Efficient Time and Space Representation of Uncertain Event Data




Abstract
1. Introduction
2. Conformance Checking over Uncertain Data
3. Process Discovery over Uncertain Data
4. Materials and Methods
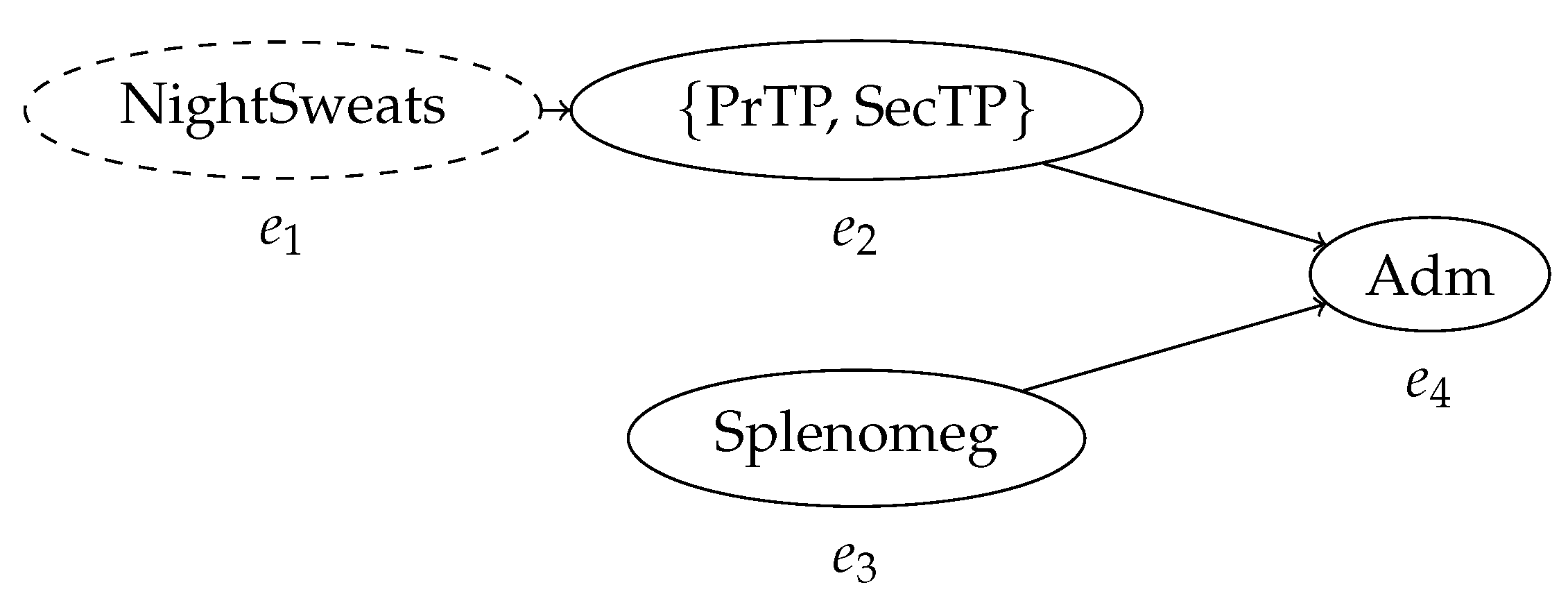
4.1. Preliminaries
- Irreflexivity: is false.
- Transitivity: and imply .
- Antisymmetry: implies that is false. It is implied by irreflexivity and transitivity [10].
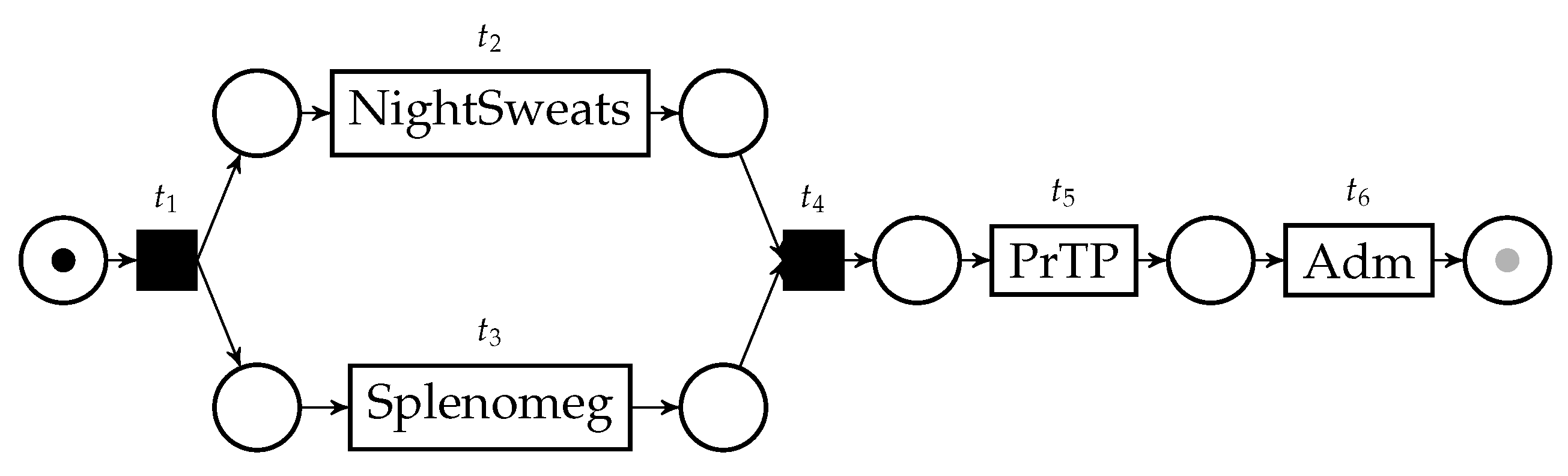
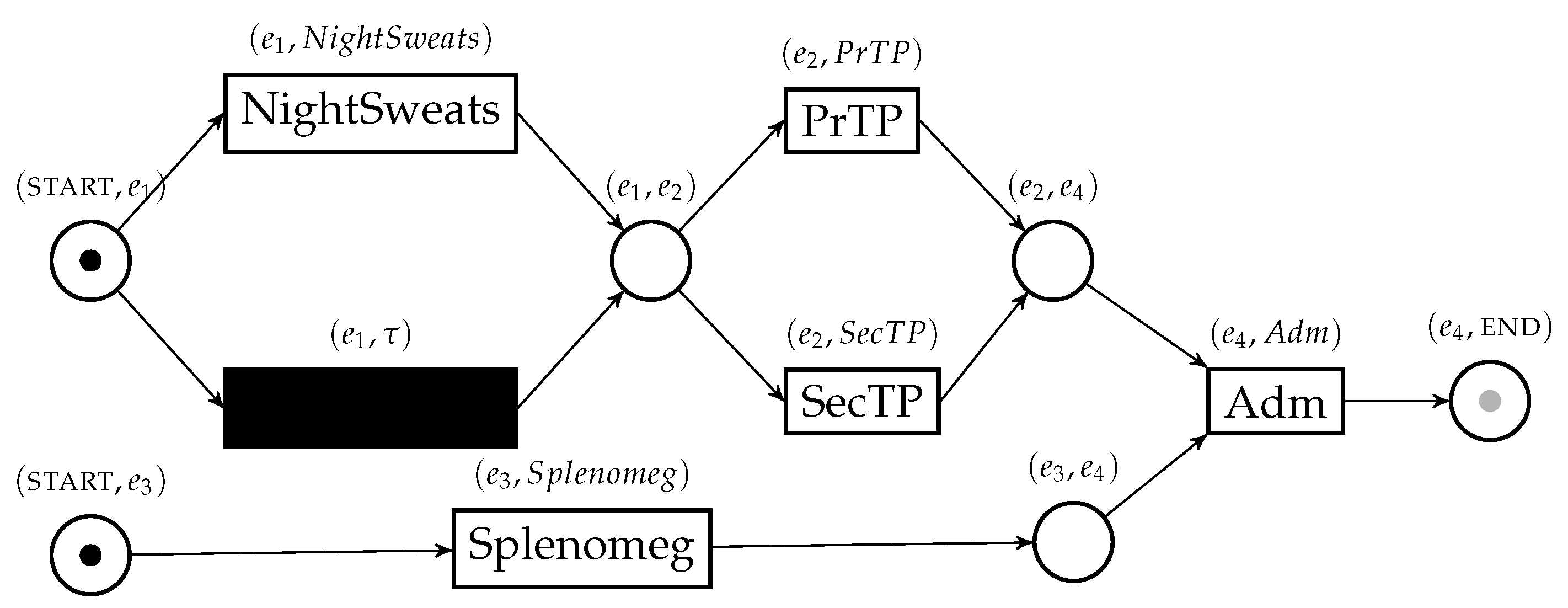
4.2. Efficient Construction of Behavior Graphs
| Algorithm 1:TimestampList() |
 |
| Algorithm 2:BehaviorGraph(TimestampList()) |
 |
- an identifier, which in the list construction is an integer representing the rank of the uncertain event by minimum timestamp (computed in line 3);
- the activity labels associated with the event ;
- the attribute , which will carry the information regarding indeterminate events;
- the type of timestamp that generated this entry—if it is a minimum or maximum of an interval.
| Algorithm 3:ProcessUncertainLog |
 |
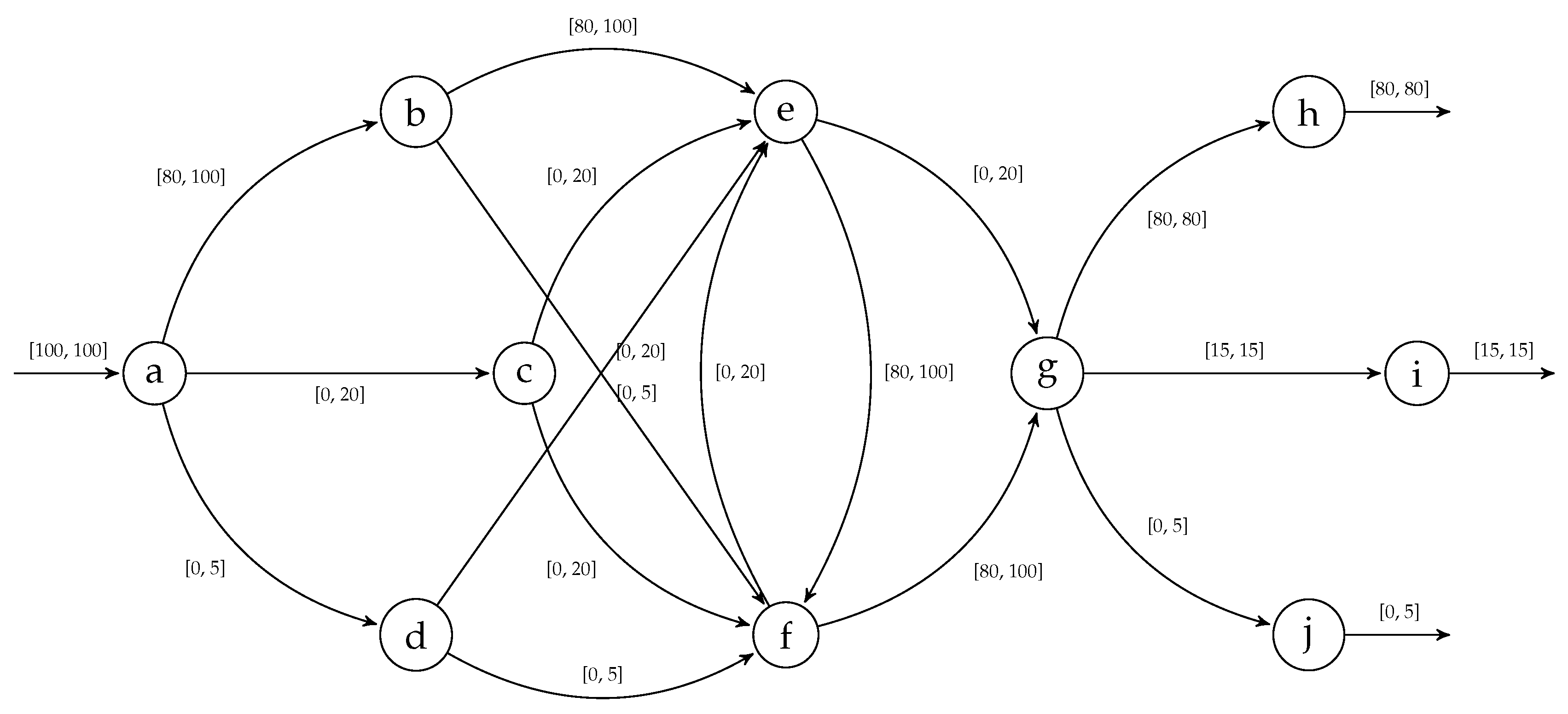
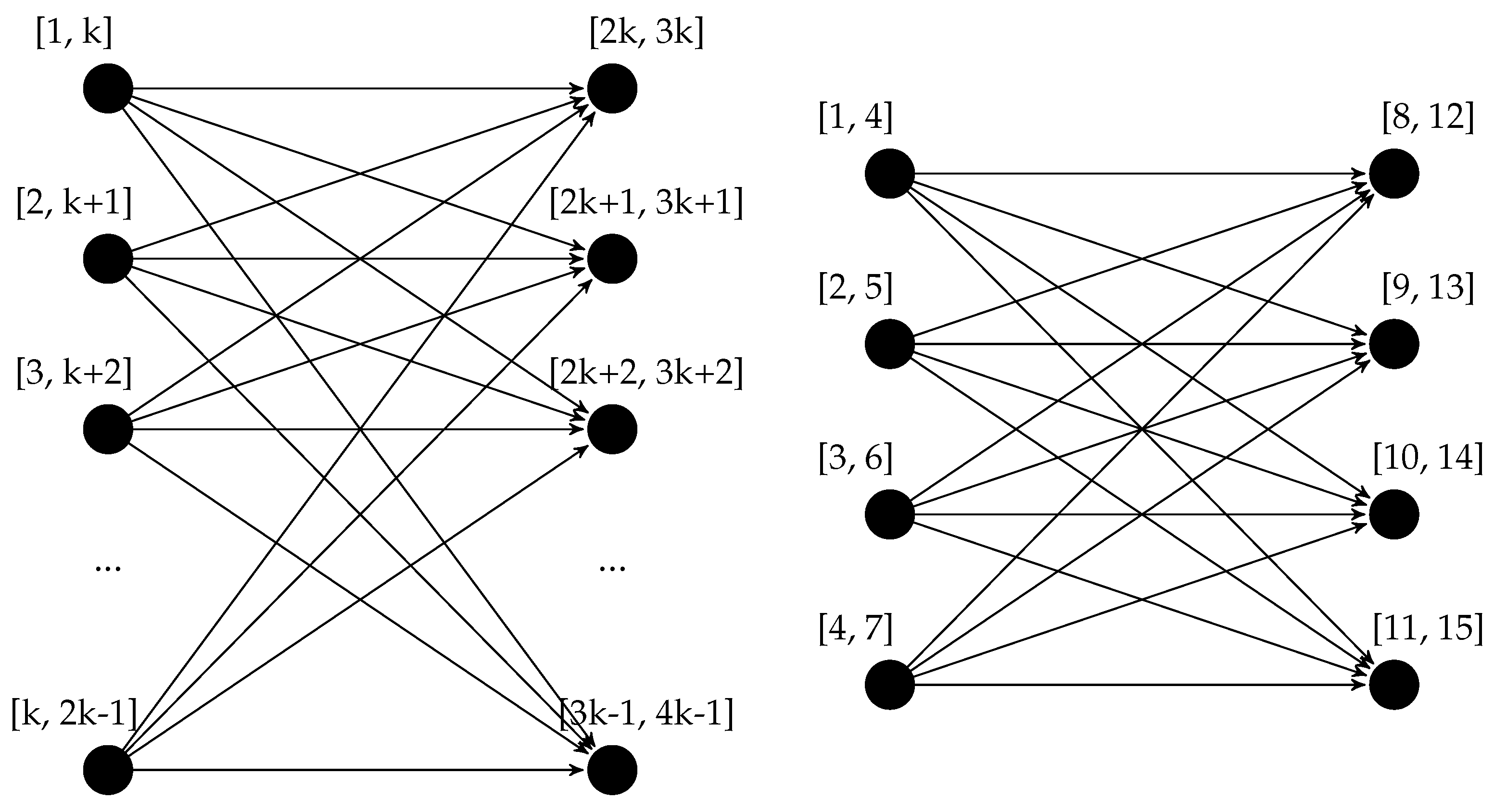
5. Asymptotic Complexity
6. Experimental Results
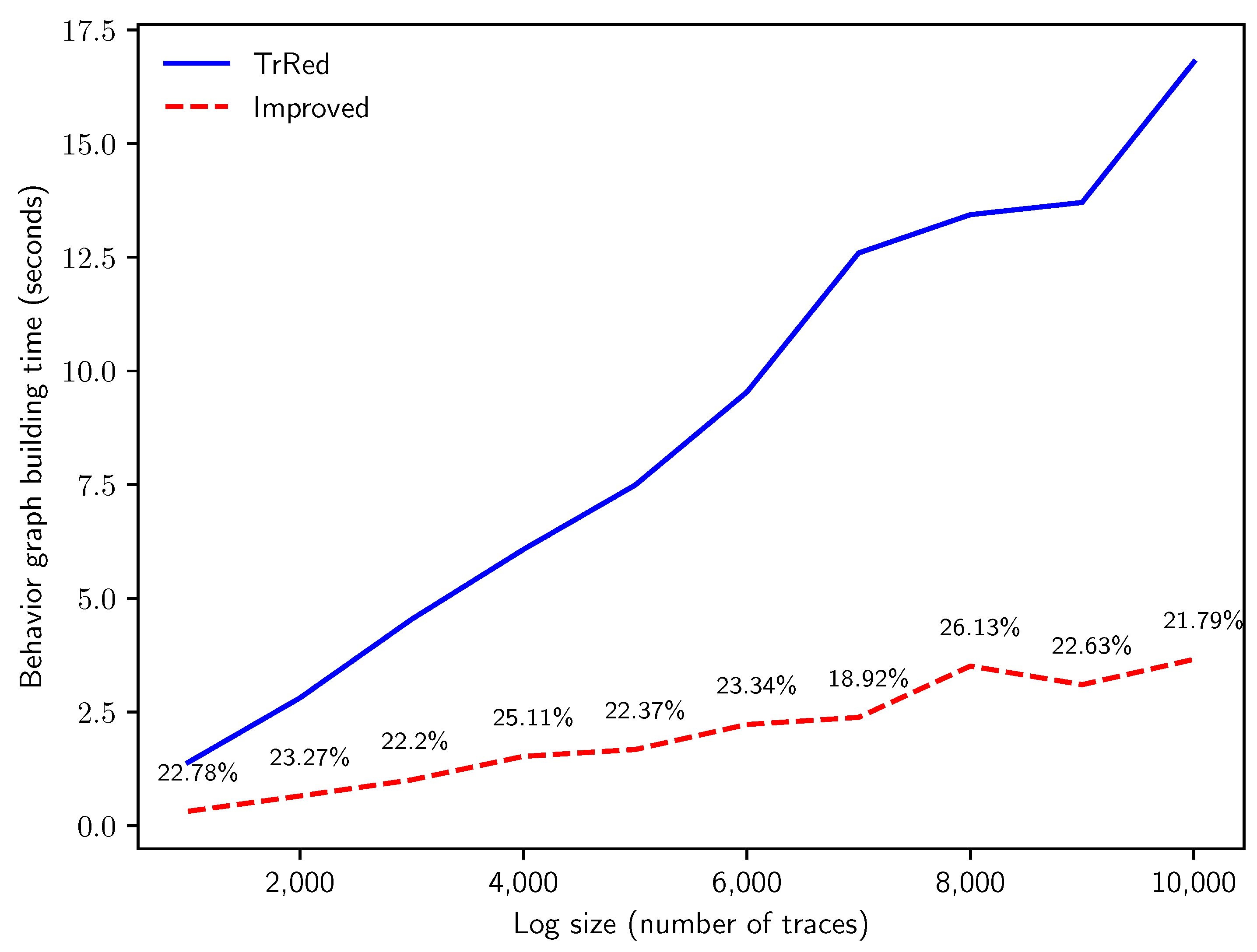
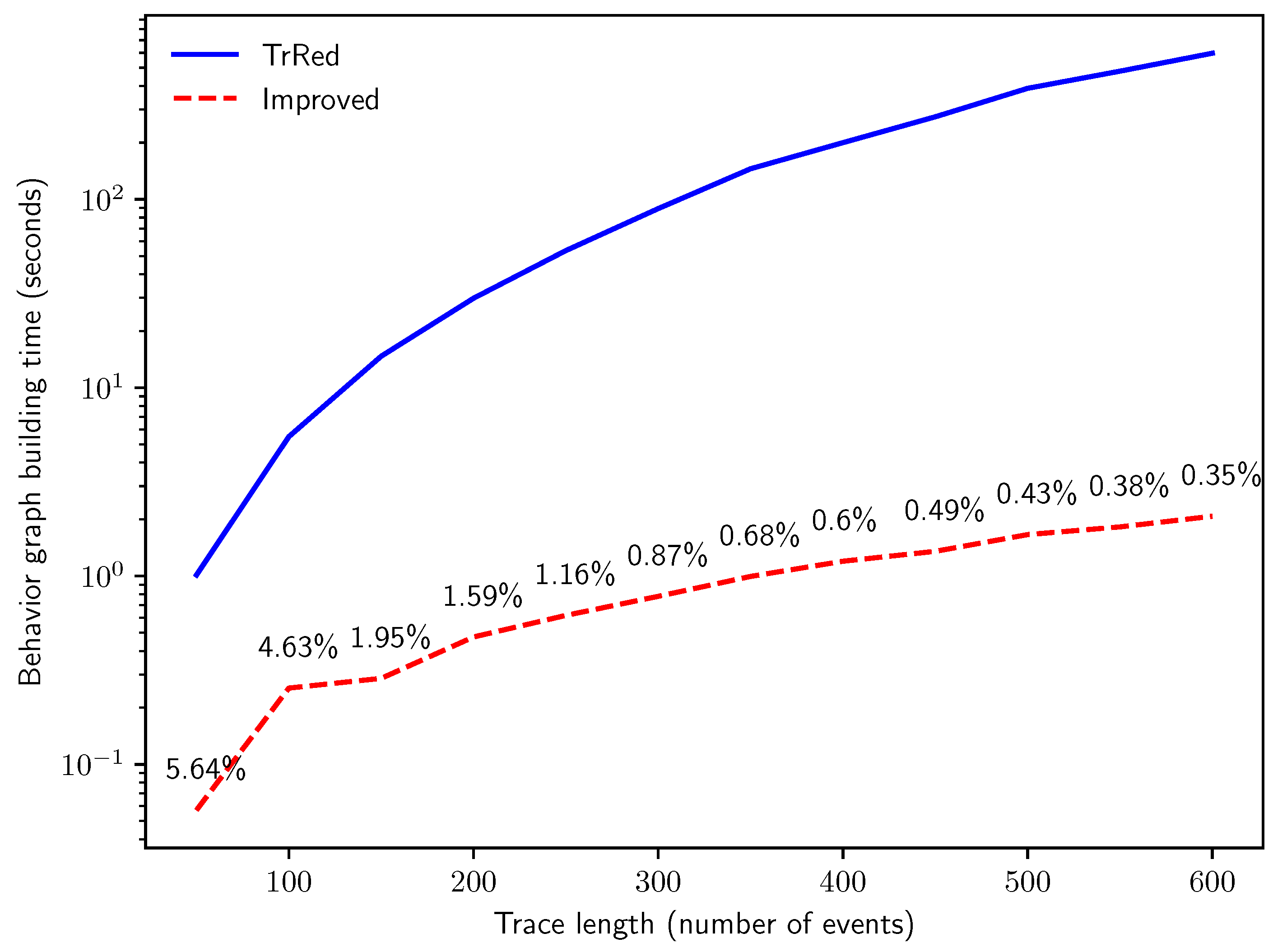
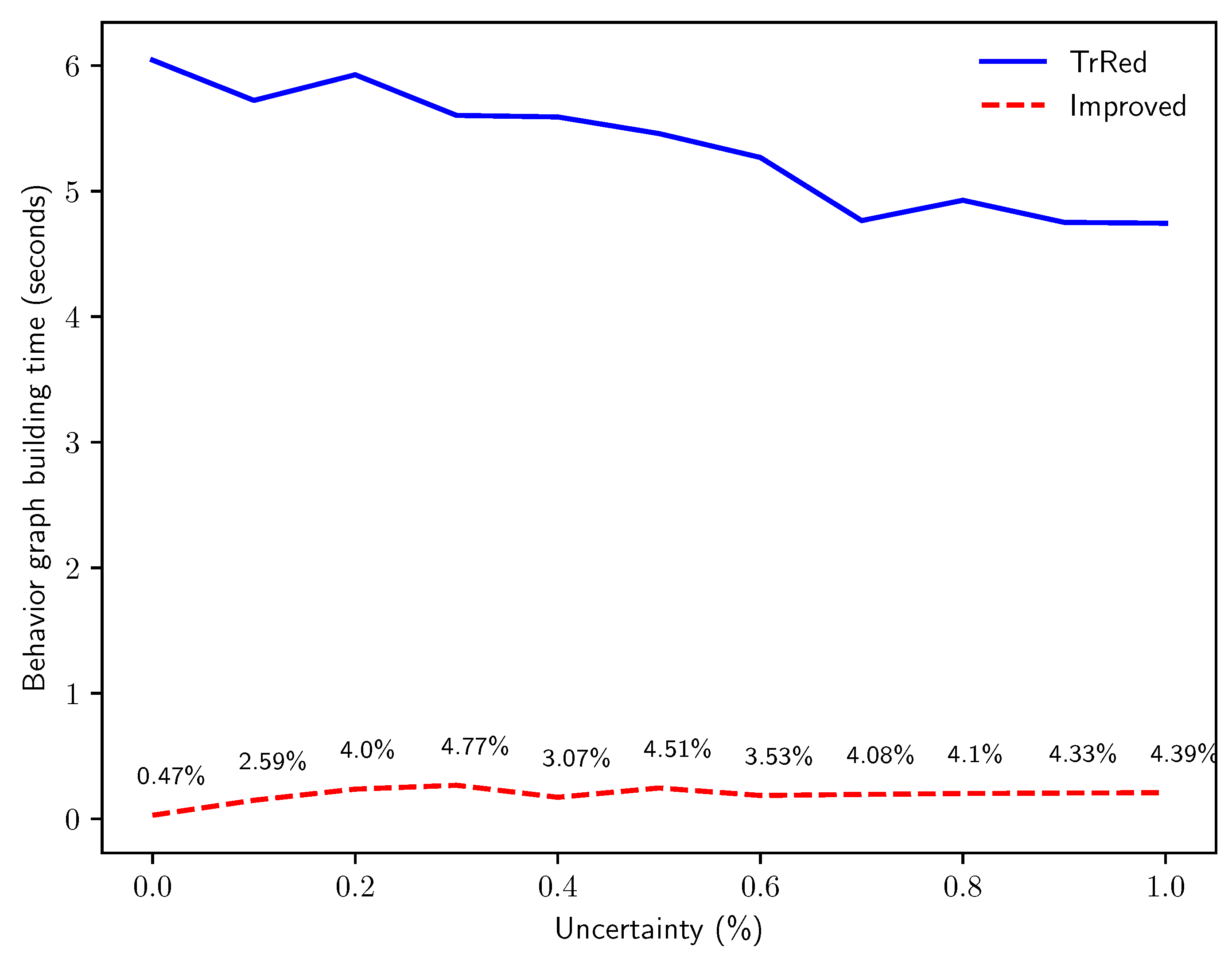
6.1. Performance of Behavior Graph Construction
- Q1: how does the computation time of the two methods compare when run on logs with an increasing number of traces?
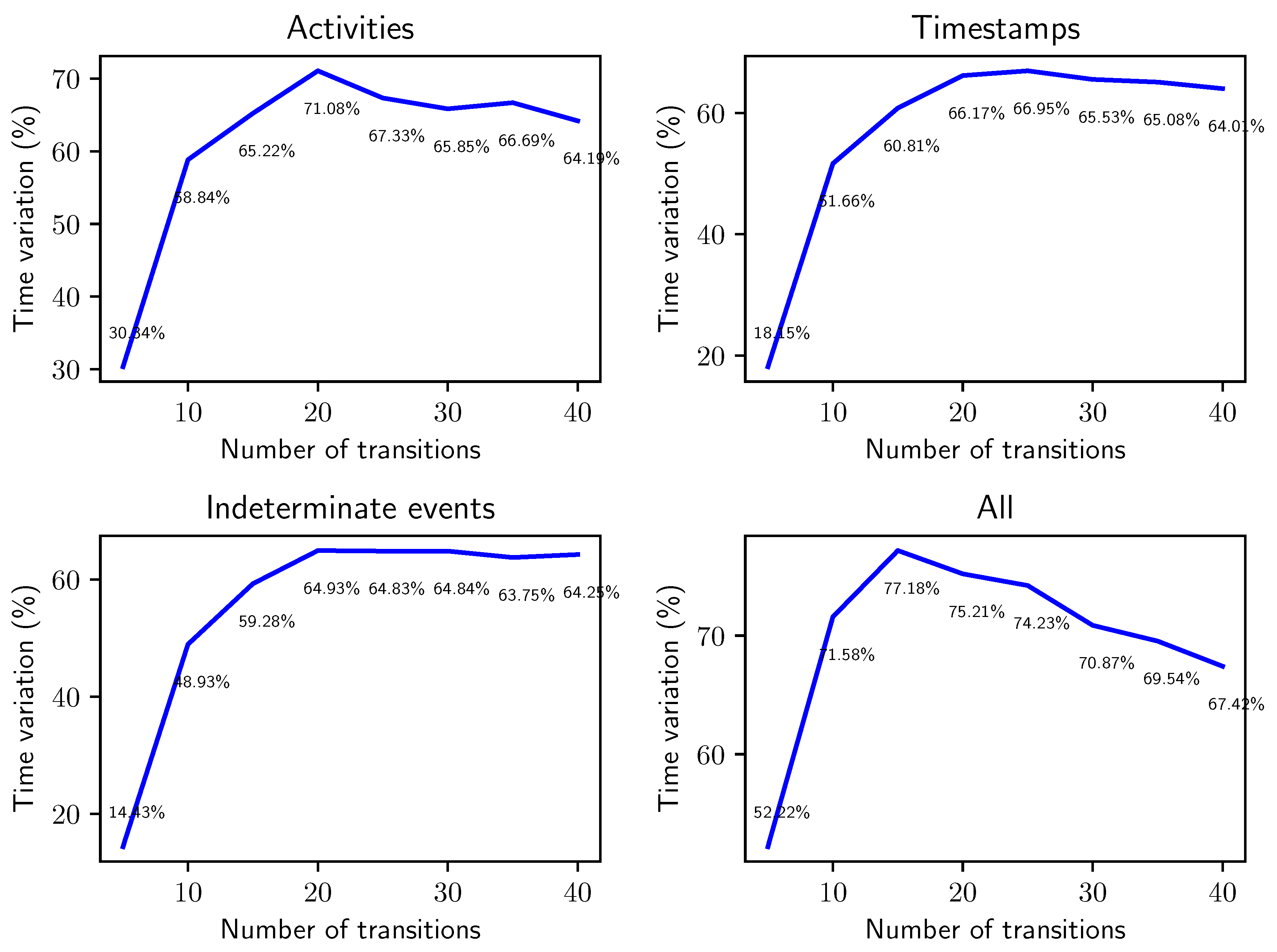
- Q2: how does the computation time of the two methods compare when run on logs with increasing trace lengths?
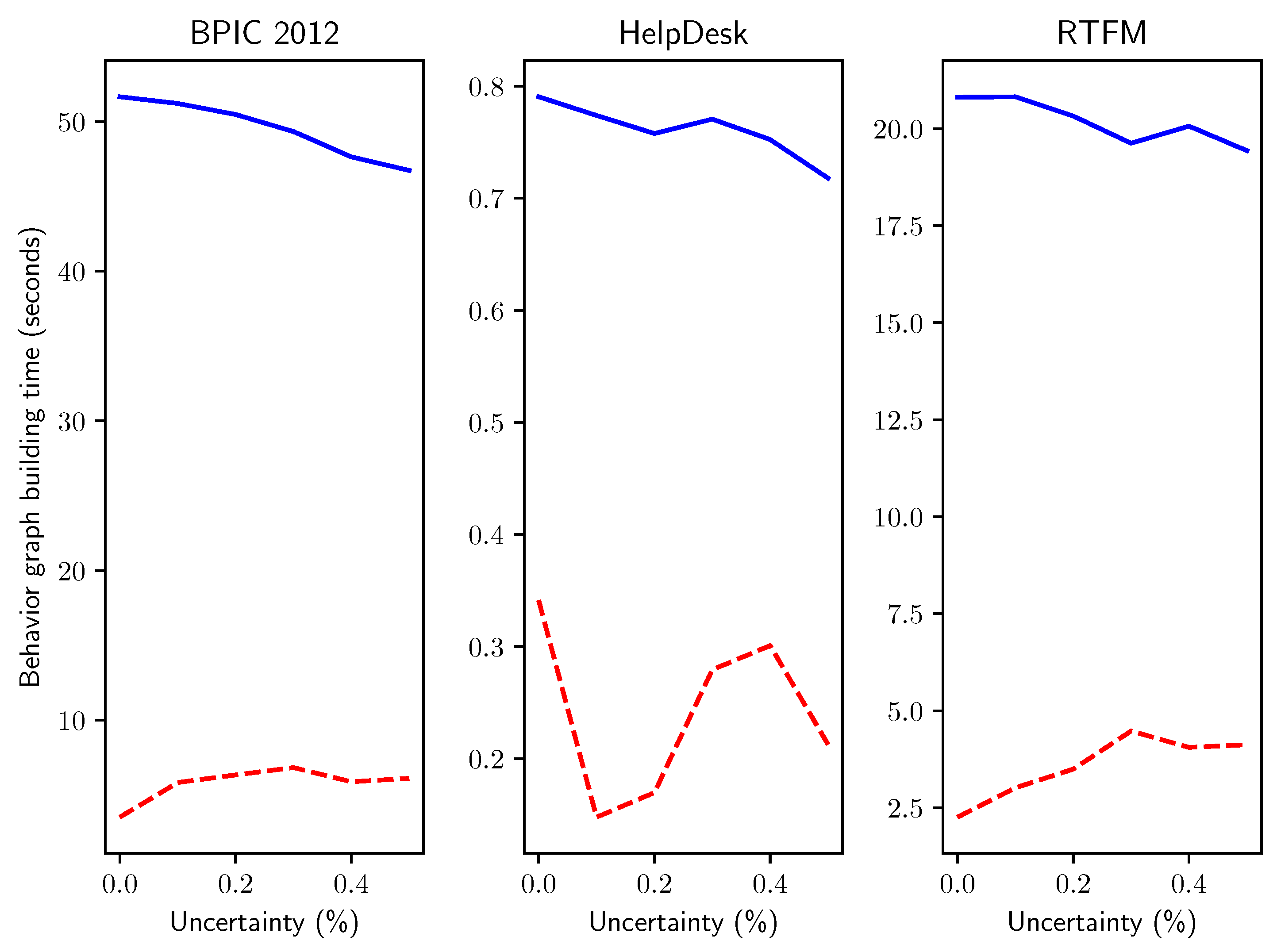
- Q3: how does the computation time of the two methods compare when run on logs with increasing percentages of events with uncertain timestamps?
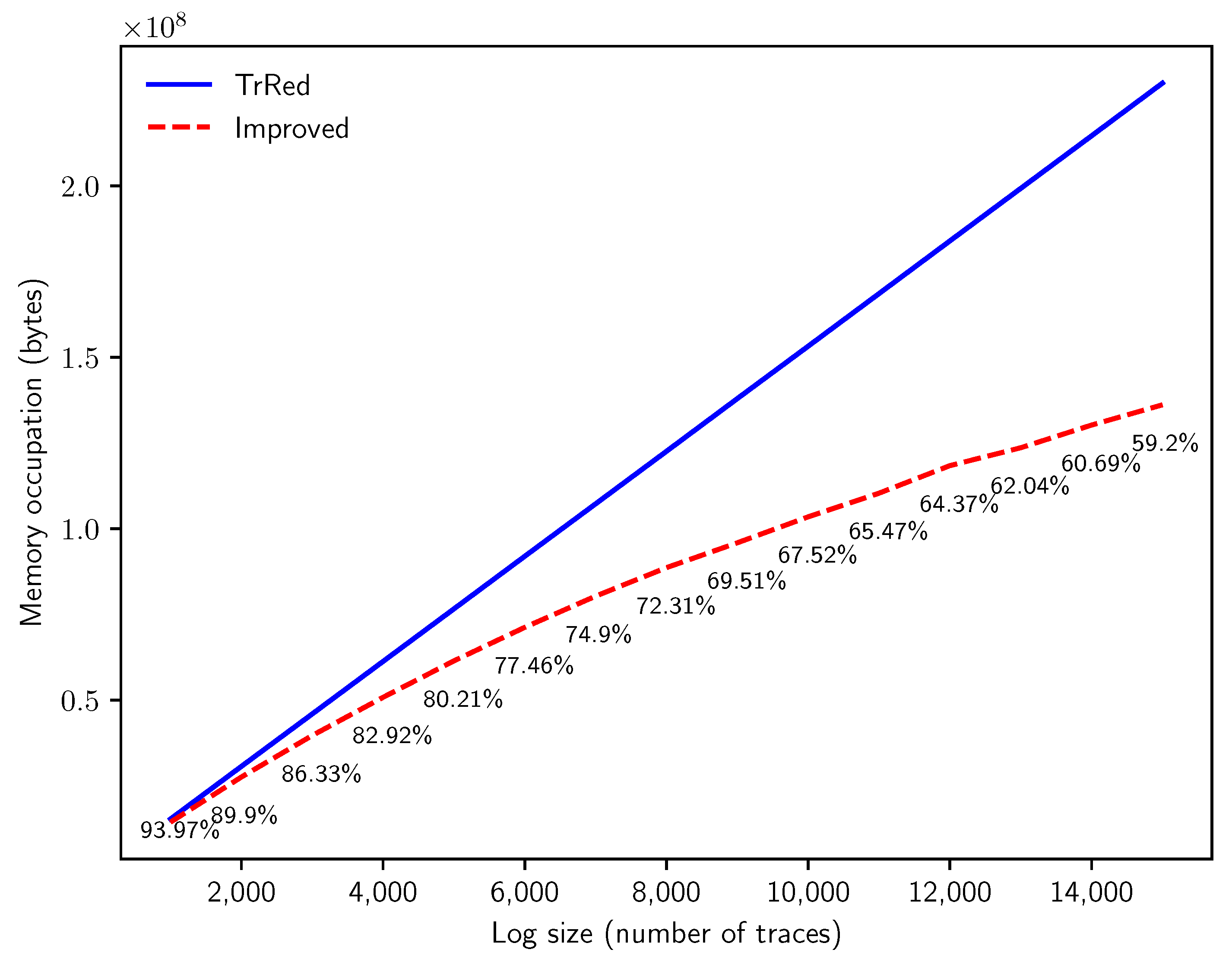
- Q4: what degree of reduction in memory consumption for the representation of an uncertain log can we attain with the novel method?
- Q5: do the answers obtained for Q3 hold when simulating uncertainty on real-life event data?
6.2. Applications of the Behavior Graph Construction
7. Related Work
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Van der Aalst, W.M.P. Process Mining: Data Science in Action; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Pegoraro, M.; van der Aalst, W.M.P. Mining uncertain event data in process mining. In Proceedings of the 2019 International Conference on Process Mining (ICPM), Aachen, Germany, 24–26 June 2019; pp. 89–96. [Google Scholar]
- Van Der Aalst, W.; Adriansyah, A.; De Medeiros, A.K.A.; Arcieri, F.; Baier, T.; Blickle, T.; Bose, J.C.; Van Den Brand, P.; Brandtjen, R.; Buijs, J.; et al. Process mining manifesto. In International Conference on Business Process Management; Springer: Berlin/Heidelberg, Germany, 2011; pp. 169–194. [Google Scholar]
- Kurniati, A.P.; Rojas, E.; Hogg, D.; Hall, G.; Johnson, O.A. The assessment of data quality issues for process mining in healthcare using Medical Information Mart for Intensive Care III, a freely available e-health record database. Health Inform. J. 2019, 25, 1878–1893. [Google Scholar] [CrossRef] [PubMed]
- Pegoraro, M.; Uysal, M.S.; van der Aalst, W.M.P. Efficient construction of behavior graphs for uncertain event data. In International Conference on Business Information Systems (BIS); Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Berti, A.; van Zelst, S.J.; van der Aalst, W.M.P. Process Mining for Python (PM4Py): Bridging the Gap Between Process- and Data Science. arXiv 2019, arXiv:1905.06169. [Google Scholar]
- Adriansyah, A.; van Dongen, B.F.; van der Aalst, W.M.P. Towards robust conformance checking. In International Conference on Business Process Management; Springer: Berlin/Heidelberg, Germany, 2010; pp. 122–133. [Google Scholar]
- Pegoraro, M.; Uysal, M.S.; van der Aalst, W.M.P. Discovering Process Models from Uncertain Event Data. In International Conference on Business Process Management; Springer: Berlin/Heidelberg, Germany, 2019; pp. 238–249. [Google Scholar]
- Leemans, S.J.J.; Fahland, D.; van der Aalst, W.M.P. Discovering block-structured process models from event logs-a constructive approach. In International Conference on Applications and Theory of Petri Nets and Concurrency; Springer: Berlin/Heidelberg, Germany, 2013; pp. 311–329. [Google Scholar]
- Flaška, V.; Ježek, J.; Kepka, T.; Kortelainen, J. Transitive closures of binary relations. I. Acta Univ. Carol. Math. Phys. 2007, 48, 55–69. [Google Scholar]
- Kalvin, A.D.; Varol, Y.L. On the generation of all topological sortings. J. Algorithms 1983, 4, 150–162. [Google Scholar] [CrossRef]
- Aho, A.V.; Garey, M.R.; Ullman, J.D. The transitive reduction of a directed graph. SIAM J. Comput. 1972, 1, 131–137. [Google Scholar] [CrossRef]
- Strassen, V. Gaussian elimination is not optimal. Numer. Math. 1969, 13, 354–356. [Google Scholar] [CrossRef]
- Coppersmith, D.; Winograd, S. Matrix multiplication via arithmetic progressions. J. Symb. Comput. 1990, 9, 251–280. [Google Scholar] [CrossRef]
- Stothers, A.J. On the Complexity of Matrix Multiplication. Ph.D. Thesis, University of Edinburgh, Edinburgh, UK, 2010. [Google Scholar]
- Williams, V.V. Multiplying matrices faster than Coppersmith-Winograd. In Proceedings of the ACM Symposium on Theory of Computing (STOC), New York, NY, USA, 19–22 May 2012; Volume 12, pp. 887–898. [Google Scholar]
- Le Gall, F. Powers of tensors and fast matrix multiplication. In Proceedings of the 39th international symposium on symbolic and algebraic computation, Kobe, Japan, 23–25 July 2014; pp. 296–303. [Google Scholar]
- D’Alberto, P.; Nicolau, A. Using recursion to boost ATLAS’s performance. In High-Performance Computing; Springer: Berlin/Heidelberg, Germany, 2005; pp. 142–151. [Google Scholar]
- Le Gall, F. Faster algorithms for rectangular matrix multiplication. In Proceedings of the 53rd Annual Symposium on Foundations of Computer Science, New Brunswick, NJ, USA, 20–23 October 2012; pp. 514–523. [Google Scholar]
- Lee, W.L.J.; Verbeek, H.M.W.; Munoz-Gama, J.; van der Aalst, W.M.P.; Sepúlveda, M. Replay using recomposition: Alignment-based conformance checking in the large. In Proceedings of the BPM Demo Track and BPM Dissertation Award co-located with 15th International Conference on Business Process Management (BPM 2017), Barcelona, Spain, 13 September 2017. [Google Scholar]
- Aggarwal, C.C.; Philip, S.Y. A survey of uncertain data algorithms and applications. IEEE Trans. Knowl. Data Eng. 2008, 21, 609–623. [Google Scholar] [CrossRef]
- Suciu, D.; Olteanu, D.; Ré, C.; Koch, C. Probabilistic databases. Synth. Lect. Data Manag. 2011, 3, 1–180. [Google Scholar] [CrossRef]
- Chui, C.K.; Kao, B.; Hung, E. Mining frequent itemsets from uncertain data. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Nanjing, China, 22–25 May 2007; pp. 47–58. [Google Scholar]
- Al-Mutawa, H.A.; Dietrich, J.; Marsland, S.; McCartin, C. On the shape of circular dependencies in Java programs. In Proceedings of the 2014 23rd Australian Software Engineering Conference, Milsons Point, Australia, 7–10 April 2014; pp. 48–57. [Google Scholar]
- Bayes, T. LII. An Essay towards solving a problem in the doctrine of chances. By the late Rev. Mr. Bayes, F.R.S. communicated by Mr. Price, in a letter to John Canton, A.M.F.R.S. Philos. Trans. R. Soc. Lond. 1763, 53, 370–418. [Google Scholar]
- Mariappan, M.; Vora, K. GraphBolt: Dependency-Driven Synchronous Processing of Streaming Graphs. In Proceedings of the Fourteenth EuroSys Conference 2019, Dresden, Germany, 25–28 March 2019; p. 25. [Google Scholar]
- Aho, A.; Lam, M.; Sethi, R.; Ullman, J.; Cooper, K.; Torczon, L.; Muchnick, S. Compilers: Principles, Techniques and Tools; Addison Wesley: Boston, MA, USA, 2007. [Google Scholar]
- Mokhov, A.; Carmona, J.; Beaumont, J. Mining conditional partial order graphs from event logs. In Transactions on Petri Nets and Other Models of Concurrency XI; Springer: Berlin/Heidelberg, Germany, 2016; pp. 114–136. [Google Scholar]
- Lu, X.; Fahland, D.; van der Aalst, W.M.P. Conformance checking based on partially ordered event data. In International Conference on Business Process Management; Springer: Berlin/Heidelberg, Germany, 2014; pp. 75–88. [Google Scholar]
- Lu, X.; Mans, R.S.; Fahland, D.; van der Aalst, W.M.P. Conformance checking in healthcare based on partially ordered event data. In Proceedings of the 2014 IEEE Emerging Technology and Factory Automation (ETFA), Barcelona, Spain, 16–19 September 2014; pp. 1–8. [Google Scholar]
- Genga, L.; Alizadeh, M.; Potena, D.; Diamantini, C.; Zannone, N. Discovering anomalous frequent patterns from partially ordered event logs. J. Intell. Inf. Syst. 2018, 51, 257–300. [Google Scholar] [CrossRef]
- Van der Aa, H.; Leopold, H.; Weidlich, M. Partial order resolution of event logs for process conformance checking. Decis. Support Syst. 2020, 136, 113347. [Google Scholar] [CrossRef]
- Leemans, S.J.J.; Polyvyanyy, A. Stochastic-Aware Conformance Checking: An Entropy-Based Approach. In International Conference on Advanced Information Systems Engineering; Springer: Berlin/Heidelberg, Germany, 2020; pp. 217–233. [Google Scholar]
- Rogge-Solti, A.; van der Aalst, W.M.P.; Weske, M. Discovering stochastic petri nets with arbitrary delay distributions from event logs. In International Conference on Business Process Management; Springer: Berlin/Heidelberg, Germany, 2013; pp. 15–27. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
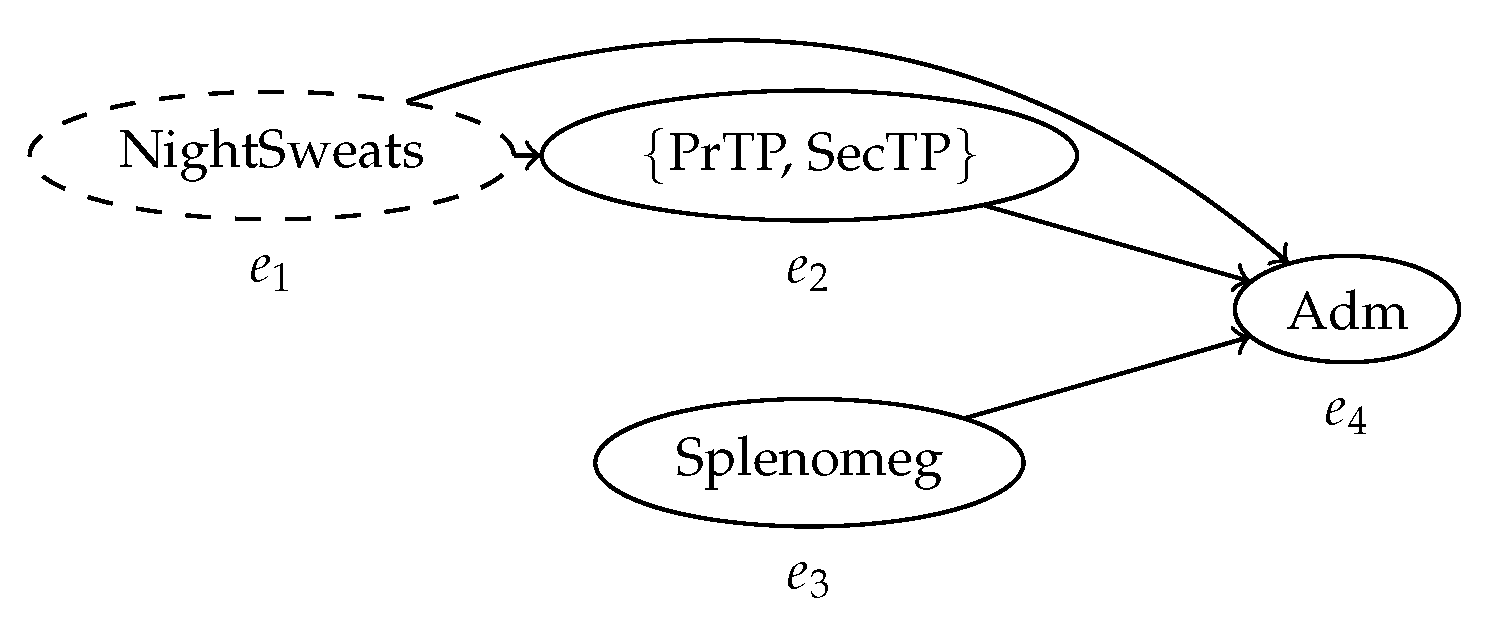
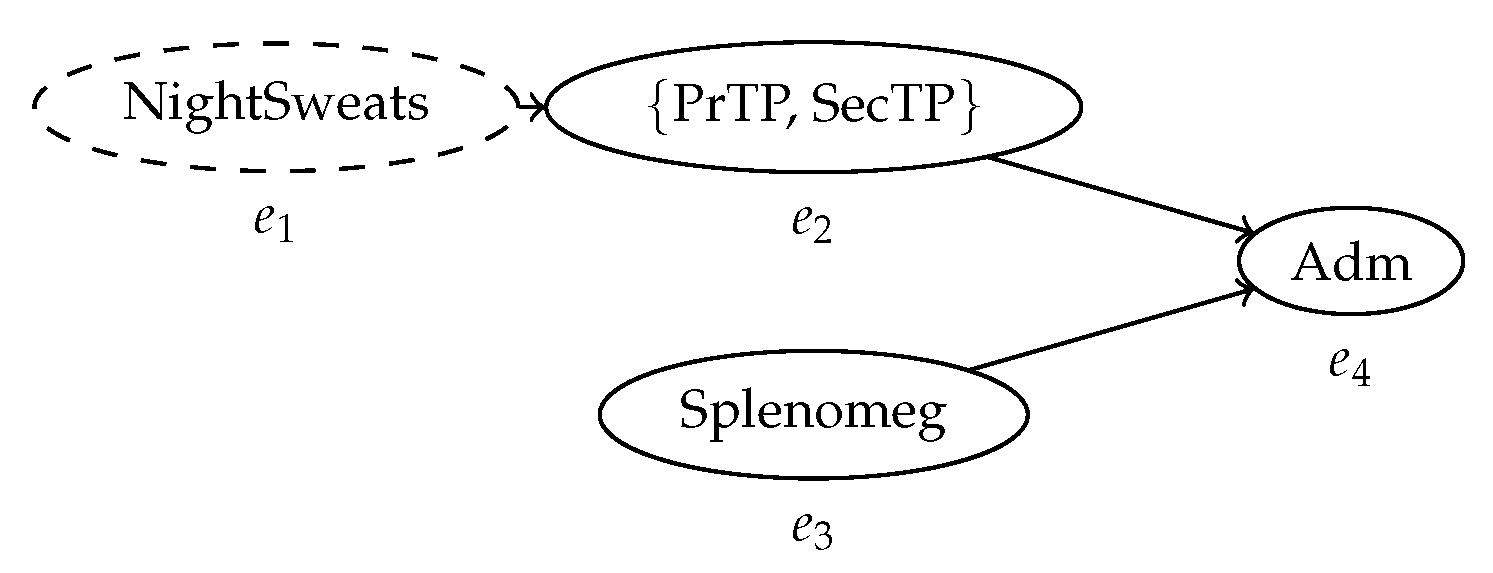
| Case ID | Event ID | Timestamp | Activity | Indet. Event |
|---|---|---|---|---|
| ID327 | 5 | NightSweats | ? | |
| ID327 | 8 | {PrTP, SecTP} | ! | |
| ID327 | [4, 10] | Splenomeg | ! | |
| ID327 | 12 | Adm | ! |
| ≫ | NightSweats | Splenomeg | ≫ | PrTP | Adm |
|---|---|---|---|---|---|
| NightSweats | Splenomeg | PrTP | Adm | ||
| ≫ | SecTP | ≫ | Splenomeg | ≫ | ≫ | Adm |
|---|---|---|---|---|---|---|
| ≫ | NightSweats | Splenomeg | PrTP | Adm | ||
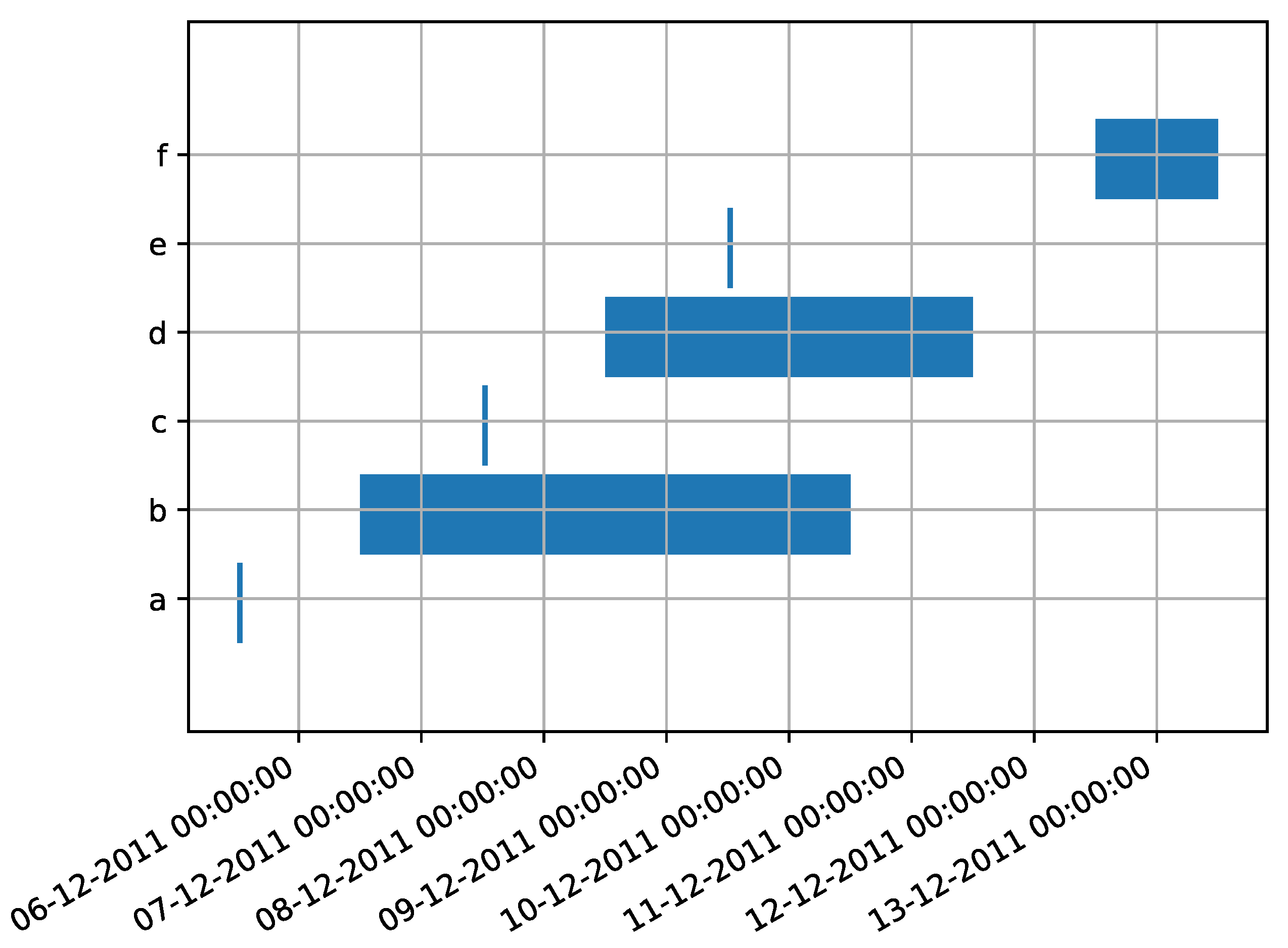
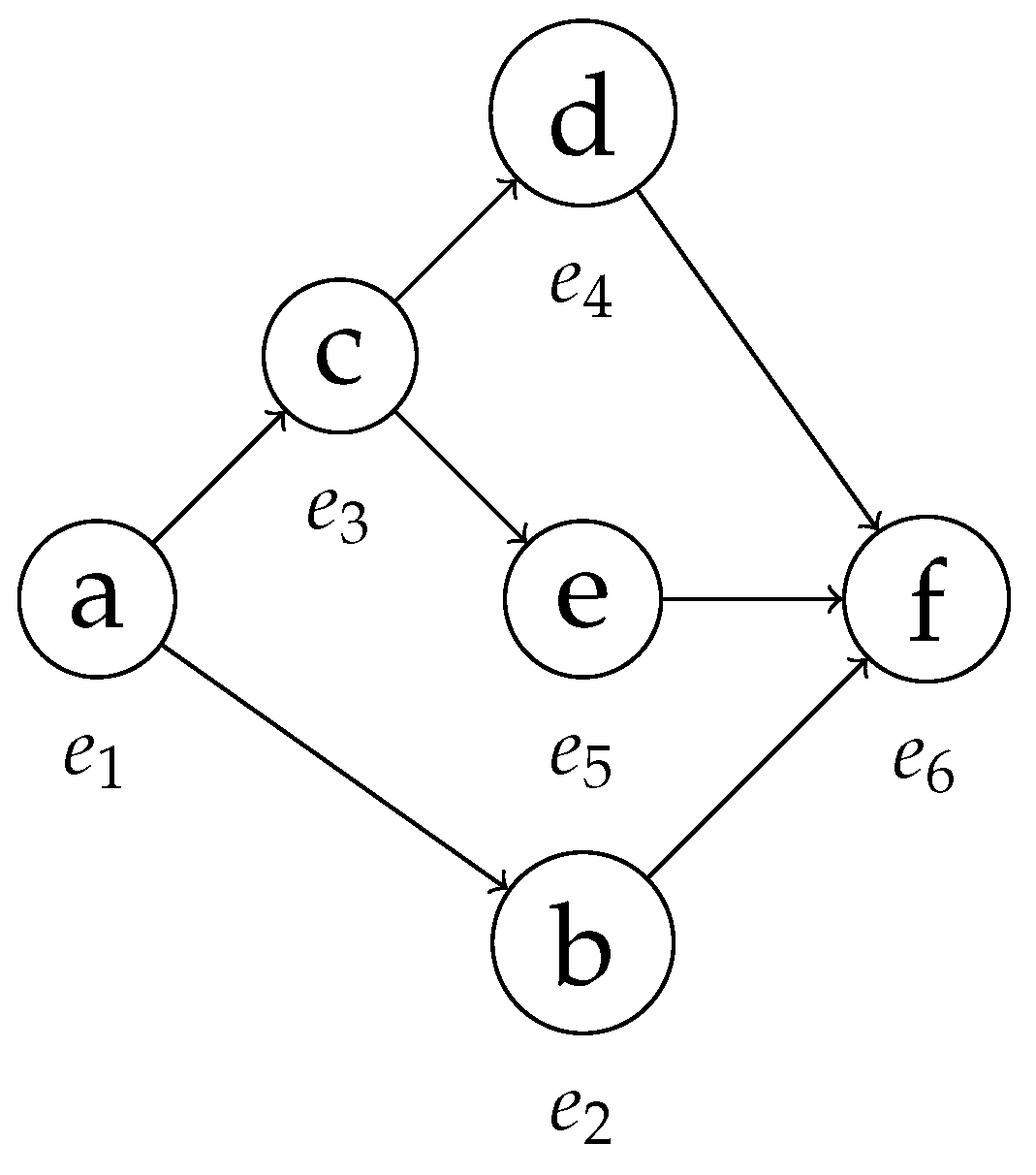
| Case ID | Event ID | Activity | Timestamp | Event Type |
|---|---|---|---|---|
| 872 | a | 5 December 2011 | ! | |
| 872 | b | [6 December 2011, 10 December 2011] | ! | |
| 872 | c | 7 December 2011 | ! | |
| 872 | d | [8 December 2011, 11 December 2011] | ! | |
| 872 | e | 9 December 2011 | ! | |
| 872 | f | [12 December 2011, 13 December 2011] | ! |
| Event | List Entry (Minimum Timestamp) | List Entry (Maximum Timestamp) |
|---|---|---|
| (5 December 2011, 1, , !, ‘MIN’) | (5 December 2011, 1, , !, ‘MAX’) | |
| (6 December 2011, 2, , !, ‘MIN’) | (10 December 2011, 2, , !, ‘MAX’) | |
| (7 December 2011, 3, , !, ‘MIN’) | (7 December 2011, 3, , !, ‘MAX’) | |
| (8 December 2011, 4, , !, ‘MIN’) | (8 December 2011, 4, , !, ‘MAX’) | |
| (9 December 2011, 5, , !, ‘MIN’) | (9 December 2011, 5, , !, ‘MAX’) | |
| (12 December 2011, 6, , !, ‘MIN’) | (13 December 2011, 6, , !, ‘MAX’) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pegoraro, M.; Uysal, M.S.; van der Aalst, W.M.P. Efficient Time and Space Representation of Uncertain Event Data. Algorithms 2020, 13, 285. https://doi.org/10.3390/a13110285
Pegoraro M, Uysal MS, van der Aalst WMP. Efficient Time and Space Representation of Uncertain Event Data. Algorithms. 2020; 13(11):285. https://doi.org/10.3390/a13110285
Chicago/Turabian StylePegoraro, Marco, Merih Seran Uysal, and Wil M. P. van der Aalst. 2020. "Efficient Time and Space Representation of Uncertain Event Data" Algorithms 13, no. 11: 285. https://doi.org/10.3390/a13110285
APA StylePegoraro, M., Uysal, M. S., & van der Aalst, W. M. P. (2020). Efficient Time and Space Representation of Uncertain Event Data. Algorithms, 13(11), 285. https://doi.org/10.3390/a13110285