In the following, we will derive a general framework for mixers that are restricted to a subspace, given by certain basis states. For example, one may want to construct a mixer for five qubits that is restricted to the subspace of , where denotes the linear span of B. In this section, we will describe the conditions for a Hamiltonian-based QAOA mixer to preserve the feasible subspace and for providing transitions between all pairs of feasible states. We also provide efficient algorithms to decompose these mixers into basis gates.
3.1. Conditions on the Mixer Hamiltonian
Theorem 1 (Mixer Hamiltonians for subspaces)
. Given a feasible subspace B as in Definition 1 and a real-valued transition matrix . Then, for the mixer constructed via the following statements hold.If T is symmetric, the mixer is well defined and preserves the feasible subspace, i.e., condition (5) is fulfilled. If T is symmetric and for all , there exists an (possibly depending on the pair) such thatthenprovides transitions between all pairs of feasible states, i.e., condition (6) is fulfilled.
Proof. Well definedness. Almost trivially
is Hermitian if
T is symmetric,
Since
is a Hermitian (and therefore normal) matrix, there exists a diagonal matrix
D, with the entries of the diagonal as the (real valued) eigenvalues of
, and a matrix
U, with columns given by the corresponding orthonormal eigenvectors. The mixer is therefore well defined through the convergent series
Reformulations. We can rewrite
in the following way
where the columns of the matrix
consist of the feasible computational basis states, i.e.,
; see
Figure 1 for an illustration.
Using that
is the identity matrix, we have that
and Equation (
13) can be written as
Preservation of the feasible subspace. Let
. Using Equation (
15), we know that
with coefficients
. Therefore, also
, since it is a sum of these terms.
Transition between all pairs of feasible states. For any pair of feasible computational basis states
, we have that
It is enough to show that is not the zero function. Since is an analytic function, it has a unique extension to . Assume that f is indeed the zero function on ; then, the extension to would also be the zero function, and all coefficients of its Taylor series would be zero. However, we assumed the existence of an such that , and hence, there exists a nonzero coefficient, which is a contradiction to f being the zero function. □
A natural question is how the statements in Theorem 1 depend on the particular ordering of the elements of B.
Corollary 1 (Independence of the ordering of B). Statements in Theorem 1 that hold for a particular ordering of computational basis states for a given B hold also for any permutation , i.e., they are independent of the ordering of elements. For each ordering, the transition matrix T changes according to , where is the permutation matrix associated with π.
Proof. We start by pointing out that the inverse matrix of exists and can be written as .
The resulting matrix
is unchanged. Following the derivation in Equation (
14), we have that
where the columns of the matrix
consist of the
permuted feasible computational basis states, i.e.,
. Inserting
, we have indeed
.
is symmetric if
T is. Assuming that
, we have that also
If the condition in Equation (
11) holds for
T, then it also holds for
. Using
, we can show that Equation (
11) holds for the permuted index pair
for
if it holds for
for
T. □
In the following, if nothing else is remarked, computational basis states are ordered with respect to increasing integer value, e.g., .
Apart from special cases, there is a lot of freedom to choose the transition matrix T that fulfills the conditions of Theorem 1. The entries of T will heavily influence the circuit complexity, which will be investigated in
Section 3.3. In addition, we have the following property which adds additional flexibility to develop efficient mixers.
Corollary 2 (Properties of mixers)
. For a given feasible subspace , let be the mixer given by Theorem 1. For any subspace with or equivalently , also is a valid mixer for B satisfying the conditions of Equations (5) and (6); see also Figure 2. Proof. Any
is in the null space of
, i.e.,
and hence
. Therefore,
, and
with
which means the feasible subspace is preserved. Condition (
6) follows similarly from the fact that
for any
. □
Corollary 2 naturally holds as well for any linear combination of mixers, i.e.,
is a mixer for the feasible subspace
as long as
. At first, it might sound counterintuitive that adding more terms to the mixer results in more efficient decomposition into basis gates. However, as we will see in
Section 5, it can lead to cancellations due to symmetry considerations.
Next, we describe the structure of the eigensystem of .
Corollary 3 (Eigensystem of mixers)
. Given the setting in Theorem 1 with a symmetric transition matrix T. Let be an eigenpair of T, then is an eigenpair of and is an eigenpair of , where as defined in Equation (14). Proof. Let be an eigenpair of T. Then, , so is an eigenpair of . The connection between and is general knowledge from linear algebra. □
An example illustrating Corollary 3 is provided by the transition matrix
with zero diagonal and all other entries equal to one. A unit eigenvector of T, which fulfills Theorem 1, is
. For any
, the uniform superpositions of these states is an eigenvector, since
This result holds irrespective of what the states are and which dimension they have.
Theorem 2 (Products of mixers for subspaces)
. Given the same setting as in Theorem 1. For any decomposition of T into a sum of Q symmetric matrices , in the following sense we construct the mixing operator viaIf all entries of T are positive, then provides transitions between all pairs of feasible states, i.e., condition (6) is fulfilled, if for all there exist (possibly depending on the pair) such that Proof. Combining Equations (
15) and (
16), we have
Using that
T only has positive entries and the condition in Equation (
20), the same argument as in Theorem 1 can be used to show that
is not the zero function, and therefore, we have transitions between all pairs of feasible states. □
As Theorem 1 leaves a lot of freedom for choosing valid transition matrices, we will continue by describing important examples for T.
3.2. Transition Matrices for Mixers
Theorem 1 provides conditions for the construction of mixer Hamiltonians that preserve the feasible subspace and provide transitions between all pairs of feasible computational basis states, namely
is symmetric; and
for all there exists an such that .
Remarkably, these conditions depend only on the dimension of the feasible subspace
, and they are independent of the specific states that constitute
B. In addition, Corollary 1 shows that these conditions are robust with respect to reordering of rows if in addition columns are reordered in the same way. Moreover, Equation (
17) shows also that the overlap between computational basis states
is independent of the specific states that
B consists of and only depends on T, since the right-hand side of the expression
is independent of the elements in
B. This allows us to describe and analyze valid transition matrices by only knowing the number of feasible states, i.e.,
. What these specific states are is irrelevant, unless one wants to look at what an optimal mixer is, which we will come back to in
Section 3.4.
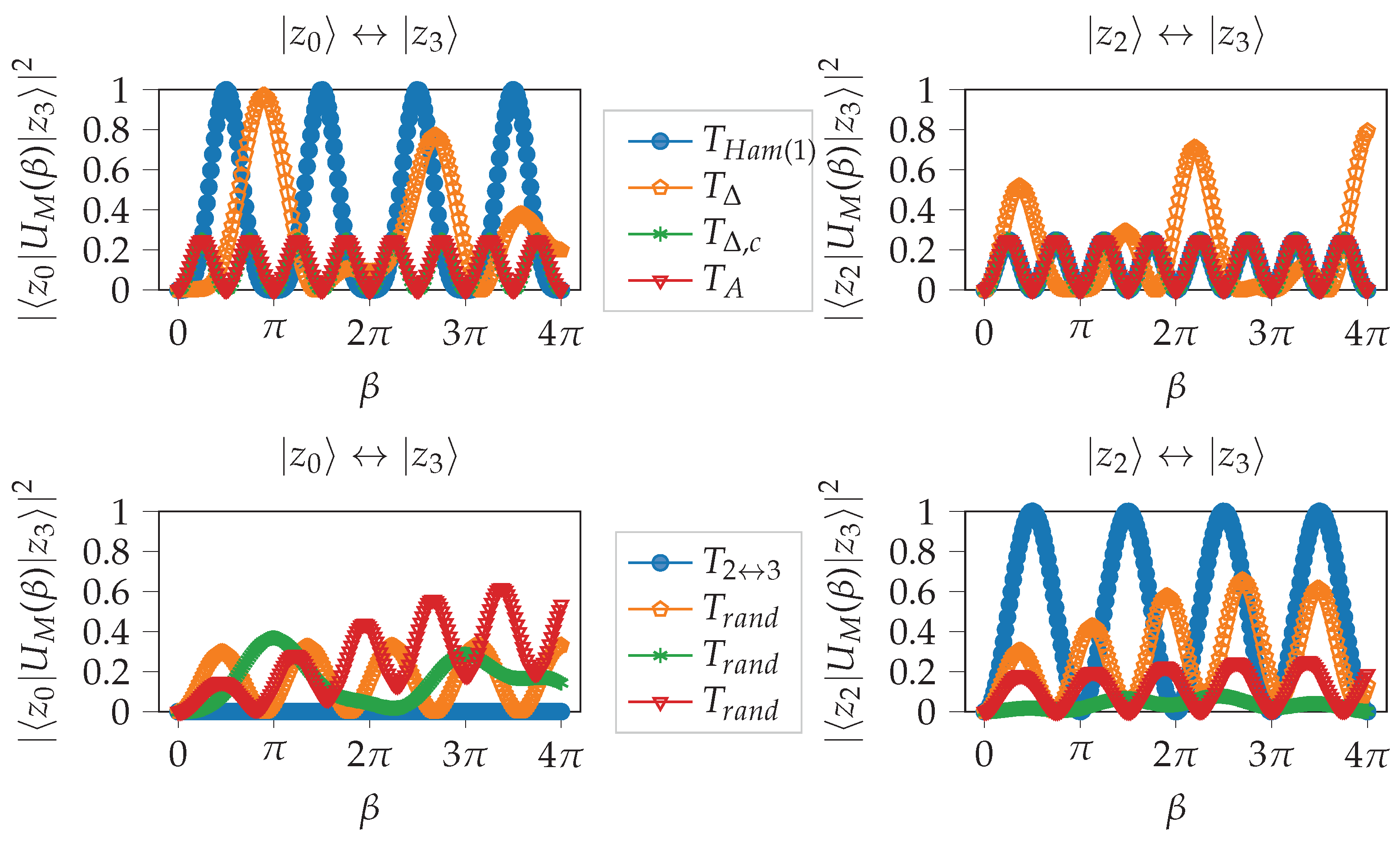
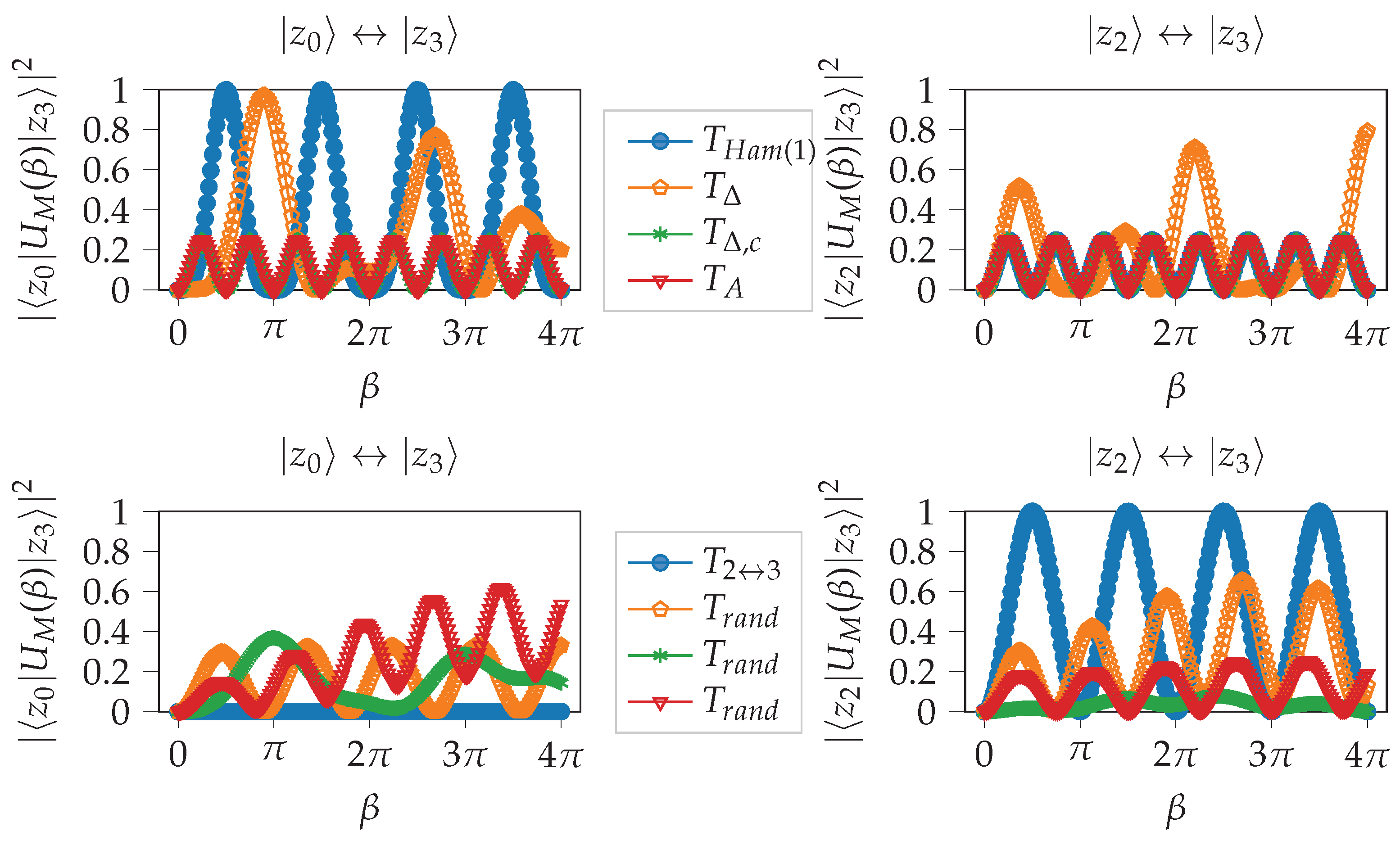
Figure 3 provides a comparison of some mixers described in the following with respect to the overlap between different states.
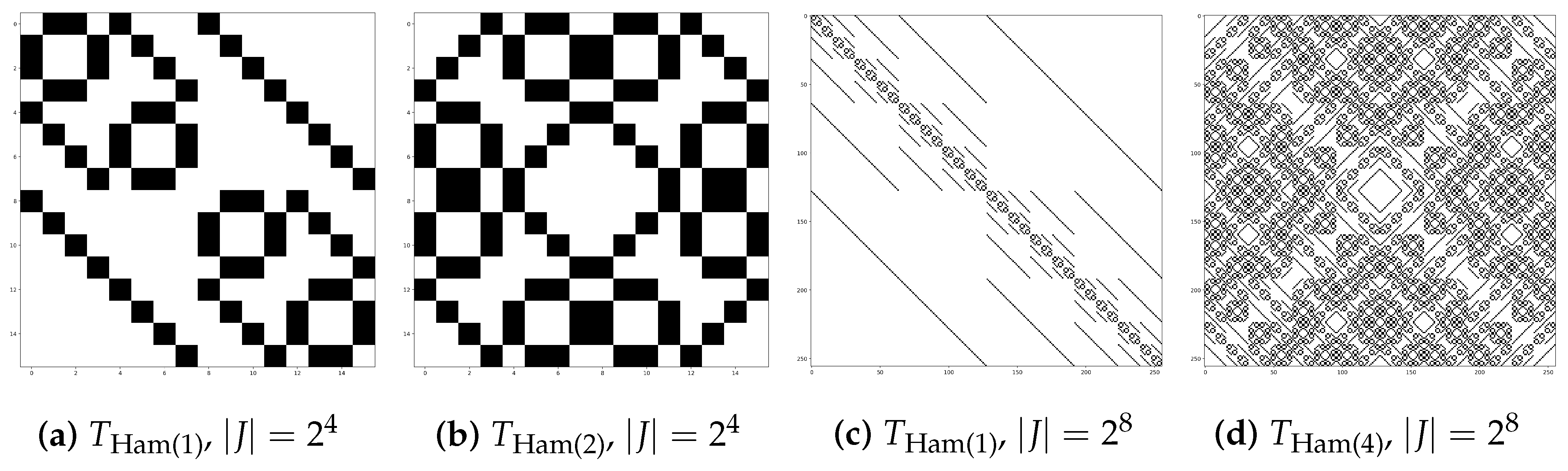
In the following, we denote the matrix for pairs of indices whose binary representation have a Hamming distance equal to
d as
Examples of the structure of
can be found in
Figure 4.
Furthermore, it will be useful to denote the matrix which has two nonzero entries at
and
as
Before we start, we point out that the diagonal entries of T can be chosen to be zero, because for all . Although trivial, we will repeatedly use that is an eigenvector of a matrix if the sum of all rows are a multiple of v.
3.2.1. Hamming Distance One Mixer
The matrix
fulfills Theorem 1 when
. The symmetry of
is due to the fact that the Hamming distance is a symmetric function. Using the identity
it can be shown that
where
are real coefficients. Therefore, it is clear that
reaches all states with Hamming distance
K. Furthermore,
is a unit eigenvector of
since the sum of each row is
n. This is because there are exactly
n other states with a Hamming distance of one for each bitstring.
3.2.2. All-to-All Mixer
We denote the matrix with all but the diagonal entries equal to one as
Trivially, fulfilles Theorem 1 and is a unit eigenvector of since the sum of each row is .
3.2.3. (Cyclic) Nearest Integer Mixer /
Inspired by the stencil of finite-difference methods, we introduce
,
as matrices with off-diagonal entries equal to one
Both matrices fulfill Theorem 1. Symmetry holds by definition, and it is easy to see that the k-th off-diagonal of and is nonzero for .
For the nearest integer mixer
, it is known that
are eigenvectors for
. For the cyclic nearest integer mixer, we have that the sum of each row/column of
is equal to two (except for
when it is one). Therefore,
is a unit eigenvector.
3.2.4. Products of Mixers and
In some cases, it will be necessary to use Theorem 2 to implement mixer unitaries. When splitting transitions matrices into odd and even entries, the following definition is useful. Denote the matrix with entries in the d-th off-diagonal for even rows equal to one
and accordingly
for odd rows. In addition, we will use
to be the cyclic version in the same way as in Equation (
28). As an example, this allows one to decompose
with
and
.
3.2.5. Random Mixer
Finally, the upper triangular entries of the mixer are drawn from a continuous uniform distribution on the interval , and the lower triangular entries are chosen such that T becomes symmetric. Since the probability of getting a zero entry is zero, such a random mixer fulfills Theorem 1 with probability 1.
3.3. Decomposition of (Constraint) Mixers into Basis Gates
Given a set of feasible (computational basis) states
, we can use Theorem 1 to define a suitable mixer Hamiltonian. The next question is how to (efficiently) decompose the resulting mixer into basis gates. In order to do so, we first decompose the Hamiltonian
into a weighted sum of Pauli-strings. A Pauli-string
P is a Hermitian operator of the form
where
. Pauli-strings form a basis of the
real vector space of all
n-qubit Hermitian operators. Therefore, we can write
with real coefficients
, where
. After using a standard Trotterization scheme [
4,
5] (which is exact for commuting Pauli-strings),
it is well-established how to implement each of the terms of the product using basis gates; see Equation (
33). We will discuss the effects of Trotterization in more detail in
Section 3.5, as there are several important aspects to consider for a valid mixer.
Here,
S is the S or Phase gate and
H is the Hadamard gate. The standard way to compute the coefficients
is given in Algorithm 1.
| Algorithm 1: Decompose given by Equation (10) into Pauli-strings via trace |
![Algorithms 15 00202 i001]() |
For
n qubits, this requires to compute
coefficients, as well as the multiplication of
matrices. However, most of these terms are expected to vanish. We therefore describe an alternative way to produce this decomposition, using the language of quantum mechanics [
24]. In the following, we use the
ladder operators used in the creation and annihilation operators from the second quantization formulation in quantum chemistry defined by
Since
, where 0 is the zero vector, we have that
. Since
, we have that
, and finally
means that
and
. Note that
As an example, consider the matrix
, which can be expressed with ladder operators as
. Another example is given by
. This approach clearly extends to the general case and leads to Algorithm 2.
| Algorithm 2: Decompose given by Equation (10) into Pauli-strings directly |
![Algorithms 15 00202 i002]() |
A comparison of the complexity of the two algorithms is given in
Table 1. The naive algorithm needs to perform a matrix–matrix multiplication with matrices of size
for each of the
coefficients. This quickly becomes prohibitive for larger
n. The algorithm based on ladder operators requires resources that scale with the number of nonzero entries of the transition matrix
T, which is much more favorable. In the end, a symbolic mathematics library is used to simplify the expressions in order to create the list of nonzero Pauli-strings.
3.5. Trotterizations
Algorithms 1 and 2 produce a weighted sum of Pauli-strings equal to the mixer Hamiltonian
defined in Theorem 1. A further complication arises when the non-vanishing Pauli-strings of the mixer Hamiltonian
do not all commute. In that case, one can not realize
exactly but has to find a suitable approximation/Trotterization; see Equation (
32). Two Pauli-strings
commute, i.e.,
if, and only if, they
fail to commute on an
even number of indices [
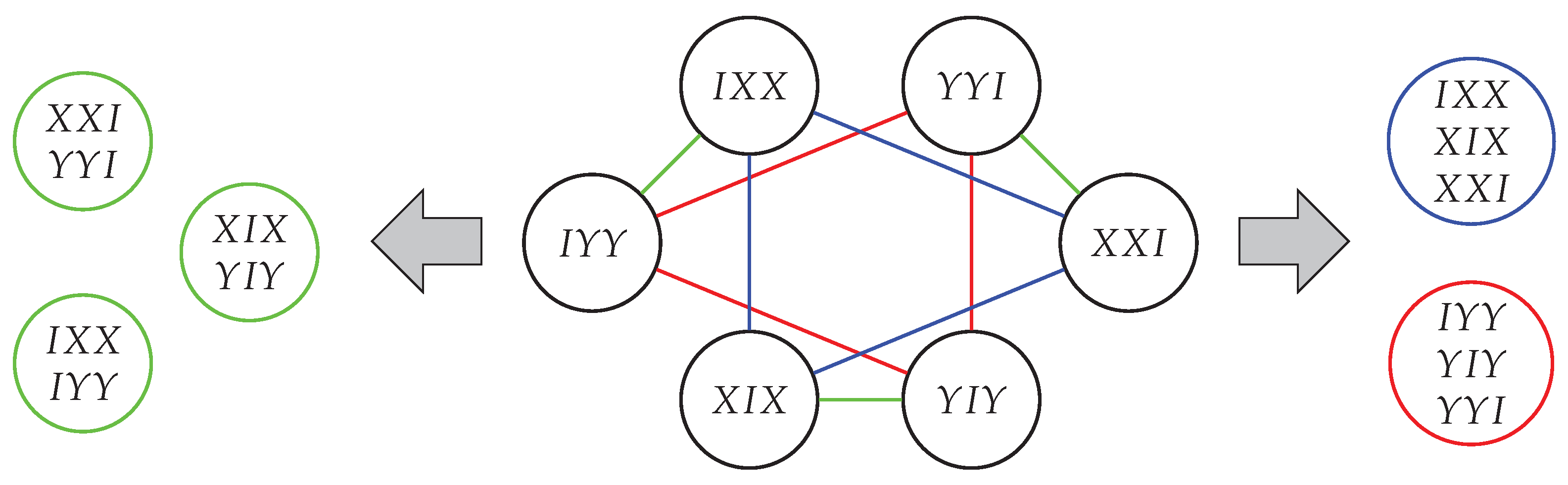
25]. An example is given in
Figure 5.
This problem is similar to a problem for observables: how does one divide the Pauli-strings into groups of commuting families [
25,
26] to maximize efficiency and increase accuracy? In order to minimize the number of measurements required to estimate a given observable, one wants to find a “min-commuting-partition”; given a set of Pauli-strings from a Hamiltonian, one seeks to partition the strings into commuting families such that the total number of partitions is minimized. This problem is NP-hard in general [
25]. However, based on Theorem 3, we expect our problem to be much more tractable.
For our case, it turns out that not all Trotterizations are suitable as mixing operators; they can either fail to preserve the feasible subspace, i.e., Equation (
5), or fail to provide transitions between all pairs of feasible states, i.e., Equation (
6). An example is given by
with the mixer
associated with
; see
Section 5.1. Looking at
Figure 5, these terms can be grouped into commuting families in two ways, which represent two (of many) different ways to realize the mixer unitary with basis gates.
The first possible Trotterization is given by and . However, it turns out that such that for all . This means that this Trotterization does not preserve the feasible subspace and does not represent a valid mixer Hamiltonian. The underlying reason for this is that the terms and are generated from the entry , but are split in this Trotterization. The same holds true for and , which are generated via .
The second possible Trotterization is given by and , which splits terms with respect to and In this case, we have that , so it does not provide an overlap between all feasible computational basis states. This can be understood via Theorem 2. We have that for all , so one can not “reach” |100⟩ from |001⟩. The opposite is not true; we have that , so such that .
We have just learned that it is a bad idea to Trotterize terms that belong to a nonzero entry of T, i.e., to . Therefore, we need to show that all non-vanishing Pauli-strings of commute; otherwise, there might exist subspaces for which we can not realize the mixer constructed in Theorem 1. Luckily, the following theorem shows that it is always possible to realize a mixer by Trotterizing according to nonzero entries of .
Theorem 3 (Pauli-strings for
commute)
. Let be two computational basis states in . Then, all non-vanishing Pauli-strings of the decomposition commute. Proof. We will prove the following more general assertion by induction. Let
be two non-vanishing Pauli-strings of the decomposition of
, and
be two non-vanishing Pauli-strings of the decomposition of
. Then,
,
and
. We will use that two Pauli-strings commute if, and only if, they
fail to commute on an
even number of indices [
25].
For , we have the following cases.
It is trivially true that and , since the maximum number of Pauli-strings is two, and in that case, one of the Pauli-strings is the identity. Moreover, is nonzero only when . In that case, .
. We assume the assumptions hold for two computational basis states
. Then, there are the following four cases
where
.
Case . According to our assumptions that all non-vanishing Pauli-strings for commute, the same holds for . Since , the rest of the assertions are trivially true, as there are no non-vanishing Pauli-strings.
Case . Our assumptions mean that non-vanishing Pauli-strings of fail to commute on an odd number of indices with non-vanishing Pauli-strings of . Therefore, non-vanishing Pauli-strings of fail to commute on an even number of indices, and, hence, commute. The same argument holds for . Finally, we prove that non-vanishing Pauli-strings of and do not commute. Either Pauli strings and stem from and , respectively, or they stem from and , respectively. In both cases, the number of commuting terms does not change, so non-vanishing Pauli-strings of and do not commute. □
The proof in Theorem 3 inspires the following algorithm to decompose into Pauli-strings. For each item in the list S that the algorithm produces, all Pauli-strings commute.
We can illustrate the difference between Algorithms 2 and 3 for
and
. With Algorithm 2, we have
and
, which can be simplified to
. With Algorithm 3, we have
and
without the need to simplify the expression.
| Algorithm 3: Decompose given by Equation (10) into Pauli-strings directly |
![Algorithms 15 00202 i003]() |
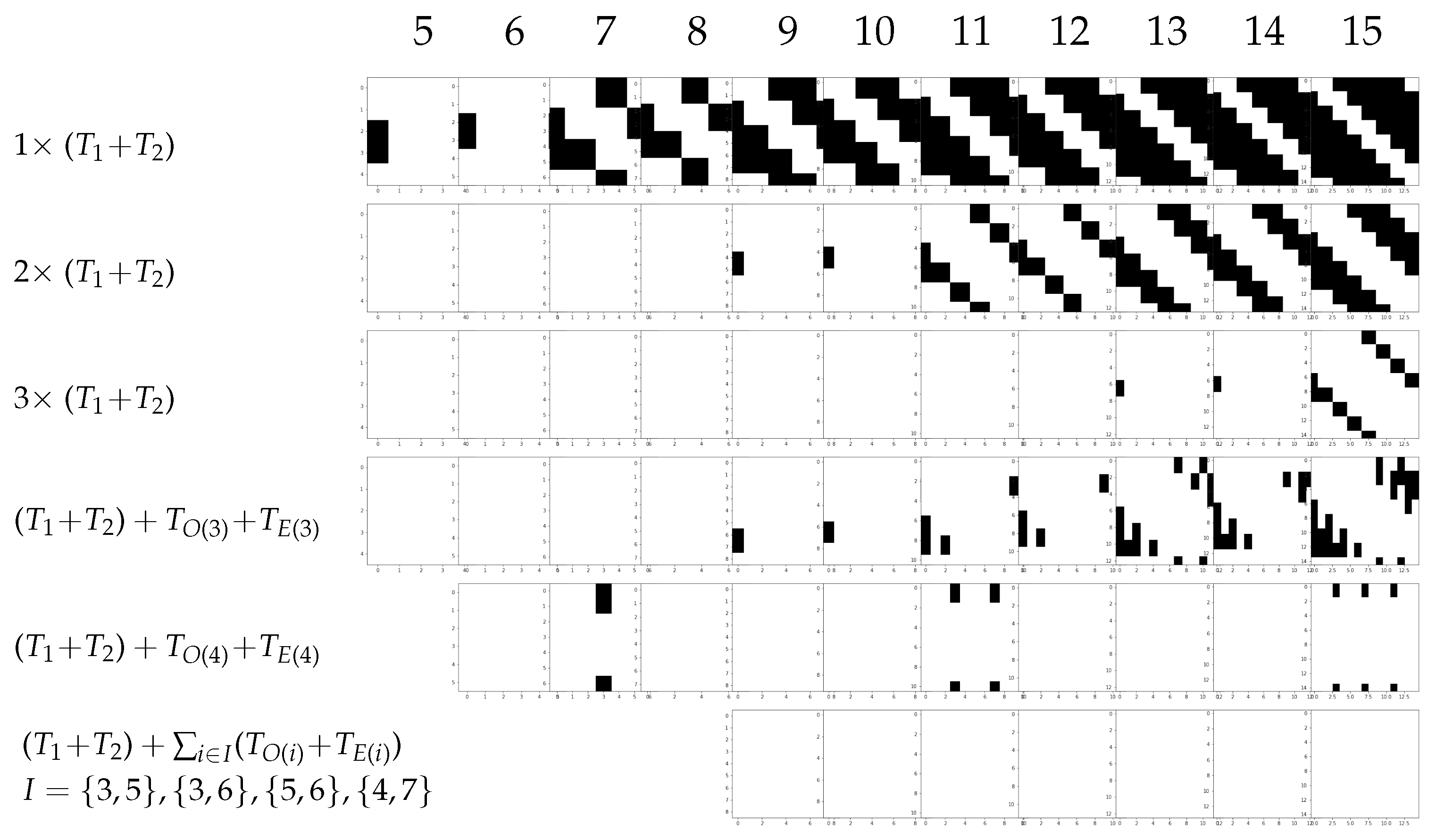
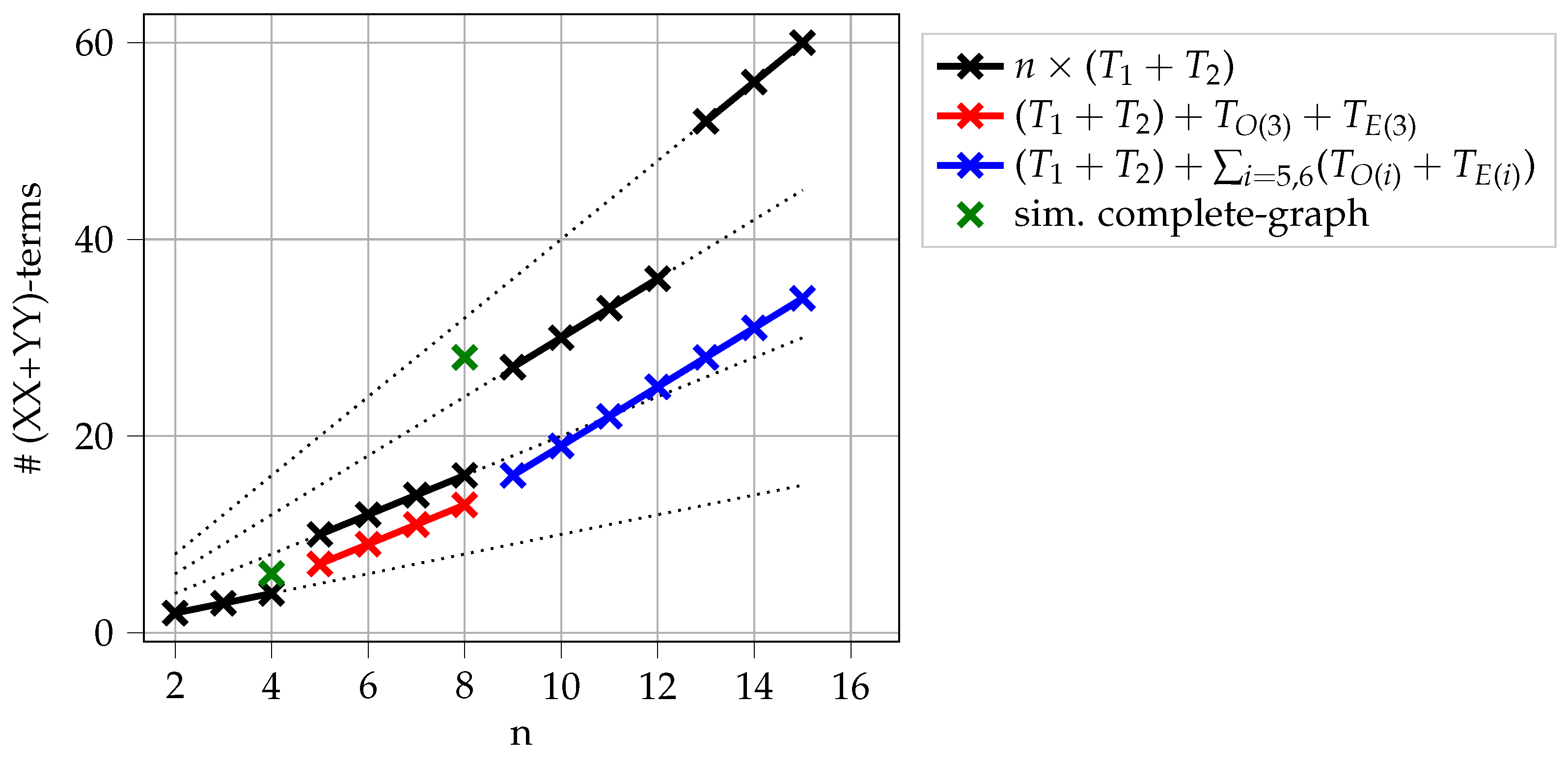
As shown above, Trotterizations can also lead to missing transitions. It is suggested in [
2] that it is useful to repeat mixers within one mixing step, which corresponds to
in Equation (
6). However, as we see in
Figure 6, there can be more efficient ways to obtain mixers that provide transitions between all pairs of feasible states. One way to do so is to construct an exact Trotterization (restricted to the feasible subspace) as described in [
19]. However, the ultimate goal is not to avoid Trotterization errors, but rather to provide transitions between all pairs of feasible states. We will revisit the topic of Trotterizations in
Section 5 in more detail for each case and show that there are more efficient ways to do so.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}