1. Introduction
1.1. Preliminary Insights: Advanced Human-Machine Interfaces and the Emerging Big Data Trend
Nowadays,
big data (e.g., References [
1,
2,
3,
4,
5]) is the emerging trend that is pervading our life. Among the so many topics in big data research,
human-machine interfaces combined with big data processing (e.g., References [
6,
7,
8]) is a critical area with several interesting and challenging aspects in both the research and industrial application context.
Basically, this line of discipline aims at integrating the well-known
big data analytics area (e.g., References [
9,
10,
11,
12]) with the enormous size of information coming from typical human-machine interfaces (e.g., References [
13,
14,
15,
16,
17]). Indeed, these sources of information generate massive amounts of data, so that analyzing these (big) data repositories with big data analytics plays a critical role, in order to feedback the state model underlying the target human-machine interface, for optimization purposes.
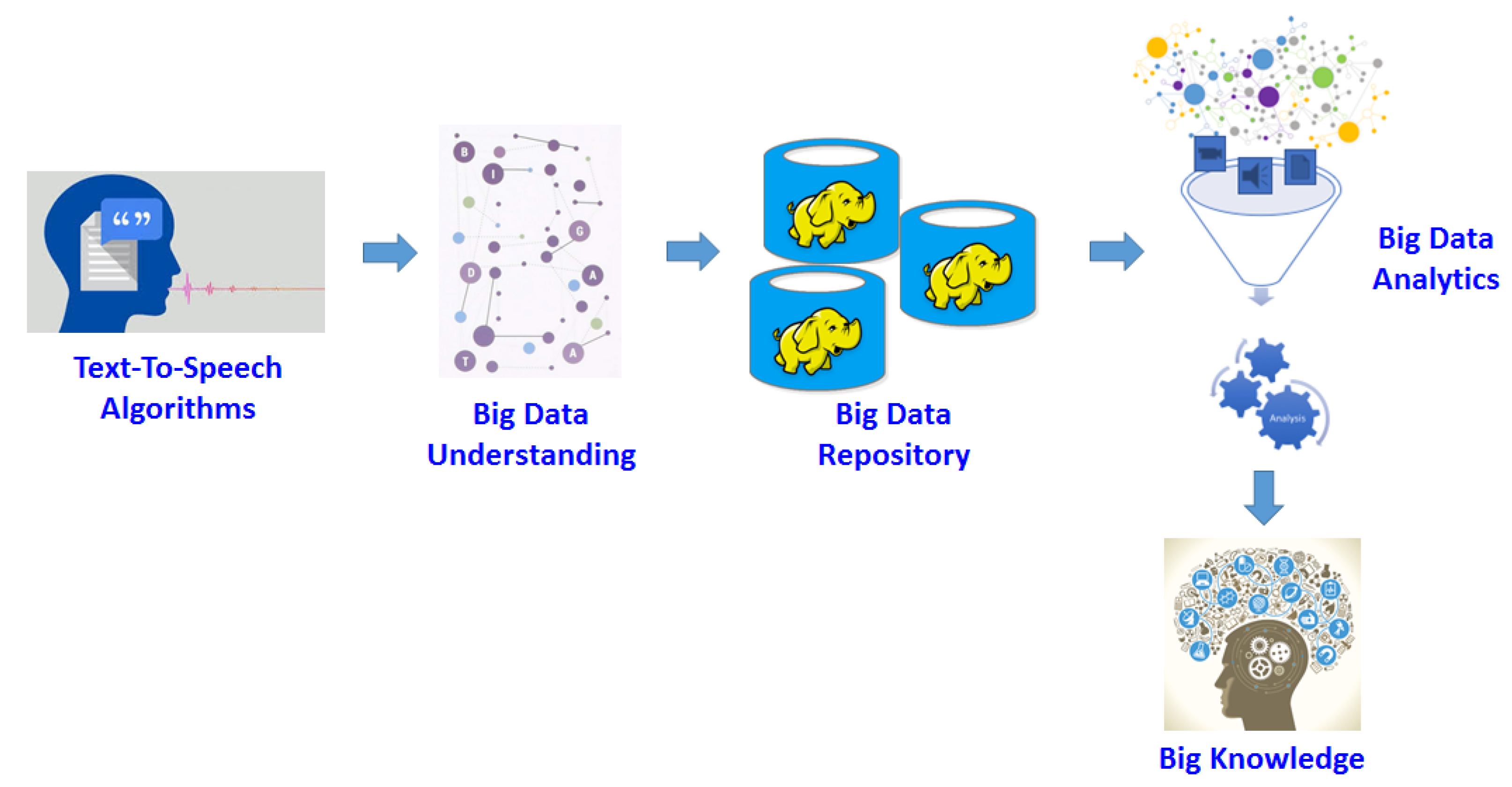
Figure 1 reports the reference architecture of the integration between human-machine interfaces and big data, where our work co-locates. Here, several layers are identified:
Text-To-Speech Algorithms: the layer where text-to-speech algorithms (like ours) execute;
Big Data Understanding: the layer where big data are derived and understood;
Big Data Repository: the layer where derived big data are stored;
Big Data Analytics: the layer where knowledge is extracted from big data;
Big Knowledge: the layer where the final knowledge is made available to users/applications.
Our research mainly focuses on this area. Indeed, in more detail, we consider a special “piece” of work represented by the problem of supporting text-to-speech and articulation of a target humanoid, which can be reasonably considered as a basic step of a major system for achieving the interaction between advanced human-machine interfaces and big data management/analytics. Therefore, our proposed genetic-fuzzy algorithm can be reasonably considered for as a component of the wider goal of supporting advanced human-machine interfaces.
1.2. Motivations
A humanoid is a robot designed to work with humans and for them. Humanoid robots have been designed to allow a robot to offer services to humans in difficult or repetitive situations. Therefore, a fundamental issue in humanoid robotics is the interaction with humans. In Reference [
18] the Cog project at MIT is described, as well as its Kismet project, which were developed in the hypothesis that a humanoid intelligence requires humanoid interactions with the world.
Indeed, nowadays there is growing interest in humanoid robotics. An autonomous humanoid robot is a complex system with a certain degree of autonomy and provides useful services to humans. Its intelligence emerges from the interaction between data collected by the sensors and the management algorithms. Sensor devices provide information about the environment useful for motion, self-localization, and avoidance of obstacles in order to introduce responsiveness and autonomy.
It would be easier for a humanoid robot to interact with humans if it was designed specifically for that purpose. For this reason, humanoid robots tend to imitate the form and the mechanical functions of the human body in some way to emulate some simple aspects of physical (i.e., movement), cognitive (i.e., understanding) and social (i.e., communication) skills of humans. Man-robot interactions and dialogue modes have been extensively studied in recent years in the robotics and AI communities.
A very important area in humanoid robotics is interaction with human beings. Since language is the most natural means of communication for humans, human-humanoid vocal interfaces should be directed to facilitate and improve the way people interact with a robot. Basically, conversational interfaces are built around speech synthesis, voice recognition, and semantic inference engines technologies. In addition to the known problems of accuracy in presence of noise, one of the main problems in voice recognition for interaction with a robot is that the human operator is generally distant from the microphone, which is mounted on the robot itself; one way to overcome this problem is to use beamforming [
19] algorithms.
The human face is an important communication channel in face-to-face communication. Through the face, many information are displayed: verbal, emotional or conversational. All of them should be carefully modeled in order to have natural looking facial animation. Speech driven facial animation has been researched much during the past decade (e.g., References [
20,
21,
22]). For human-like behavior of talking head, all facial displays need to be accurately simulated in synchrony with speech. Most efforts, so far, have focused on the synchronization of lip and tongue movements, since those movements are necessary in order to have speech intelligibility.
As for voice synthesis, it is worth noting that in Humanoid robotics is very important, if not necessary, to produce speech using a mechanical speaking head for the reason we describe briefly. The motivation of the mechanical development of the speaking robot, as described in Reference [
23], may be to conduct research on the vocal motor brain control system and to create a dynamic mechanical model for reproducing human language. In addition to telecommunications applications, medical training devices and learning devices mentioned in Reference [
23], we believe that a mechanical head derived from articulate features can ultimately lead to a robotic mechanical face with natural behavior. It is known, in fact, that there is a very high correlation between the dynamic of the vocal tract and the behavior of the facial movement, as emphasized by Yehia et al. in Reference [
24]. This was used in Reference [
25] to develop the natural animation of a talking head. In addition, as regards the talking mechanical robot, if a mechanical vocal stretch is embedded in an artificial head that emulates a human head, the artificial head should have natural movements during the production of speech spoken by the robot, provided that the artificial head is tied to the articulators by means of a kind of elastic joint.
In any case, the mechanical vocal tract must be dynamically controlled to produce a speech language, since human speech requires transitions between phonemes. This requires sufficient knowledge of the complex relationships that govern human vocalization. So far, however, no enough research has been carried out on the brain control system, so the production of the words is not yet perfectly comprehensible [
26]. This type of knowledge relates to the articulation synthesis of voice, which describes how to generate a word from a given movement of articulators (articulation trajectory). By exploiting our current knowledge, we developed fuzzy rules that link the places of articulation with corresponding acoustic parameters. The degrees of membership of the places of articulation are adapted to those of the human being who trained the system.
The purpose of this study is to build a robot that acquires a vocalization capability similar to human language development. In this paper, we consider a human-robot interaction scenario in which the robot has a humanoid speaking head. This does not necessarily mean a robotic head; in fact, we considered a software speaking head, which is a graphically image drawn on the computer screen. In addition to the obvious differences between these two alternatives, the common part is that the same articulation model should be developed in both cases. This model is responsible for estimating articulate parameters from natural language.
Our original contribution is a new articulation model based on automatic learning. The algorithm attempts to reproduce a voice signal by optimizing an articulator synthesizer and, in this way, learns the articulator characteristics of the speaker who trained the system. The idea is inspired by the theory of the
mirror neurons that there are neurons in the human brain, linked to the control of human articulators, which are activated after listening to vocal stimuli [
27,
28]. This means that human perception of speech is related to its generation. Our system can produce an artificial utterance from arbitrary written text imitating the articulation characteristics of a given speaker.
The articulators movements estimated by speech could be used to control a mechanical speaking head or, as in our case, a talking head drawn on a monitor placed on a service robot. Compared to other works on acoustic and articulation mapping, we present a method to estimate the places of articulation of an input voice through a new computational model of human vocalization. The result is that accurate articulation movements are estimated from those of the human who trained the system. The ability to produce individualized facial communication is becoming more important in modern user-computer interfaces, for example in virtual storyboards used for remote conferences. However, the proposed system does not imitate the whole face of the trainer, but only the face movements, due to movements of the articulatory organs that the trainer uses to pronounce vocal sentences. In our model implementation, only the rules for Italian phonemes have been considered. This does not limit the generality of the method—if other languages are considered, new fuzzy rules must be added. We remark that we automatically extract the fuzzy rules with a genetic programming algorithm.
1.3. Goals of Our Research
This paper describes an algorithm that automatically learns how to generate artificial voice by reproducing human voice through articulation synthesis and an optimization scheme. Our algorithm is therefore suitable for giving vocalization capabilities to talking robots by imitating the human learning process. With “vocalization ability” we refer not only to the generation of artificial voice, but also to the facial movements that accompany the generation. The algorithm requires that a human operator, as a caregiver, read a list of words aloud. The spoken words, analyzed at an acoustical and articulatory level, are automatically divided into pre-defined speech units and a knowledge base of such units is automatically built. Therefore, the algorithm can generate vocalizations from unrestricted text by concatenating the basic speech units.
Other systems to generate artificial speech together with the related facial movements have been published (e.g., References [
20,
21,
22]). Our algorithm, however, automatically generates artificial speech using the places of articulation estimated during a training phase. Optimization is realized using a genetic algorithm, on the basis of the similarity of the synthetic utterance with the original speech. In this work we estimate the face movements from the optimized degrees of membership of the places of articulation.In fact, there is a strong structural link between places of articulation and facial behavior during vocalization. The facial movements obtained were used to move a virtual face naturally during vocalization. It is worth noting that both artificial expressions and facial movements seem to clone that of the human operator who served as a virtual face caregiver, thus giving the opportunity to personalize the virtual head. It is important to note that we implemented the training phase on a GPU device so that the training phase is very fast. Time needed for training is only a few tenths of minutes needed to read a list of words.
A general model of verbal/facial communication is shown in
Figure 2. By adapting the
Figure 2 to our talking head, the concept and message generation refer to a cognitive level, and the phonatory control refer to the vocalization level we are describing in this paper. We propose a novel design of a vocalization module which is the module that converts a written message into artificial speech and facial movement. Therefore, the issues we describe here are the following:
articulatory vocalization of unrestricted text;
generation of facial movement;
synchronization of artificial speech with facial movements.
In talking head the articulatory configuration during vocalization is fundamental, because it could be used to control a mechanical talking face, such as described in Reference [
29].
Our algorithm is similar to the process of human language acquisition. Indeed, in the early days of life, human infants try to imitate the speech they heard; this process is recognized as a language acquisition process driven by a mirror neuron system [
30]. Similarly, our algorithm acquires vocalization through interaction with a human. It is important to note that it is not necessary to produce high quality artificial speech. Since our speech is used in a similarity comparison process, only low quality, yet intelligible speech, is enough. For this reason we use the simplest approach for artificial speech generation, that is the concatenation approach [
31]. A number of basic vocal units is defined, and a base of knowledge of articulatory and acoustic parameters for their generation is built. Training iterates as long as the knowledge base is not full. The acoustic parameters and corresponding articulators are obtained with the fuzzy-genetic articulation model proposed in Reference [
32], whose parameters are optimized to produce a language similar to that of a human user. In addition to guiding the synthesis of artificial language, knowledge of articulate movements is critical to providing facial movements since an important link between the movements of the internal organs of the vocal tract and the facial movements has been recognized by many researchers [
33,
34]. An important characteristic of our algorithm is that a perfect synchronization of facial movement with artificial utterances is obtained.
1.4. Paper’s Contributions
In this paper, we provide the following contributions:
an effective and efficient genetic-fuzzy algorithm for supporting automatic vocalization acquisition from a human tutor, by delivering artificial speech and facial movements (both synchronized);
a comprehensive review of state-of-the-art proposals in the related scientific area;
an extensive experimental evaluation of the proposed algorithm where we stress quantitative and qualitative parameters.
1.5. Paper Organization
The structure of this paper is the following. In
Section 4, a brief overview of our proposed algorithm is provided.
Section 2 deeply presents and discusses research that is relevant for our work. In
Section 3, some preliminary considerations on speech synthesis are outlined. In
Section 5, we provide the fuzzy-genetic articulatory model that is at the basis of our proposed algorithm.
Section 6 reports on our proposed algorithm, which is the main result of our research.
Section 7 describes some further optimizations we developed in order to further improve the effectiveness and the efficiency of our proposed algorithm. In
Section 8, we discuss a possible exploitation of our proposed algorithm, which concerns with the control of talking heads.
Section 9 describes our comprehensive experimental campaign along with derived results. Finally, in
Section 10 we provide final comments and future work for our research.
2. Related Work
In this Section, we briefly describe some previous research that is related to our work.
The research activities carried out in the last few years for the face-to-face communication between humans and humanoid robots, as reported in Reference [
35], also involved the creation of mechanically speaking heads, as we shall describe below.
At Waseda University, several prototypes for producing Japanese vowels and some consonant sounds, called WT-3, WT-2 and WT-1R, have been developed. WT-1R [
36] has articulators (tongue, lips, teeth, nasal cavities and soft palates) and vocal organs (lungs and vocal cords). It can reproduce the human voice movement and has 15 degrees of freedom. The vocal movement of the WT-1R for vocals is constant. However, consonant sounds are produced by dynamic movements of the vocal tract, to generate transitions of resonant frequencies (formant frequencies). Therefore, since Japanese voice generally consists of two phonemes, where the first is a consonant sound and the last a vowel, researchers at Waseda University have proposed considering the concatenation of three types of sounds (constant consonant sound, transient and vocal consonant sound). WT-2 [
37] is an improvement of WT-1R; has lungs, vocal cords, vocal cavity and nasal cavity and aims to reproduce the vocal trait of an adult male. WT-3 [
26] is based on human acoustic theory for the reproduction of human language; it consists of lungs, vocal cords and articulators and it can reproduce human-like articulation movements. The oral cavity was designed based on the MRI images of a human sagittal plan.
At the Kagawa University, a mechanical model of the human vocal apparatus was developed [
38] using mechatronics technology. It implements a neural network mapping between the motor positions and the voice sound produced by auditory feedback in the learning phase.
In Bib:Asada the mechanical vocal tract is excited by a mechanical vibrator that oscillates at certain frequencies and acts as an artificial larynx. The shape of the vocal tract is controlled by a neural network.
However, the development of an anthropomorphic mechanical speaking robot is very difficult as shown in References [
18,
38]. On the other hand, graphic representations of human talking heads have been developed since many years. Generally, these graphics systems are connected to a speech synthesizer that plays a signal synchronized with the facial movements. Many solutions to this synchronization problem have been proposed since now. However, very few of them go through the articulatory movements of the phonatory organs.
In addition to controlling the mechanical phonemic organ of a mechanical speaking head, knowledge of articulating movements is essential to drive the movements of the face. In fact, many researchers have experimentally demonstrated that there is an important link between the movements of the internal organs of the vocal tract and the facial movements.
Similar to the approach proposed in this document, Nishikawa et al. [
23,
26] developed an algorithm that estimates articulator parameters using Newton’s optimization.
H. Kanda et al., describe a computational model that explains the development process of human infants in the first acquisition period of the language [
39]. The model is based on recurrent neural networks.
Sargin et al., propose a joint analysis of the prosody and head movements to generate natural movements [
40].
Albrecht et al., introduce a method to add nonverbal communication to the talking head. This communication is realized by automatic generation of different facial expressions from the prosodic parameters extracted from the voice [
41].
The SyncFace [
42] system uses articulation-oriented parameters to recreate the visible articulation of a talking head during phonation.
The systems described so far require a pre-processing step. Real-time facial animation is described in Reference [
43].
Further Comparison with Mechanical-Aware Approaches
Some researchers address the problem of vocalization from a mechanical point of view, for example, Reference [
26]. They try to realize a mechanical replication of the human vocal tract, of the larynx and tongue. In addition, they develop various open and closed loop algorithms to control the movements of the mechanical organs for the production of artificial words. For example, in closed loop strategy, voice control parameters extraction is optimized by minimizing the distance between the original and the generated voice. Our work is similar to the work described in References [
23,
26] in the sense that we estimate from the input voice the articulating movements using a closed loop strategy. These parameters are then used to generate artificial replicas of the input statements on the one hand and to control the artificial phonatory organs on the other. The algorithm uses the fuzzy tone pattern introduced in Reference [
32]. However, we must note that this paper represents a breakthrough point compared to the algorithms described in Reference [
32]. The main points of improvement, which are the contributions of this paper, are as follows:
while the rules in Reference [
32] refer to the Italian language, the rules developed in this paper use the International Phonetic Alphabet (IPA) [
44] thus enabling the system to be extended to other languages;
while in Reference [
32] we use single words and short phrases, in this paper we describe a system that produces unrestricted vocalizations;
while in References [
32,
45] we control only four points around the lip, that is four face muscles to produce facial movements, in this paper we extend the number of controlled muscles to the left and right cheek, thus leading to better facial movements;
the algorithm described here uses the average pitch extracted from the tutor as the basis of the artificial prosody;
finally, we include in this paper extensive subjective evaluations of the proposed system that were impossible to execute earlier.
Vocalization of unrestricted text is performed by acquiring, at an initial stage of training, a database of basic voice units appropriately defined. The acquisition is performed automatically using the speech of a human tutor. The tutor is asked to pronounce a number of statements that are analyzed and automatically segmented into the defined small units. A database is then created and the desired vocalization is obtained by concatenating the basic vocal units.
3. Preliminaries
In this Section, we describe and discuss some preliminary considerations that are founding our research.
In this work, we generate synthetic speech with the well known Cascade-Parallel formant synthesizer [
46]. The synthesizer is driven by the following minimum set of eight acoustic parameters:
, namely the amplitudes for voicing and frication, three formant frequencies with the respective bands. It is well known that this is a quite old yet very simple approach to produce artificial speech. Indeed, the speech obtained in this way does not sound natural but rather, it is perceived as highly robotic.
The talking head produces artificial speech from unrestricted text. One of the first attempts to generate speech from arbitrary text is synthesis from concatenation approach [
47], where sets of basic speech units are defined. Each speech unit contains at least a transition between phonemes (diphone).
In conclusion, our unrestricted text is generated by diphone concatenation where each diphone (transition) is modeled with the minimum set of eight acoustic parameters. The motivation of this simple approach is that, as regards the small number of parameters which drive the synthesizer to produce transitions, the small number of acoustic parameters simplify the fuzzy rule development process. As regards the diphone concatenation approach, by concatenation of basic speech units, the motivation is that that the goal of this work is not to produce good artificial speech but to estimate good articulatory parameters, and concatenated speech is enough for that purpose.
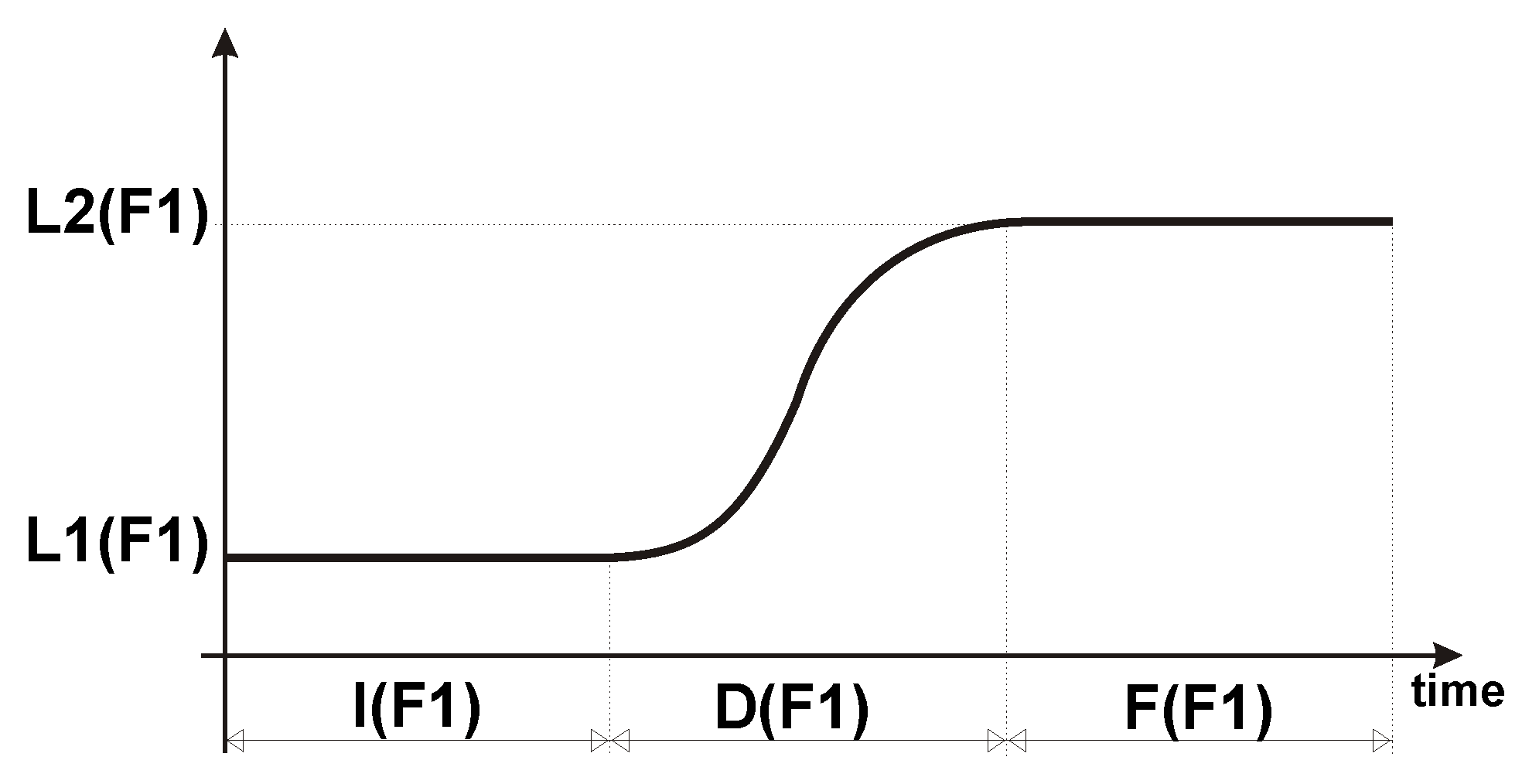
In
Figure 3 we show an example of transition of the first formant frequency between the two phonemes in a speech unit. For simplicity, each of the speech units we selected contain a single transition, thus leading to the minimum set of speech units for speech generation. In our set, we consider consonant-vowel and vowel-consonant transitions, affricate-vowel and vowel-affricate transitions and dipthongs transitions. The total number of basic speech units is 192, namely 140 consonant-vowel transitions and viceversa, 20 affricate-vowels transition and viceversa, 10 vowel-silence transitions and viceversa, 8 dipthongs, that is, vowel-vowel transitions and 14 transitions between silence and a consonant.
As shown in
Figure 3, any transition is described by the
Initial, Duration, Final and
Locus values, we call
.
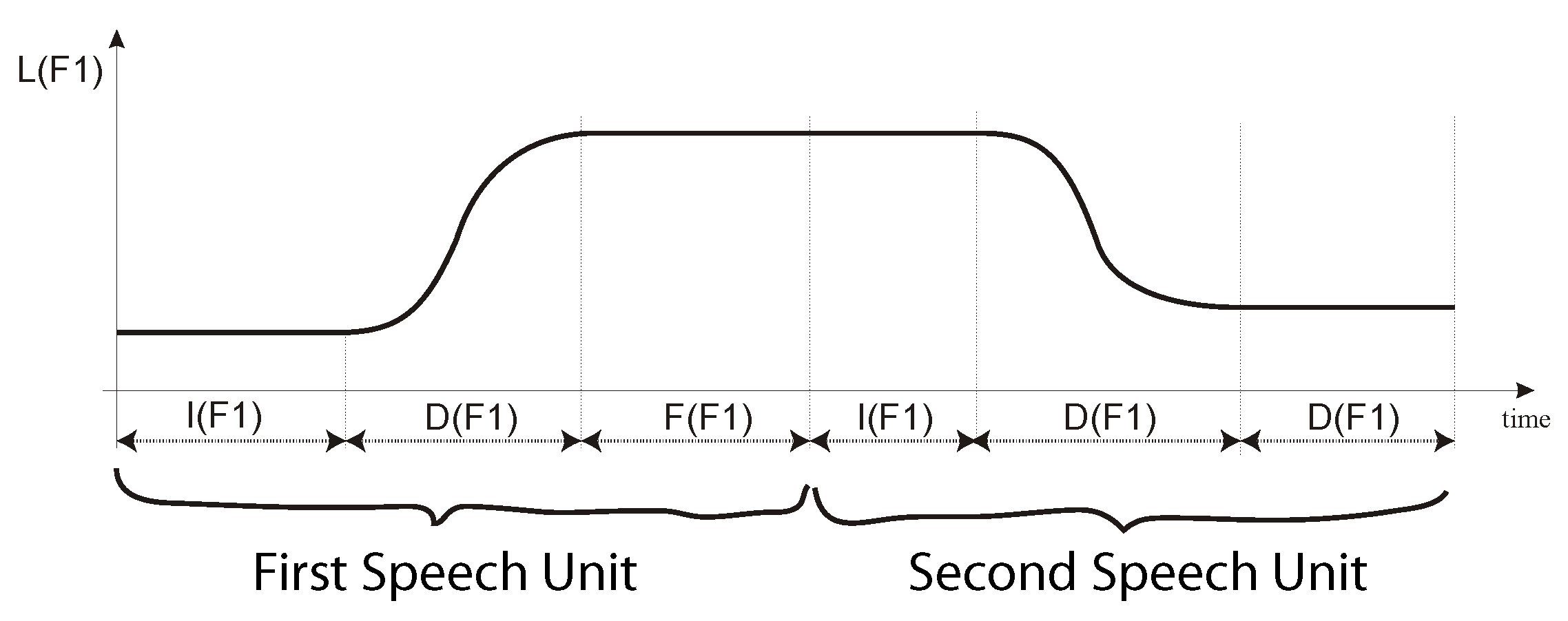
Using the
parameters, the transitions can be easily concatenated. An example of concatenation of two trajectories is shown in
Figure 4.
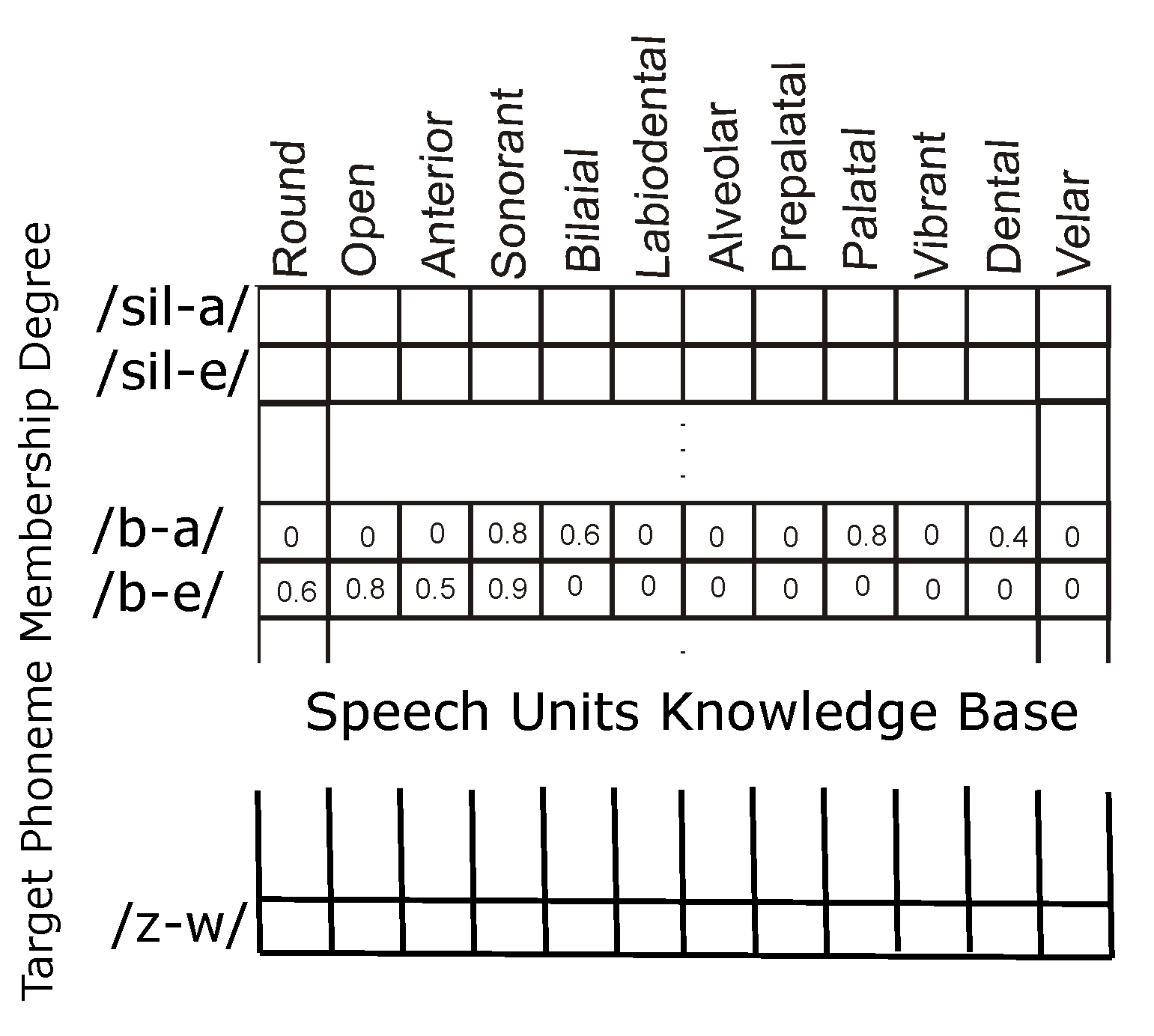
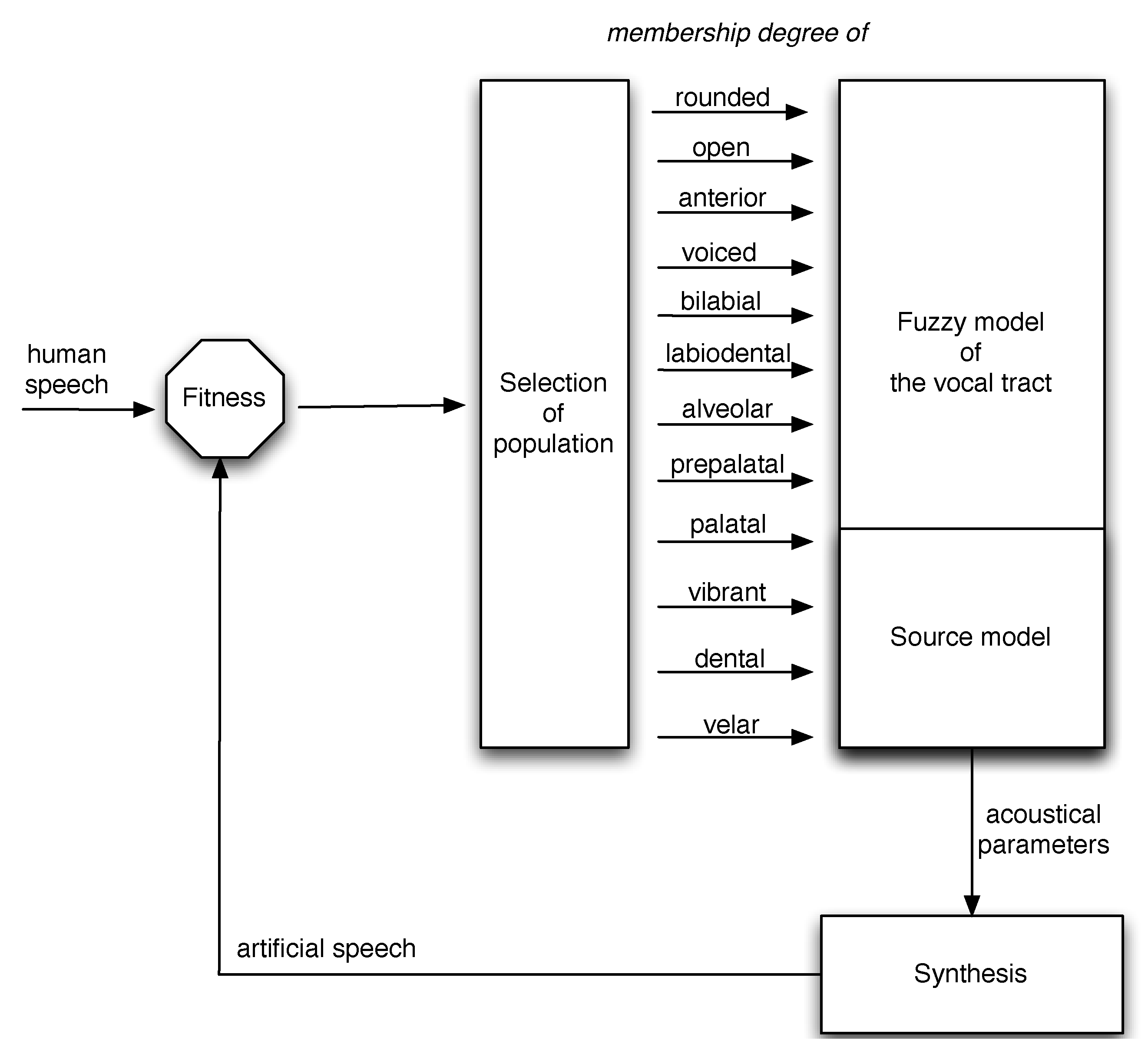
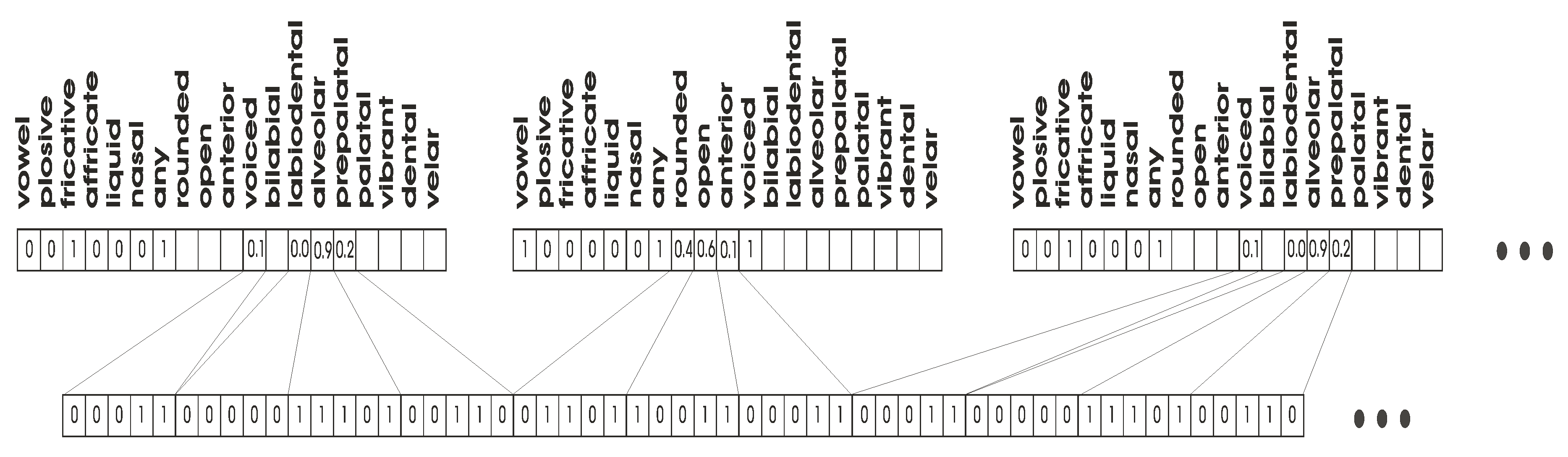
Along with the acoustic parameters that are used to synthesize the signal, we also store in the knowledge base the corresponding articulation configurations. The acoustic parameters are the transitions of formants and amplitudes (i.e., ). We considered the following twelve places of articulation: (rounded, open, front, voiced, bilabial, labiodental, alveolar, prepalatal, palatal, vibrant, dental, velar).
Articulatory parameters are the genetically optimized degrees of membership of the places of articulation. The knowledge base of articulatory parameters is reported in
Figure 5. Therefore, the knowledge base describes the membership values of all the possible transitions in the selected language for the operator who acts as trainer. Please note that the symbol
Sil means silence (therefore
/Sil-a/ is an initial part of a sentence starting with the
/a/ vowel). Moreover, note that the symbols on the vertical axis are selected from the IPA alphabet.
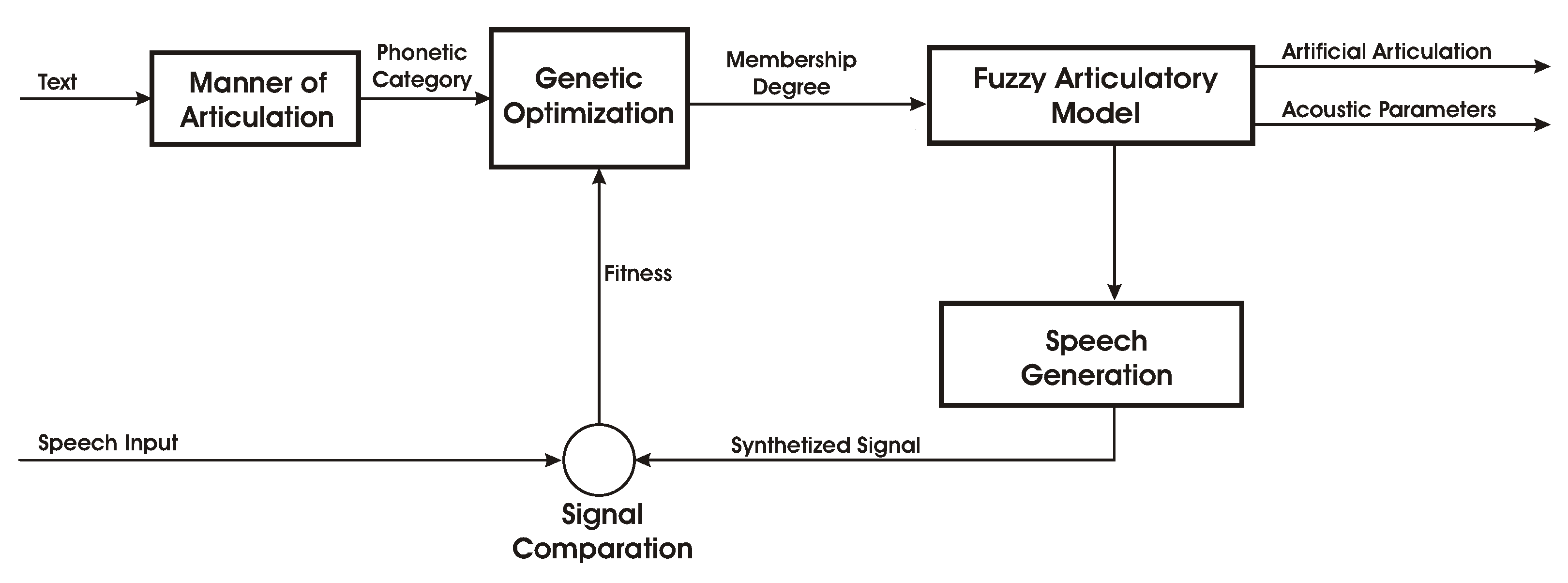
4. Algorithm Overview
Our proposed algorithm is reported in
Figure 6.
The proposed algorithm is divided into a first training phase and a second phase of facial movements generation. In the training phase (see
Figure 7), the algorithm automatically learns the acoustic and articulation characteristics of the basic vocal units from the tutor’s voice. At the end of this phase, a knowledge base is produced. In the second phase, the algorithm uses the knowledge base to generate speech and face movements. We note that the training phase should be done once for each different trainer. Of course, if you do not want to personalize facial movements, just consider a standard speaker.
It should be noted that, in this paper, we refer to the fuzzy rules defined for the Italian language. However, extension to other languages is simplified because we use IPA to build fuzzy rules.
As explained above, the knowledge base describes the membership degrees of the basic vocal units which are automatically extracted from the set of words spoken aloud in the training phase. Each vocal unit contains a transition between phonemes. Each vocal unit is stored along with its contextual information, that is, the previous and subsequent phonemes. This information is used in the concatenation phase to choose the segment that best suits the actual phonetic environment of the unit.
Under a more general umbrella, the final goal of our work is to learn automatically the place of articulation of spoken phonemes in such a way that the robot learns how to speak through articulation movements, and, indeed,
Figure 6 can be seen as the block diagram a the system for adaptive learning of human vocalization.
We now include some basis considerations to further clarify the optimization process, which is central in our work. According to the classical Distinctive Feature Theory [
48], phonemes are described in terms of
Manner of articulation and
Place of articulation, both described in binary form. The former is related to the constraints imposed to the air flow in the vocal tract while the latter refers to the point where the constraint is located. We consider the following six categories of manner of articulation:
vowel,
liquid,
nasal for the sonorant sounds, and
fricative,
affricate,
stops for obstruent sounds. In the sonorants sounds, the air flows without any obstruction or under moderated obstruction represented by the tongue or the velum. Obstruent sounds are generated under tight or complete closure in the vocal tract represented by tongue or lips. The purpose of the genetic algorithm is to find the degrees of membership of the places of articulation that optimize the similarity between input and artificial voice. Our assumption is that the optimum degrees of membership are related to the physical configuration of the human phonatory organs. For example, if we found that a phoneme is an open vowel with a membership degree of openness of 0.6, we assume that the mouth is open at a level of 60% of its maximum opening size. If a vowel has a membership degree of roundness 0.8, we set the amount of the amount of lip rounding to 80%. This assumption can be verified indirectly by the quality of the obtained results, reported in
Section 9.4.
The optimization scheme is shown in
Figure 6 The first left block, that is, the “manner of articulation” block, is fed by the text corresponding to the sentence pronounced by the operator. This block evaluates the manner of articulation of the phonemes in the sentence. For example, if the word is “nove” in Italian (“nine” in English), the manners are: nasal, vocal, fricative, vocal. This information is used to construct the chromosome and to select the correct rules from the fuzzy articulation module.
To summarize the objective of the whole system, in order to generate facial movements of a written arbitrary text, we compute first the corresponding articulatory description and we map articulation to facial movements. Articulatory description is obtained through articulatory synthesis of the voice corresponding to the written input text.
In the next sections, we focus on the main components of our proposed algorithm.
5. Fuzzy-Genetic Articulatory Model
We describe here the basis of our algorithm, which is developed upon a fuzzy-genetic articulatory model, proposed in Reference [
32] This model estimates, with a genetic optimization algorithm, the places of articulation membership degrees of a user speech. The parameters are used to produce synthetic speech which is compared to the input signal using a genetic approach. In this paper, the approach has been extended to cover the IPA phonetic symbols rather than the phonetic rules of a particular language, and the mimicking system has been extended to cover unrestricted text.
According to our point of view, however, the place of articulation is characterized in fuzzy form. Each phoneme is described with eighteen variables, six of which are Boolean and represent the manner of articulation while the remaining twelve are fuzzy and represent the place of articulation. Therefore, our phonetic description appears as an extension of the classical Distinctive Feature Theory, because a certain vagueness is introduced in the definition of the place of articulation. For example, with a fuzzy description, an
/a/ phoneme can be represented as:
which means that
is a is vowel with a frontness of
, an openness of
and a roundness of
.
It is important to remark that:
All the fuzzy sets for acoustic parameters have trapezoidal shape and are defined as follows: L1 (Initial locus), I (Initial range), D (Duration), F (Final interval), L2 (Final position). The values are divided in High, Medium, Low.
The estimation of degrees of membership of the places of articulation is made when the manner of articulation of an utterance is known, because the fuzzy rules are structured in banks. The easier way to perform manner of articulation estimation is from the text of the input utterance. However, this is not a limit because normally the estimation of facial movements, which is the goal of our algorithm, is needed to move talking heads during text to speech translation.
Since the degrees of membership of the places of articulation depend from the phonetic context, their optimal estimation should be performed in real time. This would require an excessive computational power. Our approximated but feasible approach is to estimate the degrees of membership once for a given phonetic context and a given speaker, stored in the knowledge base and used in any context and for any speaker.
As regards the fuzzy rules, consider for example the following consonants: /p/, /t/. According to IPA, they are described as voiceless, bilabial, plosive and voiceless, alveolar, plosive respectively. Calling textit p0 and textit p1 respectively the first and second phonemes, some of the fuzzy rules involved in generating the acoustic parameters for the generation of the transitions , where are vowels, are the following:
if p0 is plosive and p1 is voiced then
L1(AH) is high;
I(AH) is medium;
D(AH) is low;
F(AH) is low;
if p0 is plosive and p1 is open then
L2(F1) is medium
if p0 is alveolar and p1 is voiced then
L1(F1) is medium;
L1(F2) is medium;
L1(F3) is medium;
if p0 is alveolar and p1 is open then
L1(F1) is low;
L1(F2) is low;
L2(F3) is low;
Clearly, the goal of these fuzzy rules is to generate the transitions of the acoustic parameters that generate the correct transition. The rule decoding process is performed by a de-fuzzification operation with the fuzzy centroid approach.
Another example is a transition of a vowel towards a vowel. In this case, the opening and the anteriority of the target phoneme determine the values of the first three formants. This knowledge can be formalized as follows:
if p0 is voiced and p1 is open then
L2(F1) is medium;
if p0 is voiced and p1 is anterior then
L2(F2) is medium high;
if p0 is voiced and p1 is notAnterior then
L2(F2) is low;
if p0 is voiced and p1 is Round then
L2(F3) is low;
if p0 is voiced and p1 is notRound then
L2(F3) is medium;
Such rules can be automatically determined with genetic programming for any language, provided that a good speaker in the selected language is available as tutor. We note, however, that automatic generation of fuzzy rules is not included in this paper, and thus we assume in in this paper that the fuzzy rules are available in advance. On the other hand, the genetic optimization considered in this paper aims at computing the values of the degrees of membership for the articulatory features which minimize the distance from the input signal.
The fitness used in our genetic algorithm is based on the computation of an objective distance between original and artificial sentences [
49]. The objective measure transforms the original and artificial voice sentences into a representation which is linked to the audio psycho-physical perception in the human auditory system. This measure predicts the subjective quality of the artificial signal. The measure requires alignment between the two signals, which is performed with DTW [
50], where the slope described in Reference [
51] is used. The accumulated distance
D along the non linear mapping between the two signals is the distance between the original and synthetic utterances, we call in the following
X and
Y respectively. Clearly the genetic algorithm tries to minimize the distance
. Thus, the algorithm fitness function used for the genetic optimization of the Place of Articulation
(PA) is:
The genetic optimization algorithm finds the membership values of the fuzzy variables thay maximize the fittness, namely
,
,
. The estimation problem can be viewed as an
inverse articulatory problem, where articulatory configurations are estimated from speech. it is well known that this problem has many solutions. Hence, during otimization some constraints are imposed, as the impossibility that a plosive phoneme be simultaneously dental and velar, or that voiced consonants be completely voiced. The constraints are penalty factors added to the fittness. Calling
the penalty factors and
the number of constraints, the optimization problem can be formalized as described in Equation (
2).
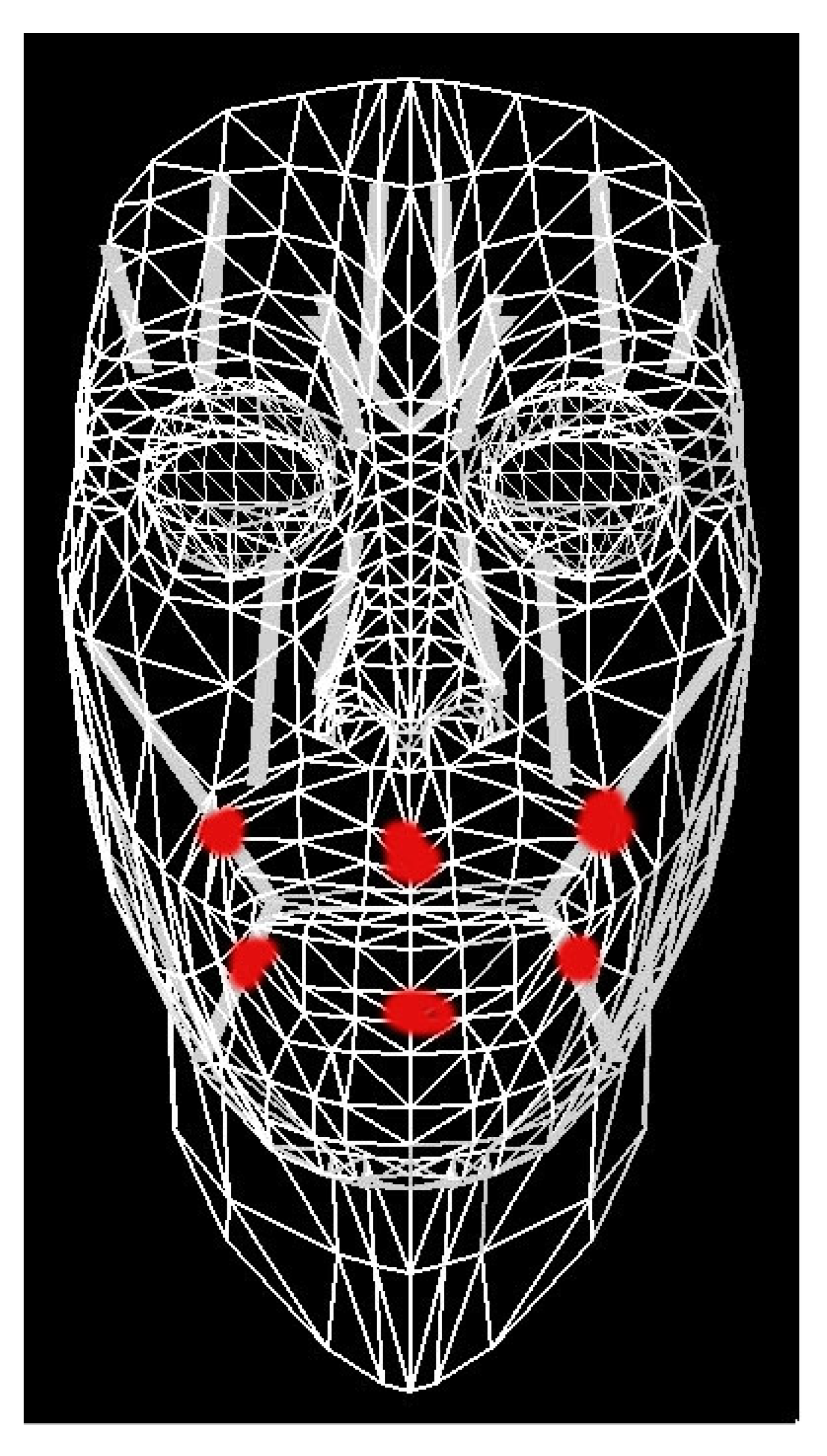
As regards facial movements, we have selected a set of muscles in a virtual face, as shown in
Figure 8.
The muscles can move the upper and lower lips, the lateral facial movements and the mouth movements. We realize a link between articulatory positions and these muscle, automatic synchronization between facial movements and artificial speech is automatically obtained, since artificial speech is obtained with articulator synthesis.
Note that the facial movements are estimated by the speech signal acquired by the tutor. The corresponding facial movements are related to the physical emissions of the utterances and do not include any particular facial expressions or feeling.
6. An Innovative Automatic Learning Algorithm for Supporting Advanced Human-Machine Interfaces
In this section, we focus on the description of the human-machine interface of the algorithm proposed in this paper. These aspects are very relevant in practical applications and this algorithm provides a decisive contribution to this in advanced interface with respect to state of the art.
In addition to producing artificial voice from a written text, our algorithm also produces facial movements by estimating articulator parameters from the entry voice.
6.1. Training Phase
During an initial phase, the membership levels of articulator parameters for the speaker who trains the system are derived. Using the membership degrees along with the fuzzy rules, the acoustic parameters are generated to generate the artificial signal. Membership degrees are stored in the knowledge base. From an operational point of view, the initial phase is realized by making the human operator say a series of words that are presented to him.
The genetic optimization module estimates, using the fuzzy set of rules, the
values of the acoustic parameters used to generate artificial speech by concatenation of the basic speech unit contained in each word. The list of words to pronounce cover the whole of the basic vocal units. These parameters are used to fill the basic vocal unit knowledge base shown in
Figure 5. which describes the estimates degrees of membership of related articulator parameters used of the phonation organs on one side and the parameters for facial control on the other side.
6.2. Synthesis Phase
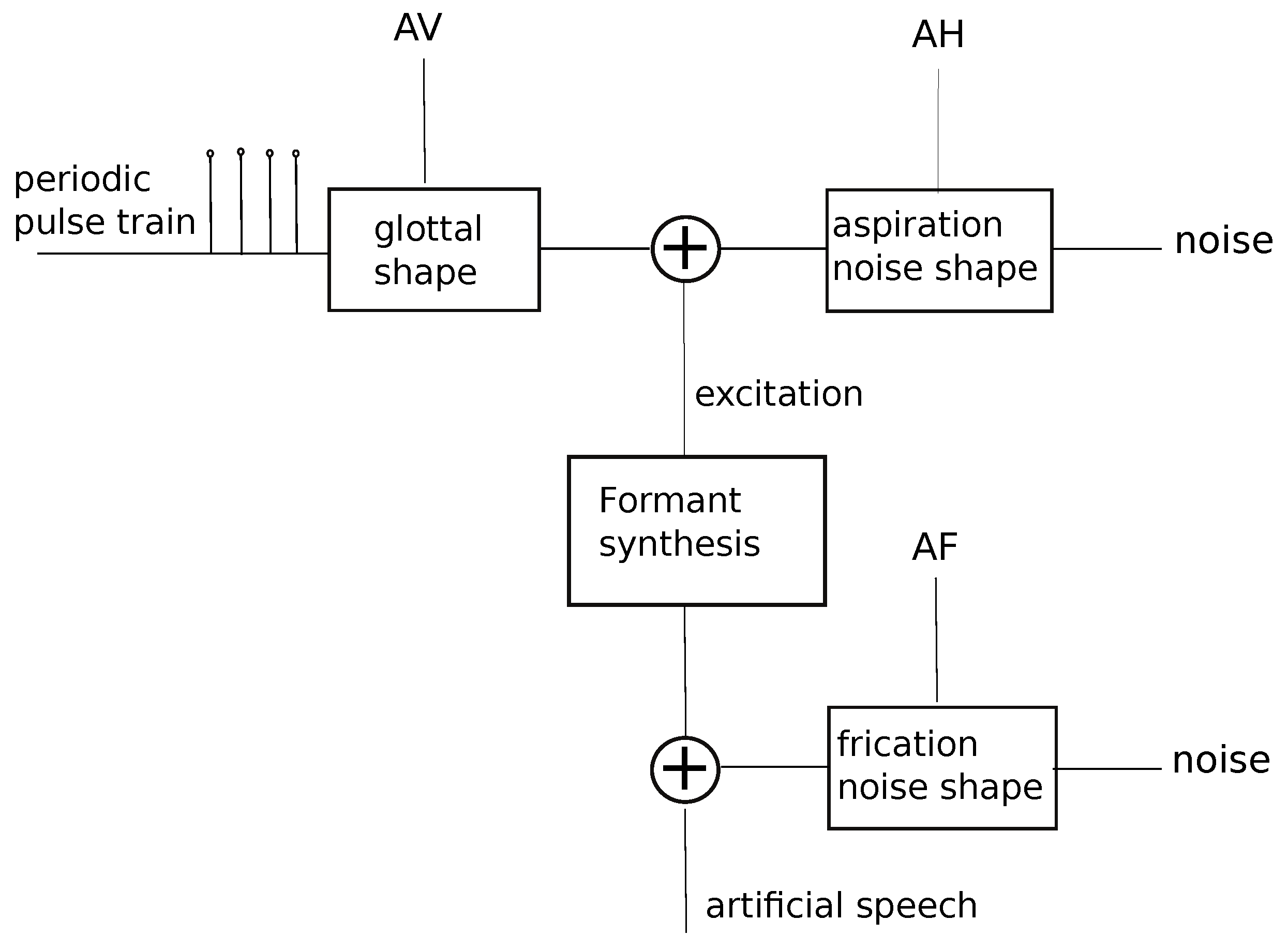
The input of the synthesis module is the text to be converted into an artificial voice by concatenating simple elementary vocal units. Using the stored membership degrees, the parameters
are obtained from the fuzzy rules and the overall path of acoustic parameters related to the artificial phrase is constructed by concatenation. From this trajectory, artificial voice is generated by synthesis for formants. To ensure greater voice naturalness, the excitation sequence is generated by adding a fricative noise to the model proposed in Reference [
52], as shown in
Figure 9.
It is well known that one of the possibilities to improve the quality of the synthetic signal by diphone concatenation is to acquire a large database of basic units, from different phonetic contexts. During synthesis, it is be possible to search for the best units, according to speech quality criteria. The goal of our algorithm is to estimate good facial movements corresponding to a synthetic speech through articulatory analysis. To this goal it is not important to achieve high speech quality, therefore we use the smallest possible dataset of speech units.
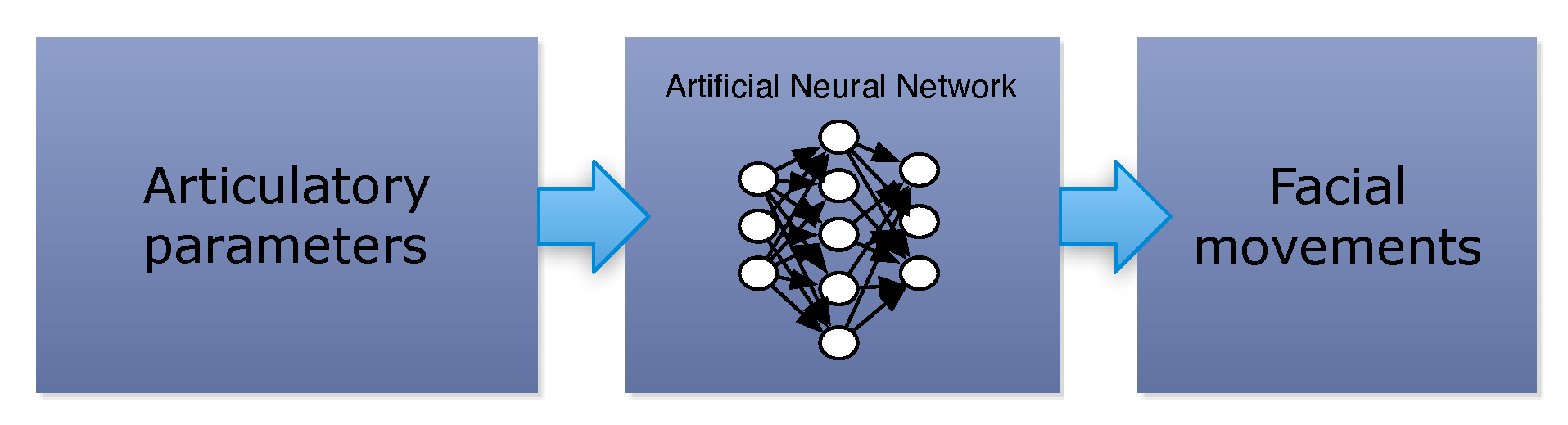
6.3. Articulatory to Facial Movements Mapping
It is known that facial movements during phonation are linked to articulation movements as shown by many authors, for example, Reference [
24]. It is commonly believed that most of the correlation between facial movements and articulators can be expressed by linear transformation. Actual measurement of articulator movements and the corresponding articulation movements it is possible but can be problematic; so we used the MOCHA-TIMIT [
53] database containing articulator and facial parameters for English phonemes. The MOCHA-TIMIT database collects data using Electro Palathograph (EPG) and Electromagnetic Articulograph (EMA). The algorithm presented in this paper, at the time, uses the Italian language. Extending fuzzy rules to English is under development; for this reason, we used the available database beforehand. We have carefully selected a subset of MOCHA-TIMIT phonemes that are similar in both languages. This because, in our work, we have developed the fuzzy rules for Italian.
Because our fuzzy-genetic optimization estimates the articulator parameters of a spoken word, a mapping between articulator and facial parameters is required to obtain the corresponding facial movements. To make this mapping, unlike what is proposed in Reference [
24], we trained a simple feedforward multilayer neural network. The network describes a nonlinear mapping (
Figure 10) between articulatory and facial movements, as described in Reference [
54].
For supervised training, we give as input to the network the articulatory parameters vector produced by the fuzzy-genetic module and as output the corresponding facial positions vector derived by the MOCHA-TIMIT database. With our fuzzy genetic algorithm we have obtained, for any given phoneme in the input sentence, several input vectors and from the MOCHA-TIMIT database the corresponding desired output vector . Training is performed with Levenberg-Marquard algorithm with input/output parameters are extracted from 460 sentence.
The output vector is applied to the Geoface model implemented by Keith Waters [
55] shown in
Figure 11. The model employs a large number of polygons for modeling the whole face. The vector is applied to the coordinates of the corresponding textures of the model.
7. Genetic Optimization of Articulatory and Acoustic Parameters
In this Section, we discuss some optimizations that are oriented to magnify effectiveness and efficiency of our proposed algorithm.
Our Genetic optimization algorithm, described in
Figure 6, aims at computing the optimum values of the degrees of membership for the articulatory features used to generate an artificial replica of the input signal.
7.1. Genetic Optimization Module
The optimal membership degrees of the articulatory places minimize the distance of artificial speech from the input speech; the text of input speech is given at input. From it, phonemes classification in terms of manner of articulation is performed.
Variables coding is a fundamental part of any genetic algorithm.We used five bits for coding the fractional part of the degrees of membership. A chromosome is built by concatenation of the binary coding of all the degrees to be optimized. in
Figure 12 we report an example of the chromosome for the optimization of the degrees of membership in case of three phonemes.
During genetic optimization this binary string is modidified using mutations, that is, by randomly changing each bit of the chromosome with a constant mutation rate equal to 2%.
7.2. Fitness Computation and Articulatory Constraints
Another fundamental aspect of this algorithm is fitness calculation, which is indicated by the large circle in
Figure 6. The similarity between the original and the artificial voice is the optimized fitness of the genetic algorithm. To represent this similarity, the spectral distortion based on the Bark scale (MBSD) derived from Reference [
56] has been used. The MBSD measure is based on a psycho-acoustic term related to the intensity of the auditory sensation. In addition, we considered an estimate of the threshold of noise masking. This measure is used to estimate the similarity between the artificial voice signal generated by our algorithm with respect to the original signal.
More in detail, the original and artificial phrases are first aligned with DTW [
50] and then divide into frames. Between the frames, the mean Euclidean distance between the spectral carriers obtained by Bark scale filters is then calculated.
In conclusion, the optimization problem with our algorithm can be formalized as follows:
where AP is the membership degrees of the articulatory parameters,
is the number of constraints and
are the penalties.
8. Possible Exploitation: Towards Control of Talking Heads
In this Section, we discuss some possible exploitation of the proposed algorithm.
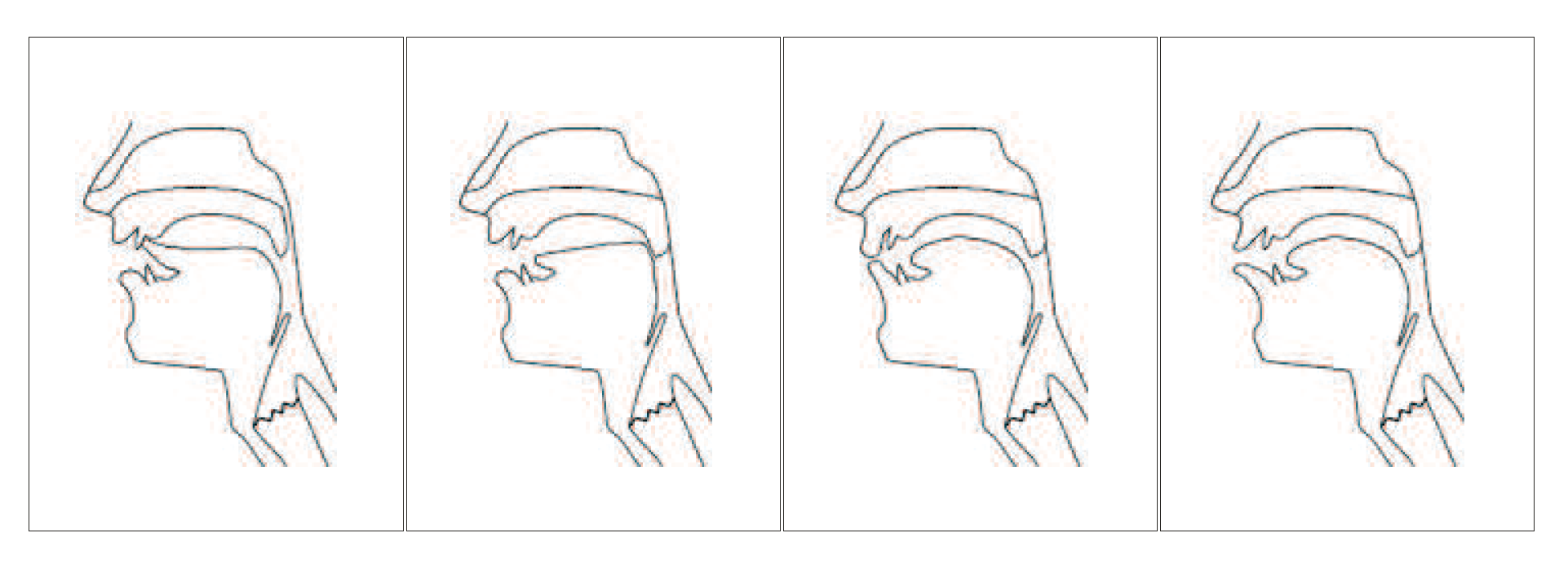
The articulation trajectories, estimated by the algorithm, are transformed into facial parameter trajectories for controlling the movements of an animated head while vocalizing. As a preliminary step towards this goal, and to verify the correctness of the algorithm, we animated a mid-sagittal section of a human head using the descriptive procedure. Note that animation movements are automatically synchronized with the artificial vocalization produced..
In
Figure 13a sequence of four frames of the animation of a mid-sagittal section of a human head related to the phonemes
is reported.
9. Experimental Assessment and Analysis
This section contains the description of our complete experimental campaign together with the derived results. In particular, our experiments have been designed and developed to evaluate the true quality of synthetic discourse.
9.1. Experimental Method
It is worth recalling that the purpose of our algorithm is to generate facial movements during phonation for natural man-machine communication. To this end, we first estimate articulatory movements from spoken speech using our
optimization algorithm and then we transform the articulatory parameters into facial movements parameters. Many authors, for example Jintao Jiang et al. [
57] have shown in fact that there exists a strong relation between articulatory and facial movements. Facial parameters are finally used to move the points corresponding to the involved facial muscles in a Geoface-articulated bone model. To measure the goodness of the generated facial movements we firstly test the quality of the synthesized speech in order to be sure that it is sufficient for supporting the subsequent optimization algorithm and then the quality of facial movements. As a matter of fact fact, the better the voice generated, the better the facial movements. The test of the generated speech is carried out with objective and subjective tests. We first test the objective quality of the generated formant transitions, which must be quite close to those extracted from the spoken voice. Then, the naturalness, quality and synchronization between facial movements and artificial vocalization are assessed with subjective experiments.
Clearly, the synthetic speech is not confused with naturally spoken speech, whose intelligibility mainly depends on its SNR. Many authors pointed out that since the perception of spoken speech is normally accompanied by face movement, the visual part of speech should be an important perception element [
58]. For this reason, graphical talking heads synchronized with synthetic speech has been developed [
59]. Subsequently, the perceptual benefits of the visual speech have been experimentally highlighted. We developed a talking head too, and in this section its performance over existing systems is reported.
The decrease of intelligibility or naturalness of synthetic speech can be modeled as a noise component added to the original speech, introducing the concept of
. We use this concept to predict, when not available, results on the benefits of the audio-visual speech over only audio. In this paper, we assume that visual speech is obtained with the viseme-driven approach described in Reference [
60] for all the considered speech synthesizers. In viseme-driven speech animation, each key pose is associated with a viseme, that is the position of the lips, jaw and tongue when producing a particular sound [
61]. In Reference [
60], the results of a subjective test of naturalness of the viseme-driven system are reported. In the test, 36 participants with normal hearing and vision tested individually the visual speech synthesis of a number of words with meaning. The average naturalness was about 0.84. This coefficient was used to weight the audio-visual subjective results of our tests.
9.2. Experiment 1: Analysis of the Transitions Generated by the Fuzzy-Genetic Model
The six phonetic classes considered in our system are the following: , , . Of course there are other classes, but we think that these six classes can be sufficient to cover most of the western languages. In theory, the six classes lead to thirty-six types of transitions between classes, like VO-PL or FR-VO; considering the transitions between phonemes, in theory we have 7560 transitions. However, many of them have been excluded, because or impossible or rarely used, so the resulting number is reduced to one hundred and ninety two (192). For the sake of completeness we report below the list of transitions used in our algorithm, where V stands for vowel and C for consonant.
70 elements /CV/, that is, such as /ba/ or /ka/;
70 elements /VC/, that is, such as /ap/ or /as/;
10 elements /V/, which are transitions between a, such as /t∫a/;
10 elements /V/, which are transitions between a vowel and an affricate;
8 elements /VV/, which are dipthongs;
14 elements /-C/, which represent transitions between silence and a consonant;
5 elements /V-/, which are transition between vowels and silence;
5 elements /-V/, which are transition between vowels and silence.
For each transition the human tutor utters a very short utterance, each containing only one transition. This operation is similar to the Knowledge Base Acquisition (KBA) discussed in
Section 4. The difference from KBA is that in that case the tutor utters a suitable number of longer words containing all the one hundred ninety two transitions. The longer word is then automatically segmented into diphones, so all the diphones are extracted from a phonetic context, so that during synthesis the best diphone is selected.
In this experiment we just test the quality of the phonetic tracks, leaving to the KBA phase the task of acquiring the articulatory data which will be used for generating the articulatory movements. The analysis of the quality of the generated transitions is performed following these five steps:
Generation of the synthetic version of each transition using the algorithm. In this way each transition, say, between the plosive and the vowel , namely the diphone, has a naturally spoken version and a synthetic version .
Phonetic speech alignment of all the segments with the same transition, for instance align
and
or
with
and so on using the DTW algorithm which is simple and efficient for this purpose [
62]. This operation synchronizes the phonetic content of the natural and synthetic segments related to the same transition.
Application of the built-in formant tracker of the
tool [
63], to each segment. The
tracker uses the
algorithm for formant extraction [
64]
Generate the of the second formant tracks by manually inspecting the spectrograms of the one hundred ninty two spoken segments.
Compute the quality measure of the formant trajectories extracted from each diphone, synthetic and natural, by comparing them with the .
The quality measure is defined as follows. First we compute the three errors described in (
4), (
5) and (
6).
where
stands for
and
for
,
N is the length of the alignement transitions, which is the number of tested frequency values,
are the thirst, second and third formant obtained by
and
are the thirst, second and third formant of the
. These three errors describe the mean squared deviations of the formant trajectories computed with the
algorithm from the
. Likewise, other three error measures derive from the comparison of the formant trajectories obtained with the proposed
algorithm from the
.
where
stands for
and
for
.
Each set of three errors must be then combined to obtain the final Mean Squared Errors with weighted sums:
In (
10) and (
11) the indexes
and
, are omitted for simplicity. Of course it should be clear that the
must be used for computing
and the
must be used for computing
. The weights
are computed such that the variances of the weighted sums is minimized [
65]. More precisely, calling
the variance of
,
the variance of
and
the variance of
(note that we omit again the indexes
for simplicity), and under the assumption of statistical independence among the three errors, the variance of
is minimized with
and
The same considerations apply to the minum variance of .
The goal of this comparison is to measure the deviation of
algorithm from the
algorithm. This comparison is reported in
Table 1. In this table, the pair of numbers corresponding to each transition represent the average deviation of
algorithm from the
algorithm respectively.
From
Table 1 we see the
algorithm give costantly very similar results to the
.
In the following we report some graphical examples of , and transitions, precisely the , , and diphones, with spectrograms anf second formant tracks.
Another test is performed on the consistency of the
transitions with the
of formant transitions [
66,
67]. According to the locus theory, the second-formant trajectory of one consonant towards vowels, by extrapolation, points back in time to the same frequency, called the
of that consonant. This is a perceptual invariant of each consonant’s transition toward the vowels, that must be necessary for correct perception of the consonants. A comparison of the
estimated from the spectrograms and from the
algorithm for the plosive phonemes /p t q d b k g/ toward all the vowels results in a 100% accuracy.
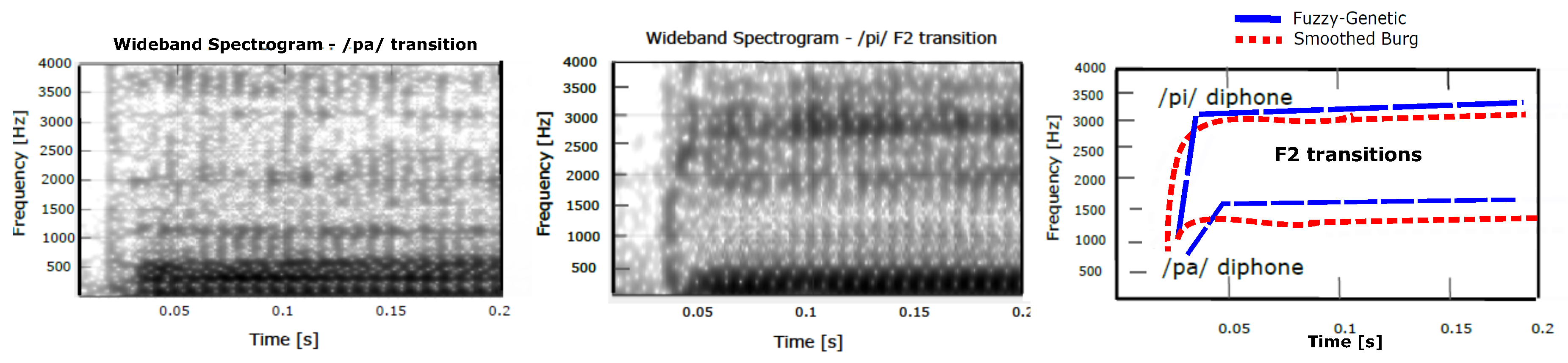
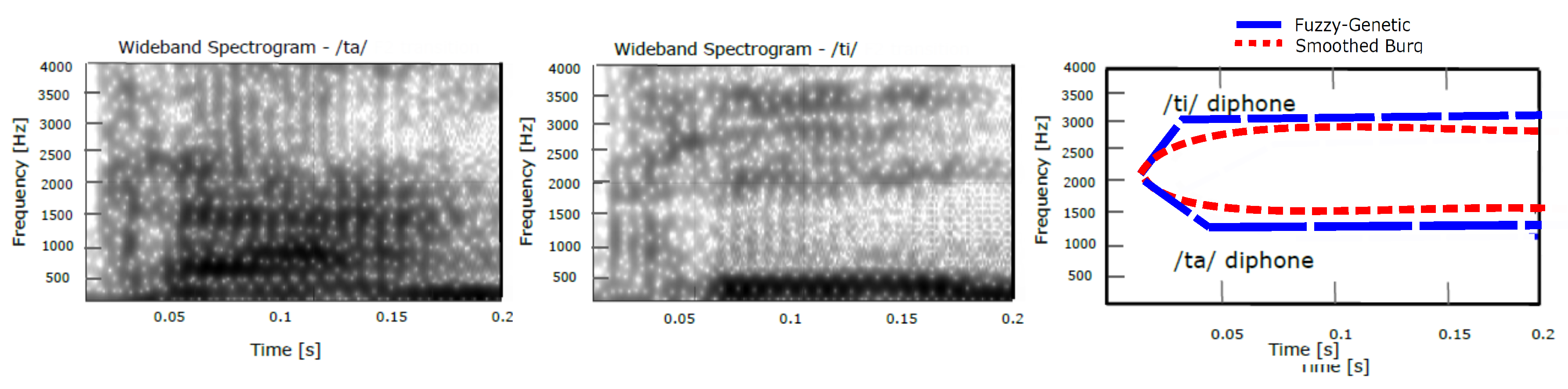
An example is shown in
Figure 14 related to the second-formant transitions of the phonemes
. As shown in
Figure 14 the obtained curves are consistent with the trajectories derived from spectrograms. In particular, we can estimate from this Figure that the second frequency locus for the transitions, is approximately 500 Hz, a value perfectly consistent with the literature (e.g., Reference [
57]).
As a further example, let’s consider the following transitions:
. The trend of the second formant determined by the algorithm is shown in
Figure 15, and corresponds to the spectrograms. In this case the locus is about 2000 Hz, which is again consistent with the literature (e.g., Reference [
57]).
Using the
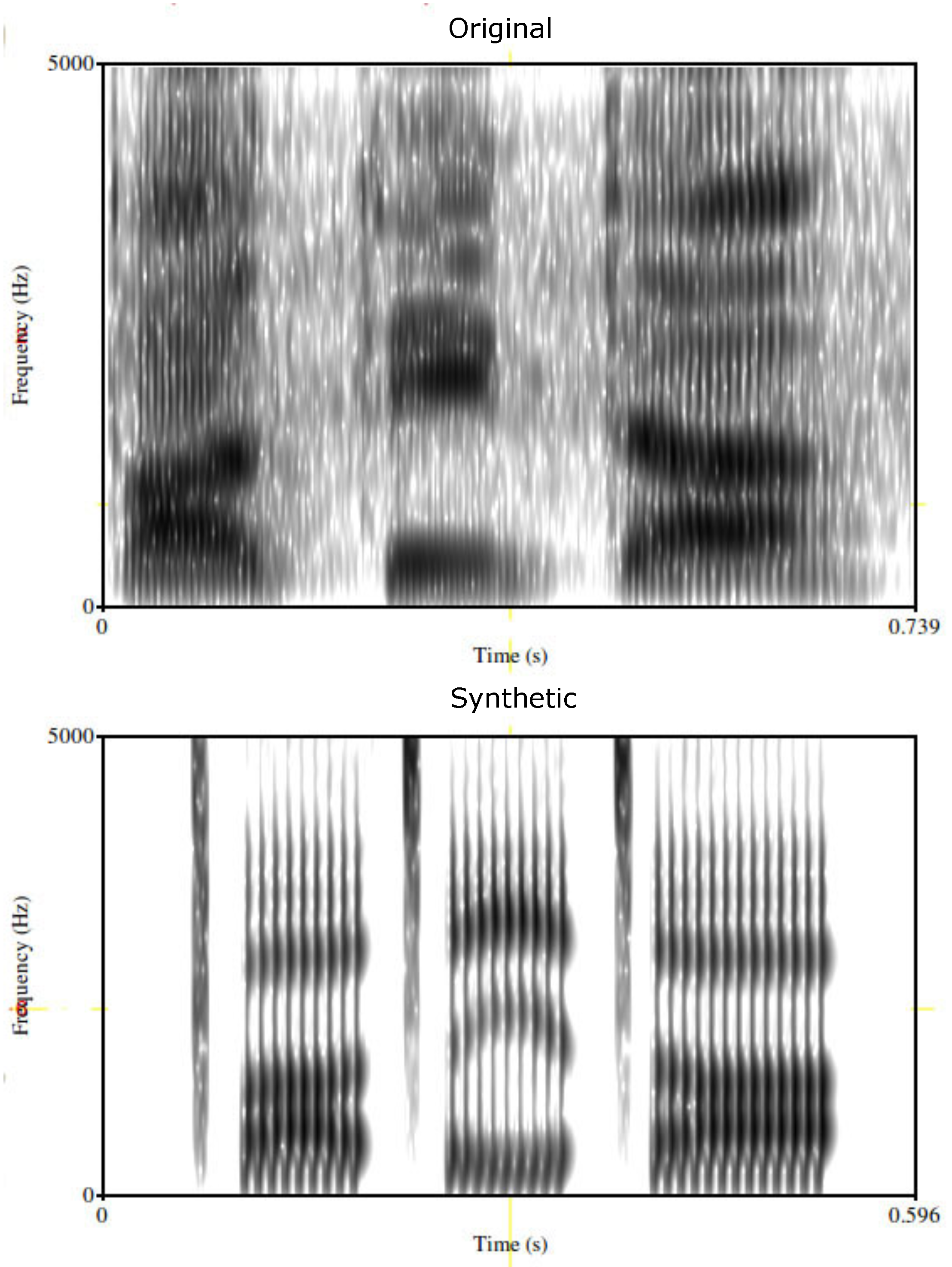
diphones, we construct by concatenation the word
. To verify the validity of the generation, we compare the spectrograms and the generated second formant (F2) trajectory of spoken and artificial words respectively. At the top of the
Figure 16 we show the spectogram of the word
spoken by the human tutor. At the bottom we show the spectrogram of the same word artificially generated.
The two spectrograms are different in timing but similar from a frequency point of view. This similarity confirm that the articulator parameters are generated correctly. We therefore can expect that facial movements are properly generated.
In conclusion, all the performed objective tests give very good results, and we now show some results of subjective tests.
9.3. Experiment 2: Subjective Evaluations
A measure of the quality of speech cannot be given exclusively through objective measures as peculiar characteristics such as intelligibility, naturalness, fluidity and intonation can only be assessed from a human listener through subjective measures.
Naturalness describes how close synthesized speech is to human speech and is usually measured by a mean opinion score (MOS) test [
68]. In a MOS test, subjects listen to speech and rate its relative perceived quality on some kind of a scale, for example,
,
,
,
,
. Then the scores are averaged across subjects.
However, “naturalness” may be difficult to judge in any type of speech. More recent authors, like Nusbaum [
69], suggest that
be measured by presenting to a group of listener a couple of sentences, one spoken by humans and the other produced by an algorithm, in our case the
. It is important to note that human speech is low pass filtered in order to make it quite worse than the original. Each listener must then decide whether the speech is produced by a human or a synthesizer. We used a much simpler criterion, that is, to say whether the naturalness of the heard word is
(POSITIVE) or not (NEGATIVE). Fifty listeners listened to a series of artificial words giving their degree of naturalness, comprehension and synchronization. The generated words include 120 meaningless words and 120 words with meaning. Moreover, all these words are also reproduced by a talking head animated with the facial movements obtained with the
algorithm. As a comparison, we considered the DECTalk speech synthesizer [
70]. Naturalness data of DECTalk is taken from Reference [
71]. Recall that we assume that the visual synthesis is performed with the algorithm described in Reference [
60].
In the following we give a very short explanation on how the results on audio-visual synthesis are obtained. From Reference [
71], the DECTalk subjective measure for audio nonsense words of 47% corresponds, using the data in Reference [
58], to an Equivalent Noise Level of about −13 dB. Adding visual information to the synthetic speech the subjective measure increases to 95% but, considering the performance of the visual system, this means an expected average subjective score of 77.08%. Likewise, a subjective score of 57% for words with meaning synthesized with DECTalk leads to an expected improvement to 79.96% with the audio-visual system.
We show in the following the results of intelligibility test on the
synthetic speech with comparison with another system. Intelligibility of synthetic voices can be measured with one of the many available tests; if it is not possible to speak about standardized evaluation tests, it can only be said that some are more frequently used than others. The basic test is clearly to compare the synthetic word which was heard by the listeners participating to the test with the word actually synthesized to see if it is correct. However, many other more complex tests are available. Going back to the early works in this area, in Reference [
72] the
(MRT) was proposed. MRT is based on the use of a rhyming words list that differ for the initial or final consonant; subjects must identify the right word within the set used as a stimulus and its output is the rate of success. MRT is a
test which allows to eliminate uncontrolled variations and it is very useful to test the intelligibility of particular aspect of the synthetic speech, as the initial or final CV transitions.
The Diagnostic Rhyme Test (DRT), described originally in Reference [
73] is a test for the evaluation of intelligibility based on the choice between two words whose initial consonants differ in a single distinctive trait, namely just a phoneme. During the test the subjects must determine which of the two words were pronounced. The subjective results are then given on a 1 to 5 scale.
However, as for the naturalness, we adopted a much simpler criterion, which is to establish whether the Comprehension of the word is
or it is too difficult. Comparison is made with the Votrax speech synthesizer [
74] and we again assume that visual synthesis is performed with the algorithm described in Reference [
60].
A further subjective test concerns the synchronization between synthetic speech and facial movements. While we tested synchronization of face movements with speech synthesized with
algorithm, comparison was made with spoken speech degraded by speech-shaped noise added to the spoken speech. The SNR of noise was
and
dB as described in Reference [
60]. However, while audiovisual results reported in Reference [
60] are related to the Viseme-Driven algorithm our results, they obtain
and not synchronization as we do. However, we assume that synchronization quality can be also expressed in terms of naturalness of the audiovisual information delivered to the human. The subjective results are described later. Note, however, that in Reference [
60] naturalness results with nonsense words are not available, and therefore we indicate NA (Not Available) for them.
In conclusion of this section, the tests carried out concern the measurement of the fundamental subjective characteristics of the artificial voice generated by the
algorithm such as: naturalness and comprehension of artificial words. Moreover, above all, the quality of facial movements, such as the perceived quality of the synchronization between artificial voice and facial movements. Naturalness and understanding of artificial voice have been measured with and without facial movements. Naturalness is reported in
Table 2. Comprehension is shown in
Table 3; of course, it emerges that comprehension of the artificial words is greater for words with meaning. It also emerges from the measurements that the facial movements helps in the understanding of artificial words. The evaluation of the synchronization of facial movements with the artificial voice is shown in
Table 4. From this evaluation it emerges that synchronization is best perceived in meaningless words than in meaningful ones, probably because facial movements are appreciated as an aid in trying to understand the words. In any case, all the objective and subjective results are very close to that obtained with existing systems and thus we are quite sure that the algorithm produces audiovisual information of high quality.
9.4. Experiment 3: Basic Speech Unit Extraction
Some examples of extraction of Basic Speech Units (BSU) are shown below. Suppose the human operator pronounces the training words / atʃa /, / ala /. The training words are divided into the following Basic Speech Units: / atʃa / = [-a] [atʃ] [tʃa] [a-]; / ala / = [-a] [al] [la] [a-]. Therefore, the articulatory characteristics of the following six BSU are stored in the knowledge base: [-a], [a-], [atʃ], [tʃa], [al], [la].
The values of the acoustic parameters
, described in terms of
, obtained from the fuzzy/genetic algorithm for the BSU / atʃa /, are shown in
Table 5. The same table shows the acoustic parameters of the following BSUs: [-a], [atʃ], [tʃa], [a-].
The values of degrees of membership of the articulator parameters estimated by the algorithm for the same BSUs are reported in
Table 6.
As a further example, in
Figure 17 we provide three snapshots of the facial movements generated by the Italian word
, (atʃa /), generated artificially. To highlight the synchronization of the facial movements with the artificial word, the signal waveform is displayed in the panel above the facial movements.
9.5. Experiment 4: Some Examples Produced for the Italian Language
In this Section, some experimental analysis of the Italian word
(nine) are reported as an example. The analysis is performed with the fuzzy-genetic algorithm with the following parameters: population size of 200 elements; mutation rate equal to
. Several algorithms for computing the parameters of the Klatt synthetizer have been proposed in the past. Many of them are presented as solutions to the ’copy synthesis’ problem, which is the problem to estimate the input parameters to reconstruct a speech signal using a speech synthesizer Copy synthesis is a difficult inverse problem because the mapping is non-linear and often is a ’from many to one’ problem. One of them is that proposed by Kasparaitis [
75], who proposed an iterative algorithm for the automatic estimation of the factors for the Klatt model using the corpus of an annotated audio record of the speaker. Another is that proposed by Laprie, [
76], who describe an approach to track formant trajectories first, and to compute the amplitudes of the resonators by an algorithm derived from cepstral smoothing they called “true envelope”.
In Reference [
77], a framework for automatically extracting the input parameters of a class of formant-based synthesizers is described. The framework is based on a genetic algorithm. Also Borges et al., in Reference [
78], describe a system based on GA optimization for automatically computing the parameters for the Klatt synthesizer. In Reference [
79] it is presented
KlattWork which relies on the 1980 version of the Klatt synthesizer. Rather than a copy synthesis system, KlattWorks is a “manager”, and is designed to allow the user to rapidly develop new synthetic speech for experiments using existing tools.
Weenink developed a class called KlattGrid, which implements a Klatt-type synthesizer. Parameters are automatically computed with the standard speech signal processing routines prodvided by the Praat program [
80]. For simplicity, the algorithm KlattGrid provided by Praat for computing the Klatt synthesis system has been used for comparison with the
algorithm,
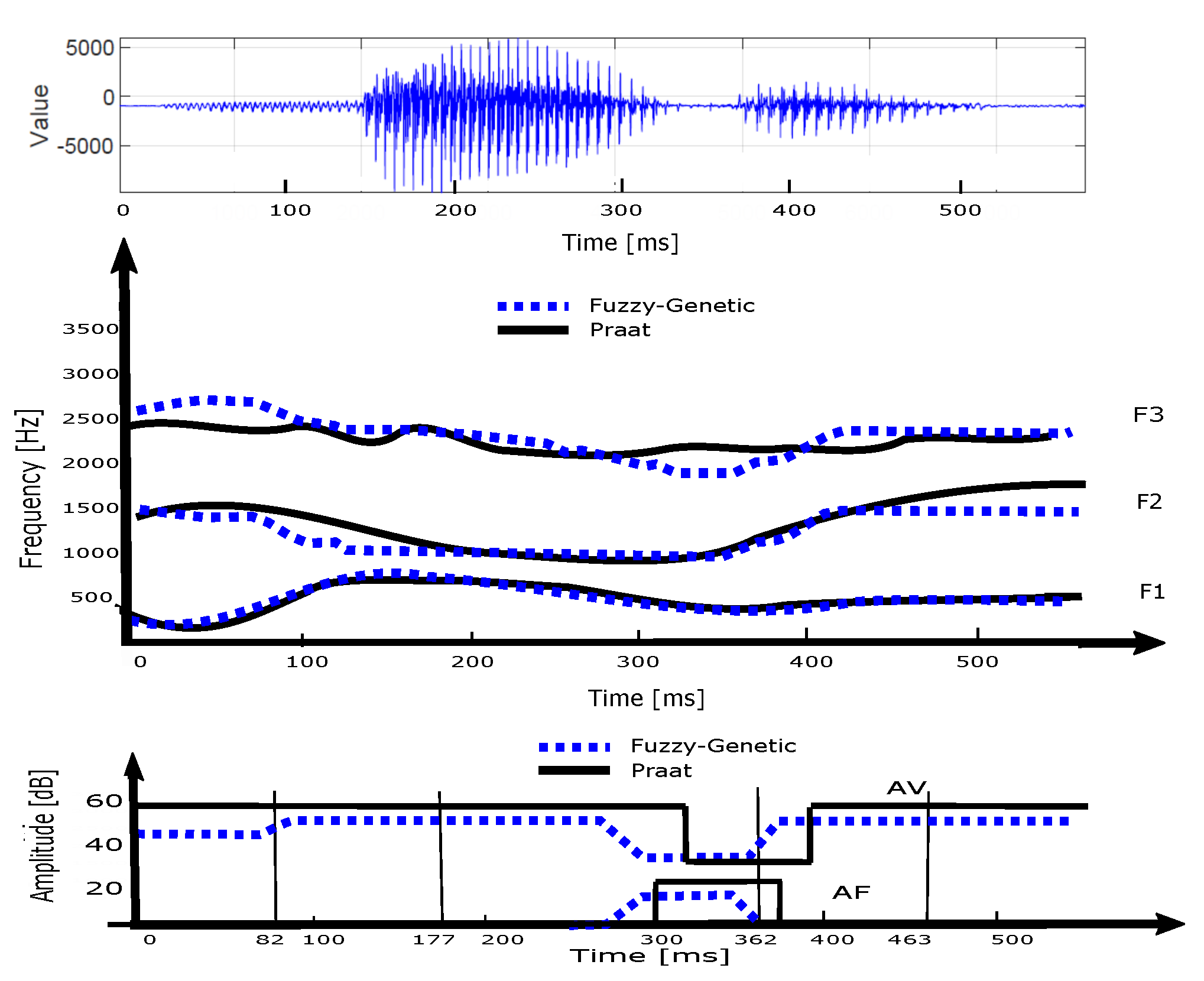
In
Figure 18 we report the trajectories of the first three formant frequencies and of the
and
amplitudes obtained with the algorithm from the word
(nine) in upper and lower panels respectively. The centers of the three phonemes of the word, that is
, are indicated by the three vertical lines.
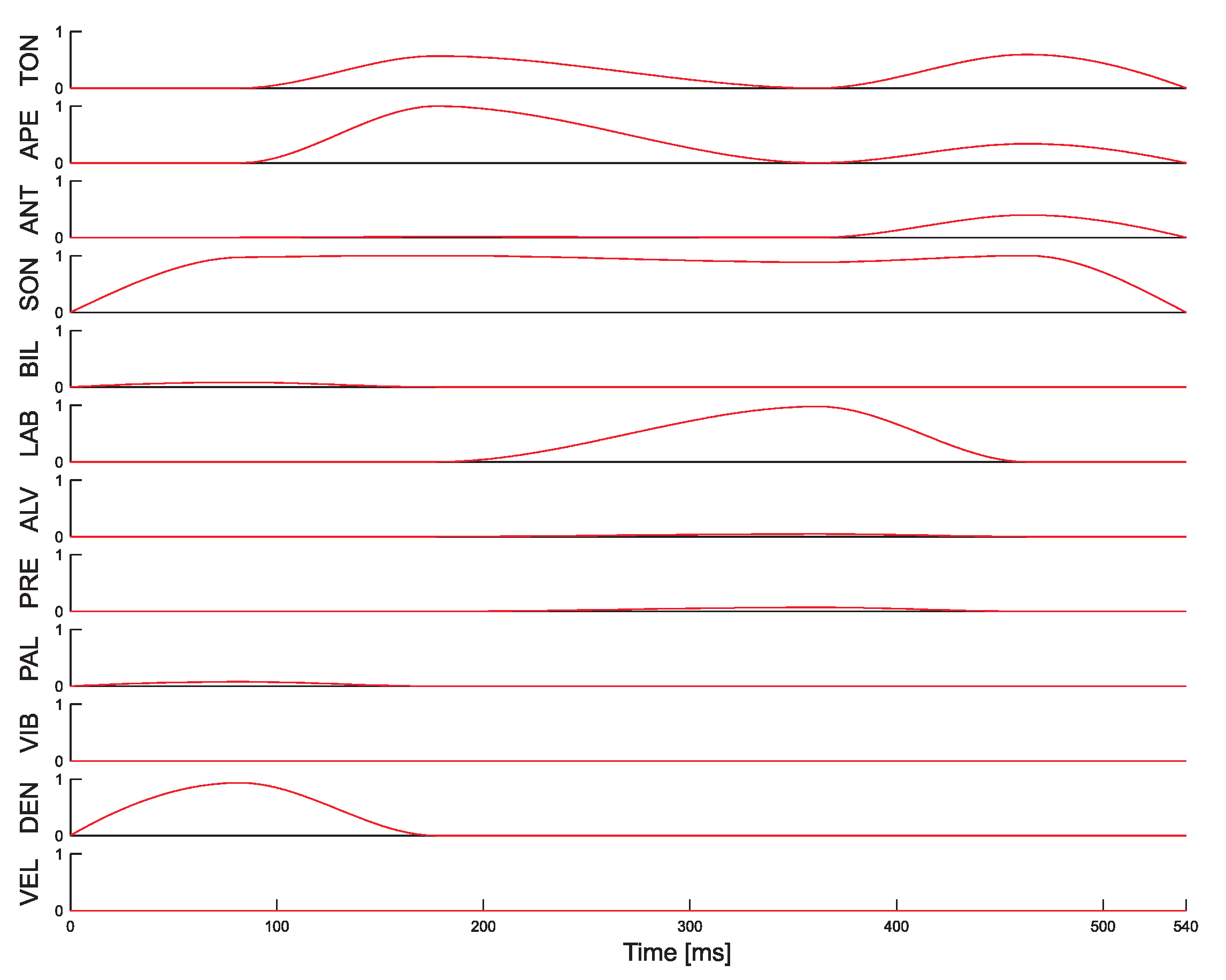
In
Figure 19 the dynamic of the membership degrees of the articulatory places of articulation is reported.
Some subjective evaluation results of a phonetic listening test are reported in
Table 7. In this test, subjects must identify the phonetic category they perceive. It comes out that the phonetic categories are quite well perceived.
10. Final Remarks and Conclusions
In this paper we describe an algorithm for automatic acquisition of human vocalization. The article is particular relevant in the context of advanced human-machine interfaces, with particular emphasis on the emerging big data trend. The algorithm is divided in two part: training phase and synthesis phase. In the training phase, the algorithm automatically gathers the articulatory characteristics of a voice uttered by a human tutor and given at input. In the synthesis phase, the articular knowledge learned in the training phase is used to describe an arbitrary input text from an articulatory point of view. It thus produces the artificial voice corresponding to the input text by articulatory synthesis on the one hand and, the facial movements synchronized with the artificial voice on the other hand. We use facial movements to animate a virtual talking head, drawn on a computer screen. Our approach allows to apply these facial movements to animate virtual speaking heads (Avatar) with the goal of achieving high-quality human-machine interfaces.
Our algorithm is based on a genetic optimization algorithm and a set of fuzzy rules to determine the degrees of membership of the places of articulation. An interesting feature of fuzzy rules, as it is well known, is that they can be easily edited and fine-tuned. The main features of the algorithm are the description of any input text in articulatory form. It is then possible to generate artificial speech by articulatory synthesis (Text to Speech Synthesis). In addition, by linear/nonlinear mapping between articulator and facial parameters, the facial configurations of an human speaker who reads the input text.
Many experimental results obtained with the algorithm are reported in the paper to highlight the quality of our work. Indeed, experimental results show that high quality facial movements synchronized with artificial speech are obtained. voice have a good degree of acceptance in subjective tests.
The most important future developments of our research are double-fold: from a side, we aim at extending our algorithm to other languages; from another side, we aim at further specializing the overall framework to emerging big data features (e.g., References [
81,
82,
83,
84,
85,
86,
87,
88,
89,
90]).























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}