

Artificial Intelligence Algorithms for Treatment of Diabetes

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Methods
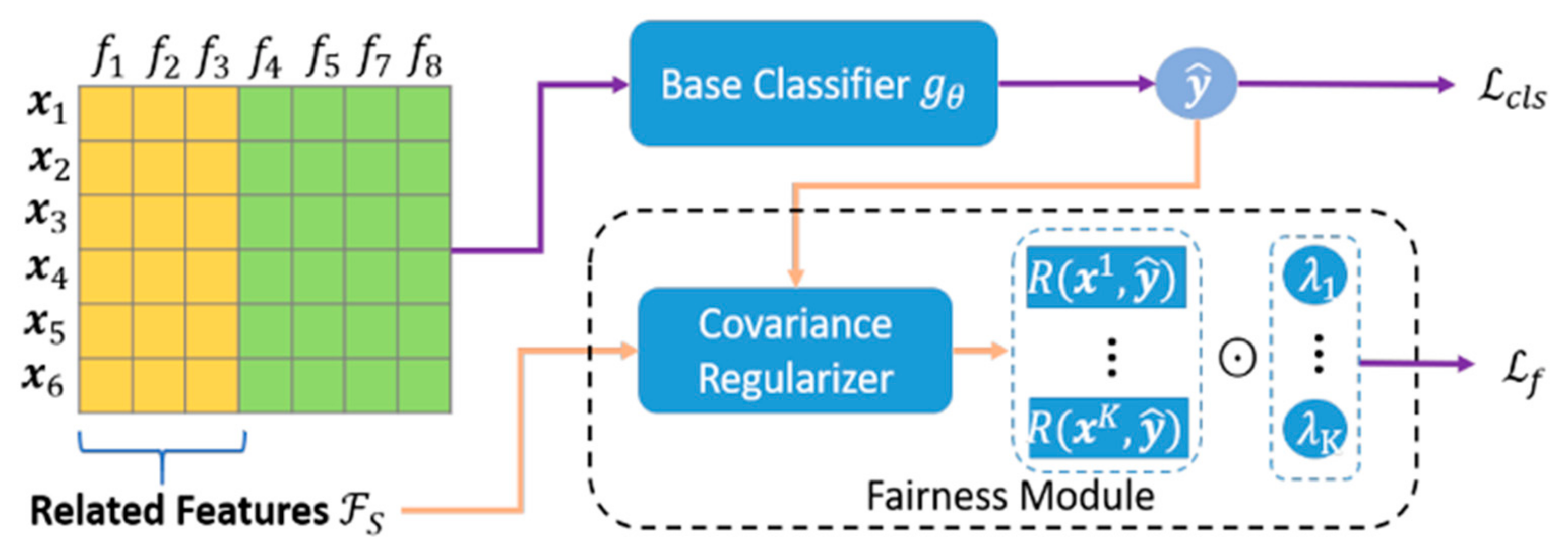
2.1. ML with Electronic Health Records for Personalized Medicine and Decision Making in T2D
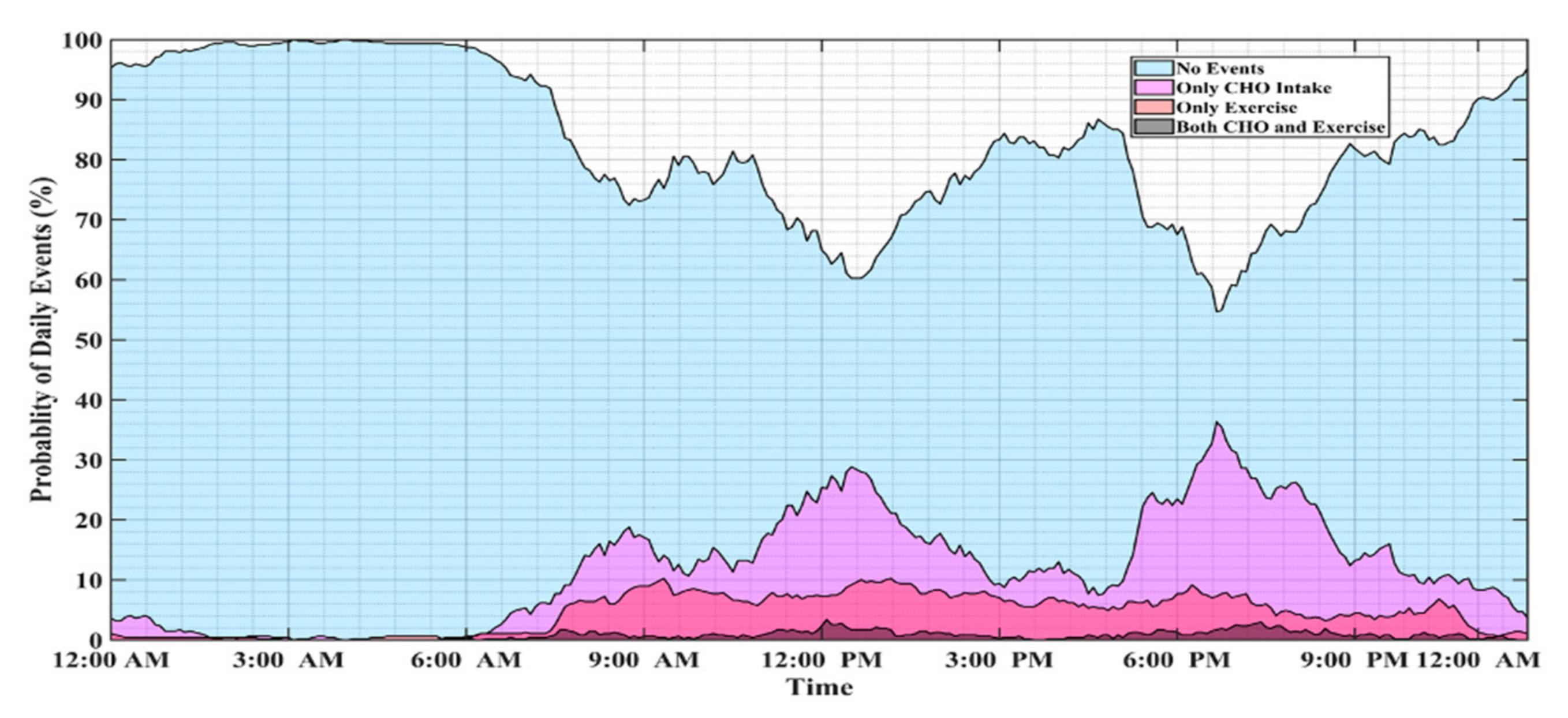
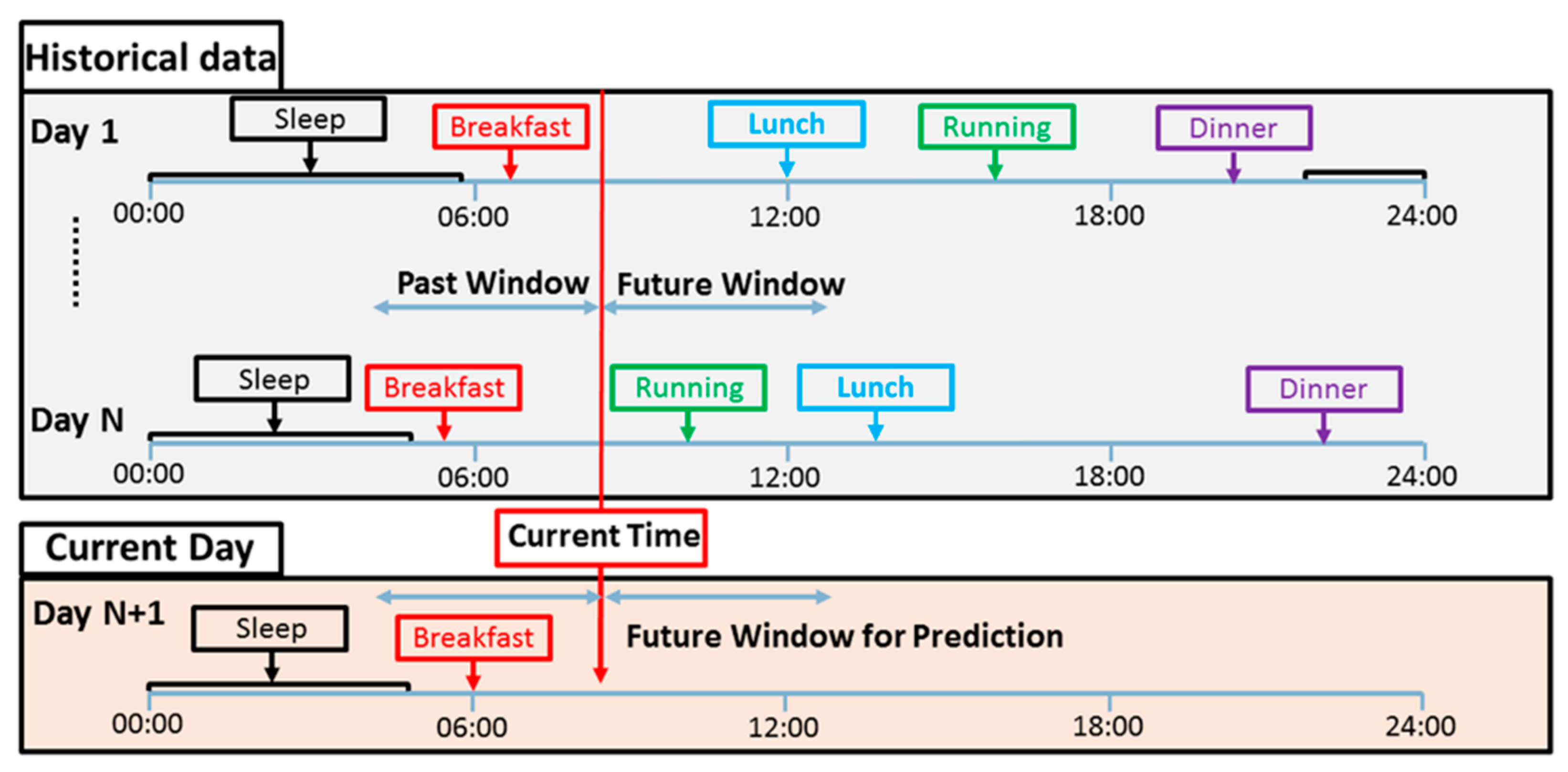
2.2. ML with Free-Living Data for Digital Health Technologies in T1D
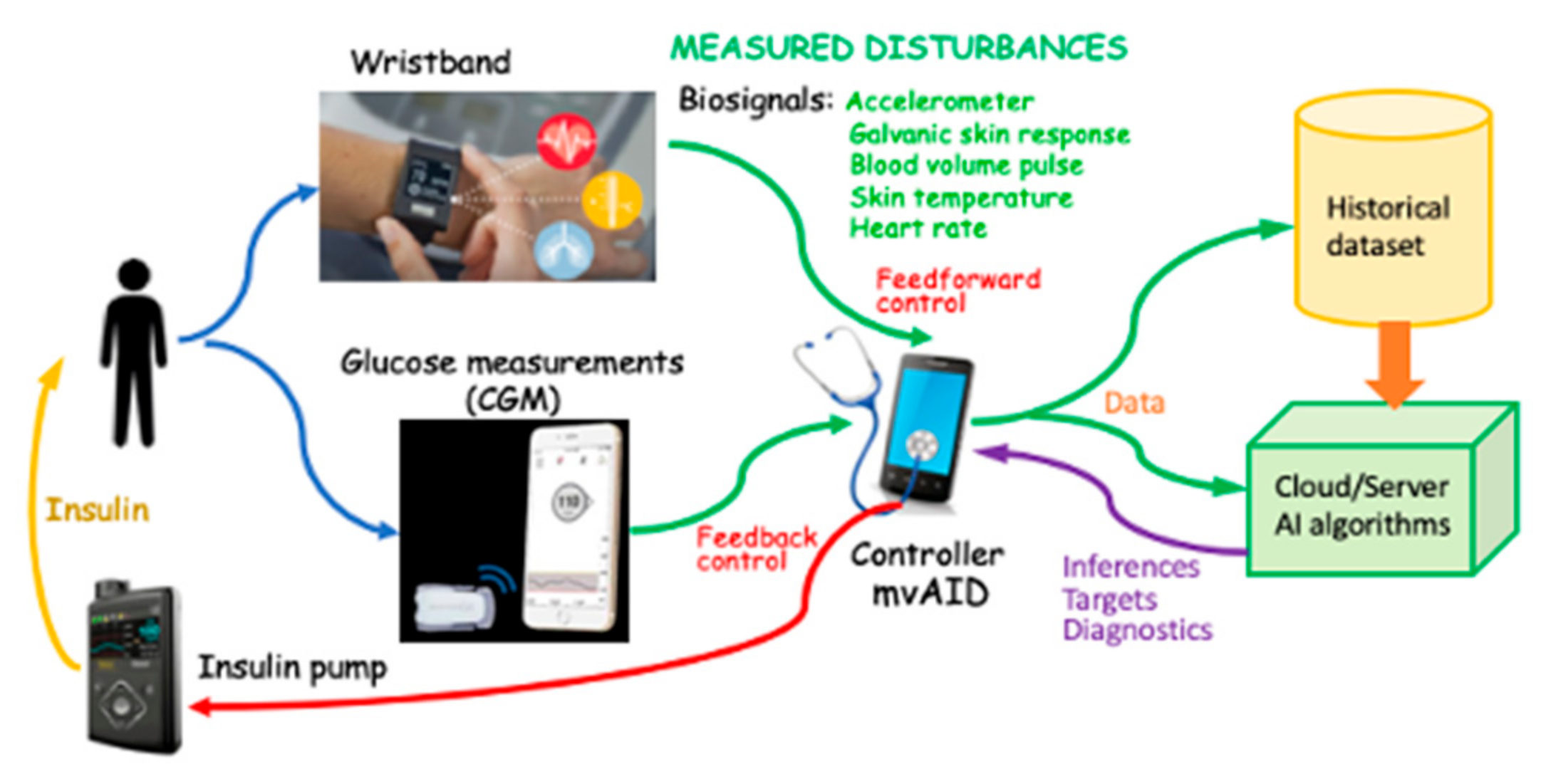
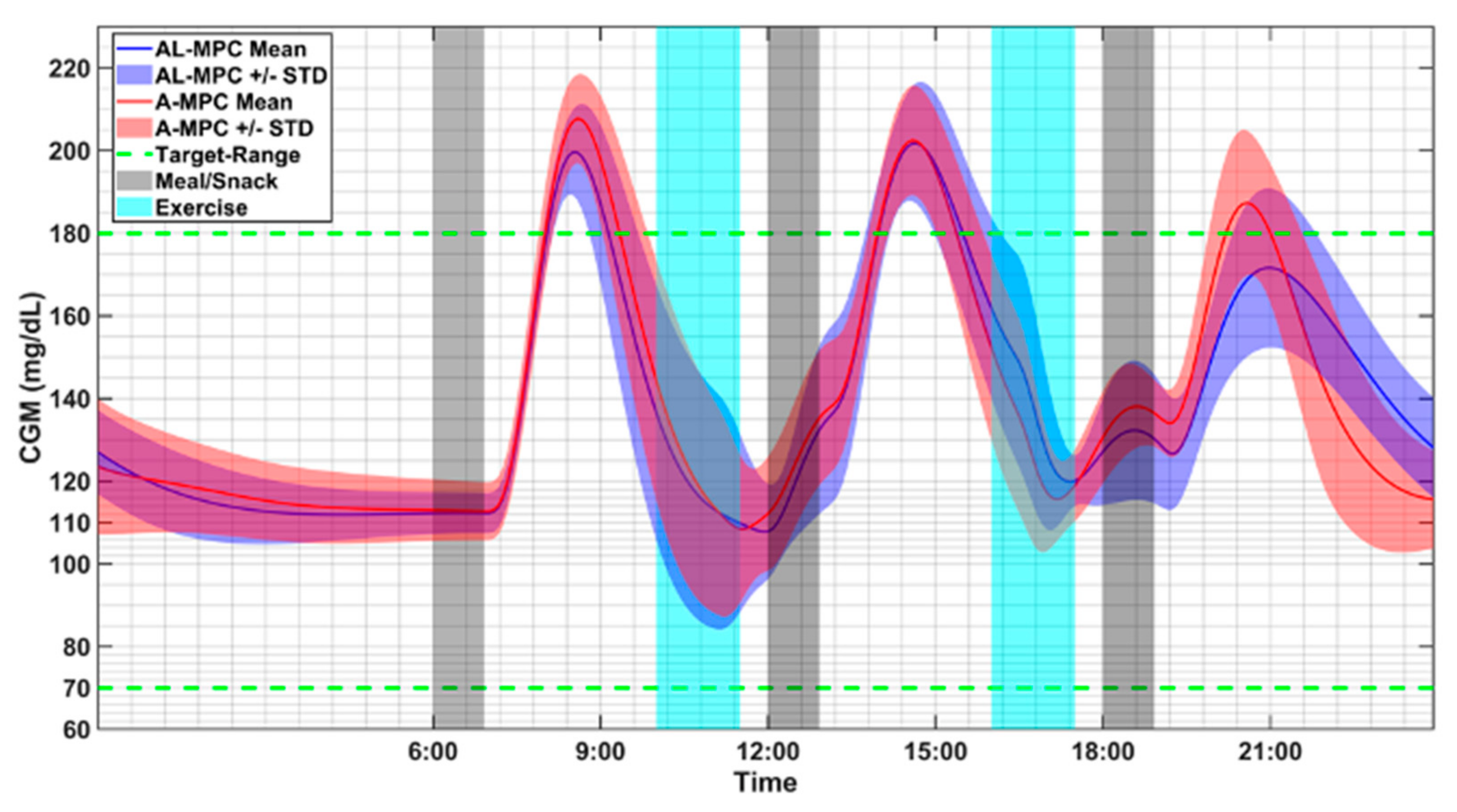
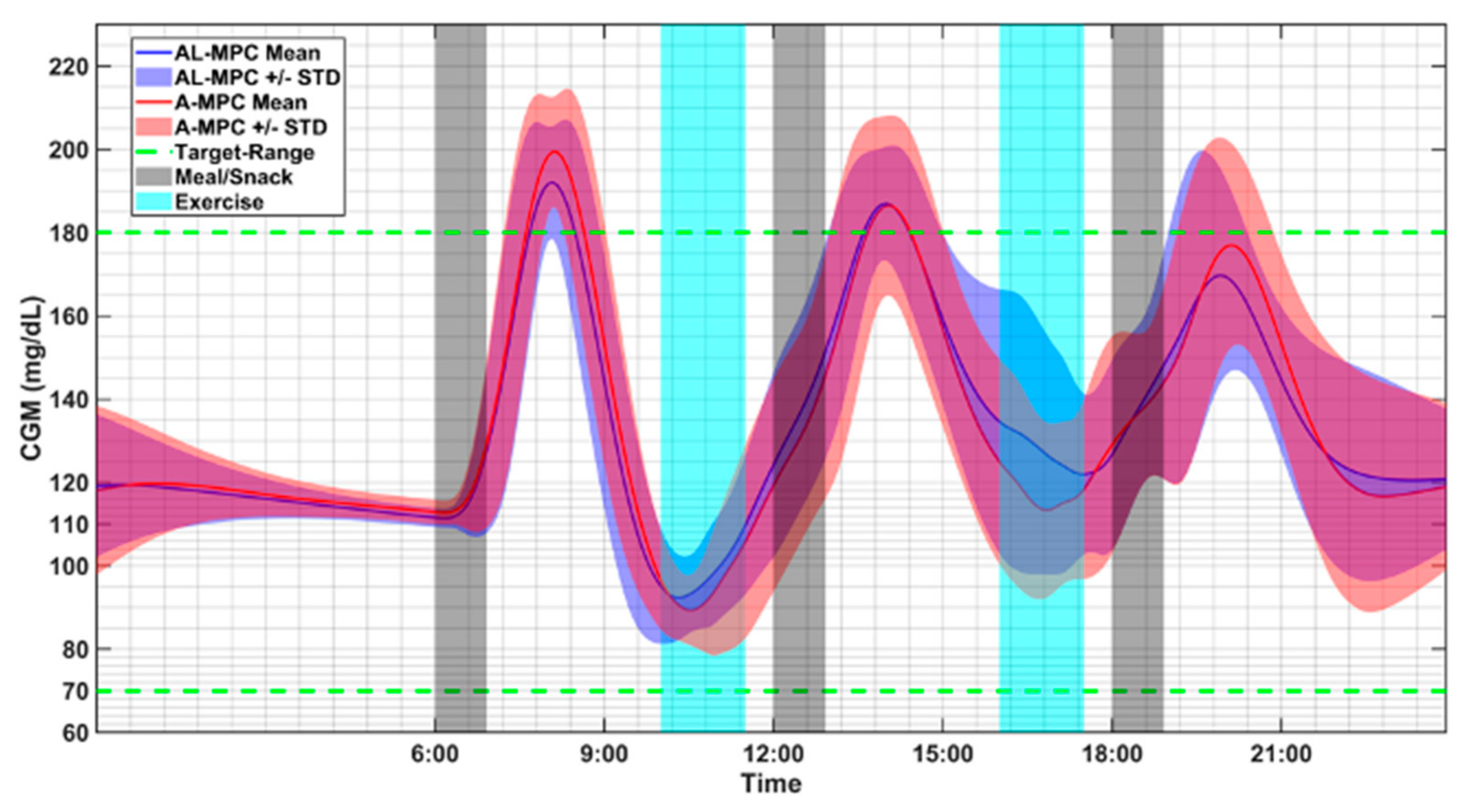
2.3. Merging ML with Automatic Control to Improve Glucose Regulation
3. Results
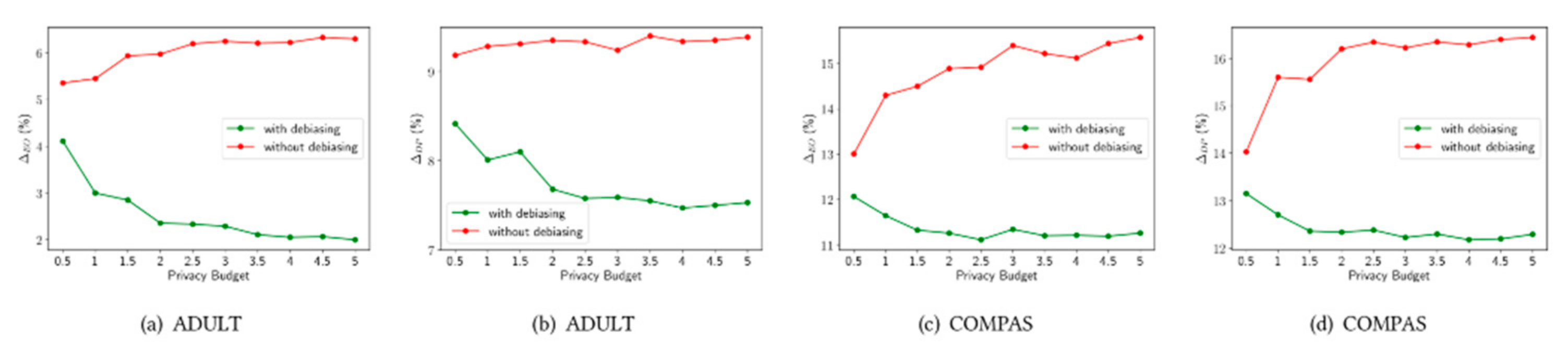
4. Discussion of Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rajpurkar, P.; Chen, E.; Banerjee, O.; Topol, E.J. AI in health and medicine. Nat. Med. 2022, 28, 31–38. [Google Scholar] [CrossRef] [PubMed]
- He, J.; Baxter, S.L.; Xu, J.; Xu, J.; Zhou, X.; Zhang, K. The practical implementation of artificial intelligence technologies in medicine. Nat. Med. 2019, 25, 30–36. [Google Scholar] [CrossRef] [PubMed]
- Dogan, E.; Sander, C.; Wagner, X.; Hegerl, U.; Kohls, E. Smartphone-Based Monitoring of Objective and Subjective Data in Affective Disorders: Where Are We and Where Are We Going? Systematic Review. J. Med. Internet Res. 2017, 19, e7006. [Google Scholar] [CrossRef] [PubMed]
- Tempelaar, D.; Rienties, B.; Nguyen, Q. Subjective data, objective data and the role of bias in predictive modelling: Lessons from a dispositional learning analytics application. PLoS ONE 2020, 15, e0233977. [Google Scholar] [CrossRef]
- Centers for Disease Control and Prevention National Diabetes Statistics Report 2022. Available online: https://nationaldppcsc.cdc.gov/s/article/CDC-2022-National-Diabetes-Statistics-Report (accessed on 11 August 2022).
- Forouhi, N.G.; Wareham, N.J. Epidemiology of diabetes. Medicine 2019, 47, 22–27. [Google Scholar] [CrossRef]
- van Ommen, B.; Wopereis, S.; van Empelen, P.; van Keulen, H.M.; Otten, W.; Kasteleyn, M.; Molema, J.J.W.; de Hoogh, I.M.; Chavannes, N.H.; Numans, M.E.; et al. From Diabetes Care to Diabetes Cure—The Integration of Systems Biology, eHealth, and Behavioral Change. Front. Endocrinol. 2018, 8, 381. Available online: https://www.frontiersin.org/articles/10.3389/fendo.2017.00381 (accessed on 13 August 2022). [CrossRef]
- Hirsch, I.B.; Juneja, R.; Beals, J.M.; Antalis, C.J.; Wright, E.E., Jr. The Evolution of Insulin and How it Informs Therapy and Treatment Choices. Endocr. Rev. 2020, 41, 733–755. [Google Scholar] [CrossRef]
- Boscari, F.; Avogaro, A. Current treatment options and challenges in patients with Type 1 diabetes: Pharmacological, technical advances and future perspectives. Rev. Endocr. Metab. Disord. 2021, 22, 217–240. [Google Scholar] [CrossRef]
- McCoy, R.G.; Van Houten, H.K.; Karaca-Mandic, P.; Ross, J.S.; Montori, V.M.; Shah, N.D. Second-Line Therapy for Type 2 Diabetes Management: The Treatment/Benefit Paradox of Cardiovascular and Kidney Comorbidities. Diabetes Care 2021, 44, 2302–2311. [Google Scholar] [CrossRef]
- Saleh, E.; Błaszczyński, J.; Moreno, A.; Valls, A.; Romero-Aroca, P.; de la Riva-Fernández, S.; Słowiński, R. Learning ensemble classifiers for diabetic retinopathy assessment. Artif. Intell. Med. 2018, 85, 50–63. [Google Scholar] [CrossRef]
- Silva, K.D.; Lee, W.K.; Forbes, A.; Demmer, R.T.; Barton, C.; Enticott, J. Use and performance of machine learning models for type 2 diabetes prediction in community settings: A systematic review and meta-analysis. Int. J. Med. Inf. 2020, 143, 104268. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Carretero, R.; Vigil-Medina, L.; Mora-Jimenez, I.; Soguero-Ruiz, C.; Barquero-Perez, O.; Ramos-Lopez, J. Use of a K-nearest neighbors model to predict the development of type 2 diabetes within 2 years in an obese, hypertensive population. Med. Biol. Eng. Comput. 2020, 58, 991–1002. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Shang, X.; Sreedharan, S.; Yan, X.; Liu, J.; Keel, S.; Wu, J.; Peng, W.; He, M. Predicting the Development of Type 2 Diabetes in a Large Australian Cohort Using Machine-Learning Techniques: Longitudinal Survey Study. JMIR Med. Inform. 2020, 8, e16850. [Google Scholar] [CrossRef] [PubMed]
- Maniruzzaman, M.; Rahman, M.J.; Ahammed, B.; Abedin, M.M. Classification and prediction of diabetes disease using machine learning paradigm. Health Inf. Sci. Syst. 2020, 8, 7. [Google Scholar] [CrossRef]
- Tarumi, S.; Takeuchi, W.; Chalkidis, G.; Rodriguez-Loya, S.; Kuwata, J.; Flynn, M.; Turner, K.M.; Sakaguchi, F.H.; Weir, C.; Kramer, H.; et al. Leveraging Artificial Intelligence to Improve Chronic Disease Care: Methods and Application to Pharmacotherapy Decision Support for Type-2 Diabetes Mellitus. Methods Inf. Med. 2021, 60, e32–e43. [Google Scholar] [CrossRef]
- Tyler, N.S.; Mosquera-Lopez, C.M.; Wilson, L.M.; Dodier, R.H.; Branigan, D.L.; Gabo, V.B.; Guillot, F.H.; Hilts, W.W.; El Youssef, J.; Castle, J.R.; et al. An artificial intelligence decision support system for the management of type 1 diabetes. Nat. Metab. 2020, 2, 612–619. [Google Scholar] [CrossRef]
- Askari, M.R.; Rashid, M.; Sun, X.; Sevil, M.; Shahidehpour, A.; Kawaji, K.; Cinar, A. Meal and Physical Activity Detection from Free-Living Data for Discovering Disturbance Patterns of Glucose Levels in People with Diabetes. BioMedInformatics 2022, 2, 297–317. [Google Scholar] [CrossRef]
- Askari, M.R.; Hajizadeh, I.; Rashid, M.; Hobbs, N.; Zavala, V.M.; Cinar, A. Adaptive-learning model predictive control for complex physiological systems: Automated insulin delivery in diabetes. Annu. Rev. Control 2020, 50, 1–12. [Google Scholar] [CrossRef]
- Le, P.; Chaitoff, A.; Misra-Hebert, A.D.; Ye, W.; Herman, W.H.; Rothberg, M.B. Use of Antihyperglycemic Medications in U.S. Adults: An Analysis of the National Health and Nutrition Examination Survey. Diabetes Care 2020, 43, 1227–1233. [Google Scholar] [CrossRef]
- Taylor, S.I.; Yazdi, Z.S.; Beitelshees, A.L. Pharmacological treatment of hyperglycemia in type 2 diabetes. J. Clin. Investig. 2021, 131, e142243. [Google Scholar] [CrossRef]
- Gloyn, A.L.; Drucker, D.J. Precision medicine in the management of type 2 diabetes. Lancet Diabetes Endocrinol. 2018, 6, 891–900. [Google Scholar] [CrossRef]
- Dennis, J.M. Precision Medicine in Type 2 Diabetes: Using Individualized Prediction Models to Optimize Selection of Treatment. Diabetes 2020, 69, 2075–2085. [Google Scholar] [CrossRef] [PubMed]
- Mao, Y.; Tan, K.X.Q.; Seng, A.; Wong, P.; Toh, S.-A.; Cook, A.R. Stratification of Patients with Diabetes Using Continuous Glucose Monitoring Profiles and Machine Learning. Health Data Sci. 2022, 2022, 892340. [Google Scholar] [CrossRef]
- Askari, M.R.; Rashid, M.; Sevil, M.; Hajizadeh, I.; Brandt, R.; Samadi, S.; Cinar, A. Artifact Removal from Data Generated by Nonlinear Systems: Heart Rate Estimation from Blood Volume Pulse Signal. Ind. Eng. Chem. Res. 2020, 59, 2318–2327. [Google Scholar] [CrossRef]
- Rashid, M.M.; Mhaskar, P.; Swartz, C.L.E. Multi-rate modeling and economic model predictive control of the electric arc furnace. J. Process Control 2016, 40, 50–61. [Google Scholar] [CrossRef]
- Sun, X.; Rashid, M.; Hobbs, N.; Askari, M.R.; Brandt, R.; Shahidehpour, A.; Cinar, A. Prior informed regularization of recursively updated latent-variables-based models with missing observations. Control Eng. Pract. 2021, 116, 104933. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Shu, K.; Wang, S.; Liu, H.; Wang, Y. Multimodal Fusion of Brain Networks with Longitudinal Couplings. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2018; Frangi, A.F., Schnabel, J.A., Davatzikos, C., Alberola-López, C., Fichtinger, G., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Cheng, L.; Shu, K.; Wu, S.; Silva, Y.N.; Hall, D.L.; Liu, H. Unsupervised Cyberbullying Detection via Time-Informed Gaussian Mixture Model. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Online, 19–23 October 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 185–194. [Google Scholar] [CrossRef]
- Shu, K.; Cui, L.; Wang, S.; Lee, D.; Liu, H. DEFEND: Explainable Fake News Detection. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 395–405, ISBN 9781450362016. [Google Scholar]
- Zhao, T.; Dai, E.; Shu, K.; Wang, S. Towards fair classifiers without sensitive attributes: Exploring biases in related features. In Proceedings of the WSDM 2022—Proceedings of the 15th ACM International Conference on Web Search and Data Mining, Tempe, AZ, USA, 21–25 February 2022; pp. 1433–1442. [Google Scholar] [CrossRef]
- Shu, K.; Mukherjee, S.; Zheng, G.; Awadallah, A.H.; Shokouhi, M.; Dumais, S. Learning with Weak Supervision for Email Intent Detection. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Online, 25–30 July 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1051–1060, ISBN 9781450380164. [Google Scholar]
- Tonekaboni, S.; Joshi, S.; McCradden, M.D.; Goldenberg, A. What Clinicians Want: Contextualizing Explainable Machine Learning for Clinical End Use. In Proceedings of the 4th Machine Learning for Healthcare Conference, Ann Arbor, MI, USA, 9–10 August 2019; Volume 106, pp. 359–380. [Google Scholar]
- Kundu, S. AI in medicine must be explainable. Nat. Med. 2021, 27, 1328. [Google Scholar] [CrossRef]
- Doshi-Velez, F.; Kim, B. Towards A Rigorous Science of Interpretable Machine Learning 2017. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Khedkar, S.; Gandhi, P.; Shinde, G.; Subramanian, V. Deep Learning and Explainable AI in Healthcare Using EHR. In Deep Learning Techniques for Biomedical and Health Informatics; Dash, S., Acharya, B.R., Mittal, M., Abraham, A., Kelemen, A., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 129–148. ISBN 978-3-030-33966-1. [Google Scholar]
- Lauritsen, S.M.; Kristensen, M.; Olsen, M.V.; Larsen, M.S.; Lauritsen, K.M.; Jørgensen, M.J.; Lange, J.; Thiesson, B. Explainable artificial intelligence model to predict acute critical illness from electronic health records. Nat. Commun. 2020, 11, 3852. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you? In ” Explaining the predictions of any classifier. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Anchors: High-Precision Model-Agnostic Explanations. In Proceedings of the AAAI Conference on Artificial Intelligenc, New Orleans, LA, USA, 2–7 February 2018; p. 32. [Google Scholar] [CrossRef]
- Forlenza, G.P.; Buckingham, B.A.; Brown, S.A.; Bode, B.W.; Levy, C.J.; Criego, A.B.; Wadwa, R.P.; Cobry, E.C.; Slover, R.J.; Messer, L.H.; et al. First Outpatient Evaluation of a Tubeless Automated Insulin Delivery System with Customizable Glucose Targets in Children and Adults with Type 1 Diabetes. Diabetes Technol. Ther. 2021, 23, 410–424. [Google Scholar] [CrossRef]
- Ware, J.; Hovorka, R. Recent advances in closed-loop insulin delivery. Metabolism 2022, 127, 154953. [Google Scholar] [CrossRef]
- Garcia-Tirado, J.; Lv, D.; Corbett, J.P.; Colmegna, P.; Breton, M.D. Advanced hybrid artificial pancreas system improves on unannounced meal response—In silico comparison to currently available system. Comput. Methods Programs Biomed. 2021, 211, 106401. [Google Scholar] [CrossRef]
- Haidar, A.; Legault, L.; Raffray, M.; Gouchie-Provencher, N.; Jacobs, P.G.; El-Fathi, A.; Rutkowski, J.; Messier, V.; Rabasa-Lhoret, R. Comparison Between Closed-Loop Insulin Delivery System (the Artificial Pancreas) and Sensor-Augmented Pump Therapy: A Randomized-Controlled Crossover Trial. Diabetes Technol. Ther. 2021, 23, 168–174. [Google Scholar] [CrossRef] [PubMed]
- Paldus, B.; Lee, M.H.; Morrison, D.; Zaharieva, D.P.; Jones, H.; Obeyesekere, V.; Lu, J.; Vogrin, S.; LaGerche, A.; McAuley, S.A.; et al. First Randomized Controlled Trial of Hybrid Closed Loop Versus Multiple Daily Injections or Insulin Pump Using Self-Monitoring of Blood Glucose in Free-Living Adults with Type 1 Diabetes Undertaking Exercise. J. Diabetes Sci. Technol. 2021, 15, 1399–1401. [Google Scholar] [CrossRef] [PubMed]
- Ekhlaspour, L.; Forlenza, G.P.; Chernavvsky, D.; Maahs, D.M.; Wadwa, R.P.; Deboer, M.D.; Messer, L.H.; Town, M.; Pinnata, J.; Kruse, G.; et al. Closed loop control in adolescents and children during winter sports: Use of the Tandem Control-IQ AP system. Pediatr. Diabetes 2019, 20, 759–768. [Google Scholar] [CrossRef] [PubMed]
- Deshpande, S.; Pinsker, J.E.; Church, M.M.; Piper, M.; Andre, C.; Massa, J.; Doyle, F.J., III; Eisenberg, D.M.; Dassau, E. Randomized Crossover Comparison of Automated Insulin Delivery Versus Conventional Therapy Using an Unlocked Smartphone with Scheduled Pasta and Rice Meal Challenges in the Outpatient Setting. Diabetes Technol. Ther. 2020, 22, 865–874. [Google Scholar] [CrossRef]
- Wilson, L.M.; Jacobs, P.G.; Riddell, M.C.; Zaharieva, D.P.; Castle, J.R. Opportunities and challenges in closed-loop systems in type 1 diabetes. Lancet Diabetes Endocrinol. 2022, 10, 6–8. [Google Scholar] [CrossRef]
- Franc, S.; Benhamou, P.-Y.; Borot, S.; Chaillous, L.; Delemer, B.; Doron, M.; Guerci, B.; Hanaire, H.; Huneker, E.; Jeandidier, N.; et al. No more hypoglycaemia on days with physical activity and unrestricted diet when using a closed-loop system for 12 weeks: A post hoc secondary analysis of the multicentre, randomized controlled Diabeloop WP7 trial. Diabetes Obes. Metab. 2021, 23, 2170–2176. [Google Scholar] [CrossRef]
- Toffanin, C.; Aiello, E.M.; Del Favero, S.; Cobelli, C.; Magni, L. Multiple models for artificial pancreas predictions identified from free-living condition data: A proof of concept study. J. Process Control 2019, 77, 29–37. [Google Scholar] [CrossRef]
- Garcia-Tirado, J.; Brown, S.A.; Laichuthai, N.; Colmegna, P.; Koravi, C.L.K.; Ozaslan, B.; Corbett, J.P.; Barnett, C.L.; Pajewski, M.; Oliveri, M.C.; et al. Anticipation of Historical Exercise Patterns by a Novel Artificial Pancreas System Reduces Hypoglycemia During and After Moderate-Intensity Physical Activity in People with Type 1 Diabetes. Diabetes Technol. Ther. 2021, 23, 277–285. [Google Scholar] [CrossRef]
- Lewis, D. How It Started, How It Is Going: The Future of Artificial Pancreas Systems (Automated Insulin Delivery Systems). J. Diabetes Sci. Technol. 2021, 15, 1258–1261. [Google Scholar] [CrossRef] [PubMed]
- Boughton, C.K.; Hovorka, R. New closed-loop insulin systems. Diabetologia 2021, 64, 1007–1015. [Google Scholar] [CrossRef] [PubMed]
- Garg, S.K.; Weinzimer, S.A.; Tamborlane, W.V.; Buckingham, B.A.; Bode, B.W.; Bailey, T.S.; Brazg, R.L.; Ilany, J.; Slover, R.H.; Anderson, S.M.; et al. Glucose Outcomes with the In-Home Use of a Hybrid Closed-Loop Insulin Delivery System in Adolescents and Adults with Type 1 Diabetes. Diabetes Technol. Ther. 2017, 19, 155–163. [Google Scholar] [CrossRef] [PubMed]
- Tauschmann, M.; Thabit, H.; Bally, L.; Allen, J.M.; Hartnell, S.; Wilinska, M.E.; Ruan, Y.; Sibayan, J.; Kollman, C.; Cheng, P.; et al. Closed-loop insulin delivery in suboptimally controlled type 1 diabetes: A multicentre, 12-week randomised trial. Lancet 2018, 392, 1321–1329. [Google Scholar] [CrossRef]
- Brown, S.A.; Kovatchev, B.P.; Raghinaru, D.; Lum, J.W.; Buckingham, B.A.; Kudva, Y.C.; Laffel, L.M.; Levy, C.J.; Pinsker, J.E.; Wadwa, R.P.; et al. Six-month randomized, multicenter trial of closed-loop control in type 1 diabetes. N. Engl. J. Med. 2019, 381, 1707–1717. [Google Scholar] [CrossRef]
- Benhamou, P.-Y.; Franc, S.; Reznik, Y.; Thivolet, C.; Schaepelynck, P.; Renard, E.; Guerci, B.; Chaillous, L.; Lukas-Croisier, C.; Jeandidier, N.; et al. Closed-loop insulin delivery in adults with type 1 diabetes in real-life conditions: A 12-week multicentre, open-label randomised controlled crossover trial. Lancet Digit. Health 2019, 1, e17–e25. [Google Scholar] [CrossRef]
- Carlson, A.L.; Bode, B.W.; Brazg, R.L.; Christiansen, M.P.; Garg, S.K.; Kaiserman, K.; Kipnes, M.; Liljenquist, D.R.; Philis-Tsimikas, A.; Pop-Busui, R.; et al. 97-LB: Safety and Glycemic Outcomes of the MiniMed Advanced Hybrid Closed-Loop (AHCL) System in Subjects with T1D. Diabetes 2020, 69, 97-LB. [Google Scholar] [CrossRef]
- Bergenstal, R.M.; Nimri, R.; Beck, R.W.; Criego, A.; Laffel, L.; Schatz, D.; Battelino, T.; Danne, T.; Weinzimer, S.A.; Sibayan, J.; et al. A comparison of two hybrid closed-loop systems in adolescents and young adults with type 1 diabetes (FLAIR): A multicentre, randomised, crossover trial. Lancet 2021, 397, 208–219. [Google Scholar] [CrossRef]
- Samadi, S.; Turksoy, K.; Hajizadeh, I.; Feng, J.; Sevil, M.; Cinar, A. Meal detection and carbohydrate estimation using continuous glucose sensor data. IEEE J. Biomed. Health Inform. 2017, 21, 619–627. [Google Scholar] [CrossRef]
- Samadi, S.; Rashid, M.; Turksoy, K.; Feng, J.; Hajizadeh, I.; Hobbs, N.; Lazaro, C.; Sevil, M.; Littlejohn, E.; Cinar, A. Automatic Detection and Estimation of Unannounced Meals for Multivariable Artificial Pancreas System. Diabetes Technol. Ther. 2018, 20, 235–246. [Google Scholar] [CrossRef]
- Turksoy, K.; Hajizadeh, I.; Hobbs, N.; Kilkus, J.; Littlejohn, E.; Samadi, S.; Feng, J.; Sevil, M.; Lazaro, C.; Ritthaler, J.; et al. Multivariable artificial pancreas for various exercise types and intensities. Diabetes Technol. Ther. 2018, 20, 662–671. [Google Scholar] [CrossRef] [PubMed]
- Forlenza, G.P.; Cameron, F.M.; Ly, T.T.; Lam, D.; Howsmon, D.P.; Baysal, N.; Kulina, G.; Messer, L.; Clinton, P.; Levister, C.; et al. Fully Closed-Loop Multiple Model Probabilistic Predictive Controller Artificial Pancreas Performance in Adolescents and Adults in a Supervised Hotel Setting. Diabetes Technol. Ther. 2018, 20, 335–343. [Google Scholar] [CrossRef] [PubMed]
- Ramkissoon, C.M.; Herrero, P.; Bondia, J.; Vehi, J. Unannounced Meals in the Artificial Pancreas: Detection Using Continuous Glucose Monitoring. Sensors 2018, 18, 884. [Google Scholar] [CrossRef]
- Gondhalekar, R.; Dassau, E.; Doyle, F.J. Velocity-weighting & velocity-penalty MPC of an artificial pancreas: Improved safety & performance. Automatica 2018, 91, 105–117. [Google Scholar] [CrossRef] [PubMed]
- Hajizadeh, I.; Rashid, M.; Samadi, S.; Sevil, M.; Hobbs, N.; Brandt, R.; Cinar, A. Adaptive Personalized Multivariable Artificial Pancreas Using Plasma Insulin Estimates. J. Process Control 2019, 80, 26040. [Google Scholar] [CrossRef]
- Feng, Q.; Du, M.; Zou, N.; Hu, X. Fair Machine Learning in Healthcare: A Review 2022. arXiv 2022, arXiv:2206.14397. [Google Scholar] [CrossRef]
- Meng, C.; Trinh, L.; Xu, N.; Liu, Y. MIMIC-IF: Interpretability and Fairness Evaluation of Deep Learning Models on MIMIC-IV Dataset 2021. arXiv 2021, arXiv:2102.06761. [Google Scholar] [CrossRef]
- Nguyen, M. Predicting Cardiovascular Risk Using Electronic Health Records. Available online: https://cs229.stanford.edu/proj2019spr/report/68.pdf (accessed on 11 August 2022).
- Pfohl, S.; Marafino, B.; Coulet, A.; Rodriguez, F.; Palaniappan, L.; Shah, N.H. Creating Fair Models of Atherosclerotic Cardiovascular Disease Risk. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, Honolulu, HI, USA, 27–28 January 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 271–278. [Google Scholar] [CrossRef]
- Logé, C.; Ross, E.; Dadey, D.Y.A.; Jain, S.; Saporta, A.; Ng, A.Y.; Rajpurkar, P. Q-Pain: A Question Answering Dataset to Measure Social Bias in Pain Management 2021. arXiv 2021, arXiv:2108.01764. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 1877–1901. Available online: https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html (accessed on 11 August 2022).
- Zafar, M.B.; Valera, I.; Gomez-Rodriguez, M.; Gummadi, K.P. Fairness Constraints: A Flexible Approach for Fair Classification. J. Mach. Learn. Res. 2019, 20, 2737–2778. [Google Scholar]
- Mehrabi, N.; Morstatter, F.; Saxena, N.; Lerman, K.; Galstyan, A. A Survey on Bias and Fairness in Machine Learning. ACM Comput. Surv. 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Chen, R.J.; Chen, T.Y.; Lipkova, J.; Wang, J.J.; Williamson, D.F.K.; Lu, M.Y.; Sahai, S.; Mahmood, F. Algorithm Fairness in AI for Medicine and Healthcare 2022. arXiv 2021, arXiv:2110.00603. [Google Scholar] [CrossRef]
- Hardt, M.; Price, E.; Srebro, N. Equality of Opportunity in Supervised Learning 2016. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 4–9 December 2016. [Google Scholar]
- Tran, C.; Fioretto, F.; Hentenryck, P. Van Differentially Private and Fair Deep Learning: A Lagrangian Dual Approach 2020. arXiv 2020, arXiv:2009.12562. [Google Scholar]
- Petersen, F.; Mukherjee, D.; Sun, Y.; Yurochkin, M. Post-processing for Individual Fairness. In Advances in Neural Information Processing Systems; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P.S., Vaughan, J.W., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 25944–25955. [Google Scholar]
- Savani, Y.; White, C.; Govindarajulu, N.S. Intra-Processing Methods for Debiasing Neural Networks. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 2798–2810. [Google Scholar]
- Na, L.; Yang, C.; Lo, C.-C.; Zhao, F.; Fukuoka, Y.; Aswani, A. Feasibility of Reidentifying Individuals in Large National Physical Activity Data Sets from Which Protected Health Information Has Been Removed with Use of Machine Learning. JAMA Netw. Open 2018, 1, e186040. [Google Scholar] [CrossRef]
- Shahid, A.R.; Talukder, S. A Study of Differentially Private Machine Learning in Healthcare. In Proceedings of the 2021 Innovations in Intelligent Systems and Applications Conference (ASYU), Elazig, Turkey, 6–8 October 2021; pp. 1–6. [Google Scholar]
- Islam, T.U.; Ghasemi, R.; Mohammed, N. Privacy-Preserving Federated Learning Model for Healthcare Data. In Proceedings of the 2022 IEEE 12th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 26–29 January 2022; pp. 281–287. [Google Scholar]
- Martin, K. Ethics of Data and Analytics: Concepts and Cases; Auerbach Publications: New York, NY, USA, 2022; ISBN 9781003278290. [Google Scholar]
- Chakrabarty, N.; Biswas, S. A Statistical Approach to Adult Census Income Level Prediction. In Proceedings of the 2018 International Conference on Advances in Computing, Communication Control and Networking (ICACCCN), Noida, India, 12–13 October 2018; pp. 207–212. [Google Scholar]
- Wang, H.; Grgic-Hlaca, N.; Lahoti, P.; Gummadi, K.P.; Weller, A. An Empirical Study on Learning Fairness Metrics for COMPAS Data with Human Supervision 2019. arXiv 2019, arXiv:1910.10255. [Google Scholar] [CrossRef]
- Dressel, J.; Farid, H. The accuracy, fairness, and limits of predicting recidivism. Sci. Adv. 2018, 4, eaao5580. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Liang, Y.; Xu, X.; Xie, S.; Hong, Y.; Shu, K. On Fair Classification with Mostly Private Sensitive Attributes. arXiv 2022, arXiv:2207.08336. [Google Scholar]
- Mosallanezhad, A.; Karami, M.; Shu, K.; Mancenido, M.V.; Liu, H. Domain Adaptive Fake News Detection via Reinforcement Learning. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 3632–3640. [Google Scholar]
- Ding, K.; Shu, K.; Shan, X.; Li, J.; Liu, H. Cross-Domain Graph Anomaly Detection. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 2406–2415. [Google Scholar] [CrossRef] [PubMed]
- Shu, K.; Wang, S.; Tang, J.; Wang, Y.; Liu, H. CrossFire: Cross Media Joint Friend and Item Recommendations. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Los Angeles, CA, USA, 5–9 February 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 522–530. [Google Scholar]
- Liang, Y.; Chen, C.; Tian, T.; Shu, K. Joint Adversarial Learning for Cross-domain Fair Classification 2022. arXiv 2022, arXiv:2206.03656. [Google Scholar] [CrossRef]
- Weinzimer, S.A.; Steil, G.M.; Swan, K.L.; Dziura, J.; Kurtz, N.; Tamborlane, W.V. Fully automated closed-loop insulin delivery versus semiautomated hybrid control in pediatric patients with type 1 diabetes using an artificial pancreas. Diabetes Care 2008, 31, 934–939. [Google Scholar] [CrossRef] [Green Version]
- Turksoy, K.; Quinn, L.; Littlejohn, E.; Cinar, A. Multivariable Adaptive Identification and Control for Artificial Pancreas Systems. IEEE Trans. Biomed. Eng. 2014, 61, 883–891. [Google Scholar] [CrossRef]
- Turksoy, K.; Bayrak, E.S.; Quinn, L.; Littlejohn, E.; Cinar, A. Multivariable adaptive closed-loop control of an artificial pancreas without meal and activity announcement. Diabetes Technol. Ther. 2013, 15, 386–400. [Google Scholar] [CrossRef]
- Hajizadeh, I.; Rashid, M.; Turksoy, K.; Samadi, S.; Feng, J.; Sevil, M.; Hobbs, N.; Lazaro, C.; Maloney, Z.; Littlejohn, E.; et al. Incorporating Unannounced Meals and Exercise in Adaptive Learning of Personalized Models for Multivariable Artificial Pancreas Systems. J. Diabetes Sci. Technol. 2018, 12, 953–966. [Google Scholar] [CrossRef] [PubMed]
- Sevil, M.; Rashid, M.; Hajizadeh, I.; Askari, M.R.; Hobbs, N.; Brandt, R.; Park, M.; Quinn, L.; Cinar, A. Discrimination of simultaneous psychological and physical stressors using wristband biosignals. Comput. Methods Programs Biomed. 2021, 199, 105898. [Google Scholar] [CrossRef] [PubMed]
- Sevil, M.; Rashid, M.; Hajizadeh, I.; Park, M.; Quinn, L.; Cinar, A. Physical Activity and Psychological Stress Detection and Assessment of Their Effects on Glucose Concentration Predictions in Diabetes Management. IEEE Trans. Biomed. Eng. 2021, 68, 2251–2260. [Google Scholar] [CrossRef] [PubMed]
- Sevil, M.; Rashid, M.; Maloney, Z.; Hajizadeh, I.; Samadi, S.; Askari, M.R.; Hobbs, N.; Brandt, R.; Park, M.; Quinn, L.; et al. Determining physical activity characteristics from wristband data for use in automated insulin delivery systems. IEEE Sens. J. 2020, 20, 12859–12870. [Google Scholar] [CrossRef]
- Rashid, M.; Samadi, S.; Sevil, M.; Hajizadeh, I.; Kolodziej, P.; Hobbs, N.; Maloney, Z.; Brandt, R.; Feng, J.; Park, M.; et al. Simulation software for assessment of nonlinear and adaptive multivariable control algorithms: Glucose–insulin dynamics in Type 1 diabetes. Comput. Chem. Eng. 2019, 130, 106565. [Google Scholar] [CrossRef]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rashid, M.M.; Askari, M.R.; Chen, C.; Liang, Y.; Shu, K.; Cinar, A. Artificial Intelligence Algorithms for Treatment of Diabetes. Algorithms 2022, 15, 299. https://doi.org/10.3390/a15090299
Rashid MM, Askari MR, Chen C, Liang Y, Shu K, Cinar A. Artificial Intelligence Algorithms for Treatment of Diabetes. Algorithms. 2022; 15(9):299. https://doi.org/10.3390/a15090299
Chicago/Turabian StyleRashid, Mudassir M., Mohammad Reza Askari, Canyu Chen, Yueqing Liang, Kai Shu, and Ali Cinar. 2022. "Artificial Intelligence Algorithms for Treatment of Diabetes" Algorithms 15, no. 9: 299. https://doi.org/10.3390/a15090299
APA StyleRashid, M. M., Askari, M. R., Chen, C., Liang, Y., Shu, K., & Cinar, A. (2022). Artificial Intelligence Algorithms for Treatment of Diabetes. Algorithms, 15(9), 299. https://doi.org/10.3390/a15090299