A Fast Randomized Algorithm for the Heterogeneous Vehicle Routing Problem with Simultaneous Pickup and Delivery




Abstract
1. Introduction
2. Materials and Methods
2.1. MILP Formulation
2.2. Nearest-Neighbor-Based Randomized Algorithm
| Algorithm 1: Nearest-Neighbor-Based Randomized Algorithm |
| parameters: Computation time limit , probability of using the nearest neighbour strategy. input: Set of and , set of vehicle . output: Set of vehicle routes ().  |
- ;
- .
- ;
- ;
- .
- ;
- ;
- ;
- .
- ;
- ;
- ;
- .
- ;
- .
3. Results
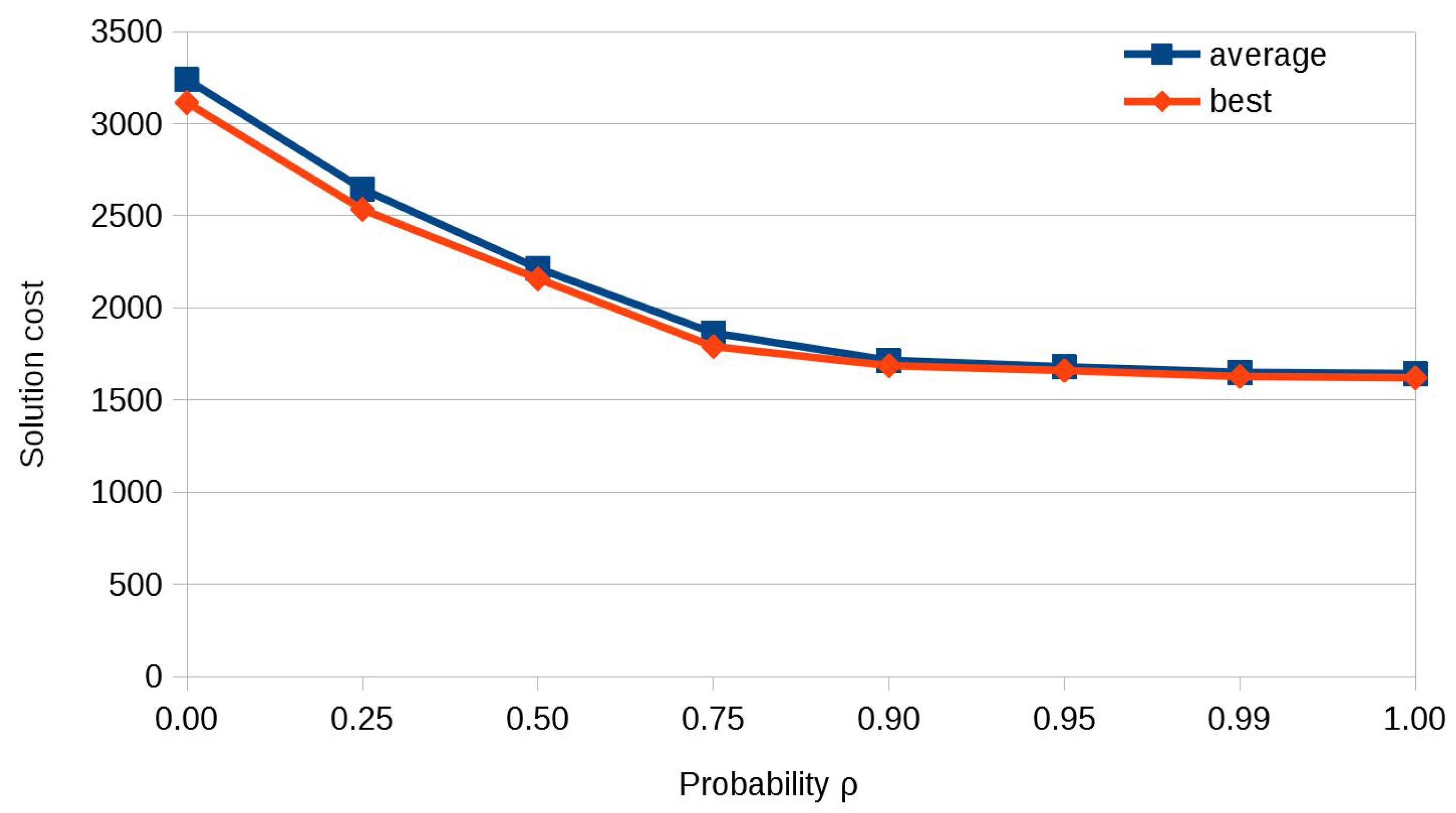
3.1. Calibration of the Probability
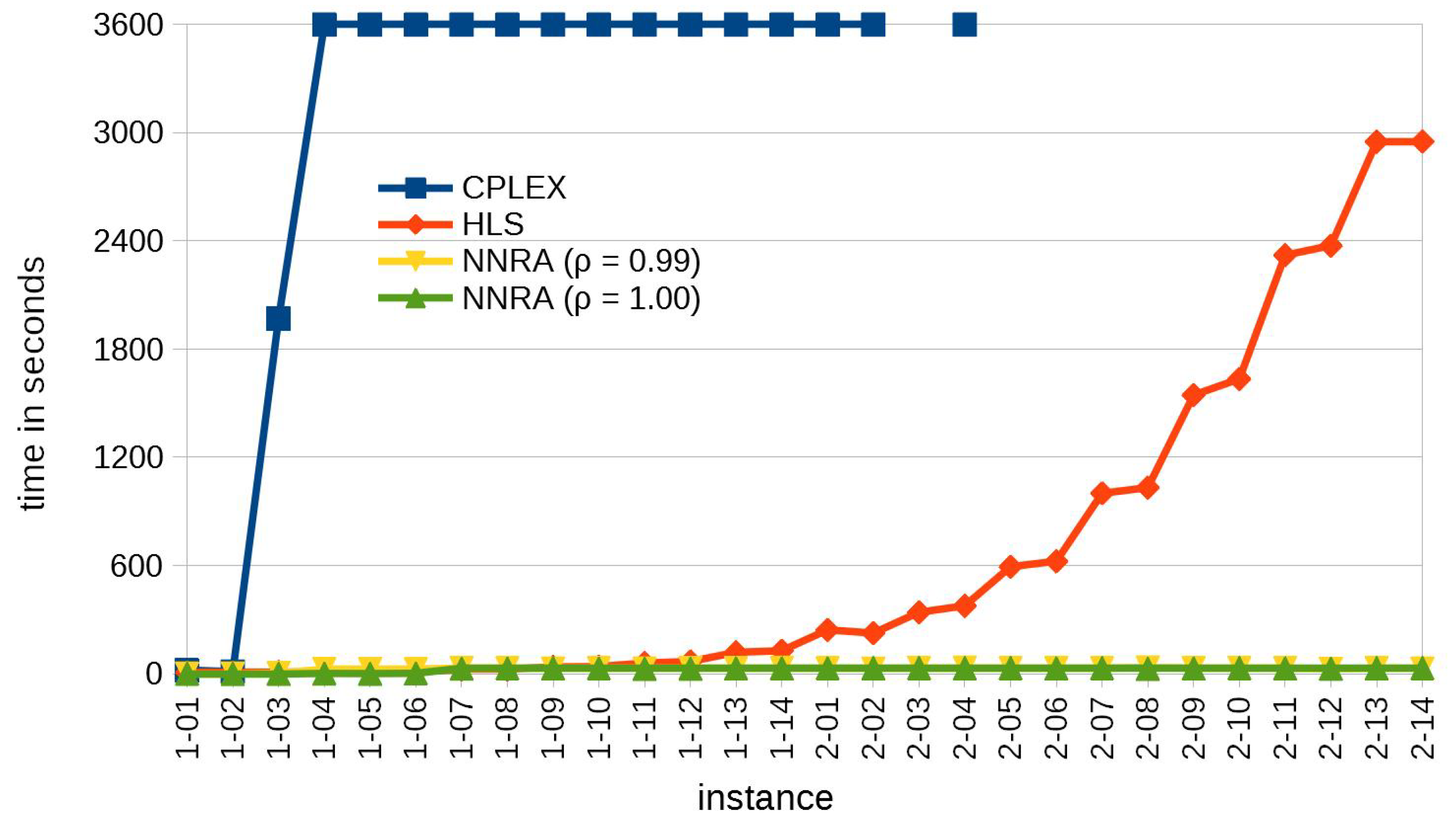
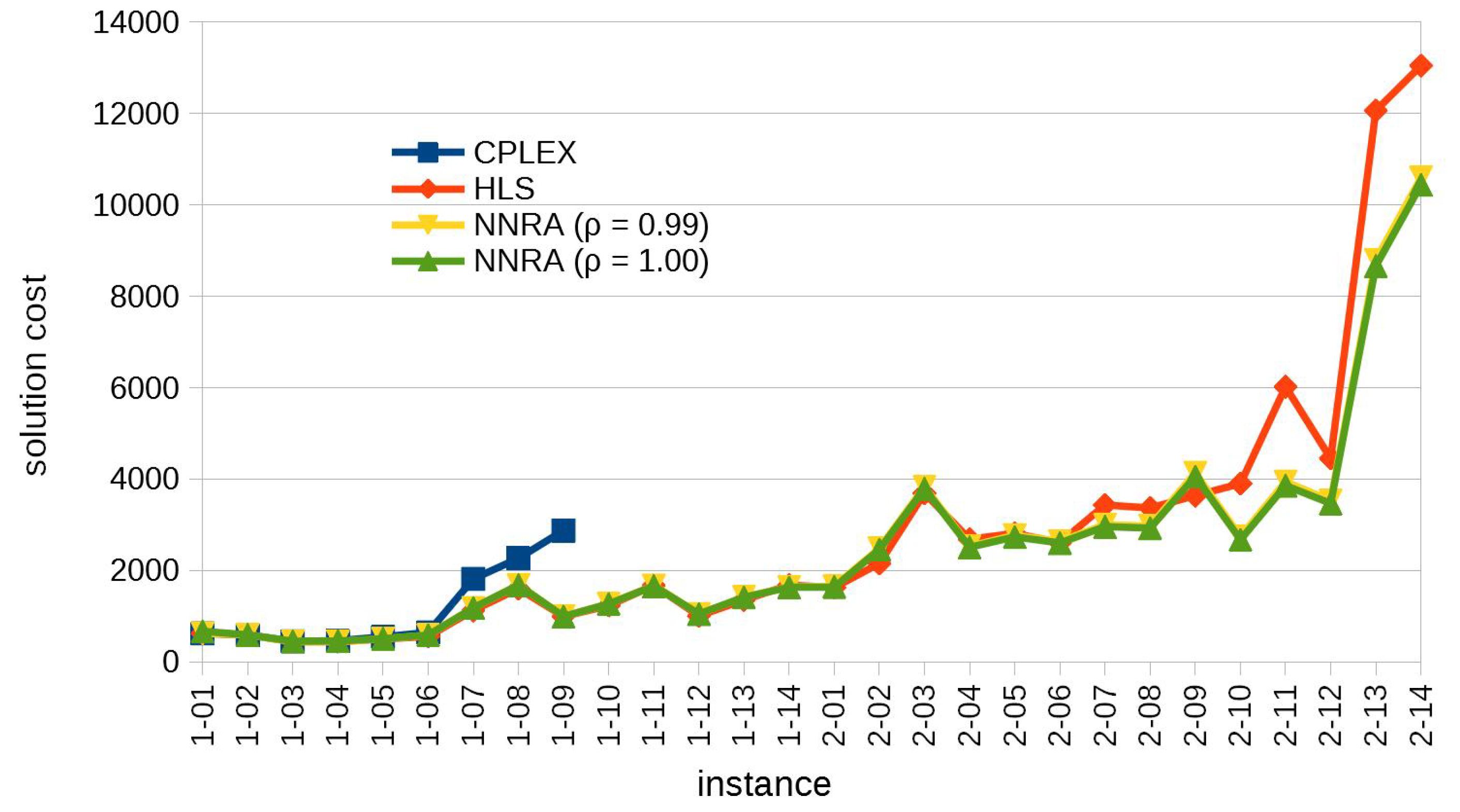
3.2. Results for Benchmark Instances
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| HLS | Adaptive hybrid local search |
| HVRPSPD | Heterogeneous vehicle routing problem with simultaneous pickup and delivery |
| MILP | Mixed integer linear programming |
| NNRA | Nearest-neighbor-based randomized algorithm |
| TSP | Traveling salesman problem |
| VRP | Vehicle routing problem |
| VRPSPD | Vehicle routing problem with simultaneous pickup and delivery |
References
- Montané, F.A.T.; Galvão, R.D. A tabu search algorithm for the vehicle routing problem with simultaneous pick-up and delivery service. Comput. Oper. Res. 2006, 33, 595–619. [Google Scholar] [CrossRef]
- Ai, T.J.; Kachitvichyanukul, V. A particle swarm optimization for the vehicle routing problem with simultaneous pickup and delivery. Comput. Oper. Res. 2009, 36, 1693–1702. [Google Scholar] [CrossRef]
- Gajpal, Y.; Abad, P. An ant colony system (ACS) for vehicle routing problem with simultaneous delivery and pickup. Comput. Oper. Res. 2009, 36, 3215–3223. [Google Scholar] [CrossRef]
- Subramanian, A.; Drummond, L.; Bentes, C.; Ochi, L.; Farias, R. A parallel heuristic for the Vehicle Routing Problem with Simultaneous Pickup and Delivery. Comput. Oper. Res. 2010, 37, 1899–1911. [Google Scholar] [CrossRef]
- Çatay, B. A new saving-based ant algorithm for the Vehicle Routing Problem with Simultaneous Pickup and Delivery. Expert Syst. Appl. 2010, 37, 6809–6817. [Google Scholar] [CrossRef]
- Subramanian, A.; Uchoa, E.; Pessoa, A.A.; Ochi, L.S. Branch-and-cut with lazy separation for the vehicle routing problem with simultaneous pickup and delivery. Oper. Res. Lett. 2011, 39, 338–341. [Google Scholar] [CrossRef]
- Goksal, F.P.; Karaoglan, I.; Altiparmak, F. A hybrid discrete particle swarm optimization for vehicle routing problem with simultaneous pickup and delivery. Comput. Ind. Eng. 2013, 65, 39–53. [Google Scholar] [CrossRef]
- Avci, M.; Topaloglu, S. An adaptive local search algorithm for vehicle routing problem with simultaneous and mixed pickups and deliveries. Comput. Ind. Eng. 2015, 83, 15–29. [Google Scholar] [CrossRef]
- Kalayci, C.B.; Kaya, C. An ant colony system empowered variable neighborhood search algorithm for the vehicle routing problem with simultaneous pickup and delivery. Expert Syst. Appl. 2016, 66, 163–175. [Google Scholar] [CrossRef]
- Kececi, B.; Altiparmak, F.; Kara, I. The heterogeneous vehicle routing problem with simultaneous pickup and delivery: A hybrid heuristic approach based on simulated annealing. In Proceedings of the CIE 2014—44th International Conference on Computers and Industrial Engineering, Istanbul, Turkey, 14–16 October 2014; pp. 412–423. [Google Scholar]
- Tian, Y.; Wu, W.Q. A heuristic algorithm for vehicle routing problem with heterogeneous fleet, simultaneous pickup and delivery. Syst. Eng. Theory Pract. 2015, 35, 183. [Google Scholar] [CrossRef]
- Kececi, B.; Altiparmak, F.; Kara, I. A Hybrid Constructive Mat-heuristic Algorithm for the Heterogeneous Vehicle Routing Problem with Simultaneous Pick-up and Delivery. In Evolutionary Computation in Combinatorial Optimization; Chicano, F., Hu, B., García-Sánchez, P., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 1–17. [Google Scholar] [CrossRef]
- Avci, M.; Topaloglu, S. A hybrid metaheuristic algorithm for heterogeneous vehicle routing problem with simultaneous pickup and delivery. Expert Syst. Appl. 2016, 53, 160–171. [Google Scholar] [CrossRef]
- Lawler, E.; Lenstra, J.K.; Rinnooy Kan, A.H.G.; Shmoys, D.B. The Travelling Salesman Problem: A Guided Tour of Combinatorial Optimization; Wiley-Interscience Series in Discrete Mathematics And Optimization; John Wiley & Sons: Chichester, UK, 1985. [Google Scholar]
- Gutin, G.; Yeo, A.; Zverovich, A. Traveling salesman should not be greedy: Domination analysis of greedy-type heuristics for the TSP. Discret. Appl. Math. 2002, 117, 81–86. [Google Scholar] [CrossRef]
- Bang-Jensen, J.; Gutin, G.; Yeo, A. When the greedy algorithm fails. Discret. Optim. 2004, 1, 121–127. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
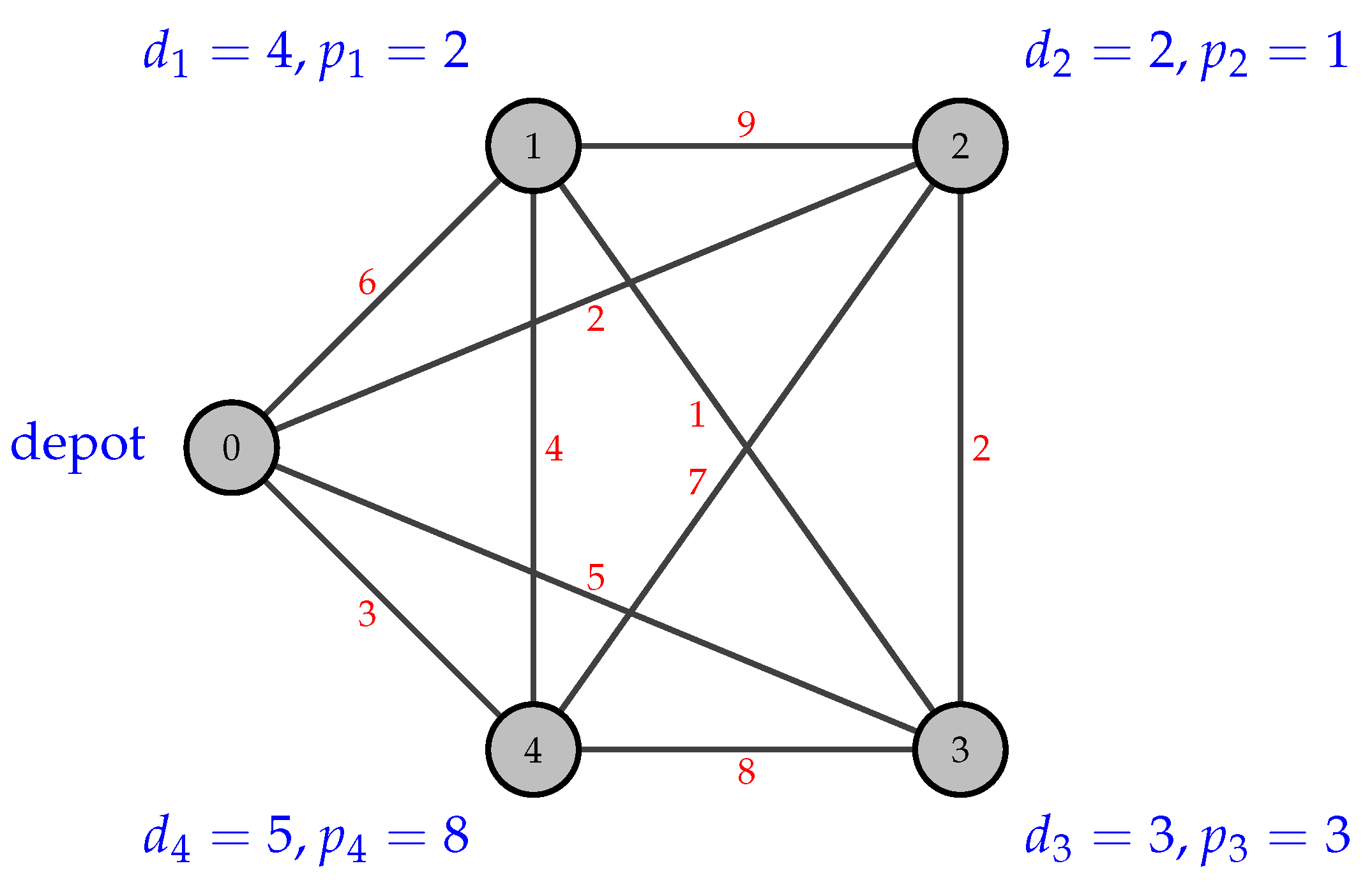
| Depot | Customer 3 | |
|---|---|---|
| delivery | – | 3 |
| pickup | – | 3 |
| load | 3 | 3 |
| Depot | Customer 3 | Customer 1 | |
|---|---|---|---|
| delivery | – | 3 | 4 |
| pickup | – | 3 | 2 |
| load | 7 | 7 | 5 |
| Depot | Customer 3 | Customer 1 | Customer 4 | |
|---|---|---|---|---|
| delivery | – | 3 | 4 | 5 |
| pickup | – | 3 | 2 | 8 |
| load | 12 | 12 | 10 | 13 |
| Depot | Customer 3 | Customer 1 | Customer 2 | |
|---|---|---|---|---|
| delivery | – | 3 | 4 | 2 |
| pickup | – | 3 | 2 | 1 |
| load | 9 | 9 | 7 | 6 |
| Depot | Customer 4 | |
|---|---|---|
| delivery | – | 5 |
| pickup | – | 8 |
| load | 5 | 8 |
| CPLEX | HLS | NNRA () | NNRA () | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| inst. | sol. | bound | time (s) | best | avg. | time (s) | best | avg. | (%) | time (s) | best | avg. | (%) | time (s) | ||||
| 1-01 | 10 | 2 | 620.2 | 620.2 | 19.2 | 620.2 | 620.2 | 17.2 | 620.2 | 620.2 | 0.0 | 0.0% | 0.3 | 665.0 | 665.0 | 0.0 | 7.2% | 0.0 |
| 1-02 | 10 | 2 | 588.5 | 588.5 | 11.1 | 588.5 | 588.5 | 14.7 | 588.5 | 588.5 | 0.0 | 0.0% | 0.1 | 589.2 | 589.2 | 0.0 | 0.1% | 0.0 |
| 1-03 | 15 | 3 | 445.1 | 445.1 | 1969.7 | 445.1 | 445.1 | 22.7 | 445.1 | 445.1 | 0.0 | 0.0% | 2.3 | 447.1 | 447.1 | 0.0 | 0.4% | 0.0 |
| 1-04 | 15 | 4 | 460.4 | 408.4 | 3600.0 | 437.1 | 437.1 | 24.5 | 442.5 | 448.1 | 0.7 | 2.5% | 25.5 | 453.9 | 453.9 | 0.0 | 3.8% | 1.1 |
| 1-05 | 20 | 3 | 543.3 | 464.1 | 3600.0 | 494.0 | 498.9 | 27.1 | 500.8 | 502.7 | 1.2 | 0.8% | 24.8 | 504.9 | 504.9 | 0.0 | 1.2% | 0.3 |
| 1-06 | 20 | 4 | 640.8 | 512.9 | 3600.0 | 542.7 | 551.9 | 26.7 | 572.2 | 580.0 | 2.8 | 5.1% | 24.5 | 583.1 | 583.1 | 0.0 | 5.7% | 2.0 |
| 1-07 | 35 | 3 | 1814.4 | 987.6 | 3600.0 | 1108.2 | 1123.4 | 56.6 | 1155.9 | 1178.9 | 5.5 | 4.9% | 29.0 | 1178.1 | 1180.6 | 4.1 | 5.1% | 28.8 |
| 1-08 | 35 | 3 | 2263.9 | 1426.9 | 3600.0 | 1586.5 | 1601.2 | 54.7 | 1663.9 | 1681.2 | 6.8 | 5.0% | 29.5 | 1663.9 | 1679.5 | 7.9 | 4.9% | 29.4 |
| 1-09 | 50 | 3 | 2872.4 | 853.4 | 3600.0 | 964.4 | 990.2 | 91.4 | 980.3 | 993.4 | 4.9 | 0.3% | 28.1 | 980.3 | 991.7 | 5.2 | 0.1% | 31.2 |
| 1-10 | 50 | 2 | – | 1039.1 | 3600.0 | 1197.7 | 1228.6 | 95.8 | 1230.0 | 1267.6 | 8.9 | 3.2% | 29.9 | 1240.2 | 1266.0 | 7.8 | 3.0% | 29.3 |
| 1-11 | 75 | 3 | – | 1279.8 | 3600.0 | 1642.2 | 1673.9 | 143.8 | 1620.7 | 1667.0 | 14.4 | −0.4% | 28.2 | 1625.8 | 1659.2 | 14.2 | −0.9% | 27.9 |
| 1-12 | 75 | 2 | – | 800.6 | 3600.0 | 973.1 | 1002.5 | 164.9 | 1012.0 | 1045.1 | 10.7 | 4.2% | 29.8 | 1010.9 | 1044.4 | 9.8 | 4.2% | 28.1 |
| 1-13 | 100 | 2 | – | 1078.3 | 3600.0 | 1299.5 | 1353.5 | 288.5 | 1375.5 | 1417.0 | 10.6 | 4.7% | 29.9 | 1372.2 | 1410.7 | 12.4 | 4.2% | 30.2 |
| 1-14 | 100 | 2 | – | 1266.8 | 3600.0 | 1658.2 | 1678.2 | 310.3 | 1595.3 | 1635.3 | 10.8 | −2.6% | 32.1 | 1587.3 | 1628.5 | 12.7 | −3.0% | 30.8 |
| 2-01 | 150 | 3 | – | 1210.8 | 3600.0 | 1499.4 | 1624.5 | 592.5 | 1627.0 | 1654.4 | 17.2 | 1.8% | 28.7 | 1627.0 | 1639.7 | 9.6 | 0.9% | 30.4 |
| 2-02 | 150 | 3 | – | 1756.6 | 3600.0 | 2144.8 | 2152.5 | 548.9 | 2425.7 | 2479.1 | 20.3 | 15.2% | 27.5 | 2369.7 | 2458.7 | 21.0 | 14.2% | 31.9 |
| 2-03 | 200 | 3 | – | – | – | 3673.1 | 3688.8 | 831.6 | 3746.3 | 3830.9 | 31.8 | 3.9% | 31.9 | 3669.8 | 3787.5 | 36.8 | 2.7% | 31.7 |
| 2-04 | 200 | 2 | – | 1757.2 | 3600.0 | 2485.3 | 2682.5 | 919.4 | 2453.8 | 2528.8 | 22.0 | −5.7% | 32.9 | 2433.8 | 2506.0 | 21.0 | −6.6% | 31.3 |
| 2-05 | 250 | 3 | – | – | – | 2639.6 | 2810.0 | 1448.1 | 2683.8 | 2769.7 | 24.0 | −1.4% | 30.0 | 2682.6 | 2732.5 | 18.0 | −2.8% | 32.0 |
| 2-06 | 250 | 2 | – | – | – | 2549.8 | 2605.6 | 1521.3 | 2528.9 | 2634.8 | 28.6 | 1.1% | 29.7 | 2516.4 | 2599.9 | 24.6 | −0.2% | 30.5 |
| 2-07 | 300 | 3 | – | – | – | 3205.0 | 3431.2 | 2440.4 | 2911.2 | 3000.9 | 29.0 | −12.5% | 31.4 | 2861.6 | 2959.4 | 26.1 | −13.8% | 31.1 |
| 2-08 | 300 | 2 | – | – | – | 3252.8 | 3364.6 | 2518.2 | 2867.7 | 2968.0 | 24.7 | −11.8% | 33.8 | 2861.8 | 2925.2 | 22.1 | −13.1% | 27.5 |
| 2-09 | 350 | 3 | – | – | – | 3457.9 | 3637.0 | 3770.1 | 3997.1 | 4136.4 | 41.5 | 13.7% | 29.3 | 3937.2 | 4055.2 | 41.4 | 11.5% | 29.8 |
| 2-10 | 350 | 2 | – | – | – | 3760.9 | 3897.5 | 3988.7 | 2622.7 | 2736.1 | 30.3 | −29.8% | 31.8 | 2613.8 | 2671.5 | 25.2 | −31.5% | 31.1 |
| 2-11 | 400 | 2 | – | – | – | 5809.5 | 6018.9 | 5662.4 | 3821.1 | 3941.9 | 37.9 | −34.5% | 30.5 | 3714.5 | 3855.6 | 36.1 | −35.9% | 30.2 |
| 2-12 | 400 | 2 | – | – | – | 4045.9 | 4447.0 | 5791.5 | 3441.5 | 3524.1 | 35.9 | −20.8% | 26.6 | 3397.1 | 3464.9 | 24.9 | −22.1% | 28.3 |
| 2-13 | 500 | 2 | – | – | – | 11,008.8 | 12,062.5 | 7200.0 | 8518.0 | 8794.8 | 87.3 | −27.1% | 30.5 | 8399.6 | 8660.7 | 89.7 | −28.2% | 30.9 |
| 2-14 | 550 | 2 | – | – | – | 12,762.0 | 13,046.3 | 7200.0 | 10,417.1 | 10,599.4 | 60.3 | −18.8% | 27.9 | 10,265.2 | 10,442.0 | 66.5 | −20.0% | 32.0 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nepomuceno, N.; Barboza Saboia, R.; Rogério Pinheiro, P. A Fast Randomized Algorithm for the Heterogeneous Vehicle Routing Problem with Simultaneous Pickup and Delivery. Algorithms 2019, 12, 158. https://doi.org/10.3390/a12080158
Nepomuceno N, Barboza Saboia R, Rogério Pinheiro P. A Fast Randomized Algorithm for the Heterogeneous Vehicle Routing Problem with Simultaneous Pickup and Delivery. Algorithms. 2019; 12(8):158. https://doi.org/10.3390/a12080158
Chicago/Turabian StyleNepomuceno, Napoleão, Ricardo Barboza Saboia, and Plácido Rogério Pinheiro. 2019. "A Fast Randomized Algorithm for the Heterogeneous Vehicle Routing Problem with Simultaneous Pickup and Delivery" Algorithms 12, no. 8: 158. https://doi.org/10.3390/a12080158
APA StyleNepomuceno, N., Barboza Saboia, R., & Rogério Pinheiro, P. (2019). A Fast Randomized Algorithm for the Heterogeneous Vehicle Routing Problem with Simultaneous Pickup and Delivery. Algorithms, 12(8), 158. https://doi.org/10.3390/a12080158