1. Introduction
Nowadays, sensing devices are widely diffused in our everyday environment, being embedded in human-carried mobile devices, Internet-of-Things (IoT), as well as monitoring systems for public utilities, transportation, and facilities. All these heterogeneous sources continuously produce data streams that can be collected and analyzed by means of Data Stream Processing (DSP) systems to extract valuable information in a near real-time fashion. The extracted knowledge can be then used to realize new intelligent services in many different domains (e.g., health-care, energy management, and Smart City).
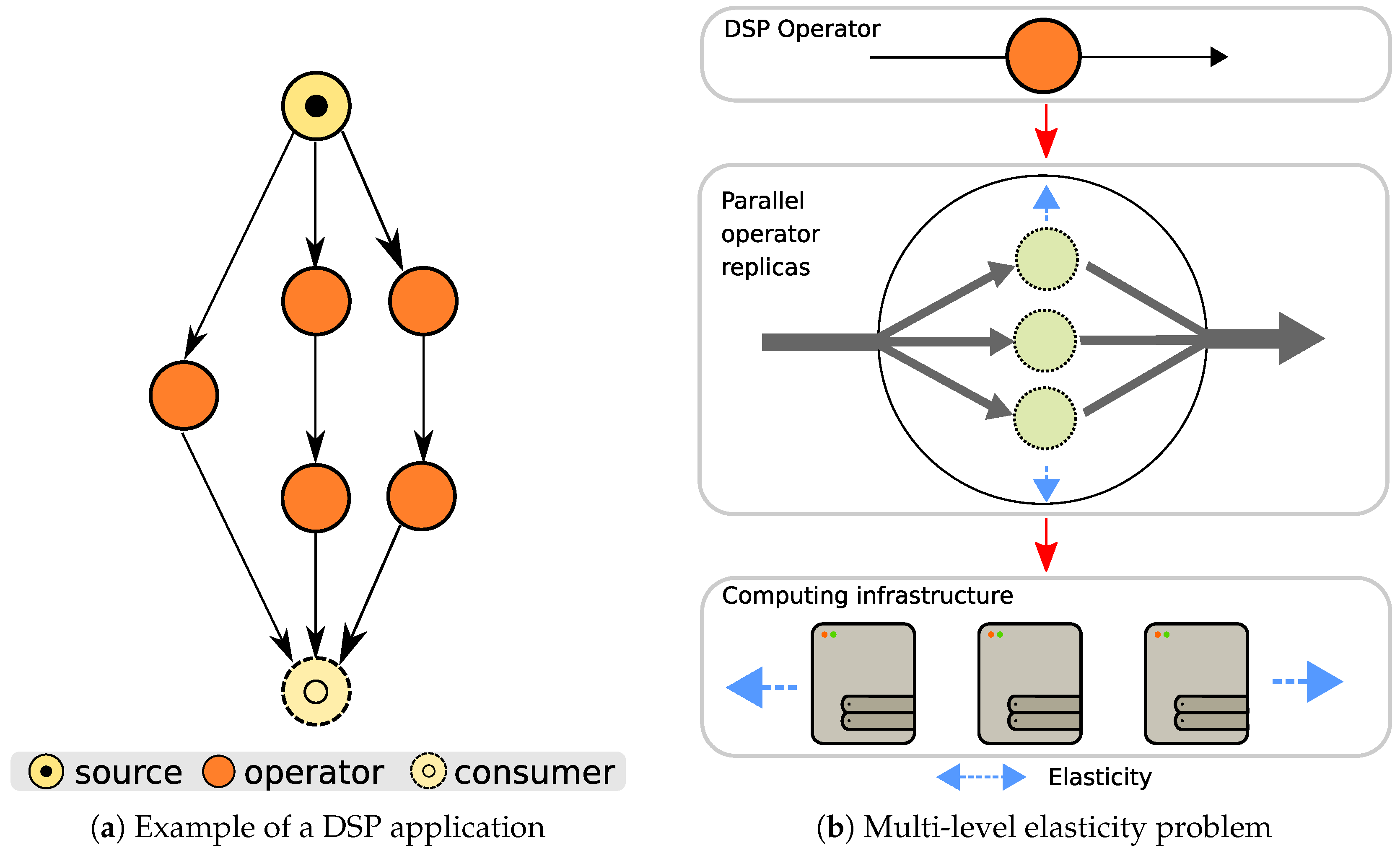
A DSP application consists of data sources, operators, and final consumers, which exchange streams and process data on-the-fly (i.e., without storing them). Each
operator can be seen as a black-box processing element that continuously receives incoming streams, applies a transformation, and generates new outgoing streams. Aiming to extract information as soon as possible, DSP applications often express strict Quality of Service (QoS) requirements, e.g., in terms of response time (e.g., [
1,
2]). Moreover, since DSP applications are long-running, these QoS requirements must be satisfied at run-time, despite the variability and the high volume of the incoming workloads.
To deal with operator overloading, a commonly adopted stream processing optimization is
data parallelism. It consists in running multiple parallel replicas of the same operator, so that the incoming data flow is split among the different replicas that carry out the computation in parallel [
3,
4]. Data parallelism (also known as fission [
4]) allows processing data in parallel on multiple computing nodes (given that a single machine cannot provide enough processing power). As DSP applications are long-running and subject to highly variable workloads, the application parallelism should be
elastically adapted at run-time to match the workload and prevent resource wastage: the number of operator replicas should be
scaled-out when then load increases, and
scaled-in as the load decreases.
Since the operator replicas run on computing resources, modern DSP systems should be able to dynamically adjust the set of computing resources to satisfy the application resource demand while avoiding costly deployment. It results a complex system which should quickly control elasticity at multiple levels, namely at the application and at the infrastructure level (e.g., [
5]). Furthermore, since data sources are usually geographically distributed, recent trends investigate the possibility of decentralizing the execution of DSP applications (e.g., [
3]). The very idea is to move DSP applications closer to the data (rather than the other way around), thus reducing the expected application response time. To this end, the ever increasing presence of distributed cloud and fog computing resources can be exploited. Besides the benefits, this new processing environment also poses new challenges which arise from the number and location of the computing resources that will host and execute the DSP application operators.
Most of the approaches proposed in the literature for managing DSP applications have been designed for cluster environments, where a single centralized control component takes deployment decisions by exploiting a global system view (e.g., [
5,
6,
7]). These solutions typically do not scale well in a highly distributed environment, given the spatial distribution, heterogeneity, and sheer size of the infrastructure itself. In fact, modern DSP systems should be able to seamlessly deal with a large number of interconnected small- and medium-sized devices (e.g., IoT devices), which continuously emit and consume data. Moreover, aggregating information from the whole infrastructure to build a global view of the system is a challenging problem on its own. To improve scalability, decentralized management solutions have been proposed in the DSP context (e.g., [
8,
9,
10,
11]). However, devising a decentralized self-adaptation policy that only relies on a local system view is, in general, not trivial. Indeed, the inherent lack of coordination of fully decentralized solutions might result in frequent deployment reconfigurations that negatively affect the application performance (e.g., [
12]).
Aiming to exploit the strengths of centralized and decentralized solutions, in our previous work [
8], we proposed a hierarchical distributed architecture for controlling the elasticity of DSP applications. Building on this solution, we then proposed
Multi-Level Elastic and Distributed DSP Framework (E2DF) [
13] to include mechanisms for realizing the infrastructure elasticity. E2DF consists of loosely coupled components that interact to realize the multi-level elasticity. In particular, it includes the Application Control System (ACS), which manages the elasticity of DSP applications, and the Infrastructure Control System (ICS), which can dynamically acquire and release computing resource for the framework. The resulting framework provides a unified solution for achieving self-adaptation of DSP systems both at the application-level and the infrastructure-level. The ACS and the ICS can be equipped with different control policies, which determine
when and
how the E2DF mechanisms should be used to adapt the DSP system both at the application-level and the infrastructure-level.
In this paper, we investigate the E2DF control architecture. As first contribution, we design a novel elasticity policy for the ICS, by resorting on Reinforcement Learning (RL). The proposed solution autonomously learns when and how to acquire and release computing resources to satisfy the applications resource demand and avoid resource wastage. RL refers to a collection of trial-and-error methods by which an agent can learn to make good decisions through a sequence of interactions with a system or environment [
14]. As such, RL allows expressing
what the user aims to obtain, instead of
how it should be obtained (as required by threshold-based policies, which are usually adopted to deal with cloud elasticity). Specifically, to design the ICS elasticity policy, we resort to a
model-based solution that instills knowledge about the system dynamics within the learning agent [
14]. Differently from the RL-based application-level elasticity policy we proposed in [
8], the model-based solution we present in this paper estimates the need of computing resources. In particular, considering active and idle resources, it estimates the ability to satisfy the future application demand. Therefore, in this new model, we deal with a different and larger set of unknown dynamics, due to the possible presence of several running applications, each with an unpredictable workload. To tackle the emerging complexity, we exploit an approximate transition probability formulation.
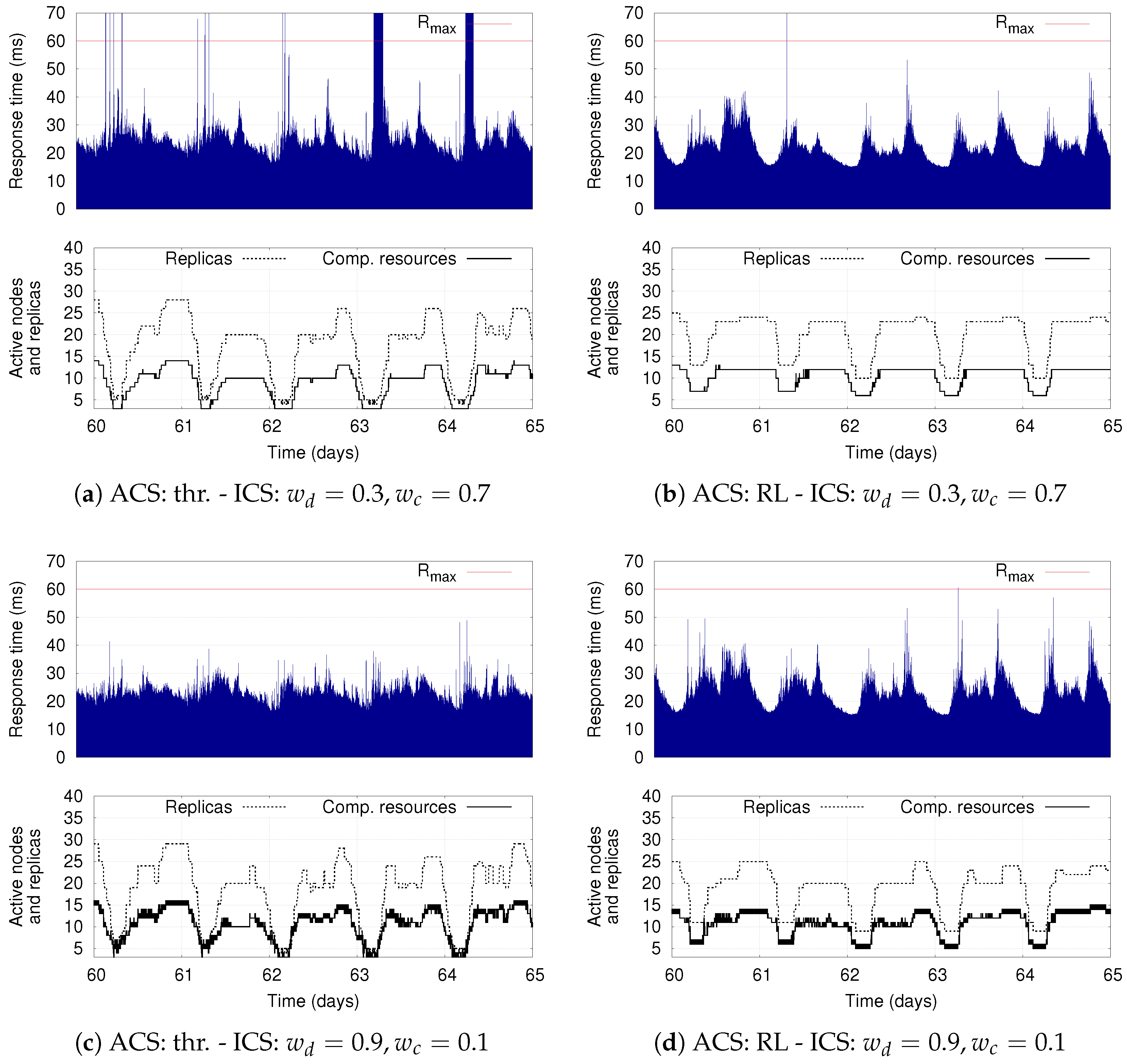
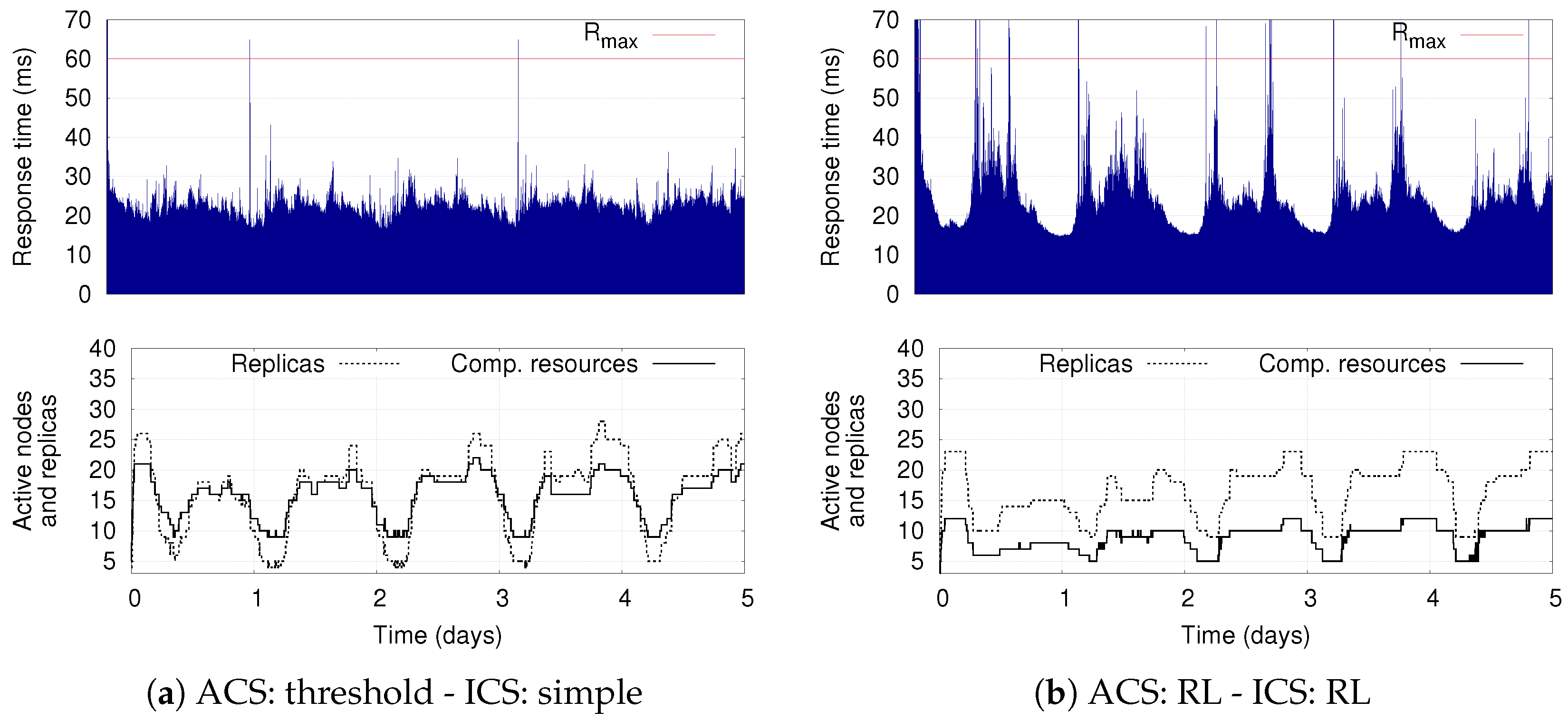
The presence of the ACS and ICS, each of which can be equipped with hierarchical control policies, results in a complex system, whose adaptation capabilities deserve a detailed analysis. Therefore, as second contribution, we extensively investigate benefits and limitations of combining different adaptation policies for the two control systems. For the ICS, we consider a simple policy that preserves a limited pool of ready-to-run computing resources as well as the more sophisticated RL-based solution that we present in this paper. For the ACS, we evaluate a simple threshold-based approach as well as the model-based RL solution presented in [
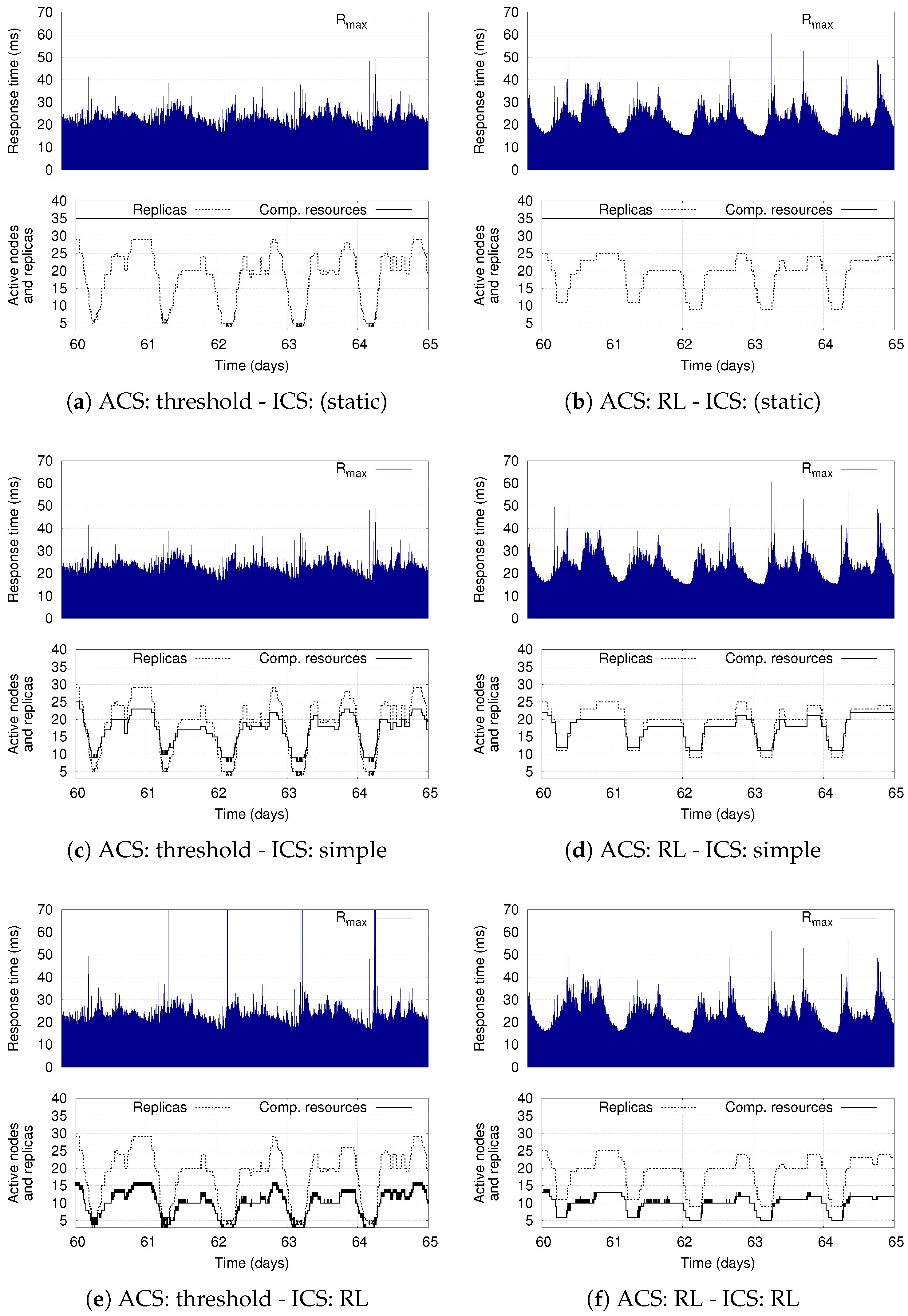
8]. The proposed evaluation has a threefold objective. First, to investigate the ability of the ACS and ICS to adapt the application deployment and the computing infrastructure, respectively. Second, to show the flexibility of the proposed RL-based policy for the ICS. Third, to discuss the time experienced by the RL policy to learn a good infrastructure elasticity policy.
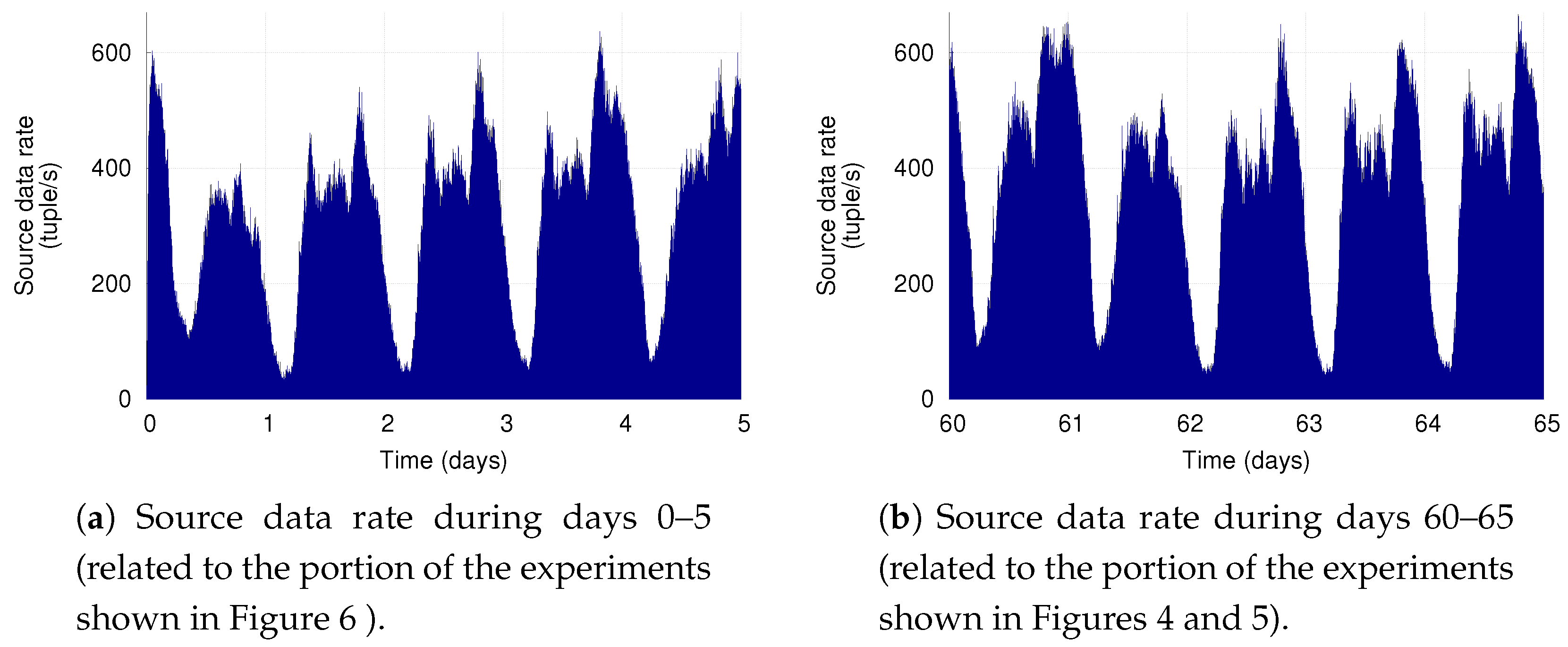
Our simulation results show the benefits of having two separate control components that autonomously adapt the deployment of DSP applications on a dynamic set of computing resources. They demonstrate the flexibility of the proposed infrastructure-level policy based on RL, which can be tuned to optimize different deployment objectives while still supporting the application-level elasticity. The results also show that the combination of RL-based solutions for the ICS as well as for the ACS represents the most flexible solution: if conveniently configured, it reduces the average number of used computing resources with respect to the other policies, while also limiting the number of application reconfigurations (thus increasing the application availability).
The rest of this paper is organized as follows. In
Section 2. we review related work; in
Section 3, we describe the system model and the problem under investigation; and, in
Section 4, we present E2DF and its hierarchical control architecture for self-adaptation. To control DSP applications and computing resources, E2DF exploits hierarchical policies (
Section 5). For the ICS, we propose novel policies resorting on a simple heuristic and on a RL-based approach (
Section 6). To show the multi-level adaptation capabilities of E2DF, we also consider some elasticity policies already proposed in literature, which can conveniently scale the number of operator replicas at run-time (
Section 7). Then, by means of simulations, we extensively evaluate the proposed RL-based control policy for the ICS and the resulting self-adaptation capabilities of E2DF (
Section 8). Finally, we conclude in
Section 9.
3. System Model and Problem Definition
3.1. DSP Application Model
A DSP application can be regarded as a directed acyclic graph (DAG), where data sources, operators, and consumers are connected by streams (see
Figure 1a) An operator is a self-contained processing element that carries out a specific operation (e.g., filtering and POS-tagging), whereas a stream is an unbounded sequence of data (e.g., tuples). DSP applications are usually employed in latency-sensitive domains [
2,
35,
36], where reduced response time is required. Although multiple definitions of response time exist in the context of DSP, the widely used one defines it as the overall processing and transmission latency from a data source to a final consumer on the application DAG. In this work, we assume that the DSP application exposes requirements in terms of response time, specifying a target value
that should not be exceeded.
To improve performance, multiple replicas can be used to run an operator, where each replica processes a subset of the incoming data flow (data parallelism). By partitioning the stream over multiple replicas, running on one or more computing nodes, the load per replica is reduced, and so is the processing latency. Since DSP applications are long-running and subject to workloads that vary over time, the number of replicas should accordingly change at run-time to meet the performance target while avoiding resource wastage (application elasticity).
3.2. Infrastructure Model
For the execution, a DSP application needs to be deployed on computing resources, which will host and execute the operators. In a large-scale environment, multiple cloud data centers and fog micro-data centers provide computing resources on-demand. A DSP system can be deployed over multiple data centers to exploit the geographic distribution of the infrastructure, and acquire resources closer to data sources and consumers. We indicate a data center or a micro-data center as a deployment region (or region, for short). A region contains computing resources that are close to each other, meaning that they can exchange data using local area networks, which result in negligible communication delay. Computing resources belonging to different regions exchange data using wide area networks, with not negligible communication delay.
We assume that a region contains virtual computing resources (i.e., either virtual machines or container running on physical machines), which can be acquired and released as needed, thus enabling infrastructure elasticity. For the sake of simplicity, in this paper, we assume that within the same region the acquired computing resources are homogeneous. Nevertheless, the proposed approach can be extended to consider the case of heterogeneous computing resources within the same region, accounting for different prices and capacities. Each region allows acquiring and release computing resources as needed; nevertheless, in accordance with the limits imposed by nowadays cloud service providers, we assume that the number of virtual resources that can be acquired in a certain time period is limited (e.g., at most 50 new virtual machines can be acquired at once). Regions well model nowadays wide-area distributed computing infrastructures: for example, the large-scale computing infrastructure of a cloud provider can be modeled as a multitude of regions, where each region includes resources of a specific availability zone within a single data center. Considering fog/edge computing scenarios, regions can also model geographically distributed micro-data centers, each one composed by a set of servers placed at network edges.
3.3. Problem Definition
Nowadays, DSP applications are executed by means of a DSP framework. The latter provides an abstraction layer where DSP applications can be more easily developed for and deployed over the distributed computing infrastructure. A DSP framework has to control the application execution to preserve acceptable run-time performance. On the other hand, it has also to control the computing infrastructure, aiming to provide enough computing resources for the execution of its DSP applications.
DSP applications are usually long-running, and their operators can experience changing working conditions (e.g., fluctuations of the incoming workload and variations in the execution environment). To preserve the application performance within acceptable bounds and avoid costly over-provisioning of system resources, the deployment of DSP applications must be conveniently reconfigured at run-time. A scaling operation changes the replication degree of an operator: a scale-out decision increases the number of replicas when the operator needs more computing resources to deal with load spikes, whereas a scale-in decreases the number of replicas when the operator under-uses its resources. Adapting at run-time the application deployment introduces a short-term performance penalty (e.g., downtime), because changing the number of operator replicas involves the execution of management operations aimed to accordingly save the operator internal state and redistribute it across the new number of replicas. Therefore, if applied too often, the adaptation actions negatively impact the application performance.
As regards the computing infrastructure, we observe that, in a static setting, the DSP framework can be executed over a statically defined cluster of nodes. However, modern technologies allow the execution over a dynamic set of resources that can be acquired and released at runtime (e.g., cloud and fog computing). This feature is suitable for addressing the dynamism of DSP applications while avoiding the cost of an over-sized infrastructure. Therefore, modern DSP frameworks should be able to efficiently scale the number of computing resources at run-time with a twofold objective: satisfy the applications’ requirements and avoid resource wastage. Moreover, to efficiently operate over the emerging geo-distributed computing environments (e.g., distributed cloud and fog computing), modern DSP frameworks should be able to seamlessly deal with a large number of resources. In this context, a centralized and monolithic framework will soon suffer from scalability issues. Conversely, despite the increased management complexity, a modular and hierarchically distributed framework allows decentralizing the management responsibilities, thus increasing its ability to oversee a large number of computing resources and DSP applications.
As illustrated in
Figure 1b, a modern DSP framework should be able to efficiently deal with the
multi-level elasticity problem: at the application level, the framework should adapt the number of operator replicas at run-time, whereas, at the infrastructure level, the framework should acquire and release computing resources as needed.
4. Hierarchical System Architecture
The complexity of the computing environment calls for systems that can autonomously adapt their behavior in face of changing working conditions. The MAPE control cycle is a well-know architectural pattern that organizes the autonomous control of a software system according to four main components (Monitor, Analyze, Plan, and Execute), which are responsible for the primary functions of self-adaptation [
16].
When the controlled system is distributed across a large number of computing nodes, a single and centralized MAPE loop may represent a system bottleneck that may compromise the system responsiveness. To overcome the limitations of a centralized control solution, we can efficiently decentralize the MAPE components according to popular design patterns, as described in [
49]. Among the different decentralization solutions, the hierarchical control pattern represents a suitable approach to manage wide-area distributed systems. The hierarchical control pattern revolves around the idea of a layered architecture, where each layer works at a different level of abstraction. In this pattern, multiple MAPE control loops work with time scales and concerns separation. Lower levels operate on a shorter time scale and deal with local adaptation. Exploiting a broader view on the system, higher levels steer the overall adaptation by providing guidelines to the lower levels.
To efficiently control the execution of elastic DSP applications in a geo-distributed computing environment, we propose
Multi-Level Elastic and Distributed DSP Framework (E2DF). It includes two management systems that are organized according to a two-layered hierarchical pattern: the Application Control System (ACS), which adapts the DSP operators deployment, and the Infrastructure Control System (ICS), which controls the computing resource elasticity.
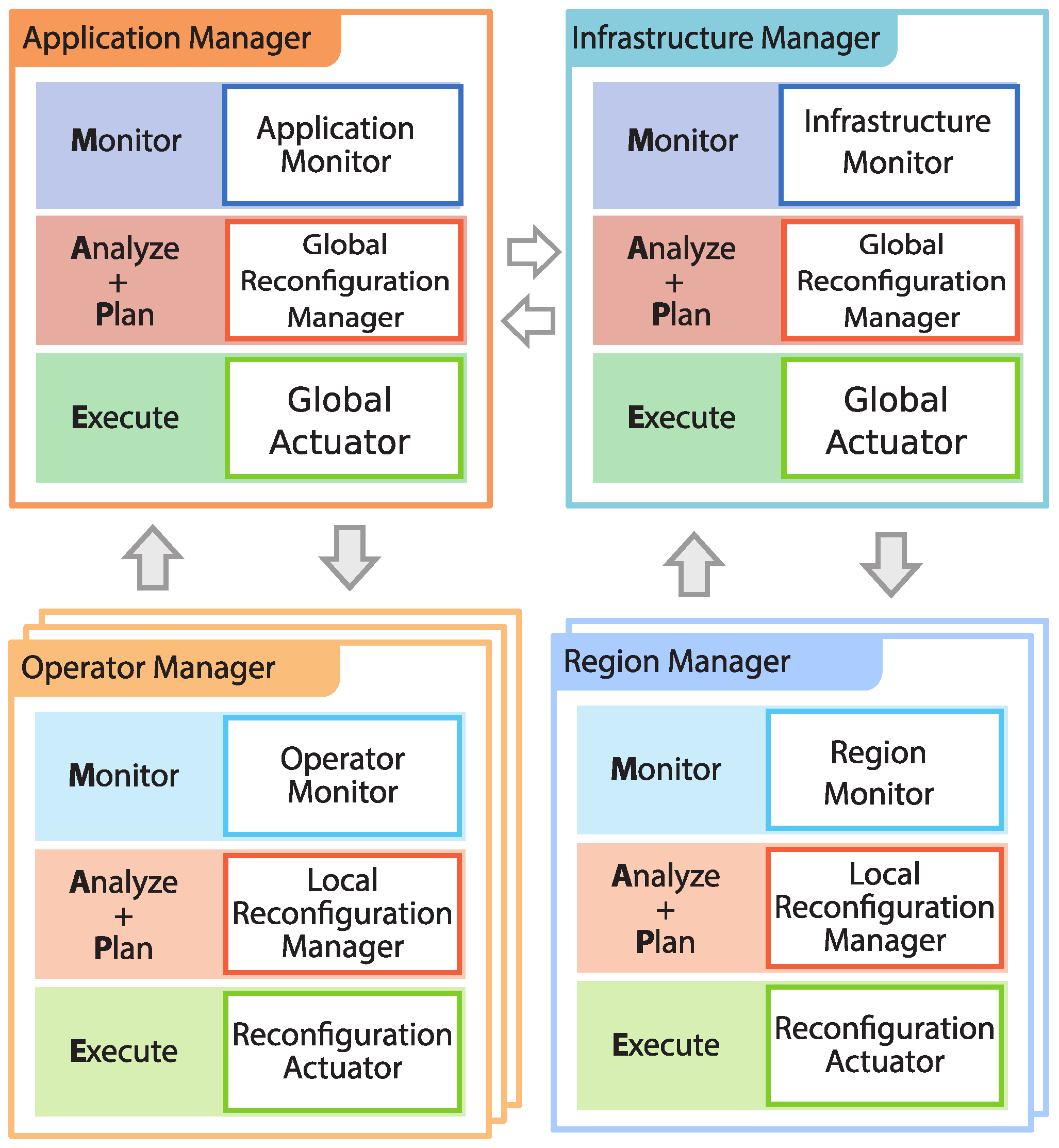
Figure 2 illustrates the conceptual architecture of E2DF, highlighting the hierarchy of the multiple MAPE loops and the system components in charge of the MAPE loop phases.
The ICS includes a centralized Infrastructure Manager (IM), which cooperates with multiple decentralized Region Managers (RMs). Similarly, the ACS comprises one centralized Application Manager (AM) and multiple decentralized Operator Managers (OMs). These components oversee the application deployment at run-time, which can be conveniently adapted when improvements of the application performance can be achieved. The IM and AM can work independently one another or can cooperate so as to realize cross-level optimizations. In such a way, the infrastructure can be adapted to better address specific application needs (e.g., to provision resources in advance or to prevent node consolidation). In this paper, we do not consider cross-level optimization, but we mainly focus on adaptation policies for the ICS.
4.1. Infrastructure Control System
When a DSP system is deployed over a large-scale environment, managing resources is not a trivial task: the number of computing resources as well as the network latency among them can introduce prohibitively high delays in managing the DSP system. To address this management challenge, we exploit the concept of deployment region, considering that resources within a single region can be managed independently from other regions. Hence, we introduce, within the DSP system, a two-layered hierarchical control system that resorts on an Infrastructure Manager (IM) and multiple Region Managers (RMs), one per each region.
The Region Manager (RM) is a distributed entity that controls computing resources within a single region. To perform these operations, the RM is organized according to the MAPE loop and realizes the lower level control loop of the ICS. The RM monitors the computing nodes used by E2DF within the region through the
Resource Monitor. The latter periodically queries the active nodes to retrieve the number of hosted application operators and the average utilization of its computing and memory resources. Then, through the
Local Reconfiguration Manager, it analyzes the monitored data and determines if new resources should be acquired, or leased ones should be released (e.g., to reduce resource wastage). To this end, the Local Reconfiguration Manager is equipped with a local policy, whose details are presented in
Section 6. When the RM local policy determines that some adaptation should occur, it issues an adaptation request to the higher layer.
At the higher layer, the
Infrastructure Manager (IM) coordinates the resource adaptation among the different computing regions through a global MAPE loop. By means of the
Infrastructure Monitor, it collects aggregated monitoring data from the different available regions. Then, through the
Global Reconfiguration Manager, the IM analyzes the monitored data and the reconfiguration requests received by the multiple RMs to decide which reconfiguration should be granted. For example, the Global Reconfiguration Manager can decide that it is more convenient to acquire resources from a specific region, so it will inhibit scaling operations proposed for other regions. According to its internal policy (see
Section 6.3), the Global Reconfiguration Manager can interact with the AM and accordingly adapt its behavior. For example, it may suggest the AM to consolidate the managed DSP operators on fewer computing nodes (the AM can conveniently accept or deny the request), or it may request to balance load among the deployment regions. Using the
Global Actuator, the IM communicates its reconfiguration decisions to each RM, which can, finally, scale the computing infrastructure by means of the their local
Reconfiguration Actuators.
4.2. Application Control System
The ACS manages the run-time adaptation of a DSP application. Similar to the ICS, it implements a two-layered hierarchical MAPE loop, where an Application Manager oversees subordinate and decentralized Operator Managers.
At the lower layer, the Operator Manager (OM) controls the reconfiguration of a single DSP operator and proposes reconfiguration requests to the higher level. The OM uses the Operator Monitor to retrieve the resources usage by the operator as well as its performance in terms of response time. By analyzing this information, the Local Reconfiguration Manager determines if any local reconfiguration action is needed. The available actions are scale-out and scale-in, which respectively increase and reduce the number of replicas per operator. When the OM determines that some adaptation should occur, it issues an operator adaptation request to the higher layer.
At the higher layer, the
Application Manager (AM) is the centralized entity that coordinates the adaptation request aiming to obtain good overall DSP application performance. By means of the
Application Monitor, it oversees the global application behavior. Then, using the
Global Reconfiguration Manager, it analyzes the monitored data and the reconfiguration requests received by the multiple OMs. The AM decides which reconfigurations should be granted by using its global policy (
Section 7.3). Then, it communicates the adaptation decisions through the
Global Actuator to each OM; finally, the latter can execute the operator adaptation actions by means of their local
Reconfiguration Actuator. We refer the reader to [
8] for further details.
5. Multi-Level Adaptation Policy
The architecture of E2DF identifies different macro-components (i.e., AM-OM and IM-RM) that cooperate to adapt the deployment of DSP applications and infrastructures at run-time. The resulting architecture is general enough to not limit the specific internal policies and goals for these components. By properly selecting the internal policy for each component, the proposed solution can work in different execution contexts, which may encompass applications with different requirements, infrastructures with heterogeneous resources, and different user preferences. As a result, the system components can work under different degree of coupling. To favor decentralization and scalability, we design internal control policies that pursuit a strict separation of concerns among the different system components.
Since the control components (i.e., AM, OMs, IM, and RMs) work at different abstraction layers, we need two-layered control policies as well. Specifically, we consider local policies, associated with each RM and OM, that are concerned about low-layer adaptation actions and exploit a fine-grained view on the controlled entities (i.e., computing resources and DSP operators). The local policies do not directly enact planned adaptation actions, which instead are communicated to the higher level components (i.e., IM or AM). Each of these components is equipped with a global policy that works at the granularity of the whole application/infrastructure and thus exploits a global level view. Based on the overall monitored performance and the application requirements (i.e., its target response time ), the global policies identify the most effective reconfigurations proposed by the decentralized agents, providing an implicit coordination mechanism among the independent local policies.
6. Infrastructure Control Policy
The ICS policies aim to dynamically acquire and release computing resources for E2DF. These strategies result from the cooperation of a global policy for the IM and a local policy for the RMs. The overall adaptation goal is to improve resource utilization (i.e., to reduce wastage), while being able to satisfy the varying demand for resources by the applications.
Each RM has visibility of the computing resources belonging to a single deployment region used by E2DF. To elastically adapt the number and type of these resources, the RM uses a
local policy, which in particular implements the planning component of the low-layer MAPE loop. In this paper, we explore two classes of RM policies: the first aims at preserving a limited pool of ready-to-run resources (
Section 6.1), and the second is based on a Reinforcement Learning approach (
Section 6.2).
The RMs send their reconfiguration request to the IM, which grants reconfiguration according to its
global policy. The latter works at the granularity of the whole infrastructure, therefore it can take advantage of a global view on the computing infrastructure. In this paper we mainly focus on local policies for controlling the infrastructure in a decentralized manner, therefore we only present a very simple global policy that coordinates the infrastructure reconfiguration requests (
Section 6.3).
6.1. Local Policy: Simple Provisioning Policy
In the simple provisioning policy, the RM preserves a predefined number of computing nodes, , in a completely idle state for the region. An idle node does not host any application component; however, it is up-and-running and ready to receive DSP operator assignments. The main idea behind this policy is to keep a limited set of ready-to-run resources that can be quickly used in case of need (i.e., they can be used without waiting the boot time of new computing resources). When the RM detects a number of idle nodes lower than , it acquires a new resource for E2DF within its region. Conversely, when too many resources are not utilized (i.e., when there are more than idle nodes), the RM proposes a scale-in operation, which frees the unused computing resources of E2DF. Observe that, since an idle node does not host any application component, it can be turned off without impacting the applications running in E2DF.
6.2. Local Policy: Reinforcement Learning Scaling Policy
Reinforcement learning approaches aim to learn the optimal strategy—in our scenario the RM scaling strategy—through experience and direct interaction with the system [
14]. A RL task basically considers an
agent who aims to minimize a long-term
cost. Considering a sequence of discrete time steps, which models the periodical activation of the local policy, at each step, the agent performs an
action, looking at the current
state of its environment (i.e., the region). The chosen action causes the payment of an immediate cost, and the transition to a new state. Both the paid cost and the next state transition usually depend on external unknown factors as well, hence are stochastic. To minimize the expected long-term (discounted) cost, the agent keeps the estimates
, which represent the expected long-run cost that follows the execution of action
a in state
s. These estimates constitute the so-called Q-function, and are used by the RM to make decisions. By observing the actual incurred costs, the RM updates these estimates over time, and by so doing, also improves its policy. RL techniques are based on the assumption that the underlying system is stationary and satisfies the Markov property. Although these properties might not hold true in real systems, RL techniques have been often applied successfully in non-Markovian domains [
14]. To cope with the (possible) lack of the stationary property, it is sufficient to use a constant (rather than decreasing) learning rate to let the learned policies adapt over time [
14].
We define the state at the beginning of the ith time interval as the triple , where is the number of active computing nodes, is the average resource utilization for the currently deployed application components, and signals whether an idle node exists. In general, is a vector containing the utilization of several resources (e.g., CPU, memory, and network bandwidth). For simplicity, in this work, we assume it to be a scalar value, representing the average CPU utilization for the running application replicas. Even though the average utilization is a real number taking values in , for the sake of analysis, we discretize it by assuming that where is a suitable quantum. We also assume that , where depends on the total amount of resources available in region r, and is statically configured. We will denote by the set of all the possible RM states.
For each state , we have a set of scaling decisions represented by a set of actions , where denotes the decision of launching a new computing node, the decision of terminating one of the active nodes, and is the do nothing decision. Obviously, not all of the above-mentioned actions are available in those states with or , where (there is no node that can be terminated), or with , where (we cannot add more computing nodes beyond the maximum available capacity).
To each triple , we associate an immediate cost function , which captures the cost of carrying out action a when the system is in state s and transitions into . Since the ICS has a two-fold goal (i.e., satisfying the application resource demand and minimizing the resource usage), in our RL model, we consider two different costs:
captures a penalty paid whenever the RM cannot satisfy all the resource acquisition requests coming from the application during the next time interval. We simply consider this cost term as a constant penalty, which is paid whatever the number of the unsatisfied resource requests is (i.e., one or more).
accounts for the cost of the active computing nodes throughout the next time interval. For simplicity, we assume that we have a constant cost per node.
Using the
Simple Additive Weighting technique [
50], we define single cost function
as the weighted sum of the different costs (normalized in the interval
):
where
is the indicator function,
refers to the number of resource acquisition requests coming from the applications that are unsatisfied, and
and
, with
, are non-negative weights for the different costs. Intuitively, the cost function allows us to
instruct the RM to discriminate between the
good system configurations and actions and the
bad configurations and actions (the larger the cost, the worse the configuration). As the RM aims at minimizing the incurred cost, it is encouraged by the cost function: (i) to reduce the number of active nodes; and (ii) to avoid rejecting resource acquisition requests coming from the application. The different weights allow us to express the relative importance of each cost term. Differently from the simple solution described in
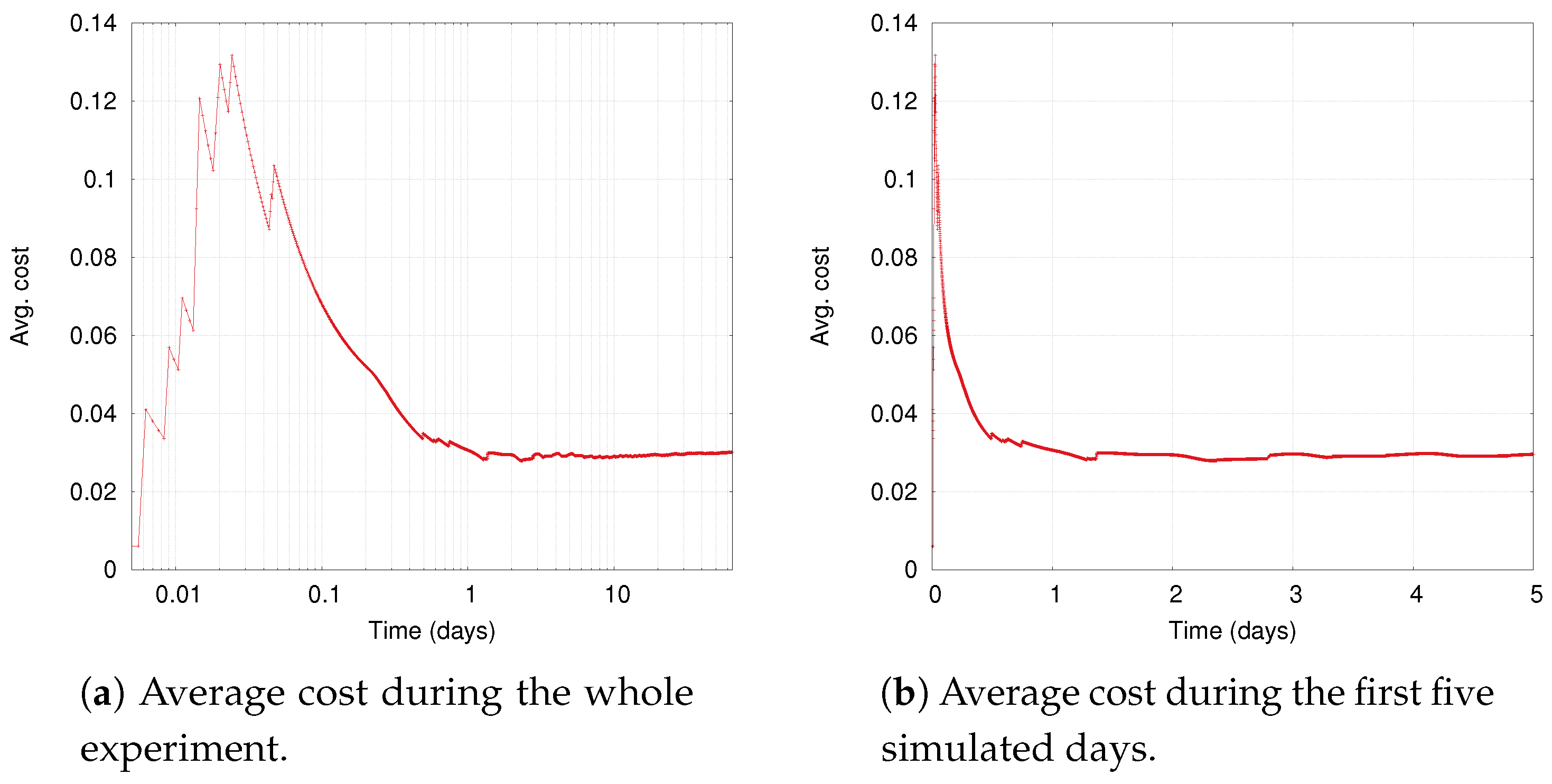
Section 6.1, this policy directly optimizes metrics that represent the ICS objectives. Therefore, by appropriately setting the weights, we expect the the local cost function to guide the agent towards meeting the global performance goals in a decentralized way.
6.2.1. Learning the Optimal Policy
At each decision time
i, the RL agent has to decide which action to take. Specifically, being in state
s, the agent relies on its
policy to pick an action. A policy
is a function that associates each state
s with an action
. Ideally, the agent relies on the
optimal policy
, which minimizes the long-term discounted cost, and satisfies the Bellman optimality equations (see [
14]). Unfortunately, we cannot explicitly determine the optimal policy without a complete and accurate system model formulation. The presence of unpredictable dynamics in the system forces the agent to
learn the policy to use at run-time.
Algorithm 1 illustrates the general RL scheme: the Q functions are first initialized (setting all to zero will often suffices) (Line 1); then, at each step i, the agent chooses an action based on the current estimates of Q (Line 3), observes the incurred cost and the next state (Line 4), and updates the Q function based on what it just experienced during step i, that is, the tuple ) (Line 5).
Different RL techniques differ for the actual learning algorithm adopted, and on the assumptions about the system. For example, the well-known Q-learning algorithm is a
model-free learning algorithm which requires no knowledge of the system dynamics, and only learns by direct experience. By doing so, Q-learning often requires much time for convergence, and thus cannot be easily adopted in real systems, as we also have shown in [
41] for the simple case of a single DSP operator in isolation. For this reason, we present a
model-based approach, which basically improves its estimates of the entire system dynamic over time, and accordingly updates the
Q function.
| Algorithm 1 RL-based operator elastic control algorithm. |
- 1:
Initialize the Q functions - 2:
loop - 3:
choose a scaling action (based on current estimates of Q) - 4:
observe the next state and the incurred cost - 5:
update the functions based on the experience - 6:
end loop
|
6.2.2. Model-Based Reinforcement Learning
Model-based RL relies on a possibly approximated system model to directly compute the Q-functions. Instead of learning the value of state and actions through experience, in this scenario, the agent uses its experience to improve the system model approximation. In particular, we consider the
full backup model-based RL approach (see [
14]), which backups the value of each state-action pair at every time step. To update the Q-function for all
and for all
, we directly use the Bellman equation [
14,
51]
We replace the unknown state transition probabilities
, and the unknown cost function
,
and
by their empirical estimates,
and
. To estimate the transition probabilities
, we first observe that
Unfortunately, the dynamics of the resource utilization and the presence of idle nodes are not fully captured by our model, as they also depend on the application workload and the adaptation actions carried on by the ACS. Therefore, a naive approach would consist in estimating the transition probabilities on-line by observing the state transition frequencies. However, since these probabilities depend on several state-action variables, the agent would need to learn a large number of parameters, possibly requiring a long transitory phase. Aiming at balancing the model accuracy and the learning velocity, we adopt an approximate probability model that relies on the following assumptions: (i) the resource utilization variations do not depend on the ICS decisions, but they depend only on the application workload changes; and (ii) the presence of an idle computing node in
only depends on its presence in
i and the latest action
. Formally, we have
Hereafter, since
u takes value in a discrete set, we will write
,
for short. Let
be the number of times the average resource utilization changes from state
to
, in the interval
,
. At time
i, the transition probabilities estimates are then
Analogously, we define the estimated transition probabilities for the variable
f, that is
. Replacing these probabilities, we derive the estimates
via (
3).
Besides the state transition probabilities, to compute the Q-function using the Bellman equation, we need an (approximate) formulation of the cost function. To estimate the immediate cost
, we first split it into two terms, that we indicate as the
known and the
unknown costs:
Comparing the expression above with Equation (
1), we observe that the known cost
accounts for the resources costs, thus it only depends on the current state and action. On the other hand, the unknown cost
accounts for the unsatisfied resource demand penalty, which depends on the resource utilization and the application behavior in the next time interval (i.e., it depends on the next state
). Since we cannot easily formulate these dynamics, we replace
with its on-line estimate
. To this end, the agent observes the incurred cost
at the end of each time interval
i and determines the “unknown” cost paid in the
ith time slot,
, as
by simply applying Equation (
4). Then, the unknown cost estimate is updated using a simple exponential weighted average:
We must note that the cost estimation rule above does not exploit all the a priori knowledge about the system. Indeed, we can heuristically assume that the expected cost due to unsatisfied resource requests is not lower when the amount of nodes is reduced and/or the utilization increases, and it is not higher with more nodes and/or a lower utilization. Therefore, after applying Equation (
5) for
, we always enforce the following constraints adjusting the estimates for states
:
The resulting Q-function update step (Line 5 of Algorithm 1) is summarized in Algorithm 2. Given the current estimates
, at any step, the RM chooses the greedy action, that is, the action with the minimum long term estimated cost,
. It is worth noting that, differently from the model-free RL algorithms, with this approach we do not need a mechanism for forcing action space exploration, which is a common issue in RL solutions [
14].
| Algorithm 2 Full backup model-based learning update. |
- 1:
Update estimates , and - 2:
for alldo - 3:
for all do - 4:
- 5:
end for - 6:
end for
|
Each learning update step requires iterating over all the states, all the actions, and all the next states. Therefore, the computational complexity is
. Given the limited amount of available actions (two or three) and the fact that many transition probabilities are equal to 0 (see Equation (
2)), the complexity reduces to
, that is, it scales linearly with the number of resources in the region. Storing the Q function in memory requires
, corresponding to
space.
6.3. Global Policy
The IM global policy implements the Analyze and Plan steps of the centralized MAPE loop. It coordinates the adaptation actions proposed by the decentralized RMs and can enforce strategies aimed to balance the number of computing resources acquired across different regions of the infrastructure. We design a simple coordination policy that accepts the reconfiguration requests proposed by the different RMs. However, more sophisticated solutions can be devised to better control the way the infrastructure is adapted. For example, the IM could exploit the information coming from the RMs to improve resource utilization by interacting with the AM; to this end, the RM could expose aggregated information on the utilization or price of resources, or on resources that can be consolidated by migrating some of the application operators.
Conceptually, the global policy periodically runs the following steps: (1) reconfiguration request prioritization; (2) acceptance of requests; and (3) post-reconfiguration actions.
In the reconfiguration request prioritization step, the global policy prioritizes the reconfiguration requests proposed by the RMs and determines which are the most worthy to be applied. The prioritization criterion depends on the specific global policy; it can favor resources belonging to a specific region (e.g., for political or economical reasons) or resources with specific quality attributes (e.g., price, availability, and processing capacity).
In the acceptance of requests step, the global policy decides which reconfiguration requests should be granted. The choice ranges from simply accepting all the proposed requests to limit somehow their number. This step allows the global policy to deal with a limited budget for the acquisition of computing resources. We consider this step to be performed by exploiting the sorted list of most worthy reconfiguration requests. In this paper, to design and evaluate decentralized RM policies, our simple global policy grants all the proposed reconfiguration requests.
In the last step, post-reconfiguration actions, the global policy can interact with the AM to propose either migration or consolidation operations. This step can be used by the IM to improve resource efficiency and load balancing, and/or limit resource wastage. For example, if the IM detects that computing resources within a region are under-utilized, it can propose the AM to consolidate its applications on a fewer number of resources, to free and dismiss some of the computing nodes. The IM can also determine that using resources belonging to a specific regions is not convenient anymore, therefore it may undertake actions to free all the used region resources. Our global policy does not currently perform any post-reconfiguration action and we let the exploitation of policies for the interplay between the IM and the AM to future work.
7. Application Control Policy
The ACS manages the DSP applications deployment through a local policy (executed by the OMs) and a global policy (executed by the AM).
The OM local policy implements the Analyze and Plan phases of the decentralized MAPE loop, which controls the execution of a single DSP operator. Running on decentralized components, this policy has only a local view of the system, which consists of the execution status of each operator replica (in terms of response time and resource utilization). We consider two different local policies. The first is a threshold-based policy whereby scaling decisions are based on the replicas CPU utilization compared to predefined threshold values (
Section 7.1). The second resorts on a more sophisticated RL solution, where the scaling policy is learned over time by interacting with the system (
Section 7.2). Whenever a scale-out decision is taken, the OM places the new operator replica within the same region where the other operator replicas are running. In the case of a scale-in decision, the OM terminates one (randomly selected) operator replica among the available ones.
To accept or reject the reconfiguration actions proposed by the OM, the AM resorts on a global policy, which implements the Analyze and Plan steps of the centralized MAPE loop. Its main goal is to coordinate the reconfiguration actions to satisfy the DSP application requirements, while minimizing the number of used computing resources. We consider a simple global policy that is only aimed to solve reconfiguration conflicts, i.e., it rejects adaptation actions when they try to allocate the same computing resource to multiple operator replicas (
Section 7.3). More sophisticated approaches (e.g., based on a token bucket to limit the number of performed reconfigurations) can be proposed as well [
8].
In the next section, we present the idea behind the different policies. Nevertheless, their details can be found in [
8].
7.1. Local Policy: Threshold-Based Policy
In the threshold-based scaling policy, the OM monitors the CPU utilization of the operator replicas. Let us denote by the utilization of replica r, which measures the fraction of CPU time used by r. When the replica utilization exceeds the target utilization level , the OM proposes to add a new replica. Conversely, the OM proposes to remove one of the n running replicas (i.e., a scale-in operation), when the average utilization of the remaining replicas would not exceed a fraction of the target utilization, i.e., when , . This avoids system oscillations with the OM executing a scale-out operation just after a scale-in one.
7.2. Local Policy: Reinforcement Learning Based Policy
To design the RL policy for the OM, we follow a similar approach to the one presented in
Section 6.2. In this case, the RL policy learns the optimal strategy for scaling a DSP operator at run-time through experience and direct interaction with the system. The RL agent consider the state of a single DSP operator and performs scaling actions, aiming to minimize a long-term cost.
We define the state of an operator based on the number of running replicas, and the measured average tuple arrival rate at the operator. For each state, we have the following reconfiguration actions: add a new operator replica (i.e., scale-out decision), remove an operator replica (i.e., scale-in decision), and a do nothing decision. We also consider that not all of these actions are available in all the states; indeed, we guarantee that at least one replica should be executed and that the operator has a maximum allowed replication degree.
As for the ICS, the RL agent is driven by a long-term cost, that depends on the immediate cost function. For the DSP operator, the immediate cost function captures three different terms:
The reconfiguration cost : Whenever the system carries out scale-out or a scale-in operation, the operator suffers a downtime period during which no tuple is processed.
The performance penalty : This is paid whenever the operator response time exceeds a per-operator bound .
The resource cost : This accounts for the cost of the computing resources used to run the operator replicas. For simplicity, we assume that we have a constant cost per operator replica.
We combine the different costs into a single cost function as the weighted sum of the costs:
where
s and
represent the operator state before and after applying the reconfiguration action
a, respectively; and
,
, and
, with
are non-negative weights for the different costs. As the OM aims to minimize the incurred cost, the cost function suggests: (i) reducing the number of requested reconfigurations; (ii) keeping the response time within the given bound; and (iii) limiting the resource usage, with the different weights expressing the relative importance of each term.
As regards the definition of the bounds , we observe that they grant a share of the global bound to each operator according to their computational weight. They could be set either statically after preliminary profiling, or dynamically estimated and adapted at run-time by the AM.
7.3. Global Policy
The AM global policy implements the Analyze and Plan steps of the centralized MAPE loop. Its main goal is to obtain satisfying application performance, by coordinating the adaptation actions proposed by the decentralized OMs. In this paper, we resort to a simple global policy that coordinates reconfigurations and prevents the enactment of conflicting reconfigurations (e.g., two operators requesting a new replica on the same computing resource).
9. Conclusions
In this paper, we present and investigate the features of Multi-Level Elastic and Distributed DSP Framework (E2DF), a hierarchical approach for elastic distributed DSP. E2DF aims to enhance DSP systems with self-adaptation capabilities, adjusting both the operators parallelism (application-level elasticity) and the amount of allocated computing resources (infrastructure-level elasticity) at run-time. In particular, E2DF includes an ACS, which adapts the elastic DSP operators deployment, and an ICS, which controls the resource elasticity. These control systems are designed according to a hierarchical decentralized MAPE control pattern, where a centralized manager controls the reconfiguration requests proposed by decentralized managers.
Within this framework, we consider different policies for the hierarchical control. In this paper, we specifically design auto-scaling approaches for the computing infrastructure. We present a first baseline solution that relies on a simple provisioning approach that always keeps a limited pool of ready-to-use idle nodes. Aiming to design a more flexible self-adaptation strategy, we have investigated RL-based approaches, where distributed agents learn which are the most valuable reconfiguration actions to perform. Specifically, we present and evaluate a model-based RL algorithm, which exploits the partially available knowledge about the system dynamics to speedup the learning process. As regards the application elasticity, we consider two existing approaches: a threshold-based scaling policy, which is widely used in the literature, and a RL-based policy, which we presented in a previous work [
8].
Our evaluation shows that our multi-level adaptation solution allows significantly reducing resource wastage with respect to statically provisioned infrastructures, with negligible application performance degradation. Interestingly, our results also demonstrate the benefits of RL-based solutions, which provide greater flexibility by autonomously learning how to meet the optimization goals specified by the user.
As future work, we will further investigate the presented hierarchical approach. We plan to design more sophisticated control policies that consider a larger set of constraints and (possibly conflicting) deployment objectives. As regards the global policy, we will explore proactive solutions that can dynamically adapt the local components behavior by providing informative feedback. Moreover, we will also study the multi-agent optimization problem that arises from the interplay between the ACS and ICS, recurring to techniques specifically targeted to this class of problems (e.g., multi-agent RL).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}