1. Introduction
Artificial neural networks are becoming an integral part of modern day reality. This technology consists of two stages: A training phase and an inference phase. The training phase is computationally expensive and typically outsourced to cluster or cloud computing. It takes place only now and then, eventually only once forever. The inference phase is implemented on the device running the application. It is repeated whenever the neural network is used. This work solely targets the inference phase after the neural network has been successfully trained.
The inference phase consists of scalar nonlinearities and matrix–vector multiplications. The former ones are much easier to implement than the latter. The target of this work is to reduce the computational cost of the following task: Multiply an arbitrary vector with a constant matrix. At the first layer of the neural network, the arbitrary vector is the input to the neural network. At a subsequent layer, it is the activation function of the respective previous layer. The constant matrices are the weight matrices of the layers that were found in the training phase and that stay fixed for all inference cycles of the neural network.
The computing unit running the inference phase need not be a general-purpose processor. With neural networks being more and more frequently deployed in low-energy devices, it is attractive to employ dedicated hardware. For some of them, e.g., field programmable gate arrays or application-specific integrated circuits with a reprogrammable weight-memory, e.g., realized in static random access memory, the data center has the option to update the weight matrices whenever it wants to reconfigure the neural network. Still, the matrices stay constant for most of the time. In this work, we will not address those updates, but focus on the most computationally costly effort: the frequent matrix–vector multiplications within the dedicated hardware.
Besides the matrix–vector multiplications, memory access is currently also considered a major bottleneck in the inference phase of neural networks. However, technological solutions to the memory access problem, e.g., stacked dynamical random access memory utilizing through-silicon vias [
1] or emerging non-volatile memories [
2], are being developed and are expected to be available soon. Thus, we will not address memory-access issues in this work. Note also that the use in neural networks is just one, though a very prominent one, of the many applications of fast matrix–vector multiplication. Many more applications, can be found. In fact, we were originally motivated by beamforming in wireless multi-antenna systems [
3,
4], but think that neural networks are even better suited for our idea, as they update their matrices much less frequently. Fast matrix–vector products are also important for applications in other areas of signal processing, compressive sensing, numerical solvers for partial differential equations, etc. This opens up many future research directions based on linear computation coding.
Various works have addressed the problem of simplifying matrix–matrix multiplications utilizing certain recursions that result in sub-cubic time-complexity of matrix–matrix multiplication (and matrix inversion) [
5,
6]. However, these algorithms and their more recent improvements, to the best of our knowledge, do not help for matrix–vector products. This work is not related to that group of ideas.
Various other studies have addressed the problem of simplifying matrix–vector multiplications in neural networks utilizing structures of the matrices, e.g., sparsity [
7,
8]. However, this approach comes with severe drawbacks: (1) It does not allow us to design the training phase and inference phase independently of each other. This restricts interoperability, hinders efficient training, and compromises performance [
9]. (2) Sparsity alone does not necessarily reduce computational cost, as it may require higher accuracy, i.e., larger word-length for the nonzero matrix elements. In this work, we will neither utilize structures of the trained matrices nor structures of the input data. The vector and matrix to be multiplied may be totally arbitrary. They may, but need not, contain independent identically distributed (IID) random variables, for instance.
It is not obvious that, without any specific structure in the matrix, significant computational savings are possible over state-of-the-art methods implementing matrix–vector multiplications. In this work, we will develop a theory to explain why such savings are possible and provide a practical algorithm that shows how they can be achieved. We also show that these savings are very significant for typical matrix-sizes in present day neural networks: By means of the proposed linear computation coding, the computational cost, if measured in number of additions and bit shifts, is reduced several times. A gain close to half the binary logarithm of the matrix size is very typical. Recent FPGA implementations of our algorithm [
10] show that the savings counted in look-up tables are even higher than the savings counted in additions and bit shifts. In this paper, however, we are concerned with the theory and the algorithmic side of linear computation coding. We leave details on reconfigurable hardware and neural networks as topics for future work.
The paper is organized as follows: In
Section 2, the general concept of computation coding is introduced. A reader that is only interested in linear functions, but not in the bigger picture, may well skip this section and go directly to
Section 3, where we review the state-of-the-art and define a benchmark for comparison. In
Section 4, we propose our new algorithm.
Section 5 and
Section 6 study its performance by analytic and simulative means, respectively.
Section 7 discusses the trade-off between the cost and the accuracy of the computations.
Section 8 summarizes our conclusions and gives an outlook for future work.
Matrices are denoted by boldface upper letters, and vectors are not explicitly distinguished from scalar variables. The sets and denote the integers and reals, respectively. The identity matrix, the all zero matrix, the all one matrix, the expectation operator, the sign function, matrix transposition, and Landau’s big O-operator are denoted by , , , , , , and , respectively. Indices to constant matrices express their dimensions. The notation counts the number of non-zero entries of the vector- or matrix-valued argument and is referred to as the zero norm. The inner product of two vectors is denoted as .
2. Computation Coding for General Functions
The approximation by an artificial neural network is the current state-of-the-art to compute a multi-dimensional function efficiently. There may be other ones, yet undiscovered, as well. Thus, we define computation coding for general multi-dimensional functions. Subsequently, we discuss the practically important case of linear functions, i.e., matrix–vector products, in greater detail.
The best starting point to understand general computation coding is rate-distortion theory in lossy data compression. In fact, computation coding can be interpreted as a lossy encoding of functions with a side constraint on the computational cost of the decoding algorithm. As we will see in the sequel, it shares a common principle with lossy source coding: Random codebooks, if suitably constructed, usually perform well.
Computation coding consists of computation encoding and computation decoding. Roughly speaking, computation encoding is used to find an approximate representation for a given and known function such that can be calculated for most arguments x in some support with low computational cost and approximates with high accuracy. Computation decoding is the calculation of . Formal definitions are as follows:
Definition 1. Given a probability space and a metric , a computation encoding with distortion D for given function is a mapping such that .
Definition 2. A computation decoding with computational cost C for given operator is an implementation of the mapping such that for all .
The computational cost operator measures the cost to implement the function . It reflects the properties of the hardware that executes the computation.
Computation coding can be regarded as a generalization of lossy source coding. If we consider the identity function and the limit , computation coding reduces to lossy source coding with being the codeword for x. Rate-distortion theory analyzes the trade-off between distortion D and the number of distinct codewords. In computation coding, we are interested in the trade-off between distortion D and computational cost C. The number of distinct codewords is of no or at most subordinate concern.
The expectation operator in the distortion constraint of Definition 1 is natural to readers familiar with rate-distortion theory. From a computer science perspective, it follows the philosophy of approximate computing [
11]. Nevertheless, hard constraints on the accuracy of computation can be addressed via distortion metrics based on the infinity norm, which enforces a maximum tolerable distortion.
The computational cost operator may also include an expectation. Whether this is appropriate or not depends on the goal of the hardware design. If the purpose is minimum chip area, one usually must be able to deal with the worst case and an expectation can be inappropriate. Power consumption, on the other hand, overwhelmingly correlates with average computational cost.
The above definitions shall not be confused with related, but different definitions in the literature of approximation theory [
12]. There, the purpose is rather to allow for proving theoretical achievability bounds than evaluating algorithms. The approach to distortion is similar. Complexity, however, is measured as the growth rate of the number of bits required to achieve a given upper bound on distortion. This is quite different from the computational cost in Definition 2.
4. Proposed Scheme for Linear Computation Coding
The shortcoming of the mailman algorithm is the restriction that the wiring matrix must be a permutation. Thus, it does not do computations except for multiplying the codebook matrix to the output of the wiring. The size of the codebook matrix grows exponentially with the number of computations it executes. As a result, the matrix dimension must be huge to achieve even reasonable accuracy.
We cure this shortcoming, allowing for a few additional entries in the wiring matrix. To keep the computational cost as low as possible, we follow the philosophy of the CORDIC algorithm and allow all non-zero entries to be signed powers of two only. We do not restrict the wiring matrix to be a rotation, since there is no convincible reason to do so. The computational cost is dominated by the number of non-zero entries in the wiring matrix. It is not particularly related to the geometric interpretation of this matrix.
The important point, as the analysis in
Section 5 will show, is to keep the aspect ratio of the codebook matrix exponential. This means the number of rows
N relates to the number of columns
K as
for some constant
R, which is
in the mailman algorithm, but can also take other values, in general. Thus, the number of columns scales exponentially with the number of rows. Alternatively, one may transpose all matrices and operate with logarithmic aspect ratios. However, codebook matrices that are not far from square perform poorly.
4.1. Aspect Ratio
An exponential or logarithmic aspect ratio is not a restriction of generality. In fact, it gives more flexibility than a linear or polynomial aspect ratio. Any matrix with a less extreme aspect ratio can be cut horizontally or vertically into several submatrices with more extreme aspect ratios. The proposed algorithm can be applied to these submatrices independently. A square matrix, for instance, can be cut into 32 submatrices of size . Even matrices whose aspect ratio is superexponential or sublogarithmic do not pose a problem. They can be cut into submatrices vertically or horizontally, respectively.
Horizontal cuts are trivial. We simply write the matrix vector product
as
such that each submatrix has exponential aspect ratio and apply our matrix decomposition algorithm to each submatrix. Vertical cuts work as follows:
Here, the input vector x must be cut accordingly. Furthermore, the submatrix–subvector products need to be summed up. This requires only a few additional computations. In the sequel, we assume that the aspect ratio is either exponential, i.e., is wide, or logarithmic, i.e., is tall, without loss of generality.
4.2. General Wiring Optimization
For given distortion measure
(see Definition 1 for details), given the upper limit on the computational cost
C, given wide target matrix
and codebook matrix
, we find the wiring matrix
such that
where the operator
measures the computational cost.
For a tall target matrix
, run the decomposition algorithm (
11) with the transpose of
and transpose its output. In that case, the wiring matrix is multiplied to the codebook matrix from the left, not from the right. Unless specified otherwise, we will consider wide target matrices in the sequel, without loss of generality.
4.2.1. Multiple Wiring Matrices
Wiring optimization allows for a recursive procedure. The argument of the computational cost operator
is a matrix–vector multiplication itself. It can also benefit from linear computation coding by a decomposition of
into a codebook and a wiring matrix via (
11). However, it is not important that such a decomposition of
approximates
very closely. Only the overall distortion of the linear function
is relevant. This leads to a recursive procedure to decompose the target matrix
into the product of a codebook matrix
and multiple wiring matrices such that the wiring matrix
in (
6) is given as
for some finite number of wiring matrices
L. Any of those wiring matrices are found recursively via
with
. This means that
serves as a codebook for
and
serves as a codebook for
.
Multiple wiring matrices are useful, if the codebook matrix is computationally cheap, but poor from a distortion point of view. The product of a computationally cheap codebook matrix with a computationally cheap wiring matrix can serve as a codebook for subsequent wiring matrices that performs well with respect to both distortion and computational cost.
Multiple wiring matrices can also be useful if the hardware favors some serial over fully parallel processing. In this case, circuitry for multiplying with can be reused for subsequent multiplication with . Note that in the decomposition phase, wiring matrices are preferably calculated in increasing order of the index ℓ, while in the inference phase, they are used in decreasing order of ℓ, at least for wide matrices.
4.2.2. Decoupling into Columns
The optimization problems (
11) and (
13) are far from trivial to solve. A pragmatic approach to simplify them is to decouple the optimization of the wiring matrix columnwise.
Let
and
denote the
columns of
and
, respectively. We approximate the solution to (
11) columnwise as
with
. This means we do not approximate the linear function
with respect to the joint statistics of its input
x. We only approximate the columns of the target matrix
ignoring any information on the input of the linear function. While in (
11), the vector
x may have particular properties, e.g., restricted support or certain statistics that are beneficial to reduce distortion or computational cost, the vector
in (
14) is not related to
x and must be general.
The wiring matrix
resulting from (
14) will fulfill the constraint
only approximately. The computational cost operator does not decouple columnwise, in general.
4.3. Computational Cost
To find a wiring matrix in practice, we need to measure computational cost. In the sequel, we do this by solely counting additions. Sign changes are cheaper than additions and their numbers are also often proportional to the number of additions. Shifts are much cheaper than additions. Fixed shifts are actually without cost on dedicated hardware such as ASICs and FPGAs. Multiplications are counted as multiple shifts and additions.
We define the non-negative function
as follows:
This function counts how many signed binary digits are required to represent the scalar
t, cf. Example 2. The number of additions to directly calculate the matrix–vector product
via the CSD representation of
is thus given by the function
as
In (
16),
denotes the
element of
. The function
is additive with respect to the rows of its argument. With respect to the column index, we have to consider that adding
terms only requires
additions. This means the function
does not decouple columnwise (although it does decouple row-wise). For columnwise decoupled wiring optimization in
Section 4.2.2, this means that
in general.
Setting
in (
13), we measure computational cost in terms of element-wise additions. Our goal is to find algorithms, for which
Although the optimization in (
13) implicitly ensures this inequality, it is not clear how to implement such an algorithm in practice. Even if we restrict it to
, the optimization (
14) is still combinatorial in
.
If the matrix contains only zeros or signed powers of two, the function
can be written as
in terms of the zero norm. The approximation (20) was used in the preliminary conference versions of this work [
4,
42,
43]. In the sequel, we continue with the exact number of additions as given in (
16).
While counting the number of additions by means of the zero norm is helpful to emphasize the similarities of linear computation coding with compressive sensing, it enforces one, though minor, unnecessary restriction: the constraint for the matrix
to contain signed powers of 2 as non-zero elements. The wiring matrix
forms linear combinations of the columns of the codebook matrix
, cf. (
6). If we form only linear combinations of
different codewords, the zero norm formulation in (
19) is perfectly fine. If we do not want to be bound by the unnecessary constraint that codewords may not be used twice within one linear combination, we have to resort to the more general formulation in (
16). While for large matrices the performance is hardly affected, for small matrices this does make a difference. This is one of several reasons why, in the preliminary conference versions of this work [
4,
42,
43], the decomposition algorithm does not perform so well for small matrices.
4.4. Codebook Design
For codebook matrices, the computational cost depends on the way they are designed. Besides being easy to multiply to a given vector, a codebook matrix should be designed such that pairs of columns are not collinear. A column that is collinear to another one is almost obsolete: It hardly helps to reduce the distortion while it needs to compute additions. In an early conference version of this work [
42], we proposed to find the codebook matrix by sparse quantization of the target matrix. While this results in significant savings of computational cost over the state of the art, there are even better designs for codebook matrices. Three of them are detailed in the sequel.
4.4.1. Binary Mailman Codebook
In the binary mailman codebook, only the all zero column is obsolete. It is shown in
Appendix B that the multiplication of the binary mailman matrix with an arbitrary vector requires at most
and
additions for column vectors and row vectors, respectively. The main issue with the binary mailman codebook is its lack of flexibility: It requires the matrix dimensions to fulfill
. This may restrict its application.
4.4.2. Two-Sparse Codebook
We choose the alphabet as a subset of the signed positive powers of two augmented by zero. Then, we find K vectors of lengths N such that no pair of vectors is collinear and each vector has zero norm equal to either 1 or 2. For sufficiently large sizes of the subset, those vectors always exist. These vectors are the columns of the codebook matrix. The ordering is irrelevant. It turns out to be useful to restrict the magnitude of the elements of to the minimum that is required to avoid collinear pairs.
4.4.3. Self-Designing Codebook
We set
with
and find the
matrix
via (
14) for
interpreting it as wiring matrix for some given auxiliary target matrix
. The auxiliary target matrix may, but need not, be identical to
. The codebook designs itself taking the auxiliary target matrix as a model.
4.4.4. Codebook Evolution
If multiple wiring matrices are used, the codebook evolves towards the target matrix. For multiple wiring matrices, the previous approximation of the target matrix serves as a codebook. Thus, with an increasing number of wiring matrices, the codebook gets closer and closer to the target matrix, no matter what initial codebook was used.
Codebook evolution can become a problem if the target matrix is not a suitable codebook, e.g., it contains collinear columns or is rank deficient. In such cases, multiple wiring matrices should be avoided or reduced to a small number.
Codebook evolution can also be helpful. This is the case if the original codebook is worse than the target matrix, e.g., because it shall be computationally very cheap as for the self-designing codebook.
4.4.5. Cutting Diversity
Target matrices that are not wide or tall are cut into wide or tall submatrices via (
9) and (
10), respectively. However, there are various ways to cut them. There is no need to form each submatrix from adjacent rows or columns of the original matrix. In fact, the choice of rows or columns is arbitrary. Some of the cuts may lead to submatrices that are good codebooks, other cuts to worse ones. These various possible cuts provide many options, which allow us to avoid submatrices that are bad codebooks. They provide diversity to ensure a certain quality in case of codebook evolution.
4.5. Greedy Wiring
Greedy wiring is one practical way to cope with the combinatorial nature of (
14). It is demonstrated in
Section 5 and
Section 6 to perform well and briefly summarized below:
Start with and .
Update such that it changes in at most a single component.
Increment s.
If , go to step 2.
For quadratic distortion measures, this algorithm is equivalent to matching pursuit [
44]. Note that orthogonal matching pursuit as in [
45] is not applicable, since restricting the coefficients to signed powers of two results in a generally sub-optimal least-squares solution that does not necessarily satisfy the orthogonality property.
4.6. Pseudo-Code of the Algorithm Used for Simulations
In
Section 4, many options for linear computation coding are presented with various trade-offs between performance and complexity, some of them even being NP-hard, which prevents them from being implemented unless the target matrices are very small. In order to clarify the algorithm we have used in our simulation results, we provide its pseudo-code here.
Algorithm 1 requires a zero mean target matrix
as input. The number of additions per row for the
ℓ-th wiring matrix is a free design variable, which is conveniently set to unity. Any initial codebook can be used. Algorithm 1 calls the subroutine Algorithm 2 to perform the decomposition in (
14) by means of greedy wiring.
| Algorithm 1 Algorithm used in the simulation results. |
- 1:
procedure MatrixFactorization - 2:
- 3:
- 4:
- 5:
- 6:
loop: - 7:
if and differ too much then - 8:
- 9:
- 10:
- 11:
goto loop. - 12:
else - 13:
return the matrix factors
|
Algorithms 1 and 2 are suited for tall matrices as used in the simulation section. This is in contrast to the wide matrices used in
Section 4.2 to
Section 4.5. For wide instead of tall matrices, just transpose both inputs and outputs of the two algorithms.
| Algorithm 2 Subroutine used in Algorithm 1. |
- 1:
procedure SubroutineGreedyWiring() - 2:
- 3:
- 4:
outer loop: - 5:
if then - 6:
- 7:
inner loop: - 8:
if then - 9:
- 10:
- 11:
- 12:
- 13:
goto inner loop. - 14:
- 15:
goto outer loop. - 16:
else - 17:
return the matrix
|
5. Performance Analysis
In order to analyze the expected distortion, we resort to a columnwise decoupling of the wiring optimization into target vectors and greedy wiring as in
Section 4.2.2 and
Section 4.5, respectively. We assume that the codebook and the target vectors are IID Gaussian random vectors. We analyze the mean-square distortion for this random ensemble. The IID Gaussian codebook is solely chosen, as it simplifies the performance analysis. In practice, the IID Gaussian random matrix
must be replaced by a codebook matrix with low computational cost, but similar performance. Simulation results in
Section 6 will show that practical codebooks perform very similar to IID Gaussian ones.
5.1. Exponential Aspect Ratio
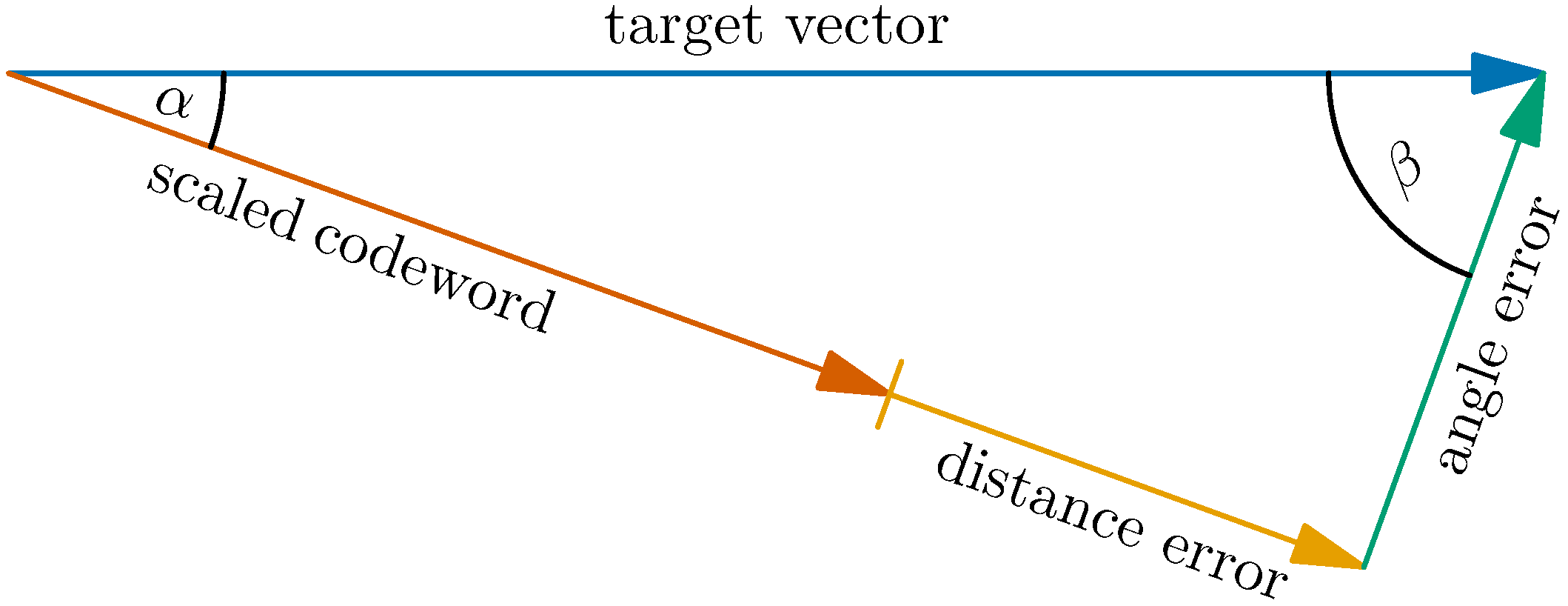
The key point to the good performance of the multiplicative matrix decomposition in (
6) is the exponential aspect ratio. The number of columns of the codebook matrix, i.e.,
K, scales exponentially with the number of its rows
N. For a linear computation code, we define the code rate as
The code rate is a design parameter that, as we will see later on, has some impact on the trade-off between distortion and computational cost.
The exponential scaling of the aspect ratio is fundamental. This is a consequence of extreme-value statistics of large-dimensional random vectors: Consider the correlation coefficients (inner products normalized by their Euclidean norms) of
N-dimensional real random vectors with IID entries in the limit
. For any set of those vectors whose size is polynomial in
N, the squared maximum of all correlation coefficients converges to zero, as
[
46]. Thus, the angle
in
Figure 1 becomes a right angle and the norm of the angle error is lower bounded by the norm of the target vector. However, for an exponentially large set of size
with rate
, the limit for
is strictly positive and given by rate-distortion theory as
[
47]. The asymptotic squared relative error of approximating a target vector by an optimal real scaling of the best codeword is therefore
. The residual error vector can be approximated by another vector of the exponentially large set to get the total squared error down to
. Applying that procedure for
s times, the (squared) error decays exponentially in
s. In practice, the scale factor cannot be a real number, but must be quantized. This additional error is illustrated in
Figure 1 and labeled distance error as opposed to the previously discussed angle error.
5.2. Angle Error
Consider a unit norm target vector
that shall be approximated by a scaled version of one out of
K codewords
that are random and jointly independent. Denoting the angle between the target vector
t and the codeword
as
, we can write (the norm of) the angle error as
The correlation coefficient between target vector
t and codeword
is given as
The angle error and the correlation coefficient are related by
We will study the statistical behavior of the correlation coefficient in order to learn about the minimum angle error.
Let denote the cumulative distribution function (CDF) of the squared correlation coefficient given target vector t. The target vector t follows a unitarily invariant distribution. Thus, the conditional CDF does not depend on it. In the sequel, we choose t to be the first unit vector of the coordinate system, without loss of generality.
The squared correlation coefficient
is known to be distributed according to the beta distribution with shape parameters
and
Section III.A in [
48], and given by
Here,
denotes the regularized incomplete Beta function [
49]. It is defined as
for
and zero otherwise. With (
24) and (
26), the distribution of the squared angle error is, thus, given by
5.3. Distance Error
Consider the right triangle in
Figure 1. The squared Euclidean norms of the angle error
and the codeword
scaled by the optimal factor
give
for a target vector of unit norm. The distance error
is maximal, if the magnitude of the optimum scale factor
is exactly in the middle of two adjacent powers of two, say
and
. In that case, we have
which results in
Due to the orthogonal projection, the magnitude of the optimal scale factor is given as
Thus, the distance error obeys
with equality, if the optimal scale factor is three quarters of a signed power of two.
It will turn out useful to normalize the distance error as
and specify its statistics by
, to avoid the statistical dependence of the angle error. The distance error is a quantization error. Those errors are commonly assumed uniformly distributed [
13]. Following this assumption, the average squared distance error is easily calculated as
Unless the angle is very small, the distance error is significantly smaller than the angle error. Their averages become equal for an angle of arccot .
Note that the factor slightly differs from the factor in Example 2. Like in Example 2, the number to be quantized is uniformly distributed within some interval. Here, however, the interval boundaries are not signed powers of two. This leads to a minor increase in the power of the quantization noise.
5.4. Total Error
Since distance error and angle error are orthogonal to each other, the total squared error is simply given as
Conditioning on the normalized distance error, the total squared error is distributed as
The unconditional distribution
is simply found by marginalization.
As the columns of the codebook matrix are jointly independent, we conclude that for
we have
For
having support in the vicinity of
, it is shown in
Appendix C to converge to
for exponential aspect ratios.
The large matrix limit (
40) does not depend on the statistics of the normalized distance error. It is indifferent to the accuracy of the quantization. This looks counterintuitive and requires some explanation. To understand that effect, consider a hypothetical equiprobable binary distribution of the normalized distance error with one of the point masses at zero. If we now discard all codewords that lead to a nonzero distance error, we force the distance error to zero. On the other side, we lose half of the codewords, so the rate is reduced by
. However, in the limit
, that comes for free. If the distribution of the angle error has any nonzero probability accumulated in some vicinity of zero, a similar argument can be made. This above argument is not new. It is common in forward error correction coding and is known as the expurgation argument [
50].
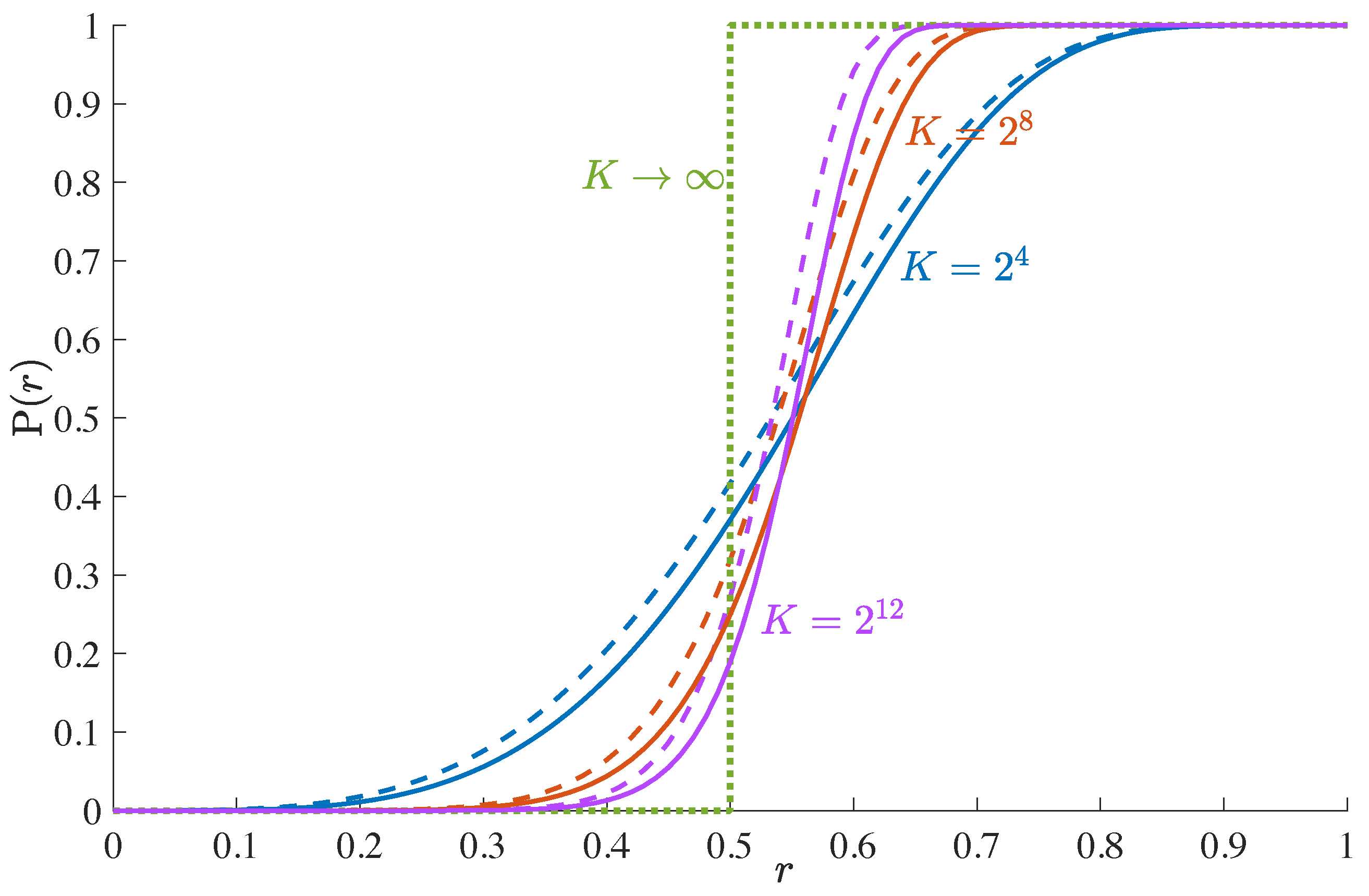
The CDF is depicted in
Figure 2 for a uniform distribution of the distance error. For increasing matrix size, it approaches the unit step function. The difference between the angle error and the total error is small.
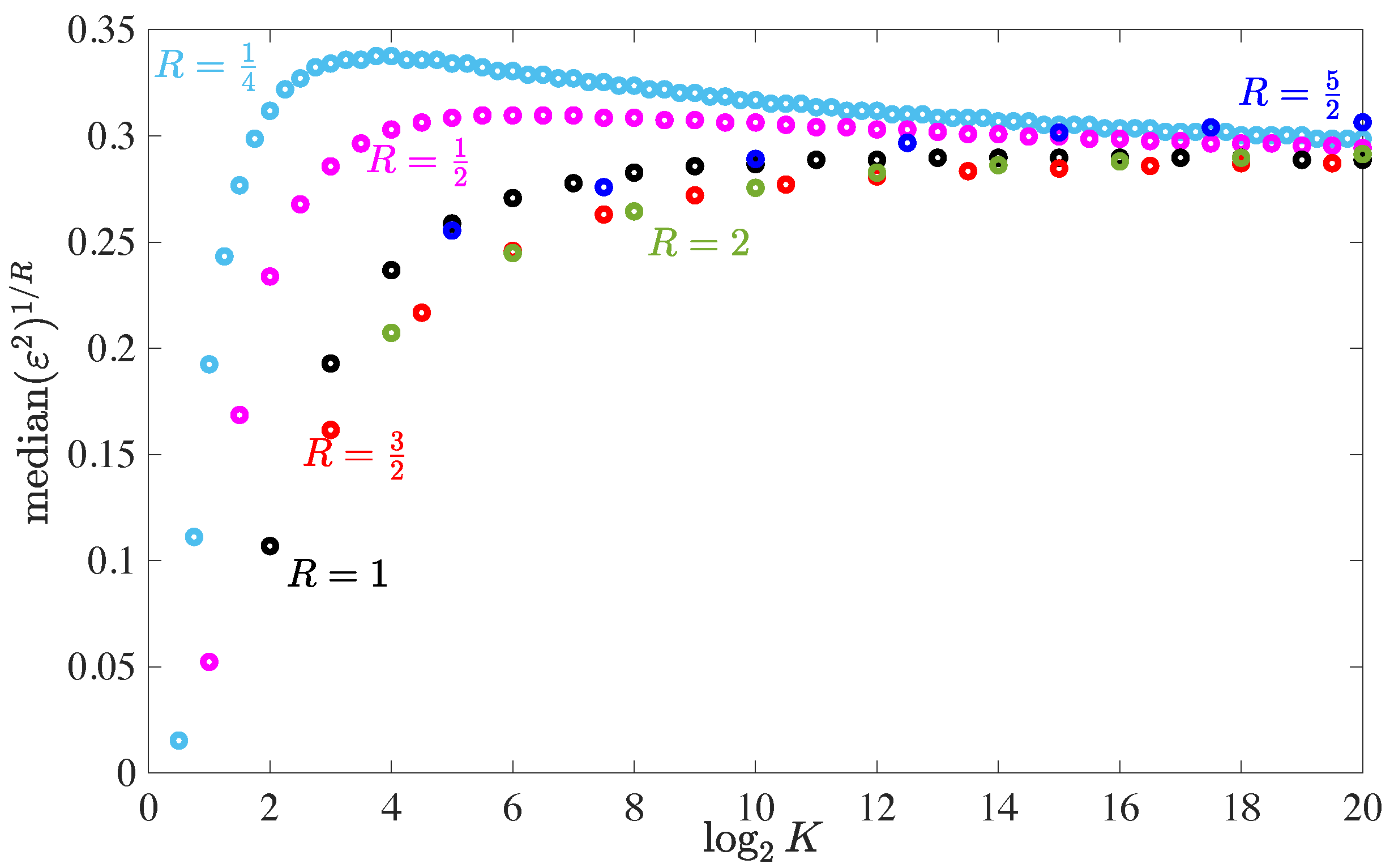
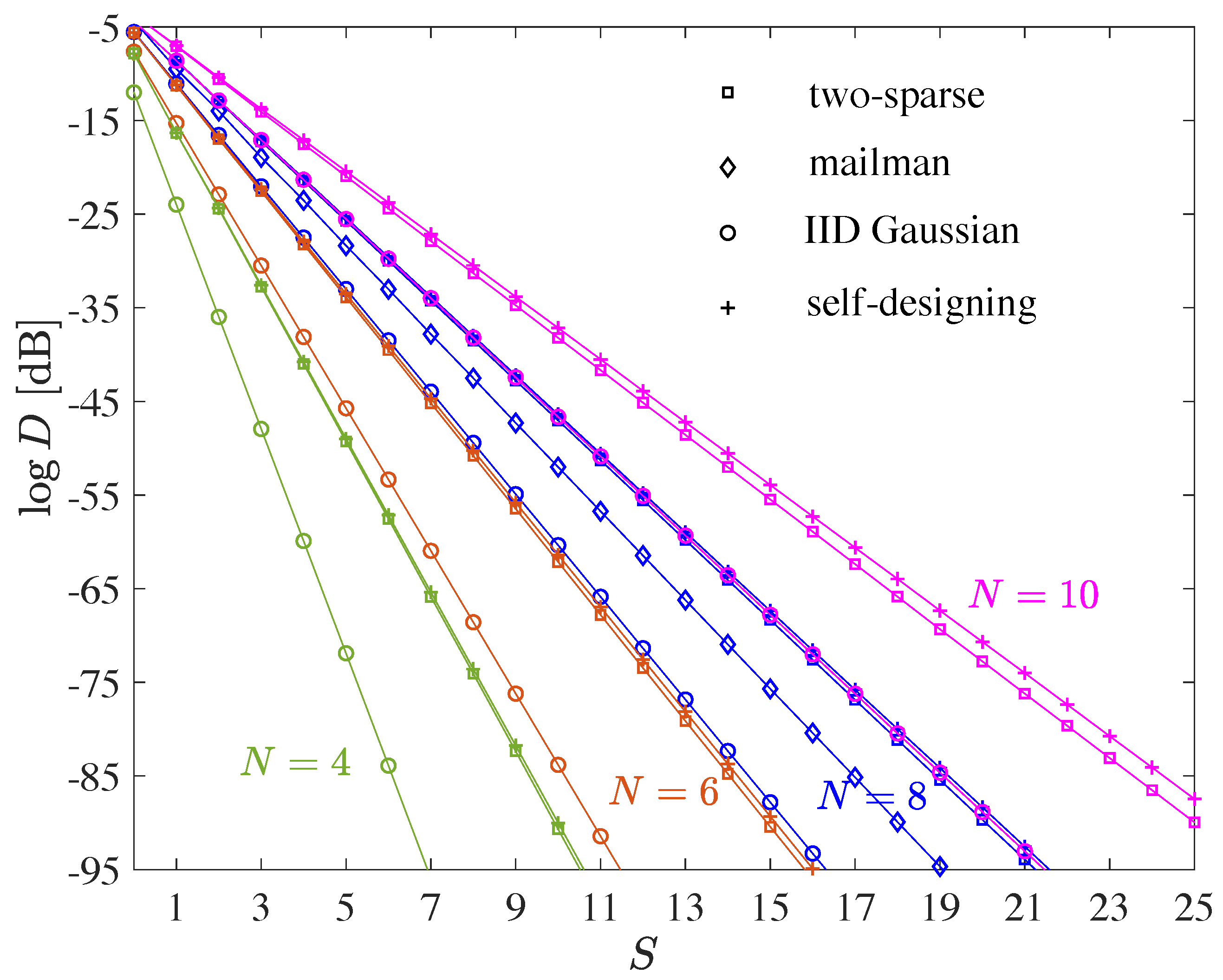
The median total squared error for a single approximation step is depicted in
Figure 3 for various rates
R. Note that the computational cost per matrix entry scales linearly with
R for fixed
K. In order to have a fair comparison, the average total squared error is exponentiated with
. For large matrices, it converges to the asymptotic value of
found in (
40), which is approached slowly from above. For small matrices, it strongly deviates from that. While for very small matrices low rates are preferred, medium-sized matrices favor moderately high rates between 1 and 2. Having the rate too large, e.g.,
, also leads to degradations.
We prefer to show the median error over the average error that was used in the conference versions [
4,
43] of this work. The average error is strongly influenced by rare events, i.e., codebook matrices with many close to collinear columns. However, such rare bad events can be easily avoided by means of cutting diversity, cf.
Section 4.4.5. The median error reflects the case that is typical, in practice.
5.5. Total Number of Additions
The exponential aspect ratio has the following impact on the trade-off between distortion and computational cost: For choices from the codebook, the wiring matrix contains nonzero signed digits according to approximation (20). Due to the columnwise decomposition, these are of them per column. At this point, we must distinguish between wide and tall matrices.
- Wide Matrices:
For the number of additions, the number of nonzero signed digits per row is relevant, as each row of is multiplied to an input vector x when calculating the product . For the standard choice of square wiring matrices, the counting per column versus counting per row hardly makes a difference on average. Though they may vary from row to row, the total number of additions is approximately equal to .
- Tall Matrices:
The transposition converts the columns into rows. Thus, is exactly the number of additions.
In order to approximate an target matrix with rows, we need approximately additions. For any desired distortion D, the computational cost of the product is by a factor smaller than the number of entries in the target matrix. This is the same scaling as in the mailman algorithm. Given such a scaling, the mailman algorithm allows for a fixed distortion D, which depends on the size of the target matrix. The proposed algorithm, however, can achieve arbitrarily low distortion by setting appropriately large, regardless of the matrix size.
Computations are also required for the codebook matrix. All three codebook matrices discussed in
Section 4.4 require at most
K and
additions for tall and wide matrices, respectively. Adding the computational costs of wiring and codebook matrices, we obtain
with
and
Normalizing to the number of elements of the
target matrix
, we have
The computational cost per matrix entry vanishes with increasing matrix size. This behavior fundamentally differs from state-of-the-art methods discussed in Examples 1 and 2, where the matrix size has no impact on the computational cost per matrix entry.
There are slightly less overall additions required, if a
square matrix is cut into tall submatrices than if it is cut into wide submatrices. Although the vertical cut requires
surplus additions due to (
10), it saves approximately
K additions due to (
41) in comparison to the horizontal cut.
7. Computation-Distortion Trade-Off
Combining the results of
Section 5.4,
Section 5.5, and
Section 6.1, we can relate the mean-square distortion to the number of additions.
Section 6.1 empirically confirmed that the distortion is given by
(at least for rates close to unity). Combining (
40) and (
21), we have
for matrices with large dimensions. Furthermore, (
43) relates the number of additions per matrix entry
to
S and
N as
Combining these three relations, we obtain
This is a much more optimistic scaling than in Example 2. For scalar linear functions, Booth’s CSD representation made the mean-square error reduce by the constant factor of 28 per addition. Due to linear computation coding as proposed in this work, the factor 28 in (
5) turns into
, the squared matrix dimension, in (
47). Since we have the free choice to go for either tall or wide submatrices, the relevant matrix dimension here is the maximum of the number of rows and columns.
We may relate the computational cost
in (
47) to the computational cost
in (
5), the benchmark set by Booth’s CSD representation. For given SQNR, this results in
For
q-bit signed integer arithmetic the SQNR is approximately given by SQNR
. Thus, we obtain
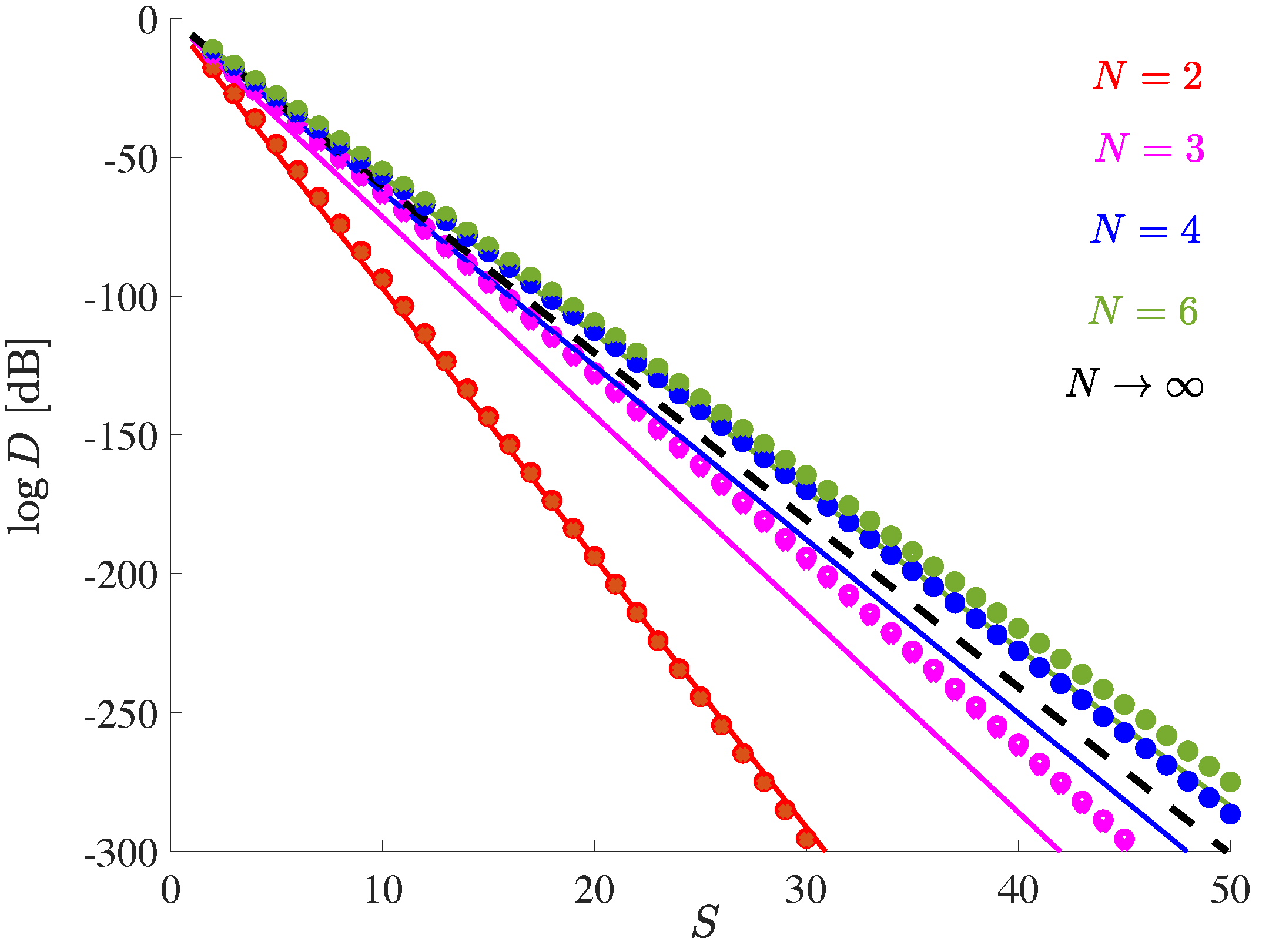
Although this formula is based on asymptotic considerations, it is quite accurate for the benchmark example. Instead of the actual 77% savings compared to CSD, which were found by simulation in
Section 6.3.1, it predicts savings of 79%. However, it does not allow to include adaptive assignments of CSDs.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}