
Analysis of Explainable Goal-Driven Reinforcement Learning in a Continuous Simulated Environment



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Explainable Reinforcement Learning
- Feature importance (FI), which explains the context of an action or what feature influenced the action.
- Learning process and MDP (LPM), which explains the experience influence over the training or the MDP components that led to a specific action.
- Policy level (PL) explains the long-term behavior as a summary of transitions.
3. Methods and Proposed Architecture
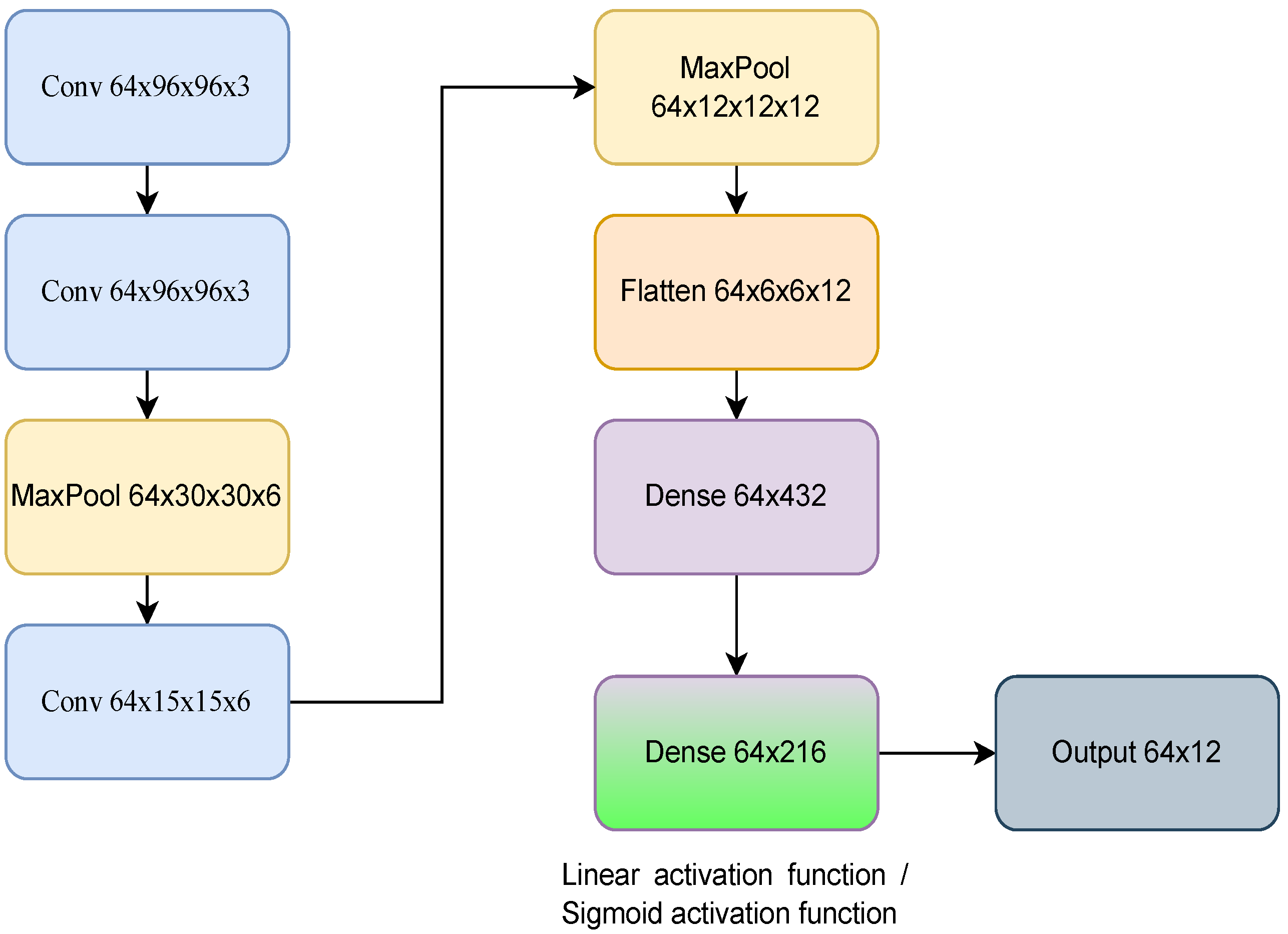
3.1. Learning-Based Method
3.2. Introspection-Based Method
| Algorithm 1 Explainable goal-driven learning approach to calculate the probability of success using the learning-based method. |
|
| Algorithm 2 Explainable goal-driven reinforcement learning approach for computing the probability of success using the introspection-based method. The algorithm is mainly based on [29] and includes the probabilistic introspection-based method. |
|
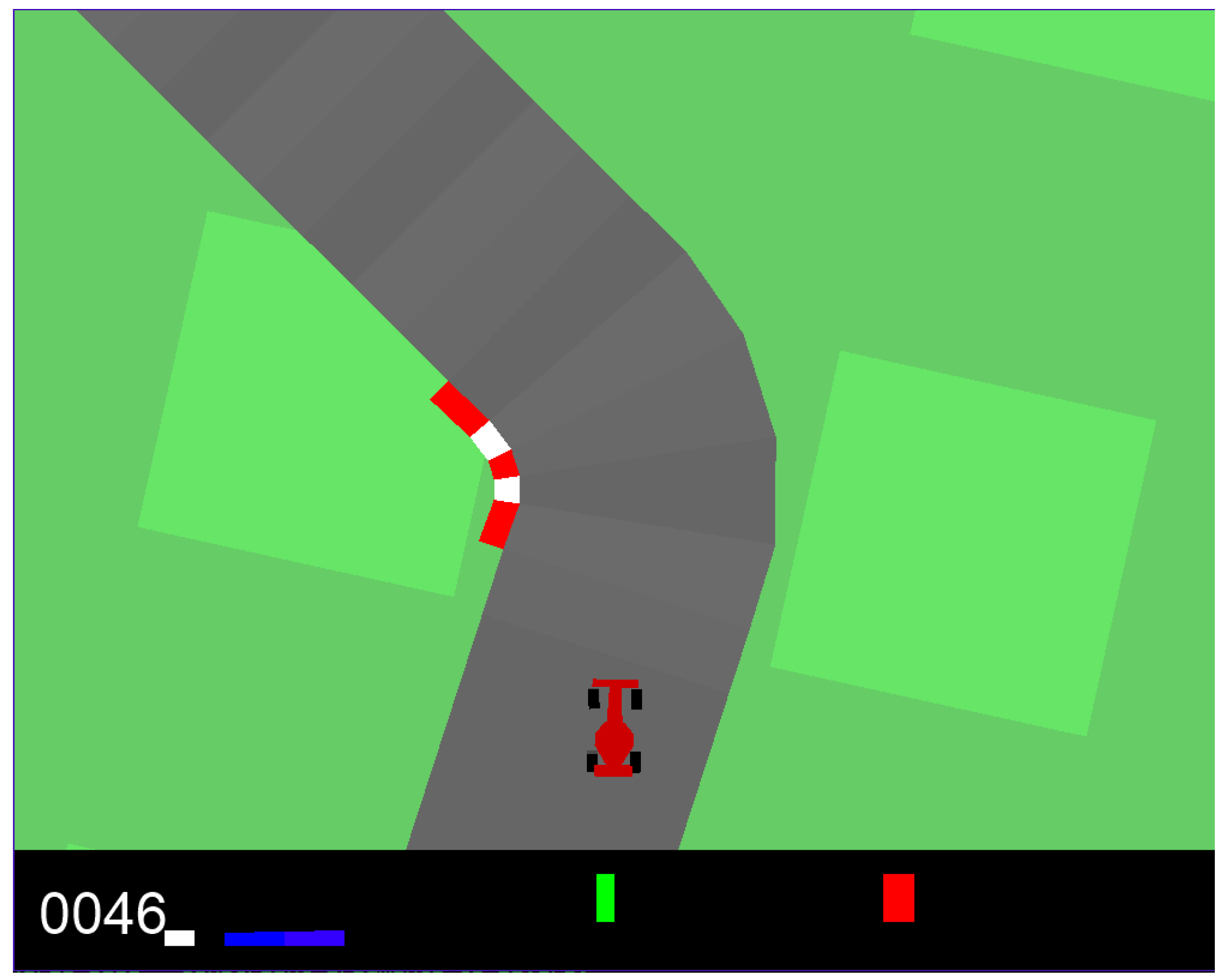
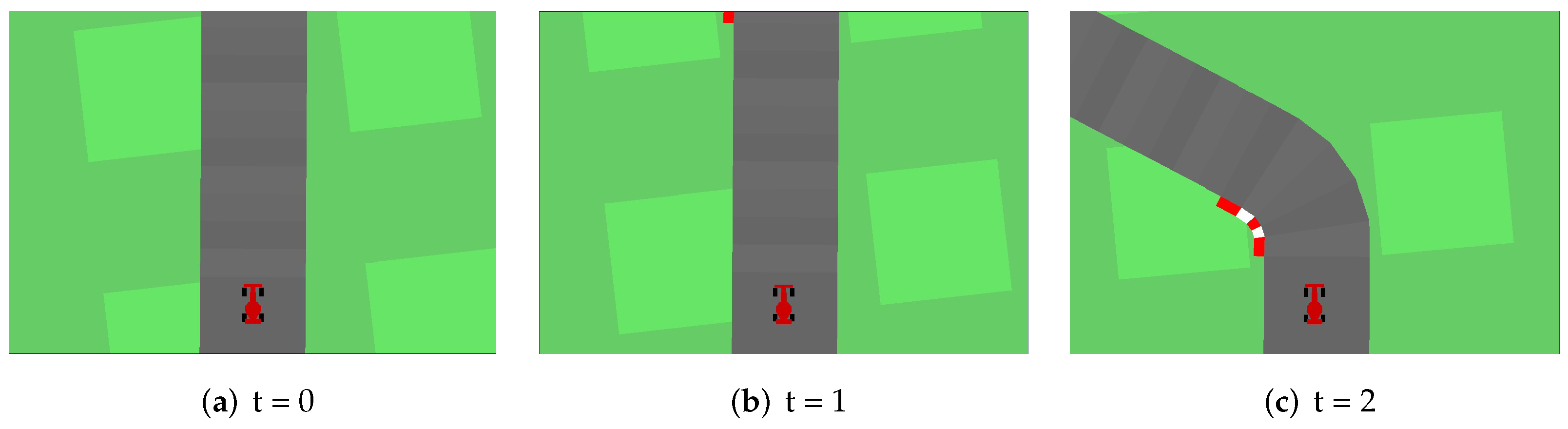
4. Experimental Scenario
5. Results
5.1. Adaptation of the Explainability Methods
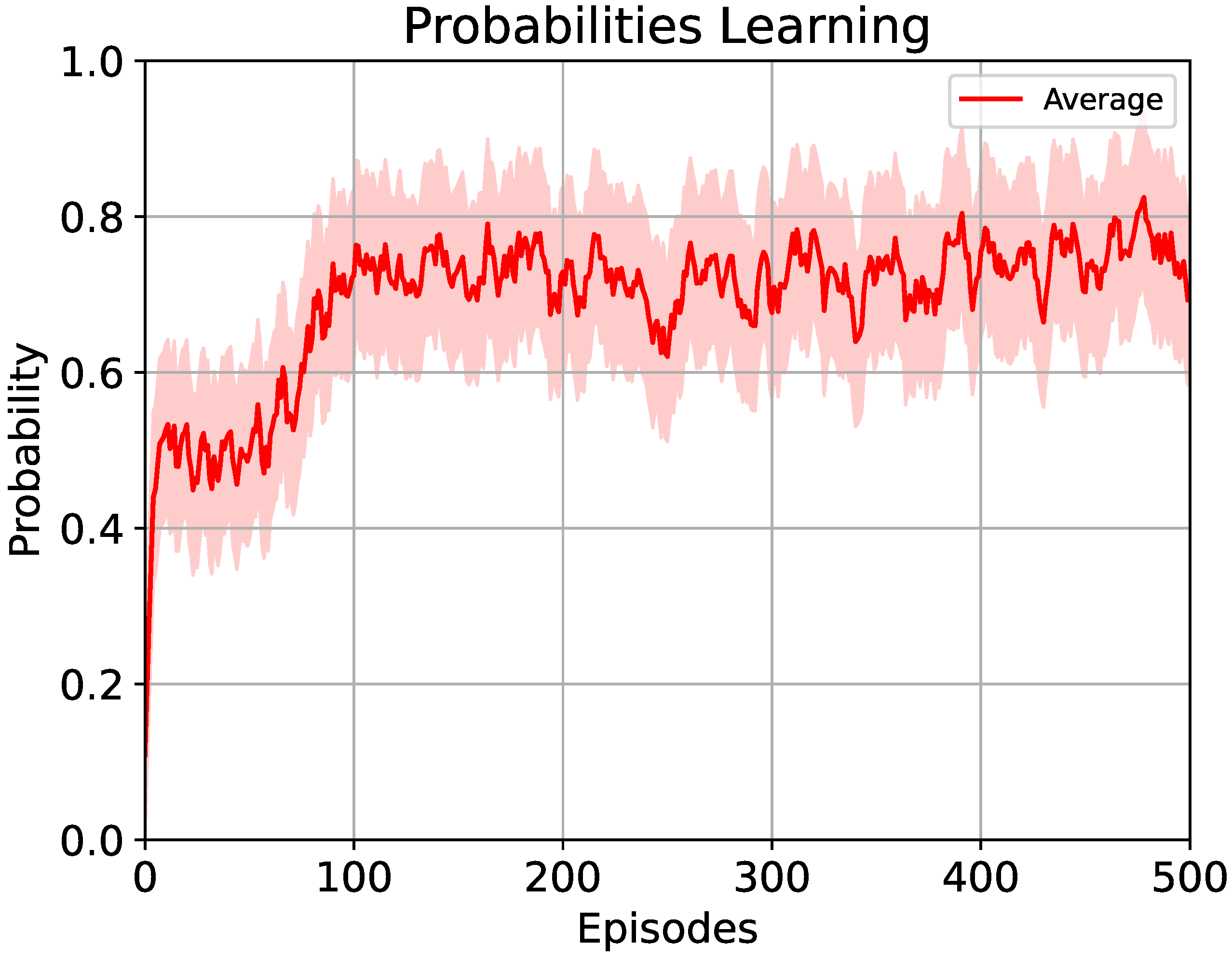
5.1.1. Learning-Based Method
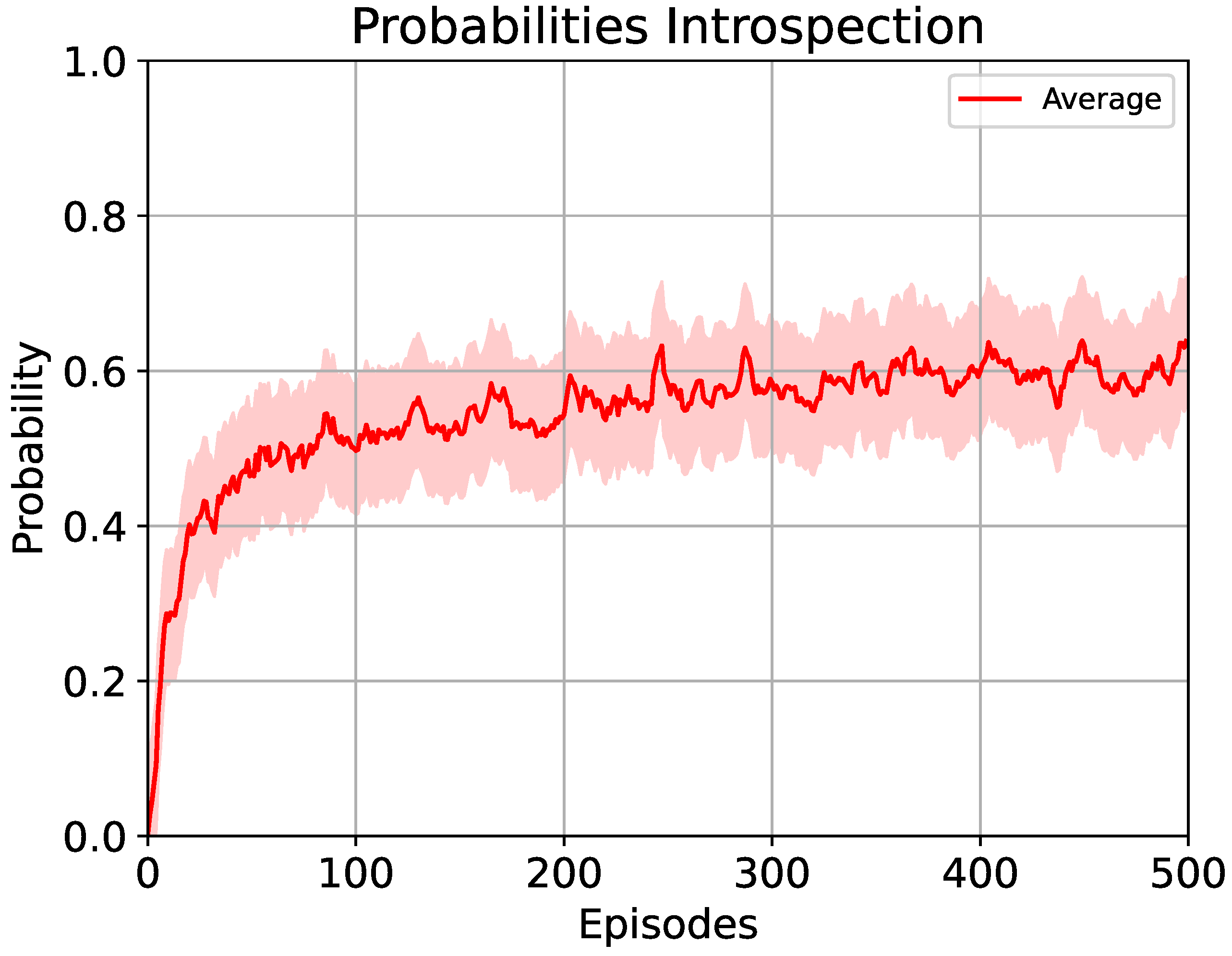
5.1.2. Introspection-Based Method
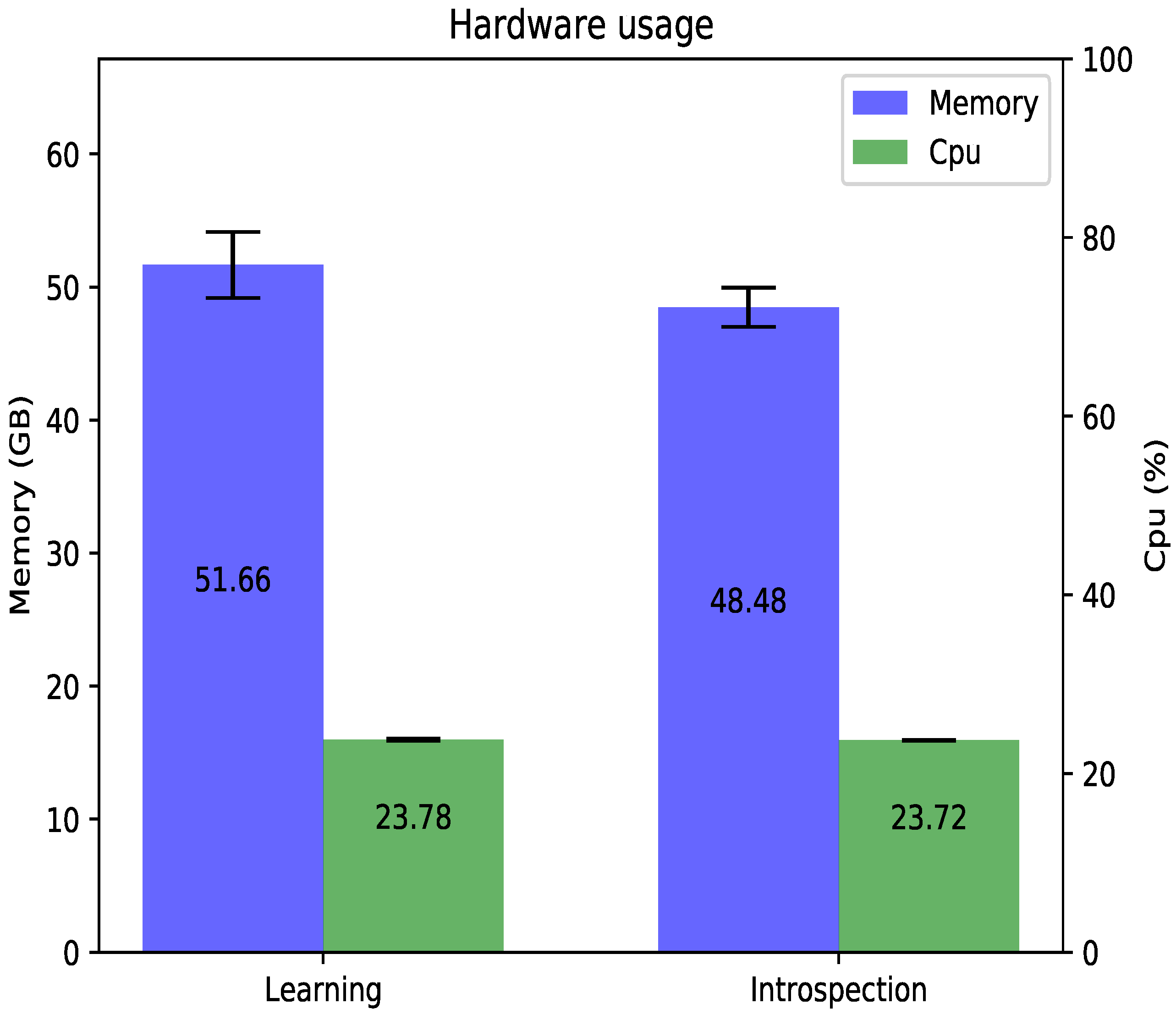
5.2. Use of Resources
5.3. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Singhal, A.; Sinha, P.; Pant, R. Use of deep learning in modern recommendation system: A summary of recent works. arXiv 2017, arXiv:1712.07525. [Google Scholar] [CrossRef]
- Bhuiyan, H.; Ashiquzzaman, A.; Juthi, T.I.; Biswas, S.; Ara, J. A survey of existing e-mail spam filtering methods considering machine learning techniques. Glob. J. Comput. Sci. Technol. 2018, 18, 21–29. [Google Scholar]
- Guo, G.; Zhang, N. A survey on deep learning based face recognition. Comput. Vis. Image Underst. 2019, 189, 102805. [Google Scholar] [CrossRef]
- Alanazi, H.O.; Abdullah, A.H.; Qureshi, K.N. A critical review for developing accurate and dynamic predictive models using machine learning methods in medicine and health care. J. Med. Syst. 2017, 41, 69. [Google Scholar] [CrossRef]
- Aradi, S. Survey of deep reinforcement learning for motion planning of autonomous vehicles. IEEE Trans. Intell. Transp. Syst. 2020, 23, 740–759. [Google Scholar] [CrossRef]
- Das, A.; Rad, P. Opportunities and challenges in explainable artificial intelligence (xai): A survey. arXiv 2020, arXiv:2006.11371. [Google Scholar]
- Dazeley, R.; Vamplew, P.; Foale, C.; Young, C.; Aryal, S.; Cruz, F. Levels of explainable artificial intelligence for human-aligned conversational explanations. Artif. Intell. 2021, 299, 103525. [Google Scholar] [CrossRef]
- Lim, B.Y.; Dey, A.K.; Avrahami, D. Why and why not explanations improve the intelligibility of context-aware intelligent systems. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Boston, MA, USA, 4–9 April 2009; pp. 2119–2128. [Google Scholar]
- Cruz, F.; Acuña, G.; Cubillos, F.; Moreno, V.; Bassi, D. Indirect training of grey-box models: Application to a bioprocess. In International Symposium on Neural Networks; Springer: Berlin/Heidelberg, Germany, 2007; pp. 391–397. [Google Scholar]
- Naranjo, F.C.; Leiva, G.A. Indirect training with error backpropagation in Gray-Box Neural Model: Application to a chemical process. In Proceedings of the 2010 XXIX International Conference of the Chilean Computer Science Society, Antofagasta, Chile, 15–19 November 2010; pp. 265–269. [Google Scholar]
- Ayala, A.; Cruz, F.; Fernandes, B.; Dazeley, R. Explainable Deep Reinforcement Learning Using Introspection in a Non-episodic Task. arXiv 2021, arXiv:2108.08911. [Google Scholar]
- Barros, P.; Tanevska, A.; Cruz, F.; Sciutti, A. Moody Learners-Explaining Competitive Behaviour of Reinforcement Learning Agents. In Proceedings of the 2020 Joint IEEE 10th International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob), Valparaiso, Chile, 7–11 September 2020; pp. 1–8. [Google Scholar]
- Dazeley, R.; Vamplew, P.; Cruz, F. Explainable reinforcement learning for Broad-XAI: A conceptual framework and survey. arXiv 2021, arXiv:2108.09003. [Google Scholar]
- Gunning, D.; Aha, D. DARPA’s Explainable Artificial Intelligence (XAI) Program. AI Mag. 2019, 40, 44–58. [Google Scholar] [CrossRef]
- Sado, F.; Loo, C.K.; Liew, W.S.; Kerzel, M.; Wermter, S. Explainable Goal-Driven Agents and Robots—A Comprehensive Review. arXiv 2020, arXiv:2004.09705. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Goodrich, M.A.; Schultz, A.C. Human-Robot Interaction: A Survey, Foundations and Trends in Human-Computer Interaction. 2007. Available online: https://www.researchgate.net/publication/220613473_Human-Robot_Interaction_A_Survey (accessed on 30 January 2022).
- Millán, C.; Fernandes, B.J.; Cruz, F. Human feedback in Continuous Actor-Critic Reinforcement Learning. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning ESANN, Bruges, Belgium, 24–26 April 2019; pp. 661–666. [Google Scholar]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Lamy, J.B.; Sekar, B.; Guezennec, G.; Bouaud, J.; Séroussi, B. Explainable artificial intelligence for breast cancer: A visual case-based reasoning approach. Artif. Intell. Med. 2019, 94, 42–53. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Chen, Y.; Yang, J.; Wu, L.; Wu, Z.; Xie, X. A reinforcement learning framework for explainable recommendation. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 587–596. [Google Scholar]
- He, L.; Aouf, N.; Song, B. Explainable Deep Reinforcement Learning for UAV autonomous path planning. Aerosp. Sci. Technol. 2021, 118, 107052. [Google Scholar] [CrossRef]
- Madumal, P.; Miller, T.; Sonenberg, L.; Vetere, F. Explainable reinforcement learning through a causal lens. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 2493–2500. [Google Scholar]
- Sequeira, P.; Gervasio, M. Interestingness elements for explainable reinforcement learning: Understanding agents’ capabilities and limitations. Artif. Intell. 2020, 288, 103367. [Google Scholar] [CrossRef]
- Cruz, F.; Dazeley, R.; Vamplew, P. Memory-based explainable reinforcement learning. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Adelaide, SA, Australia, 2–5 December 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 66–77. [Google Scholar]
- Cruz, F.; Dazeley, R.; Vamplew, P. Explainable robotic systems: Understanding goal-driven actions in a reinforcement learning scenario. Neural Comput. Appl. 2021. [Google Scholar] [CrossRef]
- Milani, S.; Topin, N.; Veloso, M.; Fang, F. A Survey of Explainable Reinforcement Learning. arXiv 2022, arXiv:2202.08434. [Google Scholar]
- Heuillet, A.; Couthouis, F.; Díaz-Rodríguez, N. Explainability in deep reinforcement learning. Knowl.-Based Syst. 2021, 214, 106685. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. Openai gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1861–1870. [Google Scholar]
- Hessel, M.; Modayil, J.; Van Hasselt, H.; Schaul, T.; Ostrovski, G.; Dabney, W.; Horgan, D.; Piot, B.; Azar, M.; Silver, D. Rainbow: Combining improvements in deep reinforcement learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Gupta, J.K.; Egorov, M.; Kochenderfer, M. Cooperative multi-agent control using deep reinforcement learning. In Proceedings of the International Conference on Autonomous Agents and Multiagent Systems, São Paulo, Brazil, 8–12 May 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 66–83. [Google Scholar]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Portugal, E.; Cruz, F.; Ayala, A.; Fernandes, B. Analysis of Explainable Goal-Driven Reinforcement Learning in a Continuous Simulated Environment. Algorithms 2022, 15, 91. https://doi.org/10.3390/a15030091
Portugal E, Cruz F, Ayala A, Fernandes B. Analysis of Explainable Goal-Driven Reinforcement Learning in a Continuous Simulated Environment. Algorithms. 2022; 15(3):91. https://doi.org/10.3390/a15030091
Chicago/Turabian StylePortugal, Ernesto, Francisco Cruz, Angel Ayala, and Bruno Fernandes. 2022. "Analysis of Explainable Goal-Driven Reinforcement Learning in a Continuous Simulated Environment" Algorithms 15, no. 3: 91. https://doi.org/10.3390/a15030091
APA StylePortugal, E., Cruz, F., Ayala, A., & Fernandes, B. (2022). Analysis of Explainable Goal-Driven Reinforcement Learning in a Continuous Simulated Environment. Algorithms, 15(3), 91. https://doi.org/10.3390/a15030091