
Extending Process Discovery with Model Complexity Optimization and Cyclic States Identification: Application to Healthcare Processes


 and
and 
Abstract
1. Introduction
2. Related Works
2.1. What Are Complexity and Interpretability in PM?
2.2. Towards Process Model Optimization
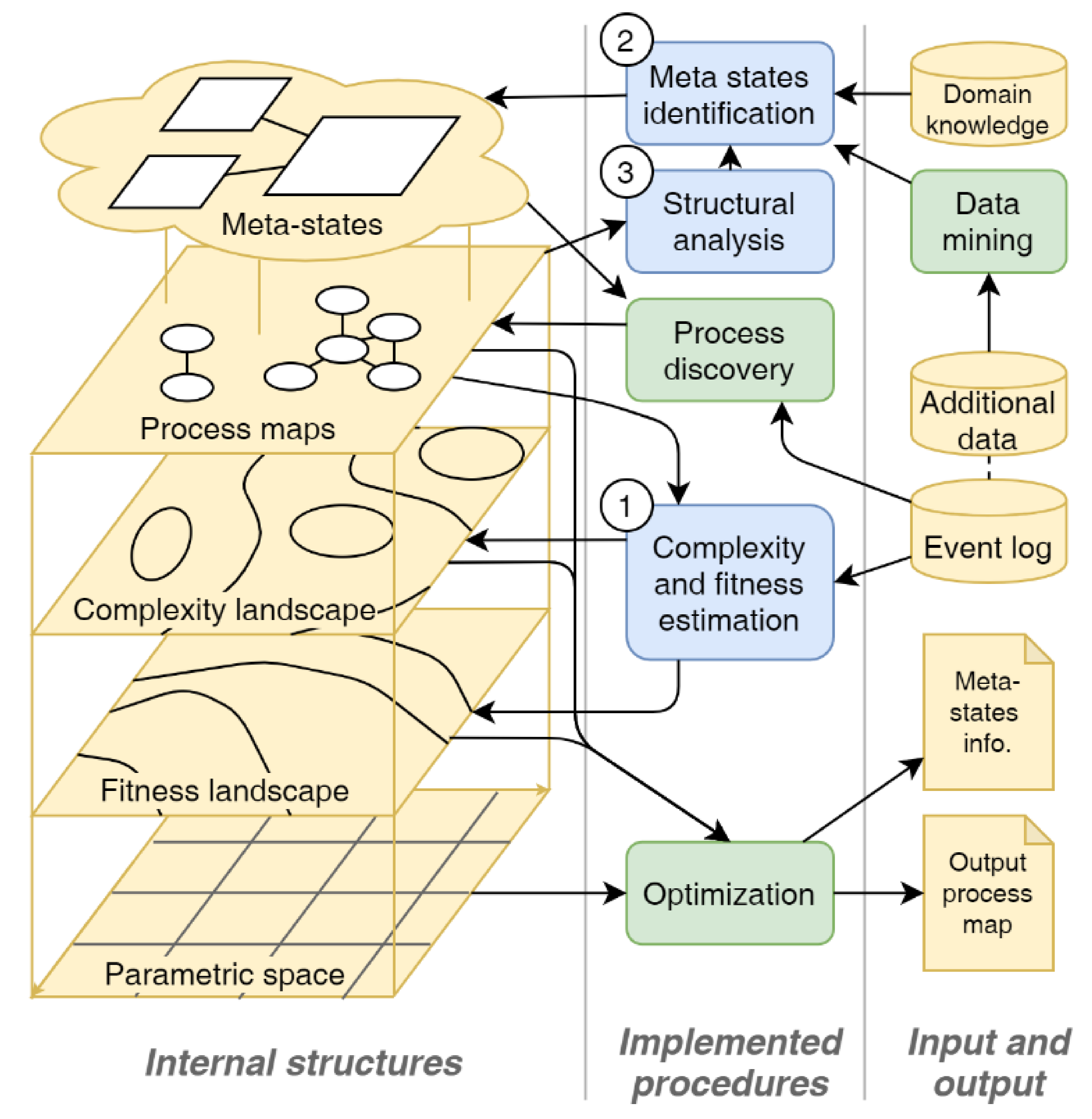
3. Conceptual Approach
3.1. Basic Idea
3.2. Process Discovery Algorithm
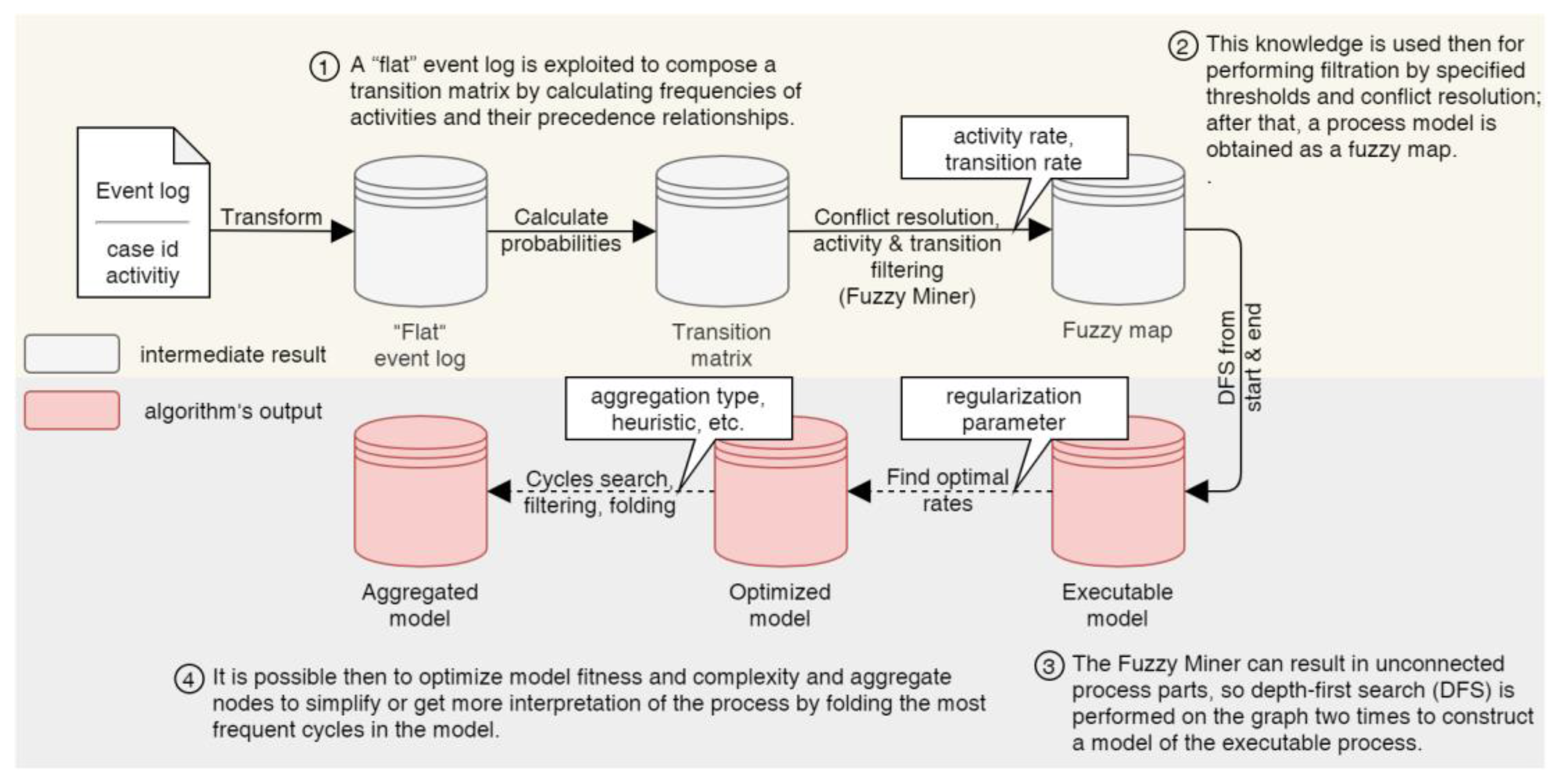
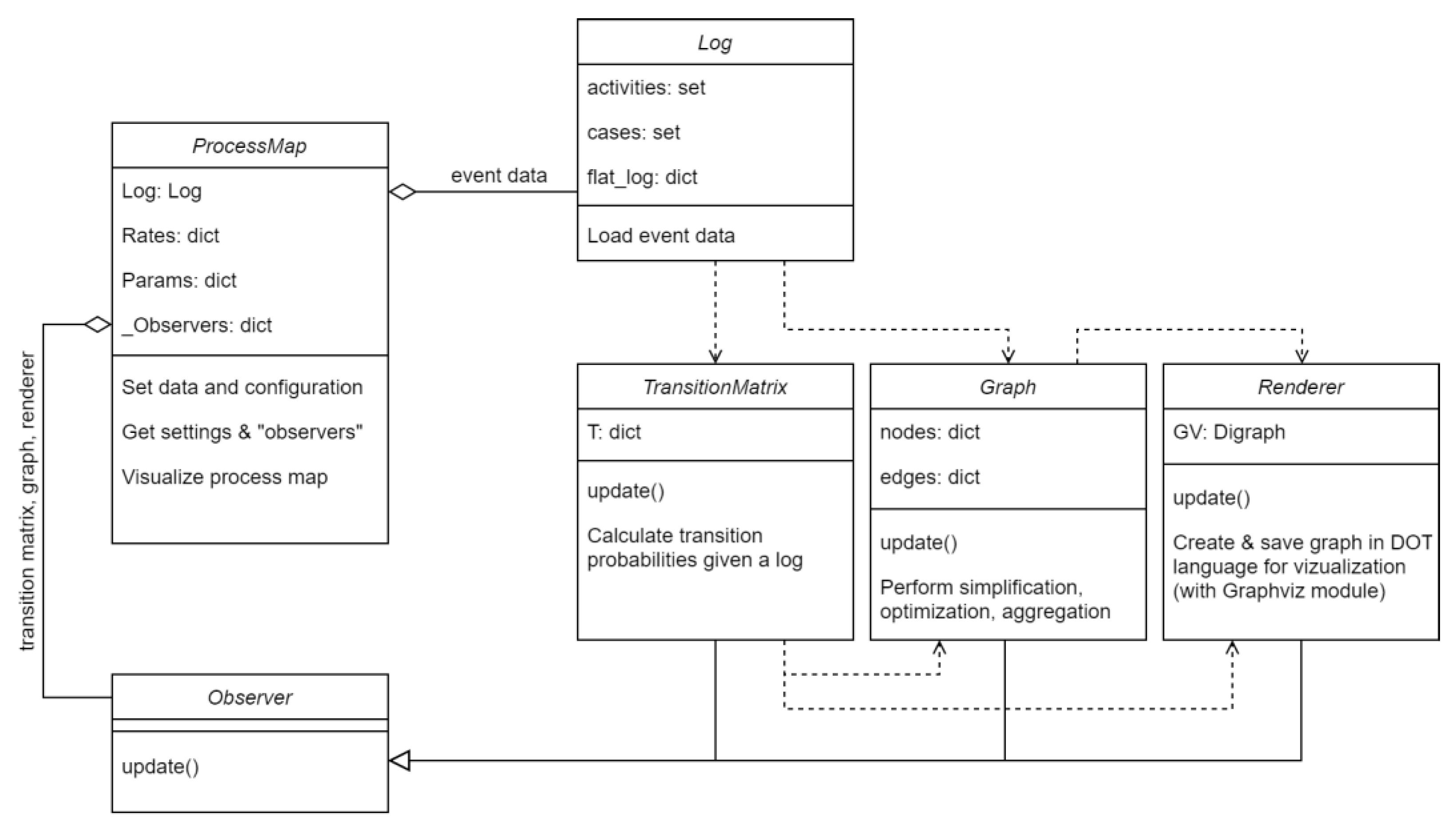
4. Implementation of the Extended Algorithm
4.1. Model Discovery
4.2. Model Optimization
- is a set of nodes, ;
- is a set of edges, ;
- is a “start” (initial) node;
- is an “end” (terminal) node;
- is an activity and transition significance defined as case frequency, a fraction of traces that contain an activity or transition:
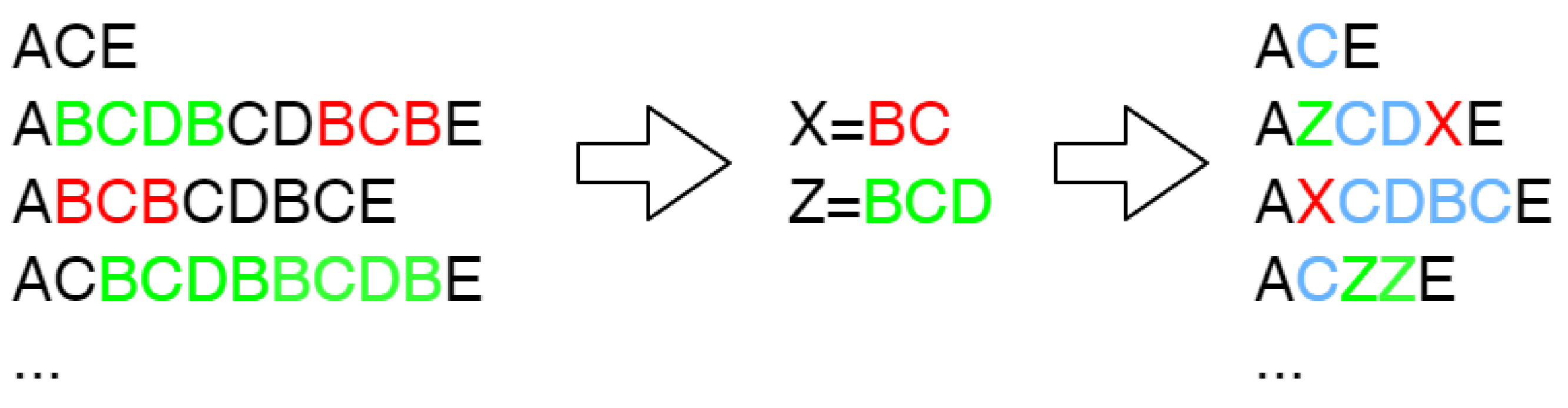
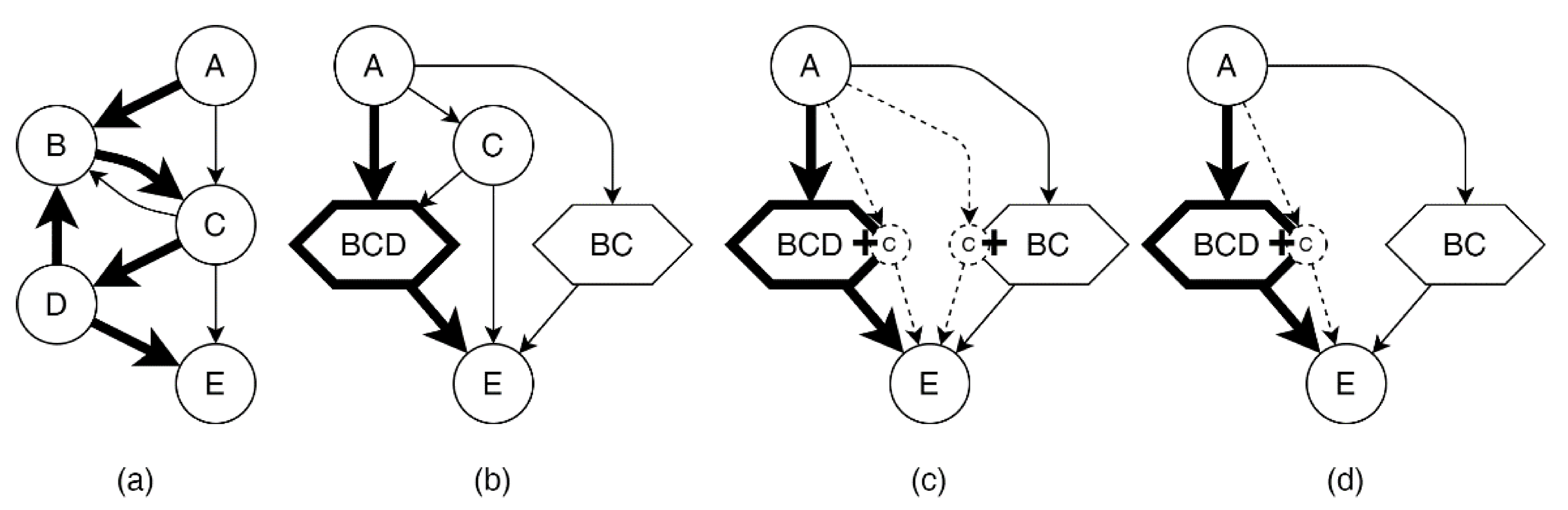
4.3. Discovering Meta-States
| Algorithm 1 Searching cycles and counting their frequencies in an event log. |
| procedure |
| Input: “Flat” event log composed of process cases |
| Output: Set of (simple) cycles found in event log , Absolute and |
| case frequencies of each cycle |
| for all cases do |
| for all unique activities do |
| while length of do |
| if then |
| // Positions of activity in case |
| end if |
| end while |
| while length of do |
| // Part of case that starts and |
| ends with activity |
| if length of = number of unique activities then |
| if then |
| k ← k + 1 |
| end if |
| // if was not found earlier within a case |
| end if |
| end while |
| end for |
| end for |
| end procedure |
| Algorithm 2 Identification of significant cycles (meta-states) in an event log. |
| procedure |
| Input: Set of (simple) cycles found in a process model by DFS; |
| Case frequency of each cycle ; |
| Number of cases in an event log; |
| Required significance of cycle to be defined as meta-state |
| Output: Set of meta-states (significant cycles) |
| for all cycles do |
| if length of then |
| if then |
| end if |
| end if |
| end for |
| end procedure |
- —meta-states, i.e., significant cycles found in the process model , and
- is a set of meta-state vertices,
- is a set of vertices not appearing in meta-states,
- is a set of edges obtained for the event log with collapsed cycles.
4.4. Software Implementation
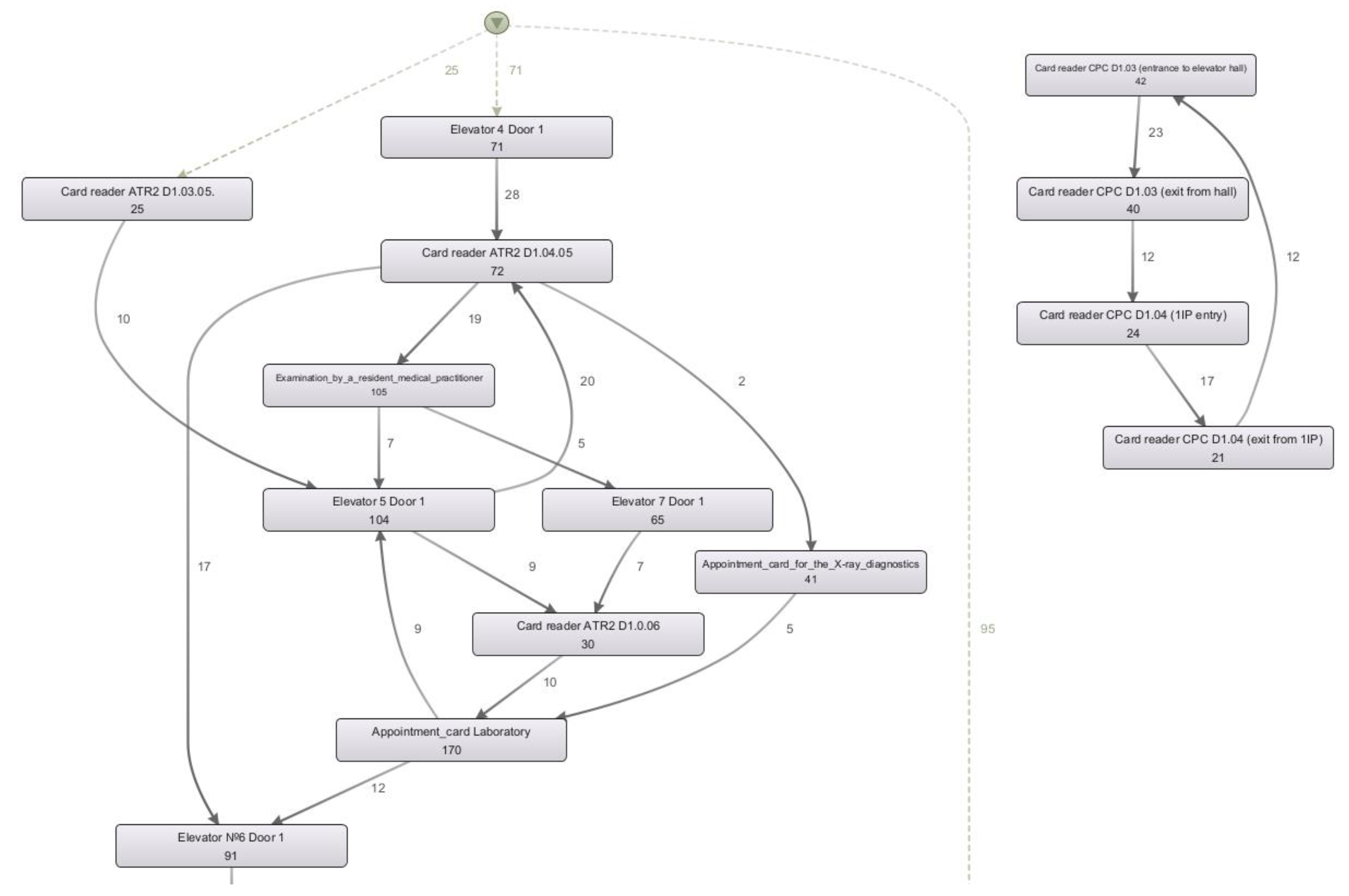
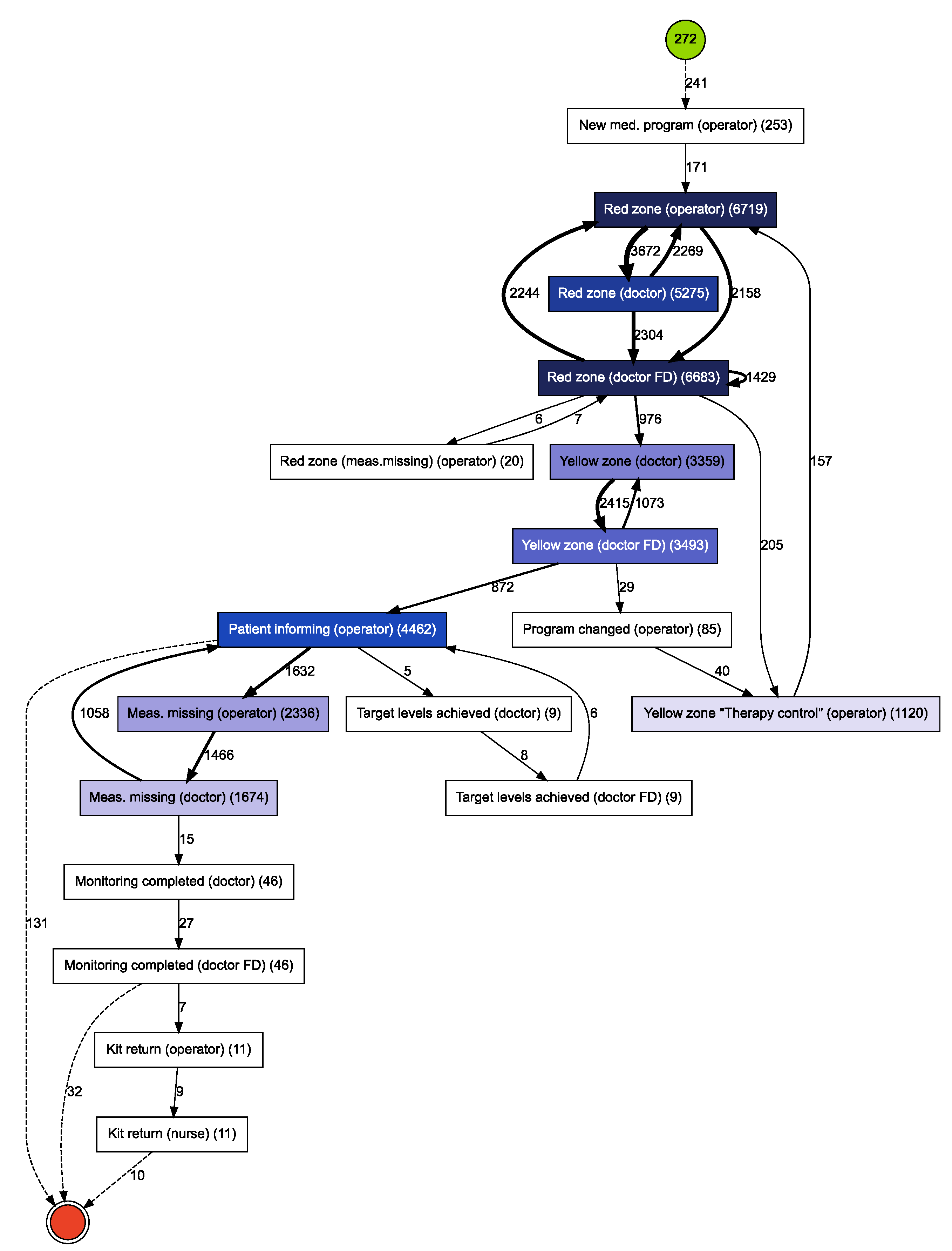
5. Experimental Study
5.1. Datasets
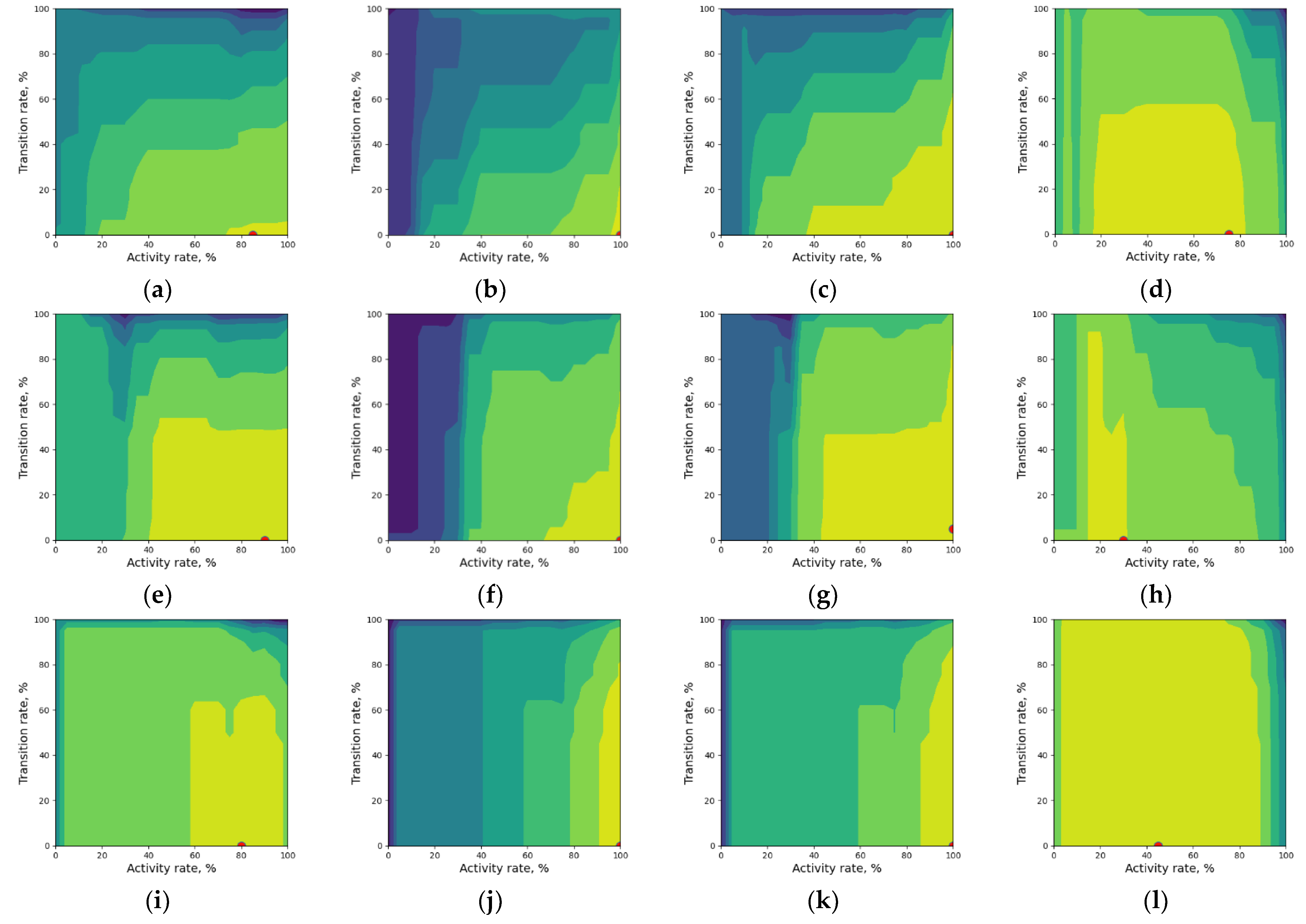
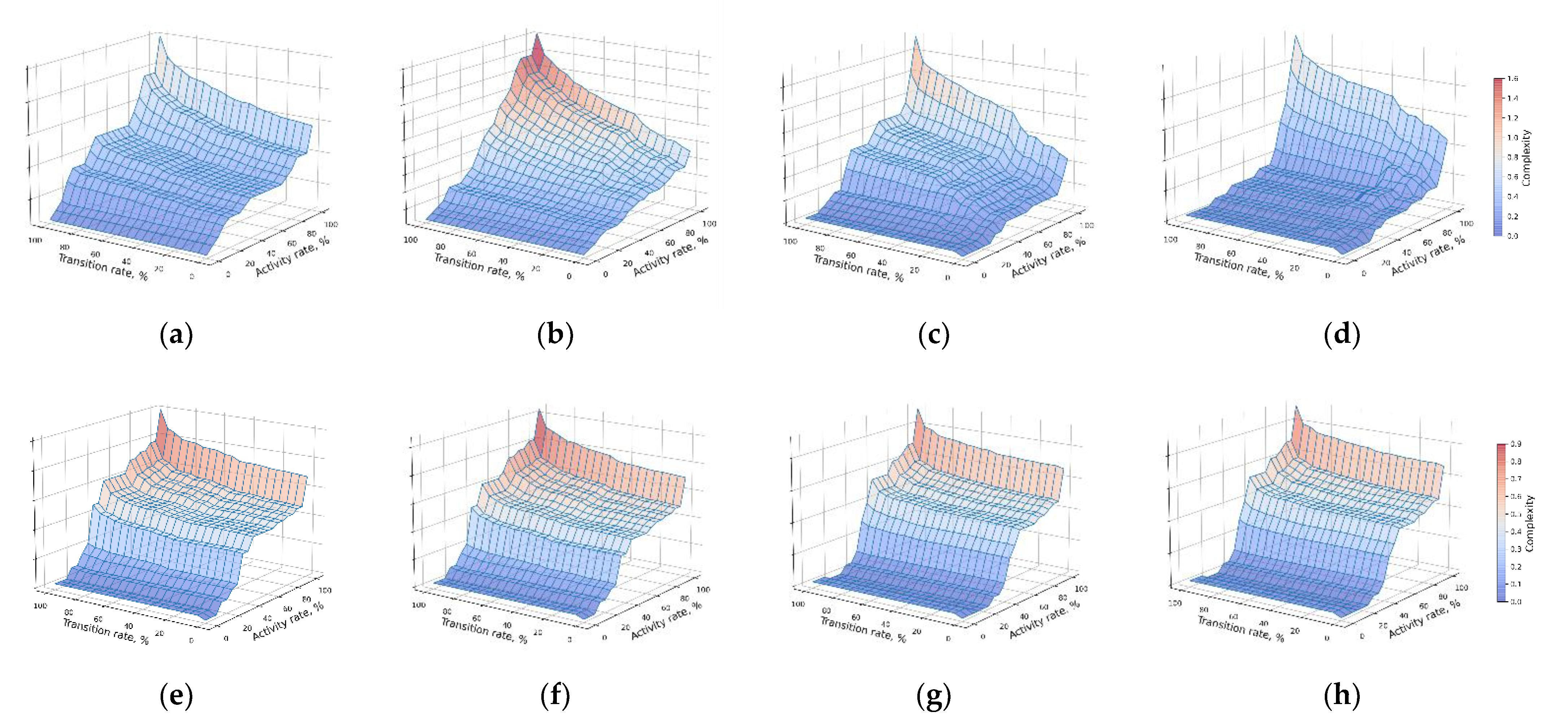
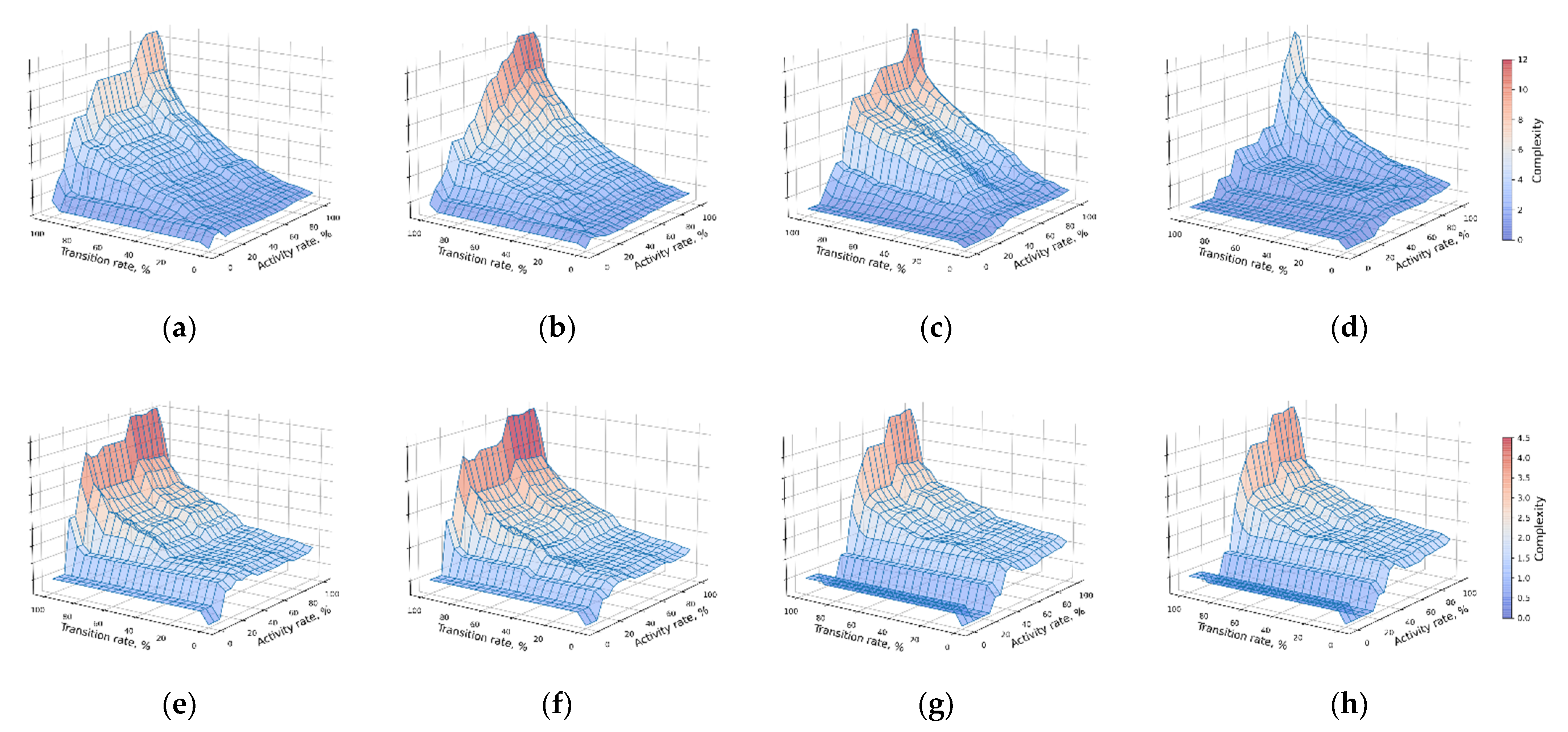
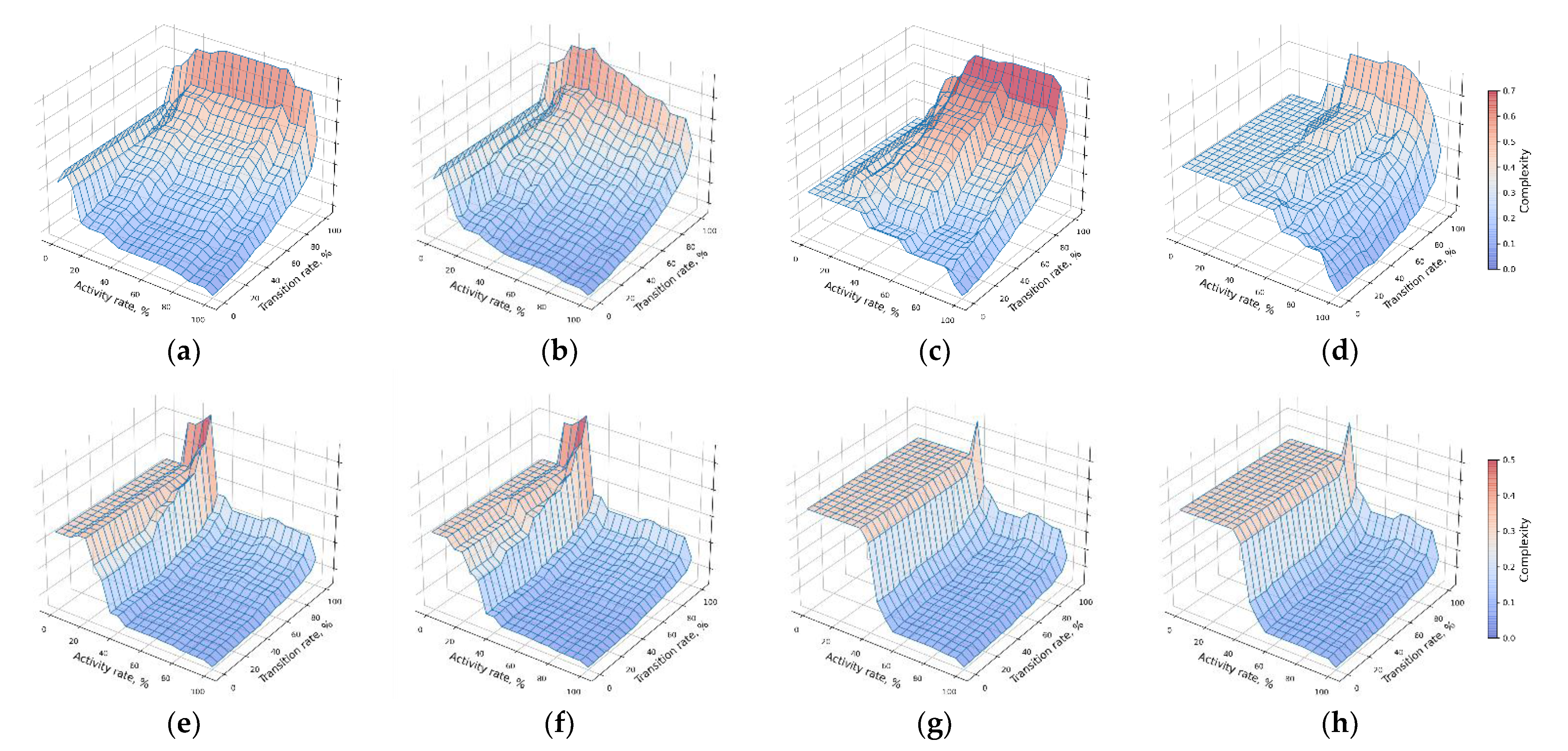
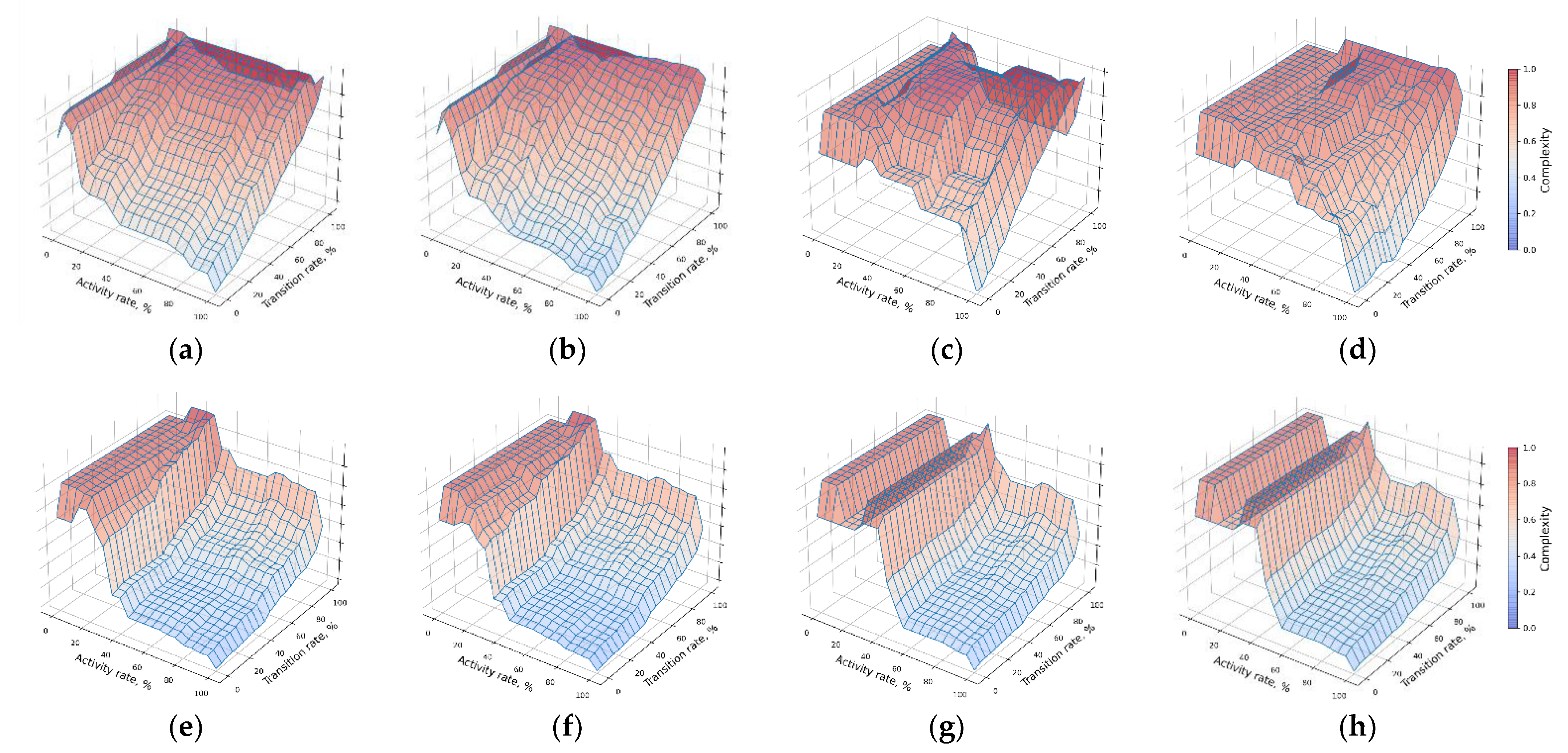
5.2. Complexity Optimization
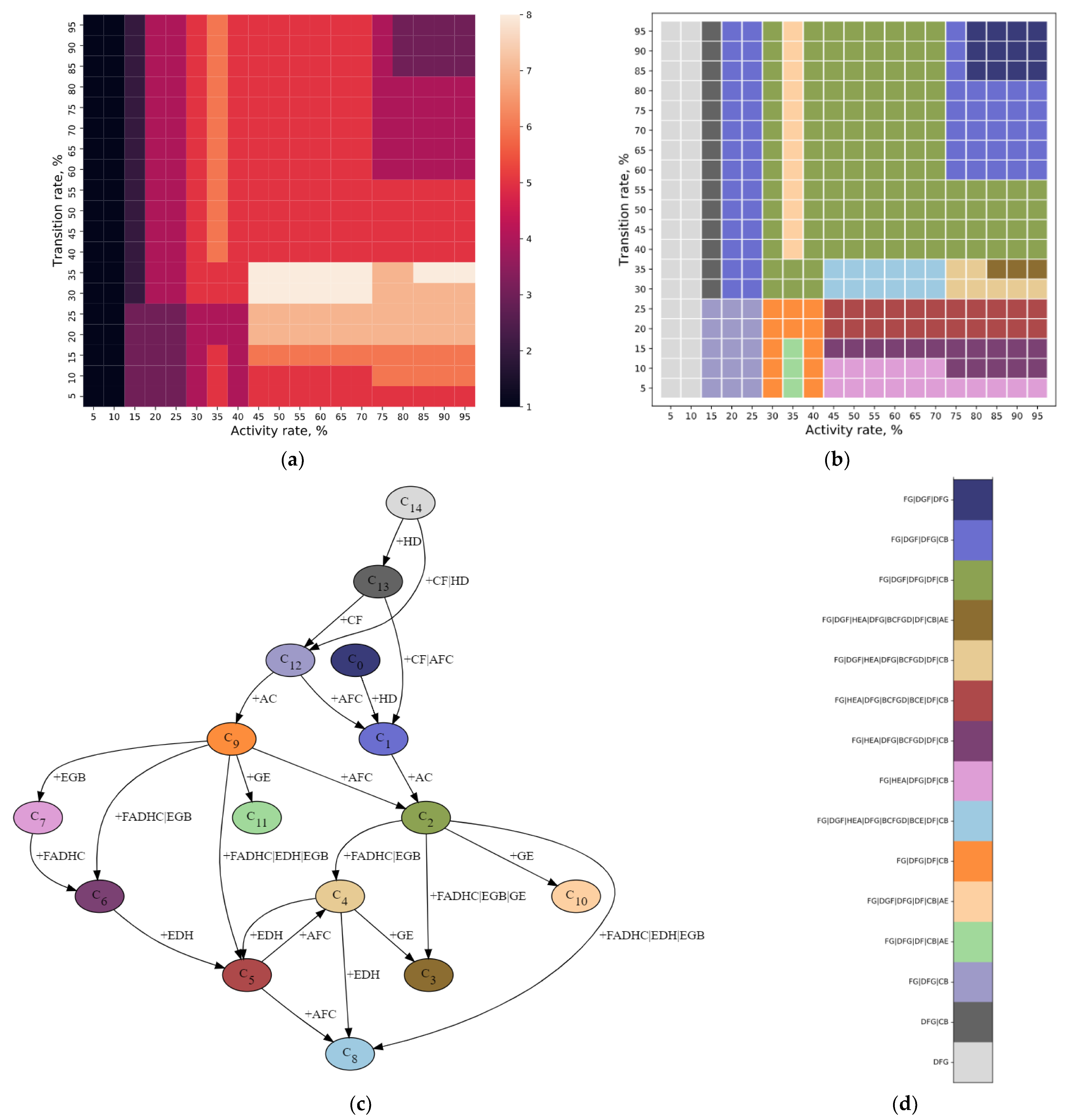
5.3. Domain Interpretation of Considered Application Scenarios
6. Discussion
7. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Van der Aalst, W. Process Mining: Data Science in Action; Springer: Berlin/Heidelberg, Germany, 2016; ISBN 9783662498514. [Google Scholar]
- dos Santos Garcia, C.; Meincheim, A.; Faria Junior, E.R.; Dallagassa, M.R.; Sato, D.M.V.; Carvalho, D.R.; Santos, E.A.P.; Scalabrin, E.E. Process mining techniques and applications—A systematic mapping study. Expert Syst. Appl. 2019, 133, 260–295. [Google Scholar] [CrossRef]
- Buijs, J.C.A.M.; Van Dongen, B.F.; Van Der Aalst, W.M.P. Quality dimensions in process discovery: The importance of fitness, precision, generalization and simplicity. Int. J. Coop. Inf. Syst. 2014, 23, 1440001. [Google Scholar] [CrossRef]
- Batista, E.; Solanas, A. Process mining in healthcare: A systematic review. In Proceedings of the 2018 9th International Conference on Information, Intelligence, Systems and Applications, IISA 2018, Zakynthos, Greece, 23–25 July 2018; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019. [Google Scholar]
- Erdogan, T.G.; Tarhan, A. Systematic Mapping of Process Mining Studies in Healthcare. IEEE Access 2018, 6, 24543–25567. [Google Scholar] [CrossRef]
- Riz, G.; Santos, E.A.P.; de Freitas Rocha Loures, E. Interoperability Assessment in Health Systems Based on Process Mining and MCDA Methods. Adv. Intell. Syst. Comput. 2017, 569, 436–445. [Google Scholar] [CrossRef]
- Martin, N.; De Weerdt, J.; Fernández-Llatas, C.; Gal, A.; Gatta, R.; Ibáñez, G.; Johnson, O.; Mannhardt, F.; Marco-Ruiz, L.; Mertens, S.; et al. Recommendations for enhancing the usability and understandability of process mining in healthcare. Artif. Intell. Med. 2020, 109, 101962. [Google Scholar] [CrossRef]
- Murdoch, W.J.; Singh, C.; Kumbier, K.; Abbasi-Asl, R.; Yu, B. Definitions, methods, and applications in interpretable machine learning. Proc. Natl. Acad. Sci. USA 2019, 116, 22071–22080. [Google Scholar] [CrossRef] [PubMed]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining Explanations: An Overview of Interpretability of Machine Learning. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; pp. 80–89. [Google Scholar]
- Mendling, J.; Reijers, H.A.; Cardoso, J. What Makes Process Models Understandable? In Business Process Management; Springer: Berlin/Heidelberg, Germany, 2007; pp. 48–63. [Google Scholar]
- Ingvaldsen, J.E.; Gulla, J.A. Industrial application of semantic process mining. Enterp. Inf. Syst. 2012, 6, 139–163. [Google Scholar] [CrossRef]
- Kinsner, W. System Complex. In Studies in Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2010; Volume 323, pp. 265–295. ISBN 9783642160820. [Google Scholar]
- Fernández-Cerero, D.; Varela-Vaca, Á.J.; Fernández-Montes, A.; Gómez-López, M.T.; Alvárez-Bermejo, J.A. Measuring data-centre workflows complexity through process mining: The Google cluster case. J. Supercomput. 2020, 76, 2449–2478. [Google Scholar] [CrossRef]
- Muketha, G.M.; Ghani, A.A.A.; Selamat, M.H.; Atan, R. A Survey of Business Process Complexity Metrics. Inf. Technol. J. 2010, 9, 1336–1344. [Google Scholar] [CrossRef]
- Figl, K. Comprehension of Procedural Visual Business Process Models: A Literature Review. Bus. Inf. Syst. Eng. 2017, 59, 41–67. [Google Scholar] [CrossRef]
- Figl, K.; Laue, R. Cognitive complexity in business process modeling. In Proceedings of the 23rd International Conference on Advanced Information Systems Engineering, London, UK, 20–24 June 2011; Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). Volume 6741, pp. 452–466. [Google Scholar]
- Cardoso, J. Business process control-flow complexity: Metric, evaluation, and validation. Int. J. Web Serv. Res. 2008, 5, 49–76. [Google Scholar] [CrossRef]
- Jung, J.-Y.; Chin, C.-H.; Cardoso, J. An entropy-based uncertainty measure of process models. Inf. Process. Lett. 2011, 111, 135–141. [Google Scholar] [CrossRef]
- Kluza, K.; Nalepa, G.J. Proposal of square metrics for measuring Business Process Model complexity. In Proceedings of the 2012 Federated Conference on Computer Science and Information Systems (FedCSIS), Wroclaw, Poland, 9–12 September 2012; pp. 919–922. [Google Scholar]
- Cardoso, J.; Mendling, J.; Neumann, G.; Reijers, H.A. A discourse on complexity of process models. In Proceedings of the 2006 International Conference on Business Process Management, Vienna, Austria, 4–7 September 2006; Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). Springer: Berlin/Heidelberg, Germany, 2006; Volume 4103, pp. 117–128. [Google Scholar]
- Suriadi, S.; Andrews, R.; ter Hofstede, A.H.M.; Wynn, M.T. Event log imperfection patterns for process mining: Towards a systematic approach to cleaning event logs. Inf. Syst. 2017, 64, 132–150. [Google Scholar] [CrossRef]
- Leonardi, G.; Striani, M.; Quaglini, S.; Cavallini, A.; Montani, S. Leveraging semantic labels for multi-level abstraction in medical process mining and trace comparison. J. Biomed. Inform. 2018, 83, 10–24. [Google Scholar] [CrossRef]
- Chiudinelli, L.; Dagliati, A.; Tibollo, V.; Albasini, S.; Geifman, N.; Peek, N.; Holmes, J.H.; Corsi, F.; Bellazzi, R.; Sacchi, L. Mining post-surgical care processes in breast cancer patients. Artif. Intell. Med. 2020, 105, 101855. [Google Scholar] [CrossRef]
- Tax, N.; Sidorova, N.; Haakma, R.; van der Aalst, W.M.P. Event abstraction for process mining using supervised learning techniques. In Lecture Notes in Networks and Systems; Springer: Cham, Switzerland, 2018; Volume 15, pp. 251–269. [Google Scholar]
- Alharbi, A.; Bulpitt, A.; Johnson, O. Improving pattern detection in healthcare process mining using an interval-based event selection method. In Proceedings of the International Conference on Business Process Management; Lecture Notes in Business Information Processing, Barcelona, Spain, 10–15 September 2017; Springer: Cham, Switzerland, 2017; Volume 297, pp. 88–105. [Google Scholar]
- vanden Broucke, S.K.L.M.; De Weerdt, J. Fodina: A robust and flexible heuristic process discovery technique. Decis. Support Syst. 2017, 100, 109–118. [Google Scholar] [CrossRef]
- Günther, C.W.; van der Aalst, W.M.P. Fuzzy Mining—Adaptive Process Simplification Based on Multi-perspective Metrics. In Proceedings of the International Conference on Business Process Management, Brisbane, Australia, 24–28 September 2007; pp. 328–343. [Google Scholar] [CrossRef]
- Batista, E.; Solanas, A. Skip Miner: Towards the Simplification of Spaghetti-like Business Process Models. In Proceedings of the 10th International Conference on Information, Intelligence, Systems and Applications, IISA 2019, Patras, Greece, 15–17 July 2019; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019. [Google Scholar]
- De Weerdt, J.; vanden Broucke, S.K.L.M.; Caron, F. Bidimensional process discovery for mining BPMN models. In Proceedings of the International Conference on Business Process Management, Eindhoven, The Netherlands, 7–8 September 2014; Lecture Notes in Business Information Processing. Springer: Cham, Switzerland, 2015; Volume 202, pp. 529–540. [Google Scholar]
- Leemans, S.J.J.; Poppe, E.; Wynn, M.T. Directly follows-based process mining: Exploration & a case study. In Proceedings of the 2019 International Conference on Process Mining, ICPM 2019, Aachen, Germany, 24–26 June 2019; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019; pp. 25–32. [Google Scholar]
- Leemans, M.; van der Aalst, W.M.P.; van den Brand, M.G.J. Hierarchical performance analysis for process mining. In Proceedings of the 2018 International Conference on Software and System Process—ICSSP’18, Gothenburg, Sweden, 26–27 May 2018; ACM Press: New York, NY, USA, 2018; pp. 96–105. [Google Scholar]
- Augusto, A.; Conforti, R.; Dumas, M.; Rosa, M. La Split miner: Discovering accurate and simple business process models from event logs. In Proceedings of the IEEE International Conference on Data Mining, ICDM, New Orleans, LA, USA, 18–21 November 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 1–10. [Google Scholar]
- Sun, H.W.; Liu, W.; Qi, L.; Du, Y.Y.; Ren, X.; Liu, X.Y. A process mining algorithm to mixed multiple-concurrency short-loop structures. Inf. Sci. 2021, 542, 453–475. [Google Scholar] [CrossRef]
- De Smedt, J.; De Weerdt, J.; Vanthienen, J. Fusion Miner: Process discovery for mixed-paradigm models. Decis. Support Syst. 2015, 77, 123–136. [Google Scholar] [CrossRef]
- Prodel, M.; Augusto, V.; Jouaneton, B.; Lamarsalle, L.; Xie, X. Optimal Process Mining for Large and Complex Event Logs. IEEE Trans. Autom. Sci. Eng. 2018, 15, 1309–1325. [Google Scholar] [CrossRef]
- Fahland, D.; Van Der Aalst, W.M.P. Simplifying discovered process models in a controlled manner. Inf. Syst. 2013, 38, 585–605. [Google Scholar] [CrossRef]
- Delias, P.; Doumpos, M.; Grigoroudis, E.; Manolitzas, P.; Matsatsinis, N. Supporting healthcare management decisions via robust clustering of event logs. Knowl.-Based Syst. 2015, 84, 203–213. [Google Scholar] [CrossRef]
- De Weerdt, J.; Vanden Broucke, S.K.L.M.; Vanthienen, J.; Baesens, B. Leveraging process discovery with trace clustering and text mining for intelligent analysis of incident management processes. In Proceedings of the 2012 IEEE Congress on Evolutionary Computation, CEC 2012, Brisbane, Australia, 10–15 June 2012. [Google Scholar]
- García-Bañuelos, L.; Dumas, M.; La Rosa, M.; De Weerdt, J.; Ekanayake, C.C. Controlled automated discovery of collections of business process models. Inf. Syst. 2014, 46, 85–101. [Google Scholar] [CrossRef]
- Becker, T.; Intoyoad, W. Context Aware Process Mining in Logistics. Procedia CIRP 2017, 63, 557–562. [Google Scholar] [CrossRef]
- Kovalchuk, S.V.; Funkner, A.A.; Metsker, O.G.; Yakovlev, A.N. Simulation of patient flow in multiple healthcare units using process and data mining techniques for model identification. J. Biomed. Inform. 2018, 82, 128–142. [Google Scholar] [CrossRef] [PubMed]
- Najjar, A.; Reinharz, D.; Girouard, C.; Gagné, C. A two-step approach for mining patient treatment pathways in administrative healthcare databases. Artif. Intell. Med. 2018, 87, 34–48. [Google Scholar] [CrossRef]
- Prodel, M.; Augusto, V.; Xie, X.; Jouaneton, B.; Lamarsalle, L. Discovery of patient pathways from a national hospital database using process mining and integer linear programming. In Proceedings of the IEEE International Conference on Automation Science and Engineering, Gothenburg, Sweden, 24–28 August 2015; IEEE Computer Society: New York, NY, USA, 2015; pp. 1409–1414. [Google Scholar]
- Camargo, M.; Dumas, M.; González-Rojas, O. Automated discovery of business process simulation models from event logs. Decis. Support Syst. 2020, 134, 113284. [Google Scholar] [CrossRef]
- De Oliveira, H.; Augusto, V.; Jouaneton, B.; Lamarsalle, L.; Prodel, M.; Xie, X. Optimal process mining of timed event logs. Inf. Sci. 2020, 528, 58–78. [Google Scholar] [CrossRef]
- Effendi, Y.A.; Sarno, R. Discovering optimized process model using rule discovery hybrid particle swarm optimization. In Proceedings of the 2017 3rd International Conference on Science in Information Technology: Theory and Application of IT for Education, Industry and Society in Big Data Era, ICSITech 2017, Bandung, Indonesia, 25–26 October 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 97–103. [Google Scholar]
- Buijs, J.C.A.M.; van Dongen, B.F.; van der Aalst, W.M.P. Discovering and navigating a collection of process models using multiple quality dimensions. In Proceedings of the International Conference on Business Process Management, Beijing, China, 26 August 2013; Lecture Notes in Business Information Processing. Springer: Cham, Switzerland, 2014; Volume 171, pp. 3–14. [Google Scholar]
- Vázquez-Barreiros, B.; Mucientes, M.; Lama, M. ProDiGen: Mining complete, precise and minimal structure process models with a genetic algorithm. Inf. Sci. 2015, 294, 315–333. [Google Scholar] [CrossRef]
- Weijters, A.J.M.M.; van der Aalst, W.M.P.; de Medeiros, A.K.A. Process Mining with the HeuristicsMiner Algorithm. Beta Work. Pap. 2006, 166, 1–34. [Google Scholar]
- Van Der Aalst, W.M.P.; De Medeiros, A.K.A.; Weijters, A.J.M.M. Genetic process mining. Lect. Notes Comput. Sci. 2005, 3536, 48–69. [Google Scholar]
- van der Aalst, W. Academic View: Development of the Process Mining Discipline. In Process Mining in Action: Principles, Use Cases and Outlook; Reinkemeyer, L., Ed.; Springer International Publishing: Cham, Switzerland, 2020; pp. 181–196. ISBN 978-3-030-40172-6. [Google Scholar]
- Van Der Aalst, W.M.P. A practitioner’s guide to process mining: Limitations of the directly-follows graph. Procedia Comput. Sci. 2019, 164, 321–328. [Google Scholar] [CrossRef]
- Leemans, S.J.J.; Fahland, D.; van der Aalst, W.M.P. Discovering Block-Structured Process Models from Event Logs Containing Infrequent Behaviour. In BPM 2013: Business Process Management Workshops; Lohmann, N., Song, M., Wohed, P., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 66–78. [Google Scholar]
- Bonchev, D.; Buck, G.A. Quantitative Measures of Network Complexity. In Complexity in Chemistry, Biology, and Ecology; Springer: Boston, MA, USA, 2005; pp. 191–235. ISBN 0387232648. [Google Scholar]
- Morzy, M.; Kajdanowicz, T.; Kazienko, P. On Measuring the Complexity of Networks: Kolmogorov Complexity versus Entropy. Complexity 2017, 2017, 3250301. [Google Scholar] [CrossRef]
- Zenil, H.; Kiani, N.; Tegnér, J. A Review of Graph and Network Complexity from an Algorithmic Information Perspective. Entropy 2018, 20, 551. [Google Scholar] [CrossRef] [PubMed]
- Zhou, B.; Carrillo-Larco, R.M.; Danaei, G.; Riley, L.M.; Paciorek, C.J.; Stevens, G.A.; Gregg, E.W.; Bennett, J.E.; Solomon, B.; Singleton, R.K.; et al. Worldwide trends in hypertension prevalence and progress in treatment and control from 1990 to 2019: A pooled analysis of 1201 population-representative studies with 104 million participants. Lancet 2021, 398, 957–980. [Google Scholar] [CrossRef] [PubMed]
- Tucker, K.L.; Sheppard, J.P.; Stevens, R.; Bosworth, H.B.; Bove, A.; Bray, E.P.; Earle, K.; George, J.; Godwin, M.; Green, B.B.; et al. Self-monitoring of blood pressure in hypertension: A systematic review and individual patient data meta-analysis. PLOS Med. 2017, 14, e1002389. [Google Scholar] [CrossRef]
- Ionov, M.V.; Zhukova, O.V.; Yudina, Y.S.; Avdonina, N.G.; Emelyanov, I.V.; Kurapeev, D.I.; Zvartau, N.E.; Konradi, A.O. Value-based approach to blood pressure telemonitoring and remote counseling in hypertensive patients. Blood Press. 2021, 30, 20–30. [Google Scholar] [CrossRef]
- Omboni, S.; Padwal, R.S.; Alessa, T.; Benczúr, B.; Green, B.B.; Hubbard, I.; Kario, K.; Khan, N.A.; Konradi, A.; Logan, A.G.; et al. The worldwide impact of telemedicine during COVID-19: Current evidence and recommendations for the future. Connect. Health 2022, 1, 7–35. [Google Scholar] [CrossRef]
- Jones, S.; Moulton, C.; Swift, S.; Molyneux, P.; Black, S.; Mason, N.; Oakley, R.; Mann, C. Association between delays to patient admission from the emergency department and all-cause 30-day mortality. Emerg. Med. J. 2022, 39, 168–173. [Google Scholar] [CrossRef]
- da Costa Sousa, V.; da Silva, M.C.; de Mello, M.P.; Guimarães, J.A.M.; Perini, J.A. Factors associated with mortality, length of hospital stay and diagnosis of COVID-19: Data from a field hospital. J. Infect. Public Health 2022, 15, 800–805. [Google Scholar] [CrossRef]
- Mannhardt, F.; de Leoni, M.; Reijers, H.A.; van der Aalst, W.M.P. Data-Driven Process Discovery—Revealing Conditional Infrequent Behavior from Event Logs. In Advanced Information Systems Engineering; Springer: Cham, Switzerland, 2017; pp. 545–560. [Google Scholar]
- Elkhovskaya, L.; Kovalchuk, S. Feature Engineering with Process Mining Technique for Patient State Predictions. Lect. Notes Comput. Sci. 2021, 12744, 584–592. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Studies | Optimization | Methods |
|---|---|---|---|
| Log pre-processing | Suriadi et al. [21], Leonardi et al. [22], Chiudinelli et al. [23], Tax et al. [24], Alharbi et al. [25], Broucke et al. [26] | ± | Outlier (events, traces) detection and removal, region-based methods for repeated tasks, topic modelling, sequence labelling |
| Behaviour filtering | Günther et al. [27], Batista et al. [28], Weerdt et al. [29], Broucke et al. [26], Leemans et al. [30,31], Augusto et al. [32], Sun et al. [33], De Smedt et al. [34] | ✓ (manual) | Activity, precedence relation, cycles, and split/join filtering; conflict resolution; attribute accounting |
| Aggregation | Suriadi et al. [21], Günther et al. [27], Leemans et al. [31], Prodel et al. [35], Fahland et al. [36] | ± | Hierarchical event structure (e.g., ICD-10 codes, software code architecture), correlation metrics, model construction folding |
| Clustering | Delias et al. [37], Weerdt et al. [38], García-Bañuelos et al. [39], Becker et al. [40], Funkner et al. [41], Najjar et al. [42] | ± | Trace and event clustering |
| Optimization problem | Prodel et al. [35,43], Camargo et al. [44], De Oliveira et al. [45], Effendi et al. [46], Buijs et al. [47], Vázquez-Barreiros et al. [48] | ✓ | Linear programming, Pareto optimality, particle swarm optimization, etc. |
| Monitoring Process | Nurse Workflow | Physician Workflow | ||
|---|---|---|---|---|
| Num. of cases | 272 | 165 | 43 | |
| Event classes | Clinical Non-clinical | Lab tests and Follow-up Triage duties | Appointments COVID-19 treatment | |
| Num. of unique events | 18 | 19 | 29 | |
| Total num. of events | 35,611 | 1042 | 1077 | |
| Case length | Max | 674 | 33 | 61 |
| Min | 3 | 1 | 1 | |
| Mean | 131 | 6 | 25 | |
| Record duration | 355 days | 454 days | 377 days | |
| Monitoring Process | Nurse Workflow | Physician Workflow | ||
|---|---|---|---|---|
| Num. of elements (activities/transitions) | Upper boundary (100/100) | 20/176 | 21/69 | 31/139 |
| Lower boundary (0/0) | 4/4 | 4/3 | 3/2 | |
| Total num. of cycles | Max | 498 | 3 | 107 |
| Min | 1 | 0 | 0 | |
| Mean | 102 | 0 | 18 | |
| Num. of significant cycles | Max | 10 | 0 | 1 |
| Min | 1 | 0 | 0 | |
| Mean | 7 | 0 | 1 | |
| Monitoring Process | Nurse Workflow | Physician Workflow | |
|---|---|---|---|
| No optimization |  |  |  |
| Optimization, no aggregation |  |  |  |
| Optimization, best aggregation |  |  |  |
| Monitoring Process | Nurse Workflow | Physician Workflow | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Agg. | NA | O | NA | O | NA | O | ||||||||
| 50/50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | ||
| 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | |||
| 0.91 | 0.91 | 0 | 0 | 0.64 | 0.64 | 0.64 | 0.64 | 0.93 | 0.93 | 0.40 | 0.40 | |||
| 2.73 | 3.13 | 5.09 | 1.60 | 1.00 | 1.00 | 1.00 | 1.00 | 1.85 | 1.90 | 1.80 | 1.80 | |||
| 0.80 | 0.74 | 1.00 | 0.90 | 0.54 | 0.54 | 0.54 | 0.54 | 0.44 | 0.45 | 0.53 | 0.53 | |||
| 0.25 | 0.20 | 0.48 | 0.35 | 0.14 | 0.14 | 0.14 | 0.14 | 0.09 | 0.10 | 0.12 | 0.12 | |||
| 0.34 | 0.50 | 0.40 | 0.10 | 0.21 | 0.21 | 0.21 | 0.21 | 0.45 | 0.45 | 0.32 | 0.32 | |||
| Optimized | 85 | 85 | 85 | 85 | 80 | 80 | 80 | 80 | 90 | 90 | 90 | 90 | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| 0.96 | 0.97 | 0.02 | 0.02 | 0.85 | 0.85 | 0.85 | 0.85 | 0.97 | 0.97 | 0.54 | 0.54 | |||
| 1.40 | 1.53 | 1.29 | 1.29 | 1.17 | 1.17 | 1.17 | 1.17 | 1.43 | 1.42 | 1.50 | 1.50 | |||
| 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| 0.96 | 0.97 | 0.07 | 0.07 | 0.99 | 0.99 | 0.99 | 0.99 | 0.98 | 0.98 | 0.54 | 0.54 | |||
| 0.38 | 0.34 | 0.44 | 0.44 | 0.40 | 0.40 | 0.40 | 0.40 | 0.29 | 0.28 | 0.30 | 0.30 | |||
| 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5 | 5 | 5 | 5 | |||
| 0.96 | 0.97 | 0.07 | 0.07 | 0.99 | 0.99 | 0.99 | 0.99 | 0.98 | 0.98 | 0.55 | 0.55 | |||
| 0.08 | 0.07 | 0.10 | 0.10 | 0.08 | 0.08 | 0.08 | 0.08 | 0.05 | 0.05 | 0.06 | 0.06 | |||
| 75 | 75 | 75 | 75 | 45 | 45 | 45 | 45 | 30 | 30 | 30 | 30 | |||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| 0.94 | 0.95 | 0.02 | 0.02 | 0.64 | 0.64 | 0.64 | 0.64 | 0.62 | 0.62 | 0.06 | 0.06 | |||
| 0.32 | 0.46 | 0.16 | 0.13 | 0.21 | 0.21 | 0.21 | 0.21 | 0.14 | 0.14 | 0.04 | 0.04 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elkhovskaya, L.O.; Kshenin, A.D.; Balakhontceva, M.A.; Ionov, M.V.; Kovalchuk, S.V. Extending Process Discovery with Model Complexity Optimization and Cyclic States Identification: Application to Healthcare Processes. Algorithms 2023, 16, 57. https://doi.org/10.3390/a16010057
Elkhovskaya LO, Kshenin AD, Balakhontceva MA, Ionov MV, Kovalchuk SV. Extending Process Discovery with Model Complexity Optimization and Cyclic States Identification: Application to Healthcare Processes. Algorithms. 2023; 16(1):57. https://doi.org/10.3390/a16010057
Chicago/Turabian StyleElkhovskaya, Liubov O., Alexander D. Kshenin, Marina A. Balakhontceva, Mikhail V. Ionov, and Sergey V. Kovalchuk. 2023. "Extending Process Discovery with Model Complexity Optimization and Cyclic States Identification: Application to Healthcare Processes" Algorithms 16, no. 1: 57. https://doi.org/10.3390/a16010057
APA StyleElkhovskaya, L. O., Kshenin, A. D., Balakhontceva, M. A., Ionov, M. V., & Kovalchuk, S. V. (2023). Extending Process Discovery with Model Complexity Optimization and Cyclic States Identification: Application to Healthcare Processes. Algorithms, 16(1), 57. https://doi.org/10.3390/a16010057