1. Introduction
Global optimization over continuous spaces is an important field of the modern scientific research and involves interesting aspects in computer science. Given an objective function f modeling a system of points which depends on a set of parameters, the task is to determine the set of parameters which optimizes f. For simplicity, in most cases the optimization problem is stated as a minimization problem.
For high dimensional problems, numerical methods are suggested which construct converging sequences of points by employing local optimizers, for example search methods. In general, procedures of this type are stochastic and rely on intensive computation to explore the solution space, without too deep enquires concerning convergence proofs. Roughly speaking, there are two main approaches: a sampling approach and an escaping approach. Examples of the sampling approach are Pure Random Search algorithms [
1], where an extensive sampling of independent points is considered, and Multistart algorithms [
2,
3], which apply local optimizers to randomly generated starting points; then the best among the found local optima is considered the global optimum. Sampling algorithms have been shown [
3] to converge in infinite time with probability 1, but in practice there is no guarantee that the best local solution found in a finite amount of computation is really the global optimum. In the escaping approach, various methods are devised for escaping from an already found local optimum, reaching other feasible points from which to restart a new local optimizer (see for example the Simulated Annealing [
4]).
In practice, most algorithms succeed for small and medium-sized problems, but the chance of finding the global optimum worsens considerably when the number of the dimensions increases, due to the necessary limitation of the sampling set size. In any case, the computation of a local solution can be very expensive and the convergence of differently started local procedures to the same local optimum is frequent and should be avoided.
In this paper we propose an adaptive strategy for finding the global minimum of a polynomial function expressed through the Frobenius norm of matrices and tensors. The considered problem is outlined in
Section 2. The Multistart algorithm, on which the adaptive strategy is based, is described in
Section 3. It implements a particularly tailored local minimization procedure with an ad-hoc stopping condition. The basic step of the adaptive strategy is implemented through a priority queue and consists in splitting the runs starting from different initial points in segments of fixed length. The processing order of the various segments is interlaced, discarding those which appear less promising. The adaptive procedure is described in
Section 4. Finally, in
Section 5 the validity of the adaptive procedure is verified through a large experimentation on both nonnegatively constrained and unconstrained problems.
2. The Problem
A widely studied problem in literature is the one of nonlinear global minimization
where
is a region determined by a set of constraints and
is a polynomial function of degree
which models the problem’s objective. Classical examples are
of nonnegativity constraints, and
when no constraint is given. Problem (
1) is NP-hard [
5]. In this paper we consider specifically objective functions expressed through the Frobenius norm of an array
whose elements are low degree polynomials in the entries of
:
We examine in particular the cases where
is a two-dimensional or a three-dimensional matrix. For example, in the two dimensional case, a problem considered in the experimentation looks for two low-rank matrices
and
such that
according to
given a nonnegative matrix
and an integer
. Problem (
3), known as Nonnegative Matrix Factorization (NMF), was first proposed in [
6] for data analysis and from then on has received much attention. It is a particular case of Problem (
1) with
as in (
2),
,
and
a vectorization of the pair
. In a columnwise vectorization,
is the matrix of elements
Since
f is a polynomial, the gradient
and the Hessian
of
f are available. From a theoretical point of view, a simple way to solve Problem (
1) in the unconstrained case would be to look for the stationary points
where
and choose whichever
minimizes
f, but this way does not appear to be practical when
N is large, even if
d is not too large, because finding a global minimum can be a very difficult task when
f has many local minima. For this reason, numerical methods have been proposed which do not try to solve
. Anyway, many numerical methods take advantage of derivative information to improve the computation.
When the dimension
N is very large, also numerical methods which require at the same time
active points might be impracticable. This is the case, for example, of methods such as Nelder–Mead algorithm [
7] which works on a polytope of
vertices, or Differential Evolution [
8] which generates at each iteration a new population of more than
points, or Simulated Annealing [
9] which for the continuous minimization uses a downhill simplex of
points. In this paper we propose a method which allows solving Problem (
1) also when
N is very large. To validate its performances against other methods, it is necessary to restrict our experimentation to dimensions where the other methods could still compute reliable solutions.
3. A Multistart Algorithm
Multistart algorithms are widely used heuristics for solving Problem (
1) [
2,
3]. Over the years, many variants and generalizations have been produced. We consider here its basic form which consists of the following steps:
start with a fixed number q of independent initial points , , randomly generated.
For , a local optimizer, say , is applied to to find an approximation of a local minimum. We assume to be an iterative procedure which, in the constrained case, takes on the nonnegativity of and denote by , , the sequence of points computed until a suitable stopping condition is satisfied. The corresponding function values estimate the quality of the approximation. Both the chosen procedure and the stopping condition employed by are of crucial importance. Ideally, the stopping condition should verify whether the local minimum has been reached within a given tolerance , but of course more practical tests must be used.
When all the q points have been processed, the point with the smallest function value is selected as an approximation of the global minimum. It is evident that the minimum found in this way is not guaranteed to suitably approximate the global minimum, even if a large number of starting points is considered.
In the experimentation we have implemented a version of the basic Multistart algorithm, here denoted by
MS, as reference. The chosen local optimizer
is particularly suitable for the problems we are considering and exploits the differentiability of the function
. Its execution time turns out to be much smaller than what is generally expected from a library method, which relies on general purpose procedures as local optimizers and does not exploit the differentiability information. The stopping condition we have implemented monitors the flatness of the approximation by assuming
as an acceptable approximation of a local minimum when
Of course, if an index
exists such that
, the algorithm stops and condition (
4) is not tested. The tolerance
is set equal to some power of the machine
. As usual, a maximum number
of allowed iterations is imposed to each run.
As an example, we have applied
MS to one of the problems described in
Section 5.3, namely problem
, generating
initial points.
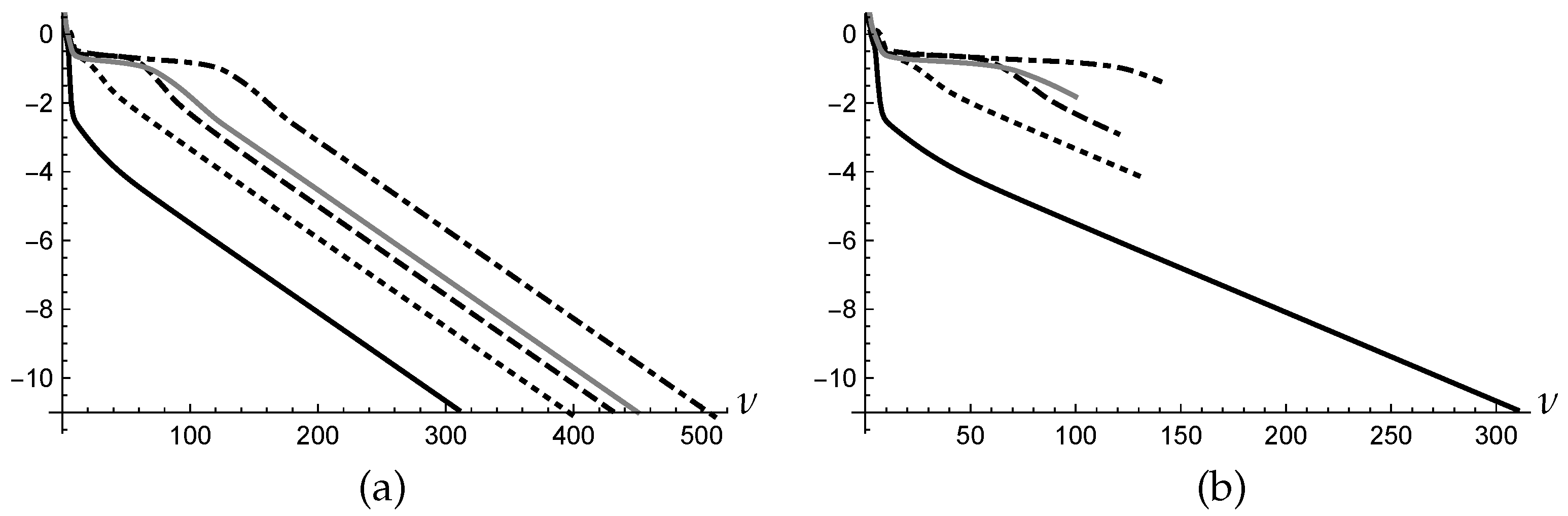
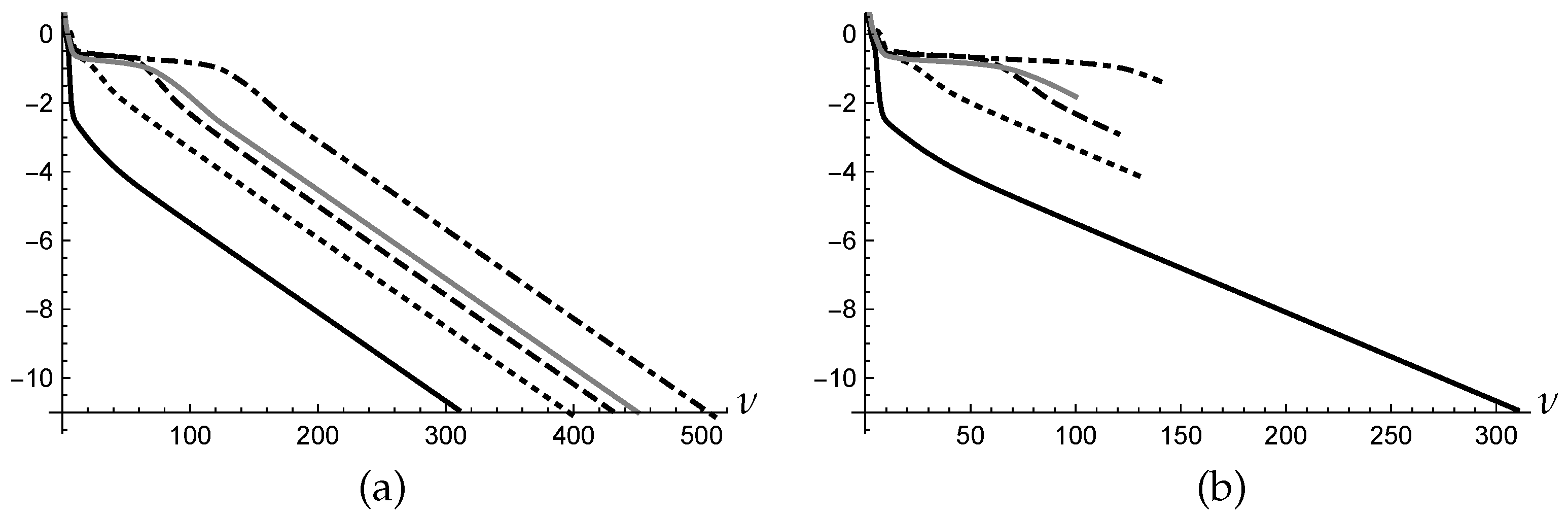
Figure 1a shows the log plot of the histories
,
, computed by
MS for
using the stopping condition (
4) with
. All the sequences converge to the same local minimum, but one (plotted with black solid line) requires 300 iterations and appears to be faster than the others which require from 400 to 500 iterations. The number of iterations of the overall execution is 2100.
Letting the local algorithm run until convergence for all the starting points is a time-consuming procedure, in particular when the iterates obtained from many different starting points lead to the same local minimum. A reasonable approach, that we presently propose, modifies this procedure adaptively. It is based on an efficient premature recognition of the more promising runs of the local algorithm and interrupts with high probability the runs which may lead to already found local minima or to local minima of larger value than those already found.
4. An Adaptive Procedure
Because of the large computational cost of the strategy described in the previous section, the straightforward implementation can be profitably applied only to small problems. For this reason we propose here a heuristic approach, which we denote by the name AD, suitable for large problems whose basic step consists in the splitting of the runs in segments of a fixed length . Each segment, identified by the index r, , stores the partial solution produced at the end of the iterations, which will be used as the starting point for the next run with the same index r. The processing order of the various segments is modified by interlacing the computation of segments with different indices r. This strategy requires segments corresponding to different r’s to be available at any moment of the computation. The segments, which appear to be the more promising ones depending on the behavior of the computed function values, are carried on and the other segments are discarded.
The strategy is accomplished using a priority queue
whose items have the form
where
is the index of the segment; it identifies the seed chosen for the random generation of the initial point following a uniform distribution between 0 and 1.
is the number of iterations computed until now by in all the segments with the same index r, i.e., starting with .
is the partial solution computed by at the end of the current rth segment.
is the array containing the function values of the last three points computed by in the current rth segment.
is an estimate of the decreasing rate of the function.
is the priority of the item, which rules the processing order of the various segments according to the minimum policy.
The belonging of an element to an item Y is denoted by using the subscript , for example denotes the index of item Y.
During the computation three global quantities, , , and , play an important role:
is the minimum of all the function values computed so far relative to all the items already processed
is the computed point corresponding to and is the index of the item where has been found.
The priority is defined by , where measures the accuracy of the last computed iterate in the current segment and measures the age of the computation of the rth seed. Between two items which have the same age, this expression favors the one with the better accuracy and, between two items which have comparable accuracies, it favors the younger one, that is the quicker one. The inclusion of the age into the priority is important to avoid that only the best item is processed and all the other items are ignored. In fact, with the increase of the age, also items which had been left behind take their turn.
At the beginning the initial points
,
, are randomly generated and
is set. The initial priorities are defined by
and the queue is formed by the
q items
where
and
is a void array.
The length of the queue, i.e., the number of items in , is found by calling the function Length. At the beginning the length is q and it is modified by the functions:
Y = Dequeue returns the item Y which has the smallest priority and deletes it from ,
Enqueue inserts the item Y into .
A further function Maxdelta returns the largest value among the quantities of all the items in .
During the computation the following quantities deriving from , and are referred (their expressions have been tested by an ad hoc experimentation):
measures the flatness of the last computed values of
f according to (
4),
measures the decreasing rate of f. If the last computed iteration increases over the preceding one. Only small increases, corresponding to limited oscillations, are tolerated,
measures the discarding level. The larger c, the higher the probability of discarding the item. Among items which have comparable values , the older one has greater probability to be discarded.
Three other functions are needed:
Random generates n numbers uniformly distributed over .
The local minimization algorithm is applied for the predefined number of iterations (in the experiments we assume ) and returns , , the minimum of the function values of the current segment, its corresponding point , the number of performed iterations and the decreasing rate . Since algorithm AD is based on the splitting into segments of the run corresponding to a single starting point, the local optimizer needs to be stationary, in order to get a computation which gives the same numerical values as if a single run had been performed without segmentation.
The following Boolean function Control verifies whether an item is promising (i.e., must be further processed) or not. For notes (a)–(e) see the text.
| Function Control; |
| the selected item Y is enqueued again if True is returned, otherwise it is discarded. |
| ; ; ; compute , and c; |
| if then return False; (a) |
| if , then return False; (b) |
| if Length and Maxdelta then return True; (c) |
| if , then return True; (d) |
| if Random then return False; (e) |
| return True; |
The decision on which course to choose depends mainly on the flatness, but other conditions are also taken into consideration as described in the following notes:
- (a)
large oscillations are not allowed,
- (b)
the flatness level has been reached,
- (c)
the selected item decreases more quickly than other items in the queue,
- (d)
the selected item has the same index r of the item where has been found,
- (e)
if none of the preceding conditions holds, the selected item is discarded with probability given by its discarding level.
After the initialization of the queue, the adaptive process AD evolves as follows: an item Y is extracted from the queue according to its priority . When enough iterations ( iterations in the experiments) have been performed for stabilizing the initial situation, the function Control is applied, and if Y is recognized promising, the function is applied to point . A new item is so built and inserted back into . If the computed is smaller than , then , and are updated. Otherwise, if Y is not promising, no new item is inserted back into , i.e., Y is discarded. At the end, and are returned. A bound is imposed on the number of iterations of the overall execution.
Our proposed algorithm is implemented in the following function Chi.
| function Chi; |
| for let Random (N); |
| initialize ; initialize according to (5); |
| ; |
| while Length and and |
| Y = Dequeue ; |
| True; |
| if then cond = Control (Y); |
| if cond then |
| ; |
| d = d + ν; h = hY + ν; χ = log10(f(x)/gmin)+h/λ; |
| Enqueue (,{r(Y),h,x,g,δ,χ}); |
| if < gmin then gmin = ; xmin = ; rmin = r(Y); |
| end if |
| end while |
| returnxmin and f(xmin); |
Figure 1b shows the log plots of the histories
obtained by applying
AD to the same problem of the example considered in
Section 3 with
MS, using also the same
initial points. Only the sequence plotted with the black solid line survives in the queue, while all the other sequences are discarded from the queue at different steps of the computation. At the end 800 overall iterations have been performed, compared with the 2100 of
MS, as it is evident from the two figures, pointing out the outperformance of
AD on
MS.
5. Experimentation
The experimentation is performed with a 3.2 GHz 8-core Intel Xeon W processor machine using IEEE 754-64 bit double precision floating point format (with
) and is carried out on the three nonnegatively constrained test problems described in
Section 5.1,
Section 5.2 and
Section 5.3 and on the unconstrained test problem described in
Section 5.4. The following methods are applied to each test problem.
With Class 2 methods the procedure used as local minimizer differs according to the presence of constraints or not. In the test problems two different situations occur:
The problem has a region
D related to nonnegativity constraints. In this case, a block nonlinear Gauss–Seidel scheme [
10] is implemented as
, in order to find constrained local minima of
. The vector
is decomposed into
disjoint subvectors, cyclically updated until some convergent criterium is satisfied. The convergence of this scheme, more specifically called in our case Alternating Nonnegative Least Squares (ANLS), is analyzed in [
10]. We apply it for the particular case of Problem (
1) with
as in (
2) in the two-dimensional case (
in
Section 5.1 and
Section 5.2) and in the three-dimensional case (
in
Section 5.3).
The problem is unconstrained (
Section 5.4). In this case the local minimizer
is a library procedure based on Levenberg-Marquardt method.
The aim of the experimentation is:
To analyze, in terms of both execution time and accuracy, the effects on the performance of Class 2 methods of the two chosen values for the tolerance
used in the stopping condition (
4). Of course, we expect that a weaker request for the tolerance (
) would result in lower accuracy and time saving than a stronger request (
). This issue is experimentally analyzed by comparing the performances of method
MS1 with those of method
MS2 and the performances of method
AD1 with those of method
AD2.
To compare the performances of the adaptive and non adaptive procedures of Class 2. We wonder whether the adaptive procedure, with its policy of discarding the less promising items, can overlook the item which eventually would turn out to be the best one. This issue is experimentally analyzed by comparing the performances of method MS1 with those of method AD1 and the performances of method MS2 with those of method AD2.
To compare the performances of Class 1 and of Class 2 methods. Naturally, we expect that in the case of constrained problems the execution times of Class 1 methods, which implement general purpose procedures, would be larger than those of Class 2, specifically tailored to functions of type (
2). Beforehand, it is not clear whether the latter ones would pay the time saving with a lower accuracy.
For each problem we assume that an accurate approximation of the solution
of (
1) is known. In the tables two performance indices are listed:
the execution time (denoted ) in seconds. In order to get a more reliable measure for this index, the same problem is run 5 times with each starting point and the average of the measures is given in the tables as .
the quantity , rounded to the first decimal digit, as a measure of accuracy. Approximately, gives the number of exact decimal digits obtained by the method. The larger , the more accurate the method. When a method produces a very good value such that , the case is marked by the symbol +.
We give now a description of the test problems together with their numerical results.
5.1. The Nonnegative Matrix Factorization
The first test problem is the NMF problem (
3) already outlined in
Section 2, i.e., given
and
, we look for the
basis matrix
and the
coefficient matrix
which minimize
under the constrains
.
ANLS is applied to
with
. An initial
is chosen and the sequences
for
, are computed.
Although the original problem (
3) is nonconvex, subproblems (
6) are convex and can be easily dealt with. In the experimentation we use for (
6) the Greedy Coordinate Descent method (called
GCD in [
11]), which is specifically designed for solving nonnegative constrained least squares problems. The attribute “Greedy” refers to the selection policy of the elements updated during the iteration, based on the largest decrease of the objective function. In our tests this method has shown to be fast and reliable. The corresponding code can be found as Algorithm 1 in [
11].
For the experimentation, given the integers
m,
n and
, two matrices
and
are generated with random elements uniformly distributed over
and the matrix
is constructed. The test problem (
3) requires computing the NMF of
M, i.e., given an integer
, two matrices
and
such that
are to be found. The following cases are considered
The dimension of the solution space is
In the cases
we expect
. The results are shown in
Table 1.
In the table we note that Class 1 methods, which use general purpose local optimizers, are more time consuming than Class 2 methods, as expected. Moreover, this gap increases with the dimension
N. Averagely, Class 1 methods are more accurate than Class 2 methods. Within the Class 2, each adaptive method is faster than the corresponding non adaptive one, as can be seen by comparing the times in column
AD1 with those in column
MS1 and the times in column
AD2 with those in column
MS2. Obviously,
MS1 and
AD1 give lower accuracies than
MS2 and
AD2 respectively, due to a weaker request on the flatness imposed by (
4). By comparing the measures
in column
AD2 with those in column
MS2, we see that
AD2 does not lose accuracy with respect to
MS2.
5.2. The Symmetric NMF
In some applications, matrix
is symmetric, then the objective function to be minimized becomes
, under the constrain
. This problem is known as symmetric NMF (SymNMF). As suggested in [
12], the solution
can be found through a nonsymmetric penalty problem of the form
being a positive parameter which acts on the violation of the symmetry. Hence, applying ANLS, we solve alternatively the two subproblems
In [
12], the sequence of penalizing parameters is constructed by setting
and
is modified according to a geometric progression of the form
with the fixed ratio
. We suggest instead to let
be modified adaptively, as shown in [
13].
Symmetric NMF problems arise naturally in clustering. Given
n points
in an Euclidean space and the number
k of the required clusters, the clustering structure is captured by a symmetric matrix
M, called
similarity matrix, whose elements
represent the similarity between
and
. These similarity values are computed through the Gaussian kernel
where
is a suitable scaling parameter, followed by the normalized cut
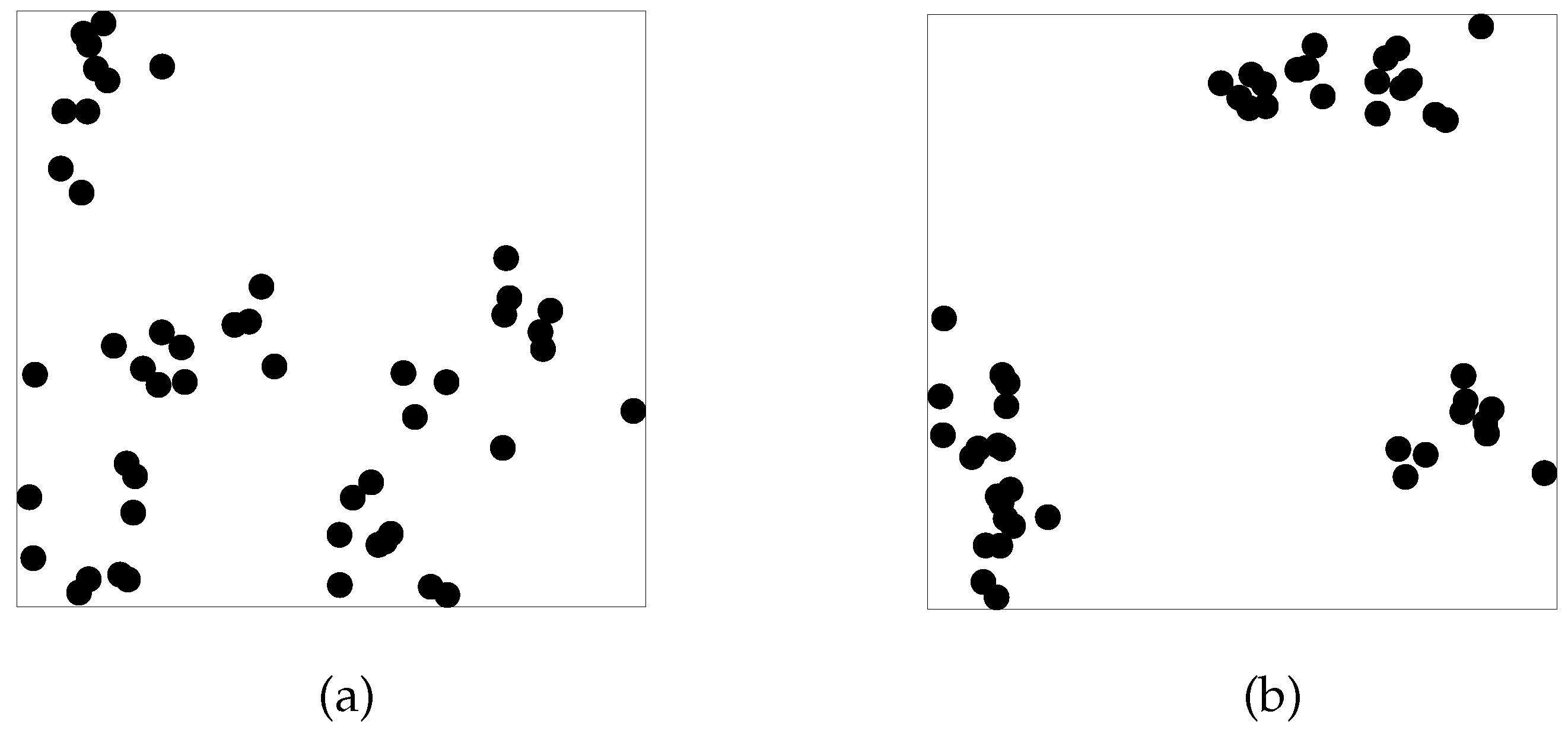
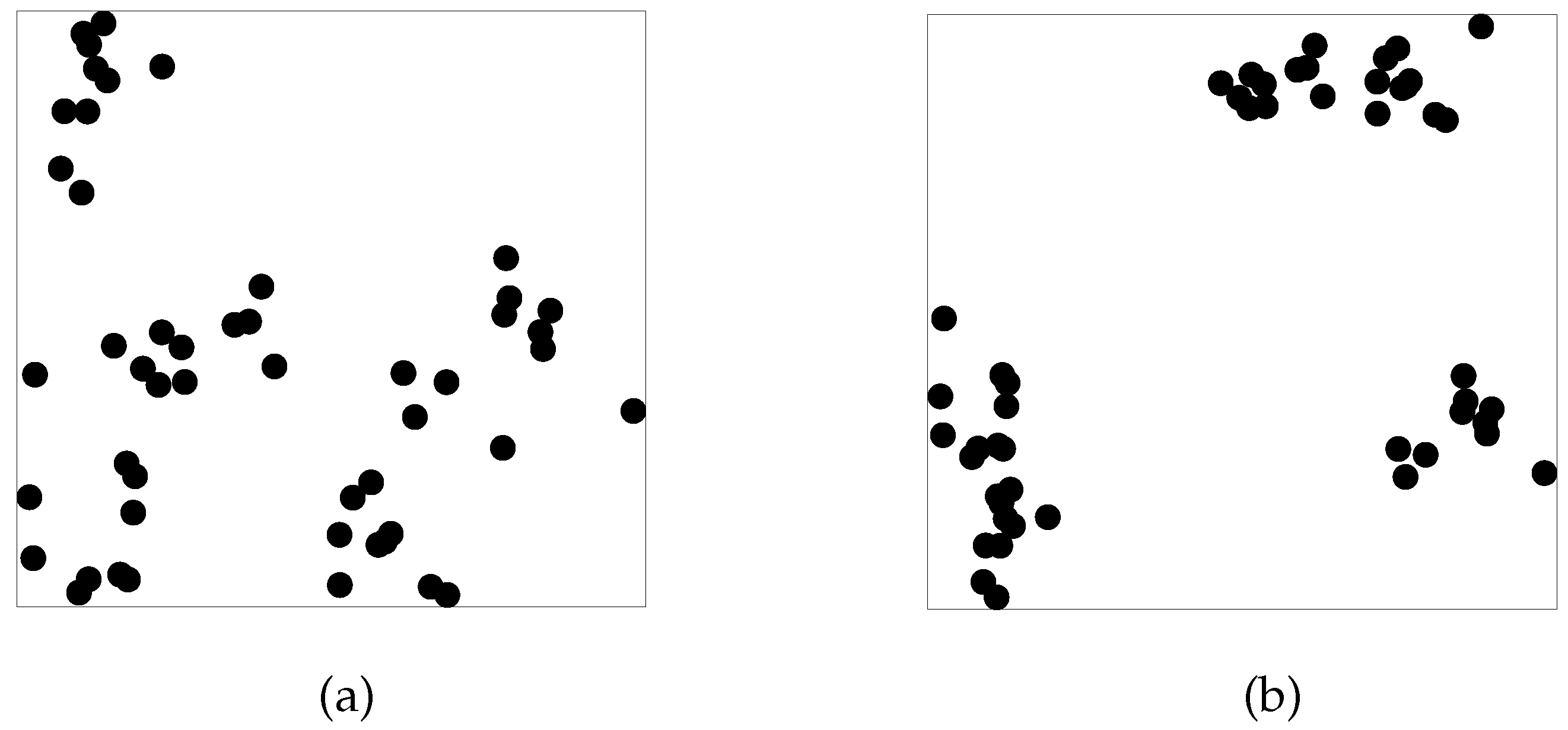
The experimentation deals with two sets
and
of
n points randomly generated in
(see
Figure 2 for
).
Set
is generated with
and set
is generated with
The number of the required clusters is fixed to
for all the cases. The dimension of the solution space is
The results are shown in
Table 2. On these problems, Class 2 methods outperform Class 1 methods in both the computational time and the accuracy. Moreover, by comparing the measures
in column
AD1 with those in column
MS1 and the measures
in column
AD2 with those in column
MS2, we see that, for each value of the tolerance
, the adaptive method and the corresponding non adaptive one share the same accuracy.
5.3. The Nonnegative Factorization of a 3rd-Order Tensor
Let T be a 3rd-order tensor, i.e., a three-dimensional array whose elements are , with , and . A common way to represent graphically T is through its (frontal) slices , , where is the matrix obtained by fixing to k the third index.
If T can be expressed as the outer product of three vectors , and , i.e., , where ∘ denotes the vector outer product, T is called rank-one tensor or triad.
Among the many factorizations of a tensor defined in the literature, we consider here the CANDECOMP/PARAFAC (in the following CP) decomposition (see [
14]) into the sum of triads, which extends in a natural way the decomposition of matrices in sum of dyads. Given an integer
, three matrices
,
and
are computed such that
where
,
and
are the
sth columns of
U,
V and
Z (see [
14,
15]). Elementwise, (
8) is written as
The objective function of the CP decomposition of
T is
The smallest integer
for which (
8) holds with equality, i.e.,
, is the
tensor rank of
T.
By flattening its slices, the elements of
T can be arranged into a matrix. For example, one can leave the
ith index and linearize the two other indices, obtaining a matrix which is denoted by
. Thus,
,
and
are the matrices whose elements are
These matrices are written in a compact way by using the notation of the Khatri-Rao product, defined as follows. Given two matrices
and
, the Khatri-Rao product
is the
matrix
where
and
are the
ith columns of
A and
B respectively, and ⊗ denotes the Kronecker product of two vectors. With this notation (
8) becomes
In the experimentation we consider the nonnegatively constrained CP decomposition and minimize (
9) by applying ANLS as the local minimizer to the three matrices given in (
10). Having fixed nonnegative
and
, the computation proceeds alternating on three combinations as follows
for
For the experimentation, given the integers
m,
n,
ℓ and
h, three matrices
A with columns
,
B with columns
and
C with columns
are generated for
with random elements uniformly distributed over
. The tensor
is then constructed. Given an integer
, the proposed problem requires computing the CP decomposition (
8) of
T into the sum of
triads under nonnegative constraints. The problem is dealt with for the two cases
and
. The following cases are considered
The dimension of the solution space is
In the cases
we expect
. The results are shown in
Table 3. From the point of view of the computational time, the performances of Class 1 and Class 2 methods agree with those seen in the other tables. From the point of view of the accuracy, Class 2 methods with the stronger request
for the tolerance are competitive with Class 1 methods.
5.4. Tensor Factorization for the Matrix Product Complexity
The theory of matrix multiplication is strictly related to tensor algebra. In particular, the concept of tensor rank plays an important role in the determination of the complexity of the product of matrices [
16]. We consider here the case of square matrices.
Given
, the elements of
can be written in the form
where
and
are the vectors obtained by vectorizing columnwise
A and rowwise
B, i.e.,
and
is expressed by the Kronecker product
where the
matrix
has elements
. The associated 3rd order tensor
is the one whose slides are
, i.e., the elements of
T are
, with
. Most elements of
T are null.
A reduction of the representation is obtained when
A is triangular. For example, in the case of an upper triangular matrix
A of size
n,
can be represented by the
elements
with a resulting reduction in the first dimension of the matrices
. If
B is a full matrix, the associated tensor has
elements.
A fact of fundamental relevance is that the complexity of the computation of the product
, i.e., the minimum number of nonscalar multiplications sufficient to compute the product, is equal to the tensor rank of
T. In the experimentation we consider problems of the form (
9) for a given integer
. If the minimum is equal to zero, then the tensor rank of
T is lower than or equal to
. The difficulty which characterizes these problems is due to the presence of large regions of near flatness of
f, leading to a slow convergence to local minima. The difficulty increases when the parameter
decreases.
The dimension of the solution space is when both A and B are full, and is when one of the matrix is triangular. In the tests we consider the following cases with matrices A and B of size and such that .
Problems TF3: A is a triangular matrix and B is a full matrix, with
Problems FF3: A and B are full matrices, with
The low accuracies of Class 1 methods point out the effective difficulty of the problems. In one case a method of Class 1 fails to give an acceptable solution and this fact is marked by the symbol −. In this case there is not a great discrepancy between the computational times of Class 1 methods and non adaptive Class 2 methods, as can be seen by comparing the times in columns NM, DE and SA with those in columns MS1 and MS2. Typically, the adaptive methods lower the computational time while maintaining better accuracies. Only for the first problem, a much better accuracy of AD2 is paid by a much larger computational time.
From the point of view of the accuracy, Class 2 methods definitely outperform Class 1 methods.
5.5. Summary of the Results
First, we analyze the effect of the chosen tolerance on Class 2 methods. The experiments confirm the expectation that stronger tolerance requests, which pay in terms of larger execution time, in general lead to more accurate results. The comparison of the performances of Class 1 and Class 2 methods shows that the accuracy of MS2 and AD2 does not appear to suffer too much with respect to the accuracy of Class 1 methods, in spite of the fact that they enjoy a much smaller execution time.
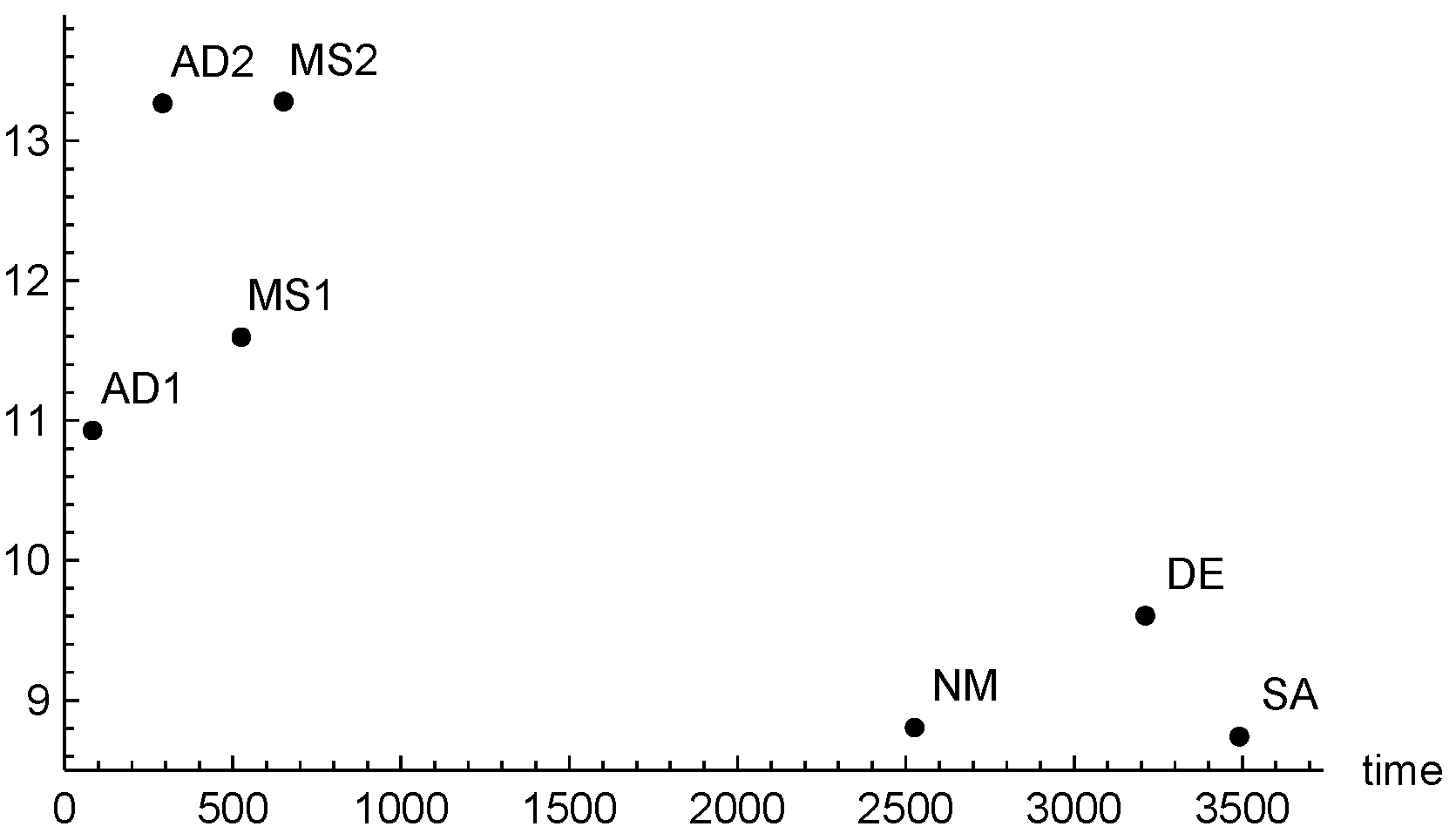
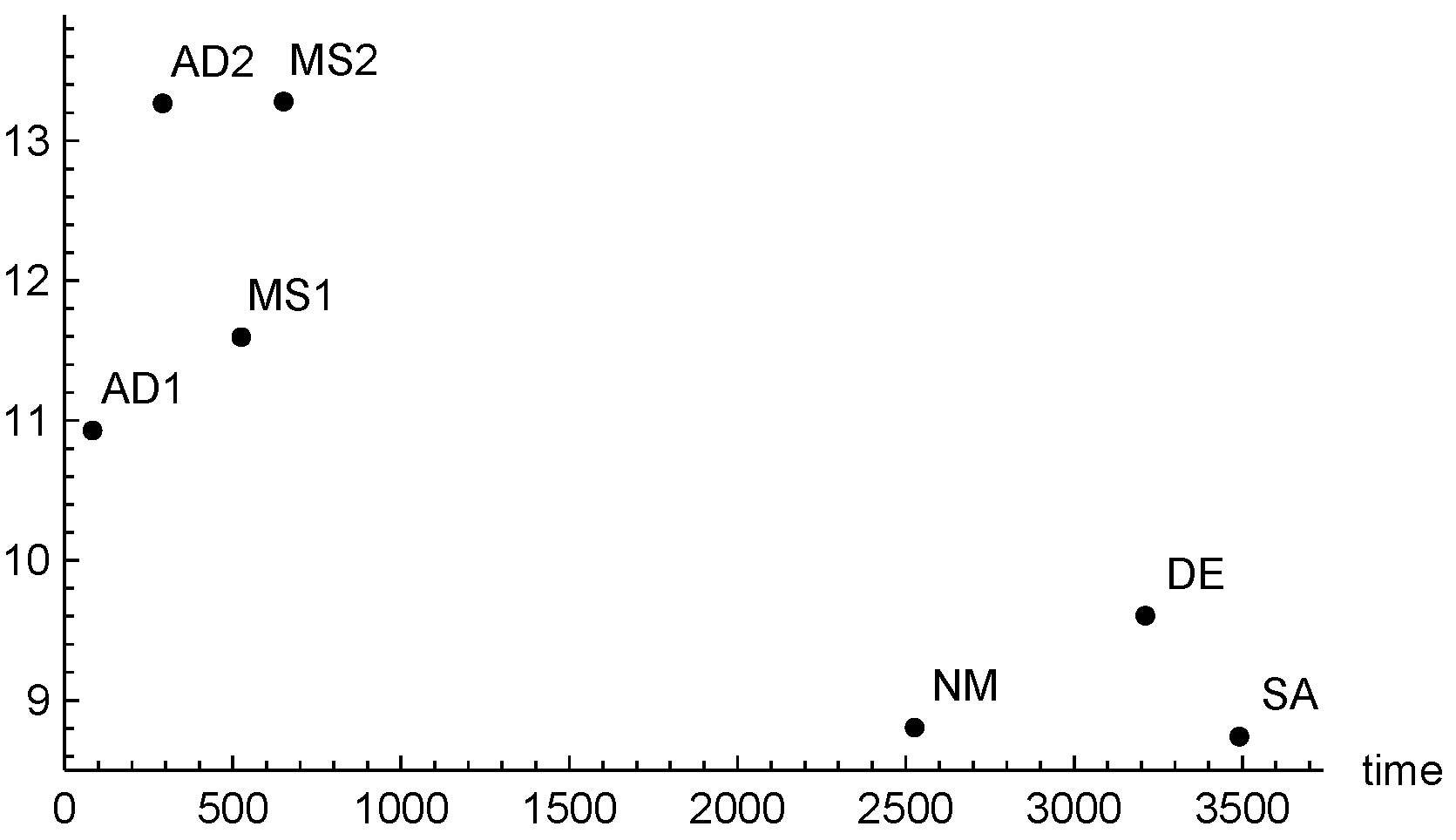
In order to summarize the results of the experimentation, we plot in
Figure 3 the average of all the values of
, taken as a measure of the methods accuracy on all the problems, versus the averaged
. The larger the ordinate value, the more accurate the method.
From the figure we see that, on average, the adaptive procedure AD2 not only is faster, but also gives comparable accuracy with MS2. This is due to the fact that the computational effort of AD2 is focused where it is more useful and is not wasted.
To study how depends on N, we need data corresponding to large values of N. A problem for which it is possible to obtain these data is the symmetric NMF applied to clustering. In fact, in this case it is easy to construct problems of the same type with increasing dimensions.
Figure 4 gives an idea of the time performance of the methods when they are applied to the cluster problem
. Class 2 methods have been run with increasing dimensions until
, corresponding to size
20,000. The execution times of
AD2 (dashed line) and
MS2 (solid line) are plotted together with the times of
NM (solid line), chosen as the representative of Class 1 for
(larger dimensions for Class 1 methods could not be considered). For the lower dimensions, the use of the adaptive method does not give advantages, because of the initialization overhead (due to the
iterations performed for stabilization before starting the adaptive strategy). This is shown by the overlap of the plots of
AD2 and
MS2 in the initial tract.
The lines which appear in the log-log plot suggest that the asymptotical behavior of the computational cost for increasing N is of the form . Very similar values of suggest that the costs of MS2 and NM have roughly the same order, while the cost of AD2 has a lower order. It is evident that the multiplicative constant , whose log is readable from the vertical offset of the lines, of MS2 and AD2 is very lower than the one of NM.


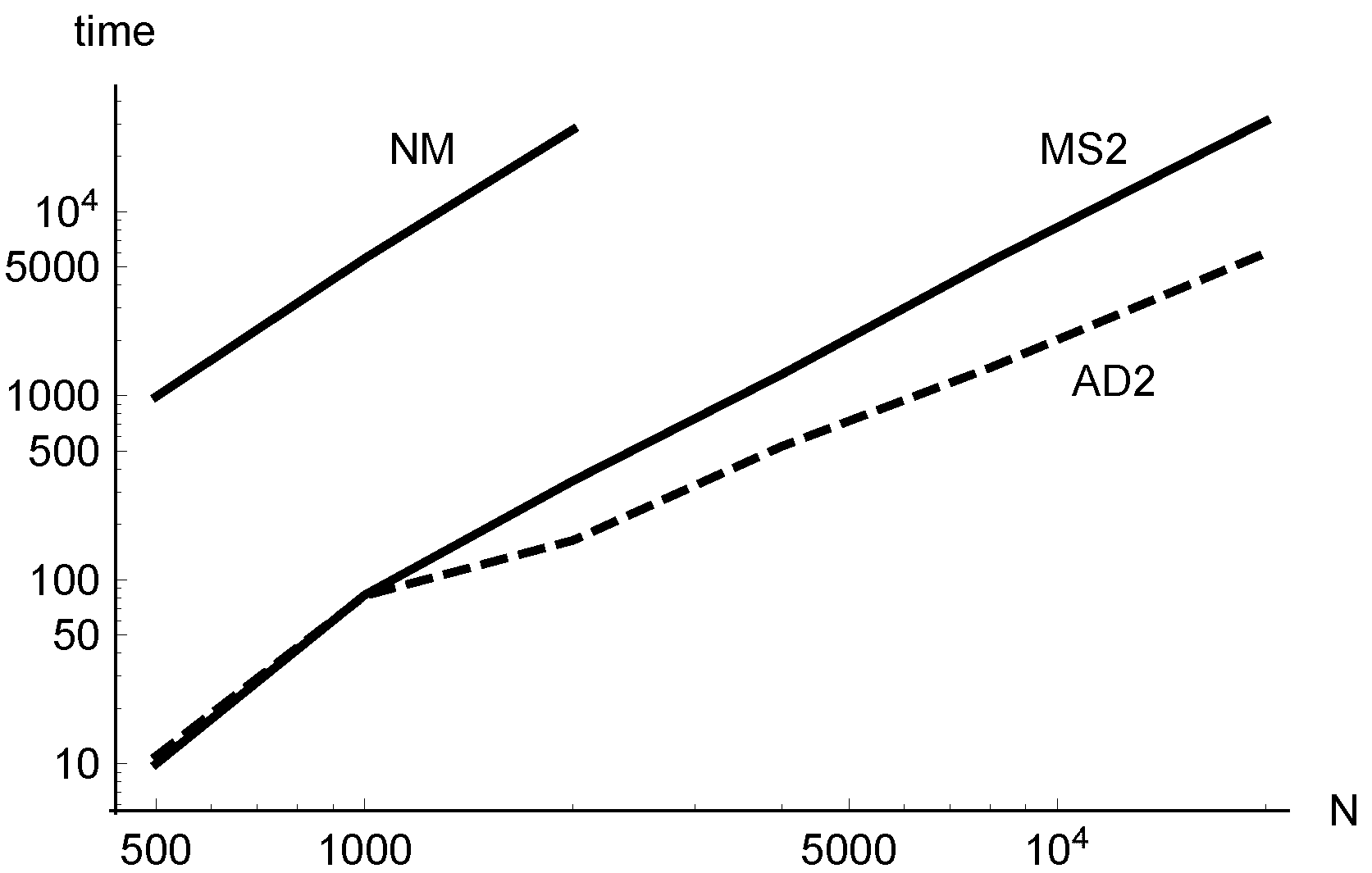

{kind=link}
{kind=link}
{kind=link}
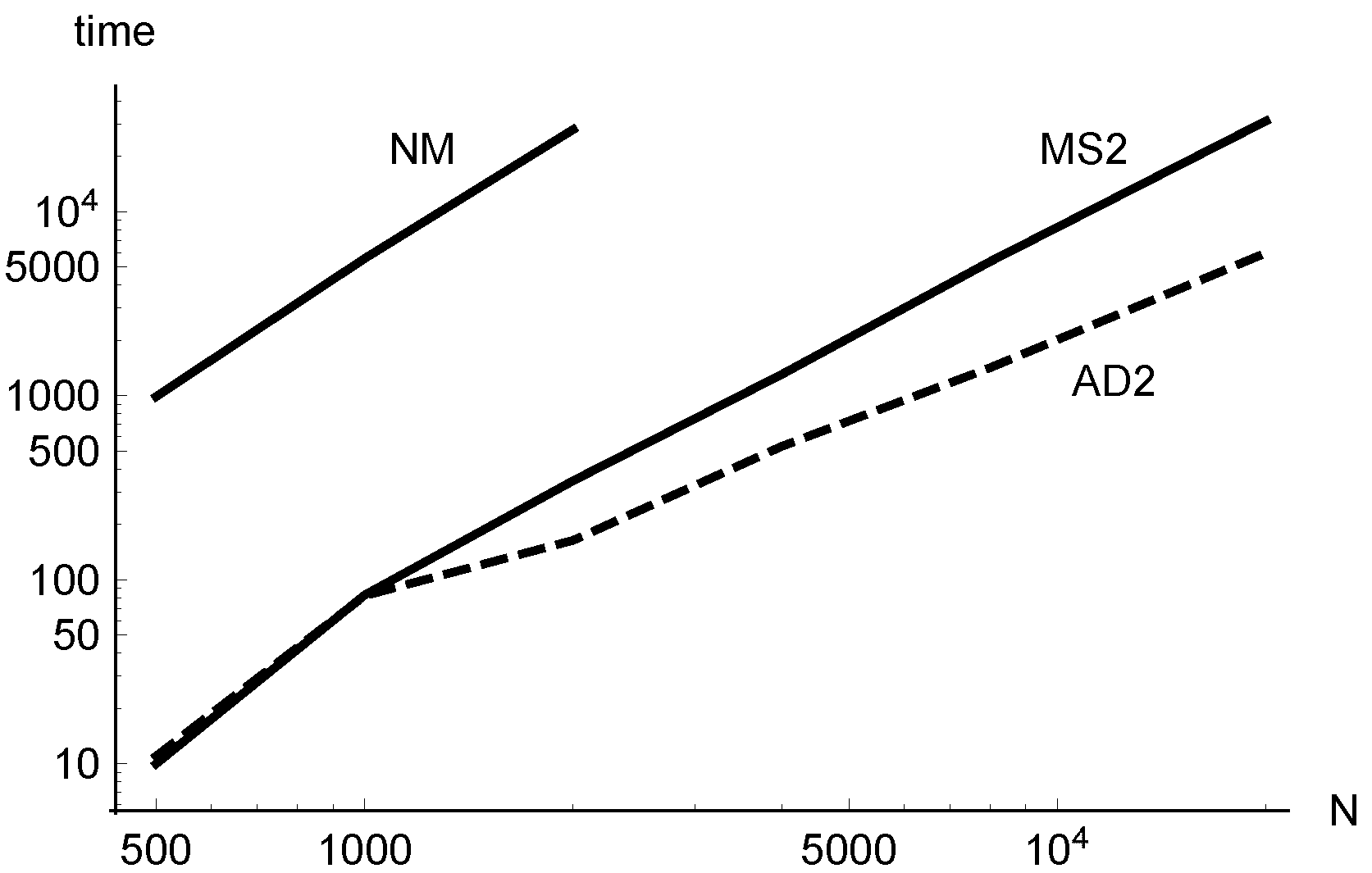{kind=link}