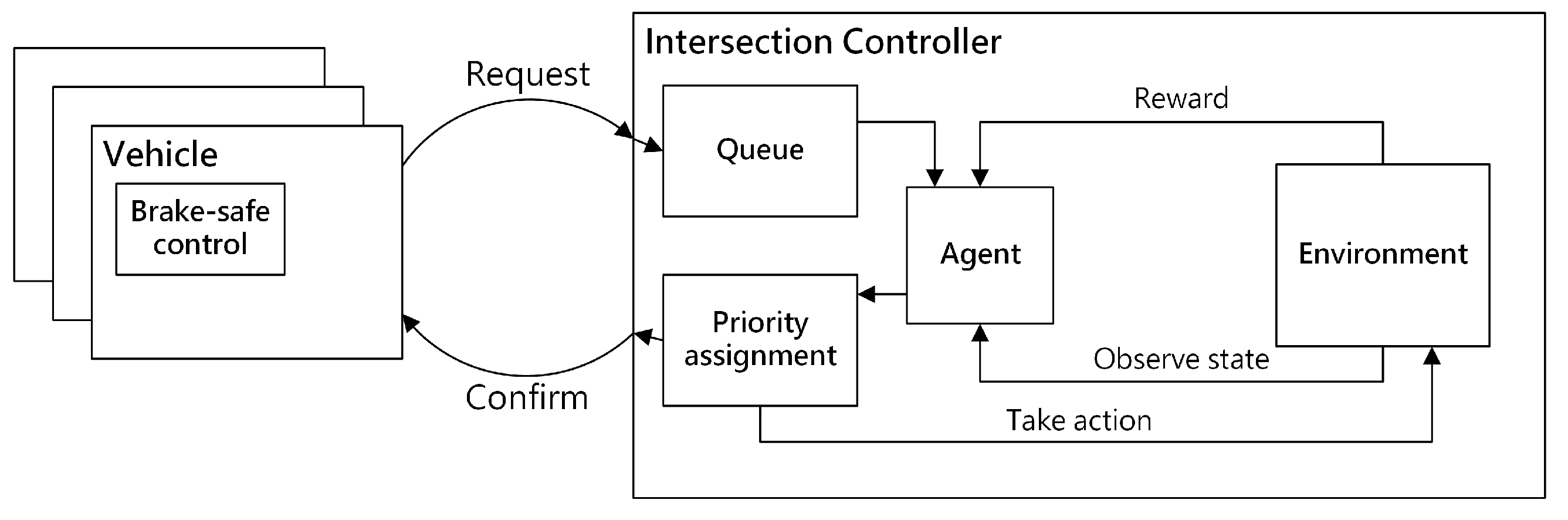
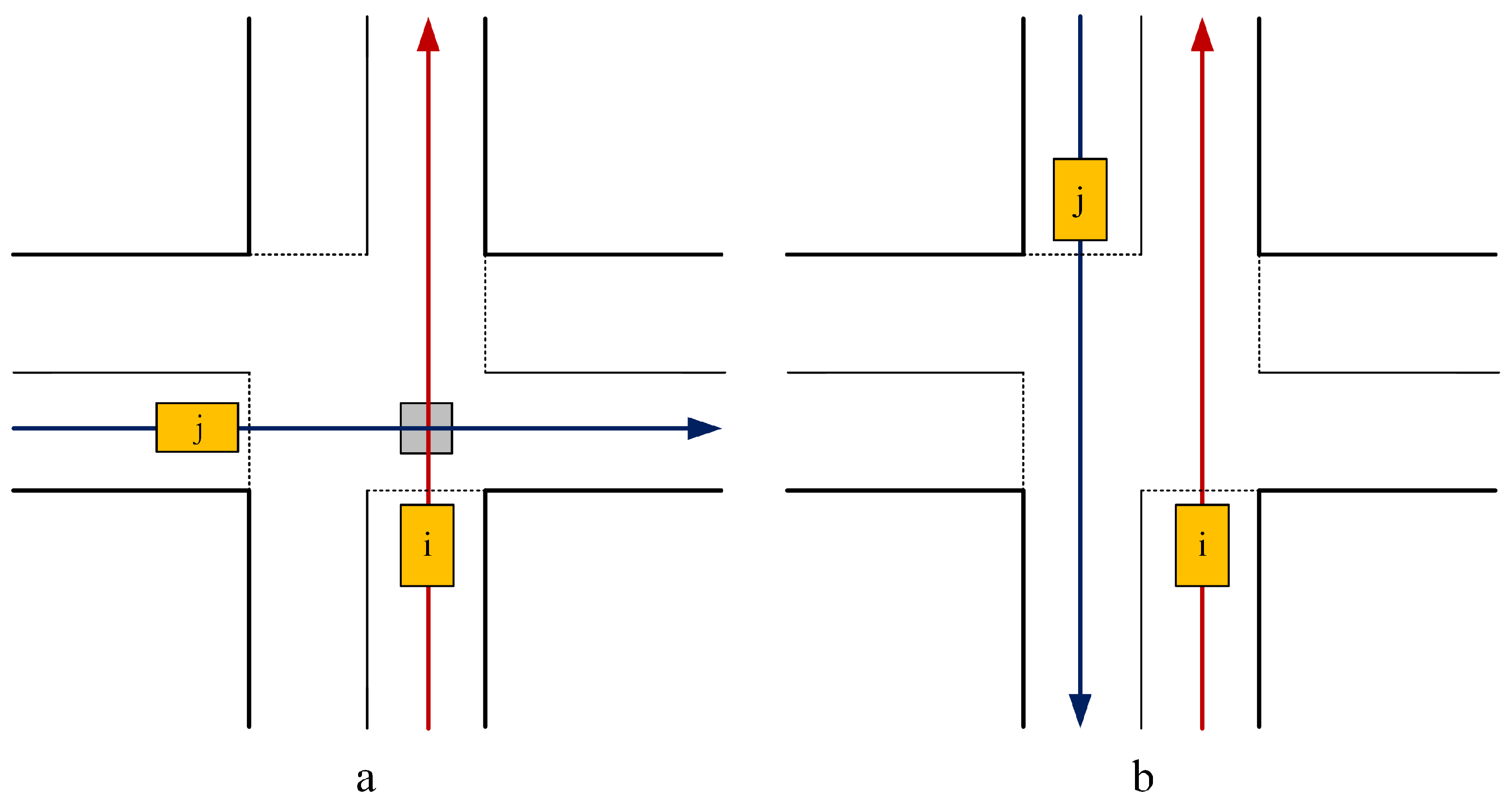
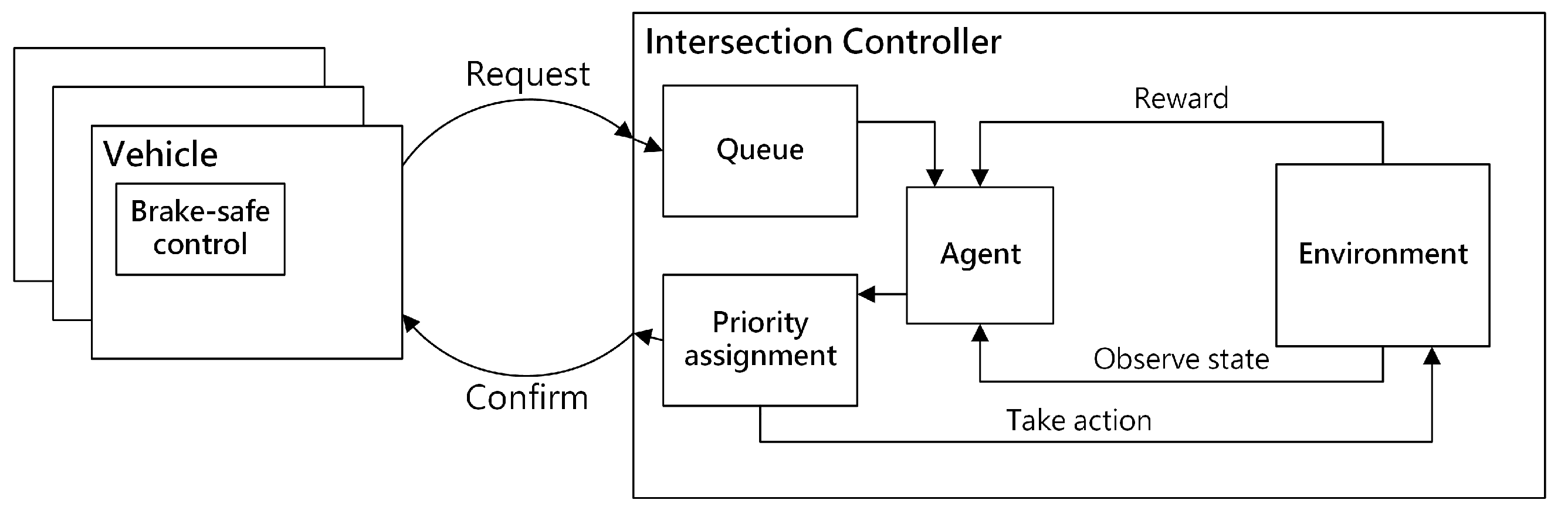
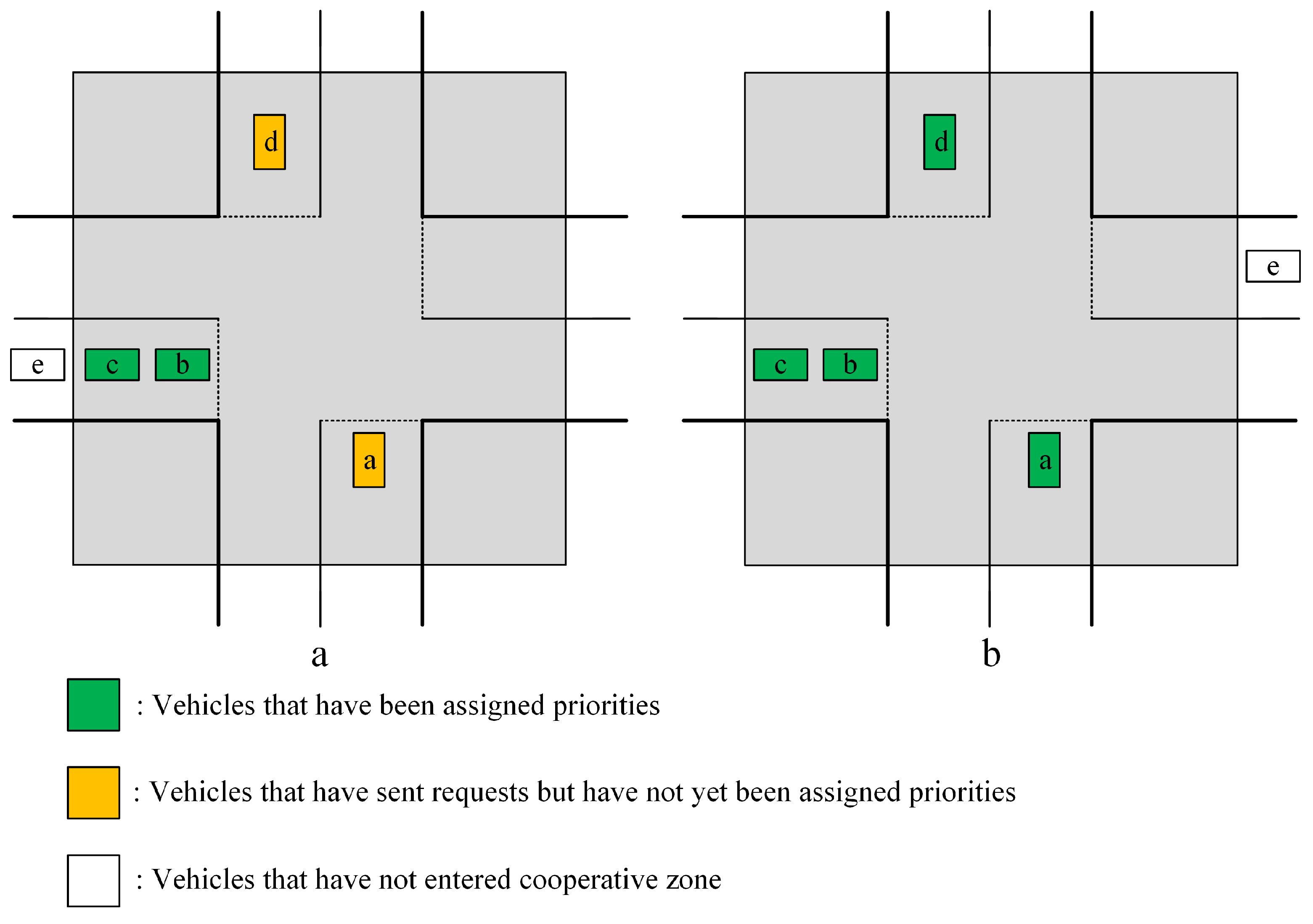
4.3.1. Evaluation of Training Results of DRLAIM
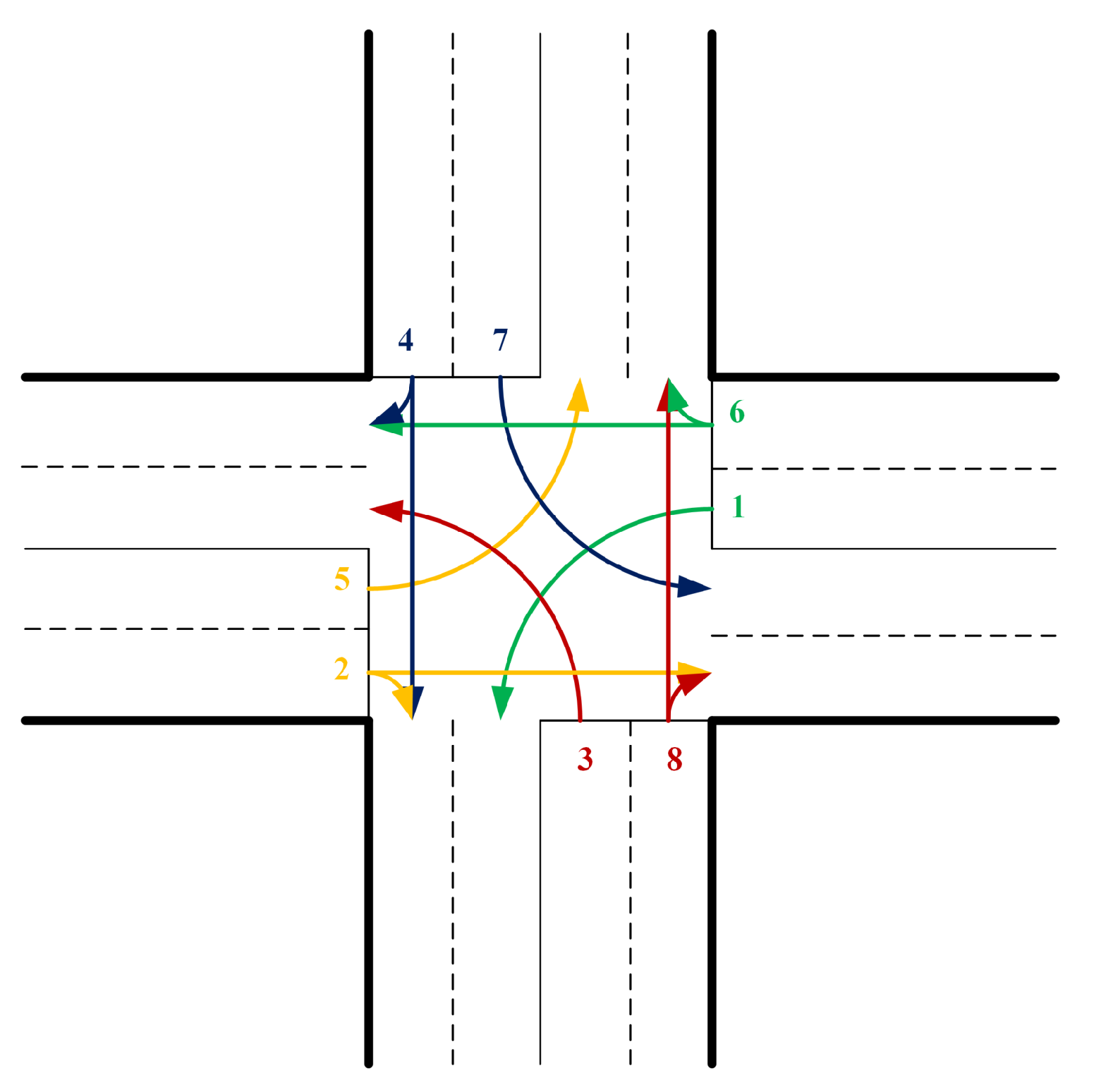
In this experiment, we first evaluate the performance of training results by using different combinations of reward functions as shown in
Table 2 where
is queue size and
is the queue size of lane
i (the same lane as
) at time
. The usage of elements
and
is to maximize the queue size difference and the throughput to enhance the efficiency of DRLAIM. The usage of element
is to avoid a situation where vehicles are waiting for a long time and still cannot go through the intersection to enhance the fairness of DRLAIM. We use these three elements to combine seven different reward functions, as shown in
Table 2. The 8th reward function lets the agent learn a policy to select an action to let vehicles in the lane with minimum queue size to pass through the intersection. We train our DRLAIM model by using different combinations of reward functions for 50 training epochs, and the action time step is taken as 0.5 s (time duration in which the agent selects an action). We then evaluate the training results of the reward function with the best performance by using a different number of training epochs and action time steps.
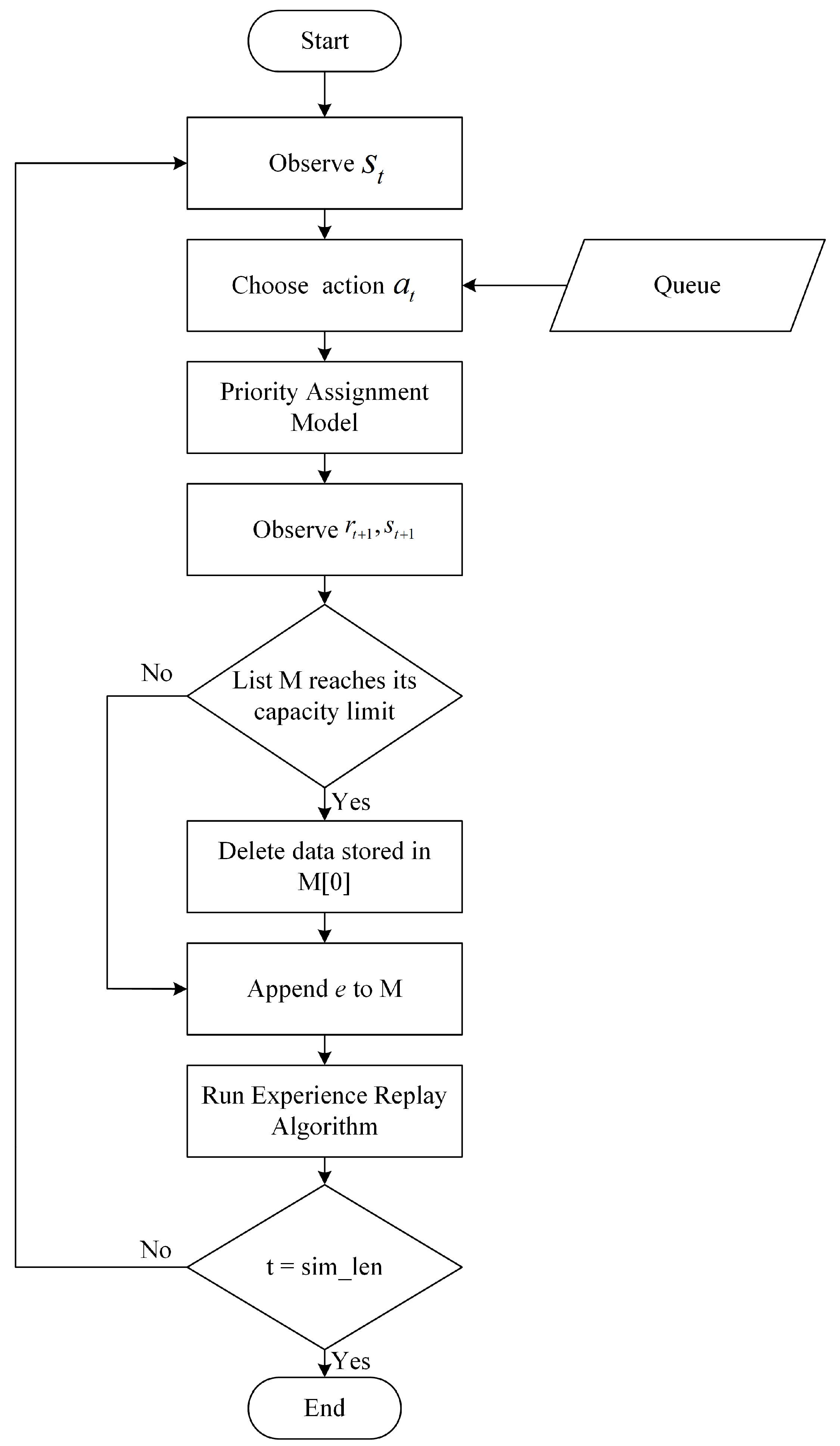
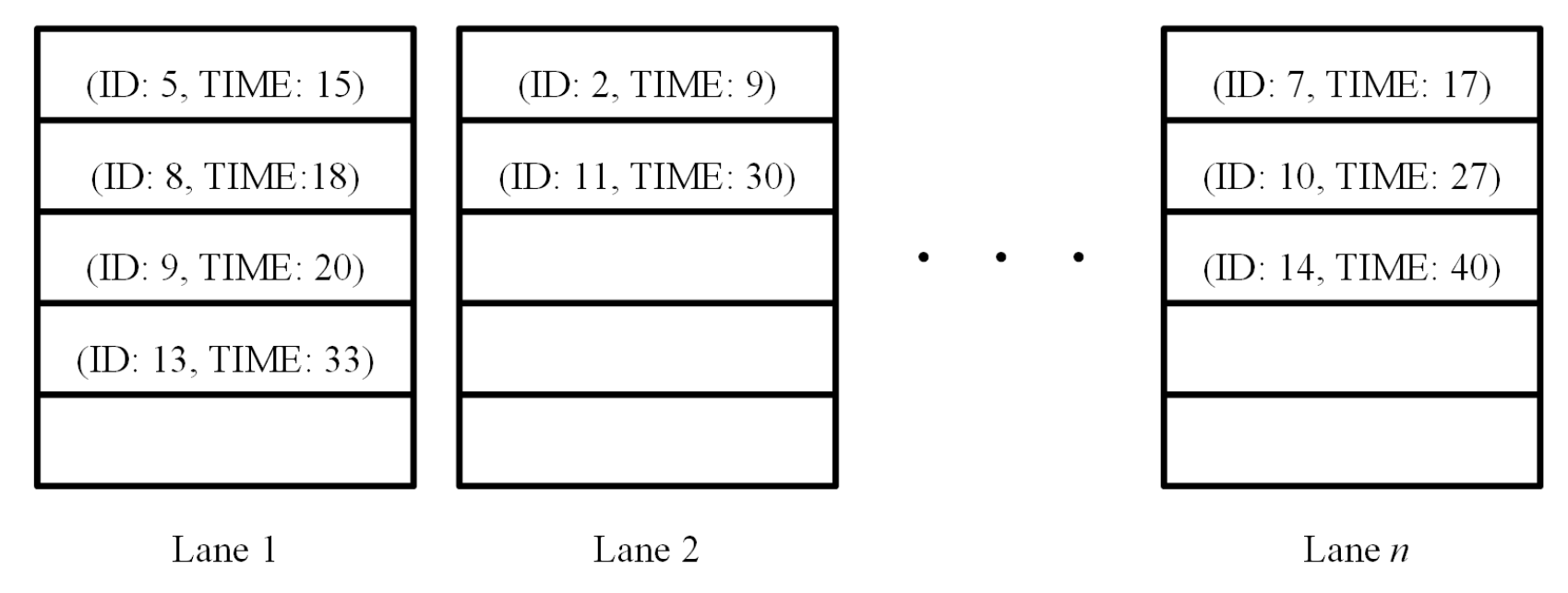
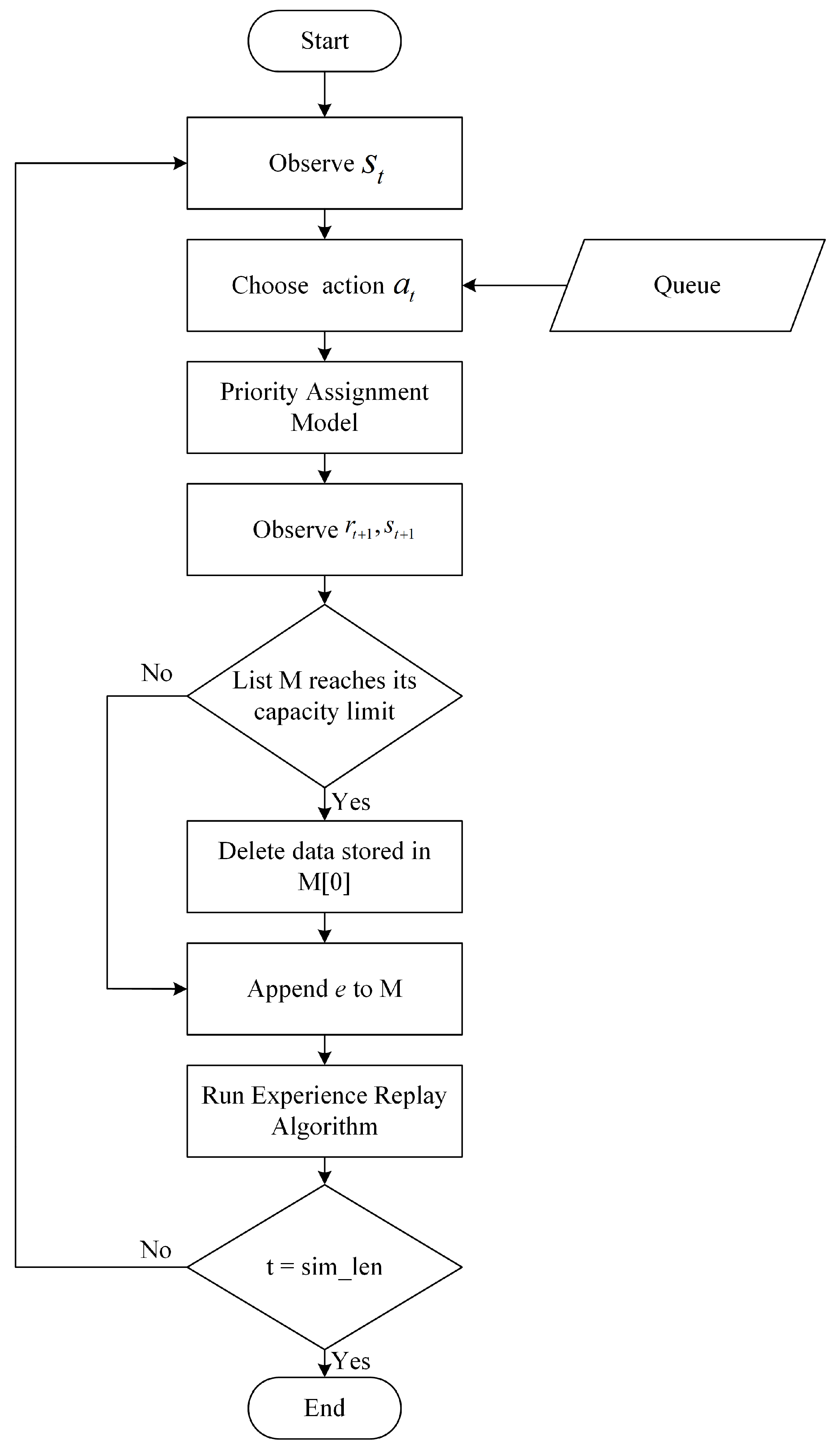
Table 3 specifies the parameters used in this experiment. In each training epoch, we simulate for 200 s by using a high inflow rate (100 vehicle arrivals per minute). The capacity of memory which stores the experience sequence set
is a set of 100,000 where
is the state of traffic environment at time
t,
is the action selected by agent at time
t,
is the reward received at time
t and
is the state of traffic environment at time
. The batch size used in training DRLAIM is 64, and the value of the discount factor used in calculating the action value function is 0.99.
We calculate the value of
, shown in Equation (
9), which is used to determine the probability for an agent to choose an action:
where
is the minimum value of which is taken as 0.01 in this work.
is the maximum value of which is taken as 1 in this work.
is the the current training epoch.
As the value of
increases, the value of
will decrease from 1 to 0.01. The reason we use Equation (
9) to decrease the value of
gradually is as follows. At the beginning of training, the agent will randomly choose an action to explore the environment because the DRLAIM has not yet learned anything; thus, we cannot use it to predict the best action. As the training proceeds, we can gradually increase the ratio to use the trained DRLAIM to predict actions. We now introduce two performance indicators to evaluate the performance of our model.
Average Queue Length (AQL): If the velocity of a vehicle in an incoming lane is smaller than 0.1 m/s, then the vehicle is considered to be in a queue. The total queue length is computed by adding the queue lengths of all incoming lanes. We will calculate the total queue length once every 0.1 s.
Average Waiting Time (AWT): The time that a vehicle is waiting in a queue is called waiting time. We will calculate the waiting time of all vehicles and record the number of vehicles waiting over the whole simulation. The summation of the waiting time of vehicles divided by the number of waiting vehicles is called the average waiting time (AWT).
Table 4 and
Table 5 show the average performance between first 10 epochs and the last 10 epochs of the 8 reward functions. We can see that the average performance of the last 10 training epochs among the 8 reward functions outperforms that of first 10 training epochs which means our DRLAIM model did learn a good policy after training.
Table 6 shows the average performance over another 10 simulations for the 8 reward functions. We can see that the average performance of reward function 7 outperforms other reward functions. According to this simulation result, we will use reward function 7 to do a further evaluation by using different training epochs and different action time steps.
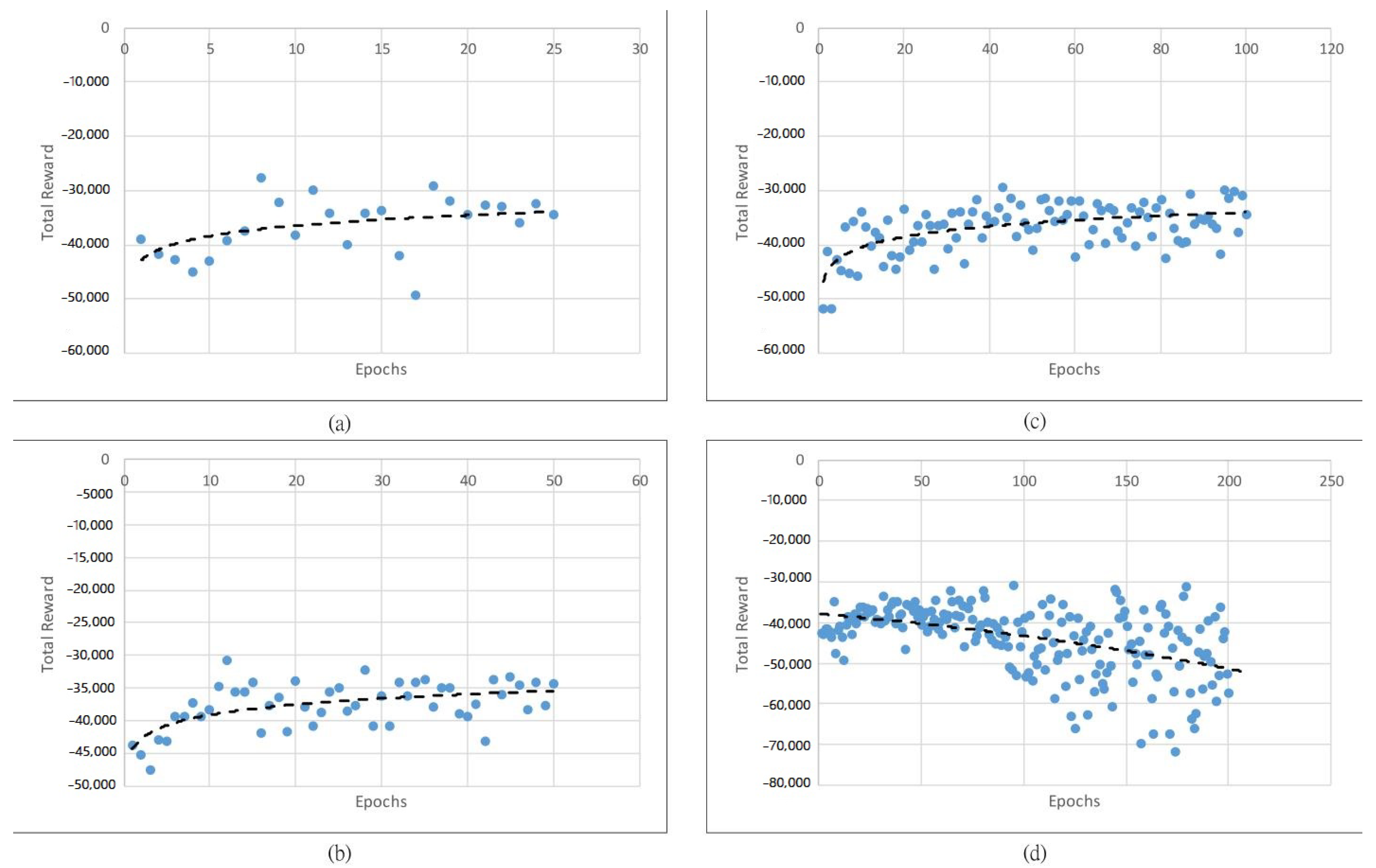
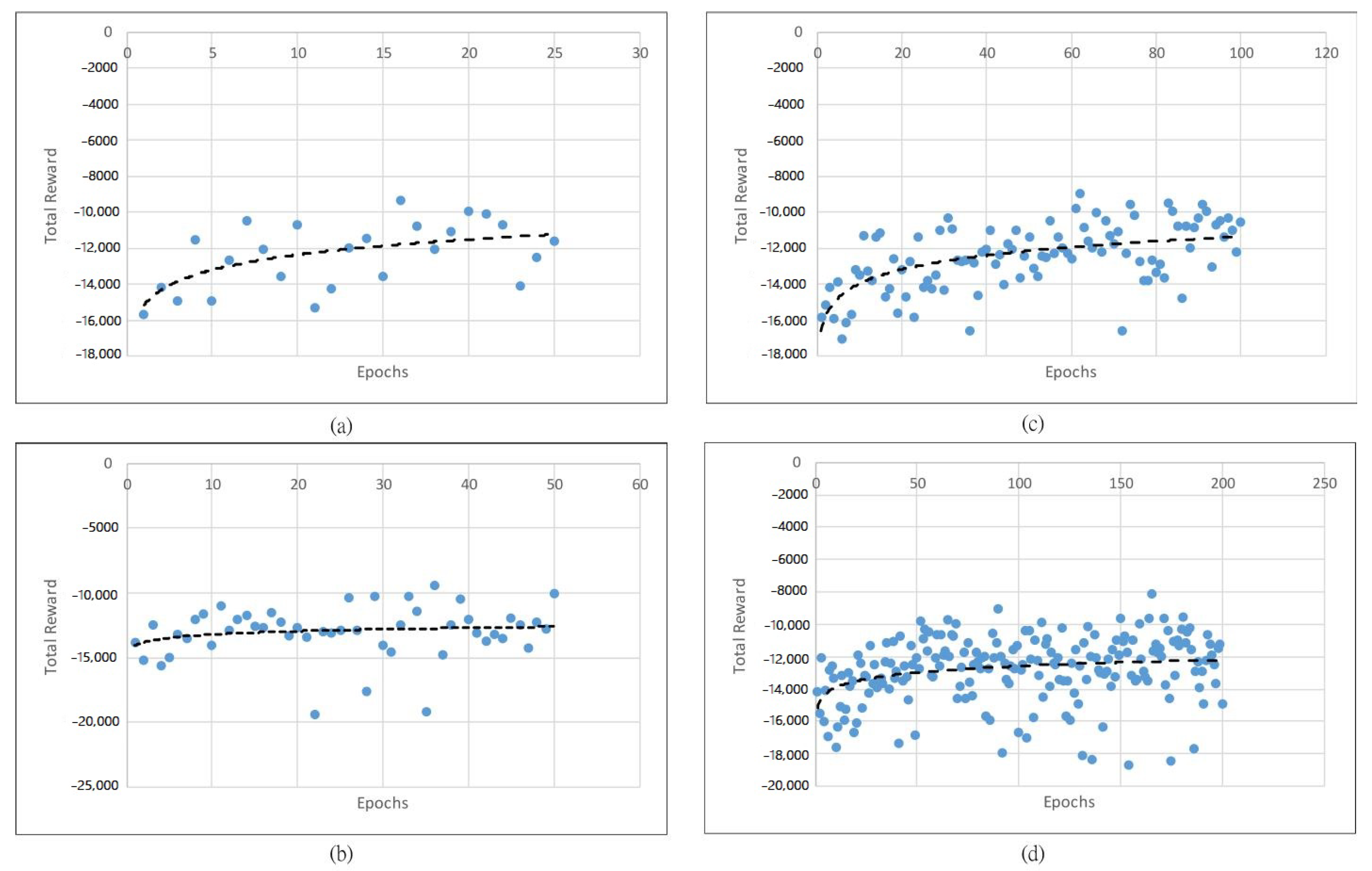
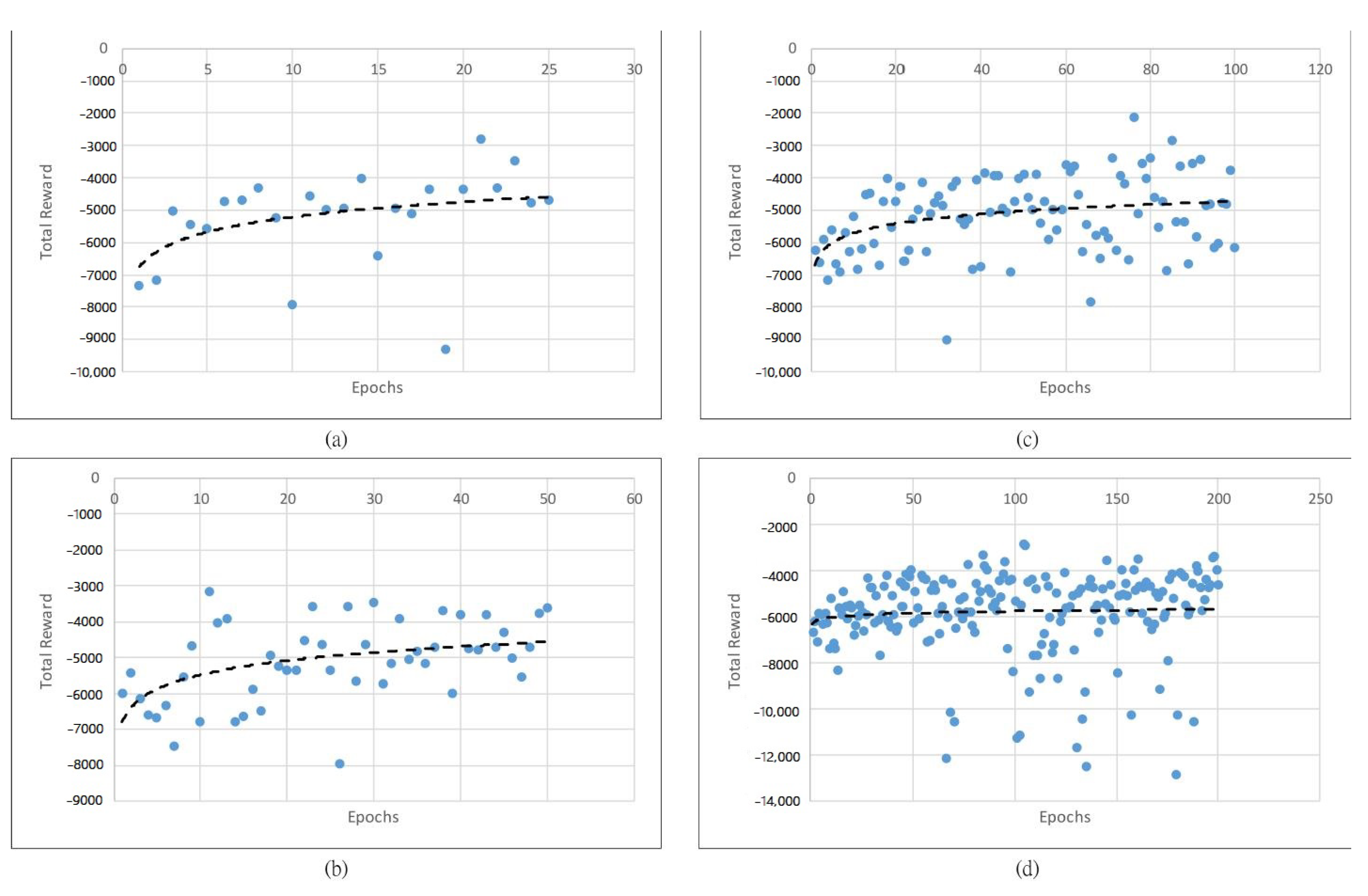
The performance of the proposed DRLAIM while training is shown in
Figure 8,
Figure 9 and
Figure 10.
Figure 8,
Figure 9 and
Figure 10 show the value of the total reward obtained after training the model by using 25, 50, and 100 and 200 training epochs and 0.2, 0.5, and 1 s action time steps, respectively. The X-axis represents the epochs, and the Y-axis represents the total reward in
Figure 8.
The total reward generated by DRLAIM is trained with 25 epochs, as shown in
Figure 8a, and it gives the total reward at 25 epochs of
. Then we have increased the epoch as 50, which is depicted in
Figure 8b, which gives the total reward as
, which has higher negative values at 25 epochs; thus we have again increased the epochs to 100 and recorded the total reward, which is
. From
Figure 8c, we can understand that during the training of the DRLAIM model at 100 epochs, we are getting lower negative reward values than at 25, 50, and 200 epochs. We can conclude that even if the number of epochs increases, the model will not give good performances. We need to decide the optimal epochs for the training model. We can see that except for the model trained with 100 epochs and time step 0.2 s, the total reward increases gradually as the number of epochs increases.
Figure 9 shows a total reward value of 25, 50, 100, and 200 epochs during time step value 0.5From
Figure 9, we can understand that our model performs well in the 50-epoch range. When we want to deploy the model in the real-time environment, we need to consider the average queue length, average waiting time and throughput with different time step values, such as 0.1, 0.2 and 1 s.
Table 7,
Table 8 and
Table 9 show the average performance over 10 simulations for the models trained with 4 different number of epochs by using 3 different action time steps. We can see that in-terms of reward performance, the trained model using 100 epochs and a time step of 0.2 s is best.
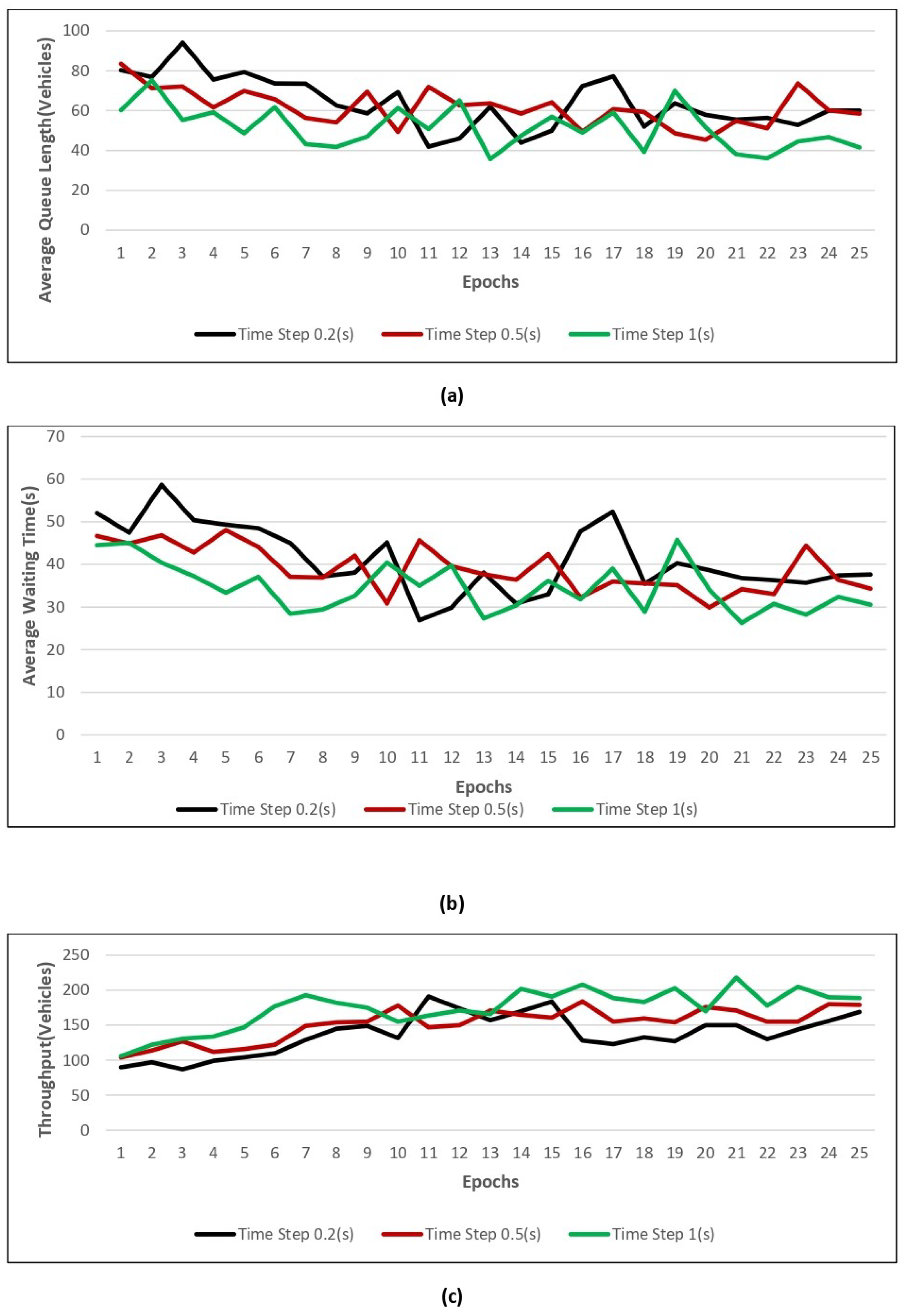
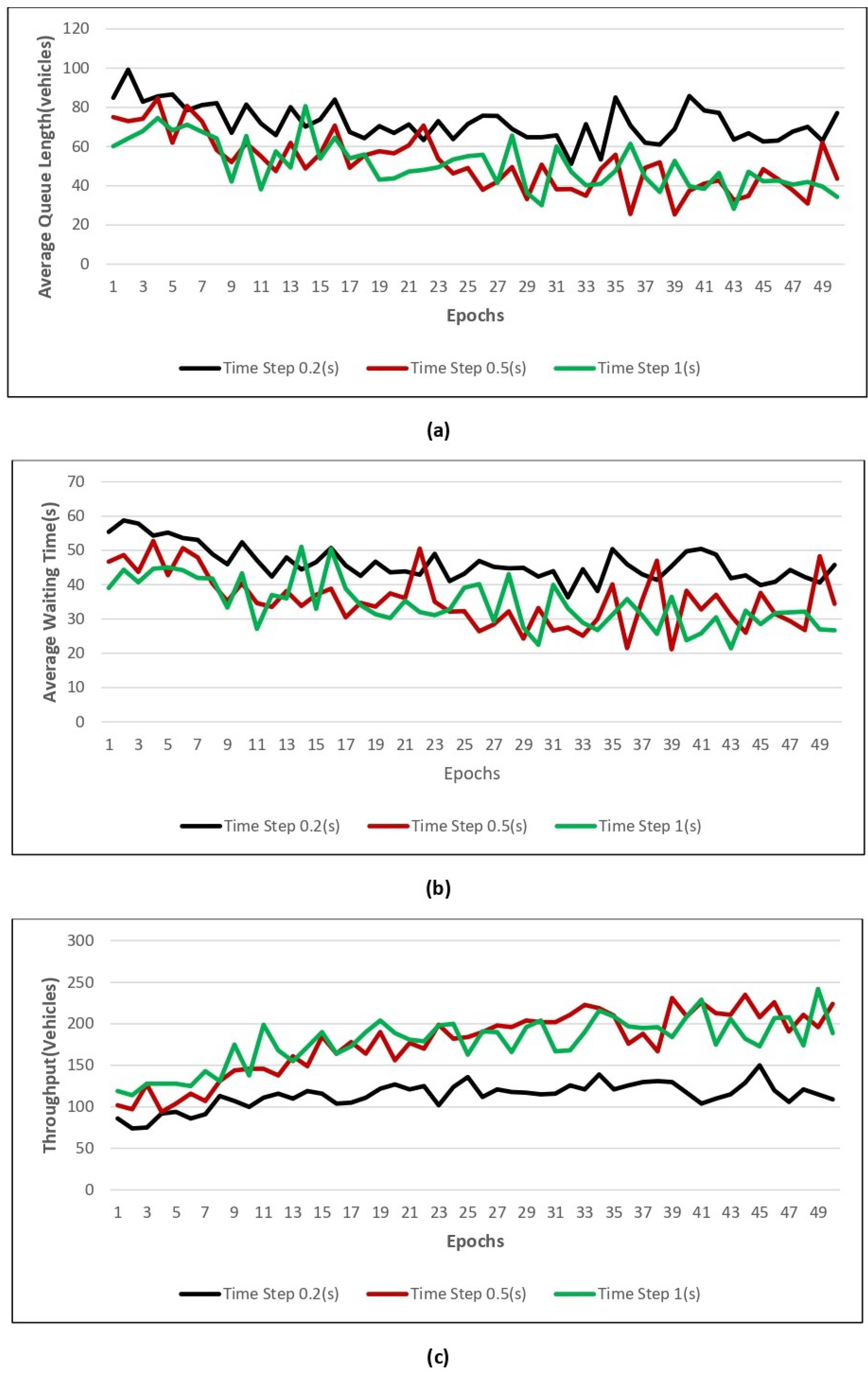
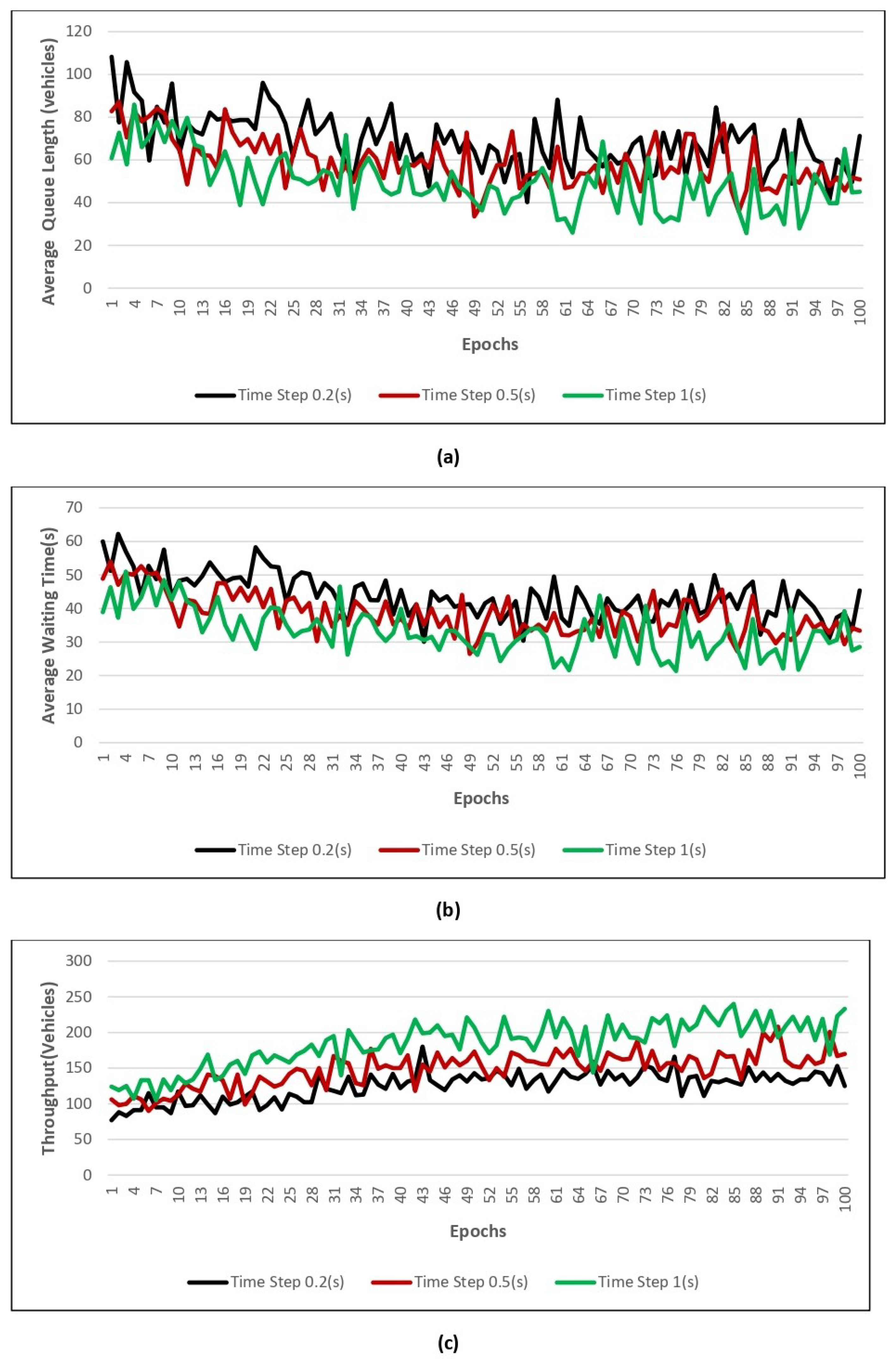
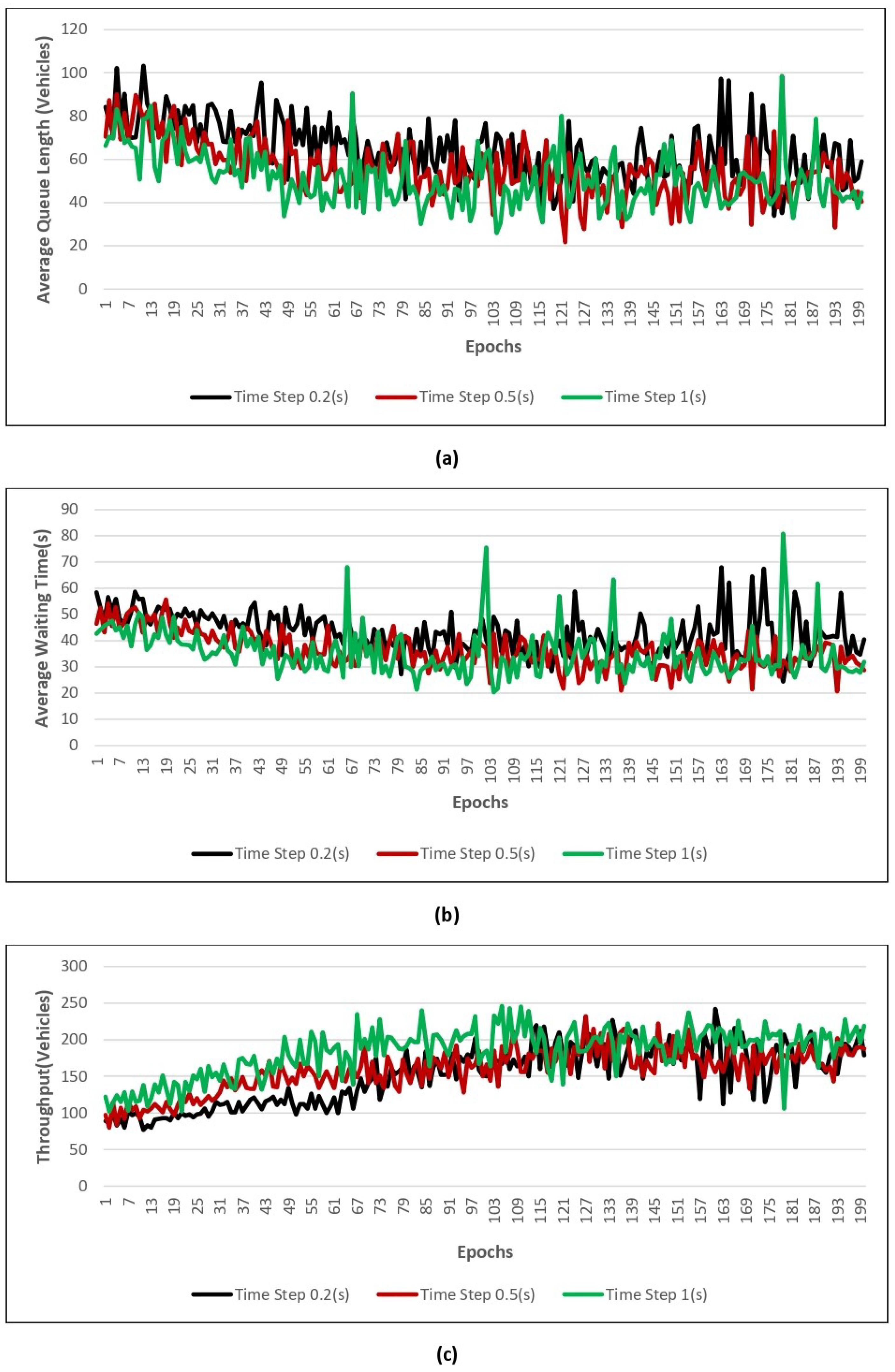
Figure 11,
Figure 12,
Figure 13 and
Figure 14 show the value of the three performance indicators introduced above, namely AQL, AWT, and throughput, for models trained with four different numbers of epochs using three different action time steps.
Figure 11 shows the performance results when training with 0.2, 0.5, and 1 time steps by using 25 epochs. From
Figure 11, we can see that it outperforms the model in terms of average waiting time, queue length, and throughput during the time step value 1. However, it is not giving good performances regarding average queue length, average waiting time, and throughput during the time step value of 1 s when the epoch is 50.
Figure 12 shows the performance results while training with 0.2, 0.5, and 1 time steps and using 50 epochs. From
Figure 12, we can understand that 50 epochs give good performances in terms of average queue length, average waiting time, and throughput during the time step value of 0.2 s.
Figure 13 shows the performance results while training with 0.2, 0.5 and 1 time steps using 100 epochs. We can understand that AWT, AVL and throughput are during the time step value 1, which is depicted in the
Figure 13.
Figure 14 shows the performance results while training with 0.2, 0.5, and 1 time step and using 200 epochs. From
Figure 14 we can conclude that 200 epochs give good performances in terms of average queue length, average waiting time, and throughput during the time step value of 1 s. Therefore, we need to decide on time steps and a number of epochs to deploy the model in the real-time environment. For example
Figure 13, we can understand that the proposed model performs well in terms of all the parameters during the time step value 1.
To find a better model, we computed the sum of the value of all the parameters and compared them with each other.
Table 7,
Table 8 and
Table 9 show the average performance over ten simulations for the models trained with 4 different numbers of epochs using 3 different action time steps. We can see that the overall performance of the trained model using 50 epochs and time step 0.5 s is best.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}