
Machine Learning Predicts Outcomes of Phase III Clinical Trials for Prostate Cancer


Abstract

1. Introduction
2. Materials and Methods
2.1. Sources of Data
2.2. Objectives of the Original Studies
- To compare time to clinical progression after two years of bicalutamide 150 mg monotherapy vs placebo.
- To compare overall survival after two years of bicalutamide 150 mg monotherapy vs placebo.
- To evaluate tolerability of two years of bicalutamide 150 mg therapy versus placebo.
- To compare treatment failure after two years of bicalutamide 150 mg monotherapy vs placebo.
2.3. Design of the Original Studies
2.4. Subjects and Datasets
2.5. Comparability of the Studies
- Age.
- Racial makeup (predominantly white, although differences in frequencies of minority races).
- Clinical stage.
- Gleason score category.
- Proportion of serious related A.E.s.
- Proportion of death within two years.
- Frequency of prior prostatectomy, reflecting different inclusion criteria (see Appendix B).
- Frequency of metastatic node disease at baseline.
- Mean PSA levels over the two-year main trial period (likely related to the greater incidence of prior prostatectomy or prostate radiation treatment before randomization).
2.6. Derivation of the Target Variable
- PSA levels did not increase by more than 0.2 ng/mL within the initial two-year trial period (efficacy), similar to the method used in the literature [25].
- ○
- ‘PSA increase’ was defined in terms of a comparison of baseline vs. 2 years. For Studies 2 and 3, ‘baseline’ was the day of randomization. For Study 1, ‘baseline’ was set at three months, to address the observation that in Study 1 (but not Studies 2 or 3) mean PSA values underwent a marked reduction (43%) from day 0 to 3 months and then, on average, stabilized. Thus, this baseline shift was an adjustment designed to ensure consistency between the three studies (i.e., the start of stable PSA values). This discrepancy between studies in the trajectory of PSA values is likely related to different entry criteria. In Study 1, subjects were required to have undergone radical prostatectomy or prostate radiation treatment (which would have caused a marked decrease in PSA levels) within the 16 weeks before randomization, a requirement not present for studies 2 or 3.
- ○
- PSA values at 2 years after randomization was operationalized by taking the mean of PSA values within a window of 600–900 days after randomization. The width of this window was designed to balance the need to include a sufficient number of data points, with the need to confine the window, so that the time points could be considered consistent.
- There were no related, serious adverse events (A.E.s) within the initial two-year trial period (safety)
- ○
- A related A.E. was considered serious if it:
- caused withdrawal from the study OR
- caused disability or incapacity OR
- required or prolonged hospitalization OR
- required intervention to prevent impairment OR
- was life-threatening
- Survived for the initial two-year trial period (safety)
- Stayed in the trial for at least 600 days (safety)
2.7. Feature Reduction
- The Chi-squared test was used to identify which categorical variables were significantly related to the target variable (‘good responders’; p < 0.05). Unrelated variables were removed.
- ANOVA was used to test which continuous variables were significantly different between the target classes (p < 0.05). Unrelated variables would have been removed, but none needed to be removed on this basis.
- Where there were high correlations between the remaining continuous predictors (Pearson’s r > 0.9), the predictor with the lower correlation with the target was removed.
2.8. Other Data Preprocessing Steps
- Extraction of data from original sas files and compilation into integrated datasets with one row per subject.
- Recoding of some variables (e.g., Gleason score and clinical stage) to make them consistent between studies.
- Imputation of missing values (mean for continuous variables, mode for categorical variables).
- Outlier inspection (there were no implausible values, so none were removed).
2.9. Final Datasets
2.10. Planned Modeling
- Three-Study Merged Dataset Models
- 2.
- Separate Study Validation Models
- 3.
- Individual Study Models
2.11. Classification Algorithms Used
2.11.1. Logistic Regression
2.11.2. K-Nearest Neighbors (KNN)
2.11.3. CatBoost
2.11.4. Extreme Gradient Boosting (XGBoost)
2.11.5. Voting Classifier
2.12. Modeling Procedures
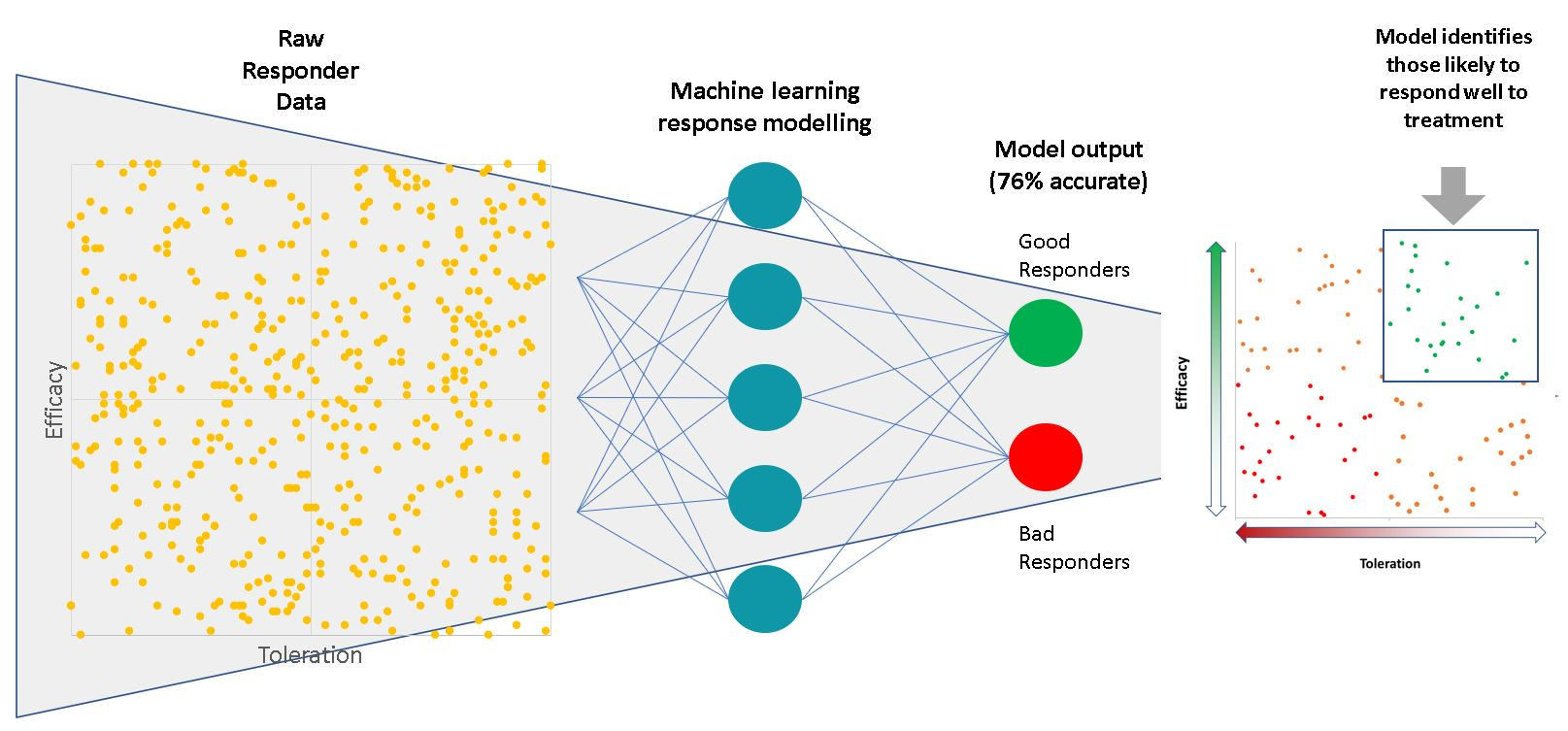
3. Results
3.1. Three-Study Merged Dataset Models
3.2. Separate Study Validation Models
3.3. Individual Study Models
4. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Outline of Study Design for the Three Studies Included in the Analyses Presented in This Paper

Appendix B. Inclusion and Exclusion Criteria for the Three Astra-Zeneca EPC Studies
| Study 1 | Study 2 | Study 3 | |
| Inclusion criteria | Adenocarcinoma of the prostate | ||
| Absence of metastatic disease | Non distant metastatic disease | ||
| Radical prostatectomy OR prostate radiation treatment within 16 weeks before randomization. | 82% | 99% | |
| Exclusion criteria | Any previous systemic therapy for prostate cancer except: 1. Neoadjuvant therapy prior to primary therapy 2. 5-alpha-reductase inhibitors | ||
| Other type of cancer (except treated skin carcinoma) within the last five years. | Other type of cancer (except treated skin carcinoma) within the last ten years. | ||
| Serum bilirubin, AST or ALT >2.5x normal upper limit | |||
| Any severe medical condition that could jeopardize trial compliance | |||
| Treatment with a new drug within previous 3 months | Patients for whom long term therapy is inappropriate due to low expected survival times | ||
| Patients at risk of transmitting infection through blood, including AIDS or other STDs or hepatitis | |||
Appendix C. Target Variable and Frequencies/Means for the Features Included in the Three-Study Merged Dataset Models and Separate Study Validation Models
| Category | Feature | Study 1 | Study 2 | Study 3 | |||
| Values | Missing | Values | Missing | Values | Missing | ||
| Assessments used to compute ‘good responders’ | Dropouts (<600 days of baseline) | 325 | 0 | 428 | 0 | 155 | 0 |
| PSA baseline (mean, ng/mL) | 0.65 | 62 | 11.5 | 24 | 24.8 | 0 | |
| PSA 2 years (mean, ng/mL) | 0.6 | 139 | 22.5 | 305 | 32.6 | 112 | |
| Prostate cancer death in 2y | 3 | 0 | 25 | 0 | 10 | 0 | |
| Related A.E. led to withdrawal 2y | 73 | 0 | 76 | 0 | 17 | 0 | |
| Related A.E. led to interventn 2y | 1 | 0 | 18 | 0 | 10 | 0 | |
| Related A.E. led to hospitalizn 2y | 2 | 0 | 19 | 0 | 6 | 0 | |
| Related A.E. led to disability 2y | 0 | 0 | 21 | 0 | 10 | 0 | |
| Related A.E. life-threatening 2y | 0 | 0 | 12 | 0 | 3 | 0 | |
| Any Serious Related A.E. in 2y | 74 | 0 | 98 | 0 | 21 | 0 | |
| Demographics | Age (mean years) | 64 | 0 | 69 | 0 | 68 | 0 |
| Clinical features | Weight (mean kg) | 85 | 0 | 76 | 0 | 81 | 6 |
| Clinical stage category | |||||||
| Category 1 | 0 | 0 | 1 | 0 | 0 | 0 | |
| Category 2 | 23 | 0 | 153 | 0 | 44 | 0 | |
| Category 3 | 131 | 0 | 245 | 0 | 89 | 0 | |
| Category 4 | 1028 | 0 | 550 | 0 | 229 | 0 | |
| Category 5 | 440 | 0 | 446 | 0 | 213 | 0 | |
| Category 6 | 3 | 0 | 45 | 0 | 13 | 0 | |
| Metastatic node disease | 462 | 0 | 41 | 0 | 24 | 0 | |
| Gleason score category | |||||||
| Category 1 | 78 | 0 | 477 | 0 | 256 | 0 | |
| Category 2 | 788 | 0 | 574 | 0 | 266 | 0 | |
| Category 3 | 759 | 0 | 363 | 0 | 63 | 0 | |
| Category 4 | 0 | 0 | 26 | 0 | 3 | 0 | |
| Previous therapies for prostate cancer | Prostatectomy | 1314 | 0 | 534 | 0 | 71 | 0 |
| Radiotherapy | 319 | 0 | 295 | 0 | 30 | 0 | |
| Biochemistry | PSA at baseline (mean, ng/mL) | 0.65 | 75 | 11 | 96 | 25 | 8 |
| PSA within 1 year before baseline (mean, ng/mL) | 9.75 | 0 | 17.28 | 0 | 23.67 | 0 | |
| Baseline AST (mean, U/L) | 18 | 0 | 21 | 0 | 22.58 | 0 | |
| Baseline ALT (mean, U/L) | 20 | 0 | 22 | 0 | 21.72 | 0 | |
| Baseline Bilirubin (mean, UMOL/L) | 0.61 | 0 | 9.37 | 0 | 10.61 | 0 | |
| Generic names of concomitant medications | Amlodipine | 61 | 0 | 46 | 0 | 26 | 0 |
| Aspirin | 385 | 0 | 247 | 0 | 76 | 0 | |
| Atenolol | 76 | 0 | 84 | 0 | 33 | 0 | |
| Diazepam | 18 | 0 | 10 | 0 | 11 | 0 | |
| Digoxin | 51 | 0 | 40 | 0 | 17 | 0 | |
| Doxazosin | 47 | 0 | 15 | 0 | 16 | 0 | |
| Enalapril | 64 | 0 | 82 | 0 | 28 | 0 | |
| Furosemide | 35 | 0 | 37 | 0 | 30 | 0 | |
| Glibenclamide | 55 | 0 | 39 | 0 | 16 | 0 | |
| Glyceryl trinitrate | 36 | 0 | 54 | 0 | 29 | 0 | |
| Lisinopril | 84 | 0 | 21 | 0 | 14 | 0 | |
| Metoprolol | 36 | 0 | 38 | 0 | 37 | 0 | |
| Nifedipine | 83 | 0 | 121 | 0 | 14 | 0 | |
| Omeprazole | 32 | 0 | 38 | 0 | 10 | 0 | |
| Paracetamol | 108 | 0 | 34 | 0 | 10 | 0 | |
| Salbutamol | 40 | 0 | 52 | 0 | 14 | 0 | |
| Simvastatin | 49 | 0 | 27 | 0 | 19 | 0 | |
| Vitamin, not otherwise specified | 255 | 0 | 14 | 0 | 0 | 0 | |
| Warfarin | 42 | 0 | 21 | 0 | 24 | 0 | |
| PCLA drug class of concomitant medications | Acetic acid derivs, rel substances | 47 | 0 | 41 | 0 | 12 | 0 |
| Alpha-adrenoreceptor blockers | 114 | 0 | 55 | 0 | 18 | 0 | |
| Analgesics and antipyretics, anilides | 154 | 0 | 60 | 0 | 18 | 0 | |
| Analgesics and antipyretics, salicylic acid and derivs | 409 | 0 | 266 | 0 | 110 | 0 | |
| Angiotensin-converting enzyme inhibitors, plain | 230 | 0 | 192 | 0 | 59 | 0 | |
| Anti-anginal vasodilators, organic nitrates | 47 | 0 | 132 | 0 | 58 | 0 | |
| Antidiabetic sulfonamides urea derivs | 89 | 0 | 79 | 0 | 26 | 0 | |
| Anxiolytic benzodiazepine derivs | 65 | 0 | 74 | 0 | 19 | 0 | |
| Beta blocking agents, plain, non-Sel | 56 | 0 | 68 | 0 | 31 | 0 | |
| Beta blocking agents, plain, Sel | 114 | 0 | 153 | 0 | 78 | 0 | |
| Digitalis glycosides | 52 | 0 | 53 | 0 | 23 | 0 | |
| Glucocorticoids | 18 | 0 | 21 | 0 | 11 | 0 | |
| High-ceiling diuretics, sulfonamides, plain | 37 | 0 | 40 | 0 | 30 | 0 | |
| Hmg coa reductase inhibitors | 176 | 0 | 63 | 0 | 31 | 0 | |
| Inhal glucocorticoids | 39 | 0 | 74 | 0 | 21 | 0 | |
| Inhal Sel beta2-adrenoceptor agonists | 48 | 0 | 80 | 0 | 28 | 0 | |
| Low-ceiling diuretics and K-sparing agents | 32 | 0 | 44 | 0 | 14 | 0 | |
| Propionic acid derivs | 154 | 0 | 38 | 0 | 15 | 0 | |
| Proton pump inhibitors | 36 | 0 | 44 | 0 | 14 | 0 | |
| Sel Ca channel blockers, dihydropyridine derivs | 172 | 0 | 186 | 0 | 63 | 0 | |
| Vitamin k antagonists | 42 | 0 | 46 | 0 | 25 | 0 | |
References
- Krittanawong, C.; Zhang, H.; Wang, Z.; Aydar, M.; Kitai, T. Artificial Intelligence in Precision Cardiovascular Medicine. J. Am. Coll. Cardiol. 2017, 69, 2657–2664. [Google Scholar] [CrossRef] [PubMed]
- Krzyszczyk, P.; Acevedo, A.; Davidoff, E.J.; Timmins, L.M.; Marrero-Berrios, I.; Patel, M.; White, C.; Lowe, C.; Sherba, J.J.; Hartmanshenn, C.; et al. The growing role of precision and personalized medicine for cancer treatment. Technology 2018, 6, 79–100. [Google Scholar] [CrossRef] [PubMed]
- Odeh, M.S.; Zeiss, R.A.; Huss, M.T. Cues they use: Clinicians’ endorsement of risk cues in predictions of dangerousness. Behav. Sci. Law 2006, 24, 147–156. [Google Scholar] [CrossRef]
- Mesko, B. The role of artificial intelligence in precision medicine. Expert Rev. Precis. Med. Drug Dev. 2017, 2, 239–241. [Google Scholar] [CrossRef]
- Myszczynska, M.A.; Ojamies, P.N.; Lacoste, A.M.B.; Neil, D.; Saffari, A.; Mead, R.; Hautbergue, G.M.; Holbrook, J.D.; Ferraiuolo, L. Applications of machine learning to diagnosis and treatment of neurodegenerative diseases. Nat. Rev. Neurol. 2020, 16, 440–456. [Google Scholar] [CrossRef]
- Denaxas, S.C.; Morley, K.I. Big biomedical data and cardiovascular disease research: Opportunities and challenges. Eur. Hear. J. Qual. Care Clin. Outcomes 2015, 1, 9–16. [Google Scholar] [CrossRef]
- Savage, N. Another set of eyes for cancer diagnostics Artificial intelligence’s ability to detect subtle patterns could help physi-cians to identify cancer types and refine risk prediction. Nature 2020, 579, S14–S16. [Google Scholar] [CrossRef]
- Cao, B.; Cho, R.Y.; Chen, D.; Xiu, M.; Wang, L.; Soares, J.C.; Zhang, X.Y. Treatment response prediction and individualized identification of first-episode drug-naïve schizophrenia using brain functional connectivity. Mol. Psychiatry 2018, 25, 906–913. [Google Scholar] [CrossRef]
- Pearson, R.; Pisner, D.; Meyer, B.; Shumake, J.; Beevers, C.G. A machine learning ensemble to predict treatment outcomes following an Internet intervention for depression. Psychol. Med. 2018, 49, 2330–2341. [Google Scholar] [CrossRef]
- Yousefi, S.; Amrollahi, F.; Amgad, M.; Dong, C.; Lewis, J.E.; Song, C.; Gutman, D.A.; Halani, S.H.; Vega, J.E.V.; Brat, D.J.; et al. Predicting clinical outcomes from large scale cancer genomic profiles with deep survival models. Sci. Rep. 2017, 7, 11707. [Google Scholar] [CrossRef]
- Zauderer, M.G.; Gucalp, A.; Epstein, A.S.; Seidman, A.D.; Caroline, A.; Granovsky, S.; Fu, J.; Keesing, J.; Lewis, S.; Co, H.; et al. Piloting IBM Watson Oncology within Memorial Sloan Kettering’s regional network. J. Clin. Oncol. 2014, 32, e17653. [Google Scholar] [CrossRef]
- Strickland, E. How IBM Watson Overpromised and Underdelivered on A.I. Health Care-IEEE Spectrum. Available online: https://spectrum.ieee.org/biomedical/diagnostics/how-ibm-watson-overpromised-and-underdelivered-on-ai-health-care (accessed on 16 March 2021).
- Mobadersany, P.; Yousefi, S.; Amgad, M.; Gutman, D.A.; Barnholtz-Sloan, J.S.; Vega, J.E.V.; Brat, D.J.; Cooper, L.A.D. Predicting cancer outcomes from histology and genomics using convolutional networks. Proc. Natl. Acad. Sci. USA 2018, 115, E2970–E2979. [Google Scholar] [CrossRef] [PubMed]
- El Naqa, I.; Grigsby, P.; Apte, A.; Kidd, E.; Donnelly, E.; Khullar, D.; Chaudhari, S.; Yang, D.; Schmitt, M.; Laforest, R.; et al. Exploring feature-based approaches in PET images for predicting cancer treatment outcomes. Pattern Recognit. 2009, 42, 1162–1171. [Google Scholar] [CrossRef]
- Chekroud, A.M.; Zotti, R.J.; Shehzad, Z.; Gueorguieva, R.; Johnson, M.K.; Trivedi, M.H.; Cannon, T.D.; Krystal, J.H.; Corlett, P.R. Cross-trial prediction of treatment outcome in depression: A machine learning approach. Lancet Psychiatry 2016, 3, 243–250. [Google Scholar] [CrossRef]
- DiMasi, J.A.; Grabowski, H.G.; Hansen, R.W. Innovation in the pharmaceutical industry: New estimates of R&D costs. J. Health Econ. 2016, 47, 20–33. [Google Scholar] [CrossRef] [PubMed]
- Dowden, H.; Munro, J. Trends in clinical success rates and therapeutic focus. Nat. Rev. Drug Discov. 2019, 18, 495–496. [Google Scholar] [CrossRef] [PubMed]
- Harrer, S.; Shah, P.; Antony, B.; Hu, J. Artificial Intelligence for Clinical Trial Design. Trends Pharmacol. Sci. 2019, 40, 577–591. [Google Scholar] [CrossRef]
- Machine-Learning-Derived Enrichment Markers in Clinical Trials. Available online: https://isctm.org/public_access/Feb2020/Presentation/Millis-Presentation.pdf (accessed on 1 May 2021).
- Haas, G.P.; Delongchamps, N.; Brawley, O.W.; Wang, C.Y.; De La Roza, G. The worldwide epidemiology of prostate cancer: Perspectives from autopsy studies. Can. J. Urol. 2008, 15, 3866. [Google Scholar] [PubMed]
- A Perlmutter, M.; Lepor, H. Androgen Deprivation Therapy in the Treatment of Advanced Prostate Cancer. Rev. Urol. 2007, 9, S3–S8. [Google Scholar]
- Levine, G.N.; D’Amico, A.V.; Berger, P.; Clark, P.E.; Eckel, R.H.; Keating, N.L.; Milani, R.V.; Sagalowsky, A.I.; Smith, M.R.; A Zakai, N. Androgen-Deprivation Therapy in Prostate Cancer and Cardiovascular Risk. CA Cancer J. Clin. 2010, 121, 833–840. [Google Scholar] [CrossRef] [PubMed]
- Iversen, P.; McLeod, D.G.; See, W.A.; Morris, T.; Armstrong, J.; Wirth, M.P.; on behalf of the Casodex Early Prostate Cancer Trialists’ Group. Antiandrogen monotherapy in patients with localized or locally advanced prostate cancer: Final results from the bicalutamide Early Prostate Cancer programme at a median follow-up of 9.7 years. BJU Int. 2010, 105, 1074–1081. [Google Scholar] [CrossRef]
- Lojanapiwat, B.; Anutrakulchai, W.; Chongruksut, W.; Udomphot, C. Correlation and diagnostic performance of the prostate-specific antigen level with the diagnosis, aggressiveness, and bone metastasis of prostate cancer in clinical practice. Prostate Int. 2014, 2, 133–139. [Google Scholar] [CrossRef]
- Okubo, T.; Mitsuzuka, K.; Koie, T.; Hoshi, S.; Matsuo, S.; Saito, S.; Tsuchiya, N.; Habuchi, T.; Ohyama, C.; Arai, Y.; et al. Two years of bicalutamide monotherapy in patients with biochemical relapse after radical prostatectomy. Jpn. J. Clin. Oncol. 2018, 48, 570–575. [Google Scholar] [CrossRef] [PubMed]
- Rust, J.; Golombok, S. The GRISS: A psychometric instrument for the assessment of sexual dysfunction. Arch. Sex. Behav. 1986, 15, 157–165. [Google Scholar] [CrossRef] [PubMed]
- Le, N.Q.K.; Do, D.T.; Chiu, F.-Y.; Yapp, E.K.Y.; Yeh, H.-Y.; Chen, C.-Y. XGBoost Improves Classification of MGMT Promoter Methylation Status in IDH1 Wildtype Glioblastoma. J. Pers. Med. 2020, 10, 128. [Google Scholar] [CrossRef]
- Ezzati, A.; Zammit, A.R.; Harvey, D.J.; Habeck, C.; Hall, C.B.; Lipton, R.B.; Initiative, F.T.A.D.N. Optimizing Machine Learning Methods to Improve Predictive Models of Alzheimer’s Disease. J. Alzheimer’s Dis. 2019, 71, 1027–1036. [Google Scholar] [CrossRef]
- Obermeyer, Z.; Emanuel, E.J. Predicting the Future—Big Data, Machine Learning, and Clinical Medicine. New Engl. J. Med. 2016, 375, 1216–1219. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
| Study 1 | Study 2 | Study 3 | |
|---|---|---|---|
| Title | A Randomized Double-Blind Comparative Trial of Bicalutamide (Bicalutamide) Versus Placebo in Patients with Early Prostate Cancer | A Randomised, Double-blind, Parallel-group Trial Comparing Bicalutamide 150 mg Once Daily With Placebo In Subjects With Non-metastatic Prostate Cancer | A Randomised, Double-blind, Parallel-group Trial Comparing Bicalutamide 150 mg Once Daily With Placebo In Subjects With Non-metastatic Prostate Cancer |
| Sites | U.S. and Canada | Mostly Europe, but also Mexico, Australia and South Africa | Sweden, Norway, Finland, Denmark |
| Year first subject enrolled | 1995 | 1995 | 1995 |
| Year study completed | 2008 | 2008 | 2008 |
| Study 1 | Study 2 | Study 3 | ||
|---|---|---|---|---|
| (n = 1625) | (n = 1440) | (n = 588) | ||
| Demographics | 64 | 69 | 68 | |
| Mean age (years) | Cauc 84% (1372) | Cauc 95% (1365) | Cauc 99% (584) | |
| Black 11% (188) | Black 1% (13) | Black 0% (0) | ||
| Race | Asian 0.7% (12) | Asian 0.5% (7) | Asian 0% (0) | |
| Hispanic 3% (46) | Hispanic 2% (25) | Hispanic 0.3% (2) | ||
| Other 0.4% (7) | Other 2% (31) | Other 0.3% (2) | ||
| Clinical features | Clinical stage | |||
| Category 1 | 0.2% (3) | 0.1% (1) | 0% (0) | |
| Category 2 | 1% (23) | 11% (153) | 7% (44) | |
| Category 3 | 8% (131) | 17% (245) | 15% (89) | |
| Category 4 | 63% (1028) | 38% (550) | 39% (229) | |
| Category 5 | 27% (440) | 31% (446) | 36% (213) | |
| Category 6 | 0% (0) | 3% (45) | 2% (13) | |
| Metastatic node disease | 28% (462) | 3% (41) | 4% (24) | |
| Gleason score category | ||||
| Category 1 | 5% (78) | 33% (477) | 44% (256) | |
| Category 2 | 48% (788) | 40% (574) | 45% (266) | |
| Category 3 | 47% (759) | 25% (363) | 11% (63) | |
| Category 4 | 0% (0) | 2% (26) | 0.5% (3) |
| Study 1 | Study 2 | Study 3 | Merged Studies 1,2,3 | Merged Studies 1, 3 | |
|---|---|---|---|---|---|
| N | 1625 | 1440 | 588 | 3653 | 2213 |
| % good responders | 71% | 30% | 16% | 46% | 56% |
| Number of features | 93 | 86 | 93 | 23 | 23 |
| Accuracy | Precision | Sensitivity | F1 | AUC | |
|---|---|---|---|---|---|
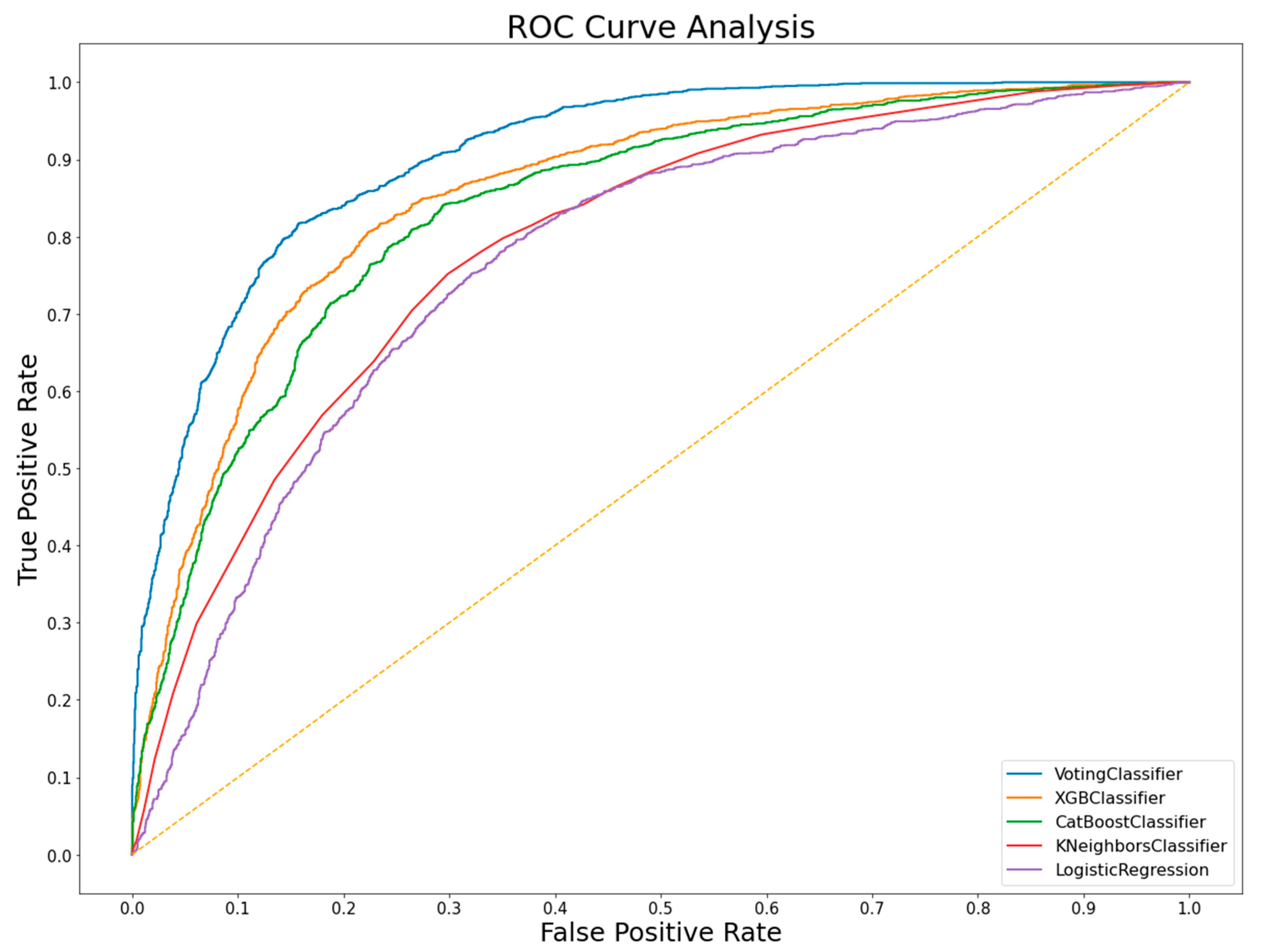
| Voting classifier | 76% | 74% | 79% | 80% | 73% |
| XGBoost | 76% | 74% | 78% | 79% | 73% |
| Catboost | 75% | 74% | 76% | 77% | 72% |
| KNN | 71% | 71% | 72% | 72% | 66% |
| Logistic Regression | 70% | 71% | 72% | 71% | 65% |
| Gini Importance | Good Responders (n = 1683) | Bad Responders (n = 1970) | |
|---|---|---|---|
| Previous prostatectomy | 0.19 | 70% | 37% |
| Previous radiotherapy | 0.17 | 20% | 15% |
| PSA at baseline (median, ng/mL) 1 | 0.14 | 0.2 | 3 |
| PSA prior to baseline (median, ng/mL) 1 | 0.09 | 10 | 17 |
| Metastatic node disease | 0.05 | 18% | 11% |
| Vitamins, not specified | 0.04 | 11% | 4% |
| Clinical stage (proportion of median category) | 0.04 | 4% | 4% |
| Diazepam | 0.03 | 0% | 1% |
| Enalapril | 0.02 | 3% | 5% |
| Anti-anginal vasodilators, organic nitrates | 0.02 | 4% | 8% |
| Glyceryl trinitrate | 0.02 | 2% | 4% |
| Vitamin K antagonists | 0.02 | 2% | 3% |
| Age (mean, years) | 0.02 | 65 | 68 |
| Aspartate aminotransferase levels (mean, U/L) | 0.02 | 19 | 21 |
| Alanine aminotransferase levels (mean, U/L) | 0.02 | 20 | 22 |
| Gleason score category (median) | 0.02 | 2 | 2 |
| Weight (mean, kg) | 0.01 | 83 | 81 |
| HMG COA reductase inhibitors | 0.01 | 9% | 6% |
| Aspirin | 0.01 | 20% | 16% |
| Propionic acid derivatives | 0.01 | 7% | 4% |
| Furosemide | 0.01 | 2% | 3% |
| Inhalational select beta2-adrenoceptor agonists | 0.01 | 3% | 4% |
| Lisinopril | 0.01 | 4% | 3% |
| Accuracy | Precision | Sensitivity | F1 | AUC | |
|---|---|---|---|---|---|
| Voting classifier | 70% | 70% | 69% | 69% | 64% |
| XGBoost | 69% | 70% | 69% | 69% | 64% |
| Catboost | 69% | 70% | 69% | 69% | 64% |
| Logistic Regression | 66% | 68% | 66% | 67% | 63% |
| KNN | 64% | 68% | 64% | 65% | 63% |
| Accuracy | Precision | Sensitivity | F1 | AUC | ||
|---|---|---|---|---|---|---|
| Study 1 (chance level 71%) | XGBoost | 77% | 86% | 92% | 87% | 78% |
| Voting classifier | 75% | 84% | 97% | 95% | 77% | |
| Catboost | 73% | 82% | 99% | 98% | 77% | |
| KNN | 71% | 83% | 83% | 71% | 71% | |
| Logistic Regression | 68% | 81% | 83% | 72% | 71% | |
| Study 2 (chance level 70%) | XGBoost | 73% | 43% | 86% | 92% | 60% |
| Voting classifier | 71% | 42% | 99% | 100% | 52% | |
| Catboost | 70% | 43% | 100% | 100% | 50% | |
| KNN | 71% | 42% | 52% | 76% | 52% | |
| Logistic Regression | 65% | 37% | 56% | 76% | 40% | |
| Study 3 (chance level 84%) | XGBoost | 84% | 2% | 76% | 94% | 10% |
| Voting classifier | 83% | 7% | 100% | 100% | 18% | |
| Catboost | 82% | 2% | 15% | 84% | 10% | |
| KNN | 81% | 15% | 47% | 88% | 25% | |
| Logistic Regression | 82% | 2% | 15% | 84% | 10% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Beacher, F.D.; Mujica-Parodi, L.R.; Gupta, S.; Ancora, L.A. Machine Learning Predicts Outcomes of Phase III Clinical Trials for Prostate Cancer. Algorithms 2021, 14, 147. https://doi.org/10.3390/a14050147
Beacher FD, Mujica-Parodi LR, Gupta S, Ancora LA. Machine Learning Predicts Outcomes of Phase III Clinical Trials for Prostate Cancer. Algorithms. 2021; 14(5):147. https://doi.org/10.3390/a14050147
Chicago/Turabian StyleBeacher, Felix D., Lilianne R. Mujica-Parodi, Shreyash Gupta, and Leonardo A. Ancora. 2021. "Machine Learning Predicts Outcomes of Phase III Clinical Trials for Prostate Cancer" Algorithms 14, no. 5: 147. https://doi.org/10.3390/a14050147
APA StyleBeacher, F. D., Mujica-Parodi, L. R., Gupta, S., & Ancora, L. A. (2021). Machine Learning Predicts Outcomes of Phase III Clinical Trials for Prostate Cancer. Algorithms, 14(5), 147. https://doi.org/10.3390/a14050147