
Cost-Sensitive Variational Autoencoding Classifier for Imbalanced Data Classification


Abstract
:1. Introduction
- -
- We propose a cost-sensitive variational autoencoding classifier for imbalanced data classification. In contrast to traditional imbalanced classification algorithms, which usually involve only one level, the proposed approach adapts to imbalanced data at the levels of data and algorithms. A cost-sensitive matrix is introduced to improve the recognition rate of minority samples, and data can be generated by generators to expand the minority classes from the data level. Experiments 1 and 2 show that this method has a good classification performance on imbalanced datasets. Experiment 1 confirmed that each category in the classification task exhibited good Precision, Recall, and F1-score by this method, with the F1-score, Precision, and Recall of the minority class (BMG) being 0.9432, 0.9644, and 0.9239, respectively. Experiment 2 confirmed that the cost-sensitive factor in this method has a beneficial effect on the Precision, Recall, and F1-score of each category, which affects minority categories more obviously than majority categories.
- -
- A cost-sensitive matrix design based on domain-knowledge embedding is proposed. In traditional methods, the determination of the misclassification cost is closely related to the number of samples in each class. Usually, the number of samples in the dataset or the proportion of samples of each class is taken as the misclassification cost, which cannot reflect the real class distribution characteristics of data well and cannot guarantee the effect of cost-sensitive learning. The proposed approach includes misclassification costs closely related to tasks by embedding domain knowledge. The design and performance of the cost matrix is improved by embedding domain knowledge. Experiment 3 verifies that the cost matrix embedded with domain knowledge can improve the performance of the proposed classifier.
2. Related Work
2.1. Research on Imbalanced Data Classification at the Data Level
2.2. Research on Imbalanced Data Classification at the Algorithm Level
2.2.1. Cost-Sensitive Method
2.2.2. Ensemble Learning Method
2.3. Research on Imbalanced Data Classification at Discriminant Criterion Level
3. Method and Algorithm
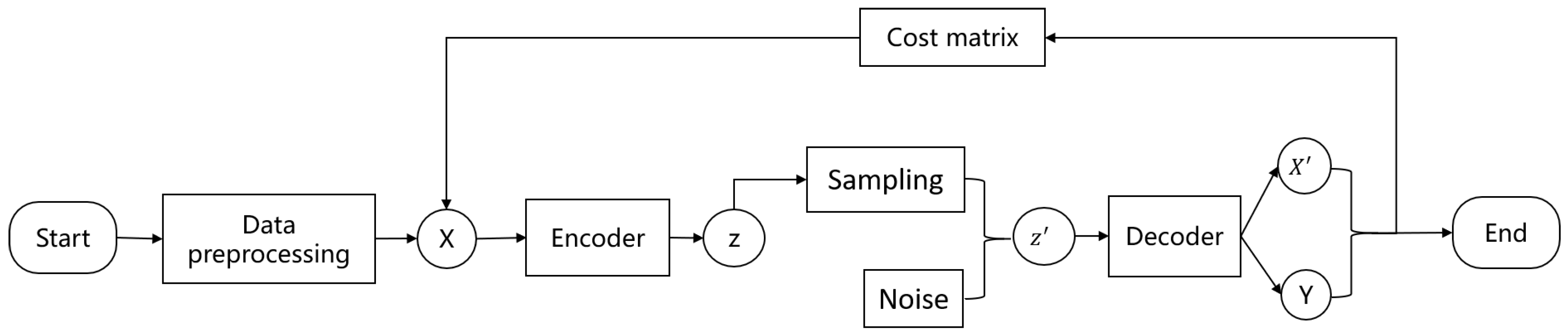
3.1. Overall Model
3.2. Cost-Sensitive Variational Auto-Encoder Classifier
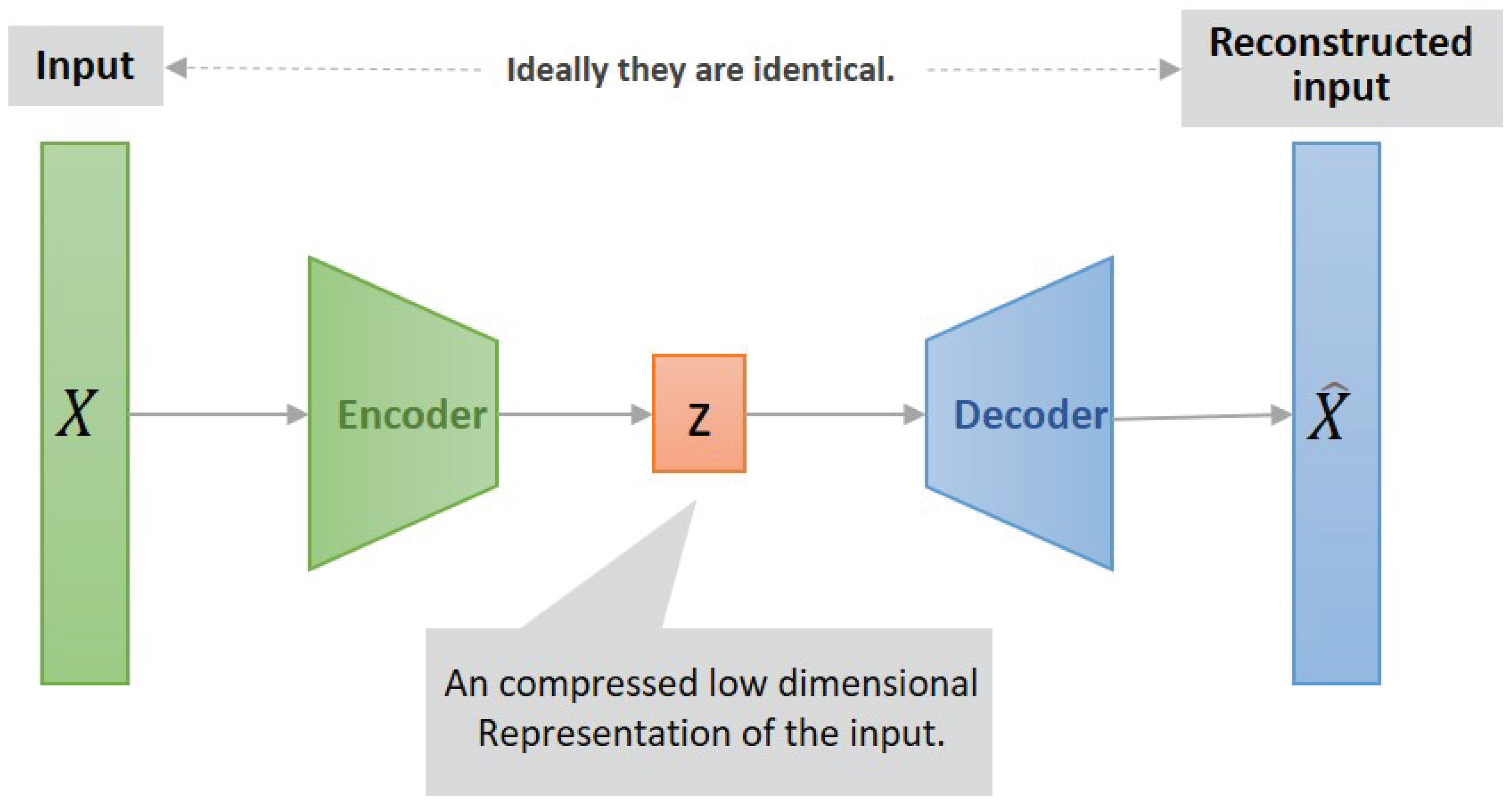
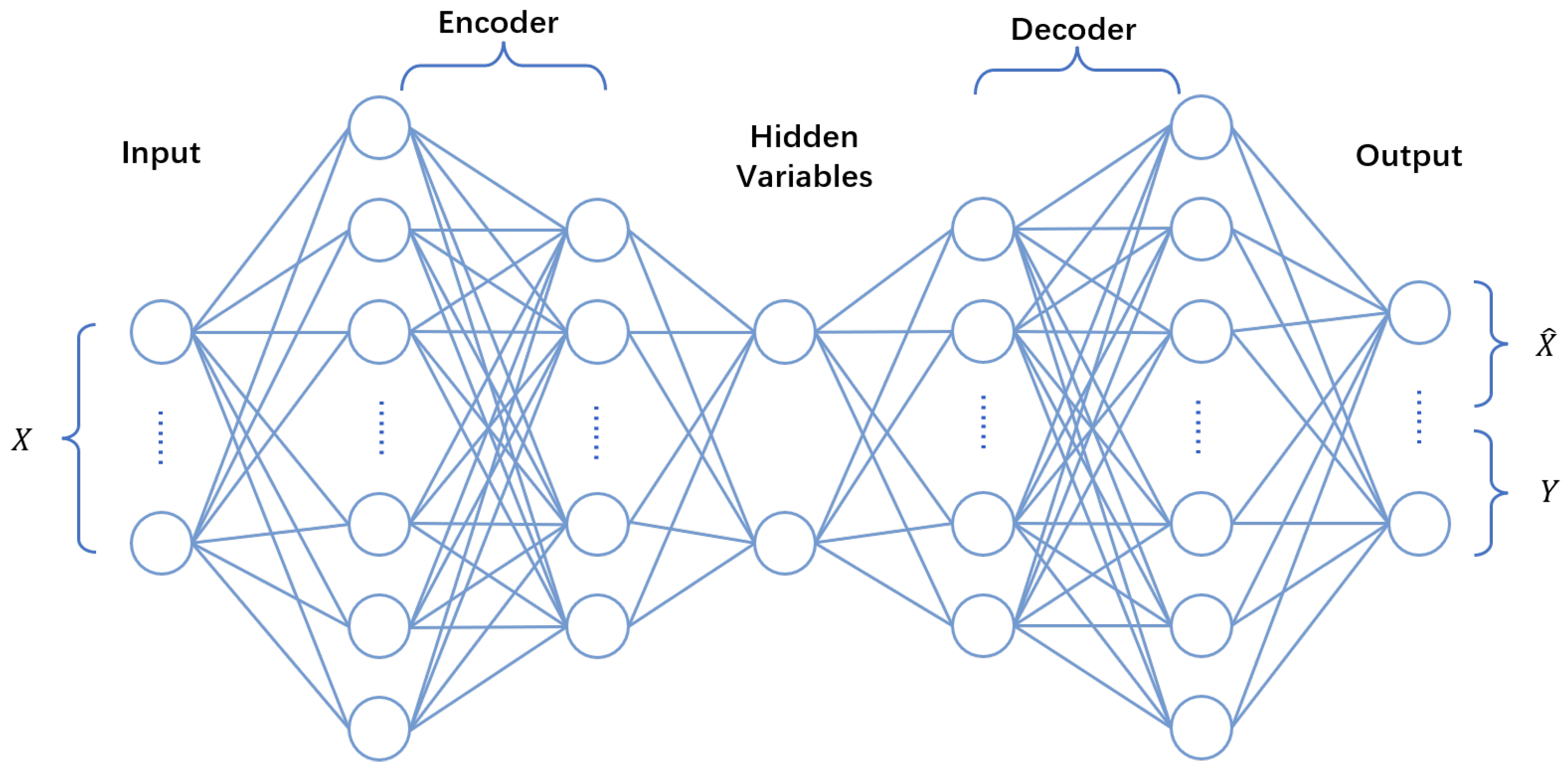
3.2.1. Variational Autoencoder
3.2.2. Variational Auto-Encoder Classifier
3.2.3. Classifier Design Based on Cost-Sensitive Factor
| Algorithm 1 Cost-sensitive Variational Autoencoding Classifier | |
| Input: training set , corresponding labels , loss weight , cost matrix | |
| Output: Model , | |
| 1: | Initialize model parameters and |
| 2: | fort in do |
| 3: | Sample in the minibatch: . |
| 4: | Encoder: . |
| 5: | Sampling: . |
| 6: | Decoder: . |
| 7: | Compute reconstruction loss: |
| 8: | . |
| 9: | Compute KL loss: |
| 10: | . |
| 11: | Compute classification loss: |
| 12: | . |
| 13: | Fuse the three losses: |
| 14: | . |
| 15: | Back propagation: . |
| 16: | Update: . |
| 17: | end for |
| 18: | return Model with parameters and |
4. Experimental Setup and Analysis of Results
4.1. Experimental Datasets
4.2. Design of Cost Sensitive Factor
4.3. Experimental Methods
4.4. Experimental Evaluation Criteria
4.5. Experimental Results and Analysis
4.5.1. Classification Performance of Cost-Sensitive VAE
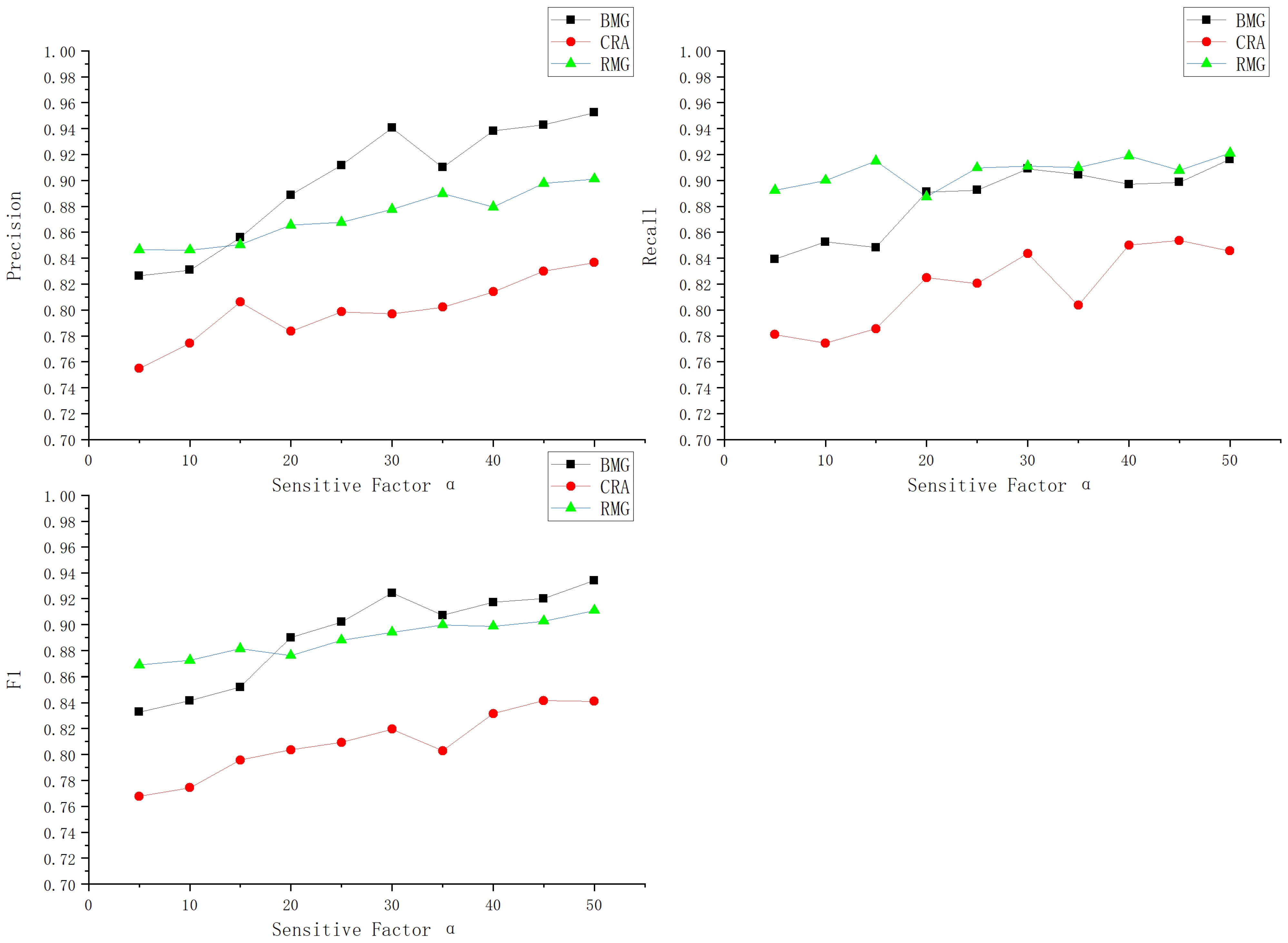
4.5.2. Impact of Different Cost-Sensitive Factor
4.5.3. Influence of Cost Matrix of Correct Domain Knowledge Embedding on F1-score
5. Discussion and Future Work
- -
- To address the imbalance of data categories, this method incorporates a cost-sensitive factor so that the misclassification cost of minority-class samples is high and that of majority-class samples is low. Then, the overall misclassification cost is used as the model optimization target to improve the classification accuracy of the minority class. The results of Experiment 1 show that, in the task of amorphous alloy material classification, the cost-sensitive VAE outperforms other algorithms that favor a particular class of metrics in a comprehensive way. The F1-score, Precision, and Recall metrics are higher for each class of the data. Among them, the F1-score, Precision, and Recall for the minority classes (BMG) were 0.9432, 0.9644, and 0.9239, respectively.
- -
- Through Experiment 2, it was shown that the F1-score, Precision, and Recall of the three types of data classifications also increased for increasing values of the adjustment factor , indicating that the cost-sensitive factor has an effect on the classification of the imbalanced data. For the minority class, the three evaluation criteria grew faster.
- -
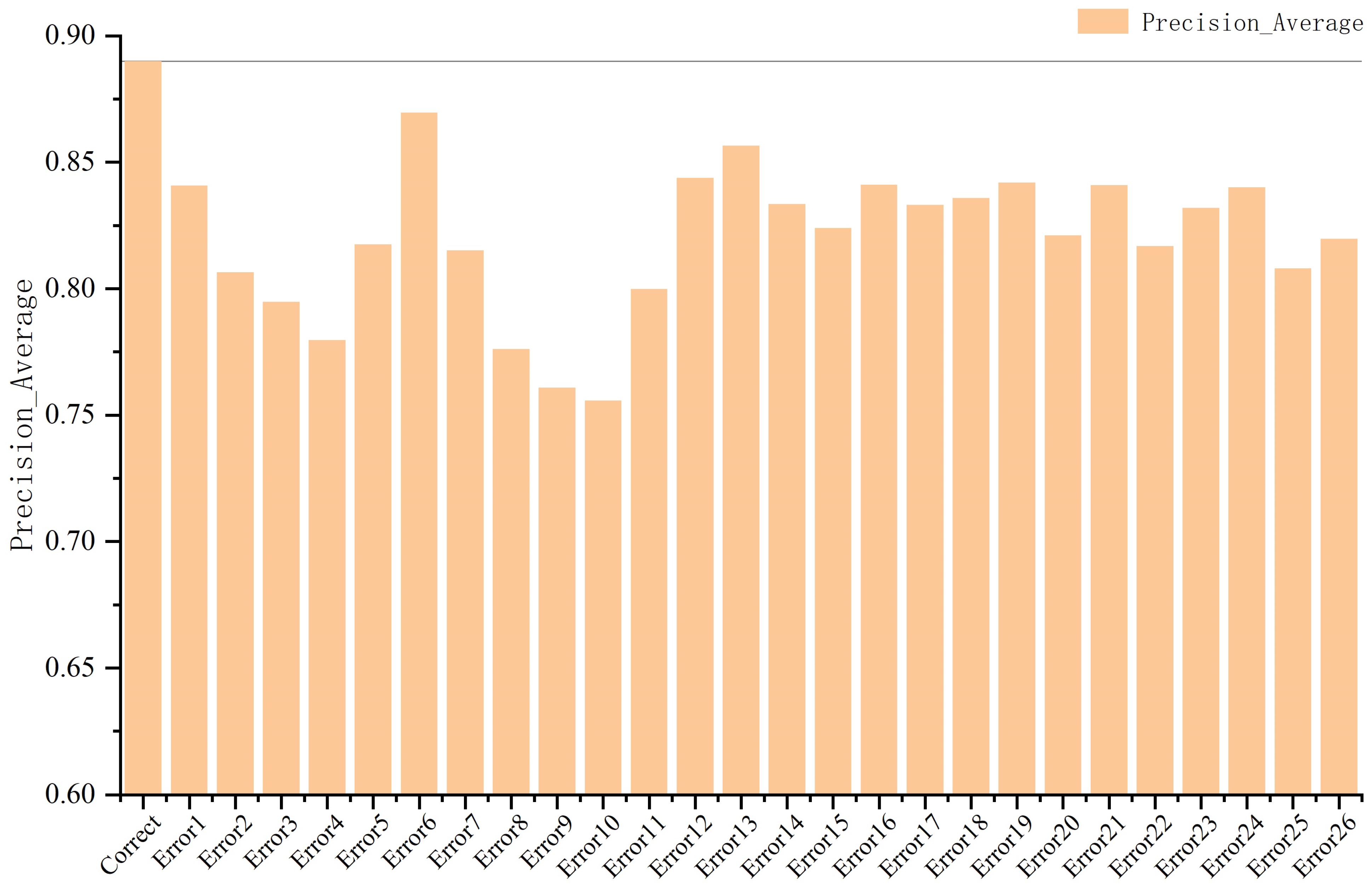
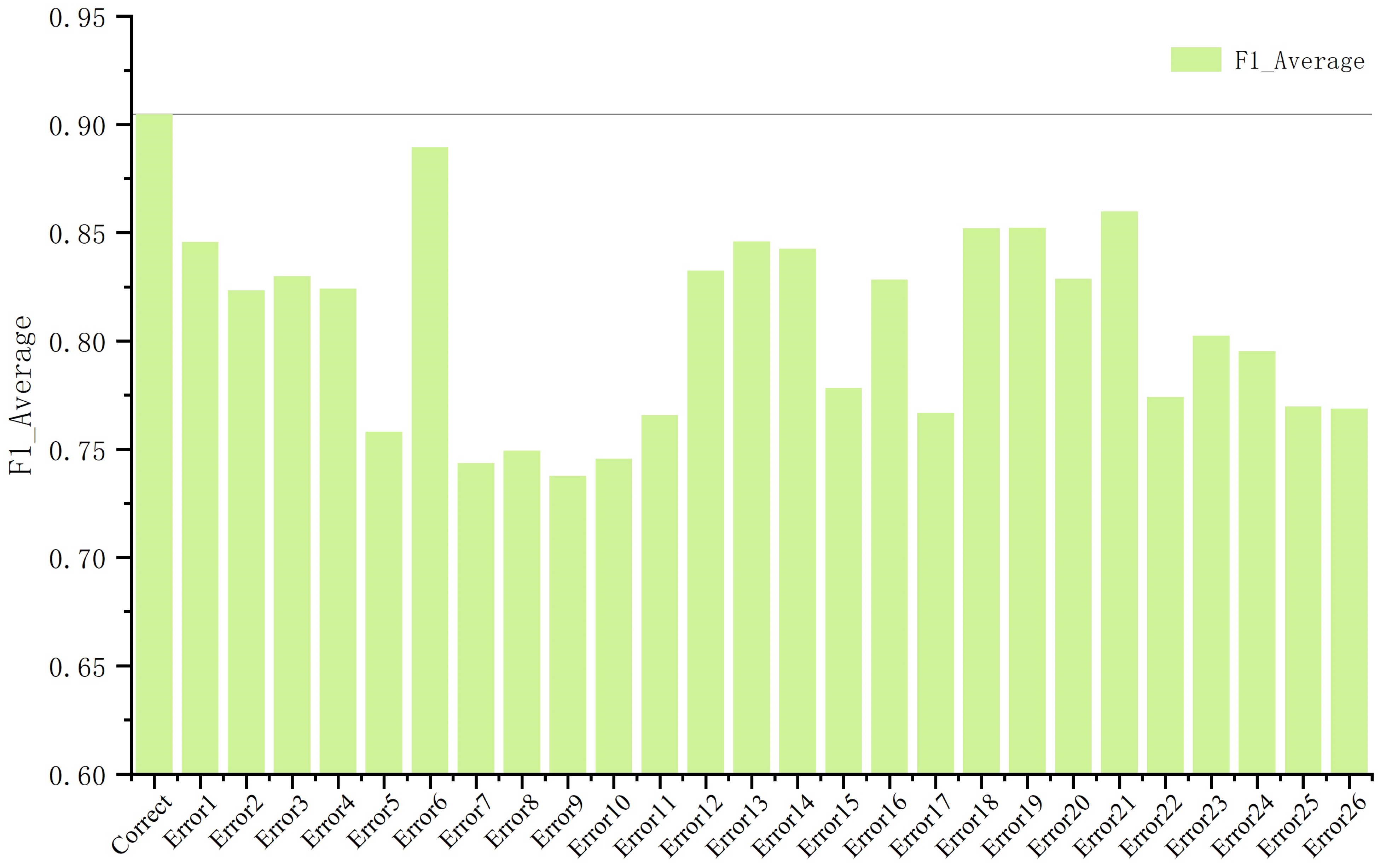
- The traditional method of designing the cost matrix is closely related to the number of samples, and generally takes the number of samples or the proportion of the number of samples as its cost, which cannot accurately reflect the real category distribution characteristics of the data. The proposed method combines the domain knowledge to design the cost matrix, and refines the cost-sensitive factor to make the cost matrix design more reasonable. The experimental results show that the method introducing correct domain knowledge results in a better F1-score, Precision, and Recall than other methods introducing wrong domain knowledge in the classification task of amorphous alloy materials. The results of Experiment 3 show that the algorithm introducing the cost matrix of correct domain knowledge exhibited a better F1-score, Precision, and Recall than the other five algorithms that introduced incorrect domain knowledge. The experimental results show that the correct cost matrix with domain knowledge can achieve a better classification effect, and that the embedding cost matrix with domain knowledge is effective.
- -
- Future studies can consider methods to learn the size of the three parameters H, M, and L through the algorithm adaptively; that is, methods designed to adaptively acquire domain knowledge adaptively.
- -
- In addition to the function of the cost-sensitive VAE classifier used in this study, the cost-sensitive VAE classifier can also generate new data by sampling the hidden variable Z and placing it into the decoder. Therefore, subsequent studies can also investigate how to compensate for the shortcomings of imbalanced datasets by generating new data.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Correct | Error1 | Error2 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| BMG | CRA | RMG | BMG | CRA | RMG | BMG | CRA | RMG | |
| BMG | 1 | H | H | 1 | H | H | 1 | H | H |
| CRA | M | 1 | M | M | 1 | M | M | 1 | M |
| RMG | L | L | 1 | M | M | 1 | H | H | 1 |
| Error3 | Error4 | Error5 | |||||||
| BMG | CRA | RMG | BMG | CRA | RMG | BMG | CRA | RMG | |
| BMG | 1 | H | H | 1 | H | H | 1 | H | H |
| CRA | L | 1 | L | L | 1 | L | L | 1 | L |
| RMG | L | L | 1 | M | M | 1 | H | H | 1 |
| Error6 | Error7 | Error8 | |||||||
| BMG | CRA | RMG | BMG | CRA | RMG | BMG | CRA | RMG | |
| BMG | 1 | H | H | 1 | H | H | 1 | H | H |
| CRA | H | 1 | H | H | 1 | H | H | 1 | H |
| RMG | L | L | 1 | M | M | 1 | H | H | 1 |
| Error9 | Error10 | Error11 | |||||||
| BMG | CRA | RMG | BMG | CRA | RMG | BMG | CRA | RMG | |
| BMG | 1 | L | L | 1 | L | L | 1 | L | L |
| CRA | M | 1 | M | M | 1 | M | M | 1 | M |
| RMG | L | L | 1 | M | M | 1 | H | H | 1 |
| Error12 | Error13 | Error14 | |||||||
| BMG | CRA | RMG | BMG | CRA | RMG | BMG | CRA | RMG | |
| BMG | 1 | L | L | 1 | L | L | 1 | L | L |
| CRA | L | 1 | L | L | 1 | L | L | 1 | L |
| RMG | L | L | 1 | M | M | 1 | H | H | 1 |
| Error15 | Error16 | Error17 | |||||||
| BMG | CRA | RMG | BMG | CRA | RMG | BMG | CRA | RMG | |
| BMG | 1 | L | L | 1 | L | L | 1 | L | L |
| CRA | H | 1 | H | H | 1 | H | H | 1 | H |
| RMG | L | L | 1 | M | M | 1 | H | H | 1 |
| Error18 | Error19 | Error20 | |||||||
| BMG | CRA | RMG | BMG | CRA | RMG | BMG | CRA | RMG | |
| BMG | 1 | M | M | 1 | M | M | 1 | M | M |
| CRA | M | 1 | M | M | 1 | M | M | 1 | M |
| RMG | L | L | 1 | M | M | 1 | H | H | 1 |
| Error21 | Error22 | Error23 | |||||||
| BMG | CRA | RMG | BMG | CRA | RMG | BMG | CRA | RMG | |
| BMG | 1 | M | M | 1 | M | M | 1 | M | M |
| CRA | L | 1 | L | L | 1 | L | L | 1 | L |
| RMG | L | L | 1 | M | M | 1 | H | H | 1 |
| Error24 | Error25 | Error26 | |||||||
| BMG | CRA | RMG | BMG | CRA | RMG | BMG | CRA | RMG | |
| BMG | 1 | M | M | 1 | M | M | 1 | M | M |
| CRA | H | 1 | H | H | 1 | H | H | 1 | H |
| RMG | L | L | 1 | M | M | 1 | H | H | 1 |
Appendix C
| Precision | Recall | F1-Score | |||||||
|---|---|---|---|---|---|---|---|---|---|
| BMG | CRA | RMG | BMG | CRA | RMG | BMG | CRA | RMG | |
| Correct | 0.9409 | 0.8313 | 0.8976 | 0.9200 | 0.7809 | 0.9239 | 0.9303 | 0.8734 | 0.9106 |
| Error1 | 0.8762 | 0.8214 | 0.8246 | 0.8178 | 0.6076 | 0.9245 | 0.8460 | 0.8196 | 0.8717 |
| Error2 | 0.8616 | 0.7597 | 0.7982 | 0.8119 | 0.5316 | 0.9070 | 0.8360 | 0.7849 | 0.8491 |
| Error3 | 0.8807 | 0.7221 | 0.7816 | 0.8533 | 0.4504 | 0.9091 | 0.8668 | 0.7823 | 0.8405 |
| Error4 | 0.8810 | 0.6898 | 0.7681 | 0.8667 | 0.4040 | 0.9036 | 0.8738 | 0.7682 | 0.8304 |
| Error5 | 0.9254 | 0.7745 | 0.7526 | 0.6252 | 0.4227 | 0.9401 | 0.7462 | 0.6919 | 0.8360 |
| Error6 | 0.9106 | 0.8255 | 0.8725 | 0.9052 | 0.7133 | 0.9231 | 0.9079 | 0.8635 | 0.8971 |
| Error7 | 0.8529 | 0.7946 | 0.7980 | 0.5926 | 0.6220 | 0.9153 | 0.6993 | 0.6789 | 0.8527 |
| Error8 | 0.8878 | 0.6892 | 0.7514 | 0.6563 | 0.4330 | 0.9040 | 0.7547 | 0.6724 | 0.8207 |
| Error9 | 0.8424 | 0.6949 | 0.7453 | 0.6415 | 0.4124 | 0.9045 | 0.7283 | 0.6671 | 0.8173 |
| Error10 | 0.8218 | 0.6944 | 0.7511 | 0.6696 | 0.4304 | 0.8959 | 0.7380 | 0.6818 | 0.8171 |
| Error11 | 0.9106 | 0.7360 | 0.7531 | 0.6637 | 0.4149 | 0.9277 | 0.7678 | 0.6980 | 0.8313 |
| Error12 | 0.9200 | 0.7787 | 0.8325 | 0.7837 | 0.6553 | 0.9102 | 0.8464 | 0.7812 | 0.8696 |
| Error13 | 0.9492 | 0.7830 | 0.8372 | 0.8030 | 0.6579 | 0.9167 | 0.8700 | 0.7928 | 0.8751 |
| Error14 | 0.8740 | 0.8015 | 0.8248 | 0.8222 | 0.6089 | 0.9167 | 0.8473 | 0.8117 | 0.8683 |
| Error15 | 0.8523 | 0.7863 | 0.8331 | 0.6667 | 0.7113 | 0.8994 | 0.7481 | 0.7216 | 0.8650 |
| Error16 | 0.8985 | 0.7919 | 0.8328 | 0.7733 | 0.6572 | 0.9132 | 0.8312 | 0.7825 | 0.8711 |
| Error17 | 0.9062 | 0.7821 | 0.8108 | 0.6296 | 0.6476 | 0.9142 | 0.7430 | 0.6976 | 0.8594 |
| Error18 | 0.8827 | 0.8005 | 0.8240 | 0.8474 | 0.5969 | 0.9177 | 0.8647 | 0.8233 | 0.8683 |
| Error19 | 0.8894 | 0.8265 | 0.8099 | 0.8341 | 0.5738 | 0.9293 | 0.8609 | 0.8303 | 0.8655 |
| Error20 | 0.9161 | 0.7519 | 0.7954 | 0.8089 | 0.5481 | 0.9078 | 0.8592 | 0.7793 | 0.8479 |
| Error21 | 0.8741 | 0.8066 | 0.8418 | 0.8637 | 0.6450 | 0.9142 | 0.8689 | 0.8342 | 0.8765 |
| Error22 | 0.8752 | 0.7698 | 0.8053 | 0.6652 | 0.6205 | 0.9059 | 0.7559 | 0.7137 | 0.8526 |
| Error23 | 0.8796 | 0.8003 | 0.8158 | 0.7141 | 0.6250 | 0.9186 | 0.7882 | 0.7547 | 0.8641 |
| Error24 | 0.8736 | 0.8302 | 0.8163 | 0.6859 | 0.6598 | 0.9229 | 0.7685 | 0.7512 | 0.8663 |
| Error25 | 0.8602 | 0.7583 | 0.8054 | 0.6652 | 0.6209 | 0.8997 | 0.7502 | 0.7087 | 0.8499 |
| Error26 | 0.8404 | 0.7905 | 0.8283 | 0.6474 | 0.7049 | 0.9005 | 0.7314 | 0.7118 | 0.8629 |
References
- Wu, X.; Kumar, V.; Quinlan, J.R.; Ghosh, J.; Yang, Q.; Motoda, H.; Mclachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Chawla, N.V.; Japkowicz, N.; Kotcz, A. Editorial: Special issue on learning from imbalanced data sets. SIGKDD Explor. 2004, 6, 1–6. [Google Scholar] [CrossRef]
- Kubat, M.; Holte, R.C.; Matwin, S. Machine Learning for the Detection of Oil Spills in Satellite Radar Images. Mach. Learn. 1998, 30, 195–215. [Google Scholar] [CrossRef] [Green Version]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Provost, F.J.; Weiss, G.M. Learning When Training Data are Costly: The Effect of Class Distribution on Tree Induction. arXiv 2011, arXiv:1106.4557. [Google Scholar]
- Chawla, N.; Japkowic, N.; Kotcz, A.; Japkowicz, N. Editorial: Special issues on learning from imbalanced data sets. Ann. Nucl. Energy 2004, 36, 255–257. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.; Mao, B. Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning. In Advances in Intelligent Computing, Proceedings of the International Conference on Intelligent Computing, ICIC 2005, Hefei, China, 23–26 August 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 878–887, Part I. [Google Scholar]
- Zhu, T.; Lin, Y.; Liu, Y. Synthetic minority oversampling technique for multiclass imbalance problems. Pattern Recognit. 2017, 72, 327–340. [Google Scholar] [CrossRef]
- Czarnowski, I. Learning from Imbalanced Data Using Over-Sampling and the Firefly Algorithm. In Proceedings of the Computational Collective Intelligence—13th International Conference, ICCCI 2021, Rhodes, Greece, 29 September–1 October 2021. [Google Scholar]
- Czarnowski, I. Learning from Imbalanced Data Streams Based on Over-Sampling and Instance Selection. In Proceedings of the Computational Science—ICCS 2021—21st International Conference, Krakow, Poland, 16–18 June 2021. Part III. [Google Scholar]
- Mayabadi, S.; Saadatfar, H. Two density-based sampling approaches for imbalanced and overlapping data. Knowl. Based Syst. 2022, 241, 108217. [Google Scholar] [CrossRef]
- Weiss, G.M. Mining with rarity. ACM SIGKDD Explor. Newsl. 2004, 6, 7–19. [Google Scholar] [CrossRef]
- Kubat, M.; Matwin, S. Addressing the Curse of Imbalanced Training Sets: One-Sided Selection. In Proceedings of the Fourteenth International Conference on Machine Learning (ICML 1997), Nashville, TN, USA, 8–12 July 1997. [Google Scholar]
- Yen, S.J.; Lee, Y.S. Cluster-based under-sampling approaches for imbalanced data distributions. Expert Syst. Appl. 2009, 36, 5718–5727. [Google Scholar] [CrossRef]
- Du, S.; Chen, S. Weighted support vector machine for classification. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Waikoloa, HI, USA, 10–12 October 2005. [Google Scholar]
- Freund, Y. Boosting a Weak Learning Algorithm by Majority. Inf. Comput. 1995, 121, 256–285. [Google Scholar] [CrossRef]
- Sahin, Y.; Bulkan, S.; Duman, E. A cost-sensitive decision tree approach for fraud detection. Expert Syst. Appl. 2013, 40, 5916–5923. [Google Scholar] [CrossRef]
- Dhar, S.; Cherkassky, V. Development and Evaluation of Cost-Sensitive Universum-SVM. IEEE Trans. Cybern. 2015, 45, 806–818. [Google Scholar] [CrossRef] [PubMed]
- Li, D.; Du, S.; Wu, T. A weighted support vector machine method and its application. J. Nat. Gas Sci. Eng. 2004, 2, 1834–1837. [Google Scholar]
- Zhang, Z.; Luo, X.; García, S.; Herrera, F. Cost-Sensitive back-propagation neural networks with binarization techniques in addressing multi-class problems and non-competent classifiers. Appl. Soft Comput. 2017, 56, 357–367. [Google Scholar] [CrossRef]
- Shen, W.; Wang, X.; Wang, Y.; Bai, X.; Zhang, Z. DeepContour: A Deep Convolutional Feature Learned by Positive-sharing Loss for Contour Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Chung, Y.; Lin, H.; Yang, S. Cost-Aware Pre-Training for Multiclass Cost-Sensitive Deep Learning. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, IJCAI 2016, New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Domingos, P.M. MetaCost: A General Method for Making Classifiers Cost-Sensitive. In Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999. [Google Scholar]
- Madong, S. What Is the MetaCost. Available online: https://zhuanlan.zhihu.com/p/85527467 (accessed on 8 October 2019).
- Galar, M.; Fernández, A.; Barrenechea, E.; Sola, H.; Herrera, F. A Review on Ensembles for the Class Imbalance Problem: Bagging-, Boosting-, and Hybrid-Based Approaches. Trans. Syst. Man Cybern. Part C Appl. Rev. 2012, 42, 463–484. [Google Scholar] [CrossRef]
- Zhang, X.; Zhuang, Y.; Wang, W.; Pedrycz, W. Transfer Boosting with Synthetic Instances for Class Imbalanced Object Recognition. IEEE Trans. Cybern. 2018, 48, 357–370. [Google Scholar] [CrossRef]
- Schapire, R.E. The strength of weak learnability. Proc. Second. Annu. Workshop Comput. Learn. Theory 1989, 5, 197–227. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a New Boosting Algorithm. In Machine Learning, Proceedings of the Thirteenth International Conference (ICML ’96), Bari, Italy, 3–6 July 1996; Lorenza Saitta: Bari, Italy, 1996; pp. 148–156. [Google Scholar]
- Fan, W.; Stolfo, S.J.; Zhang, J.; Chan, P.K. AdaCost: Misclassification Cost-Sensitive Boosting. In Proceedings of the Sixteenth International Conference on Machine Learning (ICML 1999), Bled, Slovenia, 27–30 June 1999. [Google Scholar]
- Sun, Y.; Kamel, M.S.; Wong, A.K.C.; Wang, Y. Cost-sensitive boosting for classification of imbalanced data. Pattern Recognit. 2007, 40, 3358–3378. [Google Scholar] [CrossRef]
- Chawla, N.; Lazarevic, A.; Hall, L.; Bowyer, K. SMOTEBoost: Improving Prediction of the Minority Class in Boosting. In Proceedings of the 7th European Conference on Principles of Data Mining and Knowledge Discovery, Cavtat-Dubrovnik, Croatia, 22–26 September 2003; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Feng, W.; Huang, W.; Ren, J. Class Imbalance Ensemble Learning Based on the Margin Theory. Appl. Sci. 2018, 8, 815. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Shen, S.; Li, D. Imbalanced Data Integration learning method based on updating sample weight. Comput. Sci. 2018, 45, 31–37. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Dong, J.; Qian, Q. A Density-Based Random Forest for Imbalanced Data Classification. Future Internet 2022, 14, 90. [Google Scholar] [CrossRef]


| BMG | CRA | RMG | |
|---|---|---|---|
| BMG | 1 | High | High |
| CRA | Medium | 1 | Medium |
| RMG | Low | Low | 1 |
| Algorithm | Main Parameters |
|---|---|
| Support Vector Machine | C = 1.0, Kernel = ‘rbf’ |
| K-Nearest Neighbour | N Neighbours = 5 |
| Decision Tree | Criterion = ‘gini’ |
| Bayes | Priors = None |
| Random Forest | N Estimators = 10 |
| Cost-Sensitive VAE | L = 15, = 25 |
| F1-Score | Recall | Precision | |||||||
|---|---|---|---|---|---|---|---|---|---|
| BMG | CRA | RMG | BMG | CRA | RMG | BMG | CRA | RMG | |
| Random Forest | 0.9427 | 0.8016 | 0.9184 | 0.9259 | 0.7318 | 0.9428 | 0.9601 | 0.7651 | 0.8953 |
| Support Vector Machine | 0.8017 | 0.6408 | 0.8604 | 0.6919 | 0.5271 | 0.9458 | 0.9531 | 0.8172 | 0.7892 |
| K-Nearest Neighbour | 0.9210 | 0.7497 | 0.8968 | 0.9244 | 0.6765 | 0.9328 | 0.9176 | 0.8407 | 0.8635 |
| Decision Tree | 0.8835 | 0.7417 | 0.8790 | 0.8933 | 0.7403 | 0.8805 | 0.8739 | 0.7539 | 0.8775 |
| Bayes | 0.4619 | 0.5784 | 0.6167 | 0.7274 | 0.6488 | 0.5208 | 0.3384 | 0.5218 | 0.7516 |
| Cost-sensitive VAE | 0.9432 | 0.8809 | 0.9213 | 0.9230 | 0.8209 | 0.9299 | 0.9644 | 0.8426 | 0.9129 |
| F1-Score | Recall | Precision | |||||||
|---|---|---|---|---|---|---|---|---|---|
| BMG | CRA | RMG | BMG | CRA | RMG | BMG | CRA | RMG | |
| Random Forest (Imbalanced) | 0.9380 | 0.7826 | 0.9038 | 0.9529 | 0.9237 | 0.7748 | 0.9098 | 0.79058 | 0.8979 |
| Support Vector Machine (Imbalanced) | 0.75 | 0.6536 | 0.7844 | 0.9389 | 0.7185 | 0.7188 | 0.6244 | 0.5994 | 0.8631 |
| DBRF | 0.9430 | 0.8225 | 0.9163 | 0.9437 | 0.8209 | 0.9169 | 0.9423 | 0.8241 | 0.9157 |
| Cost-Sensitive VAE | 0.9432 | 0.8809 | 0.9213 | 0.9230 | 0.8209 | 0.9299 | 0.9644 | 0.8426 | 0.9129 |
| Correct | Error1 | Error2 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| BMG | CRA | RMG | BMG | CRA | RMG | BMG | CRA | RMG | |
| BMG | 1 | H | H | 1 | H | H | 1 | H | H |
| CRA | M | 1 | M | L | 1 | L | L | 1 | L |
| RMG | L | L | 1 | L | L | 1 | H | H | 1 |
| Error3 | Error4 | None | |||||||
| BMG | CRA | RMG | BMG | CRA | RMG | BMG | CRA | RMG | |
| BMG | 1 | L | L | 1 | L | L | 1 | L | L |
| CRA | L | 1 | L | H | 1 | H | H | 1 | H |
| RMG | H | H | 1 | L | L | 1 | H | H | 1 |
| Precision | Recall | F1-Score | |||||||
|---|---|---|---|---|---|---|---|---|---|
| BMG | CRA | RMG | BMG | CRA | RMG | BMG | CRA | RMG | |
| Correct | 0.9409 | 0.8313 | 0.8976 | 0.9200 | 0.7809 | 0.9239 | 0.9303 | 0.8734 | 0.9106 |
| Error1 | 0.8807 | 0.7221 | 0.7816 | 0.8533 | 0.4504 | 0.9091 | 0.8668 | 0.7823 | 0.8405 |
| Error2 | 0.9254 | 0.7745 | 0.7526 | 0.6252 | 0.4227 | 0.9401 | 0.7462 | 0.6919 | 0.8360 |
| Error3 | 0.9106 | 0.7360 | 0.7531 | 0.6637 | 0.4149 | 0.9277 | 0.7678 | 0.6980 | 0.8313 |
| Error4 | 0.8523 | 0.7863 | 0.8331 | 0.6667 | 0.7113 | 0.8994 | 0.7481 | 0.7216 | 0.8650 |
| Error5 | 0.9062 | 0.7821 | 0.8108 | 0.6296 | 0.6476 | 0.9142 | 0.7430 | 0.6976 | 0.8594 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, F.; Qian, Q. Cost-Sensitive Variational Autoencoding Classifier for Imbalanced Data Classification. Algorithms 2022, 15, 139. https://doi.org/10.3390/a15050139
Liu F, Qian Q. Cost-Sensitive Variational Autoencoding Classifier for Imbalanced Data Classification. Algorithms. 2022; 15(5):139. https://doi.org/10.3390/a15050139
Chicago/Turabian StyleLiu, Fen, and Quan Qian. 2022. "Cost-Sensitive Variational Autoencoding Classifier for Imbalanced Data Classification" Algorithms 15, no. 5: 139. https://doi.org/10.3390/a15050139
APA StyleLiu, F., & Qian, Q. (2022). Cost-Sensitive Variational Autoencoding Classifier for Imbalanced Data Classification. Algorithms, 15(5), 139. https://doi.org/10.3390/a15050139