
Constructing the Neighborhood Structure of VNS Based on Binomial Distribution for Solving QUBO Problems


Abstract
:1. Introduction
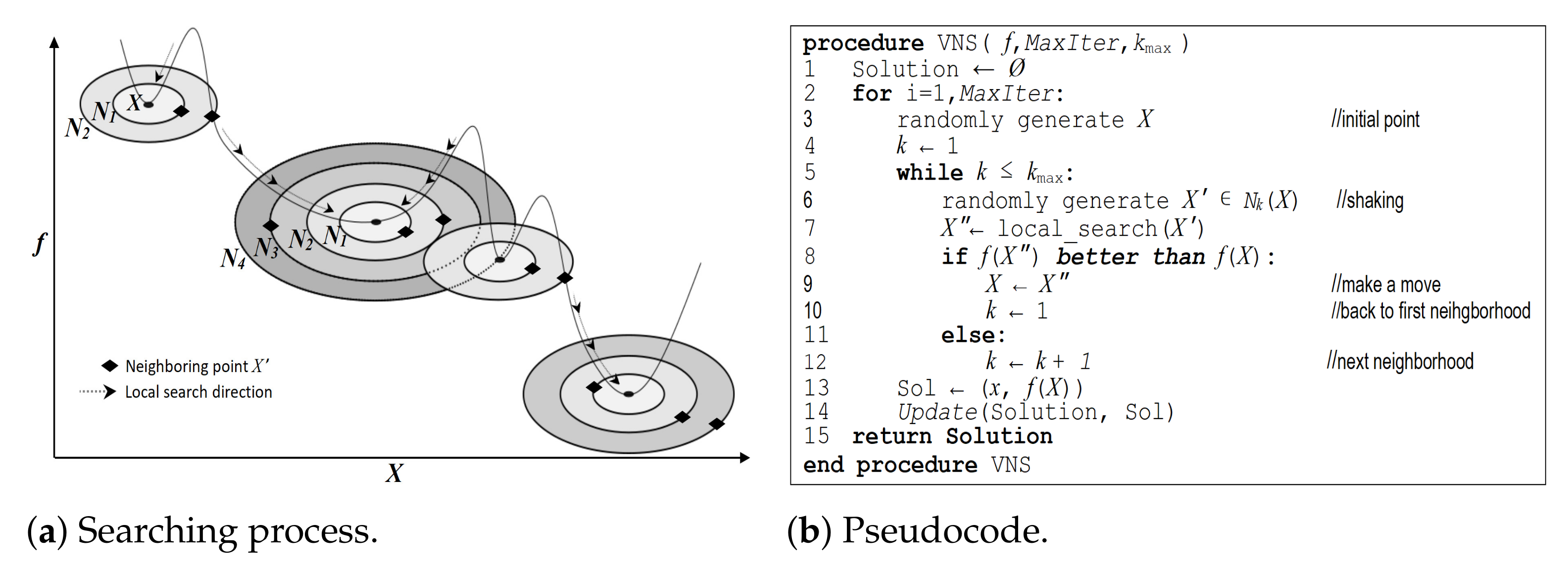
2. VNS Algorithm
- Observation 1: A local minimum for one neighborhood structure is not necessarily so for another;
- Observation 2: A global minimum is a local minimum for all of the possible neighborhood structures;
- Observation 3: For many problems, local minimums for one or several neighborhoods are relatively similar to each other.
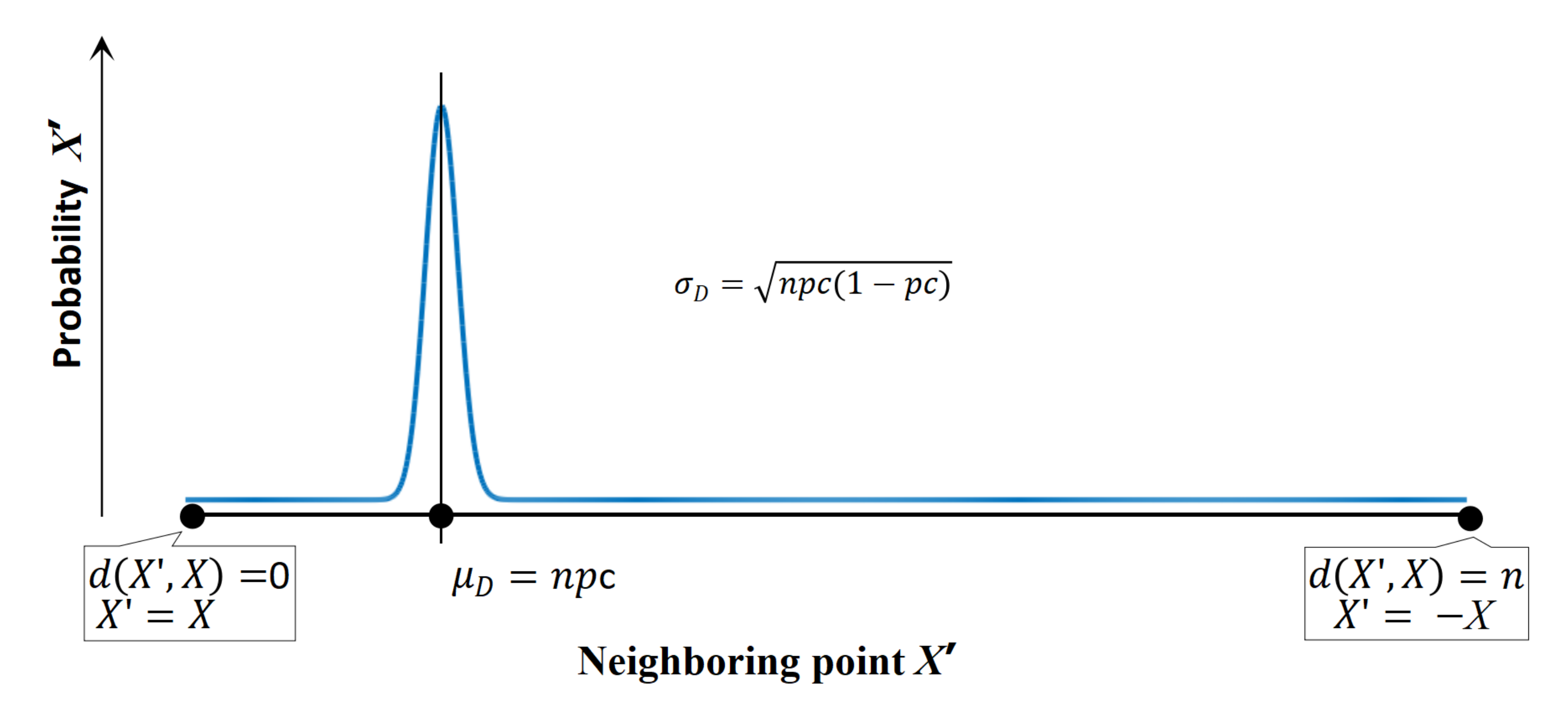
3. Proposed Neighborhood Structure
4. Benchmarking
4.1. Test on QUBO Problems
4.2. Test on Max-Cut Problems
- 1.
- if , then ;
- 2.
- if , then .
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Paschos, V.T. Applications of Combinatorial Optimizations; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2014. [Google Scholar] [CrossRef] [Green Version]
- Talbi, E.G. Metaheuristics; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2009. [Google Scholar] [CrossRef]
- Yang, X.S. Metaheuristic Optimization: Algorithm Analysis and Open Problems. In Proceedings of the Experimental Algorithms; Pardalos, P.M., Rebennack, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 21–32. [Google Scholar]
- Sörensen, K.; Glover, F.W. Metaheuristics. In Encyclopedia of Operations Research and Management Science; Gass, S.I., Fu, M.C., Eds.; Springer: Boston, MA, USA, 2013; pp. 960–970. [Google Scholar] [CrossRef]
- Glover, F.; Kochenberger, G.A. (Eds.) Handbook of Metaheuristics; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Papalitsas, C.; Andronikos, T.; Giannakis, K.; Theocharopoulou, G.; Fanarioti, S. A QUBO Model for the Traveling Salesman Problem with Time Windows. Algorithms 2019, 12, 224. [Google Scholar] [CrossRef] [Green Version]
- Date, P.; Arthur, D.; Pusey-Nazzaro, L. QUBO formulations for training machine learning models. Sci. Rep. 2021, 11, 10029. [Google Scholar] [CrossRef] [PubMed]
- Karp, R.M. Reducibility Among Combinatorial Problems. In 50 Years of Integer Programming 1958–2008: From the Early Years to the State-of-the-Art; Springer: Berlin/Heidelberg, Germany, 2010; pp. 219–241. [Google Scholar] [CrossRef]
- Glover, F.; Kochenberger, G.; Du, Y. A Tutorial on Formulating and Using QUBO Models. CoRR 2018. Available online: http://xxx.lanl.gov/abs/1811.11538 (accessed on 6 May 2022).
- Katayama, K.; Narihisa, H. Performance of simulated annealing-based heuristic for the unconstrained binary quadratic programming problem. Eur. J. Oper. Res. 2001, 134, 103–119. [Google Scholar] [CrossRef]
- Glover, F.; Kochenberger, G.A.; Alidaee, B. Adaptive Memory Tabu Search for Binary Quadratic Programs. Manag. Sci. 1998, 44, 336–345. [Google Scholar] [CrossRef] [Green Version]
- Merz, P.; Freisleben, B. Genetic Algorithms for Binary Quadratic Programming; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1999; GECCO’99; pp. 417–424. [Google Scholar]
- Boros, E.; Hammer, P.L.; Tavares, G. Local search heuristics for Quadratic Unconstrained Binary Optimization (QUBO). J. Heuristics 2007, 13, 99–132. [Google Scholar] [CrossRef]
- Mladenović, N.; Hansen, P. Variable neighborhood search. Comput. Oper. Res. 1997, 24, 1097–1100. [Google Scholar] [CrossRef]
- Duarte, A.; Sánchez, A.; Fernández, F.; Cabido, R. A Low-Level Hybridization between Memetic Algorithm and VNS for the Max-Cut Problem. In Proceedings of the 7th Annual Conference on Genetic and Evolutionary Computation, Washington, DC, USA, 25–29 June 2005; Association for Computing Machinery: New York, NY, USA, 2005. GECCO’05. pp. 999–1006. [Google Scholar] [CrossRef]
- Kim, S.H.; Kim, Y.H.; Moon, B.R. A Hybrid Genetic Algorithm for the MAX CUT Problem. In Proceedings of the 3rd Annual Conference on Genetic and Evolutionary Computation, San Fransisco, CA, USA, 7–11 July 2001; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2001. GECCO’01. pp. 416–423. [Google Scholar]
- Festa, P.; Pardalos, P.; Resende, M.; Ribeiro, C. GRASP and VNS for Max-Cut. In Proceedings of the Extended Abstracts of the Fourth Metaheuristics International Conference, Porto, Portugal, 16–20 July 2001; pp. 371–376. [Google Scholar]
- Resende, M. GRASP With Path Re-linking and VNS for MAXCUT. In Proceedings of the 4th MIC, Porto, Portugal, 16–20 July 2001. [Google Scholar]
- Ramli, M.A.M.; Bouchekara, H.R.E.H. Solving the Problem of Large-Scale Optimal Scheduling of Distributed Energy Resources in Smart Grids Using an Improved Variable Neighborhood Search. IEEE Access 2020, 8, 77321–77335. [Google Scholar] [CrossRef]
- Wang, F.; Deng, G.; Jiang, T.; Zhang, S. Multi-Objective Parallel Variable Neighborhood Search for Energy Consumption Scheduling in Blocking Flow Shops. IEEE Access 2018, 6, 68686–68700. [Google Scholar] [CrossRef]
- Garcia-Hernandez, L.; Salas-Morera, L.; Carmona-Muñoz, C.; Abraham, A.; Salcedo-Sanz, S. A Hybrid Coral Reefs Optimization—Variable Neighborhood Search Approach for the Unequal Area Facility Layout Problem. IEEE Access 2020, 8, 134042–134050. [Google Scholar] [CrossRef]
- He, M.; Wei, Z.; Wu, X.; Peng, Y. An Adaptive Variable Neighborhood Search Ant Colony Algorithm for Vehicle Routing Problem With Soft Time Windows. IEEE Access 2021, 9, 21258–21266. [Google Scholar] [CrossRef]
- El Cadi, A.A.; Atitallah, R.B.; Mladenović, N.; Artiba, A. A Variable Neighborhood Search (VNS) metaheuristic for Multiprocessor Scheduling Problem with Communication Delays. In Proceedings of the 2015 International Conference on Industrial Engineering and Systems Management (IESM), Seville, Spain, 21–23 October 2015; pp. 1091–1095. [Google Scholar] [CrossRef]
- Silva, G.; Silva, P.; Santos, V.; Segundo, A.; Luz, E.; Moreira, G. A VNS Algorithm for PID Controller: Hardware-In-The-Loop Approach. IEEE Latin Am. Trans. 2021, 19, 1502–1510. [Google Scholar] [CrossRef]
- Phanden, R.K.; Demir, H.I.; Gupta, R.D. Application of genetic algorithm and variable neighborhood search to solve the facility layout planning problem in job shop production system. In Proceedings of the 2018 7th International Conference on Industrial Technology and Management (ICITM), Oxford, UK, 7–9 March 2018; pp. 270–274. [Google Scholar] [CrossRef]
- Dabhi, D.; Pandya, K. Uncertain Scenario Based MicroGrid Optimization via Hybrid Levy Particle Swarm Variable Neighborhood Search Optimization (HL_PS_VNSO). IEEE Access 2020, 8, 108782–108797. [Google Scholar] [CrossRef]
- Zhang, S.; Gu, X.; Zhou, F. An Improved Discrete Migrating Birds Optimization Algorithm for the No-Wait Flow Shop Scheduling Problem. IEEE Access 2020, 8, 99380–99392. [Google Scholar] [CrossRef]
- Zhang, C.; Xie, Z.; Shao, X.; Tian, G. An effective VNSSA algorithm for the blocking flowshop scheduling problem with makespan minimization. In Proceedings of the 2015 International Conference on Advanced Mechatronic Systems (ICAMechS), Beijing, China, 22–24 August 2015; pp. 86–89. [Google Scholar] [CrossRef]
- Montemayor, A.S.; Duarte, A.; Pantrigo, J.J.; Cabido, R.; Carlos, J. High-performance VNS for the Max-cut problem using commodity graphics hardware. In Proceedings of the Mini-Euro Conference on VNS (MECVNS 05), Tenerife, Spain, 23–25 November 2005; pp. 1–11. [Google Scholar]
- Ling, A.; Xu, C.; Tang, L. A modified VNS metaheuristic for max-bisection problems. J. Comput. Appl. Math. 2008, 220, 413–421. [Google Scholar] [CrossRef] [Green Version]
- Hansen, P.; Mladenović, N.; Brimberg, J.; Pérez, J.A.M. Variable Neighborhood Search. In Handbook of Metaheuristics; Gendreau, M., Potvin, J.Y., Eds.; International Series in Operations Research & Management Science; Springer: Berlin/Heidelberg, Germany, 2010; Chapter 3; pp. 61–184. [Google Scholar]
- Hansen, P.; Mladenović, N.; Moreno Pérez, J.A. Variable neighbourhood search: Methods and applications. 4OR 2008, 6, 319–360. [Google Scholar] [CrossRef]
- Hansen, P.; Mladenović, N. A Tutorial on Variable Neighborhood Search; Technical report; Les Cahiers Du Gerad, Hec Montreal and Gerad: Montreal, QC, Canada, 2003. [Google Scholar]
- Festa, P.; Pardalos, P.; Resende, M.; Ribeiro, C. Randomized heuristics for the Max-Cut problem. Optim. Methods Softw. 2002, 17, 1033–1058. [Google Scholar] [CrossRef]
- Beasley, J.E. OR-Library: Distributing Test Problems by Electronic Mail. J. Oper. Res. Soc. 1990, 41, 1069–1072. [Google Scholar] [CrossRef]
- Beasley, J.E. OR-Library. 2004. Available online: http://people.brunel.ac.uk/~mastjjb/jeb/orlib/files (accessed on 22 September 2021).
- Beasley, J.E. Heuristic Algorithms for the Unconstrained Binary Quadratic Programming Problem; Technical report; The Management School, Imperial College: London, UK, 1998. [Google Scholar]
- Wiegele, A. Biq Mac Library—A Collection of Max-Cut and Quadratic 0-1 Programming Instances of Medium Size; Technical report; Alpen-Adria-Universität Klagenfurt, Institut für Mathematik, Universitätsstr: Klagenfurt, Austria, 2007. [Google Scholar]
- Helmberg, C.; Rendl, F. A Spectral Bundle Method for Semidefinite Programming. SIAM J. Optim. 2000, 10, 673–696. [Google Scholar] [CrossRef]
- Ye, Y. Gset. 2003. Available online: https://web.stanford.edu/~yyye/yyye/Gset (accessed on 22 September 2021).
- Burer, S.; Monteiro, R.D.C.; Zhang, Y. Rank-Two Relaxation Heuristics for MAX-CUT and Other Binary Quadratic Programs. SIAM J. Optim. 2002, 12, 503–521. [Google Scholar] [CrossRef] [Green Version]
- Martí; Duarte; Laguna. Maxcut Problem. 2009. Available online: http://grafo.etsii.urjc.es/optsicom/maxcut/set2.zip (accessed on 22 September 2021).
- Kochenberger, G.A.; Hao, J.K.; Lü, Z.; Wang, H.; Glover, F.W. Solving large scale Max Cut problems via tabu search. J. Heuristics 2013, 19, 565–571. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Lü, Z.; Glover, F.; Hao, J.K. Probabilistic GRASP-Tabu Search algorithms for the UBQP problem. Comput. Oper. Res. 2013, 40, 3100–3107. [Google Scholar] [CrossRef] [Green Version]
- Palubeckis, G.; Krivickienė, V. Application of Multistart Tabu Search to the Max-Cut Problem. Inf. Technol. Control 2004, 31, 29–35. [Google Scholar]
- Boros, E.; Hammer, P.L.; Sun, R.; Tavares, G. A max-flow approach to improved lower bounds for quadratic unconstrained binary optimization (QUBO). Discret. Optim. 2008, 5, 501–529, In Memory of George B. Dantzig. [Google Scholar] [CrossRef] [Green Version]
- JASP Team. JASP, Version 0.16; Computer software; JASP Team. 2021. Available online: https://jasp-stats.org/faq/ (accessed on 6 May 2022).
- Kalatzantonakis, P.; Sifaleras, A.; Samaras, N. Cooperative versus non-cooperative parallel variable neighborhood search strategies: A case study on the capacitated vehicle routing problem. J. Glob. Optim. 2020, 78, 327–348. [Google Scholar] [CrossRef]

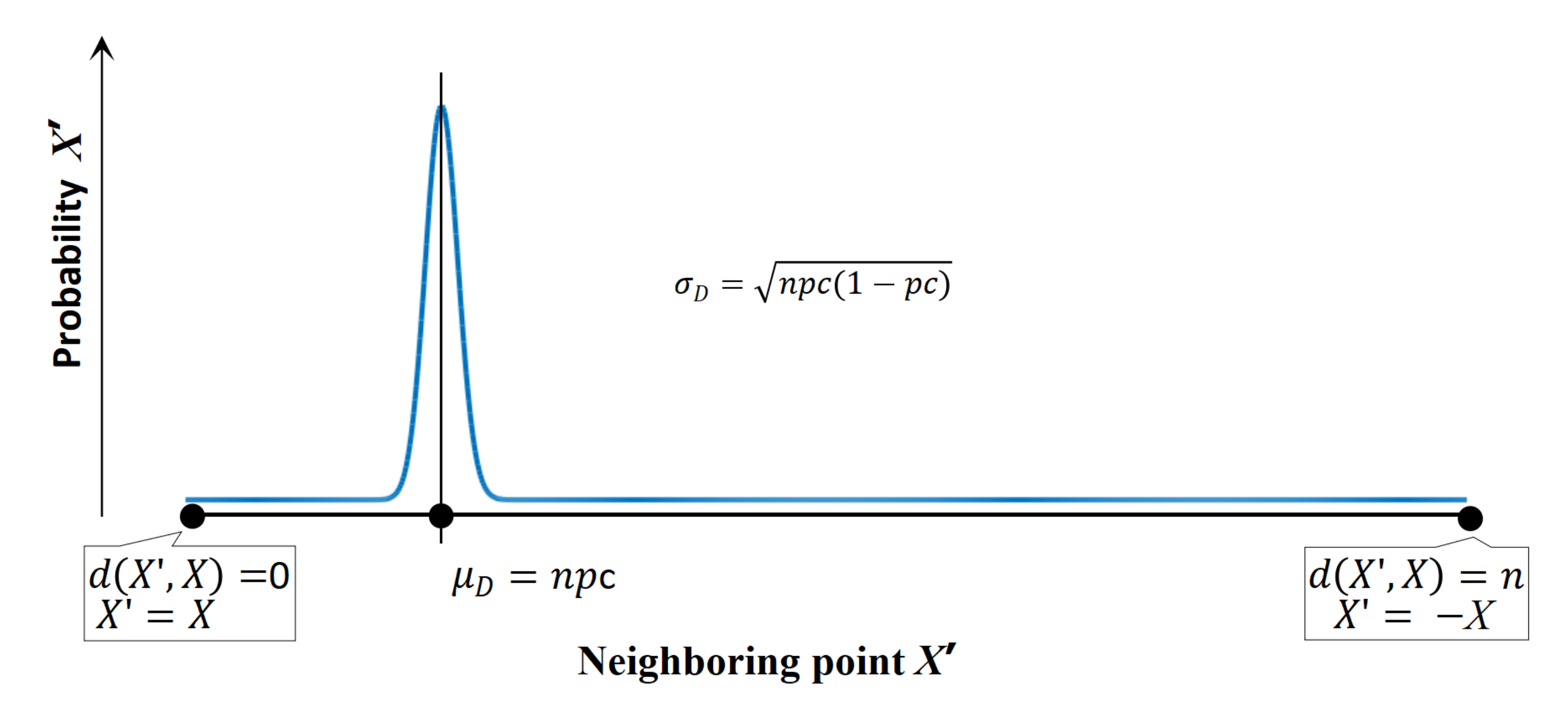



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Problem Number | n | Best Known | VNS | B-VNS | Test (p-Value) * | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| BestDif | AvgDif | Time ** | BestDif | AvgDif | Time ** | Dif | Time | |||
| 1a | 50 | 3414 | 0 | 1.667 | 0.003 | 0 | 1 | 0.003 | 0.459 | *** |
| 2a | 60 | 6063 | 0 | 0 | 0.012 | 0 | 0 | 0.011 | - | 0.006 |
| 3a | 70 | 6037 | 0 | 8.9 | 0.017 | 0 | 11.467 | 0.016 | 0.773 | *** |
| 4a | 80 | 8598 | 0 | 0 | 0.035 | 0 | 0 | 0.030 | - | 0.009 |
| 5a | 50 | 5737 | 0 | 0 | 0.004 | 0 | 3.867 | 0.003 | - | 0.041 |
| 6a | 30 | 3980 | 0 | 0 | *** | 0 | 0 | *** | - | *** |
| 7a | 30 | 4541 | 0 | 0 | *** | 0 | 0 | *** | - | *** |
| 8a | 100 | 11,109 | 0 | 1.467 | 0.128 | 0 | 0 | 0.121 | - | *** |
| 1b | 40 | 133 | 0 | 18.033 | *** | 0 | 21 | *** | 0.512 | - |
| 2b | 50 | 121 | 0 | 0.733 | *** | 0 | 2.667 | *** | 0.096 | *** |
| 3b | 60 | 118 | 0 | 4.667 | 0.001 | 0 | 8.533 | 0.001 | 0.065 | 0.401 |
| 4b | 70 | 129 | 0 | 13.867 | 0.004 | 0 | 18.733 | 0.003 | 0.112 | 0.005 |
| 5b | 80 | 150 | 0 | 0 | 0.012 | 0 | 0 | 0.011 | - | *** |
| 6b | 90 | 146 | 13 | 35.933 | 0.021 | 13 | 37.833 | 0.016 | 0.277 | *** |
| 7b | 80 | 160 | 0 | 0 | 0.027 | 0 | 2.533 | 0.025 | - | *** |
| 8b | 90 | 145 | 0 | 6.633 | 0.062 | 0 | 5.433 | 0.053 | 0.307 | *** |
| 9b | 100 | 137 | 0 | 2 | 0.156 | 0 | 2.433 | 0.141 | 1 | *** |
| 10b | 125 | 154 | 0 | 0.233 | 0.467 | 0 | 0.233 | 0.414 | 1 | *** |
| 1c | 40 | 5058 | 0 | 0 | 0.001 | 0 | 0 | 0.001 | - | 0.507 |
| 2c | 50 | 6213 | 0 | 0 | 0.003 | 0 | 0 | 0.003 | - | 0.107 |
| 3c | 60 | 6665 | 0 | 0 | 0.015 | 0 | 0 | 0.013 | - | 0.003 |
| 4c | 70 | 7398 | 0 | 0 | 0.020 | 0 | 0 | 0.017 | - | *** |
| 5c | 80 | 7362 | 0 | 0.867 | 0.035 | 0 | 0 | 0.028 | - | *** |
| 6c | 90 | 5824 | 0 | 27.467 | 0.048 | 0 | 21.167 | 0.047 | 0.186 | 0.043 |
| 7c | 100 | 7225 | 0 | 0 | 0.134 | 0 | 0 | 0.123 | - | *** |
| 1d | 100 | 6333 | 0 | 16.9 | 0.135 | 0 | 13.733 | 0.129 | 0.583 | 0.006 |
| 2d | 100 | 6579 | 0 | 31.967 | 0.152 | 0 | 19.633 | 0.145 | 0.214 | 0.022 |
| 3d | 100 | 9261 | 0 | 14.567 | 0.157 | 0 | 16.067 | 0.144 | 0.658 | *** |
| 4d | 100 | 10,727 | 0 | 5.367 | 0.166 | 0 | 9.067 | 0.151 | 0.056 | *** |
| 5d | 100 | 11,626 | 0 | 11.633 | 0.179 | 0 | 14.7 | 0.166 | 0.471 | 0.001 |
| 6d | 100 | 14,207 | 0 | 5 | 0.171 | 0 | 1.667 | 0.155 | 0.313 | *** |
| 7d | 100 | 14,476 | 0 | 8.9 | 0.194 | 0 | 7.733 | 0.173 | 0.763 | *** |
| 8d | 100 | 16,352 | 0 | 0 | 0.176 | 0 | 0 | 0.162 | - | *** |
| 9d | 100 | 15,656 | 0 | 1.13 | 0.180 | 0 | 0.3 | 0.164 | 0.305 | *** |
| 10d | 100 | 19,102 | 0 | 0 | 0.184 | 0 | 0 | 0.170 | - | *** |
| 1e | 200 | 16,464 | 0 | 12.833 | 4.689 | 0 | 11.767 | 4.237 | 0.576 | *** |
| 2e | 200 | 23,395 | 0 | 8 | 5.635 | 0 | 7.067 | 5.232 | 0.579 | 0.001 |
| 3e | 200 | 25,243 | 0 | 0 | 6.172 | 0 | 0 | 5.731 | - | *** |
| 4e | 200 | 35,594 | 0 | 0.533 | 5.071 | 0 | 0.533 | 4.697 | 1 | *** |
| 5e | 200 | 35,154 | 0 | 20.33 | 5.995 | 0 | 31.233 | 5.924 | 0.127 | 0.264 |
| 1f | 500 | 61,194 | 0 | 2 | 578.194 | 0 | 1.2 | 559.644 | 0.679 | 0.004 |
| 2f | 500 | 100,161 | 0 | 0.1 | 545.884 | 0 | 0.2 | 521.028 | 0.570 | *** |
| 3f | 500 | 138,035 | 0 | 38.967 | 521.415 | 0 | 37.9 | 521.502 | 0.594 | 0.971 |
| 4f | 500 | 172,771 | 0 | 33.6 | 440.721 | 0 | 18 | 450.550 | 0.354 | 0.050 |
| 5f | 500 | 190,507 | 0 | 2.833 | 499.021 | 0 | 3.3 | 511.853 | 0.513 | 0.04 |
| n | Problem Number | Best Known | VNS | B-VNS | Test (p-Value) * | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| BestDif | AvgDif | Time ** | BestDif | AvgDif | Time ** | Dif | Time | |||
| 50 | 1 | 2098 | 68 | 127.3 | 0.003 | 0 | 93.867 | 0.003 | 0.062 | 0.305 |
| 2 | 3702 | 0 | 15 | 0.003 | 0 | 22.967 | 0.003 | 0.497 | 0.006 | |
| 3 | 4626 | 0 | 11.367 | 0.003 | 0 | 19 | 0.003 | 0.248 | 0.025 | |
| 4 | 3544 | 0 | 21.533 | 0.003 | 0 | 19.733 | 0.003 | 0.863 | 0.006 | |
| 5 | 4012 | 0 | 10.667 | 0.003 | 0 | 2.933 | 0.003 | 0.170 | 0.677 | |
| 6 | 3693 | 0 | 1.933 | 0.003 | 0 | 2.9 | 0.003 | 0.654 | 0.190 | |
| 7 | 4520 | 0 | 4.6 | 0.003 | 0 | 4.867 | 0.003 | 0.288 | 0.031 | |
| 8 | 4216 | 0 | 18 | 0.003 | 0 | 7.333 | 0.003 | 0.117 | - | |
| 9 | 3780 | 0 | 19.367 | 0.005 | 0 | 20.267 | 0.003 | 0.887 | *** | |
| 10 | 3507 | 0 | 27.733 | 0.005 | 0 | 32.867 | 0.003 | 0.602 | *** | |
| 100 | 1 | 7970 | 42 | 150.867 | 0.080 | 0 | 173.133 | 0.076 | 0.163 | 0.034 |
| 2 | 11,036 | 0 | 15.333 | 0.083 | 0 | 19.333 | 0.078 | 0.732 | 0.001 | |
| 3 | 12,723 | 0 | 0 | 0.071 | 0 | 0 | 0.068 | - | 0.039 | |
| 4 | 10,368 | 0 | 8.333 | 0.078 | 0 | 11.533 | 0.072 | 0.984 | *** | |
| 5 | 9083 | 0 | 44.467 | 0.085 | 0 | 49.167 | 0.079 | 0.682 | 0.006 | |
| 6 | 10,210 | 0 | 2.067 | 0.088 | 0 | 4.767 | 0.080 | 0.910 | 0.006 | |
| 7 | 10,125 | 0 | 24.467 | 0.082 | 0 | 26.533 | 0.072 | 0.770 | *** | |
| 8 | 11,435 | 0 | 8.867 | 0.079 | 0 | 9 | 0.077 | 0.820 | 0.139 | |
| 9 | 11,455 | 0 | 0.6 | 0.081 | 0 | 0.6 | 0.075 | 1 | 0.004 | |
| 10 | 12,565 | 0 | 18.667 | 0.078 | 0 | 12.933 | 0.069 | 0.247 | *** | |
| 250 | 1 | 45,607 | 0 | 8 | 11.873 | 0 | 10.133 | 10.890 | 0.458 | *** |
| 2 | 44,810 | 0 | 59.267 | 12.123 | 0 | 45.033 | 11.429 | 0.147 | 0.005 | |
| 3 | 49,037 | 0 | 0 | 8.996 | 0 | 0 | 8.662 | - | 0.045 | |
| 4 | 41,274 | 0 | 20.6 | 10.539 | 0 | 33.133 | 9.743 | 0.067 | *** | |
| 5 | 47,961 | 0 | 15.933 | 9.672 | 0 | 10.933 | 8.808 | 0.611 | *** | |
| 6 | 41,014 | 0 | 8.6 | 11.766 | 0 | 11.5 | 10.973 | 0.876 | *** | |
| 7 | 46,757 | 0 | 0 | 10.624 | 0 | 0 | 10.191 | - | 0.050 | |
| 8 | 35,726 | 52 | 214.200 | 13.311 | 0 | 177 | 12.196 | 0.297 | *** | |
| 9 | 48,916 | 0 | 23.100 | 11.330 | 0 | 27.233 | 10.341 | 0.433 | *** | |
| 10 | 40,442 | 0 | 3.533 | 12.526 | 0 | 2.2 | 11.211 | 0.688 | *** | |
| 500 | 1 | 116,586 | 0 | 5.333 | 586.406 | 0 | 6.267 | 592.798 | 0.677 | 0.398 |
| 2 | 128,339 | 0 | 2.5 | 459.926 | 0 | 4.4 | 455.013 | 0.402 | 0.374 | |
| 3 | 130,812 | 0 | 0 | 501.773 | 0 | 0 | 496.806 | - | 0.432 | |
| 4 | 130,097 | 0 | 28.933 | 518.133 | 0 | 26.733 | 523.351 | 0.486 | 0.321 | |
| 5 | 125,487 | 0 | 10.4 | 521.381 | 0 | 2.6 | 516.252 | 0.380 | 0.300 | |
| Graph | Problem | n | Best Known | VNS | B-VNS | Test (p-Value) * | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| BestDif | AvgDif | Time ** | BestDif | AvgDif | Time ** | Dif | Time | ||||
| Random | G1 | 800 | 11624 | 0 | 0.033 | 180.13 | 0 | 2.533 | 158.702 | *** | *** |
| G2 | 800 | 11620 | 0 | 7.133 | 185.804 | 0 | 6.8 | 162.854 | 0.830 | *** | |
| G3 | 800 | 11622 | 0 | 1.733 | 195.169 | 0 | 2.833 | 172.003 | 0.222 | *** | |
| G4 | 800 | 11646 | 0 | 0.567 | 193.595 | 0 | 0.633 | 175.664 | 0.507 | *** | |
| G5 | 800 | 11631 | 0 | 5.133 | 191.32 | 0 | 4.433 | 169.104 | 0.654 | *** | |
| Random () | G6 | 800 | 2178 | 0 | 1.867 | 203.065 | 0 | 2.2 | 136.156 | 0.299 | *** |
| G7 | 800 | 2006 | 0 | 4.533 | 195.770 | 0 | 5.2 | 169.933 | 0.286 | *** | |
| G8 | 800 | 2005 | 0 | 3.4 | 154.650 | 0 | 2.733 | 164.133 | 0.845 | *** | |
| G9 | 800 | 2054 | 0 | 4.3 | 195.341 | 1 | 4.6 | 169.740 | 0.622 | *** | |
| G10 | 800 | 2000 | 0 | 3.2 | 160.173 | 0 | 2.333 | 141.589 | 0.191 | *** | |
| Toroidal | G11 | 800 | 564 | 14 | 25.267 | 66.274 | 20 | 27.733 | 44.726 | 0.001 | *** |
| G12 | 800 | 556 | 18 | 24.4 | 66.716 | 16 | 24.133 | 57.920 | 0.916 | *** | |
| G13 | 800 | 582 | 16 | 22.8 | 68.079 | 18 | 24.067 | 62.023 | 0.127 | *** | |
| Planar | G14 | 800 | 3064 | 29 | 37.733 | 78.656 | 32 | 39.6 | 69.983 | 0.087 | *** |
| G15 | 800 | 3050 | 31 | 38.633 | 77.195 | 32 | 39.867 | 67.350 | 0.179 | *** | |
| Random | G43 | 1000 | 6660 | 1 | 8.967 | 431.314 | 1 | 9.733 | 381.073 | 0.323 | *** |
| G44 | 1000 | 6650 | 3 | 8.467 | 428.178 | 2 | 9.533 | 375.822 | 0.114 | *** | |
| G45 | 1000 | 6654 | 0 | 12.067 | 425.304 | 1 | 11.033 | 374.124 | 0.445 | *** | |
| G46 | 1000 | 6654 | 9 | 16.1 | 410.047 | 5 | 16.633 | 373.864 | 0.494 | *** | |
| G47 | 1000 | 6654 | 9 | 20.433 | 415.607 | 13 | 20.267 | 370.332 | 0.472 | *** | |
| Planar | G51 | 1000 | 3846 | 39 | 47.433 | 194.891 | 39 | 49.533 | 192.633 | 0.070 | 0.007 |
| G52 | 1000 | 3849 | 41 | 49.1 | 126.208 | 42 | 50.033 | 110.035 | 0.265 | *** | |
| Problem | n | Best Known | VNS | B-VNS | Test (p-Value) * | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| BestDif | AvgDif | Time ** | BestDif | AvgDif | Time ** | Dif | Time | |||
| sg3dl052000 | 125 | 112 | 0 | 1.2 | 0.042 | 0 | 1.8 | 0.039 | 0.058 | *** |
| sg3dl054000 | 125 | 114 | 0 | 1.333 | 0.043 | 0 | 2.133 | 0.039 | 0.158 | *** |
| sg3dl056000 | 125 | 110 | 0 | 1.333 | 0.041 | 0 | 1.467 | 0.038 | 0.803 | *** |
| sg3dl058000 | 125 | 108 | 0 | 1.333 | 0.043 | 0 | 1.6 | 0.039 | 0.312 | *** |
| sg3dl0510000 | 125 | 112 | 0 | 3.267 | 0.042 | 0 | 2.4 | 0.039 | 0.030 | *** |
| sg3dl102000 | 1000 | 900 | 20 | 28.867 | 402.421 | 18 | 30.200 | 350.943 | 0.237 | *** |
| sg3dl104000 | 1000 | 896 | 18 | 28.667 | 431.393 | 20 | 28.733 | 351.443 | 0.928 | *** |
| sg3dl106000 | 1000 | 886 | 24 | 31.267 | 359.999 | 28 | 34.467 | 322.743 | 0.004 | *** |
| sg3dl108000 | 1000 | 880 | 16 | 26.867 | 380.613 | 20 | 28.600 | 311.638 | 0.058 | *** |
| sg3dl1010000 | 1000 | 890 | 18 | 28.800 | 390.797 | 20 | 29.733 | 354.691 | 0.397 | *** |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pambudi, D.; Kawamura, M. Constructing the Neighborhood Structure of VNS Based on Binomial Distribution for Solving QUBO Problems. Algorithms 2022, 15, 192. https://doi.org/10.3390/a15060192
Pambudi D, Kawamura M. Constructing the Neighborhood Structure of VNS Based on Binomial Distribution for Solving QUBO Problems. Algorithms. 2022; 15(6):192. https://doi.org/10.3390/a15060192
Chicago/Turabian StylePambudi, Dhidhi, and Masaki Kawamura. 2022. "Constructing the Neighborhood Structure of VNS Based on Binomial Distribution for Solving QUBO Problems" Algorithms 15, no. 6: 192. https://doi.org/10.3390/a15060192
APA StylePambudi, D., & Kawamura, M. (2022). Constructing the Neighborhood Structure of VNS Based on Binomial Distribution for Solving QUBO Problems. Algorithms, 15(6), 192. https://doi.org/10.3390/a15060192