Cross-Camera Erased Feature Learning for Unsupervised Person Re-Identification

Abstract
1. Introduction
- We use generated images to reduce the gap between cameras. Generated images can provide additional supervision information for unsupervised person re-identification.
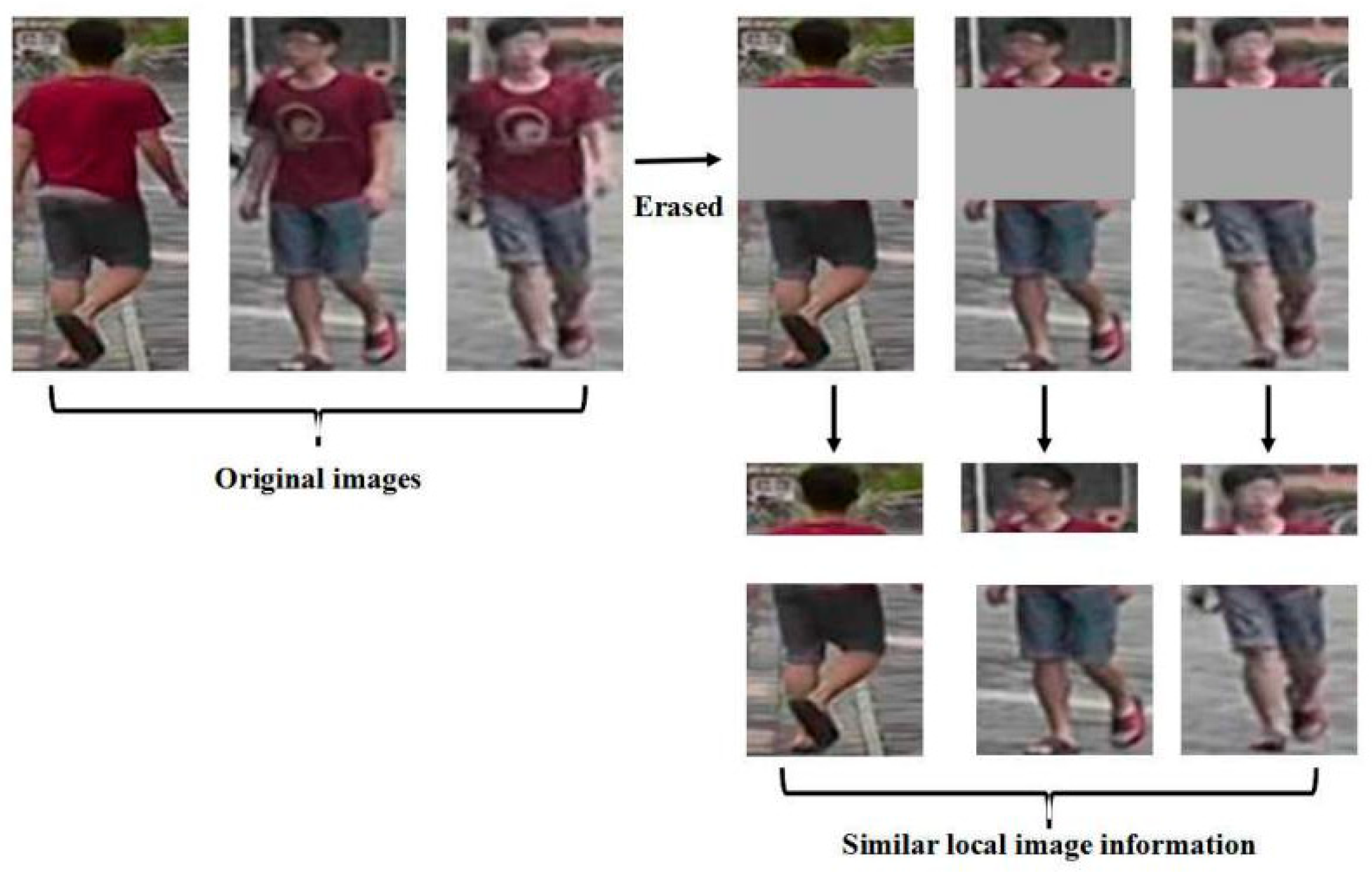
- We use BEFNet to generate erased images so that the network can learn the features of local detail. At the same time, the similarity calculation between erased parts is more accurate and more suitable for unsupervised person re-identification.
- We join to learn global and erased parts to improve the robustness of CEFL. Global and erased features are used together in feature learning which are successful conjunction of BFENet.
2. Related Work
3. Materials and Methods
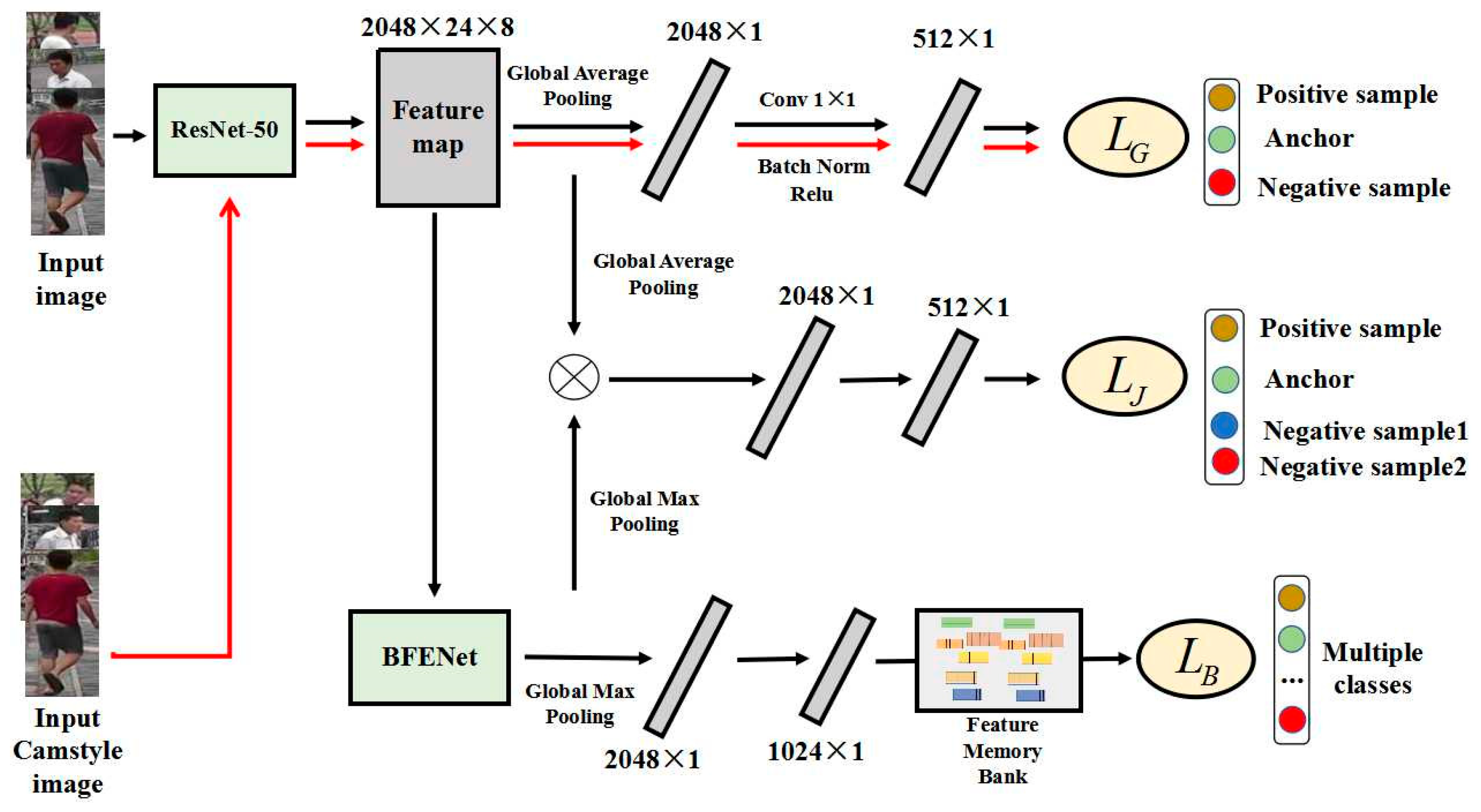
3.1. Network Structure
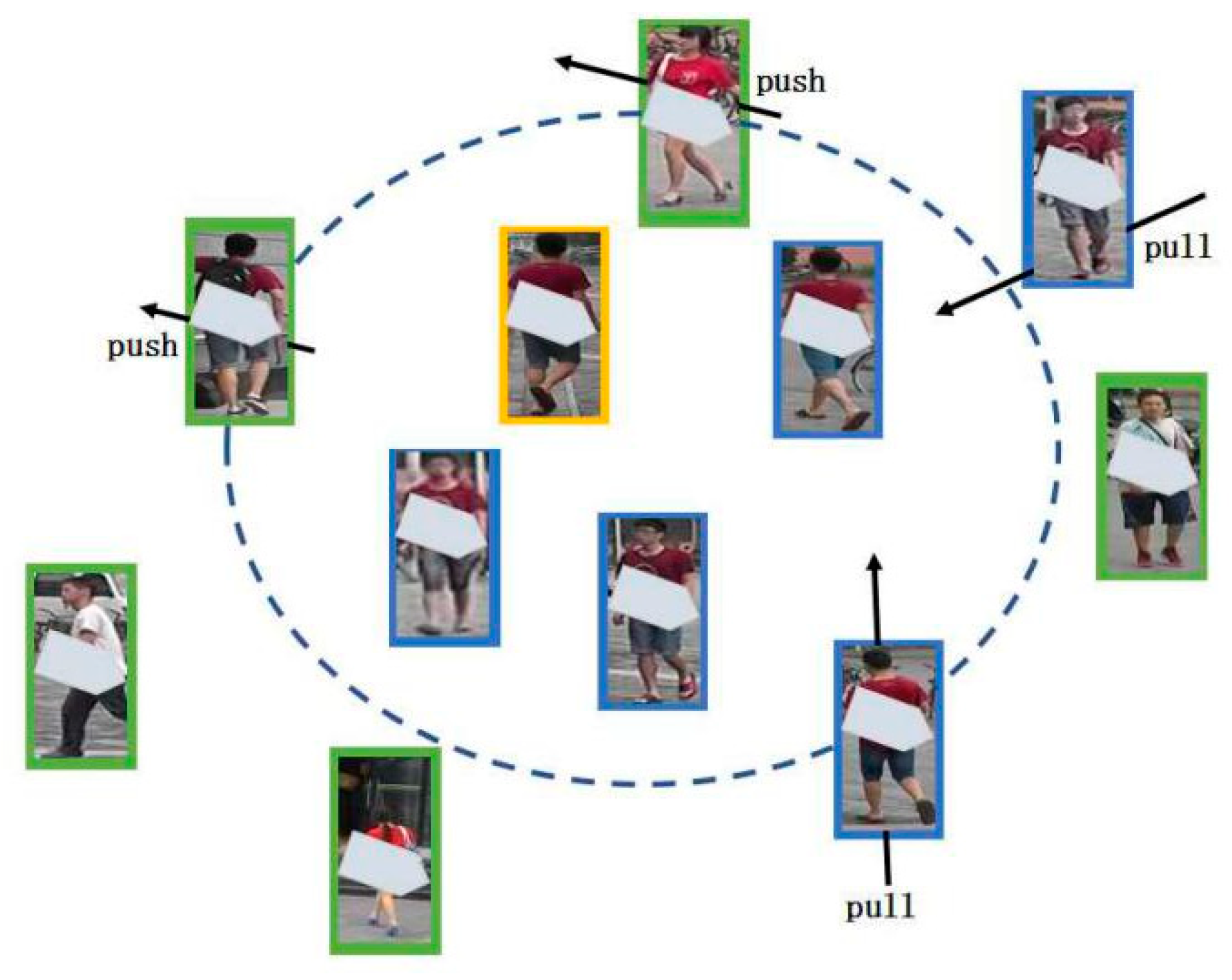
3.2. Cross-Camera Global Feature Learning
3.3. Erased Partial Feature Learning
3.4. Joint Global and Partial Feature Learning
4. Results
4.1. Datasets and Evaluation Protocol
4.2. Implementation Details
4.3. Comparison with the State-of-the-Art
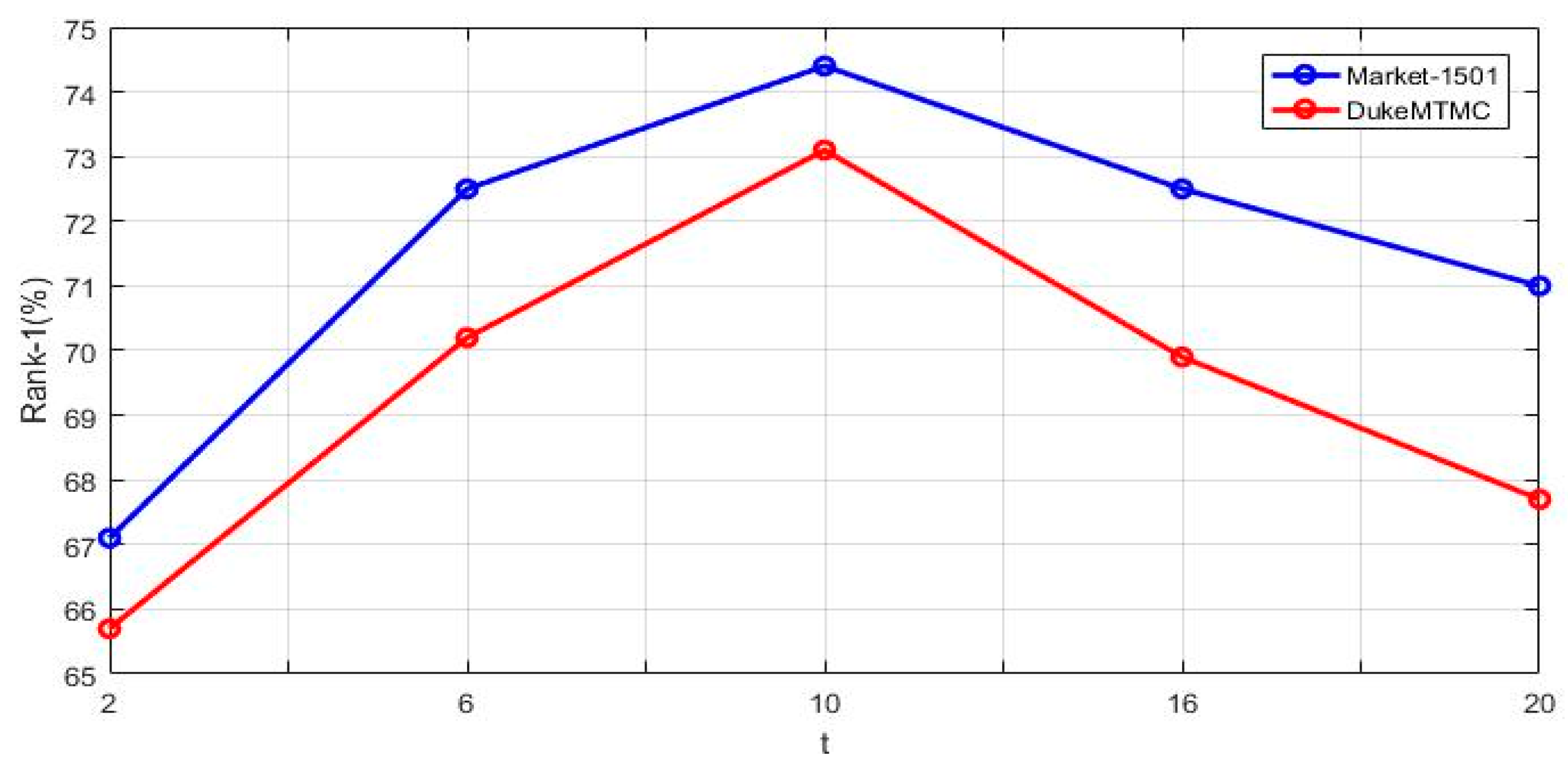
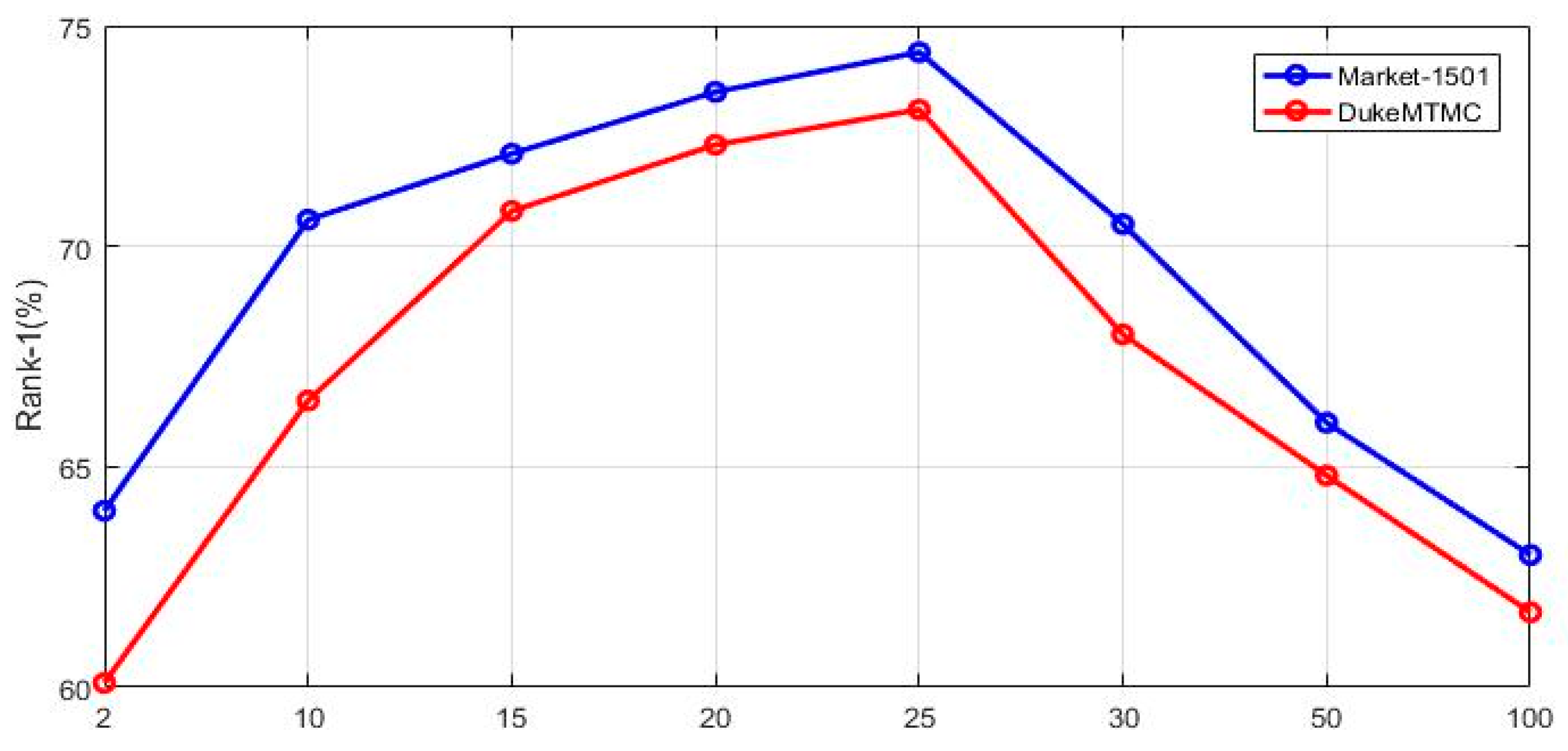
4.4. Experimental Details Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bak, S.; Carr, P.; LaLonde, J.-F. Domain adaptation through synthesis for unsupervised person re-identification. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 189–205. [Google Scholar]
- Chen, Y.-C.; Zhu, X.; Zheng, W.-S.; Lai, J.-H. Person Re-Identification by Camera Correlation Aware Feature Augmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 392–408. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Gong, S.; Zhu, X.; Wang, S. Person Re-Identification by Discriminative Selection in Video Ranking. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2501–2514. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Gong, S.; Zhu, X.; Xiang, T. Human-in-the-Loop Person Re-identification. In Proceedings of the European Conference on Computer Vision, Lecture Notes in Computer Science, Amsterdam, The Netherlands, 8–16 October 2016; Volume 9908, pp. 405–422. [Google Scholar]
- Liao, S.; Hu, Y.; Zhu, X.; Li, S.Z. Person re-identification by Local Maximal Occurrence representation and metric learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2197–2206. [Google Scholar] [CrossRef]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q.; Liang, Z.; Liyue, S.; Lu, T.; ShengJin, W.; et al. Scalable Person Re-identification: A Benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1116–1124. [Google Scholar] [CrossRef]
- Wei, L.; Zhang, S.; Gao, W.; Tian, Q. Person Transfer GAN to Bridge Domain Gap for Person Re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 79–88. [Google Scholar]
- Wang, J.; Zhu, X.; Gong, S.; Li, W. Transferable joint attribute-identity deep learning 3641 for unsupervised person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2275–2284. [Google Scholar]
- Deng, W.; Zheng, L.; Ye, Q.; Kang, G.; Yang, Y.; Jiao, J. Image-image domain adaptation with preserved self-similarity and domain-dissimilarity for person reidentification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 994–1003. [Google Scholar]
- Peixi, P.; Tao, X.; Yaowei, W.; Massimiliano, P.; Shaogang, G.; Tiejun, H.; Yonghong, T. Unsupervised cross-dataset transfer learning for person reidentification. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1306–1315. [Google Scholar] [CrossRef]
- Zhong, Z.; Zheng, L.; Li, S.; Yang, Y. Generalizing a person retrieval model hetero-and homogeneously. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 172–188. [Google Scholar]
- Yu, H.-X.; Wu, A.; Zheng, W.-S. Crossview asymmetric metric learning for unsupervised person reidentification. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 994–1002. [Google Scholar] [CrossRef]
- Yu, H.-X.; Wu, A.; Zheng, W.-S. Unsupervised person re-identification by deep asymmetric metric embedding. Trans. Pattern Anal. Mach. Intell. 2020, 42, 956–973. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.; Dong, X.; Zheng, L.; Yan, Y.; Yang, Y. A Bottom-up Clustering Approach to Unsupervised Person Re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27–28 January 2019; pp. 8738–8745. [Google Scholar]
- Yu, H.; Zheng, W.; Wu, A.; Guo, X.; Gong, S.; Lai, J. Unsupervised Person Re-identification by Soft Multi-label Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2148–2157. [Google Scholar]
- Zhong, Z.; Zheng, L.; Zheng, Z.; Li, S.; Yang, Y. Camera Style Adaptation for Person Re-identification. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 172–188. [Google Scholar]
- Ergys, R.; Francesco, S.; Roger, Z.; Rita, C.; Carlo, T. Performance measures and a data set for multi-target, multi-camera tracking. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Li, W.; Zhu, X.; Gong, S. Harmonious attention network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2285–2294. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S.W. Beyond part models: Person retrieval with refined part pooling. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. Deepreid: Deep filter pairing neural network for person re-identification. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), OhioComp, DC, USA, 24–27 June 2014; pp. 152–159. [Google Scholar]
- Xiao, T.; Li, H.; Ouyang, W.; Wang, X. Learning deep feature representations with domain guided dropout for person reidentification. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1249–1258. [Google Scholar]
- Cheng, D.; Gong, Y.; Zhou, S.; Wang, J.; Zheng, N. Person re-identificaiton by multi-channel parts-based cnn with improved triplet loss function. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1335–1344. [Google Scholar]
- Dai, Z.; Chen, M.C.; Gu, X.; Zhu, S.; Tan, P. Batch DropBlock Network for Person Re-identification and Beyond. In Proceedings of the 12th International Conference on Computer Vision Systems, Thessaloniki, Greece, 23–25 September 2019. [Google Scholar]
- Michela, F.; Loris, B.; Alessandro, P.; Vittorio, M.; Marco, C. Person re-identification by symmetry-driven accumulation of local features. In Proceedings of the European Conference on Computer Vision (ECCV), San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Tetsu, M.; Takahiro, O.; Einoshin, S.; Yoichi, S. Hierarchical gaussian descriptor for person re-identification. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Liu, X.; Song, M.; Tao, D.; Zhou, X.; Chen, C.; Bu, J. Semi-supervised coupled dictionary learning for person re-identification. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), OhioComp, DC, USA, 24–27 June 2014; pp. 3550–3557. [Google Scholar]
- Elyor, K.; Tao, X.; Shaogang, G. Dictionary learning with iterative laplacian regularisation for unsupervised person re-identification. Brit. Mac. Vis. Confer. 2015. [Google Scholar] [CrossRef]
- Elyor, K.; Tao, X.; Zhenyong, F.; Shaogang, G. Person re-identification by unsupervised l1 graph learning. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 178–195. [Google Scholar]
- Hehe, F.; Liang, Z.; Yi, Y. Unsupervised person re-identification: Clustering and fine-tuning. Trans. Pat. Ana. Mac. Intel. 2017, 994–1002. [Google Scholar] [CrossRef]
- Yifan, S.; Liang, Z.; Weijian, D.; Shengjin, W. Svdnet for pedestrian retrieval. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3800–3808. [Google Scholar]
- Zhao, L.; Li, X.; Zhuang, Y.; Wang, J. Deeply-learned part-aligned representations for person reidentification. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3219–3228. [Google Scholar] [CrossRef]
- Su, C.; Li, J.; Zhang, S.; Xing, J.; Gao, W.; Tian, Q. Pose-driven deep convolutional model for person re-identification. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3960–3969. [Google Scholar] [CrossRef]
- Zheng, L.; Huang, Y.; Lu, H.; Yang, Y. Pose invariant embedding for deep person re-identification. Trans. Imag. Process. 2017, 4500–4509. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.; Yu, H.-X.; Wu, A.; Zheng, W.-S. Patch-based Discriminative Feature Learning for Unsupervised Person Re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3633–3642. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. Sphereface: Deep hypersphere embedding for face recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Honolulu, HI, USA, 21–26 July 2017; pp. 212–220. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A discriminative feature learning approach for deep face recognition. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; Volume 9911, pp. 499–515. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Market1501 | |||
|---|---|---|---|---|
| Rank-1 | Rank-5 | Rank-10 | mAP | |
| LOMO [5] | 27.2 | 41.6 | 49.1 | 8.0 |
| BoW [6] | 35.8 | 52.4 | 60.3 | 14.8 |
| UMDL [10] | 34.5 | 52.6 | 59.6 | 12.4 |
| PUL [29] | 45.5 | 60.7 | 66.7 | 20.5 |
| CAMEL [30] | 54.5 | − | − | 26.3 |
| DECAMEL [31] | 60.2 | 76.0 | 81.1 | 32.4 |
| PTGAN [7] | 38.6 | − | 66.1 | − |
| SPGAN+LMP [9] | 57.7 | 75.8 | 82.4 | 26.7 |
| TJ-AIDJ [8] | 58.2 | 74.8 | 81.1 | 26.5 |
| HHL [11] | 62.2 | 78.8 | 84.0 | 31.4 |
| BUC [32] | 66.2 | 79.6 | 84.5 | 38.3 |
| MAR [33] | 67.7 | 81.9 | − | 40.0 |
| PAUL [34] | 68.5 | 82.4 | 87.4 | 40.1 |
| EFDL (Ours) | 74.4 | 85.5 | 88.9 | 47.6 |
| Method | DukeMTMC | |||
|---|---|---|---|---|
| Rank-1 | Rank-5 | Rank-10 | mAP | |
| LOMO [5] | 12.3 | 21.3 | 26.6 | 4.8 |
| BoW [6] | 17.1 | 28.8 | 34.9 | 8.3 |
| UMDL [10] | 18.5 | 31.4 | 37.6 | 7.3 |
| PUL [29] | 30.0 | 43.4 | 48.5 | 16.4 |
| PTGAN [7] | 27.4 | − | 50.7 | − |
| SPGAN+LMP [9] | 46.4 | 62.3 | 68.0 | 26.2 |
| TJ-AIDJ [8] | 44.3 | 59.6 | 65.0 | 23.0 |
| HHL [11] | 46.9 | 61.0 | 66.7 | 27.2 |
| BUC [32] | 47.4 | 62.6 | 68.4 | 27.5 |
| MAR [33] | 67.1 | 79.8 | − | 48.0 |
| PAUL [34] | 72.0 | 82.7 | 86.0 | 53.2 |
| EFDL (Ours) | 73.1 | 83.7 | 86.9 | 55.4 |
| Branch | Market-1501 (mAP) | DukeMTMC (mAP) |
|---|---|---|
| CL | 20.2 | 18.8 |
| EL | 23.5 | 32.3 |
| CL+EL | 39.7 | 48.2 |
| CEFL | 47.6 | 55.4 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, S.; Gao, L. Cross-Camera Erased Feature Learning for Unsupervised Person Re-Identification. Algorithms 2020, 13, 193. https://doi.org/10.3390/a13080193
Wu S, Gao L. Cross-Camera Erased Feature Learning for Unsupervised Person Re-Identification. Algorithms. 2020; 13(8):193. https://doi.org/10.3390/a13080193
Chicago/Turabian StyleWu, Shaojun, and Ling Gao. 2020. "Cross-Camera Erased Feature Learning for Unsupervised Person Re-Identification" Algorithms 13, no. 8: 193. https://doi.org/10.3390/a13080193
APA StyleWu, S., & Gao, L. (2020). Cross-Camera Erased Feature Learning for Unsupervised Person Re-Identification. Algorithms, 13(8), 193. https://doi.org/10.3390/a13080193