
A Machine Learning Approach for Solving the Frozen User Cold-Start Problem in Personalized Mobile Advertising Systems

Abstract
:1. Introduction
1.1. Advertisement Personalization Systems
1.2. Cold-Start Problem
- The new user—When there is a new user in the system that has not yet interacted with enough data objects (e.g., rated very few movies). Due to lack of data, the system is not able to generate an accurate model and, thus, it cannot provide adequate recommendations to him/her [6]. A special case of cold-start arises when there is no data at all available for the user (also referred as ‘frozen start/user’) [7,8]. This situation is even more difficult and most of the systems face trouble in providing suggestions [9,10,11].
1.3. Stating the Problem, Motivation, and Objective
2. Related Works and Contribution
2.1. Related Works
- Works that focus on the cold-start problem from the new item perspective (when a new advertisement is added into the system).
- Works that focus on the cold-start problem from the new user viewpoint.
2.1.1. New Item
2.1.2. New User
2.2. Challenges, Limitations, and Contribution
- Works that try to alleviate the new user cold-start problem, need at least a few user-item associations to work (e.g., user have rated some items). If there is a user with no data at all, a “frozen user”, the models face issues [24]. There is a lack of such works in the literature, although there are many works that focus on the “frozen” item problem (first category above), especially regarding the advertisement domain.
- Approaches that collect data from other sources (e.g., social data) could not be applied if these data are not available, or face interoperability problems [25].
- Approaches that require the user to fill-in a lot of information before using the system may discourage him/her from using it [7].
- The contribution of this research can be summarized in the following points:
- Presents state-of-the-art approaches about the cold-start problem in advertisement systems and highlights challenges, limitations, and paths for future research. The special case of the ‘frozen user’ problem is discussed.
- Explores the potential of state-of-the-art personalization algorithms and models about the frozen user problem by conducting experiments on existing datasets. These algorithms have not been tested with this input and for the frozen user purpose.
- Proposes a novel predicting approach to design personalized advertisement systems that can deal with the ‘frozen user problem’. The philosophy of this approach is to use specific attributes that could be gathered from a new user (attributes associated with the application and the device–they can be called ‘user independent’), existing datasets, and machine learning methods to predict CTR for a ‘frozen user’. One big advantage is that various datasets can be employed for training and testing, and the approach can be easily applied in any system. The approach includes all the above steps (attribute and data, algorithms/model, development) and is discussed in detail below.
3. Approach Description
- Identify relevant attributes and datasets.
- Perform experiments and check state-of-the-art algorithms and models’ performances in order to validate the approach.
- Development/Application implementation.
- Step 1.
- Identify attributes and relative datasets
- Time (hour, time period, day)
- Application or/and site category
- Application name/id
- Advertisement position (where the advertisement will be displayed)
- Advertisement form (image, video)
- Device type, size and model
- Connection type
- Advertisement id
- Advertisement category
- Step 2.
- Conduct experiments and check models’ performances
- Step 3.
- Development/application implementation
4. Validation and Implementation
- Step 1.
- Identify attributes and relative datasets
- Time (time period)
- Application and site category and domain
- Application name and id
- Advertisement position (where the advertisement will be displayed)
- Device type and model
- Connection type
- Time period
- Application and site category
- Display form of an ad material
- App level 1 category of an ad task
- App level 2 category of an ad task
- Application ID of an ad task
- Application tag of an ad task
- Application score/rating
- Device name and size
- Model release time
- Connection type
- Step 2.
- Conduct offline experiments and check models’ performances/validation
- Traditional/baseline models such as:
- ◦
- GradientBoost—Gradient boosting is a machine learning technique for regression, classification and other tasks, which produces a prediction model in the form of an ensemble of weak prediction models, typically decision trees. Gradient boosting involves three elements: (a) A loss function to be optimized, (b) a weak learner to make predictions, and (c) an additive model to add weak learners to minimize the loss function [31].
- ◦
- CatBoost—is an algorithm for gradient boosting on decision trees. A gradient boosting framework attempts to solve for categorical features using a permutation driven alternative compared to the classical algorithm [32].
- ◦
- Logistic Regression—a statistical model that uses a logistic function to model a binary dependent variable. It is used in statistical software to understand the relationship between the dependent variable and one or more independent variables by estimating probabilities using a logistic regression equation [33].
- ◦
- LightGBM—Light gradient boosting machine, is a distributed gradient boosting framework for machine learning originally developed by Microsoft. It is based on decision tree algorithms and used for ranking, classification and other machine learning tasks [34]
- Deep learning state-of-the-art such as:
- ◦
- ONN—Operational neural networks (ONNs), can be heterogeneous and encapsulate neurons with any set of operators to boost diversity and to learn highly complex and multi-modal functions or spaces with minimal network complexity and training data. The operation-aware embedding method learns different representations for each feature when performing different operations [35].
- ◦
- xDeepfm—eXtreme Deep Factorization Machine (xDeepFM). A compressed interaction network-CIN (which aims to generate feature interactions in an explicit fashion and at the vector-wise level) is combined with a classical Deep NN into one unified model. The xDeepFM is able to learn certain bounded-degree feature interactions explicitly and arbitrary low- and high-order feature interactions implicitly [36].
- ◦
- IFM—Input-aware factorization machine (IFM) learns a unique input-aware factor for the same feature in different instances via a neural network [37].
- ◦
- DCN V2—An improved version of deep and cross network (DCN), which automatically and efficiently learns bounded-degree predictive feature interaction. DCN keeps the benefits of a DNN model, and beyond that, it introduces a novel cross network that is more efficient in learning certain bounded-degree feature interactions. In particular, DCN explicitly applies feature crossing at each layer, requires no manual feature engineering, and adds negligible extra complexity to the DNN model [38].
- ◦
- FiBiNet—FiBiNET is an abbreviation for ‘feature importance and bilinear feature interaction network’. Proposes to dynamically learn the feature importance and fine-grained feature interactions. On the one hand, the FiBiNET can dynamically learn the importance of features via the squeeze-excitation network (SENET) mechanism; on the other hand, it is able to effectively learn the feature interactions via bilinear function [39].
- ◦
- FLEN—Field-leveraged embedding network (FLEN) devises a field-wise bi-interaction pooling technique. By suitably exploiting field information, the field-wise bi-interaction pooling captures both inter-field and intra-field feature conjunctions with a small number of model parameters and an acceptable time complexity [28].
- ◦
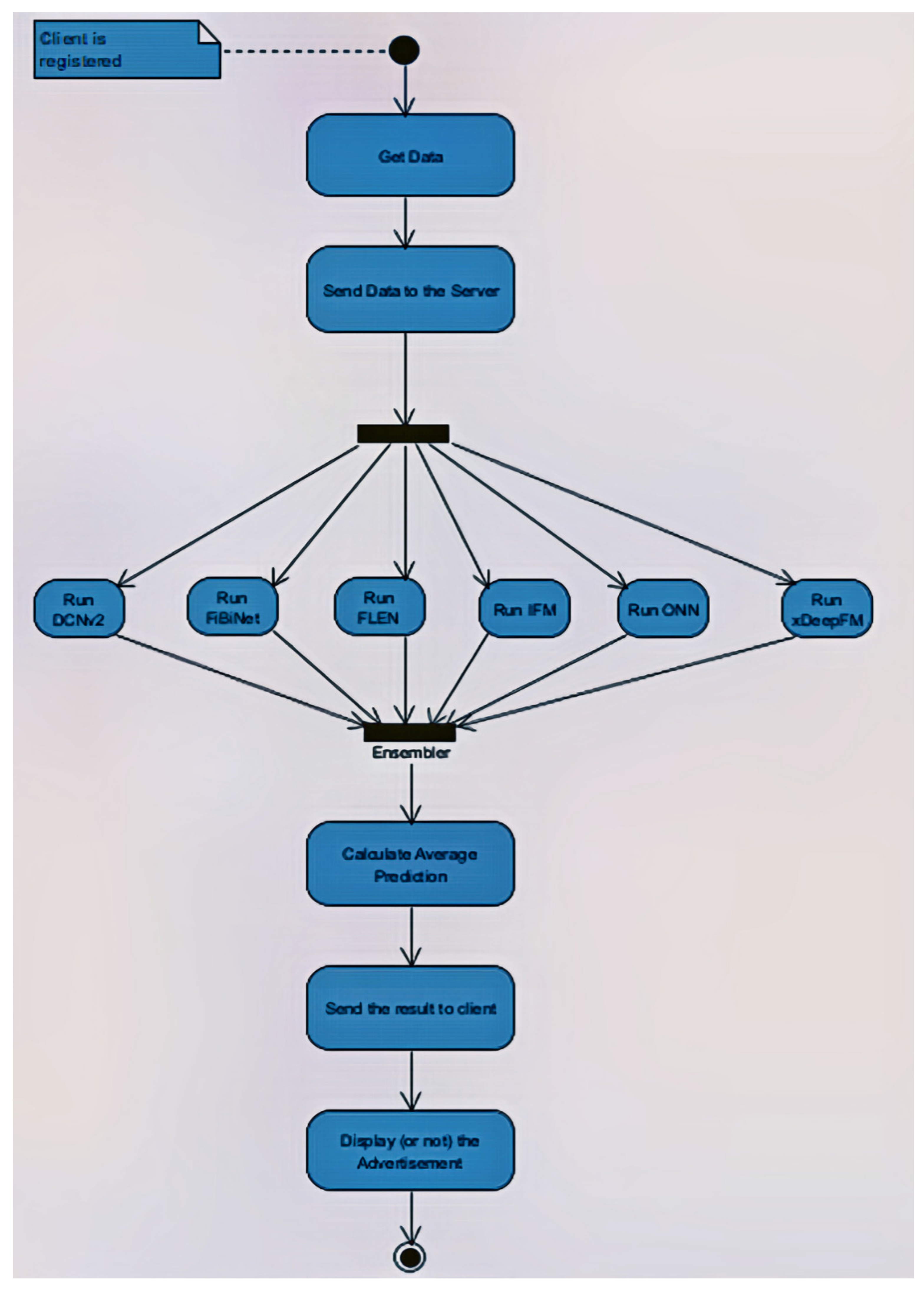
- Ensembler—Ensembling various models and combining the predictions of different models is a technique that is used by many researchers for improving results [5,35]. In our case, an average-based ensembler has been built. In more detail, the six state-of-the-art deep learning models that are described above are used [40]. After training the models, the average of predictions from all the models is used to make the final prediction (the average probability that a user will accept the advertisement).
- Data were shuffled balanced and 80% used for training and 20% for testing.
- The same tuning was followed for the models.
- AUC and log-loss were calculated.
- Step 3
- Development/application implementation
5. Conclusions, Discussion, and Future Directions
- Use device and application-related variables that could be gathered from a new user.
- Train and test state-of-the-art machine learning models in existing datasets.
- Implement a client-server architecture that gets user data and predicts his/her interest for the advertisement using a deep learning ensembler.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments

Conflicts of Interest
References
- Rula, J.P.; Jun, B.; Bustamante, F.E. Mobile AD(D): Estimating mobile app session times for better ads. In Proceedings of the 16th International Workshop on Mobile Computing Systems and Applications, Santa Fe, NM, USA, 12–13 February 2015; pp. 123–128. [Google Scholar] [CrossRef]
- Faroqi, H.; Mesbah, M.; Kim, J. Behavioural advertising in the public transit network. Res. Transp. Bus. Manag. 2020, 32, 100421. [Google Scholar] [CrossRef]
- Capurso, N.; Mei, B.; Song, T.; Cheng, X.; Yu, J. A survey on key fields of context awareness for mobile devices. J. Netw. Comput. Appl. 2018, 118, 44–60. [Google Scholar] [CrossRef]
- Jiménez, N.; San-Martín, S. Attitude toward m-advertising and m-repurchase. Eur. Res. Manag. Bus. Econ. 2017, 23, 96–102. [Google Scholar] [CrossRef]
- Yagci, M.; Gurgen, F. A ranker ensemble for multi-objective job recommendation in an item cold start setting. In Proceedings of the Recommender Systems Challenge 2017, New York, NY, USA, 27 August 2017. Part F1305. [Google Scholar] [CrossRef]
- Manchanda, S.; Yadav, P.; Doan, K.; Sathiya Keerthi, S. Targeted display advertising: The case of preferential attachment. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 1868–1877. [Google Scholar]
- Viktoratos, I.; Tsadiras, A.; Bassiliades, N. Combining community-based knowledge with association rule mining to alleviate the cold start problem in context-aware recommender systems. Expert Syst. Appl. 2018, 101, 78–90. [Google Scholar] [CrossRef]
- Ahmed, T.; Srivastava, A. A data-centric and machine based approach towards fixing the cold start problem in web service recommendation. In Proceedings of the 2014 IEEE Students’ Conference on Electrical, Electronics and Computer Science, Bhopal, India, 1–2 March 2014. [Google Scholar] [CrossRef]
- Aggarwal, K.; Yadav, P.; Keerthi, S.S. Domain adaptation in display advertising. In Proceedings of the 13th ACM Conference on Recommender Systems, Copenhagen, Denmark, 16–20 September 2019; pp. 178–186. [Google Scholar] [CrossRef]
- Ha, I.; Oh, K.J.; Jo, G.S. Personalized advertisement system using social relationship based user modeling. Multimed. Tools Appl. 2015, 74, 8801–8819. [Google Scholar] [CrossRef]
- Chen, Y.; Berkhin, P.; Li, J.; Wan, S.; Yan, T.W. Fast and Cost-Efficient Bid Estimation for Contextual Ads. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 477–478. [Google Scholar] [CrossRef] [Green Version]
- Yi, P.; Yang, C.; Zhou, X.; Li, C. A movie cold-start recommendation method optimized similarity measure. In Proceedings of the 2016 16th International Symposium on Communications and Information Technologies (ISCIT), Qingdao, China, 26–28 September 2016; pp. 231–234. [Google Scholar] [CrossRef]
- Embarak, O.H. Like-minded detector to solve the cold start problem. In Proceedings of the 2018 Fifth HCT Information Technology Trends (ITT), Dubai, United Arab Emirates, 28–29 November 2018; Volume 2, pp. 300–305. [Google Scholar] [CrossRef]
- Shah, P.; Yang, M.; Alle, S.; Ratnaparkhi, A.; Shahshahani, B.; Chandra, R. A practical exploration system for search advertising. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; Part F1296. pp. 1625–1631. [Google Scholar] [CrossRef]
- Cao, D.; Wu, X.; Zhou, Q.; Hu, Y. Alleviating the New Item Cold-Start Problem by Combining Image Similarity. In Proceedings of the 2019 IEEE 9th International Conference on Electronics Information and Emergency Communication (ICEIEC), Beijing, China, 12–14 July 2019; pp. 589–595. [Google Scholar] [CrossRef]
- Richardson, M.; Dominowska, E.; Ragno, R. Predicting clicks. In Proceedings of the 16th international conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; p. 521. [Google Scholar] [CrossRef]
- Pan, F.; Li, S.; Ao, X.; Tang, P.; He, Q. Warm up cold-start advertisements: Improving CTR predictions via learning to learn ID embeddings. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 695–704. [Google Scholar] [CrossRef]
- Rong, Y.; Wen, X.; Cheng, H. A Monte Carlo algorithm for cold start recommendation. In Proceedings of the WWW ‘14: Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; pp. 327–336. [Google Scholar] [CrossRef]
- Shen, T.; Chen, H.; Ku, W.S. Time-aware location sequence recommendation for cold-start mobile users. In Proceedings of the SIGSPATIAL ’18: Proceedings of the 26th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 6–9 November 2018; pp. 484–487. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, J. A Collective Bayesian Poisson Factorization Model for Cold-start Local Event Recommendation Categories and Subject Descriptors. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 1455–1464. [Google Scholar]
- Wang, H.; Hara, T.; Amagata, D.; Niu, H.; Kurokawa, M.; Maekawa, T.; Yonekawa, K. Preliminary investigation of alleviating user cold-start problem in e-commerce with deep cross-domain recommender system. In Proceedings of the WWW ’19: Companion Proceedings of the 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 398–403. [Google Scholar] [CrossRef]
- Herce-Zelaya, J.; Porcel, C.; Bernabé-Moreno, J.; Tejeda-Lorente, A.; Herrera-Viedma, E. New technique to alleviate the cold start problem in recommender systems using information from social media and random decision forests. Inf. Sci. 2020, 536, 156–170. [Google Scholar] [CrossRef]
- Aharon, M.; Anava, O.; Avigdor-Elgrabli, N.; Drachsler-Cohen, D.; Golan, S.; Somekh, O. ExcUseMe: Asking Users to Help in Item Cold-Start Recommendations. In Proceedings of the 9th ACM Conference on Recommender Systems, Vienna, Austria, 16–20 September 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 83–90. [Google Scholar] [CrossRef]
- Son, L.H. Dealing with the new user cold-start problem in recommender systems: A comparative review. Inf. Syst. 2016, 58, 87–104. [Google Scholar] [CrossRef]
- Verma, D.; Gulati, K.; Shah, R.R. Addressing the cold-start problem in outfit recommendation using visual preference modelling. In Proceedings of the 2020 IEEE Sixth International Conference on Multimedia Big Data (BigMM), New Delhi, India, 24–26 September 2020. [Google Scholar] [CrossRef]
- Wu, S.; Yu, F.; Yu, X.; Liu, Q.; Wang, L.; Tan, T.; Shao, J.; Huang, F. TFNet: Multi-Semantic Feature Interaction for CTR Prediction. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, China, 25–30 July 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1885–1888. [Google Scholar] [CrossRef]
- Forcier, J.; Bissex, P.; Chun, W. Python Web Development with Django; Addison-Wesley: Boston, MA, USA, 2008. [Google Scholar]
- Chen, W.; Zhan, L.; Ci, Y.; Lin, C. FLEN: Leveraging Field for Scalable CTR Prediction. 2019. Available online: http://arxiv.org/abs/1911.04690 (accessed on 15 September 2021).
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X.; Dong, Z. DeepFM: An End-to-End Wide & Deep Learning Framework for CTR Prediction. arXiv 2018, arXiv:1703.04247. Available online: http://arxiv.org/abs/1804.04950 (accessed on 16 September 2021).
- Zainurossalamia Za, S.; Tricahyadinata, I. An Analysis on the Use of Google AdWords to Increase E-Commerce Sales. Int. J. Soc. Sci. Manag. 2017, 4, 60. [Google Scholar] [CrossRef] [Green Version]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. Catboost: Unbiased boosting with categorical features. Adv. Neural Inf. Process. Syst. 2018, 2018, 6638–6648. [Google Scholar]
- Ma, J.; Chen, X.; Lu, Y.; Zhang, K. A click-through rate prediction model and its applications to sponsored search advertising. In Proceedings of the International Conference on Cyberspace Technology (CCT 2013), Beijing, China, 23 November 2013; pp. 500–503. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 2017, 3147–3155. [Google Scholar]
- Yang, Y.; Xu, B.; Shen, S.; Shen, F.; Zhao, J. Operation-aware Neural Networks for user response prediction. Neural Networks 2020, 121, 161–168. [Google Scholar] [CrossRef] [PubMed]
- Lian, J.; Chen, Z.; Zhou, X.; Xie, X.; Zhang, F.; Sun, G. xDeepFM: Combining explicit and implicit feature interactions for recommender systems. In Proceedings of the KDD ’18: The 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018; pp. 1754–1763. [Google Scholar] [CrossRef] [Green Version]
- Yu, Y.; Wang, Z.; Yuan, B. An input-aware factorization machine for sparse prediction. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 1466–1472. [Google Scholar] [CrossRef] [Green Version]
- Wang, R.; Shivanna, R.; Cheng, D.; Jain, S.; Lin, D.; Hong, L.; Chi, E. DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-Scale Learning to Rank Systems. Association for Computing Machinery: New York, NY, USA, 2021; Volume 1, ISBN 9781450383127. [Google Scholar]
- Huang, T.; Zhang, Z.; Zhang, J. Fibinet: Combining feature importance and bilinear feature interaction for click-through rate prediction. In Proceedings of the 13th ACM Conference on Recommender Systems, Copenhagen, Denmark, 16–20 September 2019; pp. 169–177. [Google Scholar] [CrossRef] [Green Version]
- Haider, C.M.R.; Iqbal, A.; Rahman, A.H.; Rahman, M.S. An ensemble learning based approach for impression fraud detection in mobile advertising. J. Netw. Comput. Appl. 2018, 112, 126–141. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, F.; Huang, P.; Xing, S.; Zhao, X. A Hierarchical Attention Model for CTR Prediction Based on User Interest. IEEE Syst. J. 2020, 14, 4015–4024. [Google Scholar] [CrossRef]
- Bach, M.; Werner, A.; Palt, M. The Proposal of Undersampling Method for Learning from Imbalanced Datasets. Procedia Comput. Sci. 2019, 159, 125–134. [Google Scholar] [CrossRef]
- Liu, D.; Xu, S.; Chen, L.; Wang, C. Some observations on online advertising: A new advertising system. In Proceedings of the 2015 IEEE/ACIS 14th International Conference on Computer and Information Science (ICIS), Las Vegas, NV, USA, 28 June–1 July 2015; pp. 387–392. [Google Scholar] [CrossRef]
- Chen, S. The Emerging Trend of Accurate Advertising Communication in the Era of Big Data—The Case of Programmatic, Targeted Advertising; Springer: Singapore, 2020; Volume 156, ISBN 9789811397134. [Google Scholar]
- Viktoratos, I.; Tsadiras, A.; Bassiliades, N. A context-aware web-mapping system for group-targeted offers using semantic technologies. Expert Syst. Appl. 2015, 42, 4443–4459. [Google Scholar] [CrossRef]
- Andronie, M.; Lăzăroiu, G.; Iatagan, M.; Hurloiu, I.; Dijmărescu, I. Sustainable Cyber-Physical Production Systems in Big Data-Driven Smart Urban Economy: A Systematic Literature Review. Sustainability 2021, 13, 751. [Google Scholar] [CrossRef]
- Yang, S.; Carlson, J.R.; Chen, S. How augmented reality affects advertising effectiveness: The mediating effects of curiosity and attention toward the ad. J. Retail. Consum. Serv. 2020, 54, 102020. [Google Scholar] [CrossRef]
- Nelson, A.; Neguriță, O. Big Data-driven Smart Cities. Geopolit. Hist. Int. Relat. 2020, 12, 37–43. Available online: https://www.jstor.org/stable/26939892 (accessed on 25 September 2021).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
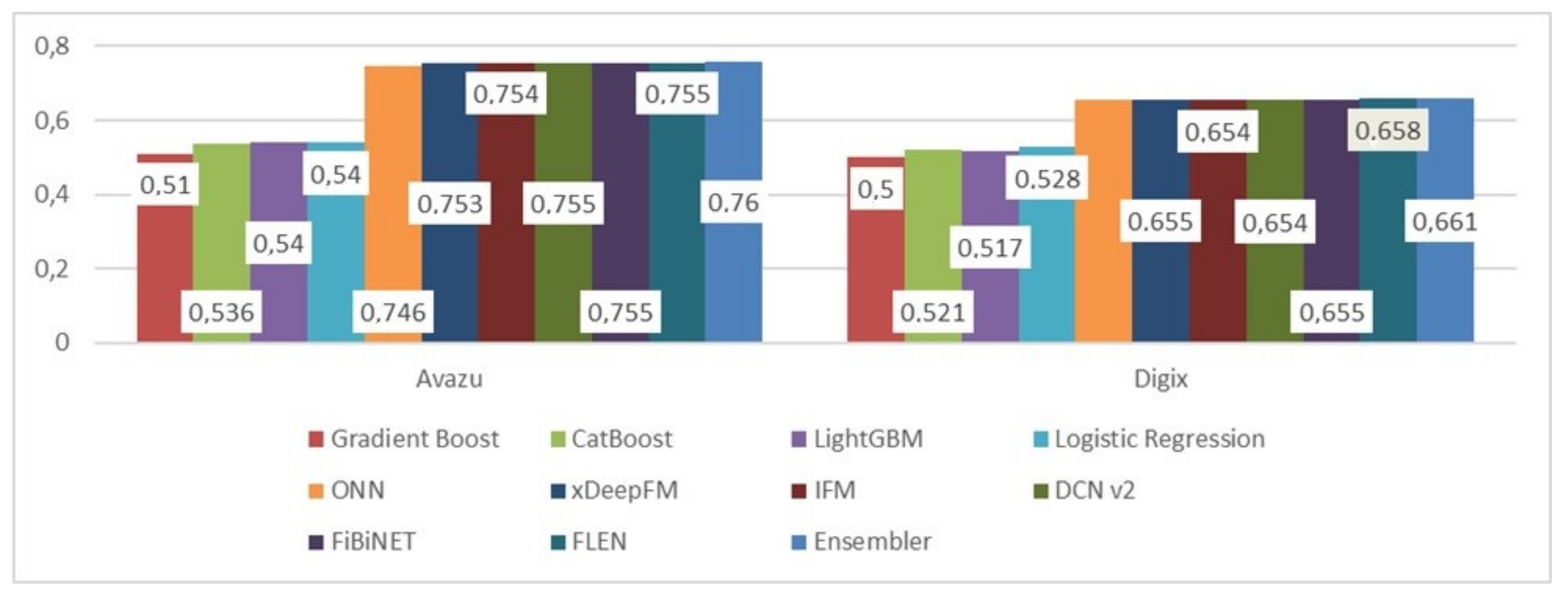
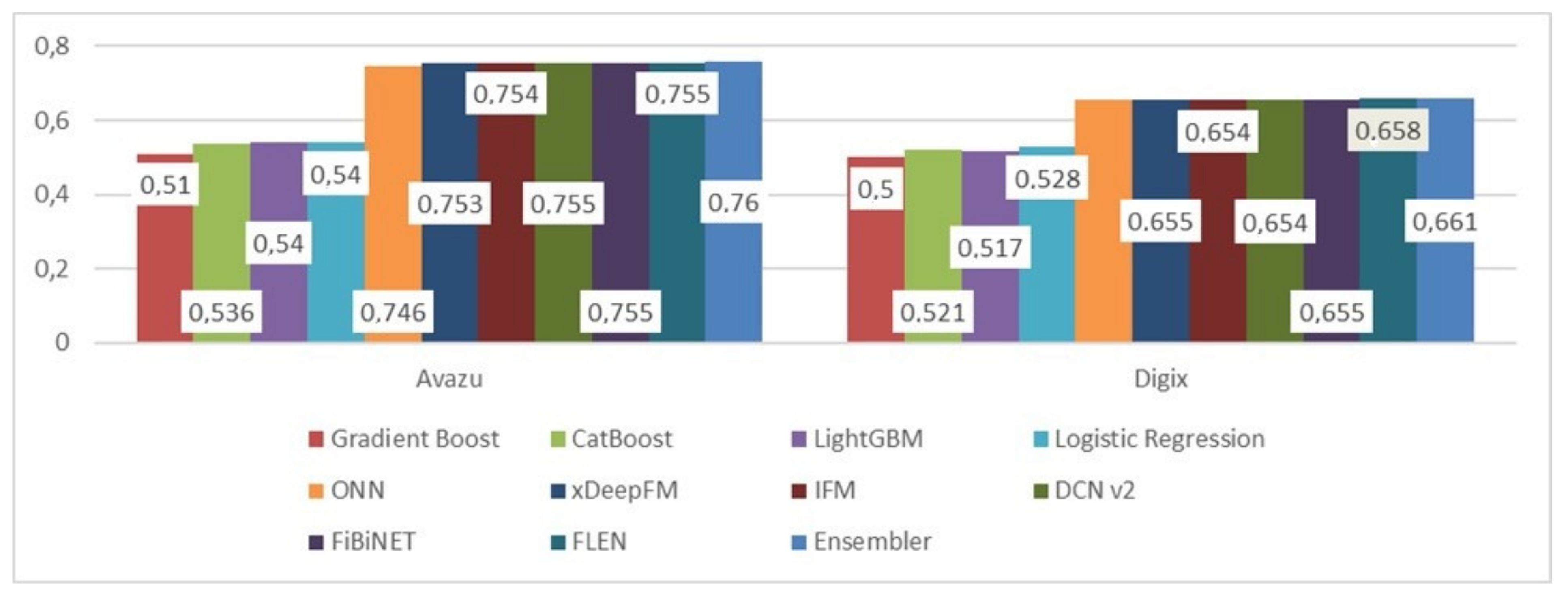
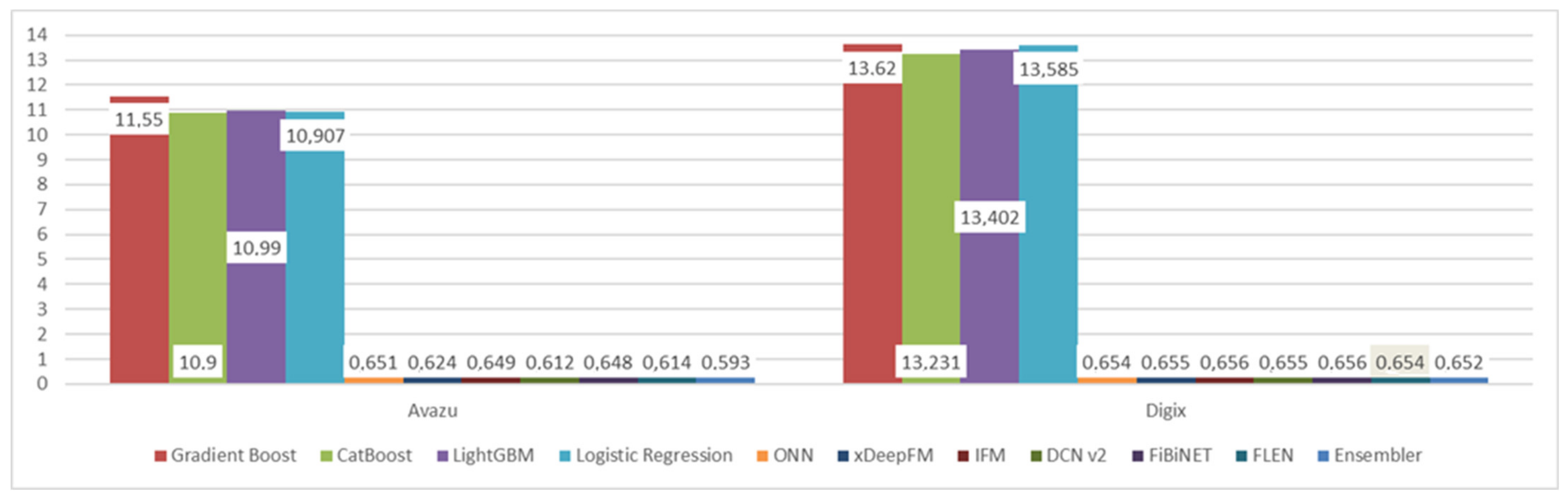
| Avazu | DIGIX | |||
|---|---|---|---|---|
| Model | AUC | Log-Loss | AUC | Log-Loss |
| Gradient Boost | 0.51 | 6.1 | 0.50 | 7.89 |
| CatBoost | 0.536 | 5.45 | 0.521 | 7.81 |
| LightGBM | 0.54 | 5.876 | 0.517 | 7.867 |
| Logistic Regression | 0.54 | 5.46 | 0.528 | 7.83 |
| ONN | 0.746 | 0.397 | 0.657 | 0.654 |
| xDeepFM | 0.753 | 0.383 | 0.655 | 0.655 |
| IFM | 0.754 | 0.382 | 0.654 | 0.656 |
| DCN v2 | 0.755 | 0.38 | 0.654 | 0.655 |
| FiBiNET | 0.755 | 0.381 | 0.655 | 0.656 |
| FLEN | 0.755 | 0.381 | 0.658 | 0.654 |
| Ensembler | 0.76 | 0.371 | 0.661 | 0.496 |
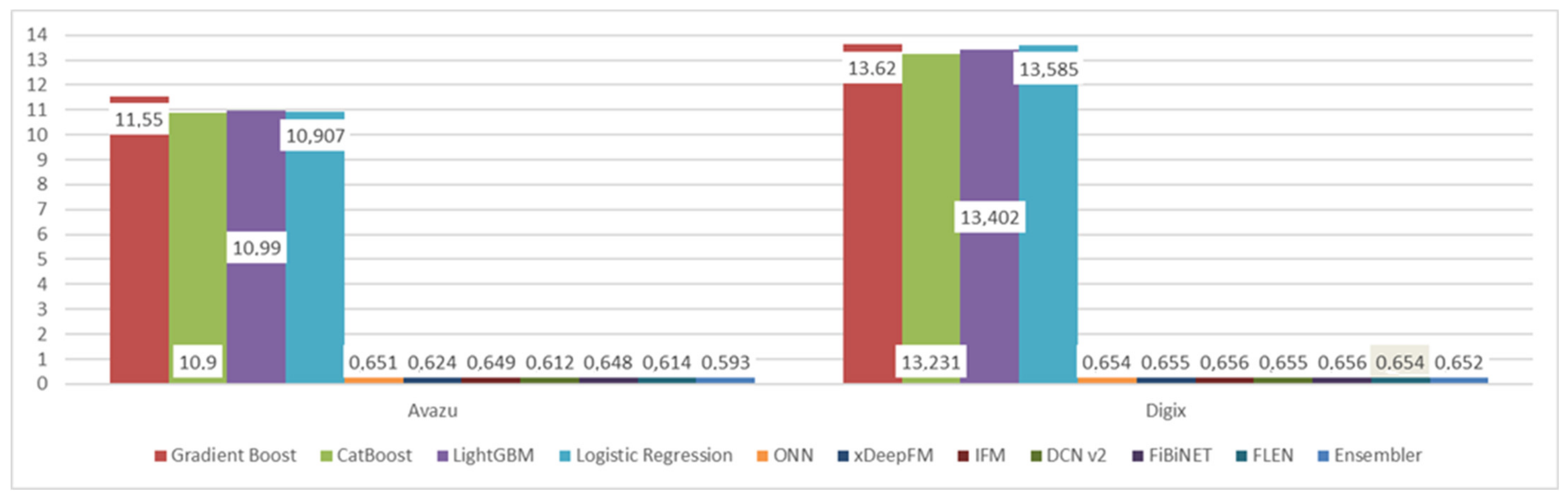
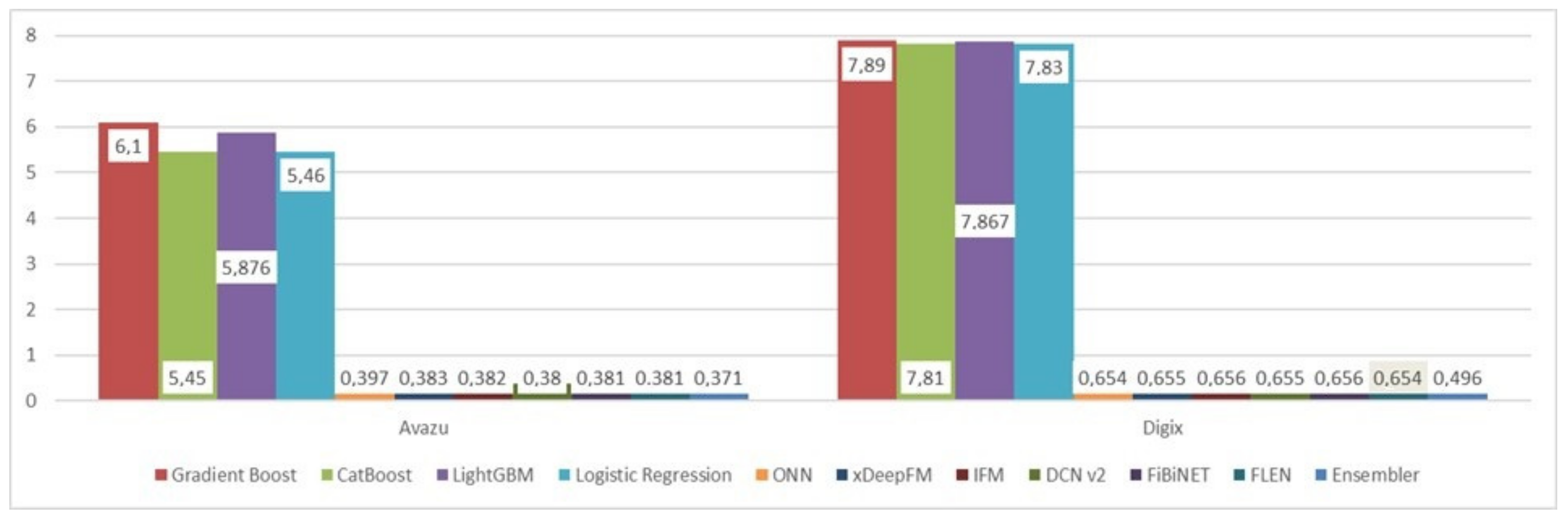
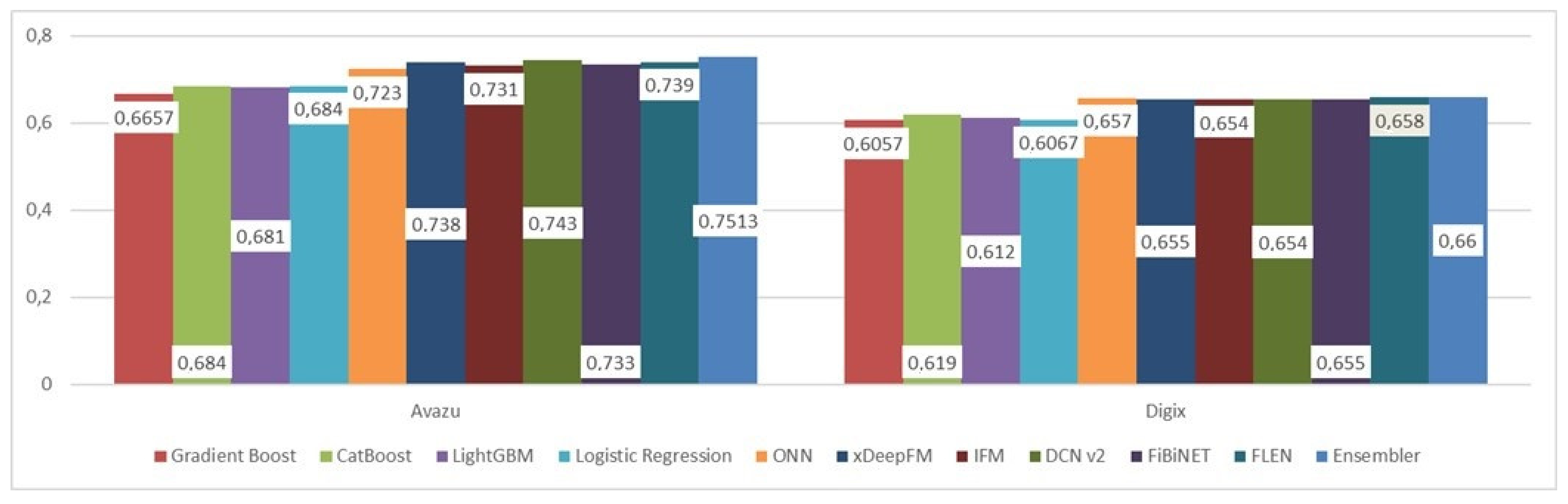
| Undersampled (1:1) | Avazu | DIGIX | ||
|---|---|---|---|---|
| Model | AUC | Log-Loss | AUC | Log-Loss |
| Gradient Boost | 0.6657 | 11.55 | 0.6057 | 13.62 |
| CatBoost | 0.684 | 10.90 | 0.619 | 13.231 |
| LightGBM | 0.681 | 10.99 | 0.612 | 13.402 |
| Logistic Regression | 0.684 | 10.907 | 0.6067 | 13.585 |
| ONN | 0.723 | 0.651 | 0.657 | 0.654 |
| xDeepFM | 0.738 | 0.624 | 0.655 | 0.655 |
| IFM | 0.731 | 0.649 | 0.654 | 0.656 |
| DCN v2 | 0.743 | 0.612 | 0.654 | 0.655 |
| FiBiNET | 0.733 | 0.648 | 0.655 | 0.656 |
| FLEN | 0.739 | 0.614 | 0.658 | 0.654 |
| Ensembler | 0.7513 | 0.593 | 0.66 | 0.652 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Viktoratos, I.; Tsadiras, A. A Machine Learning Approach for Solving the Frozen User Cold-Start Problem in Personalized Mobile Advertising Systems. Algorithms 2022, 15, 72. https://doi.org/10.3390/a15030072
Viktoratos I, Tsadiras A. A Machine Learning Approach for Solving the Frozen User Cold-Start Problem in Personalized Mobile Advertising Systems. Algorithms. 2022; 15(3):72. https://doi.org/10.3390/a15030072
Chicago/Turabian StyleViktoratos, Iosif, and Athanasios Tsadiras. 2022. "A Machine Learning Approach for Solving the Frozen User Cold-Start Problem in Personalized Mobile Advertising Systems" Algorithms 15, no. 3: 72. https://doi.org/10.3390/a15030072
APA StyleViktoratos, I., & Tsadiras, A. (2022). A Machine Learning Approach for Solving the Frozen User Cold-Start Problem in Personalized Mobile Advertising Systems. Algorithms, 15(3), 72. https://doi.org/10.3390/a15030072