In this section, we evaluate the performances of our GSSNMF on the California Innocence Project dataset [
18] and the 20 Newsgroups dataset [
19]. Specifically, we compare GSSNMF with SSNMF for performance in classification (measured by the Macro-F1 score, i.e., the averaged F1-score which is sensitive to different distributions of different classes [
20]) and with classical NMF, TS-NMF, and Guided NMF for performance in topic modeling (measured by the
coherence score [
21]).
4.1. Pre-Processing of the CIP Dataset
A nonprofit, clinical law school program hosted by the California Western School of Law, the California Innocence Project (CIP) focuses on freeing wrongfully-convicted prisoners, reforming the criminal justice system, and training upcoming law students [
18]. Every year, the CIP receives over 2000+ requests for help, each containing a case file of legal documents. Within each case file, the
Appellant’s Opening Brief (AOB) is a legal document written by an appellant to argue for innocence by explaining the mistakes made by the court. This document contains crucial information about the crime types relevant to the case, as well as potential evidence within the case [
18]. For our final dataset, we include all AOBs in case files that have assigned crime labels, totaling 203 AOBs. Each AOB is thus associated with one or more of thirteen crime labels:
assault,
drug,
gang,
gun,
kidnapping,
murder,
robbery,
sexual,
vandalism,
manslaughter,
theft,
burglary, and
stalking.
To pre-process data, we remove numbers, symbols, and stopwords according to the NLTK English stopwords list [
22] from all AOBs; we also perform stemming to reduce inflected words to their original word stem. Following the work of [
18,
23,
24], we apply
term-frequency inverse document frequency (TF-IDF) [
25] to our dataset of AOBs. TF-IDF retains the relative simplicity of a bag-of-words representation while additionally moderating the impact of words that are common to every document, which can be detrimental to performance [
26,
27,
28,
29]. We generated the corpus matrix
with parameters
max_df = 0.8,
min_df=0.04, and
max_features = 700 in the function
TfidfVectorizer.
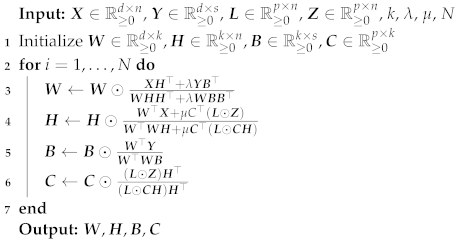
For our topic modeling methods, we need to preset the potential number of topics, which corresponds to the rank of corpus matrix
. To determine the proper range of the number of topics, we analyze the singular values of
. The magnitudes of singular values are positively related to the increment in proportion variance explained by adding on more topics, or increasing rank, to split the corpus matrix
[
30]. In this way, we use the number of singular values to approximate the rank of
.
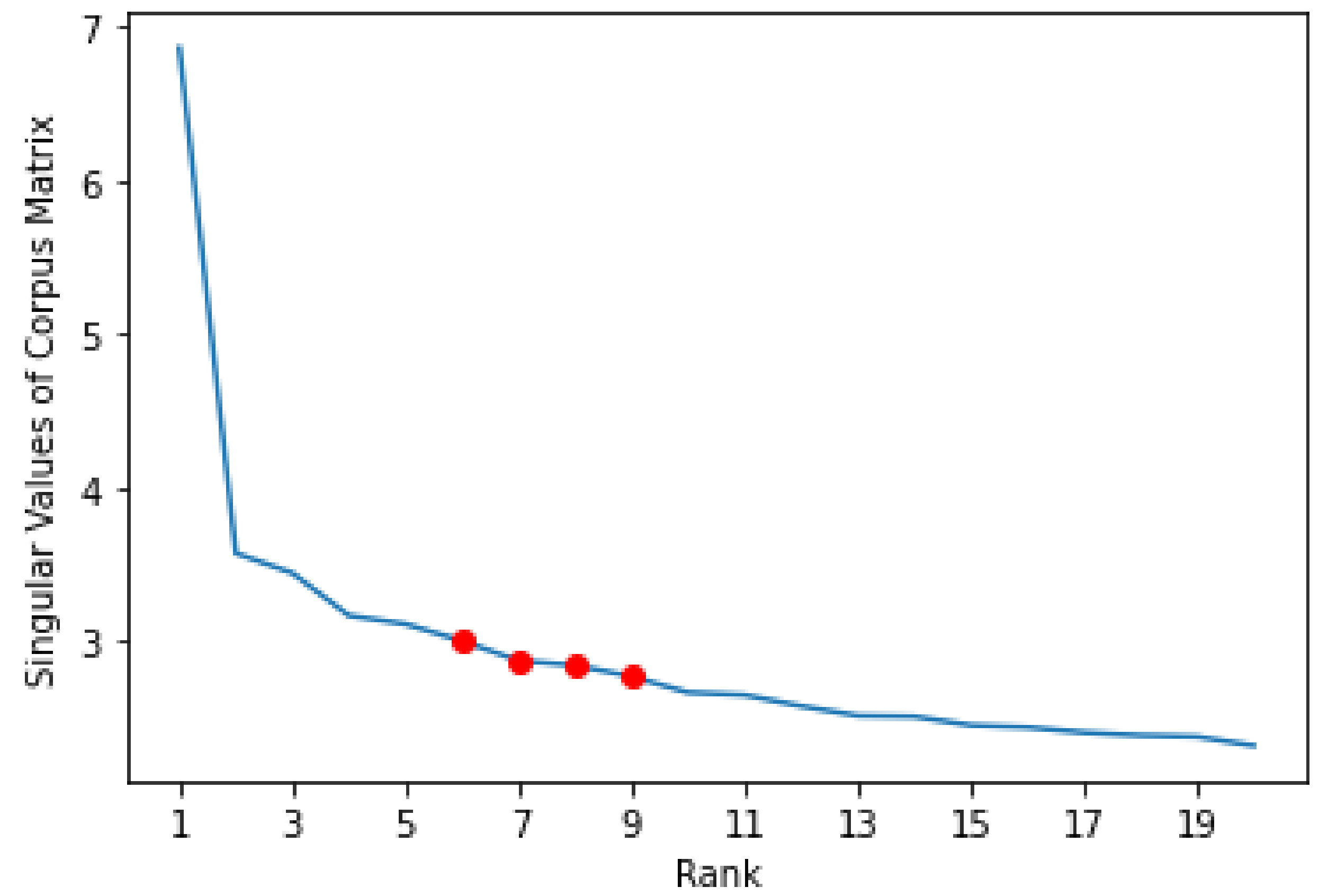
Figure 1 plots the magnitudes of the singular values of corpus matrix
against the number of singular values, which is also the approximated rank. By examining this plot, we see that a range for potential rank is between 6 to 9, since the magnitudes of the singular values start to level off around this range.
4.2. Classification on the CIP Dataset
Taking advantage of Cross-Validation methods [
31], we randomly split all AOBs into
training set with labeled information and
testing set without labels. In practice,
of the columns of the masking matrix
are set to
for the training set, and the rest are set to
for the testing set. As a result, the label matrix
is masked by
into a corresponding training label matrix
and a corresponding testing label matrix
. We then perform SSNMF and GSSNMF to reconstruct
by setting the number of topics as 8. Given the multi-label characteristics of the AOBs, we compare the performance between SSNMF and GSSNMF with a measure of classification accuracy: the
Macro F1-score, which is designed to access the quality of multi-label classification on
[
20]. The Macro F1-score is defined as
where
p is the number of labels and F1-score
is the F1-score for topic
i. Notice that the Macro F1-score treats each class with equal importance; thus, it will penalize models which only perform well on major labels but not minor labels. In order to handle the multi-label characteristics of the AOB dataset, we first extract the number of labels assigned to each AOB in the testing dataset. Then, for each corresponding column
i of the reconstructed
, we set the largest
elements in each column to be 1 and the rest to be 0, where
is the actual number of labels assigned to the
ith document in the testing set.
We first tune the parameter of
in SSNMF to identify a proper range of
for which SSNMF performs the best on the AOB dataset under the Macro F1-score. Then, for each selected
in the proper range, we run GSSNMF with another range of
. While there are various choices of seed words, we naturally pick the class labels themselves as seed words for our implementation of GSSNMF. As a result, for each combination of
, we conduct 10 independent Cross-Validation trials and average the Macro F1-scores. The results are displayed in
Figure 2.
We see that, in general, when incorporating the extra information from seed words, GSSNMF has a higher Macro F1-score than SSNMF. As an example, we extract the reconstructed testing label matrix by SSNMF and GSSNMF along with the actual testing label matrix from a single trial. In this instance, SSNMF has a Macro F1-score of 0.672 while GSSNMF has a Macro F1-score of 0.765. By comparing the reconstructed matrices with the actual label matrix, we generate two difference matrices representing the correct and incorrect labels produced by the two methods respectively. The matrices are visualized in
Figure 3. Given the fact that
murder is a major label, without the extra information from seed words, SSNMF makes many incorrect classifications on the major label murder. In comparison, through user-specified seed words, GSSNMF not only reduces the number of incorrect classifications along the major label murder, but also better evaluates the assignment of other labels, achieving an improved classification accuracy.
4.3. Topic Modeling on the CIP Dataset
In this section, we test the performance of GSSNMF for topic modeling by comparing it with Classical NMF, Guided NMF, and TS-NMF on the CIP AOB dataset. Specifically, we conduct experiments for the range of rank identified in
Section 4.1, running tests for various values of
and
for each rank. To measure the effectiveness of the topics discovered by Guided NMF and GSSNMF, we calculate the
topic coherence score defined in [
21] for each topic. The coherence score
for each topic
i with
N most probable keywords is given by
In the above Equation (
8),
denotes the
document frequency of keyword
w, which is calculated by counting the number of documents that keyword
w appears in at least once.
denotes the
co-document frequency of keyword
w and
, which is obtained by counting the number of documents that contain both
w and
. In general, the topic coherence score seeks to measure how well the keywords that define a topic make sense as a whole to a human expert, providing a means for consistent interpretation of accuracy in topic generation. A large positive
coherence score indicates that the keywords from a topic are highly cohesive, as judged by a human expert.
Since we are judging the performance of methods that generate multiple topics, we calculate coherence scores
for each topic that is generated by Guided NMF or GSSNMF and then take the average. Thus, our final measure of performance for each method is the
averaged coherence score :
where
k is the number of topics (or rank) we have specified.
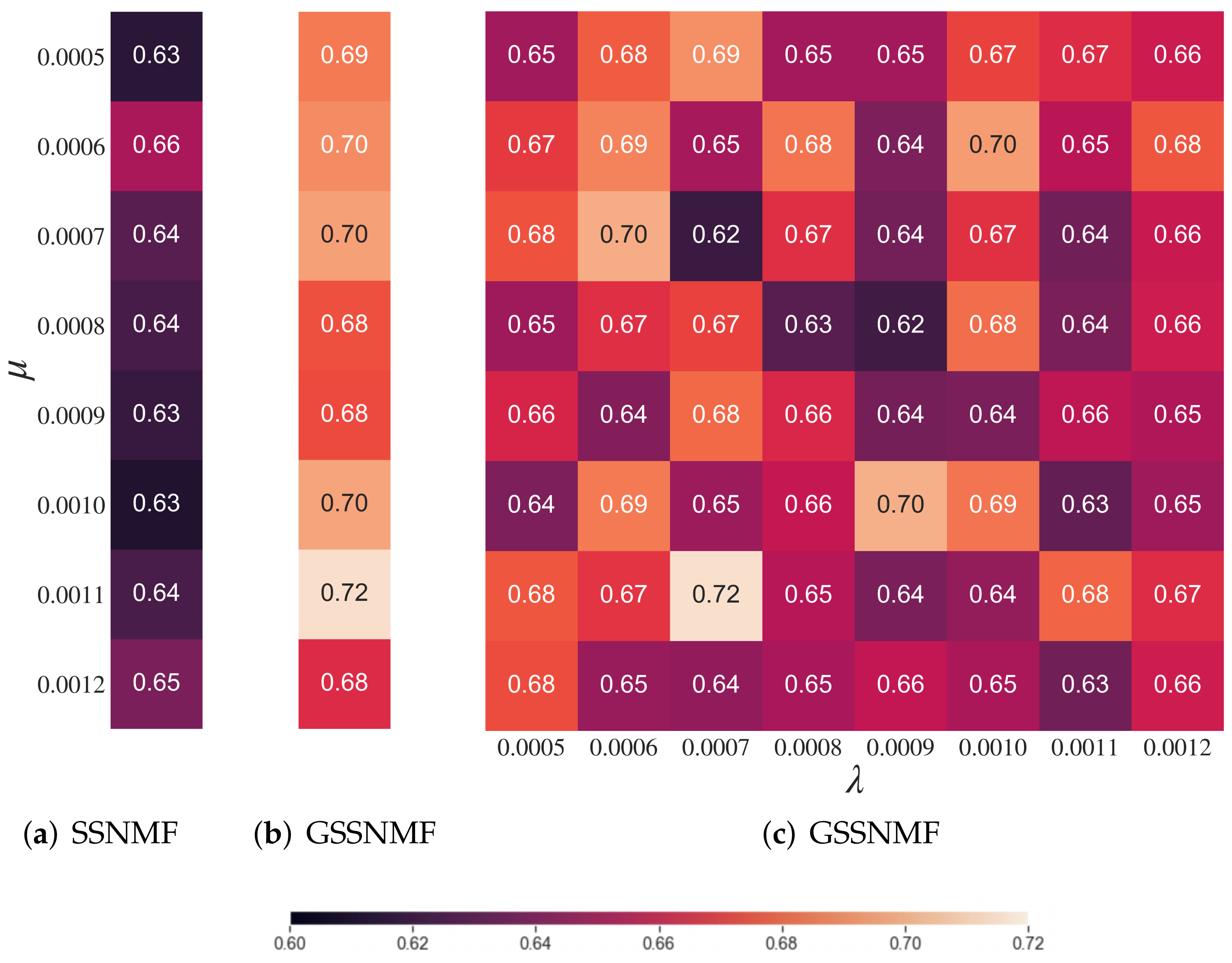
As suggested by
Figure 1, a proper rank falls between 6 and 9. Starting with the generation of 6 topics from the AOB dataset, we first find a range of
in which Guided NMF generates the highest mean
over 10 independent trials. In our computations, we use the top 30 keywords of each topic to generate each coherence score; then, for each trial, we obtain an individual
, allowing us to average the 10
from the 10 trials into the mean
. Based on the proper range of
, we then choose a range of
for our GSSNMF to incorporate the label information into topic generation. Again, for each pair of
, we run 10 independent trials of GSSNMF and calculate
for each trial to generate a mean
. With these ranges in mind, we work towards the following goal: for a given “best"
of Guided NMF, we improve topic generation performance by implementing GSSNMF with a “best”
that balances how much weight GSSNMF should place on the new information of predetermined labels for each document. We then repeat the same process for ranks 7, 8, and 9, and plot the mean
against each
in
Figure 4. The corresponding choice of
can be found in
Appendix B. We can see that, most of the time, for a given
, we are able to find such
that GSSNMF can generate a higher mean
than Guided NMF in topic modeling across various ranks. Ultimately, we also see that a GSSNMF result always outperforms even the highest-performing Guided NMF result.
In
Table 1, we provide an example of the outputs of topic modeling from Guided NMF using
and from GSSNMF using
and
for a rank of 7. Note that we output only the top 10 keywords under each identified topic group for ease of viewing, but our coherence scores are measured using the top 30 keywords. Thus, while the top 10 probable keywords of the generated topics may look similar across the two methods, and the coherence scores calculated from the top 30 probable keywords reveal that GSSNMF produces more coherent topics as a whole in comparison to Guided NMF. Specifically, GSSNMF demonstrates an ability to produce topics with similar levels of coherence (as seen from the small variance in individual coherence scores
of each topic), while Guided NMF produces topics that may vary in level of coherence (as seen from the large variance in individual coherence scores
for each topic). This further illustrates that GSSNMF is able to use the additional label information to execute topic modeling with better coherence.
We also compare GSSNMF to two other NMF methods—classical NMF and TS-NMF—on the basis of topic modeling performance on the CIP dataset. Following our methodology for applying GSSNMF to this data, we ran 10 independent trials of classical NMF for each rank from 6 to 9 and computed the mean
for each rank. The results for classical NMF, Guided NMF, and GSS-NMF using ranks 6–9 are summarized in
Table 2. For the rank 6–9 approximations, while classical NMF slightly outperforms GSSNMF on the basis of the topic coherence score
, GSSNMF retains the advantage that the generated topics are guided by a priori information, whereas classical NMF has no such guarantee. As noted in
Section 2.4, when TS-NMF is applied for topic modeling, the number of latent topics must be exactly equal to the number of different labels. In the case of the CIP data, the AOBs have 13 possible labels, so we ran TS-NMF on the CIP data with a rank of 13, computing
over 10 independent trials. TS-NMF (using rank 13) had
, which outperforms our recorded GSSNMF results for the same data. This could be a result of the structure of the CIP dataset, together with being constrained to use a rank of 13 when applying TS-NMF. As shown in
Table 3, at least four of the topics generated by TS-NMF were all clearly related to gang activity, which is one of the labels used by TS-NMF. While the resulting topics are highly coherent, the abundance of closely related topics obscures the latent structure of the data. This arises from the fact that TS-NMF must use a rank exactly equal to the number of different labels, which may not accurately reflect the true low-rank structure of the data. In this case, we see that this splits larger topics into more specific subtopics that have several words in common. This increases
, but the resulting topics do not correspond well to the original labels.
4.4. Pre-Processing of the 20 Newsgroups Dataset
The original 20 Newsgroups dataset [
19] is a collection of around 20,000 individual news documents. The dataset is organized into 20 different Newsgroups, each corresponding to a topic. For this experiment, we select documents from nine newsgroups. From each group, we randomly select 200 documents. As a result, our dataset contains a total of 1800 documents from the categories:
comp.graphics, comp.sys.mac.hardware, sci.crypt, rec.motorcycles, rec.sport.baseball, sci.med, sci.space, talk.politics.guns, talk.religion.misc. We then evaluate the performance of GSSNMF on this subset of the original 20 Newsgroups data.
To pre-processs the data, we follow the same approaches as for the CIP data, namely, removing numbers, symbols, and stopwords, and stemming the remaining words. Using TF-IDF, we generated the corpus matrix with parameters max_df = , and max_features = 2000 in the function TfidfVectorizer.
To determine the potential number of topics for these data, we also analyze the singular values of
.
Figure 5 demonstrates the distribution of the singular values of
, which is also the potential number of topics. From
Figure 5, one can see that the potential topic number should be between 6 to 9 where the magnitudes of the singular values start to level off.
4.5. Classification on the 20 Newsgroups Dataset
For classification, we follow a similar approach to [
14] so that comparisons may be drawn. Namely, we group the nine selected topics into five classes, as described in
Table 4, i.e., we view the data as containing five classes, which may be subdivided into nine latent topics. Training label data are then constructed for these five classes, and seed words are designed for each of the nine topics. Further details in the methodology are identical to those in
Section 4.2.
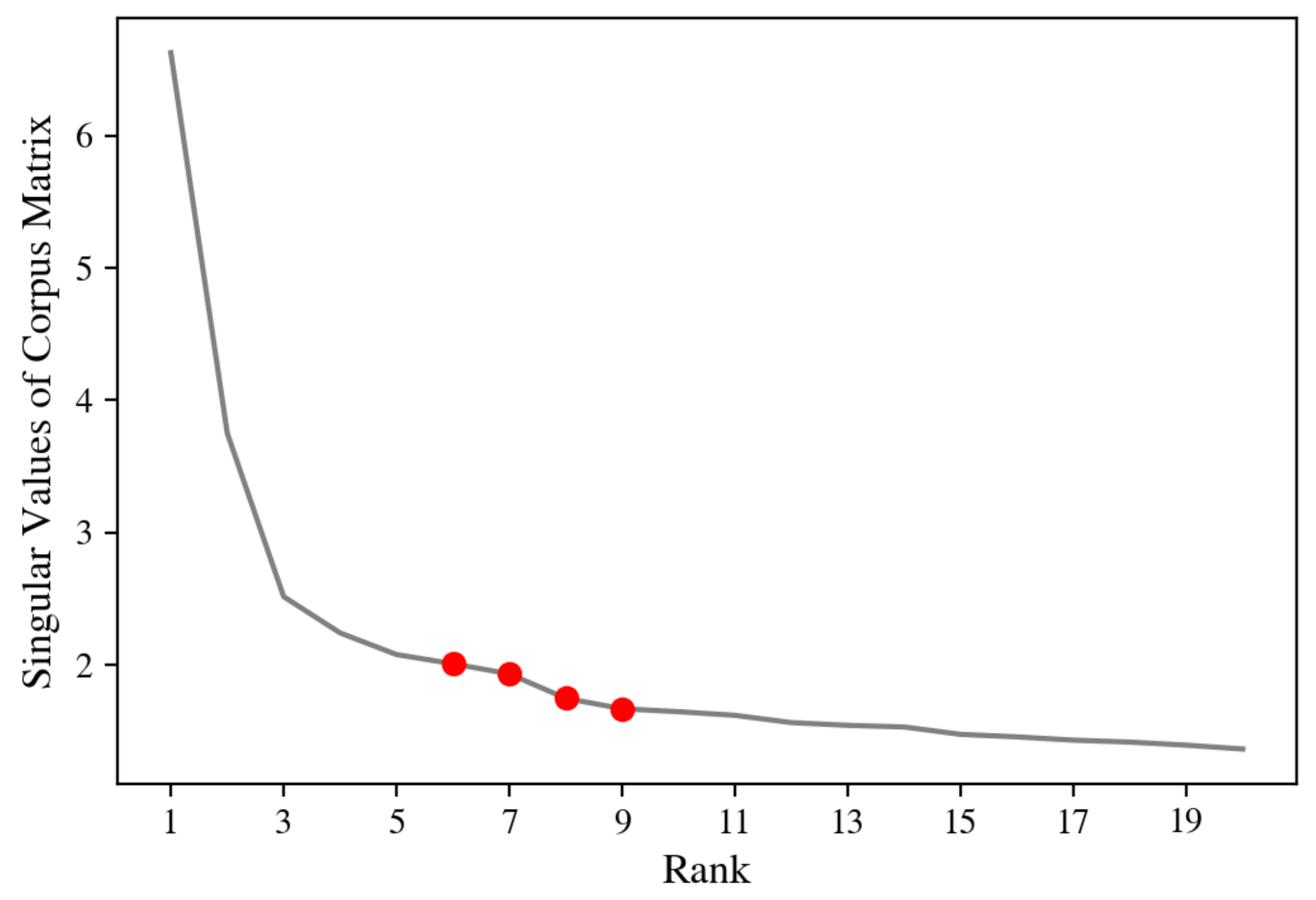
Similarly to the analysis of the CIP dataset, we begin by tuning
to yield the best possible results for SSNMF, again in terms of the Macro F1-score. Scores for selected values of
around this maximum are given in
Figure 6. For these values of
, we then run GSSNMF over a range of
, the best scores following this tuning are presented in
Figure 6.
We see that, as in the CIP data experiments, GSSNMF is able to leverage the additional seed word information to outperform the classification performance of SSNMF. The smaller absolute difference in scores compared to the CIP results is likely due to the overall higher scores for this dataset.
4.6. Topic Modeling on the 20 Newsgroups Dataset. Note That TS-NMF’s Rank Has to Equal the Number of Classes; as a Result, It Only Has Rank 9 Topic Modeling Result
In this section, we test the performance of GSSNMF for topic modeling by comparing it with Classical NMF, Guided NMF, and TS-NMF on the 20 Newsgroups data. For each proper rank indicated by
Figure 5, we run a range of
and
to select the best parameter for Guided NMF and GSSNMF. Note that both classical NMF and TS-NMF do not require the selection of
and
. To quantify the performance, we also measure the
averaged coherence score as described in Equation (
9) using the top 30 keywords of each topic. The resulting
scores are recorded in
Table 5 along with the choices of parameters. The
scores indicate that our GSSNMF algorithm outperforms the other NMF methods in rank 6, 7, and 8 topic modeling. For the rank 9 topic modeling, even though TS-NMF outperforms our GSSNMF, the
scores are fairly close. In addition, GSSNMF does generate the highest overall
score in the rank 6 topic modeling. This is an indication that the “true rank" for topic modeling in this subset of 20 Newsgroups data might not be 9; however, TS-NMF does not offer such flexibility and freedom to choose different ranks for topic modeling other than fixing the rank to be the number of labels. This further illustrates that GSSNMF can use additional label information for a more coherent topic model while not being limited by the additional label information.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





