
Hypothesis Testing Fusion for Nonlinearity Detection in Hedge Fund Price Returns


Abstract
1. Introduction
- Patton and Ramadorai [8] and Lo [10] proposed a model with a loading factor having different values depending on the risk factor (i.e., and, thus nonlinearly, depends on ), the simplest loading function being a threshold model. This threshold model possibly conveys the less or more liquid periods [5].
- The first is to expose the design of this HT fusion algorithm. Hypotheses have to be carefully defined and the fusion process carefully designed to avoid false conclusions on HT and fusion algorithm robustness, as previously stated. In particular, several points are generally overlooked in operational decisions, such as the pdf under the null hypothesis, key features in the decision process, or the information shared by several HT.
- The second aim of the paper is the application of the decision rule to detect nonlinearity in HF price returns. We first inspect whether there is a relationship with the a priori classification and the nonlinearity detection in two databases. These databases, respectively, provided by TASS and Standard and Poors (S&P), contain several styles of HFs and we seek to inspect whether some styles exhibit nonlinear feature, unlike the others.
2. Nonlinearity Detection Hypothesis Testing
- : The signal can be modeled as the output of a linear system driven by an iid (independent and identically distributed) non-symmetric random excitation.
- : The signal cannot be modeled as the output of a linear system driven by an iid non symmetric random excitation and we decide that the system is nonlinear (driven by a normal excitation). In this case, the input is assumed to be Gaussian, since considering other input statistics only involves an additional nonlinear transform.
- The estimated index denoted of the jth HT.
- The probability , derived from the estimated index value and the pdf of the estimated probability under (see Equation (2)), denoted .
- The decision , provided by after fixing the threshold on the probability (i.e., fixing the p-value), this threshold/p-value being possibly different for each HT.
2.1. Robustness
- The HT robustness involves correctly defining a performance metric for the HT (such a comparison has already been completed, see [24,28,29], but with non rigorous definition of the two hypotheses, as seen below). As usual, two types of error are possible, the TIEP (Type I Error Probability), denoted that is the probability of rejecting the null hypothesis although right; and the Type II Error Probability (TIIEP, i.e., the error of accepting the null hypothesis although false, denoted ). The usual HT decision making involves fixing , thus deriving threshold T using the index pdf function under and then comparing the index to this value, leading to the acceptance or rejection of . Admitting that the two errors have the same importance in the decision process, the mean Bayesian risk of the HT (see [25] chapter one) is equal to:This criterion is the parameter to minimize as the metric of performance in what follows.
- In order to rigorously estimate the HT robustness and derive the parameters needed for the HT fusion algorithm, TS under the two hypotheses have to be simulated. However, the (linear/nonlinear) TS sets have to be carefully designed. The nonlinear TS set can be derived from nonlinear models. In this paper and in [30], we consider three kinds of second-order nonlinear system:As usual, in TS modeling, the excitation is assumed to be iid white normal noise, while is assumed to convey the statistical properties of the observed TS. Volterra models (4a) are easily derived by nonlinear expansion for differentiable nonlinear transfer function and the ACF finite length model, unlike the other two (when the summation upper bounds are finite). There are necessary conditions for the stability of QARMA ((4c), Quadratic Autoregressive Moving Average Model, see [31,32,33]) or bilinear ((4b), see [34,35,36] for instance), extensively used in econometric TS modeling. A first inspection of the polynomial models of Equations (4a)–(4c) shows that these models contain two kernels, a first linear kernel and a quadratic one. Thus, for nonlinear systems, the excitation variance induces different weights of each (linear/quadratic) kernel and thus fairly different outputs. For instance, a weak variance induces a strong weight of the linear kernel output and thus an almost linear TS, making the nonlinearity detection fairly difficult. For this reason, the metric performance (Equation (3)) also depends on the NonLinear Energy Ratio (NLER, that is the energy from the quadratic kernel over the total energy). In what follows, we have considered NLER values of 0.25, 0.5 and 0.75 (i.e., weakly, fairly, strongly nonlinear systems).
- The system simulating the linear system (hypotheses ) also has to be carefully designed. In fact, for each generated output of nonlinear systems, the corresponding output linear system requires:
- 1.
- Having the same second order moment, i.e., the same ACF and then the same Power Spectrum Density (PSD). In fact, the second order moment has an effect on the variance of the estimated indices. Thus, after estimating the theoretical ACF/PDF by choosing one of the three models, initializing the model parameters and the excitation variance (see above), we derive the theoretical ACF of the output; this ACF is used to calculate the transfer function of the linear system. This requirement of having the same ACF under the two hypotheses is preserved by the surrogate data method (that can be seen as a Bootstrap method for nonlinearity detection, see [37,38,39,40]), used for deriving a linear TS, and then the index pdf under , from an observed and possibly nonlinear TS.
- 2.
- Being non Gaussian. In the previously mentioned papers on the HT robustness, the excitation is Gaussian under . Indeed, comparing a linear Gaussian TS and a skewed nonlinear TS induces a normality HT, which is much easier than a nonlinearity HT. The surrogate data method loosens this requirement (since the equivalent linear TS is normal) inducing an overperformance of the HT. The excitation, in the case, has to have a zero mean and a skewness, providing the same value of skewness for the linear/nonlinear TS.
Thus, the linear and nonlinear TS (i.e., the two hypotheses TS set) have the same ACF at all lags and the same third-order moment at lag (0,0), as seen below. - A last point is that the statistical index pdf derived on hypothesis is derived under the asymptotical assumption using the central limit theorem for instance. As observed in [30], for the HT presented below, we observe a strong departure between the statistical index pdf (under ) and the theoretical pdf, turning the decision, linear/nonlinear, non-robust. In order to make a robust decision, the pdf under has to derived for the learning base, as described in Section 4.1.
2.2. Tested Nonlinearity Hypothesis Tests
2.2.1. Non-Parametric Fourier Domain Tests
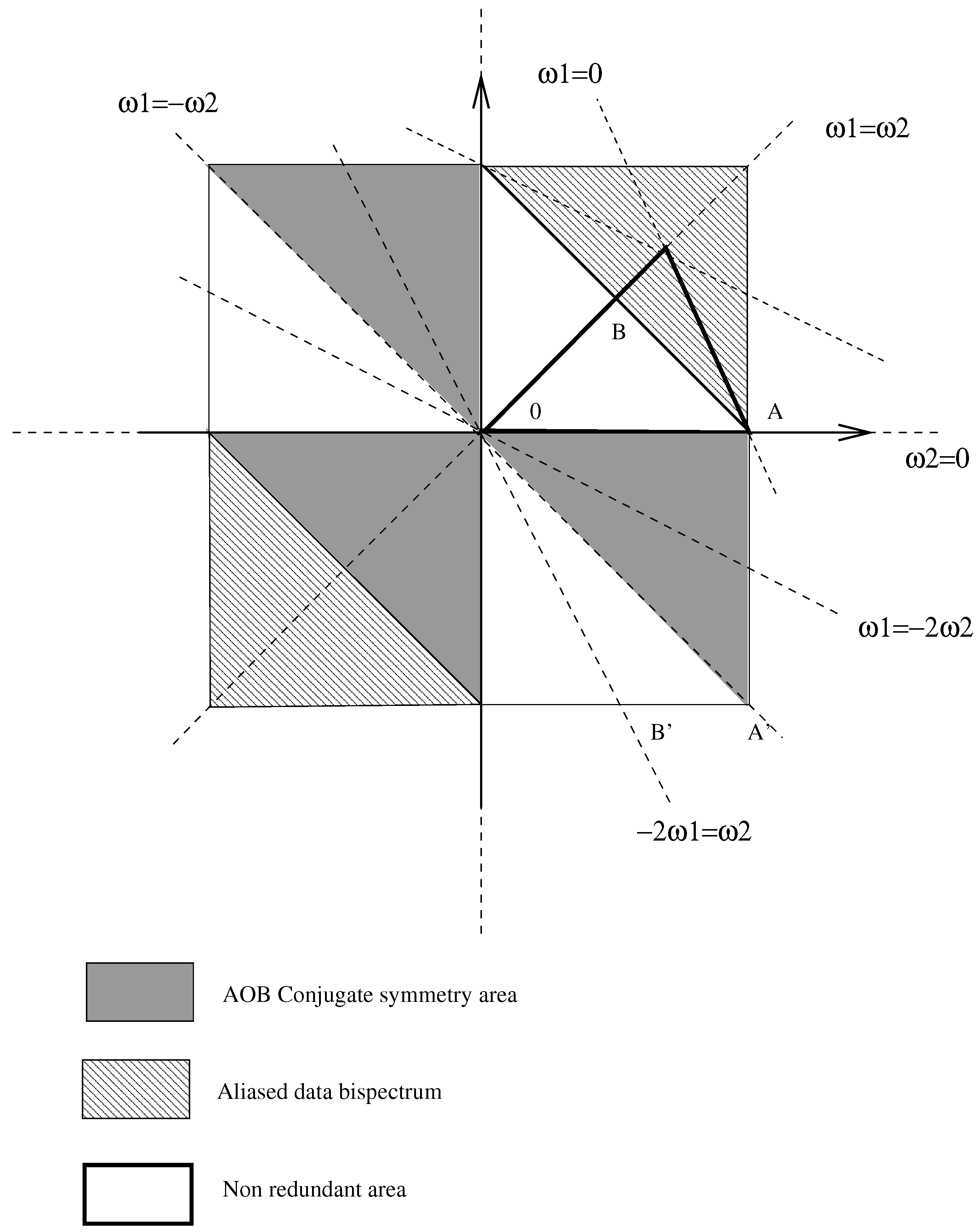
- The first selected index was proposed by Erdem and Tekalp in [23] and uses the bicepstrum (defined as the inverse Fourier transform of the bispectrum logarithm), which has the property of being null outside the lines (see Equation (6)). In [24], Le Caillec and Garello derive an HT based on the test of the nullity of the bicepstrum components outside these three lines. This index is denoted in the latter part of the same paper.
- In the same paper, they propose another based on two relationships involving, respectively, the bispectrum phase (at different bifrequencies) and the bispectrum magnitude logarithm (also at different bifrequencies).where is the bispectrum phase and an arbitrary lag. These properties being verified for a linear TS, we then form two sets of variables from the relationship of Equation (7). The test estimates the two variables (for all the possible bifrequencies) linking the bispectrum phase and the log-magnitude in Equation (7). After normalization (in order to have a unit variance for both variables [24]), index is given by the interquartile of the concatenated variables.
2.2.2. Non-Parametric Time Domain Tests
- The idea developed by Hjellvik and Tjøstheim in [41] compares the best nonlinear predictor at lag k, i.e., the conditional mathematical expectation denoted with the best linear predictor, i.e., the value of the TS at lag k multiplied by the correlation coefficient with , with . This test estimates the conditional mean as well as the pdf of with a Kernel Density Estimate (KDE, i.e., a Regressogram/Nadaraya-Watson estimate). The final index is given by the mean square error between the best predictor (calculated with the estimated pdf). In the same article, the authors propose a similar test based on a parametric model as seen in Section 2.3.
- The last non parametric index, , was exposed in [40] by Paluš. It is given by the difference between the dimensional redundancy and the linear redundancy. The dimensional redundancy is defined as the entropy of the TS samples (multiplied by ) minus the joined entropy of adjacent TS samples. The linear redundancy is defined as half the difference of the sum of logarithms of the diagonal entries of the covariance matrix minus the sum of logarithms of the eigenvalues of the same covariance matrix. Under , these two quantities are equal (for practical decision we use the absolute value of the difference in order to have a right sided HT, as previously stated). The limiting parameter of this approach is the “embedding dimension” . In Section 4, we set as in [40].
2.3. Tests Based on Parametric Linear and Nonlinear Models
- Tsay index: In [29], Tsay improves a test proposed by Keenan [50] derived from the one-degree test (of additivity) by Tukey [51]. In this paper, we consider only the Tsay indices (F and C tests) since they provide slightly better results than Keenan’s indices. After the model identification and the residual estimation, we regress the TS squared samples over the TS samples at previous lags and we estimate the new residuals (obviously this step involves Higher Order Statistics, HOS, as explicitly mentioned in Keenan [50] and Section 2.2.1). The last step involves finding a correlation between the residuals of the TS fitting and the residuals of the squared TS fitting. If the TS is linear, then the two kinds of residuals are uncorrelated. This property is verified by using the F-distribution test. We denote this index in the rest of the paper. Due to bad results of a Volterra model, Tsay proposes a second test based on the correlation of the squared residuals with the TS samples. This test is the C test and is denoted in the latter part of this paper.
- Luukkonen et al. index. The test proposed by Luukkonen et al. is based on whether the TS can be modeled by a Smooth Transition AutoRegressive (STAR) model. By expanding the STAR model up to the third order, this model can be rewritten as a Nonlinear AutoRegressif model containing nonlinear terms , , and . The HT of nonlinearity is based on the test of the nullity of the nonlinear kernel coefficients. As for the Tsay index, the first step involves calculating the residual after regression of over an AR model and we denote , the sum of the squared residuals. Finally, the residuals are regressed (using a mean least squares criterion) on , , and , (then HOS are also involved in this step). The squared sum of these new residuals is denoted leading to the nonlinearity index , N being the TS length. This procedure being fairly complicated due the large number of parameters to be estimated, the authors propose a simpler test based on a reduced QARMA model (4b). In this test, the index is then given by where is the sum of the squared residuals of the nonlinear regression of over and (see [42]). Other nonlinear models are difficult to identify, in particular Volterra model, except in simplified cases such a Wiener and Hammerstein second-order models [52,53,54].
- BDS test: The idea developed by Brock et al. in [43], always verifies that the residuals are white, is close to Order Statistics (see [55]). They define the sequence The distance between two sequences is defined as The index is based on the number of sequences whose distance is below a given threshold Index is defined as the difference between the number of sequences of length m (with a distance below the threshold) with the number of sequences of length 1 powered at m (with a distance also below the threshold). This difference is normalized in order that the index has standard normal statistics. When the model is well fitted, the noise is iid and the index is close to 0. In this index, two parameters have to be fixed. The first is the sequence length m (if we choose m too small, then will be always close to 0 whatever the model is) and the second is the value of (in fact, if is too small, then the number of close sequences will not be large enough for a robust estimate of ). In Section 4, we test the values , and , , , with being the standard deviation of the residuals.
- Peña and Rodriguez test. Peña and Rodriguez in [44] propose a test based on the logarithm of the determinant of the correlation matrix of the squared residuals. In other words, we havewhere is the normalized correlation matrix of the squared residuals (the normalizing coefficient is and the size of this square matrix of dimension m, k being the lag of the correlation coefficient). The idea behind this test is to verify that the correlation matrix is diagonal (i.e., the residuals are white and then the model is well fitted). In this test, the parameter m has to be chosen. As proposed by the authors, m is determined by the greatest correlation length in the residual. This estimation of the correlation is performed as the MA order estimation described below.
- Hjellvik and Tjøstheim test on residuals. Always with the idea of comparing the best predictor and the linear predictor (see Section 2.2.2), Hjellvik and Tjøstheim compare the two predictors for the residuals (always under an AR model fitting). The idea behind this calculation is to find nonlinear terms in the residuals, as stated in the introduction to this section. In this case, the index is also defined as the mean square error between the two predictors.
- The main drawback of the previously presented approaches is to be based on an AR model and then they assumed that the process is infinite memory. In [45], we propose a HT based on an MA model (i.e., with finite ACF), that is of particular interest in our case since HF returns are assumed to verify this property of finite memory. The order of the MA process is to detect a lag above which the autocorrelation function is null. Such an order estimate can be performed either by a Ljung-Box test or with a Hotteling by estimating the correlation sequence over subsignals (in the results of Section 4, we use four sub signals). We estimate the MA parameters by a Giannakis’ formula since we have (see [56,57]). Unlike the AR model, MA are not necessarily invertible (the transfer function can vanish). Since the residual are not available as for the previous indices, we propose to verify that the estimated coefficients agree with the estimated ACF as:where is the estimated MA order, is the estimated second-order moment, is the MA coefficient estimated by a Giannakis’ formula and is estimated to minimize . When the TS is the output of a linear MA model, then is theoretically null, but non-null under , (see [45], for practical implementation).
3. HT Fusion Algorithms
3.1. Topology and Mutual Information
- The first is to consider jointly the results of the HT (i.e., the probability ) and make a decision from all these values. Thus, we have to classify the TS (linear/nonlinear) with an array of probabilities. This topology is named centralized topology.
- In the second, each HT makes a decision, and the final decision is performed from these individual decisions. The classification is performed from an array of the decision. This framework is a parallel distributed decision.
- Finally, the last topology is called a serial (or sequential) distributed decision. Each detector can make a decision depending on the robustness of the decision, for instance. This approach can be interesting when all the HT do not have the same reliability using first the more robust and then the others if needed.
3.2. Fusion Methods
- Neural Network on probability and Entropy/Log-Probability (NN and NNL). The first two methods are based on Neural Networks (NNs). Details of the architecture are given in [30]. We use the learning base to train the NN and estimate the results on the validation base. The first NN has for input the probability for all the indices of Section 2, assuming that the NN discard the non-pertinent input (i.e., non robust HT, but also shared information in order to robustify the final decision), the output being 0 or 1 according to the hypothesis. For the same kind of NN, the same process is developed over the Log-Probability and then the NN input is the entropy. The idea being to ease the elimination of the shared information but possibly losing the robustness information borne by the probabilities.
- Maximum Likehood (ML). Obviously, since we have a labeled (linear/nonlinear) database, we can estimate the joint multivariate density pdf of all the probabilities and make the decision:In this case, the (resp. ) is the joint probability density of the , under (resp. ). The threshold is fixed according to value . This joint probability could be estimated either on all the HT or by only considering the more robust ones, as previously stated.
- Optimized Decision (OD). This approach [59] first concatenates the decision of each HT into an array , the final decision being made as:(resp. ) is the probability of under (resp. ). Thus, has possible values, n being the number of selected HT. One advantage of the approach is that it is set to different TIEP for each decision, but it needs an operational research of all the p-values to take into account, the possible correlation between the decisions, this optimization being performed over a predefined bounded grid.
- Decision with Security Offset (DSO). This approach needs first to rank the HT according to the performance over the learning based. The idea is to make this ranking using first the most robust HT, except when its decision is not sure, i.e., when the pdf at the estimated value is close to:When there is not a decision, the second-most robust test is tested. The process is repeated, in case of failure, until the less robust HT. If none of the HT can provide a “robust” decision, in the meaning of Equation (13), then the final decision is given by the more robust (i.e., first) HT. and are estimated over the learning basis, by an exhaustive search, in order to minimize .
- Maximum of Entropy (ME). One of the few papers [25,60], taking into account the MI between the indices in the final decision. This decision is given by:where and , and thus, is the entropy (i.e., the uncertainty) of the hypothesis conditionally to the final decision . Unlike the ML, the thresholds are given by the data according to their MI. However, the main difficulty is to estimate the coefficient since a recursive optimization process between the acceptation region and the estimate of this coefficient has to be performed ([30], Section 3 of [60], Chapter 7 [25]).
- Geometric Mean (GM). An ad-hoc approach is obviously to estimate a fused probability as the weighted geometric mean of the probability of each HT:In [30], it is shown that entropy of the weighted geometric mean is a linear combination of the entropy of each HT weighted by . These weights are obviously derived from the learning base by an optimization process, the decision being made on the value of p. As seen in the results of [30], the more robust is an HT, the higher is its weight; in some cases, a single HT can concentrate all the mass.

{kind=link}
| Method | Type | Merged Quantity | Ref. |
|---|---|---|---|
| Neural networks on probability (NN) | Centralized | Probability | [61] |
| Neural networks on log-probability (NNL) | Centralized | Entropy | [61] |
| Maximum likehood (ML) | Centralized | Probability | [25] |
| Optimal decision (OD) | Parallel distributed | Decision | [59] |
| Decision with security offset (DSO) | Serial distributed | Probability | [25] |
| Maximum of entropy (ME) | Parallel distributed | Decision | [25,60] |
| Geometric mean (GM) | Centralized | Probability |
4. Results
4.1. Nonlinearity Detection in Small Simulated TS
- As stated in the Introduction, robustness for a small TS length (, see first line of Table 3) is generally weak. Two HT give fairly good results and . Indices , , and are less robust but not totally inefficient, unlike the remaining HT. As expected, the performance in the HT depends on the nonlinear system. For instance , and lead to fairly good decisions on QARMA models. outperforms the others for bilinear/Volterra models. Moreover, the NLER, as previously stated, interferes in the performance. Weakly nonlinear TS led to poor results, in particular, for all TS lengths. Other details, in particular, on the optimal hyperparameters are given in [30].
- Amazingly, the MI under the two hypotheses (see Tables 4 and 5 of [30]), does not make clusters appear inside the 12 HT, all the pairs of HT having the same MI level, even for the closest ones (e.g., and ). The only conclusions that we can draw from the MI estimates are: first, the MI increases with the TS length, the HT giving the same decision as they become more robust; second, the MI is slightly higher under , the HT giving a similar decision for nonlinear TS unlike the case.
- Obviously, for the selection of our fusion method, we mainly consider the results on the validation basis. In particular, even for NNs, we obtain the best results over the learning basis, while the DSO method gives the best results on the validation basis. The performance remains close for all TS lengths, except for the ML method that improves by passing from to . As seen, the input data is a key feature for neural networks, since the NN with entropy as input underperform the NN with probability as input; the reason being that the entropy is not discriminant, as seen in the previous point. As seen, the performance improvement is slight, passing from from 0.21 for alone to 0.18 for the DSO and as seen in [30] for , the decision is performed by the most robust HT, i.e., at the outset or at the outcome of the DSO process.
4.2. Hedge Fund Nonlinearity
- The first one is that the number of TS classified as nonlinear is much greater in the TASS base than in the S&P base. For instance, 53.9% are classified as nonlinear for the first HF base, but only 36.3% for the second one.
- According to Table 5, we can observe four situations:
- The HFs mostly classified as linear in the two bases. For instance, Event-driven, Emerging Market, Fixed Income and Distressed Securities.
- The HFs mostly classified as nonlinear in the two bases (for the reason exposed in the previous point, an equivalent number of linear/nonlinear HFs in the S& P base leads to a conclusion of nonlinearity detection). These nonlinear styles are Equity Hedge, Equity Non Hedge and Managed Future.
- The Hedge funds equivalently classified as nonlinear or linear in both bases. Four styles are in this category, Funds of Funds, Sector, Macro and Relative Values Arbitrage. As observed in [17], Macro has near normal statistics but are sometimes classified as nonlinear.
- The last family is that classified as nonlinear in a base and linear in the other one. These styles are Convertible arbitrage, Merger Arbitrage and Equity Market Neutral. For this last family no conclusion can be drawn.
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Joenväärä, J.; Kaupplia, M.; Kahra, H. Hedge fund portfolio Selection with characteristics. J. Bank. Financ. 2021, 132, 106232. [Google Scholar] [CrossRef]
- Fung, W.; Hsieh, D. Hedge fund Benchmark: A risk based approach. Financ. Anal. J. 2004, 60, 63–80. [Google Scholar] [CrossRef]
- Fung, W.; Hsieh, D.; Naik, N.; Ramadorai, T. Hedge fund, Risk and Capital Formation. J. Financ. 2008, 63, 1777–1803. [Google Scholar] [CrossRef]
- Kosowski, R.; Naik, N.; Teo, M. Do the hedge funds deliver alpha? A Bayesian and bootstrap analysis. J. Financ. Econ. 2007, 84, 229–264. [Google Scholar] [CrossRef]
- Titman, S.; Tiu, C. Do the best Hedge Funds Hedge? Rev. Financ. Stud. 2011, 24, 123–168. [Google Scholar] [CrossRef]
- Brandt, M.; Santa-Clara, P.; Valkanov, R. Parametric portfolio policies: Exploiting characteristics in the cross-section of equity return. Rev. Financ. Stud. 2009, 22, 3411–3447. [Google Scholar] [CrossRef]
- Brandt, M.; Santa-Clara, P. Dynamic portfolio selection by augmenting the asset space. J. Financ. 2006, 61, 2187–2217. [Google Scholar] [CrossRef]
- Patton, A.; Ramadorai, T. On the High-Frequency Dynamics of Hedge Fund Risk exposures. J. Financ. 2013, LXVIII, 597–635. [Google Scholar] [CrossRef]
- Patton, A. Are “Market Neutral” Hedge Funds Really Market Neutral? Rev. Econ. Stud. 2009, 27, 2495–2530. [Google Scholar] [CrossRef]
- Lo, A. Risk management for Hedge Funds: Introduction and Overview. Financ. Anal. J. 2001, 57, 3731–3777. [Google Scholar] [CrossRef]
- Agarwal, V.; Naik, N. Multi-Period Performance Persistence Analysis of Hedge Funds. J. Financ. Quant. Anal. 2000, 35, 327–339. [Google Scholar] [CrossRef]
- Akermann, C.; McEnally, R.; Ravencraft, D. The performance of hedge funds: Risk, return and incentives. J. Financ. 1999, 54, 833–874. [Google Scholar] [CrossRef]
- Le Caillec, J.-M. Testing conditional independence to determine shared information in a data/signal fusion process. Signal Process. 2018, 143, 7–19. [Google Scholar] [CrossRef]
- Barber, D. Bayesian Reasoning and Machine Learning; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Amin, G.; Kat, H. Hedge Funds Performance 1990–2000: Do the “Money Machine” Really add values. J. Financ. Quant. Anal. 2003, 38, 251–274. [Google Scholar] [CrossRef]
- Leland, H. Beyond Mean-Variance: Risk and Performance Measures for Portfolios with Nonsymmetric Distribution; Working Paper; Haas School of Business: Berkely, CA, USA, 1999. [Google Scholar]
- Agarwal, V.; Naik, N. Performance Evaluation of Hedge Funds with Options-Based and By-and-Hold Strategies; Technical Report; Centre for Hedge Fund Research and Education: Londa, France, 2000. [Google Scholar]
- Dybvig, P. Distributional Analysis of Portfolio Choice. J. Bus. 1988, 61, 369–393. [Google Scholar] [CrossRef]
- Dybvig, P. Inefficient dynamic strategies or How to throw away a million dollars in the stock market. Rev. Financ. Stud. 1988, 1, 67–88. [Google Scholar] [CrossRef]
- Hinich, M. Testing For Gaussianity and linearity of a stationary time series. J. Time Ser. Anal. 1980, 3, 169–176. [Google Scholar] [CrossRef]
- Priestley, M. Non-Linear and Non Stationary Time Series Analysis; Academic Press, Harcourt Brace Jonavich: London, UK, 1988. [Google Scholar]
- Subba Rao, T.; Gabr, M. A test for linearity of time series analysis. J. Time Ser. Anal. 1982, 1, 145–158. [Google Scholar]
- Tekalp, A.; Erdem, A. Higher-Order Spectrum Factorization in One and Two Dimensions with Applications in Signal Modeling and Nonminimum Phase System Identification. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 1537–1549. [Google Scholar] [CrossRef]
- Le Caillec, J.-M.; Garello, R. Comparison of statistical indices using third order spectra for nonlinearity detection. Signal Process. 2004, 3, 499–525. [Google Scholar] [CrossRef]
- Varshney, P. Distributed Detection and Data Fusion; Springer: New York, NY, USA, 1997. [Google Scholar]
- Amenc, N.; Curtis, S.; Martellini, L. The Alpha and Omega of Hedge Fund Performance Measurement; Working Paper; Edhec Risk and Asset Management Research Center: Nice, France, 2003. [Google Scholar]
- Nikias, C.; Mendel, J. Signal Processing With Higher Order Spectra. IEEE Signal Mag. 1993, 10, 10–37. [Google Scholar] [CrossRef]
- Peña, D.; Rodriguez, J. Detecting nonlinearity in time series by model selection criteria. Int. J. Forecast. 2005, 21, 731–748. [Google Scholar] [CrossRef]
- Tsay, R. Nonlinearity Test for Time Series. Biometrika 1986, 73, 461–466. [Google Scholar] [CrossRef]
- Le Caillec, J.-M.; Montagner, J. Fusion of hypothesis testing for nonlinearity detection in small time series. Signal Process. 2013, 93, 1295–1307. [Google Scholar] [CrossRef]
- Chen, S.; Billings, S. Representation of non-linear systems: The NARMAX model. Int. J. Control 1989, 3, 1013–1032. [Google Scholar] [CrossRef]
- Le Caillec, J.-M.; Garello, R. Nonlinear system identification using autoregressive quadratic models. Signal Process. 2001, 81, 357–379. [Google Scholar] [CrossRef]
- Leontaritis, I.; Billings, S. Input-output parametric models for nonlinear systems part II: Stochastic nonlinear model. Int. J. Control 1985, 329–344. [Google Scholar] [CrossRef]
- Brillinger, D. A study of Second and Third-Order Spectral procedures and maximum likehood in the identification of a Bilinear system. IEEE Trans. Acoust. Speech Signal Process. 1990, 38, 1238–1245. [Google Scholar] [CrossRef]
- Lee, J.; Mathews, V. A stability condition for certain bilinear systems. IEEE Trans. Signal Process. 1994, 42, 1871–1873. [Google Scholar]
- Mohler, R. Bilinear Control Processes; Academic: New York, NY, USA, 1973. [Google Scholar]
- Schreiber, T.; Schmitz, A. Improved Surrogate Data for Nonlinearity Tests. Phys. Rev. Lett. 1996, 77, 635–638. [Google Scholar] [CrossRef]
- Schreiber, T.; Schmitz, A. Surrogate time series. Physica D 2000, 142, 346–382. [Google Scholar] [CrossRef]
- Theiler, J.; Eubank, S.; Longtin, A.; Galdrikian, B.; Farmer, J. Testing for nonlinearity in time series: The method of surrogate data. Physica D 1992, 58, 77–94. [Google Scholar] [CrossRef]
- Paluš, M. Testing for nonlinearity using redundancies: Quantitative and qualitative aspects. Physica D 1995, 80, 186–205. [Google Scholar] [CrossRef]
- Hjellvik, V.; Tjøstheim, D. Nonparametric tests of linearity for time series. Biometrika 1995, 82, 351–368. [Google Scholar] [CrossRef]
- Luukkonen, R.; Saikkonen, P.; Teräsvirta, T. Testing Linearity Againt Smooth Transition Autoregressive Models. Biometrika 1988, 75, 491–499. [Google Scholar] [CrossRef]
- Brock, W.; Dechert, W.; Scheinkman, J.; LeBaron, B. A Test for independence based on the correlation dimension. Econom. Rev. 1996, 15, 197–235. [Google Scholar] [CrossRef]
- Peña, D.; Rodriguez, J. The log of the determinant of the autocorrelation matrix for testing goodness of fit in time series. J. Stat. Plan. Inference 2006, 8, 2706–2718. [Google Scholar] [CrossRef]
- Le Caillec, J.-M. Hypothesis testing for nonlinearity detection based on an MA model. IEEE Trans. Signal Process. 2008, 56, 816–821. [Google Scholar] [CrossRef]
- Le Caillec, J.-M.; Garello, R. Asymptotic bias and variance of conventional bispectrum estimates for 2-D signals. Multidimens. Syst. Signal Process. 2005, 10, 49–84. [Google Scholar] [CrossRef]
- Bondon, P.; Benidir, M.; Picinbono, B. Polyspectrum modeling Using Linear or Quadratic Filters. IEEE Trans. Signal Process. 1993, 41, 692–702. [Google Scholar] [CrossRef][Green Version]
- Djurić, P. Asymptotic MAP Criteria for model selection. IEEE Trans. Signal Process. 1998, 46, 2726–2734. [Google Scholar] [CrossRef]
- Stoica, P.; Selén, Y. A review of information criterion rules. IEEE Signal Process. Mag. 2004, 21, 36–42. [Google Scholar] [CrossRef]
- Keenan, D.M. A Tukey Nonadditivity-Type Test for Times Series Nonlinearity. Biometrika 1985, 72, 39–44. [Google Scholar] [CrossRef]
- Tukey, J. One degree of freedom for non-additivity. Biometrics 1949, 5, 232–242. [Google Scholar] [CrossRef]
- Le Caillec, J.-M. Time series nonlinearity modeling: A Giannakis formula type approach. Signal Process. 2003, 83, 1759–1788. [Google Scholar] [CrossRef]
- Le Caillec, J.-M. Time Series Modeling by a Second-Order Hammerstein System. IEEE Signal Process. 2008, 56, 96–110. [Google Scholar] [CrossRef]
- Le Caillec, J.-M. Spectral inversion of second order Volterra models based on the blind identification of Wiener models. Signal Process. 2011, 91, 2541–2555. [Google Scholar] [CrossRef]
- David, H. Order Statistics, 2nd ed.; John Wiley & Sons: New York, NY, USA, 1981. [Google Scholar]
- Giannakis, G. Cumulants: A Powerful Tool in Signal processing. Proc. IEEE 1987, 75, 1333–1334. [Google Scholar] [CrossRef]
- Giannakis, G.; Swami, A. On Estimating Non-causal Non-minimum Phase ARMA Models of Non Gaussian Processes. IEEE Trans. Acoust. Speech Signal Process. 1990, 38, 478–495. [Google Scholar] [CrossRef]
- Ahmad, I.; Lin, P. A non parametric estimation of the entropy for absolutely continuous distributions. IEEE Trans. Inf. Theory 1976, 22, 372–375. [Google Scholar] [CrossRef]
- Drakopoulos, E.; Lee, C. Optimum multisensor Fusion of Correlated Local Decisions. IEEE Trans. Aerosp. Electron. Syst. 1991, 27, 593–606. [Google Scholar] [CrossRef]
- Pomorski, D. Entropy based optimization for binary detection networks. In Proceedings of the 3rd International Conference on Information Fusion, Paris, France, 10–13 July 2000; Volume II, pp. ThC4–ThC10. [Google Scholar]
- Cybenko, G. Approximations by superpositions of sigmoidal functions. Math. Control Signals, Syst. 1989, 4, 303–314. [Google Scholar] [CrossRef]
- Schetzen, J. The Volterra and Wiener Theories of Nonlinear Systems; John Wiley & Sons: New York, NY, USA, 1980. [Google Scholar]
- Brealey, R.; Kaplanis, E. Changes in the Factor Exposure of Hedge Funds; Technical Report; London School of Business: London, UK, 2001. [Google Scholar]
- Amenc, N.; Bonnet, S.; Henry, G.; Martellini, L.; Weytens, A. La Gestion Alternative; Economica: Paris, France, 2004. [Google Scholar]
- Sarantis, N. Modeling nonlinearities in real effective exchange rate. J. Int. Money Financ. 1999, 18, 27–45. [Google Scholar] [CrossRef]
- Brown, S.; Goetzmann, W.; Ibbotson, R. Offshore Hedge Funds: Survival and Performance 1989–1995. J. Bus. 1999, 72, 91–117. [Google Scholar] [CrossRef]
- Hutchinson, M.C.; Nguyen, M.H.Q.; Mulcahy, M. Private Hedge fund firm’ incentive and performance: Evidence from audited filings. Eur. J. Financ. 2022, 28, 291–306. [Google Scholar] [CrossRef]

| Index Number | Type | Reference |
|---|---|---|
| Non parametric | Bicepstrum [23,24] | |
| Non parametric | Bispectrum [24] | |
| Non parametric | Best predictor [41] | |
| Non parametric | Dimensional redundancy [40] | |
| Parametric | F test [29] | |
| Parametric | C test [29] | |
| Parametric | Third order procedure [42] | |
| Parametric | Augmented First order procedure [42] | |
| Parametric | BDS [43] | |
| Parametric | Log Determinant [44] | |
| Parametric | Best predictor on residuals [41] | |
| Parametric | MA model [45] |
| N | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 128 | 357 | 466 | 426 | 458 | 409 | 405 | 483 | 473 | 207 | 361 | 429 | 270 |
| 256 | 330 | 470 | 405 | 478 | 359 | 364 | 480 | 473 | 181 | 343 | 424 | 224 |
| 512 | 292 | 465 | 384 | 491 | 306 | 317 | 472 | 461 | 168 | 337 | 419 | 193 |
| 1024 | 260 | 465 | 353 | 474 | 251 | 275 | 471 | 456 | 161 | 323 | 410 | 218 |
| 2048 | 228 | 470 | 327 | 459 | 202 | 238 | 477 | 454 | 160 | 302 | 400 | 216 |
| 4096 | 205 | 472 | 298 | 443 | 156 | 205 | 479 | 452 | 153 | 263 | 391 | 192 |
| N | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 128 | 90 | 196 | 381 | 406 | 203 | 337 | 218 | 274 | 187 | 180 | 410 | 500 | 193 | 251 |
| 256 | 96 | 194 | 338 | 410 | 206 | 337 | 222 | 312 | 160 | 147 | 415 | 500 | 169 | 273 |
| 512 | 110 | 204 | 338 | 397 | 198 | 306 | 224 | 310 | 165 | 147 | 422 | 500 | 159 | 269 |
| 1024 | 111 | 210 | 339 | 390 | 176 | 288 | 217 | 291 | 192 | 156 | 359 | 500 | 147 | 247 |
| 2048 | 119 | 225 | 338 | 381 | 147 | 251 | 182 | 278 | 165 | 147 | 317 | 500 | 131 | 250 |
| 4096 | 125 | 227 | 338 | 366 | 102 | 185 | 134 | 249 | 158 | 158 | 205 | 427 | 120 | 219 |
| HF Style | Linear | Nonlinear | Linear | Nonlinear |
|---|---|---|---|---|
| Fund of Funds | 25 | 27 | 75 | 35 |
| Event-Driven | 10 | 4 | 19 | 6 |
| Emerging Market | 7 | 1 | 10 | 3 |
| Convertible Arbitrage | 2 | 7 | 16 | 2 |
| Equity Non-Hedge | 5 | 14 | 15 | 12 |
| Fixed Income | 3 | 0 | 11 | 5 |
| Managed Future | 18 | 18 | 31 | 29 |
| Equity Hedge | 17 | 30 | 47 | 34 |
| Merger Arbitrage | 7 | 5 | 3 | 7 |
| Foreign Exchange | 4 | 5 | 8 | 1 |
| Sector | 8 | 7 | 8 | 5 |
| Equity Market Neutral | 4 | 11 | 11 | 3 |
| Distressed Securities | 5 | 1 | 11 | 6 |
| Macro | 4 | 6 | 13 | 7 |
| Relative Value Arbitrage | 1 | 2 | 7 | 8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Le Caillec, J.-M. Hypothesis Testing Fusion for Nonlinearity Detection in Hedge Fund Price Returns. Algorithms 2022, 15, 260. https://doi.org/10.3390/a15080260
Le Caillec J-M. Hypothesis Testing Fusion for Nonlinearity Detection in Hedge Fund Price Returns. Algorithms. 2022; 15(8):260. https://doi.org/10.3390/a15080260
Chicago/Turabian StyleLe Caillec, Jean-Marc. 2022. "Hypothesis Testing Fusion for Nonlinearity Detection in Hedge Fund Price Returns" Algorithms 15, no. 8: 260. https://doi.org/10.3390/a15080260
APA StyleLe Caillec, J.-M. (2022). Hypothesis Testing Fusion for Nonlinearity Detection in Hedge Fund Price Returns. Algorithms, 15(8), 260. https://doi.org/10.3390/a15080260