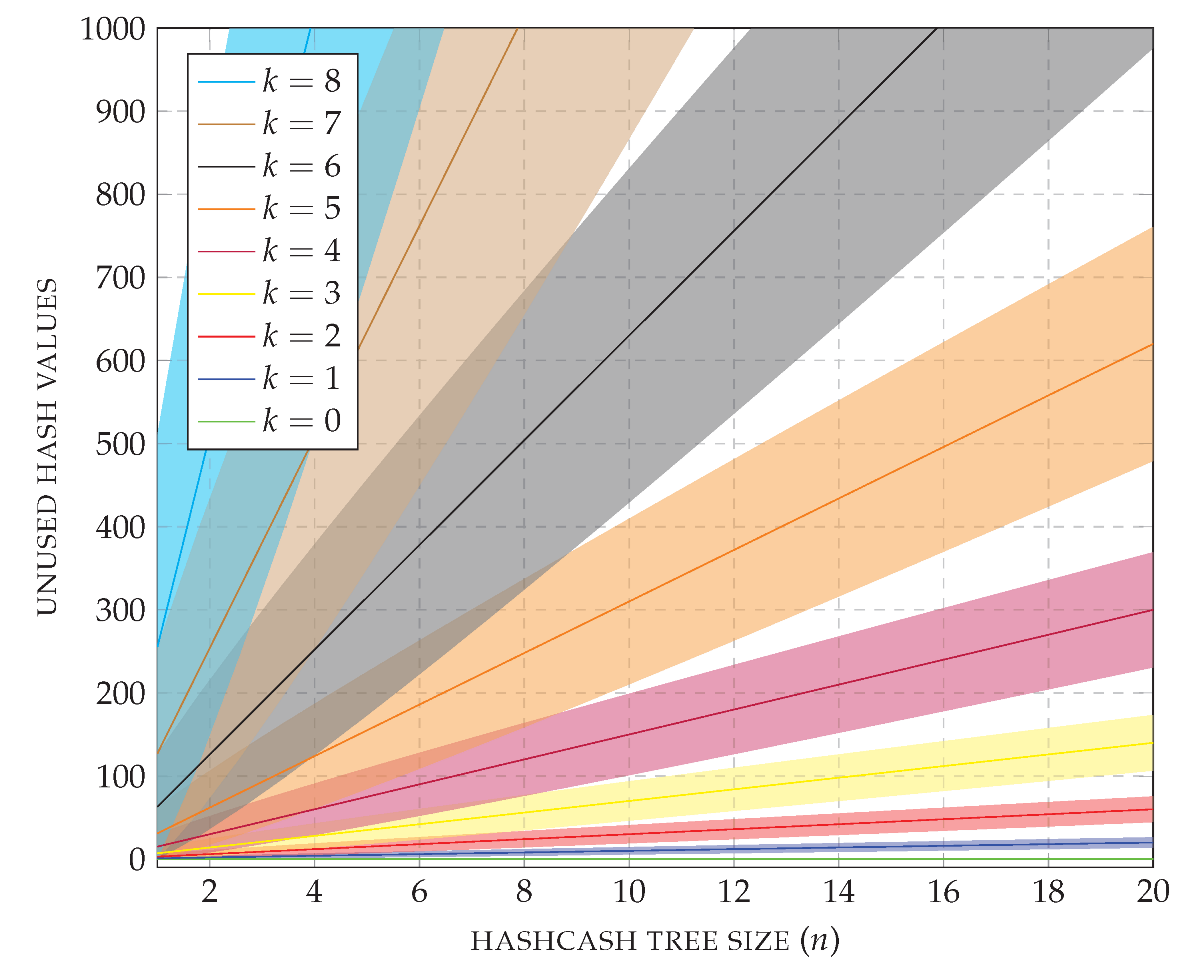
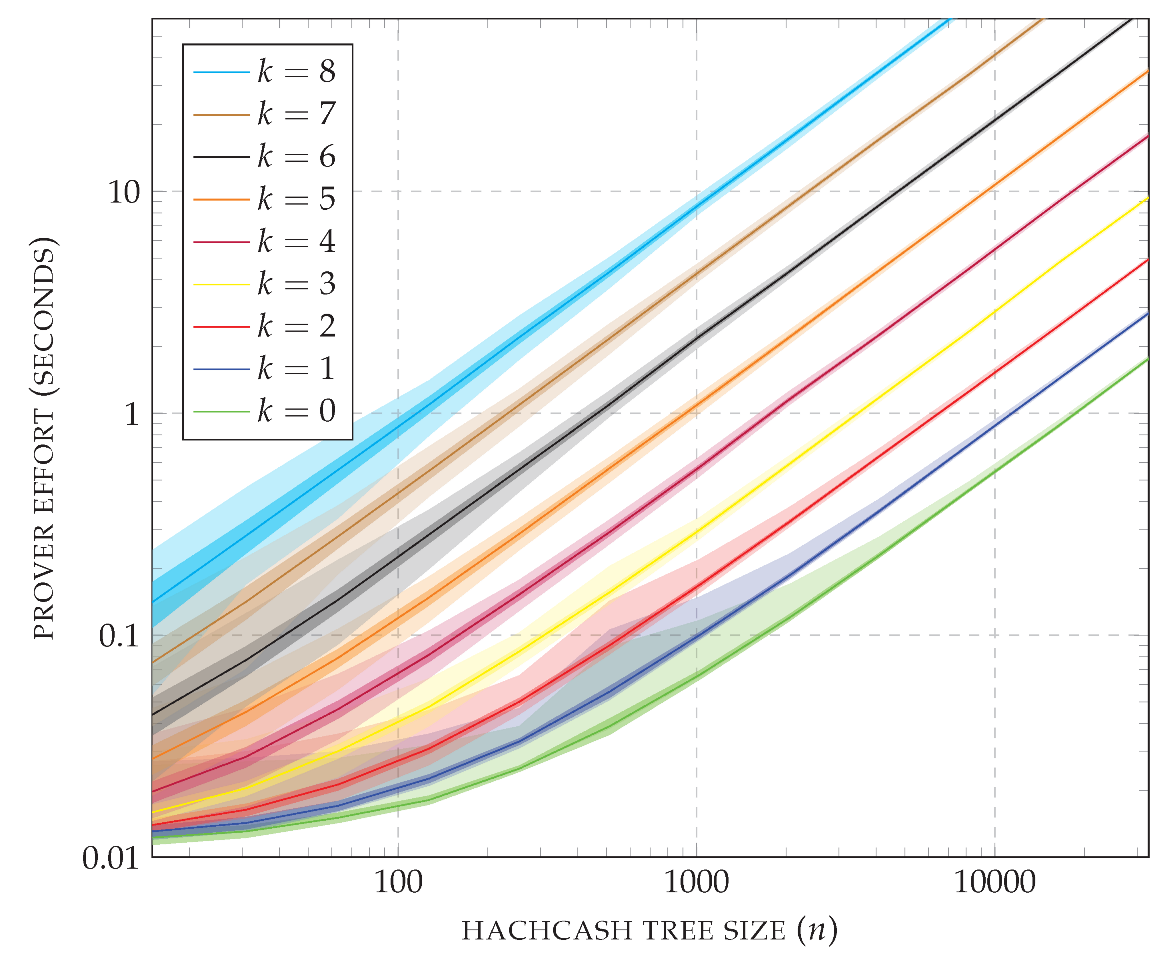
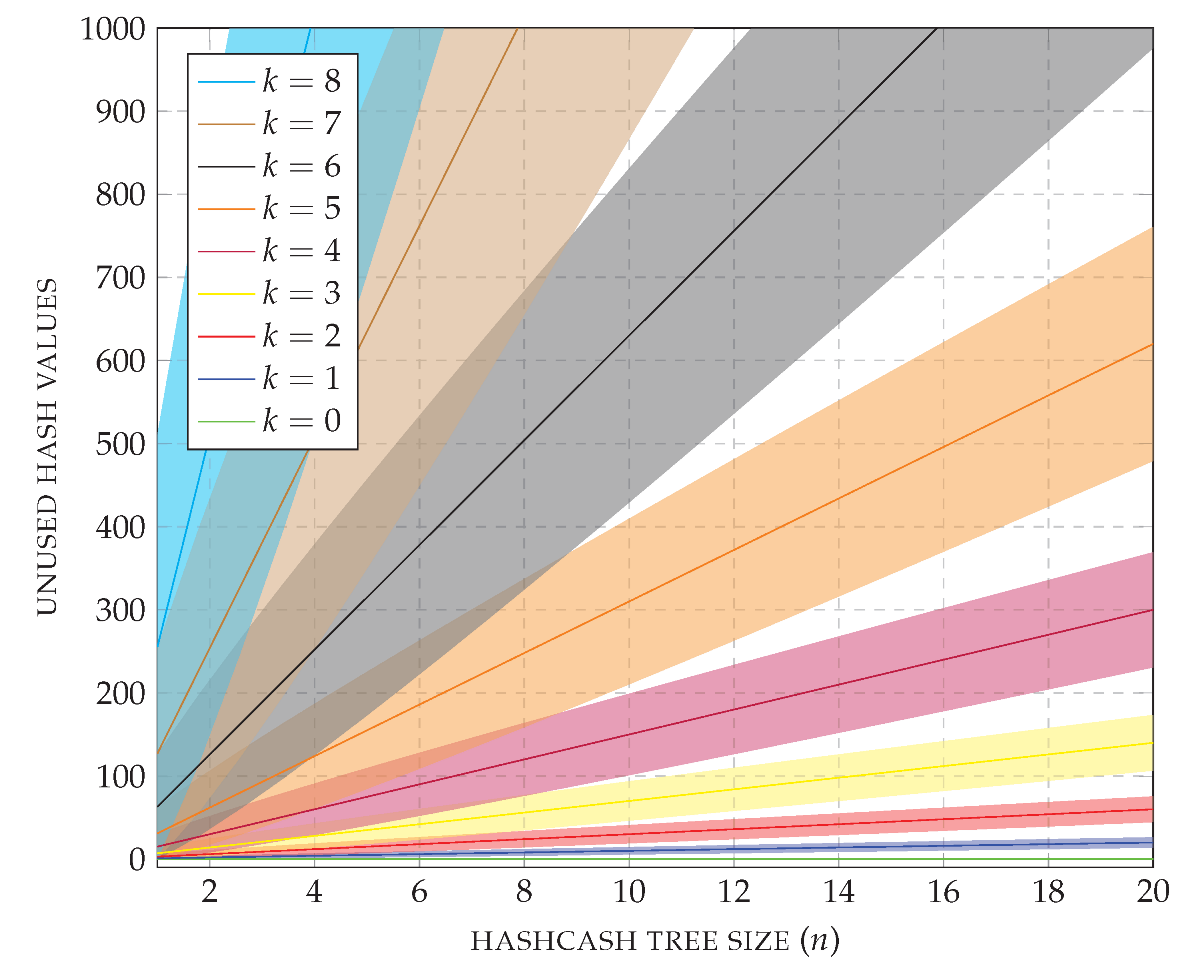
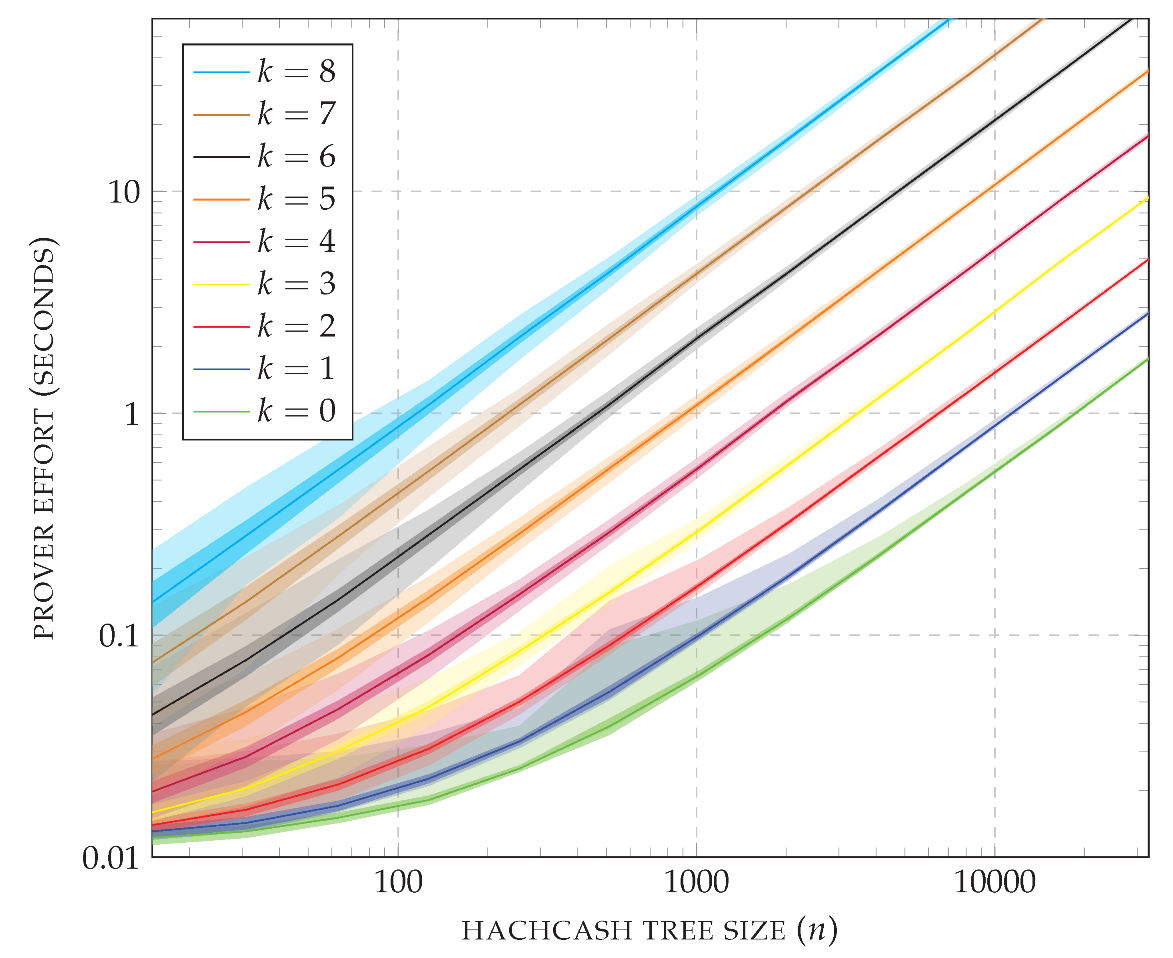
A summary of the measured and computed values is shown in
Figure 14. The plot uses logarithmic axes and reports the average CPU usage of the prover; times within the standard deviation are colored in dark shades, and other times between the minimum and the maximum CPU usage are colored in light shades. As a first observation, each increment of the prefix length (
k) causes a jump in the effort required by the prover to solve the puzzle. Recall that for
, the CPP is essentially the one based on hashcash alone. On the other hand, for every fixed value of
k, the prover effort scales linearly on the size of the hashcash tree (
n). Observing the standard deviation, it is possible to conclude that all hashcash trees are computed with similar effort once
k and
n are fixed. As a final observation on the plot, note that for
(i.e., essentially using hash trees) the puzzle is solved in less than 2 s even for the largest case of
= 32,767. If storing a node takes 34 bytes (32 bytes for the SHA-256 hash value and 2 bytes for the witness), a hashcash tree of size
= 32,767 requires around 1024 KiB of memory. In contrast, note that for
and
the puzzle is solved in around 2.26 s and the hashcash tree can be stored in around 136 KiB. Similarly, for
and
the puzzle is solved in around 2.20 s and the hashcash tree can be stored in around 68 KiB.
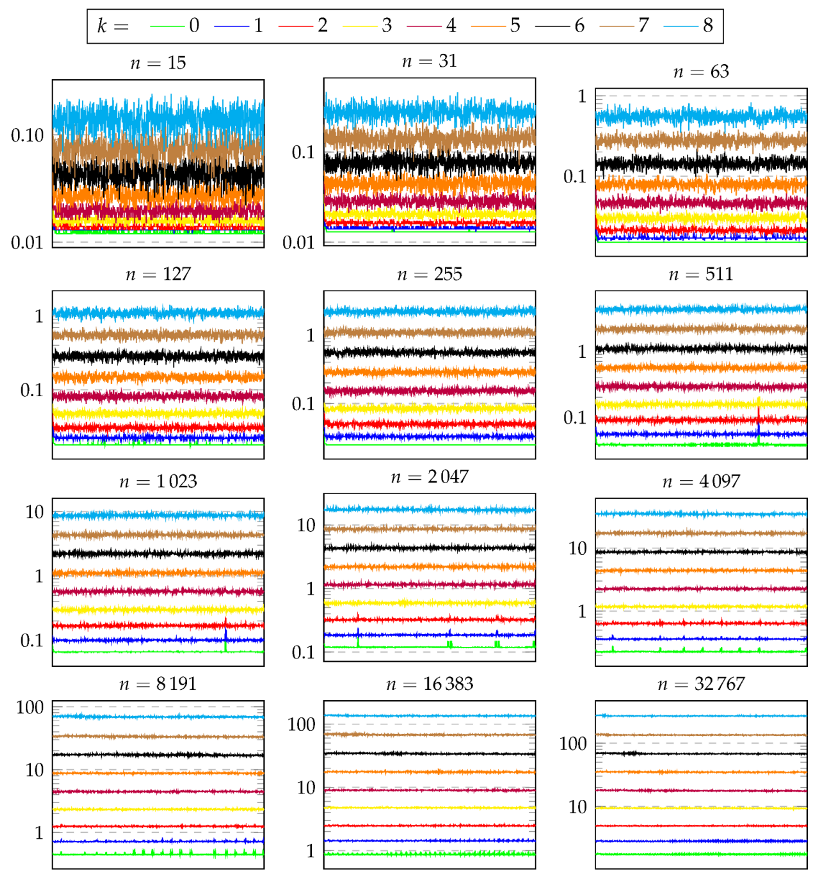
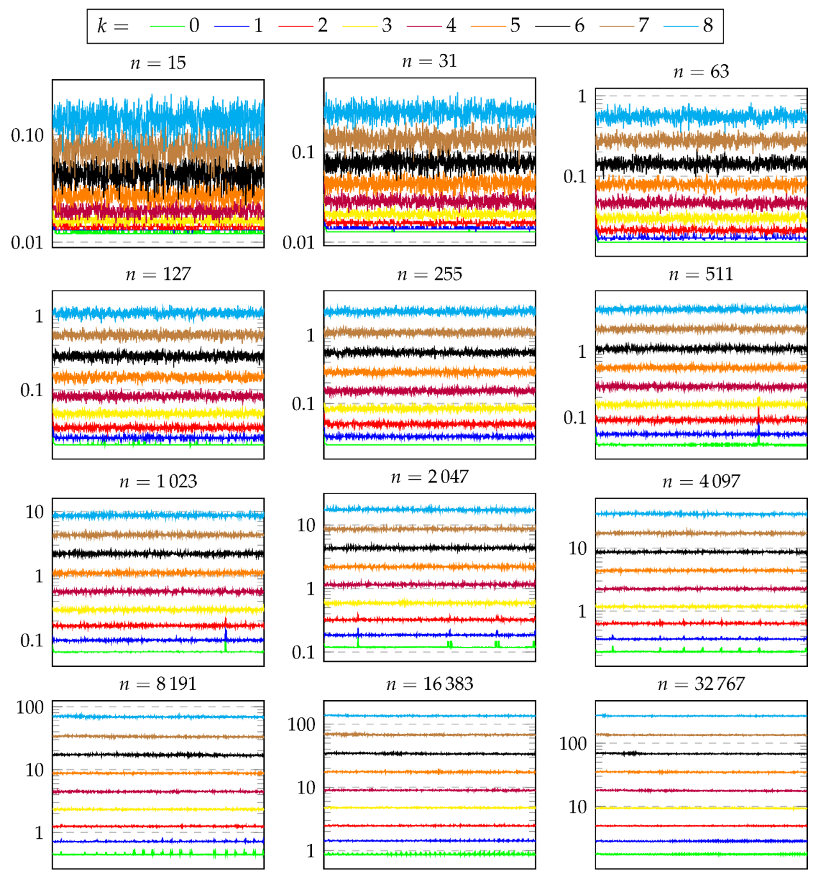
Figure 15 shows the measured prover effort for each solved CPP. There is a plot for each tested value of
n. Each of these plots reports one line for each tested value of
k. The lines are obtained by plotting the measured CPU time (
y axis) for each solved CPP (
x axis). It can be observed that the computation of hashcash trees of size up to
is very fast, always below 1 s. On the contrary, the computation of hashcash trees of size
is very slow for
, requiring at least 10 s. Focusing on the remaining values of
n, from 127 to 4095, the values of
k that lead to CPU times between 0.1 s and 10 s are 4, 5, and 6.
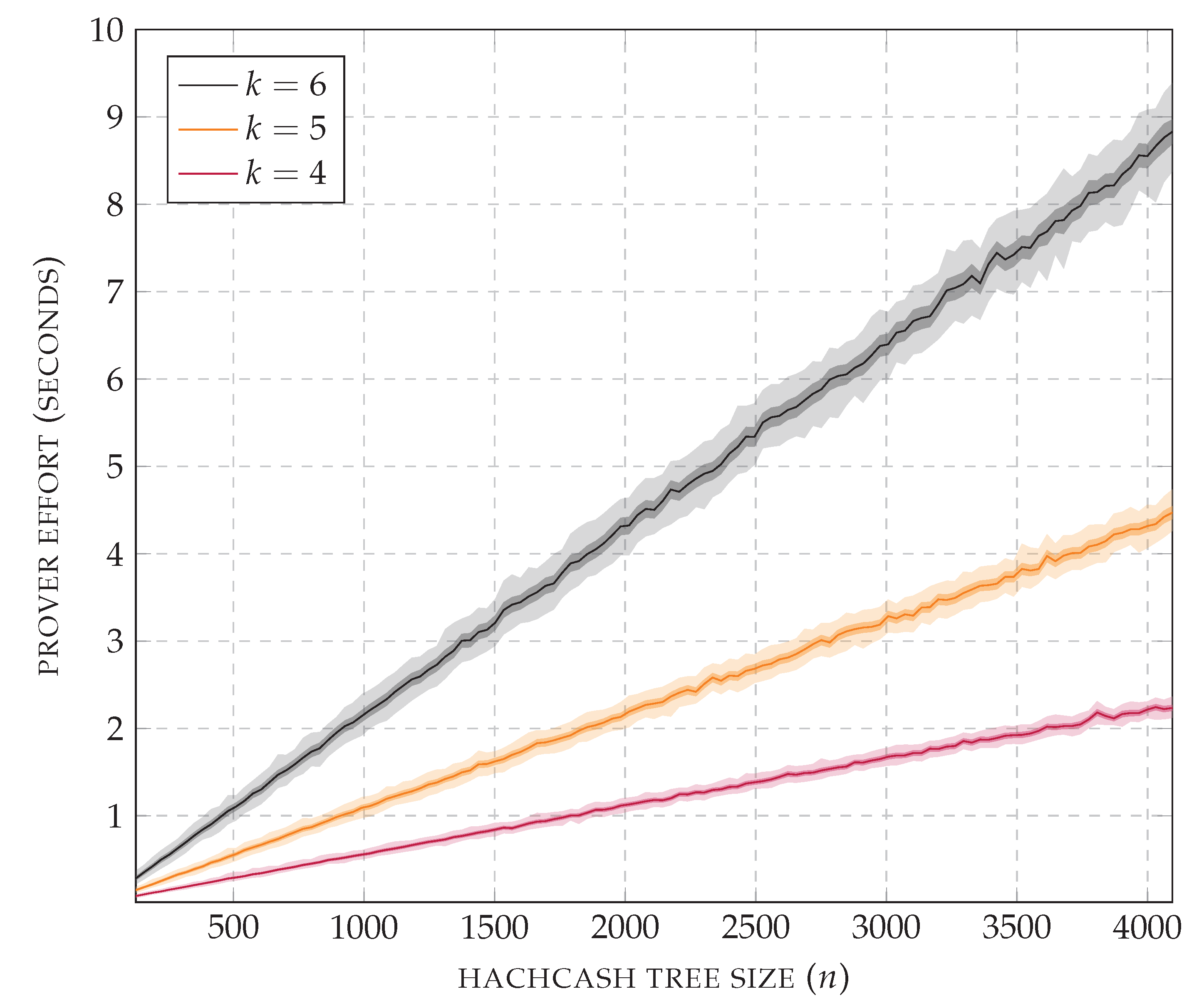
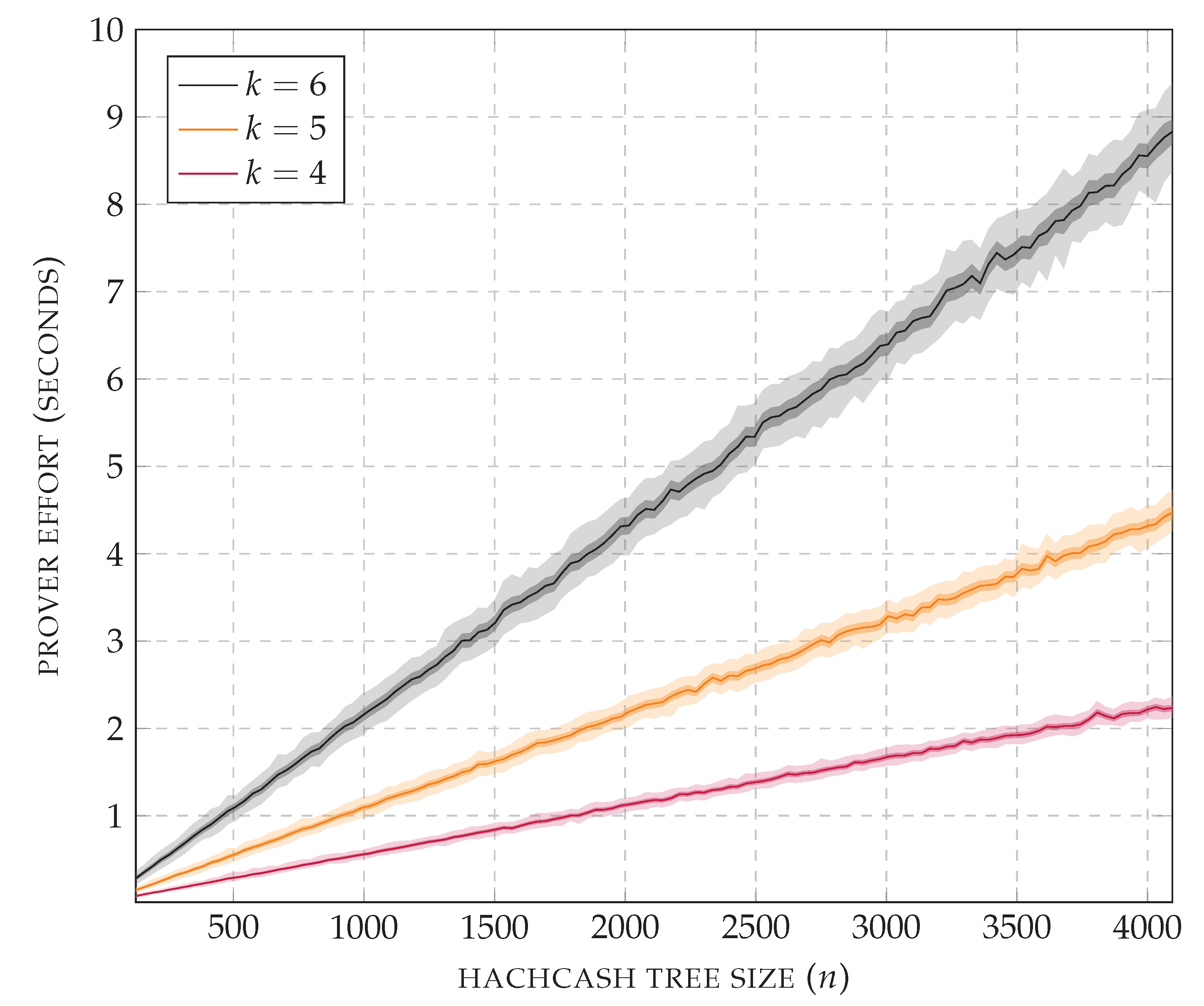
Figure 16 is focused on the values of
k identified above. The benchmark was run by increasing the size of the generated hashcash tree linearly, with steps of 32 nodes. For each tested size, 1000 hashcash trees were generated. The plot reports the average CPU time used by the prover, with values within the standard deviation and within the minimum and maximum measured values. For all three prefix lengths, the prover effort scales linearly, confirming that the verifier can precisely control the difficulty of the puzzle. The measured verifier effort, including the CPU usage for running FastAPI, is the following: for
, it is around 12.7 ms per request, with standard deviation 0.3 ms; for
, it is around 12.9 ms per request, with standard deviation 0.4 ms; for
, it is around 13.4 ms per request, with standard deviation 0.6 ms.
6. Related Work
Detecting DoS attacks is challenging and addressed by sophisticated techniques, among them some based on machine learning [
4,
5,
6]; a survey on DoS detection techniques is given by de Neira et al. [
7]. As an earlier barrier against DoS attacks, prevention techniques can be adopted to protect sensitive services and assets of an organization [
14,
15]. This article introduces a client puzzle protocol as a prevention technique to mitigate DoS attacks.
The concept of the client puzzle was introduced by Juels and Brainard [
16], who suggested their application to prevent denial-of-service (DoS) attacks. The main characteristic of client puzzles is that they can be solved by a polynomial-time entity upon spending a certain amount of resources, and therefore a server may provide access to some of its assets in exchange of a valid solution for a new client puzzle. A similar concept is given by Dwork and Naor [
9] with the notion of pricing function to combat junk emails, and by Rivest, Shamir, and Wagner [
17] with the notion of timed-lock puzzle as a tool to realize timed-release crypto. Client puzzles are expected to be unforgeable and difficult to solve [
18] and possibly to have determinable difficulty and parallel computation resistance [
19].
Client puzzles can be categorized as CPU-bound and memory-bound. In CPU-bound client puzzles, the prover effort is measured by the amount of CPU cycles needed to solve a puzzle; several client puzzles belong to this category [
9,
11,
16,
17,
18,
20,
21,
22]. In memory-bound client puzzles, the prover effort is measured by the amount of memory look-ups needed to solve a puzzle; the main argument in support of memory-bound client puzzles is that CPU power varies more than memory look-up speed for different computers [
23,
24,
25].
The CPP presented in
Section 3 is CPU-bound and combines hashcash [
11] and hash trees [
26]. The main obstacle to using hashcash alone is its unbounded probability cost. The length
k of the prefix is the only parameter that can be used to control the difficulty of the puzzle, and both difficulty and variance increase exponentially when
k increases (see Proposition 1). An attempt to gain more control on the difficulty of puzzles was performed by Juels and Brainard [
16], who essentially designed a CPP involving several sub-puzzles. The results shown by Theorem 1 for hashcash trees can be extended to such a CPP when sub-puzzles are hashcash computations. On the other hand, such a CPP requires verifying (and therefore transmitting) the solutions of all sub-puzzles, while a logarithmic number of solutions is sufficient to verify a hashcash tree (see Theorem 2).
A CPP based on hash trees was designed by Coelho [
12]. It can be seen as a solution–verification version of the CPP proposed in
Section 3; when the prefix length is fixed to
(i.e., hashcash is disabled), the tree is computed based on the service description and several leaves are selected for the verification phase based on the root hash value. The difficulty of the puzzle is determinable with high precision, but the size of hash trees can grow quickly. This is a downside of the protocol, given the fact that the hash tree must be stored (or recomputed) by the prover in order to provide the labels for the verification phase, which are discovered only after the root hash value is computed. The proposed CPP can rely on smaller trees because the difficulty of computing a single node can also be controlled via the length of the required prefix, i.e., by enabling hashcash.
Differently from previously defined protocols, in addition to the first interaction with the server to obtain the challenge for accessing the requested service, the proposed protocol expects a commitment on the computed solution before disclosing the portion required to prove the legitimacy of the client (see
Figure 4). This is in particular contrast with the non-interactive approach by Raikwar and Gligoroski [
27], whose protocol is explicitly designed to limit the interaction with the server to the verification phase (see
Figure 2). Another fundamental difference with the protocol by Raikwar and Gligoroski is the adopted crypthographic technique: Raikwar and Gligoroski opted for deterministic
verifiable delay function (VDF) [
28], while the protocol proposed in this article is based on the non-deterministic hashcash algorithm. Given the fact that the non-determinism is essentially mitigated by the use of short prefixes, as shown in
Section 5, adopting hashcash instead of VDF is justified by a simpler implementation.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
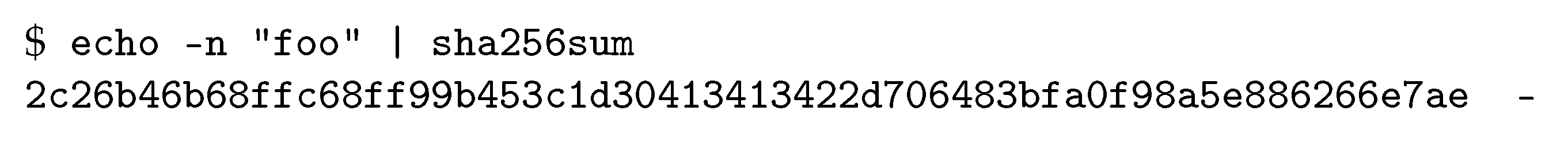{kind=link}
{kind=link}
{kind=link}
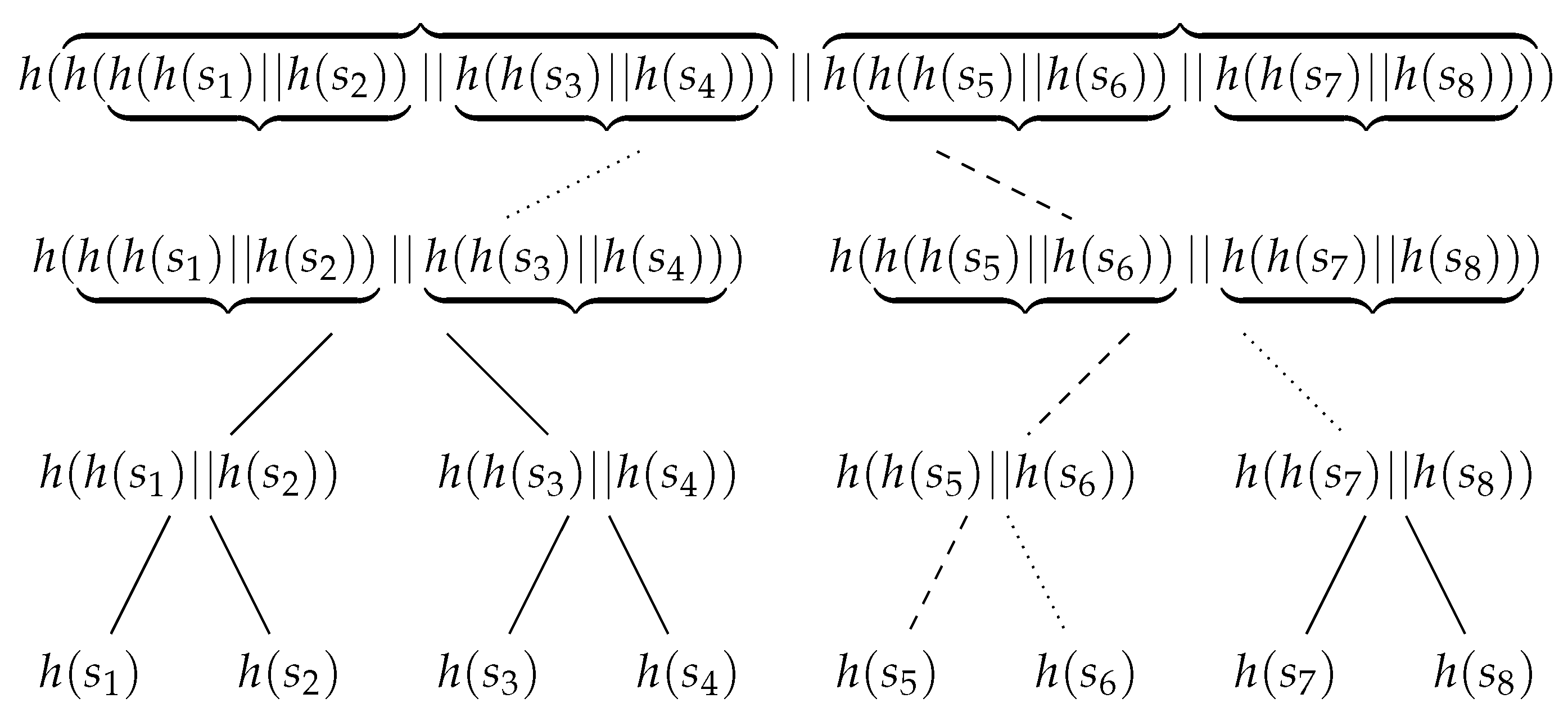{kind=link}
{kind=link}
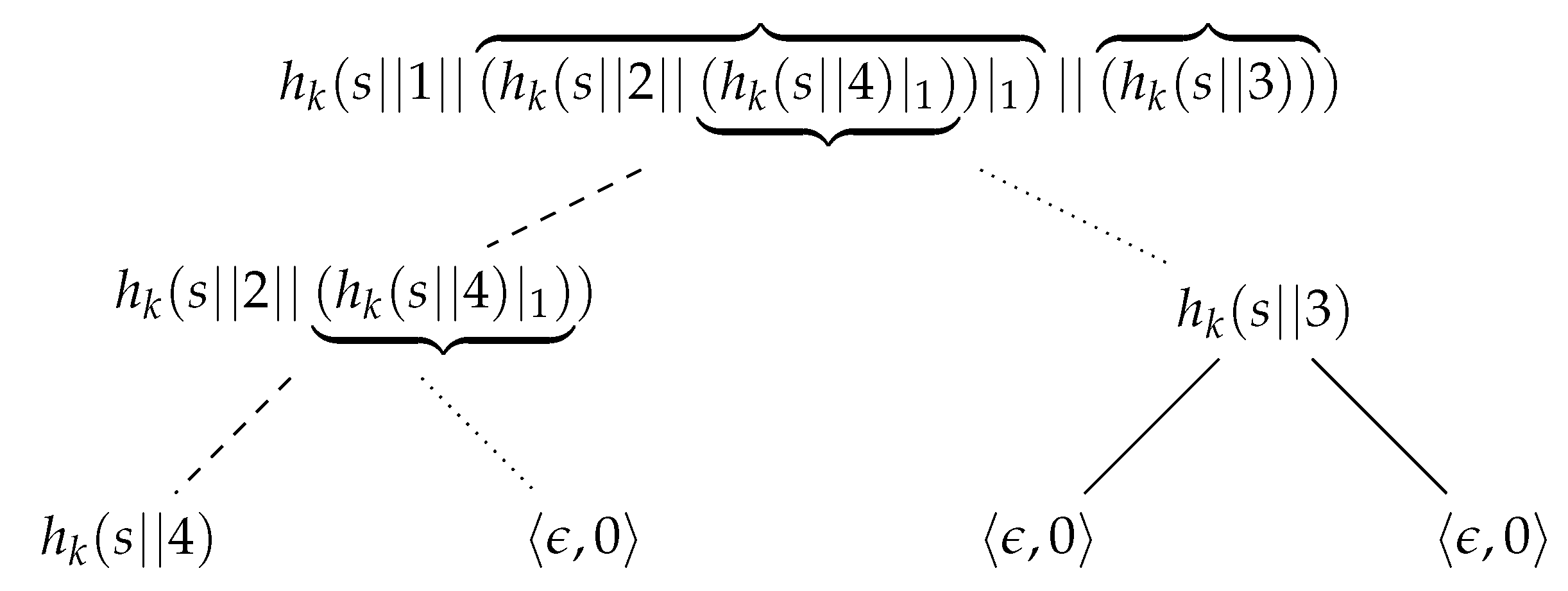{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}