1. Introduction
Multiple instance learning (MIL) is a recent machine learning paradigm [
1,
2,
3], which consists of classifying sets of points. Each set is called bag, while the points inside the bags are called instances. The main characteristic of an MIL problem is that in the learning phase the instance labels are hidden and only the labels of the bags are known.
An MIL seminal paper is [
4], where a drug-design problem has been faced. Such a problem consists of determining whether a drug molecule (bag) is active or non-active. A molecule provides the desired drug effect (positive label) if, and only if, at least one of its conformations (instances) binds to the target site. The crucial question is that it is not known a priori which conformation makes the molecule active.
Some MIL applications are image classification [
5,
6,
7,
8], drug discovery [
9,
10], classification of text documents [
11], bankruptcy prediction [
12], and speaker identification [
13].
For this kind of problems, there are various solutions in the literature that fall into three different classes: instance-space approaches, bag-space approaches, and embedding-space approaches. In instance-space approaches, classification is performed at the instance level, finding a separation surface directly in the instance space, without looking at the global structure of the bags; the label of each bag is determined as an aggregation of the labels of its corresponding instances. Vice-versa, in bag-space approaches (for example, see [
14,
15,
16]), the separation is performed at a global level, considering the bag as a whole entity. A compromise between these two kinds of approaches is constituted by embedding-space techniques, where each bag is represented by one feature vector and the classification is consequently performed in the instance space. An example of an embedding-space approach is presented in [
17].
The method we propose uses the instance-space approach and provides a separation hyperplane for the binary case, where the objective is to discriminate between positive and negative bags. We start from the standard MIL assumption stating that a bag is positive if, and only if, at least one of its instances is positive and it is negative whenever all its instances are negative.
Some examples of linear instance-space MIL classifiers can be found in [
18,
19,
20,
21,
22]. In particular, in [
18], two different models have been proposed. The first one is a mixed-integer nonlinear optimization problem solved using a heuristic technique based on the block coordinate descent method [
23] and faced in [
19] using a Lagrangian relaxation technique. The second model, which will be the objective of our analysis in the next section, is a nonsmooth nonconvex optimization problem, solved in [
21] using the bundle type method described in [
24]. In [
20], a semi-proximal support vector machine (SVM) approach is used, coming from a compromise between the classical SVM [
25] and the proximal approach proposed in [
26] for supervised classification. Finally, an optimization problem with bilinear constraints is analyzed in [
22], where each positive bag is expressed as a convex combination of its instances and a local solution is obtained by solving successive linear programs.
Recently, nonlinear instance-space MIL classifiers have also been proposed in the literature, such as in [
27] and in [
28], where a spherical separation approach is adopted: in particular, in the former a variable neighborhood search method [
29] is used, while in the latter a DC (difference of convex) model is solved using an appropriate DC algorithm [
30]. In passing, we stress that many DC models have been introduced in machine learning, in the supervised [
31,
32,
33,
34,
35], semisupervised [
36,
37] and unsupervised cases [
38,
39,
40].
In this work, we propose a DC optimization model providing a linear classifier for binary MIL problems. The solution method we adopt is the proximal bundle method introduced in [
30] for the minimization of nonsmooth DC functions. The paper is organized as follows. In the next two sections, we describe, respectively, the DC optimization model and the corresponding nonsmooth solution algorithm. Finally, in
Section 4, we report the results of our numerical experimentation performed on some data sets drawn from the literature.
2. A DC Decomposition of the SVM-Based MIL
We tackle a binary MIL problem whose objective is to discriminate between
m positive bags and
k negative ones using a hyperplane
where
and
. Indicating by
,
, the index set of the instances belonging to the ith positive bag and by
,
, the index set of the instances belonging to the
ith negative bag, we recall that, on the basis of the standard MIL assumption, a bag is positive if, and only if, at least one of its instances is positive and it is negative vice-versa. As a consequence, while a positive bag is allowed to, possibly, straddle the hyperplane, the negative bags should lie completely on the negative side.
More formally, indicating by
the
jth instance of a positive or negative bag, the hyperplane
performs a correct separation if, and only if, the following conditions hold:
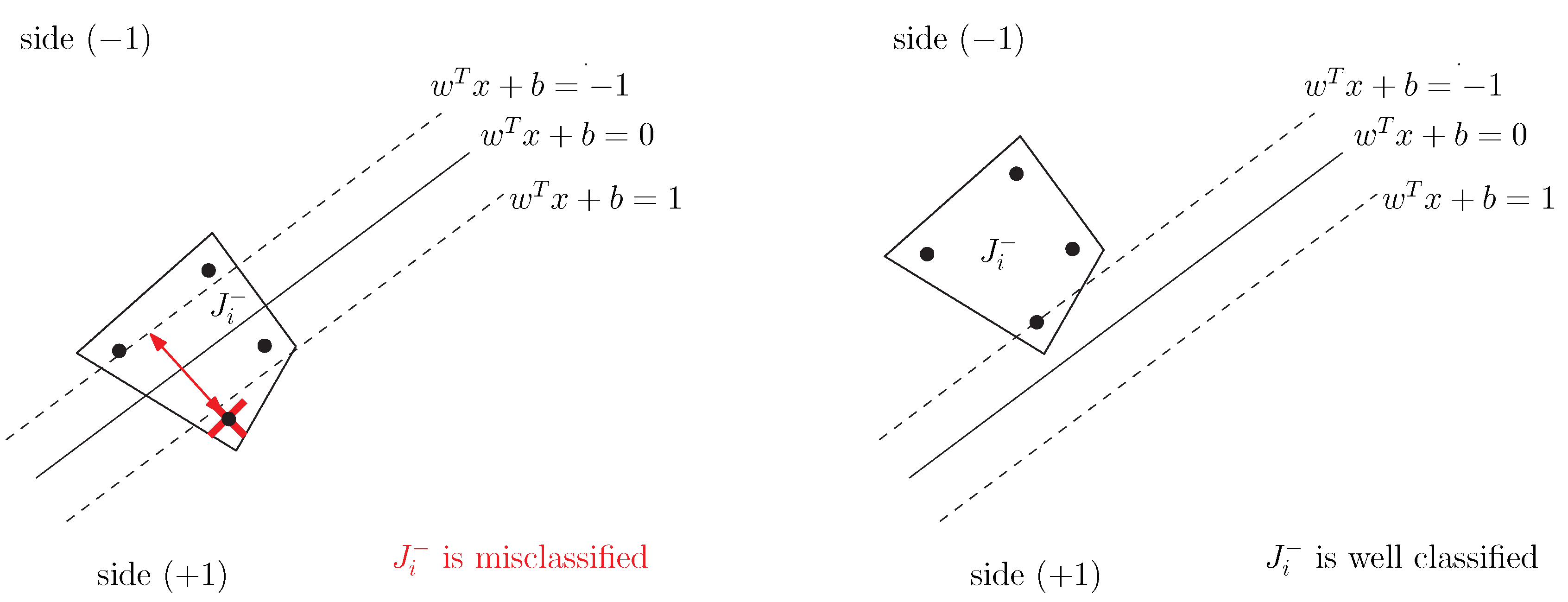
As a consequence (see
Figure 1 and
Figure 2), a positive bag
,
, is misclassified if
and a negative one
,
, is misclassified if
Then, we come out with the following error function, already introduced in [
18]:
where
represents the trade-off between two objectives: the maximization of the separation margin, characterizing the classical SVM [
25] approach, and the minimization of the classification error.
To minimize function
f, we propose a DC decomposition based on the following formula:
where
h is a convex function. By applying Equation (
2) to our case, we can write
f in the form:
where
and
are convex functions. Hence, we come up with the following nonconvex nonsmooth optimization problem, DC-MIL,
3. Solving DC-MIL Using a Nonsmooth DC Algorithm
We start by recalling some preliminary property of the DC optimization problem, by adopting the same notation as above. Given the DC optimization problem
where both
and
are convex nonsmooth functions, we say that a point
is a local minimizer if
is finite and there exists a neighborhood
of
such that
Considering that, in general, the Clarke subdifferential calculus cannot be used to compute subgradients of the DC function since
where
denotes Clarke’s subdifferential, different stationary points can be defined for nonsmooth DC functions. A point
is called inf-stationary for problem Equation (
4) if
Furthermore, a point
is called Clarke stationary for problem Equation (
4) if
while, it is called a critical point of
f if
Denoting the set of inf-stationary points by
, the set of Clarke stationary points by
, and the set of critical points of the function
f by
, the following inclusions hold
as shown in (Proposition 3, [
30]).
Nonsmooth DC functions have attracted the interest of several researchers, both, from the theoretical and from the algorithmic viewpoint. Focusing in particular on the algorithmic side, the most relevant contribution has probably been provided by the methods based on the linearization of function
(see, [
41] and references therein), where the problem is tackled via successive convexifications of function
f. In the last years, nonsmooth-tailored DC programming has experienced a lot of attention as it has a lot of practical applications (see [
28,
42]). In fact, several nonsmooth DC algorithms have been developed ([
30,
43,
44,
45,
46,
47]).
Here, we adopt the algorithm DCPCA, a bundle-type method introduced in [
30] to solve problem Equation (
4), which is based on a model function built by combining two convex piecewise approximations, each related to one component function. More in details, a simplified version of DCPCA works as follows:
It iteratively builds two separate piecewise-affine approximations of the component functions, grouping the corresponding information in two separate bundles.
It combines the two convex piecewise-affine approximations and generates a DC piecewise-affine model.
The DC (hence, nonconvex) model is locally approximated using an auxiliary quadratic program, whose solution is used to certify approximate criticality, or to generate a descent search-direction to be explored via a backtracking line-search approach.
Whenever no descent is achieved along the search direction, the bundle of the first function is enriched, thus, obtaining a better model function with this being the fundamental feature of any cutting plane algorithm.
In fact, the DCPCA is based on constructing a model function as the pointwise maximum of several concave piecewise-affine pieces. To construct this model, starting from some cutting-plane ideas, the information coming from the two component functions are kept separate in two bundles. We denote the stability center by
z (i.e., an estimate of the minimizer), and by
I and
L, the index sets of the points generated by the algorithm where the information of function
and
have been evaluated, respectively. Therefore, we denote the two bundles of information as
and
where, for every
,
with
and, for every
,
with
We remark that both component functions, along with their subgradients, could be evaluated at some iterate-point, and, indeed, we assume that and , where and .
To approximate the difference function
at a given iteration
k the following nonconvex model function
is introduced
which is defined as the maximum of finitely many concave piecewise-affine functions. The model- function
is used to state a sufficient descent condition of the type
where
. The interesting property of such a model-function is that whenever the sufficient descent is not achieved at points that are close to the stability center, say
, then an improved cutting-plane model can be obtained by only updating the bundle of
with the appropriate information related to the point
. On the other hand, it looks obviously difficult to adopt the minimization of the model-function
as a building block of any algorithm, given its nonconvexity. In fact, DCPCA does not require the direct minimization of
, but the search direction can be obtained by solving the following auxiliary quadratic problem:
where
. We observe that
as
is assumed to contain the information about the current stability center. More precisely, DCPCA works by forcing
to be a singleton, hence by letting
. Denoting the unique optimal solution of Equation (
QP(
I)) by
, a standard duality argument ensures that
where
,
, are the optimal variables of the dual of
, with
.
Given that any starting point
, DCPCA returns an approximate critical point
, see (Theorem 1, [
30]). The following parameters are adopted: the optimality parameter
, the subgradient threshold
, the linearization-error threshold
, the approximate line-search parameter
, and the step-size reduction parameter
. In Algorithm 1, we report an algorithmic scheme of the main iteration, namely of the set of steps where the stability center is unchanged. An exit from the main iteration is obtained as soon as a stopping criterion is satisfied or whenever the stability center is updated. To make the presentation clearer, without impairing convergence properties, we skip the description of some rather technical steps, which are strictly related to the management of bundle
. Details can be found in [
30].
| Algorithm 1 DCPCA Main Iteration |
| 1: Solve QP(I) and obtain | ▹ Find the search-direction and the predicted-reduction |
| 2: if then | ▹ Stopping test |
| 3: set and exit | ▹ Return the approximate critical point |
| 4: end if | |
| 5: Set | ▹ Start the line-search |
| 6: if then | ▹ Descent test |
| 7: set | ▹ Make a serious step |
| 8: calculate and | ▹ | |
| 9: update for all and for all | ▹ | |
| 10: set | ▹ | |
| 11: set | ▹ | |
| 12: update appropriately I and L, and go to 1 | ▹ | |
| 13: else if then | ▹ Closeness test |
| 14: set and go to 6 | ▹ Reduce the step-size and iterate the line-search |
| 15: end if | |
| 16: Calculate | ▹ Make a null step |
| 17: calculate | ▹ | |
| 18: set , update appropriately I, and go to 1 | ▹ | |
We remark that the stopping condition
, checked at Step 2 of the DCPCA, is an approximate
-criticality condition for
. Indeed, taking into account Equation (12), the stopping condition ensures that
which in turn implies that
and
such that
namely, that
an approximate
-criticality condition for
, see Equation (
9).
4. Results
We tested the performance of the algorithm DCPCA applied to the DC-MIL formulation (
3) by adopting two sets of medium- and large-size problems extracted from [
18]. The relevant characteristics of each problem are reported in
Table 1 and
Table 2, where we list the problem dimension
n, the number of instances, and the number of bags.
The two-level cross-validation protocol has been used to tune C and to train the classifier. Before proceeding with the training phase, the model-selection phase is aimed at finding a promising value of parameter C in the set , using a lower-level cross-validation protocol on each training set. The selected C value, for each training set, is the one returning the highest average test-correctness in the model-selection phase.
Choosing a good starting point is a critical phase to ensure good performance for a local optimization algorithm like DCPCA. For each training set, denoting the barycenter of all the instances belonging to positive bags by
and the barycenter of all the instances belonging to negative bags by
, we have selected the starting point
by setting
and choosing
such that the corresponding hyperplane correctly classifies all the positive bags.
We adopted the Java implementation of algorithm DCPCA by running the computational experiments on a 3.50 GHz Intel Core i7 computer. We limited the computational budget for every execution of DCPCA to 500 and 200 evaluations of the objective function for medium-size and large-size problems, respectively, and we restricted the size of the bundle to 100 elements adopting a restart strategy, as soon as, the bundle size exceeds the threshold and a new stability center is obtained. The QP solver of IBM ILOG CPLEX 12.8 has been used to solve quadratic subprograms. The following set of parameters, according to the notation introduced in [
45], has been selected: the optimality parameter
, the subgradient threshold
, the approximate linesearch parameter
, the step-size reduction parameter
, and the linearization-error threshold
.
We compare our DC-MIL approach against the algorithms mi-SVM [
18], MI-SVM [
18], MICA [
22], MIL-RL [
19], and for medium-size problems also against the MIC
[
21] and DC-SMIL [
28]. All such methods have been briefly surveyed in the introduction section.
To analyze the reliability of our approach, in
Table 3 and
Table 4, we report the numerical results in terms of the percentage test-correctness averaged over 10 folds, with the best performance being underlined. We remark that some data are not reported in
Table 5 as the corresponding results are obtained by adopting only nonlinear kernels in [
18,
22]. Moreover, to provide some insight into the efficiency of DC-MIL, we report in
Table 5 and
Table 6, the average train-correctness (
train, %), the average cpu time (
cpu, sec), the average number of function evaluations (
nF), and the average number of subgradient evaluations of the two functions (
nG1 and
nG2). The reliability results show a good and balanced performance of the DC-MIL approach equipped with DCPCA, both, for the medium-size problems, where in one case DC-MIL slightly outperforms the other approaches, and for the large-size problems. Moreover, we observe that our approach looks strongly efficient as it manages to achieve high train-correctness in reasonably small execution times even for large-size problems.

 ,
, 



{kind=link}
{kind=link}