Detection of Suicide Ideation in Social Media Forums Using Deep Learning



Abstract
1. Introduction
- N-gram analysis: we evaluate the n-gram analysis to show that the expressions of suicidal tendencies and reduced social engagements are often discussed in suicide-related forums. We identify the transition towards the social ideation associated with different psychological stages such as heightened self-focused attention, a manifestation of hopelessness, frustration, anxiety or loneliness.
- Classical features analysis: using CNN, LSTM and LSTM-CNN combined model analysis, we evaluate bag of words, TF-IDF and statistical features performance over word embedding.
- Comparative evaluation: we explore the performance of LSTM-CNN combined class of deep neural networks as our proposed model for detection of suicide ideation tasks to improve the state-of-the-art method. In terms of evaluation metrics, we compare its strength and potential with CNN and LSTM deep learning techniques and four traditional machine learning classifiers including SVM, NB, RF and XGBoost) on the real-world dataset.
2. Background and Related Work
3. Datasets
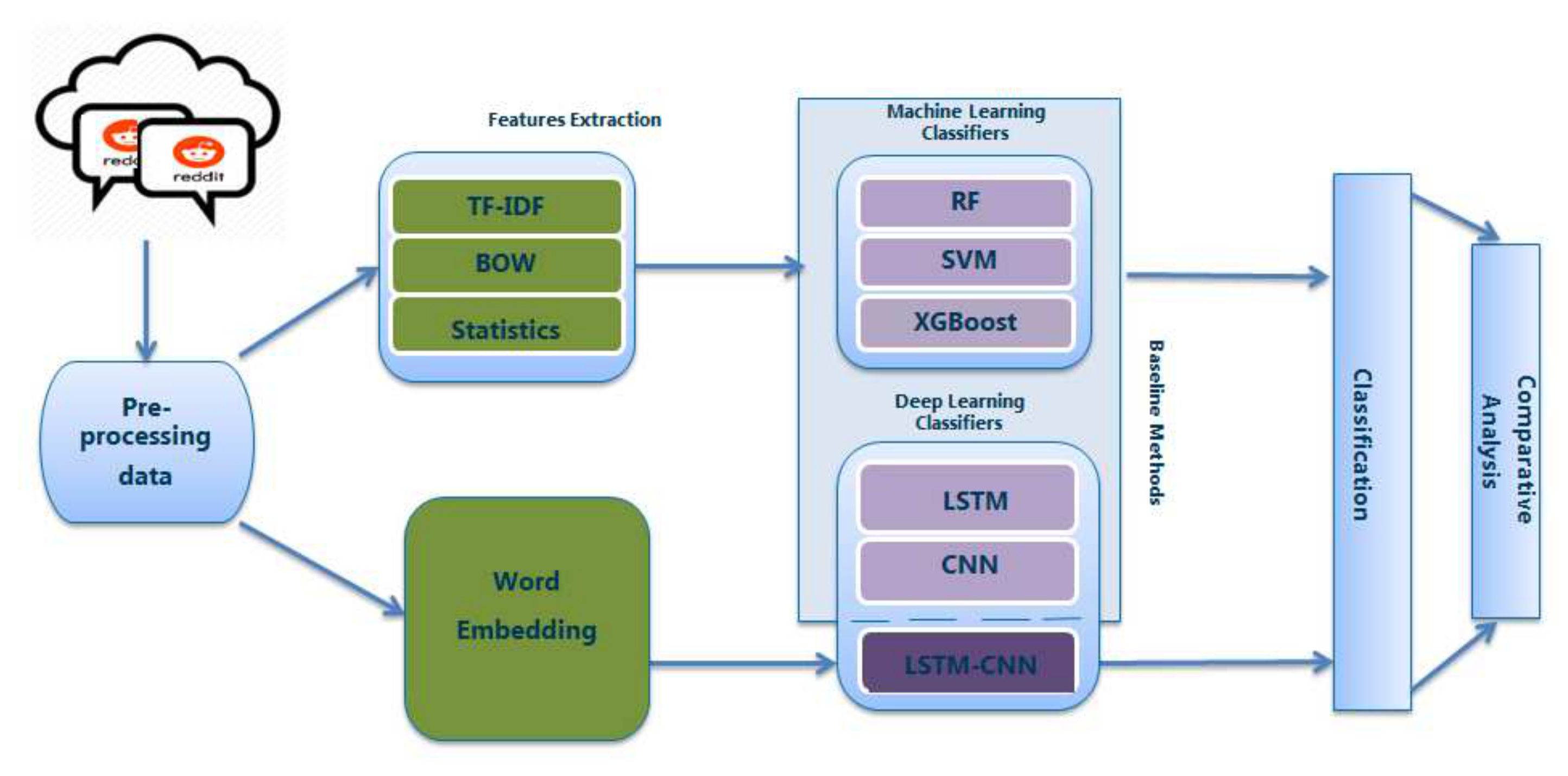
4. Methodology
4.1. Pre-Processing
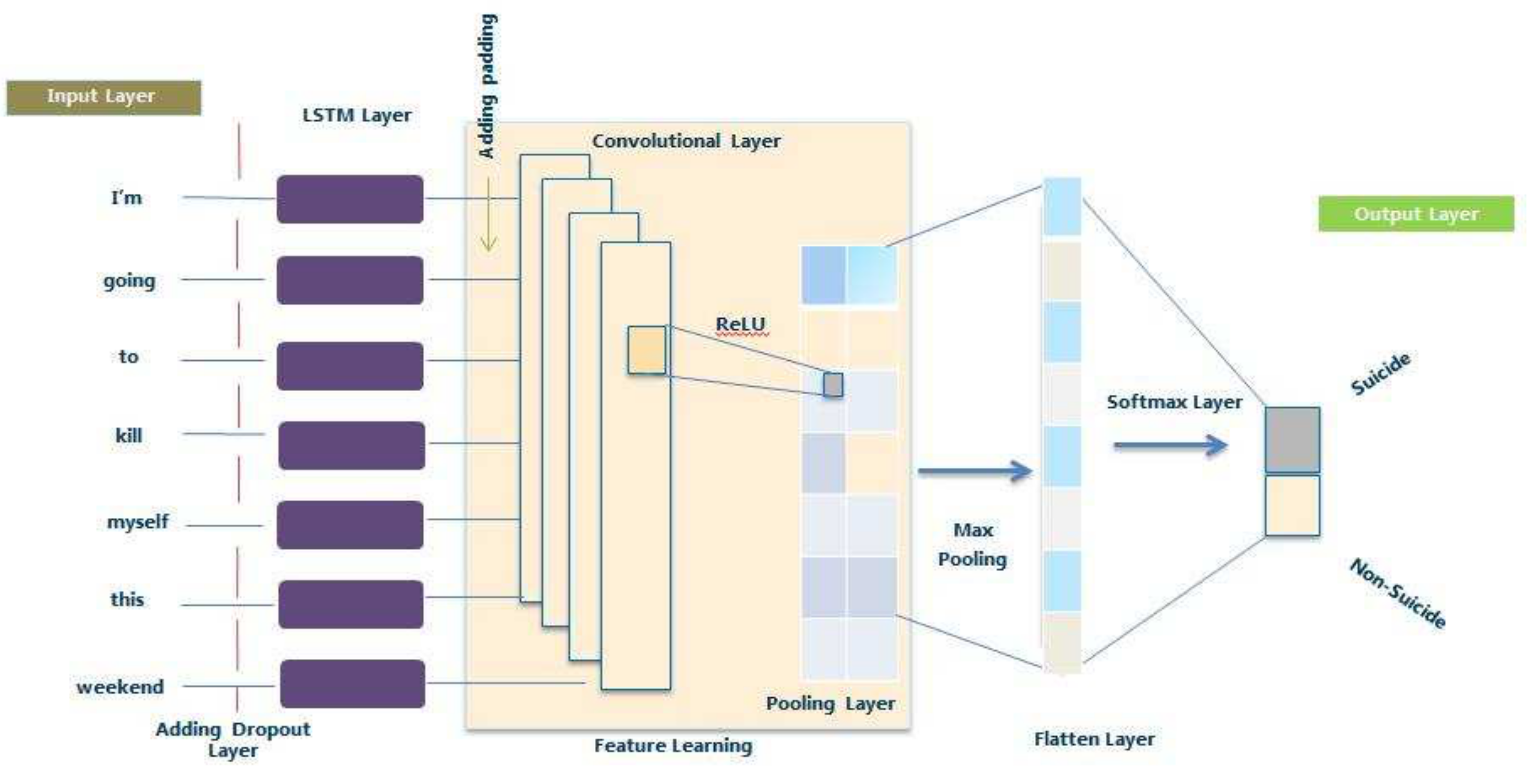
4.2. Proposed Network Model
4.3. Baseline
4.4. Model Architecture and Its Parameters
4.5. Evaluation Metrics
5. Experimental Results
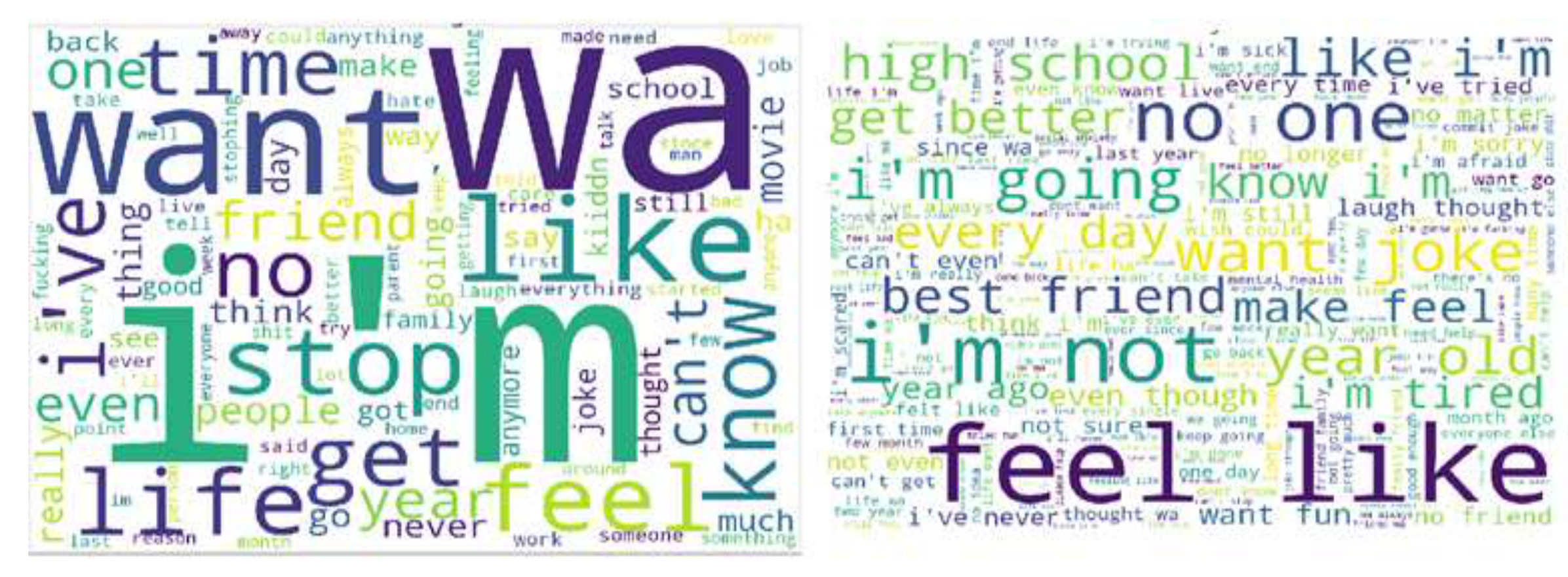
5.1. Data Analysis Results
5.2. Classification Analysis Results
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- World Health Organization. National Suicide Prevention Strategies: Progress, Examples and Indicators; World Health Organization: Geneva, Switzerland, 2018. [Google Scholar]
- Beck, A.T.; Kovacs, M.; Weissman, A. Hopelessness and suicidal behavior: An overview. JAMA 1975, 234, 1146–1149. [Google Scholar] [CrossRef] [PubMed]
- Silver, M.A.; Bohnert, M.; Beck, A.T.; Marcus, D. Relation of depression of attempted suicide and seriousness of intent. Arch. Gen. Psychiatry 1971, 25, 573–576. [Google Scholar] [CrossRef] [PubMed]
- Klonsky, E.D.; May, A.M. Differentiating suicide attempters from suicide ideators: A critical frontier for suicidology research. Suicide Life-Threat. Behav. 2014, 44, 1–5. [Google Scholar] [CrossRef] [PubMed]
- Pompili, M.; Innamorati, M.; Di Vittorio, C.; Sher, L.; Girardi, P.; Amore, M. Sociodemographic and clinical differences between suicide ideators and attempters: A study of mood disordered patients 50 years and older. Suicide Life-Threat. Behav. 2014, 44, 34–45. [Google Scholar] [CrossRef] [PubMed]
- DeJong, T.M.; Overholser, J.C.; Stockmeier, C.A. Apples to oranges?: A direct comparison between suicide attempters and suicide completers. J. Affect. Disord. 2010, 124, 90–97. [Google Scholar] [CrossRef] [PubMed]
- De Choudhury, M.; Kiciman, E.; Dredze, M.; Coppersmith, G.; Kumar, M. Discovering shifts to suicidal ideation from mental health content in social media. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San José, CA, USA, 9–12 December 2016; ACM: New York, NY, USA, 2016; pp. 2098–2110. [Google Scholar]
- Marks, M. Artificial Intelligence Based Suicide Prediction. Yale J. Health Policy Law Ethics 2019. Forthcoming. [Google Scholar]
- Kumar, M.; Dredze, M.; Coppersmith, G.; De Choudhury, M. Detecting changes in suicide content manifested in social media following celebrity suicides. In Proceedings of the 26th ACM conference on Hypertext & Social Media, Prague, Czech Republic, 4–7 July 2015; ACM: New York, NY, USA, 2015; pp. 85–94. [Google Scholar]
- Ji, S.; Long, G.; Pan, S.; Zhu, T.; Jiang, J.; Wang, S. Detecting Suicidal Ideation with Data Protection in Online Communities. In Proceedings of the International Conference on Database Systems for Advanced Applications, Chiang Mai, Thailand, 22–25 April 2019; Springer: Berlin, Germany, 2019; pp. 225–229. [Google Scholar]
- Yang, Y.; Zheng, L.; Zhang, J.; Cui, Q.; Li, Z.; Yu, P.S. TI-CNN: Convolutional neural networks for fake news detection. arXiv 2018, arXiv:1806.00749. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Černockỳ, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the Eleventh Annual Conference of the International Speech Communication Association, Makuhari, Chiba, Japan, 26–30 September 2010. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, CA, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Coppersmith, G.; Ngo, K.; Leary, R.; Wood, A. Exploratory analysis of social media prior to a suicide attempt. In Proceedings of the Third Workshop on Computational Linguistics and Clinical Psychology, San Diego, CA, USA, 16 June 2016; pp. 106–117. [Google Scholar]
- Hsiung, R.C. A suicide in an online mental health support group: Reactions of the group members, administrative responses, and recommendations. CyberPsychol. Behav. 2007, 10, 495–500. [Google Scholar] [CrossRef]
- Jashinsky, J.; Burton, S.H.; Hanson, C.L.; West, J.; Giraud-Carrier, C.; Barnes, M.D.; Argyle, T. Tracking suicide risk factors through Twitter in the US. Crisis 2014, 35, 51–59. [Google Scholar] [CrossRef]
- Colombo, G.B.; Burnap, P.; Hodorog, A.; Scourfield, J. Analysing the connectivity and communication of suicidal users on twitter. Comput. Commun. 2016, 73, 291–300. [Google Scholar] [CrossRef]
- Niederkrotenthaler, T.; Till, B.; Kapusta, N.D.; Voracek, M.; Dervic, K.; Sonneck, G. Copycat effects after media reports on suicide: A population-based ecologic study. Soc. Sci. Med. 2009, 69, 1085–1090. [Google Scholar] [CrossRef] [PubMed]
- Ueda, M.; Mori, K.; Matsubayashi, T.; Sawada, Y. Tweeting celebrity suicides: Users’ reaction to prominent suicide deaths on Twitter and subsequent increases in actual suicides. Soc. Sci. Med. 2017, 189, 158–166. [Google Scholar] [CrossRef] [PubMed]
- Desmet, B.; Hoste, V. Emotion detection in suicide notes. Expert Syst. Appl. 2013, 40, 6351–6358. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L.; Chiu, D.; Liu, T.; Li, X.; Zhu, T. Detecting suicidal ideation in Chinese microblogs with psychological lexicons. In Proceedings of the 2014 IEEE 11th Intl. Conf. on Ubiquitous Intelligence and Computing and 2014 IEEE 11th Intl. Conf. on Autonomic and Trusted Computing and 2014 IEEE 14th Intl. Conf. on Scalable Computing and Communications and Its Associated Workshops, Bali, Indonesia, 9–12 December 2014; pp. 844–849. [Google Scholar]
- Braithwaite, S.R.; Giraud-Carrier, C.; West, J.; Barnes, M.D.; Hanson, C.L. Validating machine learning algorithms for Twitter data against established measures of suicidality. JMIR Ment. Health 2016, 3, e21. [Google Scholar] [CrossRef]
- Sueki, H. The association of suicide-related Twitter use with suicidal behaviour: A cross-sectional study of young internet users in Japan. J. Affect. Disord. 2015, 170, 155–160. [Google Scholar] [CrossRef]
- O’Dea, B.; Wan, S.; Batterham, P.J.; Calear, A.L.; Paris, C.; Christensen, H. Detecting suicidality on Twitter. Internet Interv. 2015, 2, 183–188. [Google Scholar] [CrossRef]
- Wood, A.; Shiffman, J.; Leary, R.; Coppersmith, G. Language signals preceding suicide attempts. In Proceedings of the CHI 2016 Computing and Mental Health Workshop, San Jose, CA, USA, 7–12 May 2016. [Google Scholar]
- Okhapkina, E.; Okhapkin, V.; Kazarin, O. Adaptation of information retrieval methods for identifying of destructive informational influence in social networks. In Proceedings of the 2017 IEEE 31st International Conference on Advanced Information Networking and Applications Workshops (WAINA), Taipei, Taiwan, 27–29 March 2017; pp. 87–92. [Google Scholar]
- Sawhney, R.; Manchanda, P.; Singh, R.; Aggarwal, S. A computational approach to feature extraction for identification of suicidal ideation in tweets. In Proceedings of the ACL 2018, Student Research Workshop, Melbourne, Australia, 15–20 July 2018; pp. 91–98. [Google Scholar]
- Aladağ, A.E.; Muderrisoglu, S.; Akbas, N.B.; Zahmacioglu, O.; Bingol, H.O. Detecting suicidal ideation on forums: Proof-of-Concept study. J. Med. Internet Res. 2018, 20, e215. [Google Scholar] [CrossRef]
- Wang, C.; Jiang, F.; Yang, H. A hybrid framework for text modeling with convolutional rnn. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; ACM: New York, NY, USA, 2017; pp. 2061–2069. [Google Scholar]
- Sawhney, R.; Manchanda, P.; Mathur, P.; Shah, R.; Singh, R. Exploring and learning suicidal ideation connotations on social media with deep learning. In Proceedings of the 9th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Brussels, Belgium, 31 October–1 November 2018; pp. 167–175. [Google Scholar]
- Ji, S.; Yu, C.P.; Fung, S.f.; Pan, S.; Long, G. Supervised learning for suicidal ideation detection in online user content. Complexity 2018, 2018, 6157249. [Google Scholar] [CrossRef]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A convolutional neural network for modelling sentences. arXiv 2014, arXiv:1404.2188. [Google Scholar]
- Yin, W.; Schütze, H. Multichannel variable-size convolution for sentence classification. arXiv 2016, arXiv:1603.04513. [Google Scholar]
- Gehrmann, S.; Dernoncourt, F.; Li, Y.; Carlson, E.T.; Wu, J.T.; Welt, J.; Foote, J., Jr.; Moseley, E.T.; Grant, D.W.; Tyler, P.D.; et al. Comparing deep learning and concept extraction based methods for patient phenotyping from clinical narratives. PLoS ONE 2018, 13, e0192360. [Google Scholar] [CrossRef] [PubMed]
- Morales, M.; Dey, P.; Theisen, T.; Belitz, D.; Chernova, N. An investigation of deep learning systems for suicide risk assessment. In Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology, Minneapolis, MN, USA, 6 June 2019; pp. 177–181. [Google Scholar]
- Bhat, H.S.; Goldman-Mellor, S.J. Predicting Adolescent Suicide Attempts with Neural Networks. arXiv 2017, arXiv:1711.10057. [Google Scholar]
- Gaur, M.; Alambo, A.; Sain, J.P.; Kursuncu, U.; Thirunarayan, K.; Kavuluru, R.; Sheth, A.; Welton, R.; Pathak, J. Knowledge-aware assessment of severity of suicide risk for early intervention. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; ACM: New York, NY, USA, 2019; pp. 514–525. [Google Scholar]
- Du, J.; Zhang, Y.; Luo, J.; Jia, Y.; Wei, Q.; Tao, C.; Xu, H. Extracting psychiatric stressors for suicide from social media using deep learning. BMC Med. Inform. Decis. Mak. 2018, 18, 43. [Google Scholar] [CrossRef] [PubMed]
- Yao, H.; Rosenthal, R.W.F. Detection of Suicidality among Opioid Users on Reddit: A Machine Learning Based Approach. J. Med. Internet Res. 2019. [Google Scholar] [CrossRef]
- Hermann, K.M.; Kocisky, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching machines to read and comprehend. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 1693–1701. [Google Scholar]
- Hill, F.; Bordes, A.; Chopra, S.; Weston, J. The goldilocks principle: Reading children’s books with explicit memory representations. arXiv 2015, arXiv:1511.02301. [Google Scholar]
- He, H.; Lin, J. Pairwise word interaction modeling with deep neural networks for semantic similarity measurement. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 937–948. [Google Scholar]
- Maziarz, M.; Piasecki, M.; Rudnicka, E.; Szpakowicz, S.; Kędzia, P. plWordNet 3.0—A Comprehensive Lexical-Semantic Resource. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics, Osaka, Japan, 11–16 December 2016; pp. 2259–2268. [Google Scholar]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Sosa, P.M. Twitter Sentiment Analysis Using Combined LSTM-CNN Models. 2017. Available online: https://www.academia.edu/35947062/Twitter/_Sentiment/_Analysis/_using/_combined/_LSTM-CNN/_Models (accessed on 23 December 2019).
- Zhang, J.; Li, Y.; Tian, J.; Li, T. LSTM-CNN Hybrid Model for Text Classification. In Proceedings of the 2018 IEEE 3rd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 October 2018; pp. 1675–1680. [Google Scholar]
- Ahmad, S.; Asghar, M.Z.; Alotaibi, F.M.; Awan, I. Detection and classification of social media-based extremist affiliations using sentiment analysis techniques. Hum.-Centric Comput. Inf. Sci. 2019, 9, 24. [Google Scholar] [CrossRef]
- Orabi, A.H.; Buddhitha, P.; Orabi, M.H.; Inkpen, D. Deep learning for depression detection of twitter users. In Proceedings of the Fifth Workshop on Computational Linguistics and Clinical Psychology: From Keyboard to Clinic, New Orleans, LA, USA, 5 June 2018; pp. 88–97. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Yan, S. Understanding LSTM Networks. 2015. Available online: https://colah.github.io/posts/2015-08-Understanding-LSTMs/ (accessed on 16 July 2019).
- Olah, C.; Yan, S. Understanding LSTM and Its Diagrams. MLReview.com 2016. Available online: https://medium.com/mlreview/understanding-lstm-and-its-diagrams-37e2f46f1714 (accessed on 16 July 2019).
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- Srinivas, S.; Sarvadevabhatla, R.K.; Mopuri, K.R.; Prabhu, N.; Kruthiventi, S.S.; Babu, R.V. A taxonomy of deep convolutional neural nets for computer vision. Front. Robot. AI 2016, 2, 36. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 649–657. [Google Scholar]
- Sosa, P.M.; Sadigh, S. Twitter Sentiment Analysis with Neural Networks. 2016. Available online: https://www.academia.edu/30498927/Twitter_Sentiment_Analysis_with_Neural_Networks (accessed on 23 December 2019).
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical evaluation of rectified activations in convolutional network. arXiv 2015, arXiv:1505.00853. [Google Scholar]
- Hochreiter, S. The vanishing gradient problem during learning recurrent neural nets and problem solutions. Int. J. Uncertain. Fuzziness -Knowl.-Based Syst. 1998, 6, 107–116. [Google Scholar] [CrossRef]
- Norouzi, M.; Ranjbar, M.; Mori, G. Stacks of convolutional restricted boltzmann machines for shift-invariant feature learning. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2735–2742. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Nguyen, D.; Widrow, B. Improving the learning speed of 2-layer neural networks by choosing initial values of the adaptive weights. In Proceedings of the 1990 IJCNN IEEE International Joint Conference on Neural Networks, San Diego, CA, USA, 17–21 June 1990; pp. 21–26. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Garcia, B.; Viesca, S.A. Real-time american sign language recognition with convolutional neural networks. In Convolutional Neural Networks for Visual Recognition; Stanford University: Stanford, CA, USA, 2016; pp. 225–232. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Schütze, H.; Manning, C.D.; Raghavan, P. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008; Volume 39, pp. 293–311. [Google Scholar]
- Joachims, T. Text categorization with support vector machines: Learning with many relevant features. In Lecture Notes in Computer Science, Proceedings of the European Conference on Machine Learning, Chemnitz, Germany, 21–23 April 1998; Springer: Berlin, Germany, 1998; pp. 137–142. [Google Scholar]
- De Choudhury, M.; Gamon, M.; Counts, S.; Horvitz, E. Predicting depression via social media. In Proceedings of the Seventh International AAAI Conference on Weblogs and Social Media, Bosten, MA, USA, 8–11 July 2013. [Google Scholar]
- Rish, I. An empirical study of the naive Bayes classifier. In Proceedings of the IJCAI 2001 Workshop on Empirical Methods in Artificial Intelligence, New York, NY, USA, 4–6 August 2001; Volume 3, pp. 41–46. [Google Scholar]
- McCallum, A.; Nigam, K. A comparison of event models for naive bayes text classification. In Proceedings of the AAAI-98 Workshop on Learning for Text Categorization, Madison, WI, USA, 26–27 July 1998; Volume 752, pp. 41–48. [Google Scholar]
- Sebastiani, F. Machine learning in automated text categorization. ACM Comput. Surv. (CSUR) 2002, 34, 1–47. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.; Abe, N. A short introduction to boosting. J.-Jpn. Soc. Artif. Intell. 1999, 14, 1612. [Google Scholar]
- Schapire, R.E.; Singer, Y.; Singhal, A. Boosting and Rocchio applied to text filtering. In Proceedings of the SIGIR, Melbourne, Australia, 24–28 August 1998; Volume 98, pp. 215–223. [Google Scholar]
- Brownlee, J. Deep Learning for Time Series Forecasting: Predict the Future with MLPs, CNNs and LSTMs in Python; Machine Learning Mastery: New York, NY, USA, 2018. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Ikonomakis, M.; Kotsiantis, S.; Tampakas, V. Text classification using machine learning techniques. WSEAS Trans. Comput. 2005, 4, 966–974. [Google Scholar]
- Wang, Z.; Qian, X. Text categorization based on LDA and SVM. In Proceedings of the 2008 IEEE International Conference on Computer Science and Software Engineering, Wuhan, China, 12–14 December 2008; Volume 1, pp. 674–677. [Google Scholar]
- Fiori, A. Innovative Document Summarization Techniques: Revolutionizing Knowledge Understanding: Revolutionizing Knowledge Understanding; IGI Global: Hershey, PA, USA, 2014. [Google Scholar]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; ACM: New York, NY, USA, 2008; pp. 160–167. [Google Scholar]
- Basu, T.; Murthy, C. A feature selection method for improved document classification. In Proceedings of the International Conference on Advanced Data Mining and Applications, Nanjing, China, 15–18 December 2012; Springer: Berlin, Germany, 2012; pp. 296–305. [Google Scholar]
- Stirman, S.W.; Pennebaker, J.W. Word use in the poetry of suicidal and nonsuicidal poets. Psychosom. Med. 2001, 63, 517–522. [Google Scholar] [CrossRef]
- Zhang, Y.; Wallace, B. A sensitivity analysis of (and practitioners’ guide to) convolutional neural networks for sentence classification. arXiv 2015, arXiv:1510.03820. [Google Scholar]
- Zeiler, M.D.; Ranzato, M.; Monga, R.; Mao, M.; Yang, K.; Le, Q.V.; Nguyen, P.; Senior, A.; Vanhoucke, V.; Dean, J.; et al. On rectified linear units for speech processing. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 3517–3521. [Google Scholar]
- Dahl, G.E.; Sainath, T.N.; Hinton, G.E. Improving deep neural networks for LVCSR using rectified linear units and dropout. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 8609–8613. [Google Scholar]
- Vu, N.T.; Adel, H.; Gupta, P.; Schütze, H. Combining recurrent and convolutional neural networks for relation classification. arXiv 2016, arXiv:1605.07333. [Google Scholar]
- Ji, S.; Pan, S.; Li, X.; Cambria, E.; Long, G.; Huang, Z. Suicidal Ideation Detection: A Review of Machine Learning Methods and Applications. arXiv 2019, arXiv:1910.12611. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Suicidal Posts | Non-Suicidal Posts |
|---|---|
| Want to die, end it now, I wanna die with a blunt. I’m going to kill myself this weekend. | There is no one “correct” way to talk to someone struggling with suicidal thoughts, Children of suicide parents. |
| I want to slit my wrists tonight, I tried to commit suicide. | I think you should tell people how you feel, I think suicide is a permanent option that most of the time results out of a temporary issue. |
| I wish guns for suicide, nobody cares if I die. I want to die Where can i go to commit Suicide?? | Will you ever get over the news that one of your parents committed suicide? |
| Where can i go to commit suicide?? I don’t know what else to do. | Friend has given up, seriously considering suicide. |
| Just over life, die alone, sleep forever. I’m writing my suicide note right now. I plan to kill myself soon. | National Suicide Prevention online chat. I think suicide is a permanent option that most of the time results out of a temporary issue. |
| What’s the point in living when I will always be alone. | Method used in chris cornell and chester bennington’s suicides. |
| LSTM—CNN Model Layers | Parameters | Values |
|---|---|---|
| Convolutional layer | Number of filters | 2, 4, 6, 8 |
| Kernel sizes | 2, 3, 4 | |
| Padding | ’Same’ | |
| Activation function | ’ReLU’ | |
| Pooling layer | Pooling size | Max-Pooling |
| LSTM layer and other | Units | 100 |
| Embedding dimension | 300 | |
| Batch size | 8 | |
| Number of epochs | 10 | |
| Dropout | 0.5 | |
| Fully connected layer | SoftMax |
| Methods | Feature Type | Acc. | F1-Score | Recall | Precision |
|---|---|---|---|---|---|
| RF | Statistics | 77.2 | 75.1 | 73.9 | 76.3 |
| TF-IDF | 81.8 | 80.9 | 83.4 | 80.5 | |
| Bag of Words | 81.1 | 78.6 | 77.9 | 81.1 | |
| Statistics + TF IDF+ Bag of Words | 85.6 | 84.1 | 84 | 85 | |
| SVM | Statistics | 79.6 | 79 | 70 | 60 |
| TF-IDF | 81.2 | 82.7 | 87.2 | 78.7 | |
| Bag of Words | 80.6 | 81.1 | 81.8 | 80.4 | |
| Statistics + TF IDF+ Bag of Words | 83.5 | 83.8 | 85.5 | 82.1 | |
| NB | Statistics | 68.2 | 71.3 | 76.3 | 67.6 |
| TF-IDF | 78.6 | 76.1 | 75.6 | 80.5 | |
| Bag of Words | 79.8 | 78.4 | 78.9 | 79.7 | |
| Statistics + TF IDF+ Bag of Words | 82.5 | 81.5 | 83.4 | 80.8 | |
| XGBOOST | Statistics | 76.3 | 76.1 | 75.6 | 80.5 |
| TF-IDF | 85.6 | 84.1 | 84.0 | 85.8 | |
| Bag of Words | 83.1 | 82.6 | 84.4 | 81.6 | |
| Statistics + TF ID F+ Bag of Words | 88.3 | 83.1 | 84.3 | 88.4 | |
| LSTM | Word2vec | 91.7 | 92.6 | 90.5 | 94.8 |
| CNN | 90.6 | 92.8 | 93.8 | 91.8 | |
| LSTM-CNN | 93.8 | 93.4 | 94.1 | 93.2 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tadesse, M.M.; Lin, H.; Xu, B.; Yang, L. Detection of Suicide Ideation in Social Media Forums Using Deep Learning. Algorithms 2020, 13, 7. https://doi.org/10.3390/a13010007
Tadesse MM, Lin H, Xu B, Yang L. Detection of Suicide Ideation in Social Media Forums Using Deep Learning. Algorithms. 2020; 13(1):7. https://doi.org/10.3390/a13010007
Chicago/Turabian StyleTadesse, Michael Mesfin, Hongfei Lin, Bo Xu, and Liang Yang. 2020. "Detection of Suicide Ideation in Social Media Forums Using Deep Learning" Algorithms 13, no. 1: 7. https://doi.org/10.3390/a13010007
APA StyleTadesse, M. M., Lin, H., Xu, B., & Yang, L. (2020). Detection of Suicide Ideation in Social Media Forums Using Deep Learning. Algorithms, 13(1), 7. https://doi.org/10.3390/a13010007