
Locally Scaled and Stochastic Volatility Metropolis– Hastings Algorithms


Abstract
:1. Introduction
- We present two novel MCMC algorithms being the Locally Scaled Metropolis–Hastings and Stochastic Volatility Metropolis–Hastings methods.
- We present the first application of Bayesian inference of the Merton [26] jump diffusion model across the share, currency and cryptocurrency financial markets.
- Numerical experiments using various targets are provided, demonstrating significant improvements of the proposed method over the random walk Metropolis–Hastings algorithm.
2. Methods
2.1. Random Walk Metropolis–Hastings Algorithm
| Algorithm 1: The Metropolis–Hastings Algorithm |
 |
2.2. Metropolis Adjusted Langevin Algorithm
2.3. Hamiltonian Monte Carlo and the No-U-Turn Sampler
2.4. Locally Scaled and Stochastic Volatility Metropolis–Hastings Algorithms
- For LSMH: and
- For SVHM: and
3. Experiments
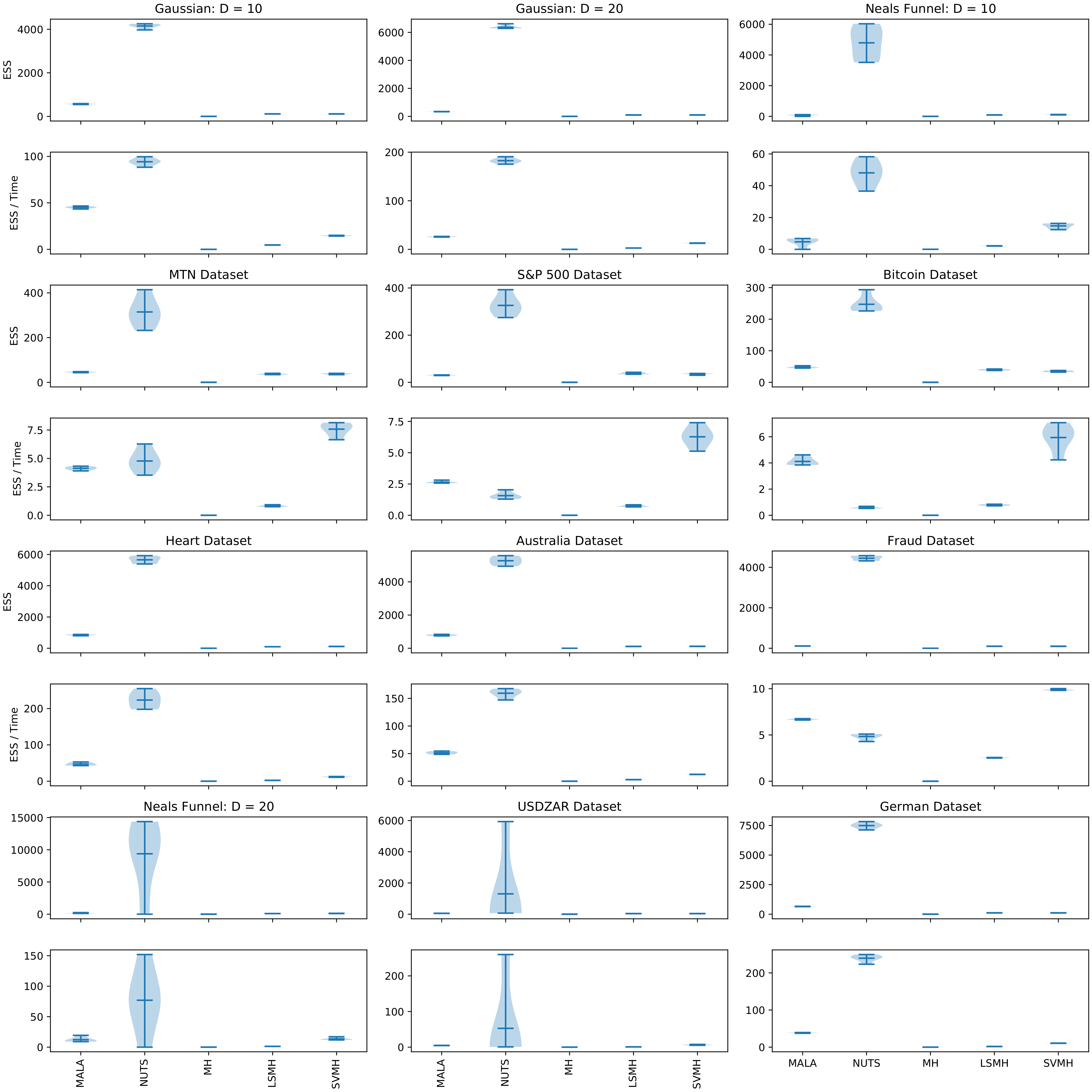
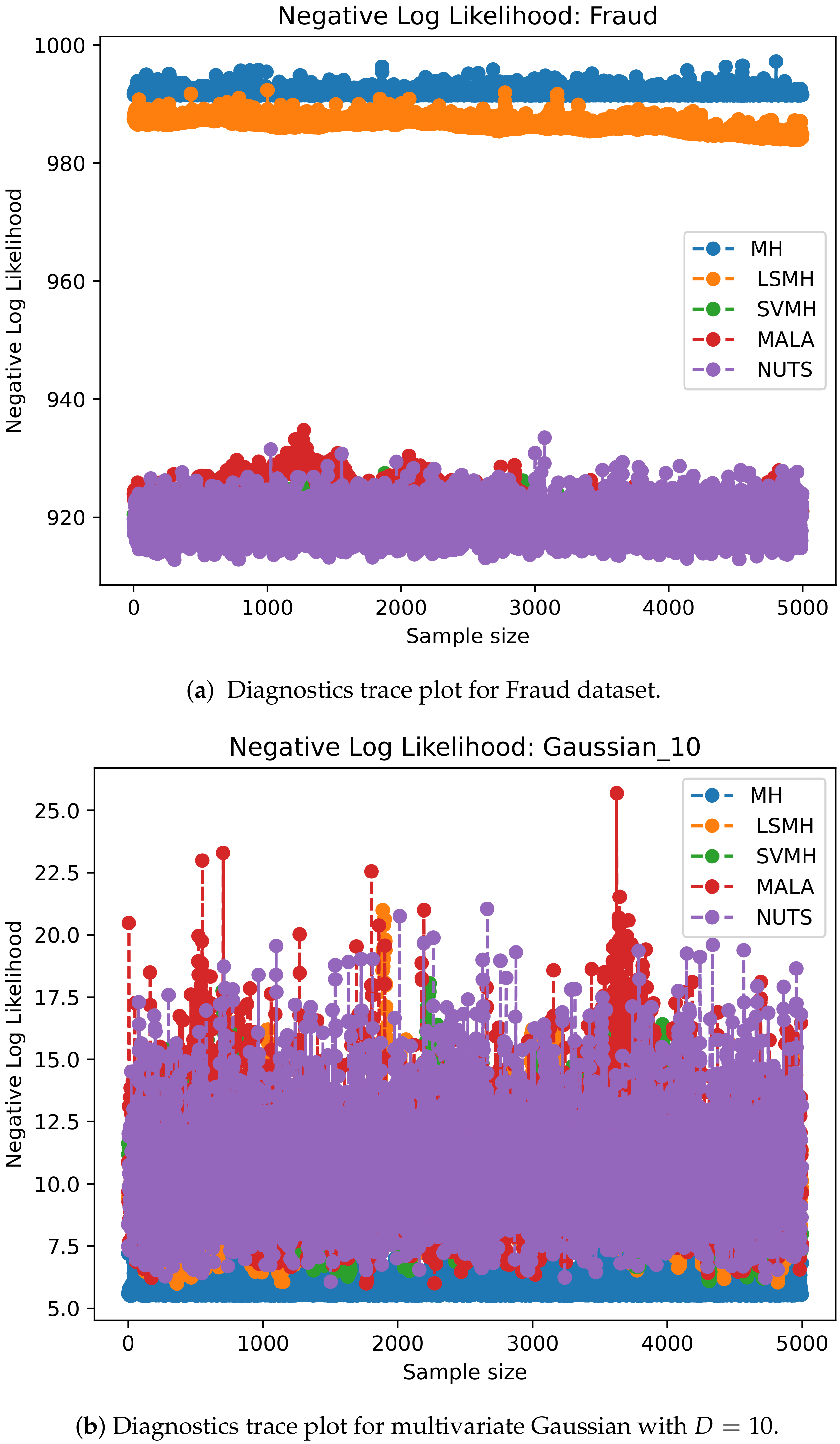
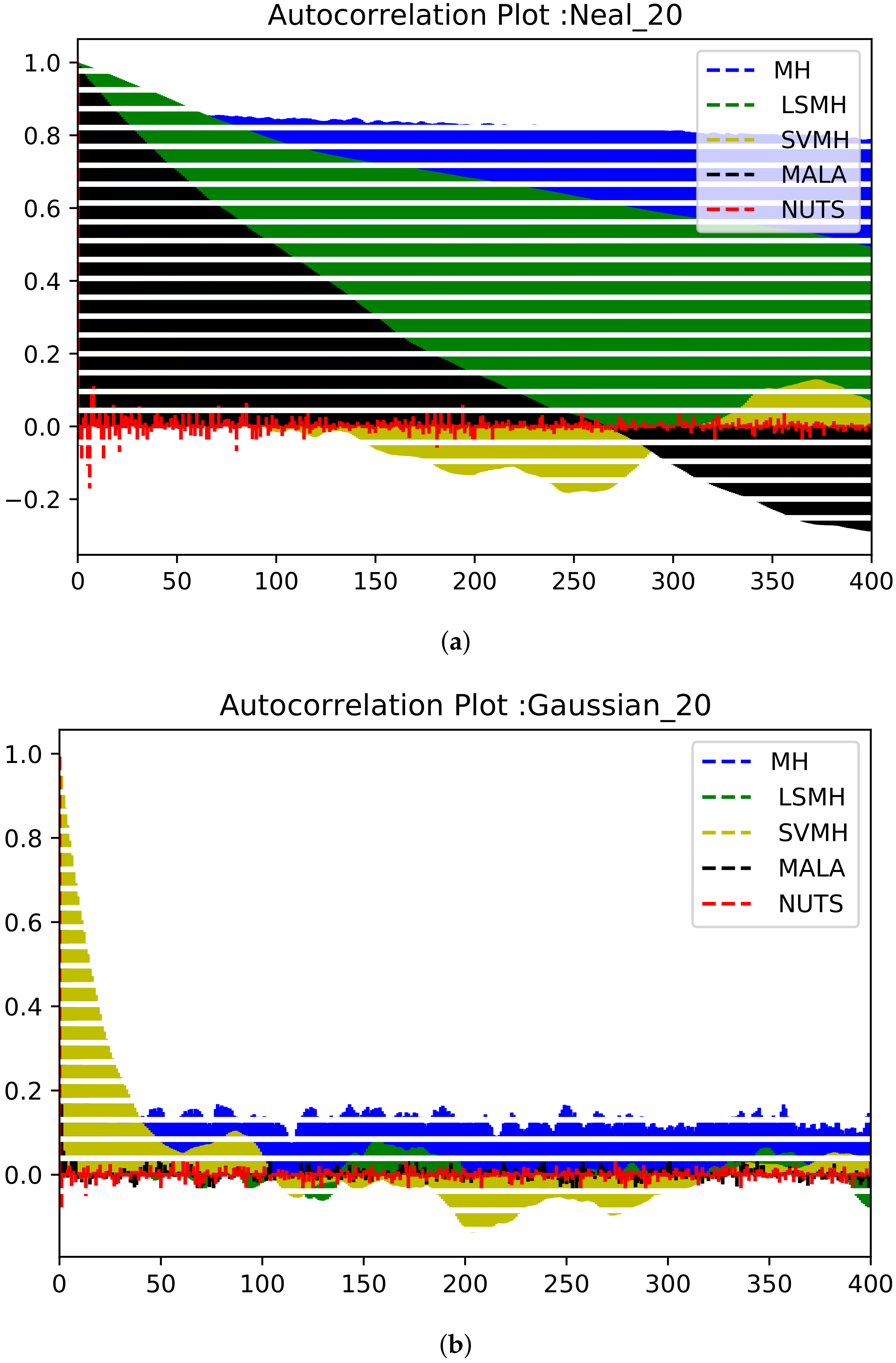
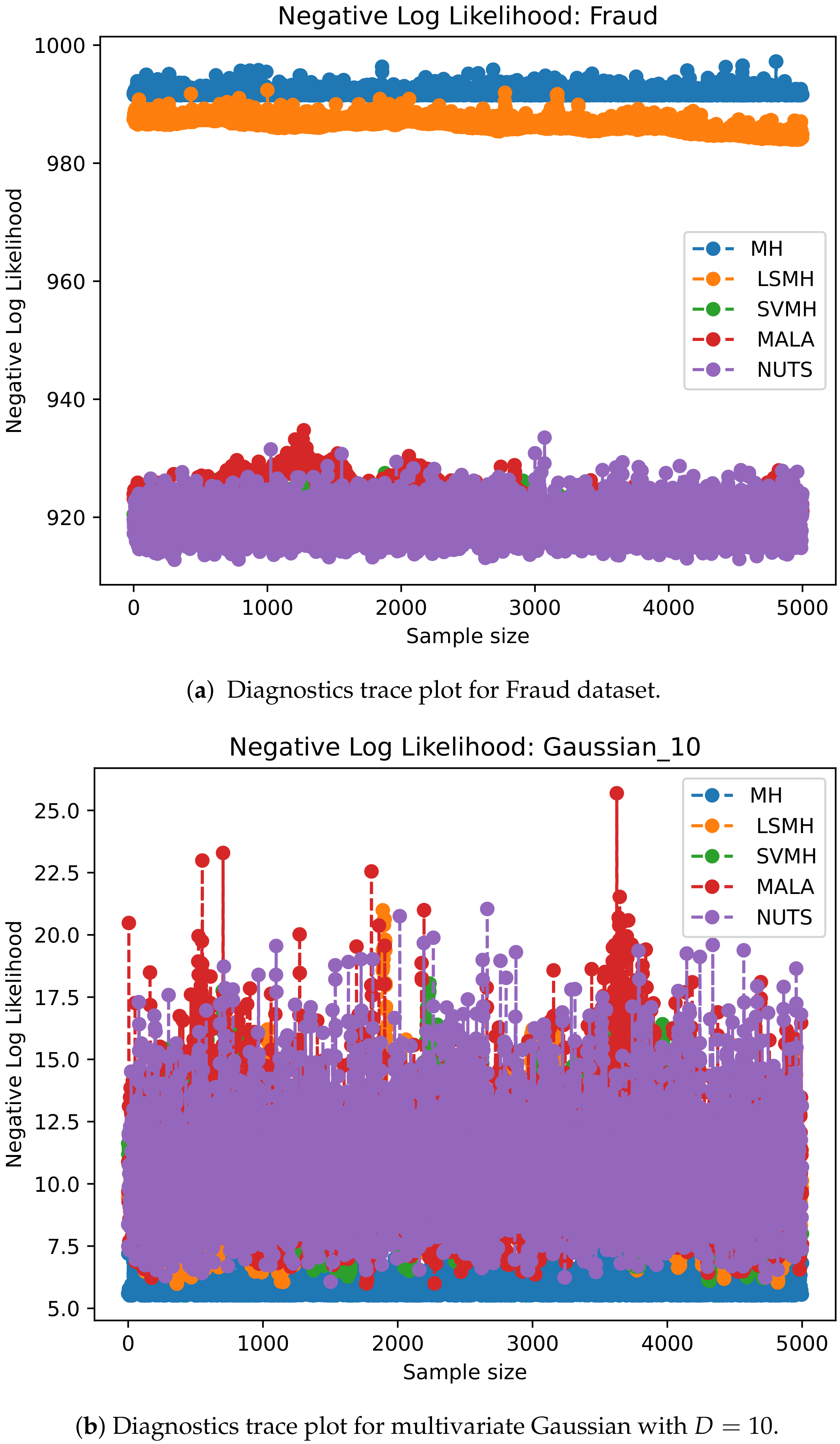
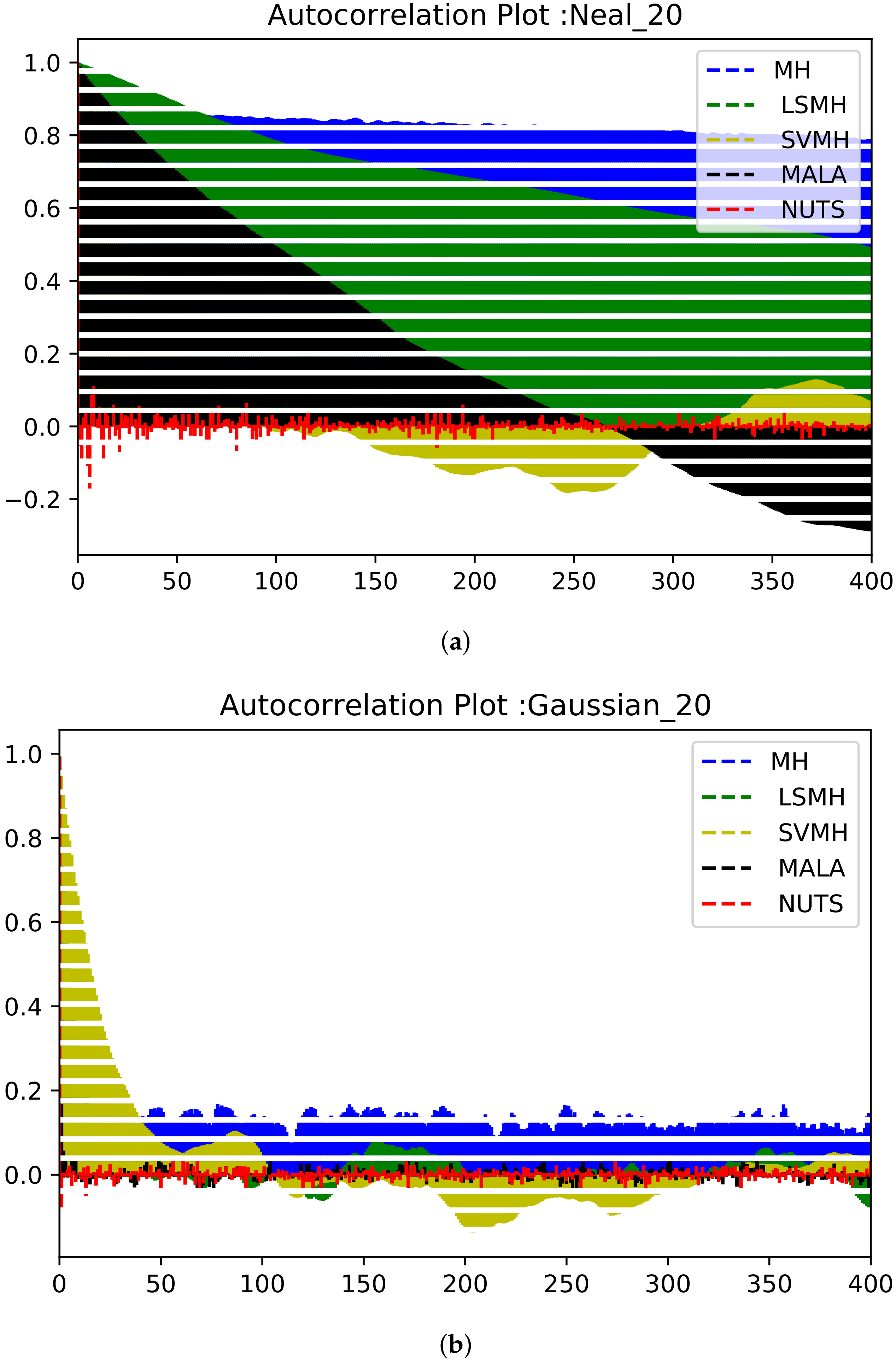
3.1. Performance Metrics
3.2. Scale Matrix and Step Size Tuning
3.3. Simulation Study
3.4. Real World Application
3.4.1. Merton Jump Diffusion Model
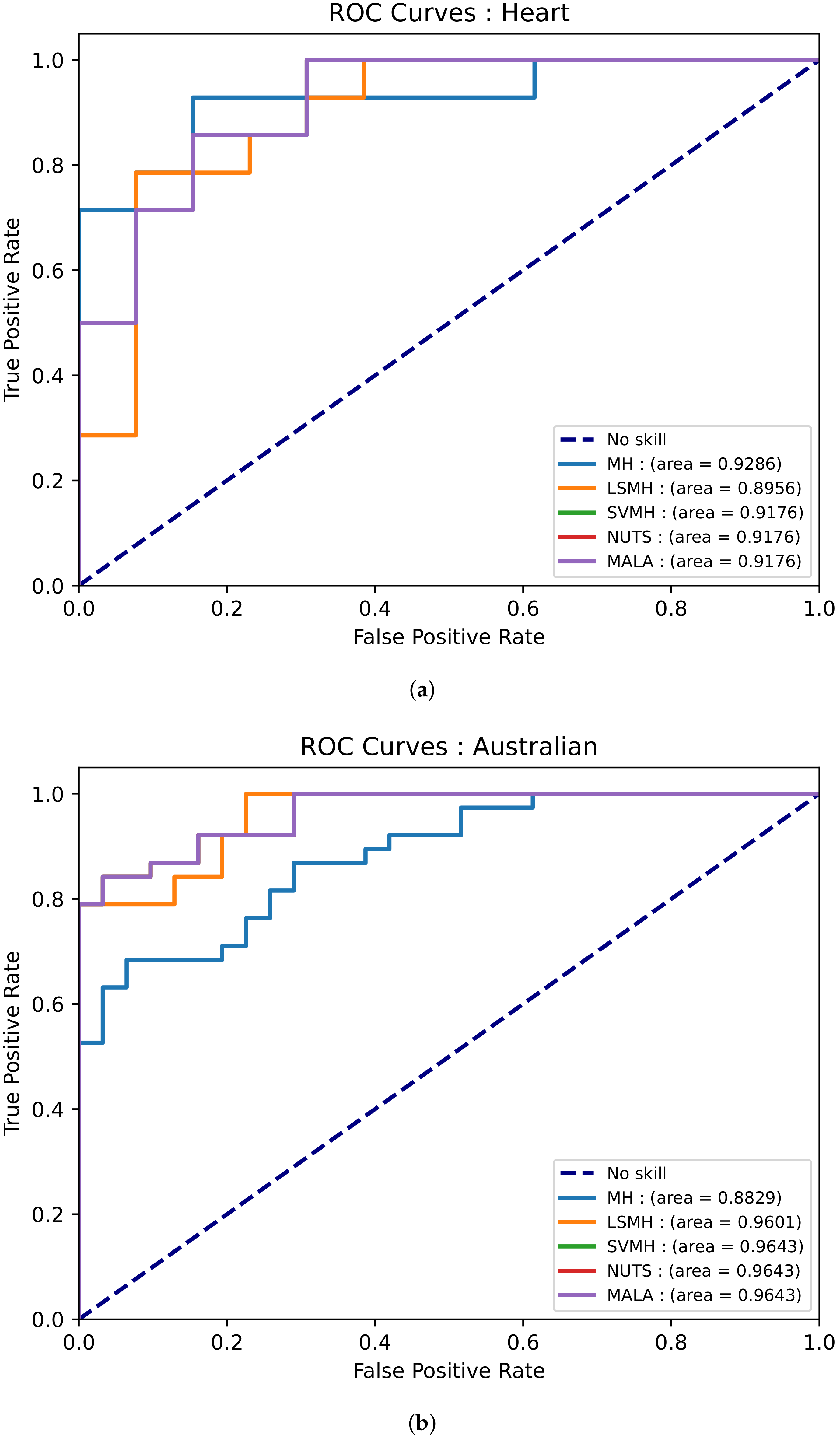
3.4.2. Bayesian Logistic Regression
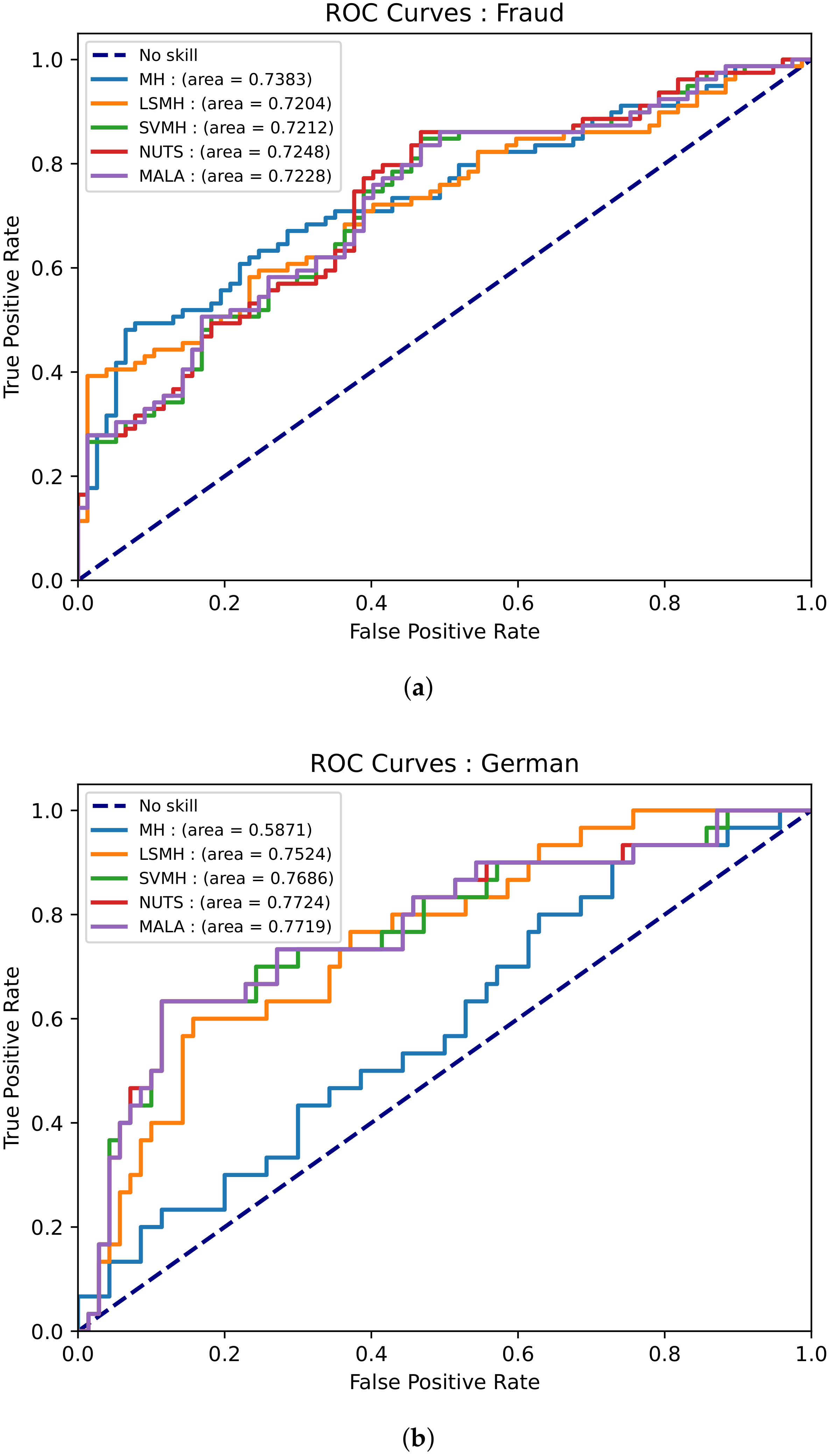
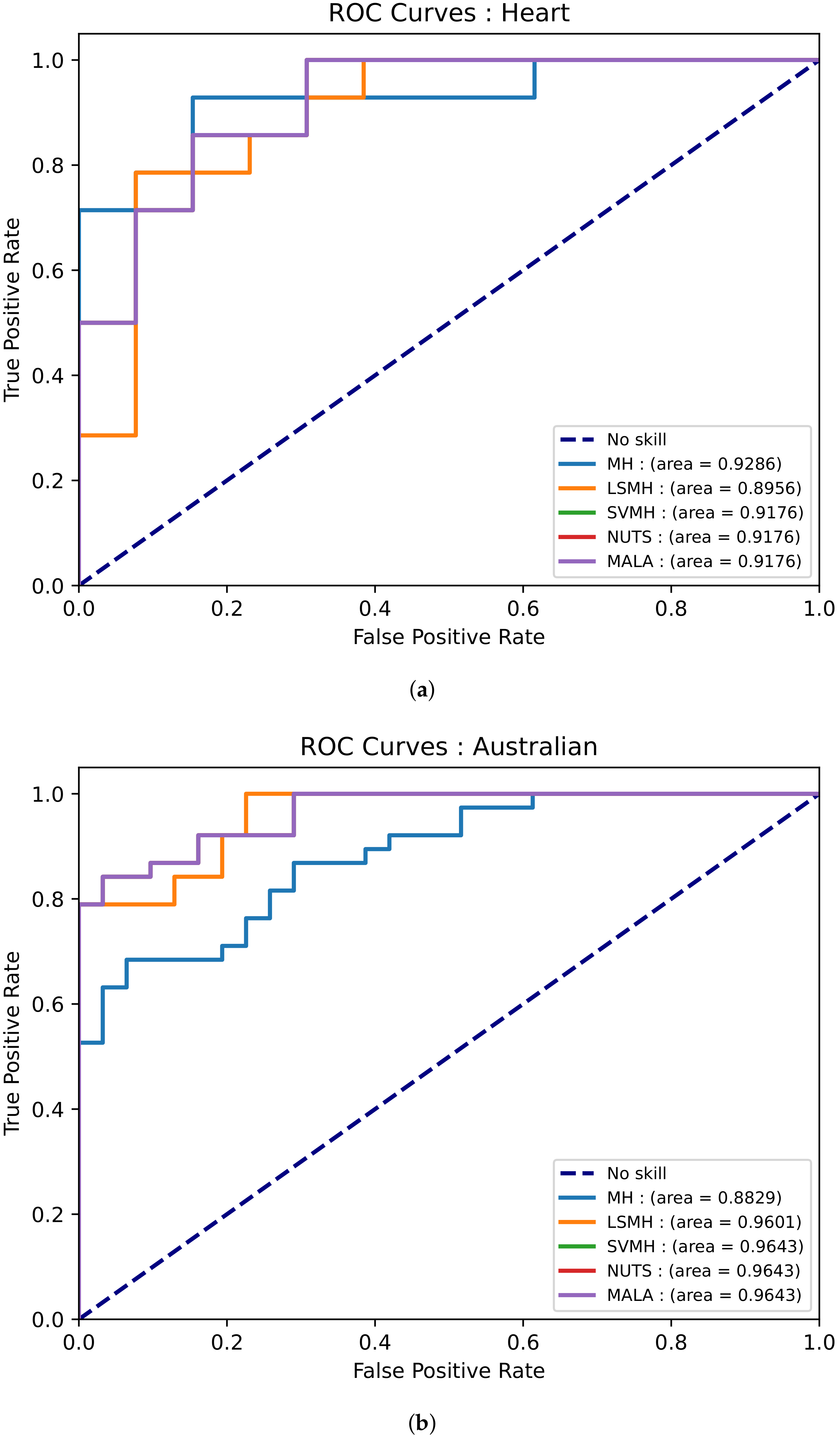
3.4.3. Datasets
- Heart dataset—This dataset has 13 features and 270 data points. The purpose of the dataset is to predict the presence of heart disease based on medical tests performed on a patient [49].
- Australian credit dataset—This dataset has 14 features and 690 data points. This dataset aims to assess applications for credit cards [49].
- German credit dataset—This dataset has 25 features and 1000 data points. This dataset aimed to classify a customer as either good or bad credit [49].
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Neal, R.M. Bayesian learning via stochastic dynamics. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1993; pp. 475–482. [Google Scholar]
- Neal, R.M. MCMC Using Hamiltonian Dynamics. Available online: https://arxiv.org/pdf/1206.1901.pdf%20http://arxiv.org/abs/1206.1901 (accessed on 27 November 2021).
- Neal, R.M. Bayesian Learning for Neural Networks; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 118. [Google Scholar]
- Girolami, M.; Calderhead, B. Riemann manifold langevin and hamiltonian monte carlo methods. J. R. Stat. Soc. Ser. B 2011, 73, 123–214. [Google Scholar] [CrossRef]
- Radivojević, T.; Akhmatskaya, E. Mix & Match Hamiltonian Monte Carlo. arXiv 2017, arXiv:1706.04032. [Google Scholar]
- Mongwe, W.T.; Mbuvha, R.; Marwala, T. Antithetic Magnetic and Shadow Hamiltonian Monte Carlo. IEEE Access 2021, 9, 49857–49867. [Google Scholar] [CrossRef]
- Mongwe, W.T.; Mbuvha, R.; Marwala, T. Antithetic Riemannian Manifold And Quantum-Inspired Hamiltonian Monte Carlo. arXiv 2021, arXiv:2107.02070. [Google Scholar]
- Mbuvha, R.; Marwala, T. Bayesian inference of COVID-19 spreading rates in South Africa. PLoS ONE 2020, 15, e0237126. [Google Scholar] [CrossRef] [PubMed]
- Mongwe, W.T.; Mbuvha, R.; Marwala, T. Magnetic Hamiltonian Monte Carlo With Partial Momentum Refreshment. IEEE Access 2021, 9, 108009–108016. [Google Scholar] [CrossRef]
- Mbuvha, R. Parameter Inference Using Probabilistic Techniques. Ph.D. Thesis, University Of Johannesburg, Johannesburg, South Africa, 2021. [Google Scholar]
- Mbuvha, R.; Mongwe, W.T.; Marwala, T. Separable Shadow Hamiltonian Hybrid Monte Carlo for Bayesian Neural Network Inference in wind speed forecasting. Energy AI 2021, 6, 100108. [Google Scholar] [CrossRef]
- Hastings, W.K. Monte Carlo sampling methods using Markov chains and their applications. Biometrika 1970, 57, 97–109. [Google Scholar] [CrossRef]
- Roberts, G.O.; Stramer, O. Langevin diffusions and Metropolis-Hastings algorithms. Methodol. Comput. Appl. Probab. 2002, 4, 337–357. [Google Scholar] [CrossRef]
- Duane, S.; Kennedy, A.D.; Pendleton, B.J.; Roweth, D. Hybrid monte carlo. Phys. Lett. B 1987, 195, 216–222. [Google Scholar] [CrossRef]
- Sweet, C.R.; Hampton, S.S.; Skeel, R.D.; Izaguirre, J.A. A separable shadow Hamiltonian hybrid Monte Carlo method. J. Chem. Phys. 2009, 131, 174106. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mongwe, W.T.; Mbuvha, R.; Marwala, T. Adaptively Setting the Path Length for Separable Shadow Hamiltonian Hybrid Monte Carlo. IEEE Access 2021, 9, 138598–138607. [Google Scholar] [CrossRef]
- Mongwe, W.T.; Mbuvha, R.; Marwala, T. Utilising Partial Momentum Refreshment in Separable Shadow Hamiltonian Hybrid Monte Carlo. IEEE Access 2021, 9, 151235–151244. [Google Scholar] [CrossRef]
- Tripuraneni, N.; Rowland, M.; Ghahramani, Z.; Turner, R. Magnetic hamiltonian monte carlo. In Proceedings of the International Conference on Machine Learning (PMLR), Sydney, Australia, 6–11 August 2017; pp. 3453–3461. [Google Scholar]
- Mongwe, W.T.; Mbuvha, R.; Marwala, T. Quantum-Inspired Magnetic Hamiltonian Monte Carlo. PLoS ONE 2021, 16, e0258277. [Google Scholar] [CrossRef] [PubMed]
- Mongwe, W.T.; Mbuvha, R.; Marwala, T. Adaptive Magnetic Hamiltonian Monte Carlo. IEEE Access 2021, 9, 152993–153003. [Google Scholar] [CrossRef]
- Yang, J.; Roberts, G.O.; Rosenthal, J.S. Optimal scaling of random-walk metropolis algorithms on general target distributions. Stoch. Process. Their Appl. 2020, 130, 6094–6132. [Google Scholar] [CrossRef]
- Roberts, G.O.; Rosenthal, J.S. Optimal scaling for various Metropolis-Hastings algorithms. Stat. Sci. 2001, 16, 351–367. [Google Scholar] [CrossRef]
- Vogrinc, J.; Kendall, W.S. Counterexamples for optimal scaling of Metropolis–Hastings chains with rough target densities. Ann. Appl. Probab. 2021, 31, 972–1019. [Google Scholar] [CrossRef]
- Dahlin, J.; Lindsten, F.; Schön, T.B. Particle Metropolis–Hastings using gradient and Hessian information. Stat. Comput. 2015, 25, 81–92. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Zhang, Z. Quantum-Inspired Hamiltonian Monte Carlo for Bayesian Sampling. arXiv 2019, arXiv:1912.01937. [Google Scholar]
- Merton, R.C. Option pricing when underlying stock returns are discontinuous. J. Financ. Econ. 1976, 3, 125–144. [Google Scholar] [CrossRef] [Green Version]
- Levy, D.; Hoffman, M.D.; Sohl-Dickstein, J. Generalizing hamiltonian monte carlo with neural networks. arXiv 2017, arXiv:1711.09268. [Google Scholar]
- Yan, G.; Hanson, F.B. Option pricing for a stochastic-volatility jump-diffusion model with log-uniform jump-amplitudes. In Proceedings of the 2006 American Control Conference, Minneapolis, MN, USA, 14–16 June 2006; IEEE: Piscataway, NJ, USA, 2006; p. 6. [Google Scholar]
- Brooks, S.; Gelman, A.; Jones, G.; Meng, X.L. Handbook of Markov Chain Monte Carlo; CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- Betancourt, M. A conceptual introduction to Hamiltonian Monte Carlo. arXiv 2017, arXiv:1701.02434. [Google Scholar]
- Gu, M.; Sun, S. Neural Langevin Dynamical Sampling. IEEE Access 2020, 8, 31595–31605. [Google Scholar] [CrossRef]
- Hoffman, M.D.; Gelman, A. The No-U-turn sampler: Adaptively setting path lengths in Hamiltonian Monte Carlo. J. Mach. Learn. Res. 2014, 15, 1593–1623. [Google Scholar]
- Afshar, H.M.; Oliveira, R.; Cripps, S. Non-Volume Preserving Hamiltonian Monte Carlo and No-U-TurnSamplers. In Proceedings of the International Conference on Artificial Intelligence and Statistics (PMLR), Virtual Conference, 13–15 April 2021; pp. 1675–1683. [Google Scholar]
- Betancourt, M.J. Generalizing the no-U-turn sampler to Riemannian manifolds. arXiv 2013, arXiv:1304.1920. [Google Scholar]
- Betancourt, M. A general metric for Riemannian manifold Hamiltonian Monte Carlo. In Proceedings of the International Conference on Geometric Science of Information, Paris, France, 28–30 August 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 327–334. [Google Scholar]
- Vats, D.; Flegal, J.M.; Jones, G.L. Multivariate output analysis for Markov chain Monte Carlo. Biometrika 2019, 106, 321–337. Available online: http://xxx.lanl.gov/abs/https://academic.oup.com/biomet/article-pdf/106/2/321/28575440/asz002.pdf (accessed on 27 November 2021). [CrossRef] [Green Version]
- Hoffman, M.D.; Gelman, A. The No-U-Turn Sampler: Adaptively Setting Path Lengths in Hamiltonian Monte Carlo. arXiv 2011, arXiv:1111.4246. [Google Scholar]
- Andrieu, C.; Thoms, J. A tutorial on adaptive MCMC. Stat. Comput. 2008, 18, 343–373. [Google Scholar] [CrossRef]
- Neal, R.M. Slice sampling. Ann. Stat. 2003, 31, 705–741. [Google Scholar] [CrossRef]
- Betancourt, M.; Girolami, M. Hamiltonian Monte Carlo for hierarchical models. In Current Trends in Bayesian Methodology with Applications; CRC Press: Boca Raton, FL, USA, 2015; Volume 79, pp. 2–4. [Google Scholar]
- Heide, C.; Roosta, F.; Hodgkinson, L.; Kroese, D. Shadow Manifold Hamiltonian Monte Carlo. In Proceedings of the International Conference on Artificial Intelligence and Statistics (PMLR), Virtual Conference, 13–15 April 2021; pp. 1477–1485. [Google Scholar]
- Cont, R. Empirical properties of asset returns: Stylized facts and statistical issues. Quant. Financ. 2001, 1, 223–236. [Google Scholar] [CrossRef]
- Mongwe, W.T. Analysis of Equity and Interest Rate Returns in South Africa under the Context of Jump Diffusion Processes. Master’s Thesis, University of Cape Town, Cape Town, South Africa, 2015. [Google Scholar]
- Aït-Sahalia, Y.; Li, C.; Li, C.X. Closed-form implied volatility surfaces for stochastic volatility models with jumps. J. Econom. 2021, 222, 364–392. [Google Scholar] [CrossRef]
- Alghalith, M. Pricing options under simultaneous stochastic volatility and jumps: A simple closed-form formula without numerical/computational methods. Phys. A Stat. Mech. Its Appl. 2020, 540, 123100. [Google Scholar] [CrossRef]
- Van der Stoep, A.W.; Grzelak, L.A.; Oosterlee, C.W. The Heston stochastic-local volatility model: Efficient Monte Carlo simulation. Int. J. Theor. Appl. Financ. 2014, 17, 1450045. [Google Scholar] [CrossRef] [Green Version]
- Press, S.J. A compound events model for security prices. J. Bus. 1967, 40, 317–335. [Google Scholar] [CrossRef]
- Google-Finance. Google Finance. Available online: https://www.google.com/finance/ (accessed on 15 August 2021).
- Michie, D.; Spiegelhalter, D.J.; Taylor, C.C.; Campbell, J. (Eds.) Machine Learning, Neural and Statistical Classification; Ellis Horwood: New York, NY, USA, 1995. [Google Scholar]
- Mongwe, W.T.; Malan, K.M. A Survey of Automated Financial Statement Fraud Detection with Relevance to the South African Context. South Afr. Comput. J. 2020, 32, 74–112. [Google Scholar] [CrossRef]
- Mongwe, W.T.; Malan, K.M. The Efficacy of Financial Ratios for Fraud Detection Using Self Organising Maps. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, Australia, 1–4 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1100–1106. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Features | N | Model | D |
|---|---|---|---|---|
| MTN | 1 | 1 000 | BJDP | 5 |
| S&P 500 Index | 1 | 1 007 | BJDP | 5 |
| Bitcoin | 1 | 1 461 | BJDP | 5 |
| USDZAR | 1 | 1 425 | BJDP | 5 |
| Heart | 13 | 270 | BLR | 14 |
| Australian credit | 14 | 690 | BLR | 15 |
| Fraud | 14 | 1 560 | BLR | 15 |
| German credit | 24 | 1 000 | BLR | 25 |
| Dataset | Mean | Standard Deviation | Skew | Kurtosis |
|---|---|---|---|---|
| MTN | 0.03013 | 20.147 | ||
| S&P 500 Index | 0.00043 | 0.01317 | 21.839 | |
| Bitcoin | 0.00187 | 0.04447 | 13.586 | |
| USDZAR | 0.00019 | 0.00854 | 0.117 | 1.673 |
| MTN dataset | |||||
| (in sec) | NLL (Train) | NLL (Test) | |||
| NUTS | 314 | 65 | 4.77 | −2153 | −174 |
| MALA | 45 | 11 | 4.14 | −2153 | −174 |
| MH | 0 | 5 | 0.00 | −1981 | −173 |
| LSMH | 36 | 45 | 0.82 | −2056 | −180 |
| SVMH | 37 | 5 | 7.56 | −2144 | −174 |
| S&P 500 dataset | |||||
| NUTS | 326 | 209 | 1.56 | −2942 | −278 |
| MALA | 30 | 11 | 2.64 | −2910 | −286 |
| MH | 0 | 5 | 0.73 | −2544 | −283 |
| LSMH | 37 | 51 | 0.00 | −2782 | −300 |
| SVMH | 35 | 6 | 6.27 | −2911 | −286 |
| Bitcoin dataset | |||||
| NUTS | 247 | 426 | 0.58 | −2387 | −286 |
| MALA | 47 | 11 | 4.11 | −2315 | −291 |
| MH | 0 | 5 | 0.00 | −2282 | −286 |
| LSMH | 39 | 50 | 0.78 | −2286 | −289 |
| SVMH | 34 | 6 | 5.94 | −2325 | −291 |
| USDZAR dataset | |||||
| NUTS | 1302 | 118 | 52.76 | −4457 | −489 |
| MALA | 54 | 11 | 4.61 | −4272 | −475 |
| MH | 0 | 5 | 0.00 | −3 978 | −446 |
| LSMH | 37 | 52 | 0.72 | −4272 | −475 |
| SVMH | 36 | 6 | 6.48 | −4272 | −474 |
| Heart dataset | |||||
| (in sec) | NLL (train) | NLL (test) | |||
| NUTS | 5656 | 25 | 223.34 | 132 | 56 |
| MALA | 848 | 18 | 47.14 | 132 | 56 |
| MH | 0.29 | 9 | 0.04 | 298 | 67 |
| LSMH | 97 | 41 | 2.38 | 352 | 82 |
| SVMH | 114 | 9 | 12.01 | 132 | 56 |
| Australian credit dataset | |||||
| NUTS | 5272 | 33 | 159.40 | 248 | 70 |
| MALA | 787 | 15 | 51.43 | 248 | 70 |
| MH | 0 | 7 | 0.00 | 750 | 112 |
| LSMH | 109 | 37 | 2.89 | 407 | 88 |
| SVMH | 115 | 9 | 12.35 | 247 | 70 |
| Fraud dataset | |||||
| NUTS | 4449 | 921 | 4.84 | 919 | 144 |
| MALA | 110 | 16 | 6.69 | 921 | 143 |
| MH | 0 | 8 | 0.00 | 993 | 150 |
| LSMH | 98 | 38 | 2.54 | 983 | 146 |
| SVMH | 96 | 10 | 9.88 | 919 | 143 |
| German credit dataset | |||||
| NUTS | 7493 | 31 | 239.57 | 510 | 134 |
| MALA | 654 | 16 | 38.65 | 510 | 134 |
| MH | 0.0 | 8 | 0.00 | 1 662 | 267 |
| LSMH | 110 | 62 | 1.76 | 745 | 174 |
| SVMH | 107 | 10 | 10.58 | 510 | 134 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mongwe, W.T.; Mbuvha, R.; Marwala, T. Locally Scaled and Stochastic Volatility Metropolis– Hastings Algorithms. Algorithms 2021, 14, 351. https://doi.org/10.3390/a14120351
Mongwe WT, Mbuvha R, Marwala T. Locally Scaled and Stochastic Volatility Metropolis– Hastings Algorithms. Algorithms. 2021; 14(12):351. https://doi.org/10.3390/a14120351
Chicago/Turabian StyleMongwe, Wilson Tsakane, Rendani Mbuvha, and Tshilidzi Marwala. 2021. "Locally Scaled and Stochastic Volatility Metropolis– Hastings Algorithms" Algorithms 14, no. 12: 351. https://doi.org/10.3390/a14120351
APA StyleMongwe, W. T., Mbuvha, R., & Marwala, T. (2021). Locally Scaled and Stochastic Volatility Metropolis– Hastings Algorithms. Algorithms, 14(12), 351. https://doi.org/10.3390/a14120351