Towards Cognitive Recommender Systems

 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
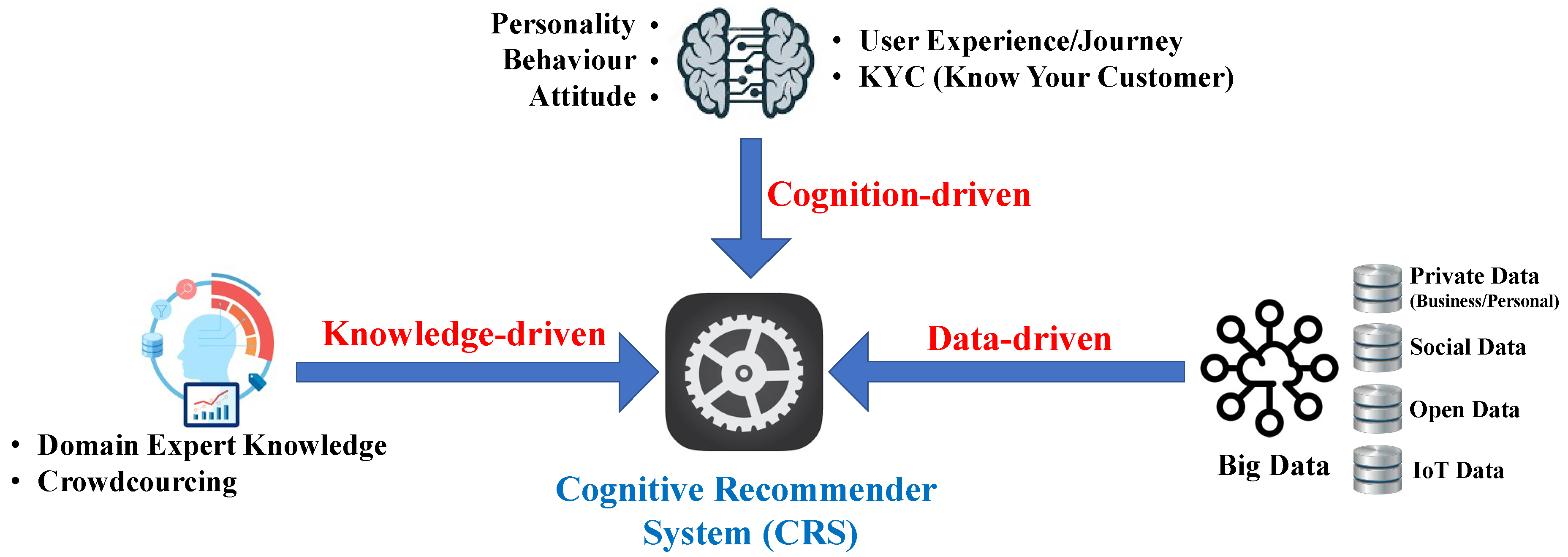
- data-driven—which enables leveraging Artificial Intelligence and Machine Learning technologies to contextualize the Big Data generated on Open, Private and Social platforms/systems to improve the accuracy of recommendations [14]. The goal is to facilitate the use of content and collaborative filtering, and focus on the shift from statistical modeling to deep learning-based modeling (Deep Learning Recommendation Models) to improve correlations between features and attributes to generate better predictions;
- cognition-driven—which enables understanding the users’ personality and analyze their behaviour and attitude over time. The goal is to improve recommendation performance with cognitive science and Neural Magic by leveraging neural embedding frameworks, include our previous work, Personality2Vec [17], to design mechanisms for personalized task recommendation.
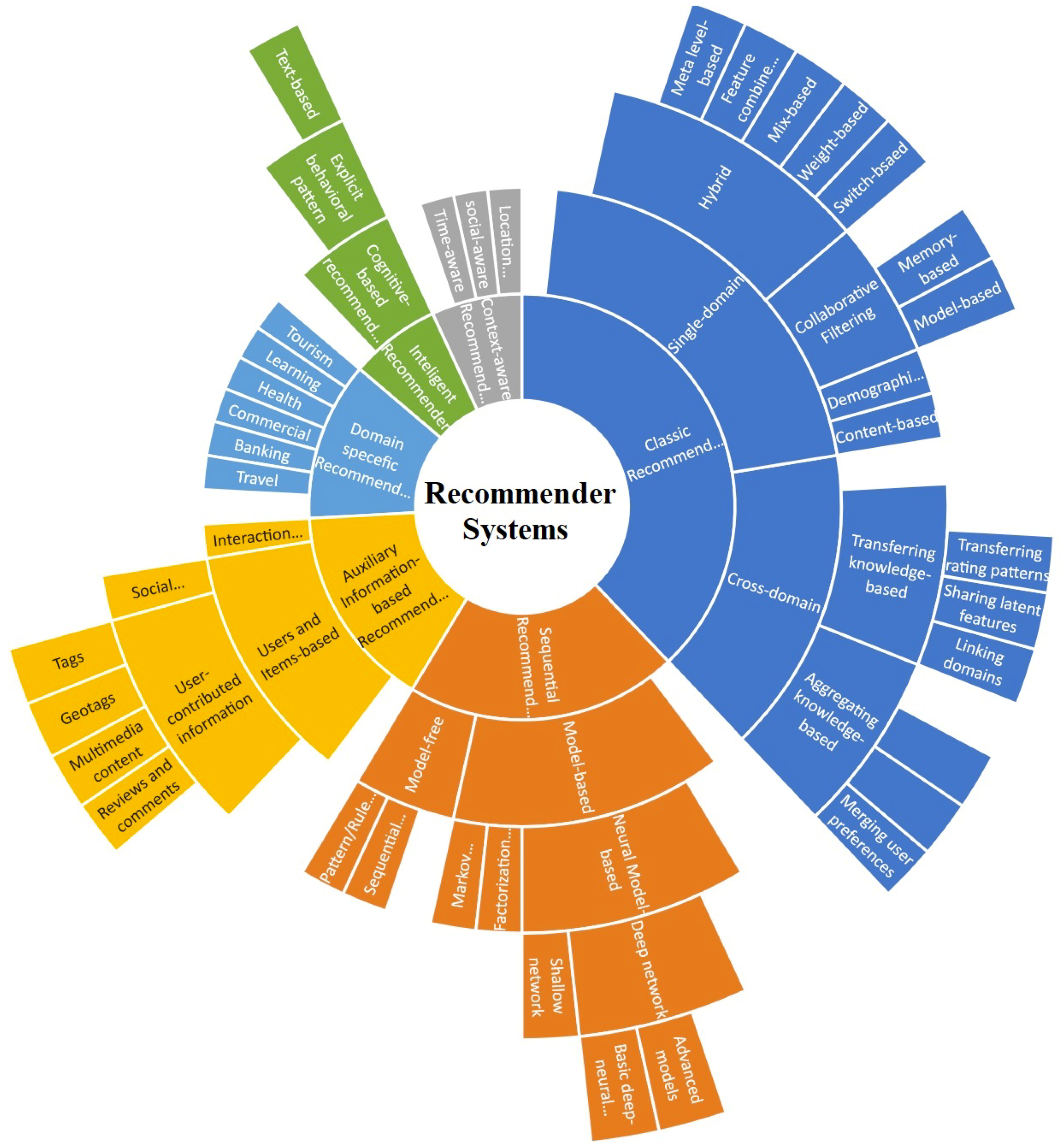
2. Background and Related Work
2.1. Classic Recommender Systems
2.1.1. Single-Domain Recommenders
2.1.2. Cross-Domain Recommenders
2.2. Sequential Recommenders
2.2.1. Model-Free Approaches
2.2.2. Model-Based Approaches
2.3. Context-Aware Recommenders
2.4. Auxiliary Information-Based Recommender
2.4.1. Users and Items-Based
2.4.2. Interaction-Based
2.5. Intelligent Recommenders
2.5.1. Cognitive-Based Recommenders
2.5.2. Crowdsourcing Recommenders
2.5.3. Domain-Specific Recommenders
2.6. Summary of the Related Work
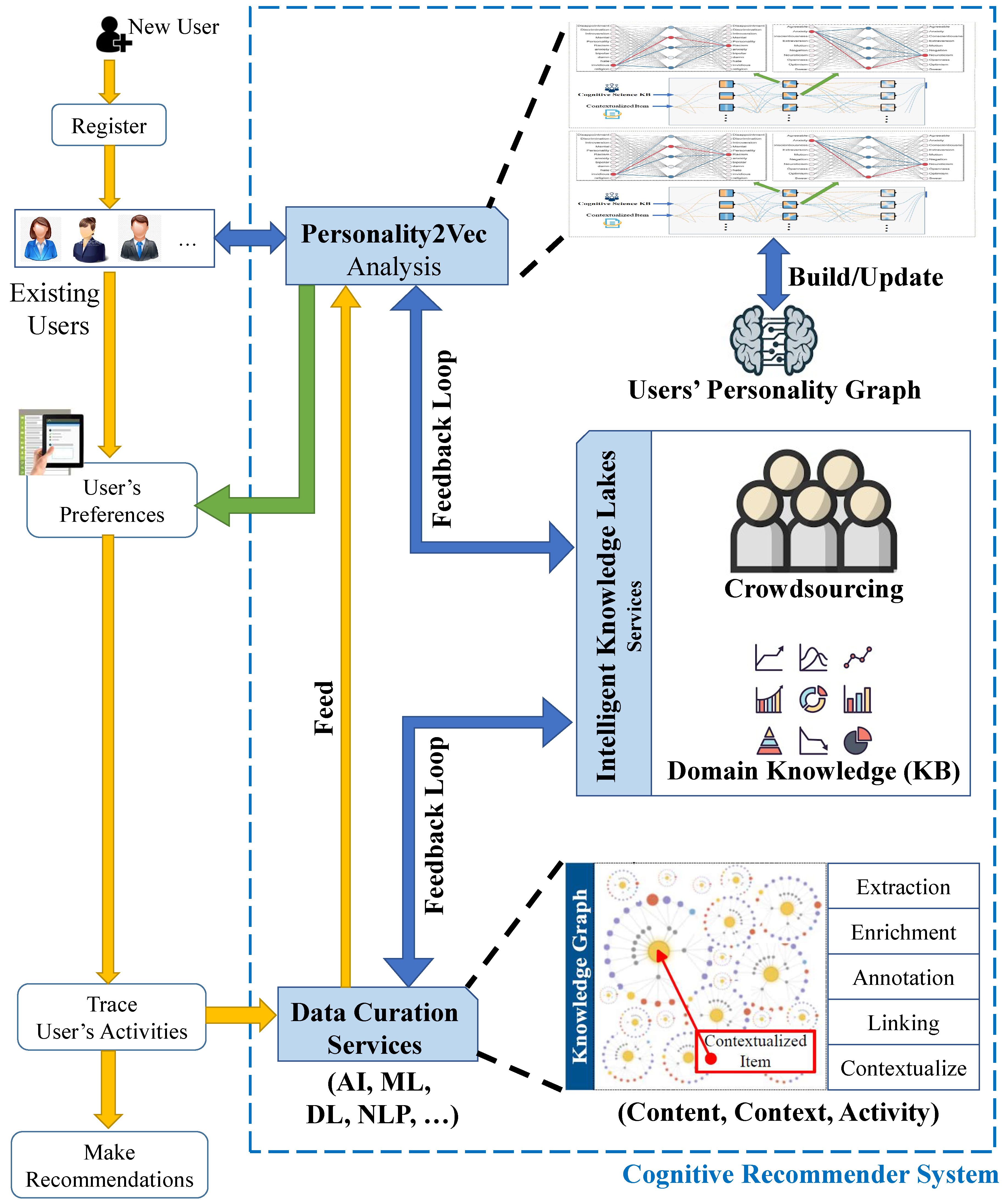
3. A General Framework for Cognitive Recommender Systems
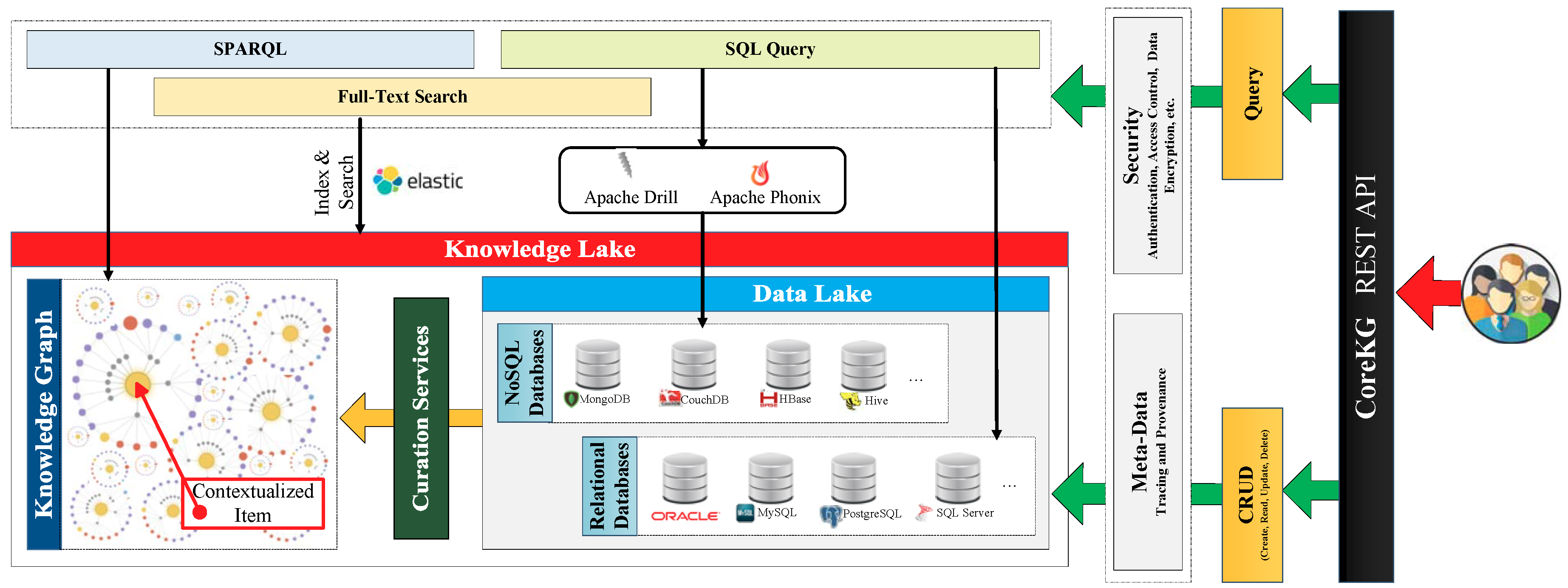
3.1. Data-Driven: Curation Services
3.2. Knowledge-Driven: Intelligent Knowledge Lakes
3.2.1. Domain Knowledge
3.2.2. Crowdsourcing
- Cold-start problem—existing work has been suggesting a user-item rating matrix and users/items information such as user profiles and item contents. However, this information are primarily biased and it will be challenging to identify reliable item neighbors relevant to the cold-start items. In this context, Crowdsourcing has the potential to bring the knowledge of the crowd for new items recommendations. As illustrated in Figure 3, in our proposed approach there are two feedback loops to the crowdsourcing platforms: (i) Data Curation Services Feedback Loop, at this level the Data Curation Services benefits from annotating and enriching the extracted information items from the crowd workers. In particular, we leverage Crowdsourcing techniques to mimic the domain expert knowledge using feedback, surveys, interviews and more, to build a domain specific knowledge base and use that knowledge to improve correlations between features and attributes to generate better predictions. An interesting motivating scenario, would be in risk-aware Recommender Systems, where it would be important to understand the risk level of the customer’s situation (e.g., during the COVID-19 pandemic (https://en.wikipedia.org/wiki/COVID-19_pandemic)), where it may be dangerous to recommend items the user may not desire in her current situation if the risk level is high. Accordingly, the aim of a Cognitive Recommender System is to use rules together with techniques such as learning and crowdsourcing to strengthen desirable and accurate recommendations and minimize or eliminate undesirable recommendations;(ii) Personality2vec Analysis Feedback Loop, at this level we will leverage the knowledge of the crowd to understand changes in user’s behaviour and feedback, such as ratings and clicks, as well as detecting information about environment changes, such as changes in location and time, while the user is travelling.
- Bias and Variance—Given that the features and related data used for training recommendations generated by algorithms and gathered by humans, biases may get into data preparation and training phases. This is mainly because the big data generated on a large scale, never-ending, and ever-changing. To address this challenge we leverage our previous work [101,102] which combines the crowdsourcing techniques and link them back to rule-based systems to generate feedback loops that can be adopted over-time to deal with Biases (i.e., the simplifying assumptions made by the model to make the target function easier to approximate) and Variance (i.e., the amount that the estimate of the target function will change given different training data).
3.3. Cognition-Driven: Personality2Vec
- : which specifies that a customer applied for a car loan on a specific date T1 (YY/MM/DD).
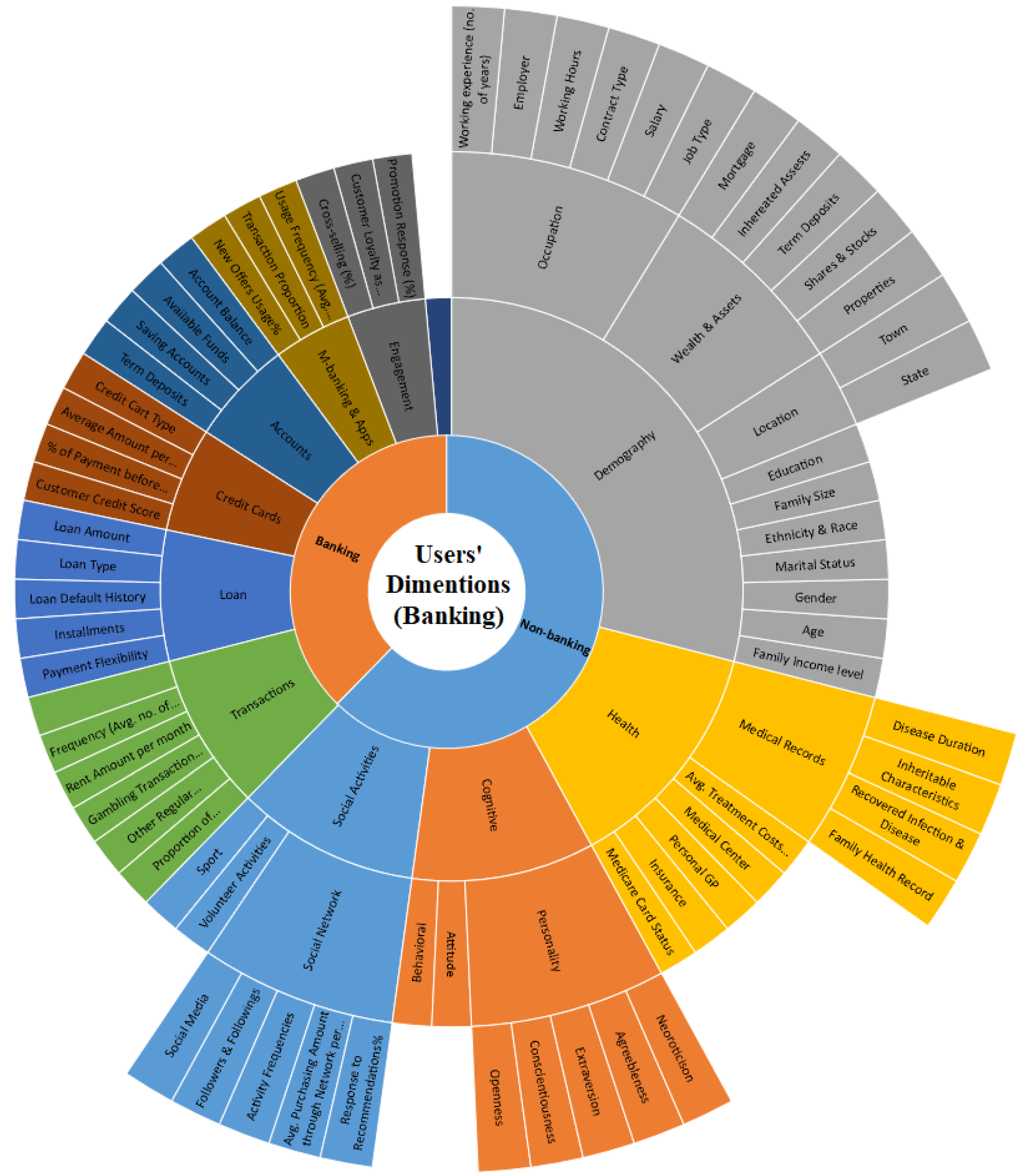
- : which specifies that at timestamp T1 the customers wealth and assets analysis shows a healthy sign. This can be done through an automatic trigger for Wealth-assets analysis (see the demography category in Figure 6) when the customer applies for a loan.
- : which specifies that at timestamp T1 the customer has a valid health insurance. This can be done through an automatic trigger for health analysis (see the category health in Figure 6) when the customer applies for a loan.
- : which specifies that at timestamp T1 the customer has a valid credit card with no background issue (e.g., late payments, fraudulent card applications, or skimming). This can be done through an automatic trigger for a credit check process (see the ontology in Figure 6) when the customer applies for a loan.
- : which specifies that at timestamp T1 the customers’ transactions involved no risks or frauds such as suspicious transactions to blacklisted partners/countries. This can be done through an automatic trigger for a transaction check process (see the ontology in Figure 6) when the customer applies for a loan.
- : which specifies that at timestamp T1 the customers’ social activities does not include any risks such as radicalization, money laundering or child pornography. This can be done through an automatic trigger for a social activity check process (Figure 6) when the customer applies for a loan.
4. Experimental Settings and Analysis
4.1. Users’ Personality Acquisition
- “Openness to Experience: creative, open-minded, curious, reflective, and not conventional”.
- “Agreeableness: cooperative, trusting, generous, helpful, nurturing, not aggressive or cold”.
- “Extroversion: Assertive, amicable, outgoing, sociable, active, not reserved or shy”.
- “Conscientiousness: preserving, organized, and responsible”.
- “Neuroticism (Emotional Stability): relaxed, self-confident, not moody, easily upset, or easily stressed”.
4.2. Dataset
4.3. Evaluation Metrics
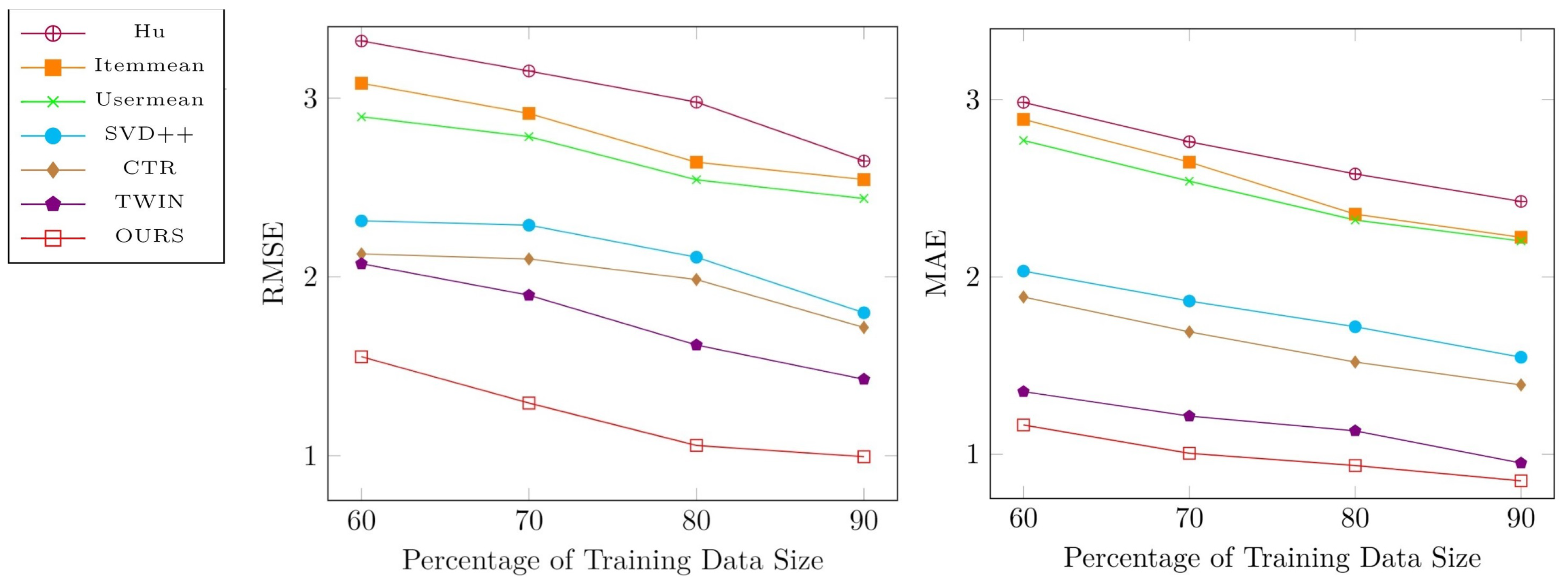
4.4. Performance Analysis and Comparison
5. Conclusions and Future Work
- A future direction in context-aware recommendations would be to build users’ personality graph for different contexts, such as time, location, health and education. Considering this important factor into account may result in enhancing the accuracy of RSs, since users usually make different decisions in different situations.
- A future direction in Cross-domain recommendations would be to build the users’ personality graph in the source domain and then make a recommendation in the target domain. This is important as in related domains such as movies and books, users’ behaviour may be similar. This can help us to not only improve the recommendation performance but also deal with the cold-start problem when new user joins a system and there is a lack of available information about him/her.
- Time-aware Cognitive RSs is another opening research domain. The main goal of cognitive RSs is to use state-of-the-art models and techniques to be able to understand human’s behaviour and make smart recommendations. However, in real-world scenarios, users’ behaviours may change over time. Hence, detecting changes in users’ activities and behaviours may open the door to various potential research directions.
- Group-aware Cognitive RSs can be another interesting future work. In this context, relating users’ personality graphs may discover similar interests and thus helping to overcome data sparsity problem in RSs.
- Another interesting line of work would be a Multi-step interactive Cognitive RS. Usually, the users’ decision-making process may contain multiple steps rather than just one step. Interact with users through a feedback loop at each step can help RSs to fully understand the users’ needs and interests.
- Another future work direction would focus on using gamification techniques (e.g., BitLife (https://bitlife-life-simulator.fandom.com/)) to learn from the RS users’ activities as well as decision making (how they choose the best next steps in specific situations) and enable the Cognitive RS to think and learn like a human, led to more humanized recommendations.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ricci, F.; Rokach, L.; Shapira, B. (Eds.) Recommender Systems Handbook; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Jannach, D.; Zanker, M.; Felfernig, A.; Friedrich, G. Recommender Systems—An Introduction; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Wang, S.; Hu, L.; Wang, Y.; Cao, L.; Sheng, Q.Z.; Orgun, M.A. Sequential Recommender Systems: Challenges, Progress and Prospects. arXiv 2020, arXiv:2001.04830. [Google Scholar]
- Adomavicius, G.; Tuzhilin, A. Toward the Next Generation of Recommender Systems: A Survey of the State-of-the-Art and Possible Extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Wang, S.; Cao, L.; Wang, Y. A Survey on Session-based Recommender Systems. arXiv 2019, arXiv:1902.04864. [Google Scholar]
- Beheshti, S.; Benatallah, B.; Sakr, S.; Grigori, D.; Motahari-Nezhad, H.R.; Barukh, M.C.; Gater, A.; Ryu, S.H. Process Analytics—Concepts and Techniques for Querying and Analyzing Process Data; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar] [CrossRef]
- Ying, H.; Zhuang, F.; Zhang, F.; Liu, Y.; Xu, G.; Xie, X.; Xiong, H.; Wu, J. Sequential Recommender System based on Hierarchical Attention Networks. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 3926–3932. [Google Scholar]
- Chen, X.; Xu, H.; Zhang, Y.; Tang, J.; Cao, Y.; Qin, Z.; Zha, H. Sequential Recommendation with User Memory Networks. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018; pp. 108–116. [Google Scholar]
- Huang, J.; Zhao, W.X.; Dou, H.; Wen, J.; Chang, E.Y. Improving Sequential Recommendation with Knowledge-Enhanced Memory Networks. In Proceedings of the41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 505–514. [Google Scholar]
- Nilsson, N.J. Principles of Artificial Intelligence; Morgan Kaufmann: Burlington, MA, USA, 2014. [Google Scholar]
- Markman, A.B. Knowledge Representation; Psychology Press: London, UK, 2013. [Google Scholar]
- Hassenzahl, M.; Tractinsky, N. User experience-a research agenda. Behav. Inf. Technol. 2006, 25, 91–97. [Google Scholar] [CrossRef]
- Howe, J. The rise of crowdsourcing. Wired Mag. 2006, 14, 1–4. [Google Scholar]
- Beheshti, A.; Benatallah, B.; Tabebordbar, A.; Motahari-Nezhad, H.R.; Barukh, M.C.; Nouri, R. DataSynapse: A Social Data Curation Foundry. Distrib. Parallel Databases 2019, 37, 351–384. [Google Scholar] [CrossRef]
- Beheshti, A.; Benatallah, B.; Sheng, Q.Z.; Schiliro, F. Intelligent Knowledge Lakes: The Age of Artificial Intelligence and Big Data. In Proceedings of the Web Information Systems Engineering—WISE 2019 Workshop, Demo, and Tutorial, Hong Kong and Macau, China, 19–22 January 2020; U, L.H., Yang, J., Cai, Y., Karlapalem, K., Liu, A., Huang, X., Eds.; Revised Selected Papers; Communications in Computer and Information Science. Springer: Berlin/Heidelberg, Germany, 2019; Volume 1155, pp. 24–34. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Beheshti, A.; Hashemi, V.M.; Yakhchi, S.; Motahari-Nezhad, H.R.; Ghafari, S.M.; Yang, J. personality2vec: Enabling the Analysis of Behavioral Disorders in Social Networks. In Proceedings of the WSDM ’20: The Thirteenth ACM International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; pp. 825–828. [Google Scholar] [CrossRef]
- Salton, G. Automatic Text Processing: The Transformation, Analysis, and Retrieval of Information by Computer; Addison-Wesley: Boston, MA, USA, 1989. [Google Scholar]
- Pelikán, E. Principles of Forecasting—A Short Overview. In Proceedings of the SOFSEM ’99, Theory and Practice of Informatics, 26th Conference on Current Trends in Theory and Practice of Informatics, Milovy, Czech Republic, 27 November–4 December 1999; Pavelka, J., Tel, G., Bartosek, M., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 1999; Volume 1725, pp. 311–327. [Google Scholar]
- Lilien, G.L.; Rao, A.G. A Model for Allocating Retail Outlet Building Resources across Market Areas. Oper. Res. 1976, 24, 1–14. [Google Scholar] [CrossRef][Green Version]
- Rich, E. User Modeling via Stereotypes. Cogn. Sci. 1979, 3, 329–354. [Google Scholar] [CrossRef]
- Fernández-Tobías, I.; Cantador, I.; Kaminskas, M.; Ricci, F. Cross-domain recommender systems: A survey of the State of the Art. In Proceedings of the 2nd Spanish Conference on Information Retrieval, Valencia, Spain, 17–19 June 2012. [Google Scholar]
- Baeza-Yates, R.A.; Ribeiro-Neto, B.A. Modern Information Retrieval; ACM Press/Addison-Wesley: Boston, MA, USA, 1999. [Google Scholar]
- Si, L.; Jin, R. Flexible Mixture Model for Collaborative Filtering. In Proceedings of the 20th International Conference on Machine Learning (ICML 2003), Washington, DC, USA, 21–24 August 2003; pp. 704–711. [Google Scholar]
- Singhal, A. Modern Information Retrieval: A Brief Overview. IEEE Data Eng. Bull. 2001, 24, 35–43. [Google Scholar]
- Pazzani, M.J. A Framework for Collaborative, Content-Based and Demographic Filtering. Artif. Intell. Rev. 1999, 13, 393–408. [Google Scholar] [CrossRef]
- Zhao, W.X.; Guo, Y.; He, Y.; Jiang, H.; Wu, Y.; Li, X. We know what you want to buy: A demographic-based system for product recommendation on microblogs. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’14, New York, NY, USA, 24–27 August 2014; pp. 1935–1944. [Google Scholar]
- Balabanovic, M.; Shoham, Y. Content-Based, Collaborative Recommendation. Commun. ACM 1997, 40, 66–72. [Google Scholar] [CrossRef]
- Cotter, P.; Smyth, B. PTV: Intelligent Personalised TV Guides. In Proceedings of the Seventeenth National Conference on Artificial Intelligence and Twelfth Conference on on Innovative Applications of Artificial Intelligence, Austin, TX, USA, 30 July–3 August 2000; Kautz, H.A., Porter, B.W., Eds.; AAAI Press/The MIT Press: Cambridge, MA, USA, 2000; pp. 957–964. [Google Scholar]
- Sahebi, S.; Brusilovsky, P. Cross-Domain Collaborative Recommendation in a Cold-Start Context: The Impact of User Profile Size on the Quality of Recommendation. In User Modeling, Adaptation, and Personalization, Proceedings of the 21th International Conference, UMAP 2013, Rome, Italy, 10–14 June 2013; Carberry, S., Weibelzahl, S., Micarelli, A., Semeraro, G., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7899, pp. 289–295. [Google Scholar]
- Shapira, B.; Rokach, L.; Freilikhman, S. Facebook single and cross domain data for recommendation systems. User Model. User-Adapt. Interact. 2013, 23, 211–247. [Google Scholar] [CrossRef]
- Berkovsky, S.; Kuflik, T.; Ricci, F. Mediation of user models for enhanced personalization in recommender systems. User Model. User-Adapt. Interact. 2008, 18, 245–286. [Google Scholar] [CrossRef]
- Berkovsky, S.; Kuflik, T.; Ricci, F. Distributed collaborative filtering with domain specialization. In Proceedings of the 2007 ACM Conference on Recommender Systems, RecSys 2007, Minneapolis, MN, USA, 19–20 October 2007; pp. 33–40. [Google Scholar]
- Givon, S.; Lavrenko, V. Predicting social-tags for cold start book recommendations. In Proceedings of the 2009 ACM Conference on Recommender Systems, RecSys 2009, New York, NY, USA, 23–25 October 2009; pp. 333–336. [Google Scholar]
- Chung, R.; Sundaram, D.; Srinivasan, A. Integrated personal recommender systems. In Proceedings of the 9th International Conference on Electronic Commerce: The Wireless World of Electronic Commerce, University of Minnesota, Minneapolis, MN, USA, 19–22 August 2007; Volume 258, pp. 65–74. [Google Scholar]
- Koren, Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 426–434. [Google Scholar]
- Pan, W.; Xiang, E.W.; Liu, N.N.; Yang, Q. Transfer Learning in Collaborative Filtering for Sparsity Reduction. In Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2010, Atlanta, GA, USA, 11–15 July 2010. [Google Scholar]
- Pan, W.; Liu, N.N.; Xiang, E.W.; Yang, Q. Transfer Learning to Predict Missing Ratings via Heterogeneous User Feedbacks. In Proceedings of the 22nd International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011; pp. 2318–2323. [Google Scholar]
- Abel, F.; Bittencourt, I.I.; Henze, N.; Krause, D.; Vassileva, J. A Rule-Based Recommender System for Online Discussion Forums. In Adaptive Hypermedia and Adaptive Web-Based Systems, 5th International Conference, AH 2008, Hannover, Germany, 29 July–1 August 2008. Proceedings; Nejdl, W., Kay, J., Pu, P., Herder, E., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5149, pp. 12–21. [Google Scholar]
- Lin, W.; Alvarez, S.A.; Ruiz, C. Efficient Adaptive-Support Association Rule Mining for Recommender Systems. Data Min. Knowl. Discov. 2002, 6, 83–105. [Google Scholar] [CrossRef]
- Huang, Z.; Chen, H.; Zeng, D.D. Applying associative retrieval techniques to alleviate the sparsity problem in collaborative filtering. ACM Trans. Inf. Syst. 2004, 22, 116–142. [Google Scholar] [CrossRef]
- Song, W.; Yang, K. Personalized Recommendation Based on Weighted Sequence Similarity. In Practical Applications of Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2014; pp. 657–666. [Google Scholar]
- Le, D.; Fang, Y.; Lauw, H.W. Modeling Sequential Preferences with Dynamic User and Context Factors. In Machine Learning and Knowledge Discovery in Databases, Proceedings of the European Conference, ECML PKDD 2016, Riva del Garda, Italy, 19–23 September 2016, Proceedings, Part II; Frasconi, P., Landwehr, N., Manco, G., Vreeken, J., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9852, pp. 145–161. [Google Scholar]
- Zhang, Z.; Nasraoui, O. Efficient Hybrid Web Recommendations Based on Markov Clickstream Models and Implicit Search. In Proceedings of the 2007 IEEE/WIC/ACM International Conference on Web Intelligence, WI 2007, Silicon Valley, CA, USA, 2–5 November 2007; IEEE Computer Society: Washington, DC, USA, 2007; pp. 621–627. [Google Scholar]
- Chen, S.; Moore, J.L.; Turnbull, D.; Joachims, T. Playlist prediction via metric embedding. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD’12, Beijing, China, 12–16 August 2012; pp. 714–722. [Google Scholar]
- Hidasi, B.; Tikk, D. General factorization framework for context-aware recommendations. Data Min. Knowl. Discov. 2016, 30, 342–371. [Google Scholar] [CrossRef]
- Rendle, S.; Freudenthaler, C.; Schmidt-Thieme, L. Factorizing personalized Markov chains for next-basket recommendation. In Proceedings of the 19th International Conference on World Wide Web, WWW 2010, Raleigh, NC, USA, 26–30 April 2010; pp. 811–820. [Google Scholar]
- Goth, G. Deep or shallow, NLP is breaking out. Commun. ACM 2016, 59, 13–16. [Google Scholar] [CrossRef]
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep Learning Based Recommender System: A Survey and New Perspectives. ACM Comput. Surv. 2019, 52, 5:1–5:38. [Google Scholar] [CrossRef]
- Wu, C.; Ahmed, A.; Beutel, A.; Smola, A.J.; Jing, H. Recurrent Recommender Networks. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, WSDM 2017, Cambridge, UK, 6–10 February 2017; pp. 495–503. [Google Scholar]
- Yuan, F.; Karatzoglou, A.; Arapakis, I.; Jose, J.M.; He, X. A Simple Convolutional Generative Network for Next Item Recommendation. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, WSDM 2019, Melbourne, Australia, 11–15 February 2019; pp. 582–590. [Google Scholar]
- Wu, S.; Tang, Y.; Zhu, Y.; Wang, L.; Xie, X.; Tan, T. Session-Based Recommendation with Graph Neural Networks. In Proceedings of the The Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, Honolulu, HI, USA, 27 January–1 February 2019; pp. 346–353. [Google Scholar]
- Wang, S.; Hu, L.; Cao, L.; Huang, X.; Lian, D.; Liu, W. Attention-Based Transactional Context Embedding for Next-Item Recommendation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, LA, USA, 2–7 February 2018; pp. 2532–2539. [Google Scholar]
- Tang, J.; Belletti, F.; Jain, S.; Chen, M.; Beutel, A.; Xu, C.; Chi, E.H. Towards Neural Mixture Recommender for Long Range Dependent User Sequences. In Proceedings of the World Wide Web Conference, WWW 2019, San Francisco, CA, USA, 13–17 May 2019; pp. 1782–1793. [Google Scholar]
- Adomavicius, G.; Tuzhilin, A. Context-Aware Recommender Systems. In Recommender Systems Handbook; Ricci, F., Rokach, L., Shapira, B., Kantor, P.B., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 217–253. [Google Scholar]
- Wilson, E. Corpora as Expert Knowledge Domains: The Oxford Advanced Learner’s Dictionary. In Database and Expert Systems Applications, 4th International Conference, DEXA’93, Prague, Czech Republic, 6–8 September 1993, Proceedings; Marík, V., Lazanský, J., Wagner, R.R., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1993; Volume 720, pp. 428–435. [Google Scholar]
- Webster, M. Merriam-Webster. 2006. Available online: https://www.docketalarm.com/cases/PTAB/IPR2013-00342/Inter_Partes_Review_of_U.S._Pat._8323060/11-21-2014-Board/Exhibit-3001-Exhibit_3001/ (accessed on 1 July 2020).
- Lieberman, H.; Selker, T. Out of context: Computer systems that adapt to, and learn from, context. IBM Syst. J. 2000, 39, 617–632. [Google Scholar] [CrossRef]
- Hong, J.; Suh, E.; Kim, S. Context-aware systems: A literature review and classification. Expert Syst. Appl. 2009, 36, 8509–8522. [Google Scholar] [CrossRef]
- Schilit, B.N.; Theimer, M.M. Disseminating active map information to mobile hosts. Netw. IEEE 1994, 8, 22–32. [Google Scholar] [CrossRef]
- del Carmen Rodríguez-Hernández, M.; Ilarri, S.; Lado, R.T.; Hermoso, R. Location-Aware Recommendation Systems: Where We Are and Where We Recommend to Go. In Proceedings of the Workshop on Location-Aware Recommendations, LocalRec 2015, Co-Located with the 9th ACM Conference on Recommender Systems (RecSys 2015), Vienna, Austria, 19 September 2015; Volume 1405, pp. 1–8. [Google Scholar]
- Baltrunas, L.; Amatriain, X. Towards time-dependant recommendation based on implicit feedback. In Proceedings of the Third ACM Conference on Recommender Systems; ACM: New York, NY, USA, 2009. [Google Scholar]
- Daly, E.M.; Haahr, M. Social Network Analysis for Information Flow in Disconnected Delay-Tolerant MANETs. IEEE Trans. Mob. Comput. 2009, 8, 606–621. [Google Scholar] [CrossRef]
- Shi, Y.; Larson, M.A.; Hanjalic, A. Collaborative Filtering beyond the User-Item Matrix: A Survey of the State of the Art and Future Challenges. ACM Comput. Surv. 2014, 47, 3:1–3:45. [Google Scholar] [CrossRef]
- Agarwal, D.; Chen, B. Regression-based latent factor models. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; IV, J.F.E., Fogelman-Soulié, F., Flach, P.A., Zaki, M.J., Eds.; ACM: New York, NY, USA, 2009; pp. 19–28. [Google Scholar]
- Koenigstein, N.; Dror, G.; Koren, Y. Yahoo! music recommendations: Modeling music ratings with temporal dynamics and item taxonomy. In Proceedings of the 2011 ACM Conference on Recommender Systems, RecSys 2011, Chicago, IL, USA, 23–27 October 2011; Mobasher, B., Burke, R.D., Jannach, D., Adomavicius, G., Eds.; ACM: New York, NY, USA, 2011; pp. 165–172. [Google Scholar]
- Moshfeghi, Y.; Piwowarski, B.; Jose, J.M. Handling data sparsity in collaborative filtering using emotion and semantic based features. In Proceeding of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2011, Beijing, China, 25–29 July 2011; Ma, W., Nie, J., Baeza-Yates, R., Chua, T., Croft, W.B., Eds.; ACM: New York, NY, USA, 2011; pp. 625–634. [Google Scholar]
- Kwak, H.; Lee, C.; Park, H.; Moon, S.B. What is Twitter, a social network or a news media? In Proceedings of the 19th International Conference on World Wide Web, WWW 2010, Raleigh, NC, USA, 26–30 April 2010; Rappa, M., Jones, P., Freire, J., Chakrabarti, S., Eds.; ACM: New York, NY, USA, 2010; pp. 591–600. [Google Scholar]
- Konstas, I.; Stathopoulos, V.; Jose, J.M. On social networks and collaborative recommendation. In Proceedings of the 32nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2009, Boston, MA, USA, 19–23 July 2009; Allan, J., Aslam, J.A., Sanderson, M., Zhai, C., Zobel, J., Eds.; ACM: New York, NY, USA, 2009; pp. 195–202. [Google Scholar]
- Robu, V.; Halpin, H.; Shepherd, H. Emergence of consensus and shared vocabularies in collaborative tagging systems. TWEB 2009, 3, 14:1–14:34. [Google Scholar] [CrossRef]
- Tso-Sutter, K.H.L.; Marinho, L.B.; Schmidt-Thieme, L. Tag-aware recommender systems by fusion of collaborative filtering algorithms. In Proceedings of the 2008 ACM Symposium on Applied Computing (SAC), Fortaleza, Brazil, 16–20 March 2008; Wainwright, R.L., Haddad, H., Eds.; ACM: New York, NY, USA, 2008; pp. 1995–1999. [Google Scholar]
- Cheng, Z.; Caverlee, J.; Lee, K. You are where you tweet: A content-based approach to geo-locating twitter users. In Proceedings of the 19th ACM Conference on Information and Knowledge Management, CIKM 2010, Toronto, ON, Canada, 26–30 October 2010; Huang, J., Koudas, N., Jones, G.J.F., Wu, X., Collins-Thompson, K., An, A., Eds.; ACM: New York, NY, USA, 2010; pp. 759–768. [Google Scholar]
- Davidson, J.; Liebald, B.; Liu, J.; Nandy, P.; Vleet, T.V.; Gargi, U.; Gupta, S.; He, Y.; Lambert, M.; Livingston, B.; et al. The YouTube video recommendation system. In Proceedings of the 2010 ACM Conference on Recommender Systems, RecSys 2010, Barcelona, Spain, 26–30 September 2010; Amatriain, X., Torrens, M., Resnick, P., Zanker, M., Eds.; ACM: New York, NY, USA, 2010; pp. 293–296. [Google Scholar]
- Adomavicius, G.; Mobasher, B.; Ricci, F.; Tuzhilin, A. Context-Aware Recommender Systems. AI Mag. 2011, 32, 67–80. [Google Scholar] [CrossRef]
- Böhmer, M.; Hecht, B.; Schöning, J.; Krüger, A.; Bauer, G. Falling asleep with Angry Birds, Facebook and Kindle: A large scale study on mobile application usage. In Proceedings of the 13th International Conference on Human Computer Interaction with Mobile Devices and Services, Stockholm, Sweden, 30 August–2 September 2011; ACM: New York, NY, USA, 2011; pp. 47–56. [Google Scholar] [CrossRef]
- Hussain, A. Cognitive Computation: An Introduction. Cogn. Comput. 2009, 1, 1–3. [Google Scholar] [CrossRef]
- Gutierrez-Garcia, J.O.; lopez neri, E. Cognitive Computing: A Brief Survey and Open Research Challenges. In Proceedings of the 2015 3rd International Conference on Applied Computing and Information Technology/2nd International Conference on Computational Science and Intelligence, Okayama, Japan, 12–16 July 2015. [Google Scholar] [CrossRef]
- Brasil, L.M.; de Azevedo, F.M.; Barreto, J.M. Hybrid expert system for decision supporting in the medical area: Complexity and cognitive computing. Int. J. Med. Inform. 2001, 63, 19–30. [Google Scholar] [CrossRef]
- Fortino, G.; Guerrieri, A.; Russo, W.; Savaglio, C. Integration of agent-based and Cloud Computing for the smart objects-oriented IoT. In Proceedings of the IEEE 18th International Conference on Computer Supported Cooperative Work in Design, CSCWD 2014, Taiwan, China, 21–23 May 2014; Hou, J., Trappey, A.J.C., Wu, C., Chang, K., Liao, C., Shen, W., Barthès, J.A., Luo, J., Eds.; IEEE: Piscataway, NJ, USA, 2014; pp. 493–498. [Google Scholar]
- Bhati, R.; Prasad, S. Open domain question answering system using cognitive computing. In Proceedings of the 2016 6th International Conference-Cloud System and Big Data Engineering (Confluence), Noida, India, 14–15 January 2016; pp. 34–39. [Google Scholar] [CrossRef]
- Hossain, M.S. Patient State Recognition System for Healthcare Using Speech and Facial Expressions. J. Med. Syst. 2016, 40, 272:1–272:8. [Google Scholar] [CrossRef]
- Zhang, Y. GroRec: A Group-Centric Intelligent Recommender System Integrating Social, Mobile and Big Data Technologies. IEEE Trans. Serv. Comput. 2016, 9, 786–795. [Google Scholar] [CrossRef]
- Ziani, A.; Azizi, N.; Schwab, D.; Aldwairi, M.; Chekkai, N.; Zenakhra, D.; Cheriguene, S. Recommender System Through Sentiment Analysis. In Proceedings of the International Conference on Automatic Control, Telecommunications and Signals, Annaba, Algeria, 11–12 December 2017. [Google Scholar]
- García-Crespo, Á.; Chamizo, J.; Rivera, I.; Mencke, M.; Palacios, R.C.; Gómez-Berbís, J.M. SPETA: Social pervasive e-Tourism advisor. Telemat. Inform. 2009, 26, 306–315. [Google Scholar] [CrossRef]
- Schiaffino, S.N.; Amandi, A. Building an expert travel agent as a software agent. Expert Syst. Appl. 2009, 36, 1291–1299. [Google Scholar] [CrossRef]
- Burke, R.D.; Hammond, K.J.; Young, B.C. Knowledge-Based Navigation of Complex Information Spaces. In Proceedings of the Thirteenth National Conference on Artificial Intelligence and Eighth Innovative Applications of Artificial Intelligence Conference, AAAI 96, IAAI 96, Portland, OR, USA, 4–8 August 1996; Clancey, W.J., Weld, D.S., Eds.; AAAI Press/The MIT Press: Cambridge, MA, USA, 1996; Volume 1, pp. 462–468. [Google Scholar]
- Chen, Z.; Meng, X.; Zhu, B.; Fowler, R.H. WebSail: From On-line Learning to Web Search. Knowl. Inf. Syst. 2002, 4, 219–227. [Google Scholar] [CrossRef]
- Billsus, D.; Pazzani, M.J. User Modeling for Adaptive News Access. User Model. User-Adapt. Interact. 2000, 10, 147–180. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Expert-Driven Validation of Rule-Based User Models in Personalization Applications. Data Min. Knowl. Discov. 2001, 5, 33–58. [Google Scholar] [CrossRef]
- Cortes, C.; Fisher, K.; Pregibon, D.; Rogers, A. Hancock: A language for extracting signatures from data streams. In Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Boston, MA, USA, 20–23 August 2000; Ramakrishnan, R., Stolfo, S.J., Bayardo, R.J., Parsa, I., Eds.; ACM: New York, NY, USA, 2000; pp. 9–17. [Google Scholar]
- Yakhchi, S.; Beheshti, A.; Ghafari, S.M.; Orgun, M.A. Enabling the Analysis of Personality Aspects in Recommender Systems. arXiv 2020, arXiv:2001.04825. [Google Scholar]
- Ghafari, S.M.; Yakhchi, S.; Beheshti, A.; Orgun, M.A. SETTRUST: Social Exchange Theory Based Context-Aware Trust Prediction in Online Social Networks. In Data Quality and Trust in Big Data—5th International Workshop, QUAT 2018, Held in Conjunction with WISE 2018, Dubai, UAE, 12–15 November 2018; Hacid, H., Sheng, Q.Z., Yoshida, T., Sarkheyli, A., Zhou, R., Eds.; Revised Selected Papers; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11235, pp. 46–61. [Google Scholar]
- Morita, M.; Shinoda, Y. Information Filtering Based on User Behavior Analysis and Best Match Text Retrieval; Springer: London, UK, 1994. [Google Scholar]
- Aldhahri, E.; Shandilya, V.; Shiva, S.G. Towards an Effective Crowdsourcing Recommendation System: A Survey of the State-of-the-Art. In Proceedings of the 2015 IEEE Symposium on Service-Oriented System Engineering, SOSE 2015, San Francisco, CA, USA, 30 March–3 April 2015; pp. 372–377. [Google Scholar]
- Meehan, K.; Lunney, T.; Curran, K.; McCaughey, A. Context-aware intelligent recommendation system for tourism. In Proceedings of the 2013 IEEE International Conference on Pervasive Computing and Communications Workshops, PERCOM 2013 Workshops, San Diego, CA, USA, 18–22 March 2013; pp. 328–331. [Google Scholar]
- Lin, C.; Xie, R.; Li, L.; Huang, Z.; Li, T. PRemiSE: Personalized news recommendation via implicit social experts. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management, CIKM’12, Maui, HI, USA, 29 October–2 November 2012; Chen, X., Lebanon, G., Wang, H., Zaki, M.J., Eds.; ACM, 2012; pp. 1607–1611. [Google Scholar]
- Yuen, M.; King, I.; Leung, K. Task Matching in Crowdsourcing. In Proceedings of the 2011 IEEE International Conference on Internet of Things (iThings) & 4th IEEE International Conference on Cyber, Physical and Social Computing (CPSCom), Dalian, China, 19–22 October 2011; pp. 409–412. [Google Scholar]
- Beheshti, A.; Benatallah, B.; Nouri, R.; Tabebordbar, A. CoreKG: A Knowledge Lake Service. Proc. VLDB Endow. 2018, 11, 1942–1945. [Google Scholar] [CrossRef]
- González-Carrasco, I.; Palacios, R.C.; Cuadrado, J.L.L.; García-Crespo, Á.; Ruíz-Mezcua, B. PB-ADVISOR: A private banking multi-investment portfolio advisor. Inf. Sci. 2012, 206, 63–82. [Google Scholar] [CrossRef]
- Beheshti, A.; Benatallah, B.; Nouri, R.; Chhieng, V.M.; Xiong, H.; Zhao, X. CoreDB: A Data Lake Service. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, CIKM 2017, Singapore, 6–10 November 2017; pp. 2451–2454. [Google Scholar]
- Tabebordbar, A.; Beheshti, A.; Benatallah, B.; Barukh, M.C. Adaptive Rule Adaptation in Unstructured and Dynamic Environments. In Web Information Systems Engineering—WISE 2019—20th International Conference, Hong Kong, China, 26–30 November 2019, Proceedings; Cheng, R., Mamoulis, N., Sun, Y., Huang, X., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11881, pp. 326–340. [Google Scholar] [CrossRef]
- Tabebordbar, A.; Beheshti, A. Adaptive rule monitoring system. In Proceedings of the 1st International Workshop on Software Engineering for Cognitive Services, SE4COG@ICSE 2018, Gothenburg, Sweden, 27–28 May 2018; pp. 45–51. [Google Scholar]
- Beheshti, S.; Benatallah, B.; Motahari-Nezhad, H.R. Scalable graph-based OLAP analytics over process execution data. Distrib. Parallel Databases 2016, 34, 379–423. [Google Scholar] [CrossRef]
- Beheshti, S.; Benatallah, B.; Motahari Nezhad, H.R.; Allahbakhsh, M. A Framework and a Language for On-Line Analytical Processing on Graphs. In Web Information Systems Engineering—WISE 2012—13th International Conference, Paphos, Cyprus, 28–30 November 2012. Proceedings; Wang, X.S., Cruz, I.F., Delis, A., Huang, G., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7651, pp. 213–227. [Google Scholar] [CrossRef]
- Narayanan, A.; Chandramohan, M.; Venkatesan, R.; Chen, L.; Liu, Y.; Jaiswal, S. graph2vec: Learning distributed representations of graphs. arXiv 2017, arXiv:1707.05005. [Google Scholar]
- Goldberg, Y.; Levy, O. word2vec Explained: Deriving Mikolov et al.’s negative-sampling word-embedding method. arXiv 2014, arXiv:1402.3722. [Google Scholar]
- Beheshti, S.; Tabebordbar, A.; Benatallah, B.; Nouri, R. On Automating Basic Data Curation Tasks. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017; pp. 165–169. [Google Scholar]
- He, R.; McAuley, J.J. Ups and Downs: Modeling the Visual Evolution of Fashion Trends with One-Class Collaborative Filtering. In Proceedings of the 25th International Conference on World Wide Web, WWW 2016, Montreal, QC, Canada, 11–15 April 2016; pp. 507–517. [Google Scholar]
- McAuley, J.J.; Targett, C.; Shi, Q.; van den Hengel, A. Image-based Recommendations on Styles and Substitutes. arXiv 2015, arXiv:1506.04757. [Google Scholar]
- Burger, J. Introduction to Personality; Scott Foresman and Company: Glenview, IL, USA, 2011. [Google Scholar]
- Funder, D. Personality; W. W. Norton & Company: New York, NY, USA, 2001; pp. 197–221. [Google Scholar]
- Costa, P.; McCrae, R. Domains and Facets: Hierarchical Personality Assessment Using the Revised NEO Personality Inventory. J. Personal. Assess. 1995, 64, 21–50. [Google Scholar] [CrossRef] [PubMed]
- Cantador, I.; Fernández-Tobías, I.; Bellogín, A. Relating Personality Types with User Preferences in Multiple Entertainment Domains. In Late-Breaking Results, Project Papers and Workshop Proceedings of the 21st Conference on User Modeling, Adaptation, and Personalization, Rome, Italy, 10–14 June 2013; Volume 997. [Google Scholar]
- Wang, C.; Blei, D.M. Collaborative topic modeling for recommending scientific articles. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 448–456. [Google Scholar]
- Roshchina, A.; Cardiff, J.; Rosso, P. Evaluating the Similarity Estimator component of the TWIN Personality-based Recommender System. In Proceedings of the Eighth International Conference on Language Resources and Evaluation, LREC 2012, Istanbul, Turkey, 23–25 May 2012; pp. 4098–4102. [Google Scholar]









© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Beheshti, A.; Yakhchi, S.; Mousaeirad, S.; Ghafari, S.M.; Goluguri, S.R.; Edrisi, M.A. Towards Cognitive Recommender Systems. Algorithms 2020, 13, 176. https://doi.org/10.3390/a13080176
Beheshti A, Yakhchi S, Mousaeirad S, Ghafari SM, Goluguri SR, Edrisi MA. Towards Cognitive Recommender Systems. Algorithms. 2020; 13(8):176. https://doi.org/10.3390/a13080176
Chicago/Turabian StyleBeheshti, Amin, Shahpar Yakhchi, Salman Mousaeirad, Seyed Mohssen Ghafari, Srinivasa Reddy Goluguri, and Mohammad Amin Edrisi. 2020. "Towards Cognitive Recommender Systems" Algorithms 13, no. 8: 176. https://doi.org/10.3390/a13080176
APA StyleBeheshti, A., Yakhchi, S., Mousaeirad, S., Ghafari, S. M., Goluguri, S. R., & Edrisi, M. A. (2020). Towards Cognitive Recommender Systems. Algorithms, 13(8), 176. https://doi.org/10.3390/a13080176