Design Limitations, Errors and Hazards in Creating Decision Support Platforms with Large- and Very Large-Scale Data and Program Cores


 ,
,  ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- Management of goods in road, rail, sea and intermodal transportation. These operations are very complex, involving public and/or private train, truck and ship owner companies, goods owners and buyers, transport operators, intermodal terminal operators, infrastructure providers, safety and security operators, etc. [7,8,9];
- The ability to efficiently update a DS system;
- The flexible expansion of the DSS;
- The consistent reducibility of an information system;
- The ability to make changes to the information system;
- The upgrading of the DSS.
2. The Tendency to Increase the Volume and Complexity of Data and Program Collection of the DSS
- (a)
- Advances in information technology and communications (ITC) have created a market for DSSs with very large-scale data and program collections.
- (b)
- The same ITC advances have opened the way to engineers to attempt to develop DSSs that tackle very big and/or complicated practical problems. Two related examples follow:
- The effort for developing the European Transport Information System for Policy Support (ETIS).
- A second example is the information system for the port of Rotterdam. This system includes a huge amount of geographical information. It is noteworthy that the port of Rotterdam incorporates more than 5000 docs, an airport, a considerably large storage area for alumina and abundant apron spaces for temporary storage of goods and containers.
- (c)
- The inclusion and use of data, which are directly or indirectly georeferenced (map-related data), in a DSS. In the first case, the direct one, the exact co-ordinates of an object are explicitly provided. On the contrary, in the second case, the indirect one, there is a link to an object, which determines the data co-ordinates. For example, if an accident takes place at a specific point of a certain road and then, if the exact co-ordinates of the accident location are registered in an IS, this event is directly georeferenced. On the other hand, if the registered information is something like the following: “the accident happened at the 23rd kilometer of the road from city A to city B”, then the event is indirectly georeferenced.
- (d)
- Finally, special DSS architecture requirements, like the following:
- Distributed and/or geographically dispersed systems, where properly selected duplication of part of the information and programs must be implemented, in order to increase the efficiency of the local systems. For example, a very frequently accessed part of information by all sub-systems must be preferably kept in every local sub-system.
- Umbrella-type systems that receive and process information in real time from a large number of heterogeneous, autonomous and, possibly, legacy systems. Sometimes, these systems may cover a large part or the whole of a continent. Such is the case of a European system for maritime surveillance, the complexity and size of which is evident.
3. Severe Difficulties Appearing in the Actual Deployment of a Very Large-Scale Decision Support System
- In many transport DS systems, practically all problems referred to in the present work have already emerged, due to the huge size and complexity of the involved data. As a first example, we state the large number (more than 50) of Federated States in the USA. An analogous second example is the European Transport Information System, which is a DSS for supporting transport policy decisions in all EU countries.
- Engineers and other scientists that have developed the pioneering versions of the transport DS systems have faced a considerable number of serious difficulties and problems, many of which still remain unsolved. It must be emphasized that for a considerable number of these difficulties and problems, the severity of the resulting hazards may be anticipated.
3.1. Early Design Errors and Serious Difficulties Due to the Large Data and Program Collection Characteristics
- (a)
- A prevailing design mentality in connection with the first transport DS systems was the following: “Get all related or even loosely related data first and then organize them”. Practice, though, proved that this design mentality leads to disasters. In fact, it turned out that:
- This way of data acquisition does not guarantee a precise/consistent, methodological collection of data. On the contrary, the random, heuristic and ad hoc data collection, as a rule, results in a core with data and programs that are non-interoperable, internally inconsistent, practically impossible to organize or update properly and impossible to upgrade.
- Due to the aforementioned problems concerning the selected data, the core of the corresponding DSS practically collapses under the weight of the non-organizable data collections.
- (b)
- It must be pointed out that, after this early approach, the designers of a large-scale decision support system apply carefully designed data acquisition methodologies. However, it turns out that in practical cases, there are several characteristics, inherent to the elements of large data collections, which create severe difficulties and problems to the designers of the information system to be used as a platform of the DSS. Some of these characteristics will be presented immediately below.
- (i)
- As a rule, in a very large DS system, the data are multi-thematic; hence, it is logical to expect a great variability of definitions, meanings and contents associated with the data.
- (ii)
- The aforementioned variability is frequently accompanied by a great diversity of forms and formats of the elements of the data collection. This diversity practically always asks for a different handling of each subset of similar data.
- (iii)
- (Complexity is another serious problem associated with large-scale data collections and the corresponding DS systems. The term “complexity” is used in order to describe data with a particularly great number of interconnections, inter-relations and interdependencies.
- (iv)
- Data polymorphism can easily destroy an arbitrary DS system. For example, the most common computer object in transport, the “transport link”, may literally have tenths or even hundreds of different definitions, meanings and data contents. Thus, the link between two cities A and B may refer to:
- Various road connections, where each road has its own characteristics (e.g., a highway with a given number of lanes with or without tolls, a national road, a secondary street, etc.);
- Various train connections, each one frequently with its own characteristics, such as high-velocity trains (TGV), intercity trains, local trains, commercial trains, etc.;
- Airplane connections, with airports having different connections with the city center;
- Seaways, where each way frequently includes ferries, container carriers, bulk carriers, tankers, cruisers, etc.;
- Inland navigation, etc.
- (c)
- In many cases, large data and program collections must be distributed in several systems, which may be geographically dispersed. Achieving an efficient operation of each such sub-system, as well as maintaining a proper communication among the individual systems, while keeping the large data and program core healthy and consistent, is a difficult task indeed.
- (d)
- The huge numbers of external data sources of large DS systems: In a considerable number of cases, the large DSS data core must handle data from a huge number of different, heterogeneous and autonomous external sources, such as databases and/or various data collections. For example, the European Transport Information System for Policy Support (ETIS) receives data from more than 500 external sources [20], which are indeed heterogeneous and autonomous. Handling this number of different sources is a very difficult task and, in most cases, tackling this task is by no means automatic. Indeed, usually, a large initial effort by experts is required, in order to create a first version of an interoperable, internally consistent data and program core [34].
- (e)
- In a large data collection, a considerable number of differences in the meaning and/or definition of common variables, coming from different sources, may appear. Thus, the task of defining the exact meaning and form of the variables that are common to many sources of the DS system may prove to be extremely difficult.
- (f)
- The next difficulty concerns the “level of detail” (abbreviated as LoD) or “granularity”. We shall try to clarify the content and importance of the term “level of detail” by means of the following example, concerning Google Maps. In fact, this application starts from offering a global earth projection. Then, the user may gradually increase the level of detail at an arbitrary point of the projection, according to his/her desire. At each such selection of the user, a more detailed map of the associated area appears on the screen. At certain levels, new geographical objects appear on the screen. For example, one may select a specific country and see its map. Subsequently, one may choose an area of this country and see the corresponding map in more detail. After a sequence of successive selections, where each one of them offers a greater level of detail, one may suddenly see some cities as points and some sketches of roads; hence, new objects appear. Further increase of the detail may offer more and more dense maps of the desired area. If one selects the option “satellite”, more and more detailed images of the selected area appear on the screen. In the higher detail level, the user may see individual public buildings and constructions, houses and details of them.
3.2. Extreme Problems in Deploying, Managing, Maintaining, Updating and Upgrading Very Large-Scale Decision Support Systems
- (a)
- Since the DSS platform is not sustainable in many cases [38], an effort for redesigning the DSS must be repeated after a short time period, when considerable changes must be accommodated. We would like to emphasize that the time period, after which it is necessary to redesign a certain DS system [39] (p. 4) [40,41], may frequently be as short as few years only, for example, 4 or 5 years.
- (b)
- Serious difficulties in updating a large-scale decision support system: In such a system, the great number of the involved data, the significant complexity and polymorphism of them, the heterogeneity and dispersion of the data sources, as well as the fact that the various source data bases have been designed with a different mentality/approach, make the necessary, regular updating of the overall information system too difficult or even impossible. In fact, the problem is far more severe. The aforementioned factors render DSS upgrading much more difficult; as a rule, upgrading comprises improvement of existing data sets and programs, as well as incorporation of new data sets and programs, so that additional problems can be tackled by the DSS.
- (c)
- Upgrading a large-scale decision support system is, very frequently, impossible: We would like to point out that, when a serious upgrading of a system is required, then, as a rule, a new DS system is frequently designed ad hoc, without a systematic methodology; this approach asks for a migration of the data and program core of the old system to the new one, a task which is extremely difficult and, in certain cases, impossible to achieve. Evidently, the new DS system will definitely manifest the very same problems as the old one, concerning updating and upgrading.
- (d)
- The DSS lifecycle may strongly depend on the duration of the incumbency of the decision authorities: It is very well known that, in western-type democracies, the authorities who take decisions frequently change in a smooth way. This fact may render the time duration of the incumbency of the policy makers comparable to the time period, which is necessary for the deployment of a new or improved DS system. Thus, for example, very often, the policy priorities may drastically change, as a result of changes in the decision authorities. In this way, a DS system that has just begun to work may become partially or totally obsolete. Consequently, the DS system must be drastically changed or even redesigned from the beginning. Hence, it is imperative to design information systems in such a way so that maximum re-use of the existing data and programs can be achieved.
4. Contemporary, Mainstream Methodologies for Creating Large-Scale Decision Support Systems
- (a)
- A comprehensive list of the general issues/problems, for which the DS system must provide support. We will use for it the term “thematic list”.
- (b)
- A decomposition of each one of the aforementioned issues/problems to subcategories, further subcategories, etc., up to the fundamental, non-separable issues/problems. We will employ for this process the term “thematic decomposition”. For example, the general transport issue of “social/environmental impacts of transport” must initially discriminate between the subcategories “harmful impacts” and “beneficial impacts”. Then, the subcategory of “harmful impacts” must, among others, include:
- “Noise”;
- “Congestion”;
- “Pollutant emissions”.
- “Improved connectivity” (e.g., better island connectivity);
- “Transport time reduction”;
- “Growth” (e.g., residential or commercial relocation for a better environment, improvement of trade conditions, economic growth, etc.).
- (c)
- An ensemble of methods for either acquiring the indicators or computing them from the relevant data, using proper mathematical models.
- (d)
- A complete list of the data, from which indicators must be evaluated.
- (e)
- A complete list of the corresponding software, that is, programs that will implement the aforementioned abstract objects.
- (f)
- A sufficient/adequate ensemble of “metadata”, which are necessary for the description of all indicators, data, acquisition or evaluation methods and the justification of their choice. It must be emphasized that this step is quite often partially considered or even neglected in the design of impressively numerous very large-scale information systems. Designing a very large-scale information system and including a poor/insufficient set of metadata is a grave error that will practically render the system non-maintainable, non-upgradable and non-modifiable.
- A user interface architectural tier, that is, an adequate number of computer systems to handle the communication of the users with the DS system. Nowadays, this is achieved through the Internet and/or an Intranet, if confidentiality reasons dictate so.
- One or more databases and/or data warehouses specifically designed to handle large ensembles of data. The entire set of these tools is frequently called “data tier”. We note that the data tier may include specialized hardware, such as hardware “storages” or other similar components.
- A cluster of computer systems, sometimes called “application tier”, implementing the computational methods for the evaluation of the indicators, using data from the previous data tier. Additionally, the ITS engineers may include custom software for satisfying particular needs of the users of a DS system for data visualization and/or specialized processing.
- A set of computer systems for the communication and mediation of the DSS with external data bases.
5. A Novel, Systematic Methodology for Designing, Maintaining and Upgrading a Very Large-Scale Decision Support System
- (a)
- Development of a specialized meta-database, able to store the entire aforementioned abstract structure produced by the experts, using a corresponding template, which is more analytically described below. For this meta-database, we shall use the name “teleological meta-database” [47] or simply “meta-database”, for reasons that will become clear in the following steps.
- (b)
- Insertion in this template of the thematic entities/entries of the system and the associated “thematic decomposition”, which ends up to the “non-separable objects” of the DSS in hand; these actions and terms will be more extensively analyzed in Section 5.1.
- (c)
- Further filling of the template of the teleological meta-database with all the necessary indicator descriptions. At the same time, the analytic description of the exact method(s) of acquiring or evaluating these indicators must be included in this meta-database.
- (d)
- Further inclusion in the teleological meta-database of the complete list of characteristics of the DSS external sources, together with all necessary information for accessing them.
- (e)
- Incorporation of all the documentation metadata in the teleological meta-database; this documentation must fully cover the entire set of data, programs and other components and actions of the DSS.
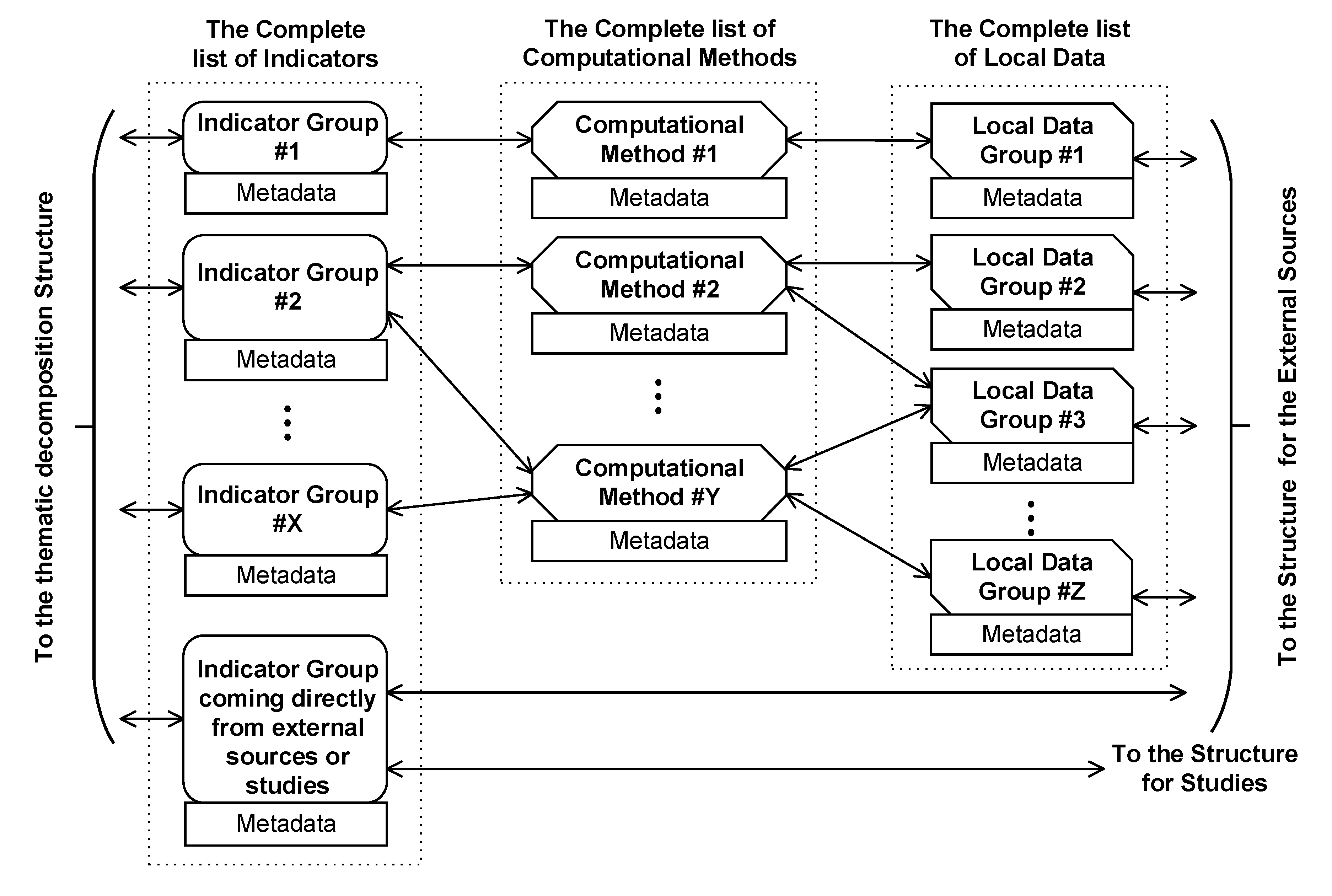
5.1. The Part of the Template that Includes the Compete Thematic Decomposition
- The entire thematic list of the DSS incorporates issues I1, I2, …, IN.
- Each such issue is decomposed into successive sub-issues, for example, issue I1 is at the first level decomposed into sub-issues SI1,1, SI1,2, …, SI1,K1. Similarly, issue IN is decomposed into sub-issues SIN,1, SIN,2, …, SIN,KN.
- In an analogous manner, sub-issue SI1,1 is decomposed into SI1,1,1, SI1,1,2, SI1,1,3, …, SI1,1,M1, and so on.
- The decomposition process in connection with each initial thematic issue stops, when all non-separable objects, associated with this issue have been determined. In this way, for each issue IJ (J = 1,2, …, N), a specific number of paths is obtained. We emphasize that the number of these paths as well as the depth of each path, as a rule, are not constant. We employ the symbol NS for the non-separable object of each such path. Thus, for example, issue I1 is eventually decomposed into F1 non-separable objects, giving rise to “last-leaves” NS1,1, NS1,2,..., NS1,F1.
- We have used a double arrow to indicate a connection of two arbitrary objects of the tree-like structure, in order to make clear that each sub-issue must “know” all previous sub-issues and the initial issue(s) that have generated it.
- We would like to emphasize that each issue and sub-issue is naturally linked to a set of metadata.
- The dotted arrows have been used to indicate that the entire structure is not a tree, but a graph, most probably, an acyclic one.
- The gray arrows that originate at the final non-separable objects of this tree-like, graph structure of Figure 1 manifest that this structure is linked to another one, that deals with the indicators and/or the data of the system.
5.2. The Template Part Covering the DSS Indicators and/or Data and Their Acquisition or Evaluation Method(s)
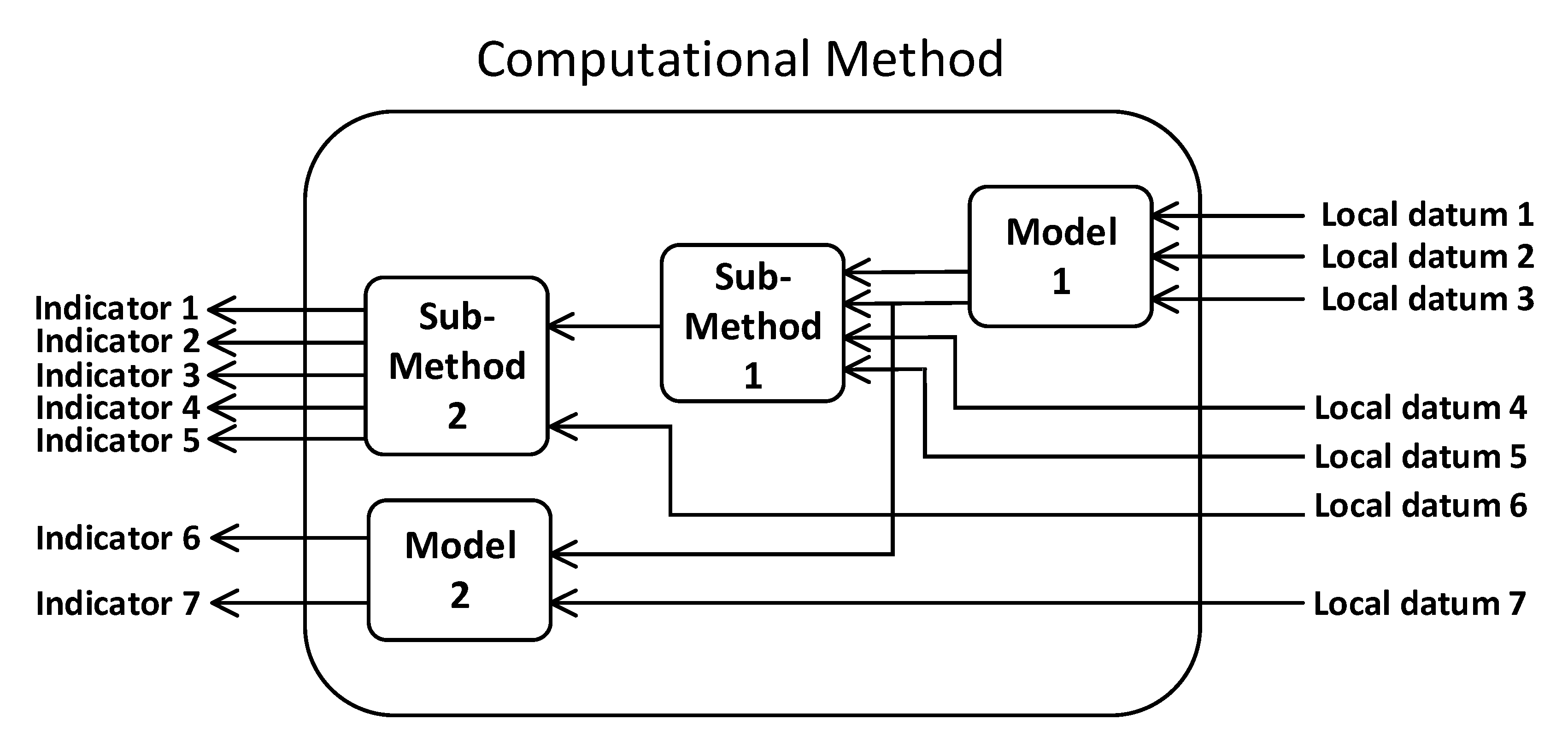
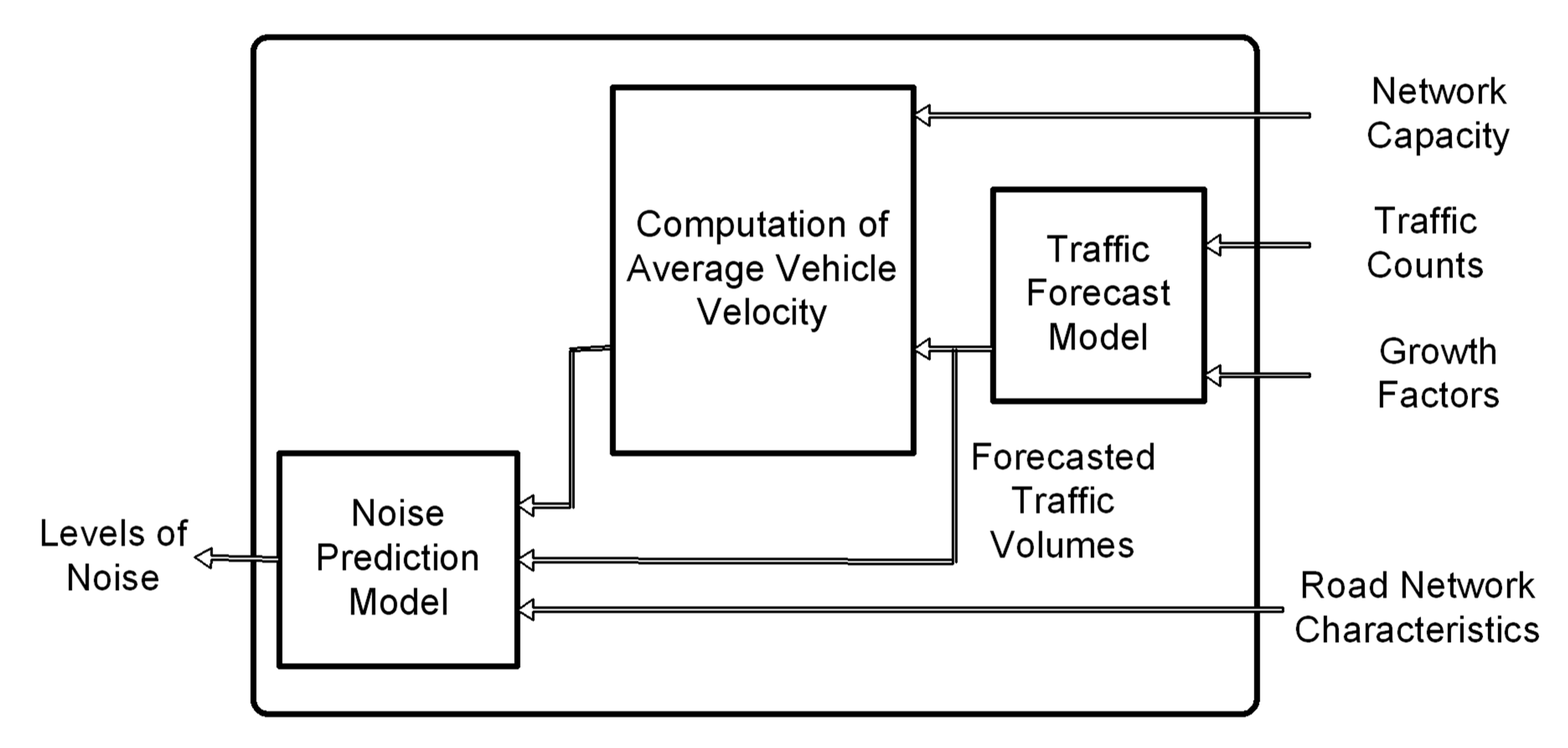
- (a)
- For each indicator (or group of indicators), the DS system uses a specific computing methodology, which employs certain data in order to evaluate the indicator(s).
- (b)
- The indicator (or group of indicators) may come directly from external sources, needing no further (or minimal) processing, and they are stored intact in the DS system.
- (c)
- Finally, there are groups of indicators, which are the results of studies and/or development of external group of experts. These indicator(s) are also stored intact in the DS system.
5.3. Including the External Sources and the Way to Access Them in the Template
- (a)
- A complete description of the information furnished by the external sources.
- (b)
- A full documentation concerning the method(s), which the mediator employs in order to evaluate the various indicators or data.
- (c)
- The exact methodology and the frequency with which the data and/or indicators reaching the main system must be updated.
- (d)
- Since a part (sometimes considerable) of the indicator ensemble may come from studies/R&D projects, these studies or projects can be considered as an “off-line” kind of external sources. It is necessary to describe the information associated with these indicators adequately, so that future expert users of the DS system can clearly and unambiguously understand the following:
- The quality of the indicators;
- Any possible special characteristics these indicators possess;
- Any limitations of the use of the group of specific indicators.
5.4. Including a Complete, Structured Description of Experts’ Knowledge in the Teleological Meta-Database
- (a)
- The external sources control access to sensitive information, that is, information covered by GDPR; and/or, probably,
- (b)
- The administration of the main core of the DSS have analogous rights.
5.5. Incorporating the Proper Documentation and Navigation Information for the Users in the Teleological Meta-Database
- The first is scientific: The expert designer of the system has to provide proper content titles or even content synopses, that can facilitate the unfamiliar user in navigating the DS system easily and without mistakes.
- The second one is technical: It aims at helping the user to understand the information system and the user interface. It must be provided by the ITC expert(s) who built the IS.
6. Substantial Advantages of a Decision Support System Developed on the Basis of the Proposed New Teleological Meta-Database
- (a)
- It must include the purpose and use of the employed indicators and/or of each datum.
- (b)
- It must incorporate the entire thematic list, that is, all issues and sub-issues and the exact way each one of them is linked to the entities of (a) immediately above.
- (c)
- All software programs of the DSS must be directly linked to the entities referred to in (a) and (b) immediately above.
- (d)
- The aforementioned software programs of the DSS must be very well documented, and this documentation must be properly placed in the template of the meta-database in a clear-cut manner.
- (a)
- Correct and efficient updating of the DS system.
- (b)
- Make changes to the content of the DSS.
- (c)
- Upgrade and/or expand the content of the DS system, by including further classes of issues, sub-issues, data, indicators, associated computational methods, new external sources, together with the corresponding mediators, etc. In fact, by exploiting the structure of the meta-database, one may achieve a consistent, considerable growth of the DS system. Without the use of the proposed teleological meta-database, there is a serious risk that such growth of the DSS may render it unmanageable.
- (d)
- Reduce the content of the DS system, by eliminating a subset of the aforementioned entities, without causing any damage to the remaining system at all.
7. Conclusions
- (a)
- The efficient updating of the DS system;
- (b)
- The flexible expansion of the DSS;
- (c)
- The consistent reduction of the information system;
- (d)
- The ability to modify the system;
- (e)
- The upgradability of the DSS, etc.
- (a)
- A complete thematic decomposition;
- (b)
- A complete list of all indicators and/or data and their acquisition or evaluation method(s);
- (c)
- A complete list of all the external sources of the system, together with the way to access them;
- (d)
- An absolutely sufficient and structured description of the experts’ knowledge concerning the whole system;
- (e)
- The proper documentation and navigation information for users in this (teleological) meta-database.
Author Contributions
Funding
Conflicts of Interest
References
- Fagerholt, K. A computer-based decision support system for vessel fleet scheduling—Experience and future research. Decis. Support Syst. 2004, 37, 35–47. [Google Scholar] [CrossRef]
- Fagerholt, K.; Johnsen, T.A.V.; Lindstad, H. Fleet deployment in liner shipping: A case study. Marit. Policy Manag. 2009, 36, 397–409. [Google Scholar] [CrossRef]
- Clemente, M.; Fanti, M.P.; Iacobellis, G.; Nolich, M.; Ukovich, W. A Decision Support System for User-Based Vehicle Relocation in Car Sharing Systems. IEEE Trans. Syst. Man Cybern. Syst. 2017, 48, 1283–1296. [Google Scholar] [CrossRef]
- Bolman, B.; Jak, R.G.; Van Hoof, L. Unravelling the myth—The use of Decisions Support Systems in marine management. Mar. Policy 2018, 87, 241–249. [Google Scholar] [CrossRef]
- Gil, M.; Wróbel, K.; Montewka, J.; Goerlandt, F. A bibliometric analysis and systematic review of shipboard Decision Support Systems for accident prevention. Saf. Sci. 2020, 128, 104717. [Google Scholar] [CrossRef]
- Pieri, G.; Cocco, M.; Salvetti, O. A Marine Information System for Environmental Monitoring: ARGO-MIS. J. Mar. Sci. Eng. 2018, 6, 15. [Google Scholar] [CrossRef]
- Caris, A.; Macharis, C.; Janssens, G.K. Decision support in intermodal transport: A new research agenda. Comput. Ind. 2013, 64, 105–112. [Google Scholar] [CrossRef]
- Qaiser, F.H.; Ahmed, K.; Sykora, M.; Choudhary, A.K.; Simpson, M. Decision support systems for sustainable logistics: A review and bibliometric analysis. Ind. Manag. Data Syst. 2017, 117, 1376–1388. [Google Scholar] [CrossRef]
- Dotoli, M.; Epicoco, N.; Falagario, M.; Seatzu, C.; Turchiano, B. A Decision Support System for Optimizing Operations at Intermodal Railroad Terminals. IEEE Trans. Syst. Man Cybern. Syst. 2016, 47, 487–501. [Google Scholar] [CrossRef]
- Zhan, J.; Ling, A.; An, N.; Li, L.; Sha, Y.; Li, X.; Liu, G. Building a Practical Ontology for Emergency Response Systems. In Proceedings of the IEEE Computer Society: Proceedings on, International Conference in Computer Science and Software Engineering CSSE ‘08 2008, Hubei, China, 12–14 December 2008; Volume 4, pp. 222–225. [Google Scholar] [CrossRef]
- Comfort, L.K.; Sungu, Y.; Johnson, D.; Dunn, M. Complex Systems in Crisis: Anticipation and Resilience in Dynamic Environments. J. Contingencies Crisis Manag. 2001, 9, 144–158. [Google Scholar] [CrossRef]
- Sakellariou, S.; Tampekis, S.; Samara, F.; Sfougaris, A.; Christopoulou, O. Review of state-of-the-art decision support systems (DSSs) for prevention and suppression of forest fires. J. For. Res. 2017, 28, 1107–1117. [Google Scholar] [CrossRef]
- Rauner, M.S.; Niessner, H.; Odd, S.; Pope, A.; Neville, K.; O’Riordan, S.; Sasse, L.; Tomic, K. An advanced decision support system for European disaster management: The feature of the skills taxonomy. Central Eur. J. Oper. Res. 2018, 26, 485–530. [Google Scholar] [CrossRef]
- McCown, R.L. Changing systems for supporting farmers’ decisions: Problems, paradigms, and prospects. Agric. Syst. 2002, 74, 179–220. [Google Scholar] [CrossRef]
- Salewicz, K.A.; Nakayama, M. Development of a web-based decision support system (DSS) for managing large international rivers. Glob. Environ. Chang. 2004, 14, 25–37. [Google Scholar] [CrossRef]
- Ayed, M.B.; Ltifi, H.; Kolski, C.; Alimi, A.M. A user-centered approach for the design and implementation of KDD-based DSS: A case study in the healthcare domain. Decis. Support Syst. 2010, 50, 64–78. [Google Scholar] [CrossRef]
- Sisk, G.M.; Miles, J.C.; Moore, C.J. Designer Centered Development of GA-Based DSS for Conceptual Design of Buildings. J. Comput. Civ. Eng. 2003, 17, 159–166. [Google Scholar] [CrossRef]
- Tavasszy, L.A.; Smeenk, B.; Ruijgrok, C.J. A DSS for modelling logistic chains in freight transport policy analysis. Int. Trans. Op. Res. 1998, 5, 447–459. [Google Scholar] [CrossRef]
- Ocalir-Akunal, E.V. Decision support systems in transport planning. Procedia Eng. 2016, 161, 1119–1126. [Google Scholar] [CrossRef]
- Ballis, A. Implementing the European Transport information System. Transp. Res. Rec. J. Transp. Res. Board 2006, 1957, 23–31. [Google Scholar] [CrossRef]
- Yatskiv, I.; Yurshevich, E. Data Actualization Using Regression Models in Decision Support System for Urban Transport Planning. In Proceedings of the 10th International Conference on Dependability and Complex Systems DepCoS-RELCOMEX 2015, Brunów, Poland, 29 June–3 July 2015; Volume 365. [Google Scholar] [CrossRef]
- Damart, S.; Roy, B. The uses of cost–benefit analysis in public transportation decision-making in France. Transp. Policy 2009, 16, 200–212. [Google Scholar] [CrossRef]
- Barfod, M.B.; Salling, K.B.; Leleur, S. Composite decision support by combining cost-benefit and multi-criteria decision analysis. Decis. Support Syst. 2011, 51, 167–175. [Google Scholar] [CrossRef]
- Sacchelli, S. A Decision Support System for trade-off analysis and dynamic evaluation of forest ecosystem services. iFor.-Biogeosci. For. 2018, 11, 171–180. [Google Scholar] [CrossRef]
- Loseto, G.; Scioscia, F.; Ruta, M.; Gramegna, F.; Ieva, S.; Pinto, A.; Scioscia, C. Knowledge-Based Decision Support in Healthcare via Near Field Communication. Sensors 2020, 20, 4923. [Google Scholar] [CrossRef] [PubMed]
- Spoladore, D.; Sacco, M. Semantic and Dweller-Based Decision Support System for the Reconfiguration of Domestic Environments: RecAAL. Electronics 2018, 7, 179. [Google Scholar] [CrossRef]
- Moreira, M.W.L.; Rodrigues, J.J.P.C.; Korotaev, V.; Al-Muhtadi, J.; Kumar, N. A Comprehensive Review on Smart Decision Support Systems for Health Care. IEEE Syst. J. 2019, 13, 3536–3545. [Google Scholar] [CrossRef]
- Encyclopaedia Britannica. Information System. Available online: https://www.britannica.com/topic/information-system (accessed on 6 December 2020).
- Archive of the European Integration (AEI); European Sources Online (ESO). Information Guide: Trans-European Networks. University of Pittsburgh, Cardiff EDC, 2013. Available online: http://aei.pitt.edu/75428/ (accessed on 25 October 2020).
- Port of Rotterdam. Port Community System. Available online: https://www.portofrotterdam.com/en/doing-business/services/service-range/port-community-system (accessed on 25 October 2020).
- Gerard, J.; Gunn, H.; Walker, W. National and International Freight Transport Models: An Overview and Ideas for Future Development. Transp. Rev. 2004, 24, 103–124. [Google Scholar] [CrossRef]
- De Jong, G.; Vierth, I.; Tavasszy, L.; Ben-Akiva, M. Recent developments in national and international freight transport models within Europe. Transportation 2013, 40, 347–371. [Google Scholar] [CrossRef]
- Rich, J.; Nielsen, O.A.; Brems, C.; Hansen, C.O. Overall design of the Danish national transport model. In Proceedings of the Annual Transport Conference; Aalborg University: Aalborg, Denmark, 2010; Volume 17, ISSN 1603-9696. [Google Scholar]
- Chiehyeon, L.; Kim, K.J.; Maglio, P. Smart Cities with Big Data: Reference models, challenges, and considerations. Sci. Direct 2018, 82, 86–99. [Google Scholar] [CrossRef]
- Gerike, R.; Schulz, A. Workshop Synthesis: Surveys on long-distance travel and other rare events. Transp. Res. Procedia 2018, 32, 535–541. [Google Scholar] [CrossRef]
- Sillitto, H.G. Design principles for Ultra-Large-Scale (ULS) Systems. INCOSE Int. Symp. 2010, 20, 63–82. [Google Scholar] [CrossRef]
- Gabriel, R.P.; Northrop, L.; Schmidt, D.C.; Sullivan, K. Ultra-large-scale systems. In Proceedings of the Companion to the 21st ACM SIGPLAN Symposium on Object-Oriented Programming Systems, Languages, and Applications (OOPSLA 2006), Portland, OR, USA, 22–26 October 2006; Association for Computing Machinery: New York, NY, USA, 2006; pp. 632–634. [Google Scholar] [CrossRef]
- Arnott, D.; Dodson, G. Decision Support Systems Failure; Springer: Berlin/Heidelberg, Germany, 2008; Volume 1, pp. 763–790. [Google Scholar] [CrossRef]
- Jovic, M.; Tijan, E.; Zgaljic, D.; Karanikic, P. SWOT analysis of selected digital technologies in transport economics. In Proceedings of the 43rd International Convention on Information, Communication and Electronic Technology, Digitalizing Logistics processes (DIGLOGS), Opatija, Croatia, 28 September–2 October 2020. [Google Scholar]
- Limitations & Disadvantages of Decision Support Systems. Available online: https://www.managementstudyguide.com/limitations-and-disadvantages-of-decision-support-systems.htm (accessed on 25 October 2020).
- Disadvantages of Decision Support Systems. Available online: http://dsssystem.blogspot.com/2010/01/disadvantages-of-decision-support.html (accessed on 25 October 2020).
- United Nations, Treaty Collection, Depositary, Environment. A Kyoto Protocol to the United Nations Framework Convention on Climate Change. Available online: https://treaties.un.org/pages/ViewDetails.aspx?src=TREATY&mtdsg_no=XXVII-7a&chapter=27&lang=en (accessed on 25 October 2020).
- United Nations, Climate Change, Process and Meetings. The Kyoto Protocol-Status of Ratification. Available online: https://unfccc.int/process/the-kyoto-protocol/status-of-ratification (accessed on 25 October 2020).
- Grubb, M.; Vrolijk, C.; Brack, D. Routledge Revivals: Kyoto Protocol (1999): A Guide and Assessment; Routledge: Abingdon-on-Thames, UK, 2018; ISBN 9781315147024. [Google Scholar] [CrossRef]
- Oberthür, S.; Hermann, E.O. The Kyoto Protocol: International Climate Policy for the 21st Century; Springer Science & Business Media: Berlin, Germany, 1999. [Google Scholar] [CrossRef]
- Dearle, A. Software Deployment, Past, Present and Future; Future of Software Engineering (FOSE): Minneapolis, MN, USA, 2007; pp. 269–284. [Google Scholar] [CrossRef]
- Kavvadia, H. Teleology in Systems Analysis and Design Methods. SSRN Electron. J. 2020. [Google Scholar] [CrossRef]
- Méline, J.; Van Hulst, A.; Thomas, F.; Chaix, B. Road, rail, and air transportation noise in residential and workplace neighborhoods and blood pressure (RECORD Study). Noise Health 2015, 17, 308–319. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Yang, H. Managing congestion and emissions in road networks with tolls and rebates. Transp. Res. Part B Methodol. 2012, 46, 933–948. [Google Scholar] [CrossRef]
- Atymtayeva, L.; Kozhakhmet, K.; Bortsova, G. Building a knowledge base for expert system in information security. Soft Comput. Artif. Intell. Adv. Intell. Syst. Comput. 2014, 270, 57–76. [Google Scholar] [CrossRef]
- Breuil, D. On knowledge based management systems: Integrating artificial intelligence and database technologies. Eur. J. Oper. Res. 1988, 33, 354–355. [Google Scholar] [CrossRef]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koukoutsis, E.; Papaodysseus, C.; Tsavdaridis, G.; Karadimas, N.V.; Ballis, A.; Mamatsi, E.; Mamatsis, A.R. Design Limitations, Errors and Hazards in Creating Decision Support Platforms with Large- and Very Large-Scale Data and Program Cores. Algorithms 2020, 13, 341. https://doi.org/10.3390/a13120341
Koukoutsis E, Papaodysseus C, Tsavdaridis G, Karadimas NV, Ballis A, Mamatsi E, Mamatsis AR. Design Limitations, Errors and Hazards in Creating Decision Support Platforms with Large- and Very Large-Scale Data and Program Cores. Algorithms. 2020; 13(12):341. https://doi.org/10.3390/a13120341
Chicago/Turabian StyleKoukoutsis, Elias, Constantin Papaodysseus, George Tsavdaridis, Nikolaos V. Karadimas, Athanasios Ballis, Eirini Mamatsi, and Athanasios Rafail Mamatsis. 2020. "Design Limitations, Errors and Hazards in Creating Decision Support Platforms with Large- and Very Large-Scale Data and Program Cores" Algorithms 13, no. 12: 341. https://doi.org/10.3390/a13120341
APA StyleKoukoutsis, E., Papaodysseus, C., Tsavdaridis, G., Karadimas, N. V., Ballis, A., Mamatsi, E., & Mamatsis, A. R. (2020). Design Limitations, Errors and Hazards in Creating Decision Support Platforms with Large- and Very Large-Scale Data and Program Cores. Algorithms, 13(12), 341. https://doi.org/10.3390/a13120341