Robust Visual Tracking via Patch Descriptor and Structural Local Sparse Representation


Abstract
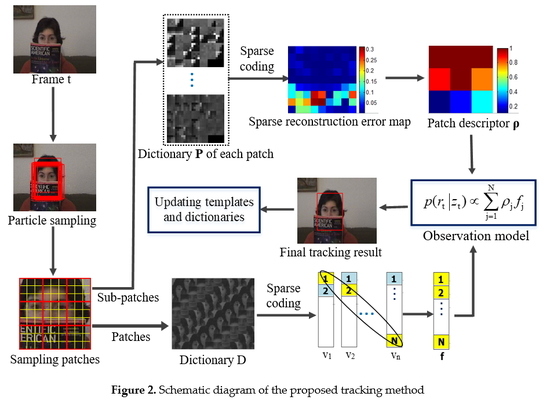
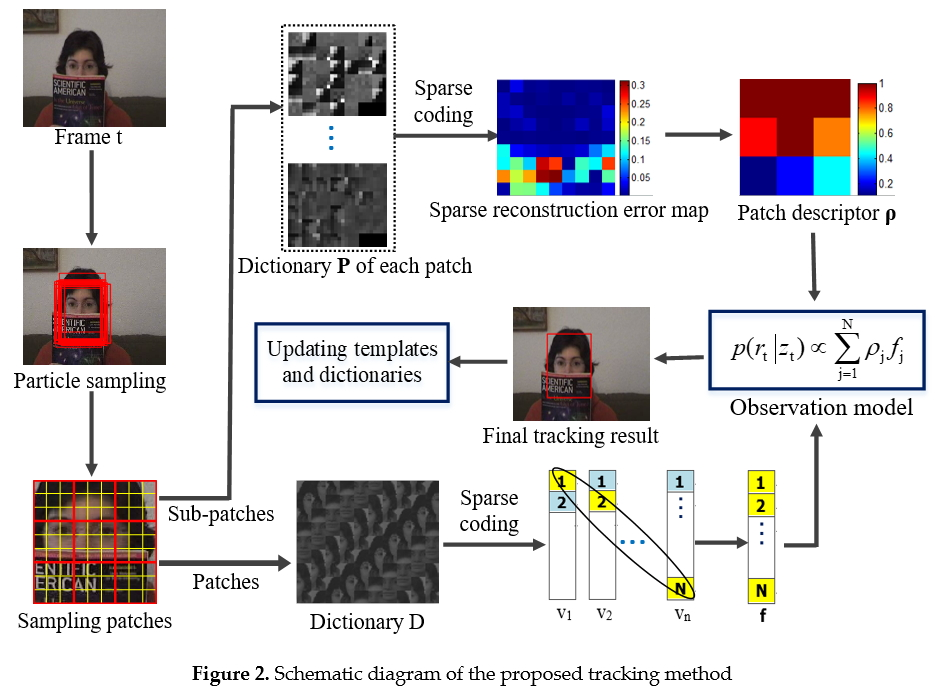
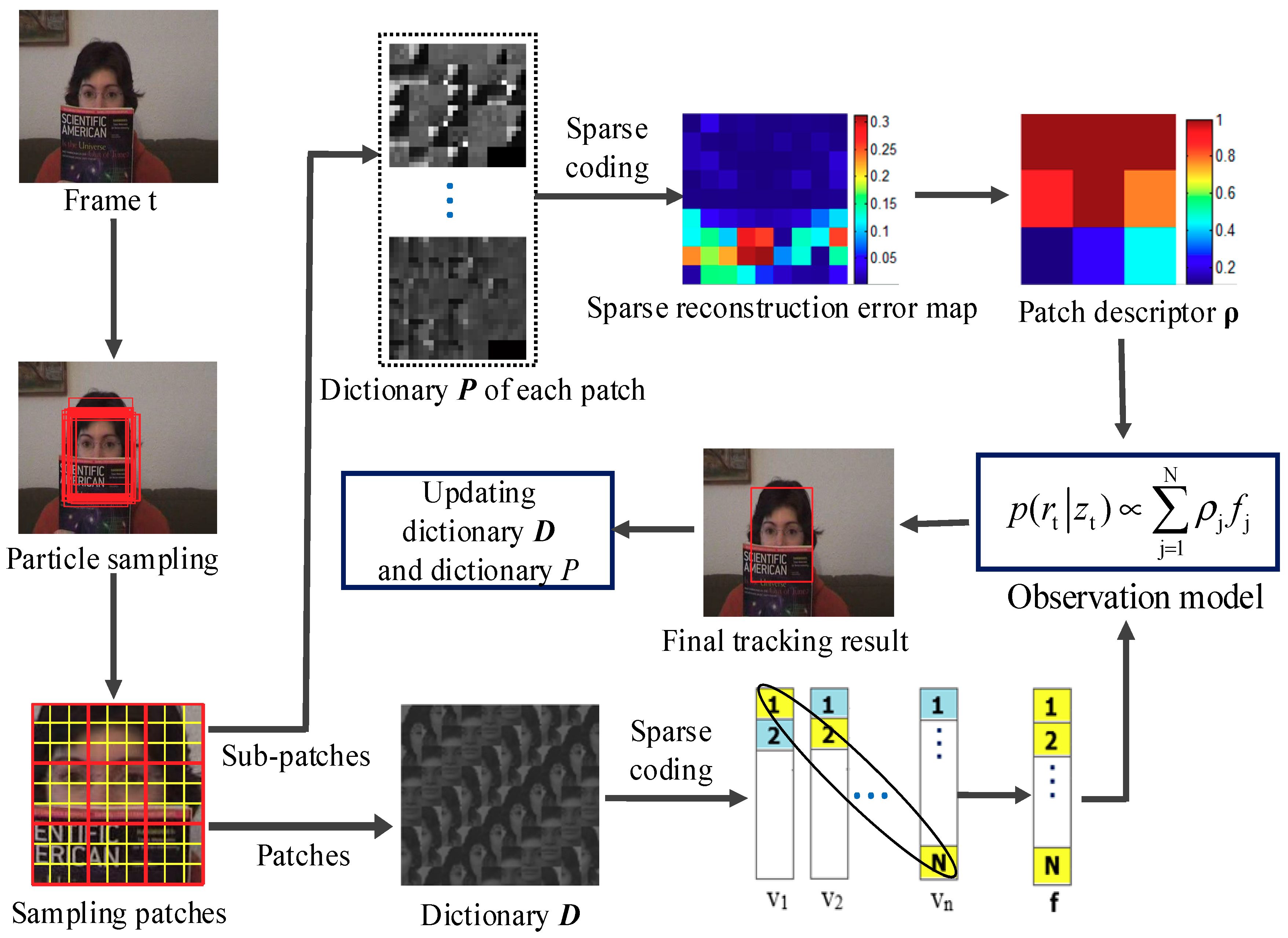
1. Introduction
2. Related Work
2.1. Patch-Based Tracking Methods
2.2. Strategies for Alleviating Model Drift
3. Patch Descriptor and Structural Local Sparse Representation
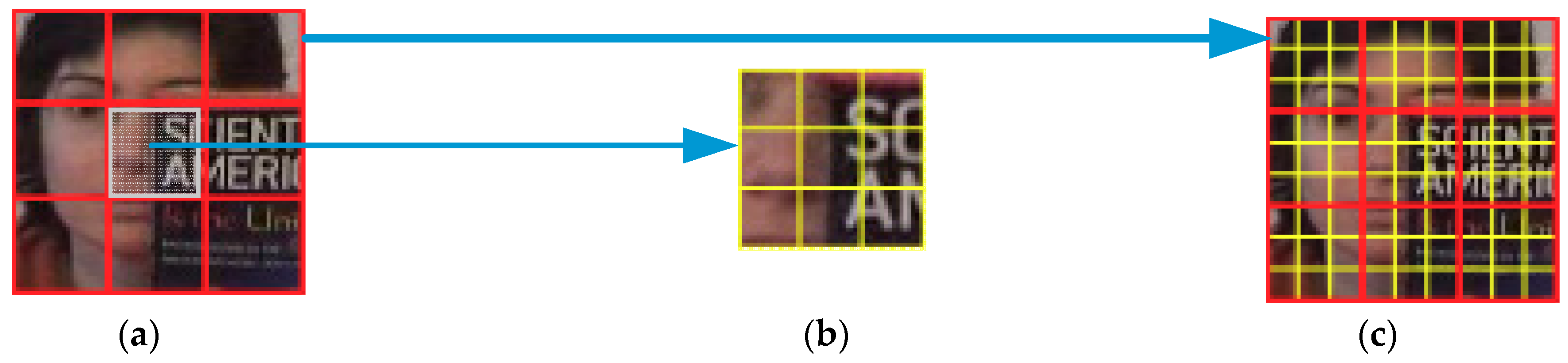
3.1. Target Region Division
3.2. Structural Local Sparse Representation
3.3. Patch Descriptor
4. Object Tracking
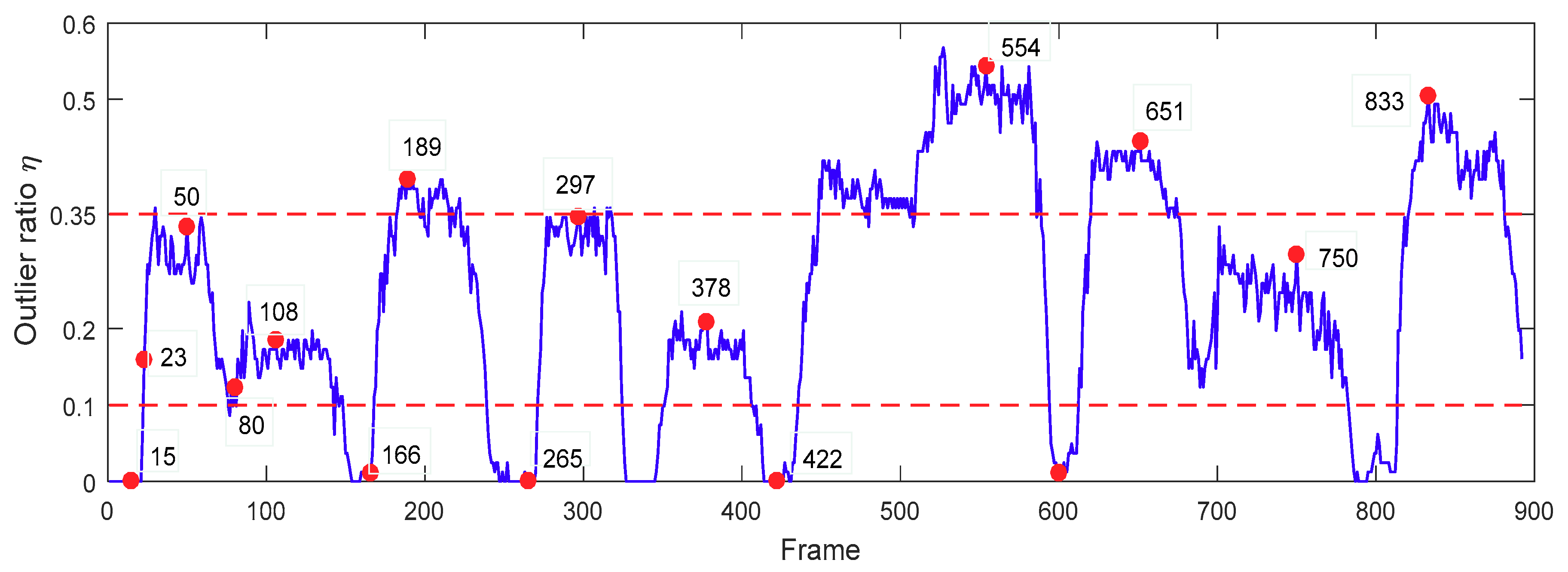
5. Update Scheme
| Algorithm 1. Method for template update. |
| Input: Observation vector r, eigenvectors U, average observation , outlier ratio , thresholds tr1 and tr2, template set T, the current frame f (f > n) |
| 1: if mod(f,5) = 0 and then |
| 2: Generate a sequence of number in ascending order and normalize them into [0, 1] as the probability for template update; |
| 3: Generate a random number between 0 and 1 which is for the selection of which template to be discarded; |
| 4: if |
| 5: Solve Equation (8) and obtain q and e; |
| 6: Add = Uq to the end of the template set T; |
| 7: else if |
| 8: Solve Equation (10) and obtain the recovered sample ; |
| 9: Solve Equation (8) and obtain q and e; |
| 10: Add = Uq to the end of the template set T; |
| 11: end if |
| 12: end if |
| Output: New template set T |
6. Experiments
6.1. Experiment Settings
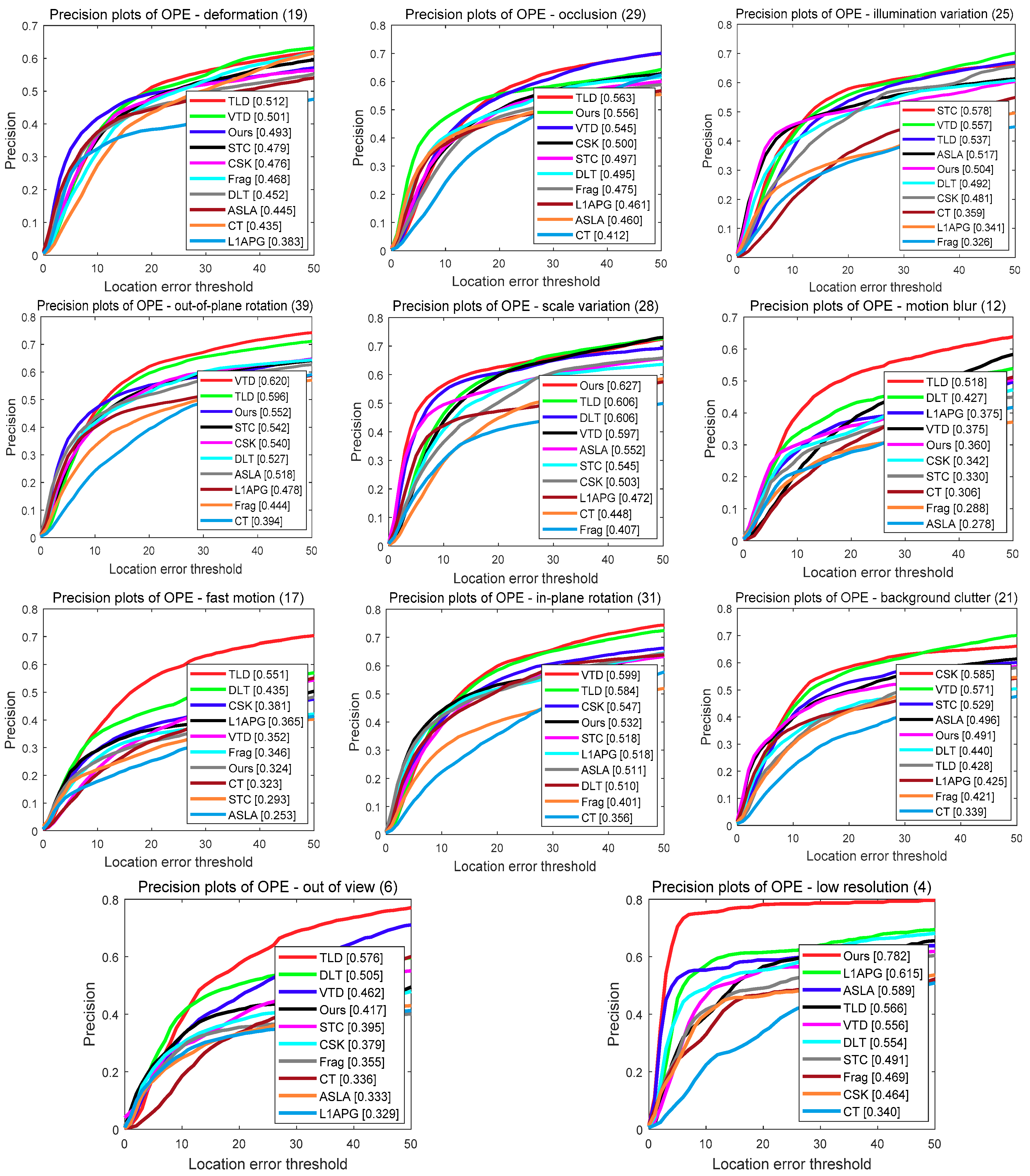
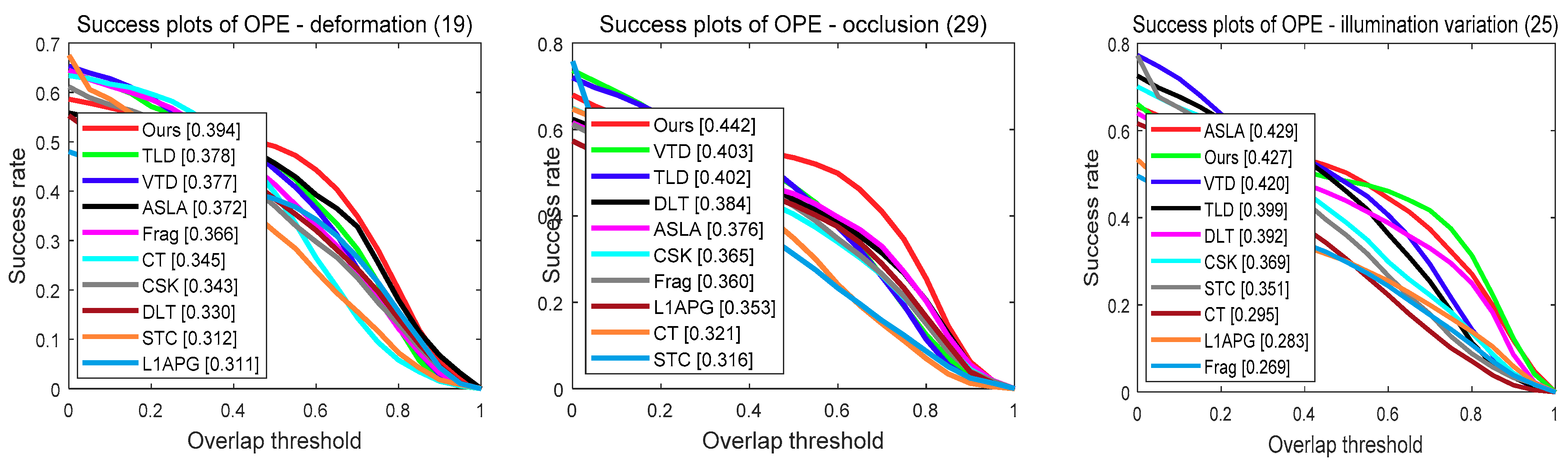
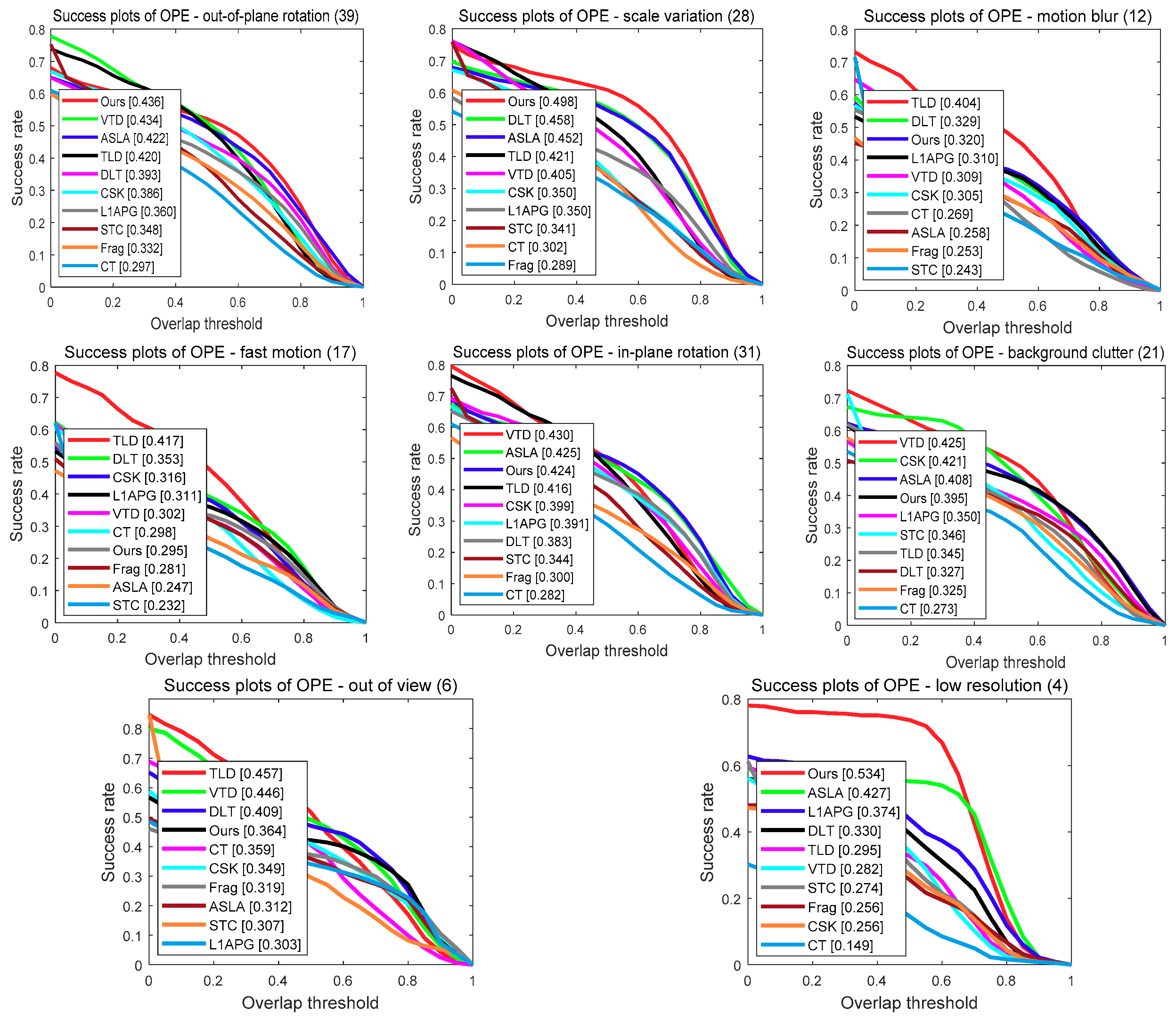
6.2. Overall Performance
6.3. Attribute-Based Analysis
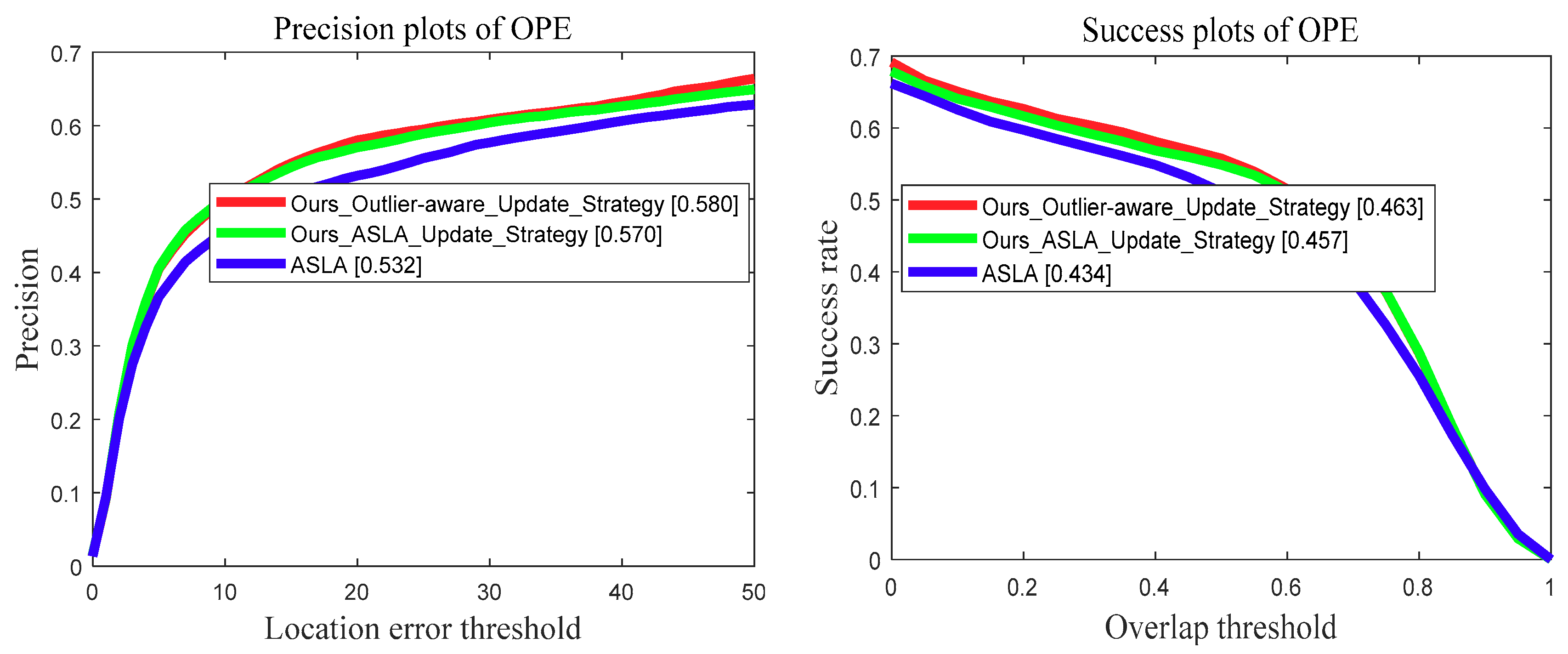
6.4. Evaluation of Template Update Strategy
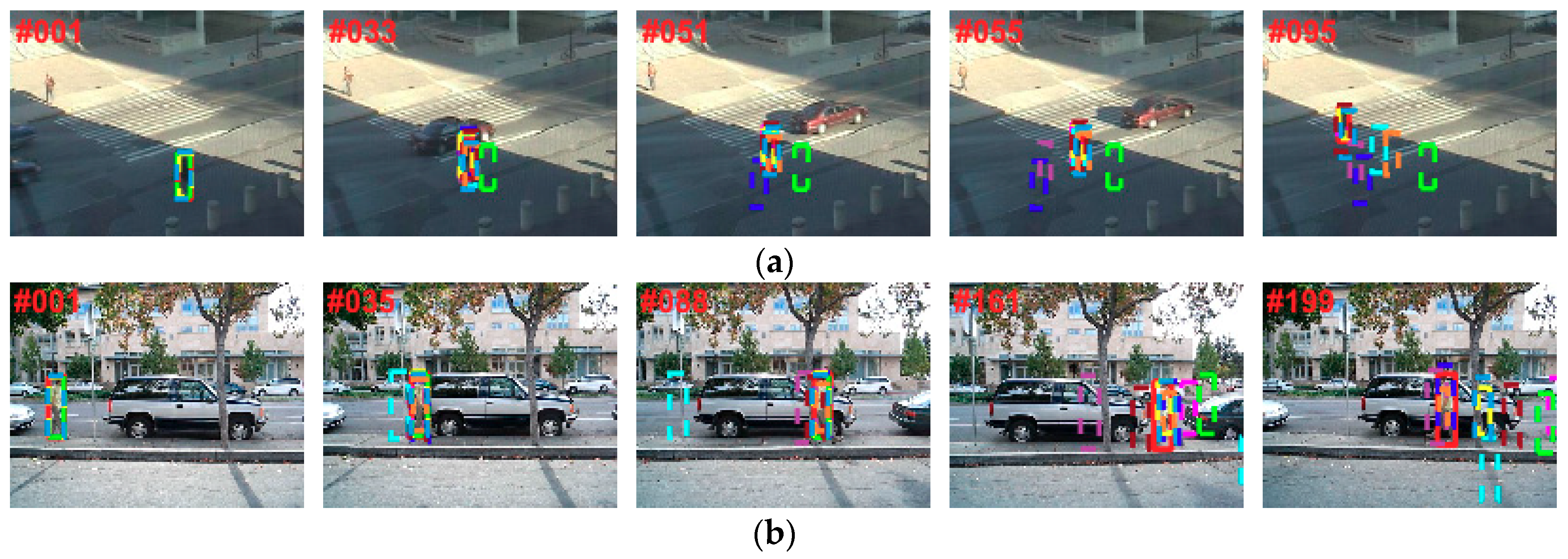
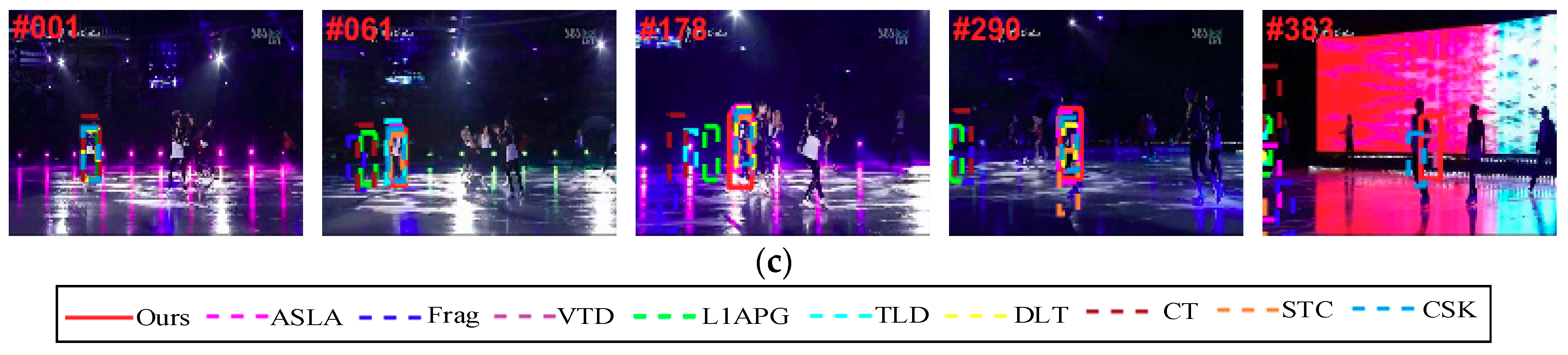
6.5. Typical Results Analysis
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Krafka, K.; Khosla, A.; Kellnhofer, P.; Kannan, H. Eye Tracking for Everyone. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2176–2184. [Google Scholar]
- Bharati, S.P.; Wu, Y.; Sui, Y.; Padgett, C.; Wang, H. Real-Time Obstacle Detection and Tracking for Sense-and-Avoid Mechanism in UAVs. IEEE Trans. Intell. Veh. 2018, 3, 185–197. [Google Scholar] [CrossRef]
- Zheng, F.; Shao, L.; Han, J. Robust and Long-Term Object Tracking with an Application to Vehicles. IEEE Trans. Intell. Transp. Syst. 2018. [Google Scholar] [CrossRef]
- Ross, D.A.; Lim, J.; Lin, R.S.; Yang, M.H. Incremental Learning for Robust Visual Tracking. Int. J. Comput. Vis. 2008, 77, 125–141. [Google Scholar] [CrossRef]
- Kwon, J.; Lee, K.M. Visual Tracking Decomposition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 1269–1276. [Google Scholar]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust Face Recognition via Sparse Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Mei, X.; Ling, H.B. Robust Visual Tracking using L1 Minimization. In Proceedings of the International Conference on Computer Vision (ICCV), Kyoto, Japan, 29 September–2 October 2009; pp. 1436–1443. [Google Scholar]
- Mei, X.; Ling, H.B. Robust Visual Tracking and Vehicle Classification via Sparse Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2259–2272. [Google Scholar] [PubMed]
- Jia, X.; Lu, H.; Yang, M.H. Visual Tracking via Adaptive Structural Local Sparse Appearance Model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 1822–1829. [Google Scholar]
- Guo, J.; Xu, T.; Shen, Z.; Shi, G. Visual Tracking via Sparse Representation with Reliable Structure Constraint. IEEE Signal Process. Lett. 2017, 24, 146–150. [Google Scholar] [CrossRef]
- Lan, X.; Zhang, S.; Yuen, P.C.; Chellappa, R. Learning Common and Feature-specific Patterns: A Novel Multiple-sparse-representation-based Tracker. IEEE Trans. Image Process. 2018, 27, 2022–2037. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Li, Z.; Wang, Z. Joint Compressive Representation for Multi-Feature Tracking. Neurocomputing 2018, 299, 32–41. [Google Scholar] [CrossRef]
- Avidan, S. Ensemble Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 261–271. [Google Scholar] [CrossRef] [PubMed]
- Grabner, H.; Leistner, C.; Bischof, H. Semi-supervised On-line Boosting for Robust Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Marseille, France, 12–18 October 2008; pp. 234–247. [Google Scholar]
- Babenko, B.; Yang, M.H.; Belongie, S. Visual Tracking with Online Multiple Instance Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 983–990. [Google Scholar]
- Hare, S.; Saffari, A.; Torr, P.H.S. Struck: Structured Output Tracking with Kernels. In Proceedings of the International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 263–270. [Google Scholar]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual Object Tracking using Adaptive Correlation Filters. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. Exploiting the Circulant Structure of Tracking-by-detection with Kernels. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 702–715. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Accurate Scale Estimation for Robust Visual Tracking. In Proceedings of the British Machine Vision Conference (BMVC), Nottingham, UK, 1–5 September 2014; pp. 65.1–65.11. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Golodetz, S.; Miksik, O.; Torr, P.H.S. Staple: Complementary Learners for Real-Time Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1401–1409. [Google Scholar]
- Ma, C.; Huang, J.B.; Yang, X.; Yang, M.H. Hierarchical Convolutional Features for Visual Tracking. In Proceedings of the International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 3074–3082. [Google Scholar]
- Qi, Y.; Zhang, S.; Qin, L.; Yao, H.; Huang, Q.; Lim, J.; Yang, M.H. Hedged Deep Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4303–4311. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. ECO: Efficient Convolution Operators for Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6638–6646. [Google Scholar]
- Li, X.; Hu, W.; Shen, C.; Zhang, Z.; Dick, A.; Hengel, A.V.D. A Survey of Appearance Models in Visual Object Tracking. ACM Trans. Intell. Syst. Technol. 2013, 4, 58:1–58:48. [Google Scholar] [CrossRef]
- Wu, Y.; Lim, J.; Yang, M.H. Online Object Tracking: A Benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]
- Adam, A.; Rivlin, E.; Shimshoni, I. Robust Fragments-based Tracking using the Integral Histogram. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New York, NY, USA, 17–22 June 2006; pp. 798–805. [Google Scholar]
- Kwon, J.; Lee, K.M. Tracking of a Non-Rigid Object via Patch-based Dynamic Appearance Modeling and Adaptive Basin Hopping Monte Carlo Sampling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 1208–1215. [Google Scholar]
- Zhang, T.; Jia, K.; Xu, C.; Ma, Y.; Ahuja, N. Partial Occlusion Handling for Visual Tracking via Robust Part Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 1258–1265. [Google Scholar]
- Cai, Z.; Wen, L.; Lei, Z.; Vasconcelos, N.; Li, S.Z. Robust Deformable and Occluded Object Tracking with Dynamic Graph. IEEE Trans. Image Process. 2014, 23, 5497–5509. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Valstar, M.; Martinez, B.; Khan, M.H. TRIC-track: Tracking by Regression with Incrementally Learned Cascades. In Proceedings of the International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 4337–4345. [Google Scholar]
- Sun, C.; Wang, D.; Lu, H. Occlusion-Aware Fragment-Based Tracking with Spatial-Temporal Consistency. IEEE Trans. Image Process. 2016, 8, 3814–3825. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Zhu, J.; Hoi, S.C.H. Reliable Patch Trackers: Robust Visual Tracking by Exploiting Reliable Patches. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 353–361. [Google Scholar]
- Chen, W.; Zhang, K.; Liu, Q. Robust Visual Tracking via Patch Based Kernel Correlation Filters with Adaptive Multiple Feature Ensemble. Neurocomputing 2016, 214, 607–617. [Google Scholar] [CrossRef]
- Kalal, Z.; Mikolajczyk, K.; Matas, J. Tracking-Learning-Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1409–1422. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Ma, S.; Sclaroff, S. MEEM: Robust Tracking via Multiple Experts Using Entropy Minimization. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 188–203. [Google Scholar]
- Ma, C.; Yang, X.; Zhang, C.; Yang, M.H. Long-term Correlation Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5388–5396. [Google Scholar]
- Danellja, M.; Häger, G.; Khan, F.S.; Felsberg, M. Adaptive Decontamination of the Training Set: A Unified Formulation for Discriminative Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NA, USA, 26 June–1 July 2016; pp. 1430–1438. [Google Scholar]
- Shi, R.; Wu, G.; Kang, W.; Wang, Z.; Feng, D.D. Visual Tracking Utilizing Robust Complementary Learner and Adaptive Refiner. Neurocomputing 2017, 260, 367–377. [Google Scholar] [CrossRef]
- Everingham, M.; Gool, L.V.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, L.; Liu, Q.; Zhang, D.; Yang, M.H. Fast Visual Tracking via Dense Spatio-Temporal Context Learning. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 127–141. [Google Scholar]
- Wang, N.; Yeung, D.Y. Learning a Deep Compact Image Representation for Visual Tracking. In Proceedings of the Advances in Neural Information Processing Systems, Stateline, NV, USA, 5–8 December 2013; pp. 809–817. [Google Scholar]
- Zhang, K.; Zhang, L.; Yang, M.H. Real-Time Compressive Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 864–877. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| VTD | Frag | TLD | L1APG | STC | CSK | DLT | CT | ASLA | Ours | |
|---|---|---|---|---|---|---|---|---|---|---|
| Singer1 | 4.19 | 88.87 | 8.00 | 53.35 | 5.76 | 14.01 | 3.04 | 15.53 | 3.29 | 2.98 |
| David | 11.59 | 82.07 | 5.12 | 13.95 | 12.16 | 17.69 | 66.20 | 10.49 | 5.07 | 4.36 |
| Freeman3 | 23.96 | 40.47 | 29.33 | 33.13 | 39.44 | 53.90 | 4.00 | 65.32 | 3.17 | 2.06 |
| CarScale | 38.45 | 19.74 | 22.60 | 79.77 | 89.35 | 83.01 | 22.65 | 25.95 | 24.64 | 14.11 |
| Dudek | 10.30 | 82.69 | 18.05 | 23.46 | 25.60 | 13.39 | 8.81 | 26.53 | 15.26 | 11.82 |
| Crossing | 26.13 | 38.59 | 24.34 | 63.43 | 34.07 | 8.95 | 1.65 | 3.56 | 1.85 | 1.54 |
| Walking2 | 46.24 | 57.53 | 44.56 | 5.06 | 13.83 | 17.93 | 2.18 | 58.53 | 37.42 | 1.95 |
| Freeman4 | 61.68 | 72.27 | 39.18 | 22.12 | 45.61 | 78.87 | 48.09 | 132.59 | 70.24 | 4.57 |
| David3 | 66.72 | 13.55 | 208.00 | 90.00 | 6.34 | 56.10 | 55.87 | 88.66 | 87.76 | 6.39 |
| FaceOcc1 | 20.20 | 10.97 | 27.37 | 17.33 | 250.40 | 11.93 | 22.72 | 25.82 | 78.06 | 13.58 |
| Skating1 | 9.34 | 149.35 | 145.45 | 158.70 | 66.41 | 7.79 | 52.38 | 150.44 | 59.86 | 15.47 |
| Football | 13.64 | 5.36 | 14.26 | 15.11 | 16.13 | 16.19 | 191.4 | 11.91 | 15.00 | 4.13 |
| Average | 27.70 | 55.12 | 48.86 | 47.95 | 50.43 | 31.65 | 39.92 | 51.23 | 33.47 | 6.91 |
| VTD | Frag | TLD | L1APG | STC | CSK | DLT | CT | ASLA | Ours | |
|---|---|---|---|---|---|---|---|---|---|---|
| Singer1 | 0.49 | 0.21 | 0.73 | 0.29 | 0.53 | 0.36 | 0.85 | 0.35 | 0.79 | 0.86 |
| David | 0.56 | 0.17 | 0.72 | 0.54 | 0.52 | 0.40 | 0.25 | 0.50 | 0.75 | 0.76 |
| Freeman3 | 0.30 | 0.32 | 0.45 | 0.35 | 0.25 | 0.30 | 0.70 | 0.002 | 0.75 | 0.75 |
| CarScale | 0.43 | 0.43 | 0.45 | 0.50 | 0.45 | 0.42 | 0.62 | 0.43 | 0.61 | 0.65 |
| Dudek | 0.80 | 0.54 | 0.65 | 0.69 | 0.59 | 0.72 | 0.79 | 0.65 | 0.74 | 0.78 |
| Crossing | 0.32 | 0.31 | 0.40 | 0.21 | 0.25 | 0.48 | 0.72 | 0.68 | 0.79 | 0.78 |
| Walking2 | 0.33 | 0.27 | 0.31 | 0.76 | 0.52 | 0.46 | 0.82 | 0.27 | 0.37 | 0.81 |
| Freeman4 | 0.16 | 0.14 | 0.34 | 0.35 | 0.16 | 0.13 | 0.14 | 0.005 | 0.13 | 0.61 |
| David3 | 0.40 | 0.67 | 0.10 | 0.38 | 0.43 | 0.50 | 0.46 | 0.31 | 0.43 | 0.71 |
| FaceOcc1 | 0.68 | 0.82 | 0.59 | 0.75 | 0.19 | 0.80 | 0.59 | 0.64 | 0.32 | 0.79 |
| Skating1 | 0.53 | 0.13 | 0.19 | 0.10 | 0.35 | 0.50 | 0.43 | 0.09 | 0.50 | 0.52 |
| Football | 0.56 | 0.70 | 0.49 | 0.55 | 0.51 | 0.55 | 0.23 | 0.61 | 0.53 | 0.71 |
| Average | 0.46 | 0.39 | 0.45 | 0.46 | 0.40 | 0.47 | 0.55 | 0.38 | 0.56 | 0.73 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, Z.; Sun, J.; Yu, J.; Liu, S. Robust Visual Tracking via Patch Descriptor and Structural Local Sparse Representation. Algorithms 2018, 11, 126. https://doi.org/10.3390/a11080126
Song Z, Sun J, Yu J, Liu S. Robust Visual Tracking via Patch Descriptor and Structural Local Sparse Representation. Algorithms. 2018; 11(8):126. https://doi.org/10.3390/a11080126
Chicago/Turabian StyleSong, Zhiguo, Jifeng Sun, Jialin Yu, and Shengqing Liu. 2018. "Robust Visual Tracking via Patch Descriptor and Structural Local Sparse Representation" Algorithms 11, no. 8: 126. https://doi.org/10.3390/a11080126
APA StyleSong, Z., Sun, J., Yu, J., & Liu, S. (2018). Robust Visual Tracking via Patch Descriptor and Structural Local Sparse Representation. Algorithms, 11(8), 126. https://doi.org/10.3390/a11080126