
Query Rewriting for Incremental Continuous Query Evaluation in HIFUN



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
Motivation and Contributions
- We use the HIFUN language to define the continuous query problem and give a high-level generic algorithm for its solution.
- Then we map the generic algorithm to the physical level, implementing the evaluation mechanism both as SQL queries and MapReduce tasks.
- Further, we show how HIFUN query rewriting can be implemented in the physical layer.
- Finally, we experimentally show that our implementation provides considerable benefits in terms of efficiency.
2. Related Work
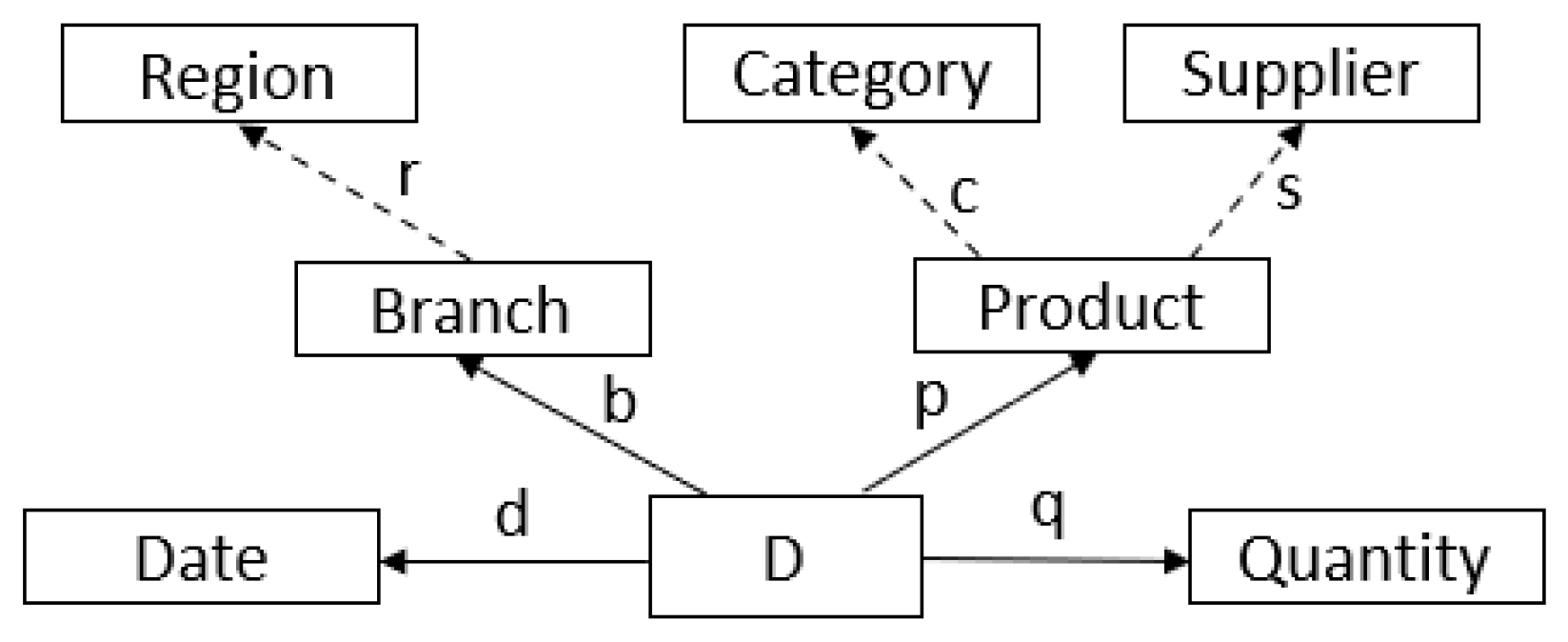
3. Preliminaries—The HIFUN Query Language
- Grouping. Group together all invoices j of D such that .
- Measuring. Apply q to each invoice j of the -group to find the corresponding quantity .
- Aggregation. Sum up the s thus obtained to get a single value .
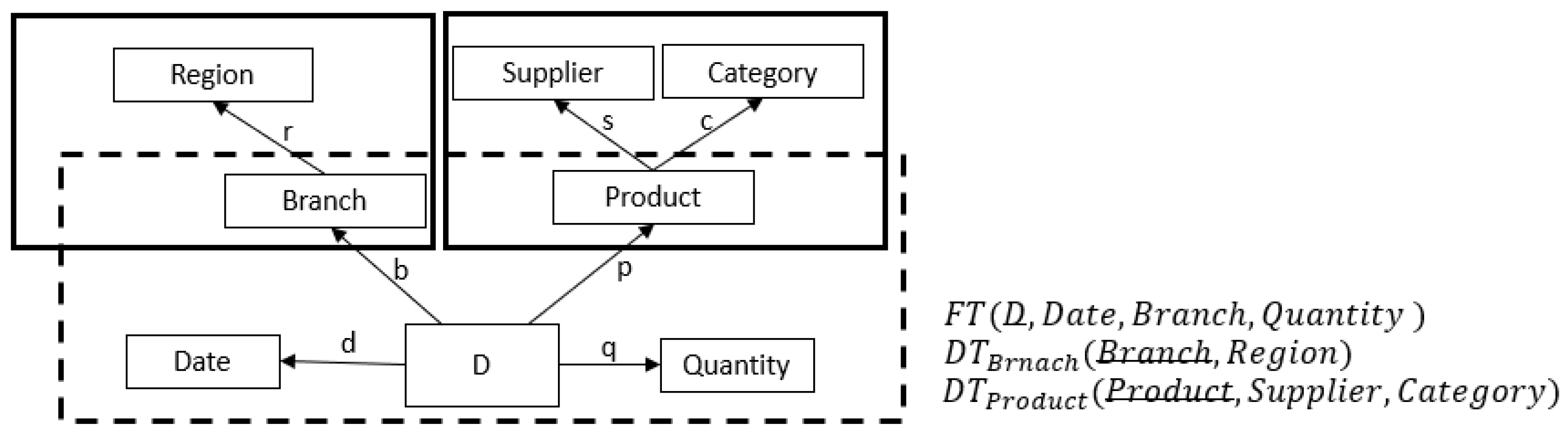
3.1. Analysis Context
3.2. Query Rewriting
4. Methods
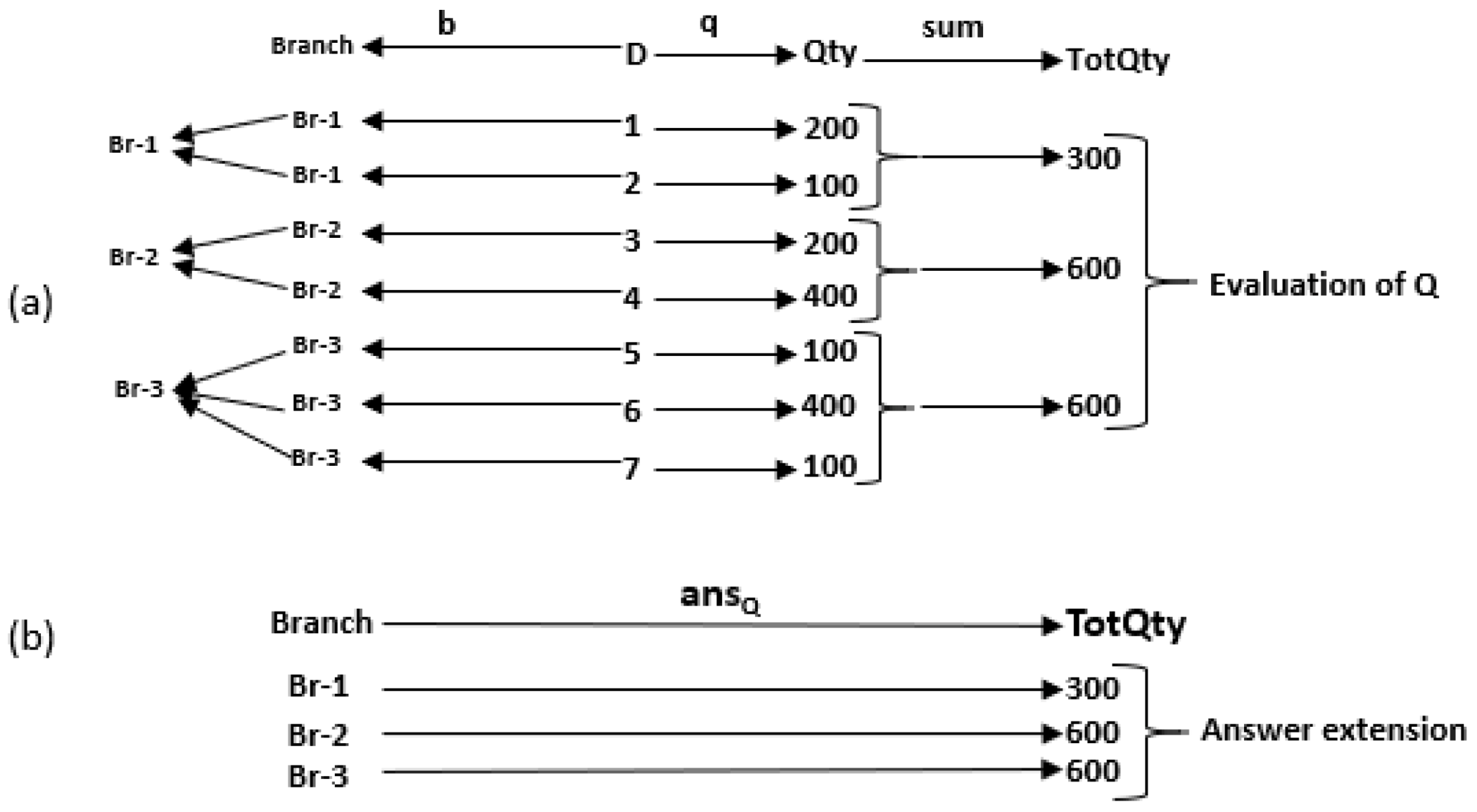
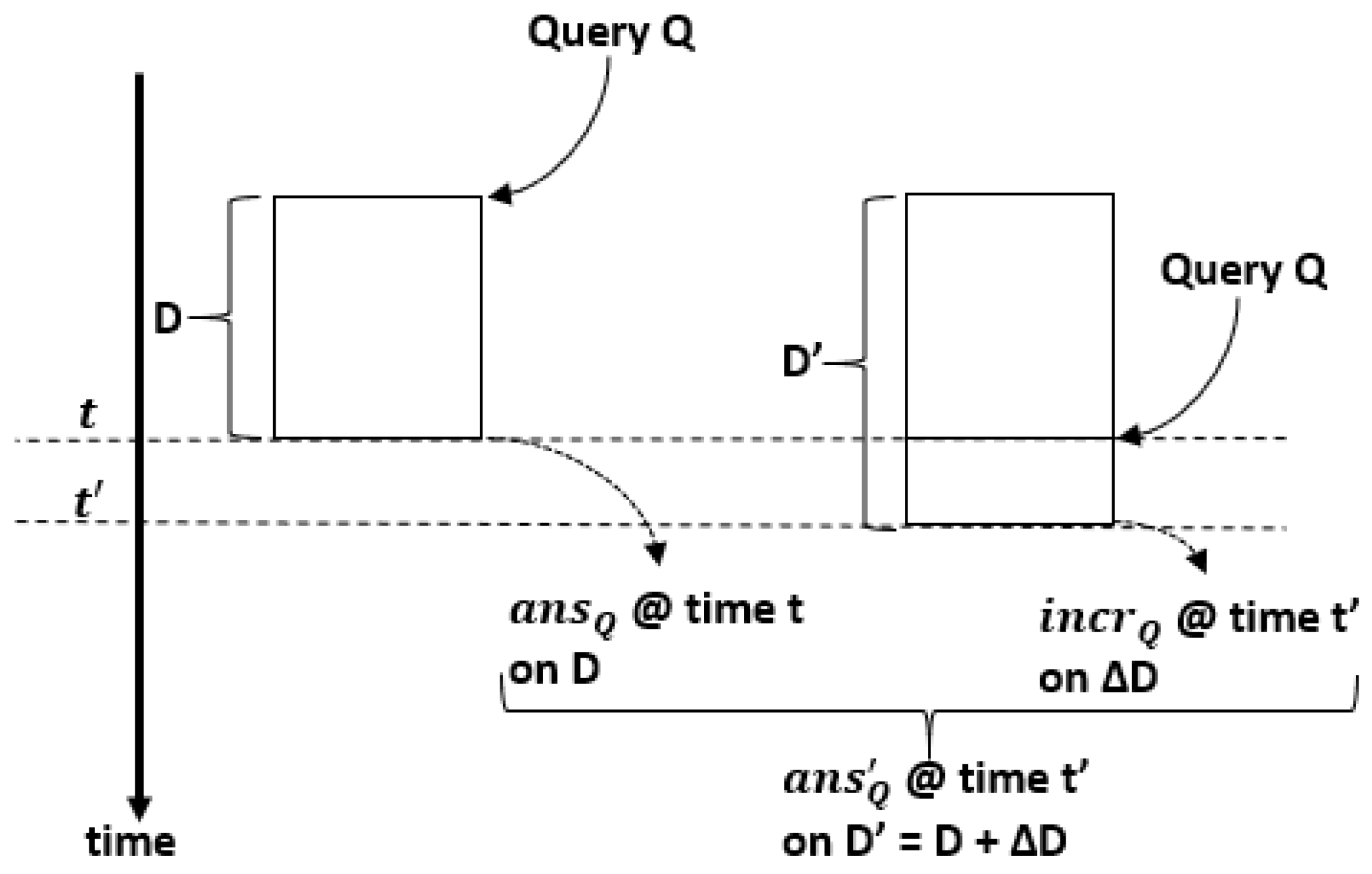
4.1. Incremental Computation in HIFUN
- op= sum: if i is in ;if i is in ; if i is in ;
- op= min: if i is in ; if i is in ; if i is in ;
- op= max: if i is in ; if i is in ; if i is in ;
- op= count: if i is in ; if i is in ; if i is in ;
- op = avg:
- -
- if i is in ;
- -
- if i is in ;
- -
- if i is in ;
4.2. System Implementation
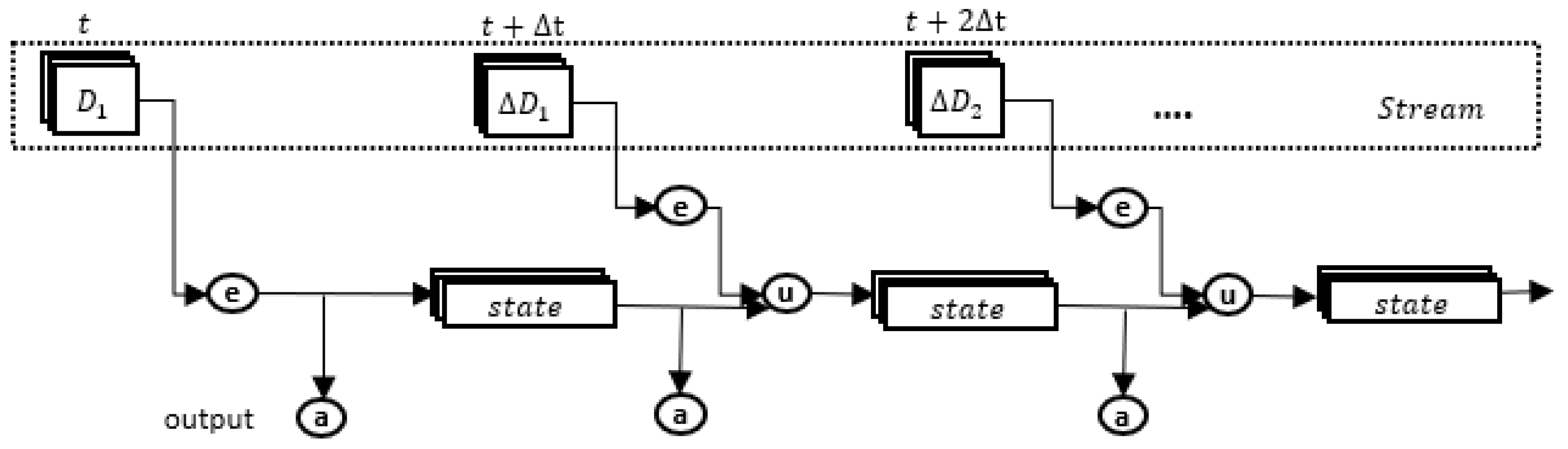
4.2.1. Continuous HIFUN Queries over Micro-Batches
4.2.2. Continuous HIFUN Queries Using MapReduce
- (a)
- Query Input Preparation. A set of attributes which are included in grouping and measuring part of Q is used to extract the information from the initial unstructured dataset. A map function is used that applies the given attributes to each record of the initial DStream and returns a new DStream which contains the information useful for the next evaluation steps.
- (b)
- Grouping Partition Construction. In this step, a map function constructs the grouping partition as follows. The mapper receives the tuples created from the previous step and extracts the key–value pairs. The result is a new PairDStream in which the key K is the value of the grouping attribute of each data item or the value of the grouping attributes if the domain of is the Cartesian product of two or more grouping attributes. The value V is the value of the measuring attribute of each data item.
- (c)
- Grouping Partition Reduction. In this step a reduce function is used to merge the values of each key using a query operation , and a new DStream is created as the query answer of the current micro-batch.
Incremental Evaluation
4.2.3. Translating Continuous HIFUN Queries to SQL
Generic Evaluation Schema to SQL
- Select Branch, sum(Quantity) As ansQ(Branch)
- From FT
- Group by Branch
- Select Supplier, Category, sum(Quantity)
- As ansQ(Supplier, Category)
- From join (FT, DTProduct)
- Group by Supplier, Category
Rewritings to SQL
5. Results
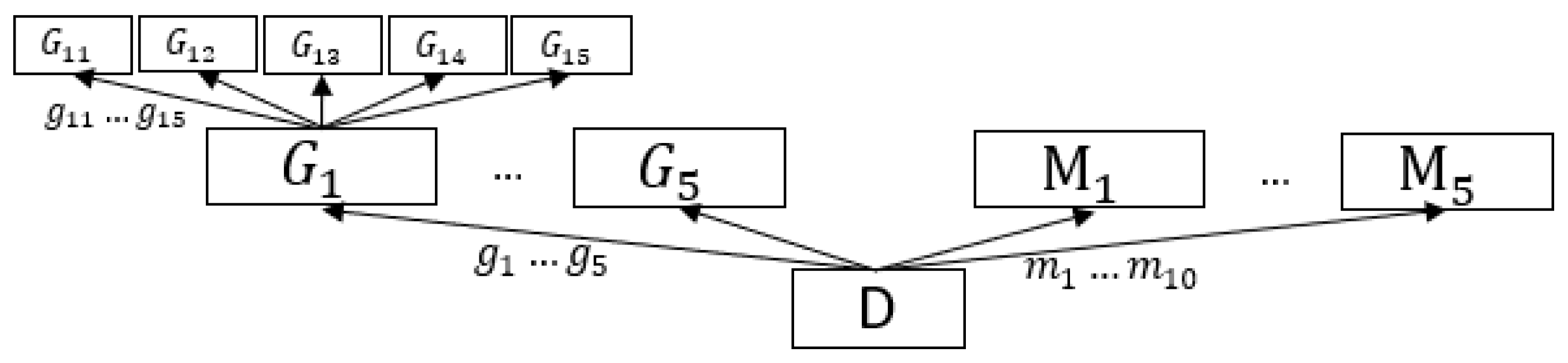
5.1. Setup and Datasets
5.2. Results
5.2.1. Defining the Queries
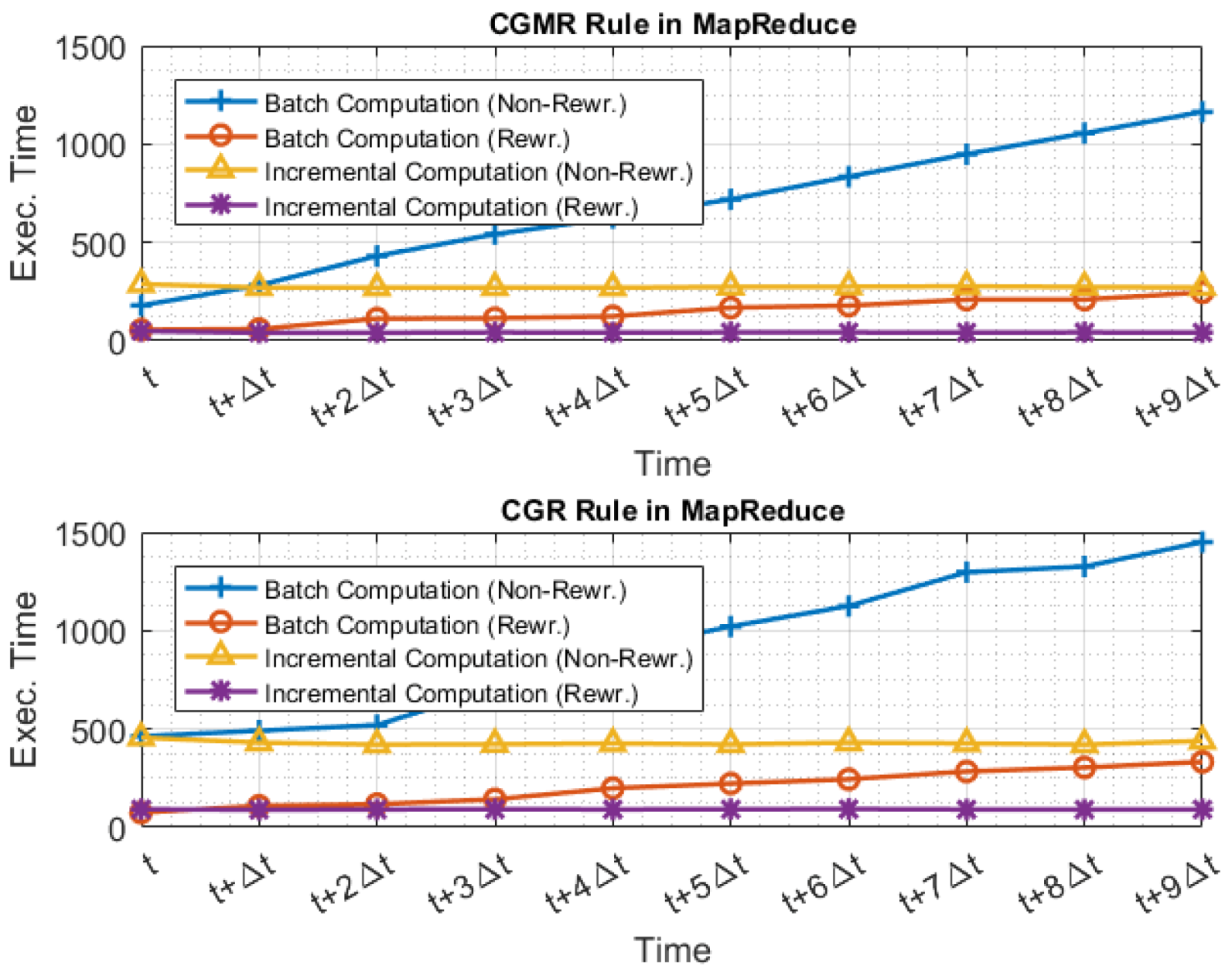
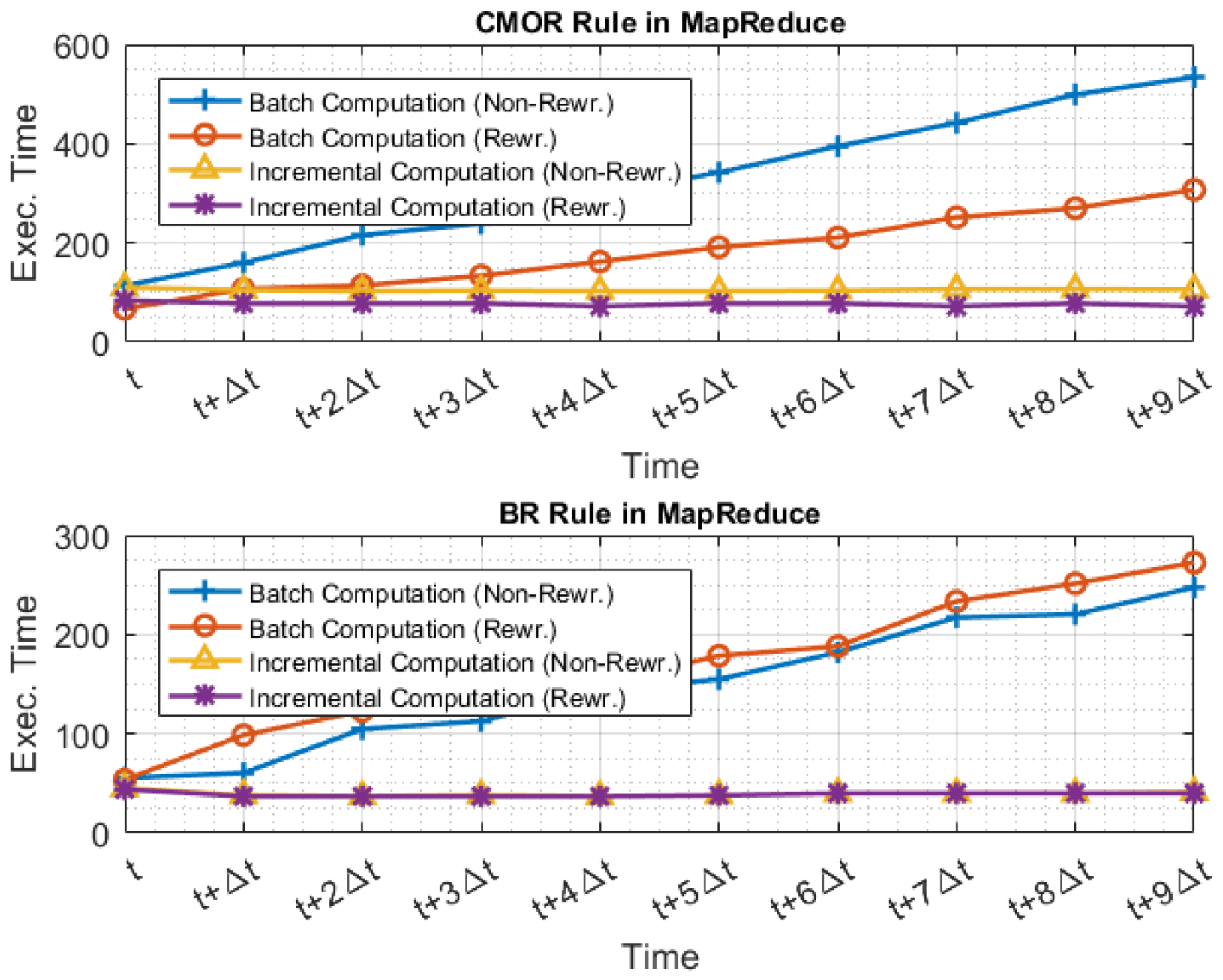
5.2.2. Evaluating Incrementality
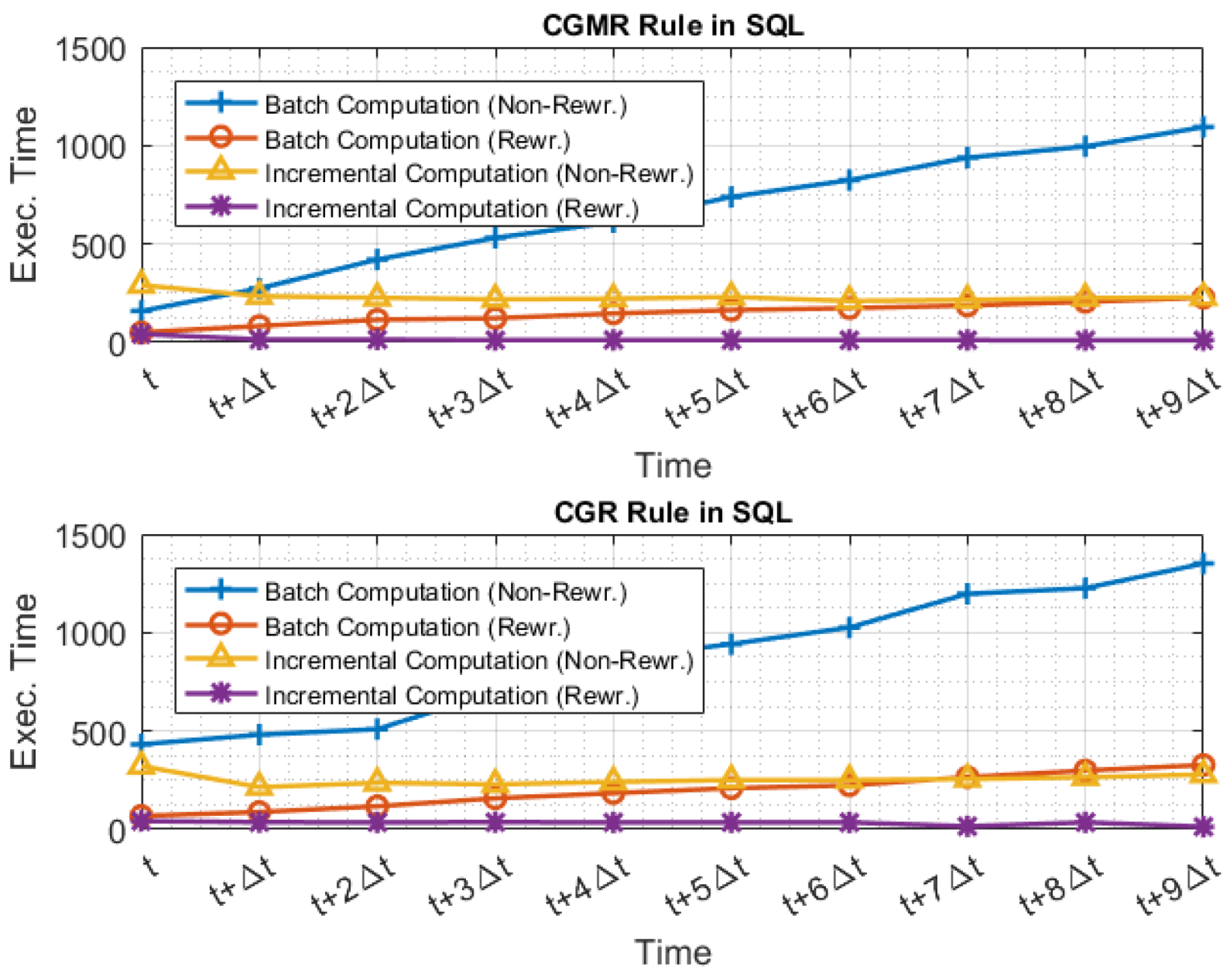
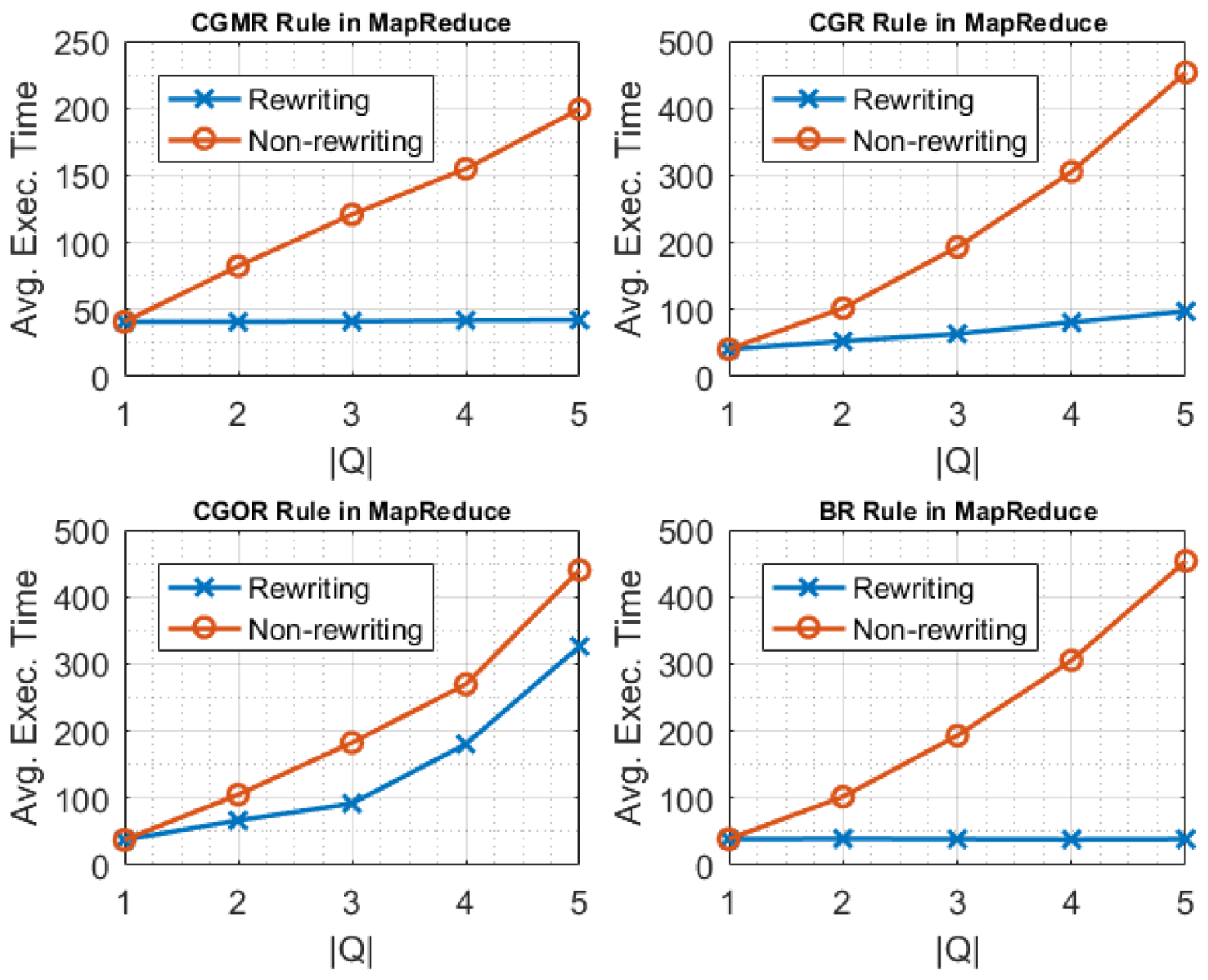
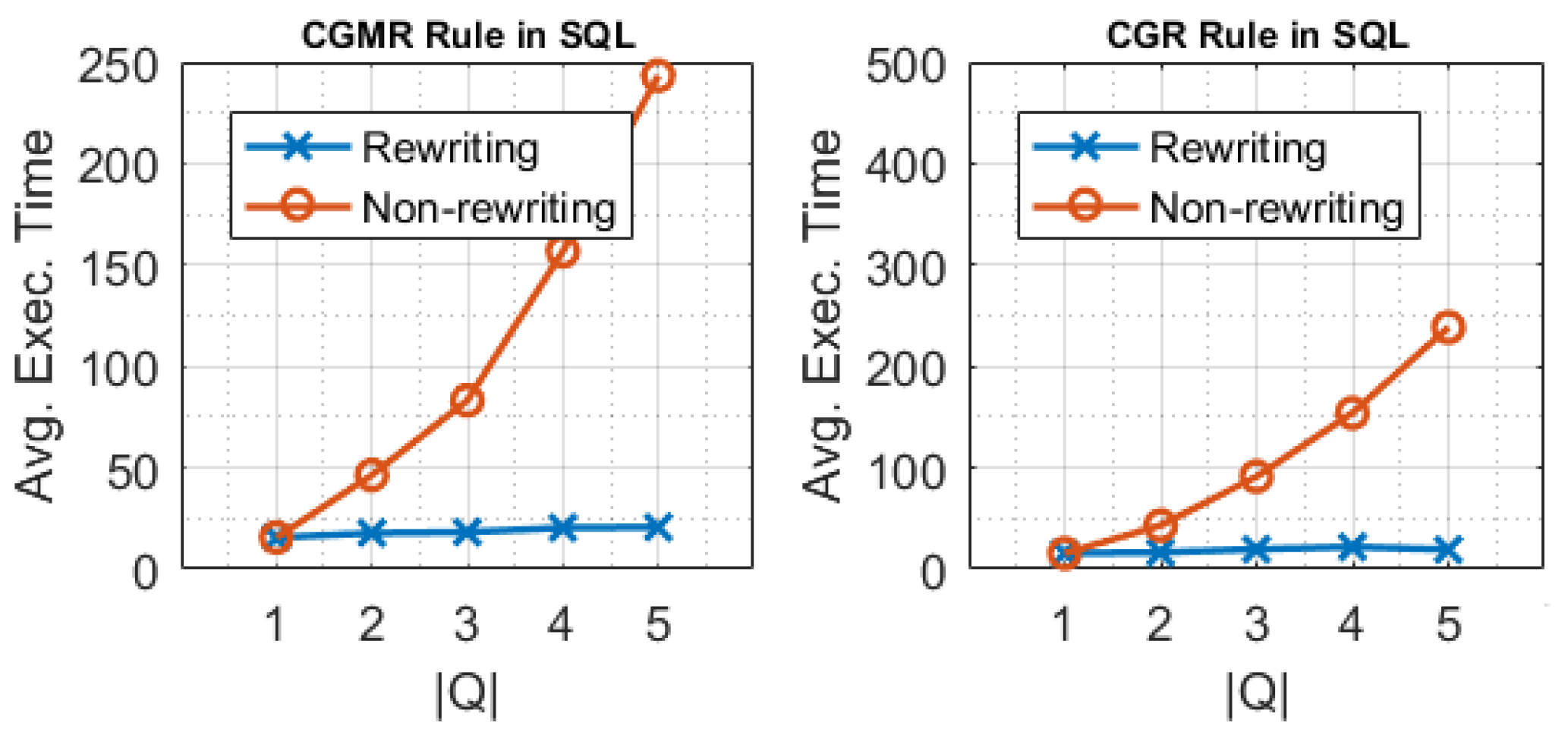
5.2.3. Evaluating Rewritings
6. Conclusions
Limitations and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Mello, B.; Rios, R.; Lira, C.; Prazeres, C. FoT-Stream: A Fog platform for data stream analytics in IoT. Comput. Commun. 2020, 164, 77–87. [Google Scholar] [CrossRef]
- Kondylakis, H.; Dayan, N.; Zoumpatianos, K.; Palpanas, T. Coconut: Sortable summarizations for scalable indexes over static and streaming data series. VLDB J. 2019, 28, 847–869. [Google Scholar] [CrossRef]
- Queiroz, W.; Capretz, M.A.; Dantas, M. An approach for SDN traffic monitoring based on big data techniques. J. Netw. Comput. Appl. 2019, 131, 28–39. [Google Scholar] [CrossRef]
- Carcillo, F.; Dal Pozzolo, A.; Le Borgne, Y.A.; Caelen, O.; Mazzer, Y.; Bontempi, G. SCARFF: A scalable framework for streaming credit card fraud detection with spark. Inf. Fusion 2018, 41, 182–194. [Google Scholar] [CrossRef]
- Banerjee, A.; Chakraborty, C.; Kumar, A.; Biswas, D. Chapter 5—Emerging trends in IoT and big data analytics for biomedical and health care technologies. In Handbook of Data Science Approaches for Biomedical Engineering; Balas, V.E., Solanki, V.K., Kumar, R., Khari, M., Eds.; Academic Press: Cambridge, MA, USA, 2020; pp. 121–152. [Google Scholar] [CrossRef]
- Kondylakis, H.; Bucur, A.I.D.; Crico, C.; Dong, F.; Graf, N.M.; Hoffman, S.; Koumakis, L.; Manenti, A.; Marias, K.; Mazzocco, K.; et al. Patient empowerment for cancer patients through a novel ICT infrastructure. J. Biomed. Inform. 2020, 101, 103342. [Google Scholar] [CrossRef]
- Agathangelos, G.; Troullinou, G.; Kondylakis, H.; Stefanidis, K.; Plexousakis, D. Incremental Data Partitioning of RDF Data in SPARK; Springer: Cham, Swizterland, 2018. [Google Scholar]
- Kondylakis, H.; Plexousakis, D. Ontology Evolution in Data Integration: Query Rewriting to the Rescue. In Proceedings of the Conceptual Modeling—ER 2011, 30th International Conference, ER 2011, Brussels, Belgium, 31 October–3 November 2011; Volume 6998, Lecture Notes in Computer Science. Jeusfeld, M.A., Delcambre, L.M.L., Ling, T.W., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 393–401. [Google Scholar] [CrossRef]
- Pappas, A.; Troullinou, G.; Roussakis, G.; Kondylakis, H.; Plexousakis, D. Exploring Importance Measures for Summarizing RDF/S KBs. In Proceedings of the Semantic Web—14th International Conference—ESWC 2017, Portorož, Slovenia, 28 May–1 June 2017; Part I; Volume 10249, Lecture Notes in Computer Science. pp. 387–403. [Google Scholar] [CrossRef]
- Troullinou, G.; Kondylakis, H.; Stefanidis, K.; Plexousakis, D. Exploring RDFS KBs Using Summaries. In Proceedings of the Semantic Web—ISWC 2018—17th International Semantic Web Conference, Monterey, CA, USA, 8–12 October 2018; Part I; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2018; Volume 11136, pp. 268–284. [Google Scholar] [CrossRef]
- Bolt, C.R. Hadoop: The Definitive Guide; OReilly Media, Inc.: Sebastopol, CA, USA, 2014. [Google Scholar]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Jakóbczyk, M.T. Practical Oracle Cloud Infrastructure; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Karimov, J.; Rabl, T.; Katsifodimos, A.; Samarev, R.; Heiskanen, H.; Markl, V. Benchmarking Distributed Stream Data Processing Systems. In Proceedings of the 2018 IEEE 34th International Conference on Data Engineering (ICDE), Paris, France, 16–19 April 2018; pp. 1507–1518. [Google Scholar]
- Zaharia, M.; Das, T.; Li, H.; Hunter, T.; Shenker, S.; Stoica, I. Discretized streams: Fault-tolerant streaming computation at scale. In Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles, Farmington, PA, USA, 3–6 November 2013. [Google Scholar]
- Armbrust, M.; Das, T.; Torres, J.; Yavuz, B.; Zhu, S.; Xin, R.; Ghodsi, A.; Stoica, I.; Zaharia, M. Structured Streaming: A Declarative API for Real-Time Applications in Apache Spark. In Proceedings of the 2018 International Conference on Management of Data, Houston, TX, USA, 10–15 June 2018. [Google Scholar]
- Iqbal, M.; Soomro, T.R. Big Data Analysis: Apache Storm Perspective. Int. J. Comput. Trends Technol. 2015, 19, 9–14. [Google Scholar] [CrossRef]
- Carbone, P.; Katsifodimos, A.; Ewen, S.; Markl, V.; Haridi, S.; Tzoumas, K. Apache Flink™: Stream and Batch Processing in a Single Engine. IEEE Data Eng. Bull. 2015, 38, 28–38. [Google Scholar]
- Akidau, T.; Bradshaw, R.W.; Chambers, C.; Chernyak, S.; Fernández-Moctezuma, R.; Lax, R.; McVeety, S.; Mills, D.; Perry, F.; Schmidt, E.; et al. The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing. Proc. VLDB Endow. 2015, 8, 1792–1803. [Google Scholar] [CrossRef]
- Alami, K.; Maabout, S. A framework for multidimensional skyline queries over streaming data. Data Knowl. Eng. 2020, 127, 101792. [Google Scholar] [CrossRef]
- Ramesh, S.; Baranawal, A.; Simmhan, Y. Granite: A distributed engine for scalable path queries over temporal property graphs. J. Parallel Distrib. Comput. 2021, 151. [Google Scholar] [CrossRef]
- Kvet, M.; Matiasko, K. Flower Master Index for Relational Database Selection and Joining; Springer: Cham, Switzerland, 2021; pp. 181–202. [Google Scholar] [CrossRef]
- Kvet, M.; Kršák, E.; Matiaško, K. Study on Effective Temporal Data Retrieval Leveraging Complex Indexed Architecture. Appl. Sci. 2021, 11, 916. [Google Scholar] [CrossRef]
- Dam, T.L.; Chester, S.; Nørvåg, K.; Duong, Q.H. Efficient top-k recently-frequent term querying over spatio-temporal textual streams. Inf. Syst. 2021, 97, 101687. [Google Scholar] [CrossRef]
- Dhont, M.; Tsiporkova, E.; Boeva, V. Layered Integration Approach for Multi-View Analysis of Temporal Data; Springer: Cham, Switzerland, 2020; pp. 138–154. [Google Scholar] [CrossRef]
- Babu, S.; Widom, J. Continuous queries over data streams. SIGMOD Rec. 2001, 30, 109–120. [Google Scholar] [CrossRef]
- Franklin, A.; Gantela, S.; Shifarraw, S.; Johnson, T.R.; Robinson, D.J.; King, B.R.; Mehta, A.M.; Maddow, C.L.; Hoot, N.R.; Nguyen, V.; et al. Dashboard visualizations: Supporting real-time throughput decision-making. J. Biomed. Inform. 2017, 71, 211–221. [Google Scholar] [CrossRef]
- Laurent, D.; Lechtenbörger, J.; Spyratos, N.; Vossen, G. Monotonic complements for independent data warehouses. VLDB J. 2001, 10, 295–315. [Google Scholar] [CrossRef][Green Version]
- Ahmad, Y.; Kennedy, O.; Koch, C.E.; Nikolic, M. DBToaster: Higher-order Delta Processing for Dynamic, Frequently Fresh Views. Proc. VLDB Endow. 2012, 5, 968–979. [Google Scholar] [CrossRef]
- Spyratos, N.; Sugibuchi, T. HIFUN—A high level functional query language for big data analytics. J. Intell. Inf. Syst. 2018, 51, 529–555. [Google Scholar] [CrossRef]
- Spyratos, N.; Sugibuchi, T. A High Level Query Language for Big Data Analytics. Available online: http://publications.ics.forth.gr/tech-reports/2017/2017.TR467_HiFu_Query_Language_Big_Data_Analytics.pdf (accessed on 8 May 2021).
- Papadaki, M.E.; Spyratos, N.; Tzitzikas, Y. Towards Interactive Analytics over RDF Graphs. Algorithms 2021, 14, 34. [Google Scholar] [CrossRef]
- Zervoudakis, P.; Kondylakis, H.; Plexousakis, D.; Spyratos, N. Incremental Evaluation of Continuous Analytic Queries in HIFUN. In International Workshop on Information Search, Integration, and Personalization; Springer: Cham, Switzerland, 2019; pp. 53–67. [Google Scholar]
- Garcia-Molina, H.; Ullman, J.D.; Widom, J. Database Systems—The Complete Book (International Edition); Pearson Education: London, UK, 2002. [Google Scholar]
- Le, D.; Chen, R.; Bhatotia, P.; Fetze, C.; Hilt, V.; Strufe, T. Approximate Stream Analytics in Apache Flink and Apache Spark Streaming. arXiv 2017, arXiv:1709.02946. [Google Scholar]
- Terry, D.; Goldberg, D.; Nichols, D.; Oki, B.M. Continuous queries over append-only databases. In Proceedings of the SIGMOD ’92, San Diego, CA, USA, 3–5 June 1992. [Google Scholar]
- Chen, J.; DeWitt, D.; Tian, F.; Wang, Y. NiagaraCQ: A scalable continuous query system for Internet databases. In Proceedings of the SIGMOD ’00, Dallas, TX, USA, 16–18 May 2000. [Google Scholar]
- Liu, L.; Pu, C.; Tang, W. Continual Queries for Internet Scale Event-Driven Information Delivery. IEEE Trans. Knowl. Data Eng. 1999, 11, 610–628. [Google Scholar]












Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zervoudakis, P.; Kondylakis, H.; Spyratos, N.; Plexousakis, D. Query Rewriting for Incremental Continuous Query Evaluation in HIFUN. Algorithms 2021, 14, 149. https://doi.org/10.3390/a14050149
Zervoudakis P, Kondylakis H, Spyratos N, Plexousakis D. Query Rewriting for Incremental Continuous Query Evaluation in HIFUN. Algorithms. 2021; 14(5):149. https://doi.org/10.3390/a14050149
Chicago/Turabian StyleZervoudakis, Petros, Haridimos Kondylakis, Nicolas Spyratos, and Dimitris Plexousakis. 2021. "Query Rewriting for Incremental Continuous Query Evaluation in HIFUN" Algorithms 14, no. 5: 149. https://doi.org/10.3390/a14050149
APA StyleZervoudakis, P., Kondylakis, H., Spyratos, N., & Plexousakis, D. (2021). Query Rewriting for Incremental Continuous Query Evaluation in HIFUN. Algorithms, 14(5), 149. https://doi.org/10.3390/a14050149