1. Introduction
In the industry field, machines are often supposed to be continuously available for processing assigned jobs. However, this assumption is not totally realistic in real-world cases. For instance, machines may be subject to unavailability periods due to many reasons, such as preventive maintenance [
1], corrective maintenance [
2], and tool-change activities [
3]. There are two main concerns related to the temporary unavailability of a machine. The first is related to the increased costs caused by stopping the machine’s activity, while the second is linked to the difficulty in taking decisions regarding the balance between resource unavailability and production. Therefore, a proper planning strategy in a manufacturing system is necessary for it to operate in the most cost-effective way.
Scheduling under machine-unavailability constraints has attracted the attention of many researchers, and many real applications can be found. In [
4], the authors listed two applications in the aerospace industry where the machine must be stopped to change microdrilling tools after a fixed number of use times. Another application was mentioned by [
5] related to electric-battery vehicles that require refuelling operations.
In this paper, we study a scheduling problem on
m uniform parallel machines with multiple unavailability constraints with the objective to minimize the makespan, which is the completion time of the last assigned job. The reason behind the choice of such an objective is that minimizing the makespan can ensure a good load balance among the machines. We followed three-field
classification, developed by [
6], to represent the problem as
. In the first field,
Q denotes uniform parallel machine setting,
m represents the number of considered machines, and
states that each machine is unavailable during
k periods in the planning horizon. In the second field,
,
a indicates that the machines are subject to availability constraints. Lastly, the third field,
, describes the objective to be minimized, that is, the completion time of the last processed job, denoted by
.
Many papers in the literature studied parallel machine-scheduling problems with availability constraints, but very few considered a uniform parallel machine setting. To the best of our knowledge, only two related papers exist so far, [
7,
8]. In [
7], the authors studied the uniform parallel machine-scheduling problem where each machine could be unavailable during one period of time. The considered performance measures were total completion times and makespan. Two types of jobs were treated, namely, identical and nonidentical jobs. Linear programming models and optimal algorithms were developed to solve the problem where jobs are identical. For the case of nonidentical jobs, the authors proved that the problem is NP-hard, and proposed a quadratic program and a heuristic that were tested on large-sized problem instances. The online version of the problem was studied in [
8]. The authors considered the case of two machines under the constraint of one periodically unavailable machine. The identical- and uniform-machine cases were investigated. The objective was to minimize the makespan. The solution approach consisted of optimal algorithms with competitive ratios.
Furthermore, most research papers studied the case of identical parallel machines. For example, [
9,
10,
11,
12,
13] studied various identical parallel machine problems allowing various types of unavailable intervals for machines.
The shortage in research in this area, and the important applications of the investigated problem in reality motivated the author of this paper to explore this area more and contribute to the scientific research on it. Uniform parallel machine scheduling can be found in the manufacturing field where the same type of job can be processed on new and old machines that have different speeds. As an example, a printing task can take much more time on an old machine than on a new one.
In this paper, the main contributions are a quadratic programming-model (QM) formulation of a uniform parallel machine with multiple availability constraints and an algorithm that provides optimal solutions. To the best of our knowledge, the proposed QM is the first such formulation for scheduling on uniform parallel machine with availability constraints.
The content of this paper is organized as follows. Problem notations are laid in
Section 2. In
Section 3.1, a quadratic model for the problem with makespan as an objective is developed.
Section 3.2 details an algorithm proposed for makespan-performance measurement. The proposed algorithm was tested on different problem instances, and results are displayed in
Section 4. Finally, a general conclusion is formulated in
Section 5.
2. Notations
For accuracy of description, by ‘unavailability interval’ we denote the time interval in which the machine is not available for processing any job, whereas the time interval between two consecutive unavailability intervals is called the ‘availability interval’ of the machine.
In this paper, we consider m uniform parallel machines that can process n jobs. Each job j, is characterized by processing time and completion time . We assumed that the jobs were ready at time 0 and could be processed once at any time, but could not be interrupted once started. Since we consider uniform parallel machines, each machine i, , can process at most one job at a time at speed . So, the processing time of any job j depends on the machine on which it is processed and is equal to , ; . Without loss of generality, we assumed that jobs were indexed in order, that is, . We assumed that the machine could process the next job once the previous one was finished. Thus, no setup time was considered. Let and be the starting and ending time of the unavailability period on machine i, respectively. Without loss of generality, we assumed that all machines were available at the beginning of the planning horizon. By , we denote the length of the availability interval on machine i.
The problem was to find a job assignment on machines that minimizes the makespan. As stated earlier, the problem of scheduling jobs on uniform parallel machines subject to unavailability constraints has not been studied before. Therefore, a mathematical formulation of the problem can be of great interest. Thus, in
Section 3.1, we detail a mathematical model to describe the problem under consideration.
3. Proposed Solution Approach for
In this section, we studied the scheduling problem on uniform parallel machine, where each machine i can be unavailable during unavailability periods in its planning horizon. Thus, there are availability intervals. The objective was to minimize the makespan.
It is easy to see that
is NP-hard. To see this, let
for every machine
Then the problem reduces to the identical parallel machine-scheduling problem under availability constraints that was proved to be NP-hard by [
14].
3.1. Mathematical Model
Using the above-listed decision variables, the problem can be modeled as a quadratic program as follows:
Subject to
where
d is a large positive number.
Equation (
1) minimizes the makespan. Equation (
2) guarantees that, when all jobs are completed before the start of the 1st unavailability period, the unavailability duration is not considered in the evaluation of the completion time of the last job assigned to machine
i. There are
m of these constraints. Equation (
3) states that the completion time of the last job assigned to machine
i is at most equal to the makespan. There are
m of these constraints. Equation (
4) guarantees that no more than one
is equal one for a given machine
i. There are
m of these constraints. The total processing time of the jobs assigned to a given availability interval cannot exceed the length of that interval. This is shown by Equation (
5). There are
of these constraints. Equation (
6) assures that, if a job is assigned to a machine, it can be processed on only one availability interval of that machine. There are
n constraints of this type. Equations (
7) and (
8) define the non-negativity constraints about the decision variables used to develop the mathematical model.
The above quadratic model () can be optimally solved by CPLEX for problem instances with up to 73 machines. Therefore, a good polynomial algorithm that can solve large and more complicated problems, and provide promising results is of great interest.
The Largest Processing Time algorithm (
) is a famous rule used to build heuristics for scheduling problems with a makespan criterion. For example, in [
15] the authors proposed
-based heuristics to solve
and
problems, respectively. The
rule sorts jobs into a nonincreasing order of their processing times and then assigns a job to the machine on which it can finish as early as possible.
3.2. Proposed-Solution Approach
The approach proposed to solve the problem of scheduling on parallel machines under unavailability constraints consists of two steps. The first step focuses on assigning jobs to different available machines using a newly proposed LPT-Based Heuristic, named . The second step, named , tries to improve solutions obtained by . The Main Algorithm, named , is a combination of and .
3.2.1. Heuristic Procedure
The main idea of
is to divide the set of jobs
N into two subsets. The first set includes jobs that can be assigned to one of the machines’ availability intervals. The second set contains the remaining jobs. The
consists of two phases. The first is the main phase, as it schedules the maximum of jobs. First, for every machine, a list of job candidates is formed on the basis of whether they could fit the machine’s availability intervals except the last ones. This step is achieved by using the
procedure shown in Algorithm 1. Second, jobs in every constructed list are sorted in decreasing order of their processing times. Then, for every machine, starting from machine 1, select the first job in the candidate list of machine 1. If the selected job is only in that machine’s list, assign it to the availability interval that can fit it. Otherwise, assign it to the machine on which it can finish as early as possible. The first phase ends when all the machines’ job-candidate lists are empty. The remaining unscheduled jobs are input for the second phase. The pseudocode of the
heuristic is shown in Algorithm 2.
Table 1 lists notations used to develop Algorithms 1 and 2.
| Algorithm 1. |
- 1:
procedure (Input , m, , ) - 2:
- 3:
for to m do - 4:
- 5:
for to n do - 6:
- 7:
if () then - 8:
- 9:
- 10:
- 11:
end if - 12:
- 13:
end for - 14:
- 15:
end for - 16:
- 17:
Sort the jobs in every in a nonincreasing order of their processing times. - 18:
- 19:
end procedure - 20:
|
| Algorithm 2. |
- 1:
procedure (Input , m, , , . Output ) - 2:
- 3:
for to m do - 4:
- 5:
for to do - 6:
- 7:
- 8:
- 9:
end for - 10:
- 11:
- 12:
- 13:
- 14:
- 15:
end for - 16:
- 17:
Call - 18:
- 19:
while () do - 20:
- 21:
Among the jobs of , select the job with the highest processing time. Let l be that job and the machine(s) to which it can be assigned. - 22:
- 23:
if (l exists in more than one ) then - 24:
- 25:
Assign l to the machine on which it can finish as early as possible. - 26:
- 27:
else Assign l to machine - 28:
- 29:
Update - 30:
- 31:
end if - 32:
- 33:
- 34:
- 35:
Update of the machine to which job l was assigned. - 36:
- 37:
Call - 38:
- 39:
if () then - 40:
- 41:
if () then - 42:
- 43:
- 44:
- 45:
Schedule the jobs of according to rule. - 46:
- 47:
Calculate - 48:
- 49:
end if - 50:
- 51:
- 52:
- 53:
end if - 54:
- 55:
end while - 56:
- 57:
- 58:
- 59:
return S. - 60:
- 61:
end procedure
|
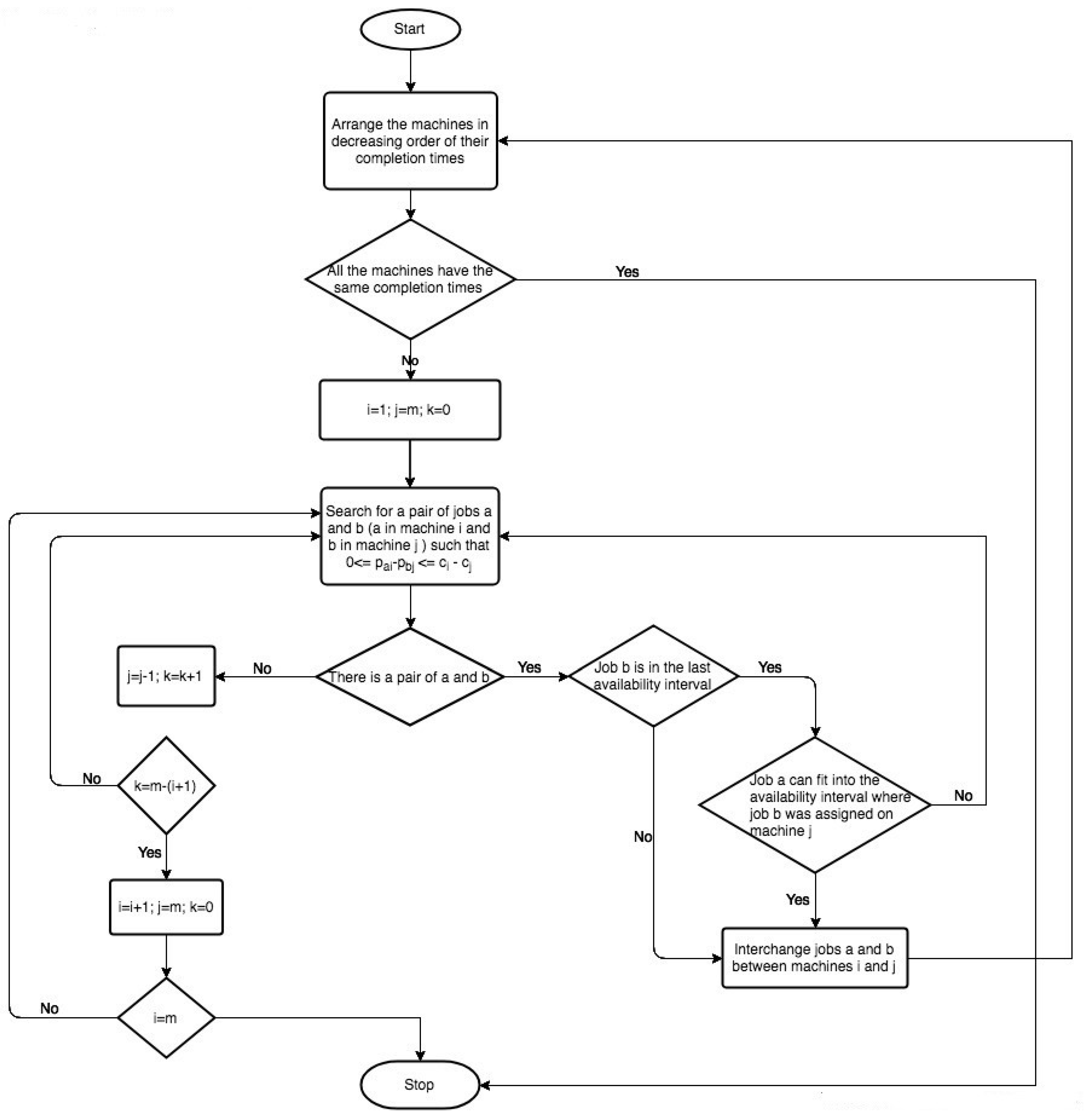
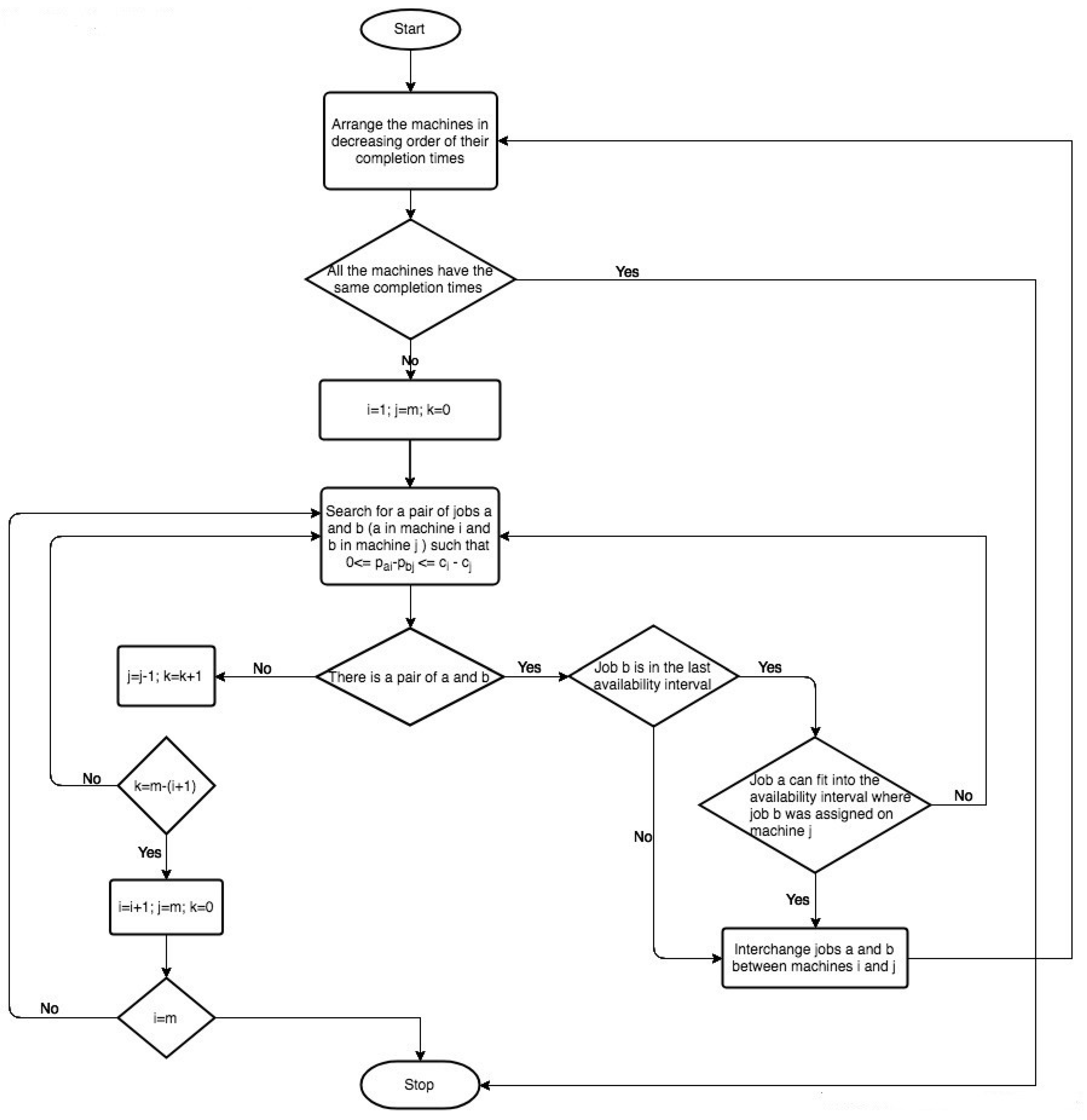
3.2.2. Improvement Procedure
The idea of the improvement procedure was inspired from a local-search heuristic proposed in [
16], developed to solve the scheduling problem of parallel identical-batch processing machines. The aim of the improvement procedure was to try to balance the load of different machines so that the completion times of the last jobs in every machine are almost the same. This improvement can be achieved by interchanging pairs of jobs between the most loaded machine and other machines. The flowchart of the aforementioned heuristic is shown in
Figure 1.
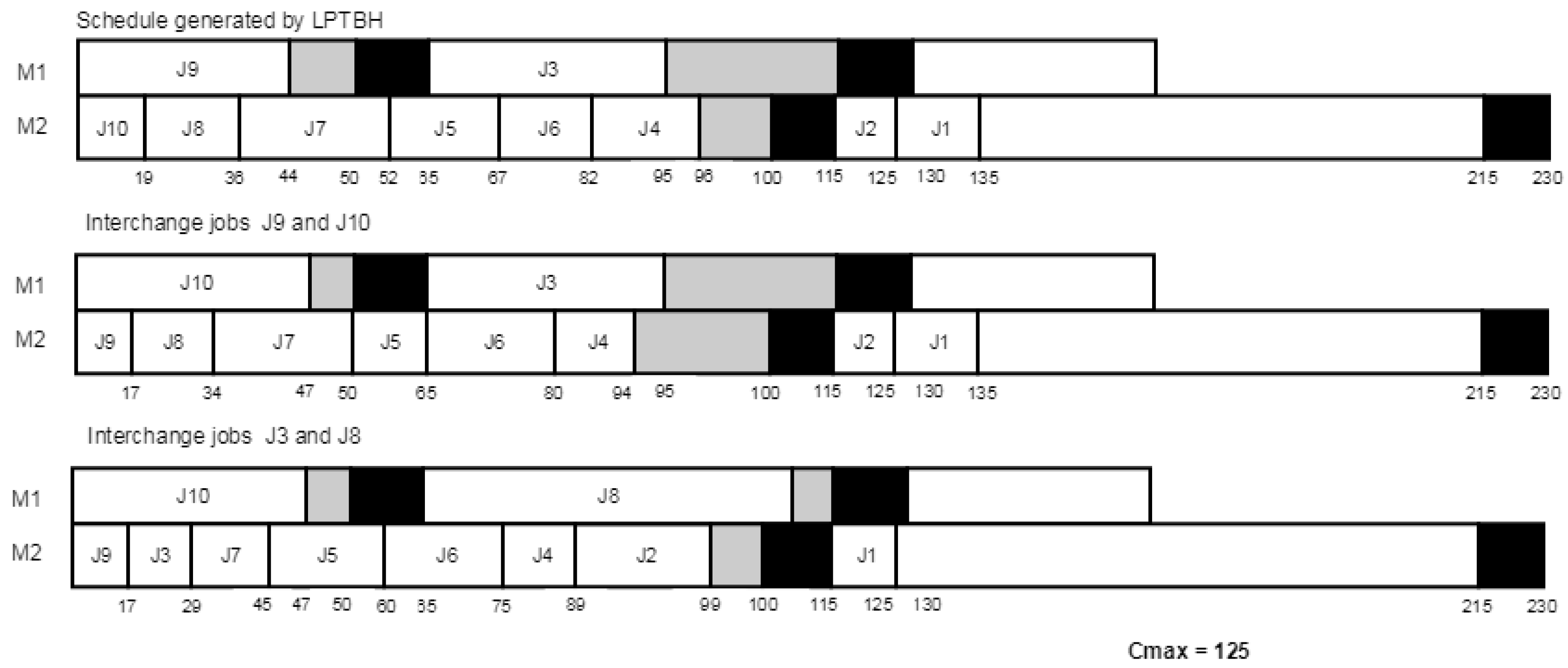
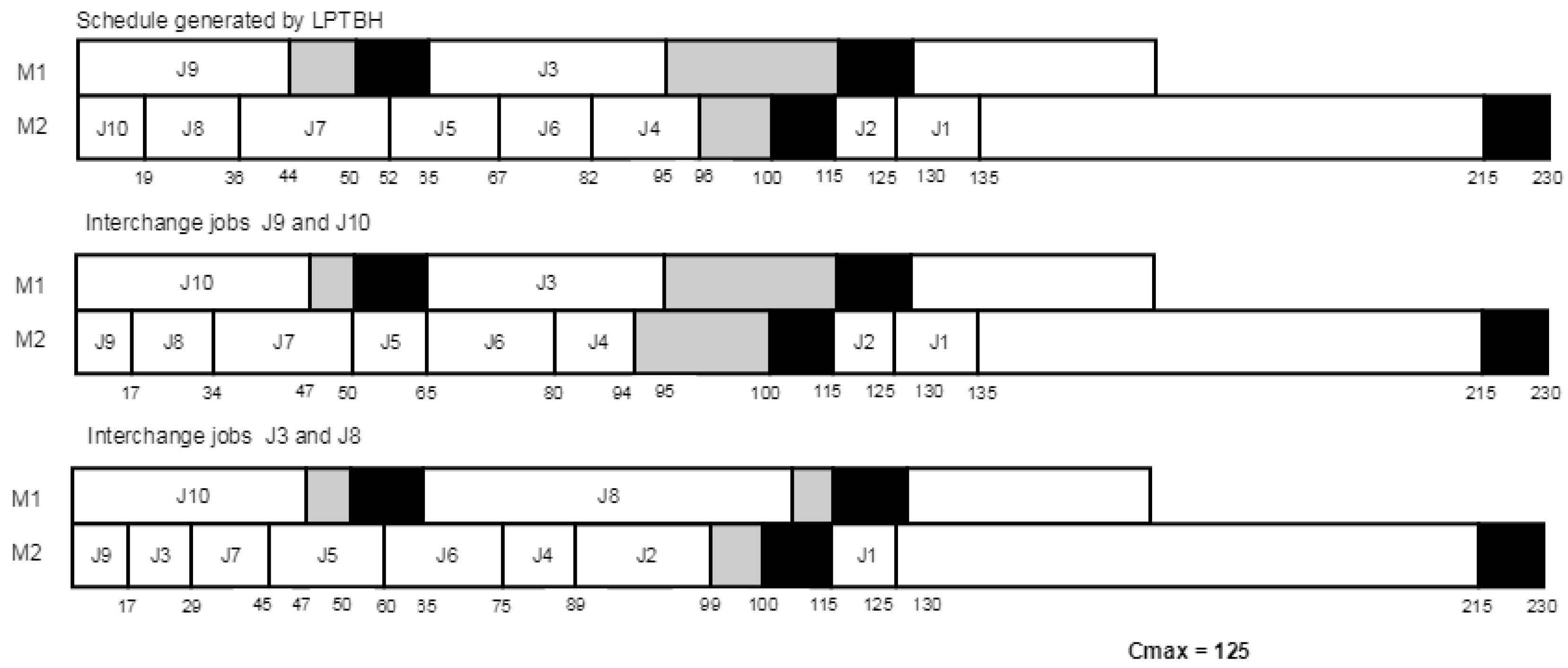
In order to illustrate the proposed heuristic, let us consider a problem instance with 2 machines and 10 jobs.
Table 2 summarizes the input data, and
Figure 2 and
Figure 3 show the Gantt charts of solutions obtained by
and
, respectively.
Note that after interchanging a pair of jobs between two machines, the procedure looks to shift jobs to the left whenever the idle time interval on the machine can fit them. In the above example, after interchanging jobs and , shifted job to the left since it could fit in the idle time interval.
4. Experiment Results
For the purpose of evaluating the performance of the proposed algorithm, many problem instances were tested. These were generated after examining the important factors that significantly impacted the performance of the proposed algorithm. The first factor was the number of jobs n to be processed that directly affects the machines’ load. The second important factor is the number of machines m that has an impact on the assignment of jobs to machines. Job processing times may play a role in the efficiency of the proposed algorithm. Thus, we generated problem instances with different job processing times. The algorithm was coded in IntelliJ IDEA. In addition, the quadratic model was modelled in IBM ILOG CPLEX Optimization Studio 12.7. The proposed heuristic was implemented using programming language Java. We ran all test problems on an Intel Core i5 2.5 Gigahertz, 4 Gigabyte RAM Macintosh HD.
In order to avoid useless computational time, the program was stopped for two possible reasons. The first was when the CPLEX became unable to generate a solution within the time limit of 3600 s (1 h). The second reason was due to memory overflow. At this point, the best feasible solution found within the time limit was recorded.
4.1. Data Generation
A deep empirical study was conducted with the aim to generate datasets that would help to correctly analyze the efficiency of the proposed algorithm. By the end, two dataset series were considered, namely,
and
. In fact, the way to generate dataset series
was inspired from Graham’s data-generation process [
17] addressing
problems. The parameters used to generate
and
are summarized in
Table 3 and
Table 4, respectively.
The starting and ending times
and
of the unavailability periods were generated according to Equations (
9) and (
10), respectively.
4.2. Experiments
In this section, we outline different experiments that were conducted to evaluate the performance of the
and the proposed algorithm. In all experiments, Central Processing Unit time (
) represents the time in seconds required to find the optimal or best feasible solution.
Table 5 and
Table 6 show the results obtained by
and
for small and large job processing times, respectively.
Table 5 clearly shows that the proposed algorithm was generating optimal solutions with a
time of less than 1 second for all problem instances. Quadratic model
was also able to provide optimal schedules in a reasonable time. By considering much longer processing times than in the previous data series, we still obtained optimal solutions in reasonable
time even though the quadratic model became slower than in the first batch of problem instances. The proposed algorithm outperformed the quadratic model in terms of computational time that was still less than 1 second.
Table 6 confirms these observations.
In order to investigate the limitations of the proposed quadratic model, a second dataset series, namely,
was considered.
Table 7 reports the computational results for both
and
The computational results displayed in
Table 7 show that quadratic model
was able to generate an optimal solution within a time limit for problems with up to 73 machines.
On the basis of the computational results shown in
Table 7, the quadratic model was not able to generate optimal solutions in a reasonable time and for bigger problems. Therefore, proposed procedure
was tested for large-sized problems and compared to an adapted form of
, proposed earlier by the author of this paper in [
7].
Table 8 reports the obtained results for problem instances with
and
Table 8 shows that
outperformed
for all problem instances with slightly higher
time than the time of
for most instances. In addition, run time increased with problem size.



{kind=link}
{kind=link}
{kind=link}