1. Introduction
Machine learning seeks to develop techniques for building models that can accurately and efficiently predict unseen data based on a given training dataset. It is widely used in the areas of computer vision, natural language processing, and many other fields. There is a growing demand for cloud-based machine learning services, where users can upload query data and get back their predicted result. However, these classifiers sometimes require access to sensitive data, raising concerns about the security and privacy of the query data. For example, a client may have to reveal their entire medical record to the diagnosis server. Any leak of such data can have severe repercussions, and it is crucial to ask whether this prediction service can run without revealing any information. Similarly, the model is the result of dedicated research, with considerable effort and resources expended in its development cycle. It is a valuable asset for an organization; exposing it is not an option. Furthermore, recent work [
1] shows that models are susceptible to inversion attacks, which recover information about the training data when given access to the model. Therefore, machine learning as a service protocol is only secure if, after execution, the client only learns the result, and the server learns nothing.
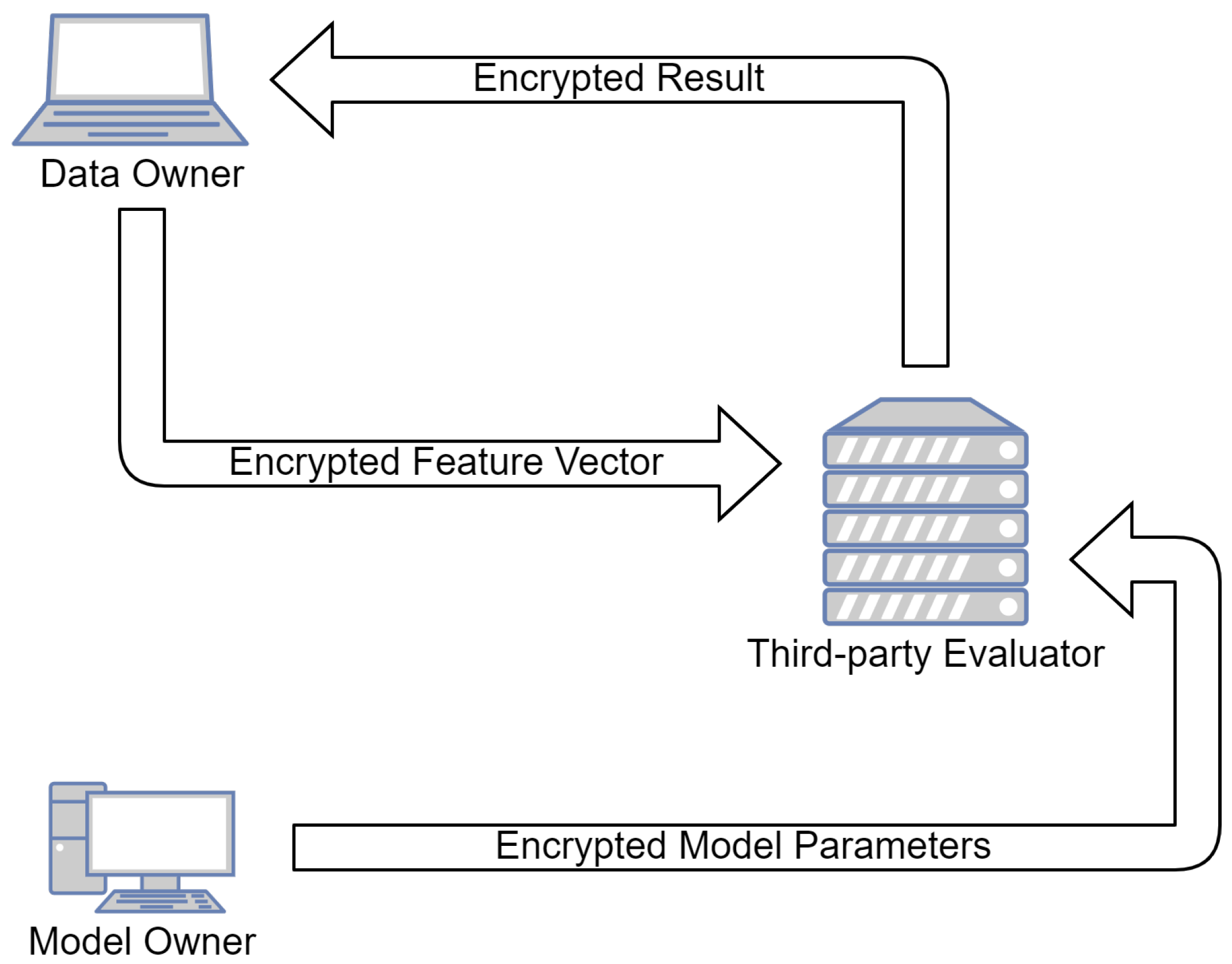
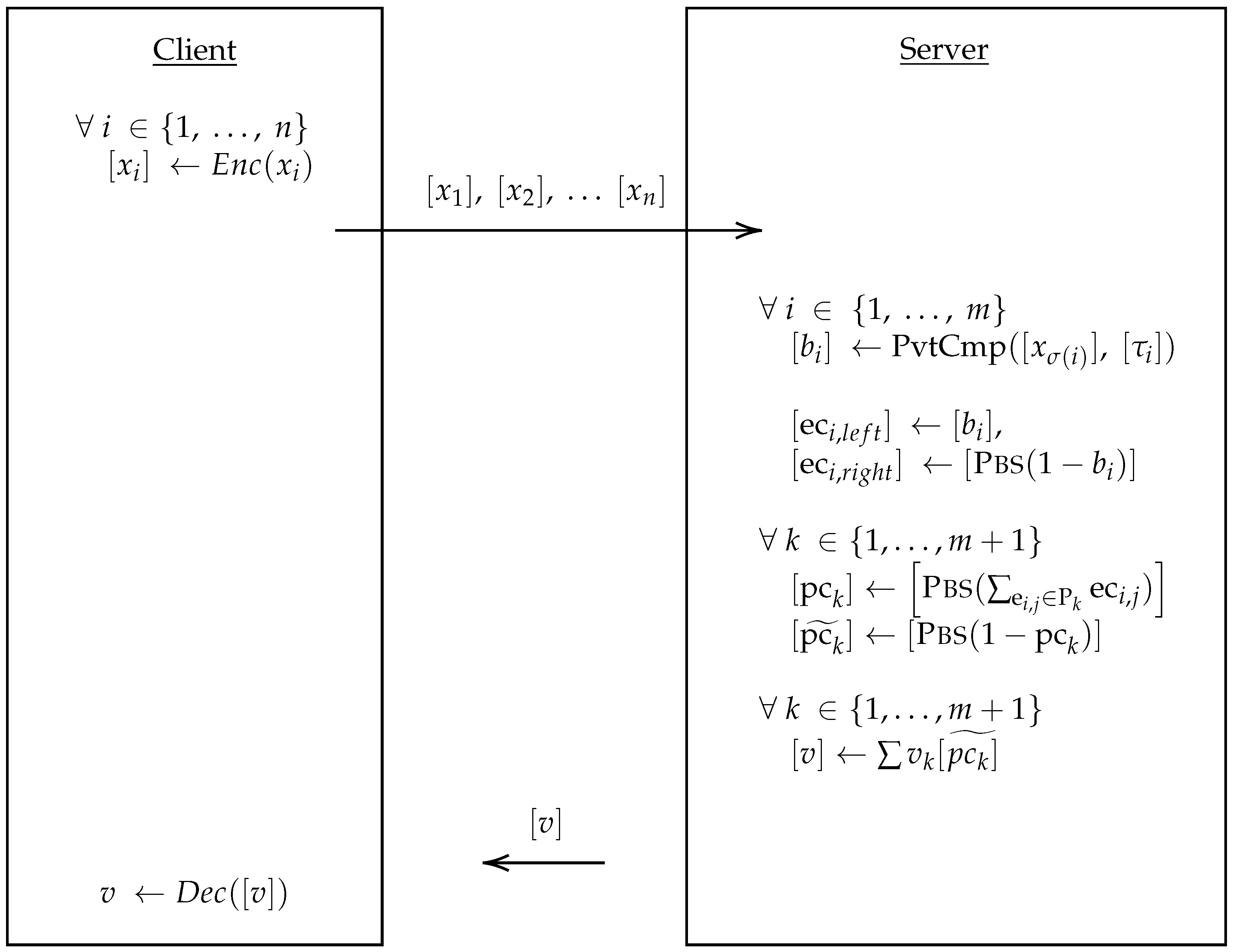
A decision tree is a classifier that is more efficient when the data have a hierarchical structure. It is a binary tree storing a threshold in each branching node and a classification result in the leaf nodes. The classifier compares the thresholds with the feature vector elements and decides which node to traverse. This level-by-level traversal continues until it arrives at some leaf node representing the classification result. A decision tree requires less parameter tuning and training cost than other classifiers, such as neural networks. In this work, we focus on privacy-preserving classification using a decision tree. The secure evaluation of the decision tree involves the data owner, the model owner and a third-party evaluator, such as a cloud server. The model owner encrypts the model, and the data owner encrypts the feature vector. A third-party evaluator, such as a public cloud service, evaluates the query using the encrypted model parameters and returns the result, which the data owner decrypts, as shown in
Figure 1. The main challenge in secure evaluation is to have an efficient way to compare the thresholds with the feature vector securely. We propose a secure comparison algorithm using fully homomorphic encryption (FHE) [
2] and a decision tree evaluation protocol that preserves all the functionality without compromising the privacy of the data and model owners.
This work aims to design and implement a private decision tree evaluation protocol that is both efficient and non-interactive. To this end, we propose a new non-interactive private comparison method that allows its output to be further used in the decision tree evaluation. This method can compare two encrypted integers,
a and
b, and return a ciphertext that decrypts to 1 if
and 0 otherwise. We encrypt each nibble of integer
a and
b using the fully homomorphic encryption over the torus (TFHE) [
3] scheme, and then we compare the encrypted nibbles using programmable bootstrapping [
4]. Since the TFHE scheme supports bootstrapping, we can use the encrypted output in further homomorphic operations. This method’s non-interactive property is used in the non-interactive private decision tree evaluation protocol. In this protocol, we use our private comparison method to compare the thresholds of the decision tree with the feature vector elements. Then, we use the output of the private comparison method to traverse the decision tree to evaluate the classification result. We implemented and conducted rigorous experiments to study the effect of different bit lengths to assess scalability. We also conducted experiments with decision trees trained with real datasets from the UCI machine learning repository [
5] and compared them with the existing protocols.
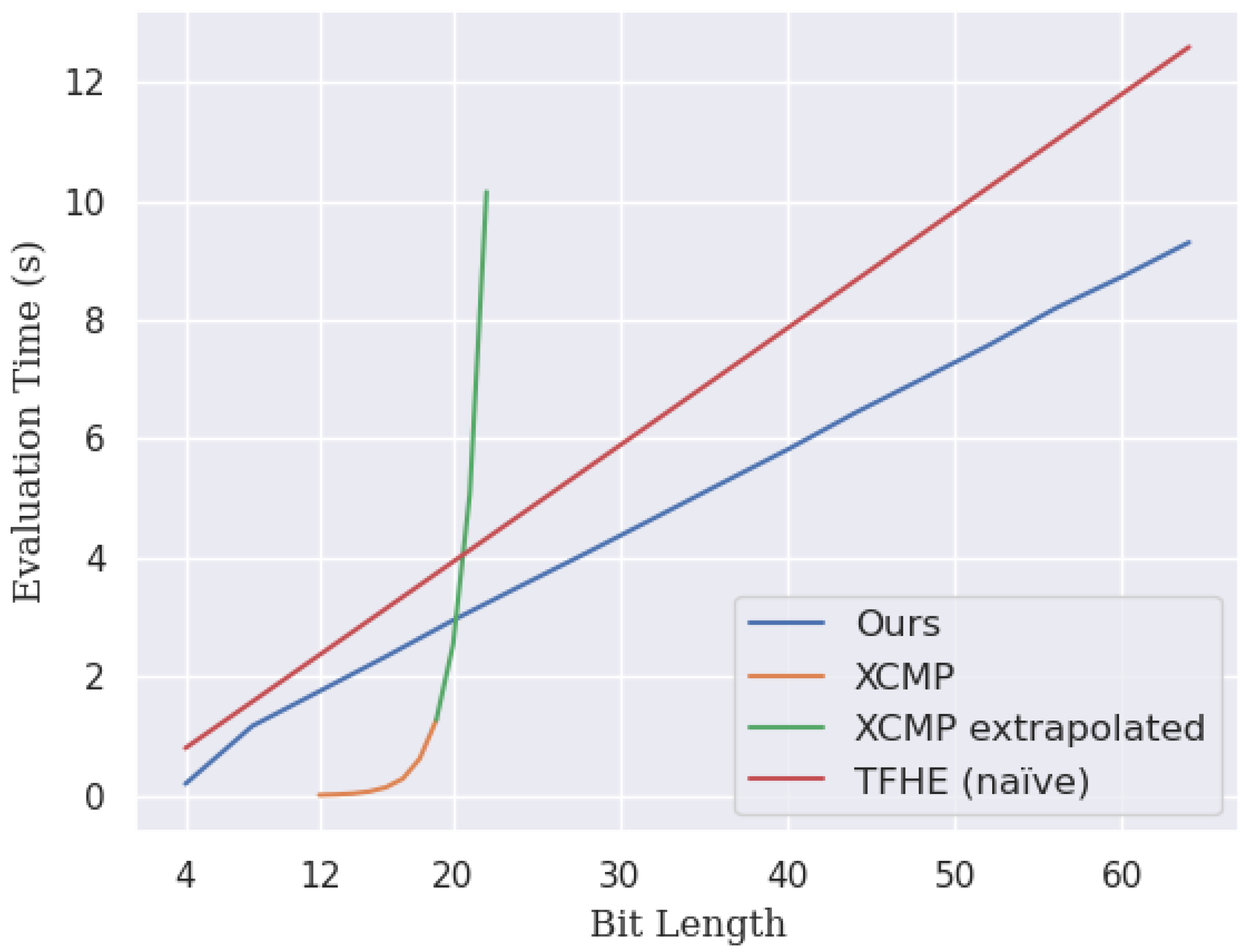
Existing approaches to the comparison of encrypted integers are not suitable for our purpose. The performance of bit-wise comparison operation using naive TFHE encryption is very slow and grows linearly with bit length. The state-of-the-art comparison operation using XCMP [
6] only performs well for integers with a small bit length and grows exponentially with bit length. Even though the comparison operation proposed by Iliashenko et al. [
7] can make the comparison for arbitrary length, it is hard to accelerate the comparison operation, as it is not using a
-cyclotomic polynomial. It also does not support the bootstrapping needed for our decision tree evaluation protocol. Therefore, we propose the first multi-bit comparison method using the TFHE scheme to compare integers.
In summary, we make the following improvements to the existing protocols:
Our private comparison method operates on two encrypted inputs with 128-bit security, facilitating the use of third-party evaluators, such as the public cloud. The performance of our method scales linearly with the input bit length and the depth of the decision tree.
Our decision tree evaluation protocol is non-interactive, where the client sends encrypted input and receives the encrypted output. There is no other interaction between the client and the server.
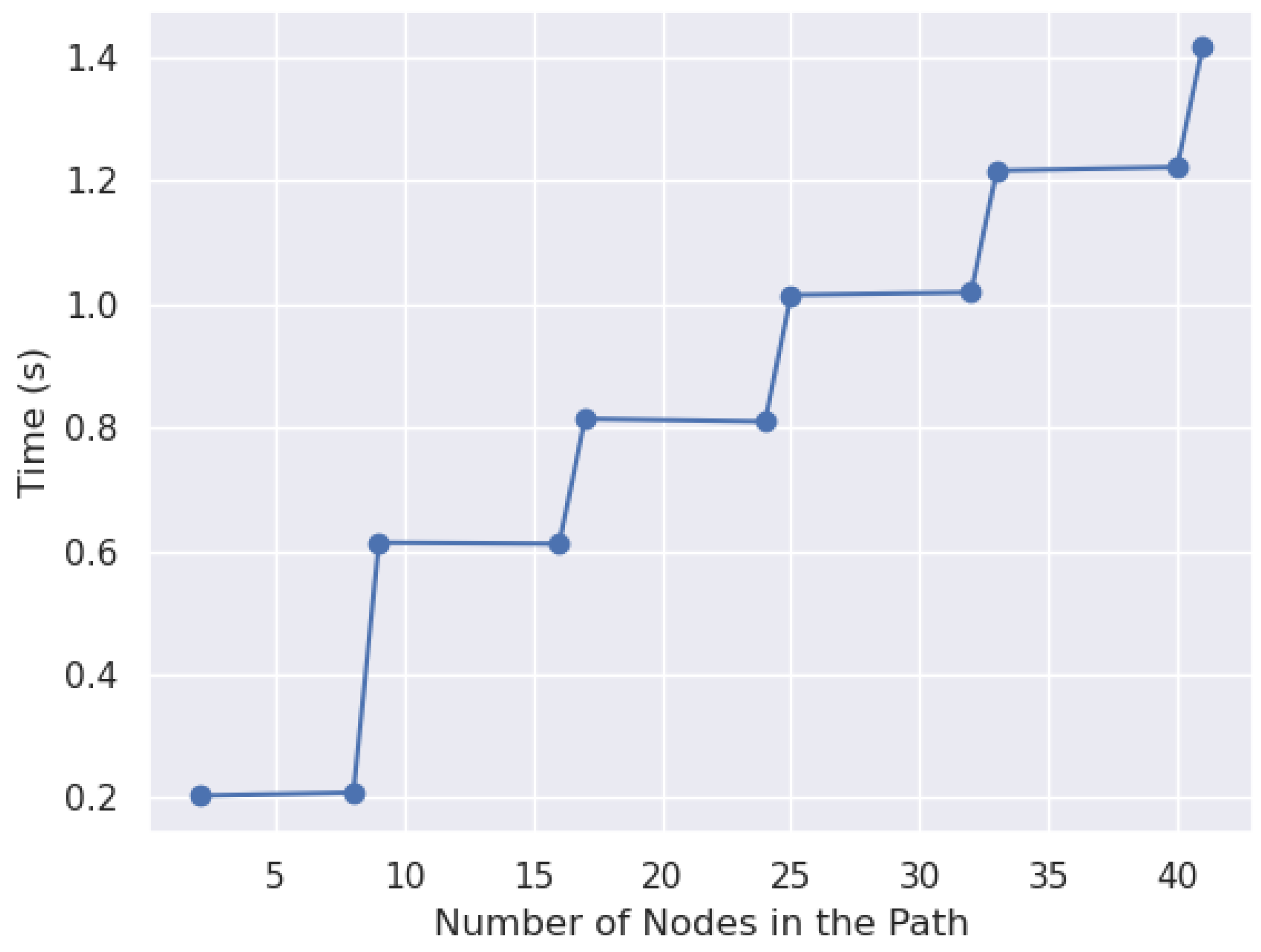
Experimentally evaluated the effect of bit lengths to assess the scalability of our method compared to other methods.
In our implementation, we conducted experiments with decision trees trained with widely used real datasets from the UCI machine learning repository [
5] and compared them with the existing protocols.
The final output of the protocol consists of a ciphertext that decrypts the classification result. This can be extended to the decision tree returning categorical values, using one-hot encoding. The results from multiple decision trees can be combined to evaluate random forest classification.
The rest of the paper is organized as follows. The next section discusses related work on secure decision tree evaluation and integer comparison.
Section 3 introduces the main ideas in fully homomorphic encryption and decision tree evaluation. Using an enhanced comparison protocol,
Section 4 and
Section 5 propose a new method for evaluating decision trees in a privacy-preserving manner. The computational complexity and performance are discussed in
Section 6. Finally,
Section 7 concludes the paper.
2. Related Work
Earlier works [
8,
9] focus on securely constructing the decision tree using data mining techniques on joint data without sharing the participant’s data. With the advent of cloud computing, privacy-preserving decision tree evaluation has become increasingly important. Generic secure multiparty computation protocols, such as Yao’s garbled circuits [
10], were proposed for this problem. However, this approach requires one party to create the circuit and the other to evaluate it, resulting in the client participating in the computation. It also incurs high communication costs.
Specialized protocols for the private evaluation of decision trees were subsequently developed that only used generic methods as and when needed. Brickell et al. [
11] and Barni et al. [
12] proposed a secure protocol for linear branching programs that utilizes both garbled circuits and homomorphic encryption. After that, new interactive protocols were built for decision tree evaluation using a combination of fully homomorphic encryption (FHE), oblivious transfer (OT), and somewhat homomorphic encryption (SHE), requiring multiple rounds of communication. All suffer from high communication and computation overhead. These protocols also do not allow the model to be shared with an evaluator without leaking the model.
Order-preserving encryption (OPE) was proposed by Agrawal et al. [
13] and is a type of encryption scheme that preserves the order relationship between plaintexts. Boneh et al. [
14] proposed the order-revealing encryption (ORE) scheme, which uses multi-linear maps to generalize OPE. Even though these schemes look appealing for integer comparison operation, their order-revealing nature results in the leakage of plaintext from ciphertext using frequency analysis and is vulnerable to inference attacks [
15].
Efficient homomorphic encryption-based integer comparison methods, such as the DGK protocol [
16,
17,
18], compare an encrypted integer with a plaintext integer. Multiple rounds of interaction during protocol execution are required for methods such as that of Bost et al. [
19]. The comparison operation from Illashenko et al. [
7] does not support bootstrapping and is unsuitable for our purpose. The current state-of-the-art non-interactive integer comparison protocol XCMP [
6] has a limitation on the bit length of the inputs.
3. Preliminaries
This section presents some fundamental concepts used in the rest of the paper. In particular, we describe and revisit the TFHE encryption scheme and decision tree structure before applying it in privacy-preserving decision tree evaluation. Further, we discuss a combinational digital circuit that comprises comparators and multiplexers.
3.1. Fully Homomorphic Encryption
Homomorphic encryption, unlike traditional encryption, allows the user to operate on ciphertexts securely. A fresh homomorphic encryption ciphertext is a summation of the plaintext
, a mask
which is removable using the secret key, and an initial noise which can be removed using the modulus
p operations. The initial noise is usually sampled from discrete Gaussian distribution and is small in terms of the coefficient’s size. Whenever we perform a homomorphic operation, we add additional noise to the ciphertexts. At some point, if the noise becomes too big, we will not be able to decrypt the ciphertext successfully. In this paper, we use a fully homomorphic encryption scheme, where the ciphertext is refreshed using the bootstrapping technique to reduce the noise level whenever it exceeds a certain threshold. We choose the TFHE scheme [
3] to implement our algorithms, as its bootstrapping technique is programmable to evaluate complex functions.
Gentry [
2] defines
Bootstrapping as a technique to reduce the noise in the ciphertext when it grows beyond a specific limit. It is done using a bootstrapping key, which is nothing but the encryption of a secret key using another secret key, i.e.,
. Given a ciphertext
corresponding to encryption of plaintext
m, then
. Let
be a function which decrypts a ciphertext given a secret key
x. Let
be the decryption using the bootstrapping key
.
Hence, is another encryption of the same message m, but with a lower noise level.
Let us denote
as the real torus.
is the real torus modulo
q.
is the integer subset
. We use the notation
to denote that
a is sampled uniformly at random from a set
S. Similarly,
denotes sampling from a probability distribution
. For a real number
x,
denotes the nearest integer to
x. The standard algorithms [
3] for key generation, encryption, decryption, homomorphic operations, and bootstrapping are below.
KeyGen() On input security parameter , the key generator generates a secret key and public parameters . n is a positive integer. p and q are chosen such that . A normal distribution over is used to create a discretized error distribution over . The private key is sampled uniformly at random from , i.e., . The plaintext space is .
Encrypt sk(μ) The encryption of
is given by
with
for a random vector
and a small noise
Decrypt sk(c) To decrypt
, use private key
, compute
and return
Addition of ciphertexts Let
and
be respective TLWE encryptions of
and
, i.e.,
,
,
, and
small. Then
is a valid encryption of
provided that the additive noise
remains small.
Multiplication by a known constant Let
be a small integer, and ciphertext
c be the
where
. By multiplying
K with every vector component of
c, we obtain
. If
, then
provided that the resulting noise is kept small.
Bootstrapping In Gentry’s seminal thesis [
2], bootstrapping is performed by homomorphically decrypting a ciphertext using its key’s encryption to reduce the noise in the ciphertext.
The bootstrapping of a TLWE ciphertext encrypted with secret key is done in three steps.
This operation returns a ring (torus polynomials) LWE ciphertext in . This operation rotates a test polynomial homomorphically (the reason for naming it blind rotation) using a bootstrapping key, which consists of a list of encryptions of the elements of the secret key s.
This operation extracts the constant coefficient of , resulting in an LWE ciphertext in
This final step uses key-switching keys to return to the original LWE ciphertext in , encrypted with the original secret key s.
More details can be found in reference [
3].
Programmable Bootstrapping This technique converts a high-noise ciphertext into a new one with less noise while simultaneously evaluating a function on the encrypted data. It is achieved by encoding a look-up table in the test polynomial used in the blind rotate operation during bootstrapping. Consider a function
and a noisy ciphertext
; programmable bootstrapping outputs a new ciphertext
, having a small amount of noise. Regular bootstrapping is a case of programmable bootstrapping where
f is the identity function. The details regarding look-up table construction can be found in reference [
4].
3.2. Combinational Digital Circuits
In this section, we give a brief overview of the combinational digital circuits that are used in our integer comparator circuits.
3.2.1. Comparator
A comparator decides whether two numbers are greater or less than the other or equal. It receives two n-bit binary numbers, X and Y, and outputs the comparison outcome as a bit. There are two common types of comparators. An equality comparator indicates whether X equals Y, and a magnitude comparator indicates whether the value of X is greater or lesser than the Y value.
The equality comparator is the more straightforward circuit compared to the magnitude comparator. It uses the XNOR gate to check that bits in X and Y corresponding to the same column are equal. If it is valid for all the columns, the numbers are equal.
The magnitude comparator also compares each bit of two numbers, such as
and
. It starts from the most significant bits, checking if the pair of bits is equal and assigning the result to
.
It then continues checking for the next most significant pair till it reaches the least significant pair of bits. Hence, and .
If
, then the following equation evaluates to 1.
Suppose the most significant bits are , where , irrespective of the bit values in other places of the number. This logic corresponds to the first term in the equation. On the other hand, if the most significant bits are equal, if the next significant bit is greater than as evaluated by the second term in the equation. Finally, the third term evaluates to one if the least significant bit is greater than and all other bits are the same.
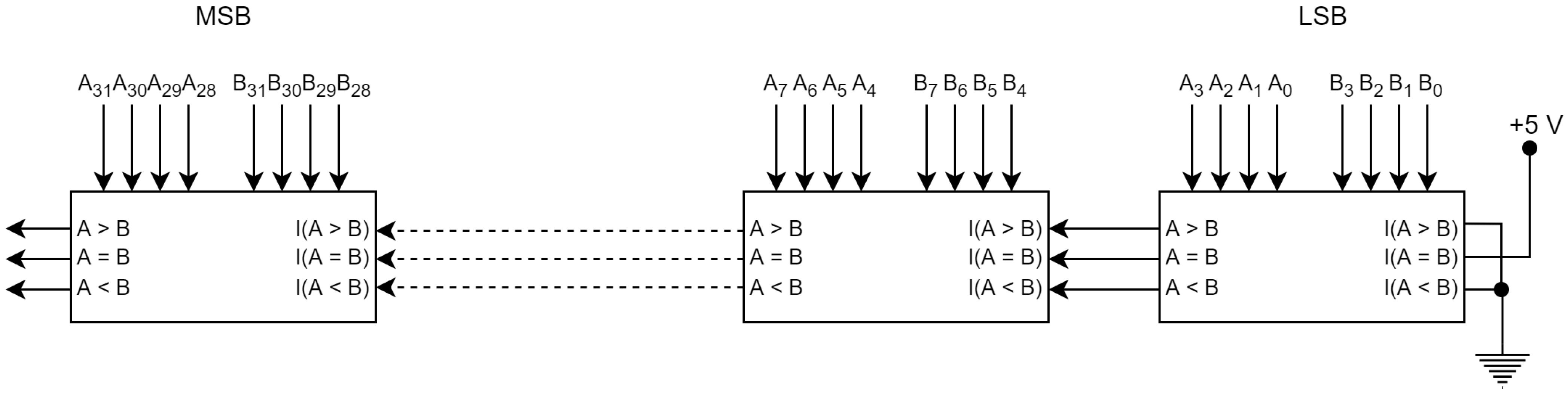
The IC 7485 is a TTL family 16-pin 4-bit magnitude comparator with outputs
, and
. Words of larger length are compared by cascading these comparator chips one after another, as shown in
Figure 2.
The rightmost cascading inputs are connected to fixed logic values, and the leftmost cascading outputs provide important final outputs. Instead of the 4-bit comparator, a single-bit comparator can be used at each step. It tracks whether the numbers corresponding to the compared bit pairs are greater or lesser.
3.2.2. Multiplexer
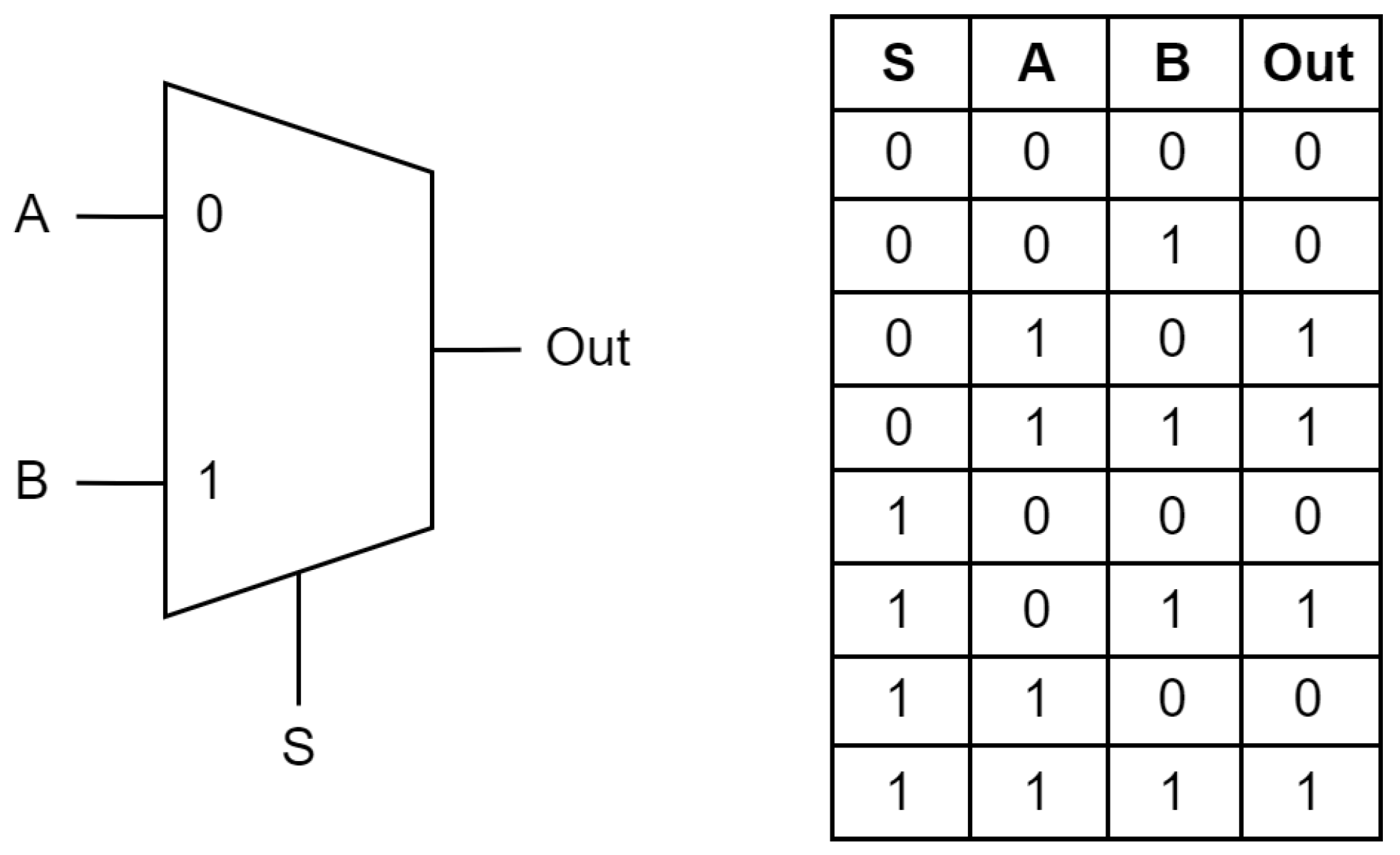
Multiplexing means transmitting many information units over a smaller number of channels or lines. The function of a multiplexer is to choose an output from a selection of inputs such as a rotary switch. A digital multiplexer (MUX) is a combinational circuit that selects one of data input lines based on an n-bit address, directing it to one output line. A set of selection lines controls the selection of a particular input line.
A typical multiplexer has
information inputs
,
n select inputs
and one information output
Y. The simplest multiplexer when
is a
-to-1 multiplexer, shown in
Figure 3. The single selection variable S has two values, 0 and 1. When
, the multiplexer selects and outputs the first input,
A. Similarly, when
, the multiplexer selects the second input
B. Optimizing the truth table with Karnaugh maps gives the equation
.
3.3. Decision Tree
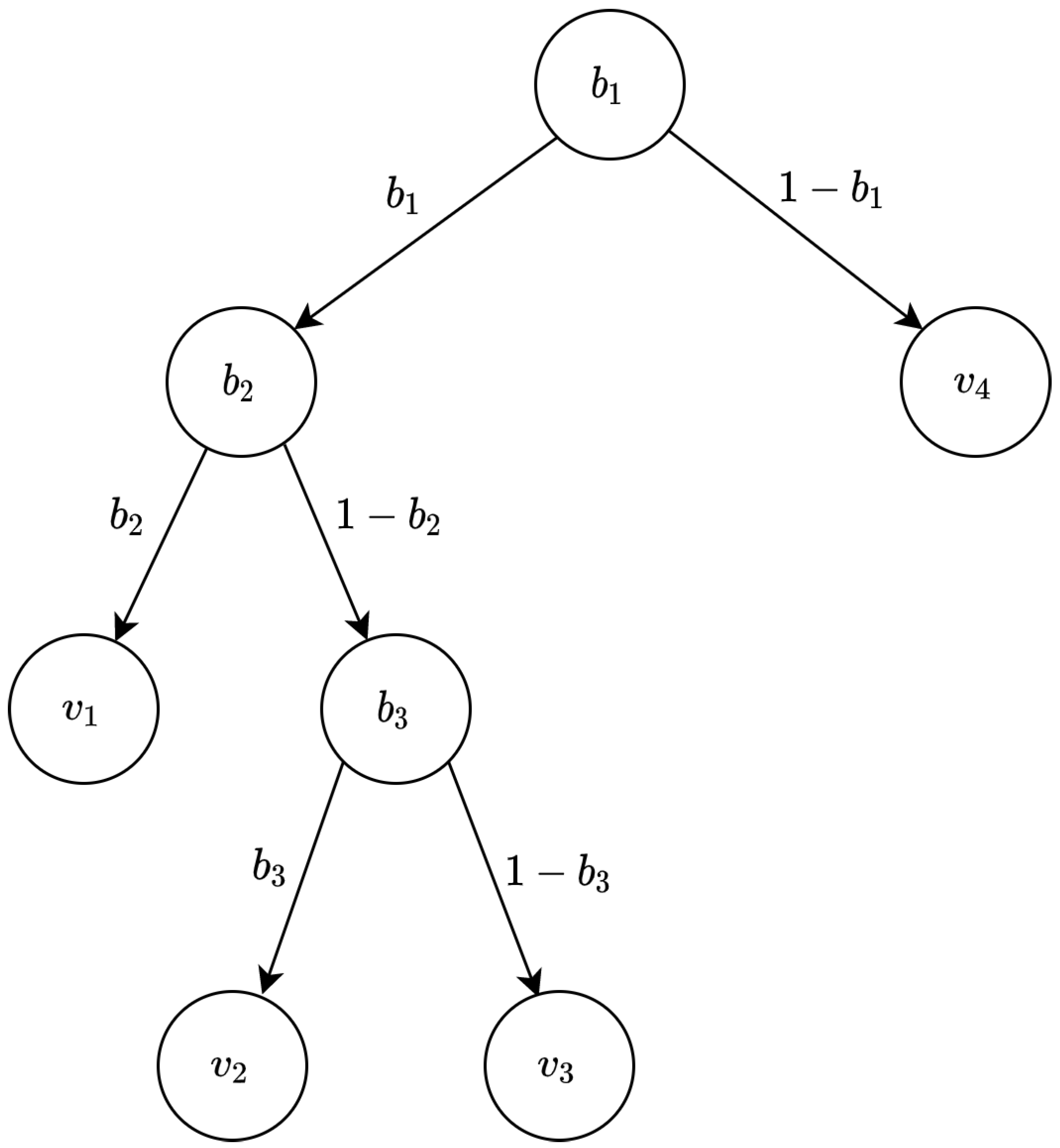
A decision tree is a popular classification model capable of fitting complex datasets. They are the fundamental building blocks for powerful machine learning algorithms, such as random forest. Decision tree training algorithms, such as CART, produce a binary tree where the interior nodes always contain two children. It is built by recursively splitting the data into smaller parts until the data are split into a single leaf node. The decision tree is a white-box model, where their decisions are more accessible to interpret than a black-box model, such as neural networks.
Given an attribute vector
, the decision tree evaluates the input vector
x and returns the output class. The decision tree with
m internal nodes implements a function
that maps an attribute vector
to a classification result in
. A decision tree with
m decision nodes is a binary tree with
m + 1 leaf nodes. The leaf nodes contain the output class
, and the interior nodes contain the threshold value
.
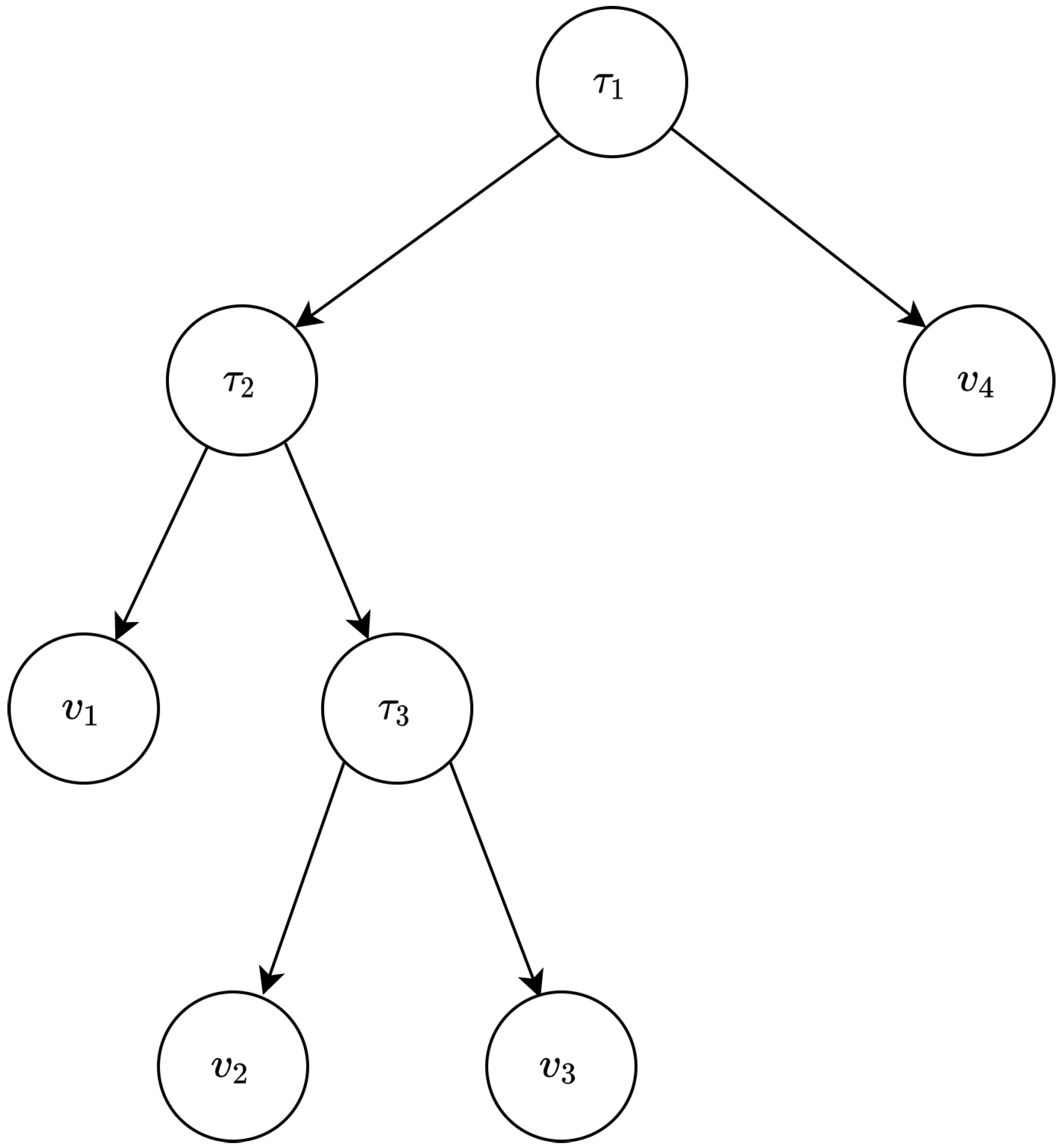
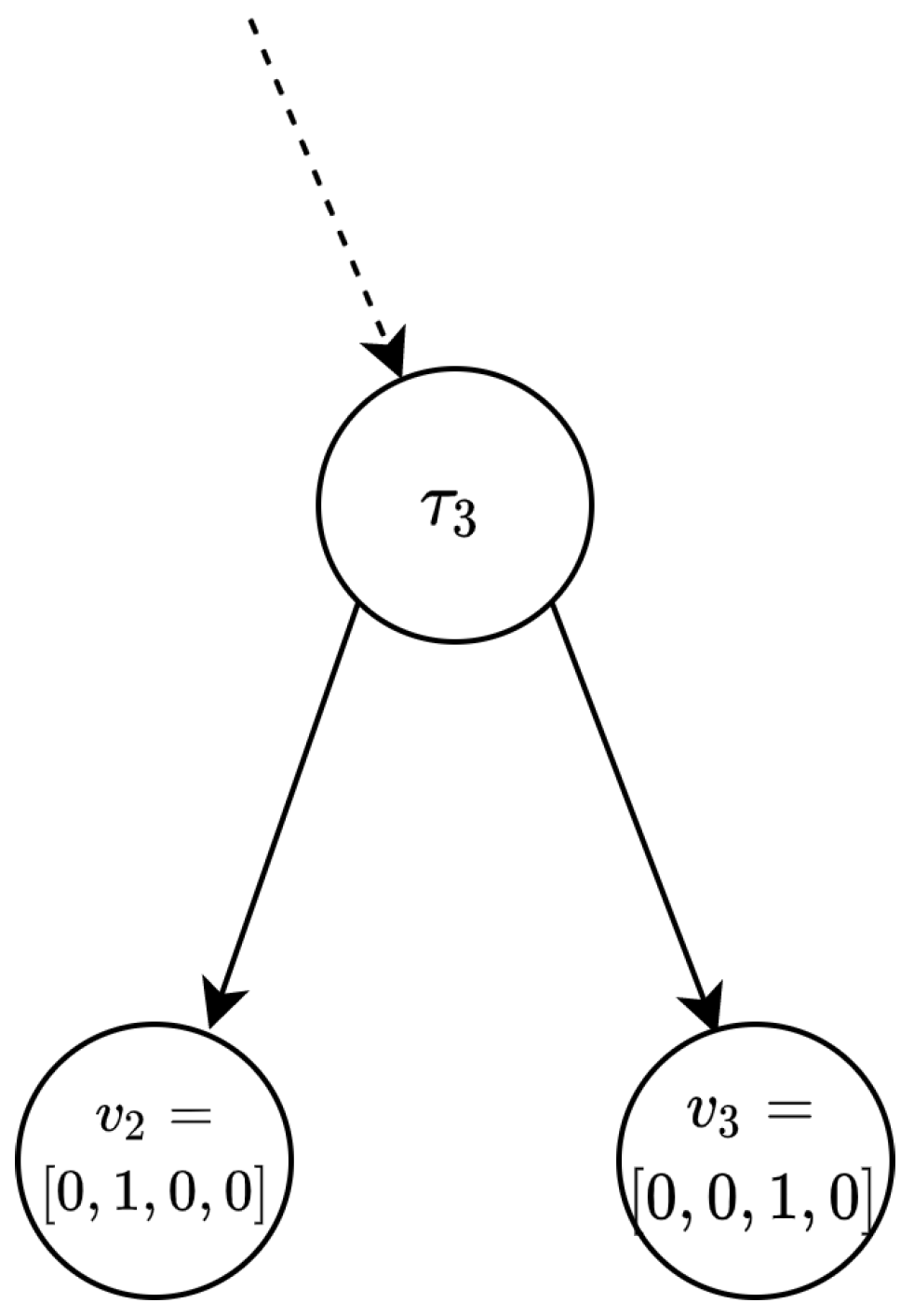
Figure 4 shows a decision tree with
decision nodes. The decision at each node is a comparison test on one of the feature attributes
to a threshold value
for node
i. The
is the feature attribute index used to make the decision. Decision tree evaluation starts from the root. It then moves on to the left or right child node based on the test on the current node. This step continues until reaching a leaf node storing the output class. The depth of a decision tree, denoted by
d, is the length of the longest path between the root and any leaf.
4. Private Comparison of Integers
This section presents our novel comparison algorithm for encrypted integers, which is the critical component of our privacy-preserving decision tree evaluation.
We encrypt an unsigned integer by considering it a sequence of 4-bit integers or nibbles. The first nibble is the most significant, and the last nibble is the least significant. Each of these nibbles is encrypted separately using TFHE [
3] encryption. The encrypted nibbles are then concatenated to form the encrypted integer.
The 4-bit integers are encoded to the plaintext space
, where
. The value of
p should be greater than 4-bits. As the leading bits, these extra bits accommodate the result of homomorphic operations such as addition. These leading bits are called padding bits [
4] and are initialized to zero. The number of padding bits is denoted by
.
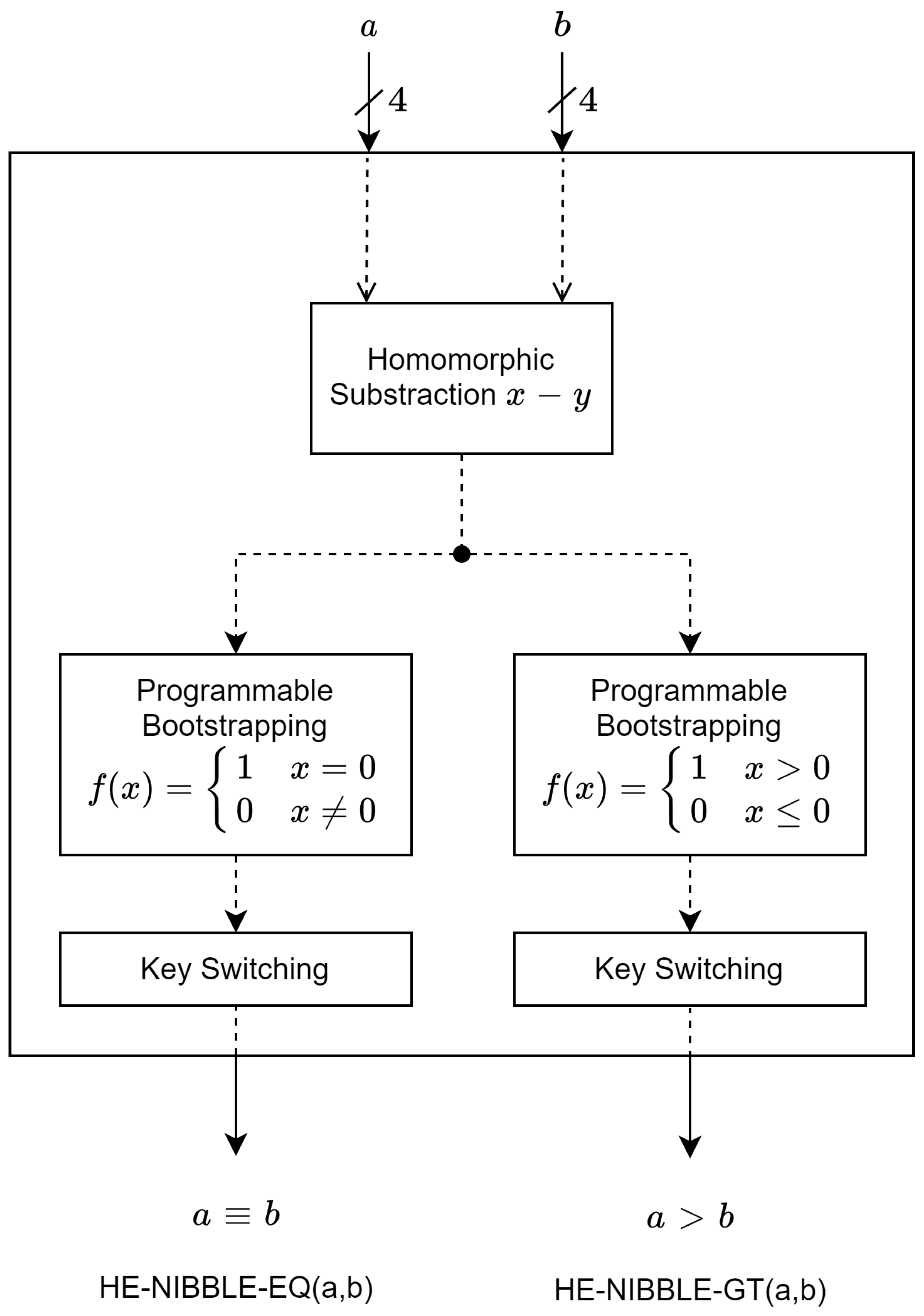
4.1. Nibble Comparator
We define two operations on encrypted nibble:
HE-Nibble-Eq and
HE-Nibble-Gt. The first operation is a homomorphic equality operation, and the second is a homomorphic greater-than operation. Both of the operations start by subtracting the first encrypted nibble from the second encrypted nibble, as shown in
Figure 5. The subtraction result is a ciphertext with
bits of padding.
The resulting ciphertext is then bootstrapped, using programmable bootstrapping. The univariate function, passed to the bootstrapping function for equality, checks if the input is zero. If it is true, it returns one. Else, it returns zero. Similarly, the univariate function checks if the input is greater than zero for greater-than checking. We also specify the programmable bootstrapping function to output the final ciphertext with the initial bits of padding.
4.2. Integer Comparator
We compare the encrypted integers by cascading encrypted nibble comparators, similar to cascading comparators in
Figure 2. Each comparator takes in two encrypted nibbles and the output from the previous comparator. If both the encrypted nibbles are equal, then the output of the comparator is the same as the output of the previous comparator. If the encrypted nibbles are not equal, then the output of the comparator is as follows. If the first encrypted nibble is greater than the second encrypted nibble, it is one. Otherwise, it is zero. A 2-to-1 multiplexer can realize this.
The equality and greater-than evaluation of the encrypted nibbles are done using the nibble comparator described in
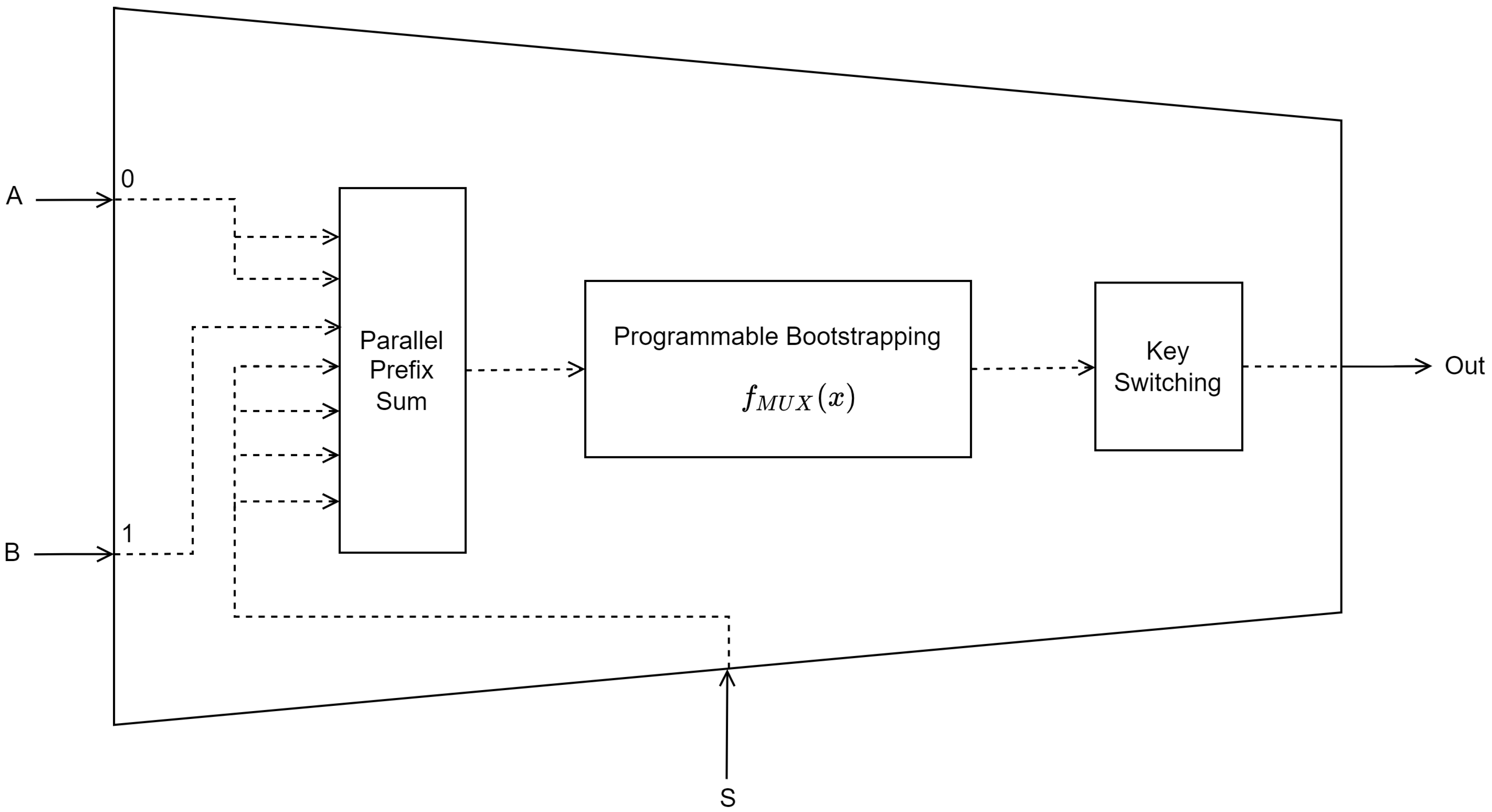
Figure 5. We design a homomorphic multiplexer
HE-Mux algorithm which takes encrypted bits in the input and selection lines as described in Algorithm 1. Let
A and
B be the inputs and
S be the selection line of the mux. We encode the
A,
B and
S as bits of a binary number represented as
, with
S being the most significant bit. The equivalent decimal number is deduced by multiplying
S by
,
A by
, and
B by one and then adding all the terms. The output of the multiplexer is the encrypted bits of the decimal number.
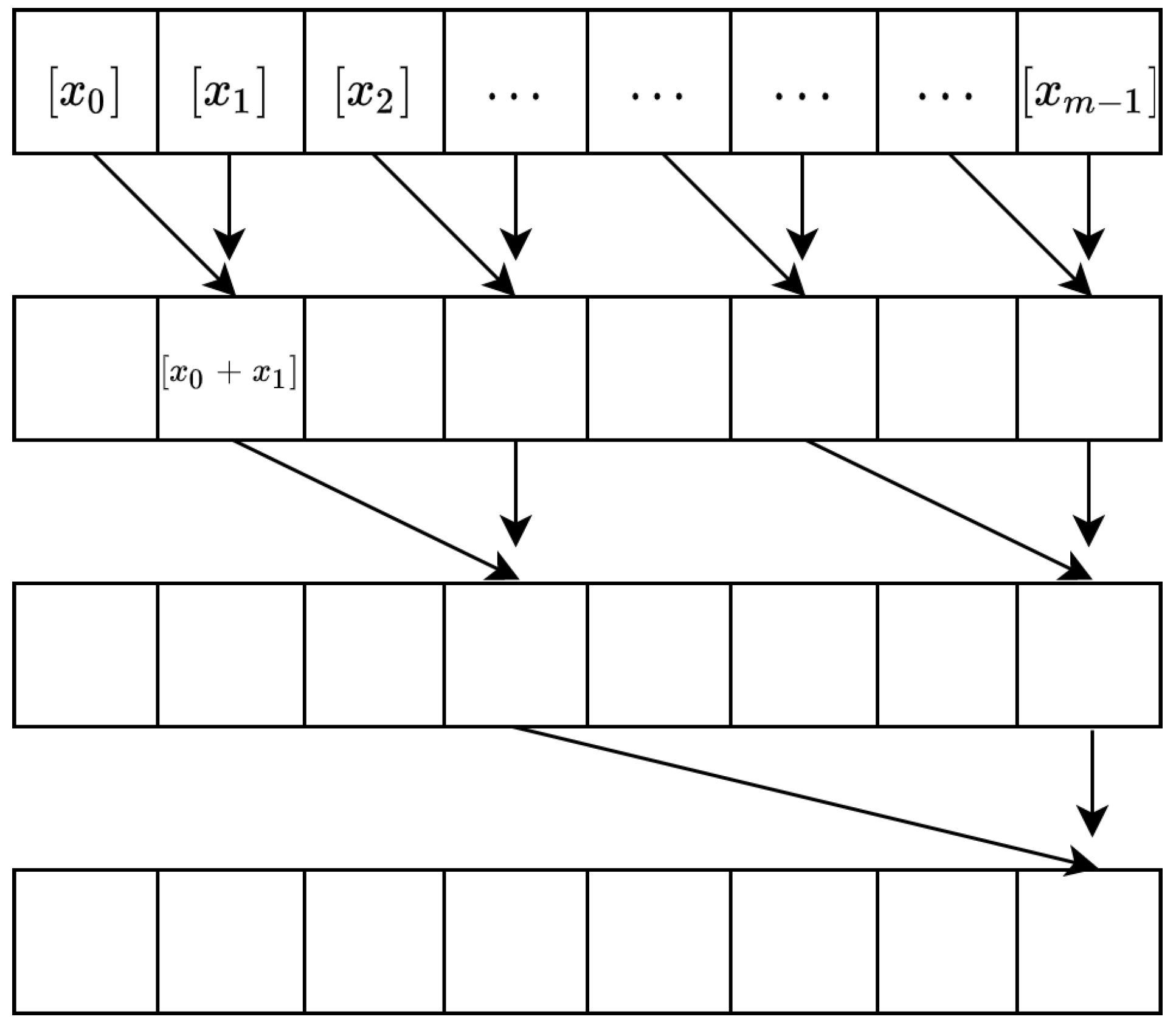
We achieve the binary to decimal conversion homomorphically by using the parallel prefix sum [
20] technique shown in Algorithm 2. If the encrypted bits have a padding
of 4, it is arranged in an array of length
.
S is duplicated four times, and
A is duplicated twice in the array. We append encryptions of zero to fill the array. We then use the
Parallel-Prefix-Sum algorithm to sum the encrypted bits. The output is the encrypted sum.
| Algorithm 1HE-Mux |
Input: Condition S, Input A, Input B, Zero ∅ Output:A if Condition , B if Parallel-Prefix-Sum Pbs Ks return
|
| Algorithm 2Parallel-Prefix-Sum |
Input: An encrypted array of length n, encryption of zero Output: Sum of all the elements of the array Append zeros to the array for to do for to do HE-Nibble-Add end for end for return
|
Adding two ciphertexts decreases the padding and increases the noise in the output ciphertext. This decrease happens at every algorithm iteration, as shown in
Figure 6. The
Parallel-Prefix-Sum algorithm ensures that the two ciphertexts in the add operation have the same padding.
The resulting sum is then bootstrapped using programmable bootstrapping with the function
that evaluates the following truth table of the multiplexer shown in
Figure 3.
The final value is key switched to obtain the multiplexer output. All the operations in the multiplexer are summarized in
Figure 7.
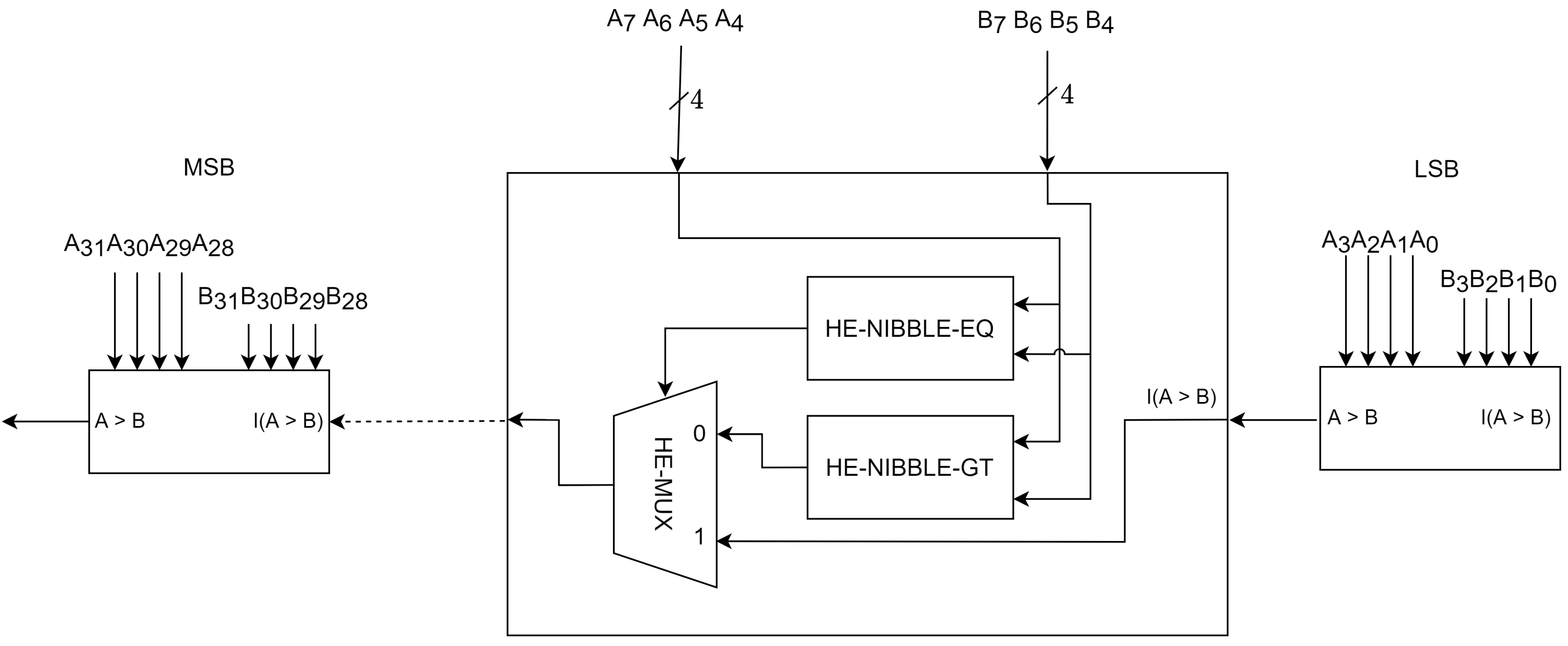
Our comparison algorithm
PvtCmp of two encrypted integers of length
n nibbles is summarized in Algorithm 3. If the encrypted integers contain just one nibble, then the result of the nibble comparator function
HE-Nibble-Gt is used. Otherwise, the encrypted integers are traversed from the least significant nibble to the most significant nibble. The encrypted nibbles are compared using the nibble comparator functions
HE-Nibble-Gt and
HE-Nibble-Eq, and multiplexed using the
HE-Mux multiplexer. The result is rippled from right to left, as shown in
Figure 8, and the final result from the most significant nibble is returned.
| Algorithm 3PvtCmp: Encrypted Greater Than Comparison Function |
Input: An encrypted array , of length n nibbles, encryption of zero Output: Encrypted 1 if , encrypted 0 otherwise ifthen return HE-Nibble-Gt end if for to do HE-Nibble-Eq HE-Nibble-Gt HE-Mux end for return
|
7. Conclusions and Future Work
This paper introduced a new non-interactive integer comparison protocol using TFHE with programmable bootstrapping. This protocol was tested with 128-bit security and scaled linearly with the input bit length. As an application, we developed an efficient protocol for the private evaluation of decision trees. The evaluation is done in a non-interactive manner, where there is no interaction between the client and server. The model owner can delegate the evaluation to a third-party evaluator, and the client can be offline after sending the feature vector to the evaluator. We experimented with widely used real datasets from the UCI machine learning repository and compared them with the existing protocols. The protocol can be extended to perform more complex inferences using random forest classification.
An important future extension to the protocol is to support ensemble and gradient boosting methods. This extension is possible if we can extend the protocol with homomorphic operations, such as division on encrypted numbers. Our solution evaluates the tree encrypted with the client’s public key. Therefore, it requires a key distribution mechanism to share the client’s public key with the model owner. An exciting direction for future work is to use multi-key homomorphic encryption [
28,
29] to encrypt the tree and the feature vector with different keys. This technique eliminates the need for key distribution between the client and the model owner.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}