Pseudo Random Number Generation through Reinforcement Learning and Recurrent Neural Networks


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
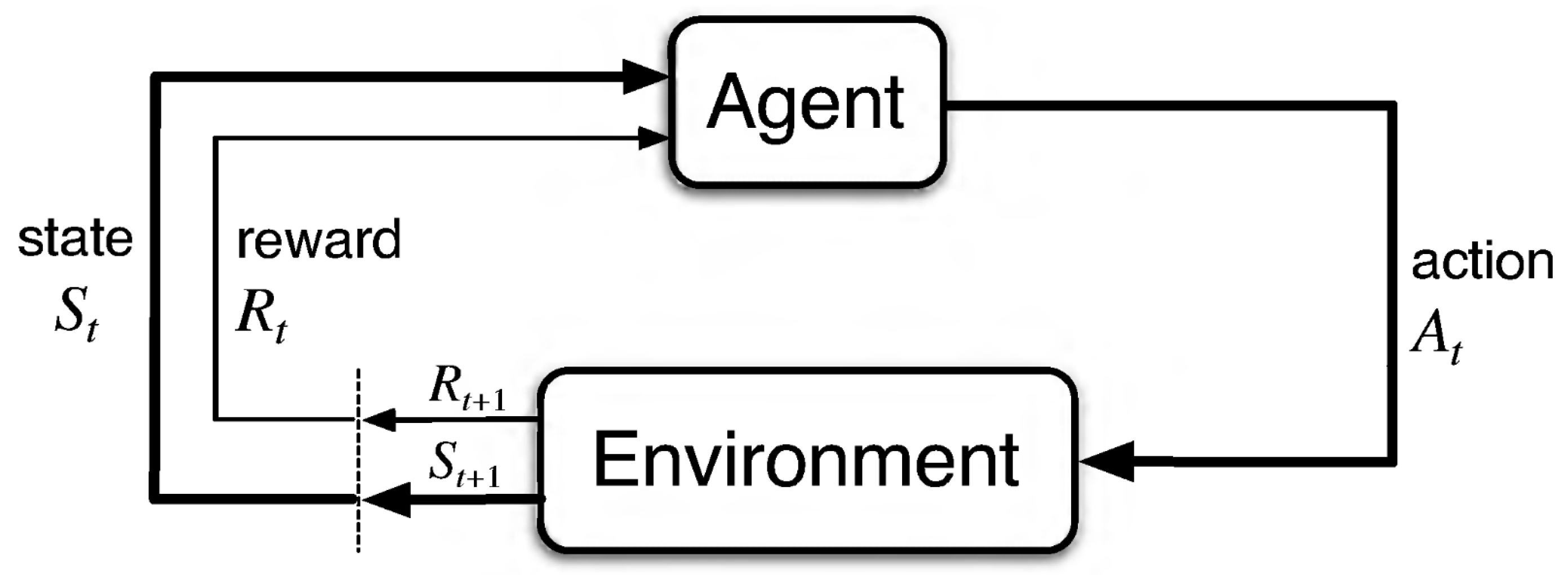
2.1. Reinforcement Learning (RL)
2.2. Modeling a PRNG as a MDP
2.3. Reward and NIST Test Suite
2.4. Neural Network Architecture
2.5. Framework
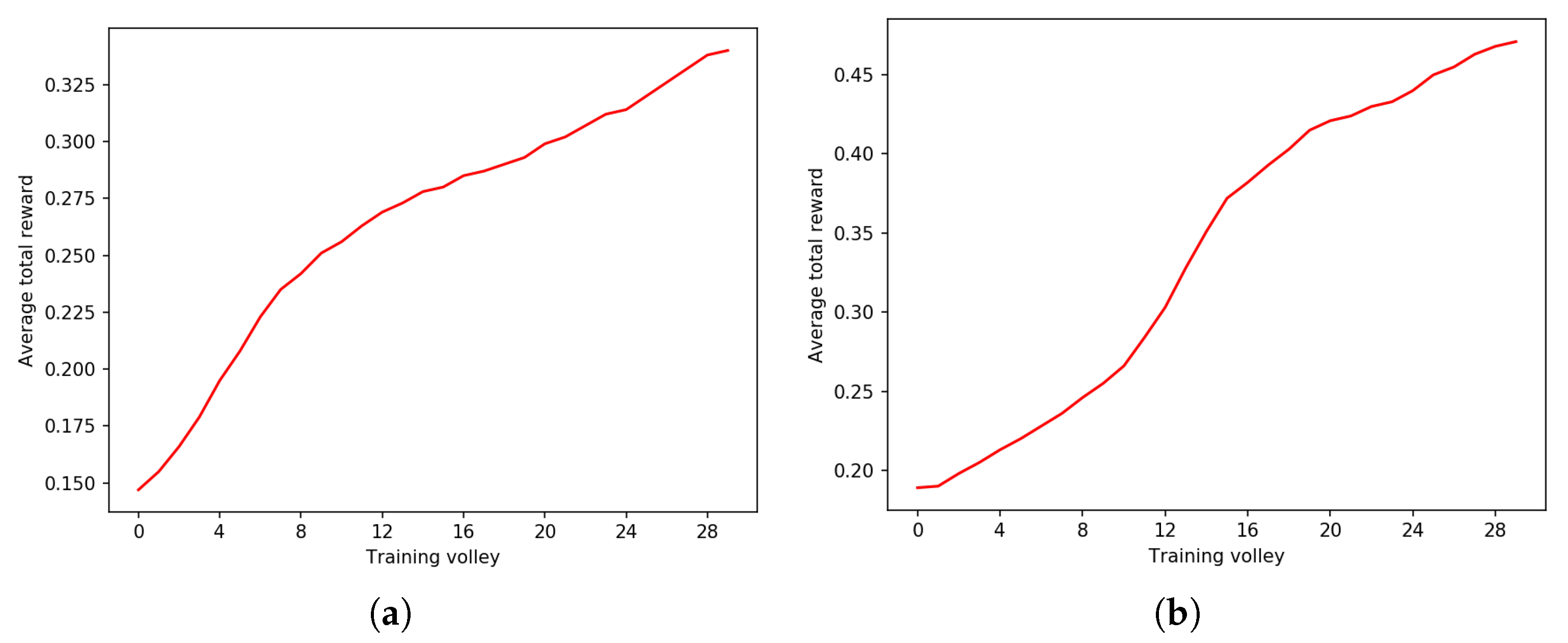
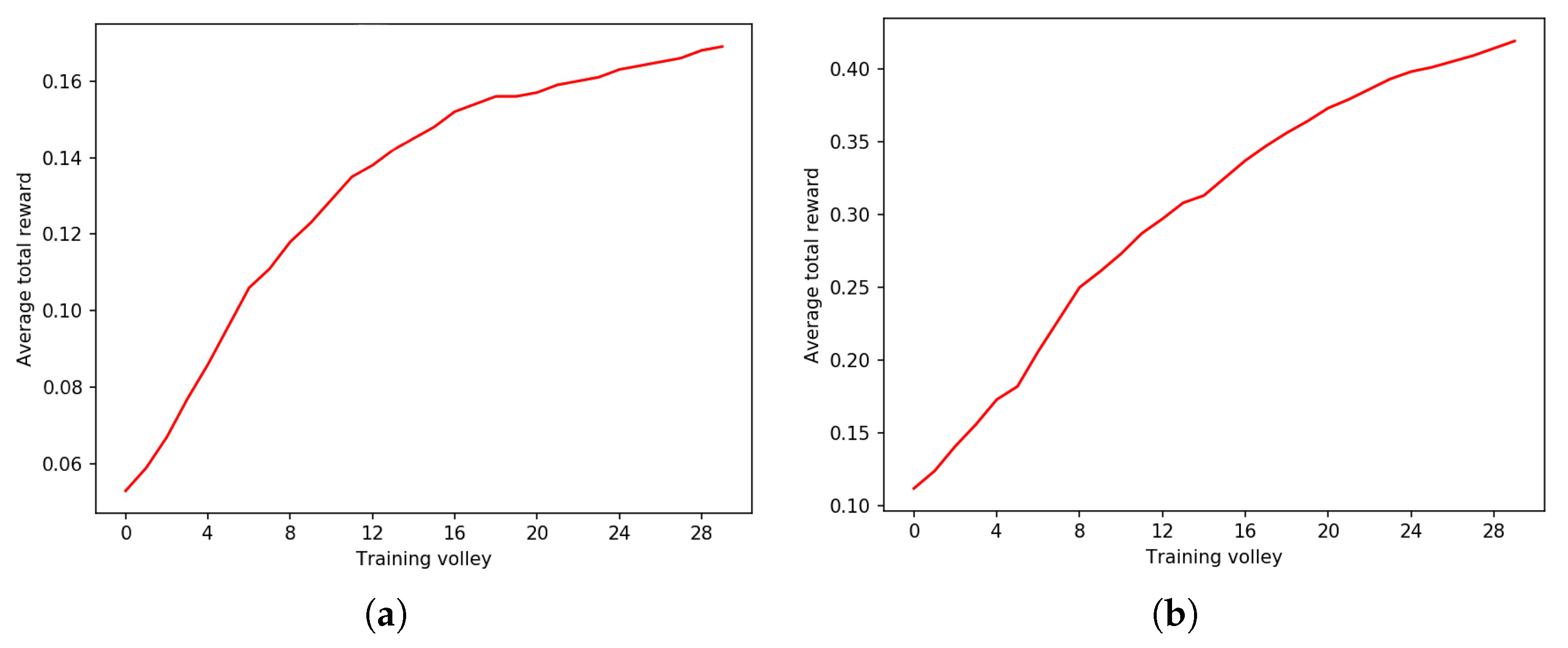
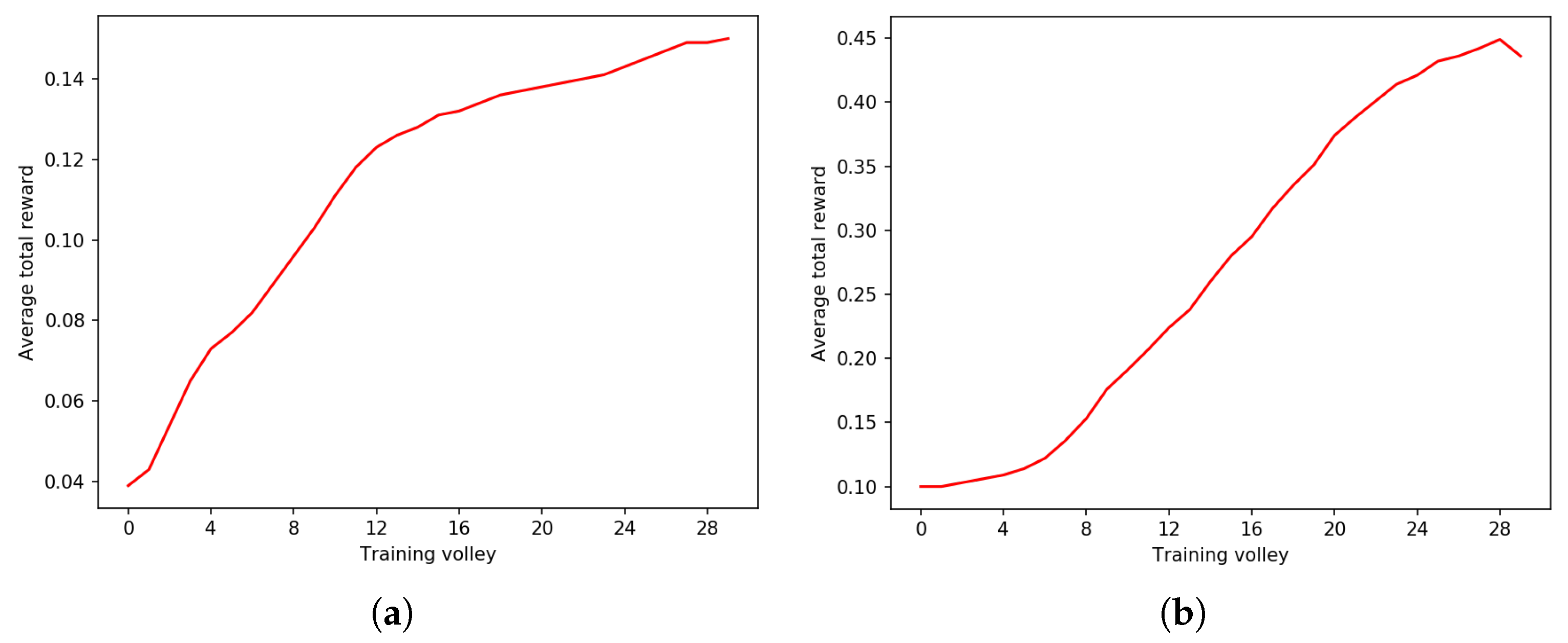
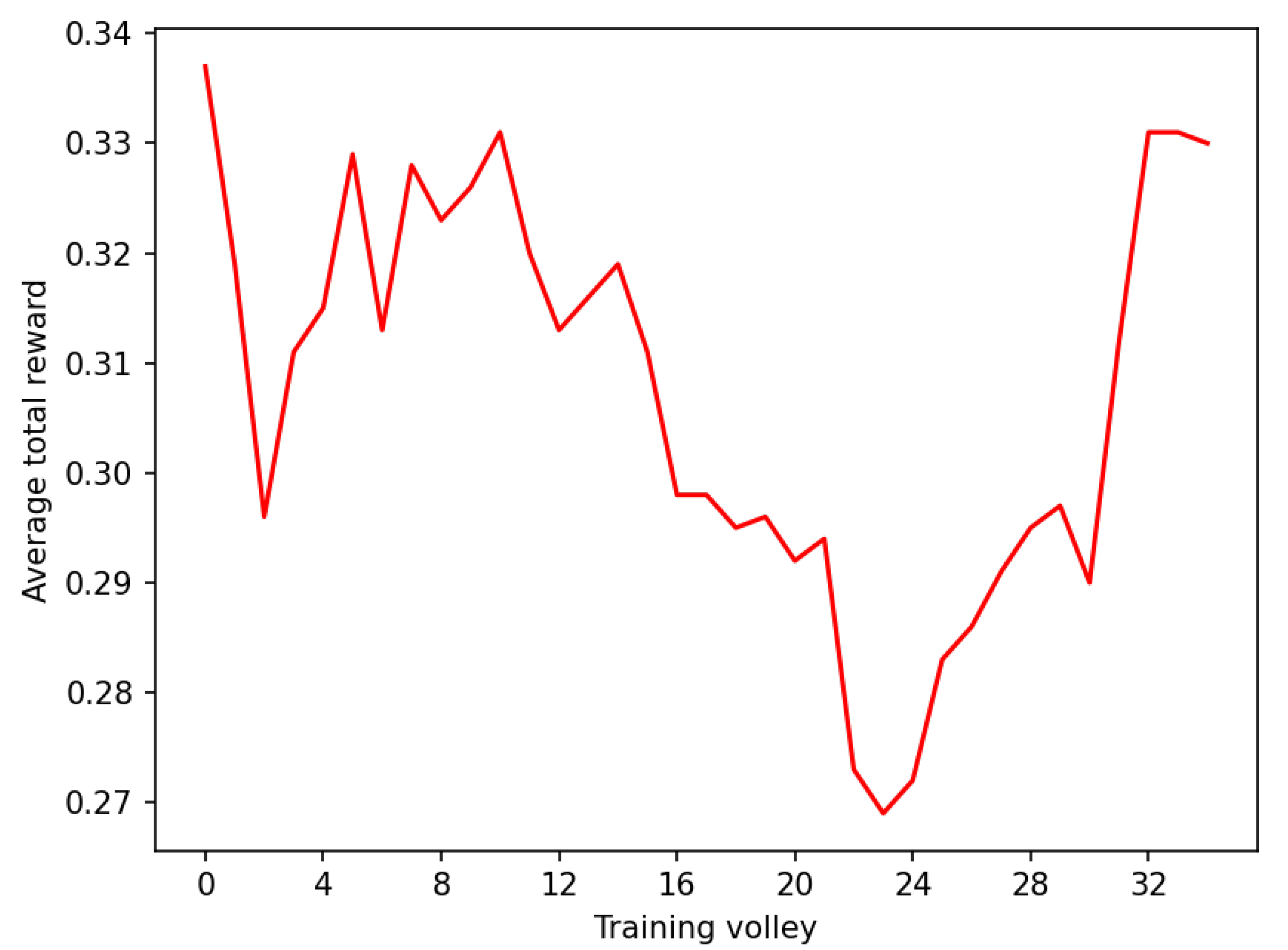
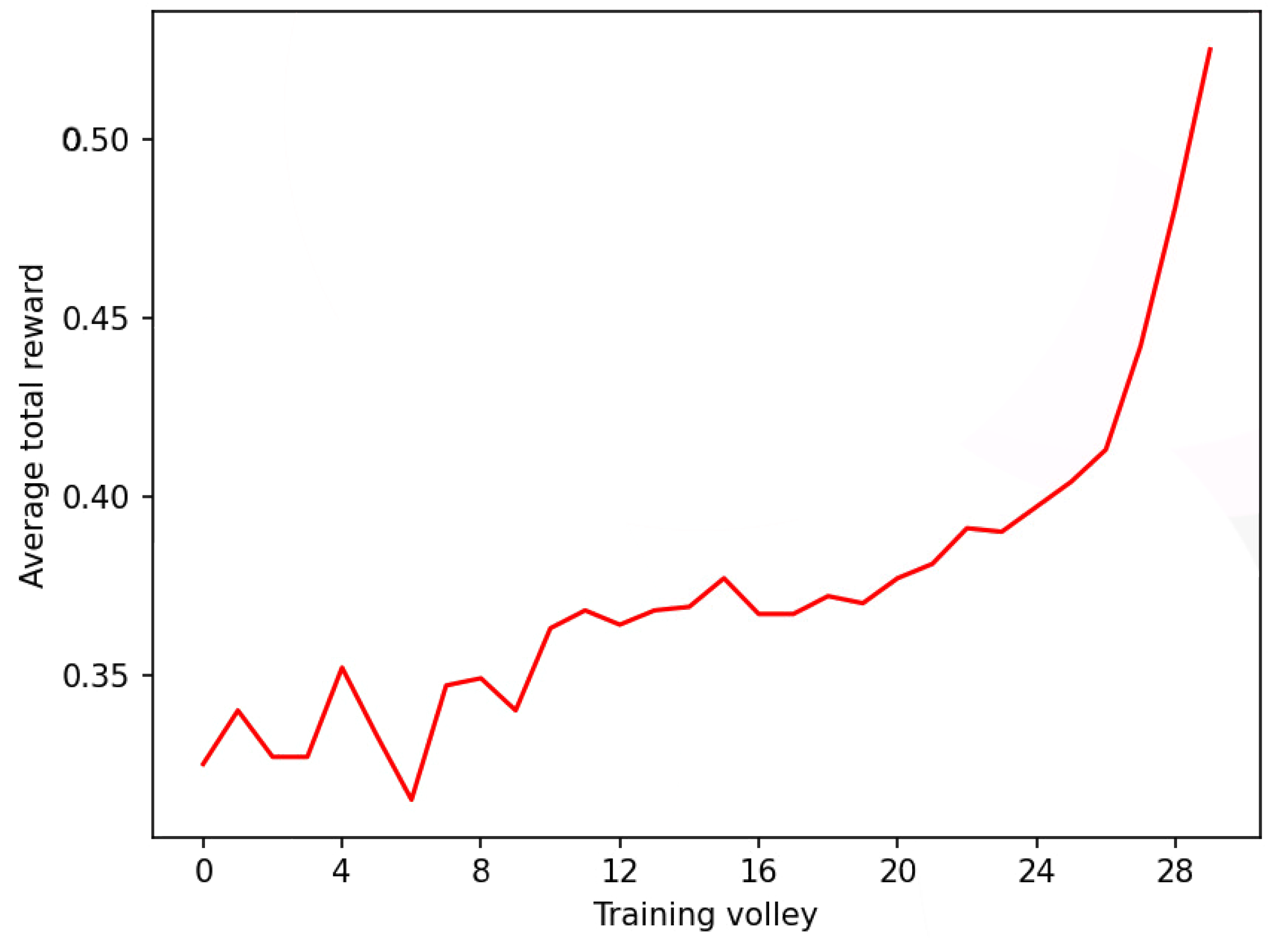
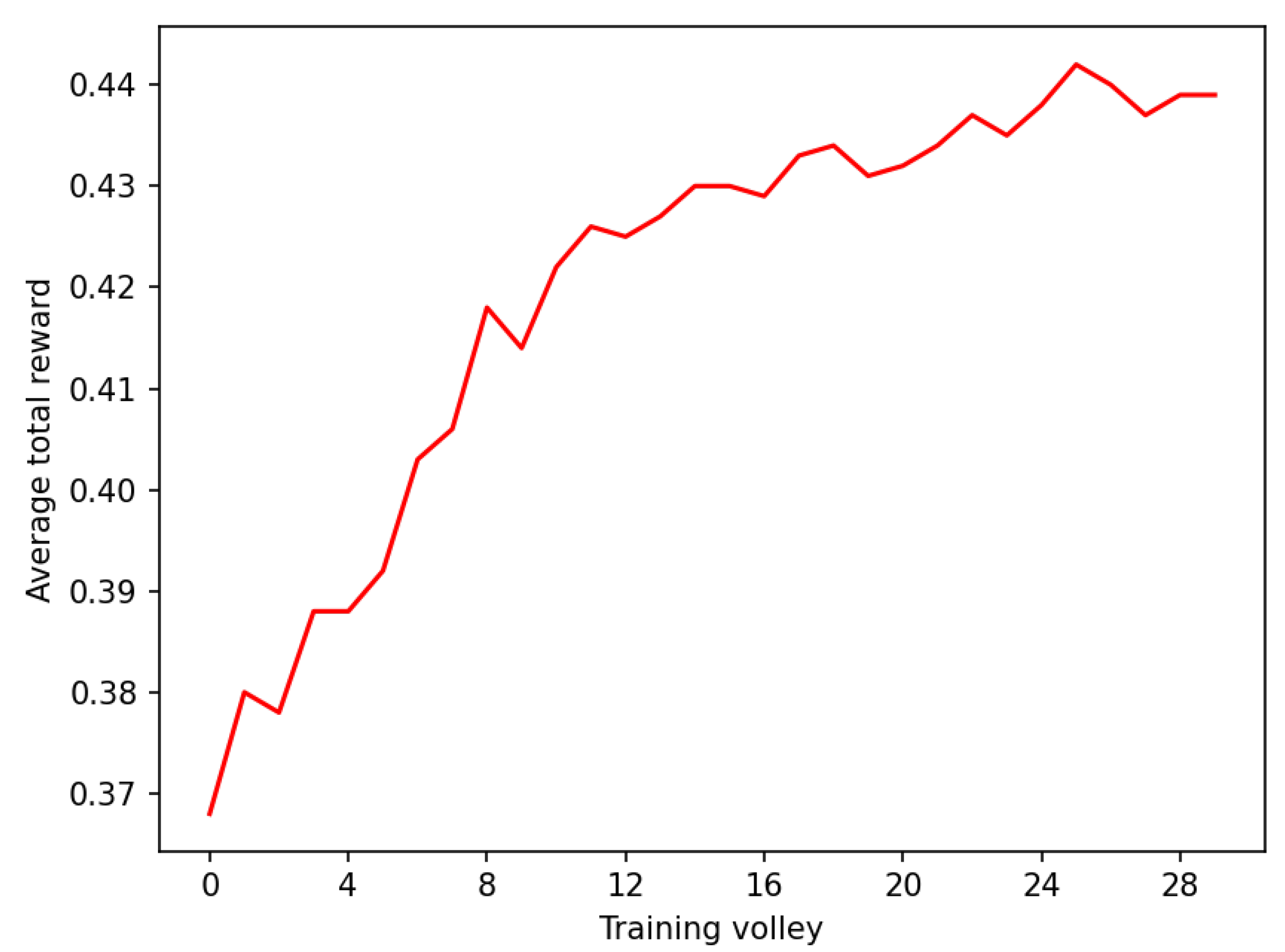
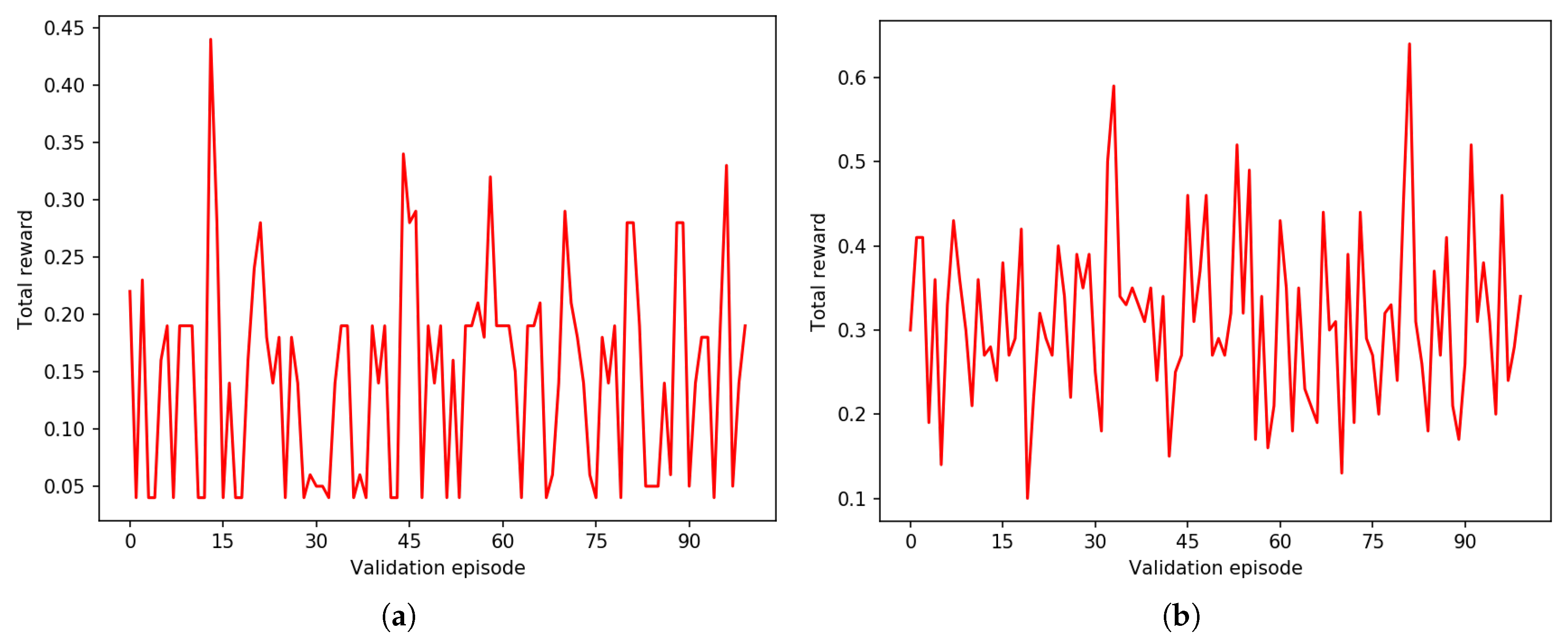
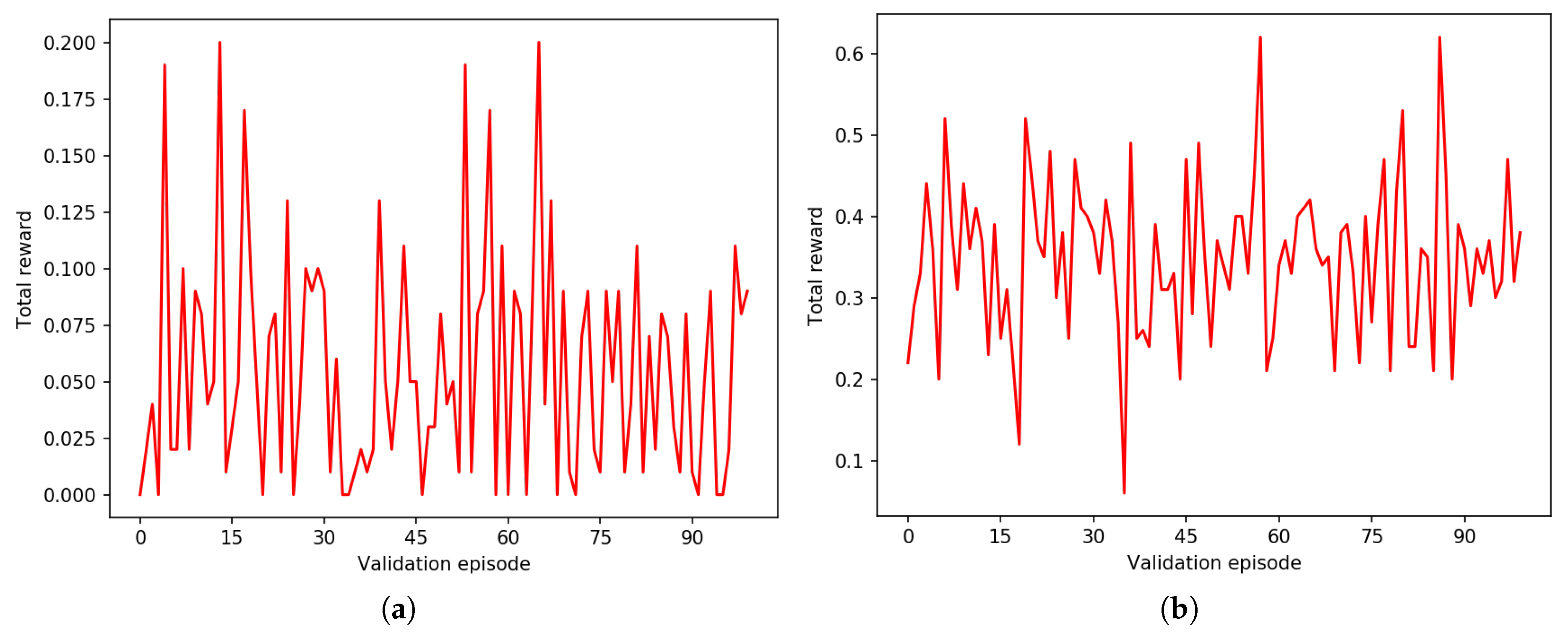
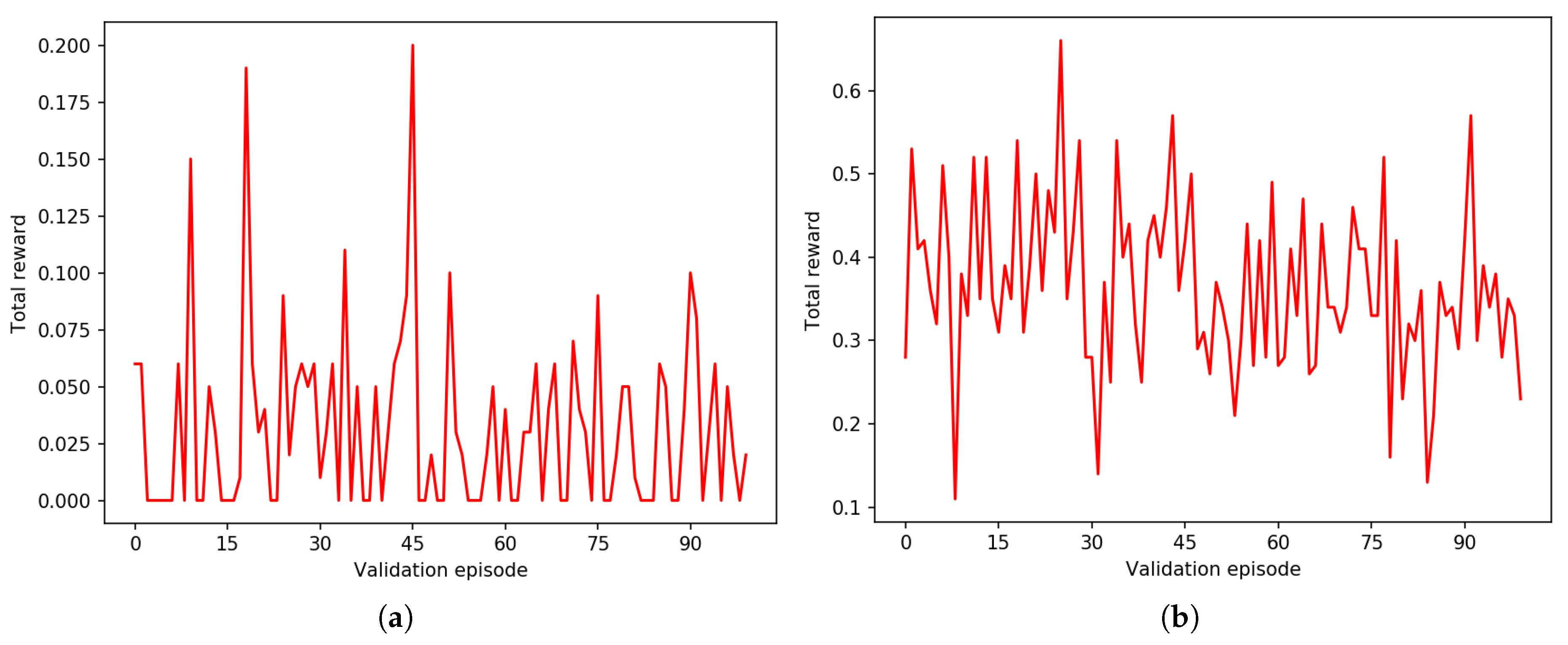
3. Results
4. Discussion
- Devise a different, less sparse, reward function.
- Devise an algorithm using RF modified with a continuous action space. In this way, we can append sequences of any length without increasing the size of . Some preliminary experiments show that this approach could work, but at the time of writing, it still presents some performance issues, and is a work in progress.
- RF could be used to intelligently stack generated periods. For example, one could train a policy to stack sequences generated by one or multiple PRNGs, even with different sequence lengths. This would generate PRNGs with very long periods without a sensible drop in quality. This approach could use a mixture of state-of-the-art PRNGs, DRL generators like the ones seen in this paper, and so on. A challenge of this approach is how to measure the change in the NIST score when appending a random sequence to another.
- The upper bound given by the episodes’ length T could be overcome, or at least mitigated, by other architectures capable of maintaining memory for a time longer than recurrent neural networks, like attention models.
Comparison with Relevant Research
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| PRNG | Pseudo-Random Number Generator |
| MDP | Markov Decision Process |
| NIST | National Institute of Standards and Technology |
| RL | Reinforcement Learning |
| DRL | Deep Reinforcement Learning |
| LSTM | Long-Short Term Memory |
| GRU | Gated Recurrent Unit |
| PG | Policy Gradient |
| PPO | Proximal Policy Optimization |
| BF | Binary Formulation |
| RF | Recurrent Formulation |
| ReLU | Rectified Linear Unit |
| GAE | Generalized Advantage Estimation |
References
- Bassham, L.E., III; Rukhin, A.L.; Soto, J.; Nechvatal, J.R.; Smid, M.E.; Barker, E.B.; Leigh, S.D.; Levenson, M.; Vangel, M.; Banks, D.L.; et al. Sp 800-22 rev. 1a. a Statistical Test Suite for Random and Pseudorandom Number Generators for Cryptographic Applications; National Institute of Standards & Technology: Gaithersburg, MD, USA, 2010.
- Desai, V.; Patil, R.; Rao, D. Using layer recurrent neural network to generate pseudo random number sequences. Int. J. Comput. Sci. Issues 2012, 9, 324–334. [Google Scholar]
- Hughes, J.M. Pseudo-random Number Generation Using Binary Recurrent Neural Networks. Ph.D. Thesis, Kalamazoo College, Kalamazoo, MI, USA, 2007. [Google Scholar]
- Abdi, H. A neural network primer. J. Biol. Syst. 1994, 2, 247–281. [Google Scholar] [CrossRef]
- De Bernardi, M.; Khouzani, M.; Malacaria, P. Pseudo-Random Number Generation Using Generative Adversarial Networks. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2018; pp. 191–200. [Google Scholar]
- Pasqualini, L.; Parton, M. Pseudo Random Number Generation: A Reinforcement Learning approach. Procedia Comput. Sci. 2020, 170, 1122–1127. [Google Scholar] [CrossRef]
- Pasqualini, L. Pseudo Random Number Generation through Reinforcement Learning and Recurrent Neural Networks. GitHub Repository. 2020. Available online: https://github.com/InsaneMonster/pasqualini2020prngrl (accessed on 23 November 2020).
- Sutton, R.; Barto, A. Reinforcement Learning: An Introduction; Adaptive Computation and Machine Learning Series; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arxiv 2017, arXiv:1707.06347. [Google Scholar]
- OpenAI. Proximal Policy Optimization. OpenAI Web Site. 2018. Available online: https://spinningup.openai.com/en/latest/algorithms/ppo.html (accessed on 23 November 2020).
- Schulman, J.; Moritz, P.; Levine, S.; Jordan, M.; Abbeel, P. High-dimensional continuous control using generalized advantage estimation. arxiv 2015, arXiv:1506.02438. [Google Scholar]
- Duell, S.; Udluft, S.; Sterzing, V. Solving partially observable reinforcement learning problems with recurrent neural networks. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 709–733. [Google Scholar]
- Wang, L.; Zhang, W.; He, X.; Zha, H. Supervised Reinforcement Learning with Recurrent Neural Network for Dynamic Treatment Recommendation. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ’18), New York, NY, USA, 19–23 August 2018; pp. 2447–2456. [Google Scholar] [CrossRef]
- Chakraborty, S. Capturing Financial markets to apply Deep Reinforcement Learning. arxiv 2019, arXiv:1907.04373. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Zahavy, T.; Haroush, M.; Merlis, N.; Mankowitz, D.J.; Mannor, S. Learn what not to learn: Action elimination with deep reinforcement learning. Adv. Neural Inf. Process. Syst. 2018, 3562–3573. Available online: https://proceedings.neurips.cc/paper/2018/hash/645098b086d2f9e1e0e939c27f9f2d6f-Abstract.html (accessed on 23 November 2020).











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pasqualini, L.; Parton, M. Pseudo Random Number Generation through Reinforcement Learning and Recurrent Neural Networks. Algorithms 2020, 13, 307. https://doi.org/10.3390/a13110307
Pasqualini L, Parton M. Pseudo Random Number Generation through Reinforcement Learning and Recurrent Neural Networks. Algorithms. 2020; 13(11):307. https://doi.org/10.3390/a13110307
Chicago/Turabian StylePasqualini, Luca, and Maurizio Parton. 2020. "Pseudo Random Number Generation through Reinforcement Learning and Recurrent Neural Networks" Algorithms 13, no. 11: 307. https://doi.org/10.3390/a13110307
APA StylePasqualini, L., & Parton, M. (2020). Pseudo Random Number Generation through Reinforcement Learning and Recurrent Neural Networks. Algorithms, 13(11), 307. https://doi.org/10.3390/a13110307