1. Introduction
Modernizing the economy requires a strong network: business, scientific research, entertainment, and education demand a dependable and secure network infrastructure. If the network infrastructure is broken, personal information will be disclosed, and society will be in disarray. In April 2020, the World Health Organization (WHO) unveiled an uptick in cyber intrusions, exposing 450 email addresses and passwords. Cybersecurity research is therefore vital for society’s progress and stability. Traditionally, firewalls are used to safeguard network infrastructure and data confidentiality. An Intrusion Detection System (IDS), however, analyses network traffic in real-time and alerts or reacts to questionable traffic and thus can provide necessary information for preventing harmful assaults that could destroy IT infrastructure. Packet-level and flow-level analyses are two fundamental methods for designing IDS; however, flow-level-based IDS research is relatively more predominant than packet-level-based IDS research.
Conventional IDSs (Con-IDS) rely on pattern matching, which requires user-defined filtering criteria [
1]. Setting up perfect filtering rules is challenging, even for specialists, thus limiting the use of Con-IDS to small networks. Hackers may easily bypass manually defined rules. Furthermore, there is no mechanism for proper rule updating. Seeing the success of Artificial Intelligence (AI) in many research fields, network engineers and researchers are investigating its applications in cybersecurity. Using AI in IDS can effectively minimize issues related to Con-IDS [
2,
3,
4,
5,
6,
7]. Deep Neural Networks (DNNs) can learn typical properties of network assaults and apply categorization or detection, eliminating the need for explicit user-defined rules [
8]. Because neural networks are a type of black box to everyone, hackers cannot acquire what kind of patterns and relationships are captured by the neural networks. Therefore, it is more challenging for hackers to create unique assaults that can evade detection. In particular, there has been a push towards agent-based IDS solutions that can learn from their surroundings and adapt to new threats in ways that humans cannot (e.g., by acting appropriately in response to a given or a novel threat) [
9].
Reinforcement Learning (RL) is the prominent method of using automated agents for detection and classification problems. In many ways, RL and IDS are extremely compatible. RL algorithms are used for solving Markov Decision Process (MDP) problems [
10]. In essence, network flow is a form of a dynamic process that a Markov process may represent. Furthermore, intrusion detection might be regarded as a distinct game. The RL agent in IDS may observe the patterns of attacks on various ecosystems and use that information to plan for future defenses that will be more effective. Depending on the nature of the input it receives from the environment, an RL technique may reward or punish a given activity, increasing its capacity to protect the environment (e.g., in a trial-and-error interaction, identify what works better with a specific environment). Throughout its lifetime, an RL agent can improve its powers. Several RL-based IDS have been presented to offer autonomous cyber protection solutions for various environments. The use cases range from the Internet of Things (IoT) and wireless networks to the cloud [
11,
12,
13,
14,
15]. During the learning process, the RL agent can use its observations to execute self-learning capabilities without the need for human supervision or expert knowledge [
16]. However, the majority of the currently available methods are either unable to cope with a huge dataset or cannot fully recognize authentic network activity reliably. This is because an RL agent often faces the state explosion problem when confronted with large learning states. In recent years, proposals have been made to overcome the major limitation of existing RL approaches by introducing Deep Reinforcement Learning (DRL) techniques capable of learning in an environment with a vast number of states. Using deep neural networks throughout the learning process, DRL approaches such as deep Q-learning have shown promise in solving the state explosion problem [
17].
Contributions of the Proposed Work
Different intrusion datasets are used to train and assess the several DRL-based IDS approaches that have been reported in the recent research literature [
18,
19]. Nonetheless, the majority of the work aims to improve the detection performance compared to other methods of their kind. Many of them only scratch the surface of developing and implementing a DRL-based IDS approach without providing essential details, such as how the DQL agent can be formulated in light of an RL principle or how to fine-tune hyper-parameters for improved self-learning and interaction with the underlying network. Furthermore, in the existing literature, flow and packet-level intrusion detection is usually treated separately by using different methods. In this paper, we intend to exploit the application of RL to provide a unified framework for intrusion detection problems at both the packet level and flow level. We achieve this by strategically formulating intrusion detection problems into an RL problem and then designing the overall IDS structure in a DQN framework. The proposed method can not only detect malicious attacks but also classify their types. To summarize, the contributions of this paper are listed as follows:
By means of a proposed image embedding scheme, network traffic data are transformed into time-series first and then image data so that it can be processed by CNN and 1D-CNN-based architecture of the RL agent to tackle the intrusion detection problem.
Flow information is attached with the dataset used for the packet-level IDS to incorporate the temporal information for further performance improvement.
The exploration module is designed based on a CGAN and the -greedy policy for the flow level IDS.
An anomaly detection model is designed for the packet-level and flow-level IDS to detect unknown novel attacks.
In order to improve the robustness of the final detection, a sample agent with a complement reward policy of the RL agent is introduced in the RL framework for adversarial training.
Finally, since RL is known to be sensitive to the hyper-parameters chosen, in this paper, a Bayesian search is conducted to find the optimal parameters.
In the remainder of the paper,
Section 2 includes a brief review of related work.
Section 3 and
Section 4 introduce in detail the proposed intrusion detection frameworks at the packet level and flow level, respectively.
Section 5 includes results for both packet-level and flow-level experiments. Finally,
Section 6 draws conclusions and discusses future work.
2. Related Work
Q-learning, which does not require a model, has been lauded as a promising research strategy, mainly applied to complex decision-making problems. This strategy is useful when others, such as classical optimization and supervised learning methods, are inapplicable [
20]. The strength of Q-learning lies in its efficient output, its adaptability via learning, and its potential for integration with other models.
Research into the use of machine learning in cybersecurity, including DRL [
21,
22,
23], both supervised and unsupervised learning, has been conducted in previous work [
19,
20,
24,
25]. The authors of [
24] presented a systematic overview of DRL regarding cybersecurity. They discussed the DRL-based security solutions for autonomous and non-autonomous physical systems as well as the game theory-based multi-agent DRL cyber-attack defense system. The studies were conducted in light of real-world and virtual settings. In [
25], the authors demonstrated how adversarial learning can help improve the robustness of the DRL-based IDS model used for cyber defense. In their approach, adversarial training was performed by randomly sampling a session from the dataset and generating a positive reward based on the prediction at first, and then the environment was forced to predict wrong. Doing this, the environment acts as an adversarial agent and causes the classifier to further learn better underlying features that ultimately improve the robustness of the DRL-based IDS system. In [
19], the authors applied the NSL-KDD [
26] and AWID [
27] datasets to the study of many DRL algorithms for intrusion detection, including Double Deep Q-Network (DDQN), Deep Q-Network (DQN), Policy Gradient (PG), and Actor-Critical (AC) methods. The supervised machine learning algorithms were trained on those datasets to categorize intrusion occurrences. They used the idea of a virtual environment and sampling methods to replace the interaction module of RL training. It was demonstrated how DRL may outperform alternative machine learning methods when applied to today’s data networks requiring immediate attention and reaction. The results show that DDQN is superior to the competing methods in terms of classification performance and learning speed.
Based on the stateful MDP, deep Q-learning was suggested in [
28,
29]. They contrasted their method’s efficacy with conventional planning-based and DRL-based IDS, using metrics such as execution time, batch size, and cumulative reward to measure performance.
In [
30], the authors advocated installing an RL agent on routers so that they might learn from network traffic and divert it away from the target server. They also proposed the novel idea of using the Coordinated Team Learning (CTL) approach rather than the classical multi-agent RL-training. Their proposed algorithm was able to handle the scalability issue with the network traffic in a much better way. In addition, Hidden Markov Models (HMMs) were presented in [
31] as a machine learning technique for detecting multi-step assaults by predicting the attacker’s next move. The authors used the preliminary offline training where the IDS prediction was compared with the stored database information to avoid over-fitting. The authors of [
32] presented a decision-theoretic framework based on the cost-sensitive and self-optimizing performance, called Anomaly Detection And Response System (ADRS), and they also examined its operation in autonomous networks.
The authors of [
33] created an effective IDS by fusing the multi-objective decision problem with evolutionary algorithms. They treated an IDS as a multi-attribute decision-making issue that must consider factors such as implementation cost, resource limitation, time efficiency, and modification costs. This multi-objective problem sought a solution to bring down these functions’ values before reacting to threats. A weighted linear combination method was used for preprocessing the network traffic. The idea was to map the different network traffic to a similar metric that could improve the classification accuracy.
Recently, in [
34], an efficient way of fine-tuning the hyper-parameters for DQ-learning was suggested by the authors. They evaluated on the NSL-KDD dataset that a small exploration rate achieves better classification accuracy.
An online version of DQN-based IDS was proposed in [
35]. The idea was to use the auto-encoders in the Q-network of RL as function approximators. It helped to improve the classification accuracy while real-world data were processed through the RL-trained network. The use of auto-encoders greatly reduces the effect of human interaction and thus achieves significantly higher efficiency during the online training mode.
Most previous IDS research work is focused on how to improve the performance, or how the suggested strategies fare in contrast to others of a similar kind that rely on Machine Learning (ML). Based on the literature review, in this paper, our goal is to provide a general RL framework for both packet- and flow-level IDS problems with improved robustness. The proposed method can not only detect the attack traffic but can also match the attack traffic into separate classes, including normal traffic and different types of attacks, which, to the best of the authors’ knowledge, has not been widely studied in the literature. The structure of the IDS at the packet and flow level is clearly laid out, and the design of each module is elaborated on in detail. The robustness of the proposed algorithm is improved by using the notion of a negative (sample) agent during the RL training. The exploration rate is adjusted based on the extensive search and bound method. Quantitative results of the proposed RL algorithms are shown to verify that the presented framework can effectively classify the regular traffic with higher accuracy and explicitly identify each attack separately using both packet and flow level information.
3. The Proposed IDS Framework at the Packet Level
In the packet-level intrusion detection, messages and headers transported by network packets are primarily extracted for detecting malignant traffic [
2,
3]. A packet structure consists of messages generated in the application layer and three headers generated in the network layers. The content of messages generated in the application layer is different for different protocols. For example, HTTP generates particular HTTP request messages. Other headers carry further information. TCP and UDP, with TCP and UDP headers, are the two most common protocols in the transportation layer. IP, with the IP header, is the most common protocol in the network layer. Similarly, an Ethernet header is generated in the Physical/Ethernet layer. The knowledge carried inside these headers is called a field.
The proposed IDS framework at packet-level is shown in
Table 1. The framework consists of two major modules and a number of sub-modules. The Preprocessing module is devised for data transformation and feature engineering. The Reinforcement Learning module is devised for training the IDS with RL approaches. This module further comprises a training module and an interaction module. An additional anomaly detection module is designed in this paper to detect those novel attacks blind to the training module.
3.1. Preprocessing Module
Inspired by the adoption of natural language processing (NLP) techniques, such as word2vec, in processing massive text documents and metadata files [
36,
37], an embedding method, namely the image embedding of network packets for the RL-based IDS, is proposed in this section.
Table 2 shows the main steps of the preprocessing module.
In step 1, the network traffic recorded in the ’pcap’ files is separated into small traffic files according to the session-based partition rules. One common rule is that if two packets share the same 5-tuple knowledge (source IP, source port, destination IP, destination port, transportation protocol), then they will be categorized in the same session. After partition, several separated sessions stored in ‘pcap’ files containing various packets recorded in the order of capture time are obtained.
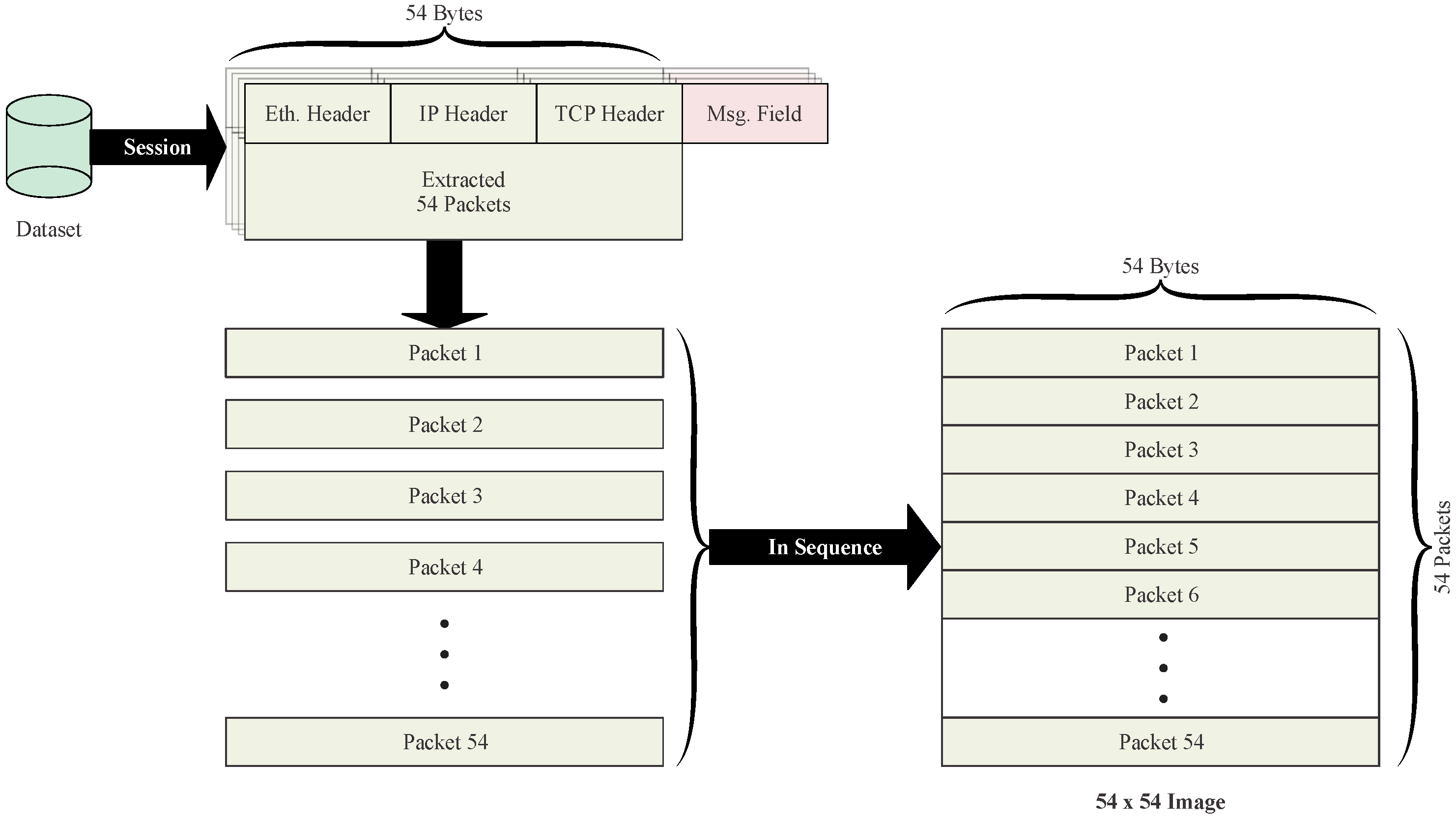
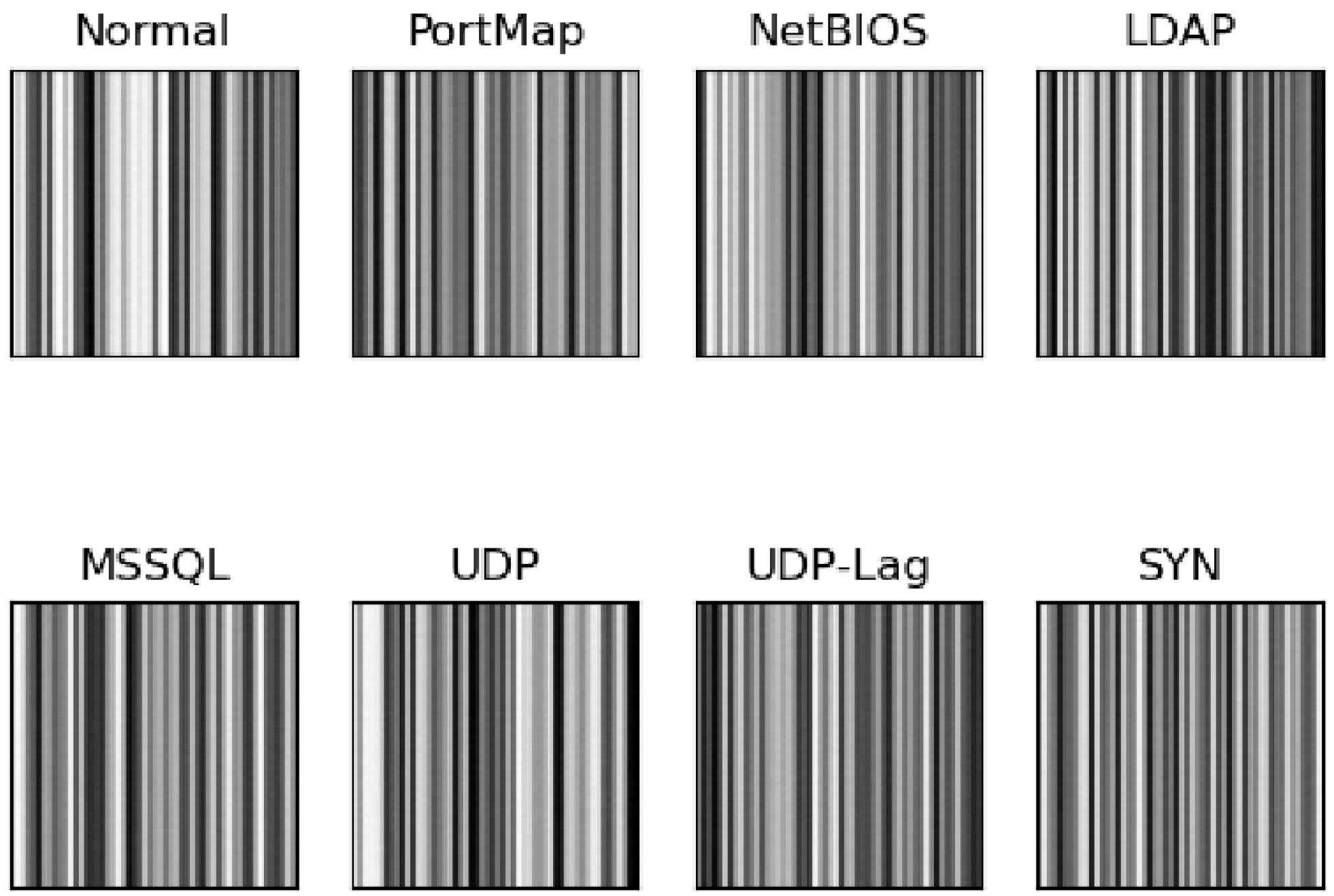
In step 2, the separated sessions are converted into images using the proposed image embedding method. Generally, a network packet in a session consists of an Ethernet header, a TCP or UDP header, an IP header and application messages. The total field length of the first three headers (except the application message) is 54 bytes. The application message field is dropped during image embedding because of its varying length. The 54-byte packet with selected fields is converted to a line of the image, with each byte representing one pixel. Using one session as an example, the whole procedure of image embedding is illustrated in
Figure 1. Thus, a session is transformed into a standard image format with a fixed size of 54 × 54, an image consisting of only 54 packets, as shown in
Figure 2. For sessions with more than 54 packets, additional images were created by repeating the embedding for the extra packets. Zero-padding is used if the number of remaining packets is less than 54 to ensure the fixed image size of 54 × 54. It is essential to embed packets in the order in which they appear in the session. This way, session information is implicitly attached to the packet-level experiments.
In step 3, after image embedding, each session is labeled according to the time stamp given in the log file of the raw dataset. Finally, in the last step, all generated images’ pixels are normalized into [0, 1] from [0, 255].
3.2. Reinforcement Learning Module
Before developing a reinforcement learning module, it is necessary to transfer the intrusion detection problem into an RL-based problem. For this purpose, the intrusion detection problem has been compared to the Atari games studied in [
38], considering intrusion detection as a special game. The comparison is shown in
Table 3.
The agent can take the following trajectory until it reaches the end (last packet) of a session:
In the Atari game, the agent repeats until it reaches the terminated state (game over) of an episode. Similarly, the intrusion detection agent can also take the above trajectory until it reaches the session’s end (last image). The state is the game screen in the Atari game, and in IDS, the state is also an image after image embedding on the sessions. The action space of the Atari game contains game operations, which can be expressed as discrete numbers, e.g., 0 (one step left), 1 (one step right), 2 (one step up), etc. The action space of the IDS, however, contains the types of the traffic class, which can also be expressed as discrete numbers such as 0 (normal), 1 (attack 1), 2 (attack 2), etc. The reward system is different for the above two problems. For the IDS, the reward system has to be designed carefully. After conducting the research, it has been found that the reward scale significantly impacts the performance of reinforcement learning algorithms. Thus, inspired by the reward clip for the code-level optimization implemented in the Atari game agent [
39], the following reward feedback rule has been designed: if the prediction made by the agent is correct, the reward is 1; otherwise, the reward is
.
Table 4 shows the significance of the trajectory and the transformation between RL and IDS.
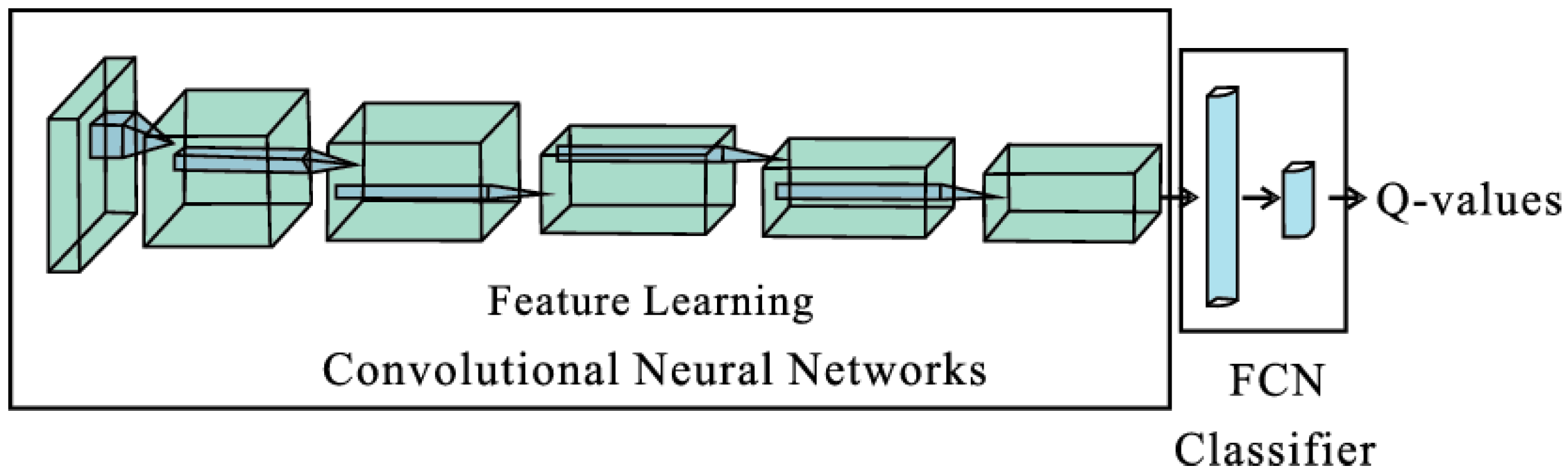
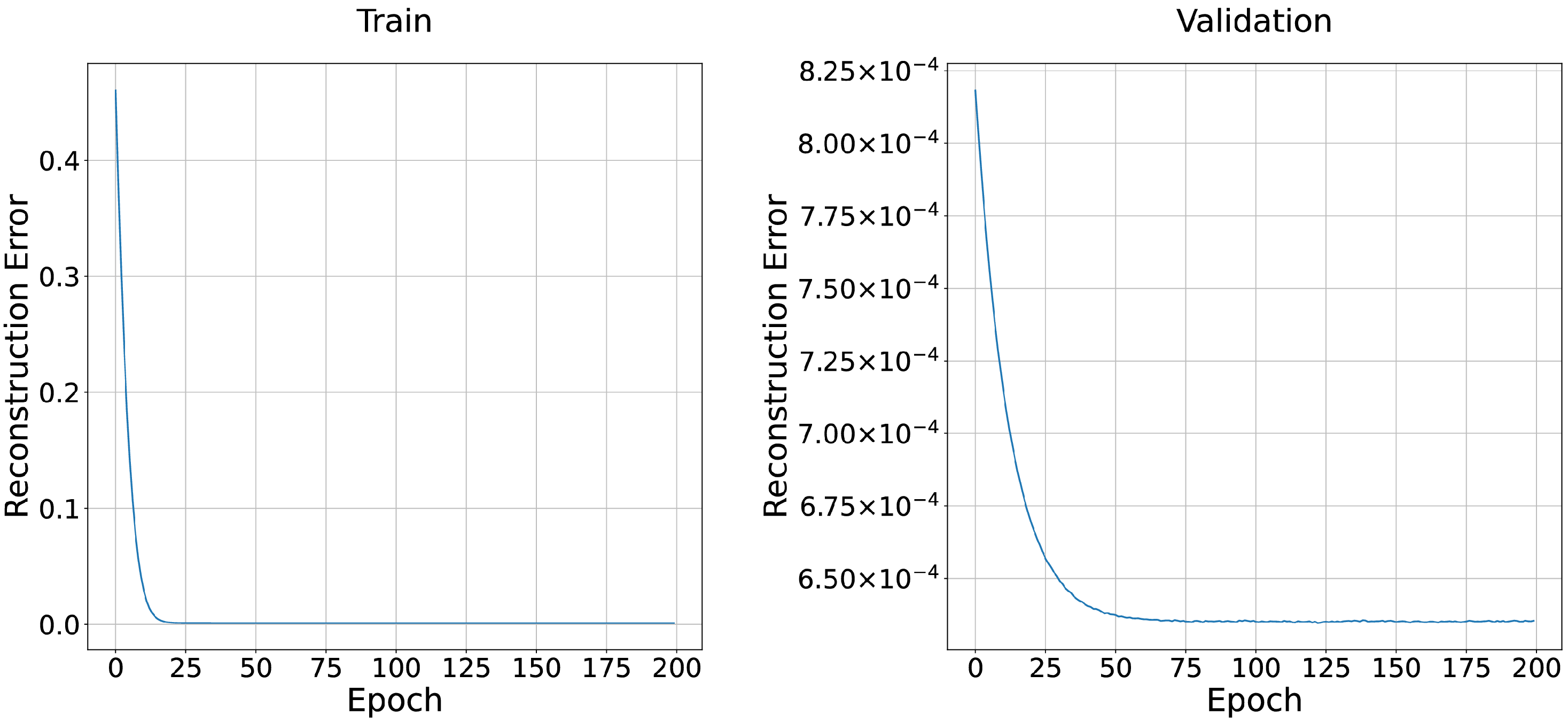
DQN learning is an excellent choice for solving discrete problems and is much easier to implement compared to Proximal Policy Optimization (PPO). After identifying these essential reinforcement learning ingredients, we start designing our reinforcement learning module. Convolutional Neural Networks (CNNs) are chosen as the network structure of the IDS agent since the input states are images. It should be noted that 1D-CNN is also appropriate for the IDS. Each session’s images are treated as a type of time-series data since packets embedded in the image are arranged in chronological order according to the capture time. Therefore, 1D-CNN is chosen as an appropriate choice for comparison during the evaluation of the proposed IDS. The main structure of the two RL agents, i.e., DQN-CNN and DQN-1D-CNN, are shown in
Figure 3.
The input states of the RL agents are a finite batch of images. CNN and 1D-CNN are applied for feature extraction on DQN-CNN and DQN-1D-CNN, respectively. An additional fully connected layer is deployed for final classification and detection. The output is Q-values of the current state, and the prediction/action is decided based on the following set of equations.
where
is the learning rate and
is the reward discount factor. The final action is calculated as
As shown in
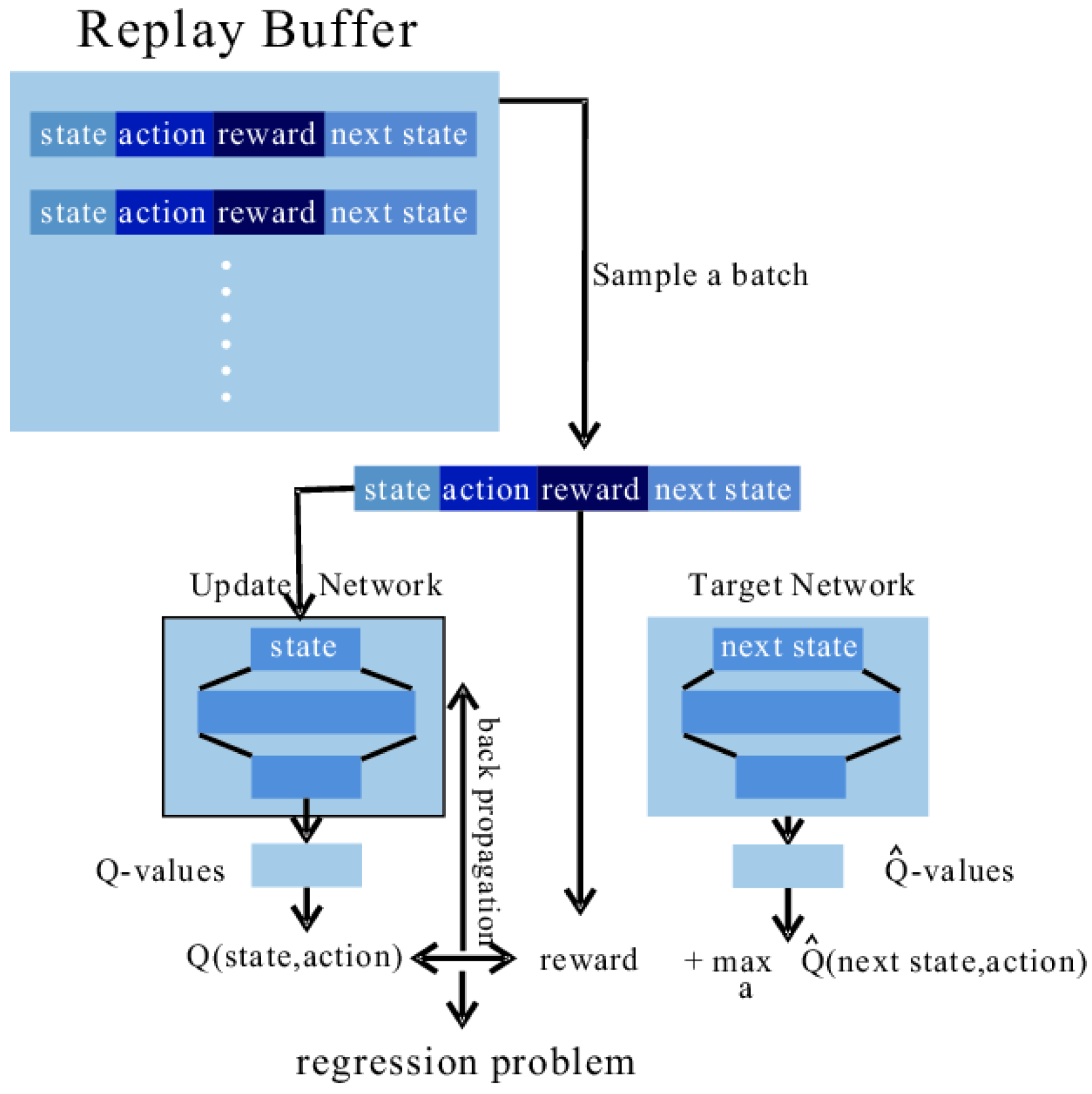
Table 1, the RL module in the IDS has two sub-modules, the interaction module and the training module. The complete procedure of the interaction module is shown in Algorithm 1. The complete procedure of the training module is shown in
Figure 4 (taking DQN as an example). Two networks (the Update and the Target) operate together to achieve the approximate regression. The functionality of the target network is to improve the training stability [
40] by fixing the regression target in
N steps. The structure of the update network is the same as that of the agent, while the target network copies the structure from the update network and is initialized with the same parameters of the update network. The update network is updated through back propagation (BP), and the target network is updated by copying the parameters from the update network every
N times.
| Algorithm 1 Interaction Module |
- 1:
procedureStart Interacting - 2:
top: - 3:
Randomly sample a session and obtain its label - 4:
Take the first image in the session as current state - 5:
Feed into agent and obtain action/prediction - 6:
Feed and label into reward mechanism, obtain reward - 7:
- 8:
loop: - 9:
- 10:
if Last image in the session then - 11:
Store into replay buffer - 12:
break - 13:
else - 14:
Take next image in the session as next state - 15:
Store into replay buffer - 16:
end if - 17:
goto loop - 18:
goto top - 19:
end procedure
|
The training module and the interaction module work alternately. For example, once the replay buffer is full, training for a specified number of epochs can start. After training, the new agent is set to interact with the environment and store new data into the replay buffer while removing the old data. The complete pack-level IDS algorithm, including both the interaction module and training module, is shown in Algorithm 2.
| Algorithm 2 Deep Q-Learning Framework for Detection at Packet-level |
- 1:
procedureDeep Q-Learning - 2:
Extract sessions from raw traffic file - 3:
Split sessions based on session-based rule - 4:
Conduct image embedding on each session - 5:
Initialize Q function for agent, set target Q function - 6:
for 1…m iterations do - 7:
Start interacting until replay buffer is full - 8:
for 1…n epochs do - 9:
Sample a batch data from replay buffer - 10:
Target - 11:
Update Q function through back propagation to make close to y - 12:
Every C steps reset - 13:
Interact to replace old data - 14:
end for - 15:
end for - 16:
end procedure
|
3.3. Anomaly Detection Module
The purpose of the anomaly detection module is to detect novel attacks that are blind to the training set by considering them as anomaly classes. This is important for a robust IDS because, in reality, it is impossible to include all types of attacks in the training set.
The Q-values output generated by the agent is tested against the set manual threshold ’
’ for anomaly detection. If the confidence score (Q-value) is smaller than
, the input session image will be determined as the ’anomaly’ attack. Conversely, the class that belongs to the max confidence score is the expected detection result. Equation (
3) shows the mathematical formulation of the anomaly detection module.
4. The Proposed IDS Framework at Flow-Level
In flow-level intrusion detection, the traffic flow characteristics, which usually contain numerous packets, are extracted for detecting attacks [
4,
5,
6,
7]. Flow information includes the statistics of a flow, such as the number of packets, the duration, the average packet size, etc. A 5-tuple knowledge defines a flow that includes source IP, source port, transportation protocol, destination IP and destination port [
41]. The number of packets in the flow is a valuable feature for flow-level IDS. The work in [
4] contains evidence that Denial of Service (DoS) and Distributed Denial of Service (DDoS) attacks tend to transmit a large number of packets in a short time. The flow duration, the average packet size in the flow, and the transportation protocol can also be considered important features. Recently, many datasets have been collected and published for flow-level intrusion detection research.
The whole IDS framework at the flow level is shown in
Table 5. The overall architecture is quite similar to the one proposed in
Table 1 with some minor modifications in two modules, i.e., preprocessing and RL module.
4.1. Preprocessing Module
The complete data preprocessing module is shown in
Table 6. The dataset collected for flow-level research always involves some discrete and categorical features, such as protocols and packet size.
In step 1, the discrete and categorical features are converted into continuous features, which can be processed by DNNs. With regard to the transformation of categorical features, the most simple and common approach is one-hot encoding. One-hot encoding has many advantages over other encoding approaches, one of which being the easy implementation. For the transformation of discrete features, an N-bit binary encoding approach can be used. The value of N, which ensures that N-bit binaries can encode all values of this discrete feature, is chosen based on the maximum value of the feature.
In step 2, max–min normalization is performed on the encoded dataset, converting all values to [0, 1]. Notably, after implementing one-hot encoding and binary encoding, data dimension considerably increases. A single hidden layer Stacked Auto Encoder (SAE) is then used with this encoded dataset for dimension reduction in the final step to counter this problem. The SAE-based approach helps in conducting dimension reduction and feature extraction. The SAE model is pre-trained, and then the encoder is extracted as the primary structure of the RL agent, as shown in
Table 7.
4.2. Reinforcement Learning Module
Table 8 describes the important elements of the RL module of flow-level IDS. For brevity, only the parts that are different from the RL module of packet-level IDS are detailed in this section.
The action represents the prediction performed by the agent. Furthermore, the flow level reward mechanism is the same as that of the packet level. However, the state and episode for the RL module, in the case of flow-level IDS, are defined differently. For the packet level, ’pcap’ files are separated into different sessions; then, through image embedding, these sessions are transformed into images, which are considered as the states. However, network traffic features provided by the dataset are used directly as the states at the flow level. Moreover, at the packet level, packets embedded in the image and images in a session are arranged in chronological order (capture time). Thus, a session is viewed as an episode. Nonetheless, the data collected in the dataset has been shuffled at the flow level, so there is no apparent chronological order. The episode’s length needs to be determined and is assumed to be fixed in the interaction process. Furthermore, the main structure of the update module is a Fully Connected Neural Network (FCN).
In the proposed RL module of flow-level IDS, in addition to the detection agent, we also design a sample agent to facilitate the adversarial training. The agent performs the intrusion class’s correct prediction (the action) by achieving maximum rewards. The sample agent provides guidance (the action) for the next class to be sampled from. To improve the variability, the sample agent tends to counteract the agent. It chooses a class that is most likely to be misclassified and suggests it as the class to be sampled from for the next state.
For this reason, the reward feedback of the agent and the sample agent is the opposite. If the agent’s prediction is wrong, the reward feedback of the sample agent is 1; otherwise, if the agent’s prediction is correct, the reward feedback of the sample agent is −1: this way, the sample agent functions as the adversarial training agent. The objective of the sample agent is to ensure that those state-action pairs with high classification error rates can be adequately trained.
In the interaction stage, we should create a simulation environment. We take the preprocessed dataset as the simulation environment. In our experiments, we focus on episodic tasks; hence, we fix the length of an episode in advance. The complete interaction module is shown in
Figure 5. All of the traffic features collected in the dataset can be considered as the states. In the beginning, a state is randomly sampled from the dataset. Feeding the state into the agent (classifier), the agent then outputs the prediction (action) of the current state. Feeding the action-label pair into the reward mechanism, we can obtain the reward. If the current state is not reaching the end of the present episode, we also feed the current state to the sample agent and obtain the next sample class. Afterward, we sample the next state that belongs to this class from the dataset. Next, we store the state, action, reward and next state in the replay buffer. Subsequently, treat the next state as the current state and repeat the above process. It should be noted that if the current state is reaching the end of the episode, we store state, action, reward into the replay buffer and then randomly sample a state from the dataset, which indicates that a new episode is launched.
The flow level IDS training approach is identical to that illustrated in
Figure 4. The SAE-based feature extractor and the overall network design for the update and target networks are shown in
Table 7. It should be emphasized that the agent and the sample agent must be trained at the same time.
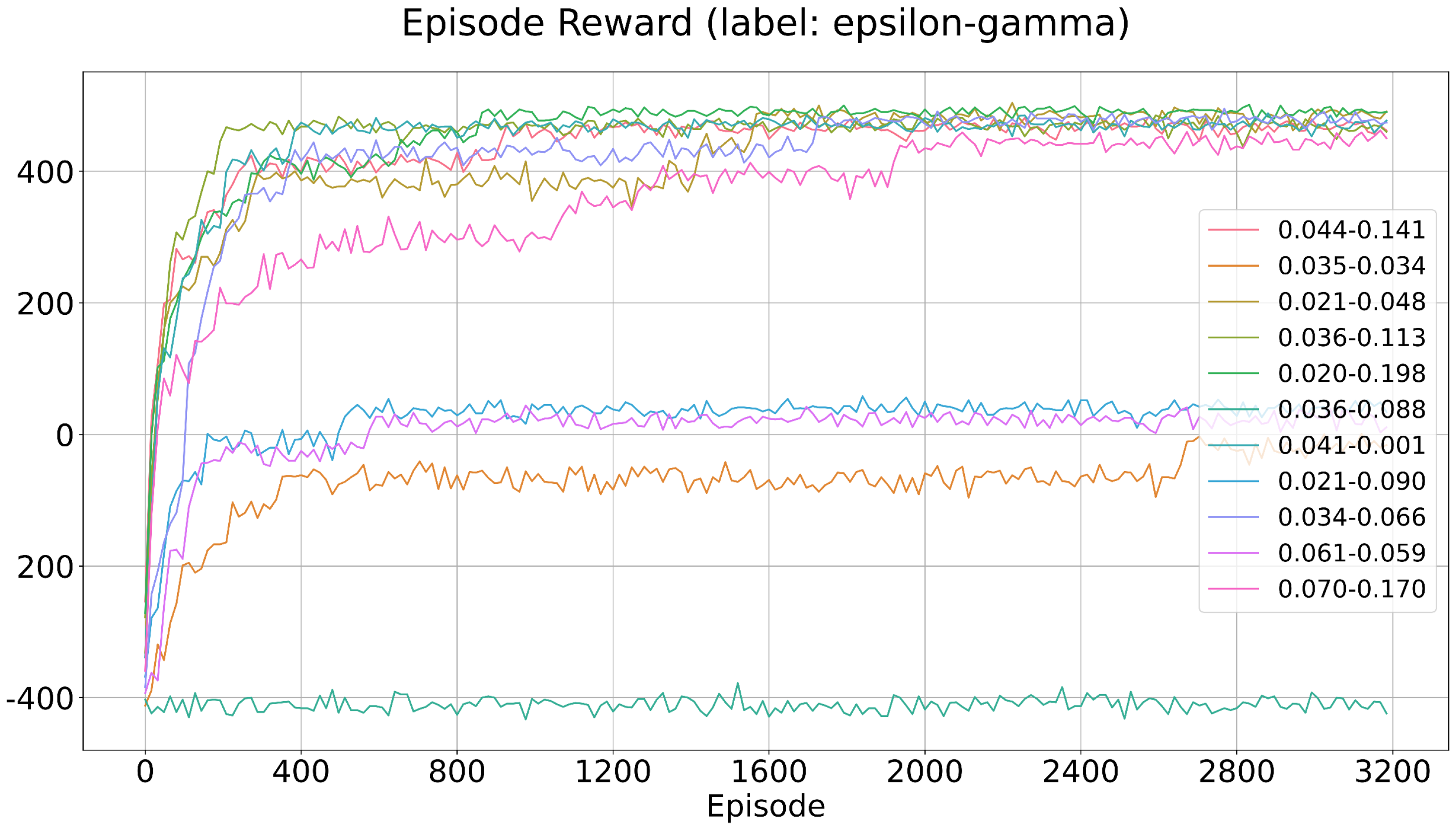
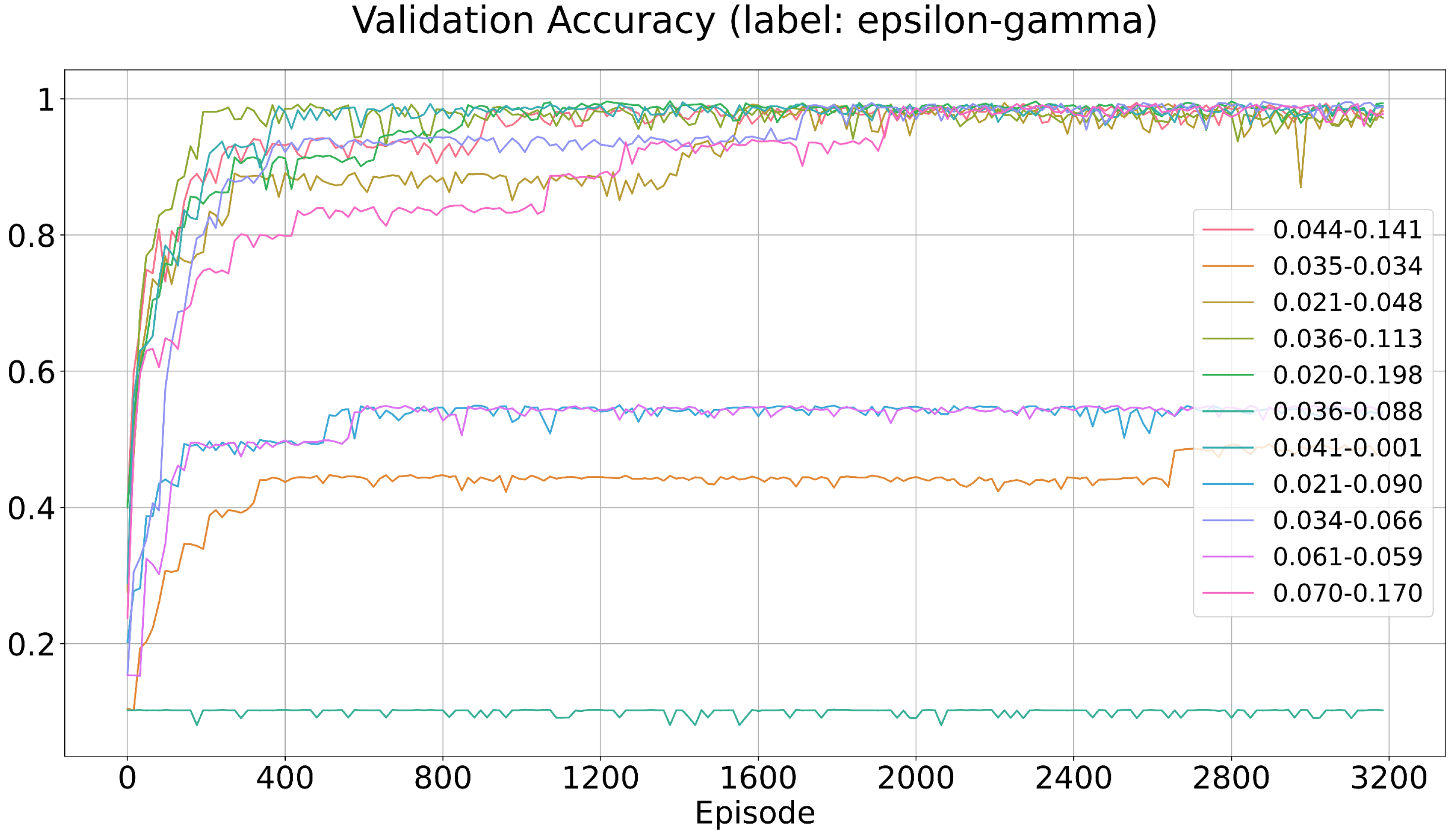
4.3. The Exploration Module
Most datasets collected for intrusion detection are unbalanced. This is because the vast majority of traffic in the real world is normal traffic, so it is easier to collect normal traffic than malignant traffic. In RL, the exploration module is conductive to solve these class imbalance problems. In the proposed flow-level IDS, both the
-greedy policy and Conditional Generative Adversarial Network (CGAN) are used for the exploration. Equation (
4) shows the
-greedy policy applied to the sample agent, where
controls the exploration degree.
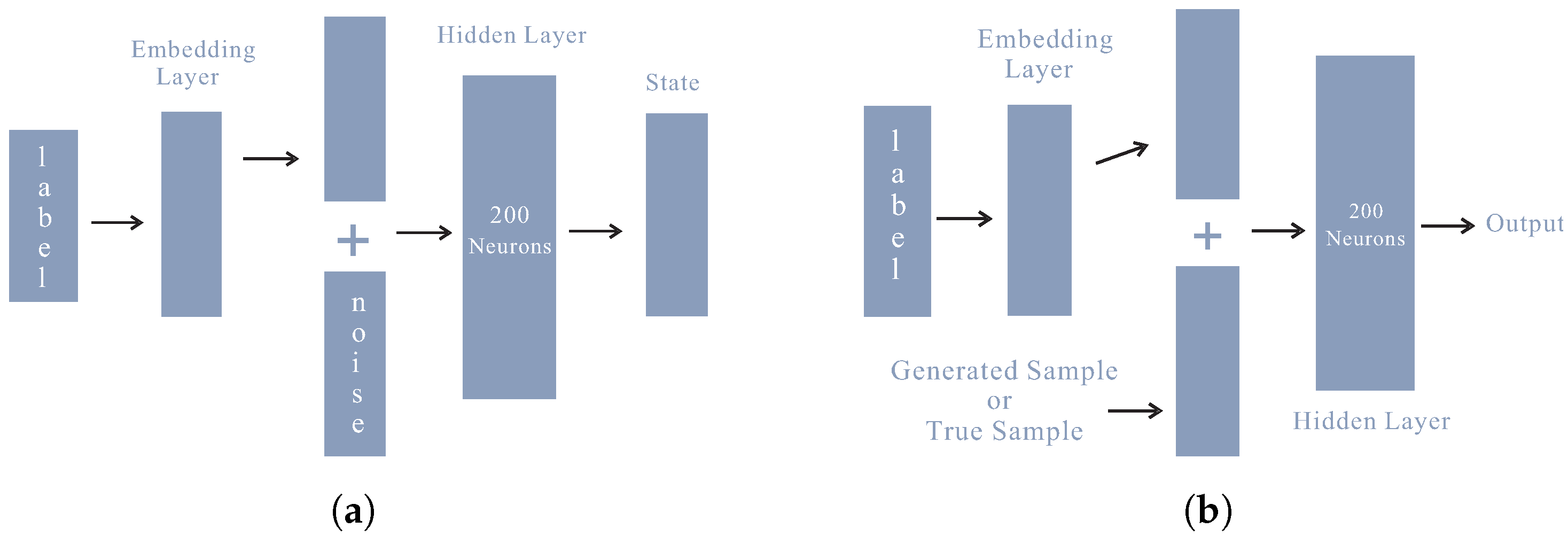
The purpose of CGAN is to generate some novel attack flows for each class, which will augment the fixed dataset. The CGAN exploration rate
controls the extent of the exploration. The CGAN takes the class label and noise as the input and outputs a state that belongs to each class. The architecture of both the generator and discriminator is shown in
Figure 6. The generator’s functionality is to generate simulated states that can deceive the discriminator.
The output of the discriminator is a numerical value ranging in [0, 1]. An output threshold of 0.5 was set to differentiate between the true and generated samples. If the output of the discriminator is greater than this threshold, the input label is marked as a true sample; otherwise, if the output is less than the pre-defined threshold, the input sample is marked as a generated or augmented sample.
The quality of the generated samples is assured by training an additional sample classifier for the dataset composed of generated samples. Only the generated samples correctly classified by the classifier are retained as generated samples to augment the overall dataset. The complete algorithm of Deep Q-Learning with an exploration module is shown in Algorithm 3.
| Algorithm 3 Deep Q-Learning Framework for Detection at Packet-level |
- 1:
procedureDeep Q-Learning - 2:
Conduct preprocessing on dataset - 3:
Pretrain a stacked autoencoder - 4:
Train the CGAN - 5:
Initialize Q function for agent, set target Q function - 6:
Initialize the agent replay buffer and the sample agent replay buffer for training the agent and the sample agent, respectively - 7:
Copy parameters to Q and from the encoder - 8:
Set target Q-function - 9:
for each episode do - 10:
Randomly choose from the dataset - 11:
for each sample within the episode, do - 12:
Given state , take action based on Q - 13:
Given state , take action based on () - 14:
Compare with the true label, obtain the reward and - 15:
Derive the next state: choose for which the true label is from dataset or CGAN, with a probability of 1- and , respectively - 16:
Store into the agent replay buffer - 17:
Store into the sample agent replay buffer - 18:
Sample a batch from the agent replay buffer - 19:
Sample a batch from the sample agent replay buffer - 20:
Target - 21:
Update Q through back propagation to make close to y - 22:
Target - 23:
Update through back propagation to make close to - 24:
For each C steps reset - 25:
end for - 26:
end for - 27:
end procedure
|














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}