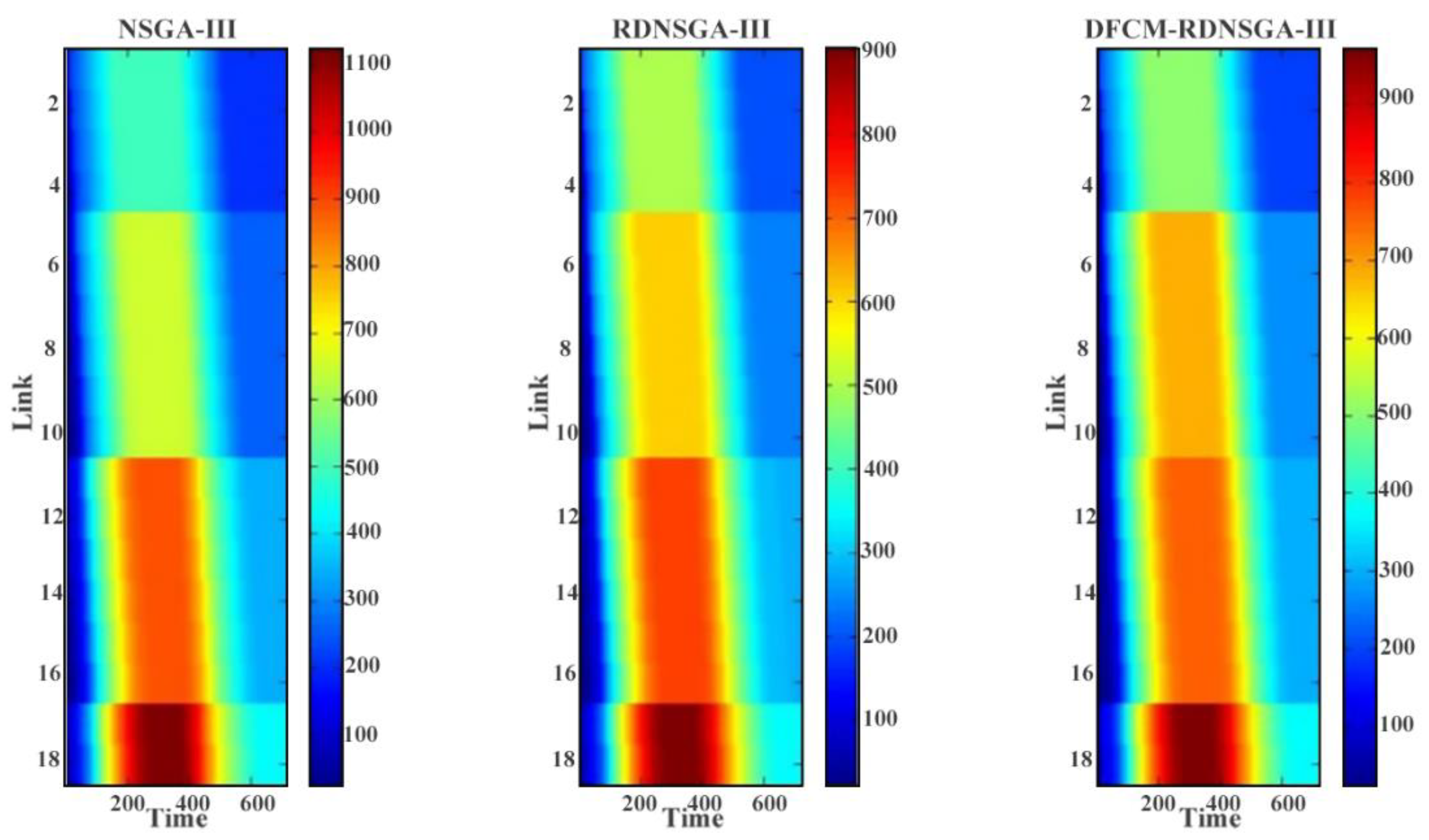
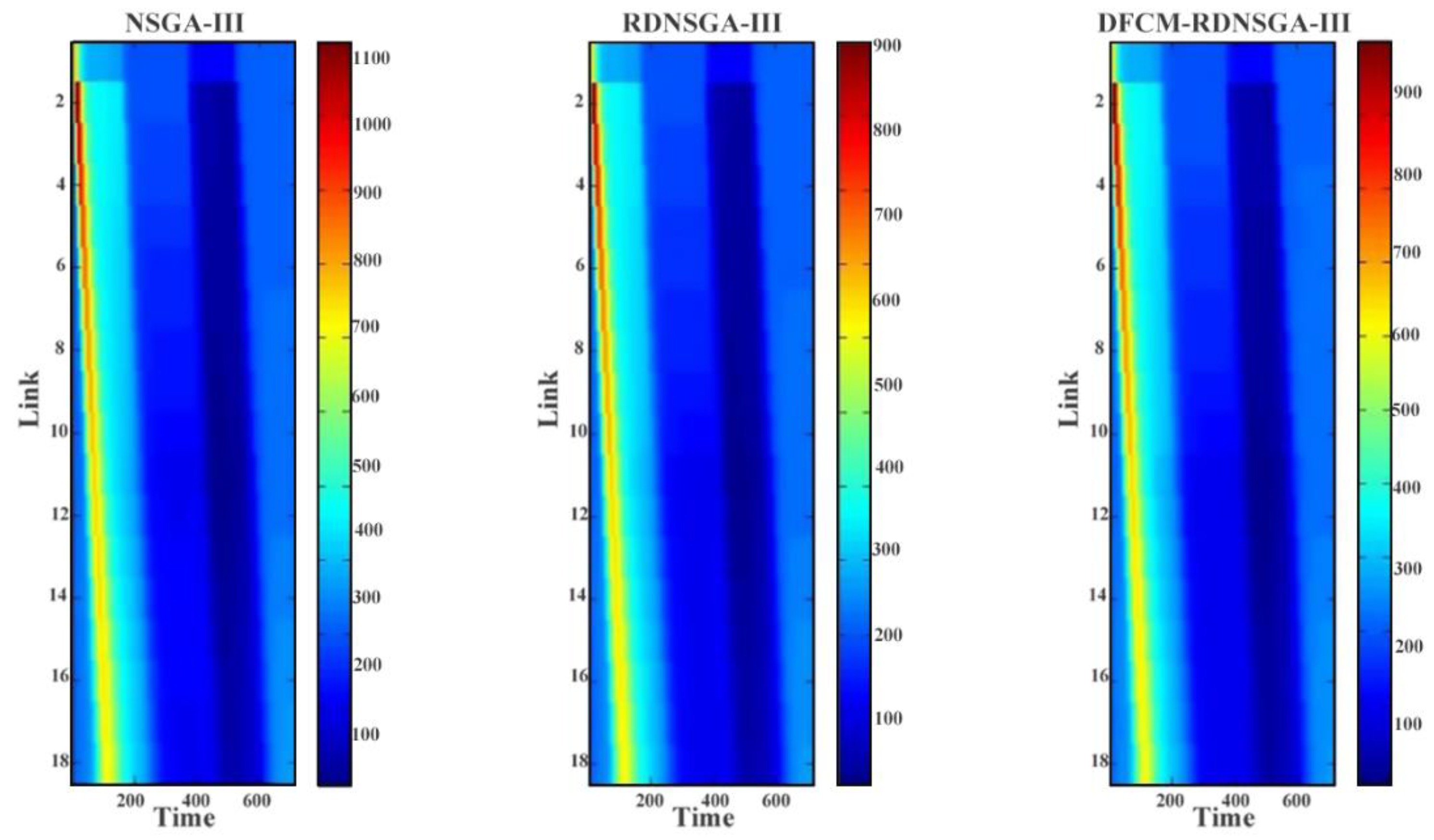
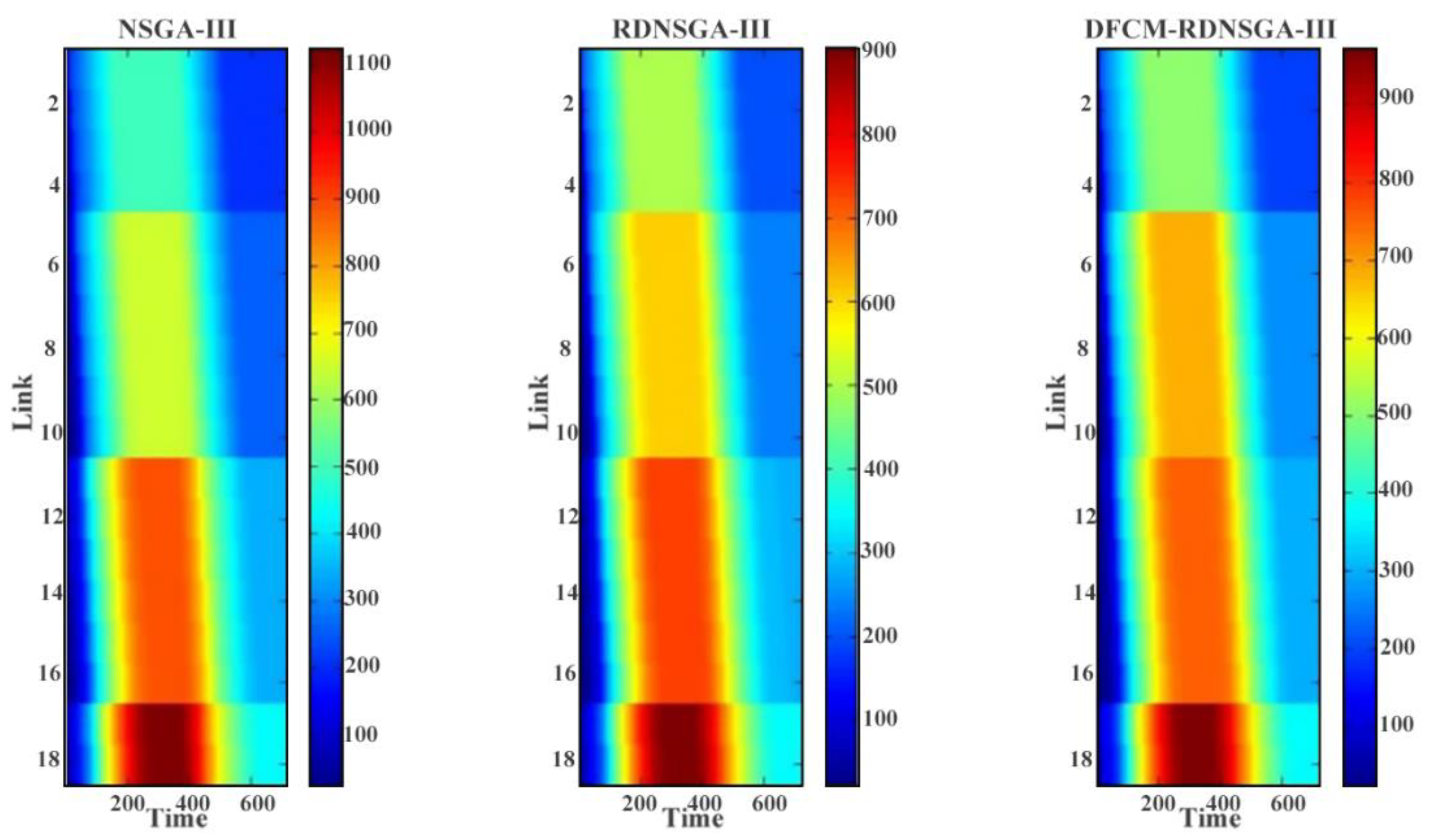
Based on the original NSGA-III algorithm, the environment detection operator is introduced to store the environment information and the set of optimal solutions corresponding to the current environment. Additionally, the robust dynamic objective function is set to meet the needs of robust dynamic optimization. Secondly, in order to solve the problem of the difficulty of determining the Pareto fronts in the optimization process, a density fuzzy c-means clustering algorithm DFCM is proposed to determine the distribution of Pareto fronts. This algorithm can detect the distribution of solutions in the target space, track the Pareto front continuously, and guide the search direction of the algorithm. Finally, combining the robust dynamic optimization algorithm given in this section with density fuzzy c-means clustering algorithm DFCM, a robust dynamic nondominated sorting multi-objective genetic algorithm based on the density fuzzy c-means clustering algorithm DFCM-RDNSGA-III is proposed. The details of the proposed algorithm are shown in the following.
4.1. Robust Dynamic Nondominated Sorting Multi-Objective Genetic Algorithm RDNSGA-III
In the robust dynamic nondominated sorting multi-objective genetic algorithm RDNSGA-III proposed in this section, there are two main improvements:
1. In terms of dynamic characteristics, an environment detection operator is introduced based on the NSGA-III algorithm to test whether the external environment has changed. If environmental variations are detected, optimization will be restarted to obtain the optimal solutions which satisfy the current environment. Moreover, in the process of the algorithm operating, the environment information and the optimal solution sets corresponding to the current environment will be stored. It is ensured that repeated optimization under a similar environment can be avoided during the dynamic optimizing process;
2. In terms of robustness, the robust dynamic objective function is introduced to measure the robustness of the solutions in the nondominated sorting, i.e., the robust dynamic objective function is used to sort the solutions. By minimizing the average value of the objective function in multiple continuous temporal windows, the solution with stronger robustness is not only applicable to the current dynamic environment, but also applicable to multiple continuous dynamic environments. The robust dynamic objective function setting has been described in detail in Formula (1) to Formula (3) above.
The framework of the RDNSGA-III algorithm is described as follows:
Step 1: Initialize the environment detection parameter, set the environmental detection counter , the maximum environmental detection times , and to store the current environment information and corresponding optimal solutions.
Step 2: If the environment detection counter , or if the environment detection counter and the environment has changed, go to step 3. Otherwise, copy the current population , and go to step 12.
Step 3: Initialize algorithm parameters, including the maximum iterations , the number of the population , the current generation , initialize the population , nondominated solution set , archive set , and reference point set .
Step 4: Recombine, crossover and mutate the population to generate offspring population , .
Step 5: Combine archive set and offspring population to generate the combined population , .
Step 6: Perform the nondominated sorting operation on the combined population and generate the nondominated solution set . Perform nondominated sorting on the nondominated solution set to obtain the set , , where denotes the nondominated solution sets with nondomination level , respectively, .
Step 7: Generate nondominated solution set .
Step 8: Generate the next-generation population . If the number of solutions in is exactly equal to , i.e., , the next generation of parent population is generated directly, , and , return to step 2; otherwise, structure with , i.e., . The remaining solutions need to be selected from the layer according to the niche count, i.e., the number of solutions that the population needs to select from is .
Step 9: Generate reference points; the reference point set .
Step 10: Associate the solutions in the solution set with the reference points.
Step 11: Calculate the niche count of each reference point in the reference point set , select elements according to the niche count to construct the population , and select solutions from to join the population .
Step 12: Reserve the existing population, randomly take out half of the solutions and store them in the archive set . Let ; if , go to step 4. if , output the final solution set , and go to step 13.
Step 13: Save the current environment information and the final optimal solution to the optimal solution set , and add it to . Let + 1; if , go to step 2. If , output the final optimal solution set.
4.2. The Robust Dynamic Nondominated Sorting Multi-Objective Genetic Algorithm Based on Density Fuzzy C-Means Method DFCM-RDNSGA-III
In the paper [
24], it is pointed out that the main challenge of solving the Pareto front distribution problem is the unknown distribution of Pareto optimal fronts in multi-objective optimization algorithms. The paper [
25] pointed out that clustering algorithms can help multi-objective optimization algorithms detect the distribution of solutions in the objective space and guide the search to the Pareto fronts. However, the randomness of initial cluster generation and the difficulty of determining the number of initial cluster centers occur when using fuzzy c-means clustering algorithm. Therefore, a density-based clustering method (DBSCAN) [
26] is adopted in this paper to conduct density clustering of the initial cluster centers when initializing the cluster centers.
The reasons to adopt this method can be explained from three aspects. Firstly, the spatial characteristics of data points can be reflected, and the rationality of cluster center distribution can be ensured when using density clustering, therefore improving the quality of the initial cluster centers of the fuzzy c-means clustering algorithm. Secondly, the number of cluster centers does not need to be set in advance because cluster centers can be generated automatically according to the specific density distribution of the population, which can solve the problem of setting the number of cluster centers by trial and error in fuzzy c-means clustering algorithm. In addition, through the fuzzy c-means clustering algorithm, the given initial cluster center set is continuously optimized, and the position of the cluster center is adjusted; therefore the shape information of more real Pareto fronts can be obtained.
Based on the RDNSGA-III algorithm in
Section 4.1 and the DFCM algorithm proposed in paper [
26], a robust dynamic nondominated sorting multi-objective genetic algorithm based on density fuzzy c-means method DFCM-RDNSGA-III is proposed in this section. The major improvement of this algorithm is that, in the following description of the DFCM-RDNSGA-III algorithm, specifically in Steps 9 and 10, the difficulty of determining Pareto fronts during the algorithm optimization process is solved based on density fuzzy c-means method DFCM. Specific distribution of the Pareto fronts can be acquired through adopting this clustering method. By describing the Pareto fronts through cluster centers, the distribution of the solutions over the objective space is detected, and the Pareto fronts can be tracked continuously [
27]. Therefore, the search direction can be guided towards the Pareto fronts, leading to an increase in population diversity and convergence speed. Additionally, the details of the improvement are presented in sub-algorithm 1 and sub-algorithm 2 in this section.
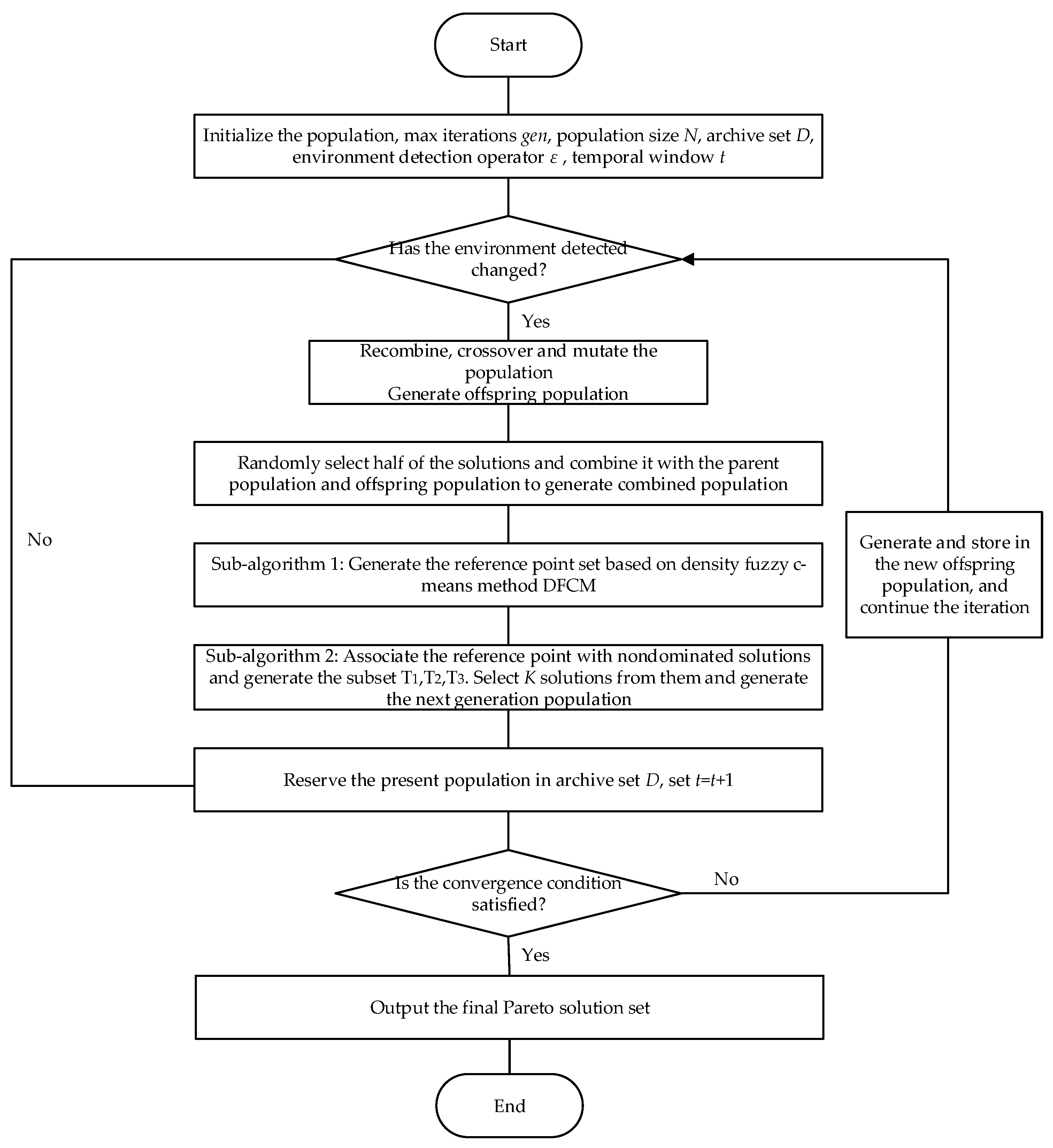
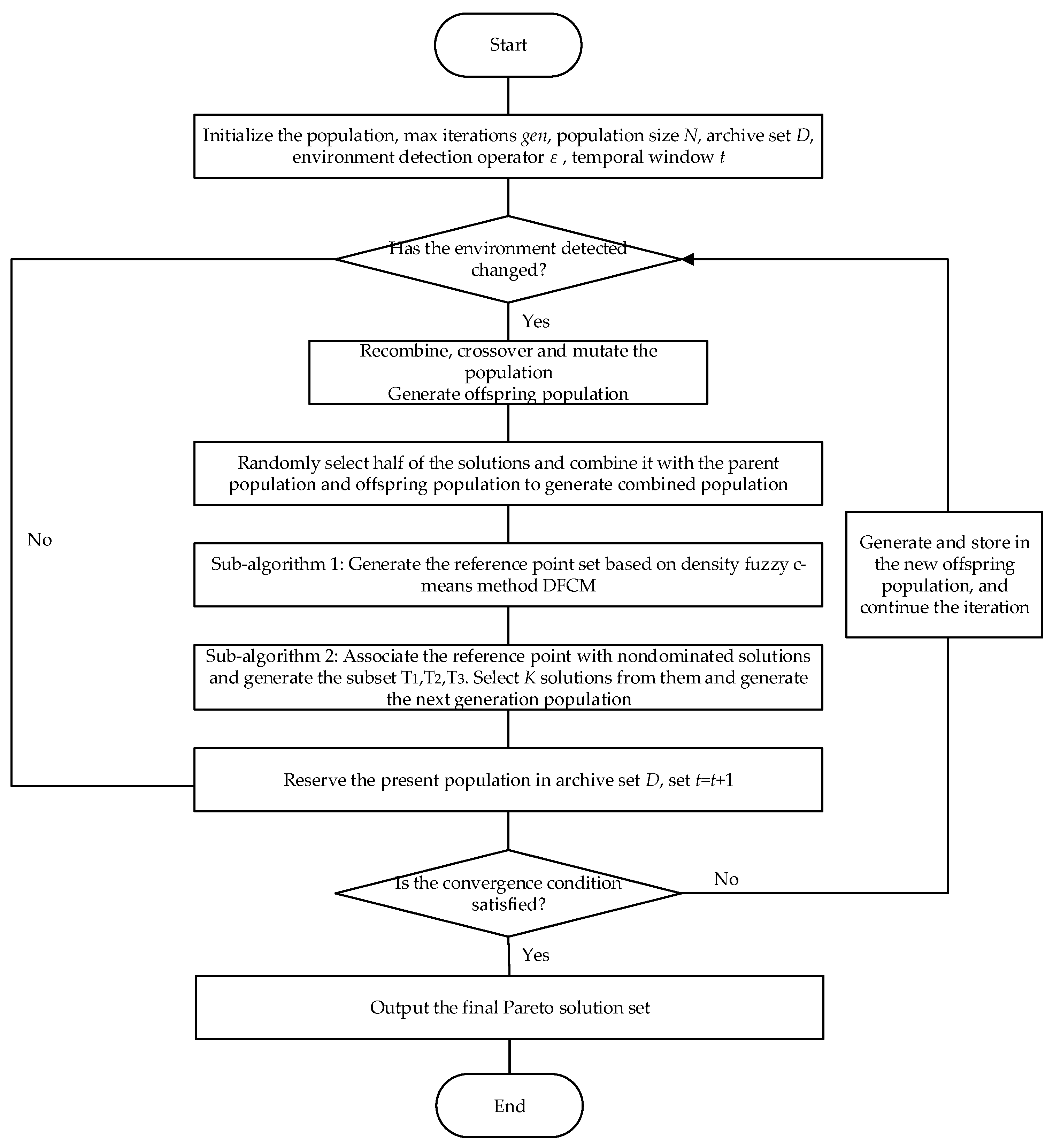
The flowchart of the proposed algorithm DFCM-NSGA-III is given in
Figure 1. The framework of the proposed algorithm DFCM-NSGA-III will be described first, then sub-algorithm 1 and sub-algorithm 2 used in the proposed algorithm will be discussed later.
Specifically, the execution steps of the DFCM-RDNSGA-III algorithm are as follows:
Step 1: Initialize the environment detection parameter, set the environmental detection counter , the maximum environmental detection times , and set to store the current environment information and corresponding optimal solutions.
Step 2: Initialize the optimization process of the algorithm, or if and the environment has changed, go to Step 3. Otherwise, copy the current population , and go to Step 11.
Step 3: Initialize algorithm parameters, including the maximum iterations , the number of population , the current generation , the population , the nondominated solution set , the archive set , and the reference point set .
Step 4: Recombine, crossover and mutate the population to generate the offspring population , .
Step 5: Randomly select half of the solutions as the set from the current archive set . Combine the parent population and offspring population to generate the combined population , .
Step 6: Perform the nondominated sorting operation on the combined population , and generate the nondominated solution set . Perform nondominated sorting on the nondominated solution set to obtain the set , , where denotes the nondominated solution sets with nondomination level , respectively, .
Step 7: Generate nondominated solution set .
Step 8: Generate the next generation population . If the number of solutions in is exactly equal to , i.e., , the next generation of parent population is generated directly, , and , go to Step 2; otherwise, construct with , i.e., . The remaining solutions need to be selected from the layer according to the niche count, i.e., the number of solutions that the population needs to be selected from is .
Step 9: Generate reference points according to the density fuzzy c-means clustering algorithm DFCM and construct the reference point set . The specific process is described in sub-algorithm 1.
Step 10: Associate the solutions in the solution set with the reference points. Calculate the niche count of each reference point in the reference point set , select elements according to the niche count to construct the population , and select solutions from as set to join the population . The specific process is shown in sub-algorithm 2.
Step 11: Reserve the existing population, randomly take out half of the solutions and store them in the archive set . Let . If , return to step 4. If , output the final solution set , and go to Step 12.
Step 12: Save the current environment information and the final optimal solution to the optimal solution set , and add it to . Let + 1; if , go to Step 2. If , output the final optimal solution set.
(1) Sub-algorithm 1: Calculate the cluster centers of and generate reference point set according to the algorithm DFCM.
Step 1: Initialize the radius of neighborhood , and the minimum number of samples .
Step 2: Generate the initial cluster center set . Calculate the initial membership degree of all solutions to the initial cluster center set in the current situation, . denotes the number of cluster centers; denotes the fuzzy allocation matrix index used to control the degree of fuzzy overlap. refers to the th solution and denotes the th cluster center.
Step 3: Calculate the initial adaptiveness function of fuzzy c-means clustering algorithm, , where G denotes the number of all solutions in the and denotes the number of cluster centers.
Step 4: If the adaptiveness function does not reach the acceptable extent or if the maximum number of iterations is satisfied, go to Step 5; otherwise, end the procedure and output the clustering result.
Step 5: Update the cluster centers to form a new cluster center set .
Step 6: Update the membership degree and adaptiveness function according to the new cluster centers and repeat Steps 3–5 until the output conditions are satisfied. Finally, output the final clustering results , i.e., the reference point set .
Step 7: Generate the solution set of the corresponding solutions included in the th cluster center according to the cluster center set . Define the set of all the cluster centers and the solutions included as .
(2) Sub-algorithm 2: Solution selection method based on the density fuzzy c-means clustering algorithm DFCM.
Sub-algorithm 2 provides the solution selection method based on the density fuzzy c-means clustering algorithm DFCM. The purpose is to select solutions from , , and join them to the set to construct the next generation population. The specific process is described as follows.
Step 1: Calculate the distance of all the solutions in and each reference point in reference point set . , denotes the th solution in , while denotes the th reference point in the reference point set .
Step 2: Initialize the number of all the solutions of distributed by , . being dominated by can be denoted as . If is dominated by , set .
Step 3: For reference points, if , select the solution among all the solutions that has the closest distance to the reference point, and join it to set . If , except the solutions in , the remained solutions are put into the set . Otherwise, add all the solutions except the solutions in and to the set .
Step 4: If the number of the solutions in is equal to ), i.e., , then . If the number of solutions in is greater than or equal to subtracted by the number of solutions in , i.e., , then randomly select the remained solutions in and construct the solution set , . If the number of solutions in the set is greater than or equal to subtracted by the number of solutions in and , i.e., , then randomly select the remaining solutions in and construct the solution set , . Finally, output the set of solutions selected from .
Taking into account the computational complexity of the existing and proposed algorithms, the worst-case computational complexity of NSGA-III is
, [
23]. The algorithms RDNSGA-III and DFCM-RDNSGA-III are both proposed on the basis of NSGA-III. Therefore, the computational complexity of the two algorithms can be computed analogously by following the method in the paper [
23]. The nondominated sorting of a population of size 2
N having
M-dimensional objective vectors requires
(usually
). For DFCM-RDNSGA-III, calculating the cluster centers in step 9 requires
(sub-algorithm 1). The density determination of the reference points requires
. In step 10 of DFCM-RDNSGA-III, the solution selection based on the density fuzzy c-means clustering method requires
(sub-algorithm 2). Therefore, the computational complexity of DFCM-RDNSGA-III in the worst case is
, which is a little larger comparable to NSGA-III and RDNSGA-III.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}