
An Improved Multi-Label Learning Method with ELM-RBF and a Synergistic Adaptive Genetic Algorithm


Abstract
:1. Introduction
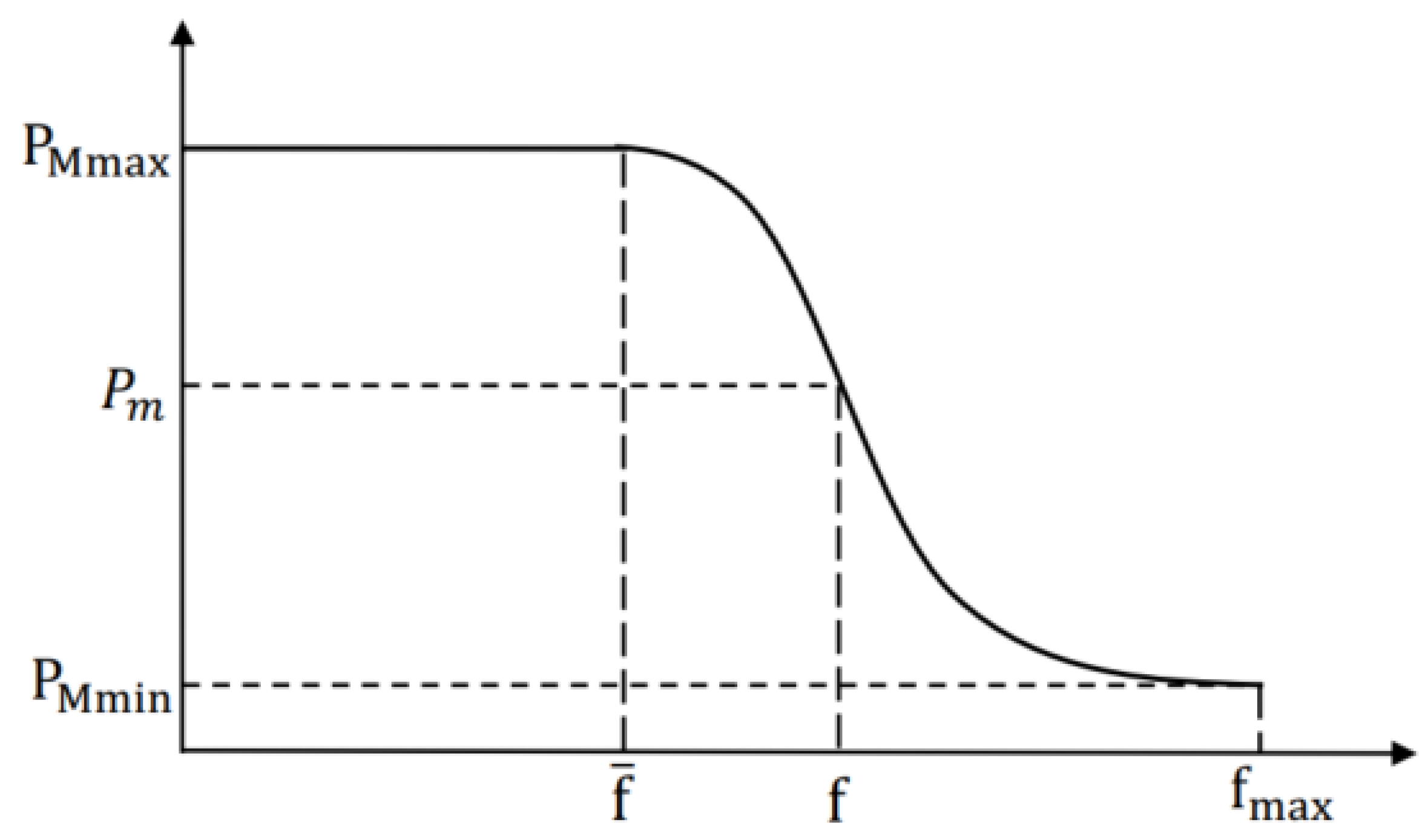
- To avoid falling into a local optimal solution, we present two adaptive optimization measures in SAGA. One is about adjusting the range of fitness value, which is used to maintain population diversity and provide adequate power for evolution. The other is mainly reflected in calculating the crossover and mutation probability, which are the two crucial factors in the optimization process.
- In order to promote the performance of ELM-RBF, we utilize SAGA presented in this paper to optimize ILW and HLB, and then propose a modified extreme learning model for multi-label classification, ELM-RBF-SAGA.
- Sufficient experiments have been carried out on several public datasets to verify model’s performance. Experimental results demonstrate that SAGA is very effective in optimizing ELM-RBF. In addition, ELM-RBF-SAGA has obvious advantages over comparing methods and is very suitable for multi-label classification.
2. Related Works
2.1. Original ELM and Kernel ELM
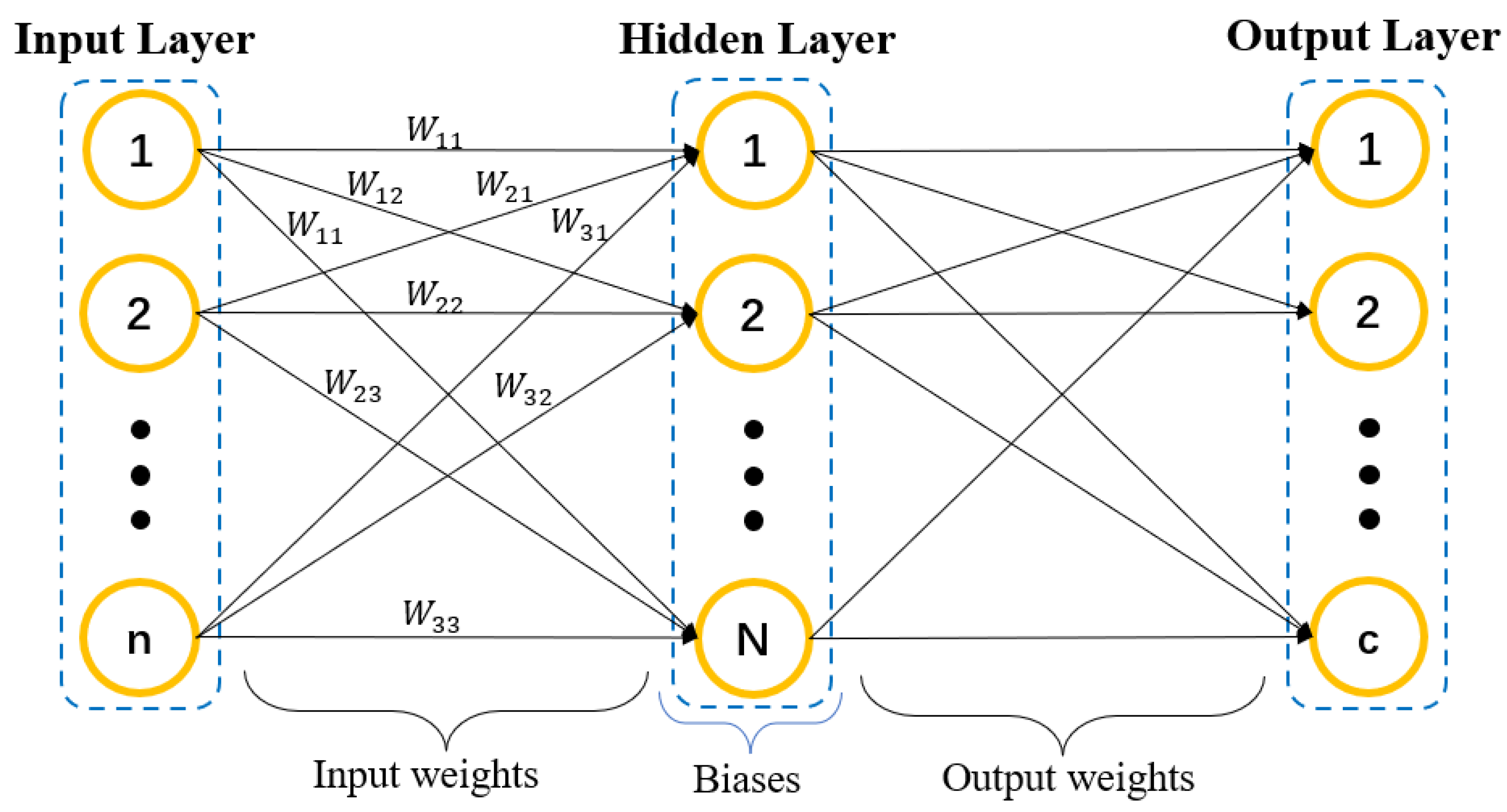
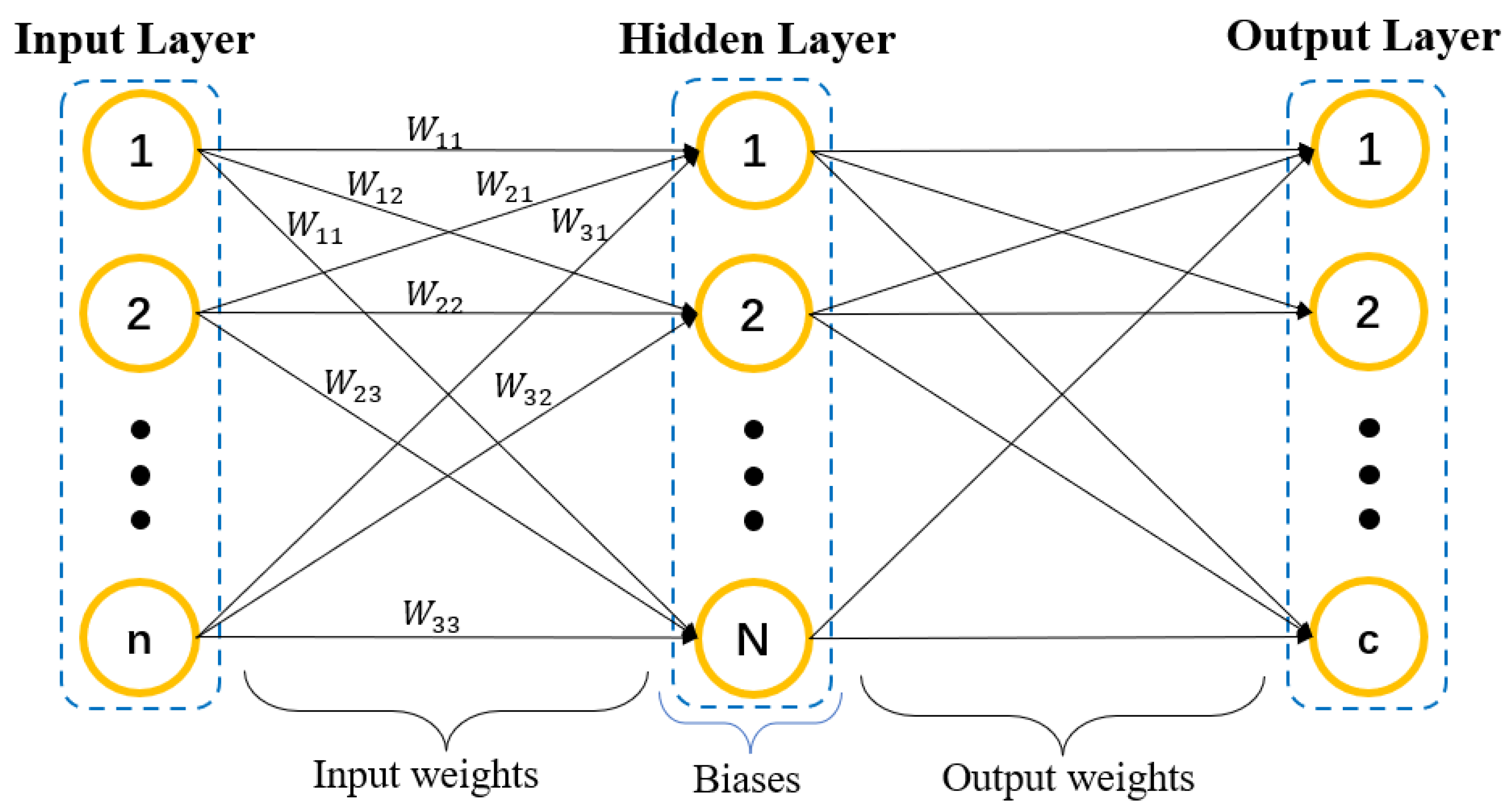
2.2. ELM-RBF
2.3. Genetic Algorithm
3. Methodology
3.1. Synergistic Adaptive Genetic Algorithm
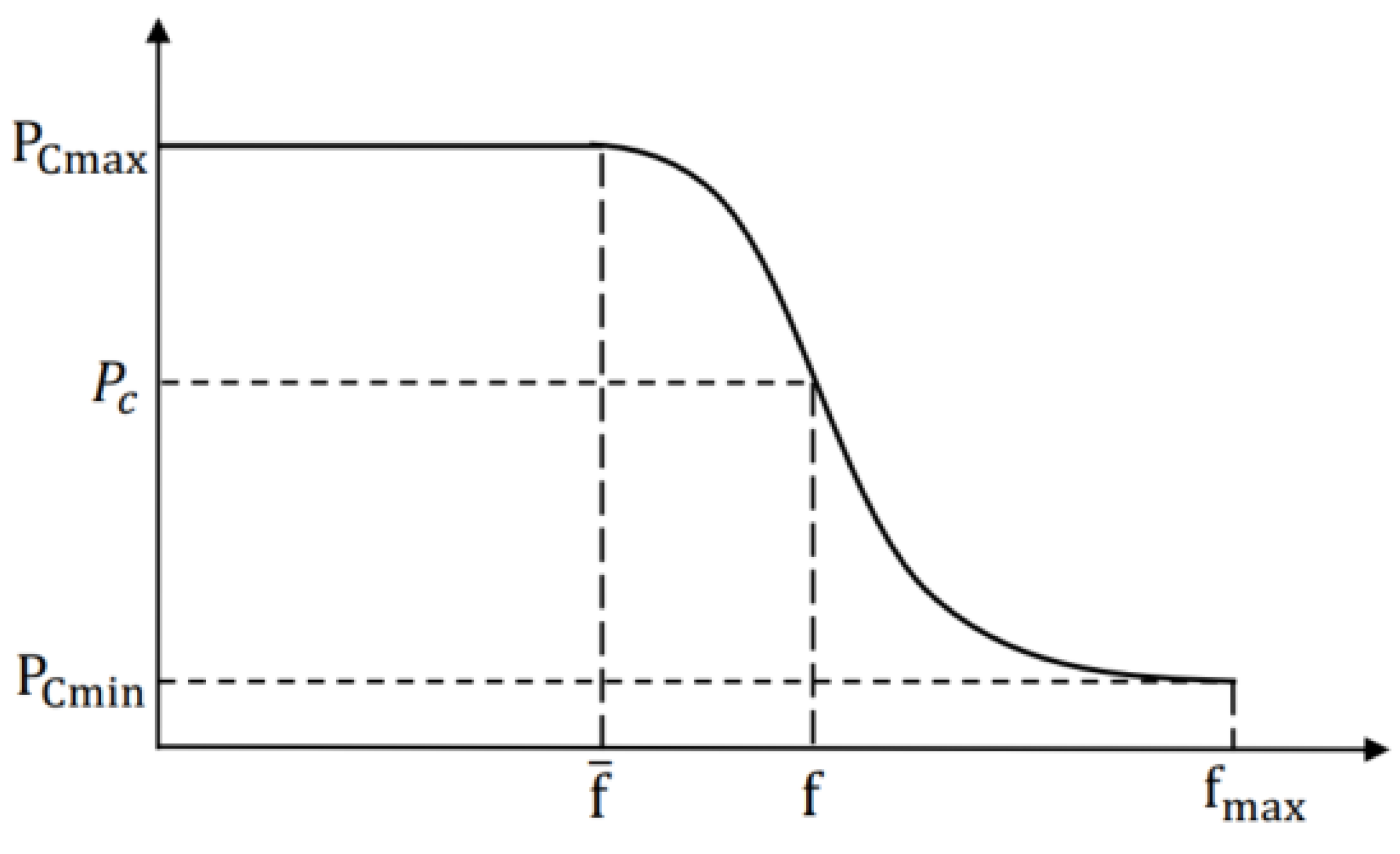
3.1.1. Maintaining the Population Diversity
3.1.2. Adaptive Probabilities of Crossover and Mutation
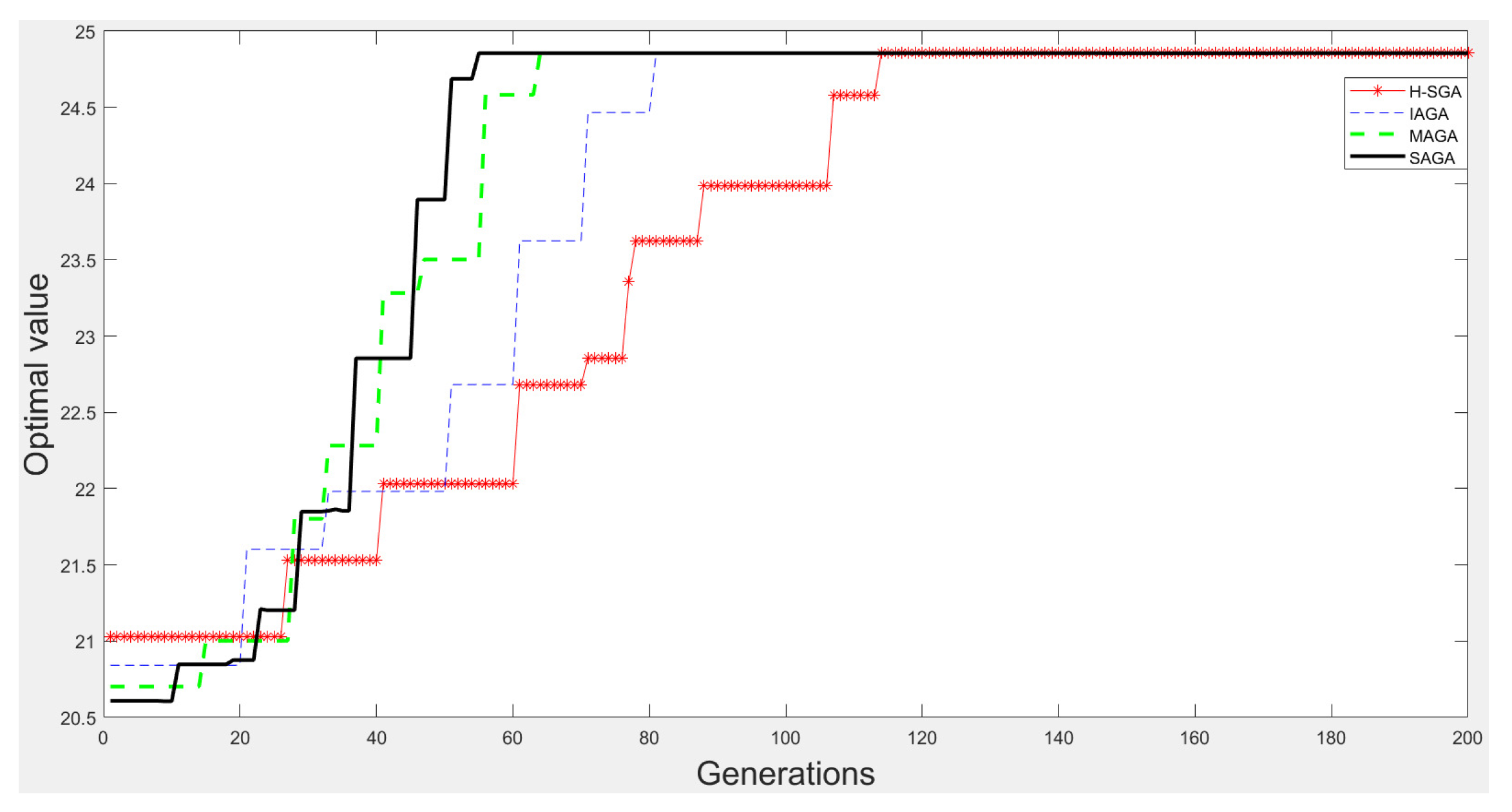
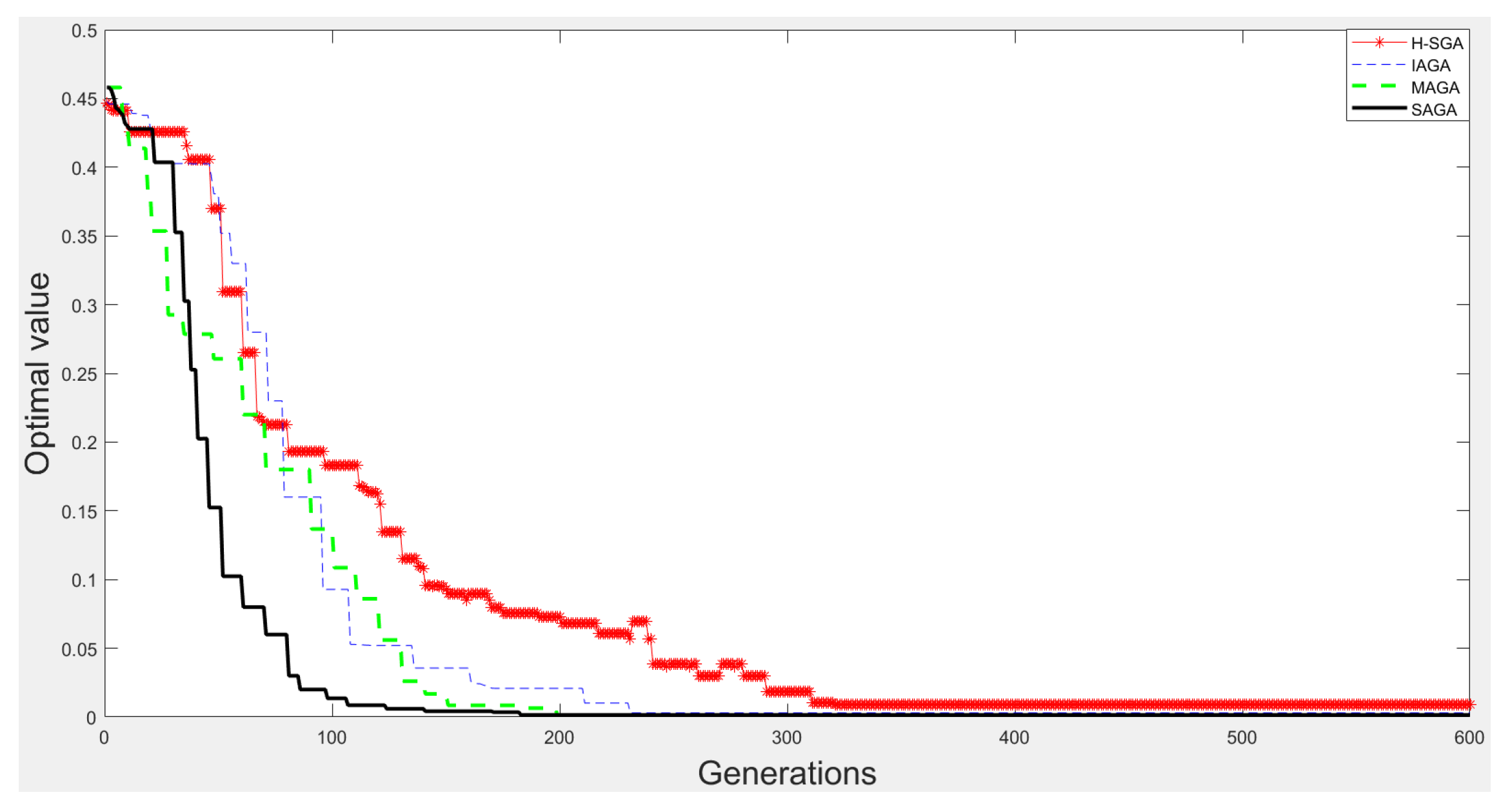
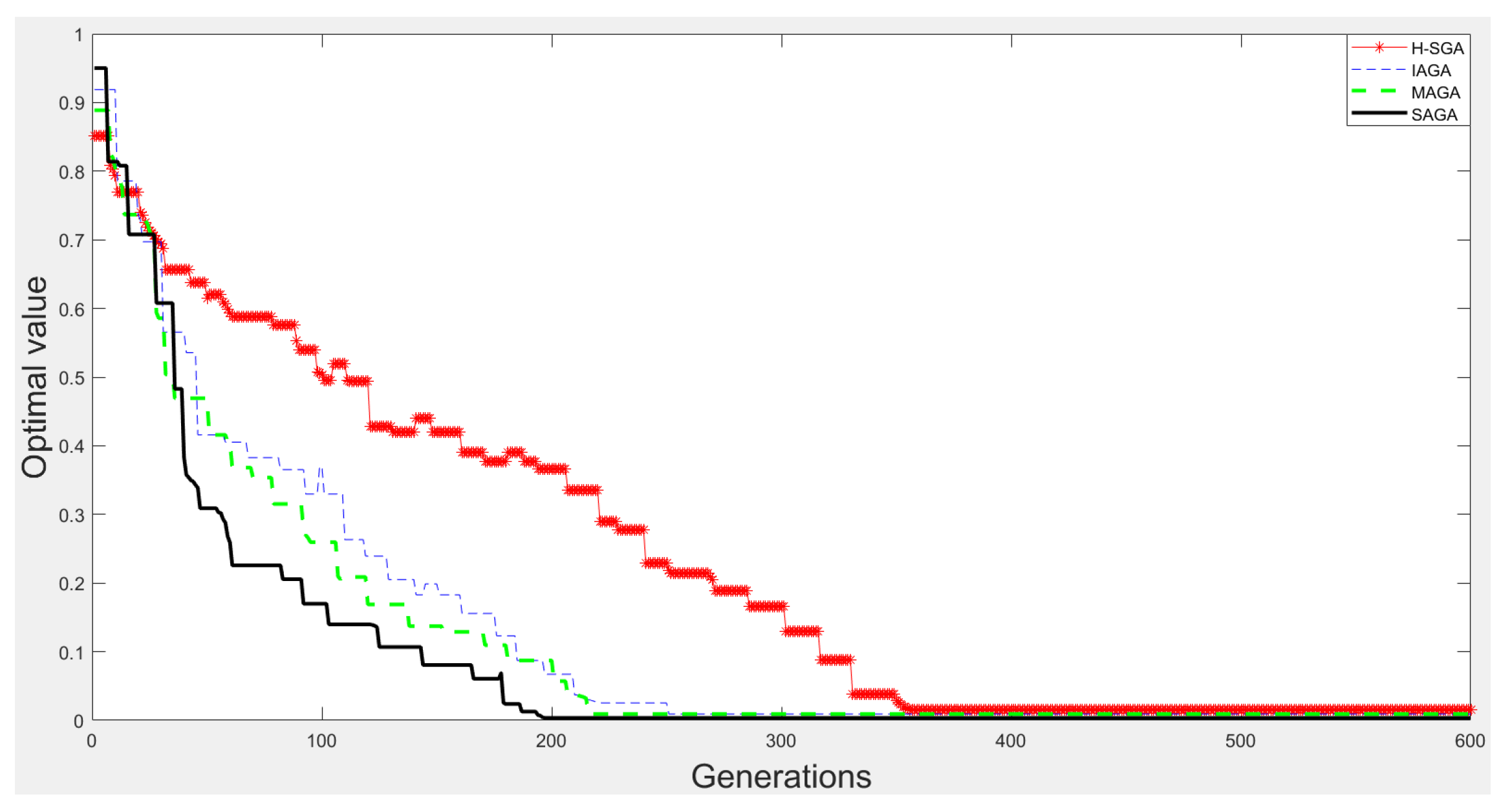
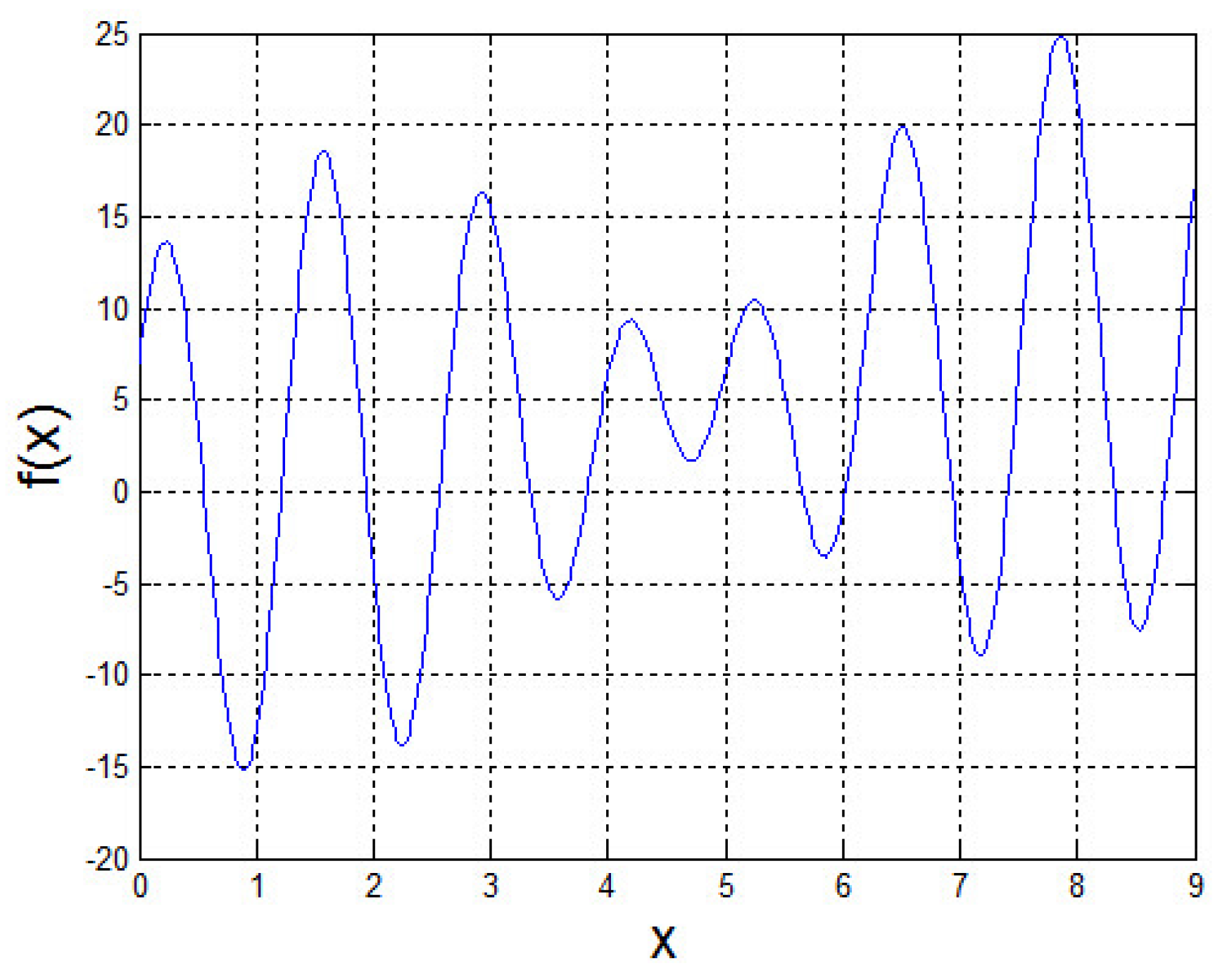
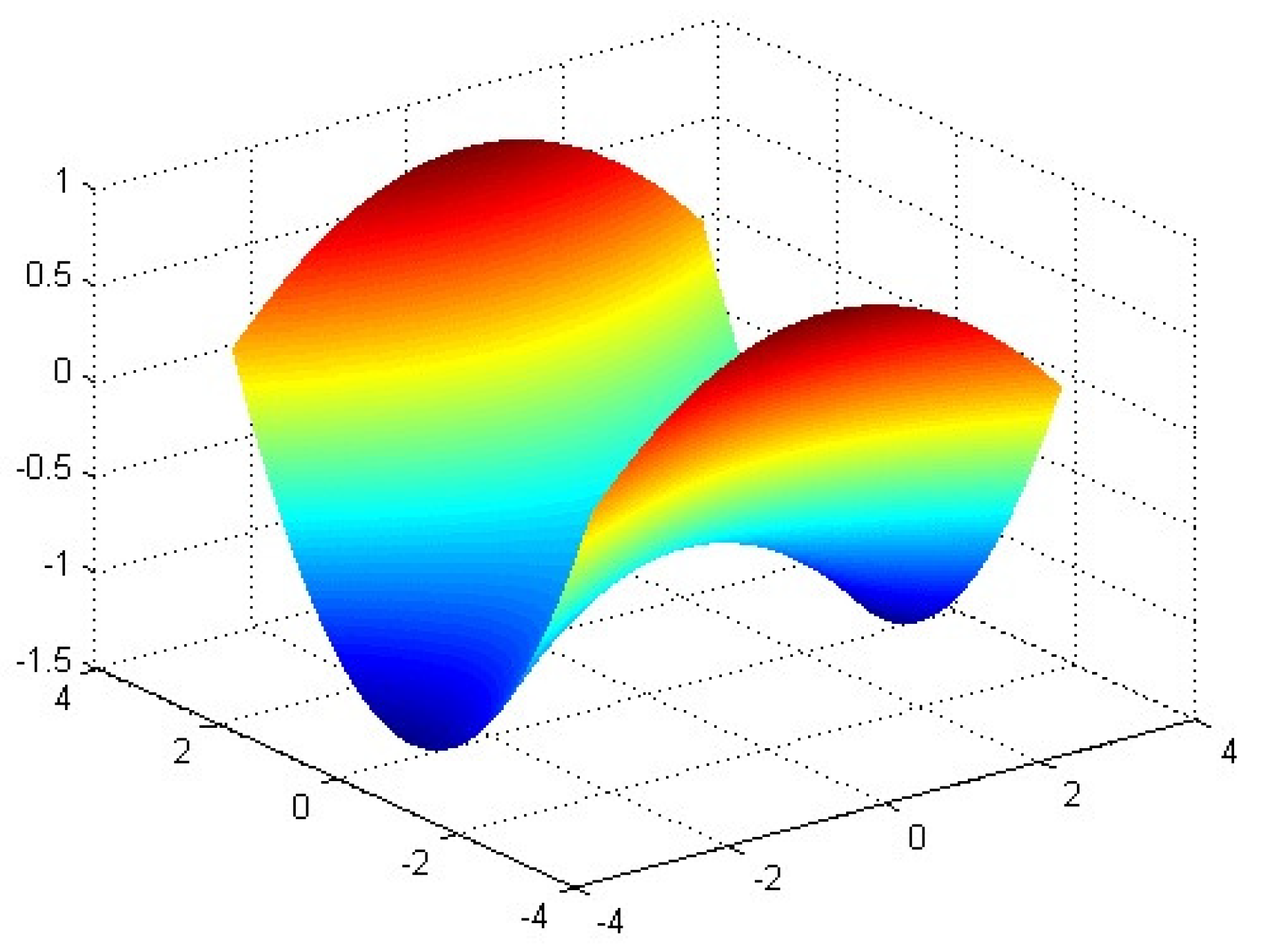
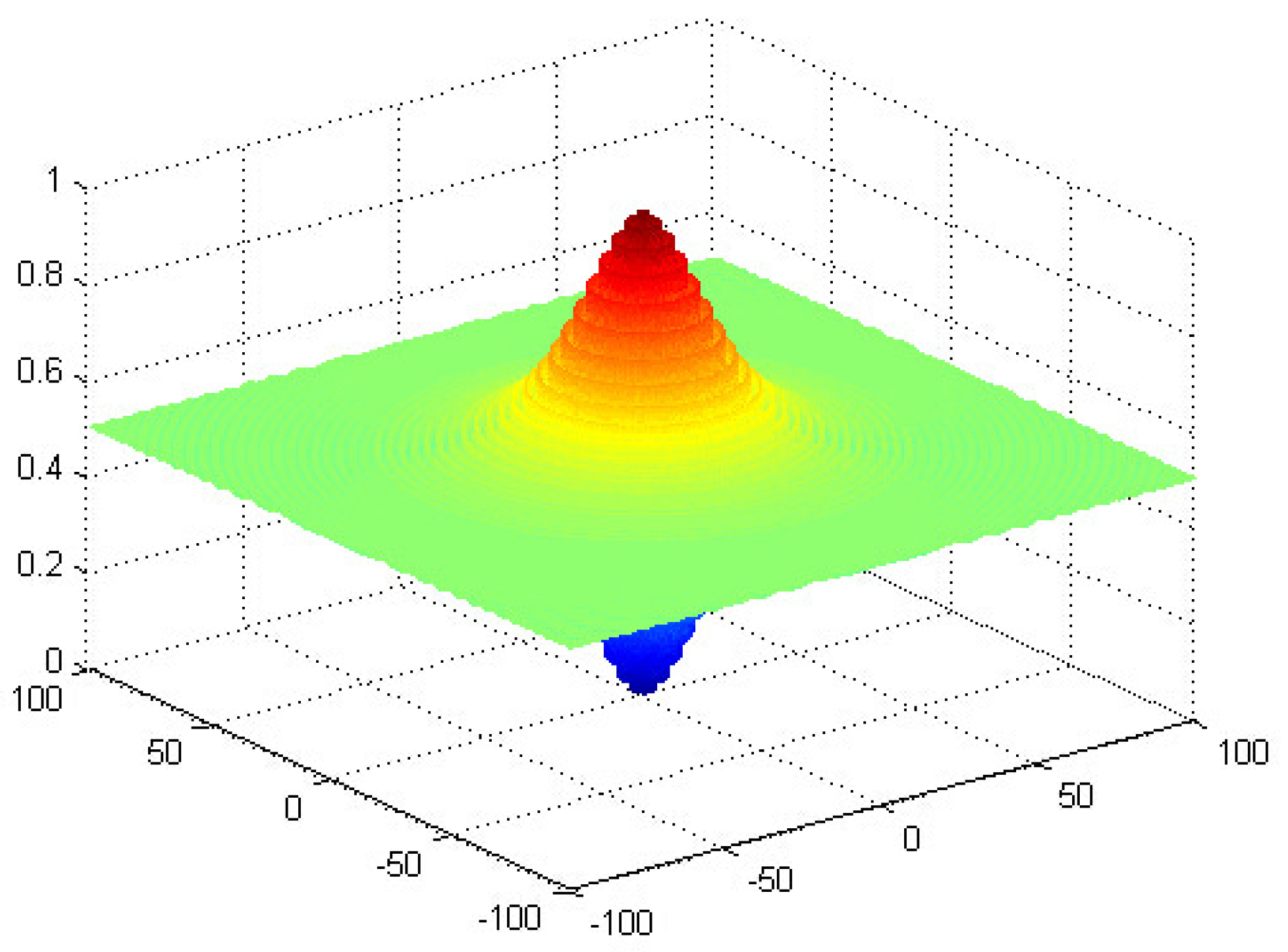
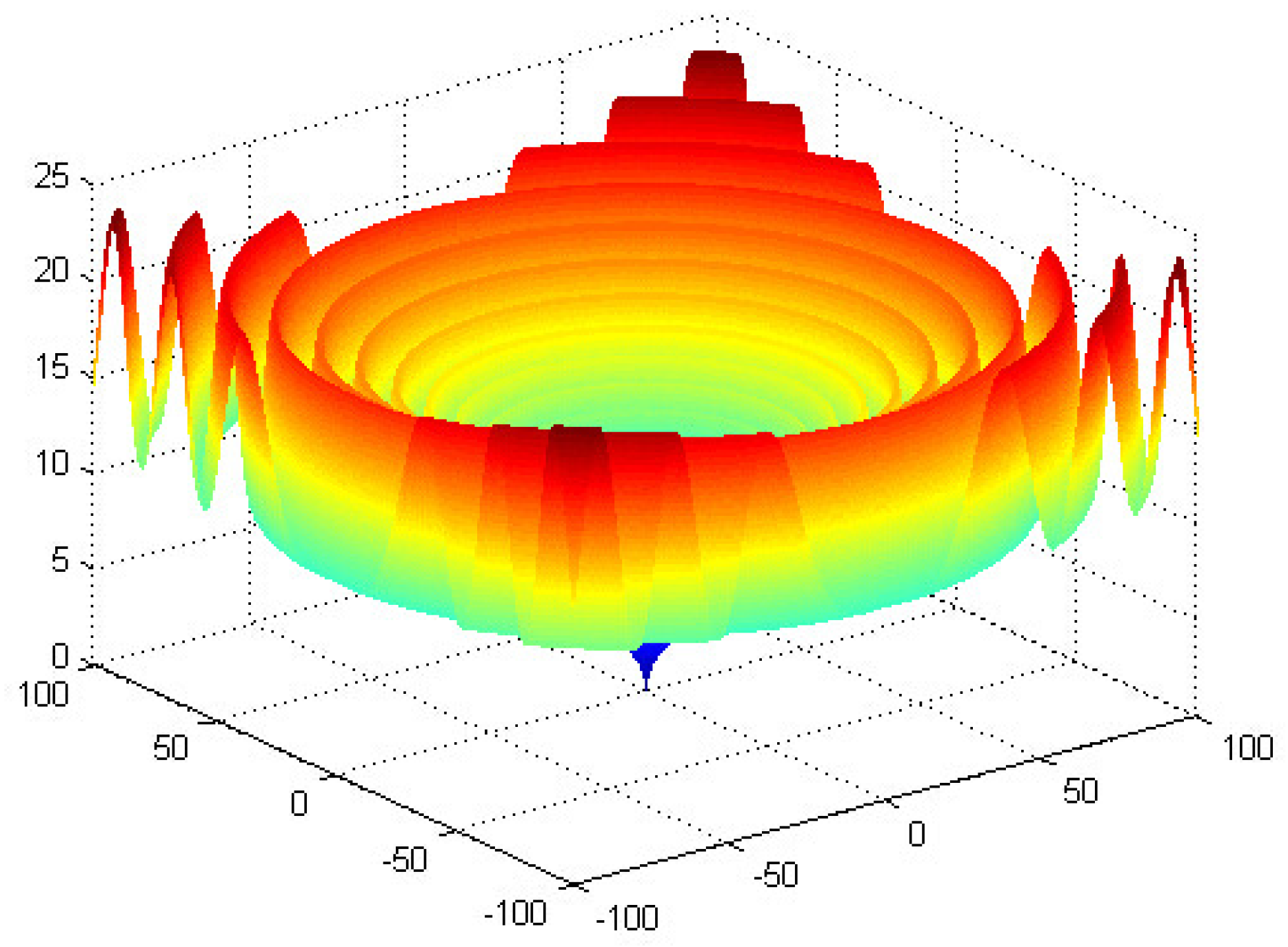
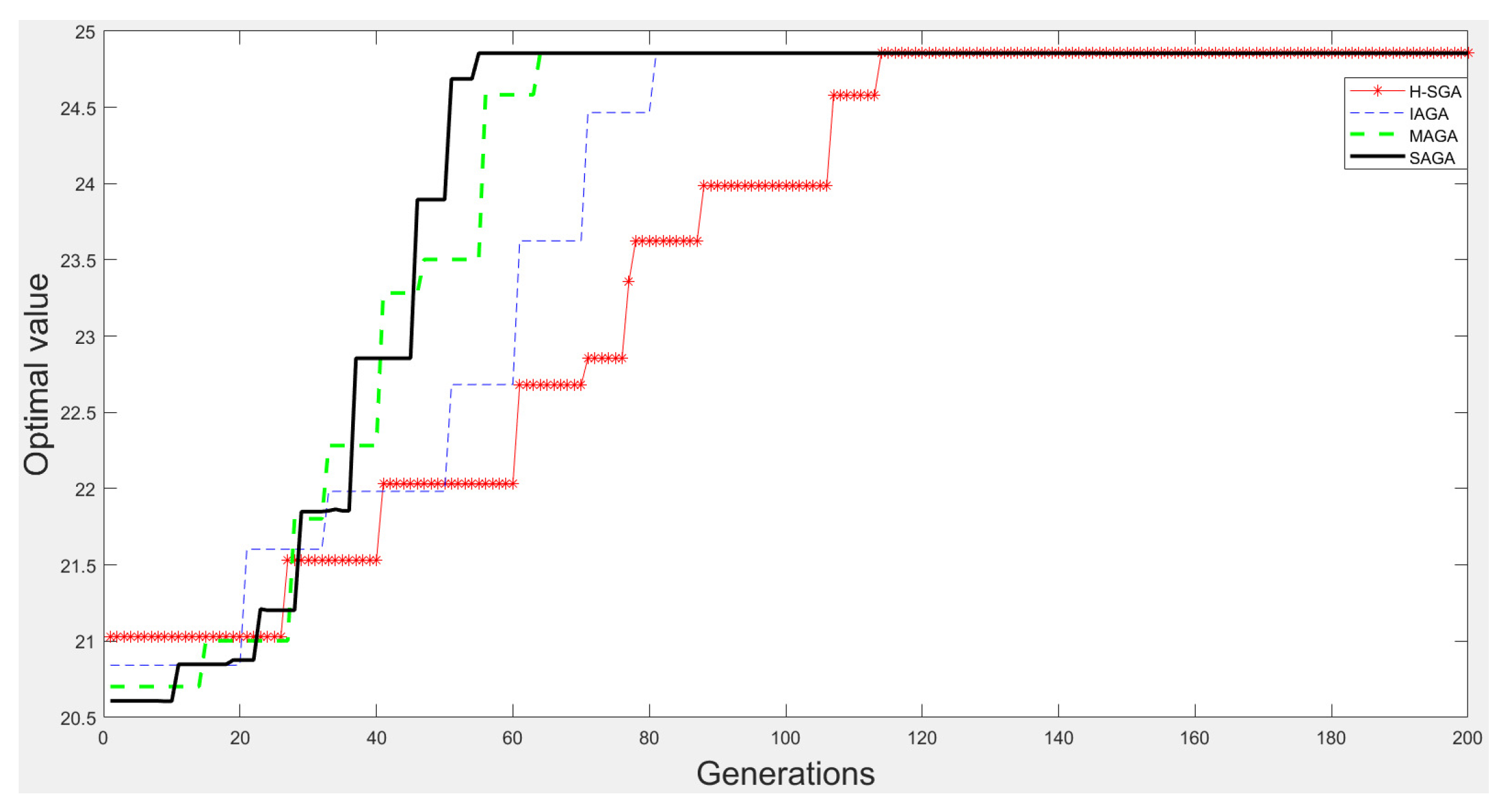
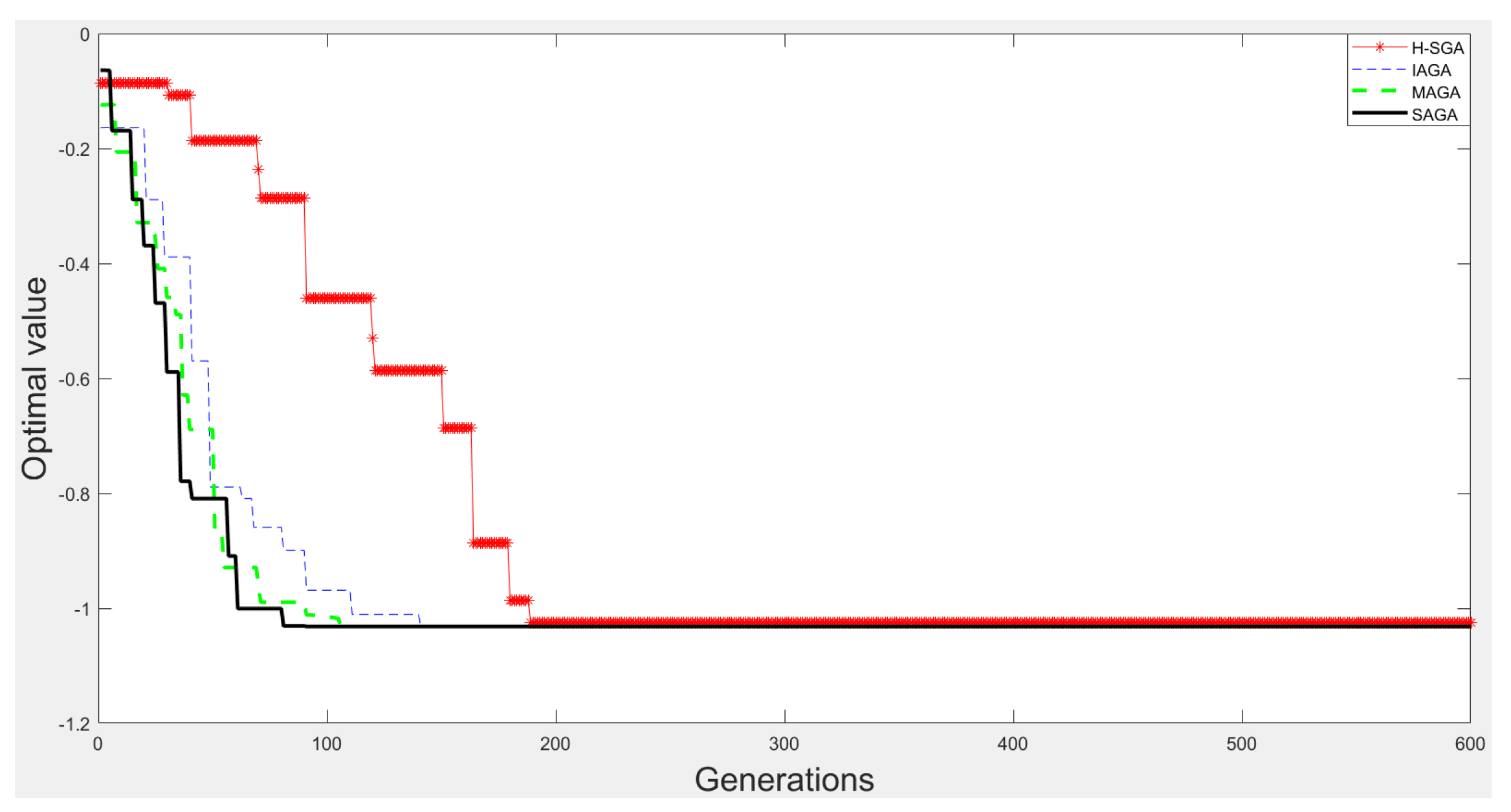
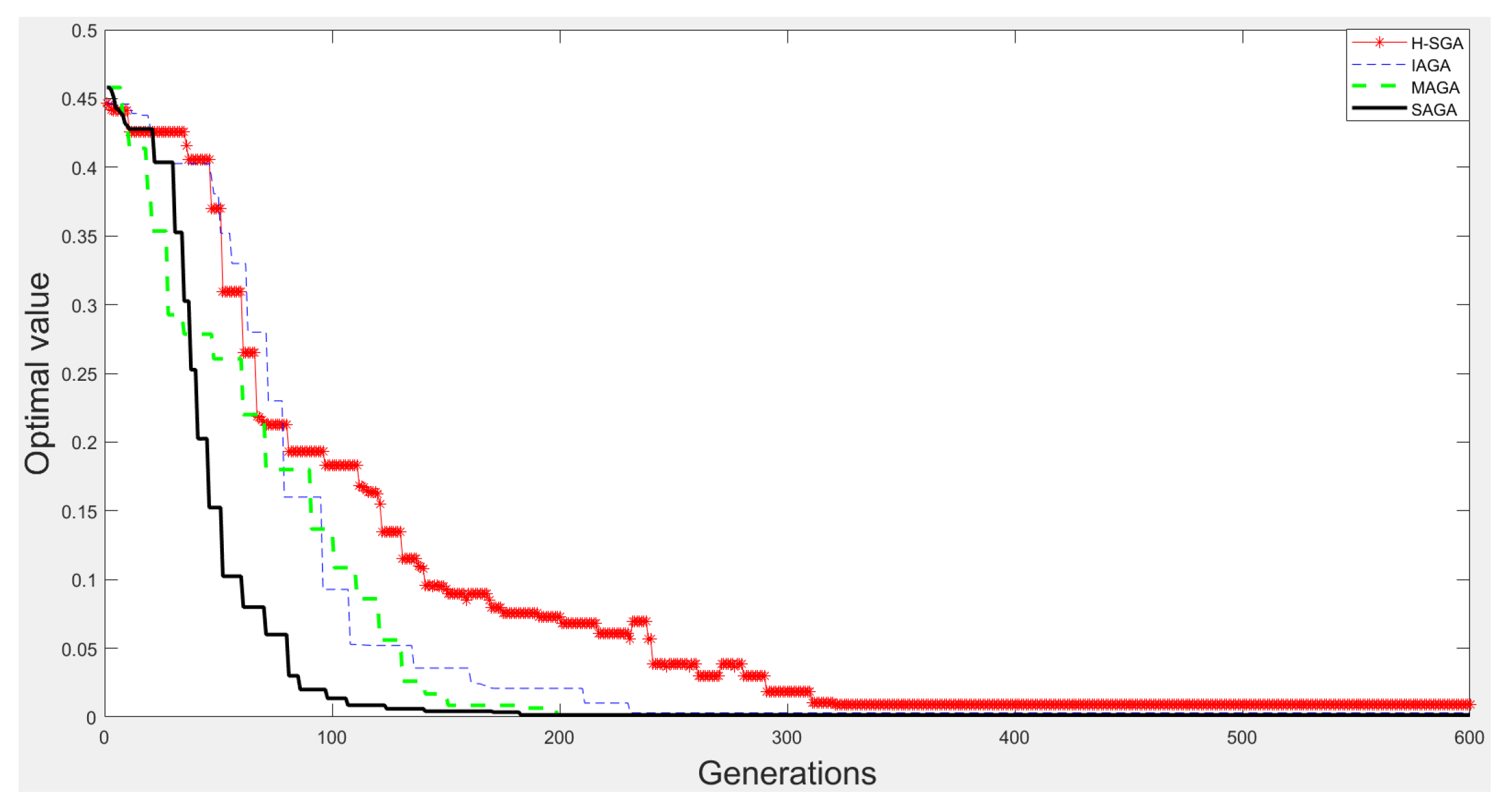
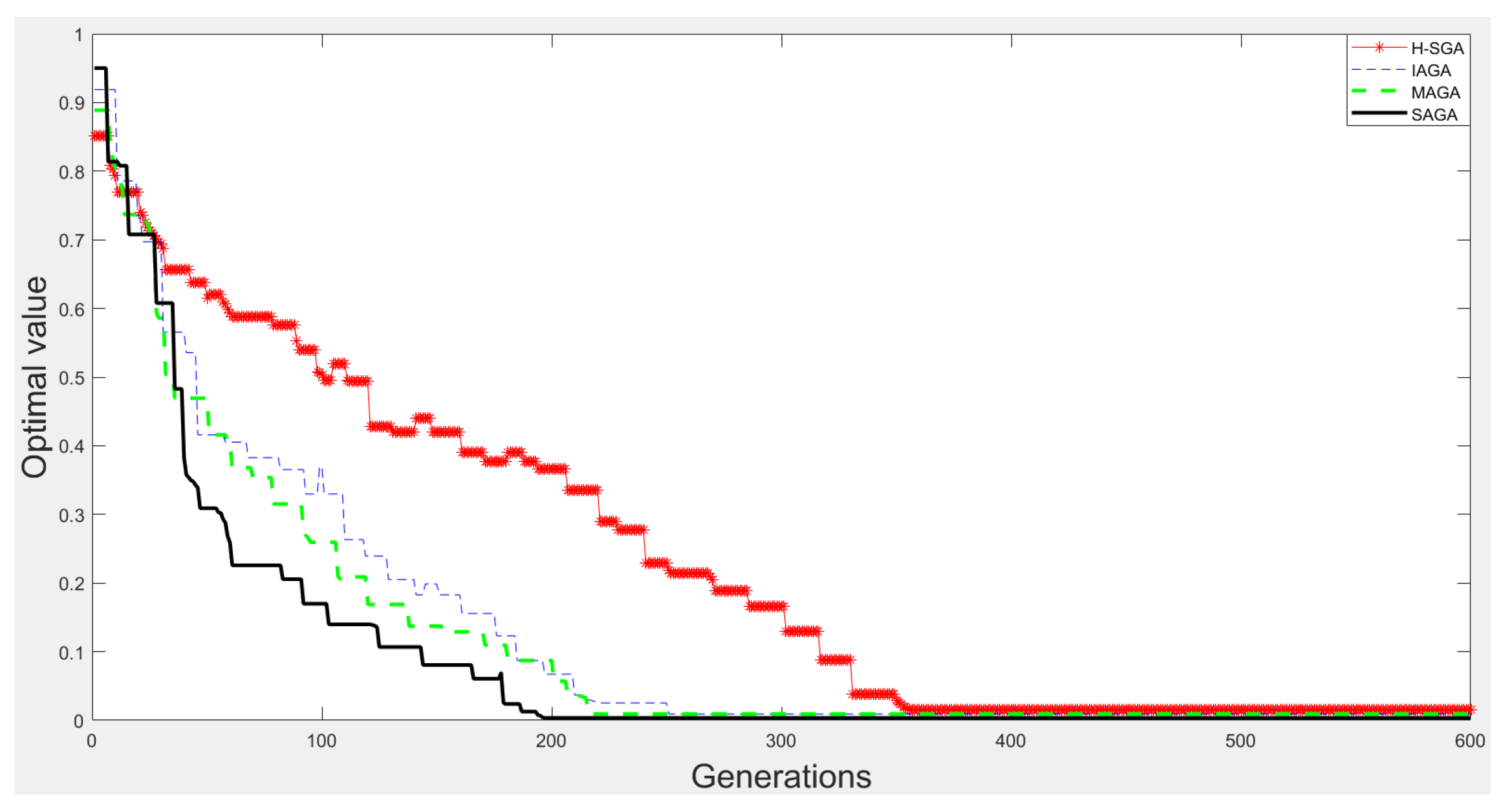
3.1.3. Optimization Experiments
3.2. ELM-RBF-SAGA
- Build ELM-RBF network model.
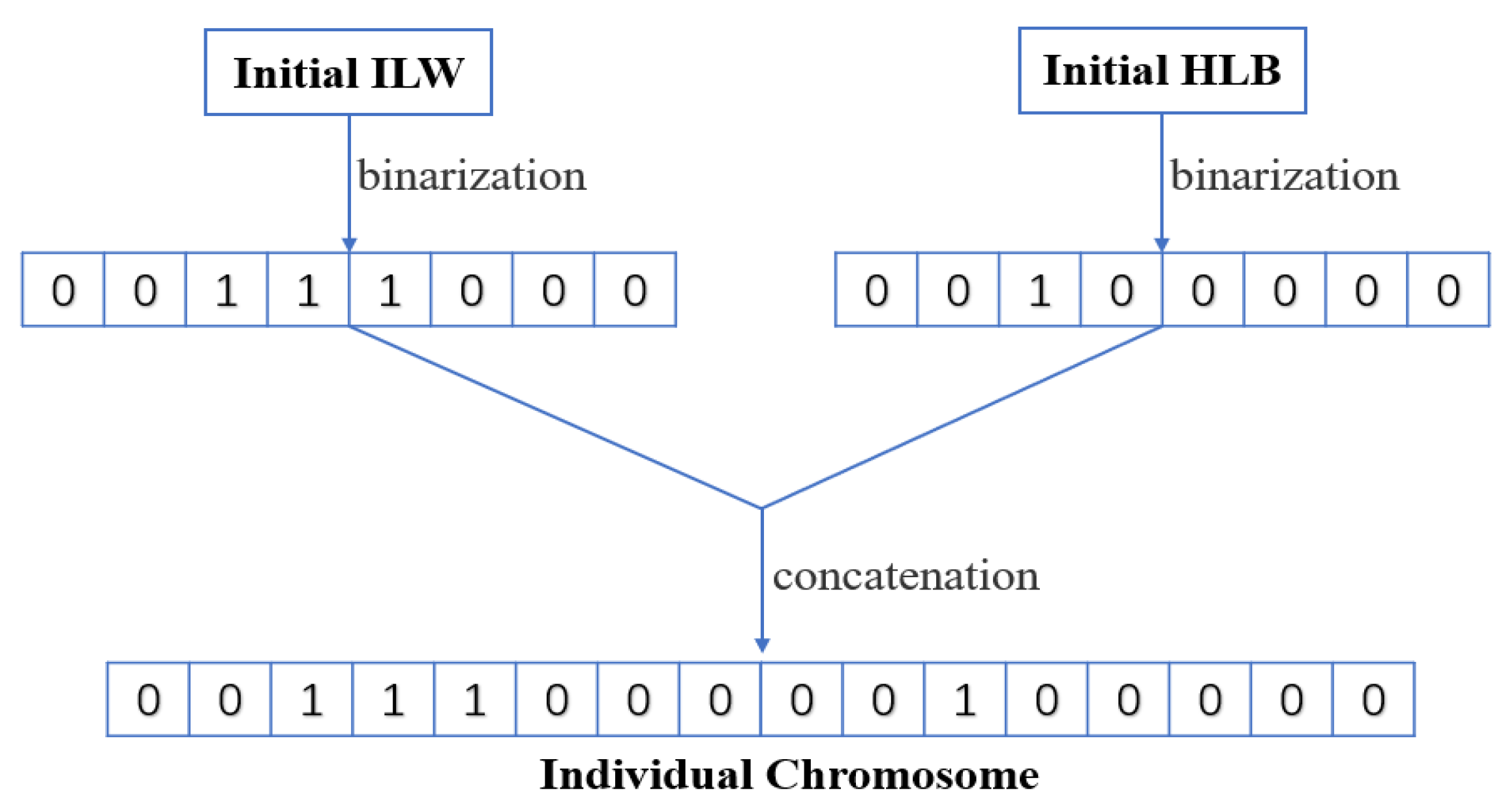
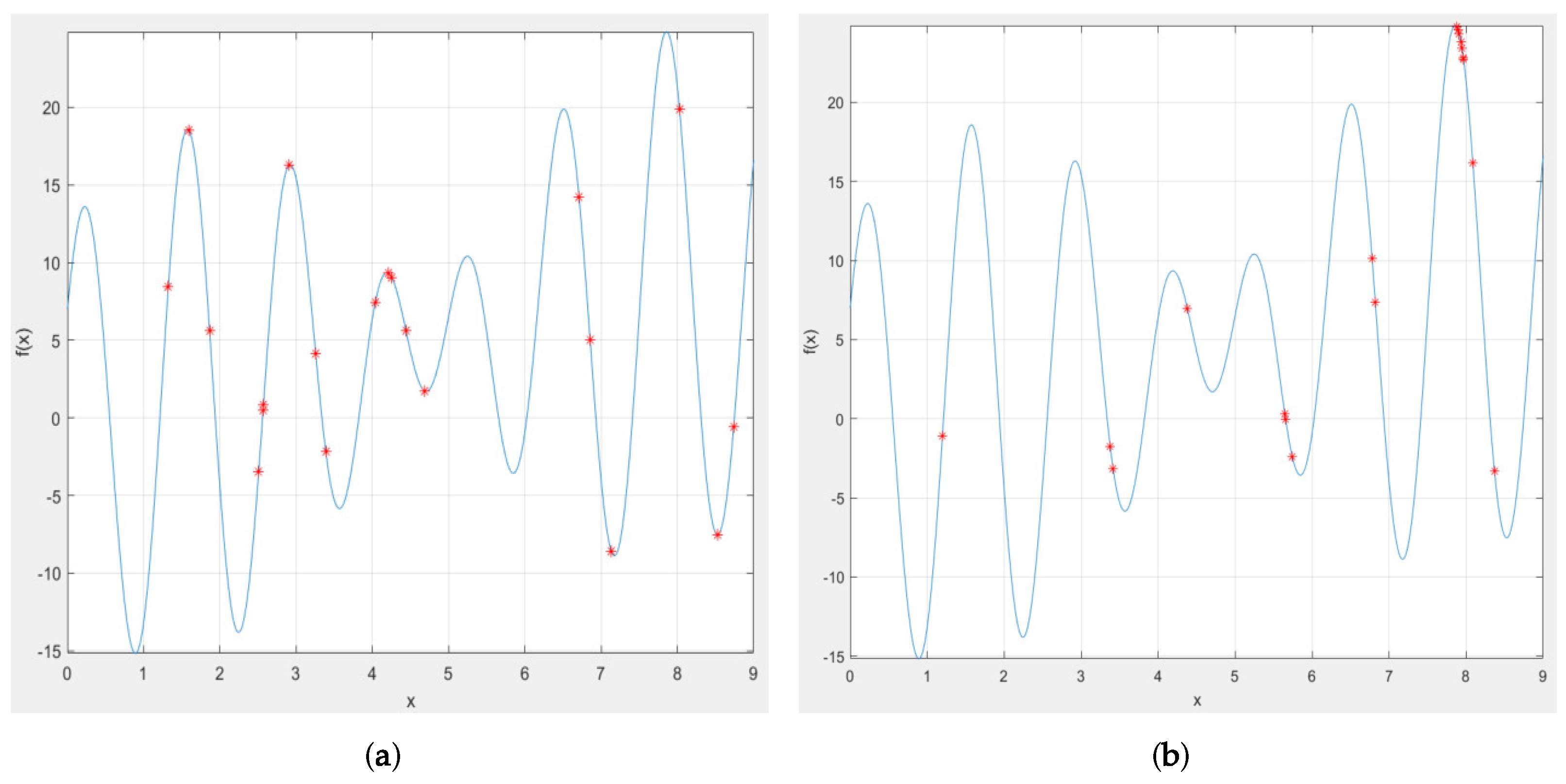
- Initialize population in SAGA. ILW and HLB of ELM-RBF are encoded in individual genes as shown in Figure 13, and the evolutionary population is initialized accordingly. Figure 14 demonstrates the variation trend of population before and after evolution. It can be clearly seen from Figure 14a that the initial individuals are aimlessly distributed. However, after iterative optimization, the population is consciously close to the global optimal position as exhibited in Figure 14b.
- Set fitness function of SAGA. The error function of ELM-RBF is taken as the fitness function of SAGA, and then the fitness values of initial population are calculated.
- Perform selecting operation. With the continuous advancement of evolution, the calculation error will gradually be reduced. As a result, it is necessary to take the reciprocal of fitness function to select the individuals with “high fitness”.
- Adjust individual fitness according to Equations (10) and (11).
- Update the and in SAGA according to Equations (12) and (13).
- Perform crossover and mutation according to new and .
- Compute the fitness value of new individual based on Equation (18). These individuals with superior performance are preserved to compose the next evolutionary group.
- Iterate steps 4–8 until the termination condition is satisfied, for instance, the number of iterations or the minimum error.
- Decode the individual gene with the best fitness value. ELM-RBF is initialized with the decoded ILW and HLB to obtain the optimal network structure, which is used for multi-label classification as shown in Section 2.2.
4. Experiments and Discussion
4.1. Comparing Algorithms
- ML-KNN [40]: This model is a classic multi-label classification approach.
- ML-ELM-RBF [41]: This model extends ELM-RBF to deal with multi-label classification.
- ML-KELM [42]: This model makes use of an efficient projection framework to produce an optimal solution.
- ML-CK-ELM [43]: In this model, a specific module is constructed based on several predefined kernels to promote classification accuracy.
4.2. Experimental Datasets
4.3. Evaluation Metrics
4.4. Experimental Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Read, J.; Pfahringer, B.; Holmes, G.; Frank, E. Classifier chains for multi-label classification. Mach. Learn. 2011, 85, 333–359. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Zhou, Z. A Review on Multi-Label Learning Algorithms. IEEE Trans. Knowl. Data Eng. 2014, 26, 1819–1837. [Google Scholar] [CrossRef]
- Hüllermeier, E.; Fürnkranz, J.; Cheng, W.; Brinker, K. Label ranking by learning pairwise preferences. Artif. Intell. 2008, 172, 1897–1916. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Zhou, H.; Ding, X.; Zhang, R. Extreme Learning Machine for Regression and Multiclass Classification. IEEE Trans. Syst. Man Cybern. Part B 2012, 42, 513–529. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Zhu, Q.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Li, J.; Shi, X.; You, Z.; Yi, H.; Chen, Z.; Lin, Q.; Fang, M. Using Weighted Extreme Learning Machine Combined With Scale-Invariant Feature Transform to Predict Protein-Protein Interactions From Protein Evolutionary Information. IEEE ACM Trans. Comput. Biol. Bioinform. 2020, 17, 1546–1554. [Google Scholar] [CrossRef]
- Liang, X.; Zhang, H.; Lu, T.; Gulliver, T.A. Extreme learning machine for 60 GHz millimetre wave positioning. IET Commun. 2017, 11, 483–489. [Google Scholar] [CrossRef]
- Cervellera, C.; Macciò, D. An Extreme Learning Machine Approach to Density Estimation Problems. IEEE Trans. Cybern. 2017, 47, 3254–3265. [Google Scholar] [CrossRef]
- Liang, Q.; Wu, W.; Coppola, G.; Zhang, D.; Sun, W.; Ge, Y.; Wang, Y. Calibration and decoupling of multi-axis robotic Force/Moment sensors. Robot.-Comput.-Integr. Manuf. 2018, 49, 301–308. [Google Scholar] [CrossRef]
- Chen, H.; Gao, P.; Tan, S.; Tang, J.; Yuan, H. Online sequential condition prediction method of natural circulation systems based on EOS-ELM and phase space reconstruction. Ann. Nucl. Energy 2017, 110, 1107–1120. [Google Scholar] [CrossRef]
- Huang, G.; Siew, C.K. Extreme learning machine: RBF network case. In Proceedings of the 8th International Conference on Control, Automation, Robotics and Vision, ICARCV 2004, Kunming, China, 6–9 December 2004; pp. 1029–1036. [Google Scholar] [CrossRef]
- Niu, M.; Zhang, J.; Li, Y.; Wang, C.; Liu, Z.; Ding, H.; Zou, Q.; Ma, Q. CirRNAPL: A web server for the identification of circRNA based on extreme learning machine. Comput. Struct. Biotechnol. J. 2020, 18, 834–842. [Google Scholar] [CrossRef]
- Wong, P.; Huang, W.; Vong, C.; Yang, Z. Adaptive neural tracking control for automotive engine idle speed regulation using extreme learning machine. Neural Comput. Appl. 2020, 32, 14399–14409. [Google Scholar] [CrossRef]
- Nilesh, R.; Sunil, W. Improving Extreme Learning Machine through Optimization A Review. In Proceedings of the 7th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 19–20 March 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 906–912. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar] [CrossRef]
- Tahir, M.; Tubaishat, A.; Al-Obeidat, F.; Shah, B.; Halim, Z.; Waqas, M. A novel binary chaotic genetic algorithm for feature selection and its utility in affective computing and healthcare. Neural Comput. Appl. 2020, 1–22. [Google Scholar] [CrossRef]
- Huang, G. An Insight into Extreme Learning Machines: Random Neurons, Random Features and Kernels. Cogn. Comput. 2014, 6, 376–390. [Google Scholar] [CrossRef]
- Yang, R.; Xu, S.; Feng, L. An Ensemble Extreme Learning Machine for Data Stream Classification. Algorithms 2018, 11, 107. [Google Scholar] [CrossRef] [Green Version]
- Rajpal, A.; Mishra, A.; Bala, R. A Novel fuzzy frame selection based watermarking scheme for MPEG-4 videos using Bi-directional extreme learning machine. Appl. Soft Comput. 2019, 74, 603–620. [Google Scholar] [CrossRef]
- Zou, W.; Yao, F.; Zhang, B.; Guan, Z. Improved Meta-ELM with error feedback incremental ELM as hidden nodes. Neural Comput. Appl. 2018, 30, 3363–3370. [Google Scholar] [CrossRef]
- Wang, M.; Chen, H.; Li, H.; Cai, Z.; Zhao, X.; Tong, C.; Li, J.; Xu, X. Grey wolf optimization evolving kernel extreme learning machine: Application to bankruptcy prediction. Eng. Appl. Artif. Intell. 2017, 63, 54–68. [Google Scholar] [CrossRef]
- Ding, S.; Guo, L.; Hou, Y. Extreme learning machine with kernel model based on deep learning. Neural Comput. Appl. 2017, 28, 1975–1984. [Google Scholar] [CrossRef]
- Salaken, S.M.; Khosravi, A.; Nguyen, T.; Nahavandi, S. Extreme learning machine based transfer learning algorithms: A survey. Neurocomputing 2017, 267, 516–524. [Google Scholar] [CrossRef]
- Lin, L.; Wang, F.; Xie, X.; Zhong, S. Random forests-based extreme learning machine ensemble for multi-regime time series prediction. Expert Syst. Appl. 2017, 83, 164–176. [Google Scholar] [CrossRef]
- Peerlinck, A.; Sheppard, J.; Pastorino, J.; Maxwell, B. Optimal Design of Experiments for Precision Agriculture Using a Genetic Algorithm. In Proceedings of the IEEE Congress on Evolutionary Computation, Wellington, New Zealand, 10–13 June 2019; pp. 1838–1845. [Google Scholar] [CrossRef]
- Liu, D. Mathematical modeling analysis of genetic algorithms under schema theorem. J. Comput. Methods Sci. Eng. 2019, 19, 131–137. [Google Scholar] [CrossRef]
- Sari, M.; Tuna, C. Prediction of Pathological Subjects Using Genetic Algorithms. Comput. Math. Methods Med. 2018, 2018, 6154025. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pattanaik, J.K.; Basu, M.; Dash, D.P. Improved real coded genetic algorithm for dynamic economic dispatch. J. Electr. Syst. Inf. Technol. 2018, 5, 349–362. [Google Scholar] [CrossRef]
- Rafsanjani, M.K.; Riyahi, M. A new hybrid genetic algorithm for job shop scheduling problem. Int. J. Adv. Intell. Paradig. 2020, 16, 157–171. [Google Scholar] [CrossRef]
- Maghawry, A.; Kholief, M.; Omar, Y.M.K.; Hodhod, R. An Approach for Evolving Transformation Sequences Using Hybrid Genetic Algorithms. Int. J. Comput. Intell. Syst. 2020, 13, 223–233. [Google Scholar] [CrossRef] [Green Version]
- Srinivas, M.; Patnaik, L.M. Adaptive probabilities of crossover and mutation in genetic algorithms. IEEE Trans. Syst. Man Cybern. 1994, 24, 656–667. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Zhang, M.; Ersoy, O.K.; Sun, K.; Bi, Y. An Improved Real-Coded Genetic Algorithm Using the Heuristical Normal Distribution and Direction-Based Crossover. Comput. Intell. Neurosci. 2019, 2019, 4243853. [Google Scholar] [CrossRef]
- Li, Y.B.; Sang, H.B.; Xiong, X.; Li, Y.R. An improved adaptive genetic algorithm for two-dimensional rectangular packing problem. Appl. Sci. 2021, 11, 413. [Google Scholar] [CrossRef]
- Xiang, X.; Yu, C.; Xu, H.; Zhu, S.X. Optimization of Heterogeneous Container Loading Problem with Adaptive Genetic Algorithm. Complexity 2018, 2018, 2024184. [Google Scholar] [CrossRef] [Green Version]
- Zhang, R.; Ong, P.S.; Nee, A.Y.C. A simulation-based genetic algorithm approach for remanufacturing process planning and scheduling. Appl. Soft Comput. 2015, 37, 521–532. [Google Scholar] [CrossRef]
- Jiang, J.; Yin, S. A Self-Adaptive Hybrid Genetic Algorithm for 3D Packing Problem. In Proceedings of the 2012 Third Global Congress on Intelligent Systems, Wuhan, China, 6–8 November 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 76–79. [Google Scholar] [CrossRef]
- Yang, C.; Qian, Q.; Wang, F.; Sun, M. An improved adaptive genetic algorithm for function optimization. In Proceedings of the IEEE International Conference on Information and Automation, Ningbo, China, 1–3 August 2016; pp. 675–680. [Google Scholar] [CrossRef]
- Liu, Y.; Ji, S.; Su, Z.; Guo, D. Multi-objective AGV scheduling in an automatic sorting system of an unmanned (intelligent) warehouse by using two adaptive genetic algorithms and a multi-adaptive genetic algorithm. PLoS ONE 2019, 14, e0226161. [Google Scholar] [CrossRef] [PubMed]
- Schaffer, J.D.; Caruana, R.; Eshelman, L.J.; Das, R. A Study of Control Parameters Affecting Online Performance of Genetic Algorithms for Function Optimization. In Proceedings of the 3rd International Conference on Genetic Algorithms, Fairfax, VA, USA, 4–7 June 1989; pp. 51–60. [Google Scholar]
- Zhang, M.; Zhou, Z. ML-KNN: A lazy learning approach to multi-label learning. Pattern Recognit. 2007, 40, 2038–2048. [Google Scholar] [CrossRef] [Green Version]
- Zhang, N.; Ding, S.; Zhang, J. Multi layer ELM-RBF for multi-label learning. Appl. Soft Comput. 2016, 43, 535–545. [Google Scholar] [CrossRef]
- Wong, C.; Vong, C.; Wong, P.; Cao, J. Kernel-Based Multilayer Extreme Learning Machines for Representation Learning. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 757–762. [Google Scholar] [CrossRef]
- Rezaei Ravari, M.; Eftekhari, M.; Saberi Movahed, F. ML-CK-ELM: An efficient multi-layer extreme learning machine using combined kernels for multi-label classification. Sci. Iran. 2020, 27, 3005–3018. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Multimodal Function | |||
|---|---|---|---|---|
| H-SGA [36] | 980 | 964 | 753 | 625 |
| IAGA [37] | 993 | 982 | 895 | 863 |
| MAGA [38] | 996 | 991 | 966 | 953 |
| SAGA | 1000 | 997 | 995 | 986 |
| Method | Multimodal Function | |||
|---|---|---|---|---|
| H-SGA [36] | 113 | 191 | 320 | 356 |
| IAGA [37] | 82 | 133 | 263 | 272 |
| MAGA [38] | 62 | 105 | 198 | 215 |
| SAGA | 56 | 95 | 183 | 196 |
| Method | Multimodal Function | |||
|---|---|---|---|---|
| H-SGA [36] | 24.825632 | −1.028323 | 0.0094 | 0.0150 |
| IAGA [37] | 24.850056 | −1.031200 | 0.0030 | 0.0092 |
| MAGA [38] | 24.853056 | −1.031300 | 0.0022 | 0.0042 |
| SAGA | 24.855368 | −1.031601 | 0.0016 | 0.0035 |
| Dataset | Train | Test | Dim | Label |
|---|---|---|---|---|
| Art [40] | 2000 | 3000 | 462 | 26 |
| Business [40] | 2000 | 3000 | 438 | 30 |
| Computer [40] | 2000 | 3000 | 681 | 33 |
| Yeast [40] | 1500 | 917 | 103 | 14 |
| Evaluation Metric | Algorithm | ||||
|---|---|---|---|---|---|
| ML-KNN [40] | ML-ELM-RBF [41] | ML-KELM [42] | ML-CK-ELM [43] | ELM-RBF-SAGA | |
| Average Precision | 0.5736 | 0.6078 | 0.6132 | 0.6263 | 0.6317 |
| Coverage | 4.7539 | 5.6723 | 5.2531 | 4.5864 | 4.5826 |
| Hamming Loss | 0.0576 | 0.0535 | 0.0531 | 0.0553 | 0.0533 |
| One-Error | 0.5132 | 0.4739 | 0.4732 | 0.4698 | 0.4683 |
| Ranking Loss | 0.1273 | 0.1387 | 0.1126 | 0.1143 | 0.1131 |
| Evaluation Metric | Algorithm | ||||
|---|---|---|---|---|---|
| ML-KNN [40] | ML-ELM-RBF [41] | ML-KELM [42] | ML-CK-ELM [43] | ELM-RBF-SAGA | |
| Average Precision | 0.7541 | 0.7567 | 0.7623 | 0.7778 | 0.7773 |
| Coverage | 6.3986 | 6.4632 | 6.2573 | 6.1935 | 6.1893 |
| Hamming Loss | 0.1953 | 0.1968 | 0.1858 | 0.1864 | 0.1845 |
| One-Error | 0.2345 | 0.2376 | 0.2292 | 0.2268 | 0.2285 |
| Ranking Loss | 0.1719 | 0.1728 | 0.1613 | 0.1593 | 0.1586 |
| Evaluation Metric | Algorithm | ||||
|---|---|---|---|---|---|
| ML-KNN [40] | ML-ELM-RBF [41] | ML-KELM [42] | ML-CK-ELM [43] | ELM-RBF-SAGA | |
| Average Precision | 0.8826 | 0.8835 | 0.8863 | 0.8872 | 0.8886 |
| Coverage | 2.1576 | 2.5076 | 2.4964 | 2.4058 | 2.4032 |
| Hamming Loss | 0.0261 | 0.0258 | 0.0256 | 0.0232 | 0.0241 |
| One-Error | 0.1213 | 0.1163 | 0.1143 | 0.1156 | 0.1135 |
| Ranking Loss | 0.0356 | 0.0392 | 0.0369 | 0.0376 | 0.0342 |
| Evaluation Metric | Algorithm | ||||
|---|---|---|---|---|---|
| ML-KNN [40] | ML-ELM-RBF [41] | ML-KELM [42] | ML-CK-ELM [43] | ELM-RBF-SAGA | |
| Average Precision | 0.6718 | 0.6983 | 0.7021 | 0.7112 | 0.7136 |
| Coverage | 3.9417 | 4.3896 | 3.9863 | 3.9578 | 3.9286 |
| Hamming Loss | 0.0362 | 0.0332 | 0.0339 | 0.0341 | 0.0336 |
| One-Error | 0.3960 | 0.3329 | 0.3526 | 0.3418 | 0.3345 |
| Ranking Loss | 0.0787 | 0.0913 | 0.0856 | 0.0793 | 0.0785 |
| Evaluation Metric | Algorithm | ||||
|---|---|---|---|---|---|
| ML-KNN [40] | ML-ELM-RBF [41] | ML-KELM [42] | ML-CK-ELM [43] | ELM-RBF-SAGA | |
| Training time in Art [40] | 1.2365 | 1.1735 | 1.1967 | 1.2132 | 1.2053 |
| Testing time in Art [40] | 1.1986 | 1.1552 | 1.1624 | 1.1862 | 1.1775 |
| Training time in Business [40] | 2.4573 | 1.8521 | 1.9173 | 2.0681 | 2.1367 |
| Testing time in Business [40] | 2.1061 | 1.7647 | 1.8265 | 1.8572 | 1.9356 |
| Training time in Computer [40] | 2.8732 | 2.1369 | 2.2358 | 2.3537 | 2.2132 |
| Testing time in Computer [40] | 2.6113 | 1.9127 | 2.0526 | 2.1769 | 2.0319 |
| Training time in Yeast [40] | 1.0523 | 0.7631 | 0.8256 | 0.9572 | 0.8543 |
| Testing time in Yeast [40] | 0.8958 | 0.7239 | 0.7653 | 0.8839 | 0.7668 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, D.; Li, P.; Wulamu, A. An Improved Multi-Label Learning Method with ELM-RBF and a Synergistic Adaptive Genetic Algorithm. Algorithms 2022, 15, 185. https://doi.org/10.3390/a15060185
Zhang D, Li P, Wulamu A. An Improved Multi-Label Learning Method with ELM-RBF and a Synergistic Adaptive Genetic Algorithm. Algorithms. 2022; 15(6):185. https://doi.org/10.3390/a15060185
Chicago/Turabian StyleZhang, Dezheng, Peng Li, and Aziguli Wulamu. 2022. "An Improved Multi-Label Learning Method with ELM-RBF and a Synergistic Adaptive Genetic Algorithm" Algorithms 15, no. 6: 185. https://doi.org/10.3390/a15060185
APA StyleZhang, D., Li, P., & Wulamu, A. (2022). An Improved Multi-Label Learning Method with ELM-RBF and a Synergistic Adaptive Genetic Algorithm. Algorithms, 15(6), 185. https://doi.org/10.3390/a15060185