
A Fair and Safe Usage Drug Recommendation System in Medical Emergencies by a Stacked ANN



Abstract
:1. Introduction
2. Related Work
3. Methods and Materials
3.1. Dataset
3.1.1. Data Pre-Processing
3.1.2. Symptom Extraction and Severity Rating
3.1.3. Drug Target
3.2. Recommendation Algorithm
| Algorithm 1. Drug recommendation algorithm |
| Input: Patient data |
| Output: Recommended drug |
|
3.3. Software and Hardware Specifications
4. Results
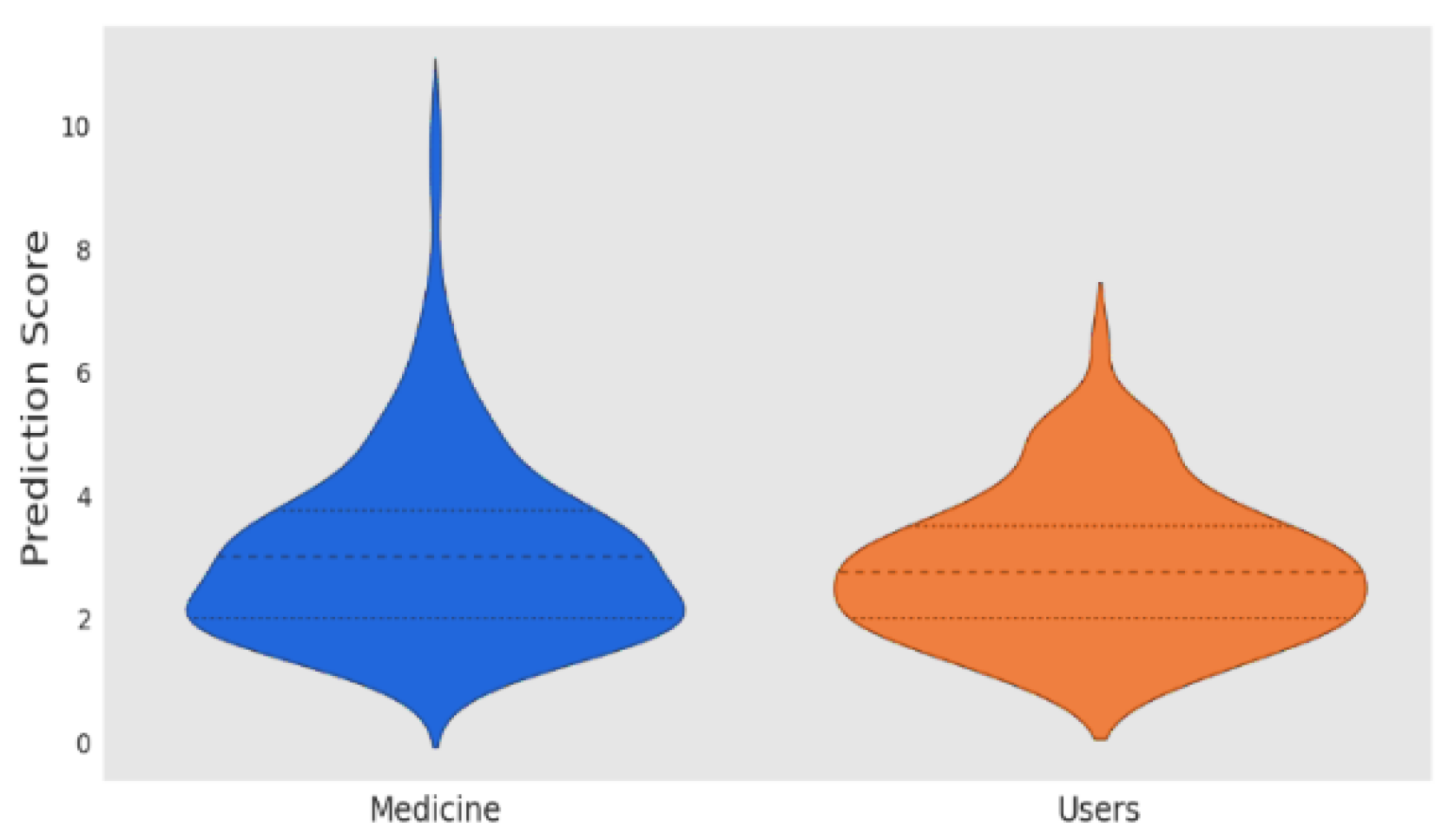
4.1. Fairness Drug Recommendation for SARS-CoV-2 Infectious Diseases Using ML and Regression
4.2. Fairness of Drug Side-Effects Predictions Using Deep Learning and Regression
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Battineni, G.; Sagaro, G.G.; Chintalapudi, N.; Di Canio, M.; Amenta, F. Assessment of Awareness and Knowledge on Novel Coronavirus (COVID-19) Pandemic among Seafarers. Healthcare 2021, 9, 120. [Google Scholar] [CrossRef] [PubMed]
- Goh, J.M.; Gao, G.; Agarwal, R. The creation of social value: Can an online health community reduce rural–urban health disparities? MIS Q. 2016, 40, 247–263. [Google Scholar] [CrossRef] [Green Version]
- Cook, S.F.; Bies, R.R. Disease Progression Modeling: Key Concepts and Recent Developments. Curr. Pharmacol. Rep. 2016, 2, 221–230. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Koren, Y. Factorization Meets the Neighborhood: A Multifaceted Collaborative Filtering Model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 426–434. [Google Scholar]
- Ye, Q.; Hsieh, C.Y.; Yang, Z.; Kang, Y.; Chen, J.; Cao, D.; He, S.; Hou, T. A unified drug-target interaction prediction framework based on knowledge graph and recommendation system. Nat. Commun. 2021, 12, 6775. [Google Scholar] [CrossRef]
- Fox, S.; Duggan, M. Health Online 2013; Pew Research Internet Project Report: Washington, DC, USA, 2013. [Google Scholar]
- Chintalapudi, N.; Angeloni, U.; Battineni, G.; di Canio, M.; Marotta, C.; Rezza, G.; Sagaro, G.G.; Silenzi, A.; Amenta, F. LASSO Regression Modeling on Prediction of Medical Terms among Seafarers’ Health Documents Using Tidy Text Mining. Bioengineering 2022, 9, 124. [Google Scholar] [CrossRef]
- Lu, J.; Wu, D.; Mao, M.; Wang, W.; Zhang, G. Recommender system application developments: A survey. Decis. Support Syst. 2015, 74, 12–32. [Google Scholar] [CrossRef]
- Huang, F.; Wang, S.; Chan, C.-C. Predicting disease by using data mining based on healthcare information system. In Proceedings of the 2012 IEEE International Conference on granular computing, Washington, DC, USA, 11–13 August 2012; pp. 191–194. [Google Scholar]
- Subramaniyaswamy, V.; Manogaran, G.; Logesh, R.; Vijayakumar, V.; Chilamkurti, N.; Malathi, D.; Senthilselvan, N. An ontology driven personalized food recommendation in IoT-based healthcare system. J. Supercomput. 2019, 75, 3184–3216. [Google Scholar] [CrossRef]
- Liang, T.P. Recommender systems for decision support. Expert Syst. Appl. 2008, 45, 385–386. [Google Scholar]
- Adomavicius, G.; Tuzhilin, A. Toward the Next Generation of Recommender Systems: A Survey of the State of the Art and Possible Extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Esfandiari, N.; Babavalian, R.; Moghadam, E.; Tabar, V. Knowledge discovery in medicine: Current issue and future trend. Expert Syst. Appl. 2014, 41, 4434–4463. [Google Scholar] [CrossRef]
- Narducci, F.; Musto, C.; Polignano, M.; de Gemmis, M.; Lops, P.; Semeraro, G. A Recommender System for Connecting Patients to the Right Doctors in the Healthnet Social Network. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 81–82. [Google Scholar]
- Han, Q.; Ji, M.; de Troya, I.M.d.R.; Gaur, M.; Zejnilovic, L. A Hybrid Recommender System for Patient-Doctor matchmaking in Primary Care. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–4 October 2018; pp. 481–490. [Google Scholar]
- Hassan, S.; Syed, Z. From Netflix to heart attacks: Collaborative filtering in medical datasets. In Proceedings of the HI’10: ACM International Health Informatics Symposium, IHI’10: ACM International Health Informatics Symposium, Arlington, VA, USA, 11–12 November 2010; pp. 128–134. [Google Scholar]
- Teodorovic, D.; Selmic, M.; Mijatovic, L. Combining case-based reasoning with Bee Colony Optimization for dose planning in well differentiated thyroid cancer treatment. Expert Syst. Appl. 2013, 40, 2147–2155. [Google Scholar] [CrossRef]
- Savova, G.K.; Masanz, J.J.; Ogren, P.V.; Zheng, J.; Sohn, S.; Kipper, K.C.; Chute, C.G. Mayo clinical text analysis and knowledge extraction system(cTAKES): Architecture component evaluation and applications. J. Am. Med. Inform. Assoc. 2010, 17, 507–513. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Davis, D.A.; Chawla, N.V.; Christakis, A.; Barabasi, A.L. Time to CARE: A collaborative engine for practical disease prediction. Data Min. Knowl. Discov. 2010, 20, 388–415. [Google Scholar] [CrossRef]
- Komkhao, M.; Lu, J.; Zhang, L. Determine Pattern Similarity in a Medical Recommender System. In International Conference on Data and Knowledge Engineering; Springer: Berlin/Heidelberg, Germany, 2012; pp. 103–114. [Google Scholar]
- Lu, X.; Huang, Z.; Duan, H. Supporting adaptive clinical treatment processes through recommendations. Comput. Methods Programs Biomed. 2012, 107, 413–424. [Google Scholar] [CrossRef]
- Caorsar, D.; Sleeman, D.H. Developing Knowledge Based System Using the Semantic web. In Proceedings of the International BCS Conference, London, UK, 22–24 September 2008; pp. 29–40. [Google Scholar]
- Burke, R. Knowledge recommender system. Encycl. Libr. Inf. Syst. 2000, 69 (Suppl. 32), 175–186. [Google Scholar]
- Wiesner, M.; Pfeifer, D. Health recommender systems: Concepts requirements technical basics and challenges. Int. J. Environ. Res. Public Health 2014, 11, 2580–2607. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bodadilla, J.; Ortega, F.; Hernando, A.; Gutierrez, A. Recommender system survey. Knowl. Based Syst. 2013, 46, 109–132. [Google Scholar] [CrossRef]
- Masaba, B.B.; Moturi, J.K.; Taiswa, J.; Mmusi-Phetoe, R.M. Devolution of healthcare system in Kenya: Progress and challenges. Public Health 2020, 189, 135–140. [Google Scholar] [CrossRef]
- Berners, L.; Hendler, J.; Lassila, O. The semantic web. Sci. Am. 2001, 284, 28–37. [Google Scholar] [CrossRef]
- Shardanad, U.; Maes, P. Social information filtering: Algorithms for automating word of mouth. Experts Syst. Appl. 1995, 95, 210–217. [Google Scholar]
- Leilei, S.; Chuanren, L.; Chonghui, G.; Hui, X.; Yanming, X. Data-Driven Automatic Treatment Regimen Development and Recommendation. In Proceedings of the International Conference on Knowledge Discovery and Data Mining(SIGKDD2016), San Francisco, CA, USA, 13–17 August 2016; pp. 1865–1874. [Google Scholar]
- Shimada, K.; Takada, H.; Mitsuyama, S.; Matsuo, H.; Otake, H.; Kunishima, H.; Kanemitsu, K.; Kaku, M. Drug recommendation system for patients with infectious diseases. AMIA Annu. Symp. Proc. 2005, 2005, 1112. [Google Scholar]
- Doulaverakis, C.; Nikolaidis, G.; Kleontas, A.; Kompatsiaris, I. GalenOWL: Ontology based drug recommendations discovery. J. Biomed. Semat. 2012, 3, 14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Y.Z.; Dafang, H.; Mohammad, A.; Atif, P.; Limei, P. CADRE: Cloud assisted drug recommendation service for online pharmacies. Mob. Netw. Appl. 2014, 20, 348–355. [Google Scholar] [CrossRef]
- Zhou, Y.; Hou, Y.; Shen, Y.; Huang, W.; Martin, F.; Cheng, F. Network based drug repurposing for novel coronavirus2019-ncov/SARS-CoV-2. Nat. Cell Discov. 2020, 6, 14. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Zheng, B.; Chen, B.; Butte, A.J.; Swamidass, S.J.; Lu, Z. A survey of current trends in computational drug repositioning. Brief. Bioinform. 2016, 17, 2–12. [Google Scholar] [CrossRef] [Green Version]
- Zeng, X.; Zhu, S.; Liu, Y.; Zhou, R.; Nussinov, C.F. DeerDR: A network based deep learning approach to in silico drug repositionoing. Bioinformatics 2019, 35, 5191–5198. [Google Scholar] [CrossRef]
- Aliper, A.; Plis, S.; Artemov, A.; Ulloa, P.; Mamoshina, A.; Zhavoronkov, A. Deep learning applications for predicting pharmacological properties of drugs and drug repurposing using transcriptomic data. Mol. Pharmcy 2016, 13, 2524–2530. [Google Scholar] [CrossRef] [Green Version]
- Haifeng, L.; Hongfei, L.; Chen, S.; Liang, Y.; Yuan, L.; Bo, X.; Zhihao, Y.; Jian, W.; Yuanyuan, S. A network representation approach for COVID-19 drug recommendation. Methods 2022, 198, 3–10. [Google Scholar]
- SNOMED CT Standard Ontology Based on the Ontology for General Medical Science. Available online: https://bioportal.bioontology.org/ontologies/SCTO (accessed on 16 May 2022).
- Available online: https://go.drugbank.com/drugs (accessed on 8 January 2022).
- Wang, X.; Sontag, D.; Wang, F. Unsupervised Learning of Disease Progression Models. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 85–94. [Google Scholar]
- Kumar, N.K.; Vigneswari, D. A Drug Recommendation System for Multi-Disease in Health Care using Machine Learning. In Advances in Communication and Computational Technology; Springer: Berlin/Heidelberg, Germany, 2021; pp. 1–12. [Google Scholar]
- Stark, B.; Knahl, C.; Aydin, M.; Samarah, M.; Elish, K.O. Better choice: A migraine drug recommendation system based on Neo4J. In Proceedings of the 2017 2nd IEEE International Conference on Computational Intelligence and Applications (ICCIA), Beijing, China, 8–11 September 2017; pp. 382–386. [Google Scholar]
- Qian, Z.; Guangquan, Z.; Jie, L.; Wu, D. A framework of hybrid recommender system for personalized clinical prescription. In Proceedings of the 10th International Conference on Intelligent Systems and Knowledge Engineering (ISKE), Taipei, Taiwan, 24–27 November 2015; pp. 1–7. [Google Scholar]
- Schäfer, H.; Hors-Fraile, S.; Karumur, R.P.; Valdez, A.C.; Said, A.; Torkamaan, H.; Ulmer, T.; Trattner, C. Towards health (aware) recommender systems. In Proceedings of the DH’17: International Conference on Digital Health, London, UK, 2–5 July 2017; pp. 157–161. [Google Scholar]
- Bankhele, S.; Mhaske, A.; Bhat, S.; Shinde, S.V. A diabetic healthcare recommendation system. Int. J. Comput. Appl. 2017, 167, 14–18. [Google Scholar] [CrossRef]
- Mahmoud, N.; Elbeh, H. Irs-t2d: Individualize recommendation system for type2 diabetes medication based on ontology and swrl. In Proceedings of the 10th International Conference on Informatics and Systems, Giza, Egypt, 9–11 May 2016; pp. 203–209. [Google Scholar]
- Toutet, F.; de Lamnallerie, X. Of chloroquine and COVID-19. Antivir. Res. 2020, 177, 104762. [Google Scholar]
- Meini, S.; Pagotto, A.; Longo, B.; Vendramin, I.; Pecori, D.; Tascini, C. Role of Lopinavir/Ritonavir in the Treatment of COVID-19: A Review of Current Evidence, Guideline Recommendations and Perceptives. J. Clin. Med. 2020, 9, 2050. [Google Scholar] [CrossRef] [PubMed]
- Takahashi, W.; Yoneda, T.; Koba, H.; Ueda, T.; Tsuji, N.; Ogawa, H.; Asakura, H. Potential mechanisms of nafamostat therapy for severe COVID-19 pneumonia with disseminated intravascular coagulation. Int. J. Infect. Dis. 2021, 102, 529–531. [Google Scholar] [CrossRef] [PubMed]
- Breining, P.; Frolund, A.L.; Hojen, J.F.; Gunst, J.D.; Staerke, N.B.; Saedder, E.; Thomas, M.C.; Little, P.; Nielsen, L.P.; Sogaard, O.S.; et al. Camostat mesylate against SARS-CoV-2 and COVID-19 Rationale, dosing and safety. Basic Clin. Pharmacol. Toxicol. 2021, 128, 204–212. [Google Scholar] [CrossRef] [PubMed]
- Sehitoglu, M.H.; Oztopuz, O.; Karaboga, I.; Ovali, M.A.; Uzun, M. Human Acid has a protective effect on gastric ulcer by alleviating inflammation in rats. Cytol. Genet. 2022, 56, 84–97. [Google Scholar] [CrossRef]
- Amit, S.; Lokhande, P.; Devarajan, V. A review on possible mechanistic insights of Nitazoxanide for repurposing in COVID-19. Eur. J. Pharmacol. 2021, 891, 173748. [Google Scholar]
- Sherief, A.E.; Noor, R.A.; Badawi, R.; Eslam, M.K.; Soliman, S.E.S.; Mohamed, S.A.E.G.; Elbahnasawy, M.; Moustafa, E.F.; Hassany, S.M.; Medhat, M.A.; et al. Clinical study evaluating the efficacy of ivermectin in COVID-19 treatment: A randomized controlled study. J. Med. Virol. 2021, 93, 5833–5838. [Google Scholar]
- Chen, J.; Li, K.; Rong, H.; Bilal, K.; Yang, N.; Li, K. A disease diagnosis and treatment recommendation system based on big data mining and cloud computing. Inf. Sci. 2018, 435, 124–149. [Google Scholar] [CrossRef] [Green Version]
- Shen, Y.; Yuan, K.; Chen, D.; Colloc, J.; Yang, M.; Li, Y.; Lei, K. An ontology-driven clinical decision support system (IDDAP) for infectious disease diagnosis and antibiotic prescription. Artif. Intell. Med. 2018, 86, 20–32. [Google Scholar] [CrossRef]
- Ali, F.; Islam, S.M.R.; Kwak, D.; Khan, P.; Ullah, N.; Yoo, S.-J.; Kwak, K.S. Type-2 fuzzy ontology-aided recommender systems for IoT–based healthcare. Comput. Commun. 2018, 119, 138–155. [Google Scholar] [CrossRef]
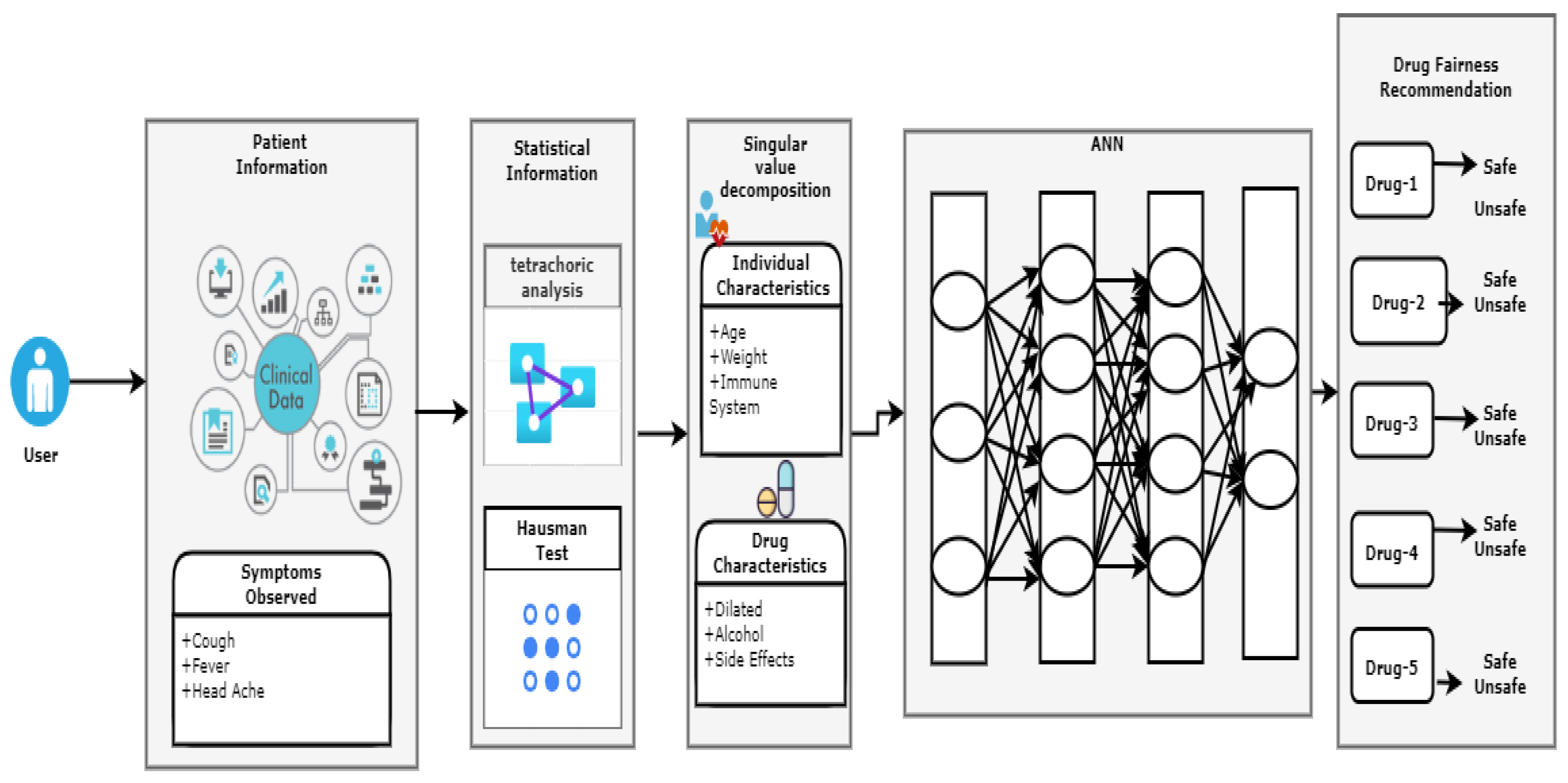


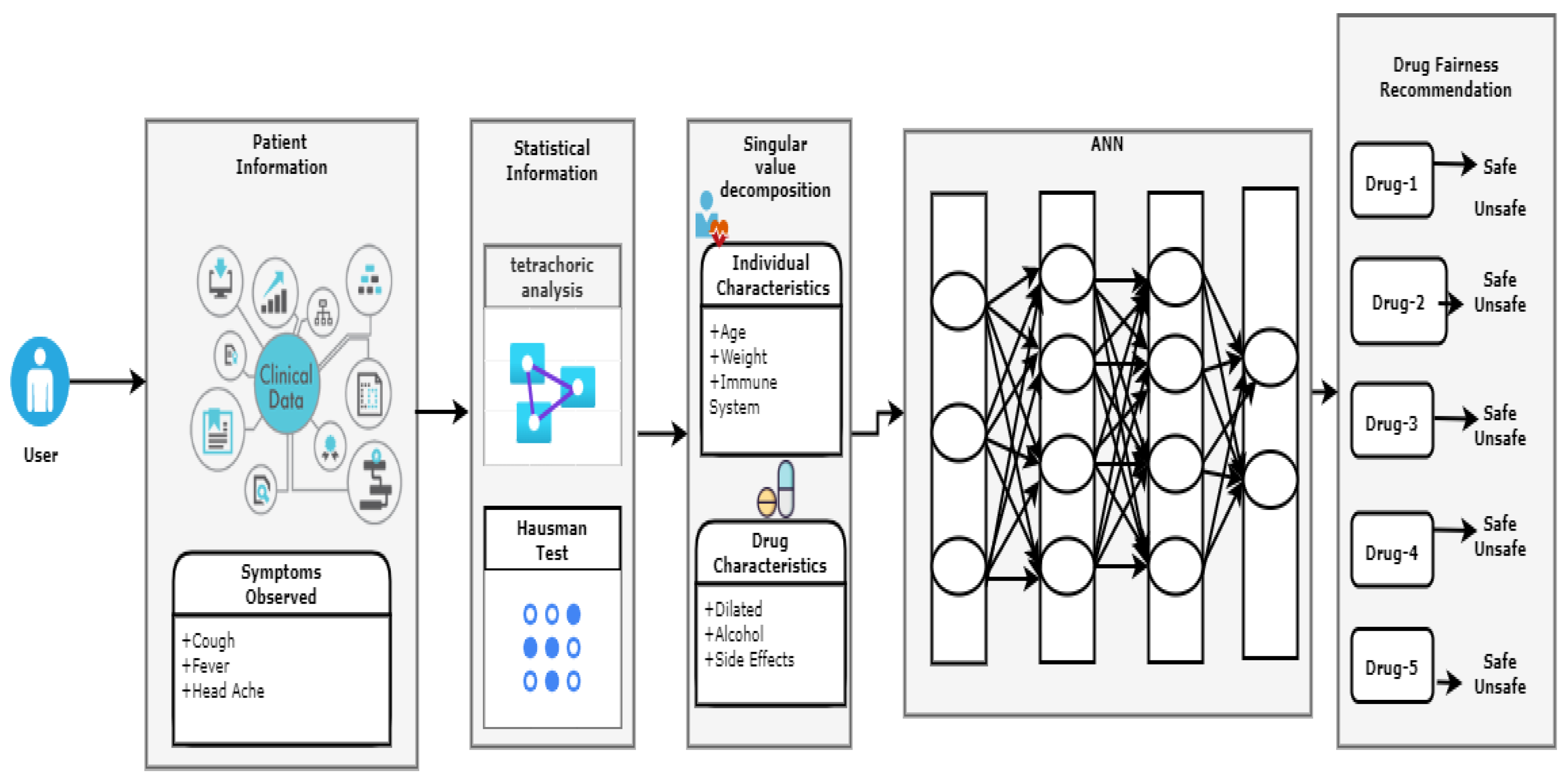{kind=link}
{kind=link}
| Feature | Values |
|---|---|
| Gender | Male, Female |
| Age | child, young, adult, old (1–65) |
| Height | In cm |
| Weight | In kg |
| Comorbidities | Diabetes, hypertension, etc. |
| COVID-19 infection | Yes or no |
| Exercise habits | Yes or no |
| Test reports | Diagnosis reports |
| Country | Country |
| Food | Veg or nonveg |
| Habits | Tea, smoking, alcohol, etc. |
| Drug Id | Drug Name | Side Effects | Disease |
|---|---|---|---|
| DB00608 | chloroquine | Headache, nausea, loss of appetite, diarrhea, stomach pain, rash, itching | Susceptible infections, SARS-CoV-2 |
| DB01601 | Lopinavir | Weakness, diarrhea, heartburn, weight loss, headache, staying asleep, muscle pain | Human immune deficiency virus, SARS-CoV-2 |
| DB00503 | Ritonavir | Drowsiness, diarrhea, gas, heartburn, headache, numbness, burning, muscle and joint pain | Human immune deficiency virus |
| DB12598 | Nafamostat | Lung swelling | SARS-CoV-2 pneumonia |
| DB13729 | Camostat | Abnormal liver, rash, nausea, diarrhea, increased potassium levels in the blood, itching, jaundice, low blood platelets, and gas | Kidney injury, SARS-CoV-2 |
| DB00927 | Famotidine | Difficulty breathing, feeling sad, racing heartbeat | Ulcers |
| DB13609 | Umifenovir | Allergic reactions | Influenza and respiratory virus |
| DB00507 | Nitazoxanide | Stomach pain, headache, upset stomach, vomiting. | Infections, anaerobic bacteria, viruses |
| DB00602 | Ivermectin | Fever, itching, joint pain, rapid heartbeat, headache, swelling of eyes, diarrhea, dizziness, loss of appetite, and sleepiness | SARS-CoV-2 |
| DB06273 | Tocilizumab | Respiratory infections, rashes, dizziness, sore throat | SARS-CoV-2 |
| DB11767 | sarilumab | Sore throat, cold scores, itching | Rheumatoid-rheumatoid arthritis |
| DB00112 | Bevacizumab | Body aches, cracks in skin, difficulty breathing | Cancer, SARS-CoV-2 |
| DB00176 | Fluvoxamine | Headache, dry mouth, feeling nervous, and trouble sleeping | Obsessive-compulsive disorder, SARS-CoV-2 |
| Hidden Layers | MAPE | RMSE |
|---|---|---|
| 1 | 0.0284 | 0.0018 |
| 2 | 0.0256 | 0.0014 |
| 3 | 0.0251 | 0.0010 |
| 4 | 0.0324 | 0.0017 |
| 5 | 0.0328 | 0.0019 |
| 6 | 0.0330 | 0.0020 |
| Recommender Model | Accuracy | Precision | Sensitivity | Specificity |
|---|---|---|---|---|
| Content-Based | 0.847 | 0.842 | 0.862 | 0.897 |
| Hybrid restricted Boltzmann machine | 0.946 | 0.932 | 0.926 | 0.927 |
| Random forest | 0.841 | 0.840 | 0.841 | 0.920 |
| K nearest neighbors | 0.840 | 0.823 | 0.824 | 0.915 |
| Support vector machine | 0.719 | 0.714 | 0.719 | 0.860 |
| Logistic regression | 0.534 | 0.522 | 0.534 | 0.767 |
| Decision Tree | 0.840 | 0.840 | 0.835 | 0.920 |
| DeerDr [35] | 0.956 | 0.945 | 0.924 | 0.919 |
| MLP [36] | 0.946 | 0.945 | 0.917 | 0.916 |
| Proposed | 0.985 | 0.96 | 0.939 | 0.929 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bhimavarapu, U.; Chintalapudi, N.; Battineni, G. A Fair and Safe Usage Drug Recommendation System in Medical Emergencies by a Stacked ANN. Algorithms 2022, 15, 186. https://doi.org/10.3390/a15060186
Bhimavarapu U, Chintalapudi N, Battineni G. A Fair and Safe Usage Drug Recommendation System in Medical Emergencies by a Stacked ANN. Algorithms. 2022; 15(6):186. https://doi.org/10.3390/a15060186
Chicago/Turabian StyleBhimavarapu, Usharani, Nalini Chintalapudi, and Gopi Battineni. 2022. "A Fair and Safe Usage Drug Recommendation System in Medical Emergencies by a Stacked ANN" Algorithms 15, no. 6: 186. https://doi.org/10.3390/a15060186
APA StyleBhimavarapu, U., Chintalapudi, N., & Battineni, G. (2022). A Fair and Safe Usage Drug Recommendation System in Medical Emergencies by a Stacked ANN. Algorithms, 15(6), 186. https://doi.org/10.3390/a15060186