
Adversarial Training Methods for Deep Learning: A Systematic Review


Abstract
:1. Introduction
- Categorize adversarial training methods. The main criteria used for the categorization were the adversarial generation methods, which refer to the standard methods that use adversarial attacks to generate adversarial samples and include these samples in training to improve the robustness of the training model [3].
- Identify the advantages and disadvantages of these adversarial training methods.
2. Background
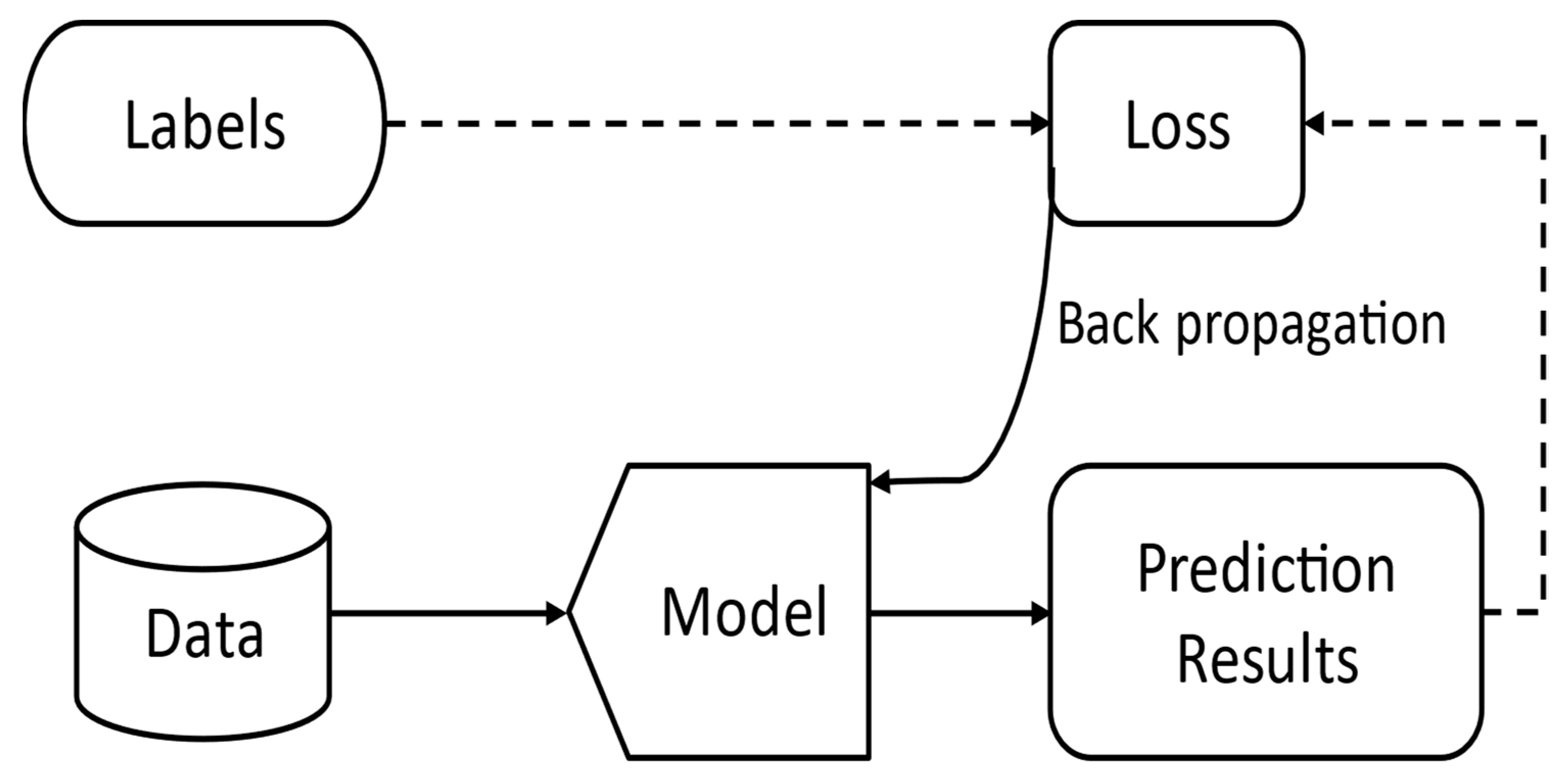
2.1. Adversarial Samples
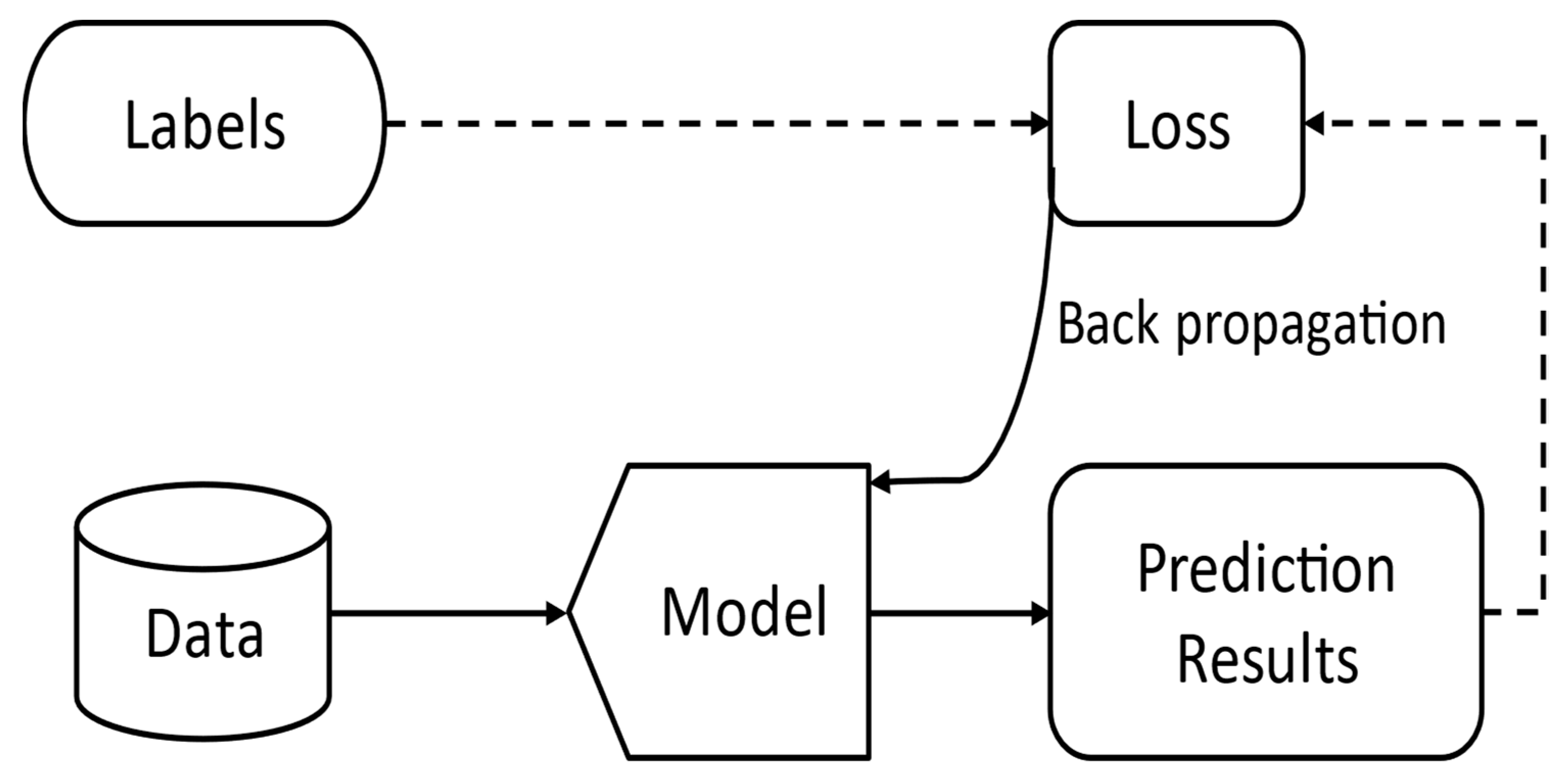
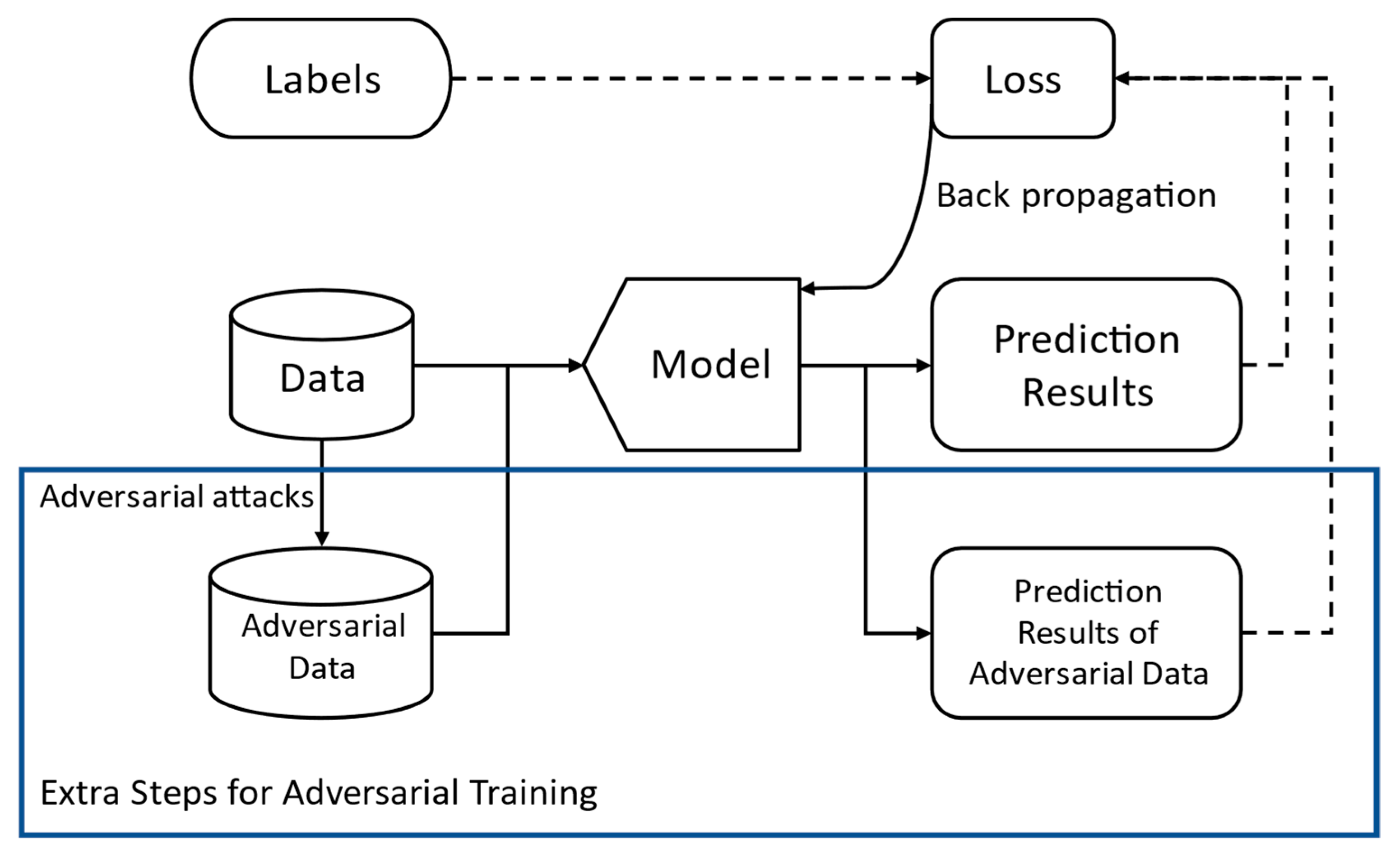
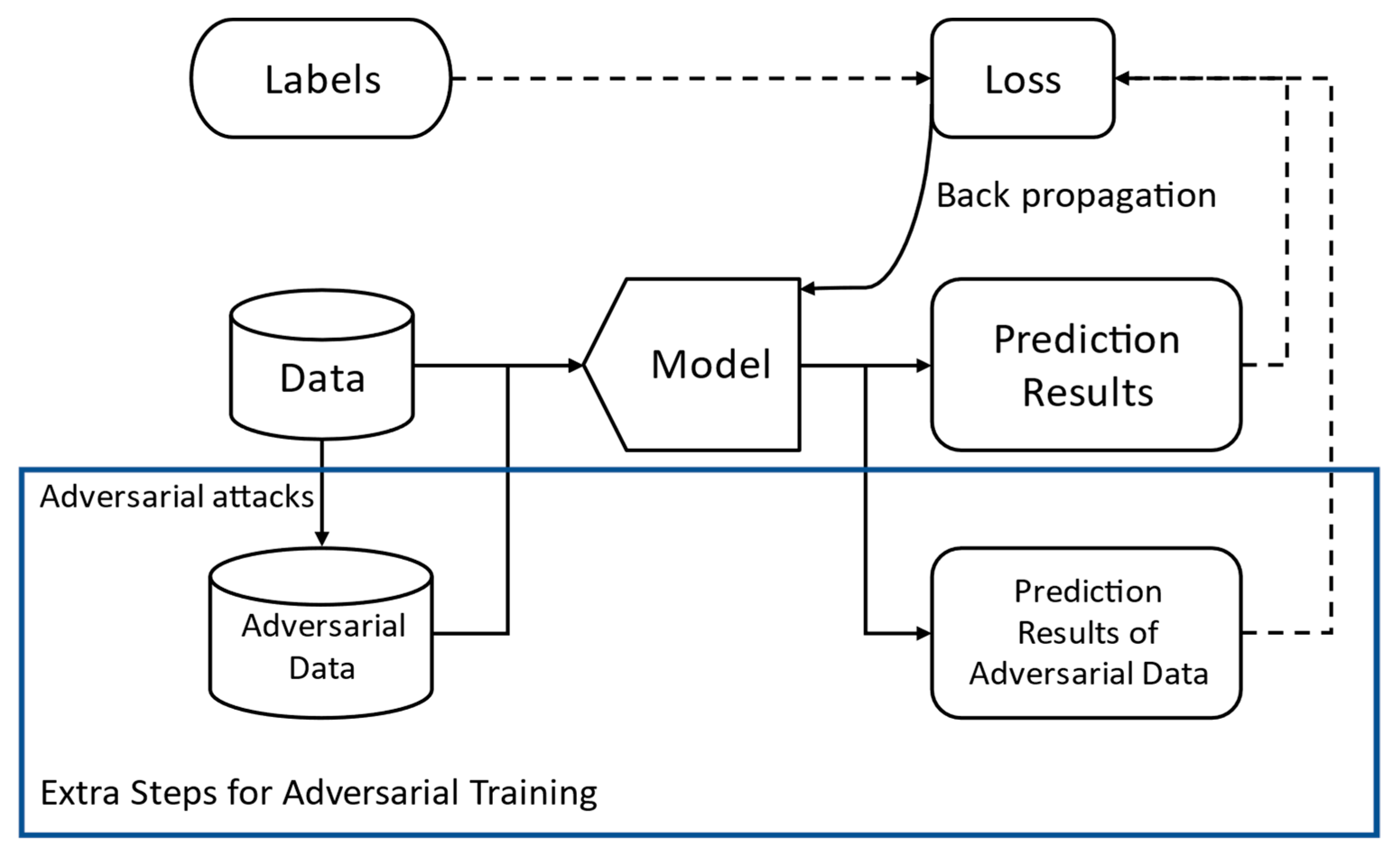
2.2. Adversarial Training
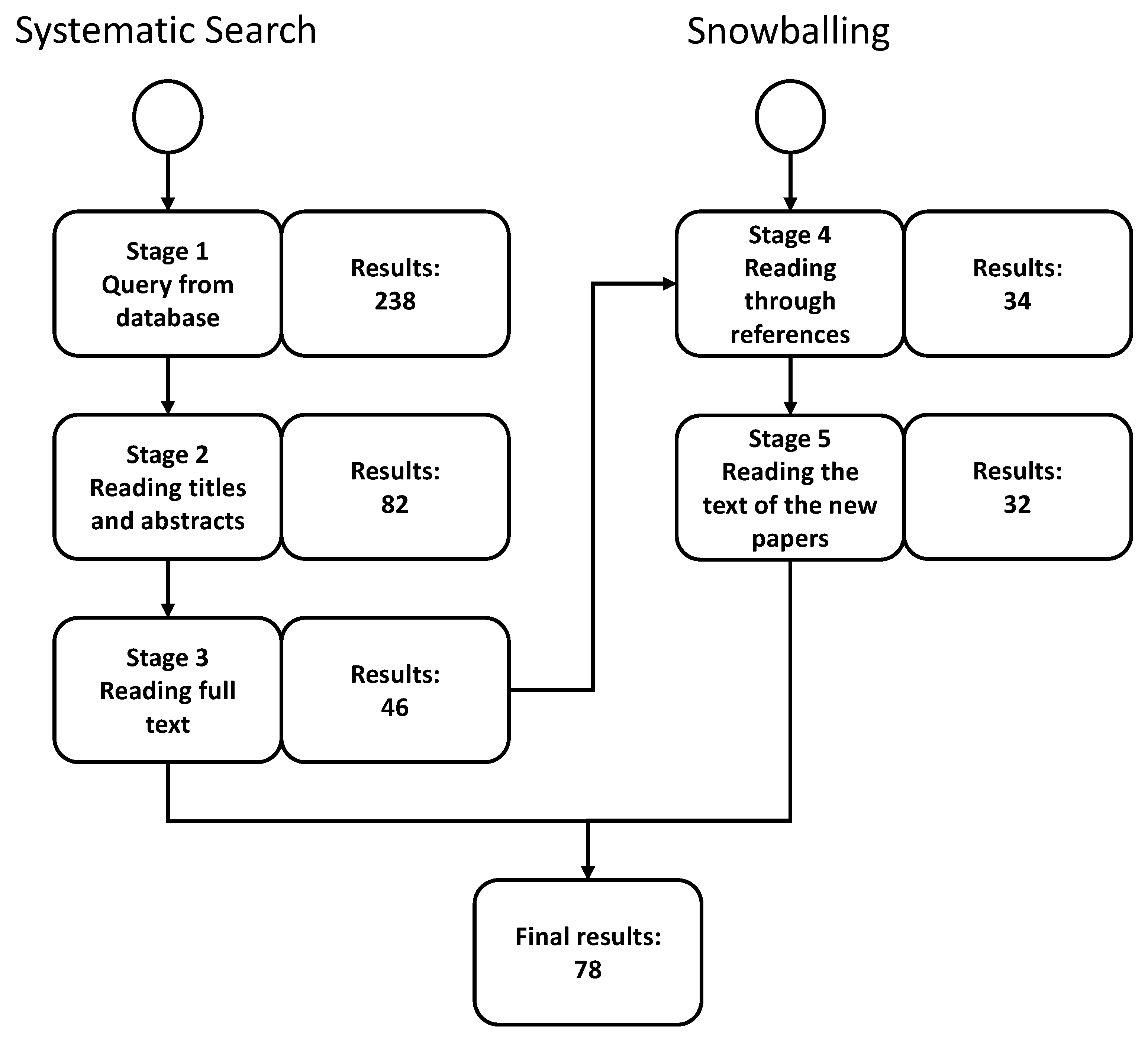
3. Survey Methodology
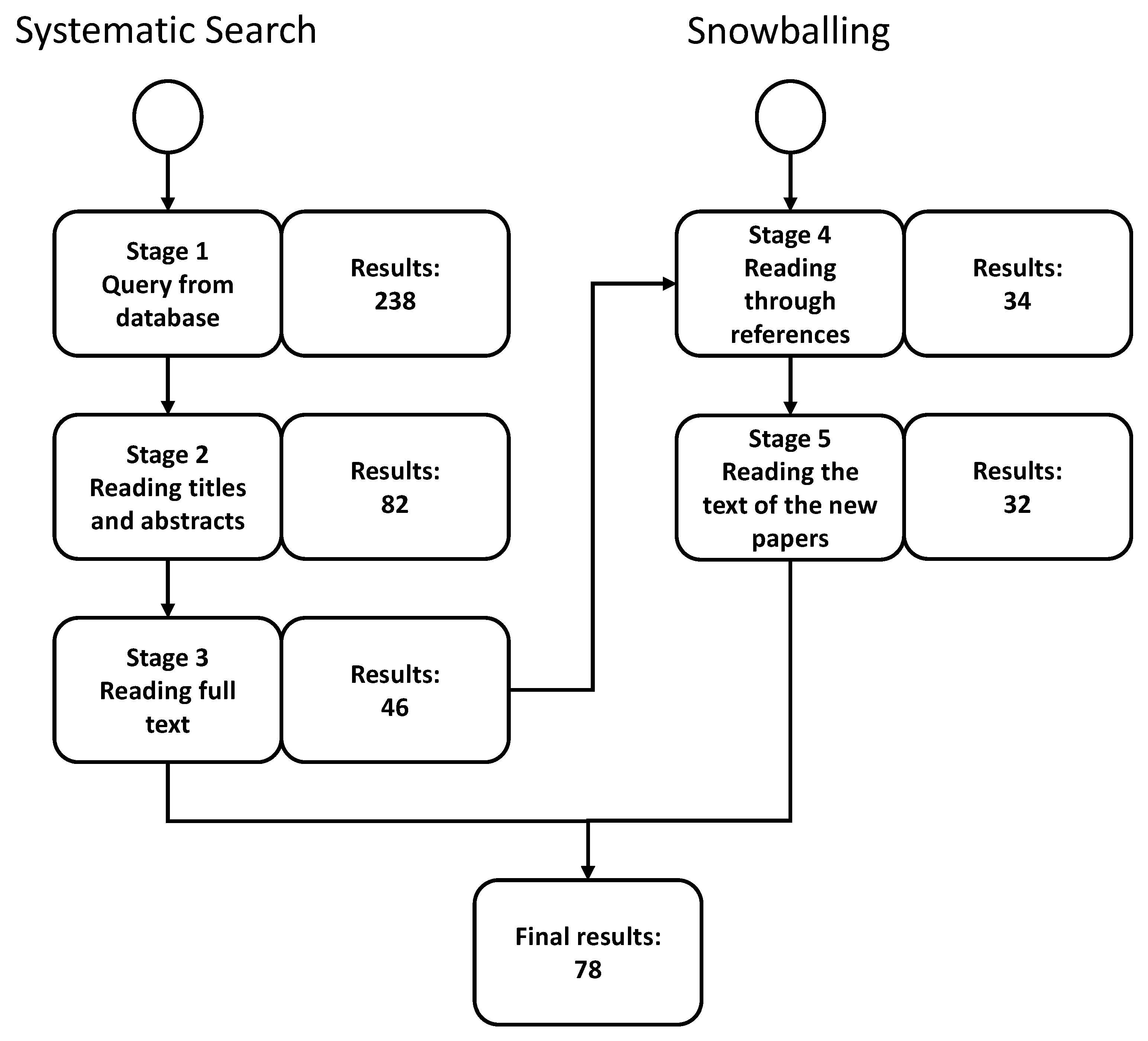
3.1. Search Strategies
(“neural network” OR “deep neural network” OR dnn OR nn OR “deep learning”) AND (“robust optimization” OR “adversarial training” OR “adversarial learning”) AND (defend* OR resist* OR against) AND (“adversarial sample*” OR “adversarial example*” OR “adversarial perturbation*“ OR “adversarial attack”).
3.2. Search Sources
3.3. Inclusion and Exclusion Criteria
3.4. Data Collection Procedure
3.5. Data Extraction Strategy
4. Findings
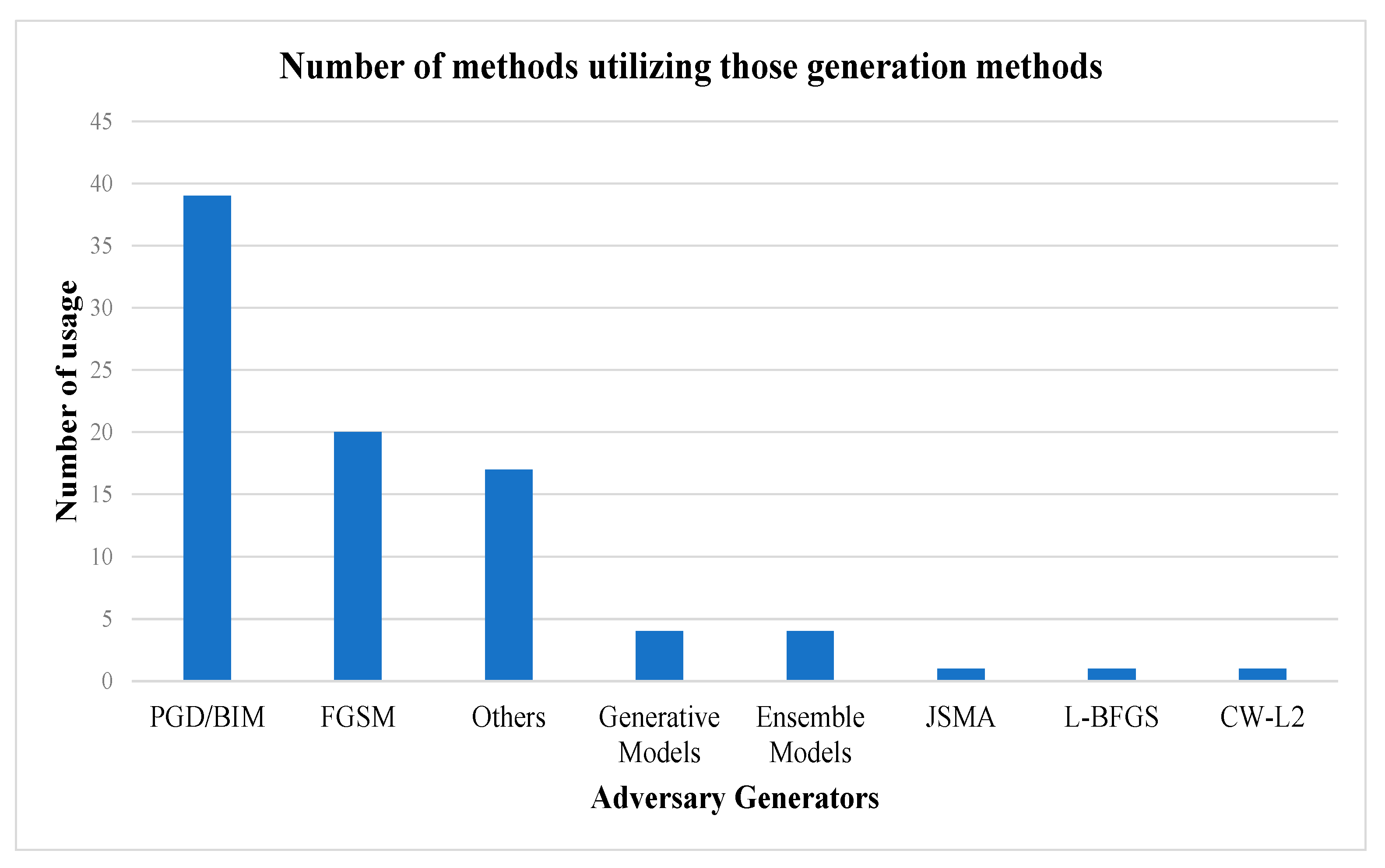
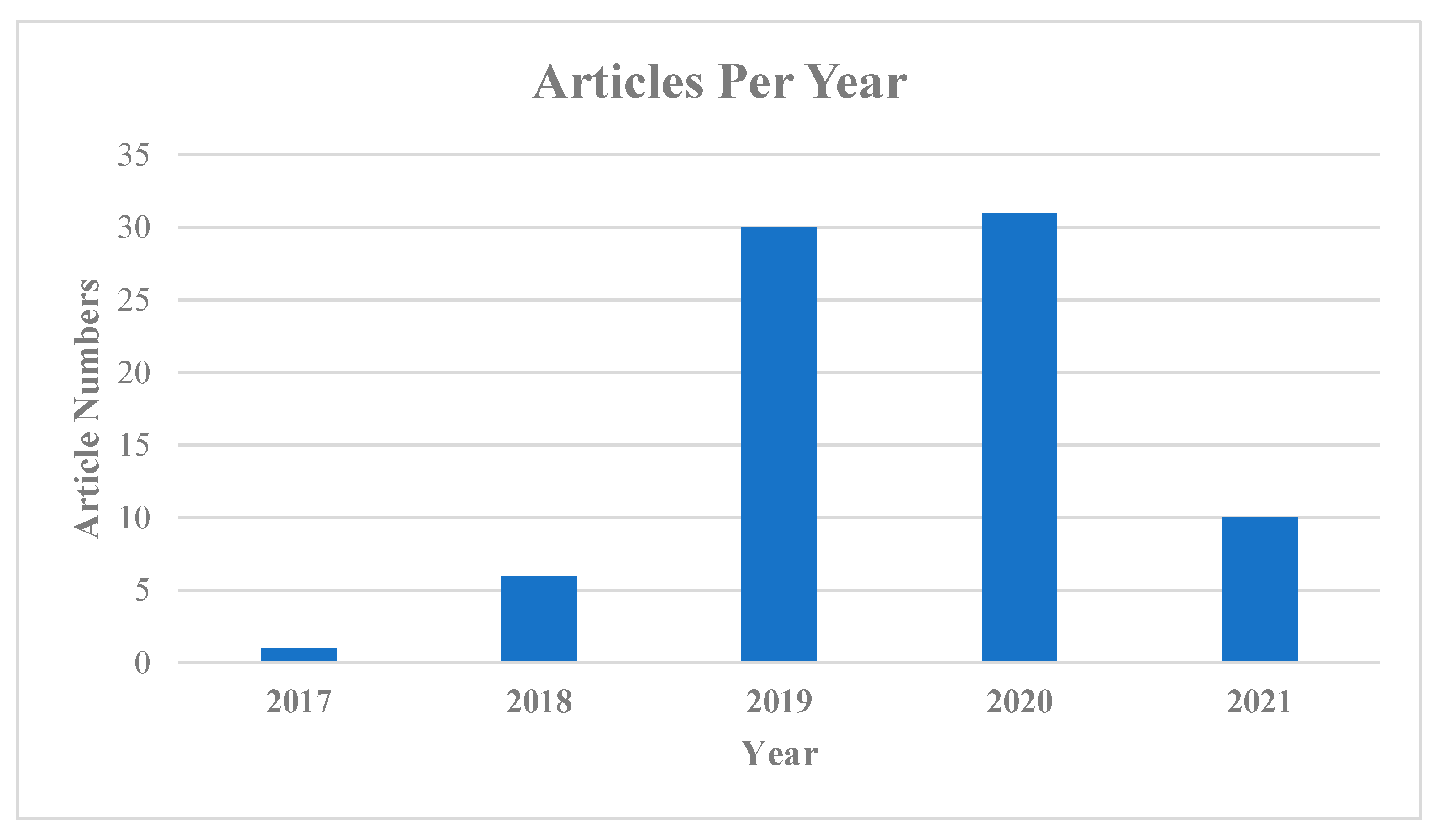
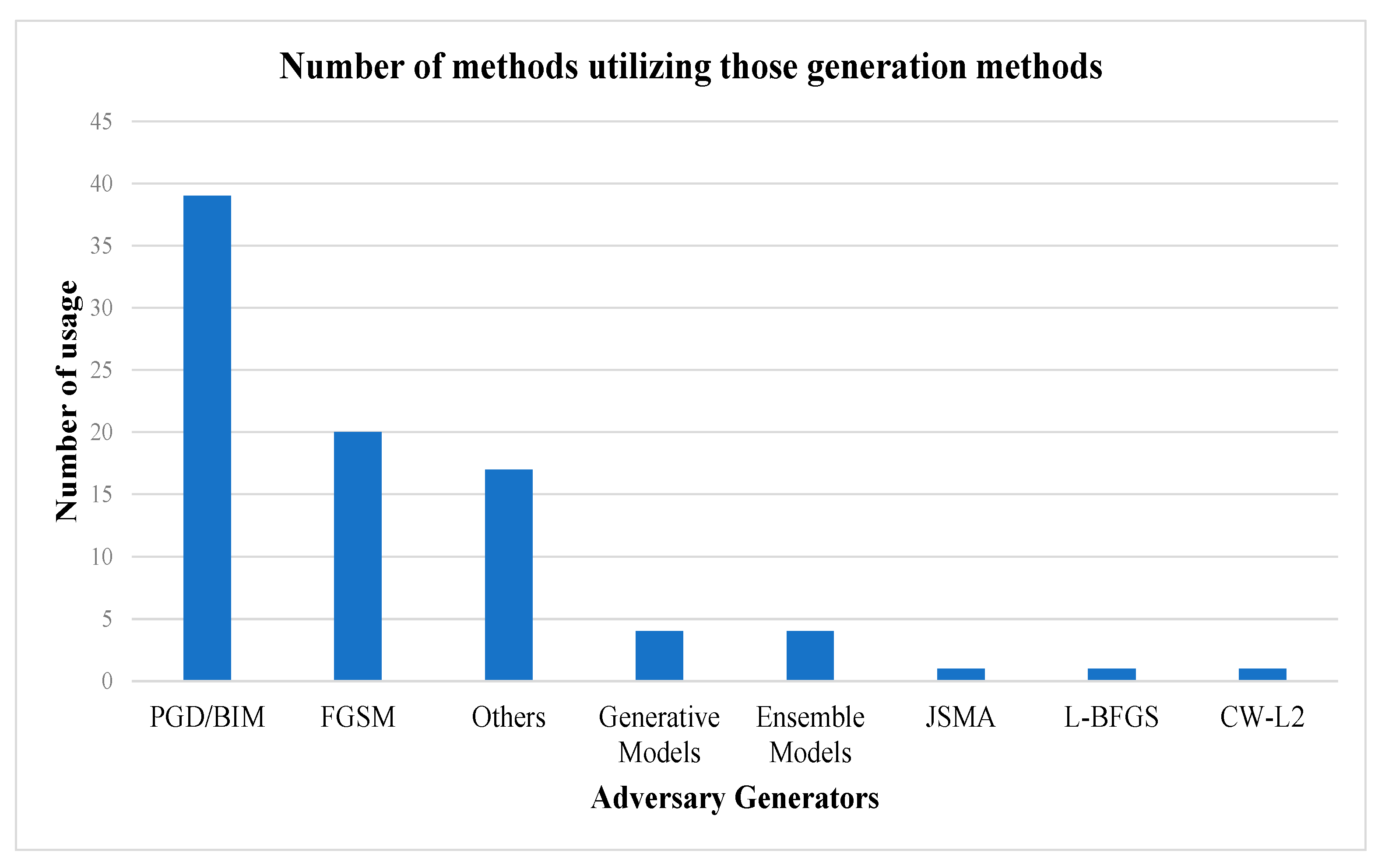
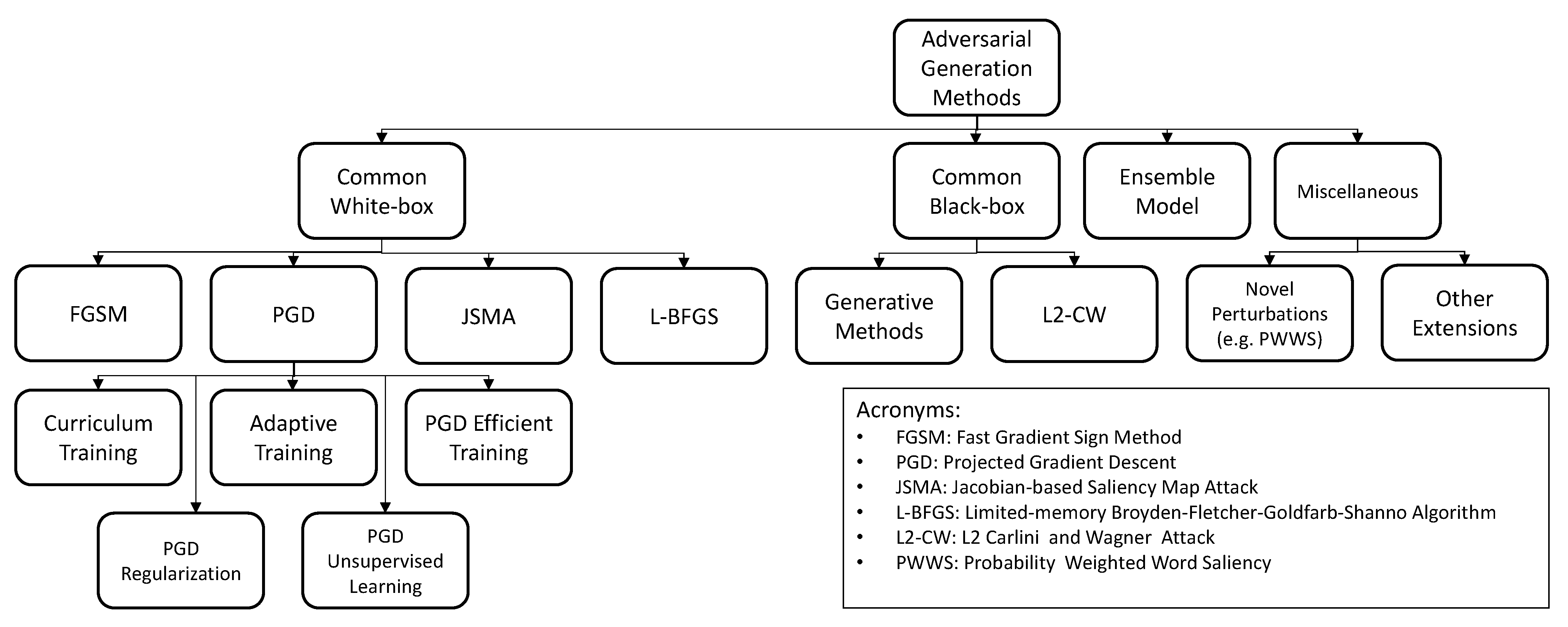
4.1. Summary of the Results
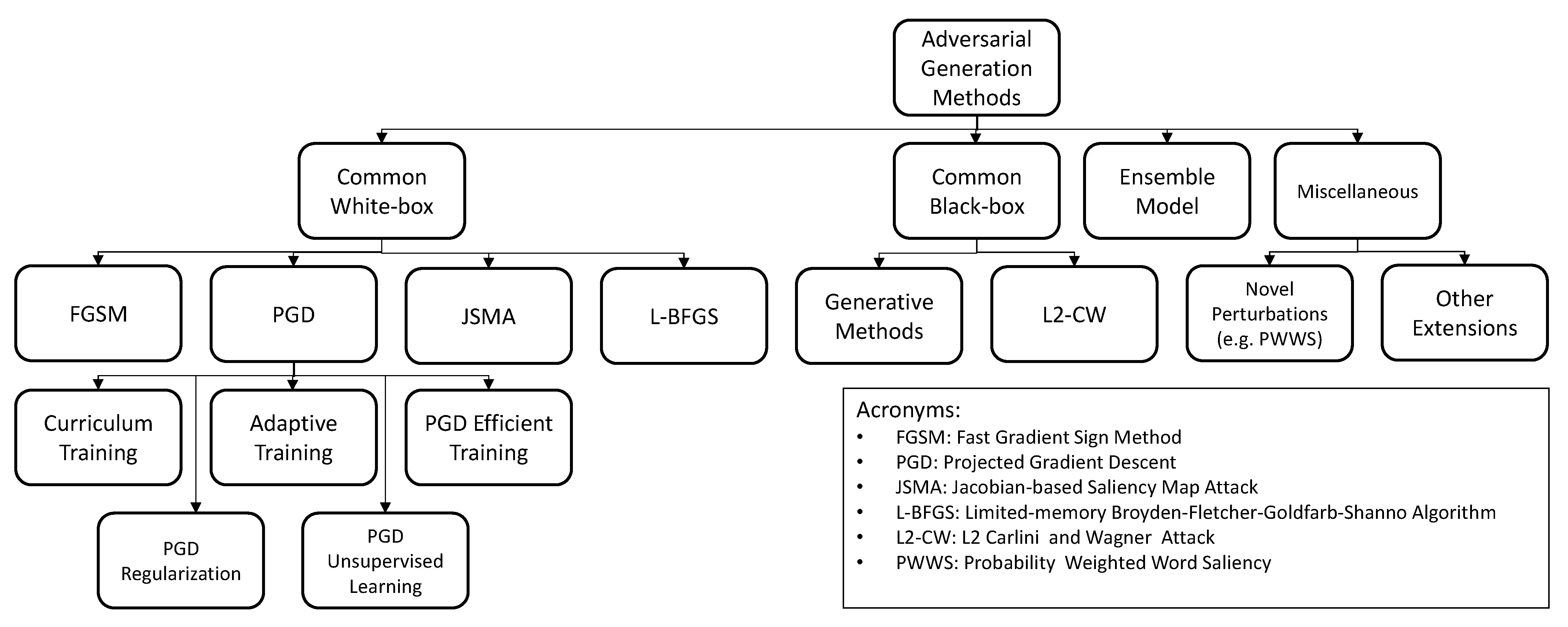
4.2. Fast Gradient Sign Method
4.3. Projected Gradient Descent and Basic Iterative Method
4.3.1. Curriculum Training
4.3.2. Adaptive Training
4.3.3. Efficient Training
4.3.4. Adversarial Regularization
4.3.5. Unsupervised/Semi-Unsupervised Training
4.3.6. Other Methods Related to PGD and BIM
4.4. L-BFGS and JSMA Methods
4.5. Generative Model
4.6. C&W-L2 Attack
4.7. Ensemble Models
4.8. Novel Perturbation Methods
4.8.1. Methods Targeting Specific Application Domains
4.8.2. Instance-Wise Perturbation
4.8.3. Adversarial Attack with Riemannian Space
4.8.4. Boundary-Guided Generation
4.8.5. Layer-Wised Perturbation
4.8.6. TUP
4.8.7. Self-Supervised Perturbation
4.8.8. Attack-Less Adversarial Training
4.8.9. Iterative Quantized Local Search
4.8.10. Feature Scatter
4.9. Adversarial Training Extension
4.9.1. Method-Based Ensemble Adversarial Training
4.9.2. Adam Optimizer with Local Linearization Regularizer
4.9.3. Adversarial Vertex Mixup
4.9.4. Adversarial Interpolation
4.9.5. Adversarial Training with Hypersphere Embedding
4.10. Summary of the Findings
4.11. Threats to Validity
4.11.1. Internal Threats
4.11.2. External Threats
4.11.3. Construct Validity
5. Discussion
5.1. Generalization Problem
5.2. Generalization and Efficiency
5.3. Against Potential Unseen Adversaries
6. Conclusions and Future Work
- The current research on adversarial training or robust neural network optimization focuses on the FGSM and PGD adversarial samples.
- The major goals of current approaches include balancing standard and adversarial generalization and efficiency. The commonly used methods include modifying the traditional FGSM and PGD and modifying the regularization terms of the training objective function.
- Some other methods have been proposed to be incorporated into adversarial training, such as generative networks and other black-box generation methods.
- Generalization problems have been studied frequently; however, there is still a gap between the standard accuracy, adversarial accuracy, and efficiency of training. Generalization towards unseen adversarial samples has been studied occasionally, but there is potentially more to explore.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Silva, S.H.; Najafirad, P. Opportunities and Challenges in Deep Learning Adversarial Robustness: A Survey. arXiv 2020, arXiv:2007.00753. [Google Scholar]
- Wiyatno, R.R.; Xu, A.; Dia, O.; de Berker, A. Adversarial Examples in Modern Machine Learning: A Review. arXiv 2019, arXiv:1911.05268. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2015, arXiv:1412.6572. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing Properties of Neural Networks. arXiv 2014, arXiv:1312.6199. [Google Scholar]
- Bai, T.; Luo, J.; Zhao, J.; Wen, B.; Wang, Q. Recent Advances in Adversarial Training for Adversarial Robustness. arXiv 2021, arXiv:2102.01356. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial Machine Learning at Scale. arXiv 2017, arXiv:1611.01236. [Google Scholar]
- Wang, H.; Yu, C.-N. A Direct Approach to Robust Deep Learning Using Adversarial Networks. arXiv 2019, arXiv:1905.09591. [Google Scholar]
- Chen, K.; Zhu, H.; Yan, L.; Wang, J. A Survey on Adversarial Examples in Deep Learning. J. Big Data 2020, 2, 71–84. [Google Scholar] [CrossRef]
- Chakraborty, A.; Alam, M.; Dey, V.; Chattopadhyay, A.; Mukhopadhyay, D. Adversarial Attacks and Defences: A Survey. arXiv 2018, arXiv:1810.00069. [Google Scholar] [CrossRef]
- Kong, Z.; Xue, J.; Wang, Y.; Huang, L.; Niu, Z.; Li, F. A Survey on Adversarial Attack in the Age of Artificial Intelligence. Wirel. Commun. Mob. Comput. 2021, 2021, 4907754. [Google Scholar] [CrossRef]
- Huang, X.; Kroening, D.; Ruan, W.; Sharp, J.; Sun, Y.; Thamo, E.; Wu, M.; Yi, X. A Survey of Safety and Trustworthiness of Deep Neural Networks: Verification, Testing, Adversarial Attack and Defence, and Interpretability. Comput. Sci. Rev. 2020, 37, 100270. [Google Scholar] [CrossRef]
- Kitchenham, B.; Charters, S. Guidelines for Performing Systematic Literature Reviews in Software Engineering; Technical Report; Keele University: Keele, UK; Durham University: Durham, UK, 2007; Volume 2. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. arXiv 2019, arXiv:1706.06083. [Google Scholar]
- Moosavi-Dezfooli, S.-M.; Fawzi, A.; Frossard, P. DeepFool: A Simple and Accurate Method to Fool Deep Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Carlini, N.; Wagner, D. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar]
- Su, J.; Vargas, D.V.; Sakurai, K. One Pixel Attack for Fooling Deep Neural Networks. IEEE Trans. Evol. Computat. 2019, 23, 828–841. [Google Scholar] [CrossRef]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. Ensemble Adversarial Training: Attacks and Defenses. arXiv 2020, arXiv:1705.07204. [Google Scholar]
- About Engineering Village|Elsevier. Available online: https://www.elsevier.com/solutions/engineering-village#:~:text=Engineering%20Village%20is%20a%20search,needs%20of%20world%20class%20engineers (accessed on 13 July 2022).
- Schott, L.; Rauber, J.; Bethge, M.; Brendel, W. Towards the First Adversarially Robust Neural Network Model on MNIST. arXiv 2018, arXiv:1805.09190. [Google Scholar]
- Vivek, B.S.; Venkatesh Babu, R. Single-Step Adversarial Training With Dropout Scheduling. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 947–956. [Google Scholar]
- Huang, T.; Menkovski, V.; Pei, Y.; Pechenizkiy, M. Bridging the Performance Gap between FGSM and PGD Adversarial Training. arXiv 2020, arXiv:2011.05157. [Google Scholar]
- Liu, G.; Khalil, I.; Khreishah, A. Using Single-Step Adversarial Training to Defend Iterative Adversarial Examples. In Proceedings of the Proceedings of the Eleventh ACM Conference on Data and Application Security and Privacy, Virtual Event USA, 26–28 April 2021; pp. 17–27. [Google Scholar]
- Wong, E.; Rice, L.; Kolter, J.Z. Fast Is Better than Free: Revisiting Adversarial Training. arXiv 2020, arXiv:2001.03994. [Google Scholar]
- Andriushchenko, M.; Flammarion, N. Understanding and Improving Fast Adversarial Training. Adv. Neural Inf. Process. Syst. 2020, 33, 16048–16059. [Google Scholar]
- Kim, H.; Lee, W.; Lee, J. Understanding Catastrophic Overfitting in Single-Step Adversarial Training. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Song, C.; He, K.; Wang, L.; Hopcroft, J.E. Improving the Generalization of Adversarial Training with Domain Adaptation. arXiv 2019, arXiv:1810.00740. [Google Scholar]
- Vivek, B.S.; Babu, R.V. Regularizers for Single-Step Adversarial Training. arXiv 2020, arXiv:2002.00614. [Google Scholar]
- Li, B.; Wang, S.; Jana, S.; Carin, L. Towards Understanding Fast Adversarial Training. arXiv 2020, arXiv:2006.03089. [Google Scholar]
- Yuan, J.; He, Z. Adversarial Dual Network Learning With Randomized Image Transform for Restoring Attacked Images. IEEE Access 2020, 8, 22617–22624. [Google Scholar] [CrossRef]
- Wan, W.; Chen, J.; Yang, M.-H. Adversarial Training with Bi-Directional Likelihood Regularization for Visual Classification. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; Volume 12369, pp. 785–800. ISBN 9783030585853. [Google Scholar]
- Qin, Y.; Hunt, R.; Yue, C. On Improving the Effectiveness of Adversarial Training. In Proceedings of the ACM International Workshop on Security and Privacy Analytics—IWSPA’19, Richardson, TX, USA, 27 March 2019; ACM Press: New York, NY, USA, 2019; pp. 5–13. [Google Scholar]
- Laugros, A.; Caplier, A.; Ospici, M. Addressing Neural Network Robustness with Mixup and Targeted Labeling Adversarial Training. In Computer Vision—ECCV 2020 Workshops; Bartoli, A., Fusiello, A., Eds.; Springer International Publishing: Cham, Switzerland, 2020; Volume 12539, pp. 178–195. ISBN 9783030682378. [Google Scholar]
- Li, W.; Wang, L.; Zhang, X.; Huo, J.; Gao, Y.; Luo, J. Defensive Few-Shot Adversarial Learning. arXiv 2019, arXiv:1911.06968. [Google Scholar]
- Liu, J.; Jin, Y. Evolving Hyperparameters for Training Deep Neural Networks against Adversarial Attacks. In Proceedings of the 2019 IEEE Symposium Series on Computational Intelligence (SSCI), Xiamen, China, 6–9 December 2019; pp. 1778–1785. [Google Scholar]
- Ren, Z.; Baird, A.; Han, J.; Zhang, Z.; Schuller, B. Generating and Protecting Against Adversarial Attacks for Deep Speech-Based Emotion Recognition Models. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7184–7188. [Google Scholar]
- Song, C.; Cheng, H.-P.; Yang, H.; Li, S.; Wu, C.; Wu, Q.; Chen, Y.; Li, H. MAT: A Multi-Strength Adversarial Training Method to Mitigate Adversarial Attacks. In Proceedings of the 2018 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Hong Kong, China, 8–11 July 2018; pp. 476–481. [Google Scholar]
- Gupta, S.K. Reinforcement Based Learning on Classification Task Could Yield Better Generalization and Adversarial Accuracy. arXiv 2020, arXiv:2012.04353. [Google Scholar]
- Chen, E.-C.; Lee, C.-R. Towards Fast and Robust Adversarial Training for Image Classification. In Computer Vision—ACCV 2020; Ishikawa, H., Liu, C.-L., Pajdla, T., Shi, J., Eds.; Springer International Publishing: Cham, Switzerland, 2021; Volume 12624, pp. 576–591. ISBN 9783030695347. [Google Scholar]
- Cai, Q.-Z.; Du, M.; Liu, C.; Song, D. Curriculum Adversarial Training. arXiv 2018, arXiv:1805.04807. [Google Scholar]
- Zhang, J.; Xu, X.; Han, B.; Niu, G.; Cui, L.; Sugiyama, M.; Kankanhalli, M. Attacks Which Do Not Kill Training Make Adversarial Learning Stronger. In Proceedings of the 37th International Conference on Machine Learning, PMLR, Online, 21 November 2020; pp. 11278–11287. [Google Scholar]
- Wang, Y.; Ma, X.; Bailey, J.; Yi, J.; Zhou, B.; Gu, Q. On the Convergence and Robustness of Adversarial Training. arXiv 2022, arXiv:2112.08304. [Google Scholar]
- Balaji, Y.; Goldstein, T.; Hoffman, J. Instance Adaptive Adversarial Training: Improved Accuracy Tradeoffs in Neural Nets. arXiv 2019, arXiv:1910.08051. [Google Scholar]
- Ding, G.W.; Sharma, Y.; Lui, K.Y.C.; Huang, R. MMA Training: Direct Input Space Margin Maximization through Adversarial Training. arXiv 2020, arXiv:1812.02637. [Google Scholar]
- Cheng, M.; Lei, Q.; Chen, P.-Y.; Dhillon, I.; Hsieh, C.-J. CAT: Customized Adversarial Training for Improved Robustness. arXiv 2020, arXiv:2002.06789. [Google Scholar]
- Shafahi, A.; Najibi, M.; Ghiasi, A.; Xu, Z.; Dickerson, J.; Studer, C.; Davis, L.S.; Taylor, G.; Goldstein, T. Adversarial Training for Free! arXiv 2019, arXiv:1904.12843. [Google Scholar]
- Zhang, H.; Shi, Y.; Dong, B.; Han, Y.; Li, Y.; Kuang, X. Free Adversarial Training with Layerwise Heuristic Learning. In Image and Graphics; Peng, Y., Hu, S.-M., Gabbouj, M., Zhou, K., Elad, M., Xu, K., Eds.; Springer International Publishing: Cham, Switzerland, 2021; Volume 12889, pp. 120–131. ISBN 9783030873578. [Google Scholar]
- Zhang, H.; Yu, Y.; Jiao, J.; Xing, E.; Ghaoui, L.E.; Jordan, M. Theoretically Principled Trade-off between Robustness and Accuracy. In Proceedings of the 36th International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 24 May 2019; pp. 7472–7482. [Google Scholar]
- Kannan, H.; Kurakin, A.; Goodfellow, I. Adversarial Logit Pairing. arXiv 2018, arXiv:1803.06373. [Google Scholar]
- Wang, Y.; Zou, D.; Yi, J.; Bailey, J.; Ma, X.; Gu, Q. Improving Adversarial Robustness Requires Revisiting Misclassified Examples. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Mao, C.; Zhong, Z.; Yang, J.; Vondrick, C.; Ray, B. Metric Learning for Adversarial Robustness. arXiv 2019, arXiv:1909.00900. [Google Scholar]
- Zhong, Y.; Deng, W. Adversarial Learning With Margin-Based Triplet Embedding Regularization. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6548–6557. [Google Scholar]
- Uesato, J.; Alayrac, J.-B.; Huang, P.-S.; Stanforth, R.; Fawzi, A.; Kohli, P. Are Labels Required for Improving Adversarial Robustness? arXiv 2019, arXiv:1905.13725. [Google Scholar]
- Carmon, Y.; Raghunathan, A.; Schmidt, L.; Liang, P.; Duchi, J.C. Unlabeled Data Improves Adversarial Robustness. arXiv 2019, arXiv:1905.13736. [Google Scholar]
- Zhai, R.; Cai, T.; He, D.; Dan, C.; He, K.; Hopcroft, J.; Wang, L. Adversarially Robust Generalization Just Requires More Unlabeled Data. arXiv 2019, arXiv:1906.00555. [Google Scholar]
- Hendrycks, D.; Mazeika, M.; Kadavath, S.; Song, D. Using Self-Supervised Learning Can Improve Model Robustness and Uncertainty. arXiv 2019, arXiv:1906.12340. [Google Scholar]
- Maini, P.; Wong, E.; Kolter, J.Z. Adversarial Robustness Against the Union of Multiple Perturbation Models. In Proceedings of the 37th International Conference on Machine Learning, Virtual Event, 21 November 2020. [Google Scholar]
- Stutz, D.; Hein, M.; Schiele, B. Confidence-Calibrated Adversarial Training: Generalizing to Unseen Attacks. In Proceedings of the 37th International Conference on Machine Learning, PMLR, Virtual Event, 21 November 2020; pp. 9155–9166. [Google Scholar]
- Dong, Y.; Deng, Z.; Pang, T.; Su, H.; Zhu, J. Adversarial Distributional Training for Robust Deep Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 8270–8283. [Google Scholar]
- Liu, G.; Khalil, I.; Khreishah, A. GanDef: A GAN Based Adversarial Training Defense for Neural Network Classifier. In ICT Systems Security and Privacy Protection; Dhillon, G., Karlsson, F., Hedström, K., Zúquete, A., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 562, pp. 19–32. ISBN 9783030223113. [Google Scholar]
- Rao, S.; Stutz, D.; Schiele, B. Adversarial Training Against Location-Optimized Adversarial Patches. In Computer Vision—ECCV 2020 Workshops; Bartoli, A., Fusiello, A., Eds.; Springer International Publishing: Cham, Switzerland, 2020; Volume 12539, pp. 429–448. ISBN 9783030682378. [Google Scholar]
- Wu, T.; Tong, L.; Vorobeychik, Y. Defending Against Physically Realizable Attacks on Image Classification. arXiv 2020, arXiv:1909.09552. [Google Scholar]
- Ruiz, N.; Bargal, S.A.; Sclaroff, S. Disrupting Deepfakes: Adversarial Attacks Against Conditional Image Translation Networks and Facial Manipulation Systems. In Computer Vision—ECCV 2020 Workshops; Bartoli, A., Fusiello, A., Eds.; Springer International Publishing: Cham, Switzerland, 2020; Volume 12538, pp. 236–251. ISBN 9783030668228. [Google Scholar]
- Jiang, Y.; Ma, X.; Erfani, S.M.; Bailey, J. Dual Head Adversarial Training. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021. [Google Scholar]
- Ma, L.; Liang, L. Increasing-Margin Adversarial (IMA) Training to Improve Adversarial Robustness of Neural Networks. arXiv 2022, arXiv:2005.09147. [Google Scholar]
- Zhang, C.; Liu, A.; Liu, X.; Xu, Y.; Yu, H.; Ma, Y.; Li, T. Interpreting and Improving Adversarial Robustness of Deep Neural Networks With Neuron Sensitivity. IEEE Trans. Image Process. 2021, 30, 1291–1304. [Google Scholar] [CrossRef]
- Bouniot, Q.; Audigier, R.; Loesch, A. Optimal Transport as a Defense Against Adversarial Attacks. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10 January 2021; pp. 5044–5051. [Google Scholar]
- Rakin, A.S.; He, Z.; Fan, D. Parametric Noise Injection: Trainable Randomness to Improve Deep Neural Network Robustness against Adversarial Attack. arXiv 2018, arXiv:1811.09310. [Google Scholar]
- Xu, H.; Liu, X.; Li, Y.; Jain, A.; Tang, J. To Be Robust or to Be Fair: Towards Fairness in Adversarial Training. In Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual Event, 1 July 2021; pp. 11492–11501. [Google Scholar]
- Xu, M.; Zhang, T.; Li, Z.; Liu, M.; Zhang, D. Towards Evaluating the Robustness of Deep Diagnostic Models by Adversarial Attack. Med. Image Anal. 2021, 69, 101977. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Zhang, H. Bilateral Adversarial Training: Towards Fast Training of More Robust Models Against Adversarial Attacks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6628–6637. [Google Scholar]
- Stutz, D.; Hein, M.; Schiele, B. Disentangling Adversarial Robustness and Generalization. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6969–6980. [Google Scholar]
- Sreevallabh Chivukula, A.; Yang, X.; Liu, W. Adversarial Deep Learning with Stackelberg Games. In Neural Information Processing; Gedeon, T., Wong, K.W., Lee, M., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 1142, pp. 3–12. ISBN 9783030368074. [Google Scholar]
- Bai, W.; Quan, C.; Luo, Z. Alleviating Adversarial Attacks via Convolutional Autoencoder. In Proceedings of the 2017 18th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), Kanazawa, Japan, 26–28 June 2017; pp. 53–58. [Google Scholar]
- Wen, J.; Hui, L.C.K.; Yiu, S.-M.; Zhang, R. DCN: Detector-Corrector Network Against Evasion Attacks on Deep Neural Networks. In Proceedings of the 2018 48th Annual IEEE/IFIP International Conference on Dependable Systems and Networks Workshops (DSN-W), Luxembourg, 25–28 June 2018; pp. 215–221. [Google Scholar]
- Pang, T.; Xu, K.; Du, C.; Chen, N.; Zhu, J. Improving Adversarial Robustness via Promoting Ensemble Diversity. In Proceedings of the 36th International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 24 May 2019; pp. 4970–4979. [Google Scholar]
- Kariyappa, S.; Qureshi, M.K. Improving Adversarial Robustness of Ensembles with Diversity Training. arXiv 2019, arXiv:1901.09981. [Google Scholar]
- Yang, H.; Zhang, J.; Dong, H.; Inkawhich, N.; Gardner, A.; Touchet, A.; Wilkes, W.; Berry, H.; Li, H. DVERGE: Diversifying Vulnerabilities for Enhanced Robust Generation of Ensembles. Adv. Neural Inf. Process. Syst. 2020, 33, 5505–5515. [Google Scholar]
- Zhang, D.; Zhang, T.; Lu, Y.; Zhu, Z.; Dong, B. You Only Propagate Once: Accelerating Adversarial Training via Maximal Principle. arXiv 2019, arXiv:1905.00877. [Google Scholar]
- Du, X.; Yu, J.; Li, S.; Yi, Z.; Liu, H.; Ma, J. Combating Word-Level Adversarial Text with Robust Adversarial Training. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18 July 2021; pp. 1–8. [Google Scholar]
- Khoda, M.; Imam, T.; Kamruzzaman, J.; Gondal, I.; Rahman, A. Selective Adversarial Learning for Mobile Malware. In Proceedings of the 2019 18th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/13th IEEE International Conference on Big Data Science and Engineering (TrustCom/BigDataSE), Rotorua, New Zealand, 5–8 August 2019; pp. 272–279. [Google Scholar]
- Kim, M.; Tack, J.; Hwang, S.J. Adversarial Self-Supervised Contrastive Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 2983–2994. [Google Scholar]
- Zhang, S.; Huang, K.; Zhang, R.; Hussain, A. Generalized Adversarial Training in Riemannian Space. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 826–835. [Google Scholar]
- Zhou, X.; Tsang, I.W.; Yin, J. Latent Adversarial Defence with Boundary-Guided Generation. arXiv 2019, arXiv:1907.07001. [Google Scholar]
- Liu, A.; Liu, X.; Yu, H.; Zhang, C.; Liu, Q.; Tao, D. Training Robust Deep Neural Networks via Adversarial Noise Propagation. IEEE Trans. Image Process. 2021, 30, 5769–5781. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, N. Layer-Wise Adversarial Training Approach to Improve Adversarial Robustness. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Wang, L.; Chen, X.; Tang, R.; Yue, Y.; Zhu, Y.; Zeng, X.; Wang, W. Improving Adversarial Robustness of Deep Neural Networks by Using Semantic Information. Knowl.-Based Syst. 2021, 226, 107141. [Google Scholar] [CrossRef]
- Naseer, M.; Khan, S.; Hayat, M.; Khan, F.S.; Porikli, F. A Self-Supervised Approach for Adversarial Robustness. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 259–268. [Google Scholar]
- Ho, J.; Lee, B.-G.; Kang, D.-K. Attack-Less Adversarial Training for a Robust Adversarial Defense. Appl. Intell. 2022, 52, 4364–4381. [Google Scholar] [CrossRef]
- Guo, Y.; Ji, T.; Wang, Q.; Yu, L.; Li, P. Quantized Adversarial Training: An Iterative Quantized Local Search Approach. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 1066–1071. [Google Scholar]
- Zhang, H.; Wang, J. Defense Against Adversarial Attacks Using Feature Scattering-Based Adversarial Training. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates, Inc.: New York, NY, USA, 2019; Volume 32. [Google Scholar]
- Lee, S.; Lee, H.; Yoon, S. Adversarial Vertex Mixup: Toward Better Adversarially Robust Generalization. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 272–281. [Google Scholar]
- Zhang, H.; Xu, W. Adversarial Interpolation Training: A Simple Approach for Improving Model Robustness. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Pang, T.; Yang, X.; Dong, Y.; Xu, K.; Zhu, J.; Su, H. Boosting Adversarial Training with Hypersphere Embedding. Adv. Neural Inf. Process. Syst. 2020, 33, 7779–7792. [Google Scholar]
- Qin, C.; Martens, J.; Gowal, S.; Krishnan, D.; Dvijotham, K.; Fawzi, A.; De, S.; Stanforth, R.; Kohli, P. Adversarial Robustness through Local Linearization. arXiv 2019, arXiv:1907.02610. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial Examples in the Physical World; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Zhang, J.; Li, C. Adversarial Examples: Opportunities and Challenges. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 2578–2593. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The Limitations of Deep Learning in Adversarial Settings. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbruecken, Germany, 21–24 March 2016. [Google Scholar]
- Ren, S.; Deng, Y.; He, K.; Che, W. Generating Natural Language Adversarial Examples through Probability Weighted Word Saliency. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 1085–1097. [Google Scholar]
- Schmidt, L.; Santurkar, S.; Tsipras, D.; Talwar, K.; Mądry, A. Adversarially Robust Generalization Requires More Data. arXiv 2018, arXiv:1804.11285. [Google Scholar]
- Xiao, C.; Li, B.; Zhu, J.-Y.; He, W.; Liu, M.; Song, D. Generating Adversarial Examples with Adversarial Networks. arXiv 2019, arXiv:1801.02610. [Google Scholar]
- Zhao, Z.; Dua, D.; Singh, S. Generating Natural Adversarial Examples. arXiv 2018, arXiv:1710.11342. [Google Scholar]
- Wang, L.; Yang, K.; Wang, W.; Wang, R.; Ye, A. MGAAttack: Toward More Query-Efficient Black-Box Attack by Microbial Genetic Algorithm. In Proceedings of the Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12 October 2020; ACM: New York, NY, USA, 2020; pp. 2229–2236. [Google Scholar]
- Chen, J.; Su, M.; Shen, S.; Xiong, H.; Zheng, H. POBA-GA: Perturbation Optimized Black-Box Adversarial Attacks via Genetic Algorithm. Comput. Secur. 2019, 85, 89–106. [Google Scholar] [CrossRef]
- Das, S.D.; Basak, A.; Mandal, S.; Das, D. AdvCodeMix: Adversarial Attack on Code-Mixed Data. In Proceedings of the 5th Joint International Conference on Data Science & Management of Data (9th ACM IKDD CODS and 27th COMAD), Bangalore, India, 8 January 2022; ACM: New York, NY, USA, 2022; pp. 125–129. [Google Scholar]
- Papernot, N.; McDaniel, P.; Swami, A.; Harang, R. Crafting Adversarial Input Sequences for Recurrent Neural Networks. In Proceedings of the MILCOM 2016—2016 IEEE Military Communications Conference, Baltimore, MD, USA, 1–3 November 2016; pp. 49–54. [Google Scholar]
- Kereliuk, C.; Sturm, B.L.; Larsen, J. Deep Learning and Music Adversaries. IEEE Trans. Multimed. 2015, 17, 2059–2071. [Google Scholar] [CrossRef]
- Liu, X.; Hsieh, C.-J. From Adversarial Training to Generative Adversarial Networks. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Taori, R.; Kamsetty, A.; Chu, B.; Vemuri, N. Targeted Adversarial Examples for Black Box Audio Systems. In Proceedings of the 2019 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 19–23 May 2019; pp. 15–20. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database Name | Descriptions |
|---|---|
| Ei Compendex | Engineering literature database |
| Inspec | Engineering, physics, and computer science literature database |
| Ei Patents | Patent application database |
| Inclusion Criteria | Exclusion Criteria |
|---|---|
| English | Other languages |
| Related to adversarial training and robust optimization | Related to other defensive methods |
| Related to adversarial attack defense | Not related to adversarial attack or defense |
| Related to neural network and deep neural network models | Not related to (deep) neural network classifiers |
| From 2016 to 2021 | The end goal was solving another domain problem |
| Related to unique solutions or improvements | Review papers |
| Methods | The Articles include the Method | Description | Advantages | Limitations | Covered Model Architectures |
|---|---|---|---|---|---|
| FGSM/eFGSM/SIM | [17,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38] | Single-step gradient-based white-box attack | Efficient; low computation complexity during the training compared to iterative methods | Suffers from low precision; may cause an overfitting problem; cannot provide enough generalization of attacks | CNN: [21,30,33,35,36,37,38] ConvNet: [26] LeNet: [20,22,27,31,34,36] VGG: [34,35] ResNet: [21,22,23,27,29,30,32,35] WideResNet: [20,21,27,28,30,38] PreActResNet: [24,25,28] ResNeXt: [32] Inception model: [17] Inception ResNet: [17] |
| PGD/IFGSM/BIM | [13,17,28,29,30,31,33,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70] | Multi-step gradient-based white-box attack | High precision attack; provides more generalization than the FGSM; uses random initialization to avoid local minima | Higher computational complexity; may also have an overfitting problem to some extent | CNN: [13,33,41,47,49,56,64] AllCNN: [59] LeNet: [31,43,48,50,51,59,67] VGG: [44,65] ResNet: [29,30,39,42,46,48,49,51,57,60,63,66,67,70] WideResNet: [13,28,30,42,43,44,45,46,47,49,50,52,53,54,55,58,63,64,66,68,70] PreActResNet: [28,56,68] RevNet: [48] Inception: [17,48,69] Inception ResNet: [17] DenseNet: [39] IPMI2019-AttnMel: [69] CheXNet: [69] Transferred VGGFace: [61] LISA-CNN: [61] GANs: [62] |
| JSMA | [31] | Saliency-based white-box attack | Can find minimal perturbations that lead to adversarial samples; focuses on the most impactful input instance, potentially finding a closer decision boundary | Could be computationally complex in the training process; not a popular method in AT, so other disadvantages need to be discovered | LeNet |
| L-BFGS | [31] | White-box iterative attack | Flexible when modifying the objective function | Could be computationally complex in the training process | LeNet |
| Auto encoder-decoder/ generative model | [7,71,72,73] | Generative model | Could be utilized in semi-unsupervised learning; more efficient than using the multistep attack during training; provides a degree of generalization against attacks | Requires pre-training of the generative model during the setup; performance might depend on the generative model; low transferability; catastrophic forgetting might happen during the process since the samples are diverse | CNN: [71,72] LeNet: [7] ResNet: [7] Convolution auto-encoder: [73] |
| CW-l2 | [74] | Grey/black-box attack | High successful rate against distillation defense method; high transferability across the model; higher efficiency than JSMA; higher success rate than the FGSM and BIM | Still a multi-iteration attack with higher computational complexity; not a popular method in AT, so other disadvantages remain to be discovered | CNN |
| Ensemble training regularization | [17,75,76,77] | Improvements on ensemble training as a defense method | Uses ensemble models as a defensive mechanic; lowers the transferability of adversarial attacks and improves the robustness of the original ensemble model; learns from the adversaries from pretrained static model to better approximate the distribution of adversarial samples | Requires a pre-trained model to perform the ensemble training | CNN: [76] ResNet: [75,76,77] Inception: [17] Inception ResNet: [17] |
| Other methods do not belong to the above categories | [78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94] | These methods are novel adversary generation methods that are proposed in different articles. These methods were proposed for specific purposes. We will discuss them in Section 4.8 and Section 4.9. | DNN (not specified): [80,82] CNN: [85,88] LeNet: [83,84,86,89] VGG: [83,84,85] AlexNet: [84] ResNet: [81,84,89] WideResNet: [85,90,91,92,93,94] PreActResNet: [78,91] Inception: [84] DenseNet: [84,89] svhnNet: [83] Adv-v3: [87] Inc-v3ens3: [87] IncRes-v2ens: [87] LSTM and Bi-LSTM: [79] | ||
| Sub-Categories of PGD AT | Motivations | Improvement/Modifications |
|---|---|---|
| Curriculum training | Reducing overfitting and improving the performance | Adjusting attack strength based on the accuracy of the model |
| Adaptive training | Improving the precision of attacks | Adapting attack strength for each data instance instead of each batch |
| Efficient training | Reducing training time and complexity | Embedding the perturbation inside the gradient update function loop; reducing the nested loops |
| Adversarial regularization | Improving on the cost functions | Modifying the loss functions and regularization terms |
| (Semi-)Unsupervised training | Solving the data hungry problem | Utilizing the unlabeled data |
| Others | See details in Section 4.3.6 | See details in Section 4.3.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, W.; Alwidian, S.; Mahmoud, Q.H. Adversarial Training Methods for Deep Learning: A Systematic Review. Algorithms 2022, 15, 283. https://doi.org/10.3390/a15080283
Zhao W, Alwidian S, Mahmoud QH. Adversarial Training Methods for Deep Learning: A Systematic Review. Algorithms. 2022; 15(8):283. https://doi.org/10.3390/a15080283
Chicago/Turabian StyleZhao, Weimin, Sanaa Alwidian, and Qusay H. Mahmoud. 2022. "Adversarial Training Methods for Deep Learning: A Systematic Review" Algorithms 15, no. 8: 283. https://doi.org/10.3390/a15080283
APA StyleZhao, W., Alwidian, S., & Mahmoud, Q. H. (2022). Adversarial Training Methods for Deep Learning: A Systematic Review. Algorithms, 15(8), 283. https://doi.org/10.3390/a15080283