The Effect of Different Deep Network Architectures upon CNN-Based Gaze Tracking




Abstract
1. Introduction
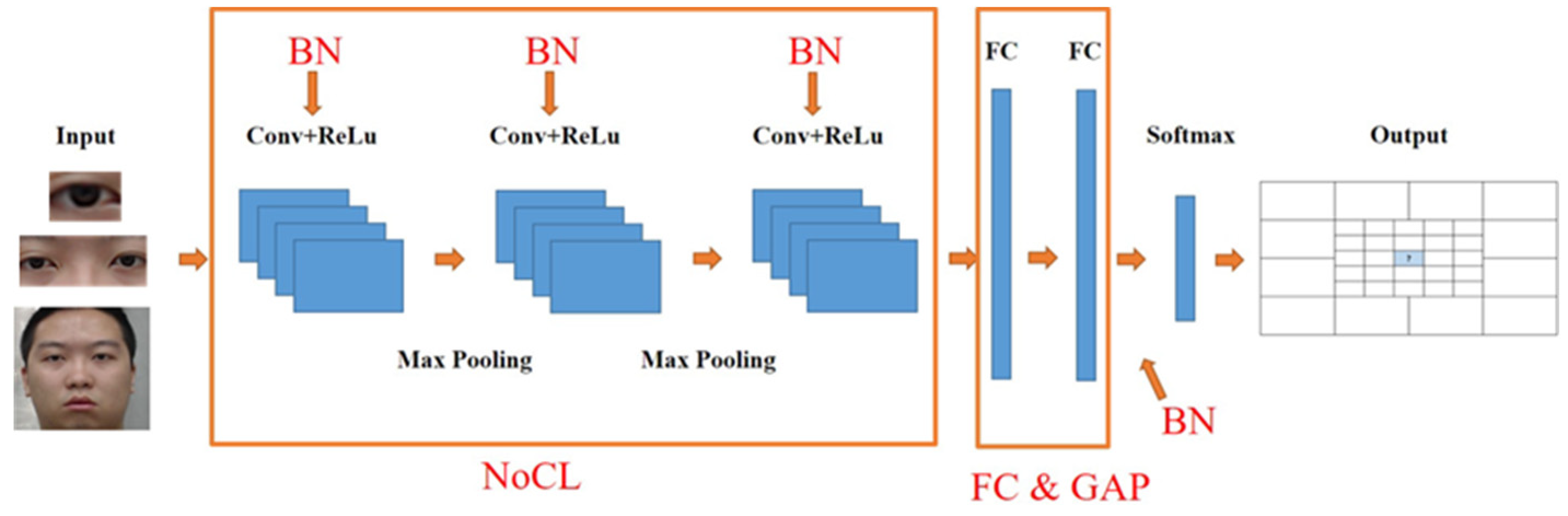
- We propose a framework for eye gaze classification to explore the effect by using different convolutional layers, batch normalization and the global average pooling layer.
- We propose three schemes, including the single eye image, double eyes image and facial image to evaluate the efficiency and computing complexity.
- We propose a novel method to build a training dataset, namely watching videos, because this is closer to the viewer’s visual behavior.
2. Materials and Methods
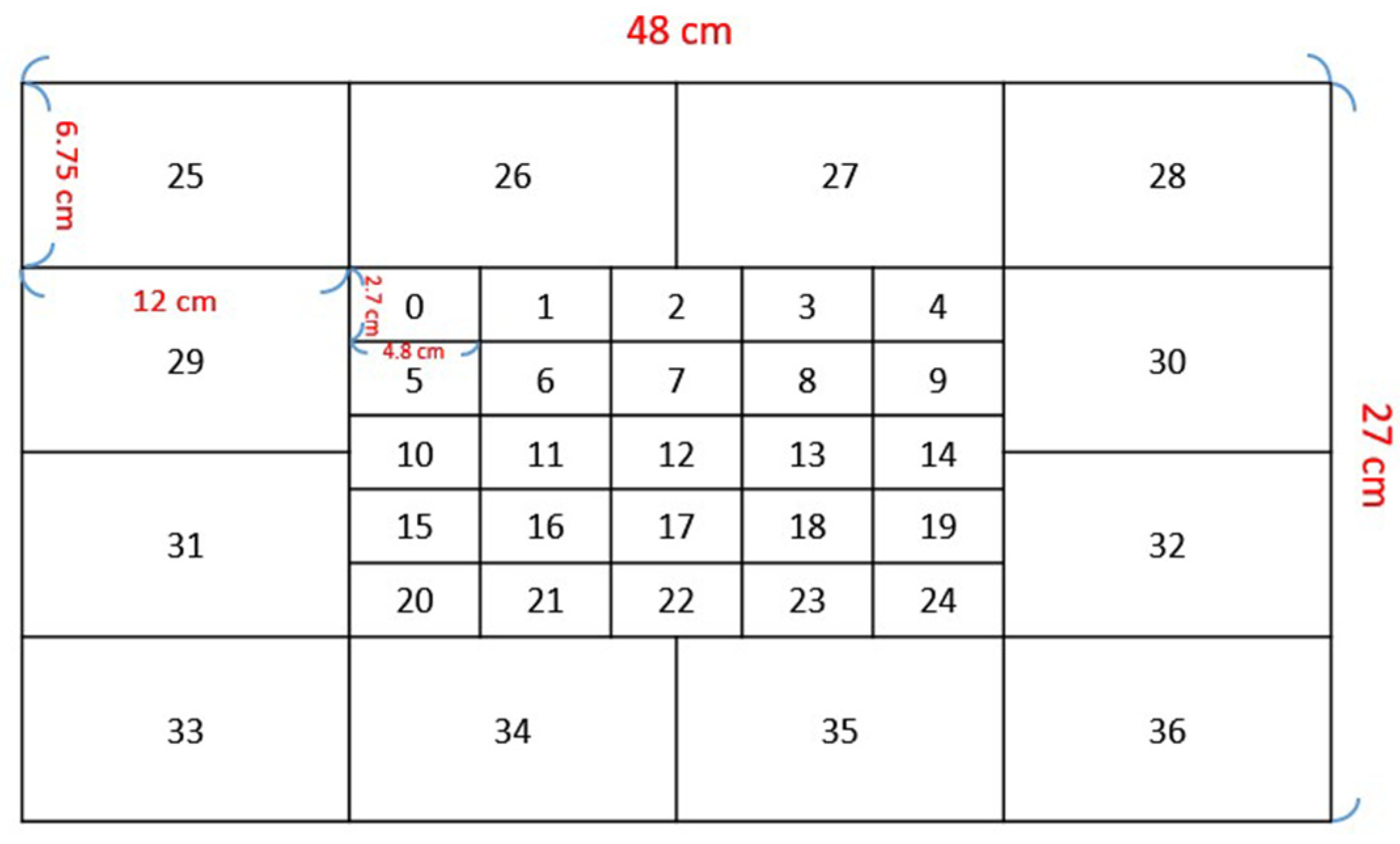
2.1. Collecting Data
2.2. Preprocessing Data
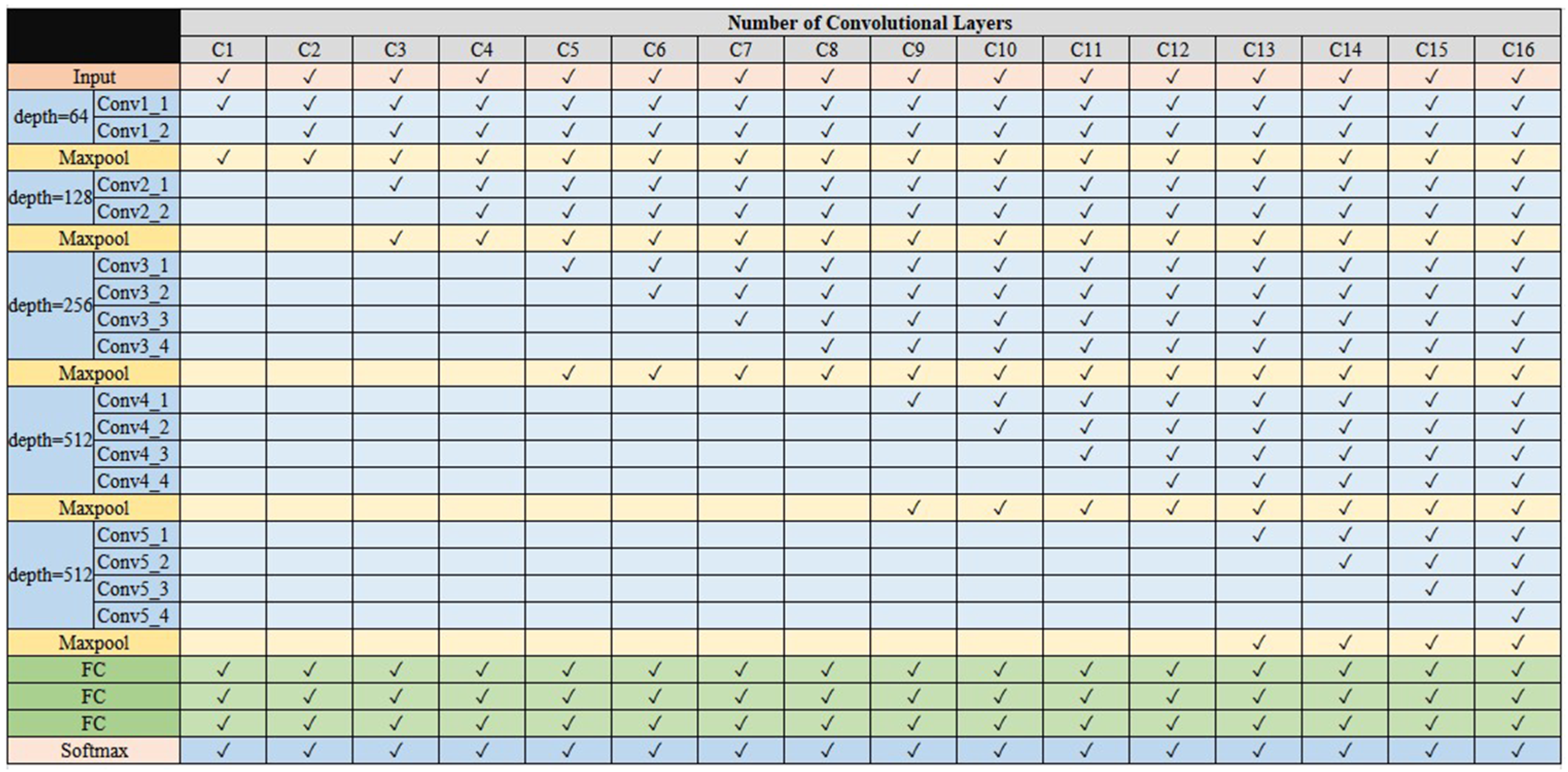
2.3. Training Model
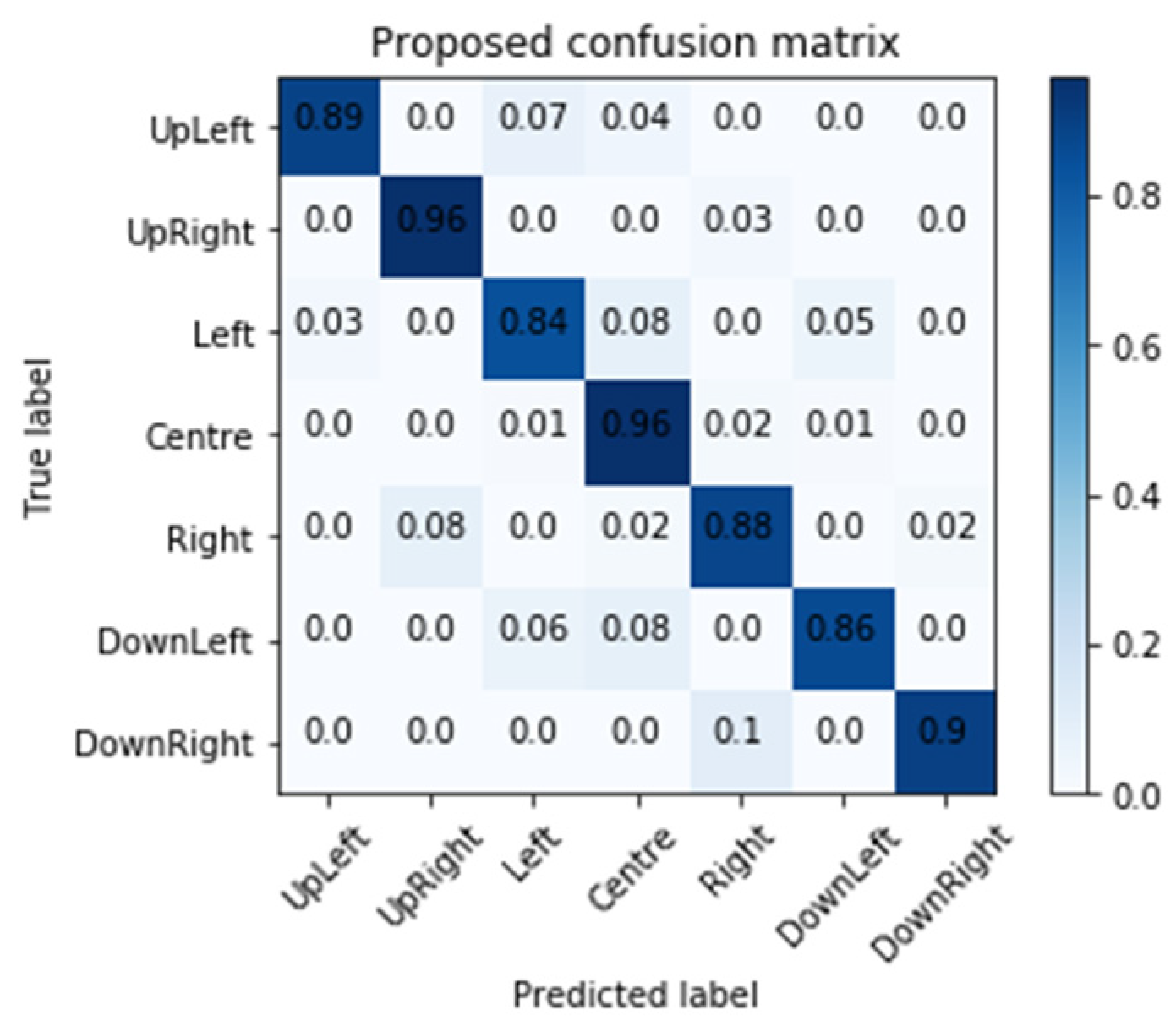
2.4. Evaluating and Testing
3. Results
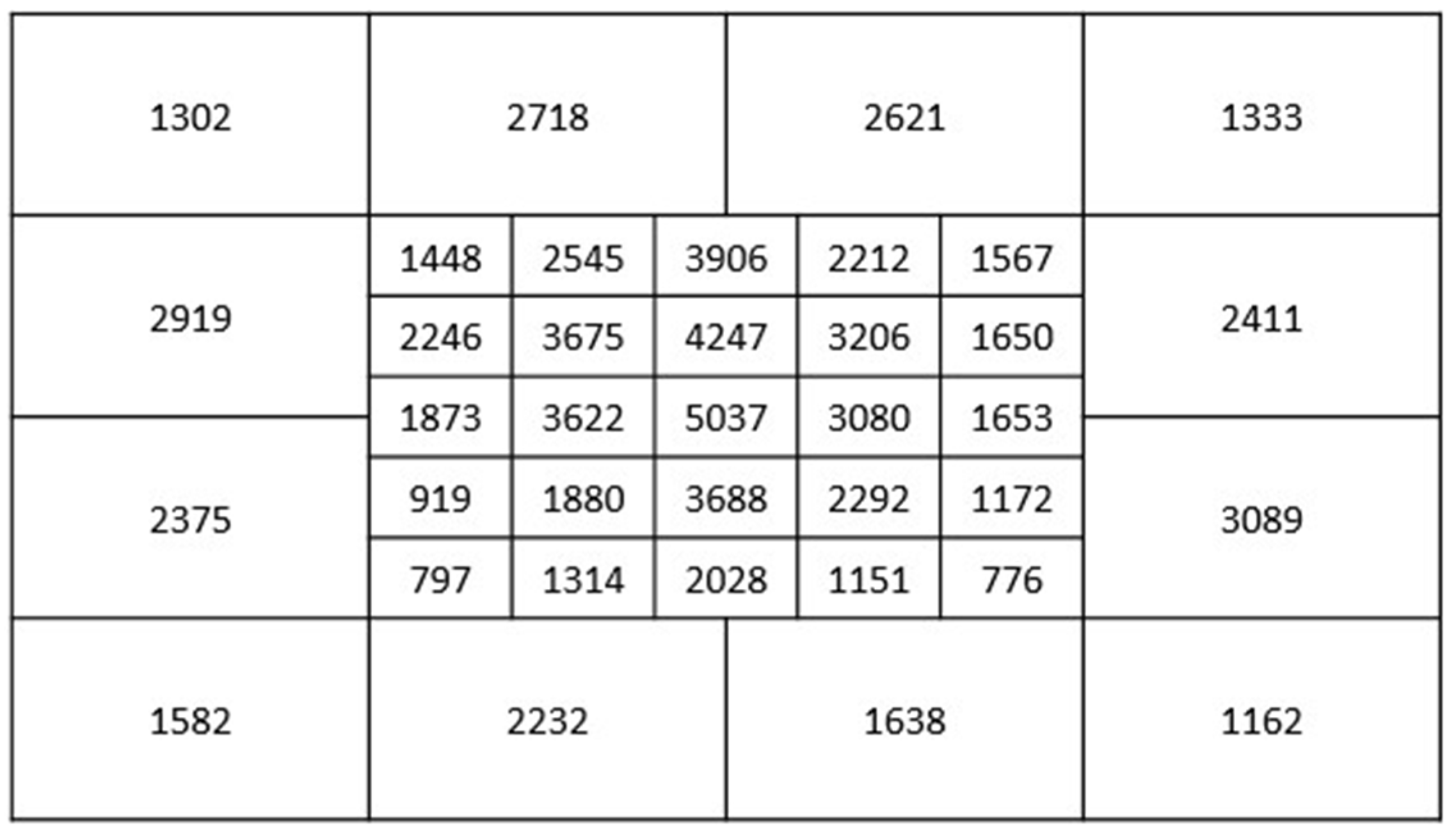
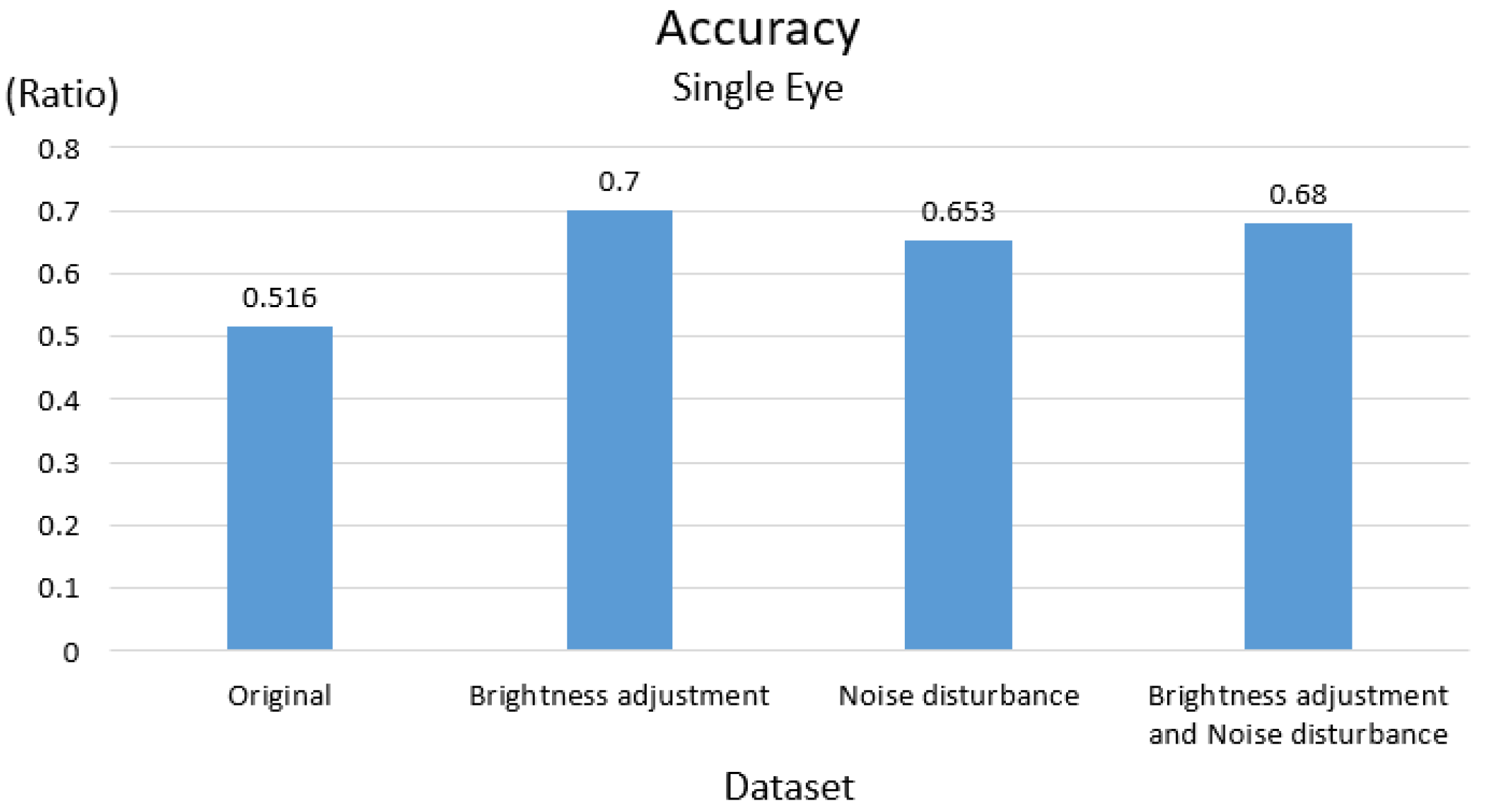
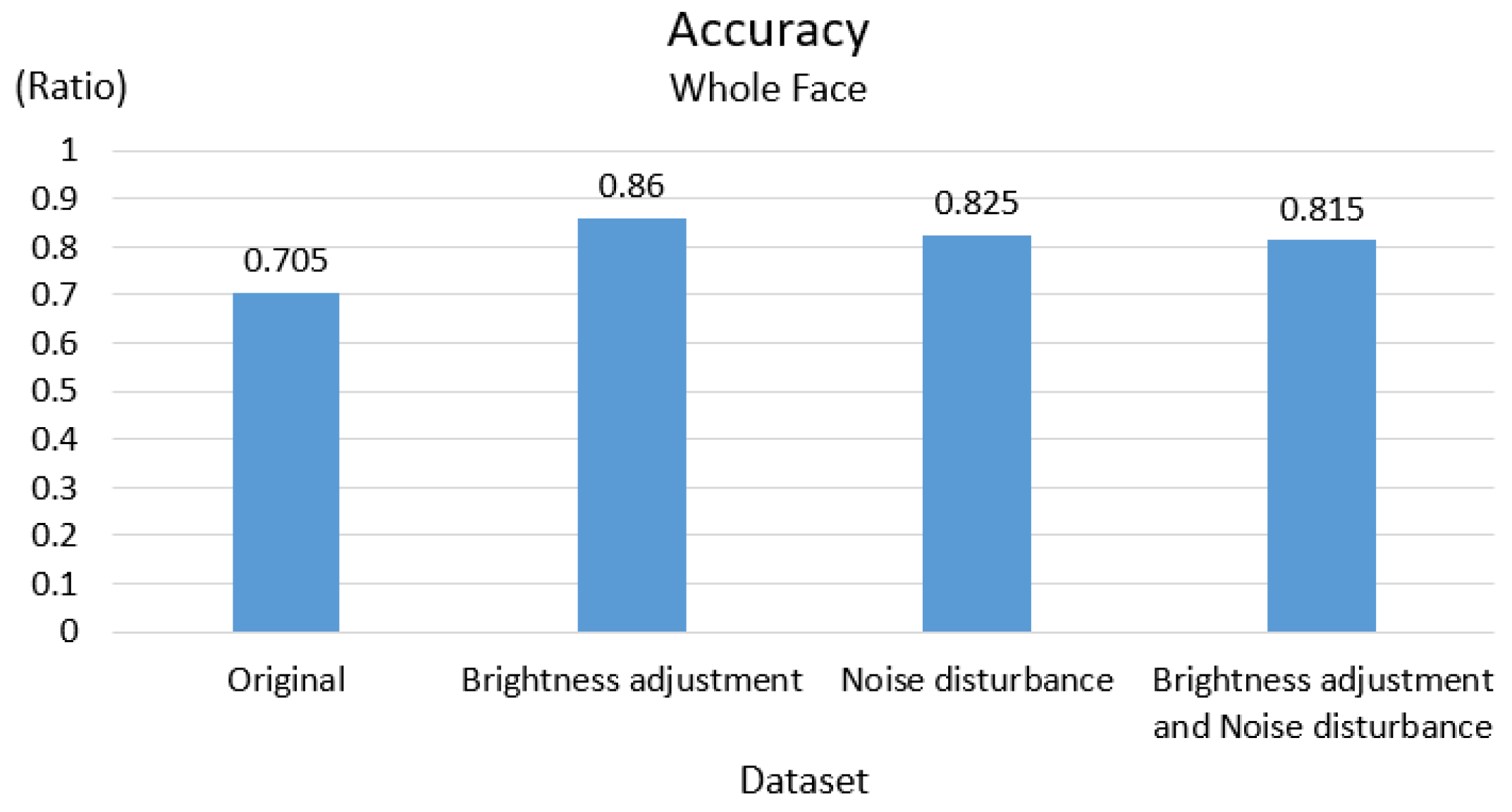
3.1. Results of Data Augmentation
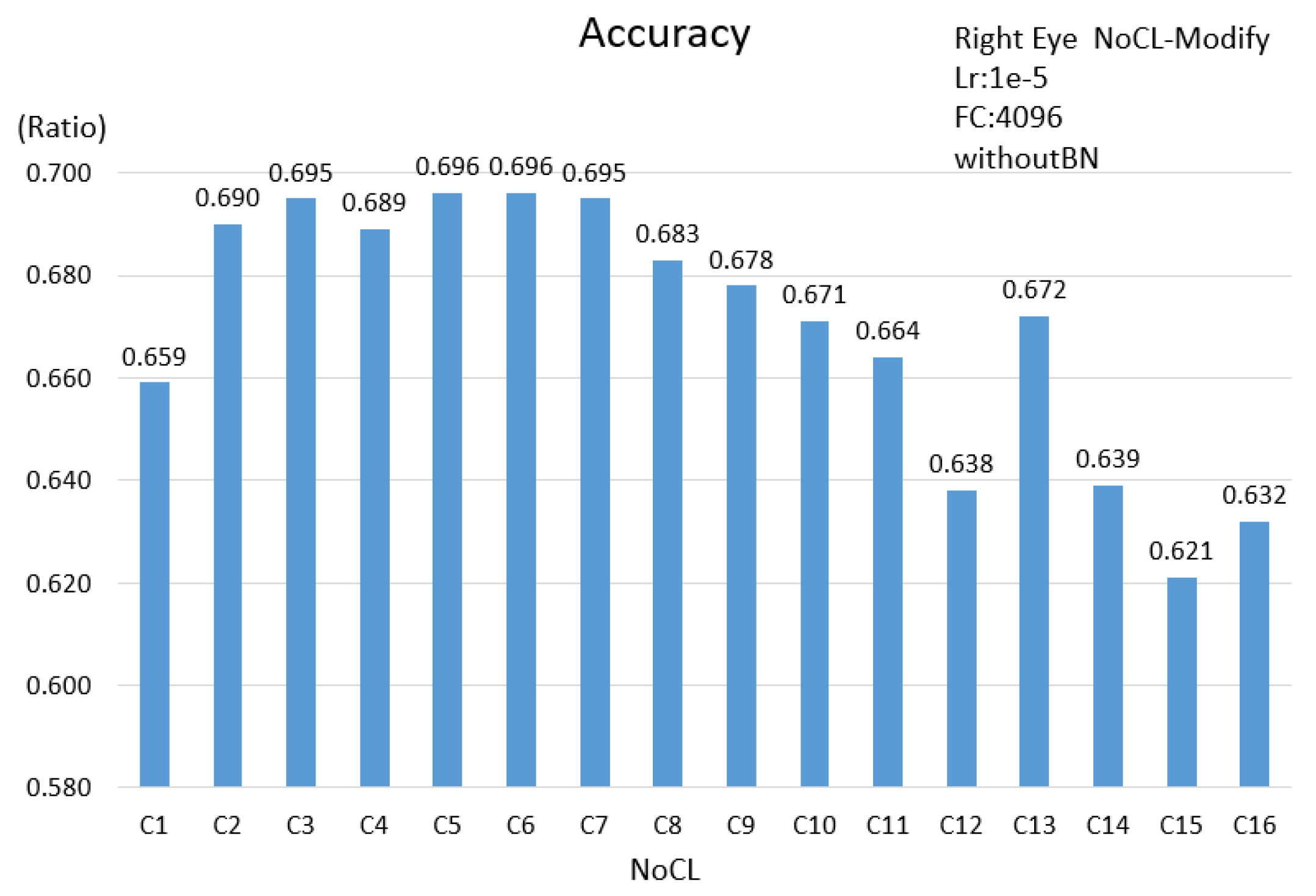
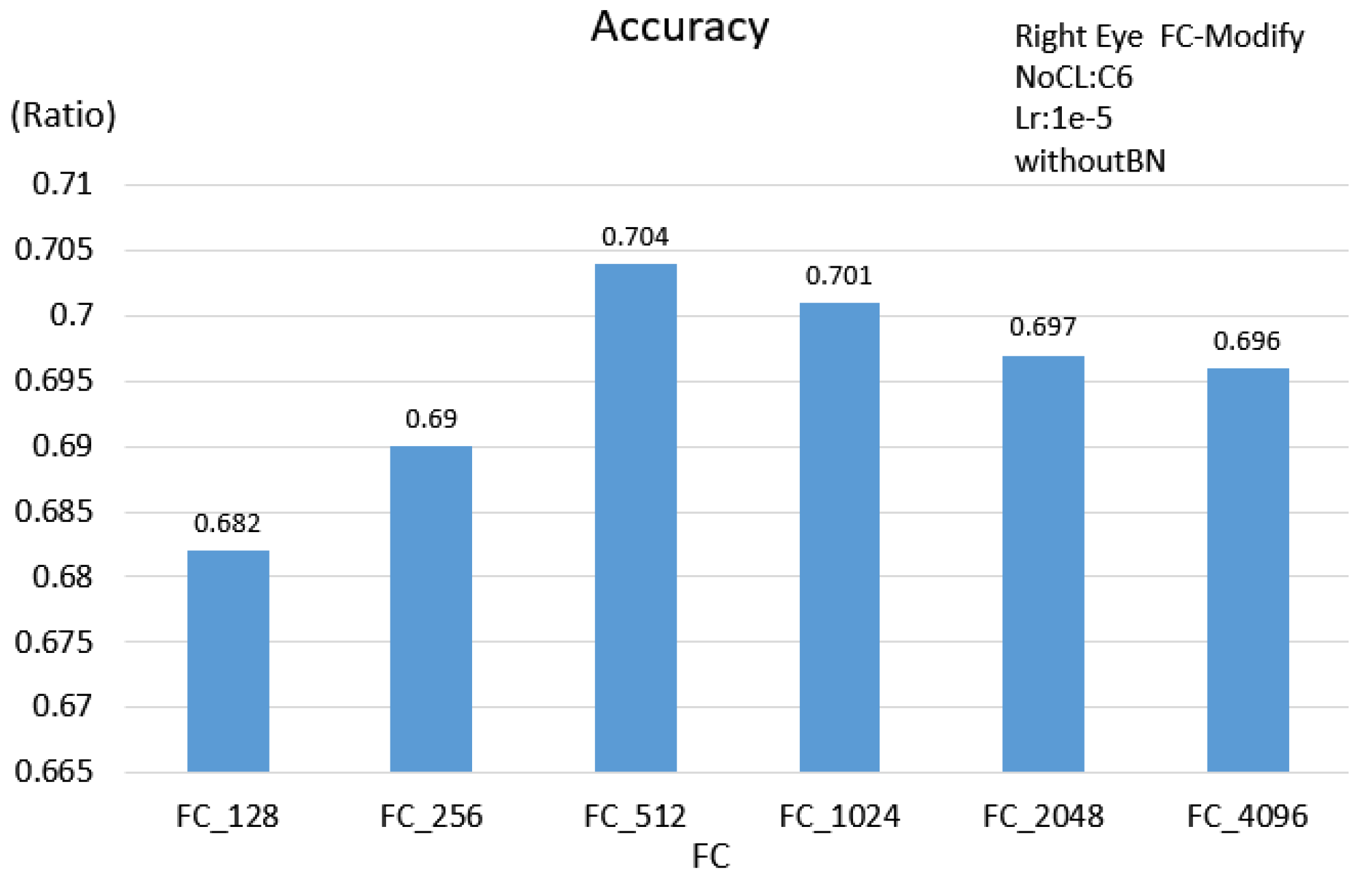
3.2. Evaluating Model
3.2.1. Single Eye Scheme
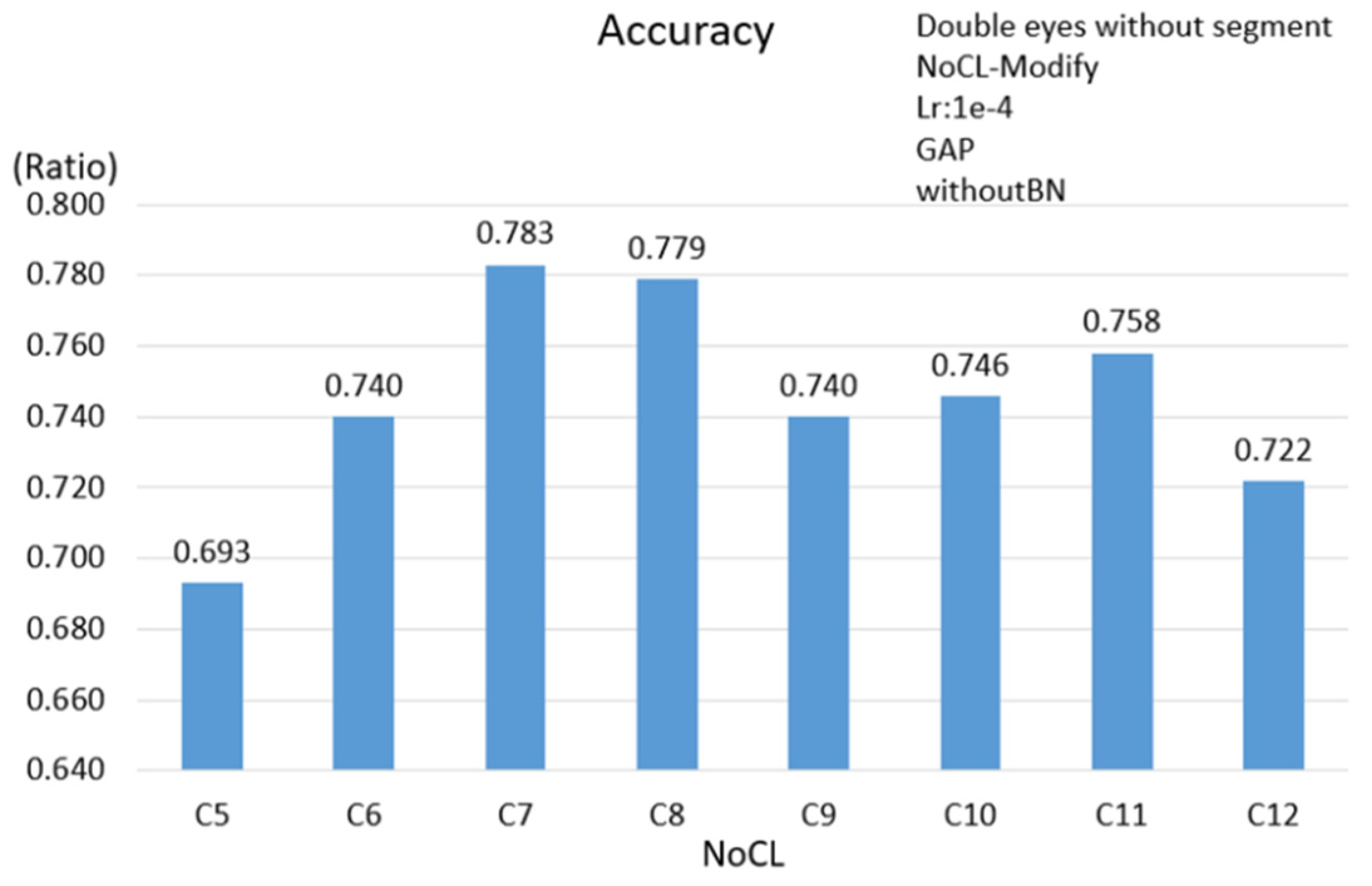
3.2.2. Double Eyes Scheme
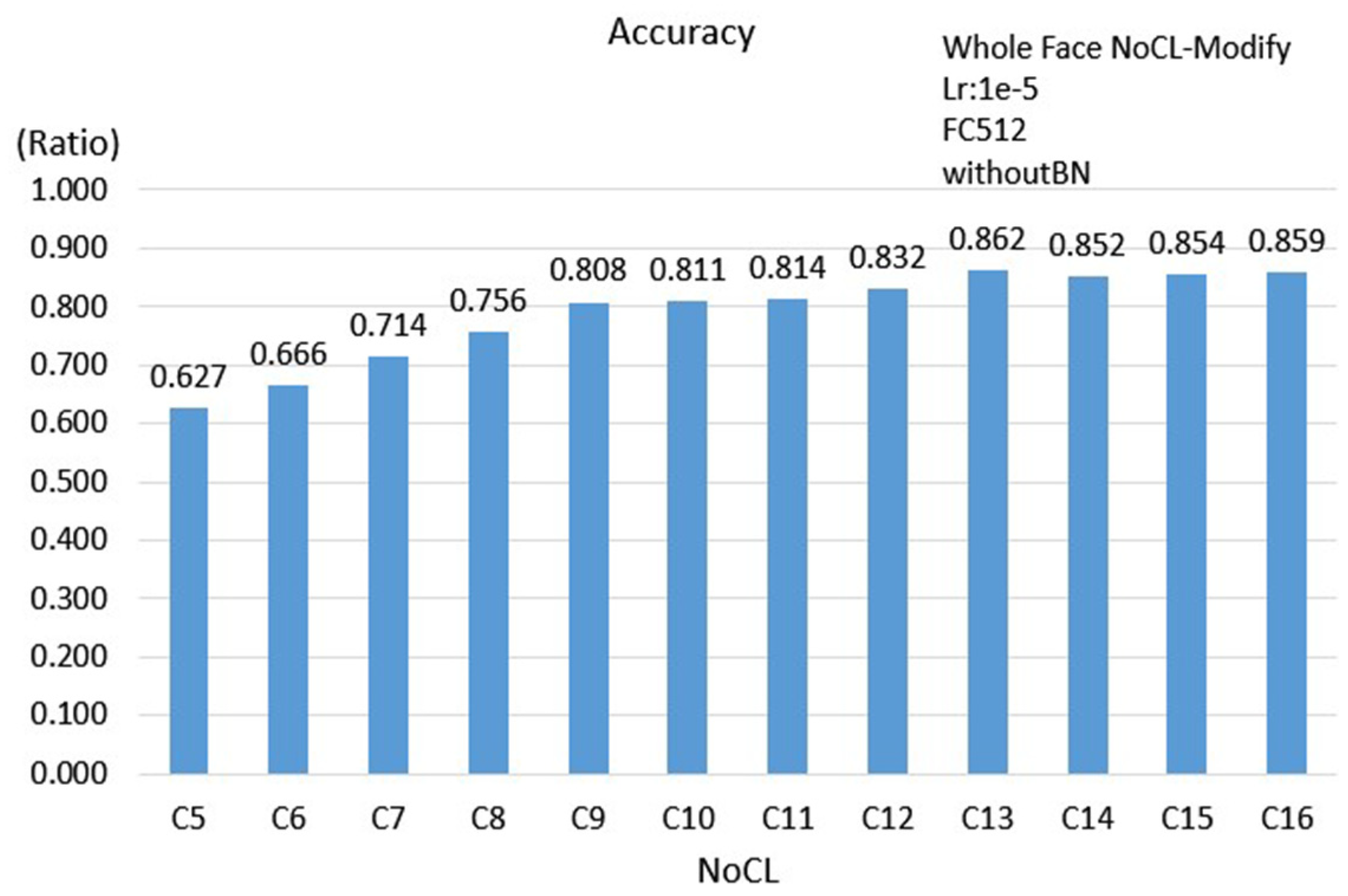
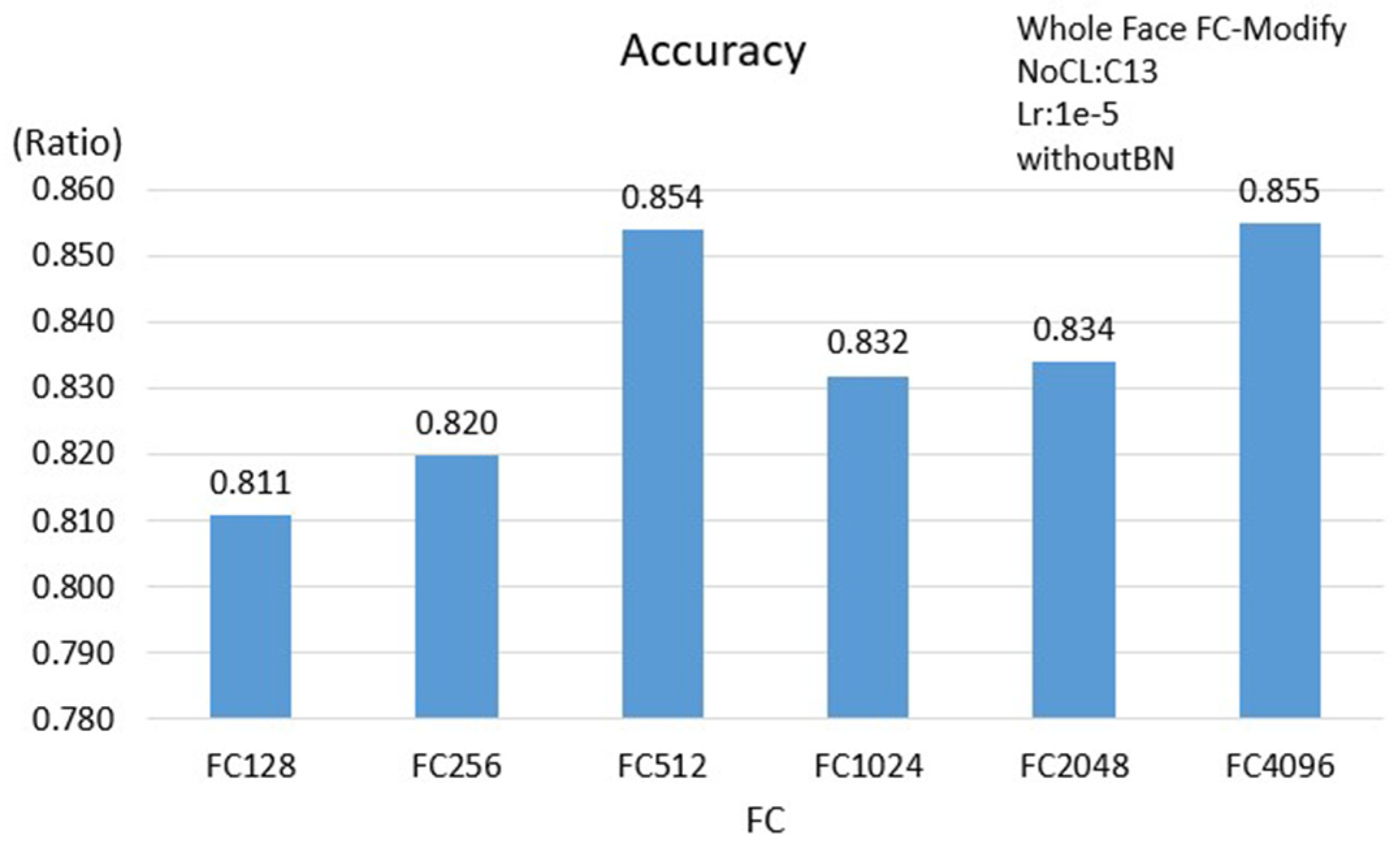
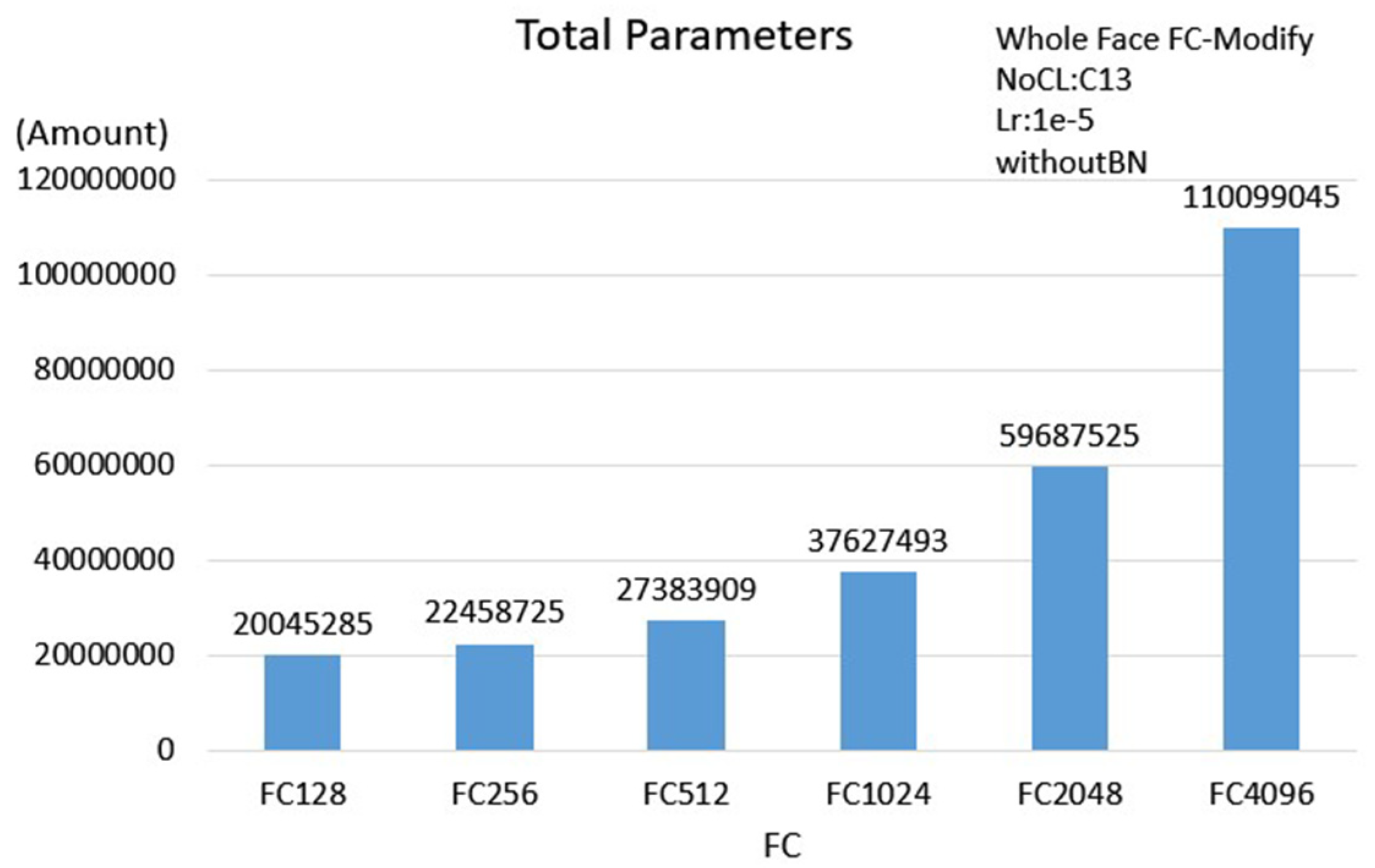
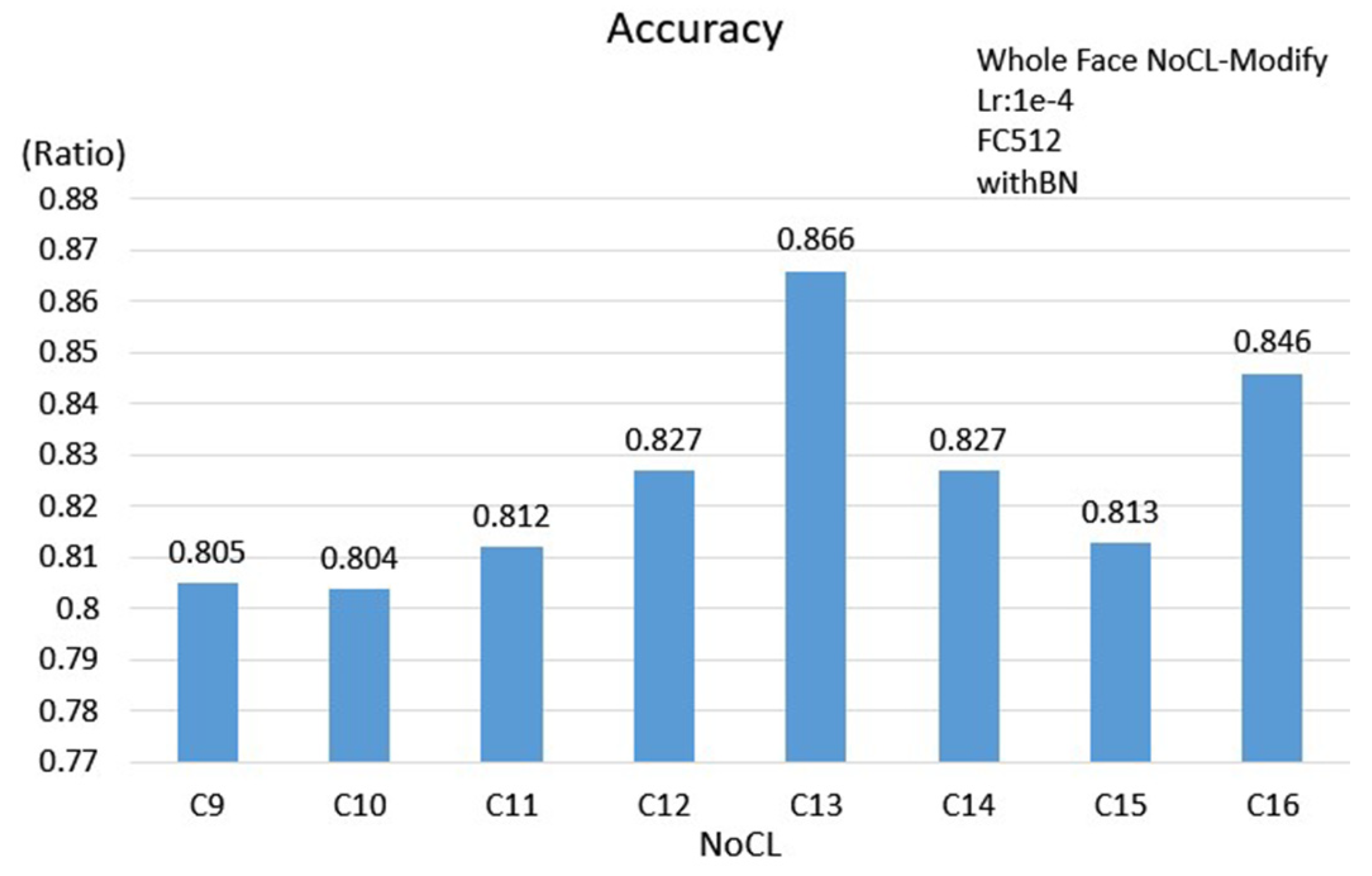
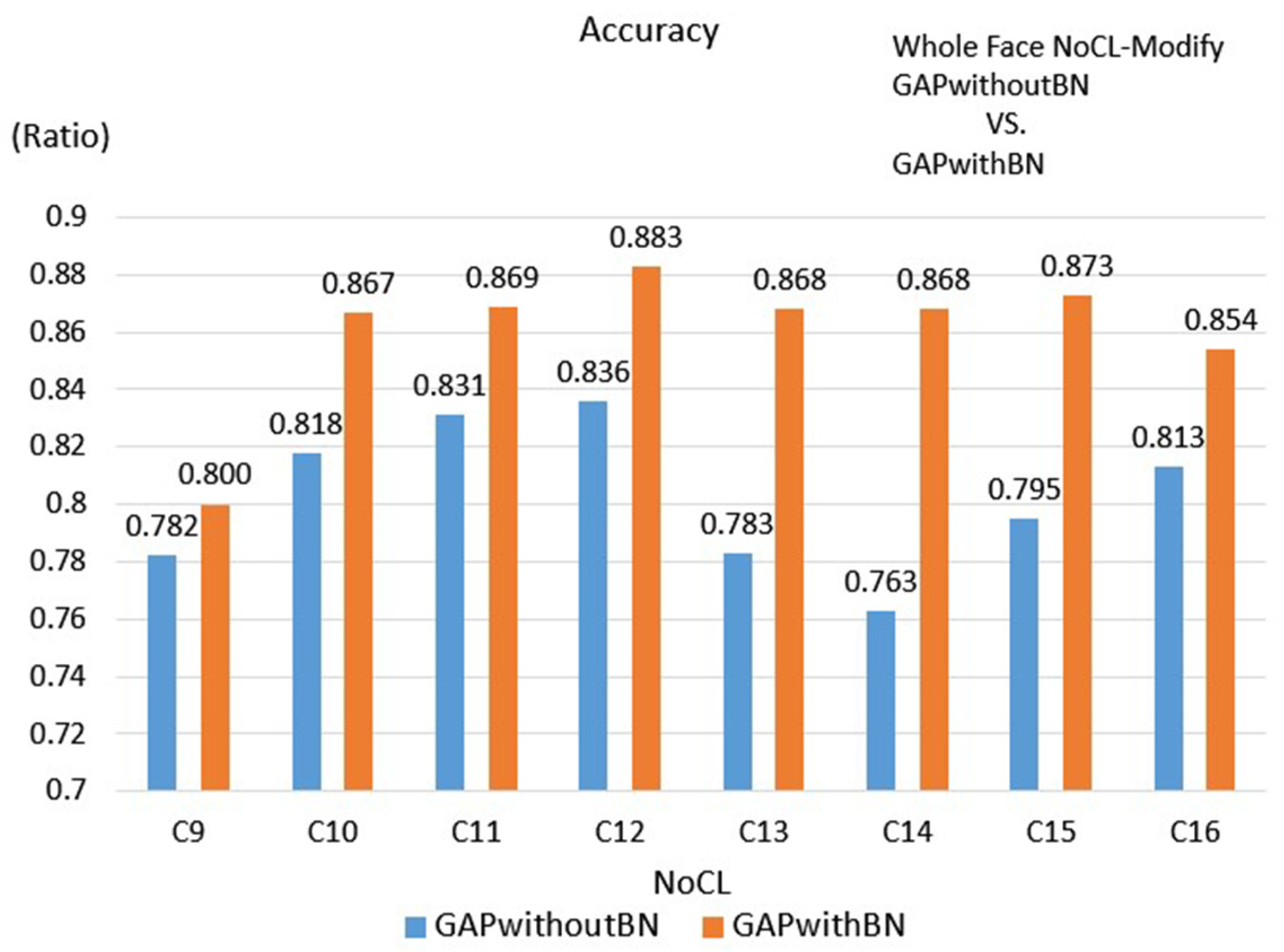
3.2.3. Face Scheme
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hicks, C.M.; Petrosoniak, A. Peak performance: Simulation and the nature of expertise in emergency medicine. Can. J. Emerg. Med. 2019, 21, 9–10. [Google Scholar] [CrossRef] [PubMed]
- Laddi, A.; Prakash, N.R. Eye gaze tracking based directional control interface for interactive applications. Multimed. Tools Appl. 2019, 78, 31215–31230. [Google Scholar] [CrossRef]
- Paul, I.J.L.; Sasirekha, S.; Maheswari, S.U.; Ajith, K.A.M.; Arjun, S.M.; Kumar, S.A. Eye gaze tracking-based adaptive e-learning for enhancing teaching and learning in virtual classrooms. In Information and Communication Technology for Competitive Strategies; Springer: Singapore, 2019; pp. 165–176. [Google Scholar]
- Hansen, D.W.; Ji, Q. In the eye of the beholder: A survey of models for eyes and gaze. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 478–500. [Google Scholar] [CrossRef] [PubMed]
- Duchowski, A. Eye Tracking Methodology: Theory and Practice; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Blignaut, P.; Wium, D. The effect of mapping function on the accuracy of a video-based eye tracker. In Proceedings of the 2013 Conference on Eye Tracking South Africa; ACM: New York, NY, USA, 2013; pp. 39–46. [Google Scholar]
- Zhu, Z.; Ji, Q. Novel Eye Gaze Tracking Techniques under Natural Head Movement. IEEE Trans. Biomed. Eng. 2007, 54, 2246–2260. [Google Scholar] [PubMed]
- Zhou, X.; Cai, H.; Shao, Z.; Yu, H.; Liu, H. 3D eye model-based gaze estimation from a depth sensor. In Proceedings of the 2016 IEEE International Conference on Robotics and Biomimetics (ROBIO), Qingdao, China, 3–7 December 2016; pp. 369–374. [Google Scholar]
- Anuradha, A.; Corcoran, P. A review and analysis of eye-gaze estimation systems, algorithms and performance evaluation methods in consumer platforms. IEEE Access 2017, 5, 16495–16519. [Google Scholar]
- Wu, Y.L.; Yeh, C.T.; Hung, W.C.; Tang, C.Y. Gaze direction estimation using support vector machine with active appearance model. Multimed. Tools Appl. 2012, 70, 2037–2062. [Google Scholar] [CrossRef]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. Appearance-based gaze estimation in the wild. In 2015 IEEE Conference on Computer Vision and Pattern Recognition; IEEE Computer Society: Washington, DC, USA, 2015. [Google Scholar]
- Krafka, K.; Khosla, A.; Kellnhofer, P.; Kannan, H.; Bhandarkar, S.; Matusik, W.; Torralba, A. Eye tracking for everyone. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2176–2184. [Google Scholar]
- Wang, Y.; Shen, T.; Yuan, G.; Bian, J.; Fu, X. Appearance-based gaze estimation using deep features and random forest regression. Knowl. Based Syst. 2016, 110, 293–301. [Google Scholar] [CrossRef]
- Lemley, J.; Kar, A.; Drimbarean, A.; Corcoran, P. Convolutional Neural Network Implementation for Eye-Gaze Estimation on Low-Quality Consumer Imaging Systems. IEEE Trans. Consum. Electron. 2019, 65, 179–187. [Google Scholar] [CrossRef]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. It’s written all over your face: Full-face appearance-based gaze estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 2299–2308. [Google Scholar]
- George, A.; Routray, A. Real-time eye gaze direction classification using convolutional neural network. In Proceedings of the 2016 International Conference on Signal Processing and Communications (SPCOM), Bangalore, India, 12–15 June 2016. [Google Scholar]
- Zhang, C.; Yao, R.; Cai, J. Efficient eye typing with 9-direction gaze estimation. Multimed. Tools Appl. 2017, 77, 19679–19696. [Google Scholar] [CrossRef]
- Kao, C.W.; Chen, H.H.; Wu, S.H.; Hwang, B.J.; Fan, K.C. Cluster based gaze estimation and data visualization supporting diverse environments. In Proceedings of the International Conference on Watermarking and Image Processing (ICWIP 2017), Paris, France, 6–8 September 2017. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2014, arXiv:1312.4400. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); Computer Vision Foundation: Washington, DC, USA, 2015. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Klare, B.F.; Klein, B.; Taborsky, E.; Blanton, A.; Cheney, J.; Allen, K.; Grother, P.; Mah, A.; Jain, A.K. Pushing the frontiers of unconstrained face detection and recognition: Iarpa janus benchmark a. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1931–1939. [Google Scholar]





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Title | Resolution (Pixel) | Length (sec) |
|---|---|---|
| Reach 1 | 1920 × 1080 | 193 |
| Mr Indifferent 2 | 1920 × 1080 | 132 |
| Jinxy Jenkins & Lucky Lou 3 | 1920 × 1080 | 193 |
| Changing Batteries 4 | 1920 × 1080 | 333 |
| Pollo 5 | 1920 × 1080 | 286 |
| Pip 6 | 1920 × 1080 | 245 |
| Experiment Number | Adjusted Parameters |
|---|---|
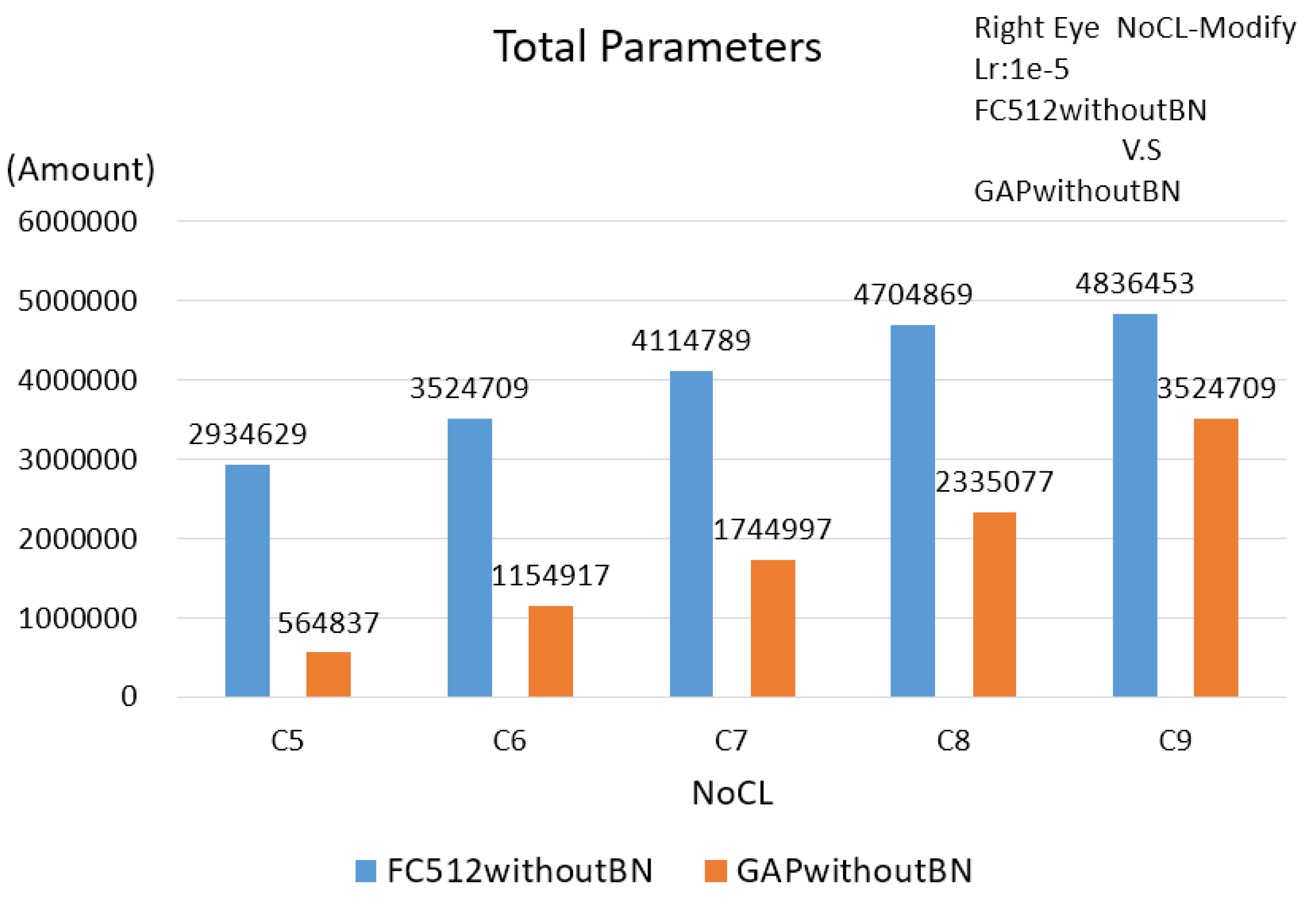
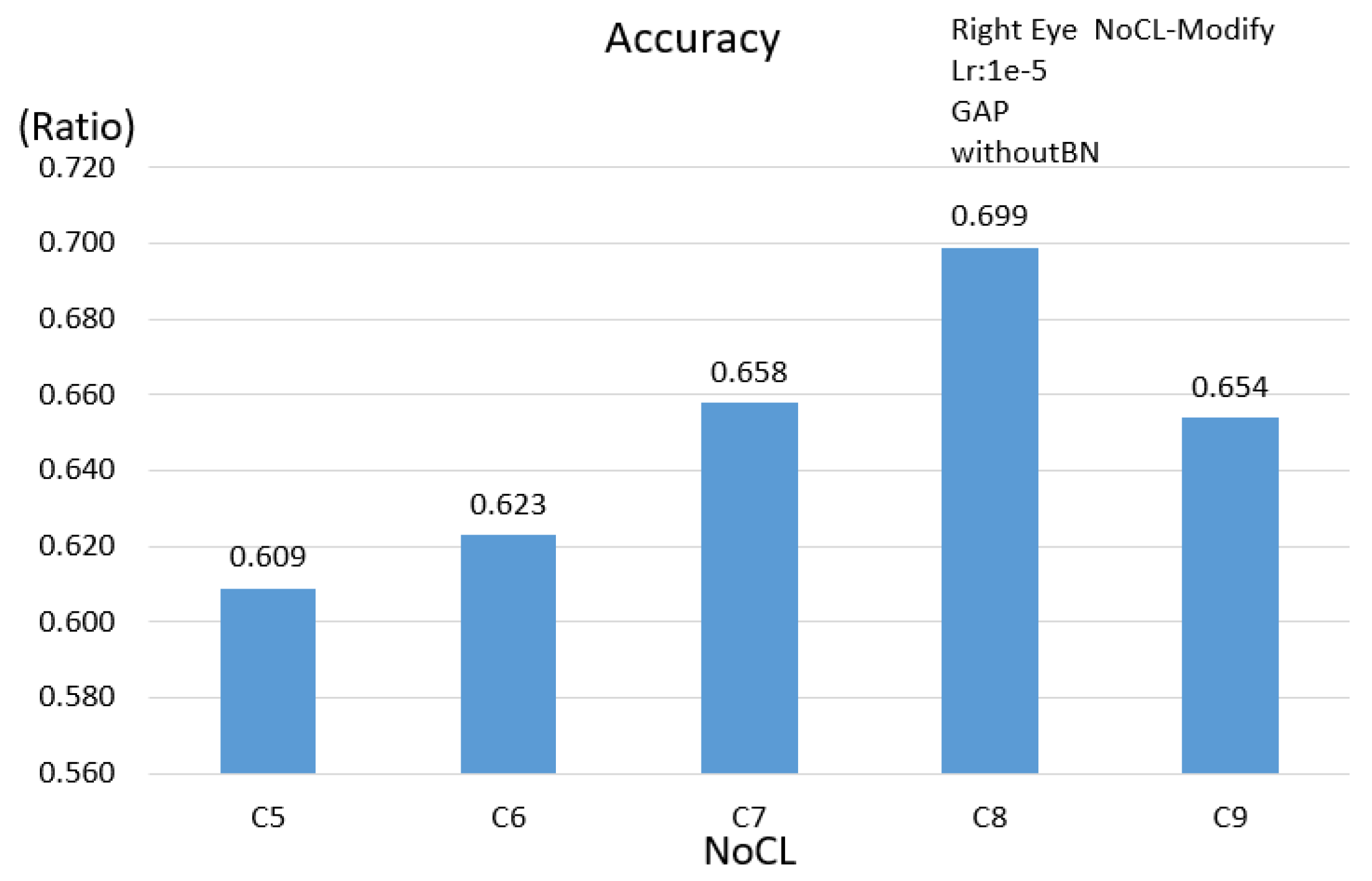
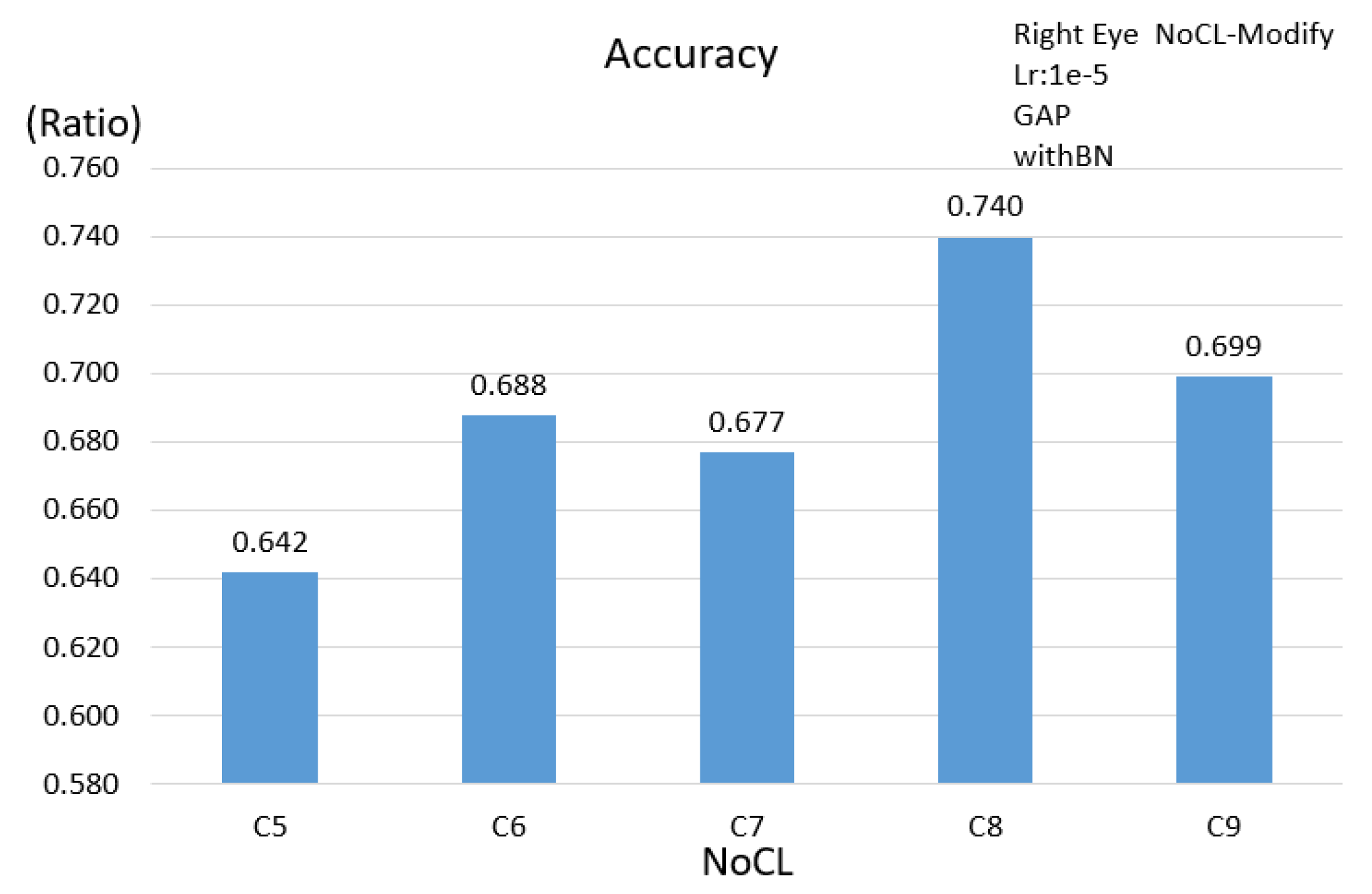
| 1 | NoCL |
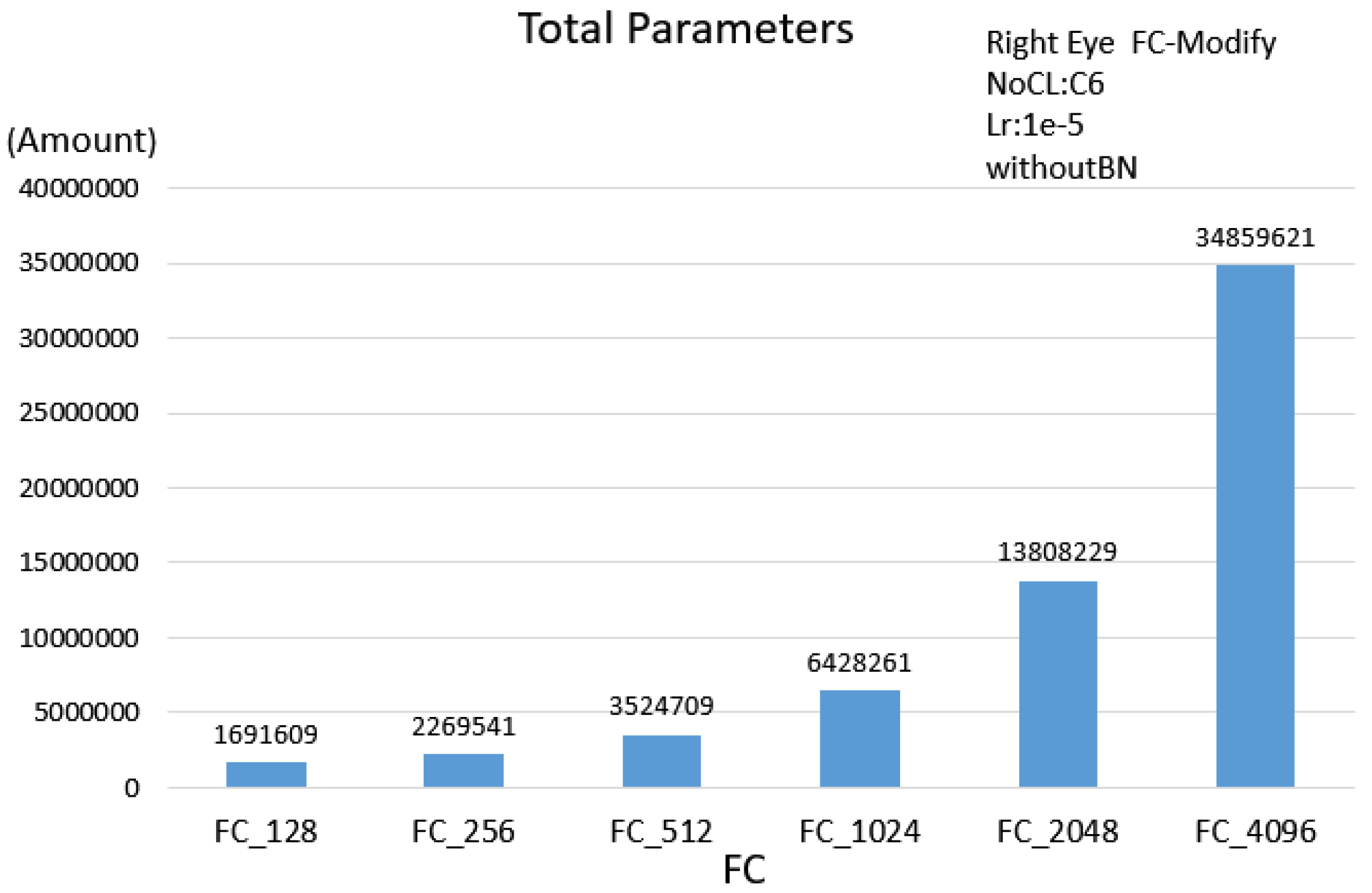
| 2 | FC |
| 3 | NoCL + BN |
| 4 | NoCL + GAP |
| 5 | NoCL + GAP + BN |
| FC512withoutBN | FC512withBN | GAPwithoutBN | GAPwithBN | |
|---|---|---|---|---|
| NoCL | C13 | C13 | C12 | C12 |
| Learning Rate | 1 × 10−5 | 1 × 10−4 | 1 × 10−5 | 1 × 10−3 |
| Accuracy | 0.862 | 0.866 | 0.836 | 0.883 |
| Loss | 0.608 | 0.571 | 0.603 | 0.613 |
| Precision | 0.861 | 0.864 | 0.838 | 0.885 |
| Recall | 0.865 | 0.865 | 0.843 | 0.885 |
| F1-Score | 0.862 | 0.864 | 0.840 | 0.885 |
| Parameters | 22664293 | 22684261 | 10604113 | 10617957 |
| Scheme | FC512withoutBN | FC512withBN | GAPwithoutBN | GAPwithBN |
|---|---|---|---|---|
| Single Eye | 0.704 | 0.689 | 0.699 | 0.740 |
| Double Eyes | 0.801 | 0.827 | 0.783 | 0.839 |
| Face | 0.862 | 0.866 | 0.836 | 0.883 |
| Parameters | FC512withoutBN | FC512withBN | GAPwithoutBN | GAPwithBN |
|---|---|---|---|---|
| Single Eye | 3524709 | 4714597 | 2335077 | 2340709 |
| Double Eyes | 6933605 | 9307237 | 1744997 | 2340709 |
| Face | 22664293 | 22684261 | 10604113 | 10617957 |
| Proposed | George (ROI) | George (ERT) | |
|---|---|---|---|
| Accuracy | 93.3 | 81.37 | 86.81 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.-H.; Hwang, B.-J.; Wu, J.-S.; Liu, P.-T. The Effect of Different Deep Network Architectures upon CNN-Based Gaze Tracking. Algorithms 2020, 13, 127. https://doi.org/10.3390/a13050127
Chen H-H, Hwang B-J, Wu J-S, Liu P-T. The Effect of Different Deep Network Architectures upon CNN-Based Gaze Tracking. Algorithms. 2020; 13(5):127. https://doi.org/10.3390/a13050127
Chicago/Turabian StyleChen, Hui-Hui, Bor-Jiunn Hwang, Jung-Shyr Wu, and Po-Ting Liu. 2020. "The Effect of Different Deep Network Architectures upon CNN-Based Gaze Tracking" Algorithms 13, no. 5: 127. https://doi.org/10.3390/a13050127
APA StyleChen, H.-H., Hwang, B.-J., Wu, J.-S., & Liu, P.-T. (2020). The Effect of Different Deep Network Architectures upon CNN-Based Gaze Tracking. Algorithms, 13(5), 127. https://doi.org/10.3390/a13050127