1. Introduction
The Internet is one of the most important infrastructures of the modern information society. With the rapid development of China’s economy, the bandwidth of the core network is increasing year by year. According to the latest statistics of China Internet Information Center (CNNIC), as of December 2018, China’s international export bandwidth has reached 8,946,570 Mbps, with an annual growth rate of 22.2% [
1]. It is a worldwide problem to manage such a large-scale network effectively and ensure its safe operation.
In the face of a complex network environment, the monitoring and protection of the backbone network is the most important and basic step [
2]. Internet management under the condition of large data-level network traffic is a hot research subject, which can be carried out from different aspects at the industrial and academic levels. To pay more attention to some core hosts in the network is a way to improve the efficiency of network management [
3].
The super point in the Internet is such a kind of core host [
4]. It is generally believed that a super point refers to a host that communicates with many other hosts. Super points play important roles in the network, such as servers, proxies, scanners [
5], hosts attacked by DDoS, etc. The detection and measurement of super points are important to network security and network management [
6].
With the increase of network size, large-scale networks usually contain multiple border entries and exits. How to detect the super point from multiple nodes is a new requirement for super points detection. Some existing algorithms, such as Double Connection Degree Sketch algorithm (DCDS) [
7], Vector Bloom Filter Algorithm (VBFA) [
8] and Compact Spread Estimator (CSE) [
9] and so on, can realize distributed super points detection by adding data merging process. However, in the distributed environment, DCDS, VBFA, CSE must send all the whole used memory, which is more than 300 MB for a 10 Gb/s network, to the main server. When detecting the super point, such a large data transmission between the sub-node and the global server will cause the peak traffic of network communication and increase the communication delay. How to reduce the communication overhead in a distributed environment is a difficult problem in the research of distributed super points detection.
Super points account for only a small portion of all hosts. In theory, only the data related to the super point should be sent to the global server to complete the super points detection. Based on this idea, a distributed super points detection algorithm, asynchronous distributed algorithm based on rough estimator (READ), is proposed in this paper. READ uses a lightweight rough estimator (RE) to generate candidate super points. Because RE takes up less memory, each sub-node only needs to send a small amount of data to the global server to generate candidate super points. READ not only reduces the detection error rate, but also reduces the communication overhead by transferring data related to candidate super points to the global server.
Part of this paper has been published at the conference of Algorithms and Architectures for Parallel Processing 2018 [
10]. This paper extends from the aspects of algorithm introduction, theoretical analysis, and experimental demonstration.The main contributions of this paper are as follows:
A method of generating candidate super points in a distributed environment using lightweight estimators is proposed.
A distributed super points detection algorithm READ with low communication overhead is proposed.
Prove theoretically that READ has lower error rate in a distributed environment.
Using the real-world high-speed network traffic to evaluate the performance of READ.
Section 2 introduces the rough estimator and the linear estimator for estimating the host’s cardinality, as well as the existing algorithms for super points detection.
Section 3 discusses the model and difficulty of distributed super points detection.
Section 4 introduces the operation principle of READ, and how READ works.
Section 5 introduces how to modify READ to work under a sliding time window.
Section 6 shows the experiment of READ with 10 Gb/s and 40 Gb/s real world network traffic, and analyzes the detection accuracy of READ in a distributed environment and the communication overhead between sub-nodes and the global server.
Section 8 summarizes READ.
3. Distributed Super Points Detection MODEL and Difficulty
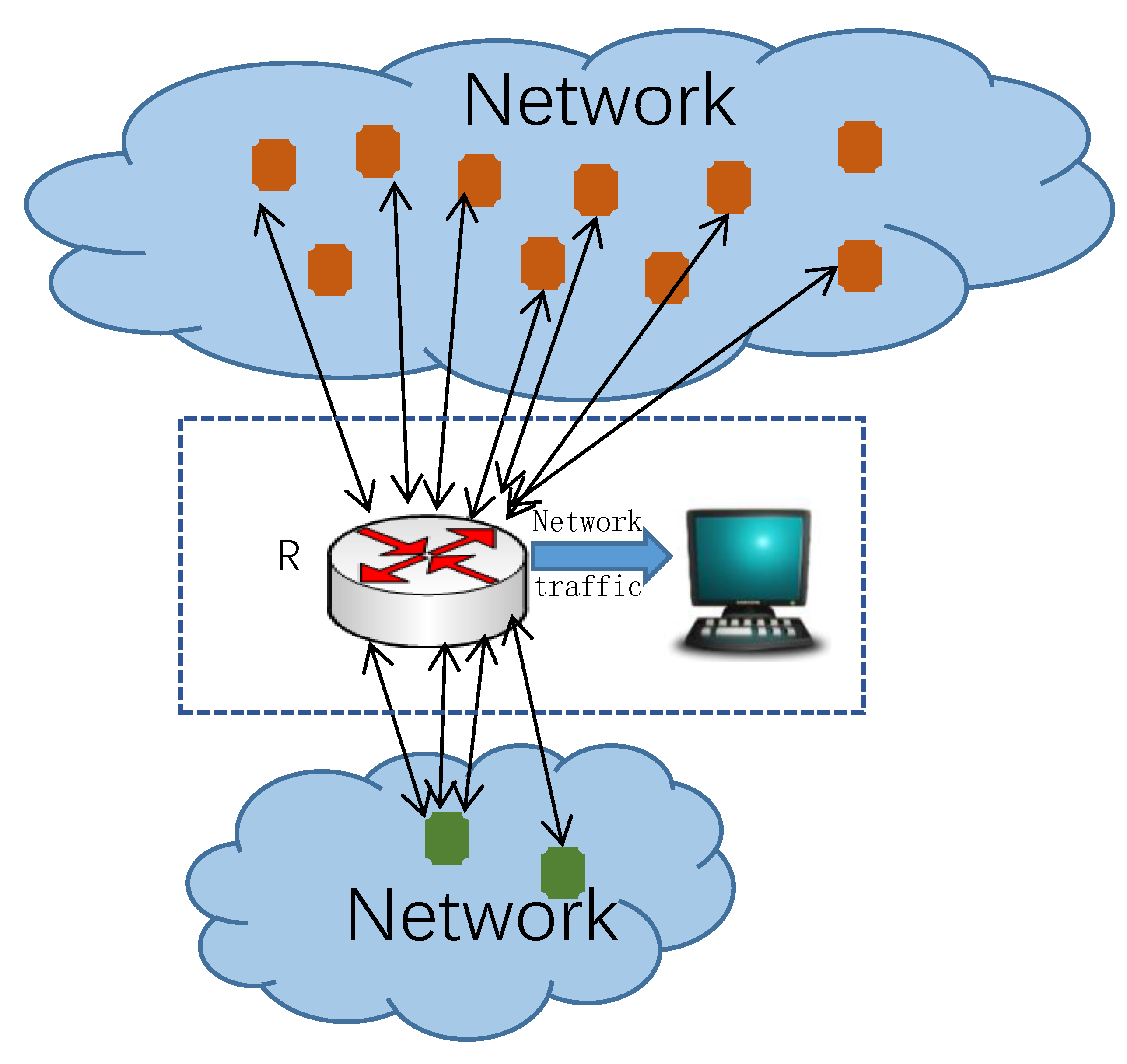
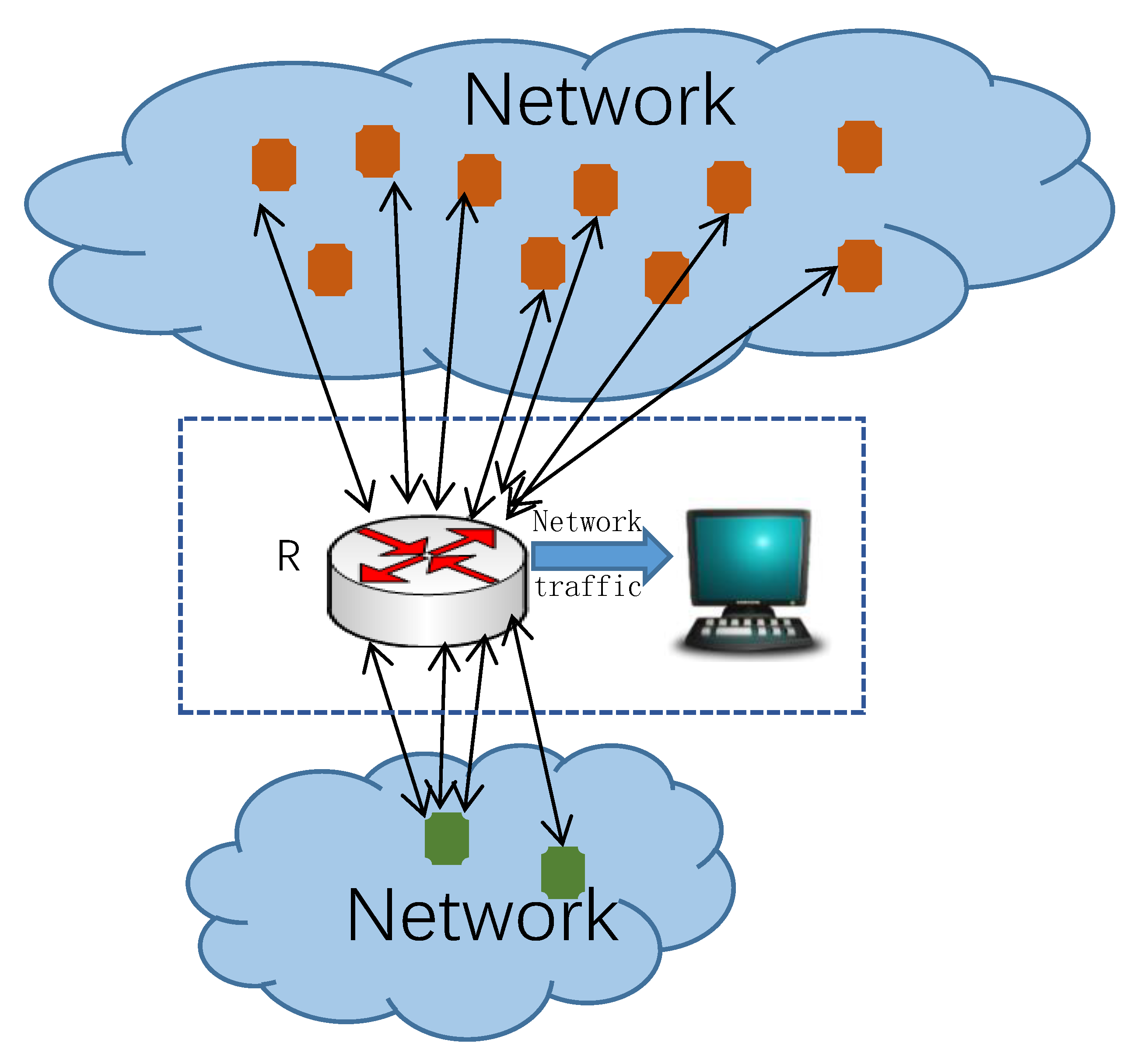
A network connected to the Internet may have multiple border routers, as shown in
Figure 2. For example, a campus network access to multiple Internet Service Provider(ISP). In
Figure 2, there are three host in the bottom network. Each host can communicate with the host in the other network through different routers. When detecting super points, the opposite host set must be collected from all routers. For example, the middle host in the bottom network communicate with more than six opposite hosts through all routers. When the cardinality threshold is 5, the middle host in the bottom network is a super point. Assuming that there is an observation node at each border router. Traffic can be observed and analyzed independently on each node. This section will discuss the algorithm of super points detection in a distributed environment.
3.1. Detection Model
For a host in the network, it may interact with different opposite hosts through different border routers. At this time, only part of the traffic of can be observed at each observation node. Assuming that the host communicates with other networks in the Internet through border routers, only part of the traffic of is forwarded on each border router. At this time, the cardinality of observed at each border router may be less than the threshold, but the cardinality of observed from all observation nodes is larger than the threshold, which will lead to the omission of super points. Therefore, it is a meaningful work to detect the super point in a distributed environment.
In the distributed environment, the global server collects data from all observation nodes and performs super points detection. The research of super points detection in a distributed environment is to study which data the global server collects from the observation nodes and how to detect the global super points on the global server.
3.2. Requirements and Difficulties
In order to find all super points in a distributed environment, it is necessary to detect them globally. A simple method is to send the IP address pairs extracted from each observation node to a global server that processes all data, and then detect the super point on the global server. This method needs to transfer a large amount of data between the global server and observation nodes. Therefore, the method of sending all IP addresses to the global server and detecting the super point on the global server cannot process the high-speed network data in real time because of the long communication time.
Another method of super points detection in a distributed environment is to run super points detection algorithms, such as DCDS, VBFA and CSE, at each observation node and then send only the master data structure to the global server for super points detection. Compared with the method of transferring all IP addresses to the global server, the method of transferring only the master data structure to the global server reduces the communication overhead between observation nodes and the global server.
However, when using this method, all observation nodes need to transmit the master data structure to the global server. When the number of observation nodes increases, the total amount of data transferred between all observation nodes and the global server will also increase. Moreover, the size of the master data structure is related to the error rate of the algorithm: the larger the master data structure, the lower the error rate of the algorithm. Therefore, the communication overhead between the observation node and the master node cannot be reduced by reducing the size of the master data structure. In addition, the transmission of all master data structures will generate a large amount of burst traffic at the end of the time window, which will increase the network burden.
How to avoid sending all master data structures to the global server and reduce the communication between observation nodes and the global server is a difficult problem in a distributed environment.
3.3. Solution of This Paper
If only part of the cardinality estimation structure at the observation node is sufficient to detect the global super point, then there is no need to transfer all of them between the observation node and the global server, which can further reduce the communication overhead. Based on this idea, this paper proposes a low communication cost distributed super points detection algorithm: Rough Estimator based Asynchronous Distributing Algorithm (READ).
In a distributed environment, it is necessary to recover the global candidate super points at the end of the time window according to the information recorded at all observation nodes. DCDS and VBFA have the function of recovering candidate super points. However, DCDS and VBFA have to use LE to recover candidate super points. Although LE has a high accuracy, it also occupies a high amount of memory, resulting in a large amount of communication between observation nodes and the global server.
RE not only runs fast, but also occupies less memory. If RE is used to generate candidate super points, a small amount of memory can be used to generate global candidate super points. The global server collects LE related to candidate super points from all observation nodes for estimating the cardinalities of candidate super points, and then completes super points detection without transmitting all cardinality estimation structure. The next section will describe how READ works.
4. RE Based Distributed Super Points Detection Algorithm READ
This section will introduce the novel low communication overhead distributed super points detection algorithm Rough Estimator based Asynchronous Distributed super points detection algorithm (READ).
4.1. Principle of READ
READ uses a data structure that can recover candidate super points to achieve distributed super points detection. It uses RE to recover candidate super points and LE to estimate cardinality of each candidate super point. Therefore, the master data structure of READ includes two parts: RE set and LE set. Scanning IP address pairs and estimating cardinalities are operations on RE and LE sets. REDA contains three main steps:
Scan IP pair on each observation node. Each observation node scans each IP address pair passing through it and updates the RE and LE sets on it.
Generate candidate super points in global server. The global server collects RE sets from all observation nodes, merges these RE sets, and generates candidate super points using the merged RE sets.
Estimate cardinalities and filter super points. After the candidate super points are obtained, the global server collects LE related to each candidate super point from all observation nodes, and estimates the cardinalities of candidate super points based on these LE.
According to the above analysis, in READ, the communication between observation nodes and the global server is divided into three stages:
Each observation node sends RE set to global server;
The global server distributes candidate super points to each observation node;
Each observation node sends LE of every candidate super point to the global server;
For READ, the sum of the communication in the three stages above is the total communication between an observation node and the global server in a time window. The number of LEs sent by observation nodes to the global server equals to the number of candidate super points. Since the number of candidate super points is less than the number of LE in the master data structure, the amount of data sent by each observation node to the global server is less than the size of LE set.
4.2. Scanning IP Pair in a Distributed Environment
Distributed scanning IP address pairs is to scan the IP address pairs collected at each observation node. Let denote the -th observation node and enote all IP address pairs in time window on . READ uses RE estimator and LE estimator to record IP information. Each observation node has the same cardinality estimation structure: the same number of RE and LE, and the same number of counters in RE and LE. The basic operation of when scanning IP address pairs is to update RE and LE.
READ uses RE to generate global candidate super points, and LE to estimate the cardinality of each global candidate super point. In a distributed environment, because only part of the network traffic can be observed at each observation node, it is impossible to determine whether a host is a global candidate super point according to RE when scanning IP address pairs. In a distributed environment, the algorithm of super points detection must be able to recover the global candidate super points directly, such as DCDS and VBFA.
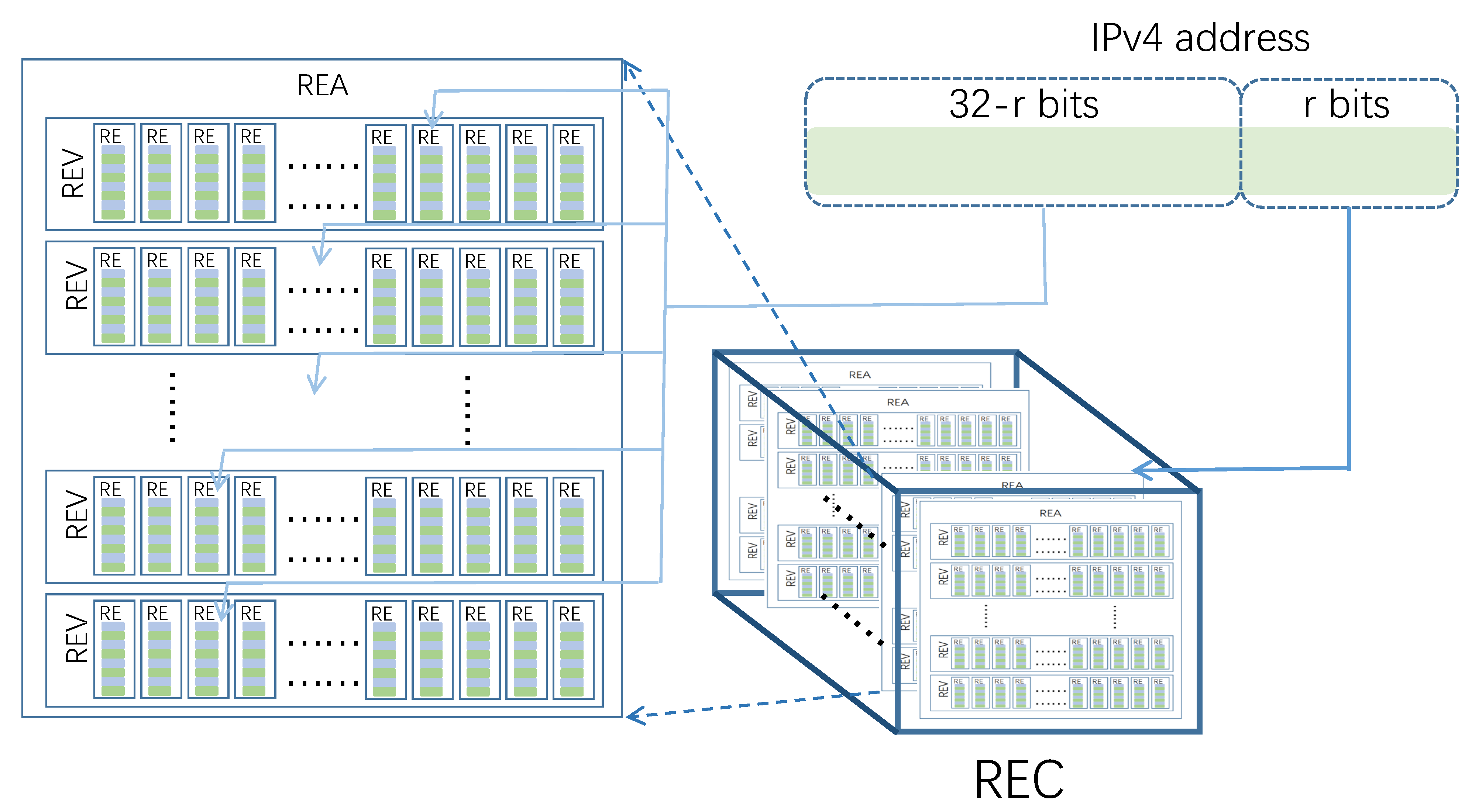
In order to recover candidate super points, READ adopts a new data structure, Rough Estimator Cube (REC). REC is a three-dimensional data structure composed of RE, as shown in
Figure 3. Inspired by VBFA, READ restores candidate super points by concatenating sub bits of RE indexes in REC.
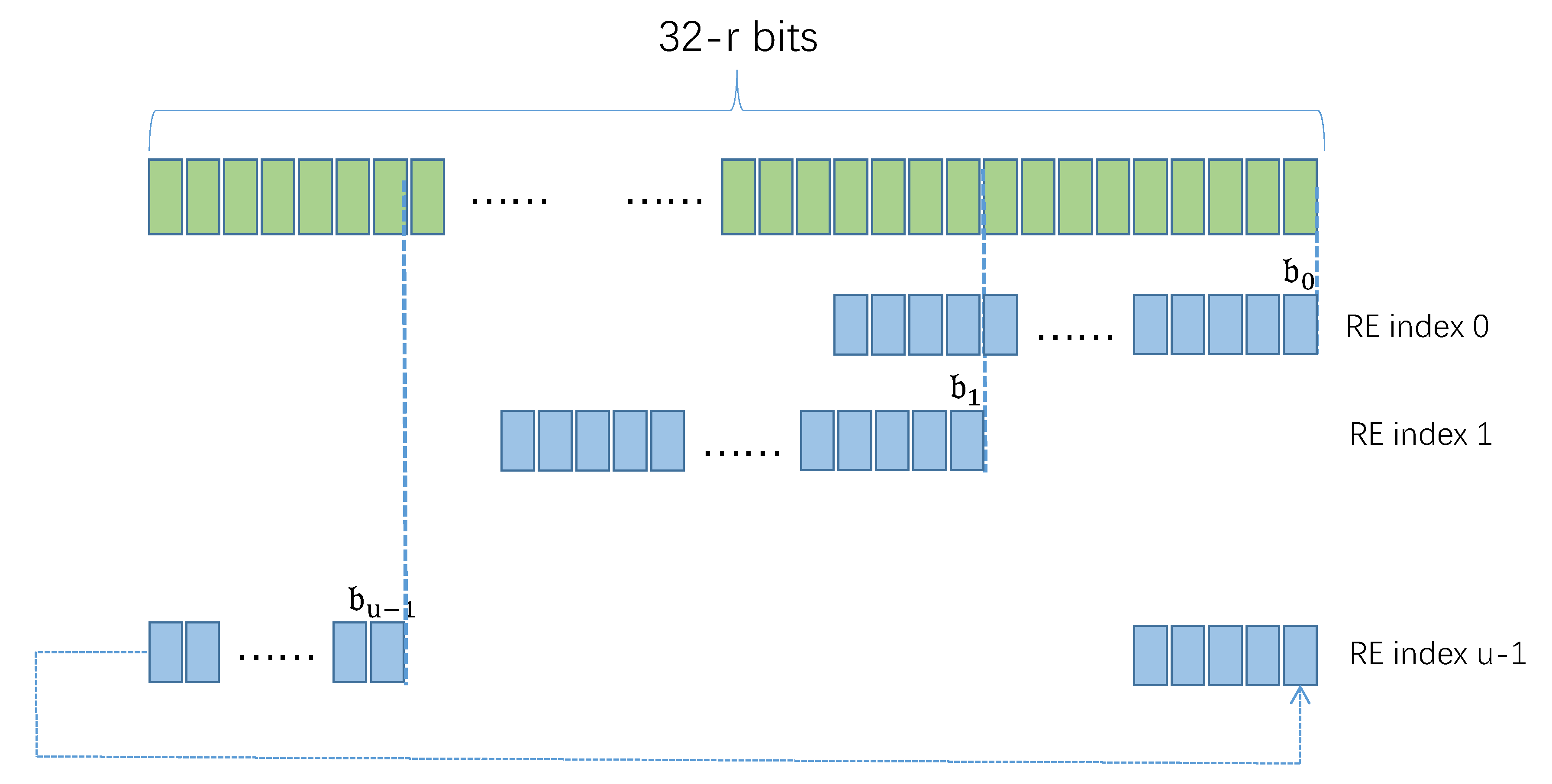
The basic element of REC is RE. Several RE constitutes a one-dimensional RE vector (REV); the set of REV constitutes a two-dimensional RE array (RE Array, REA). The three-dimensional REC can be regarded as a set of REA, which contains REA and r is a positive integer less than 32. Each REA of REC has the same structure, that is, the REA contains the same number of REV, and the associating REV contains the same number of RE. Let denote the number of REV contained in REA and denote the number of RE contained in the ith REV. Three indexes can be used to locate a RE in REC accurately.
All observation nodes have their own REC, and the structure of REC at different observation nodes is the same, that is, the r, , of REC at different observation nodes are the same. When the IP address pair is scanned at the observation node, the REC at the observation node will be updated. Let denote the REC on the observation node , denote the j-th RE of the i-th REV on the k-th REA, where k is an integer between 0 and , i is an integer between 0 and −1, and j is an integer between 0 and . In time window , for each IP address pair of READ selects RE from according to , and updates RE with . How to map to RE in REC determines whether READ can recover global candidate super points from REC.
The RE associating with are located in the same REA. READ divides into two parts: the first part is r bits on the right (Right Part, RP), and the second part is 32-r bits on the left (Left Part, LP).
READ selects a REA in the REC based on the IP of . REC has REA, so the RP of can determine only one REA in the REC. READ divides into subsets according to r bits on the right side of the IP address. Each subset of associates with a REA in the REC. During the operation of the algorithm, the number of RE in the REC is fixed, and each RE is used to record opposite hosts of multiple . When contains many IP addresses, by increasing r, the number of hosts sharing the same RE can be reduced.
The LP of
is used to select
RE in REA, i.e., one RE from each REV. Let
denote the index of RE in the
i-th REV,
.
is an integer containing
bits. Let
[j] denote the
j-th bit in
,
. READ selects
bits from the LP of
as the value of
. Let
denote the LP of
,
[i] denote the
i-th bit of
,
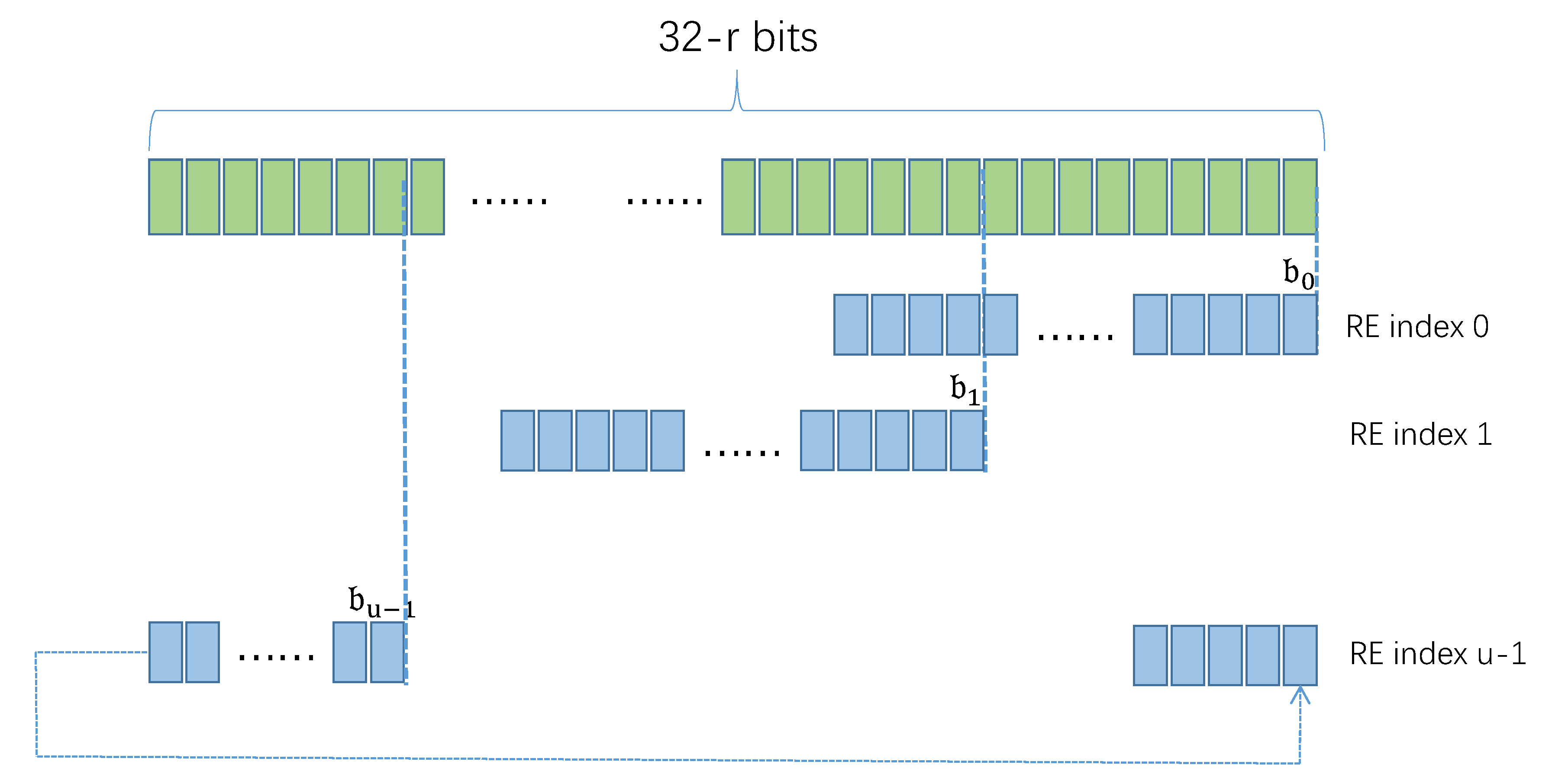
. Each bit in
associates with a bit in
, as shown in
Figure 4.
When selecting bits from
as
, READ first determines which bit in
is
[0], and then calculates the other bits in
. Let
denote the index of the 0th bit of
in
, i.e.,
[0]=
[
]. Each bit of
is calculated according to the following formula:
() is a parameter of READ, which is determined at the beginning of the algorithm. In order to recover the global candidate super point from REC, meets the following conditions when setting:
The above conditions ensure that each bit in appears in at least one , and that there are the same bits between two adjacent (associating with the same bit in ). When restoring global candidate super points, READ extracts the associating bits of from all to recover , and reduces the number of global candidate super points by using the repeated bits between two adjacent .
RE estimator only determine whether the host is a global candidate super point, but cannot give an estimate of the cardinality. Therefore, READ uses LE to estimate the cardinality of each global candidate super points.
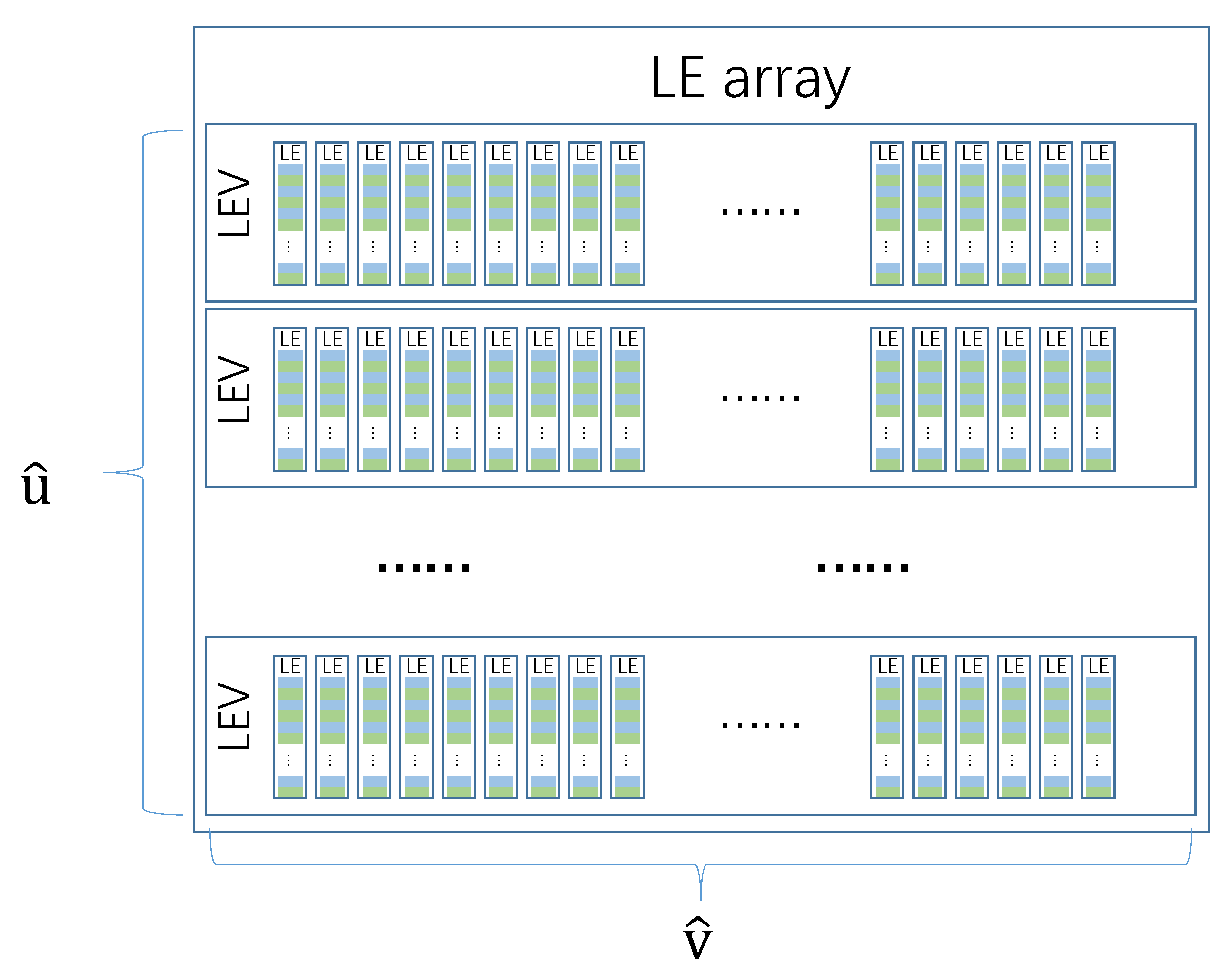
READ uses LE array of
rows and
columns to record the opposite hosts of
, as shown in
Figure 5.
LE vector (LEV) contains LE, and LEA contains LEV. Each observation node has a LEA, and the LEA at all observation nodes has the same structure. Let denote the LEA at the -th observation node, and denote the j-th LE in the i-th LEV of .
For each in , READ selects one LE from each LEV of LEA to record the opposite hosts of . READ maps to LE in LEV with random hash functions. READ uses the hash function when mapping to a LE in the i-th LEV, where . The observation node not only updates , but also when scanning .
Algorithm 1 describes how READ scans IP address pairs in one observation node. READ first determines the size of REC and LEA according to the parameters, allocates the memory needed by REC and LEA, and initializes the counters of all RE and LE. Then, it starts scanning each IP address pair in
and updates REC and LEA. When scanning IP address pairs
, READ selects a REA from the REC by using
r bits on the right side of
, and extracts
bits on the left side of
as
. Then, the index of RE in each REV is determined according to
. Here, the index of RE refers to the location of RE in REV and takes the value between
, where
is the number of RE contained in the REV. For the
i-th REV, parameter
specifies the bits in
associating with the first bit of the RE index. After the index value of RE is obtained, the RE is updated with
. Compared with updating
, updating
is much simpler, because
is only used to estimate the cardinality and does not need to restore the global candidate super point.
| Algorithm 1 scanIPair. |
Input:r,, , , , , , , Output:, - 1:
Init - 2:
Init - 3:
fordo - 4:
right r bits of - 5:
← left 32-r bits of - 6:
for u do - 7:
j=0 - 8:
for do - 9:
r - 10:
end for - 11:
Update with - 12:
end for - 13:
for do - 14:
j= - 15:
Update with - 16:
end for - 17:
end for - 18:
return,
|
After the observation node scans all IP address pairs in , and record the information of opposite hosts. By collecting and from all observation nodes, the global candidate super points can be recovered and the cardinalities of candidate super points can be estimated.
The next section describes how READ recovers global candidate super points in a distributed environment.
4.3. Generate Candidate Super Points
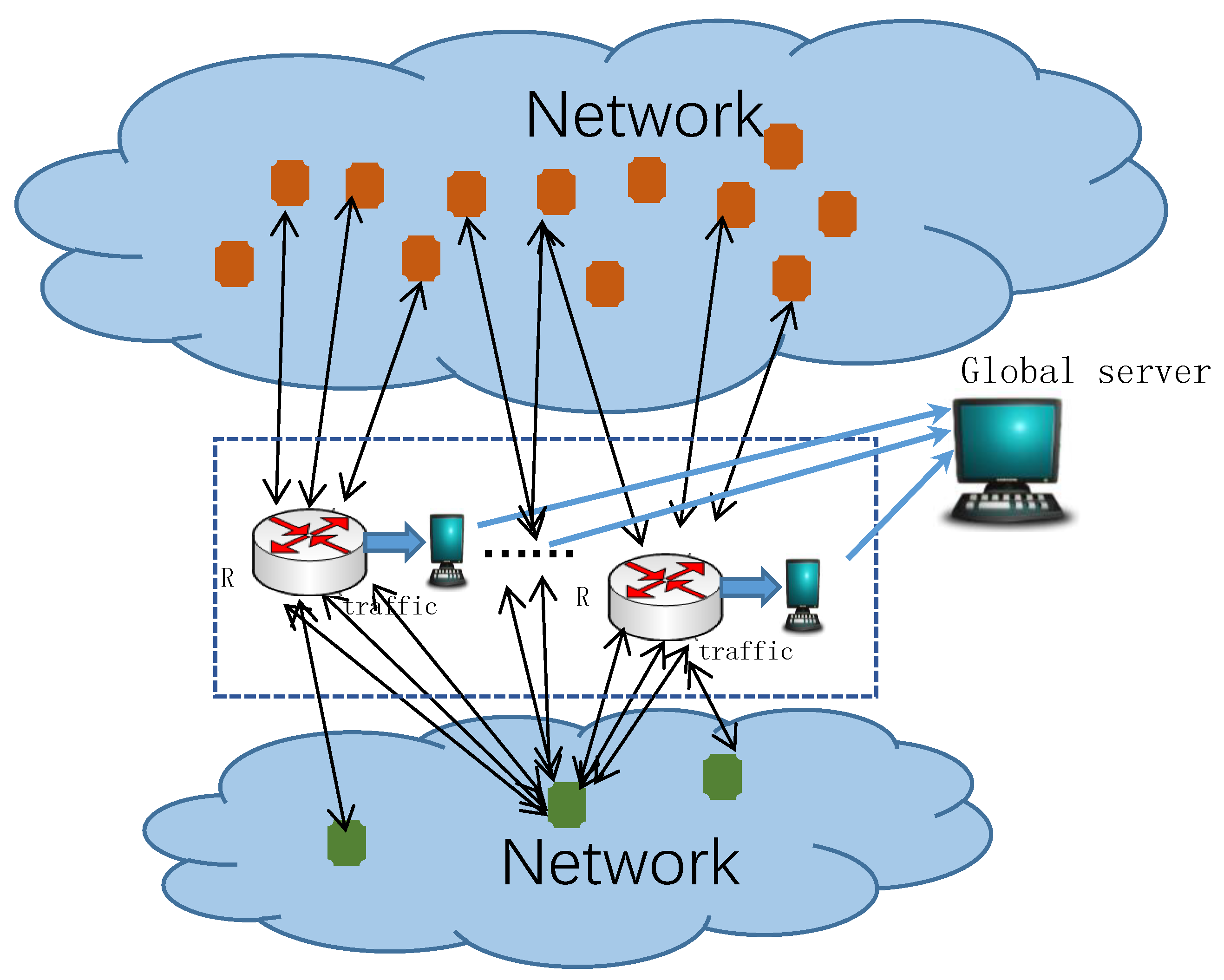
The master data structure at the observation node consists of two parts: REC and LEA. REC is used to recover global candidate super points, which has the advantage of less memory consumption; LEA is used to estimate cardinality, which has the advantage of high estimation accuracy. Each observation node can only observe part of the opposite hosts. In order to detect the super points accurately, it is necessary to collect the opposite hosts information recorded by each observation node on the global server. In this paper, the super points detected from IP address pairs of all observation nodes are called as global super points, and the generated global candidate super points are called global candidate super points. When generating global candidate super points, only RECs are collected from each observation node, as shown in
Figure 6.
After each observation node has scanned all IP address pairs in a time window, only the REC needs to be sent to the global server. The global server merges all the collected REC. The merging method is to merge the RE of different observation nodes in a “bit or” manner. In this paper, the way of combining according to “bit or” is called external merging, and the way of combining according to “bit and” is called internal merging. External merger of RE is defined as follows:
Definition 3 (RE Out merging). All bits of two RE generate a new RE according to the operation of “bit or”.
In this paper, when the operand of the operator “⨁” is two RE or two LE, it means to out merge the two RE or LE; when the operand of the operator “⨀” is two RE or two LE, it means to inner merge the two RE or LE.
The REC of all observation nodes are merged on the global server by outer merging, which ensures that any bit in the REC is still 1 in the merged global REC as long as it is set to 1 at any one observation node. Since RE uses bits to record the occurrence of opposite host, the global REC generated by outer merging contains the opposite information recorded by all observation nodes.
In this paper, the REC used to restore the global candidate super points on the global server is called as the global REC. The global REC has the same structure as the REC at all observation nodes. The global REC and the REC of all observation nodes are merged according to outer merging. There are two methods to get the global REC:
Before merging the REC, the global server initializes a REC with the same structure as the REC at the observation nodes, and sets all bits in the initialized REC to 0. Then, the REC on the global server is merged with the REC on all observation nodes one by one, and the results are saved to the global REC.
The global server takes the REC from the first observation node as the global REC, then merges the global REC with the REC from the remaining observation nodes, and saves the results to the global REC.
Among the two methods for merging global REC, method 2 is less computational than method 1, because method 2 does not need to re-initialize REC. In this paper, method 2 is used to merge the REC of observation nodes into the global REC. Let
denote the global REC, and
denote the
j-th RE of the
i-th REV in the
k-th REA of
. Assuming that the REC on
is first received as one on the global server, Algorithm 2 describes the REC merging process on the global server.
| Algorithm 2 Out Merging REC. |
Input:, , r, , Output: - 1:
- 2:
fordo - 3:
for do - 4:
for do - 5:
for do - 6:
- 7:
end for - 8:
end for - 9:
end for - 10:
end for - 11:
Return
|
The first line of Algorithm 2 takes the received as the global REC after the first merge, and then merges the remaining observation nodes into the global REC. After merging the REC at all observation nodes, Algorithm 2 outputs the global REC.
READ recovers the global candidate super points from each REA of the global REC in turn. For the k-th REA of the global REC (denoted as ), READ calculates the global candidate super points in it by the following two steps:
Find out all RE in whose estimating cardinality is greater than the threshold.
From the candidate RE, 32-r bits on the left of the candidate super point are recovered, and then concatenate with the right r bits represented by k to get the complete global candidate super point.
The above Step 1 only needs to scan all RE in
once to get a candidate RE. Let
represent the index of the candidate RE in the
i-th REV of
. Equation (
3) shows that the index of the candidate RE in
comes from the bits of certain IP address. At the same time, as can be seen from
Figure 4, if the two indexes
and
of two adjacent row,
i and
are from the same IP address, then they have
bits are the same. Conversely, if the left
bits of
are different from the right
bits of
, then
and
certainly do not come from the same IP address. When the
RE indexes comes from the same IP address, the
RE indexes are called a candidate RE tuple. Inner merge these
RE in a candidate RE tuple. If the estimated value of the inner merged RE still exceeds the threshold, the candidate RE tuple come from a global candidate hyper point.
When the candidate RE tuple comes from a global candidate super point, the candidate RE tuple can recover 32-r bits to the left part of the global super point. From the setting requirement of parameter , if the RE indexes in a candidate RE tuple comes from the same IP address , any bit of will appear at least once in the different candidate RE indexes. Therefore, 32-r bits of can be recovered from the candidate RE tuple. Then, a global candidate super point is obtained by concatenation with k, i.e., .
Depth traversal can be used to calculate all candidate RE tuples from . For example, suppose that the parameters of REC are set to r = 2, = 3, , =0, =10, =20, the candidate RE indexes of is , . The number values of some candidate RE are as follows:
11000101010101
11000110010101,
11100100011100
10010111011110,
01010001011110.
In the above example,
+
−
=4, that is, the candidate RE indexes in the two adjacent
determines whether it comes from the same IP address by the four bits on the left and the four bits on the right (the gray part in the RE index). When the candidate RE tuple is calculated by depth-first method, the candidate RE tuple is empty at the beginning, and then the first RE number is
. Test whether
and
come from the same IP address, as shown in
Figure 7.
The four bits on the left of are different from the four bits on the right of , so and come from different IP addresses. Then, test and . The four bits on the left side of are the same as the four bits on the right side of , so is added to the candidate RE tuple. Then, find the RE index from , which comes from the same IP address with . In , the four bits on the right side of are the same as the four bits on the left side of , but the four bits on the left side of are not equal to the four bits on the right side of , so cannot form a candidate RE tuple with and . In , not only are the four bits on the right side the same as the four bits on the left side of , but also the four bits on the left side of the same as the four bits on the right side of . Therefore, ,, constitutes a candidate RE tuple.
From the values of , and , it can be seen that the RE associating with the candidate RE tuple is , , . If the cardinality estimated from the inner merge RE, , still over the threshold, 30 bits of the left part of can be recovered from : “000101111001000111000101010101”. is the 2-th REA in REC. The associating binary format is “10”. Thus, the global candidate super point is “00010111100100011100010101010110”.
All REA in global REC are processed in the above way. Because the number of RE counters is small (for IPv4 address, there are only eight counters), so it is faster to scan REA and calculate the candidate RE number. Furthermore, each RE only takes up one byte of space, so REC takes up less memory and reduces the amount of data transmitted between observation nodes and the global server. However, the cardinalities of the global candidate super points cannot be estimated by RE. Estimating the cardinality requires the use of the opposite host information stored in LEA. The next section describes how to collect the opposite host information stored in LEA from the observation nodes, estimate the cardinalities of the global candidate super points, and filter out the super points.
4.4. Estimate Cardinalities of Candidate Super Points
The LEA at each observation node is used for estimating the cardinality of global candidate super points. A simple way is to send all LEAs at each observation node to the global server, and then merge all LEA of observation nodes on the global server in a “bit or” manner to get the global LEA.
In this paper, when the operand of “∑” is the LE or RE set, it means that all LE or RE in the set are merged by outer merging method; when the operand of “∏” is the LE or RE set, it means that all LE or RE in the set are merged by inner merging method.
Merging LEA of all observation nodes on the global server in the way of outer merging is equivalent to sending IP address pairs directly to the global server to update the global LEA. Because LE outer merging guarantees that any bit in the global LEA will remain 1 as long as it is set to 1 at one or more observation nodes.
After the global LEA is generated, the cardinalities of global candidate super points can be estimated according to the global LEA. Let denote a global candidate super point, denote the LE of in the i-th LEV of the -th observation node, i.e., , . Using hash functions , it is easy to find these LEs used by from the global LEA.
Let
denote the LE associating with
in the first LEV of the global LEA. Since global LEA is obtained by combining LEA from all observation nodes,
. The
LE of
on the global LEA are merged into
. Let
denote the number of bits with value “1” in
. The cardinality of
is estimated based on
by Equation (
1). If the estimated result is larger than the threshold,
is reported as a super point.
Although the above method avoids sending all IP addresses to the global server, it still needs to send the complete LEA to the global server. In order to improve the accuracy of cardinality estimating, the parameters of LEA are set to larger values. For example, when , , , LEA is 320 MB in size. When estimating cardinalities, each observation node needs to send 320MB of data to the global server.
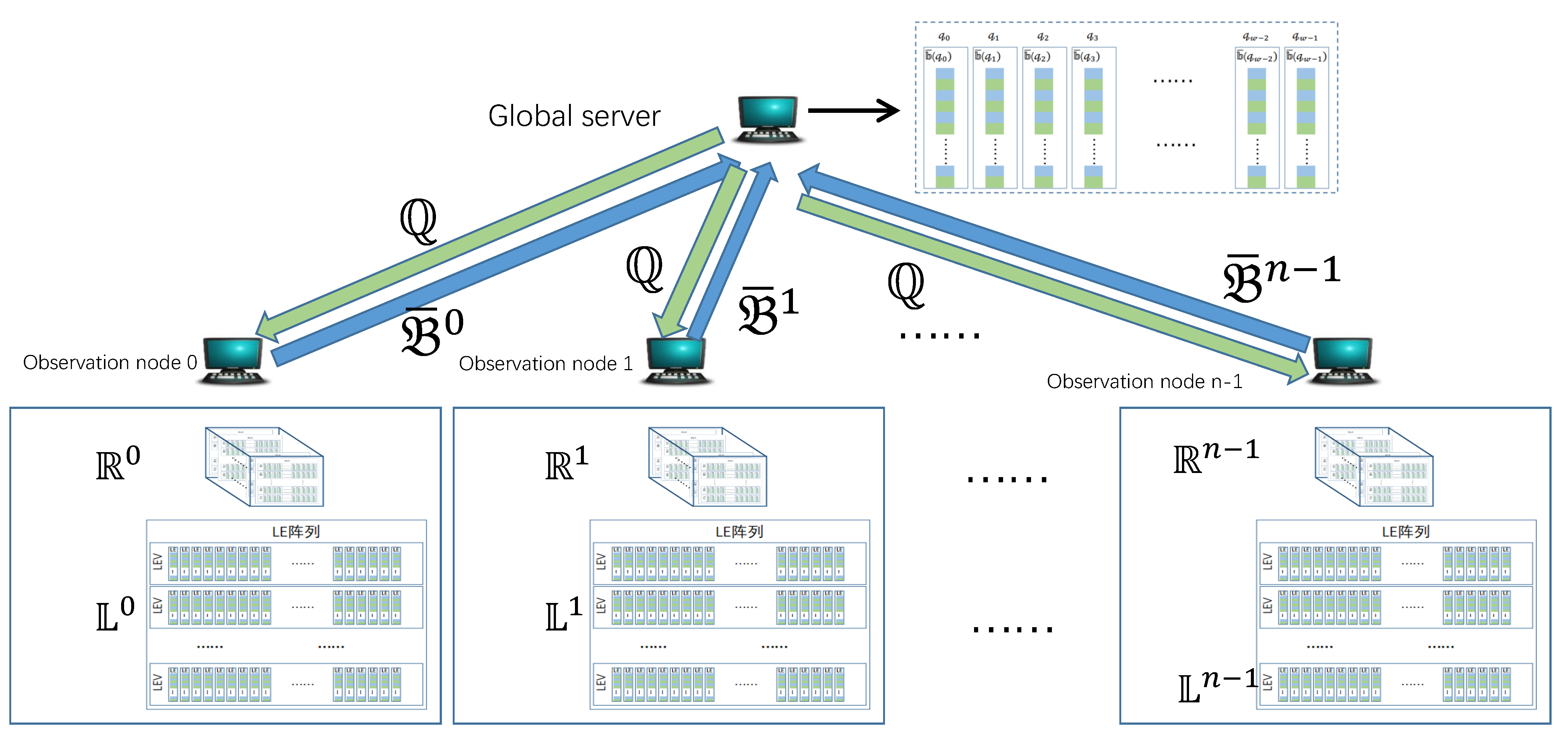
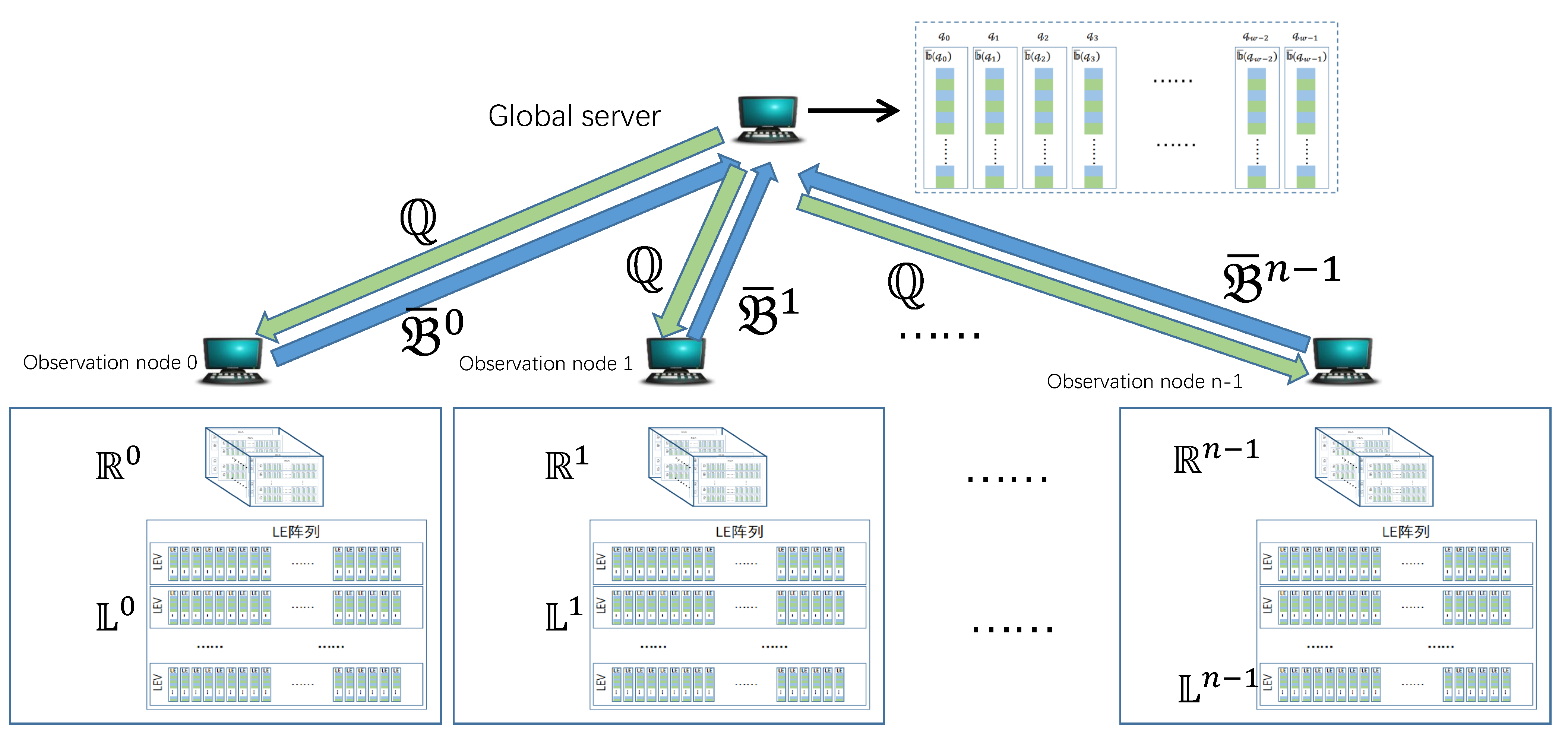
When estimating the cardinality of global candidate super point
, only
is needed. Based on this principle, READ first sends the global candidate super points to each observation node from the global server, and then each observation node sends these LE relating with candidate super points back to the global server, as shown in
Figure 8.
In
Figure 8,
denotes the set of global candidate super points,
denotes the set of LE used to estimate cardinalities of global candidate super points in
on the observation node
. For global candidate super point
, there are
LE associating with it, i.e.,
. READ does not send all of the
LE to the global server, but the result of internal merging,
. In
Figure 8,
is the LE set to be sent to the global server on the
-th observation node.
On the global server, , which is used for estimating the cardinality of , is obtained by outer merging all . Let denote the number of bits with value “1” in . Theorem 1 shows that can more accurately estimate the cardinality of than .
Theorem 1. For global candidate super point , let denote the set of opposite hosts of passing through all observation nodes in time window , denote a LE after scanning , and denote the number of bits with value “1” in . Then, these bits with value “1” in are still with value “1” in and . Furthermore, .
Proof of Theorem 1. When a bit in has value “1”, there exists an IP address pair in to set the bit to “1”. In global LEA, sets all the bits of LE associating with . After inner merging in LE, the bit is “1” in . At the same time, will appear on at least one observation node and set all the bits of LE associating with to “1”. Since the bit is “1” in at least one , the bit is still “1” after outer merging on the global server. So, and . The next step is to proof that .
Let
=
, then
. Let
, then
. To proof that
is equivalent to proof that the number of bits with value “1” in
is no more than the number of bits with value “1” in
.
is a LE and the number of bits in all
are the same. Let
denote an arbitrary bit in
. All
in different observation nodes could be written as an array in the following format:
In , represents that “bit or” operations are performed on each line, and then “bit and” operations are performed on the results; represents that “bit and” operations are performed on each line, and then “bit or” operations are performed on the results.
When , at least one row has all bits equal to “0”, and the result of “bit and” operation for each column is also 0, then . When , there is no row whose bits are all “0”. However, may still be 0. Because when each column of contains at least one bit with value “0”, then . At this time, each row may contains one or more bits with value “1”. For example, when n=3,,, , but .
When , also equals to 1. As when , at least one column in has all bits with value “1”. Then, there is no row in whose bits are all “0”. As is an arbitrary bit in , then:
When a bit has value “1” in , the bit has value “1” in ;
When a bit has value “0” in , the bit has value “0” in ;
When a bit has value “1” in , the bit may has value “0” in
So the number of bits with value “1” in is no more than that in and . □
LE estimates cardinality based on the number of bits with value “1”. Theorem 1 shows that the number of bits with value “1” in is closer to the number of bits with value “1” in the LE which is used by exclusively. So, the accuracy of estimating cardinality by is better.
READ not only does not need to transfer the entire LEA to the global server, but also has a higher accuracy in estimating cardinalities of global candidate super points. When estimating cardinalities, the amount of data transmitted between each observation node and the global server is bits, where is the number of candidate super points recovered by REC. is the data size of global candidate super points transmitting to each observation node from the global server, and is the data size of LE of candidate super points that transmitting to the global server from each observation node. When , the data transmission between an observation node and the global server is less than the data transmission of the entire LEA. Global candidate super points account for only a small portion of all IP addresses, usually hundreds to thousands. In order to improve the estimation accuracy, the value of will be more than tens of thousands. So, READ reduces the amount of data transmitted between observation nodes and the global server. READ can also apply more powerful counters to replace bits in RE and LE to realize the detection of super points under a sliding time window as discussed in the next section.
5. Distributed Super Points Detection under Sliding Time Window
READ only scans IP address pairs at each observation node, so only a sliding window counter is needed to record opposite hosts incrementally at the observation node. The master data structure at the observation node consists of two parts: REC and LEA. The estimators of REC and LEA are RE and LE, while the counters used by RE and LE are bits. So, the master data structure at the observation node can be regarded as a set of bits. Using counter DR [
20] or AT [
27] under sliding window instead of bit in REC and LEA at each observation node, distributed super points detection under sliding window can be realized.
The counter under the sliding window needs to be updated. After all LE associating with the global candidate super points are sent to the global server, the observation node can start to update the sliding counter. At the end of each time window, the REC on the global server is generated by these REC collecting from all observation nodes, there is no need to update it.
Under the sliding time window, the observation node only needs to send the active state of the counter to the global server, that is, at the end of the time window, each sliding window counter can be changed into a bit: 0 for inactivity, 1 for activity. Therefore, under sliding time window, the traffic between observation nodes and the global server is the same as that under discrete time window.
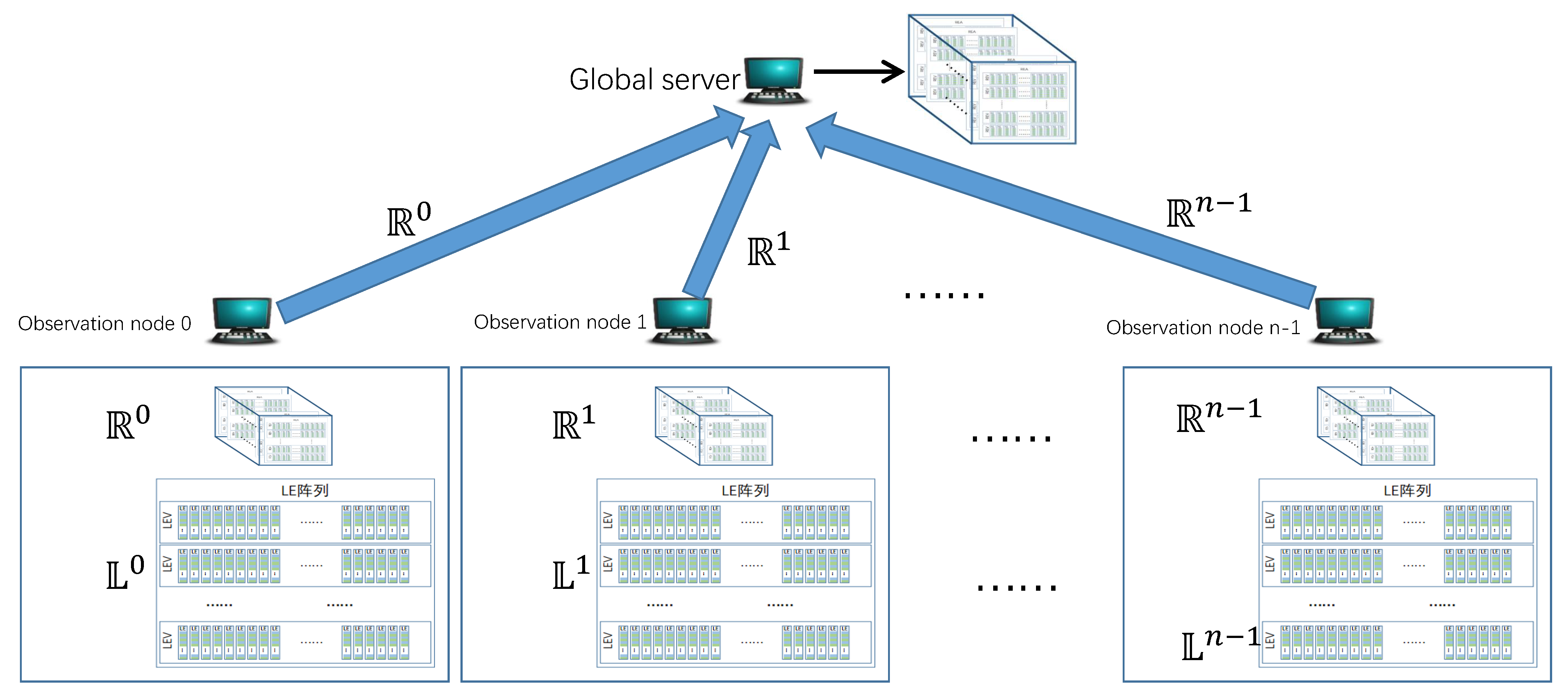
READ can be quickly deployed to distributed networks. For example, suppose that network and network communicate through three different routers. An IP address pair in the form of < , > can be extracted from the IP packet on each router. On the observation node of each router, select REs from RE cube and LEs from LE array according to ; update the selected REs and LEs according to . At the end of the time window, send the RE cubes on the three router observation nodes to the global server for merging, and generate candidate super points from the merged RE cubes. Then, the candidate super points are sent to these three router observation nodes for LEs selection. Finally, the global server collects the LEs of candidate super points from three router observation nodes and filters out the super points. The following section will evaluate READ with high-speed network traffic.
6. Experiments and Analysis
In order to test the performance of READ, four groups of high-speed network traffic are used to carry out experiments in this section. The experiment analyzes READ from the aspects of detection error rate, memory usage and running time. The experiment compared READ with DCDS, VBFA, CSE and SRLA.
6.1. Experiment Data
In this paper, four groups of high-speed network traffic are used. Two of the four sets of data come from the 10 Gb/s Caida [
28]. The other two groups are from the network boundary of the 40Gb/s CERNET in Nanjing network [
29].
The Caida data acquisition dates are 19 February 2015 and 21 January 2016 (denoted by and ), and the data acquisition dates of the two groups of CERNET Nanjing network were 23 October 2017 and 8 March 2018 (denoted by and ). The collection time of the four groups of data is one hour from 13:00. The collected data are raw IP Trace. Caida data collected Trace between Seattle and Chicago. In this paper, the IP on Seattle side is defined as , and the IP on Chicago side is defined as . IPtas data collects traces between CERNET Nanjing network and other networks. In this paper, the IP in Nanjing network is , and in the other network is .
In the experiment of this section, the length of time window is 5 min, and the threshold of super point is set to 1024. Therefore, each group of experimental data contains 12 time windows.
Table 2 lists the statistical information of each experimental data. The number of
in Caida data is more than the number of
in IPtas data, which is 1.85 times more on average. However, the average cardinality per
in Caida data is less than that in IPtas data, only
of the latter. The number of packets per second determines the number of IP address pairs that need to be processed per second. Therefore, packet speed (in millions of packets per second, Mpps) is a key attribute. As can be seen from
Table 2, the average packet speed of IPtas data is 3.89 times that of Caida data. Therefore, Caida data and IPtas data represent two different types of network data sets, which can test the effect of the algorithm more comprehensively.
6.2. The Purpose and Scheme of the Experiment
The experimental purposes of this paper are as follows:
Analyze the accuracy of READ and test whether REC can accurately generate candidate super points.
Analyze the memory occupancy and running time of READ;
Test the number of candidate super points generated by READ and the amount of data that needs to be transmitted between each observation node and the global server.
In order to process high-speed network data in real time, this paper deploys READ, DCDS, VBFA, CSE and SRLA algorithm on GPU platform. All the experiments in this paper run on a server with GPU. The running environment is: Intel Xeon E5-2643 CPU, 125 GB memory, Nvidia Titan XP GPU, 12 GB memory, Debian Linux 9.6 operating system.
In the experiment, the parameters of REC are , = 3, ; the parameters of LEA are , and . From the above parameters, it can be seen that REC occupies 3 MB of memory and LEA occupies 320 MB of memory. Because there is no distributed experimental data, the experiment in this section is carried out under a single node. However, from the previous analysis of READ, it can be seen that the error rate of READ in a distributed environment will not be higher than that in a single node environment.
6.3. Memory and False Rate
In order to analyze the memory and false rate of READ, this section compares READ with DCDS, VBFA, CSE and SRLA algorithm.
Table 3 shows the average memory occupancy and error rate of READ and comparison algorithms in different experimental data sets. False positive rate (FPR), false negative rate (FNR) and false total rate (FTR) are three kinds of false rates. Let N represent the number of super points,
represent the number of super points that are not detected out by an algorithm and
represent the number of hosts whose cardinalities are less than the threshold, but detected as super points by an algorithm. Then,
,
.
Table 3 shows that READ occupies less memory than DCDS and CSE, and only 3 MB more memory than VBFA. In terms of error rate, the error rate of READ is close to that of SRLA algorithm.
6.4. Running Time Analysis
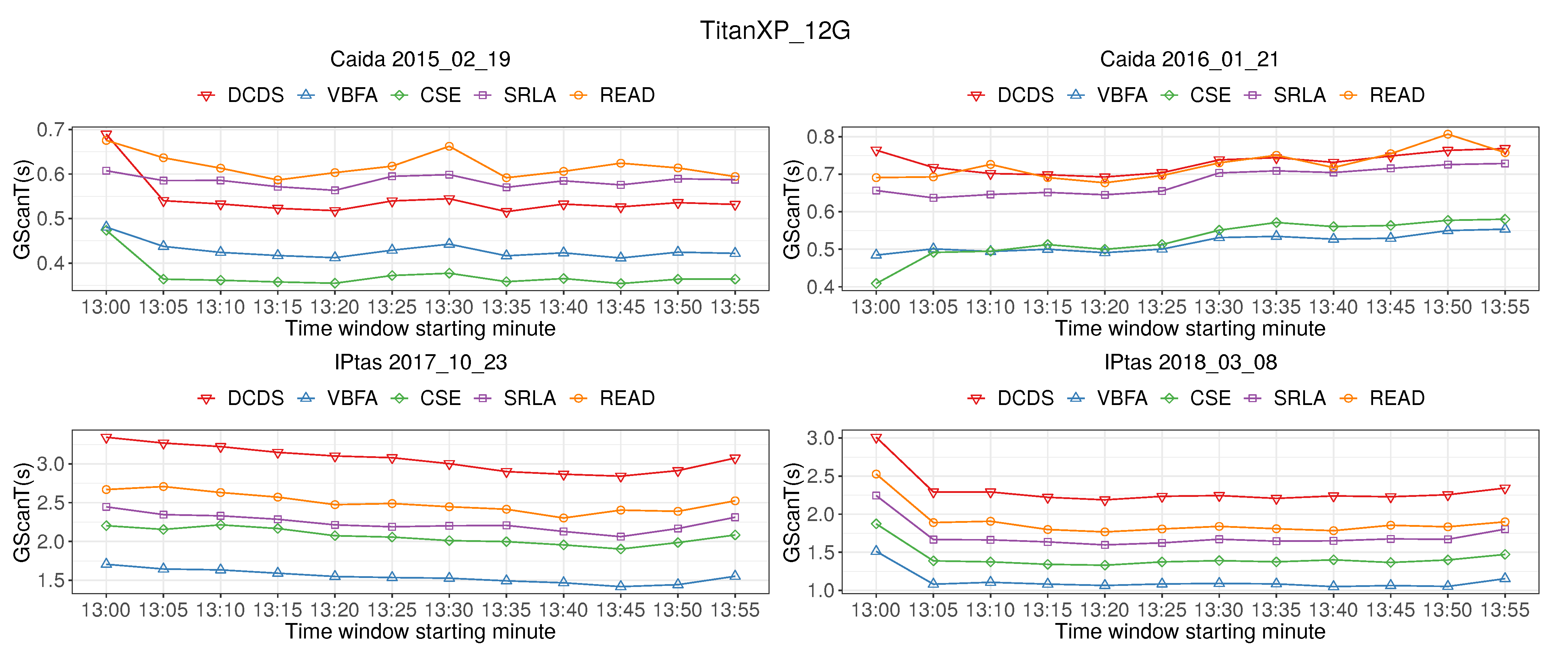
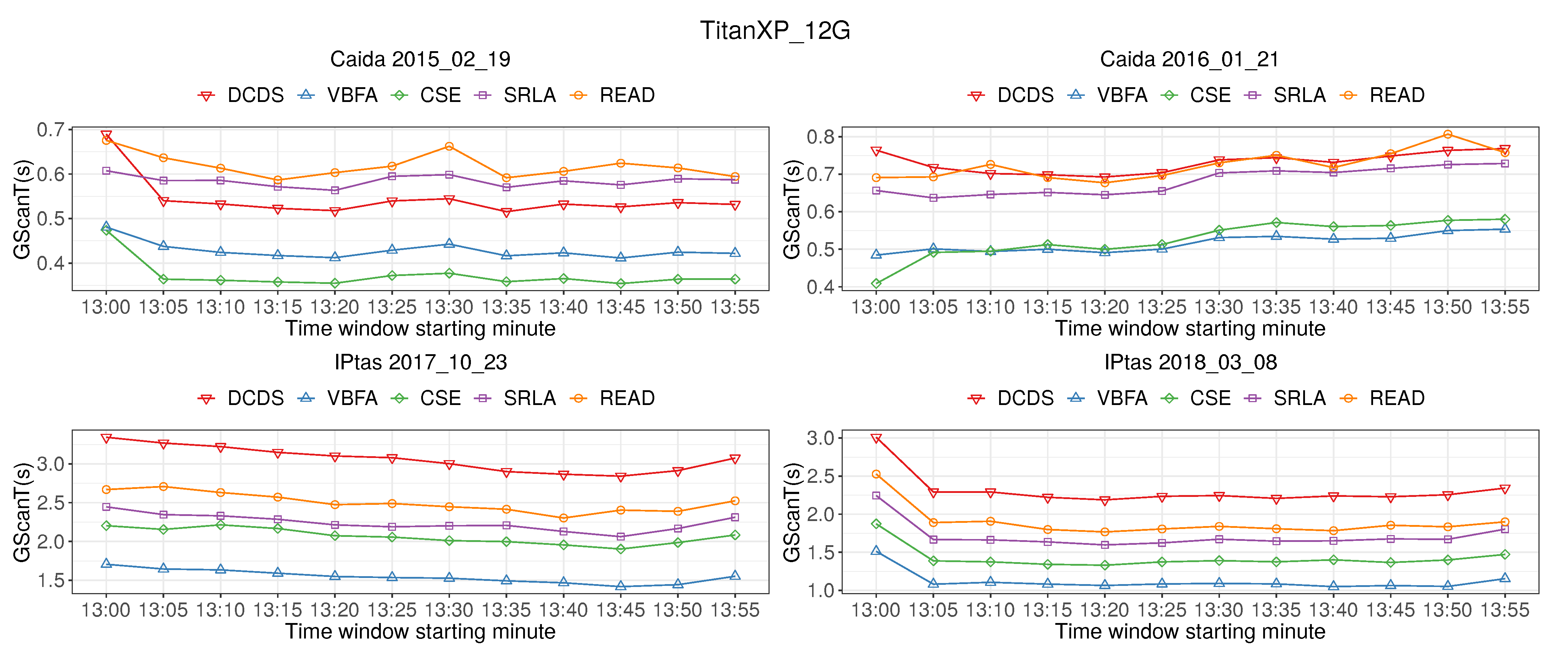
Figure 9 shows the time of IP address pairs scanning (GScanT). The graph shows that the GScanT of READ is slightly higher than that of SRLA algorithm. However, the GScanT of each algorithm is not more than 4 s, which can process 40 Gb/s of high-speed network traffic in real time.
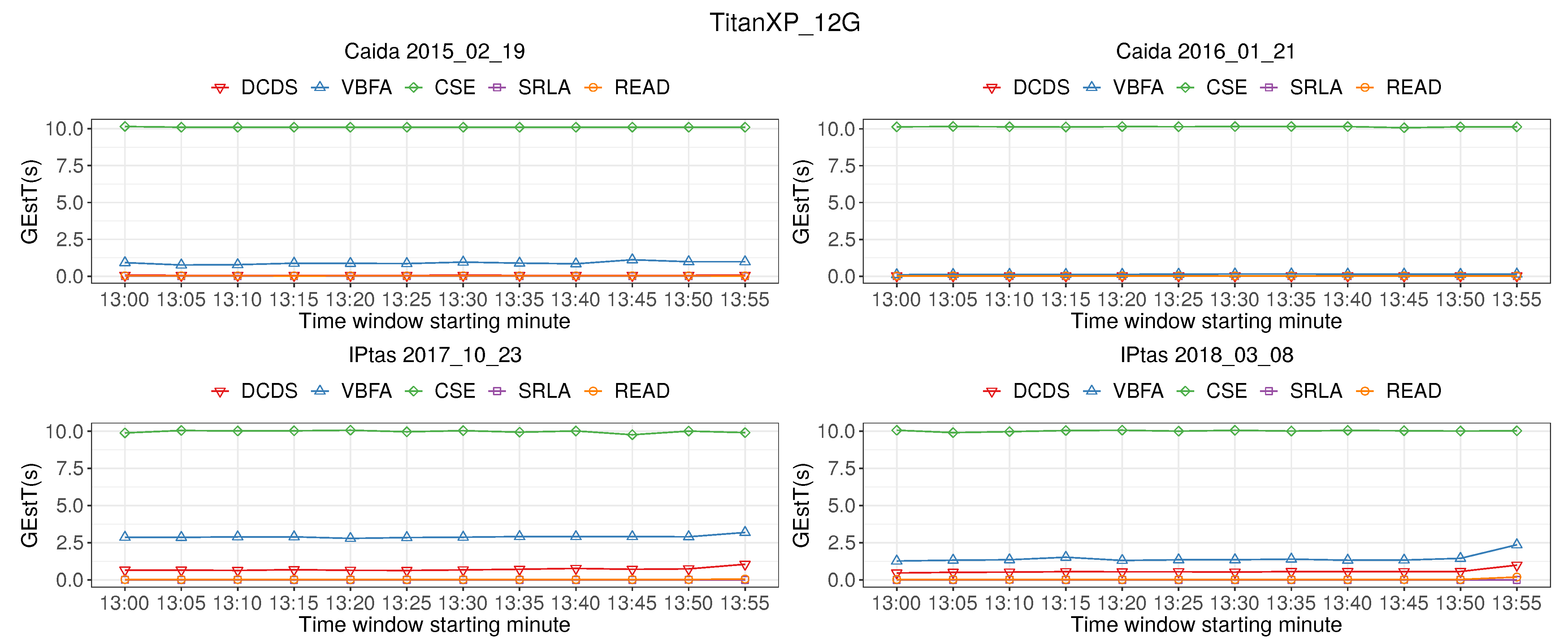
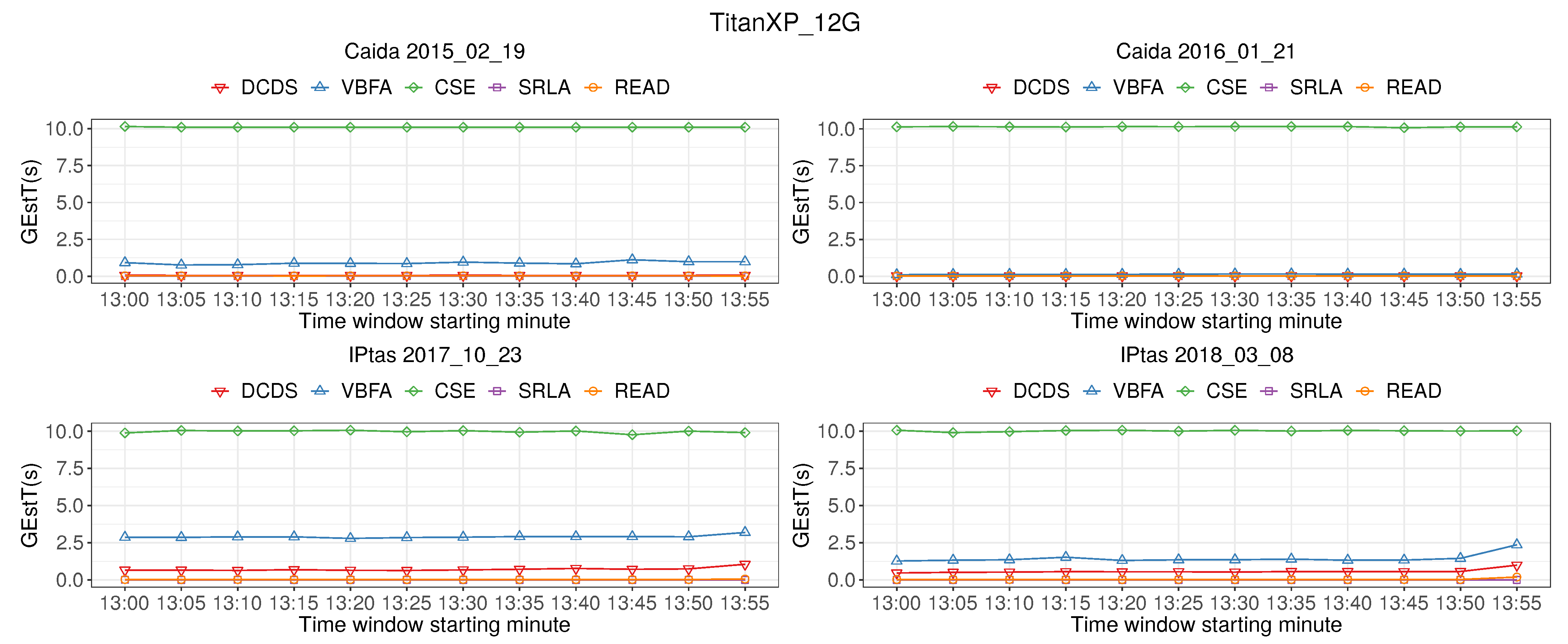
Figure 10 shows the time of candidate super point cardinality estimation (GEstT). The graph shows that GEstT of READ is close to DCDS, VBFA and SRLA algorithm, much lower than CSE, and GEstT of READ is not higher than 2.5 s. Therefore, READ can detect super points in real-time from 40 Gb/s high-speed network.
6.5. Data Transmission under Distributed Environment
READ is a distributed algorithm. In a distributed environment, data will be transmitted between each observation node and the global server, including:
REC from observation node to the global server;
Candidate super points from the global server to each observation node;
The LE set of candidate super points from each observation node to the global server.
In the above data, the size of REC is fixed. The size of candidate super points and LE in transmission depends on the number of candidate super points. From the running process of READ, it can be seen that the candidate super points generated by READ when running in a single node environment are the same as those generated when running in a distributed environment. Therefore, the number of candidate super points generated at runtime under a single node can be used to determine the size of data transmission between observation nodes and the global server in a distributed environment.
Table 4 lists data transmission between each observation node and the global server. The number of candidate super points is the number of candidate super points produced by REC. The size of candidate super points is multiplied by 4 bytes (each IPv4 address size is 4 bytes); the size of candidate super points’ LE is multiplied by
bytes (LE contains
bits,
bytes). The total amount of data transmitted is the sum of the size of REC, the size of candidate super point and the size of LE of candidate super points. The master data structure size is the sum of REC and LEV. The percentage of transmitted data is the ratio of the total amount of transmitted data to the size of the master data structure. From
Table 4, it can be seen that the average amount of data transmitted by READ between the global server and each observation node is not more than 7.5 MB, which only occupies less than
of the total size of master data structure.






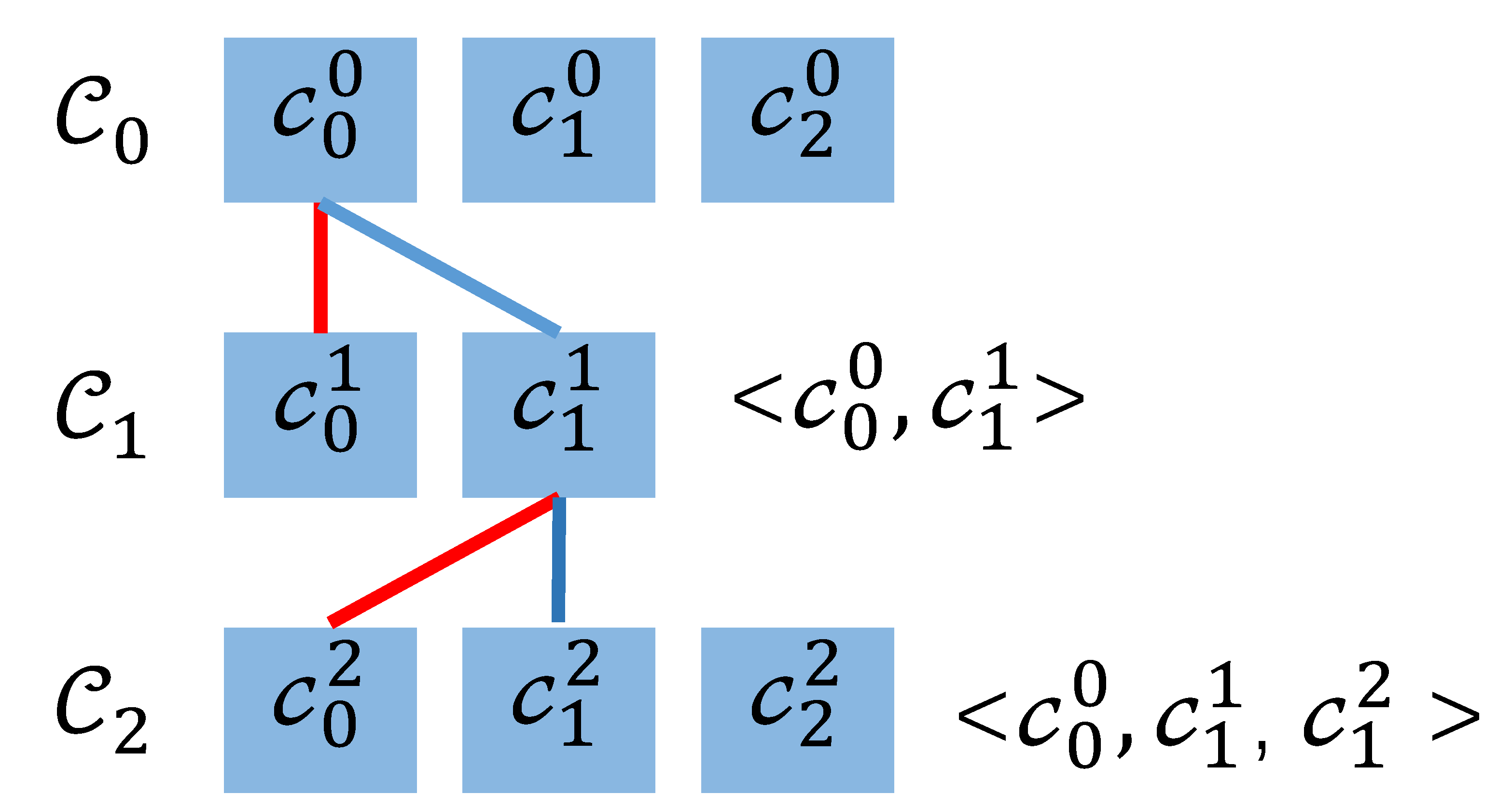

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}