
On Edge Pruning of Communication Networks under an Age-of-Information Framework

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- An efficient reduction method designed for series-parallel networks with links of exponentially distributed wait times or with links of deterministic periodic wait time.
- A pruning algorithm that determines the least significant link in the network, in terms of its effect on the AoI, and prunes it.
- A comprehensive simulation to study the effect of pruning the links on the AoI of the network and the redundancy of messages received by the destination.
2. Related Work
3. Proposed Model
3.1. Series-Parallel Networks
3.2. Age of Information
3.3. Phase-Type Distribution
3.3.1. Closure under Addition
3.3.2. Closure under Minima
4. Problem Reduction
4.1. Parallel Links Reduction
4.2. Series Links Reduction
5. Average AoI Characterization
6. Periodic Case
- When we have multiple links in parallel, they may be reduced to one link with an activation signal that is simply the summation of the activation signals of all the links. The following equation represents the aggregated function in the parallel case.
- When we have multiple signals added together in series, the reduced link of all of them is the activation function of the least common multiple (LCM) of the time periods of the links. The following equation represents the aggregated function in the series case.
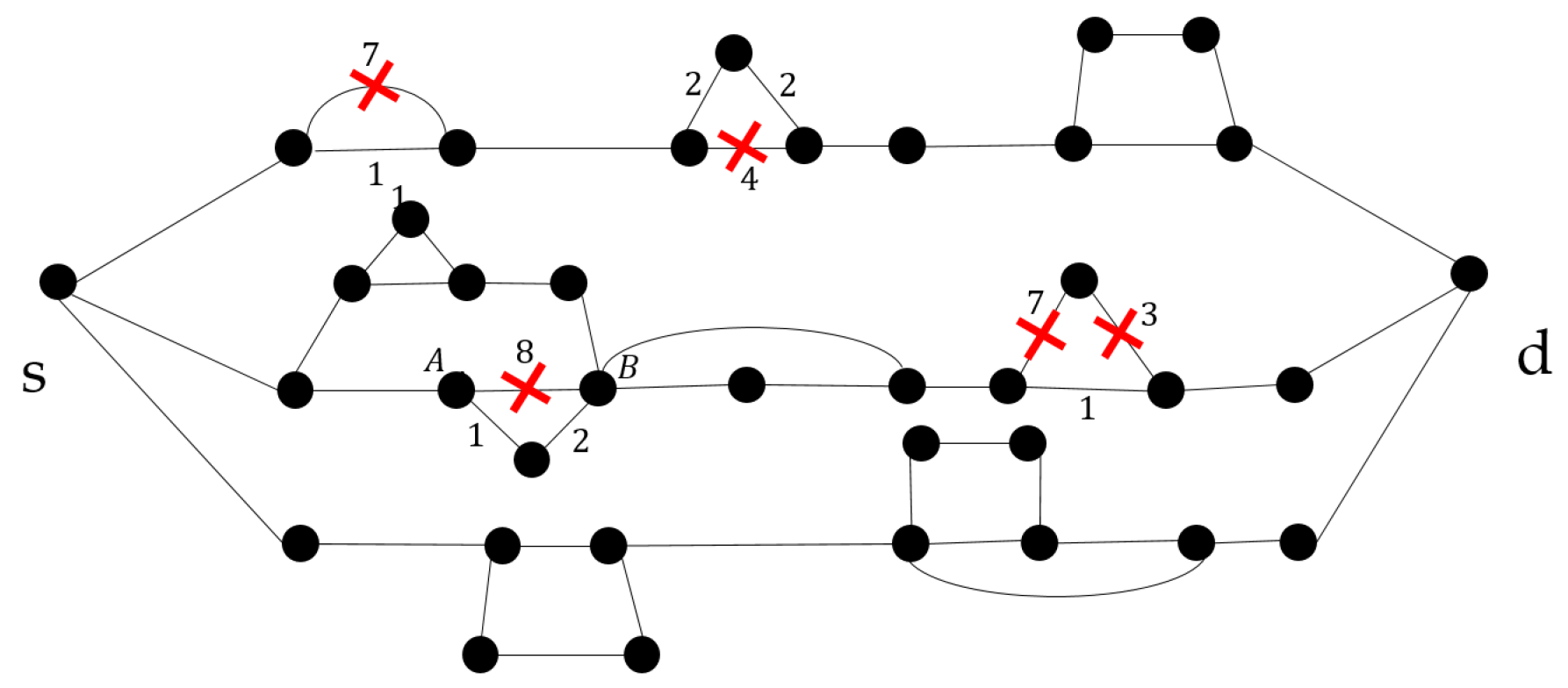
7. Pruning the Network
7.1. Pruning in the Deterministic Case
7.2. Pruning in the Probabilistic Case
| Algorithm 1 Determining the weakest link in the probabilistic case |
| Require: G. //SP Graph. Ensure: Identifying the weakest link. Initialization: . //List of AoI values. 1: for k from do 2: Remove the link . 3: for remaining do 4: Apply the series-parallel reduction. 5: Evaluate the new average value from Equation (18). 6: Add the new value to the list A. 7: Add the link back into the graph. 8: return the minimum value in A and the corresponding link. |
| Algorithm 2 Summary of the pruning method |
| Require: . //SP Graph and number of links to be pruned. Ensure: Pruning the network to reduce redundancy. 1: for x from do 2: Run Algorithm 1. 3: Prune the corresponding weakest link returned by it. 4: Obtain the new pruned SP graph G 5: Evaluate the new average value from Equation (18). 6: return the new pruned network G and its corresponding AoI. |
8. Simulation
8.1. Experimental Settings
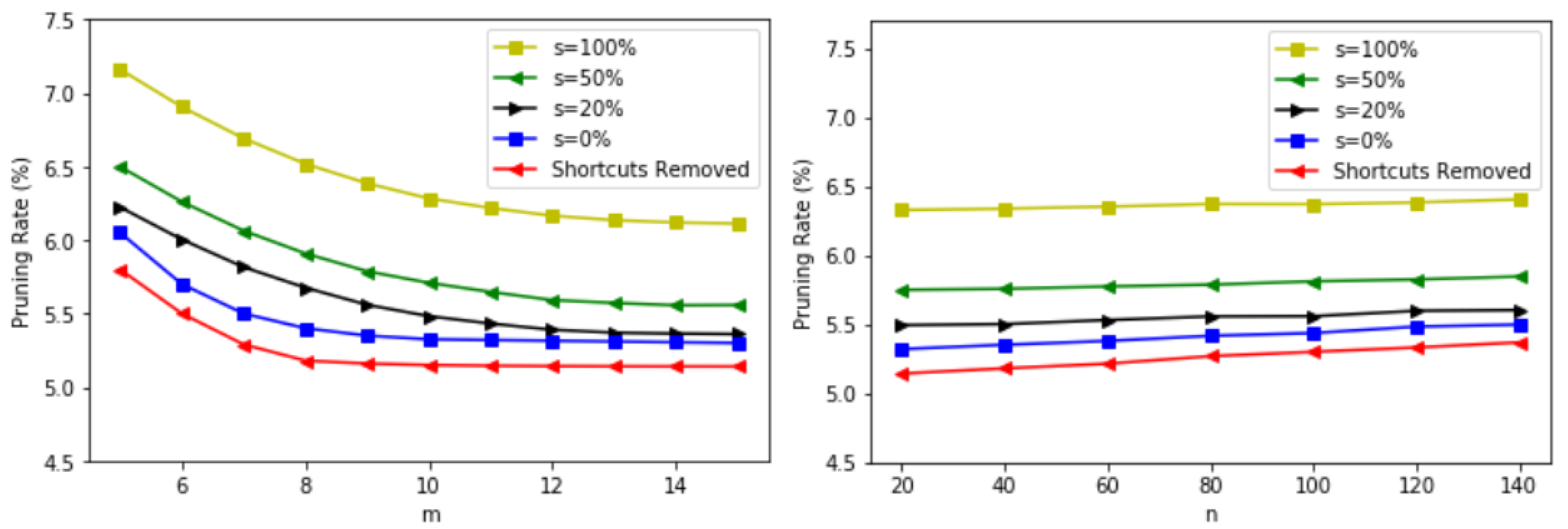
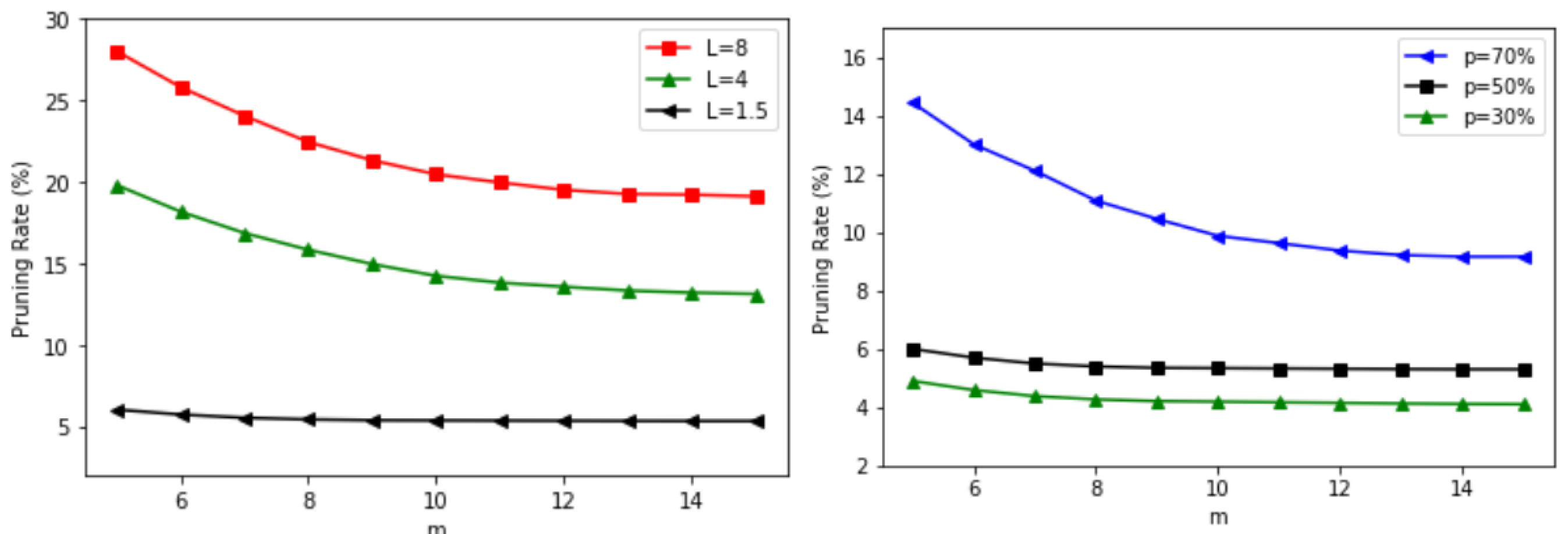
8.2. Experimental Results
8.2.1. The High-Clustered Topology
8.2.2. The Low-Clustered Topology
8.3. Simulation Summary
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pajevic, S.; Plenz, D. The organization of strong links in complex networks. Nat. Phys. 2012, 8, 429–436. [Google Scholar] [CrossRef] [PubMed]
- Latora, V.; Marchiori, M. Efficient behavior of small-world networks. Phys. Rev. Lett. 2001, 87, 198701. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Albert, R.; Jeong, H.; Barabási, A.L. Error and attack tolerance of complex networks. Nature 2000, 406, 378–382. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bellingeri, M.; Cassi, D.; Vincenzi, S. Efficiency of attack strategies on complex model and real-world networks. Phys. Stat. Mech. Its Appl. 2014, 414, 174–180. [Google Scholar] [CrossRef] [Green Version]
- Wandelt, S.; Sun, X.; Feng, D.; Zanin, M.; Havlin, S. A comparative analysis of approaches to network-dismantling. Sci. Rep. 2018, 8, 13513. [Google Scholar] [CrossRef]
- Iyer, S.; Killingback, T.; Sundaram, B.; Wang, Z. Attack robustness and centrality of complex networks. PLoS ONE 2013, 8, e59613. [Google Scholar] [CrossRef] [Green Version]
- Bellingeri, M.; Bodini, A. Threshold extinction in food webs. Theor. Ecol. 2013, 6, 143–152. [Google Scholar] [CrossRef] [Green Version]
- Caldu-Primo, J.L.; Alvarez-Buylla, E.R.; Davila-Velderrain, J. Structural robustness of mammalian transcription factor networks reveals plasticity across development. Sci. Rep. 2018, 8, 13922. [Google Scholar] [CrossRef]
- Bellingeri, M.; Cassi, D.; Vincenzi, S. Increasing the extinction risk of highly connected species causes a sharp robust-to-fragile transition in empirical food webs. Ecol. Model. 2013, 251, 1–8. [Google Scholar] [CrossRef]
- Zanin, M.; Lillo, F. Modelling the air transport with complex networks: A short review. Eur. Phys. J. Spec. Top. 2013, 215, 5–21. [Google Scholar] [CrossRef] [Green Version]
- Gallos, L.K.; Cohen, R.; Argyrakis, P.; Bunde, A.; Havlin, S. Stability and topology of scale-free networks under attack and defense strategies. Phys. Rev. Lett. 2005, 94, 188701. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Y.; Paul, G.; Havlin, S.; Liljeros, F.; Stanley, H.E. Finding a better immunization strategy. Phys. Rev. Lett. 2008, 101, 058701. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bellingeri, M.; Bevacqua, D.; Scotognella, F.; Zhe-Ming, L.U.; Cassi, D. Efficacy of local attack strategies on the Beijing road complex weighted network. Phys. Stat. Mech. Its Appl. 2018, 510, 316–328. [Google Scholar] [CrossRef] [Green Version]
- Tejedor, A.; Longjas, A.; Zaliapin, I.; Ambroj, S.; Foufoula-Georgiou, E. Network robustness assessed within a dual connectivity framework: Joint dynamics of the Active and Idle Networks. Sci. Rep. 2017, 7, 8567. [Google Scholar] [CrossRef] [Green Version]
- Yates, R.D.; Kaul, S.K. The age of information: Real-time status updating by multiple sources. IEEE Trans. Inf. Theory 2018, 65, 1807–1827. [Google Scholar] [CrossRef] [Green Version]
- Tang, H.; Wang, J.; Song, L.; Song, J. Minimizing age of information with power constraints: Multi-user opportunistic scheduling in multi-state time-varying channels. IEEE J. Sel. Areas Commun. 2020, 38, 854–868. [Google Scholar] [CrossRef] [Green Version]
- Yates, R.D.; Sun, Y.; Brown, D.R.; Kaul, S.K.; Modiano, E.; Ulukus, S. Age of information: An introduction and survey. IEEE J. Sel. Areas Commun. 2021, 39, 1183–1210. [Google Scholar] [CrossRef]
- Costa, M.; Codreanu, M.; Ephremides, A. Age of information with packet management. In Proceedings of the 2014 IEEE International Symposium on Information Theory, Honolulu, HI, USA, 29 June–4 July 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1583–1587. [Google Scholar]
- Yates, R.D. The Age of Gossip in Networks. arXiv 2021, arXiv:2102.02893. [Google Scholar]
- Li, Z.; Shen, H. Utility-based distributed routing in intermittently connected networks. In Proceedings of the 2008 37th International Conference on Parallel Processing, Portland, OR, USA, 8–12 September 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 604–611. [Google Scholar]
- Xiao, M.; Wu, J.; Liu, C.; Huang, L. Tour: Time-sensitive opportunistic utility-based routing in delay tolerant networks. In Proceedings of the 2013 Proceedings IEEE Infocom, Turin, Italy, 14–19 April 2003; pp. 2085–2091. [Google Scholar]
- Xue, Y.; Cui, Y.; Nahrstedt, K. A utility-based distributed maximum lifetime routing algorithm for wireless networks. In Proceedings of the Second International Conference on Quality of Service in Heterogeneous Wired/Wireless Networks (QSHINE’05), Lake Buena Vista, FL, USA, 22–24 August 2005; IEEE: Piscataway, NJ, USA, 2005; p. 10. [Google Scholar]
- Toh, C.K. A novel distributed routing protocol to support ad hoc mobile computing. In Proceedings of the 1996 IEEE Fifteenth Annual International Phoenix Conference on Computers and Communications, Scottsdale, AZ, USA, 27–29 March 1996; IEEE: Piscataway, NJ, USA, 1996; pp. 480–486. [Google Scholar]
- Ye, Z.; Krishnamurthy, S.V.; Tripathi, S.K. A framework for reliable routing in mobile ad hoc networks. In Proceedings of the IEEE INFOCOM 2003. Twenty-second Annual Joint Conference of the IEEE Computer and Communications Societies (IEEE Cat. No. 03CH37428), San Franciso, CA, USA, 30 March–3 April 2003; IEEE: Piscataway, NJ, USA, 2003; Volume 1, pp. 270–280. [Google Scholar]
- Zhou, F.; Malher, S.; Toivonen, H. Network simplification with minimal loss of connectivity. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, Australia, 13–17 December 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 659–668. [Google Scholar]
- Zhou, F.; Mahler, S.; Toivonen, H. Simplification of networks by edge pruning. In Bisociative Knowledge Discovery; Springer: Berlin/Heidelberg, Germany, 2012; pp. 179–198. [Google Scholar]
- Singh, L. Pruning social networks using structural properties and descriptive attributes. In Proceedings of the Fifth IEEE International Conference on Data Mining (ICDM’05), Houston, TX, USA, 27–30 November 2005; IEEE: Piscataway, NJ, USA, 2005; p. 4. [Google Scholar]
- Colbourn, C.J.; Xue, G. A linear time algorithm for computing the most reliable source on a series-parallel graph with unreliable edges. Theor. Comput. Sci. 1998, 209, 331–345. [Google Scholar] [CrossRef] [Green Version]
- Eppstein, D. Parallel recognition of series-parallel graphs. Inf. Comput. 1992, 98, 41–55. [Google Scholar] [CrossRef] [Green Version]
- Kosta, A.; Pappas, N.; Angelakis, V. Age of information: A new concept, metric, and tool. Found. Trends Netw. 2017, 12, 162–259. [Google Scholar] [CrossRef] [Green Version]
- Bladt, M. A review on phase-type distributions and their use in risk theory. ASTIN Bull. J. IAA 2005, 35, 145–161. [Google Scholar] [CrossRef]
- O’Cinneide, C.A. Phase-type distributions and invariant polytopes. Adv. Appl. Probab. 1991, 23, 515–535. [Google Scholar] [CrossRef]
- Commault, C.; Mocanu, S. Phase-type distributions and representations: Some results and open problems for system theory. Int. J. Control 2003, 76, 566–580. [Google Scholar] [CrossRef]
- Komárková, Z. Phase-Type Approximation Techniques. Ph.D. Thesis, Masarykova Univerzita, Fakulta Informatiky, Brno, Czechia, 2012. [Google Scholar]
- Papoulis, A.; Saunders, H. Probability, Random Variables and Stochastic Processes; Tata McGraw-Hill Education: New York, NY, USA, 1989. [Google Scholar]
- Raju, C.K. Products and compositions with the Dirac delta function. J. Phys. Math. Gen. 1982, 15, 381. [Google Scholar] [CrossRef]










Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sawwan, A.; Wu, J. On Edge Pruning of Communication Networks under an Age-of-Information Framework. Algorithms 2022, 15, 228. https://doi.org/10.3390/a15070228
Sawwan A, Wu J. On Edge Pruning of Communication Networks under an Age-of-Information Framework. Algorithms. 2022; 15(7):228. https://doi.org/10.3390/a15070228
Chicago/Turabian StyleSawwan, Abdalaziz, and Jie Wu. 2022. "On Edge Pruning of Communication Networks under an Age-of-Information Framework" Algorithms 15, no. 7: 228. https://doi.org/10.3390/a15070228
APA StyleSawwan, A., & Wu, J. (2022). On Edge Pruning of Communication Networks under an Age-of-Information Framework. Algorithms, 15(7), 228. https://doi.org/10.3390/a15070228