1.1. Motivation
This study proposes a secure feature selection protocol that works effectively as a preprocessor for traditional machine learning (ML). Let us consider a scenario where different data owners are interested in private ML model training (e.g., logistic regression [
1], SVM [
2,
3], and decision tree [
4,
5]) on their combined data. There is a large advantage to securely training these ML models on distributed data due to competitive advantage or privacy regulations. Feature selection is the problem of finding a subset of relevant features for model training. Using well-chosen features can lead to more accurate models, as well as speedup during model training [
6].
Consider a data set
D associated with a feature set
F and a class variable
C, where all feature values
and the corresponding class label
are defined for each datum
. In
Table 1, for example, we show a concrete example. Given a triple
, the feature selection problem is to find a minimal
that is relevant to the class
C. The relevance of
is evaluated, for example, by
, which measures the mutual information between
and
C. On the other hand,
is minimal, if any proper subset of
is no longer consistent.
To the best of our knowledge, the most common method for identifying favorable features is to choose features that show higher relevance in some statistical measures. Individual feature relevance can be estimated using statistical measures such as mutual information and Bayesian risk. For example, at the bottom row of
Table 1, the mutual information score
of each feature
to class labels is described. We can see that
is more important than
, because
.
and
of
Table 1 will be chosen to explain
C based on the mutual information score. However, a closer examination of
D reveals that
and
cannot uniquely determine
C. In fact, we find
and
with
and
but
. On the other hand, we can see that
and
uniquely determine
C using the formula
while
. As a result, the traditional method based on individual feature relevance scores misses the correct answer.
Thus, we concentrate on the concept of consistency:
is considered to be consistent if, for any
,
for all
implies
. In machine learning research, consistency-based feature selection has received a lot of attention [
8,
9,
10,
11,
12]. CWC (Combination of Weakest Components) [
8] is the simplest of such consistency-based feature selection algorithms, and even though CWC uses the most rigorous measure, it shows one of the best performances in terms of accuracy as well as computational speed compared to other methods [
7]. Throughout the proposed secure protocol, none of the parties learns the values of the data as all computations are done over ciphertexts. Next, the parties train an ML model over the pre-processed data using existing privacy-preserving training protocols (e.g., logistic regression training [
13] and decision tree [
14]). Finally, they can disclose the trained model for common use.
To design a secure protocol for feature selection, we focus on the framework of homomorphic encryption. Given a public key encryption scheme E, let denote a ciphertext of integer m; if can be computed from and without decrypting them, then E is said to be additive homomorphic, and if can also be computed, then E is said to be fully homomorphic. Furthermore, modern public key encryption must be probabilistic: when the same message m is encrypted multiple times, the encryption algorithm produces different ciphertexts of .
Various homomorphic encryption schemes have been proposed to satisfy these homomorphic properties over the last two decades. The first additive homomorphic encryption was proposed by Paillier [
15].
Somewhat homomorphic encryption that allows a sufficient number of additions and a limited number of multiplications has also been proposed [
16,
17,
18], and we can use these cryptosystems to compute more difficult problems, such as the inner product of two vectors. Gentry [
19] proposed the first fully homomorphic encryption (FHE) with an unlimited number of additions and multiplications, and since then, useful libraries for fully homomorphic encryption have been developed, particularly for bitwise operations and floating-point operations. TFHE [
20,
21] is known as the fastest fully homomorphic encryption that is optimized for bitwise operations.
For the private feature selection problem, we use TFHE to design and implement our algorithm. In this case, we assume two semi-honest parties and : each party complies with the protocol but tries to infer as much as possible about the secret from the information obtained. The parties have their own private data and and they jointly compute advantageous features for while maintaining their privacy. The goal is to jointly compute the CWC algorithm result on without revealing any other information.
In this paper, we describe the simplest case where there are two data owners, and they perform the cooperative secure computation. More generally, there are many data owners, and they encrypt with their own public keys. Since homomorphic operations cannot be applied to two data encrypted with different public keys, a simple approach would be for the server to attempt to re-encrypt them with some common public key. However, there is no guarantee that the server or the new public key can be trusted. To solve this problem, the framework of multi-key homomorphic encryption was proposed. This allows FHE operations on data encrypted with different keys, i.e., we can extend the two-party computation model to a more general case because TFHE has the required property. Using this property, its application to the framework of oblivious neural network inference [
22] has been proposed.
This should be a realistic requirement, if one wants to draw some conclusions from data that are privately distributed over more than one party. Multi-party computation (MPC) can provide effective technical solutions to realize this requirement in many cases. In MPC, certain computations that essentially rely on the distributed data are performed through cooperation among the parties. In particular, fully homomorphic encryption (FHE) is one of the critical tools of MPC. One of the most significant advantages of FHE-based MPC is thought to be that FHE realizes outsourced computation in a simple and straightforward manner: parties encrypt their private data with their public keys and send the encrypted data to a single trusted party with sufficient computational power to perform the required computation; although the computational results of the trusted party may be incorrect, if some malicious parties send incorrect data, honest parties are at least convinced that their private data have not been stolen as far as the cryptosystem used is secure. In contrast, when a party shares his/her secret with other parties to perform MPC, even if it uses a secure secret sharing scheme, collusion of a sufficient number of compromised parties may reveal the party’s secret. In general, it is difficult to prove the security of MPC protocols for the situation where we cannot deny the existence of active malicious parties, and hence, the security is very often proven assuming that all the parties are at worst semi-honest. In reality, however, even this relaxed assumption is unable to hold. Thus, the property that a party can protect its private data only relying on its own efforts should be counted as an important advantage of FHE-based MPC.
On the other hand, the current implementations of FHE are thought to be significantly inefficient, and consequently, their ranges of application are actually limited. This is currently true, but may not be true in the future: the Goldwasser–Mmicali (GM) cryptosystem [
23] is considered as the first scheme with provable security. Unfortunately, because the GM cryptosystem encrypts data in a bitwise manner, it has turned out not to have sufficient efficiency in time and memory to be used in the real world. In 2001, however, RSA-OAEP was finally proven to have both provable security and realistic efficiency [
24,
25], and is widely used through SSL/TLS. Thus, studying FHE-based MPC does not merely have theoretical meaning, but also will yield significant contributions in terms of application to the real world in the future.
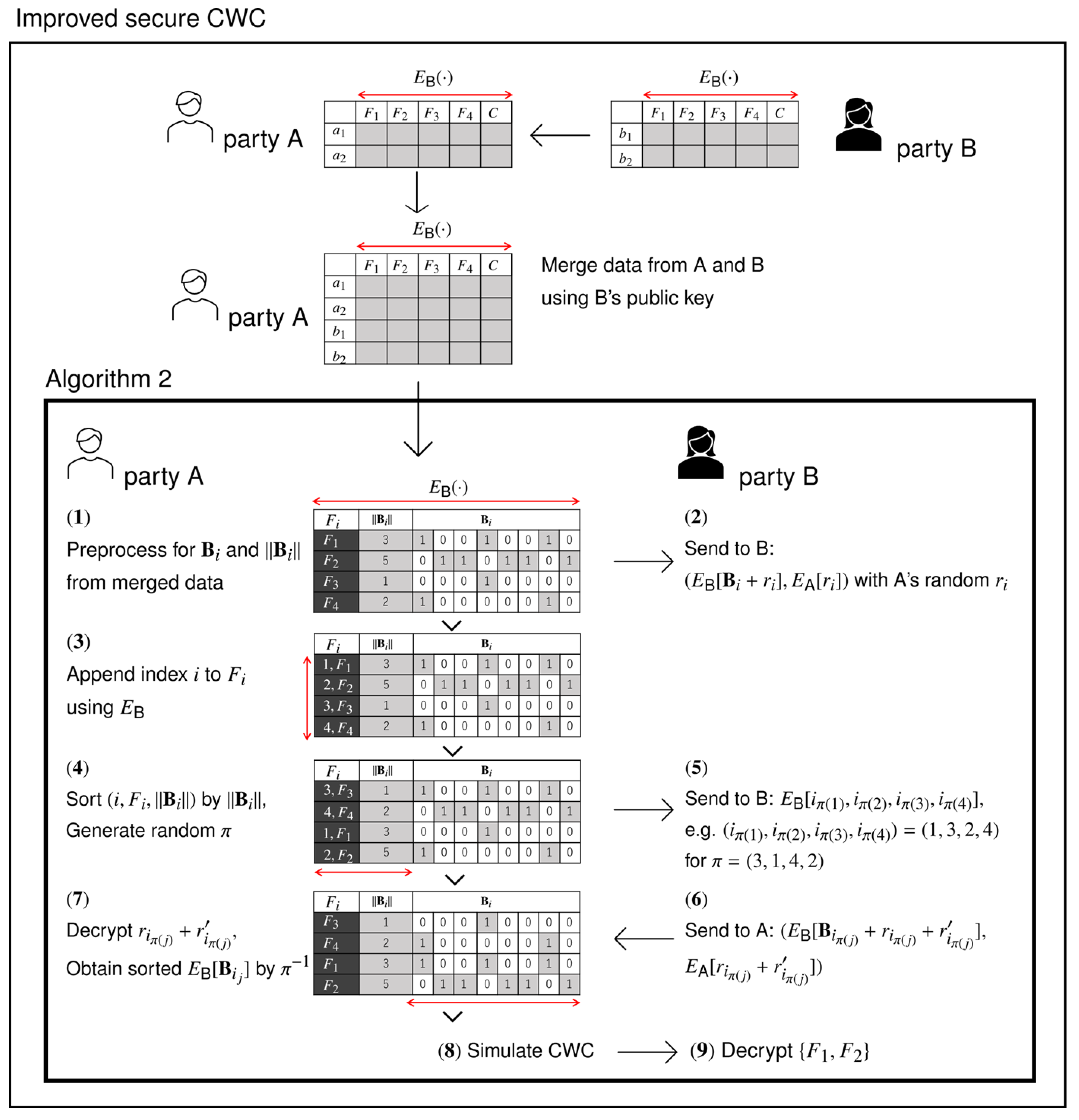
In this paper, we propose an MPC protocol which relies on FHE-based outsourced computation as well as mutual cooperation among parties. The target of our protocol is to perform the computation of CWC, a feature selection algorithm known to be accurate and efficient, preserving the privacy of the participating parties. If we fully perform CWC by FHE-based outsourced computation, we have to pay unnecessarily large costs in time in the phase of sorting the features of CWC. Therefore, in our proposed scheme, we add ingenuity so that two parties cooperate with each other to sort the features efficiently.
Converting CWC into its privacy-preserving version based on different primitives of MPC—for example, based on secret sharing techniques—is not only interesting but also useful both in theory and in practice. We will pursue this direction as well in our future work.
1.2. Our Contribution and Related Work
Table 2 summarizes the complexities of the proposed algorithms in comparison to the original CWC on plaintext. The
baseline is a naive algorithm that can simulate the original CWC [
8] over ciphertext using TFHE operations. The bottleneck of private feature selection exists in the sorting task over ciphertext, as we mention in the related work below. Our main contribution is the improved algorithm, shown as ‘improved’, which significantly reduces the time complexity caused by the sorting task. We also implement the improved algorithm and demonstrate its efficiency through experiments in comparison to the baseline.
There are mainly two private computation models, secret sharing-based MPC and public key-based MPC, and secret sharing-based MPC currently has an advantage. On the other hand, we focus on the convenience of FHE. Public key-based MPC can establish a simple mechanism to obtain results while keeping the learning model possessed by the server and the personal information of many data owners confidential from each other, relying only on cryptographic strength. The secret sharing-based MPC is faster but requires at least two trusted parties that do not collude with each other, which creates a different problem to cryptographic strength.
Other drawbacks of public key-based MPC are its security against the chosen plaintext attack (CPA) and computational cost. TFHE is, however, computationally secure against the chosen ciphertext attack (CCA), which assumes a stronger adversary than CPA so that an attacker cannot obtain meaningful information from plaintext or ciphertext within polynomial time.
In this section, we discuss related work on private feature selection as well as the benefits of our method. Rao [
26] et al. proposed a homomorphic encryption-based private feature selection algorithm. Their protocol allows the additive homomorphic property only, which invariably leaks statistical information about the data. Anaraki and Samet [
27] proposed a different method based on the rough set theory, but their method suffers from the same limitations as Rao et al., and neither method has been implemented. Banerjee et al. [
28], and Sheikhalishahi and Martinellil [
29] have proposed MPC-based algorithms that guarantee security by decomposing the plaintext into shares, as a different approach to the private feature selection, while achieving cooperative computation. Li et al. [
30] improved the MPC protocol on the aforementioned flaw and demonstrated its effectiveness through experiments.
These methods avoid partial decoding under the assumption that the mean of feature values provides a good criterion for feature selection. This assumption, however, is heavily dependent on data. The most important task in general feature selection is feature value-based sorting, and CWC and its variants [
7,
8,
11] demonstrated the effectiveness of sorting with the consistency measure and its superiority over other methods. On ciphertext, this study realizes the sorting-based feature selection algorithm (e.g., CWC).
We focus on the learning decision tree by MPC [
31] as another study that employs sorting for private ML, where the sorting is limited to the comparison of
N values of fixed length in
time by a sorting network. In the case of CWC, however, the algorithm must sort
N data points, each of which has a variable length of up to
M, so a naive method requires
time. Our algorithm reduces this complexity to
, which is significantly smaller than the naive algorithm depending on
M and
N. Through experiments, we confirm this for various data, including real datasets for ML.
Although sorting itself is not ML, a fast-sorting algorithm is an important preprocess for ML model training. In the previous result [
7], it was shown that sorting-based feature selection can classify with higher accuracy than other heuristic methods. Furthermore, preprocessing by sorting has proven to be an important task in decision tree model training [
31]. On the other hand, it is also well known that sorting can speed up ML model training. For example, in SVM, which is widely used in text classification and pattern recognition, the problem of finding the convex hull of
n points in Euclidean space can be reduced from
to
time by preprocessing it with an appropriate sorting algorithm.


 ,
, 

{kind=link}