
A Set-Theoretic Approach to Modeling Network Structure


Abstract
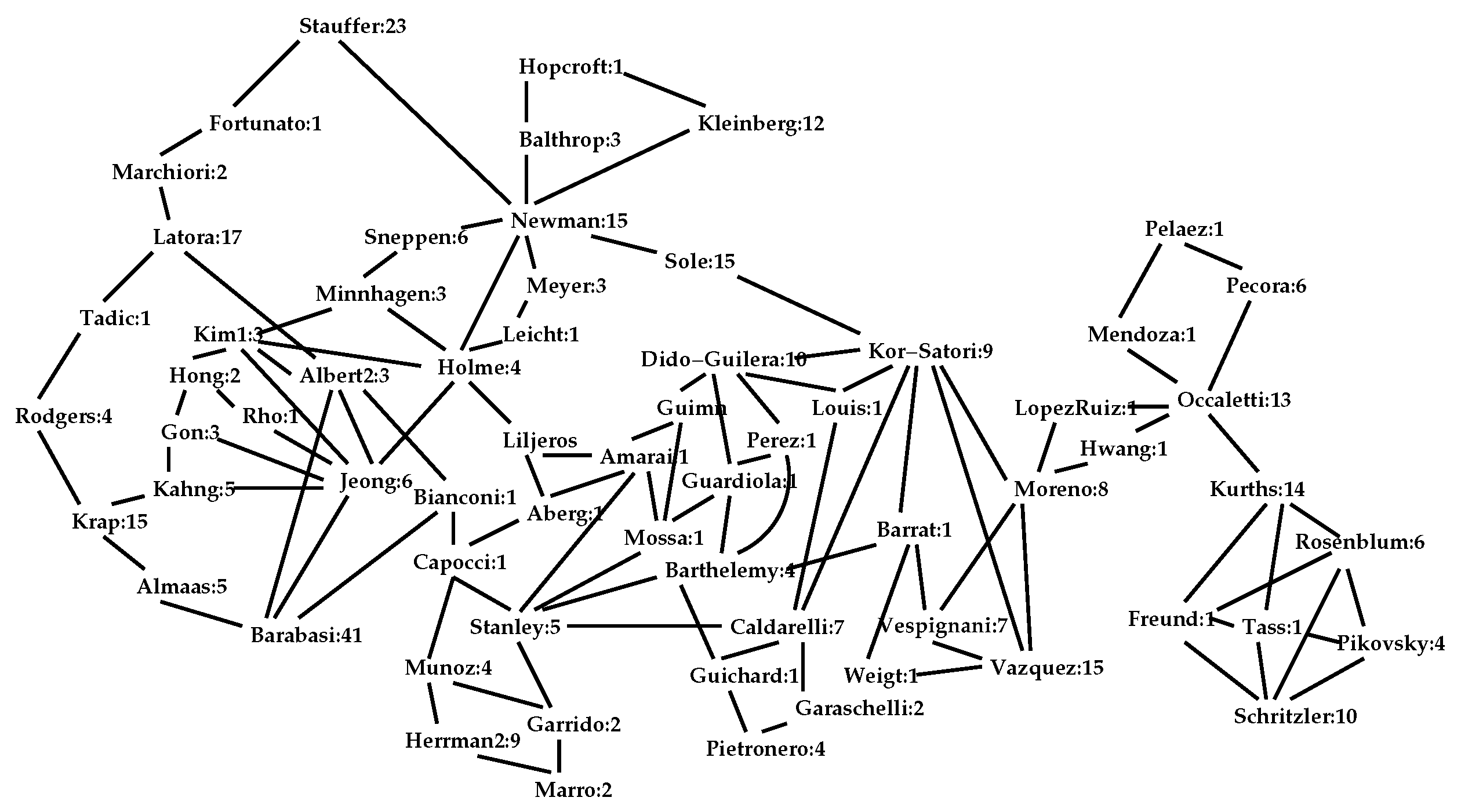
1. Introduction
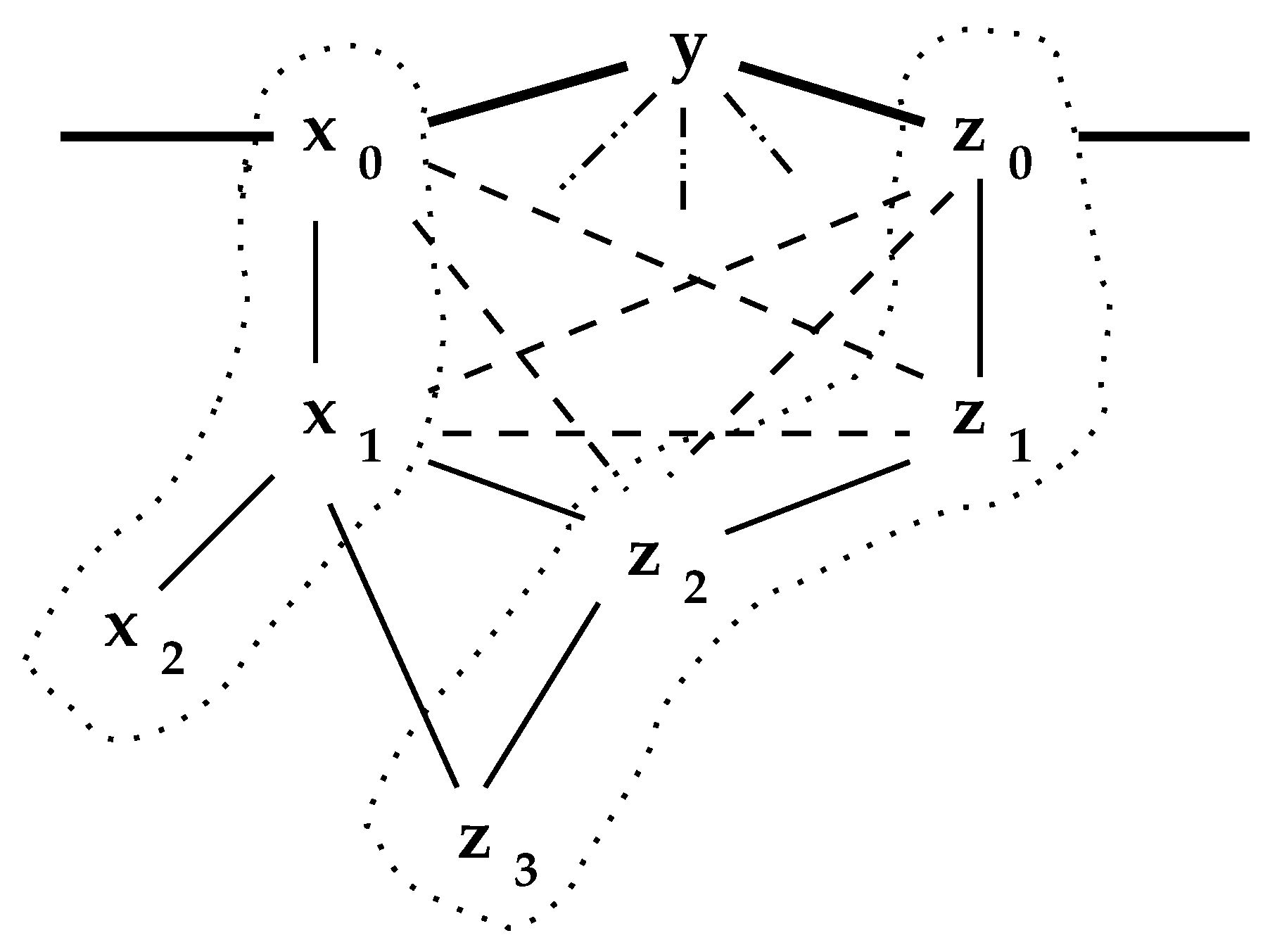
2. The Interior
2.1. The Network Interior
| while there exist reduceable nodes { |
| reducible = 0 |
| for_each {y} in N { |
| for_each {z} in {y}.nbhd - {y} { |
| if ({z}.nbhd contained_in {y}.nbhd { |
| // z is subsumed by y |
| remove z from network; |
| {y}.beta = {y}.beta union {z}.beta |
| reducible = 1 } } } } |
| Pseudocode I, , reduce_network |
2.2. Reduction Performance
3. Network Properties
| k_total = 0 |
| for_each link {x, z} in L { |
| MEET = {x}.nbhd meet {z}.nbhd |
| {x, z}.k_count = cardinality_of(MEET) |
| k_total = k_total + {x, z}.k_count } |
| n_triangles = k_total/3 |
| Pseudocode II, count_triangles |
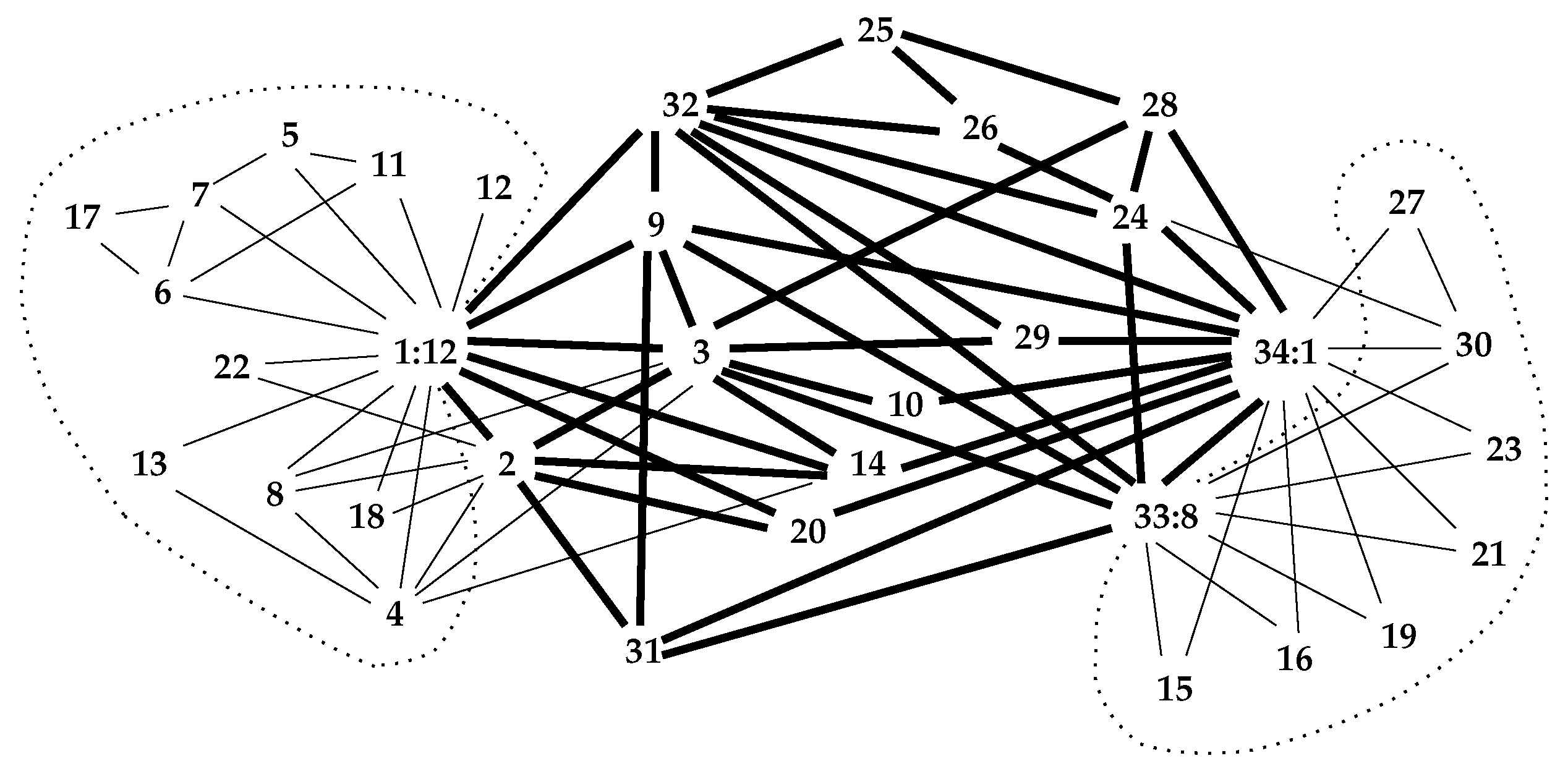
3.1. Communities
3.2. Important Nodes
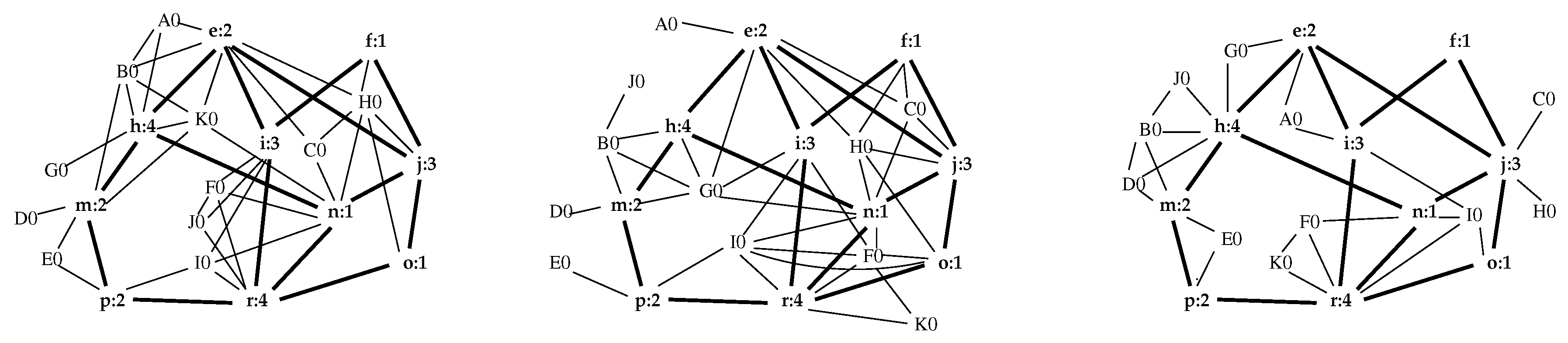
3.3. Network Properties Preserved by the Interior
3.4. Network Centrality
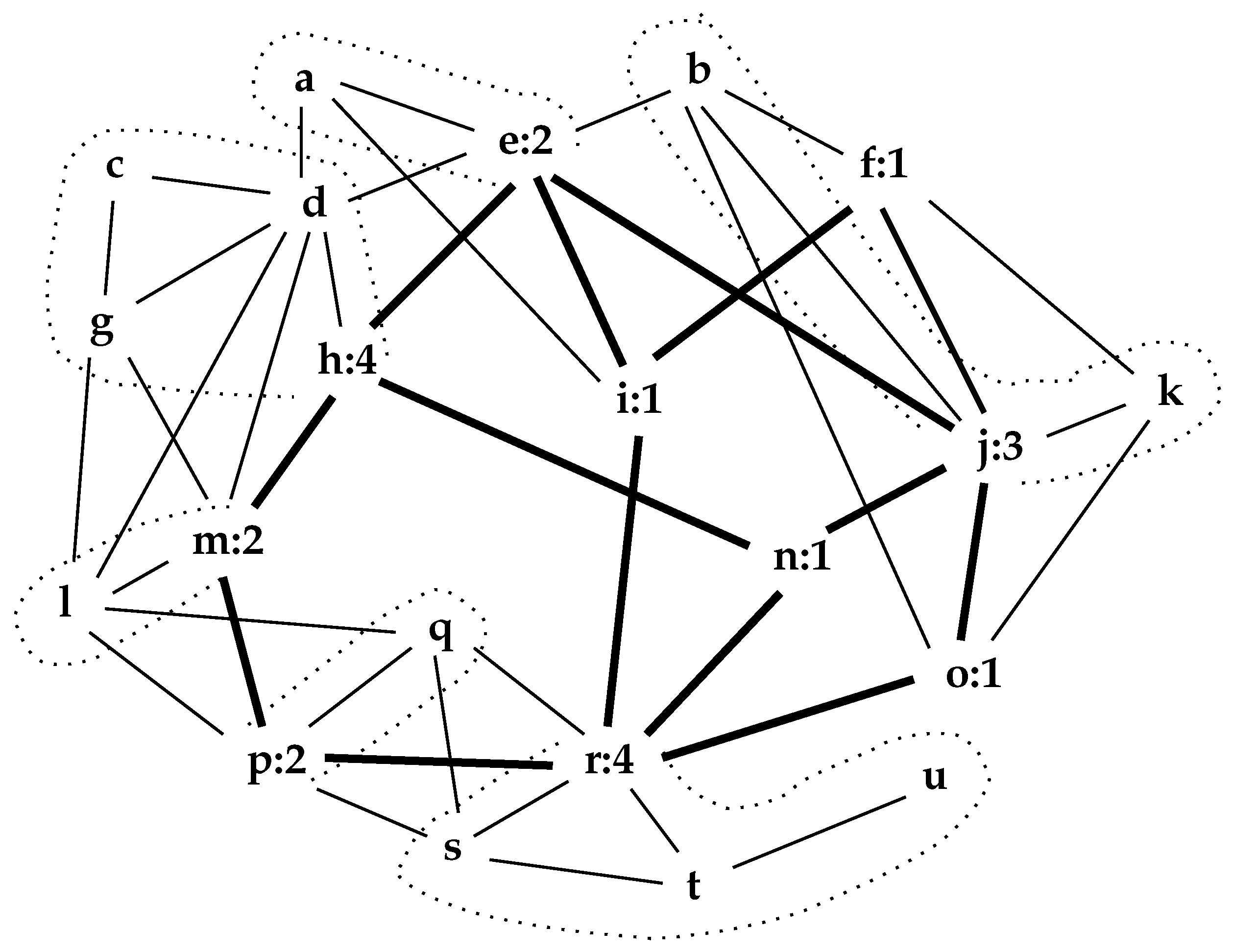
4. Network Generation by Expansion
| while still_expanding { |
| still_expanding = 0 |
| for_each y in NODES { |
| if (y.beta_count > 1) { |
| z = new_node() |
| add new_node to NODES |
| chosen = choose_subset (y.nbhd) |
| // distribute some of y.beta_count to z |
| increment = y.beta_count/(n_chosen+1) |
| y.beta_count = y.beta_count - increment |
| z.beta_count = 1 + increment |
| add (y, z) to LINKS |
| // link z to chosen nodes in y.nbhd |
| for_each x in chosen { |
| add (x, z) to LINKS } |
| still_expanding = 1 } } } |
| Pseudocode III, , expand_network |
5. Observations
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Agnarsson, G.; Greenlaw, R. Graph Theory: Modeling, Applications and Algorithms; Prentice Hall: Upper Saddle River, NJ, USA, 2007. [Google Scholar]
- Harary, F. Graph Theory; Addison-Wesley: Reading, MA, USA, 1969. [Google Scholar]
- Newman, M.E.J. Finding community structure in networks using the eigenvectors of matrices. Phys. Rev. E 2006, 74, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Newman, M. Networks; Oxford University Press: Oxford, UK, 2018. [Google Scholar]
- Orlandic, R.; Pfaltz, J.L.; Taylor, C. A Functional Database Representation of Large Sets of Objects. In Proceedings of the 25th Australasian Database Conference (ADC 2014), Brisbane, Australia, 14–16 July 2014; Wang, H., Saraf, M.A., Eds.; Springer: Cham, Switzerland, 2014; pp. 189–196. [Google Scholar]
- Zachary, W.W. An Information Flow Model for Conflict and Fission in Small groups. J. Anthropol. Res. 1977, 33, 452–473. [Google Scholar] [CrossRef]
- McKee, T.A. How Chordal Graphs Work. Bull. ICA 1993, 9, 27–39. [Google Scholar]
- White, N. Theory of Matroids; Cambridge University Press: Cambridge, UK, 1986. [Google Scholar]
- Pfaltz, J.L. Cycle Systems. Math. Appl. 2020, 9, 55–66. [Google Scholar] [CrossRef]
- Girvan, M.; Newman, M.E.J. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 2002, 99, 7821–7826. [Google Scholar] [CrossRef]
- Newman, M.E.J. Detecting community structure in networks. Eur. Phys. J. B 2004, 38, 321–330. [Google Scholar] [CrossRef]
- Newman, M.E.J. The structure and function of complex networks. SIAM Rev. 2003, 45, 167–256. [Google Scholar] [CrossRef]
- Tsourakakis, C.E.; Drineas, P.; Michelakis, E.; Koutis, I.; Faloutos, C. Spectral counting of triangles via element-wise sparsification and triangle-based link recommendation. Soc. Netw. Anal. Min. 2011, 1, 75–81. [Google Scholar] [CrossRef]
- Mollenhorst, G.; Völker, B.; Flap, H. Shared contexts and triadic closure in core discussion networks. Soc. Netw. 2012, 34, 292–302. [Google Scholar] [CrossRef]
- Granovetter, M.S. The Strength of Weak Ties. Am. J. Sociol. 1973, 78, 1360–1380. [Google Scholar] [CrossRef]
- Newman, M.E.J. Modularity and community structure in networks. Proc. Natl. Acad. Sci. USA 2006, 103, 8577–8582. [Google Scholar] [CrossRef] [PubMed]
- Fiedler, M. Algebraic Connectivity of Graphs. Czechoslovak Math. J. 1973, 23, 298–305. [Google Scholar] [CrossRef]
- McCulloh, I.; Savas, O. k-Truss Network Community Detection. In Proceedings of the 2020 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), The Hague, The Netherlands, 7–10 December 2020. [Google Scholar]
- Freeman, L.C. Centrality in Social Networks, Conceptual Clarification. Soc. Netw. 1978, 1, 215–239. [Google Scholar] [CrossRef]
- Newman, M.E.J. A measure of betweenness centrality based on random walks. Soc. Netw. 2005, 27, 39–45. [Google Scholar] [CrossRef]
- Brandes, U. A Faster Algorithm for Betweeness Centrality. J. Math. Sociol. 2001, 25, 163–177. [Google Scholar] [CrossRef]
- Pfaltz, J.L. Computational Processes that Appear to Model Human Memory. In Proceedings of the 4th International Conference, Algorithms for Computational Biology (AlCoB 2017), Aveiro, Portugal, 5–6 June 2017; pp. 85–99. [Google Scholar]
- Pfaltz, J.; Šlapal, J. Transformations of discrete closure systems. Acta Math. Hung. 2013, 138, 386–405. [Google Scholar] [CrossRef]
- Kempner, Y.; Levit, V.E. Violator spaces vs closure spaces. Eur. J. Comb. 2019, 80, 203–213. [Google Scholar] [CrossRef]
- Seierstad, C.; Opsahl, T. For the few not the many? The effects of affirmative action on presence, prominence, and social capital of female directors in Norway. Scand. J. Manag. 2011, 27, 44–54. [Google Scholar] [CrossRef]









{kind=link}
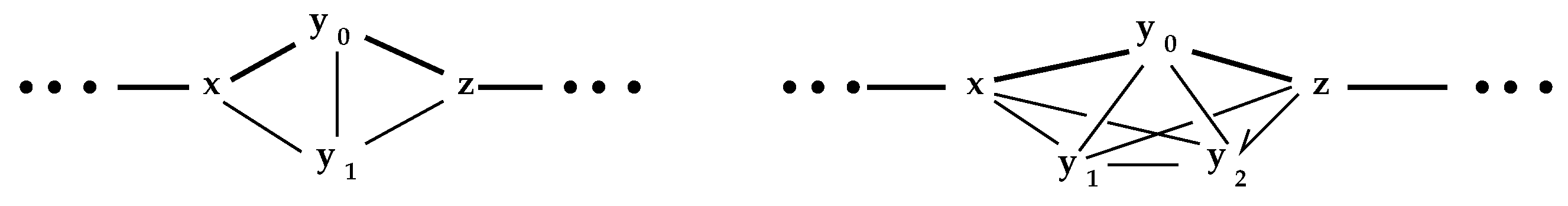{kind=link}
{kind=link}
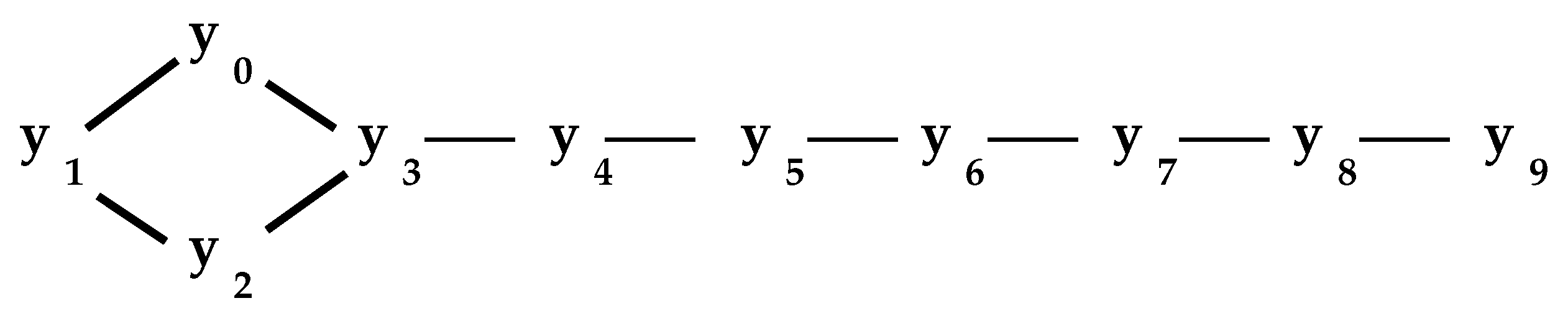{kind=link}
{kind=link}
{kind=link}
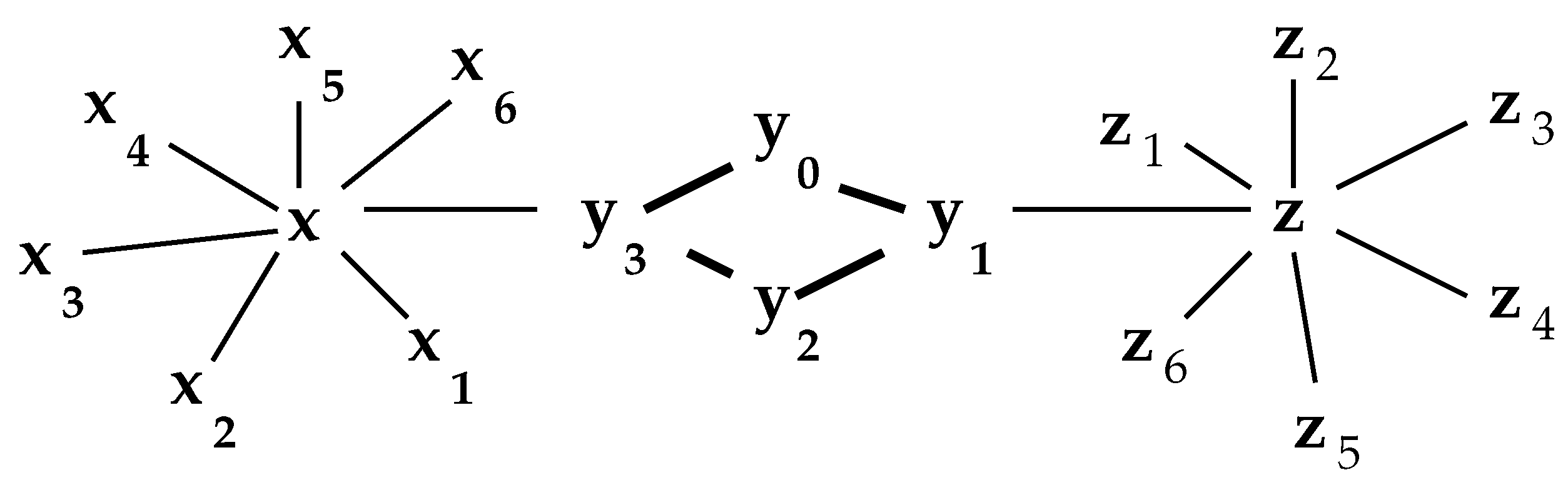{kind=link}
{kind=link}
| 21 | 44 | 2.095 | 21 | 2 | 4 | |
| exp.1 | 21 | 49 | 2.333 | 31 | 1 | 3 |
| exp.2 | 21 | 46 | 2.190 | 25 | 2 | 3 |
| exp.3 | 21 | 37 | 1.762 | 13 | 2 | 2 |
| a | b | c | d | e | f | g | h | i | j | k | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.179 | 0.182 | 0.123 | 0.350 | 0.293 | 0.155 | 0.226 | 0.234 | 0.194 | 0.231 | 0.120 | |
| A0 | B0 | C0 | D0 | e | f | E0 | h | i | j | F0 | |
| exp.1 | 0.170 | 0.295 | 0.225 | 0.033 | 0.355 | 0.129 | 0.053 | 0.306 | 0.202 | 0.265 | 0.162 |
| exp.2 | 0.048 | 0.095 | 0.203 | 0.021 | 0.262 | 0.183 | 0.026 | 0.192 | 0.254 | 0.285 | 0.303 |
| exp.3 | 0.125 | 0.212 | 0.056 | 0.187 | 0.265 | 0.120 | 0.093 | 0.353 | 0.270 | 0.243 | 0.195 |
| l | m | n | o | p | q | r | s | t | u | ||
| 0.291 | 0.293 | 0.159 | 0.174 | 0.271 | 0.220 | 0.280 | 0.187 | 0.104 | 0.022 | ||
| G0 | m | n | o | p | H0 | r | I0 | J0 | K0 | ||
| exp.1 | 0.054 | 0.190 | 0.387 | 0.133 | 0.112 | 0.265 | 0.224 | 0.164 | 0.104 | 0.272 | |
| exp.2 | 0.192 | 0.118 | 0.379 | 0.271 | 0.142 | 0.253 | 0.325 | 0.307 | 0.017 | 0.115 | |
| exp.3 | 0.144 | 0.236 | 0.336 | 0.208 | 0.163 | 0.056 | 0.369 | 0.276 | 0.132 | 0.132 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pfaltz, J.L. A Set-Theoretic Approach to Modeling Network Structure. Algorithms 2021, 14, 153. https://doi.org/10.3390/a14050153
Pfaltz JL. A Set-Theoretic Approach to Modeling Network Structure. Algorithms. 2021; 14(5):153. https://doi.org/10.3390/a14050153
Chicago/Turabian StylePfaltz, John L. 2021. "A Set-Theoretic Approach to Modeling Network Structure" Algorithms 14, no. 5: 153. https://doi.org/10.3390/a14050153
APA StylePfaltz, J. L. (2021). A Set-Theoretic Approach to Modeling Network Structure. Algorithms, 14(5), 153. https://doi.org/10.3390/a14050153