1. Introduction
The typical approach in modeling a real-world problem as a computational problem has, broadly speaking, two steps: (i) abstracting the problem into a mathematical formulation that captures the crux of the real-world problem, and (ii) asking for a best solution to the mathematical problem.
Consider the following scenario: Dr. organizes a panel discussion and has a shortlist of candidates to invite. From that shortlist, Dr. wants to invite as many candidates as possible, such that each of them will bring an individual contribution to the panel. Given two candidates, A and B, it may not be beneficial to invite both A and B, for various reasons: their areas of expertise or opinions may be too similar for both to make a distinguishable contribution, or it may be preferable not to invite more than one person from each institution. It may even be the case that A and B do not see eye-to-eye on some issues which could come up at the discussion, and Dr. wishes to avoid a confrontation.
A natural mathematical model to resolve Dr. ’s dilemma is as an instance of the Vertex Cover problem: each candidate on the shortlist corresponds to a vertex, and for each pair of candidates A and B, we add the edge between A and B if it is not beneficial to invite both of them. Removing a smallest vertex cover in the resulting graph results in a largest possible set of candidates such that each of them may be expected to individually contribute to the appeal of the event.
Formally, a vertex cover of an undirected graph G is any subset of the vertex set of G such that every edge in G has at least one end-point in G. The Vertex Cover problem asks for a vertex cover of the smallest size:
| Vertex Cover |
| Input: | Graph G. |
| Solution: | A vertex cover S of G of the smallest size. |
While the above model does provide Dr. with a set of candidates to invite that is valid in the sense that each invited candidate can be expected to make a unique contribution to the panel, a vast amount of side information about the candidates is lost in the modeling process. This side information could have helped Dr. to get more out of the panel discussion. For instance, Dr. may have preferred to invite more well-known or established people over ‘newcomers’, if they wanted the panel to be highly visible and prestigious; or they may have preferred to have more ‘newcomers’ in the panel, if they wanted the panel to have more outreach. Other preferences that Dr. may have had include: to have people from many different cultural backgrounds, to have equal representation of genders, or preferential representation for affirmative action; to have a variety in the levels of seniority among the attendants, possibly skewed in one way or the other. Other factors, such as the total carbon footprint caused by the participants’ travels, may also be of interest to Dr. . This list could go on and on.
Now, it is possible to plug in some of these factors into the mathematical model, for instance by including weights or labels. Thus, a vertex weight could indicate ‘how well-established’ a candidate is. However, the complexity of the model grows fast with each additional criterion. The classic field of multicriteria optimization [
1] addresses the issue of bundling multiple factors into the objective function, but it is seldom possible to arrive at a balance in the various criteria in a way which captures more than a small fraction of all the relevant side information. Moreover, several side criteria may be conflicting or incomparable (or both); consider in Dr.
’s case ‘maximizing the number of different cultural backgrounds’ vs. ‘minimizing total carbon footprint’.
While Dr. ’s story is admittedly a made-up one, the Vertex Cover problem is in fact used to model conflict resolution in far more realistic settings. In each case, there is a conflict graph G whose vertices correspond to entities between which one wishes to avoid a conflict of some kind. There is an edge between two vertices in G if and only if they could be in conflict, and finding and deleting a smallest vertex cover of G yields a largest conflict-free subset of entities. We describe three examples to illustrate the versatility of this model. In each case, it is intuitively clear, just like in Dr. ’s problem, that formulating the problem as Vertex Cover results in a lot of significant side information being thrown away, and that while finding a smallest vertex cover in the conflict graph will give a valid solution, it may not really help in finding a best solution, or even a reasonably good solution. We list some side information that is lost in the modeling process; the reader should find it easy to come up with any amount of other side information that would be of interest, in each case.
Air traffic control. Conflict graphs are used in the design of decision support tools for aiding Air Traffic Controllers (ATCs) in preventing untoward incidents involving aircraft [
2,
3]. Each node in the graph
G in this instance is an aircraft, and there is an edge between two nodes if the corresponding aircraft are at risk of interfering with each other. A vertex cover of
G corresponds to a set of aircraft that can be issued
resolution commands which ask them to change course, such that afterwards there is no risk of interference.
In a situation involving a large number of aircraft, it is unlikely that every choice of ten aircraft to redirect is equally desirable. For instance, in general, it is likely that (i) it is better to ask smaller aircraft to change course in preference to larger craft, and (ii) it is better to ask aircraft which are cruising to change course, in preference to those which are taking off or landing.
Wireless spectrum allocation. Conflict graphs are a standard tool in figuring out how to distribute wireless frequency spectrum among a large set of wireless devices so that no two devices whose usage could potentially interfere with each other are allotted the same frequencies [
4,
5]. Each node in
G is a user, and there is an edge between two nodes if (i) the users request the same frequency, and (ii) their usage of the same frequency has the potential to cause interference. A vertex cover of
G corresponds to a set of users whose requests can be denied, such that afterwards there is no risk of interference.
When there is large collection of devices vying for spectrum, it is unlikely that every choice of ten devices to deny the spectrum is equally desirable. For instance, it is likely that denying the spectrum to a remote-controlled toy car on the ground is preferable to denying the spectrum to a drone in flight.
Managing inconsistencies in database integration. A database constructed by integrating data from different data sources may end up being inconsistent (that is, violating specified integrity constraints) even if the constituent databases are individually consistent. Handling these inconsistencies is a major challenge in database integration, and conflict graphs are central to various approaches for restoring consistency [
6,
7,
8,
9]. Each node in
G is a database item, and there is an edge between two nodes if the two items together form an inconsistency. A vertex cover of
G corresponds to a set of database items in whose
absence the database achieves consistency.
In a database of large size, it is unlikely that all data are created equal; some database items are likely to be of better relevance or usefulness than others, and so it is unlikely that every choice of ten items to delete is equally desirable.
Getting back to our first example, it seems difficult to help Dr. with their decision by employing the ‘traditional’ way of modeling computational problems, where one looks for one best solution. If, on the other hand, Dr. was presented with a small set of good solutions that, in some sense, are far apart, then they might hand-pick the list of candidates that they consider the best choice for the panel and make a more informed decision. Moreover, several forms of side-information may only become apparent once Dr. is presented some concrete alternatives, and are more likely to be retrieved from alternatives that look very different. That is, a bunch of good quality, dissimilar solutions may end up capturing a lot of the “lost” side information. In addition, this applies to each of the other three examples as well. In each case, finding one best solution could be of little utility in solving the original problem, whereas finding a small set of solutions, each of good quality, which are not too similar to one another may offer much more help.
To summarize, real-world problems typically have complicated side constraints, and the optimality criterion may not be clear. Therefore, the abstraction to a mathematical formulation is almost always a simplification, omitting important side information. There are at least two obstacles to simply adapting the model by incorporating these secondary criteria into the objective function or taking into account the side constraints: (i) they make the model complicated and unmanagable, and, (ii) more importantly, these criteria and constraints are often not precisely formulated, potentially even unknown a priori. There may even be no sharp distinction between optimality criteria and constraints (the so-called “soft constraints”).
One way of dealing with this issue is to present a small number r of good solutions and let the user choose between them, based on all the experience and additional information that the user has and that is ignored in the mathematical model. Such an approach is useful even when the objective can be formulated precisely, but is difficult to optimize: After generating r solutions, each of which is good enough according to some quality criterion, they can be compared and screened in a second phase, evaluating their exact objective function or checking additional side constraints. In this context, it makes little sense to generate solutions that are very similar to each other and differ only in a few features. It is desirable to present a diverse variety of solutions.
It should be clear that the issue is scarcely specific to
Vertex Cover. Essentially
any computational problem motivated by practical applications likely has the same issue: the modeling process throws out so much relevant side information that any algorithm that finds just one optimal solution to an input instance may not be of much use in solving the original problem in practice. One scenario where the traditional approach to modeling computational problems fails completely is when computational problems may combined with a human sense of aesthetics or intuition to solve a task, or even to stimulate inspiration. Some early relevant work is on the problem of designing a tool which helps an architect in creating a floor plan which satisfies a specified set of constraints. In general, the number of feasible floor plans—those which satisfy constraints imposed by the plot on which the building has to be erected, various regulations which the building should adhere to, and so on—would be too many for the architect to look at each of them one by one. Furthermore, many of these plans would be very similar to one another, so that it would be pointless for the architect to look at more than one of these for inspiration. As an alternative to optimization for such problems, Galle proposed a “Branch & Sample” algorithm for generating a “limited, representative sample of solutions, uniformly scattered over the entire solution space” [
10].
The Diverse X Paradigm. Mike Fellows has proposed
the Diverse X Paradigm as a solution for these issues and others [
11]. In this paradigm, “
X” is a placeholder for an optimization problem, and we study the complexity—specifically, the fixed-parameter tractability—of the problem of finding a few different good quality solutions for
X. Contrast this with the traditional approach of looking for just one good quality solution. Let
X denote an optimization problem where one looks for a minimum-size subset of some set;
Vertex Cover is an example of such a problem. The generic form of
X is then:
| X |
| Input: | An instance I of X. |
| Solution: | A solution S of I of the smallest size. |
Here, the form that a “solution S of I” takes is dictated by the problem X; compare this with the earlier definition of Vertex Cover.
The diverse variant of problem X, as proposed by Fellows, has the form:
| Diverse X |
| Input: | An instance I of X, and positive integers . |
| Parameter: | |
| Solution: | A set of r solutions of I, each of size at most k, such that a diversity measure of is at least t. |
Note that one can construct diverse variants of other kinds of problems as well, following this model: it doesn’t have to be a minimization problem, nor does the solution have to be a subset of some kind. Indeed, the example about floor plans described above has neither of these properties. What is relevant is that one should have (i) some notion of “good quality” solutions (for X, this equates to a small size) and (ii) some notion of a set of solutions being “diverse”.
Diversity measures. The concept of diversity appears also in other fields, and there are many different ways to measure the diversity of a collection. For example, in ecology, the diversity of a set of species (“biodiversity”) is a topic that has become increasingly important in recent times—see, for example, Solow and Polasky [
12].
Another possible viewpoint, in the context of multicriteria optimization, is to require that the sample of solutions should try to represent the
whole solution space. This concept can be quantified for example by the geometric
volume of the represented space [
13,
14], or by the
discrepancy [
15]. See ([
16], Section 3) for an overview of diversity measures in multicriteria optimization.
In this paper, we follow the simple possibility of looking for a collection of good solutions that have large
distances from each other, in a sense that will be made precise below, see Equations (
1) and (
2). Direction (
2), i.e., taking the pairwise sum of all Hamming distances, has been taken by many practical papers in the area of genetic algorithms—see, e.g., [
17,
18]. This now classical approach can be traced as far back as 1992 [
19]. In [
20], it has been boldly stated that this measure (and its variations) is one of the most broadly used measures in describing population diversity within genetic algorithms. One of its advantages is that it can be computed very easily and efficiently unlike many other measures, e.g., some geometry or discrepancy based measures.
Our Problems and Results
In this work, we focus on diverse versions of two minimization problems, d-Hitting Set and Feedback Vertex Set, whose solutions are subsets of a finite set. d-Hitting Set is in fact a class of such problems which includes Vertex Cover, as we describe below. We will consider two natural diversity measures for these problems: the minimum Hamming distance between any two solutions, and the sum of pairwise Hamming distances of all the solutions.
The Hamming distance between two sets S and , or the size of their symmetric difference, is
We use
to denote the minimum Hamming distance between any pair of sets in a collection of finite sets, and
to denote the sum of all pairwise Hamming distances. (In
Section 5, we will discuss some issues with the latter formulation.)
A feedback vertex set of a graph G is any subset of the vertex set of G such that the graph obtained by deleting the vertices in S is a forest; that is, it contains no cycle.
| Feedback Vertex Set |
| Input: | A graph G. |
| Solution: | A feedback vertex set of G of the smallest size. |
More generally, a hitting set of a collection of subsets of a universe U is any subset such that every set in the family has a non-empty intersection with S. For a fixed positive integer d, the d-Hitting Set problem asks for a hitting set of the smallest size of a family of d-sized subsets of a finite universe U:
| d-Hitting Set |
| Input: | A finite universe U and a family of subsets of U, each of size at most d. |
| Solution: | A hitting set S of of the smallest size. |
Observe that both Vertex Cover and Feedback Vertex Set are special cases of finding a smallest hitting set for a family of subsets. Vertex Cover is also an instance of d-Hitting Set, with : the universe U is the set of vertices of the input graph and the family consists of all sets , where is an edge in G. There is no obvious way to model Feedback Vertex Set as a d-Hitting Set instance, however, because the cycles in the input graph are not necessarily of the same size.
In this work, we consider the following problems in the Diverse X paradigm. Using as the diversity measure, we consider Diverse d-Hitting Set and Diverse Feedback Vertex Set, where X is d-Hitting Set and Feedback Vertex Set, respectively. Using as the diversity measure, we consider Min-Diverse d-Hitting Set and Min-Diverse Feedback Vertex Set, where X is d-Hitting Set and Feedback Vertex Set, respectively.
In each case, we show that the problem is fixed-parameter tractable (), with the following running times:
Theorem 1. Diversed-Hitting Setcan be solved in time .
Theorem 2. Diverse Feedback Vertex Setcan be solved in time .
Theorem 3. Min-Diversed-Hitting Setcan be solved in time
Theorem 4. Min-Diverse Feedback Vertex Setcan be solved in time .
Defining the diverse versions Diverse Vertex Cover and Min-Diverse Vertex Cover of Vertex Cover in a similar manner as above, we get
Corollary 1. Diverse Vertex Covercan be solved in time .Min-Diverse Vertex Covercan be solved in time
Related Work. The parameterized complexity of finding a diverse collection of good-quality solutions to algorithmic problems seems to be largely unexplored. To the best of our knowledge, the only existing work in this area consists of: (i) a privately circulated manuscript by Fellows [
11] which introduces the Diverse
X Paradigm and makes a forceful case for its relevance, and (ii) a manuscript by Baste et al. [
21] which applies the Diverse
X Paradigm to
vertex-problems with the
treewidth of the input graph as an extra parameter. In this context, a
vertex-problem is any problem in which the input contains a graph
G and the solution is some subset of the vertex set of
G that satisfies some problem-specific properties. Both
Vertex Cover and
Feedback Vertex Set are vertex-problems in this sense, as are many other graph problems. The
treewidth of a graph is, informally put, a measure of how tree-like the graph is. See, e.g., ([
22], Chapter 7) for an introduction of the use of the treewidth of a graph as a parameter in designing
algorithms. The work by Baste et al. [
21] shows how to convert essentially any treewidth-based dynamic programming algorithm, for solving a vertex-problem, into an algorithm for computing a diverse set of
r solutions for the problem, with the diversity measure being the sum
of Hamming distances of the solutions. This latter algorithm is
in the combined parameter
, where
w is the treewidth of the input graph. As a special case, they obtain a running time of
for
Diverse Vertex Cover. Furthermore, they show that the
r-
Diverse versions (i.e., where the diversity measure is
) of a handful of problems have polynomial kernels. In particular, they show that
Diverse Vertex Cover has a kernel with
vertices, and that
Diverse d-
Hitting Set has a kernel with a universe size of
.
Organization of the rest of the paper. In
Section 2, we list some definitions which we use in the rest of the paper. In
Section 3, we describe a generic framework which can be used for computing solution families of maximum diversity for a variety of problems whose solutions form subsets of some finite set. We prove Theorem 1 in
Section 3.3 and Theorem 2 in
Section 4. In
Section 5, we discuss some potential pitfalls in using
as a measure of diversity. In
Section 6, we prove Theorems 3 and 4. We conclude in
Section 7.
2. Preliminaries
Given two integers p and q, we denote by the set of all integers r such that holds. Given a graph G, we denote by (resp. ) the set of vertices (resp. edges) of G. For a subset , we use to denote the subgraph of G induced by S, and for the graph . A set is a vertex cover (resp. a feedback vertex set) if has no edge (resp. no cycle). Given a graph G and a vertex v such that v has exactly two neighbors, say w and , contractingv consists of removing the edges and , removing v, and adding the edge . Given a graph G and a vertex , we denote by the degree of v in G. For two vertices in a connected graph G, we use to denote the distance between u and v in G, which is the length of a shortest path in G between u and v.
A deepest leaf in a tree T is a vertex such that there exists a root satisfying . A deepest leaf in a forest F is a deepest leaf in some connected component of F. A deepest leaf v has the property that there is another leaf in the tree at distance at most 2 from v unless v is an isolated vertex or v’s neighbor has degree 2.
The objective function
in (
2) has an alternative representation in terms of frequencies of occurrence [
21]: If
is the number of sets of
in which
v appears, then
Auxiliary problems. We define two auxiliary problems that we will use in some of the algorithms presented in
Section 3. In the
Maximum Cost Flow problem, we are given a directed graph
G, a
target , a
source vertex , a
sink vertex , and for each edge
, a
capacity , and a
cost . A
-flow, or simply
flow in
G is a function
, such that for each
,
, and for each vertex
,
. The
value of the flow
f is
and the
cost of
f is
. The objective of the
Maximum Cost Flow problem is to find the maximum cost
-flow of value
d.
The second problem is the Maximum Weight b-Matching problem. Here, we are given an undirected edge-weighted graph G, and for each vertex , a supply . The goal is to find a set of edges of maximum total weight such that each vertex is incident with at most edges in M.
3. A Framework for Maximally Diverse Solutions
In this section, we describe a framework for computing solution families of maximum diversity for a variety of hitting set problems. This framework requires that the solutions form a family of subsets of a ground set U that is upward closed: any superset of a solution S is also a solution.
The approach is as follows: In a first phase, we enumerate the class of all minimal solutions of size at most k. (A larger class is also fine as long as it is guaranteed to contain all minimal solutions of size at most k). Then, we form all r-tuples . For each such family , we try to augment it to a family under the constraints and , for each , in such a way that is maximized.
For this augmentation problem, we propose a network flow model that computes an optimal augmentation in polynomial time, see
Section 3.1. This has to be repeated for each family,
times. The first step, the generation of
, is problem-specific.
Section 3.3 shows how to solve it for
d-
Hitting Set. In
Section 4, we will adapt our approach to deal with a
Feedback Vertex Set.
3.1. Optimal Augmentation
Given a universe U and a set of subsets of U, the problem consists of finding an r-tuple that maximizes , over all r-tuples such that, for each , , and there exists such that .
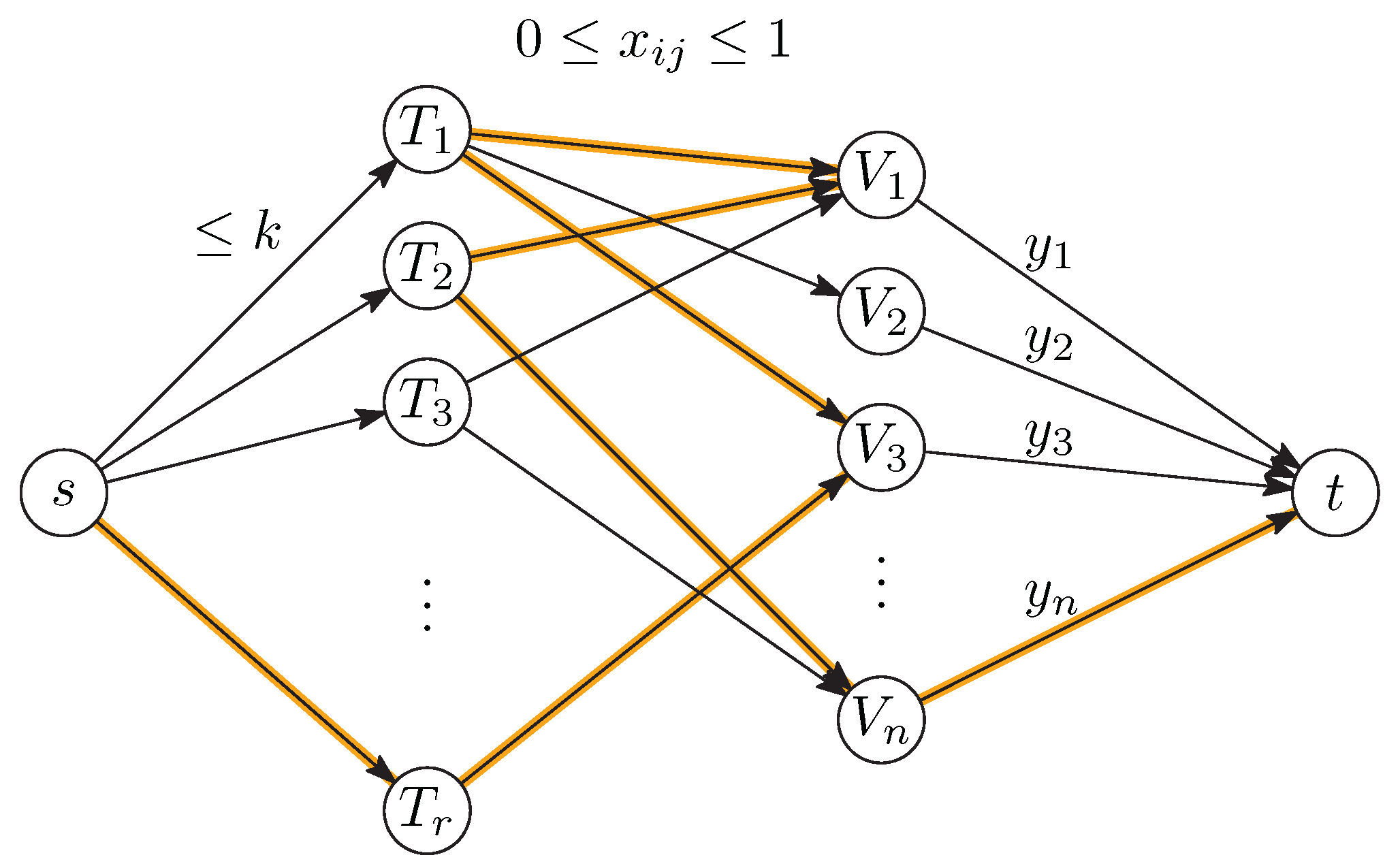
Theorem 5. Let U be a finite universe, r and k be two integers, and be a set of s subsets of U. can be solved in time .
Proof. The algorithm that proves Theorem 5 starts by enumerating all r-tuples of elements from . For each of these r-tuples, we try to augment each , using elements of U, in such a way that the diversity d of the resulting tuple is maximized and such that, for each , and . It is clear that this algorithm will find the solution to .
We show how to model this problem as a maximum-cost network flow problem with piecewise linear concave costs. This problem can be solved in polynomial time. (See, for example, [
23] for basic notions about network flows).
Without loss of generality, let
. We use a variable
to decide whether element
j of
U should belong to set
. In an optimal flow, these values are integral. Some of these variables are already fixed because
must contain
:
The size of
must not exceed
k:
Finally, we can express the number
of sets
in which an element
j occurs:
These variables
are the variables in terms of which the objective function (
3) is expressed:
These constraints can be modeled by a network as shown in
Figure 1. There are nodes
representing the sets
and a node
for each element
. In addition, there is a source
s and a sink
t. The arcs emanating from
s have capacity
k. Together with the flow conservation equations at the nodes
, this models the constraints (
5). Flow conservation at the nodes
gives rise to the flow variables
in the arcs leading to
t according to (
6). The arcs with fixed flow (
4) could be eliminated from the network, but, for ease of notation, we leave them in the model. The only arcs that carry a cost are the arcs leading to
t, and the costs are given by the concave function (
7).
There is now a one-to-one correspondence between integral flows from
s to
t in the network and solutions
, and the cost of the flow is equal to the diversity (
2) or (
3). We are thus looking for a flow of maximum cost. The
value of the flow (to total flow out of
s) can be arbitrary. (It is equal to the sum of the sizes of the sets
.)
The concave arc costs (
7) on the arcs leading to
t can be modeled in a standard way by multiple arcs. Denote the concave cost function by
, for
. Then, each arc
in the last layer is replaced by
r parallel arcs of capacity 1 with costs
,
, …,
. This sequence of values
is decreasing, starting out with positive values and ending with negative values. If the total flow along such a bundle is
y, the maximum-cost way to distribute this flow is to fill the first
y arcs to capacity, for a total cost of
, as desired.
An easy way to compute a maximum-cost flow is the longest augmenting path method. (Commonly, it is presented as the shortest augmenting path method for the minimum-cost flow). This holds for the classical flow model where the cost on each arc is a linear function of the flow. An augmenting path is a path in the residual network with respect to the current flow, and the cost coefficient of an arc in such a path must be taken with opposite sign if it is traversed in the direction opposite to the original graph.
Proposition 1 (The shortest augmenting path algorithm, cf. [
23] (Theorem 8.12))
. Suppose a maximum-cost flow among all flows of value v from s to t is given. Let P be a maximum-cost augmenting path from s to t. If we augment the flow along this path, this results in a new flow, of some value . Then, the new flow is a maximum-cost flow among all flows of value from s to t. Let us apply this algorithm to our network. We initialize the constrained flow variables
according to Equation (
4) to 1 and all other variables
to 0. This corresponds to the original solution
, and it is clearly the optimal flow of value
because it is the only feasible flow of this value.
We can now start to find augmenting paths. Our graph is bipartite, and augmenting paths have a very simple structure: They start in s, alternate back and forth between the T-nodes and the V-nodes, and finally make a step to t. Moreover, in our network, all costs are zero except in the last layer, and an augmenting path contains precisely one arc from this layer. Therefore, the cost of an augmenting path is simply the cost of the final arc.
The flow variables in the final layer are never decreased. The resulting algorithm has therefore a simple greedy-like structure. Starting from the initial flow, we first try to saturate as many of the arcs of cost as possible. Next, we try to saturate as many of the arcs of cost as possible, and so on. Once the incremental cost becomes negative, we stop.
Trying to find an augmenting path whose last arc is one of the arcs of cost , for fixed y, is a reachability problem in the residual graph, and it can be solved by graph search in time because the network has vertices. Every augmentation increases the flow value by 1 unit. Thus, there are at most augmentations, for a total runtime of . □
3.2. Faster Augmentation
We can obtain faster algorithms by using more advanced network algorithms from the literature. We will derive one such algorithm here. The best choice depends on the relation between n, k, and r. We will apply the following result about b-matchings, which are generalizations of matchings: Each node v has a given supply , specifying that v should be incident to at most v edges.
Proposition 2 ([
24])
. A maximum-weight b-matching in a bipartite graph with nodes on the two sides of the bipartition and M edges that have integer weights between 0 and W can be found in time . We will describe below how the network flow problem from above can be converted into a b-matching problem with plus nodes and edges of weight at most . Plugging these values into Proposition 2 gives a running time of for finding an optimal augmentation. This improves over the run time from the previous section unless r is extremely large (at least ).
From the network of
Figure 1, we keep the two layers of nodes
and
. Each vertex
gets a supply of
, and each vertex
gets a supply of
. To mimic the piecewise linear costs on the arcs
in the original network, we introduce
r parallel
slack edges from a new source vertex
to each vertex
. The costs are as follows. Let
with
denote the costs in the last layer of the original network, and let
. Since
, this is larger than all costs. Then, every edge
from the original network gets a weight of
, and the
r new slack edges entering each
get positive weights
. We set the supply of the extra source node to
, which imposes no constraint on the number of incident edges.
Now, suppose that we have a solution for the original network in which the total flow into vertex
is
y. In the corresponding
b-matching, we can then use
=
of the slack edges incident to
. The
maximum-weight slack edges have weights
. The total weight of the edges incident to
is therefore
using the equation
. Thus, up to an addition of the constant
, the maximum weight of a
b-matching agrees with the maximum cost of a flow in the original network.
3.3. Diverse Hitting Set
In this section, we show how to use the optimal augmentation technique developed in
Section 3 to solve the
Diverse d-
Hitting Set. For this, we use the following folklore lemma about minimal hitting sets.
Lemma 1. Let be an instance ofd-Hitting Set, and let k be an integer. There are at most inclusion-minimal hitting sets of of size at most k, and they can all be enumerated in time .
Combining Lemma 1 and Theorem 5, we obtain the following result.
Theorem 1. Diversed-Hitting Setcan be solved in time .
Proof. Using Lemma 1, we can construct the set of all inclusion-minimal hitting sets of , each of size at most k. Note that the size of is bounded by . As every superset of an element of is also a hitting set, the theorem follows directly from Theorem 5. □
4. Diverse Feedback Vertex Set
A
feedback vertex set (FVS) (also called a
cycle cutset) of a graph
G is any subset
of vertices of
G such that every cycle in
G contains at least one vertex from
S. The graph
obtained by deleting
S from
G is thus an acyclic graph. Finding an FVS of small size is an NP-hard problem [
25] with a number of applications in Artificial Intelligence, many of which stem from the fact that many hard problems become easy to solve in acyclic graphs. An example for this is the Propositional Model Counting (or #SAT) problem that asks for the number of satisfying assignments for a given CNF formula, and has a number of applications, for instance in planning [
26,
27] and in probabilistic inference problems such as Bayesian reasoning [
28,
29,
30,
31]. A popular approach to solving #SAT consists of first finding a small FVS
S of the CNF formula. Assigning values to all the variables in
S results in an acyclic instance of CNF. The algorithm assigns all possible sets of values to the variables in
S, computes the number of satisfying assignments of the resulting acyclic instances, and returns the sum of these counts [
32].
In this section, we focus on the Diverse Feedback Vertex Set problem and prove the following theorem.
Theorem 2. thm:fvsDiverse Feedback Vertex Setcan be solved in time .
In order to solve r-Diverse k-Feedback Vertex Set, one natural way would be to generate every feedback vertex set of size at most k and then check which set of k solutions provide the required sum of Hamming distances. Unfortunately, the number of feedback vertex sets is not parameterized by k. Indeed, one can consider a graph containing k cycle of size , leading to different feedback vertex sets of size k.
We avoid this problem by generating all such small feedback vertex sets up to some equivalence of degree two vertices. We obtain an exact and efficient description of all feedback vertex sets of size at most k, which is formally captured by Lemma 2. A class of solutions of a graph G, is a pair such that and is a function such that for each , , and for each , , . Given a class of solutions , we define . A class of FVS solutions is a class of solutions such that each is a feedback vertex set of G. Moreover, if and , we say that is described by . Note that is also a feedback vertex set. In a class of FVS solutions , the meaning of the function ℓ is that, for each cycle C in G, there exists such that each element of hits C. This allows us to group related solutions into only one set .
Lemma 2. Let G be a n-vertex graph. There exists a set of classes of FVS solutions of G of size at most such that each feedback vertex set of size at most k is described by an element of . Moreover, can be constructed in time .
Proof. Let
G be a
n-vertex graph. We start by generating a feedback vertex set
of size at most
k. The current best deterministic algorithm for this by Kociumaka and Pilipczuk [
33] finds such a set in time
. In the following, we use the ideas used for the iterative compression approach [
34].
For each subset , we initiate a branching process by setting , , and . Observe that, initially, as and , the graph has at most k components. In the branching process, we will add more vertices to A and B, and we will remove vertices and edges from , but we will maintain the property that and . The set C will always denote the vertex set . Note that is initially a forest; we ensure that it always remains a forest.
We also initialize a function by setting for each . This function will keep information about vertices that are deleted from G. While searching for a feedback vertex set, we consider only feedback vertex sets that contain all vertices of A but no vertex of B. Vertices in C are still undecided. The function ℓ will maintain the invariant that, for each , , and, for each , all vertices of intersect at exactly the same cycles in . Moreover, for each , the value is fixed and will not be modified anymore in the branching process. During the branching process, we will progressively increase the size of A, B, and the sets , .
By reducing , we mean that we apply the following rules exhaustively.
If there is a such that , we delete v from .
If there is an edge such that , we contract u in and set .
These are classical preprocessing rules for the
Feedback Vertex Set problem; see, for instance, ([
22], Section 9.1). Indeed, vertices of degree one cannot appear in a cycle, and consecutive vertices of degree 2 hit exactly the same cycles. After this preprocessing, there are no adjacent degree-two vertices and no degree-one vertices in
C. (Degrees are measured in
).
We start to describe the branching procedure. We work on the tuple . After each step, the value will increase, where denotes the number of connected components of .
At each step of the branching, we do the following. If or if contains a cycle, we immediately stop this branch as there is no solution to be found in it. If A is a feedback vertex set of size at most k, then is a class of FVS solutions, we add it to and stop working on this branch. Otherwise, we reduce . We pick a deepest leaf v in and apply one of the two following cases, depending on the vertex v:
Case 1: The vertex v has at least two neighbors in B (in the graph ).
If there is a path in B between two neighbors of v, then we have to put v in A, as otherwise this path together with v will induce a cycle. If there is no such path, we branch on both possibilities, inserting v either into A or into B.
Case 2: The vertex v has at most one neighbor in B.
Since v is a leaf in , it has at most one neighbor also in C. On the other hand, we know that v has degree at least 2 in . Thus, v has exactly one neighbor in B and one neighbor in C, for a degree of 2 in . Let p be the neighbor in C. Again, as we have reduced , the degree of p in is at least 3. Thus, either it has a neighbor in B, or, as v is a deepest leaf, it has another child, say w that is also a leaf in , and w has therefore a neighbor in B. We branch on the at most possibilities to allocate v, p, and w if considered, between A and B, taking care not to produce a cycle in B.
In both cases, either we put at least one vertex in A, and so increases by one, or all considered vertices are added to B. In the latter case, the considered vertices are connected, at least two of them have a neighbor in B, and no cycles were created; therefore, the number of components in B drops by one. Thus, increases by at least one. As , there can be at most branching steps.
Since we branch at most times and at each branch we have at most possibilities, the branching tree has at most leaves. Thus, for each of the at most subsets of F, we add at most elements to .
It is clear that we have obtained all solutions of FVS and they are described by the classes of FVS solutions in , which is of size . □
Proof of Theorem 2. We generate all r-tuples of the classes of solutions given by Lemma 2, with repetition allowed.
We now consider each
r-tuple
and try to pick an appropriate solution
from each class of solutions
,
, in such a way that the diversity of the resulting tuple of feedback vertex sets
is maximized. The network of
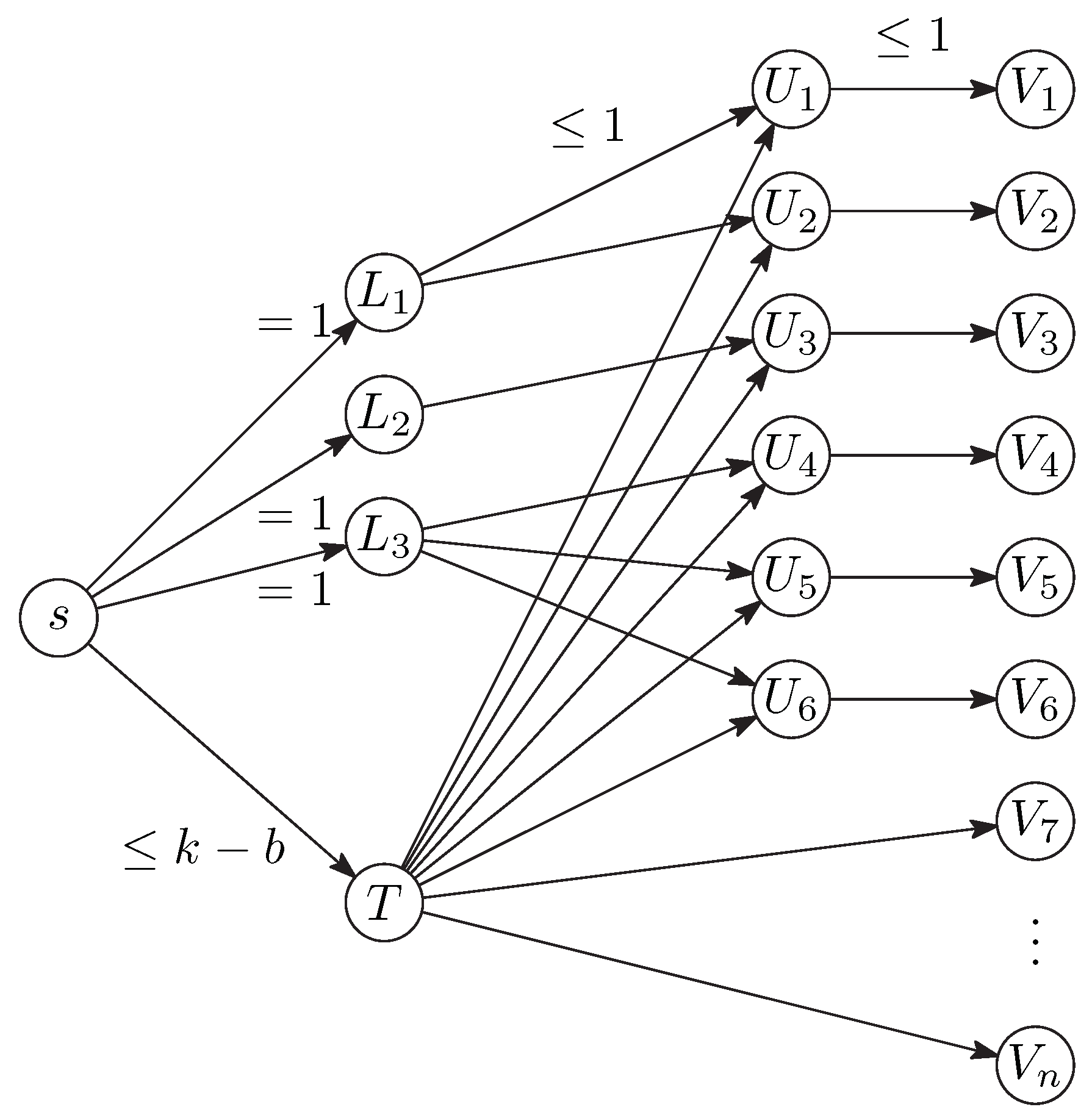
Section 3.1 must be adapted to model the constraints resulting from solution classes. Let
be a solution class, with
. For our construction, we just need to know the family
of disjoint nonempty vertex sets. The solutions that are described by this class are all sets that can be obtained by picking at least one vertex from each set
.
Figure 2 shows the necessary adaptations for
one solution
. In addition to a single node
T that is either directly of indirectly connected to all nodes
, like in
Figure 1, we have additional nodes representing the sets
. For each vertex
j that appears in one of the sets
, there is an additional node
in an intermediate layer of the network. The flow from
s to
is forced to be equal to 1, and this ensures that at least one element of the set
is chosen in the solution. Here, it is important that the sets
are disjoint.
A similar structure must be built for each set
, and all these structures share the vertices
s and
. The rightmost layer of the network is the same as in
Figure 1.
The initial flow is not so straightforward as in
Section 3.1 but is still easy to find. We simply saturate the arc from
s to each of the nodes
in turn by a shortest augmenting path. Such a path can be found by a simple reachability search in the residual network, in
time. The total running time
from
Section 3.1 remains unchanged. □
5. Modeling Aspects: Discussion of the Objective Function
In
Section 3 and
Section 4, we have used the sum of the Hamming distances,
, as the measure of diversity. While this metric is of natural interest, it appears that, in some specific cases, it may not be a useful choice. We present a simple example where the
most diverse solution according to
is not what one might expect.
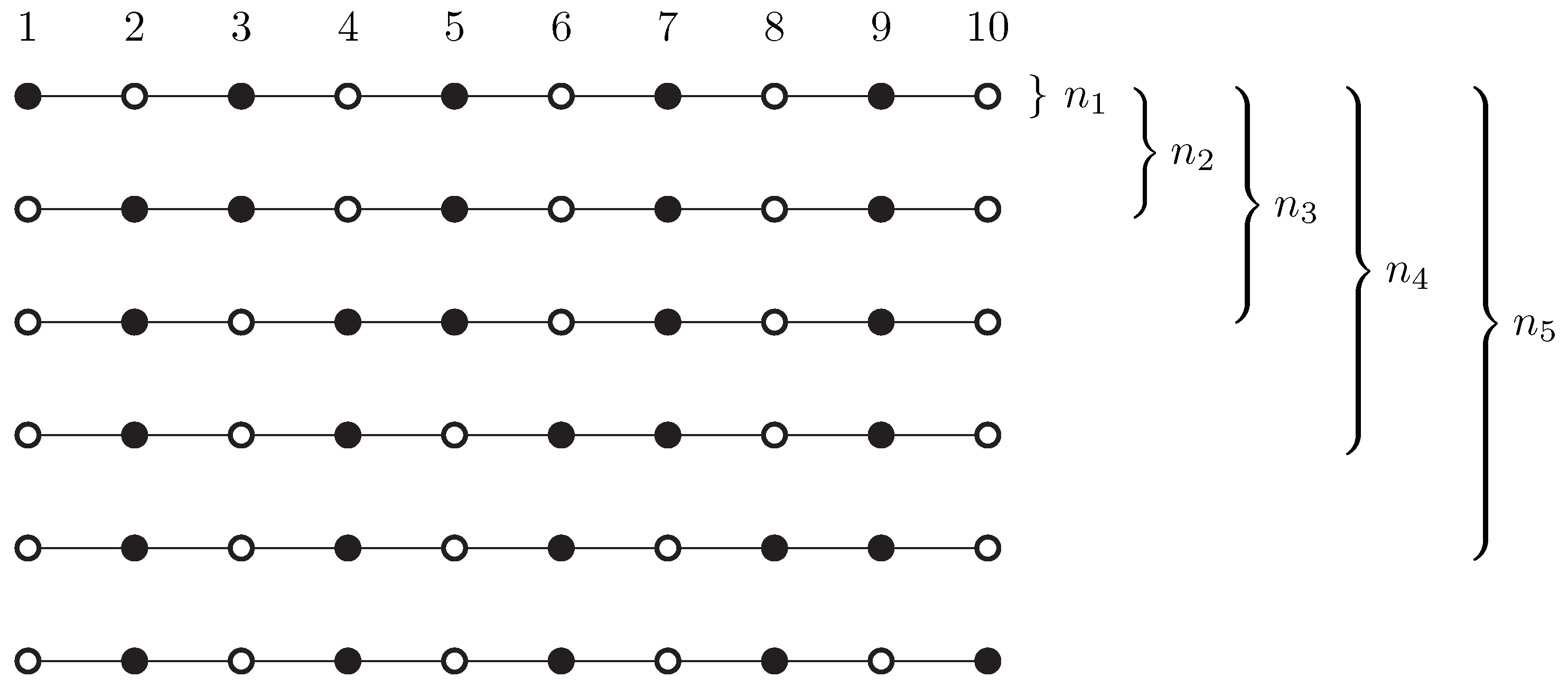
Let r be an even number. We consider the path with vertices, and we are looking for r vertex covers of size at most , of maximum diversity.
Figure 3 shows an example with
. The smallest size of a vertex cover is indeed
, and there are
r different solutions. One would hope that the “maximally diverse” selection of
r solutions would pick all these different solutions. However, no, the selection that maximizes
consists of
copies of just
two solutions, the “odd” vertices and the “even” vertices (the first and last solution in
Figure 3).
This can be seen as follows. If the selected set contains in total
copies of the first
i solutions in the order of
Figure 3, then the objective can be written as
Here, each term
accounts for two consecutive vertices
of the path in the formulation (
3). The unique way of maximizing each term individually is to set
for all
i. This corresponds to the selection of
copies of the first solution and
copies of the last solution, as claimed.
In a different setting, namely the distribution of
r points inside a square, an analogous phenomenon has been observed ([
16], Figure 1): Maximizing the sum of pairwise Euclidean distances places all points at the corners of the square. In fact, it is easy to see that, in this geometric setting, any locally optimal solution must place all points on the boundary of the feasible region. By contrast, for our combinatorial problem, we don’t know whether this pathological behavior is typical or rare in instances that are not specially constructed. Further research is needed. A notion of diversity which is more robust in this respect is the
smallest difference between two solutions, which we consider in
Section 6.
7. Conclusions and Open Problems
In this work, we have considered the paradigm of finding small diverse collections of reasonably good solutions to combinatorial problems, which has recently been introduced to the field of fixed-parameter tractability theory [
21].
We have shown that finding diverse collections of
d-hitting sets and feedback vertex sets can be done in
time. While these problems can be classified as
via the kernels and a treewidth-based meta-theorem proved in [
21], the methods proposed here are of independent interest. We introduced a method of generating a maximally diverse set of solutions from a set that either contains all minimal solutions of bounded size (
d-
Hitting Set) or from a collection of structures that in some way
describes all solutions of bounded size (
Feedback Vertex Set). In both cases, the maximally diverse collection of solutions is obtained via a network flow model, which does not rely on any specific properties of the studied problems. It would be interesting to see if this strategy can be applied to give FPT-algorithms for diverse problems that are not covered by the meta-theorem or the kernels presented in [
21].
While the problems in [
21] as well as the ones in
Section 3 and
Section 4 seek to maximize the
sum of all pairwise Hamming distances, we also studied the variant that asks to maximize the
minimum Hamming distance, taken over each pair of solutions. This was motivated by an example where the former measure does not perform as intended (
Section 5). We showed that also, under this objective, the diverse variants of
d-
Hitting Set and
Feedback Vertex Set are
. It would be interesting to see whether this objective also allows for a (possibly treewidth-based) meta-theorem.
In [
21], the authors ask whether there is a problem that is in
parameterized by a solution size whose
r-diverse variant becomes
-hard upon adding
r as another component of the parameter. We restate this question here.
Question 1 (Open Question [
21])
. Is there a problem Π with solution size k, such that Π is parameterized by k, while Diverse ,
asking for r solutions, is -hard parameterized by ? To the best of our knowledge, this problem is still wide open. We believe that the
measure is more promising to obtain such a result rather than the
measure. A possible way to tackle both measures at once might be a parameterized (and strenghtened) analogue of the following approach that is well-studied in classical complexity. Yato and Seta propose a framework [
35] to prove
-completeness of finding a
second solution to an
-complete problem. In other words, there are some problems where given one solution it is still
-hard to determine whether the problem has a different solution.
From a different perspective, one might want to identify problems where obtaining one solution is polynomial-time solvable, but finding a diverse collection of r solutions becomes -hard. The targeted running time should be parameterized by r (and maybe t, the diversity target) only. We conjecture that this is most probably - or hard in general. However, we believe it is interesting to search for well-known problems where it is not the case.

 ,
, {kind=link}
{kind=link}
{kind=link}