1. Introduction
Domination theory has its roots in the
k-Queens problem in the 18th century. Later, in 1957, Berge [
1] formally introduced the domination number of a graph. A subset of vertices
S in a graph
G is a dominating set if every vertex not in
S is adjacent to some vertex in
S. A dominating set of smallest cardinality is called a minimum dominating set. The cardinality of a minimum dominating set is called domination number of
G and is denoted by
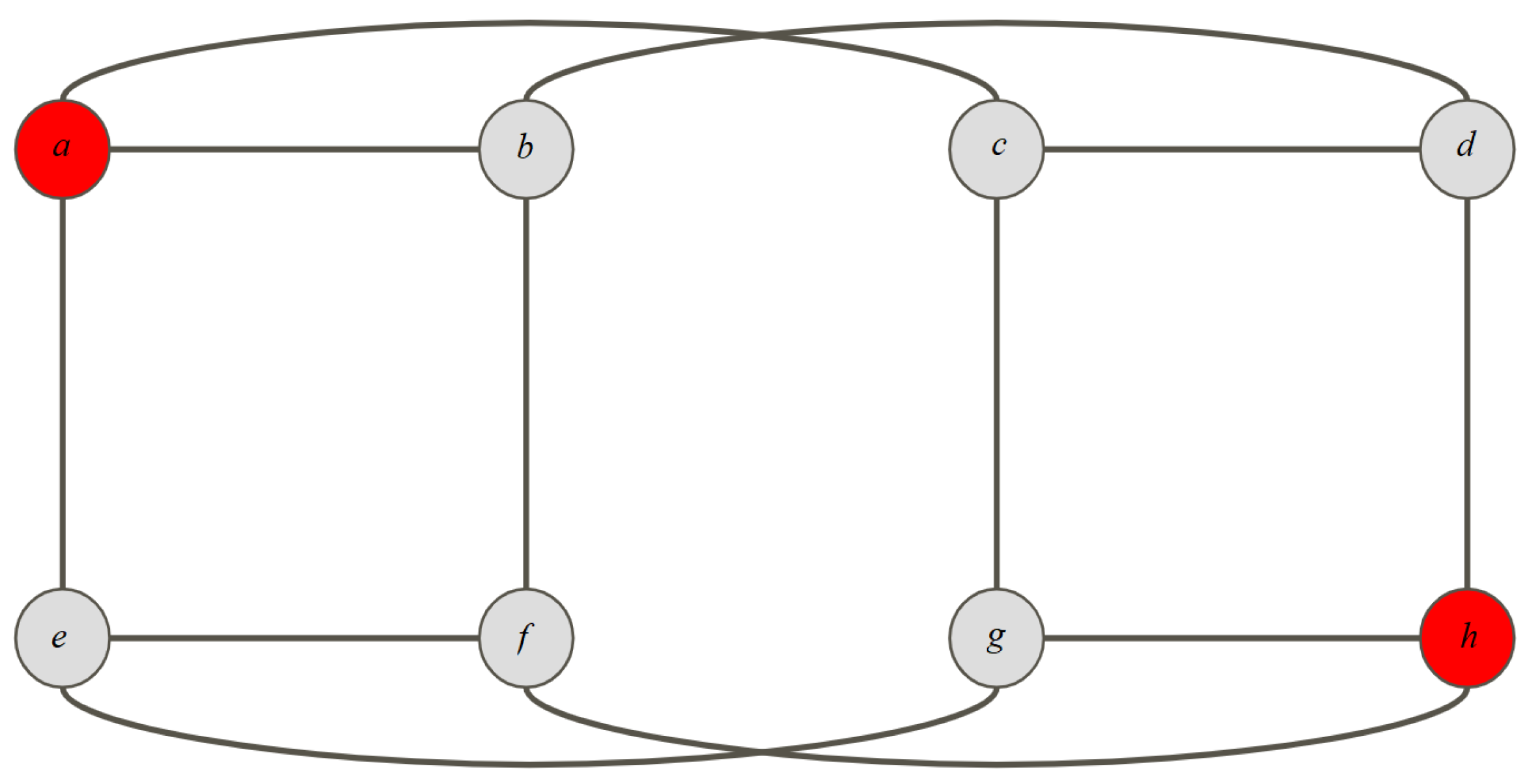
. The vertices colored red in
Figure 1 constitute a minimum dominating set in the graph
, or the three dimensional cube.
For the remainder of the paper, we assume familiarity with general concepts of graph theory as in [
2], the theory of algorithms as in [
3], and linear and integer programming concepts as in [
4], respectively. We refer the reader to the book by Haynes, Hedetniemi, and Slater [
5] as a general reference in domination theory. The problem of computing the domination number of a graph is well studied, and has extensive applications, including the design of telecommunication networks, facility location, and social networks.
Computing
is known to be an NP-hard problem, even in restricted cases, including unit disc graphs and grids [
6], and hence the researchers have focused on approximation and finding a small dominating set. A simple greedy algorithm is known to approximate
to within a logarithmic factor from the optimal value. It is known that improving the logarithmic approximation factor is also NP-hard [
7]. Hence, no algorithm for approximating
can improve the asymptotic worst-case performance ratio of the greedy algorithm. Different variations of this algorithm are proposed and some are tested in practice. See the work of Chalupa [
8], Campan et al. [
9], Eubank et al. [
10], Sanchis [
11], and Siebertz [
12].
There are other approximation algorithms for very specific classes of graphs, including planar graphs, which have better than constant performance ratio in the worst case but are more complex than the algorithms described here. See [
12] for a brief reference to some related papers.
Very recently, Bansal and Umboh [
13] and Dvořák [
14] showed that an appropriate rounding of solutions to the linear programming (LP) formulations for computing
provides dominating sets whose cardinalities are at most
and
, respectively, in polynomial time. Here,
is the arboricity of
G, and
is the value of the optimal solution to the linear programming, which is a lower bound on
. Hence, for graphs with bounded arboricity, one can improve the logarithmic performance ratio of the greedy algorithm to a constant.
The greedy algorithm is simple, fast, and is tested in practice. One anticipates that it outperforms the LP-based approach if CPU time is the criteria. Nonetheless, its performance ratio in the worst case is logarithmic even for planar graphs which have arboricity at most 3; see example 1 in the
Appendix A. For sparse graphs, the recent LP rounding methods referenced above have a bounded performance ratio, which is better than greedy, but to our knowledge, and in contrast to the greedy algorithm, the performance of the LP-based approaches have not been tested in practice. Furthermore, one would expect that for large graphs, the LP formulations would become formidable. Can one hope that a combination of these methods would give a better result than each individually, and if so, in what scenarios?
In this paper, we compare and contrast the performance of the greedy algorithm, the LP rounding algorithm, and a hybrid algorithm that combines the greedy and LP approaches. Our hybrid algorithm first solves the problem using the greedy algorithm and finds a dominating set, then takes a portion of vertices in this set and forces their values to be 1 in the linear programming formulation, solves the resulting linear program, and finally properly rounds the solution.
Our Findings
Through experimentation, all algorithms perform better than anticipated in theory, particularly with respect to the performance ratios, measured as the value of solution divided by the computed LP objective lower bound. However, each may offer advantages over the others depending on the nature of the data.
LP rounding does well on sparse real-world graphs, consistent with theory, and normally outperforms the other algorithms. On a graph with 400,000+ vertices, LP rounding took less than 15 s of CPU time to generate a solution with performance ratio 1.011, while the greedy and hybrid algorithms generated solutions of performance ratio 1.12 in similar time. It is remarkable that the hybrid algorithm can solve the problem for very large sparse graphs, where the LP formulation becomes formidable in practice. For instance, it solved a real-world graph with 7.7 million+ vertices in 106 s of CPU time with a performance ratio of 2.0075. The LP solver crashed on this problem. We indicate that the simplex-based LP package used in our experiments performed very fast, although, in theory, simplex is not necessarily polynomially time bounded.
For hypercubes and k-Queens graphs (which are not sparse) greedy outperforms the rest, consistent with theory, both in terms of speed and performance ratio. In particular, on the 12-dimensional hypercube, greedy finds a solution with performance ratio 1.7 in 0.01 s. On the other hand, the LP rounding and hybrid algorithms produce solutions with performance ratio 13 and 3.3 using 7.5 and 0.08 s of CPU time, respectively. It is notable that greedy gives optimal results in some cases where the domination number is known. Specifically, the greedy algorithm produces an optimal solution on hypercubes with dimensions where , and 4. For synthetic graphs - generated k-trees (G is a tree if it has tree width k and the addition of any edge increases the tree width by one), and k-planar graphs (G is planar if it can be drawn in the plane with no edge crossed by more than k other edges)-the LP rounding is outperformed by the other two algorithms, and the hybrid algorithm outperforms greedy.
This paper is organized as follows. In
Section 2, we set our notations and summarize related materials for the greedy algorithm. The LP rounding and hybrid algorithms are explained in sections three and four, respectively.
Section 5 (Environment, implementations and datasets), contains our materials and methods.
Section 6 contains the results for synthetic graphs (k-planar graphs and k-trees).
Section 7 and
Section 8 contain the results for hypercubes and k-Queens graphs, and real-world graphs, respectively. In
Section 9, we exclusively describe how the hybrid algorithm can be applied to very large sparse graphs, where the LP formulation becomes formidable. We present our conclusions in
Section 10.
2. Preliminaries
Throughout this paper
denotes an undirected graph on vertex set
V and edge set
E with
and
. Two vertices
where
are adjacent (or they are neighbors) if
. For any
, the degree of
x, denoted by
is the number of vertices adjacent to
x in
G. For any
, let
denote the set of all vertices in
G that are adjacent to
x. Let
denote
. Arboricity of
G, denoted by
, is the minimum number of spanning acyclic subgraphs of
G that
E can be partitioned into. By a theorem of Nash-Williams,
, where
and
are the number of vertices and edges, respectively, of the induced subgraph on the vertex set
S [
15]. Consequently,
, and thus
measures how dense
G is. It is known that
can be computed in polynomial time [
16].
Let . D is a dominating set if for every there exists such that . The domination number of G, denoted by , is the cardinality of a smallest dominating set of G. A dominating set of cardinality is called a minimum dominating set. Additional definitions will be introduced when required.
Greedy Approximation Algorithm
A simple greedy algorithm attributed to Chvátal [
17] and Lovász [
18] (for approximating the set cover problem) is known to approximate
within a multiplicative factor of
from its optimal value, where
is the maximum degree of
G and
is the
th harmonic number. Note that
. The algorithm initially labels all vertices uncovered. At iteration one, the algorithm selects a vertex
of maximum degree in
G, places
in a set
D, and labels all vertices adjacent to
as covered. In general, at iteration
, the algorithm selects a vertex
with the largest number of uncovered vertices adjacent to it, adds
to
D, and labels all of the uncovered vertices adjacent to
as covered. The algorithm stops when
D becomes a dominating set. It is easy to implement the algorithm in
time. It is known that approximating
within a factor
from the optimal is NP-hard [
7]. Hence, no algorithm for approximating
can improve the asymptotic worst-case performance ratio achieved by the greedy algorithm.
The appendix includes two examples of worst-case graphs (one sparse and one dense) for the greedy algorithm, which are derived from an instance of the set cover problem provided in [
19]. For both instances, the
performance ratio is tight.
4. Hybrid Approach
Next, we provide a description of the decomposition approach for approximating LP1 and our hybrid algorithm. Recall that a separation in is a partition of V so that no vertex of A is adjacent to any vertex of C. In this case, B is called a vertex separator in G. Let be a feasible solution to LP1, and let . Then denotes .
Lemma 1. Let be a separation in and consider the following linear programs:

Then .
Proof. Let be an optimal solution to LP1. Please note that the restrictions of X to and give feasible solutions for LP3 and LP2 of values and , and hence the claim for the lower bound on follows. □
Please note that in LP2 and LP3 the constraints are not written for all variables, and the rounding method in [
13] may not directly be applied.
Theorem 1. Let , let , let and let . Let X be an optimal solution for LP3, and let denote the sum of the weights assigned to all vertices in C. Then there is a dominating set in G of size at most .
Proof. Let
H be the set of all vertices
v in
C with
, and let
. Now apply the method in [
13] to
C to obtain a rounded solution, or a dominating set
D, of at most
vertices in
C. Finally, note that
is a dominating set in
G with cardinality at most
. □
The Hybrid Algorithm:
Fix
. Apply the greedy algorithm to
G to obtain a dominating set
, and let
be the first
vertices in
D. Now, solve the following linear program on the induced subgraph of
G with the vertex set
.
Next, let and , and apply the rounding scheme in algorithms or to C. Let H and U be the corresponding sets, and output the set .
Remark 2. Please note that with Theorem 1, the hybrid algorithm can be implemented in polynomial time. Furthermore, , and thus the hybrid algorithm has a bounded performance ratio.
Remark 3. We choose the value of α by trial and error, normally starting at .
5. Environment, Implementation, and Datasets
We used a laptop with modest computational power—8th generation Intel i5 (1.6 GHz) and 8 GB RAM—to perform the experiments. We implemented the time version of the greedy algorithm in C++. At the time of writing this paper we did not have access to packages that offer the polynomially time bounded versions of linear programming. We used IBM Decision Optimization CPLEX Modeling (DOCPLEX) for Python to solve the LP relaxation of the problem for the LP rounding and hybrid algorithms.
Our data sources are listed below.
The graph generator at † was used to create the k-planar graphs (graphs embedded in the plane with at most
k crossings per edge) and k-trees (graphs with tree width
k with largest number of edges) up to 20,000 vertices. We also used publicly available Google+ and Pokec social-network graphs, a publicly available 1,000,000-vertex planar graph
, and real-world DIMACS Graphs with up to more than 7,700,000 vertices. Furthermore, we generated the k-Queens graphs, hypercubes (up to 12 dimensions) and graphs in Example A.1 (
Figure A1) and Example A.2.
Remark 4. Throughout our experiments, the value of the solution computed by rounding algorithm was always better than the value of the solution computed by rounding algorithm , as predicted in theory. Likewise, the value of the solution computed by the hybrid algorithm using was always better compared to when was used. Throughout sections six through nine (tables), r denotes the value of the solution computed by , and h denotes the value of the solution computed by the hybrid algorithm associated with . We denote by g the value of the solution computed by the greedy algorithm. Throughout the tables in sections six through nine, the best computed values are bolded.
8. Performance on Real-World Graphs
In this section, we present the performance of LP rounding, greedy, and hybrid on the real-world social network graphs from DIMACS [
23], Google+ [
8], and Pokec [
8]. All of these graphs are sparse, but their arboricity is unknown. Since arboricity is unknown, we experiment with the threshold applied during LP rounding. Through experimentation, the best threshold which we found for rounding was
, where
. We denote the value of the solution computed by the LP rounding algorithm with this threshold as
and the value of the solution computed by the hybrid algorithm with this threshold as
. The chosen value of
was
in all cases.
Table 8 contains the results for three sparse social network graphs from DIMACS. LP rounding performs better than the greedy and hybrid approaches, with greedy ranking last out of the algorithms tested.
In
Table 9 and
Table 10, we compare
,
, and
g on the Google+ and Pokec graphs. The performance ratios, although different, happen to be very close. Thus, we list the actual sizes of the dominating sets returned by the algorithms.
Compared to the best results from [
8], which used a randomized local search algorithm that is run for up to one hour, LP rounding approaches generally produced, with the exception of a few cases, a smaller or as good solution using significantly less cpu-time at less than 0.5 s for each graph.
10. Conclusions
Our findings indicate that all of these algorithms perform better than anticipated in theory, particularly with respect to the performance ratio. The LP rounding does well on sparse real-world graphs, consistent with theory, and normally outperforms the other algorithms. For hypercubes and k-Queens graphs (which are not sparse) greedy outperforms the rest, consistent with theory, both in terms of speed and performance ratio. For synthetic graphs (generated k-trees and k-planar graphs), LP rounding is outperformed by the other two algorithms, and the hybrid algorithm outperforms greedy.
Throughout our experimentation, the hybrid algorithm was never the worst. The hybrid algorithm’s success in solving large sparse problems suggests that more research in this area will be fruitful with respect to characterizations of parameter . In particular, a theoretical research direction would be attempting to tighten the upper bound on the value of the solution computed by the hybrid algorithm, as stated in Remark 2. Can the upper bound on the value of the solution be shown to be better than with the appropriate choice of ?







{kind=link}
{kind=link}