
Circle-U-Net: An Efficient Architecture for Semantic Segmentation



Abstract
1. Introduction
- (1)
- We put forward a Circle-U-Net network with a circle connect model, which exceeds the performance of the attention mechanism. Our network improves 0.78 mIoU than adding the attention mechanism to our model. The circle connects model is robust and capable in object segment, which performs better than most state-of-the-art experiments.
- (2)
- Circle-U-Net cannot detect 2 classes, while some networks cannot see 2, 4 and 8 classes. In other words, Circle-U-Net has high power to detect than other networks.
- (3)
- We prove that the proposed method has a better performance in comparison with the state-of-the-art networks. Furthermore, we organize the rest of this paper as follows: Section 2 describes related works and Section 3 reviews the proposed Circle-U-Net structure in detail. Experimental results and comparisons are described in Section 4, followed by conclusions in Section 5.
2. Related Work
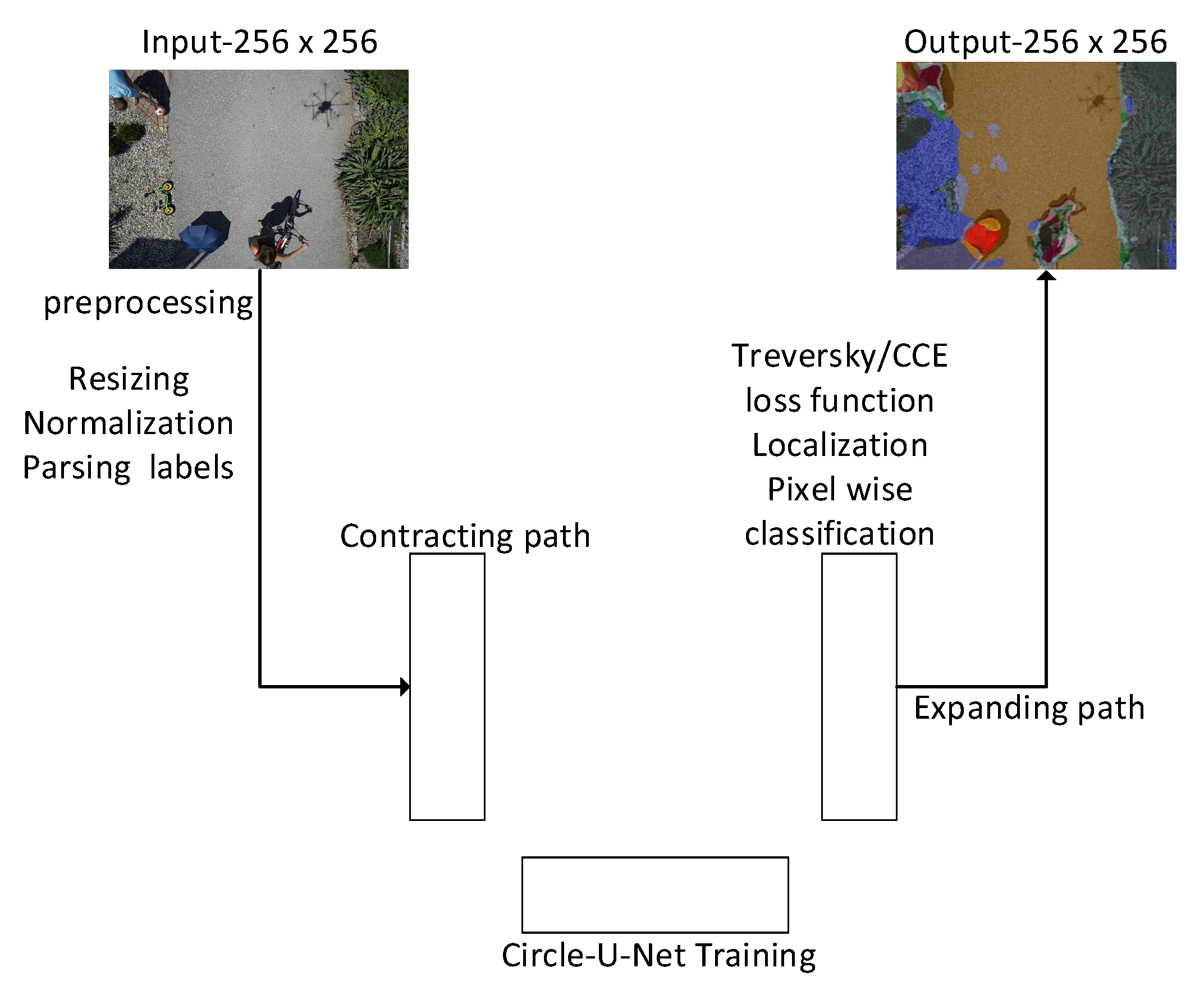
3. Method
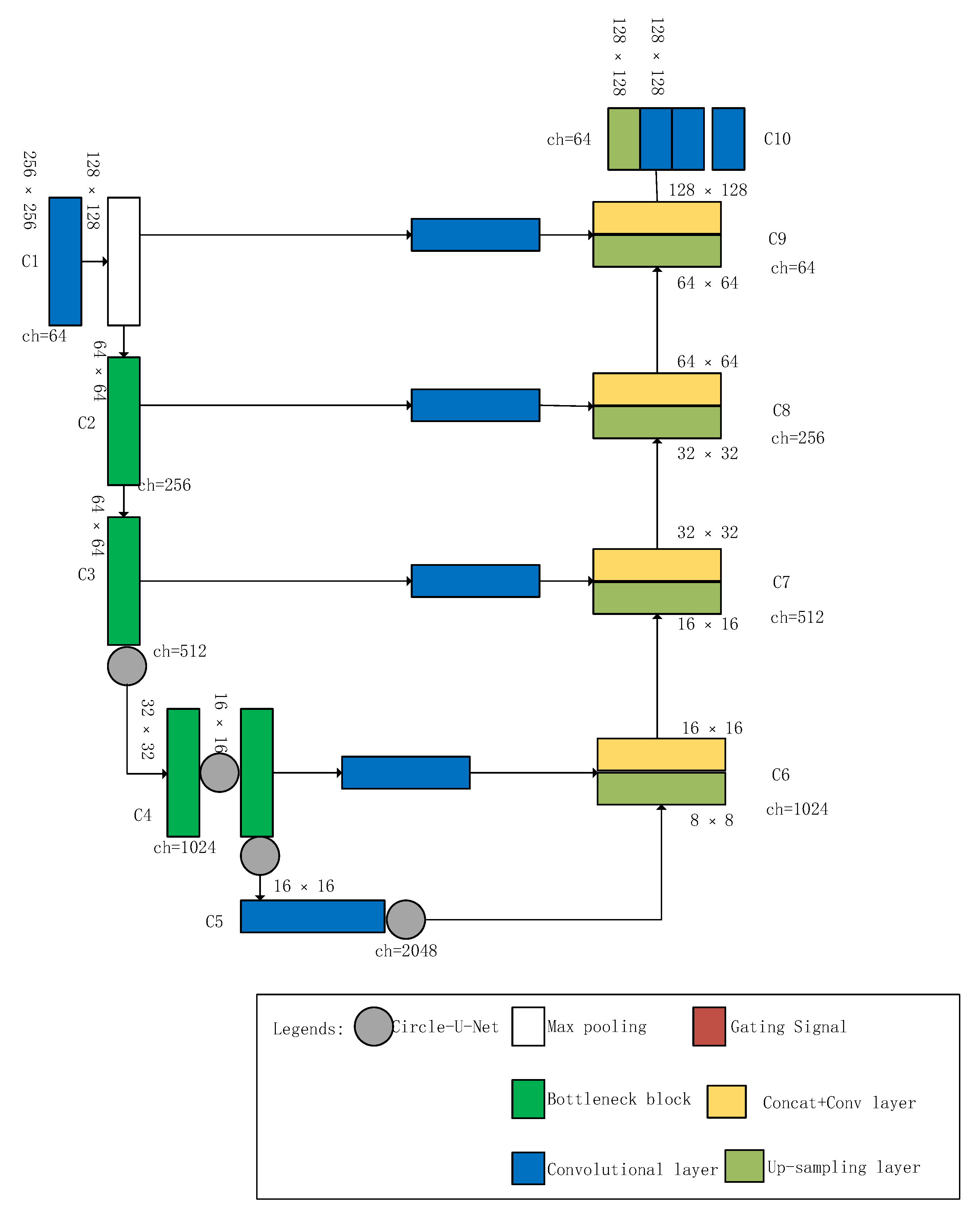
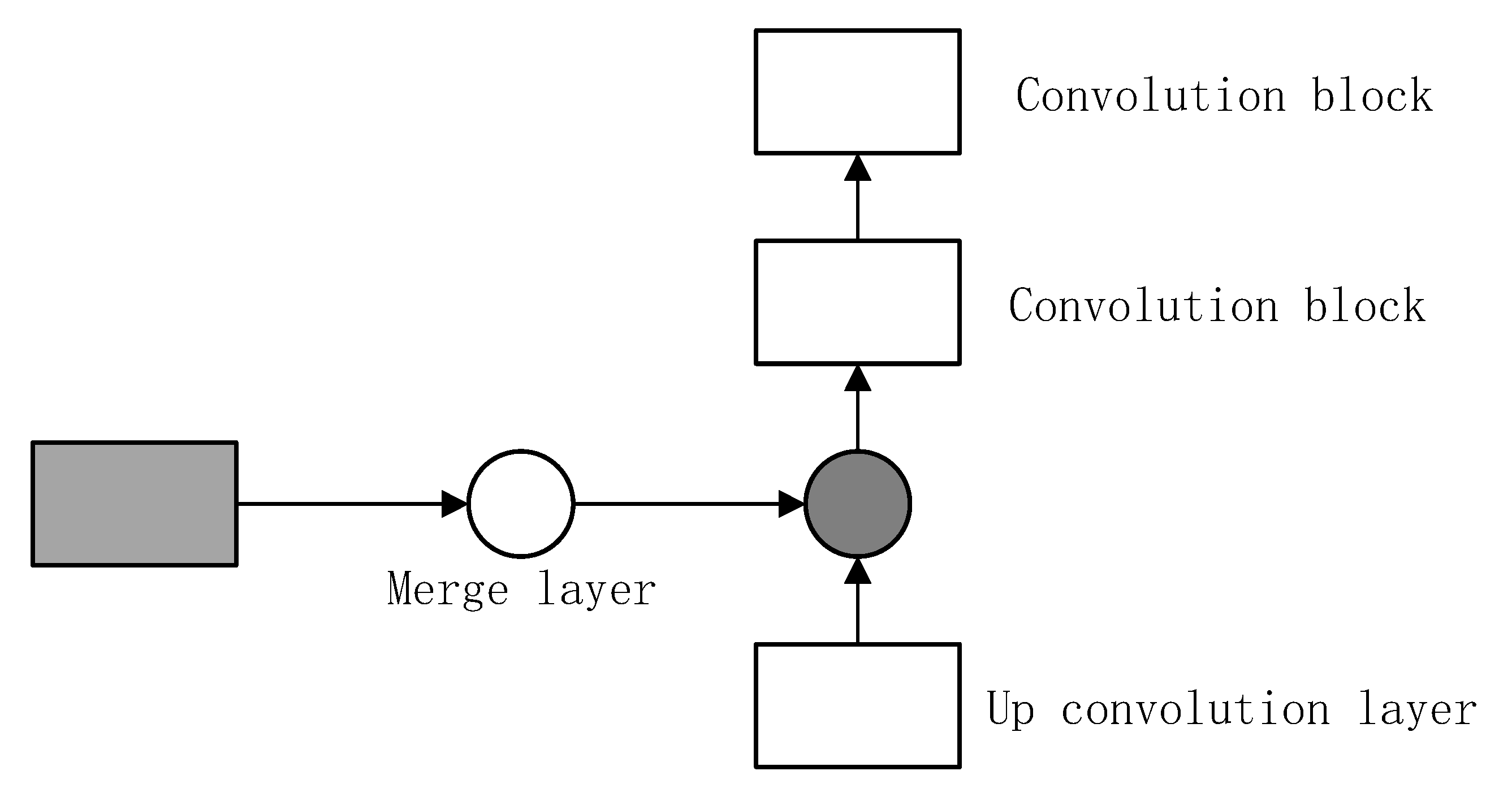
3.1. Circle-U-Net
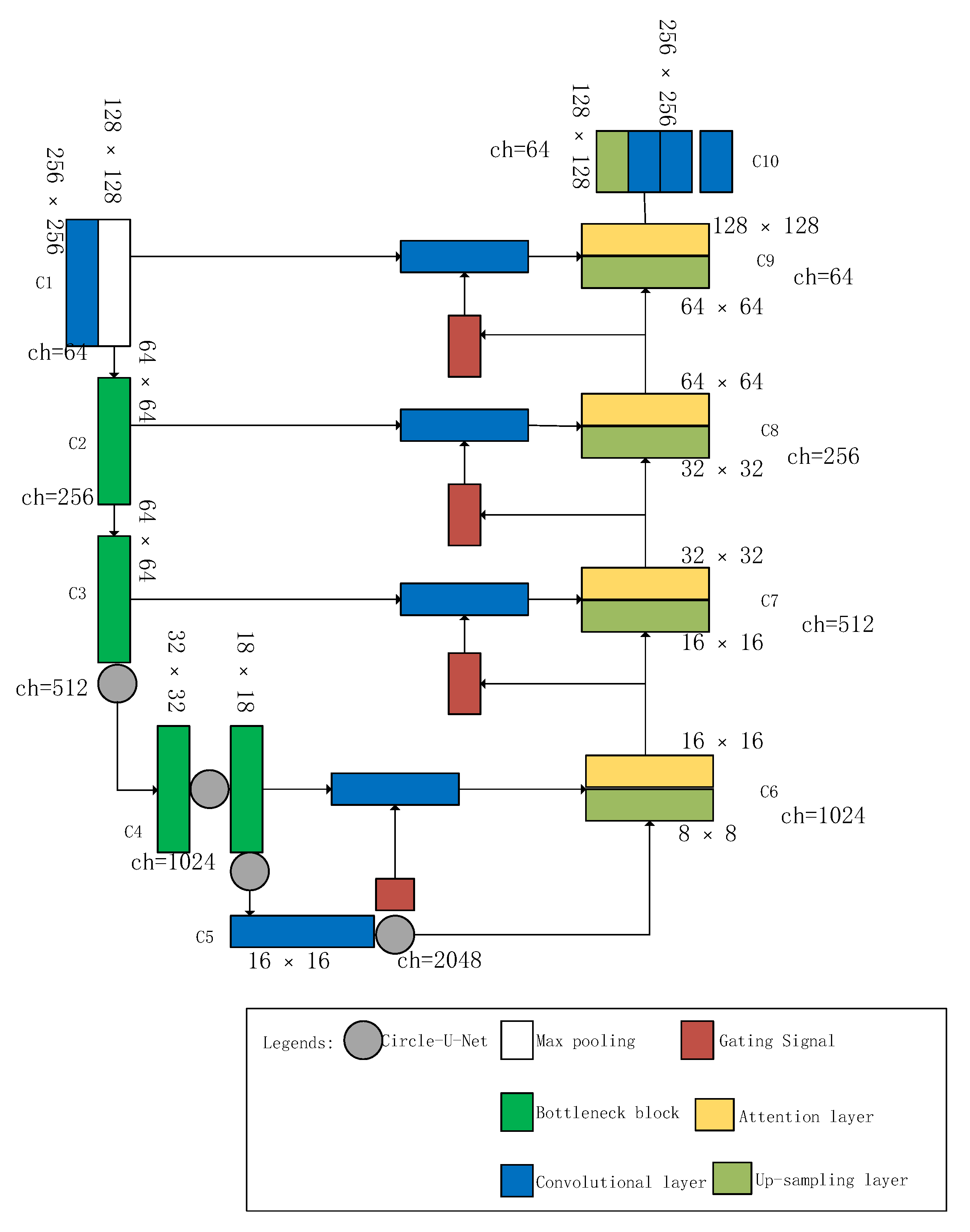
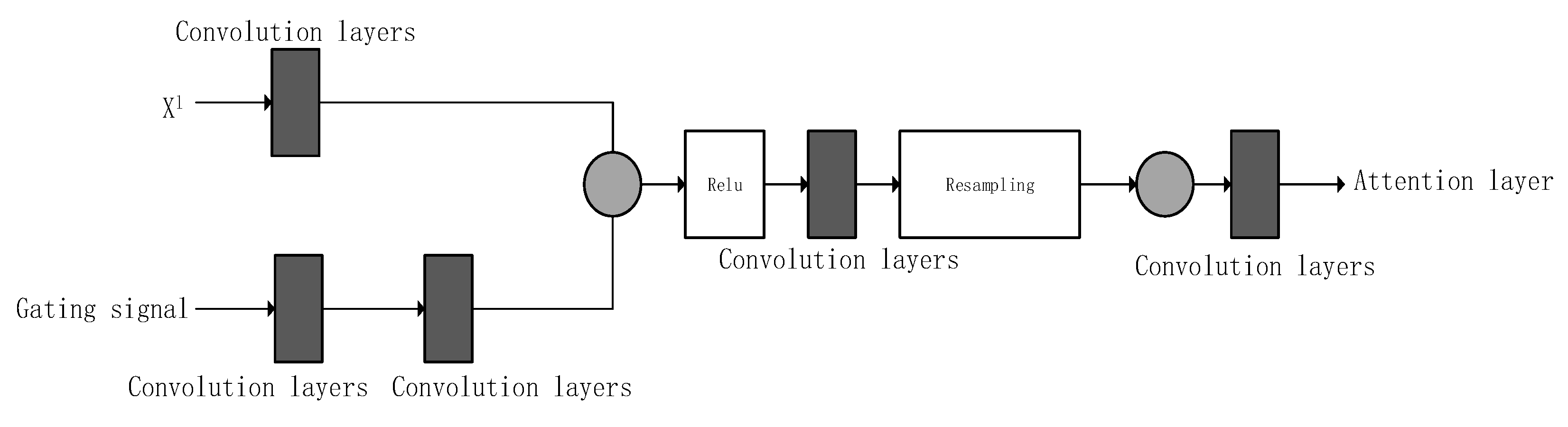
3.2. Circle-U-Net with Attention
4. Experiments
4.1. Datasets
4.2. Experimental Setup We Use the Machine with RTX 2080 Ti GPU and 256G RAM for Our Experiments
4.3. Comparison to the State of the Art
4.4. Comparing Top 8 Classes
4.5. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yang, G.; Chen, Z.; Li, Y.; Su, Z. Rapid Relocation Method for Mobile Robot Based on Improved ORB-SLAM2 Algorithm. Remote Sens. 2019, 11, 149. [Google Scholar] [CrossRef]
- Su, Z.; Li, Y.; Yang, G. Dietary Composition Perception Algorithm Using Social Robot Audition for Mandarin Chinese. IEEE Access 2020, 8, 8768–8782. [Google Scholar] [CrossRef]
- Lin, J.; Li, Y.; Yang, G. FPGAN: Face de-identification method with generative adversarial networks for social robots. Neural Netw. 2021, 133, 132–147. [Google Scholar] [CrossRef] [PubMed]
- Yang, G.; Yang, J.; Sheng, W.; Junior, F.E.F.; Li, S. Convolutional Neural Network-based Embarrassing Situation Detection under Camera for Social Robot in Smart Homes. Sensors 2018, 18, 1530. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Bhuiyan, M.A.E.; Witharana, C.; Liljedahl, A.K. Use of Very High Spatial Resolution Commercial Satellite Imagery and Deep Learning to Automatically Map Ice-Wedge Polygons across Tundra Vegetation Types. J. Imaging 2020, 6, 137. [Google Scholar] [CrossRef]
- Mahmoud, A.; Mohamed, S.; El-Khoribi, R.; Abdelsalam, H. Object Detection Using Adaptive Mask RCNN in Optical Remote Sensing Images. Int. J. Intell. Eng. Syst. 2020, 13, 65–76. [Google Scholar] [CrossRef]
- Zhao, K.; Kang, J.; Jung, J.; Sohn, G. Building Extraction from Satellite Images Using Mask R-CNN with Building Boundary Regularization. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Li, Y.; Xu, W.; Chen, H.; Jiang, J.; Li, X. A Novel Framework Based on Mask R-CNN and Histogram Thresholding for Scalable Segmentation of New and Old Rural Buildings. Remote Sens. 2021, 13, 1070. [Google Scholar] [CrossRef]
- Bhakti, B.; Innani, S.; Gajre, S.; Talbar, S. Eff-UNet: A Novel Architecture for Semantic Segmentation in Unstructured Environment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition WorkShop (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Beheshti, N.; Johnsson, L. Squeeze U-Net: A Memory and Energy Efficient Image Segmentation Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshop (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Schönfeld, E.; Schiele, B.; Khoreva, A. A U-Net Based Discriminator for Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Shibuya, E.; Hotta, K. Feedback U-net for Cell Image Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Wang, W.; Yu, K.; Hugonot, J.; Fua, P.; Salzmann, M. Recurrent U-Net for Resource-Constrained Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshop (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Chidester, B.; Ton, T.; Tran, M.; Ma, J.; Do, M.N. Enhanced Rotation-Equivariant U-Net for Nuclear Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshop (CVPRW), Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Hu, X.; Naiel, M.A.; Wong, A.; Lamm, M.; Fieguth, P. RUNet: A Robust UNet Architecture for Image Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Azad, R.; Asadi-Aghbolaghi, M.; Fathy, M.; Escalera, S. Bi-Directional ConvLSTM U-Net with Densley Connected Convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Valloli, V.K.; Mehta, K. W-Net: Reinforced U-Net for Density Map Estimation. arXiv 2019, arXiv:1903.11249. [Google Scholar]
- Jaeger, P.F.; Kohl, S.A.A.; Bickelhaupt, S.; Isensee, F.; Kuder, T.A.; Schlemmer, H.P.; Maier-Hein, K.H. Retina U-Net: Embarrassingly Simple Exploitation of Segmentation Supervision for Medical Object Detection. arXiv 2018, arXiv:1811.08661v1. [Google Scholar]
- Zhao, B.; Chen, X.; Li, Z.; Yu, Z.; Yao, S.; Yan, L.; Wang, Y.; Liu, Z.; Liang, C.; Han, C. Triple U-net: Hematoxylin-aware nuclei segmentation with progressive dense feature aggregation. Med. Image Anal. 2020, 65, 101786. [Google Scholar] [CrossRef] [PubMed]
- Alom, M.Z.; Hasan, M.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Recurrent Residual Convolutional Neural Network based on U-Net (R2U-Net) for Medical Image Segmentation. arXiv 2018, arXiv:1802.06955. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Zhou, Z.; Siddiquee, M.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Proceedings of the 4th Deep Learning in Medical Image Analysis Workshop, Granada, Spain, 9 September 2018; Springer: Cham, Switzerland, 2018; Volume 11045, pp. 3–11. [Google Scholar]
- Brostow, G.J.; Fauqueur, J.; Cipolla, R. Semantic object classes in video: A high-definition ground truth database. Pattern Recognit. Lett. 2009, 30, 88–97. [Google Scholar] [CrossRef]
- Schlemper, J.; Oktay, O.; Schaap, M.; Heinrich, M.; Kainz, B.; Glocker, B.; Rueckert, D. Attention gated networks: Learning to leverage salient regions in medical images. Med. Image Anal. 2019, 53, 197–207. [Google Scholar] [CrossRef] [PubMed]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
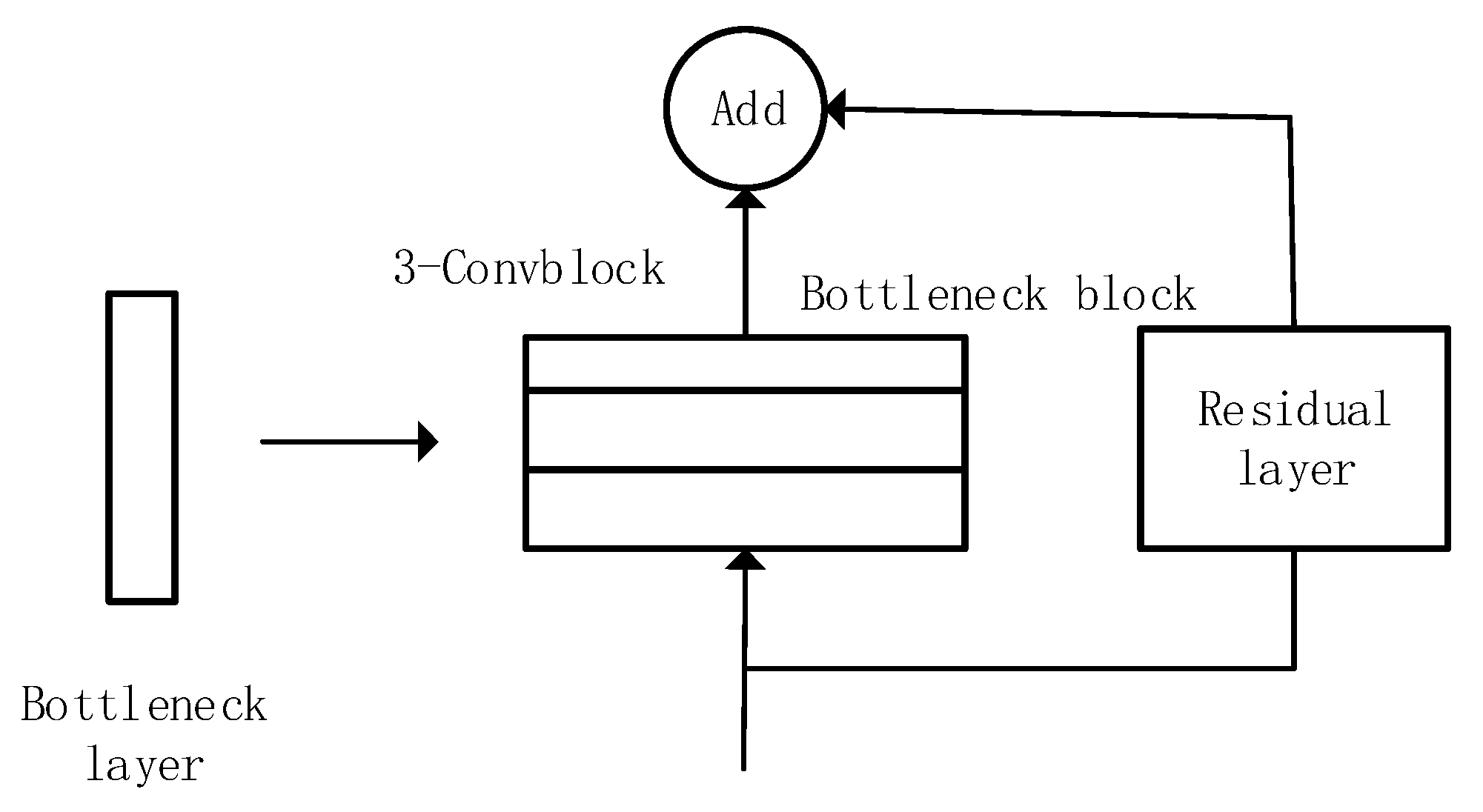
| Block Name | Number of Bottleneck Layers | Structure |
|---|---|---|
| C2 | 3 | Contains 7 × 7 with max-pooling at the first layer |
| C3 | 4 | Bottleneck with residual at the first layer |
| C4 | 23 | Bottleneck with residual at the first layer and circle connect at last |
| C5 | 3 | Bottleneck with residual at first the layer and circle connect at last |
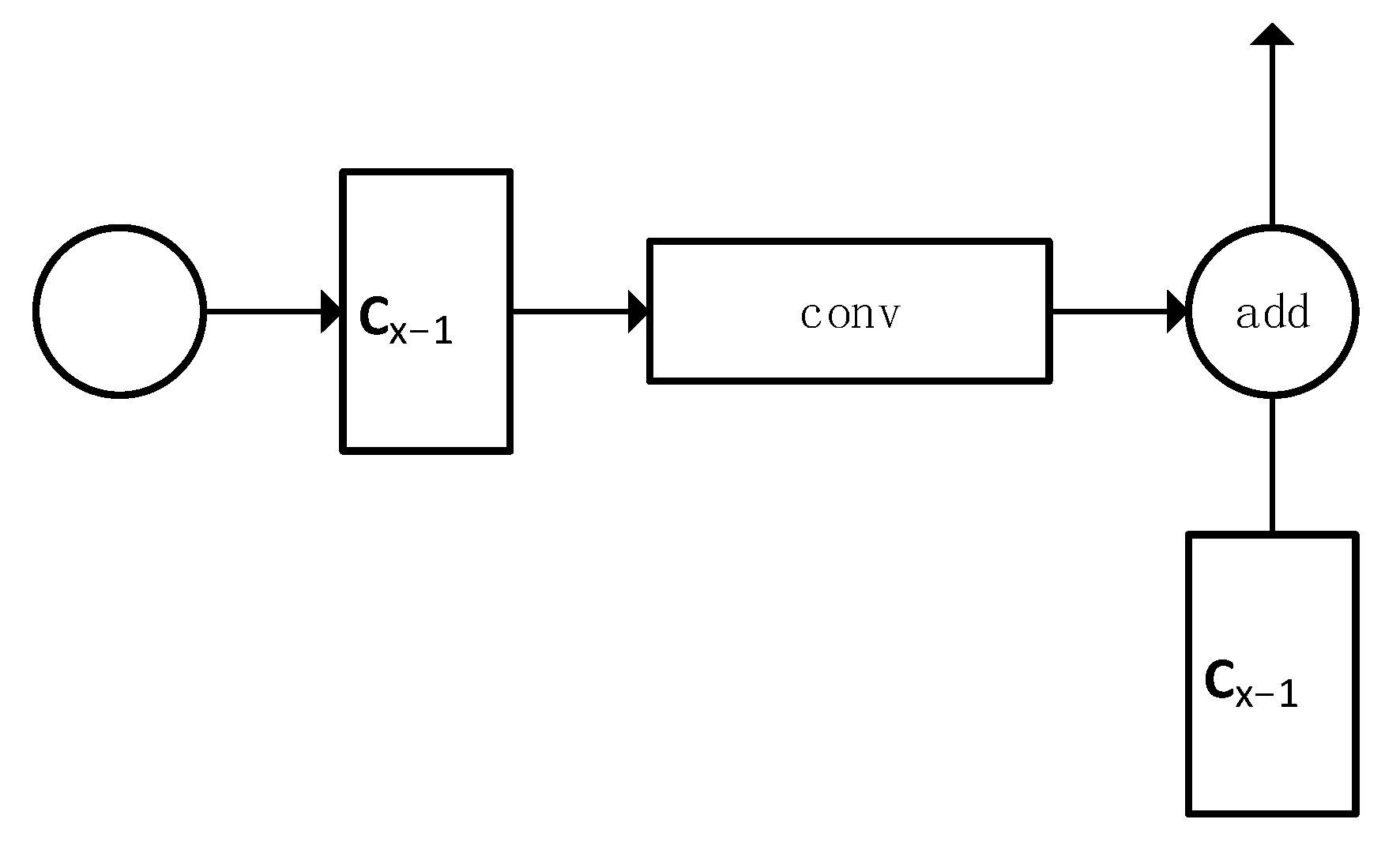
| Circle Connect Name | Connected Layers |
|---|---|
| cc1 | Conv2_1 with conv 3_4 |
| cc2 | Conv 3_1 with conv 4_11 |
| cc3 | Conv 4_11 with conv 4_23 |
| cc4 | Conv 4_1 with conv 5_3 |
| Source: https://www.tugraz.at/index.php?id=22387 (Accessed on 20 May 2021) | ||
|---|---|---|
| Total Samples | Training Sample | Testing Sample |
| 400 | 360 | 40 |
| Model | Loss Function | Accuracy | IoU |
|---|---|---|---|
| U-Net [6] | CCE | 69.90883 | 18.462254 |
| Attention U-Net [23] | CCE | 69.0122 | 16.37 |
| Squeeze U-Net [12] | CCE | 72.053033 | 19.439353 |
| ResUNet-a [27] | CCE | 71.906507 | 15.959859 |
| Circle-U-Net (without GSA and Attention) | CCE | 75.576364 | 20.620922 |
| Circle-U-Net (without GSA and Attention) | Trversky | 73.961304 | 19.437675 |
| Circle-U-Net (with Attention) | CCE | 72.75489 | 19.843579 |
| Circle-U-Net (with Attention) | Trversky | 70.40 | 17.076342 |
| Network Name | Loss Function | Accuracy (Top 8 Classes) | mIoU (8 Classes) | Undetected Classes |
|---|---|---|---|---|
| U-Net [6] | CCE | 55.16 | 0.4132 | 8 |
| Attention U-Net [23] | CCE | 58.26 | 0.4109 | 8 |
| Squeeze U-Net [12] | CCE | 59.84 | 0.4407 | 4 |
| ResUNet-a [27] | CCE | 57.17 | 0.4087 | 2 |
| Circle-U-Net (without GSA) | CCE | 59.29 | 0.4132 | 2 |
| Circle-U-Net (without GSA) | Tversky | 42.07 | 0.2720 | 4 |
| Circle-U-Net | Trversky | 59.30 | 0.4647 | 2 |
| Circle-U-Net | CCE | 56.29 | 0.5891 | 2 |
| Model | Loss Function | mIoU | Accuracy | Layers |
|---|---|---|---|---|
| Circle-U-Net (without Attention) | CCE | 19.62 | 74.57 | 101+ |
| Circle-U-Net (with Attention) | CCE | 18.84 | 73.75 | 101+ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, F.; V, A.K.; Yang, G.; Zhang, A.; Zhang, Y. Circle-U-Net: An Efficient Architecture for Semantic Segmentation. Algorithms 2021, 14, 159. https://doi.org/10.3390/a14060159
Sun F, V AK, Yang G, Zhang A, Zhang Y. Circle-U-Net: An Efficient Architecture for Semantic Segmentation. Algorithms. 2021; 14(6):159. https://doi.org/10.3390/a14060159
Chicago/Turabian StyleSun, Feng, Ajith Kumar V, Guanci Yang, Ansi Zhang, and Yiyun Zhang. 2021. "Circle-U-Net: An Efficient Architecture for Semantic Segmentation" Algorithms 14, no. 6: 159. https://doi.org/10.3390/a14060159
APA StyleSun, F., V, A. K., Yang, G., Zhang, A., & Zhang, Y. (2021). Circle-U-Net: An Efficient Architecture for Semantic Segmentation. Algorithms, 14(6), 159. https://doi.org/10.3390/a14060159