Change-Point Detection in Autoregressive Processes via the Cross-Entropy Method


Abstract
1. Introduction
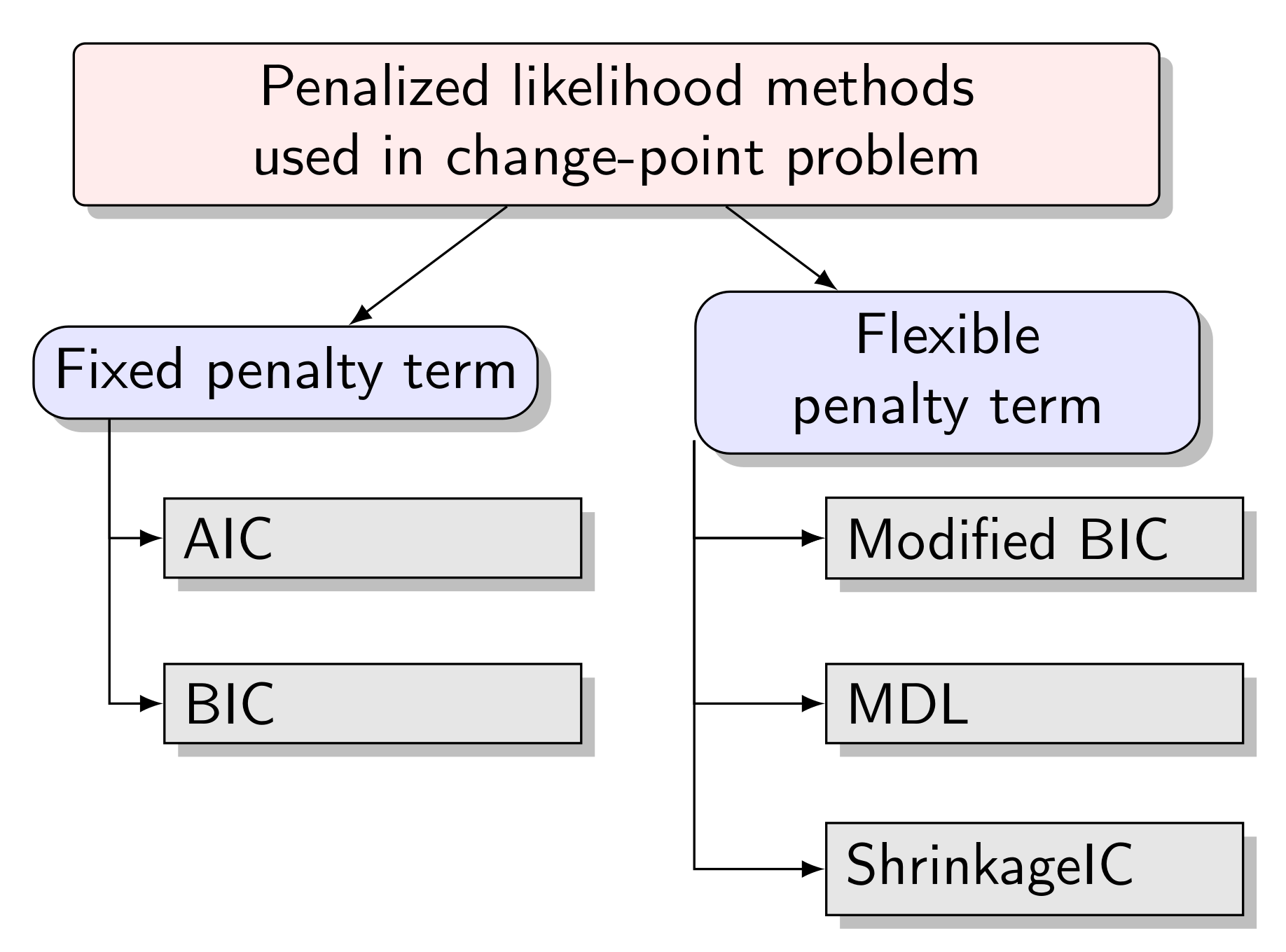
2. Model Selection Criteria
2.1. Change-Point Detection Problem
2.2. The Principle of Minimum Description Length
- For an integer parameter N, when its value is not bounded, approximately bits are encoded. If N is limited by the upper bound value , then approximately bits are needed.
- To encode a real parameter, if it is estimated from T observations, bits are required.
- As mentioned above, the first part of two-stage MDL can be considered as a negative log-likelihood function of the whole process, by assuming that the segments are independent, and using the approximation in McLeod et al. [42] for the exact loglikelihood for the AR(p) model, the likelihood of segment i can be written as (see [42] for further details), where is the Yule-Walker estimate, is the covariance determinant of first s observations.
- For the number N, the penalty term is . Since it can be considered as an integer parameter without being bounded, the code length is .
- The length for each of segments cannot exceed T. This means that, according to the integer parameter principle, the lengths of the segments can be encoded with bits.
- represents the order of the AR process for each segment, which should be an integer. So the parameter can be encoded with bits; see [7].
- For each segment i, , we estimate three real-valued parameters. These are mean shift ; autocorrelation coefficient , where ; and variance . Under the real parameter principle, each of these parameters can be computed from observations. Hence, each of them need bits.
3. The Cross-Entropy Algorithm
- Generate a sample from a probability distribution.
- In order to obtain a better sample, find the minimum cross-entropy distance between the sample distribution and a target distribution.
- Updating of the level parameter . Order the performance score increasingly, , . Let be the -quantile of the ordered performance scores, which can be denoted as,
- Updating the reference parameter . Given and , we can derive from Equation (10),
| Algorithm 1 Basic CE optimization algorithm. |
|
| Algorithm 2 The CE.AR algorithm. |
|
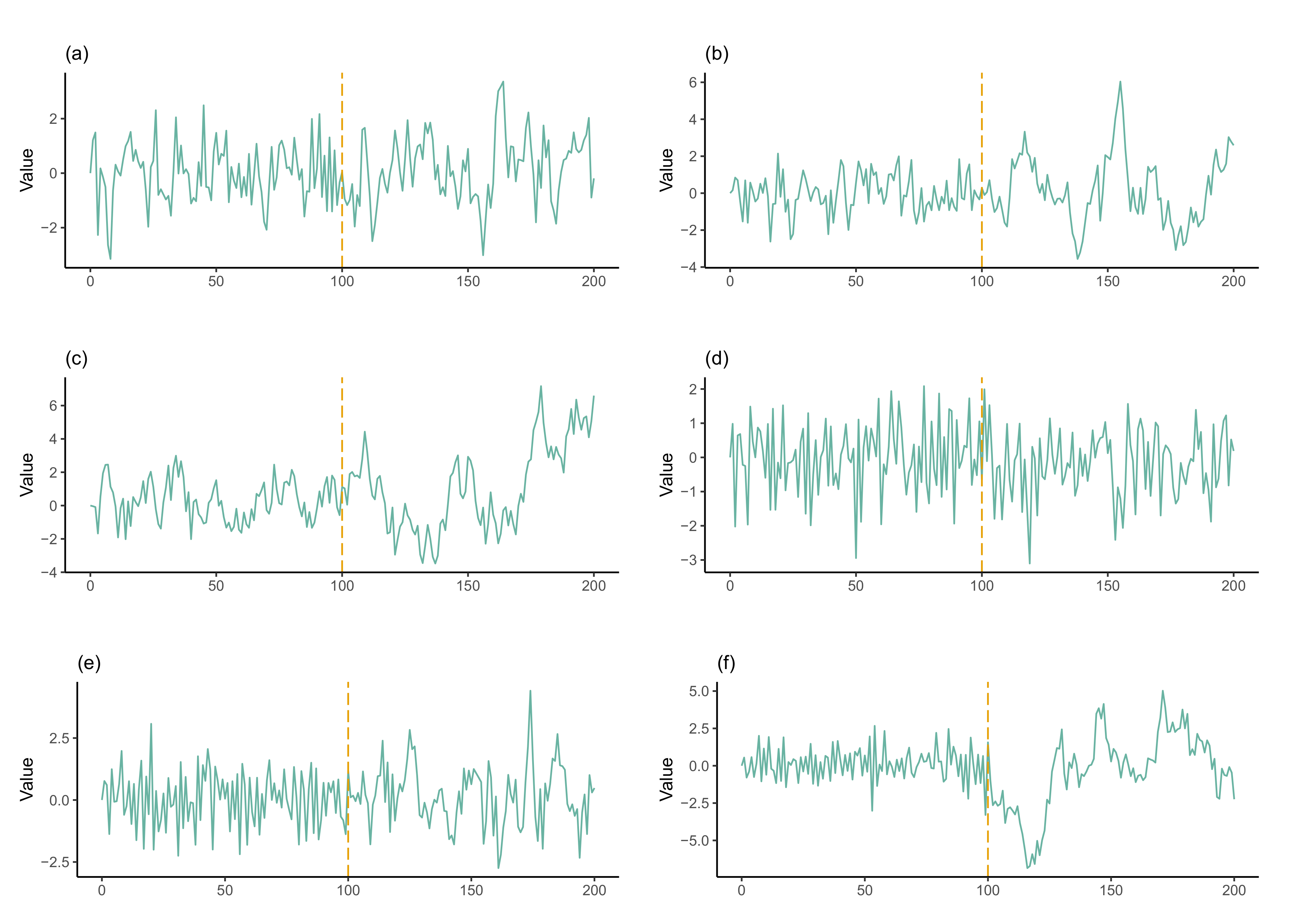
4. Numerical Experiments
4.1. Example 1: Simulated AR(1) Processes with No Change-Point
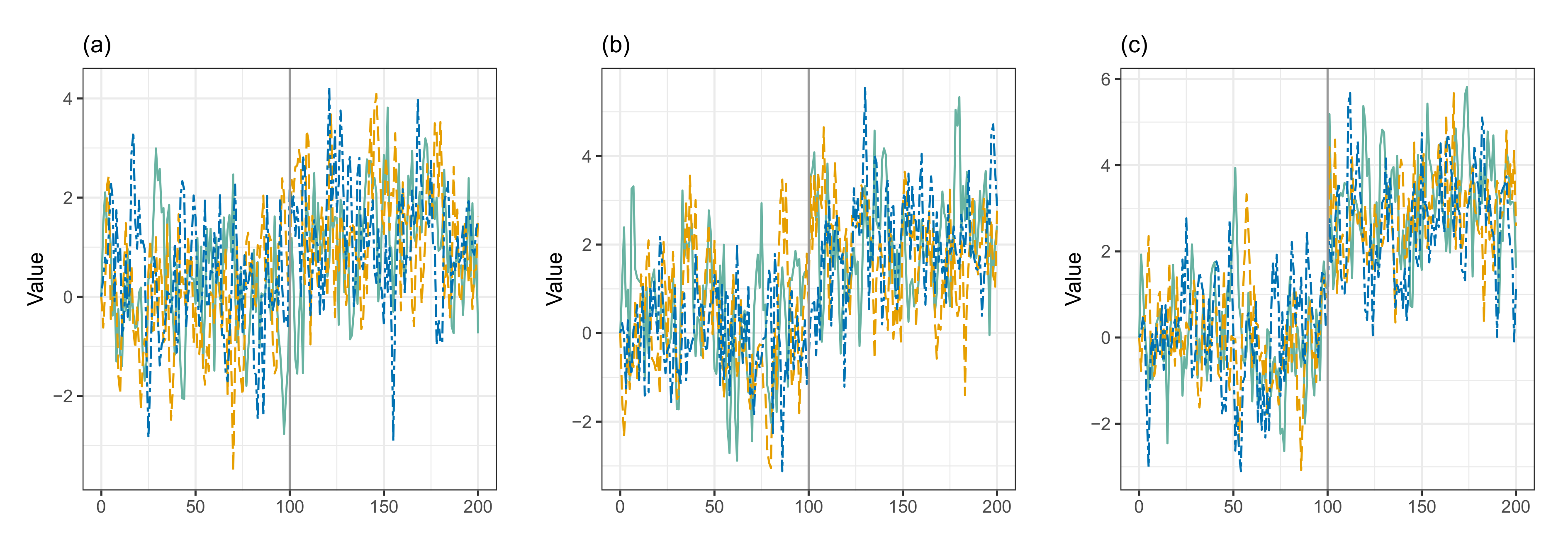
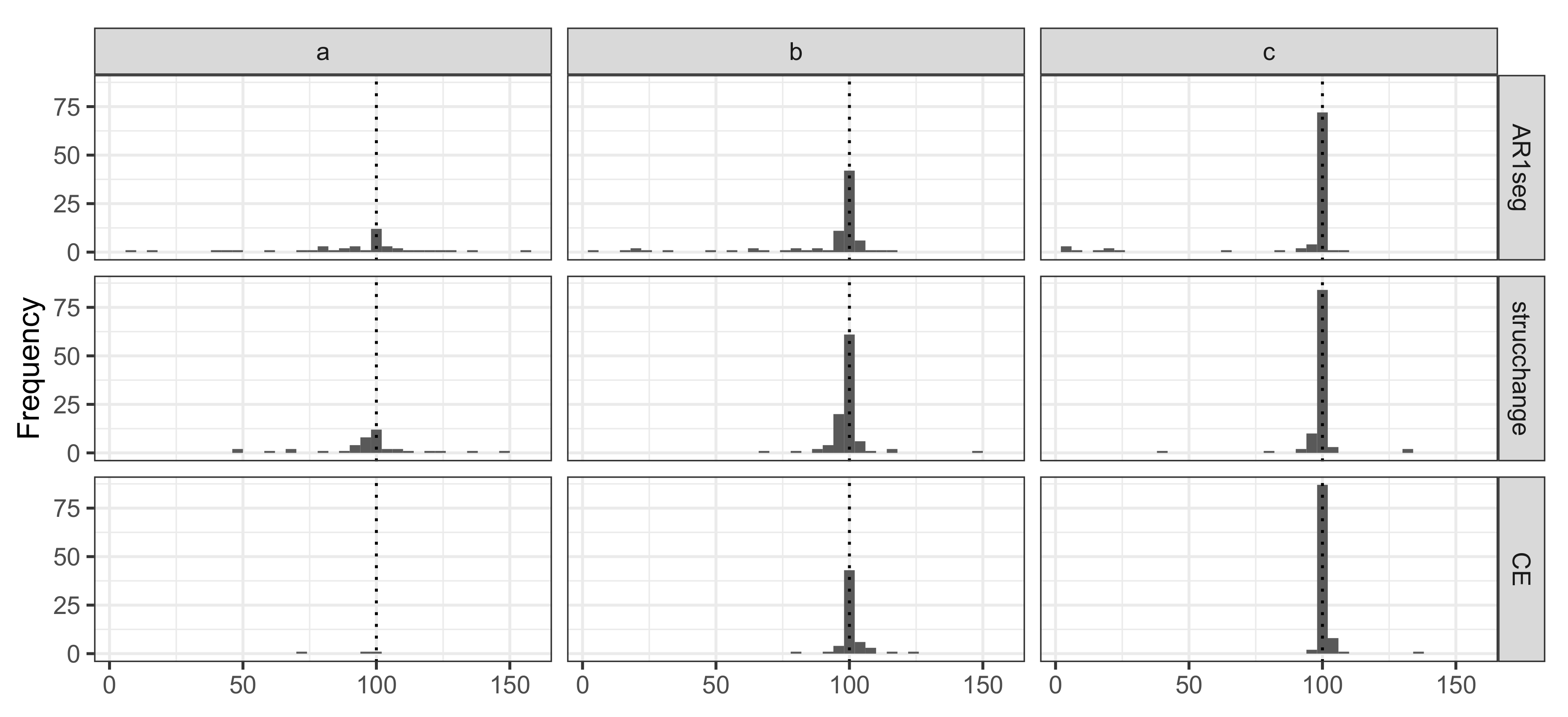
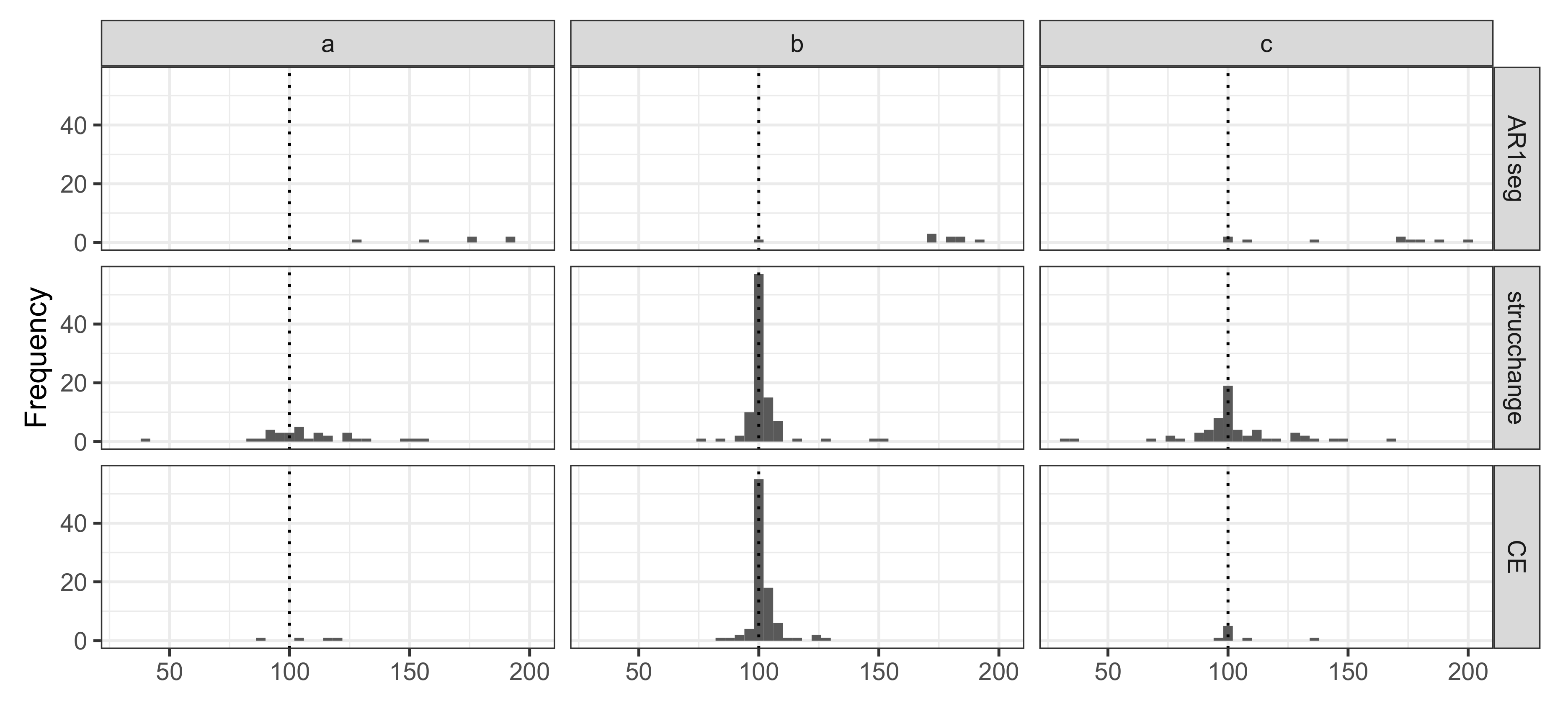
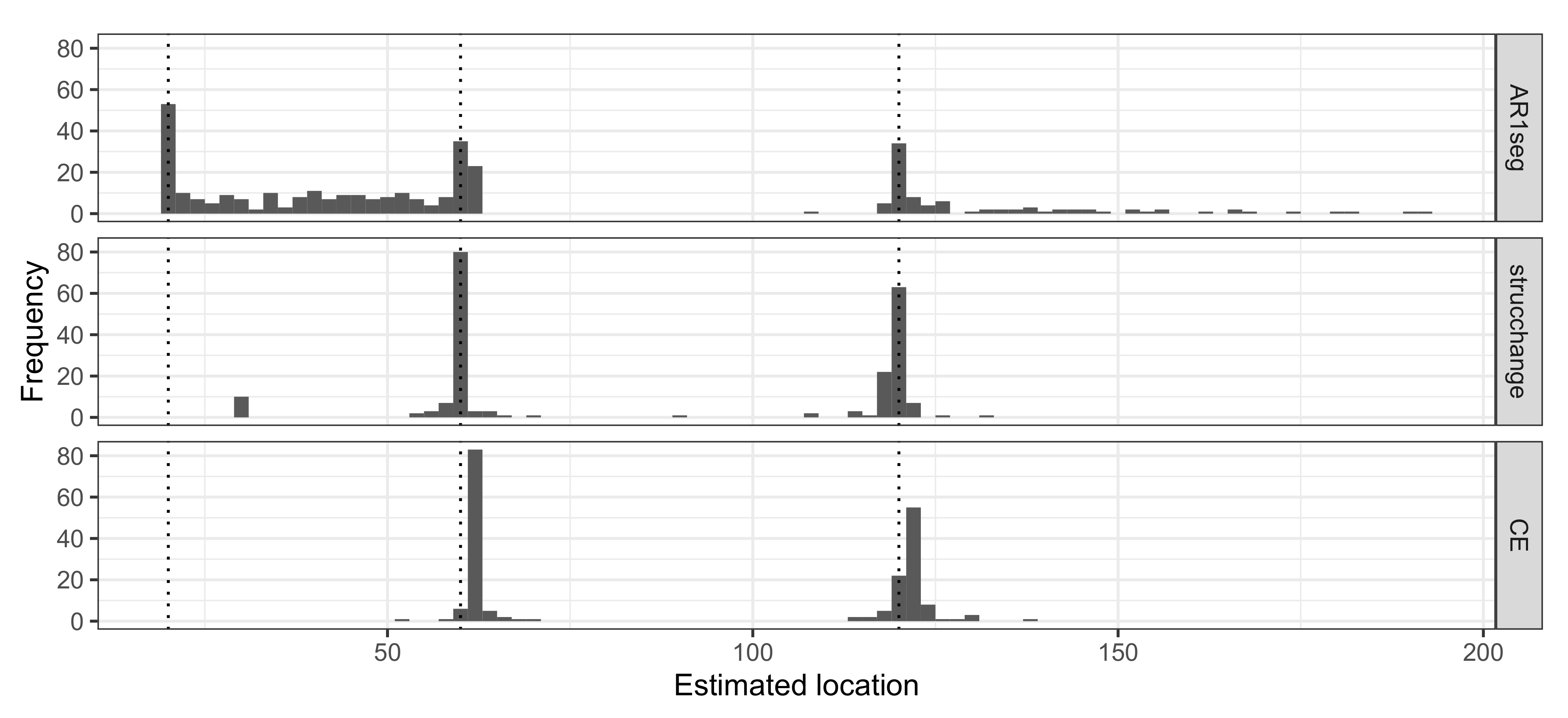
4.2. Example 2: Simulated AR(1) Processes with a Single Change-Point
4.2.1. Example 2.1
4.2.2. Example 2.2
4.3. Example 3: AR(1) Processes with Multiple Change-Points
5. Discussion
5.1. Simulation Results
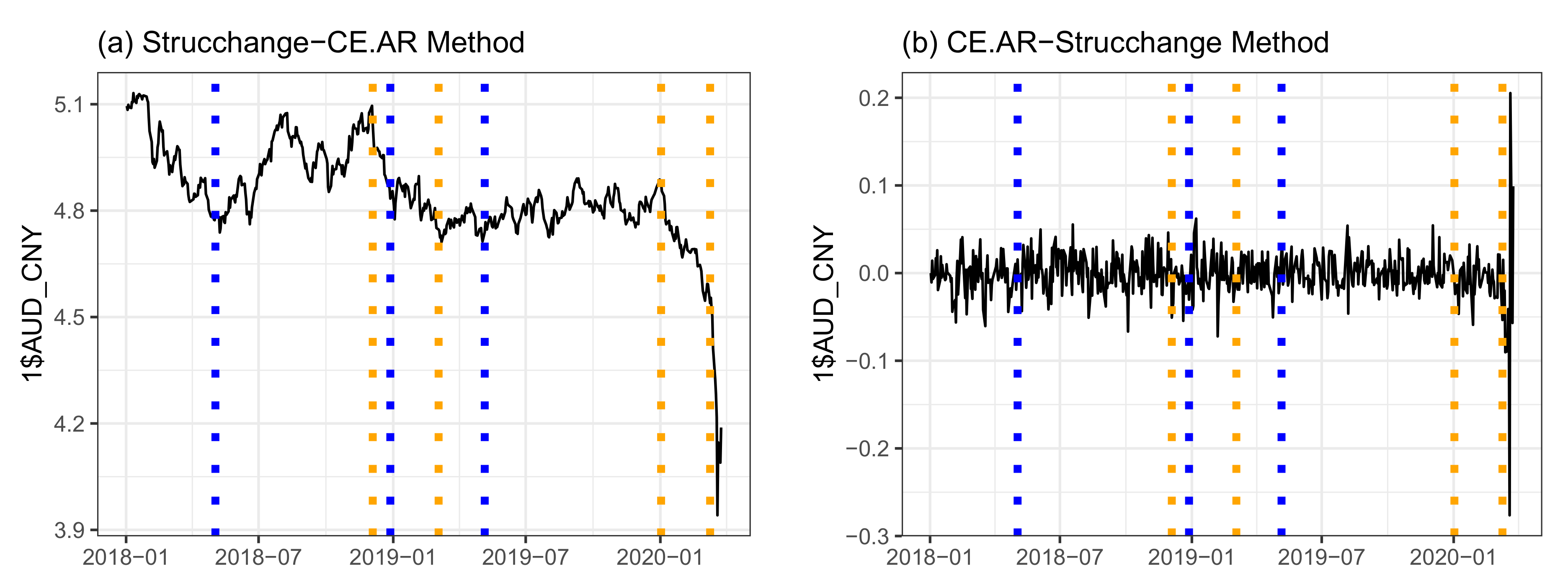
5.2. Application
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AR | Autoregressive |
| AR(1) | Autoregressive model of order 1 |
| AR(p) | Autoregressive model of order p |
| MDL | Minimum description length |
| AIC | Akaike’s information criterion |
| BIC | Bayesian information criterion |
| mBIC | Modified Bayesian information criterion |
| ShrinkageIC | A penalty function with an adjustable shrinkage parameter |
| CL | Code length |
| EM | Expectation-maximization |
| MCMC | Markov chain Monte Carlo |
| CE | Cross-Entropy |
| ARIMA | Autoregressive integrated moving average |
| MA | Moving average |
| AUD | Australian dollar |
| CNY | Chinese yuan |
References
- Aminikhanghahi, S.; Cook, D.J. A survey of methods for time series change point detection. Knowl. Inf. Syst. 2017, 51, 339–367. [Google Scholar] [CrossRef] [PubMed]
- Aue, A.; Horváth, L. Structural breaks in time series. J. Time Ser. Anal. 2013, 34, 1–16. [Google Scholar] [CrossRef]
- Zhu, X.; Li, Y.; Liang, C.; Chen, J.; Wu, D. Copula based Change Point Detection for Financial Contagion in Chinese Banking. Procedia Comput. Sci. 2013, 17, 619–626. [Google Scholar] [CrossRef][Green Version]
- Bai, J.; Perron, P. Computation and analysis of multiple structural change models. J. Appl. Econom. 2003, 18, 1–22. [Google Scholar] [CrossRef]
- Garcia, R.; Perron, P. An Analysis of the Real Interest Rate Under Regime Shifts. Rev. Econ. Stat. 1996, 78, 111–125. [Google Scholar] [CrossRef]
- Beaulieu, C.; Chen, J.; Sarmiento, J.L. Change-point analysis as a tool to detect abrupt climate variations. Philos. Trans. R. Soc. 2012, 370, 1228–1249. [Google Scholar] [CrossRef]
- Davis, R.A.; Lee, T.C.M.; Rodriguez-Yam, G.A. Structural break estimation for nonstationary time series models. J. Am. Stat. Assoc. 2006, 101, 223–239. [Google Scholar] [CrossRef]
- Priyadarshana, W.; Sofronov, G. Multiple break-points detection in array CGH data via the cross-entropy method. IEEE/ACM Trans. Comput. Biol. Bioinform. (TCBB) 2015, 12, 487–498. [Google Scholar] [CrossRef]
- Sofronov, G.; Polushina, T.; Priyadarshana, M. Sequential Change-Point Detection via the Cross-Entropy Method. In Proceedings of the 11th Symposium on Neural Network Applications in Electrical Engineering (NEUREL2012), Belgrade, Serbia, 22 September 2012; pp. 185–188. [Google Scholar]
- Brodsky, B.; Darkhovsky, B.S. Non-Parametric Statistical Diagnosis: Problems and Methods; Springer Science & Business Media: Dordrecht, The Netherlands, 2000; Volume 509. [Google Scholar]
- Fryzlewicz, P. Wild binary segmentation for multiple change-point detection. Ann. Stat. 2014, 42, 2243–2281. [Google Scholar] [CrossRef]
- Raveendran, N.; Sofronov, G. Binary segmentation methods for identifying boundaries of spatial domains. In Communication Papers of the 2017 Federated Conference on Computer Science and Information Systems (FedCSIS); Ganzha, M., Maciaszek, L., Eds.; Polskie Towarzystwo Informatyczne: Warszawa, Poland, 2017; Volume 13, pp. 95–102. [Google Scholar] [CrossRef]
- Scott, A.J.; Knott, M. A cluster analysis method for grouping means in the analysis of variance. Biometrics 1974, 30, 507–512. [Google Scholar] [CrossRef]
- Sen, A.; Srivastava, M.S. On tests for detecting change in mean. Ann. Stat. 1975, 3, 98–108. [Google Scholar] [CrossRef]
- Auger, I.E.; Lawrence, C.E. Algorithms for the optimal identification of segment neighborhoods. Bull. Math. Biol. 1989, 51, 39–54. [Google Scholar] [CrossRef]
- Bai, J.; Perron, P. Estimating and testing linear models with multiple structural changes. Econometrica 1998, 66, 47–78. [Google Scholar] [CrossRef]
- Killick, R.; Fearnhead, P.; Eckley, I.A. Optimal detection of changepoints with a linear computational cost. J. Am. Stat. Assoc. 2012, 107, 1590–1598. [Google Scholar] [CrossRef]
- Bansal, N.K.; Du, H.; Hamedani, G. An application of EM algorithm to a change-point problem. Commun. Stat. Theory Methods 2008, 37, 2010–2021. [Google Scholar] [CrossRef]
- Doerr, B.; Fischer, P.; Hilbert, A.; Witt, C. Detecting structural breaks in time series via genetic algorithms. Soft Comput. 2016, 1–14. [Google Scholar] [CrossRef]
- Polushina, T.; Sofronov, G. Change-point detection in biological sequences via genetic algorithm. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC’2011), New Orleans, LA, USA, 8 June 2011; pp. 1966–1971. [Google Scholar]
- Raveendran, N.; Sofronov, G. Identifying Clusters in Spatial Data via Sequential Importance Sampling. In Recent Advances in Computational Optimization: Results of the Workshop on Computational Optimization WCO 2017; Fidanova, S., Ed.; Springer International Publishing: Cham, Switzerland, 2019; pp. 175–189. [Google Scholar] [CrossRef]
- Sofronov, G.Y.; Evans, E.G.; Keith, J.M.; Kroese, D.P. Identifying change-points in biological sequences via sequential importance sampling. Environ. Model. Assess. 2009, 14, 577–584. [Google Scholar] [CrossRef]
- Algama, M.; Keith, J. Investigating genomic structure using changept: A Bayesian segmentation model. Comput. Struct. Biotechnol. J. 2014, 10, 107–115. [Google Scholar] [CrossRef]
- Keith, J.M. Segmenting Eukaryotic Genomes with the Generalized Gibbs Sampler. J. Comp. Biol. 2006, 13, 1369–1383. [Google Scholar] [CrossRef]
- Sofronov, G. Change-Point Modelling in Biological Sequences via the Bayesian Adaptive Independent Sampler. Int. Proc. Comput. Sci. Inf. Technol. 2011, 5, 122–126. [Google Scholar]
- Polushina, T.V.; Sofronov, G.Y. A hybrid genetic algorithm for change-point detection in binary biomolecular sequences. In Proceedings of the IASTED International Conference on Artificial Intelligence and Applications (AIA 2013), Innsbruck, Austria, 11 February 2013; pp. 1–8. [Google Scholar]
- Priyadarshana, M.; Polushina, T.; Sofronov, G. A Hybrid Algorithm for Multiple Change-Point Detection in Continuous Measurements. In Proceedings of the International Symposium on Computational Models for Life Sciences, AIP Conference Proceedings, Sydney, Australia, 27–29 November 2013; Volume 1559, pp. 108–117. [Google Scholar] [CrossRef]
- Priyadarshana, M.; Polushina, T.; Sofronov, G. Hybrid algorithms for multiple change-point detection in biological sequences. Adv. Exp. Med. Biol. 2015, 823, 41–61. [Google Scholar] [CrossRef]
- Sofronov, G.; Polushina, T.; Jayawardana, M. An improved hybrid algorithm for multiple change-point detection in array CGH data. In Proceedings of the 22nd International Congress on Modelling and Simulation, Tasmania, Australia, 8 December 2017; pp. 508–514. [Google Scholar]
- Evans, G.E.; Sofronov, G.Y.; Keith, J.M.; Kroese, D.P. Estimating change-points in biological sequences via the Cross-Entropy method. Ann. Oper. Res. 2011, 189, 155–165. [Google Scholar] [CrossRef]
- Polushina, T.; Sofronov, G. Change-point detection in binary Markov DNA sequences by the Cross-Entropy method. In Proceedings of the 2014 Federated Conference on Computer Science and Information Systems, FedCSIS 2014, Warsaw, Poland, 10 September 2014; pp. 471–478. [Google Scholar] [CrossRef]
- Polushina, T.; Sofronov, G. A Cross-Entropy method for change-point detection in four-letter DNA sequences. In Proceedings of the 2016 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Chiang Mai, Thailand, 7 October 2016; pp. 1–6. [Google Scholar]
- Priyadarshana, M.; Sofronov, G. A modified Cross-Entropy method for detecting change-points in the Sri-Lankan stock market. In Proceedings of the IASTED International Conference on Engineering and Applied Science, EAS 2012, Colombo, Sri Lanka, 27 December 2012; pp. 319–326. [Google Scholar] [CrossRef]
- Priyadarshana, M.; Sofronov, G. A modified Cross-Entropy method for detecting multiple change points in DNA count data. In Proceedings of the 2012 IEEE Congress on Evolutionary Computation, CEC 2012, Brisbane, Australia, 15 June 2012; pp. 1020–1027. [Google Scholar] [CrossRef]
- Sofronov, G.; Ma, L. Change-point detection in time series data via the Cross-Entropy method. In Proceedings of the 22nd International Congress on Modelling and Simulation, Tasmania, Australia, 8 December 2017; pp. 195–201. [Google Scholar]
- Yau, C.Y.; Zhao, Z. Inference for multiple change points in time series via likelihood ratio scan statistics. J. R. Stat. Soc. Ser. B 2016, 78, 895–916. [Google Scholar] [CrossRef]
- Chakar, S.; Lebarbier, E.; Lévy-Leduc, C.; Robin, S. A robust approach for estimating change-points in the mean of an AR(1) process. Bernoulli 2017, 23, 1408–1447. [Google Scholar] [CrossRef]
- Killick, R.; Eckley, I. Changepoint: An R Package for Changepoint Analysis. J. Stat. Softw. 2014, 58, 1–19. [Google Scholar] [CrossRef]
- Zhang, N.R.; Siegmund, D.O. A modified Bayes information criterion with applications to the analysis of comparative genomic hybridization data. Biometrics 2007, 63, 22–32. [Google Scholar] [CrossRef] [PubMed]
- Lavielle, M. Using penalized contrasts for the change-point problem. Signal Process. 2005, 85, 1501–1510. [Google Scholar] [CrossRef]
- Rissanen, J. Stochastic Complexity in Statistical Inquiry; World Scientific: Singapore, 1989. [Google Scholar]
- McLeod, A.; Zhang, Y.; Xu, C.; McLeod, M.A. Package ‘FitAR’; University Western Ontario: London, ON, Canada, 2013. [Google Scholar]
- Botev, Z.I.; Kroese, D.P.; Rubinstein, R.Y.; L’Ecuyer, P. Chapter 3—The Cross-Entropy Method for Optimization. In Handbook of Statistics; Rao, C., Govindaraju, V., Eds.; Elsevier: Amsterdam, The Netherlands, 2013; Volume 31, pp. 35–59. [Google Scholar] [CrossRef]
- Rubinstein, R.Y. Combinatorial optimization, cross-entropy, ants and rare events. In Stochastic Optimization: Algorithms and Applications; Springer: Boston, MA, USA, 2001; pp. 303–363. [Google Scholar]
- Rubinstein, R. The cross-entropy method for combinatorial and continuous optimization. Methodol. Comput. Appl. Probab. 1999, 1, 127–190. [Google Scholar] [CrossRef]
- Rubinstein, R.Y.; Kroese, D.P. The Cross-Entropy Method: A Unified Approach to Combinatorial Optimization, Monte-Carlo Simulation and Machine Learning; Springer: New York, NY, USA, 2004. [Google Scholar]
- Zeileis, A.; Leisch, F.; Hornik, K.; Kleiber, C. strucchange: An R Package for Testing for Structural Change in Linear Regression Models. J. Stat. Softw. 2002, 7, 1–38. [Google Scholar] [CrossRef]
- Alam, M.Z. Forecasting the BDT/USD exchange rate using autoregressive model. Glob. J. Manag. Bus. Res. 2012, 12, 85–96. [Google Scholar]
- Babu, A.; Reddy, S. Exchange rate forecasting using ARIMA, Neural Network and Fuzzy Neuron. J. Stock Forex Trad. 2015, 4, 1–5. [Google Scholar]
- Yıldıran, C.U.; Fettahoğlu, A. Forecasting USDTRY rate by ARIMA method. Cogent Econ. Financ. 2017, 5, 1335968. [Google Scholar] [CrossRef]
- Hyndman, R.; Khandakar, Y. Automatic time series forecasting: The forecast package for R. J. Stat. Softw. 2008, 27, 1–22. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AR parameter | |||||||||
| Algorithm | 1 | 1 | 1 | ||||||
| AR1seg | 95% | 4% | 1% | 89% | 3% | 8% | 36% | 17% | 47% |
| strucchange | 97% | 3% | 0% | 100% | 0% | 0% | 94% | 5% | 1% |
| CE.AR | 100% | 0% | 0% | 100% | 0% | 0% | 100% | 0% | 0% |
| Mean Shift | |||||||||
| Algorithm | |||||||||
| AR1seg | 58% | 29% | 13% | 20% | 65% | 15% | 10% | 68% | 22% |
| strucchange | 60% | 40% | 0% | 2% | 97% | 1% | 0% | 97% | 3% |
| CE.AR | 97% | 3% | 0% | 41% | 58% | 1% | 2% | 97% | 1% |
| Coefficient Shift | , | , | , | ||||||
| Algorithm | |||||||||
| AR1seg | 82% | 6% | 12% | 29% | 9% | 62% | 46% | 10% | 44% |
| strucchange | 68% | 32% | 0% | 0% | 97% | 3% | 36% | 61% | 3% |
| CE.AR | 96% | 4% | 0% | 6% | 92% | 2% | 90% | 8% | 2% |
| Coefficient Shift | , | , | , | ||||||
| Algorithm | |||||||||
| AR1seg | 2% | 0% | 98% | 47% | 9% | 44% | 84% | 5% | 11% |
| strucchange | 0% | 97% | 3% | 0% | 98% | 2% | 25% | 74% | 1% |
| CE.AR | 0% | 99% | 1% | 3% | 95% | 2% | 87% | 13% | 0% |
| Algorithm | ||||||
|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 4 | |||
| AR1seg | 26% | 8% | 25% | 10% | 31% | 0% |
| strucchange | 22% | 68% | 9% | 1% | 0% | 0% |
| CE.AR | 74% | 13% | 10% | 3% | 0% | 0% |
| Algorithm | ||||||
|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 4 | |||
| AR1seg | 3% | 1% | 10% | 23% | 63% | 0% |
| strucchange | 0% | 0% | 90% | 9% | 1% | 0% |
| CE.AR | 0% | 0% | 100% | 0% | 0% | 0% |
| AR1seg | strucchange | CE.AR |
|---|---|---|
| 73 | 46 | 39 |
| 73 | 30 | 19 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, L.; Sofronov, G. Change-Point Detection in Autoregressive Processes via the Cross-Entropy Method. Algorithms 2020, 13, 128. https://doi.org/10.3390/a13050128
Ma L, Sofronov G. Change-Point Detection in Autoregressive Processes via the Cross-Entropy Method. Algorithms. 2020; 13(5):128. https://doi.org/10.3390/a13050128
Chicago/Turabian StyleMa, Lijing, and Georgy Sofronov. 2020. "Change-Point Detection in Autoregressive Processes via the Cross-Entropy Method" Algorithms 13, no. 5: 128. https://doi.org/10.3390/a13050128
APA StyleMa, L., & Sofronov, G. (2020). Change-Point Detection in Autoregressive Processes via the Cross-Entropy Method. Algorithms, 13(5), 128. https://doi.org/10.3390/a13050128