
An Interaction-Based Convolutional Neural Network (ICNN) Toward a Better Understanding of COVID-19 X-ray Images


Abstract
1. Introduction
1.1. AI Systems for COVID-19 Chest X-rays
1.2. What Is XAI?
1.3. Problems in Image Classification and Deep CNNs
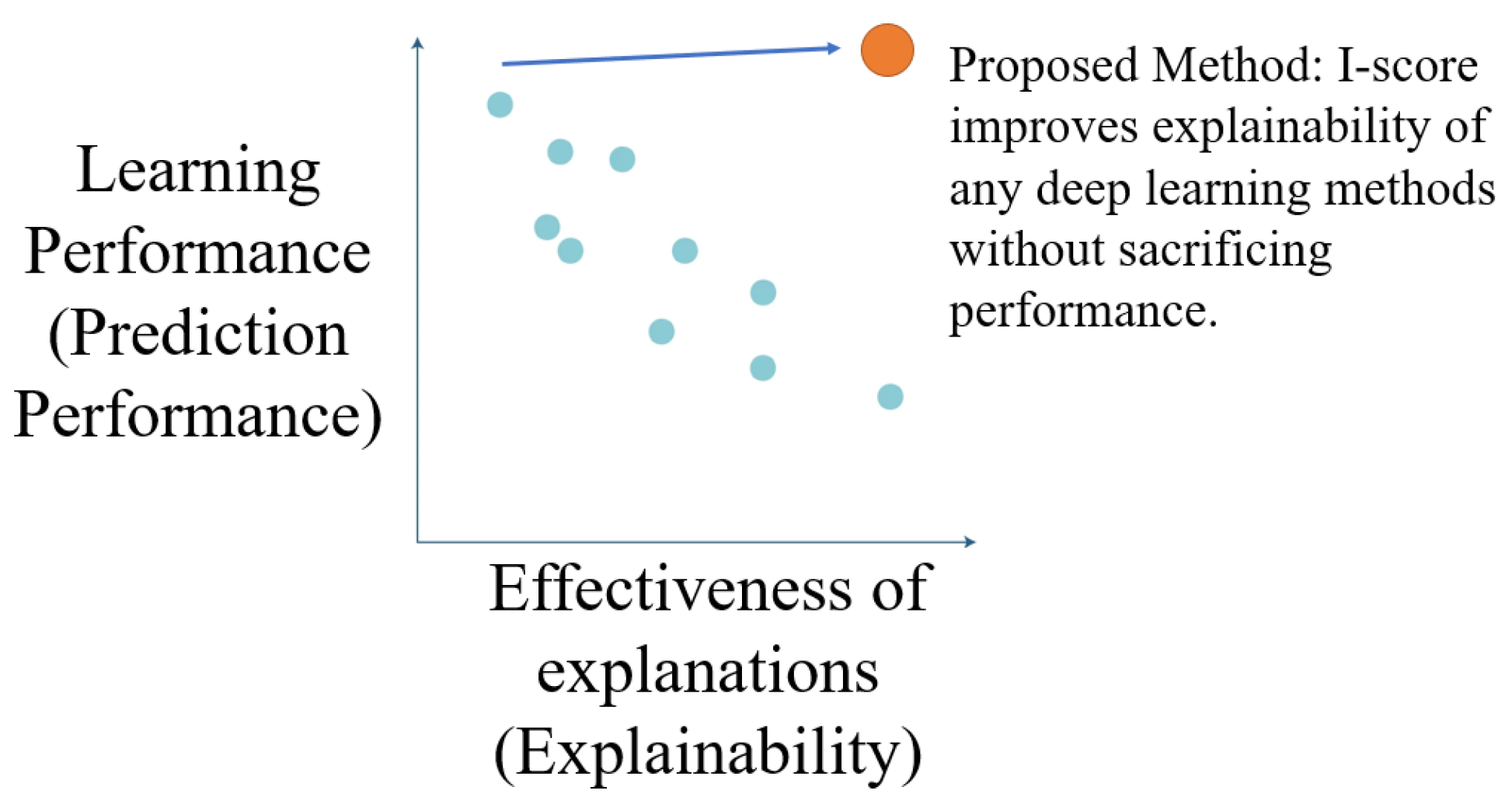
1.4. An Interaction-Based Convolutional Neural Network (ICNN) to Address XAI Problems
2. Contributions of the Paper
2.1. Why the Proposed Methodology Satisfies XAI Dimensions
2.2. Organization of the Paper
3. Proposed Method
3.1. Influence Score (I-Score)
3.2. Backward Dropping Algorithm (BDA)
- Training Set: Consider a training set of n observations, where is a p-dimensional vector of explanatory variables. The size p can be very large. All explanatory variables are discrete.
- Sampling from Variable Space: Select an initial subset of k explanatory variables ,
- Compute Standardized I-score: Calculate . For the rest of the paper, we refer o this formula as the influence measure or influence score (I-score).
- Drop Variables: Tentatively drop each variable in and recalculate the I-score with one variable less. Then drop the one that produces the highest I-score. Call this new subset , which has one variable less than .
- Return Set: Continue to the next round of dropping variables in until only one variable is left. Keep the subset that yields the highest I-score in the entire process. Refer to this subset as the return set, . This will be the most important and influential variable module from this initial training set.
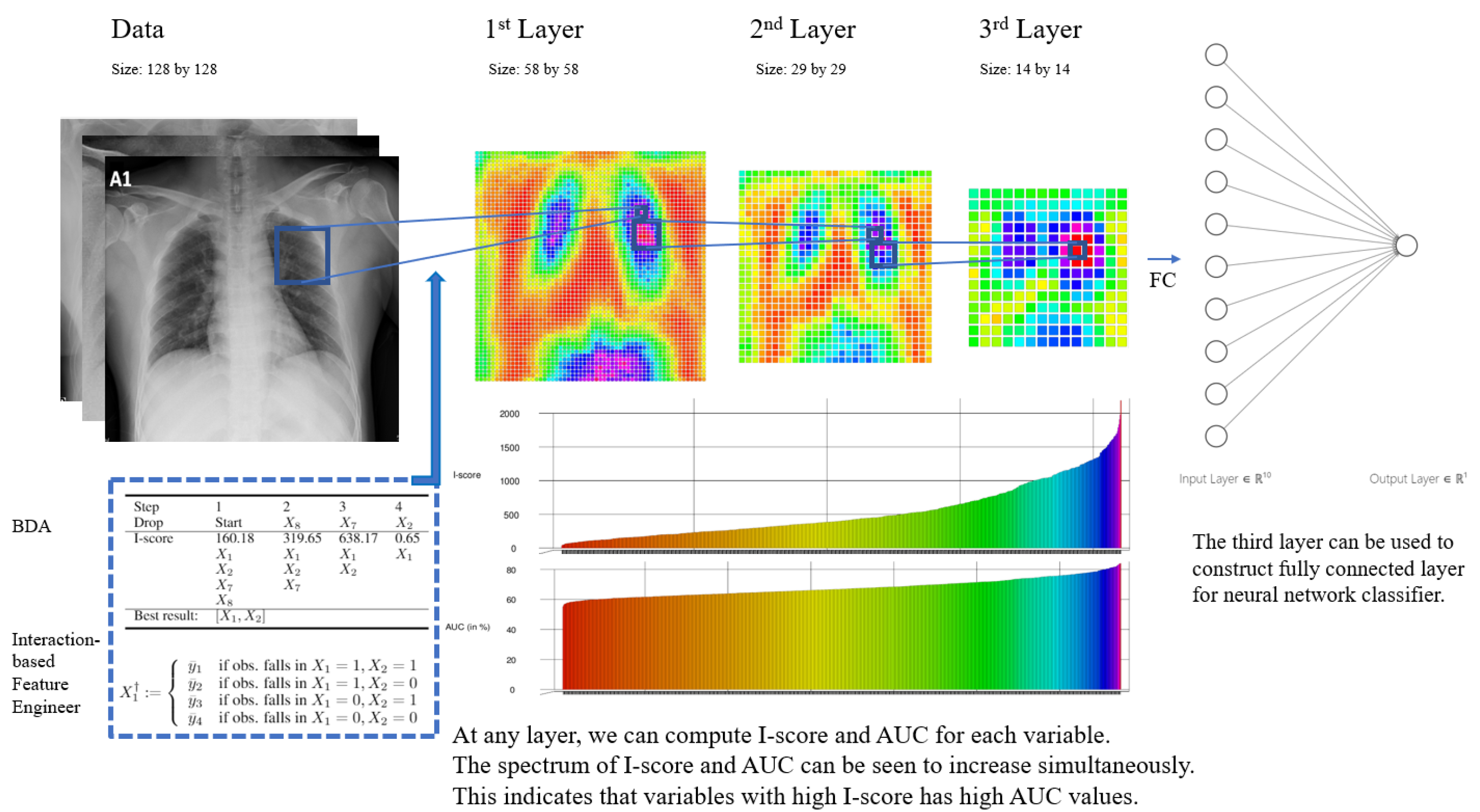
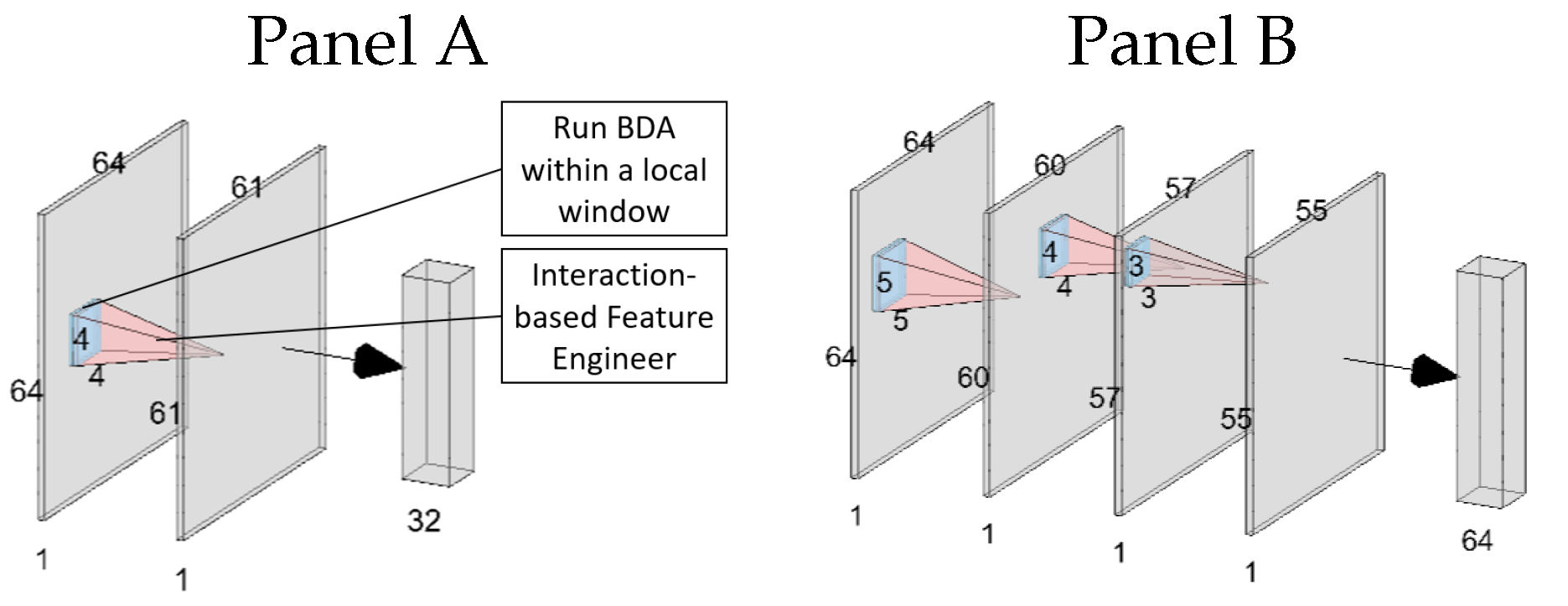
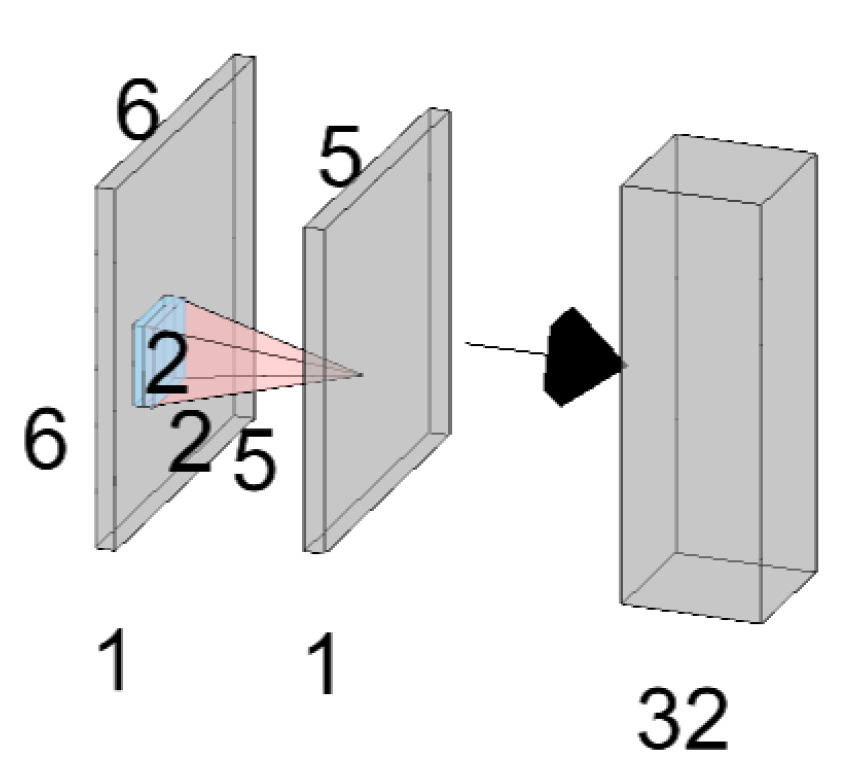
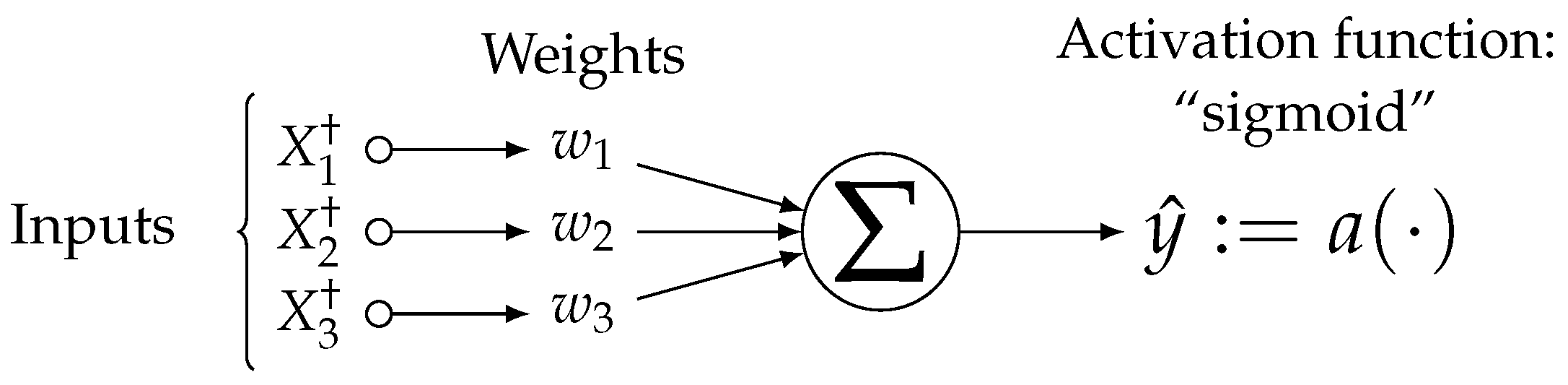
3.3. Interaction-Based Convolutional Layer
3.4. Interaction-Based Feature Engineer
3.5. Simulation with Artificial Examples
3.5.1. Artificial Example I: Variable Investigation
3.5.2. Artificial Example II: Four Modules with Discrete Variables
4. Application
4.1. Background
4.2. Model Training
4.3. Model Parameters
4.4. Evaluation Metrics
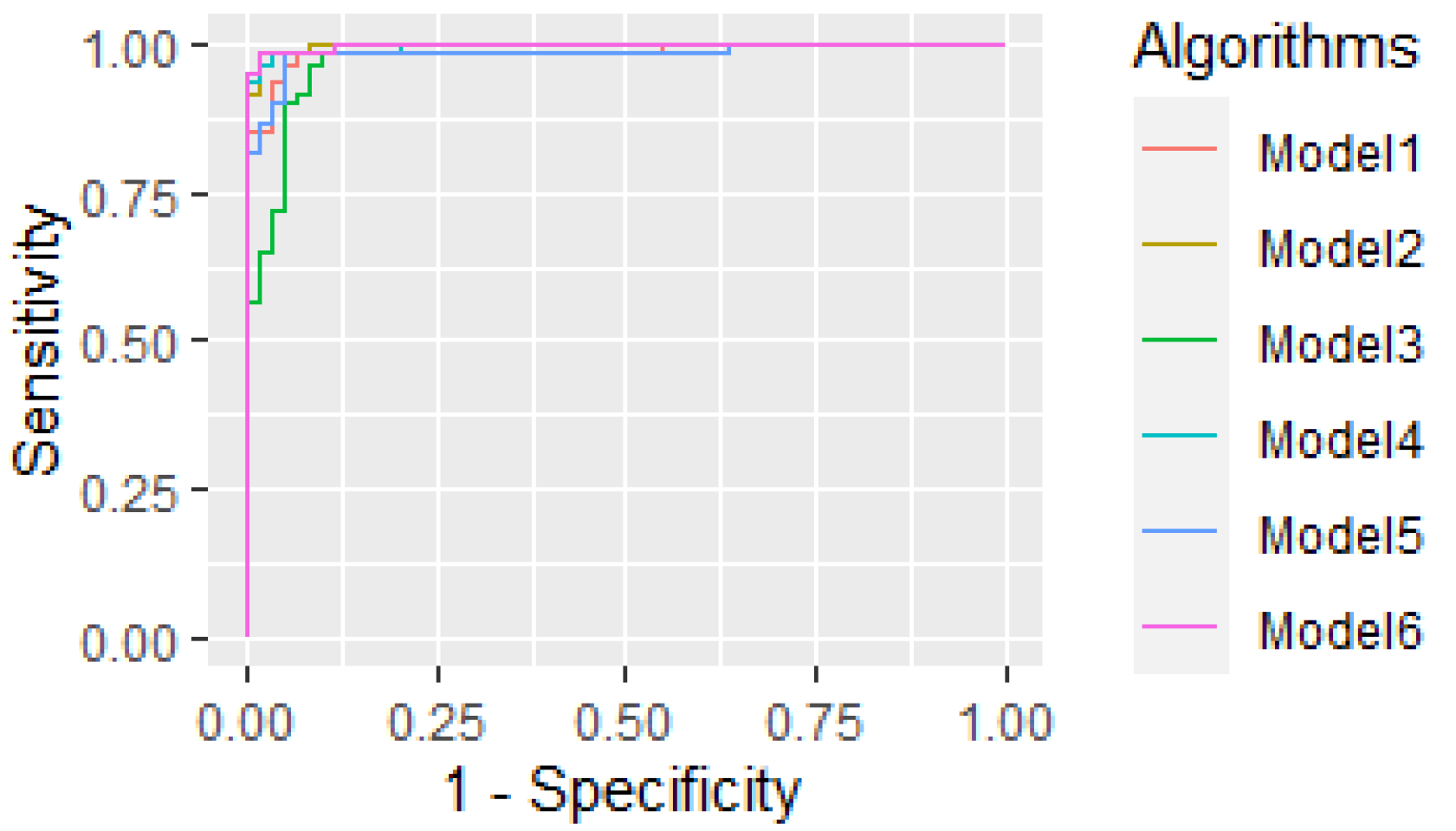
4.5. Performance: Proposed Models and AUC Values
4.6. Visualization: Images and Convolutional Layer
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Velavan, T.P.; Meyer, C.G. The COVID-19 epidemic. Trop. Med. Int. Health 2020, 25, 278. [Google Scholar] [CrossRef]
- Li, F.; Wang, Y.; Li, X.Y.; Nusairat, A.; Wu, Y. Gateway placement for throughput optimization in wireless mesh networks. Mob. Netw. Appl. 2008, 13, 198–211. [Google Scholar] [CrossRef]
- Wang, S.; Kang, B.; Ma, J.; Zeng, X.; Xiao, M.; Guo, J.; Cai, M.; Yang, J.; Li, Y.; Meng, X.; et al. A deep learning algorithm using CT images to screen for Corona Virus Disease (COVID-19). Eur. Radiol. 2021, 31, 6096–6104. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Guan, X.; Wu, P.; Wang, X.; Zhou, L.; Tong, Y.; Ren, R.; Leung, K.S.; Lau, E.H.; Wong, J.Y.; et al. Early transmission dynamics in Wuhan, China, of novel coronavirus—Infected pneumonia. N. Engl. J. Med. 2020, 382, 1199–1207. [Google Scholar] [CrossRef] [PubMed]
- Ai, T.; Yang, Z.; Hou, H.; Zhan, C.; Chen, C.; Lv, W.; Tao, Q.; Sun, Z.; Xia, L. Correlation of Chest CT and RT-PCR Testing in Coronavirus Disease 2019 (COVID-19) in China: A Report of 1014 Cases. Radiology 2020, 296, E32–E40. [Google Scholar] [CrossRef]
- Aloysius, N.; Geetha, M. A review on deep convolutional neural networks. In Proceedings of the 2017 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 6–8 April 2017; pp. 0588–0592. [Google Scholar]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Katona, J.; Ujbanyi, T.; Sziladi, G.; Kovari, A. Examine the effect of different web-based media on human brain waves. In Proceedings of the 2017 8th IEEE International Conference on Cognitive Infocommunications (CogInfoCom), Debrecen, Hungary, 11–14 September 2017; pp. 000251–000256. [Google Scholar]
- Katona, J.; Kovari, A. Speed control of Festo Robotino mobile robot using NeuroSky MindWave EEG headset based brain-computer interface. In Proceedings of the 2016 7th IEEE International Conference on Cognitive Infocommunications (CogInfoCom), Wroclaw, Poland, 16–18 October 2016; pp. 000251–000256. [Google Scholar]
- Katona, J.; Ujbanyi, T.; Sziladi, G.; Kovari, A. Electroencephalogram-Based Brain-Computer Interface for Internet of Robotic Things. Available online: https://link.springer.com/chapter/10.1007/978-3-319-95996-2_12#citeas (accessed on 2 November 2021).
- Katona, J. Analyse the Readability of LINQ Code using an Eye-Tracking-based Evaluation. Acta Polytech. Hung. 2021, 18, 193–215. [Google Scholar] [CrossRef]
- Doshi-Velez, F.; Kim, B. Towards a rigorous science of interpretable machine learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Miller, T. Explanation in artificial intelligence: Insights from the social sciences. Artif. Intell. 2019, 267, 1–38. [Google Scholar] [CrossRef]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- DARPA. Broad Agency Announcement, Explainable Artificial Intelligence (XAI). Available online: https://www.darpa.mil/attachments/DARPA-BAA-16-53.pdf (accessed on 2 November 2021).
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef]
- Lo, A.; Chernoff, H.; Zheng, T.; Lo, S.H. Framework for making better predictions by directly estimating variables’ predictivity. Proc. Natl. Acad. Sci. USA 2016, 113, 14277–14282. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Handwritten digit recognition with a back-propagation network. Adv. Neural Inf. Process. Syst. 1990, 2, 396–404. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. arXiv 2016, arXiv:1610.02357. [Google Scholar]
- Chernoff, H.; Lo, S.H.; Zheng, T. Discovering influential variables: A method of partitions. Ann. Appl. Stat. 2009, 3, 1335–1369. [Google Scholar] [CrossRef][Green Version]
- Lo, S.; Zheng, T. Backward haplotype transmission association algorithm—A fast multiple-marker screening method. Hum. Hered. 2002, 53, 197–215. [Google Scholar] [CrossRef]
- Lo, A.; Chernoff, H.; Zheng, T.; Lo, S.H. Why significant variables aren’t automatically good predictors. Proc. Natl. Acad. Sci. USA 2015, 112, 13892–13897. [Google Scholar] [CrossRef]
- Wang, H.; Lo, S.H.; Zheng, T.; Hu, I. Interaction-based feature selection and classification for high-dimensional biological data. Bioinformatics 2012, 28, 2834–2842. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Yann, L.; Corinna, C.; Christopher, J. The Mnist Database of Handwritten Digits. 1998. Available online: http://yhann.lecun.com/exdb/mnist (accessed on 2 November 2021).
- Bai, H.X.; Wang, R.; Xiong, Z.; Hsieh, B.; Chang, K.; Halsey, K.; Tran, T.M.L.; Choi, J.W.; Wang, D.C.; Shi, L.B.; et al. Artificial intelligence augmentation of radiologist performance in distinguishing COVID-19 from pneumonia of other origin at chest CT. Radiology 2020, 296, E156–E165. [Google Scholar] [CrossRef] [PubMed]
- Minaee, S.; Kafieh, R.; Sonka, M.; Soufi, G. Deep-COVID: Predicting COVID-19 from Chest X-ray Images Using Deep Transfer Learning. Med. Image Anal. 2020, 65, 101794. [Google Scholar] [CrossRef] [PubMed]
- Hand, D.J. Measuring classifier performance: A coherent alternative to the area under the ROC curve. Mach. Learn. 2009, 77, 103–123. [Google Scholar] [CrossRef]



| Panel A | Panel B |



| (A) | (B) |



| Panel A | Panel B |
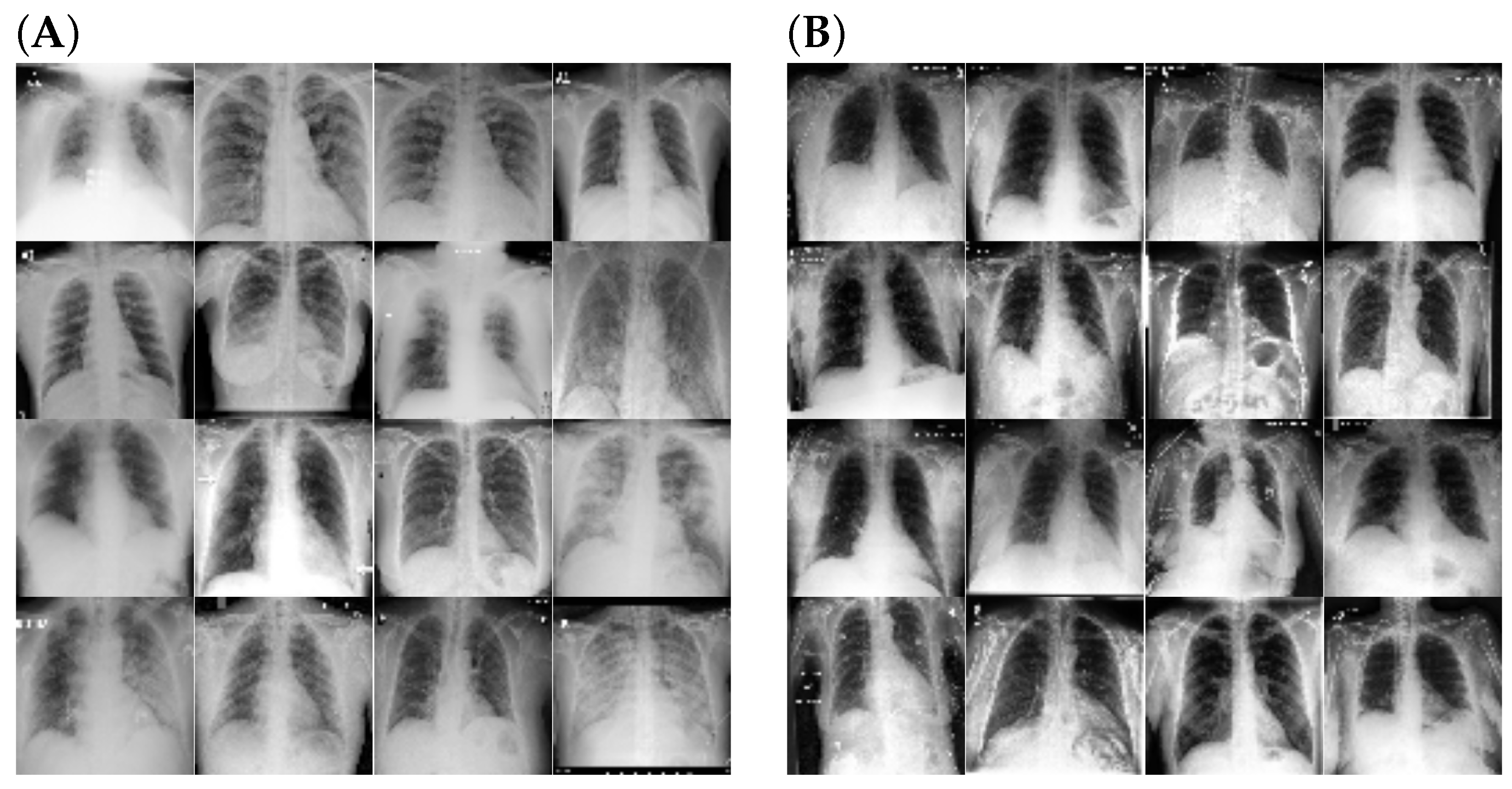
| True Label: COVID | True Label: Non-COVID |
| Input Images: 128 by 128 | Input Images: 128 by 128 |
| (Randomly select 10 samples) | (Randomly select 10 samples) |
| 1st Conv. Layer: 61 by 61 | 1st Conv. Layer: 61 by 61 |
| (Starting Point = 6, Window 2 by 2, Stride = 2) | (Starting Point = 6, Window 2 by 2, Stride = 2) |
| Remark: variables | Remark: variables |
| Same 10 images above with 3721 variables | Same 10 images above with 3,721 variables |
| Labels predicted using Model 1 | Labels predicted using Model 1 |
| 2nd Conv. Layer: 30 by 30 | 2nd Conv. Layer: 30 by 30 |
| (Starting Point = 6, Window 2 by 2, Stride = 2) | (Starting Point = 6, Window 2 by 2, Stride = 2) |
| Remark: variables | variables |
| Same 10 images above with 900 variables | Same 10 images above with 900 variables |
| Labels predicted using Model 4 | Labels predicted using Model 4 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Number of Parameters |
|---|---|
| LeNet [22] | 60,000 |
| AlexNet [8] | 60 million |
| ResNet50 [9] | 25 million |
| DenseNet [10] | 0.8–40 million |
| VGG16 [11] | 138 million |
| Step | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Drop | Start | |||
| I-score | 160.18 | 319.65 | 638.17 | 0.65 |
| Investigation by iterative dropping | ||||
| Best result: |
| New Mod. | Variables | I-Score | AUC | New Mod. | Variables | I-Score | AUC |
|---|---|---|---|---|---|---|---|
| * | X1, X2 | 638.17 | 0.75 | X28 | 1.3729 | 0.50 | |
| X7 | 1.2162 | 0.50 | X28 | 1.3729 | 0.50 | ||
| X13, X20 | 2.3597 | 0.51 | X11 | 0.2347 | 0.50 | ||
| X19, X20, X26 | 0.7218 | 0.50 | X11 | 0.2347 | 0.50 | ||
| X26, X31 | 2.6751 | 0.50 | X16, X22 | 0.0777 | 0.51 | ||
| X8, X9 | 0.5067 | 0.49 | X28 | 1.3729 | 0.51 | ||
| X8, X9 | 0.5067 | 0.50 | X28 | 1.3729 | 0.51 | ||
| X15, X21 | 1.8013 | 0.50 | X6, X12 | 0.4378 | 0.49 | ||
| X20, X21, X26, X27 | 0.7554 | 0.50 | X11, X12 | 0.6184 | 0.51 | ||
| X27, X32 | 1.017 | 0.50 | X18, X24 | 1.3814 | 0.51 | ||
| X9, X10 | 0.6894 | 0.50 | X23, X24, X29 | 0.8788 | 0.51 | ||
| X9, X10, X15 | 0.9346 | 0.51 | X30, X35 | 1.2105 | 0.51 | ||
| X15, X16, X21, X22 | 1.0933 | 0.50 |
| New Mod. | Variables | I-Score | AUC | New Mod. | Variables | I-Score | AUC |
|---|---|---|---|---|---|---|---|
| * | X1, X2 | 638.17 | 0.75 | * | X3, X4, X5 | 350.2429 | 0.75 |
| X8, X9, X13, X15, X21 | 0.6344 | 0.50 | X11 | 0.2347 | 0.51 | ||
| X19, X21, X25 | 1.4386 | 0.50 | X16, X17, X21, X22 | 0.8097 | 0.51 | ||
| X19, X21, X25 | 1.4386 | 0.50 | X28 | 1.3729 | 0.51 | ||
| X8, X9 | 0.5067 | 0.51 | X11 | 0.2347 | 0.51 | ||
| X10, X15, X21 | 0.9883 | 0.50 | X18, X24 | 1.3814 | 0.51 | ||
| X14, X15, X21, X22, X26 | 0.9816 | 0.50 | X18, X24 | 1.3814 | 0.51 | ||
| X20, X32, X33 | 2.0205 | 0.50 | X22, X23, X24, X29, X34 | 1.5684 | 0.51 |
| Algorithm | Test AUC |
|---|---|
| Theoretical Prediction | 0.75 |
| Net-3 | 0.50 |
| LeNet-5 | 0.50 |
| Interaction-based Conv. Layer: | |
| Window size: | |
| (25 modules listed in Table 3) | |
| Using defined in Equation (10) | |
| Interaction-based Conv. Layer + NN | 0.75 |
| Interaction-based Conv. Layer: | |
| Window size: | |
| (16 modules listed in Table 4) | |
| Using defined in Equation (11) | |
| Interaction-based Conv. Layer + NN | 0.76 |
| Variables: | Algorithm | Test AUC | Logistic | RF | iRF | NN |
|---|---|---|---|---|---|---|
| Training Sample Size: | Bagging | |||||
| 50 | All Var. | 0.52 | 0.52 | 0.51 | 0.51 | 0.51 |
| window, 25 mod. | 0.56 | 0.57 | 0.54 | 0.55 | 0.55 | |
| window, 16 mod. | 0.60 | 0.60 | 0.57 | 0.59 | 0.57 | |
| 100 | All Var. | 0.53 | 0.52 | 0.50 | 0.51 | 0.52 |
| window, 25 mod. | 0.60 | 0.58 | 0.55 | 0.55 | 0.55 | |
| window, 16 mod. | 0.64 | 0.62 | 0.58 | 0.59 | 0.58 | |
| 1000 | All Var. | 0.60 | 0.54 | 0.53 | 0.59 | 0.53 |
| window, 25 mod. | 0.76 | 0.75 | 0.69 | 0.74 | 0.80 | |
| window, 16 mod. | 0.77 | 0.76 | 0.71 | 0.75 | 0.77 |
| Training Sample Size: 1000 | Algorithms | Test AUC | Logistic | RF | iRF | NN |
|---|---|---|---|---|---|---|
| Variables: | Bagging | |||||
| All Var. | 0.54 | 0.52 | 0.51 | 0.53 | 0.51 | |
| I-score Modules | ||||||
| window, 121 mod. | 0.77 | 0.68 | 0.61 | 0.72 | 0.74 | |
| window, 100 mod. | 0.78 | 0.69 | 0.63 | 0.72 | 0.76 | |
| window, 81 mod. | 0.78 | 0.72 | 0.64 | 0.72 | 0.76 | |
| All Var. | 0.54 | 0.52 | 0.50 | 0.52 | 0.51 | |
| I-score Modules | ||||||
| window, 169 mod. | 0.77 | 0.64 | 0.59 | 0.70 | 0.72 | |
| window, 144 mod. | 0.77 | 0.70 | 0.60 | 0.70 | 0.73 | |
| window, 121 mod. | 0.77 | 0.70 | 0.62 | 0.71 | 0.73 |
| Data | COVID | Non-COVID |
|---|---|---|
| Total Data Downloaded from [31] | 576 | 2000 |
| Out-of-Sample: Test | 60 | 60 |
| In-Sample: Tr. and Val. | 516 | 1940 |
| In-Sample: Tr. and Val. | 5000 | 5000 |
| (upsampled) |
| Previous Work | Number of Param. | AUC |
|---|---|---|
| DenseNet161 [31] | 0.8–40 M param. | 97.6% |
| ResNet18 [31] | 11 M param. | 98.9% |
| ResNet50 [31] | 25 M param. | 99.0% |
| SqueezeNet [31] | ∼1.2 M param. * | 99.2% |
| Average | >25 M | 97–99.2% |
| Proposed Methods | Average 100,000 param. (a 99% reduction no. of param.) | 98.3–99.8% |
| Proposed Work | 1st Conv. | 2nd Conv. | Hidden | Output Layer | Num. of Param. | AUC |
|---|---|---|---|---|---|---|
| Model 1 | None | None | 2 | 7442 | 98.5% | |
| Model 2 | None | 1L (64 units) | 2 | 238,272 | 99.7% | |
| Model 3 | None | 2 | 1800 | 97.0% | ||
| Model 4 | 1L (64 units) | 2 | 57,728 | 99.6% | ||
| Model 5 | None | None | 2 | 9242 | 98.3% | |
| Model 6 | None | 1L (64 units) | 2 | 295,872 | 99.8% | |
| Remark | : Starting Point = 6 Window Size: 2 by 2 Stride = 2 Output: 61 by 61 | : Starting Point = 1 Window Size: 2 by 2 Stride = 2 Output: 30 by 30 |
| Classes | Train | Validate | Test |
|---|---|---|---|
| Healthy | 437 | 44 | 52 |
| Tuberculosis | 422 | 41 | 52 |
| Pneumonia | 88 | 9 | 1 |
| COVID-19 | 88 | 9 | 11 |
| Total | 994 | 99 | 121 |
| Model | AUC (Test Set) | No. of Parameters |
|---|---|---|
| Proposed: | ||
| ICNN (Parameters: {starting point: 6, window size: 2 by 2, stride: 2}) | 0.97 | 12,000 |
| ICNN (Parameters: {starting point: 4, window size: 3 by 3, stride: 3}) | 0.98 | 13,000 |
| Average | 0.975 | 12,500 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lo, S.-H.; Yin, Y. An Interaction-Based Convolutional Neural Network (ICNN) Toward a Better Understanding of COVID-19 X-ray Images. Algorithms 2021, 14, 337. https://doi.org/10.3390/a14110337
Lo S-H, Yin Y. An Interaction-Based Convolutional Neural Network (ICNN) Toward a Better Understanding of COVID-19 X-ray Images. Algorithms. 2021; 14(11):337. https://doi.org/10.3390/a14110337
Chicago/Turabian StyleLo, Shaw-Hwa, and Yiqiao Yin. 2021. "An Interaction-Based Convolutional Neural Network (ICNN) Toward a Better Understanding of COVID-19 X-ray Images" Algorithms 14, no. 11: 337. https://doi.org/10.3390/a14110337
APA StyleLo, S.-H., & Yin, Y. (2021). An Interaction-Based Convolutional Neural Network (ICNN) Toward a Better Understanding of COVID-19 X-ray Images. Algorithms, 14(11), 337. https://doi.org/10.3390/a14110337