Solving Multi-Document Summarization as an Orienteering Problem


Abstract
1. Introduction
2. Related Work
2.1. Statistical Approaches
2.2. Machine Learning Approaches
2.3. Clustering Approaches
2.4. Graph-Based Approaches
2.5. Semantic Approaches
2.6. Optimization-Based Approaches
2.7. Swarm-Intelligence-Based Approaches
3. Orienteering Problem
4. Ant Colony Optimization
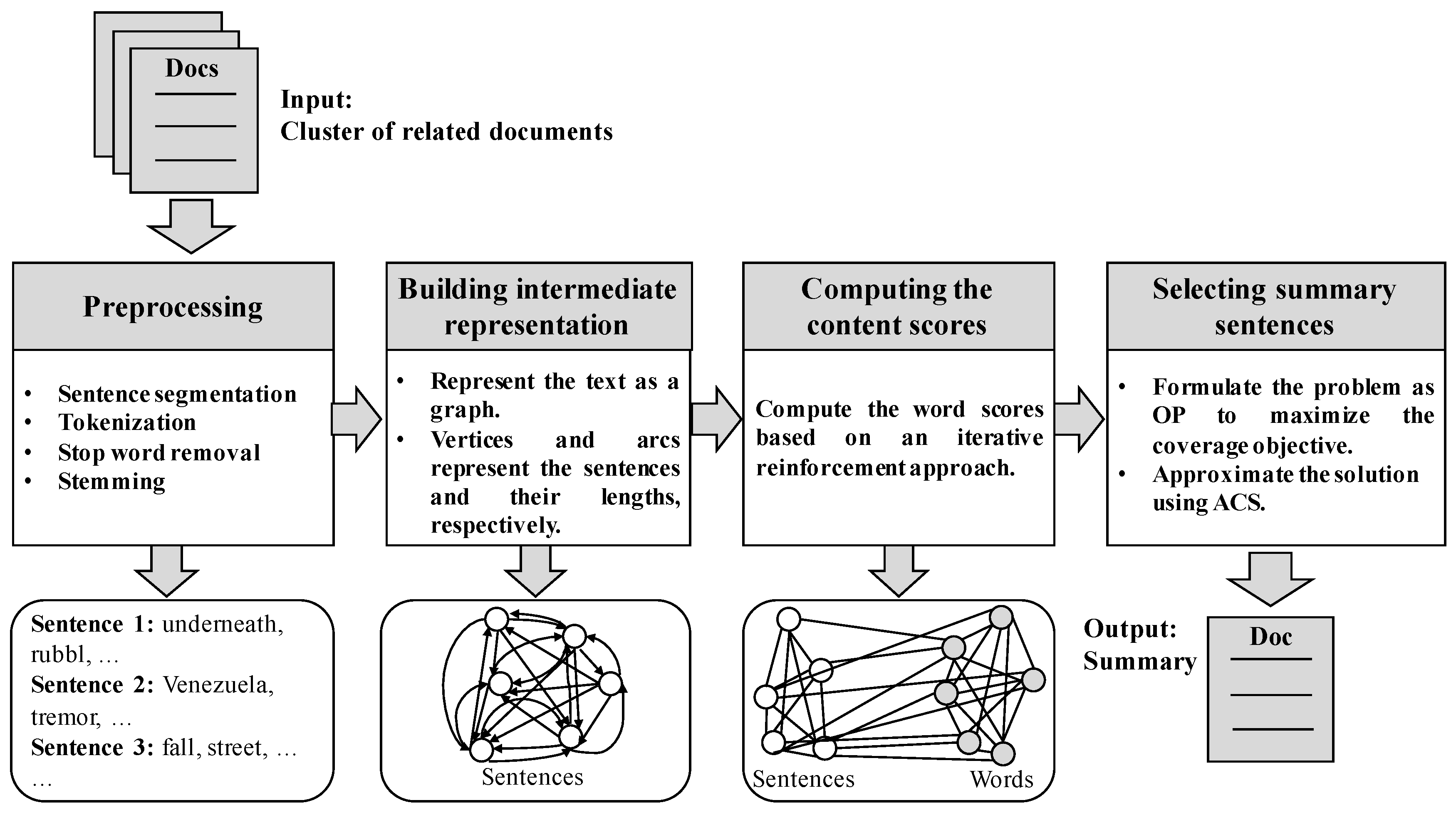
5. The Proposed Solution
5.1. Preprocessing
5.2. Building an Intermediate Representation
5.3. Computing the Content Scores
5.4. Selecting Summary Sentences
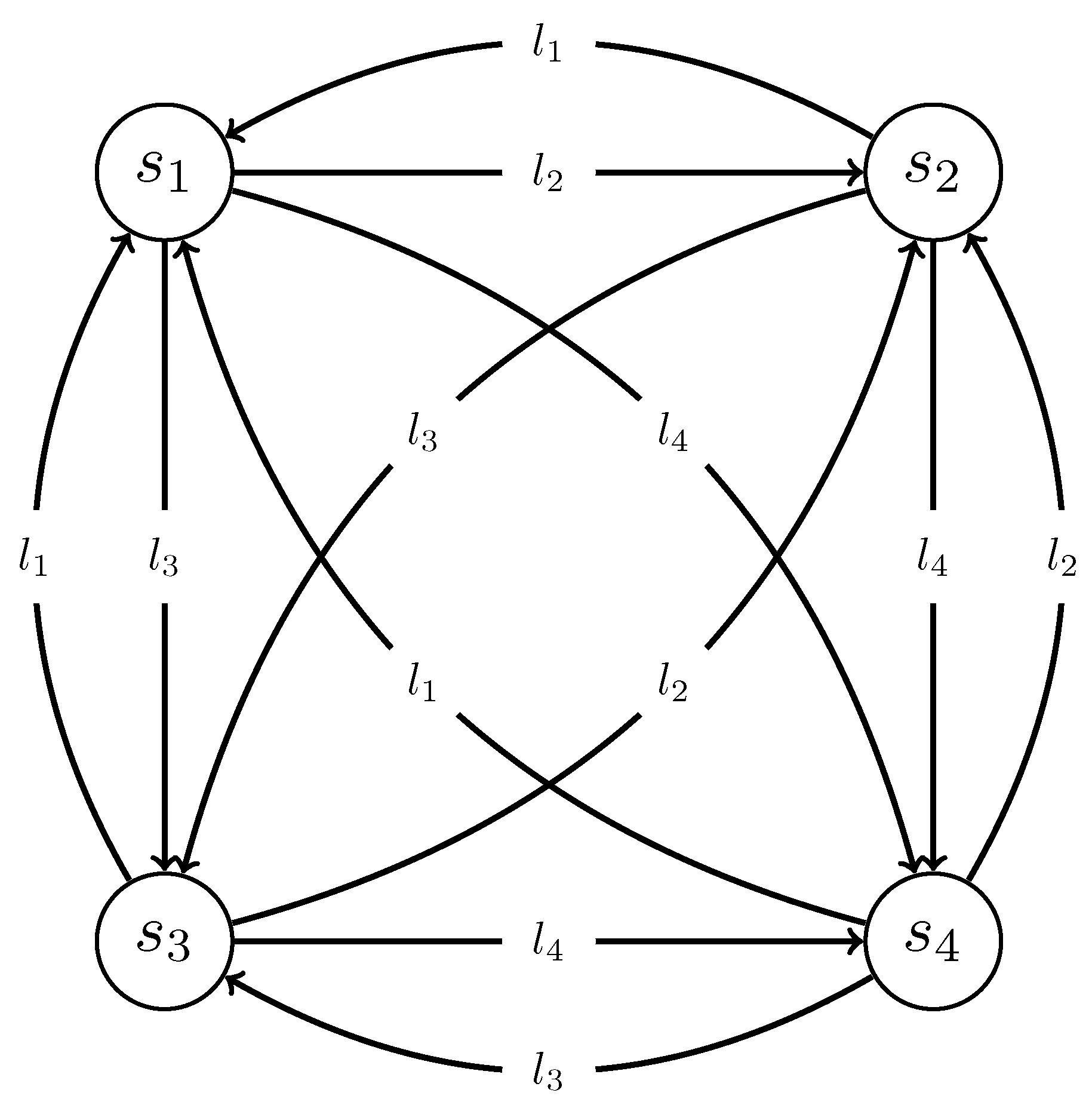
5.4.1. Encoding of an MDS Instance into an OP Instance
| Algorithm 1 Encoding of an MDS instance into an OP instance. |
|
5.4.2. Decoding a Solution to OP into a Solution to MDS
| Algorithm 2 Decoding of a solution to OP into a solution to MDS. |
|
5.4.3. Correctness of the Reduction
- The length of S is less than or equal to L, so the total traveled time of P is less than or equal to :
- Maximizing the overall content coverage score of S will maximize the total gained profit of P:
- If the traveled time of P is less than or equal to , then the total length of S is less than or equal to L:
- Maximizing the gained profit of P will maximize the score of the overall content coverage of S:
5.4.4. ACS for OP
| Algorithm 3 Approximating an OP solution using ACS. |
|
6. Experiments
6.1. Corpora
6.2. Evaluation Metrics
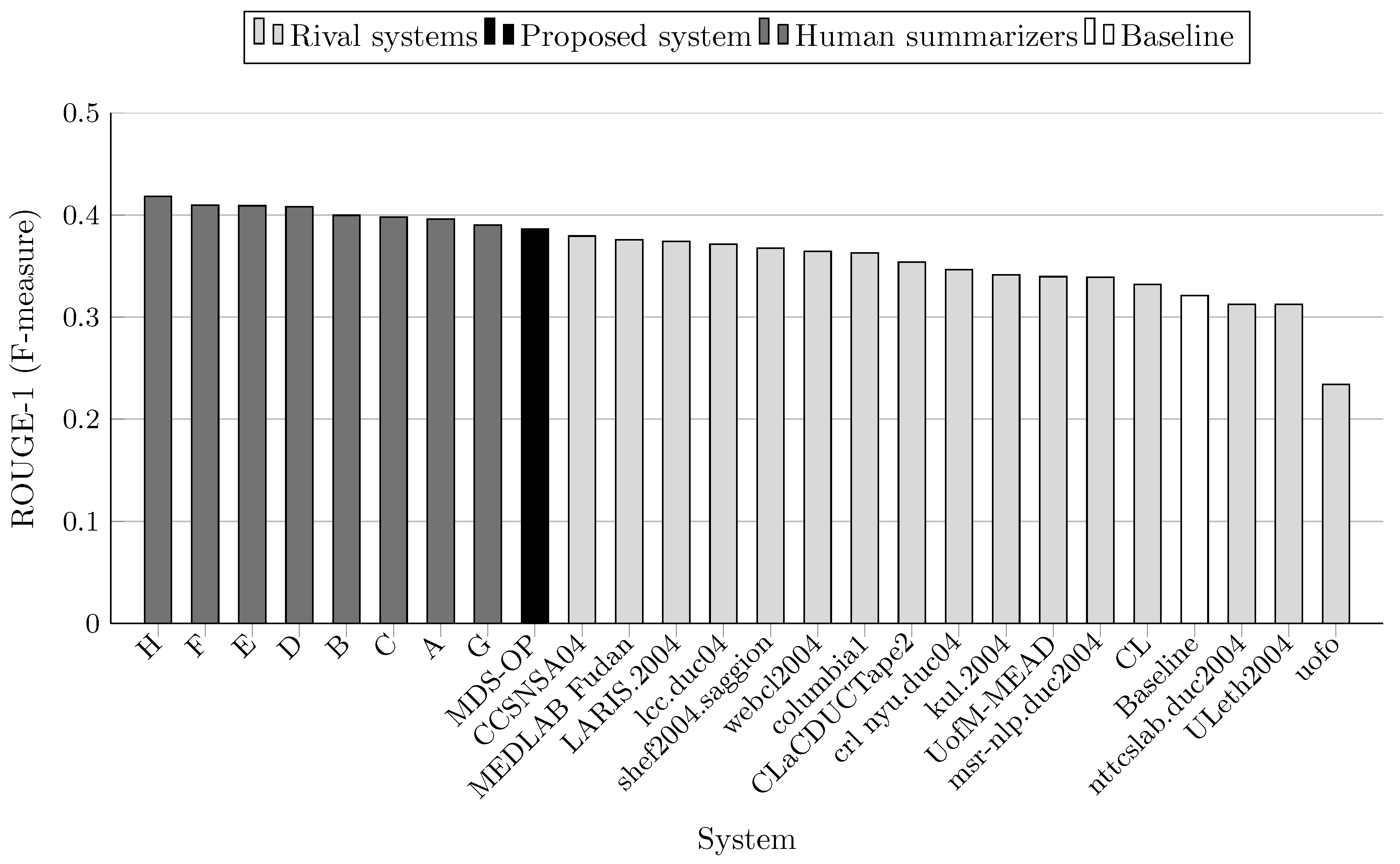
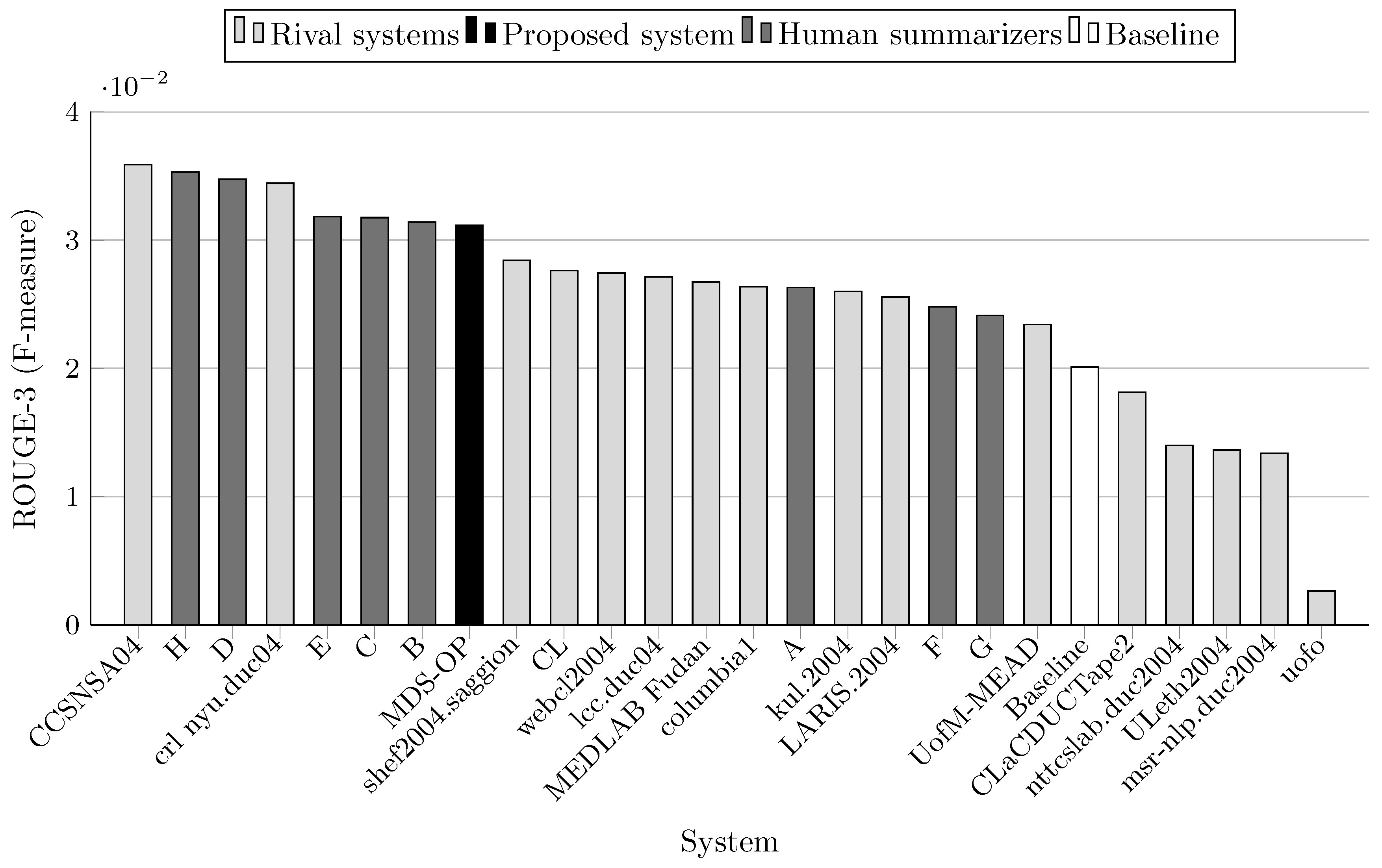
6.3. Evaluation Results
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ACO | Ant colony optimization |
| ACS | Ant colony system |
| ABC | Artificial bee colony |
| AS | Ant system |
| AutoSummENG | AUTOmatic SUMMary Evaluation based on N-gram Graphs |
| CS | Cuckoo search |
| DUC | Document understanding conference |
| GA | Genetic Algorithm |
| hLDA | Hierarchical Latent Dirichlet Allocation |
| HMM | Hidden Markov model |
| LCS | Longest common subsequence |
| MDS | Multi-document summarization |
| MeMoG | Merged Model Graph |
| MMS | Multilingual multi-document summarization |
| NP | Noun phrase |
| NPowER | N-gram graph Powered Evaluation via Regression |
| OP | Orienteering problem |
| PSO | Particle swarm optimization |
| ROUGE | Recall-Oriented Understudy for Gisting Evaluation |
| SI | Swarm intelligence |
| TAC | Text analysis conference |
| TSP | Traveling salesman problem |
| TF-IDF | Term frequency times inverse document frequency |
| TF-ISF | Term frequency times inverse sentence frequency |
References
- Wang, D.; Li, T. Weighted consensus multi-document summarization. Inf. Process. Manag. 2012, 48, 513–523. [Google Scholar] [CrossRef]
- Muthuswamy, S.; Lam, S.S. Discrete particle swarm optimization for the team orienteering problem. Memet. Comput. 2011, 3, 287–303. [Google Scholar] [CrossRef]
- Vansteenwegen, P.; Souffriau, W.; Oudheusden, D.V. The orienteering problem: A survey. Eur. J. Oper. Res. 2011, 209, 1–10. [Google Scholar] [CrossRef]
- Gunawan, A.; Lau, H.C.; Vansteenwegen, P. Orienteering Problem: A survey of recent variants, solution approaches and applications. Eur. J. Oper. Res. 2016, 255, 315–332. [Google Scholar] [CrossRef]
- Dorigo, M.; Gambardella, L.M. Ant colony system: A cooperative learning approach to the traveling salesman problem. IEEE Trans. Evolut. Comput. 1997, 1, 53–66. [Google Scholar] [CrossRef]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the ACL-04 Workshop on Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; Marie-Francine Moens, S.S., Ed.; Association for Computational Linguistics: Barcelona, Spain, 2004; pp. 74–81. [Google Scholar]
- Giannakopoulos, G.; Karkaletsis, V.; Vouros, G.; Stamatopoulos, P. Summarization System Evaluation Revisited: N-gram Graphs. ACM Trans. Speech Lang. Process. 2008, 5, 5. [Google Scholar] [CrossRef]
- Giannakopoulos, G.; Karkaletsis, V. AutoSummENG and MeMoG in evaluating guided summaries. In MultiLing Summarisation Pilot Text Analysis Conference (TAC) 2011; NIST: Gaithersburg, MD, USA, 2011. [Google Scholar]
- Giannakopoulos, G.; Karkaletsis, V. Summary Evaluation: Together We Stand NPowER-ed. In Computational Linguistics and Intelligent Text Processing; Gelbukh, A., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germnay, 2013; Volume 7817, pp. 436–450. [Google Scholar]
- Mani, I. Automatic Summarization; John Benjamins Publishing: Amsterdam, The Netherlands, 2001. [Google Scholar]
- Lloret, E.; Palomar, M. Text Summarisation in Progress: A Literature Review. Artif. Intell. Rev. 2012, 37, 1–41. [Google Scholar] [CrossRef]
- Luhn, H.P. The Automatic Creation of Literature Abstracts. IBM J. Res. Dev. 1958, 2, 159–165. [Google Scholar] [CrossRef]
- Edmundson, H.P. New Methods in Automatic Extracting. J. ACM 1969, 16, 264–285. [Google Scholar] [CrossRef]
- Litkowski, K.C. Summarization experiments in DUC 2004. In Proceedings of the 2004 Document Understanding Conference, Boston, MA, USA, 6–7 May 2004; NIST: Gaithersburg, MD, USA, 2004. [Google Scholar]
- Lacatusu, F.; Hickl, A.; Harabagiu, S.; Nezda, L. Lite-GISTexter at DUC 2004. In Proceedings of the 2004 Document Understanding Conference, Boston, MA, USA, 6–7 May 2004; NIST: Gaithersburg, MD, USA, 2004. [Google Scholar]
- Nobata, C.; Sekine, S. CRL/NYU summarization system at DUC-2004. In Proceedings of the 2004 Document Understanding Conference, Boston, MA, USA, 6–7 May 2004; NIST: Gaithersburg, MD, USA, 2004. [Google Scholar]
- Conroy, J.M.; Davis, S.T.; Kubina, J. Preprocessing and Term Weights in Multilingual Summarization. 2015. Available online: http://multiling.iit.demokritos.gr/file/download/1582 (accessed on 25 March 2018).
- Conroy, J.; Davis, S.T.; Kubina, J.; Liu, Y.K.; O’Leary, D.P.; Schlesinger, J.D. Multilingual Summarization: Dimensionality Reduction and a Step Towards Optimal Term Coverage. In Proceedings of the MultiLing 2013 Workshop on Multilingual Multi-Document Summarization, Sofia, Bulgaria, 9 August 2013; Association for Computational Linguistics: Sofia, Bulgaria, 2013; pp. 55–63. [Google Scholar]
- Balikas, G.; Amini, M.R. The Participation of UJF-Grenoble Team at Multiling 2015. 2015. Available online: http://multiling.iit.demokritos.gr/file/download/1585 (accessed on 1 April 2018).
- Hirao, T.; Suzuki, J.; Hideki, I.; Maeda, E. NTT’s Multiple Document Summarization System for DUC 2004. In Proceedings of the 2004 Document Understanding Conference, Boston, MA, USA, 6–7 May 2004; NIST: Gaithersburg, MD, USA, 2004. [Google Scholar]
- Wan, S.; Li, L.; Huang, T.; Gao, Z.; Mao, L.; Huang, F. CIST System Report for SIGdial MultiLing 2015. 2015. Available online: http://multiling.iit.demokritos.gr/file/download/1575 (accessed on 25 March 2018).
- Conroy, J.M.; Schlesinger, J.D.; Goldstein, J.; O’leary, D.P. Left-brain/right-brain multi-document summarization. In Proceedings of the 2004 Document Understanding Conference, Boston, MA, USA, 6–7 May 2004; NIST: Gaithersburg, MD, USA, 2004. [Google Scholar]
- Conroy, J.; O’Leary, D.P. Text Summarization via Hidden Markov Models and Pivoted QR Matrix Decomposition; Technical Report; University of Maryland: College Park, MA, USA, 2001. [Google Scholar]
- Litvak, M.; Dlikman, A.; Last, M. MUSEEC: A Multilingual Text Summarization Tool. 2015. Available online: http://www.aclweb.org/anthology/P16-4013 (accessed on 1 April 2018).
- Litvak, M.; Last, M. Cross-lingual training of summarization systems using annotated corpora in a foreign language. Inf. Retr. 2013, 16, 629–656. [Google Scholar] [CrossRef]
- Zhong, S.; Liu, Y.; Li, B.; Long, J. Query-oriented unsupervised multi-document summarization via deep learning model. Expert Syst. Appl. 2015, 42, 8146–8155. [Google Scholar] [CrossRef]
- Yousefi-Azar, M.; Hamey, L. Text summarization using unsupervised deep learning. Expert Syst. Appl. 2017, 68, 93–105. [Google Scholar] [CrossRef]
- Blair-Goldensohn, S.; Evans, D.; Hatzivassiloglou, V.; McKeown, K.; Nenkova, A.; Passonneau, R.; Schiffman, B.; Schlaikjer, A.; Siddharthan, A.; Siegelman, S. Columbia University at DUC 2004. In Proceedings of the 2004 Document Understanding Conference, Boston, MA, USA, 6–7 May 2004; NIST: Gaithersburg, MD, USA, 2004. [Google Scholar]
- Abdelkrime, A.; Zegour, D.E.; Hidouci, K.W. AllSummarizer system at MultiLing 2015: Multilingual single and multi-document summarization. In Proceedings of the SIGDIAL 2015 Conference, Dresden, Germany, 6–10 September 2015; pp. 237–244. [Google Scholar]
- Saggion, H.; Gaizauskas, R. Multi-document summarization by cluster/profile relevance and redundancy removal. In Proceedings of the 2004 Document Understanding Conference, Boston, MA, USA, 6–7 May 2004; NIST: Gaithersburg, MD, USA, 2004. [Google Scholar]
- Angheluta, R.; Mitra, R.; Jing, X.; Moens, M.F. KU Leuven summarization system at DUC 2004. In Proceedings of the 2004 Document Understanding Conference, Boston, MA, USA, 6–7 May 2004; NIST: Gaithersburg, MD, USA, 2004. [Google Scholar]
- Mihalcea, R.; Radev, D. Graph-Based Natural Language Processing and Information Retrieval; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Erkan, G.; Radev, D.R. The University of Michigan at DUC 2004. In Proceedings of the 2004 Document Understanding Conference, Boston, MA, USA, 6–7 May 2004; NIST: Gaithersburg, MD, USA, 2004. [Google Scholar]
- Mani, I.; Bloedorn, E. Multi-document Summarization by Graph Search and Matching. In Proceedings of the Fourteenth National Conference on Artificial Intelligence and Ninth Conference on Innovative Applications of Artificial Intelligence, Providence, Rhode Island, 27–31 July 1997; AAAI Press: Palo Alto, CA, USA, 1997; pp. 622–628. [Google Scholar]
- Zha, H. Generic Summarization and Keyphrase Extraction Using Mutual Reinforcement Principle and Sentence Clustering. In Proceedings of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval SIGIR ’02, Tampere, Finland, 11–15 August 2002; ACM: New York, NY, USA, 2002; pp. 113–120. [Google Scholar]
- Erkan, G.; Radev, D.R. LexRank: Graph-based Lexical Centrality As Salience in Text Summarization. J. Artif. Int. Res. 2004, 22, 457–479. [Google Scholar]
- Vanderwende, L.; Banko, M.; Menezes, A. Event-Centric Summary Generation; Working Notes of the Document Understanding Conference 2004; NIST: Gaithersburg, MD, USA, 2004. [Google Scholar]
- Wan, X.; Yang, J.; Xiao, J. Towards an Iterative Reinforcement Approach for Simultaneous Document Summarization and Keyword Extraction. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, Prague, Czech, 25–27 June 2007; Association for Computational Linguistics: Prague, Czech, 2007; pp. 552–559. [Google Scholar]
- Brin, S.; Page, L. The Anatomy of a Large-scale Hypertextual Web Search Engine. Comput. Netw. ISDN Syst. 1998, 30, 107–117. [Google Scholar] [CrossRef]
- Kleinberg, J.M. Authoritative Sources in a Hyperlinked Environment. J. ACM 1999, 46, 604–632. [Google Scholar] [CrossRef]
- Thomas, S.; Beutenmüller, C.; de la Puente, X.; Remus, R.; Bordag, S. ExB Text Summarizer. In Proceedings of the SIGDIAL 2015 Conference, Dresden, Germany, 6–10 September 2015; pp. 260–269. [Google Scholar]
- Wan, X.; Yang, J.; Xiao, J. Manifold-ranking Based Topic-focused Multi-document Summarization. In Proceedings of the 20th International Joint Conference on Artifical Intelligence IJCAI’07, Hyderabad, India, 6–12 January 2007; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2007; pp. 2903–2908. [Google Scholar]
- Chali, Y.; Kolla, M. Summarization techniques at DUC 2004. In Proceedings of the 2004 Document Understanding Conference, Boston, MA, USA, 6–7 May 2004; NIST: Gaithersburg, MD, USA, 2004. [Google Scholar]
- Bergler, S.; Witte, R.; Li, Z.; Khalife, M.; Chen, Y.; Doandes, M.; Andreevskaia, A. Multi-ERSS and ERSS 2004. In Proceedings of the 2004 Document Understanding Conference, Boston, MA, USA, 6–7 May 2004; NIST: Gaithersburg, MD, USA, 2004. [Google Scholar]
- Huang, L.; He, Y.; Wei, F.; Li, W. Modeling Document Summarization as Multi-objective Optimization. In Proceedings of the 2010 Third International Symposium on Intelligent Information Technology and Security Informatics (IITSI), Jinggangshan, China, 2–4 April 2010; pp. 382–386. [Google Scholar]
- Rautray, R.; Balabantaray, R.C. Bio-Inspired Algorithms for Text Summarization: A Review. In Bio-Inspired Computing for Information Retrieval Applications; IGI Global: Hershey, PA, USA, 2017; pp. 71–92. [Google Scholar]
- Shen, C.; Li, T. Multi-document Summarization via the Minimum Dominating Set. In Proceedings of the 23rd International Conference on Computational Linguistics COLING ’10, Beijing, China, 23–27 August 2010; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 984–992. [Google Scholar]
- Jaoua, K.F.; Jaoua, M.; Ben Hamadou, A. Summarization at LARIS laboratory. In Proceedings of the 2004 Document Understanding Conference, Boston, MA, USA, 6–7 May 2004; NIST: Gaithersburg, MD, USA, 2004. [Google Scholar]
- John, A.; Premjith, P.; Wilscy, M. Extractive multi-document summarization using population-based multicriteria optimization. Expert Syst. Appl. 2017, 86, 385–397. [Google Scholar] [CrossRef]
- Vanetik, N.; Litvak, M. Multilingual Summarization with Polytope Model. In Proceedings of the SIGDIAL 2015 Conference, Dresden, Germany, 6–10 September 2015; pp. 227–231. [Google Scholar]
- Lin, H.; Bilmes, J. A Class of Submodular Functions for Document Summarization. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies HLT ’11, Portland, OR, USA, 19–24 June 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; Volume 1, pp. 510–520. [Google Scholar]
- Takamura, H.; Okumura, M. Text Summarization Model Based on Maximum Coverage Problem and Its Variant. In Proceedings of the 12th Conference of the European Chapter of the Association for Computational Linguistics EACL ’09, Athens, Greece, 2 April 2009; Association for Computational Linguistics: Stroudsburg, PA, USA, 2009; pp. 781–789. [Google Scholar]
- Alguliev, R.M.; Aliguliyev, R.M.; Isazade, N.R. Formulation of document summarization as a 0–1 nonlinear programming problem. Comput. Ind. Eng. 2013, 64, 94–102. [Google Scholar] [CrossRef]
- Binwahlan, M.S.; Salim, N.; Suanmali, L. Fuzzy Swarm Diversity Hybrid Model for Text Summarization. Inf. Process. Manag. 2010, 46, 571–588. [Google Scholar] [CrossRef]
- Peyrard, M.; Eckle-Kohler, J. A General Optimization Framework for Multi-Document Summarization Using Genetic Algorithms and Swarm Intelligence. In Proceedings of the 26th International Conference on Computational Linguistics COLING 2016, Osaka, Japan, 11–16 December 2016; pp. 247–257. [Google Scholar]
- Sanchez-Gomez, J.M.; Vega-Rodríguez, M.A.; Pérez, C.J. Extractive multi-document text summarization using a multi-objective artificial bee colony optimization approach. Knowl. Based Syst. 2017. [Google Scholar] [CrossRef]
- Mosa, M.A.; Hamouda, A.; Marei, M. Ant colony heuristic for user-contributed comments summarization. Knowl. Based Syst. 2017, 118, 105–114. [Google Scholar] [CrossRef]
- Asgari, H.; Masoumi, B.; Sheijani, O. Automatic text summarization based on multi-agent particle swarm optimization. In Proceedings of the 2014 Iranian Conference on Intelligent Systems (ICIS), Bam, Iran, 4–6 February 2014; pp. 1–5. [Google Scholar]
- Mosa, M.A.; Hamouda, A.; Marei, M. Graph coloring and ACO based summarization for social networks. Expert Syst. Appl. 2017, 74, 115–126. [Google Scholar] [CrossRef]
- Rautray, R.; Balabantaray, R.C. An evolutionary framework for multi document summarization using Cuckoo search approach: MDSCS. Appl. Comput. Inf. 2017. [Google Scholar] [CrossRef]
- Tefrie, K.G.; Sohn, K.A. Autonomous Text Summarization Using Collective Intelligence Based on Nature-Inspired Algorithm. In Proceedings of the International Conference on Mobile and Wireless Technology, Kuala Lumpur, Malaysia, 26–29 June 2017; Kim, K.J., Joukov, N., Eds.; Springer: Singapore, 2018; pp. 455–464. [Google Scholar]
- Golden, B.L.; Levy, L.; Vohra, R. The orienteering problem. Nav. Res. Logist. 1987, 34, 307–318. [Google Scholar] [CrossRef]
- Chao, I.M.; Golden, B.L.; Wasil, E.A. A fast and effective heuristic for the orienteering problem. Eur. J. Oper. Res. 1996, 88, 475–489. [Google Scholar] [CrossRef]
- Feillet, D.; Dejax, P.; Gendreau, M. Traveling Salesman Problems with Profits. Transp. Sci. 2005, 39, 188–205. [Google Scholar] [CrossRef]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.J.; McClosky, D. The Stanford CoreNLP Natural Language Processing Toolkit; Association for Computational Linguistics (ACL) System Demonstrations: Stroudsburg, PA, USA, 2014; pp. 55–60. [Google Scholar]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition, 2nd ed.; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 2009. [Google Scholar]
- Giannakopoulos, G.; Kubina, J.; Conroy, J.M.; Steinberger, J.; Favre, B.; Kabadjov, M.; Kruschwitz, U.; Poesio, M. MultiLing 2015: Multilingual Summarization of Single and Multi-Documents, On-line Fora, and Call-center Conversations. In Proceedings of the SIGDIAL 2015 Conference, Dresden, Germany, 6–10 September 2015; pp. 270–274. [Google Scholar]
- Over, P.; Dang, H.; Harman, D. DUC in context. Inf. Process. Manag. 2007, 43, 1506–1520. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Number of ants (m) | Number of sentences in the text to be summarized. |
| Initial pheromone value () | , is the overall coverage (i.e., total profit) of the summary generated by following the nearest neighbor heuristic, and n is the number of sentences in this summary. |
| Pheromone decay parameters ( and ) | 0.1 |
| Heuristic exponent () | 2 |
| System ID | Research Group (Participant) | Reference |
|---|---|---|
| CCSNSA04 | NSA | [22] |
| MEDLAB_Fudan | Fudan University | * |
| CL | CL Research | [14] |
| LARIS.2004 | Laris Labs | [48] |
| ULeth2004 | University of Lethbridge | [43] |
| columbia1 | Columbia University | [28] |
| CLaCDUCTape2 | Concordia University | [44] |
| webcl2004 | ISI | * |
| kul.2004 | KU Leuven | [31] |
| lcc.duc04 | LCC | [15] |
| uofo | University of Ottawa | * |
| msr-nlp.duc2004 | Microsoft | [37] |
| crl_nyu.duc04 | CRL/NYU | [16] |
| nttcslab.duc2004 | NTT | [20] |
| shef2004.saggion | University of Sheffield | [30] |
| UofM-MEAD | University of Michigan | [33] |
| System ID | Participant | Reference |
|---|---|---|
| MMS1 | UJF-Grenoble | [19] |
| MMS2 | UWB | * |
| MMS3 | ExB | [41] |
| MMS5 | ESI-AllSummarizer | [29] |
| MMS8 | IDA-OCCAMS | [17] |
| MMS9 | GiauUngVan | * |
| MMS11 | SCE-Poly | [50] |
| MMS12 | BUPT-CIST | [21] |
| MMS13 | BGU-MUSE | [24] |
| MMS15 | NCSR/SCIFY-NewSumRerank | * |
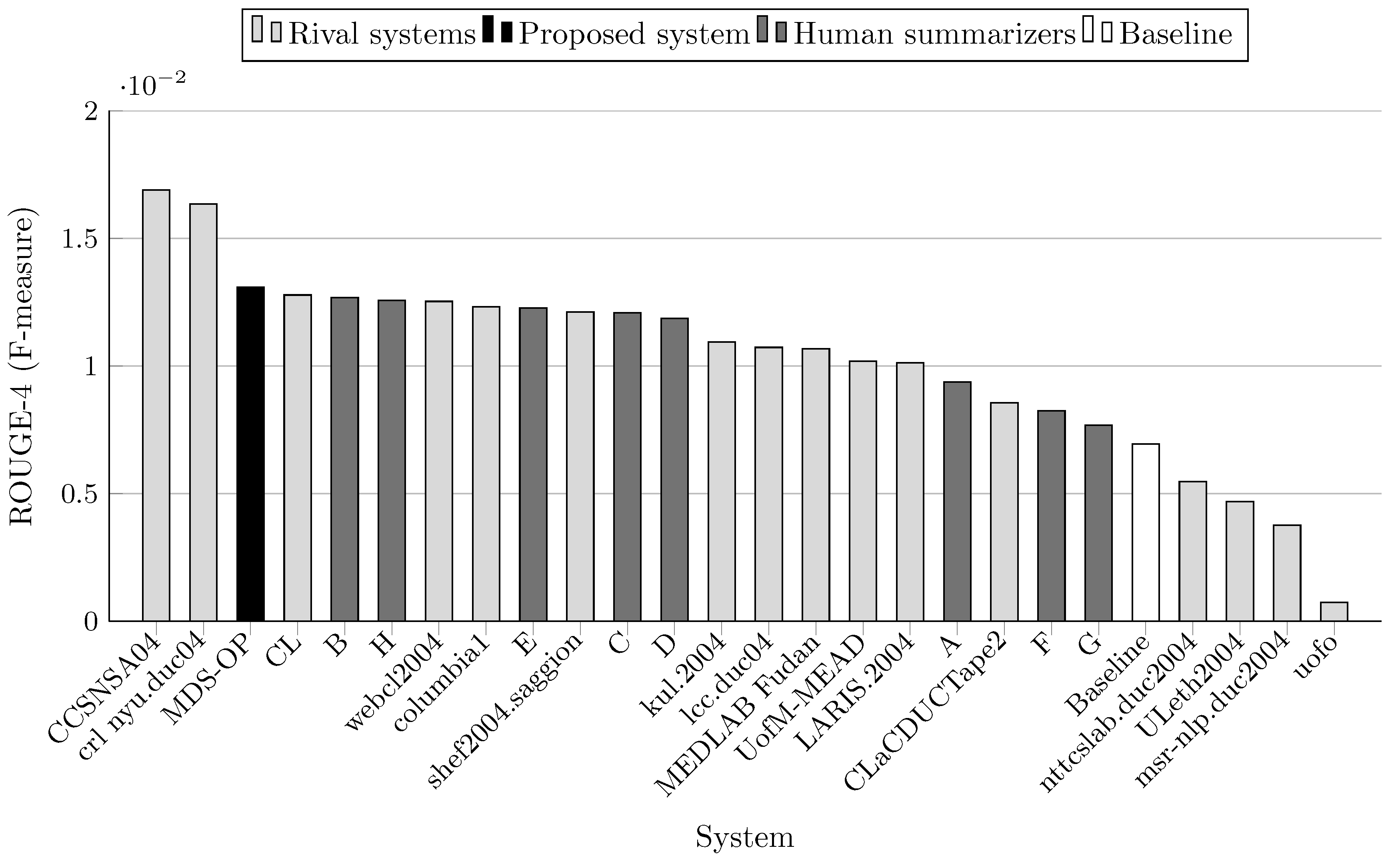
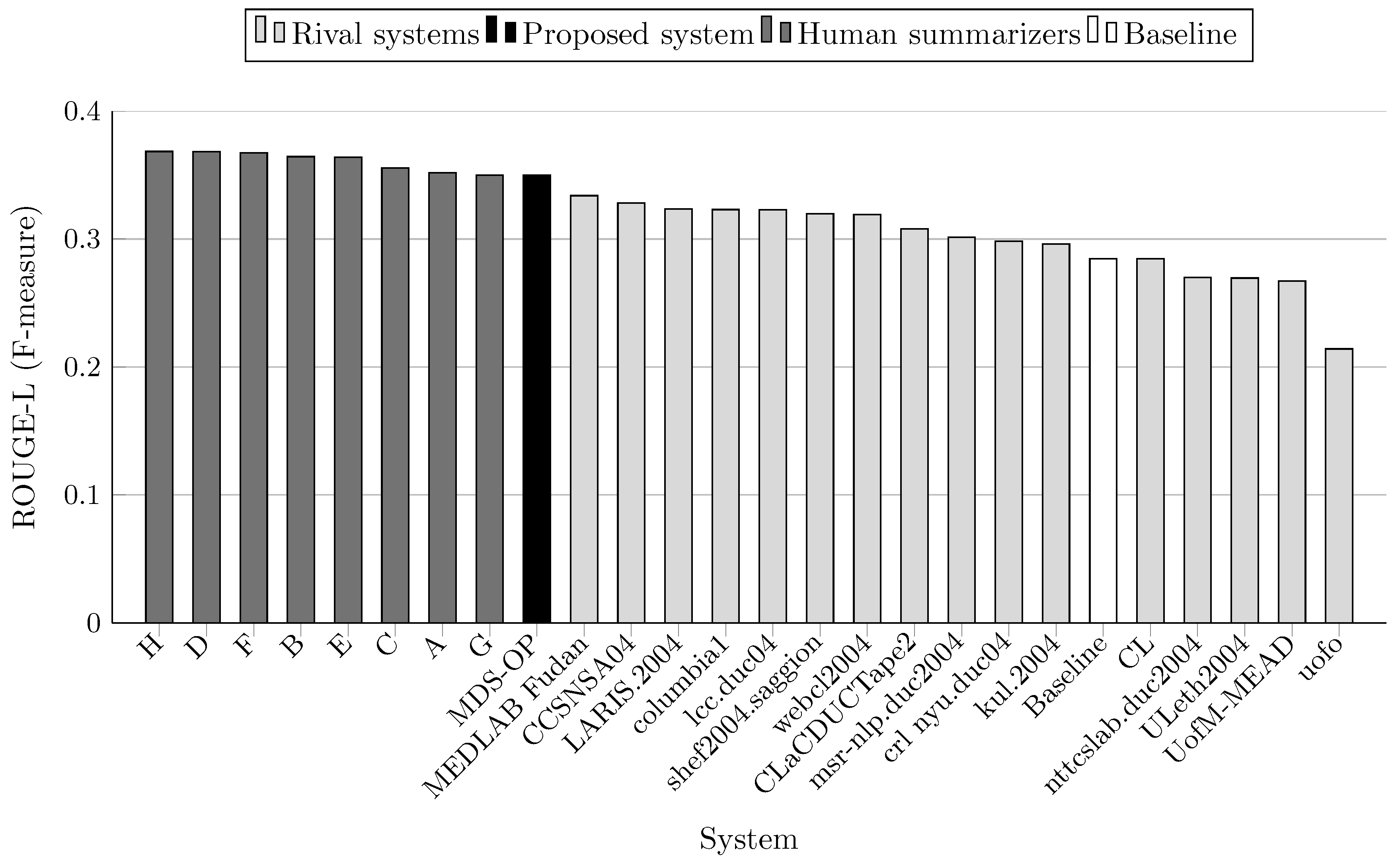
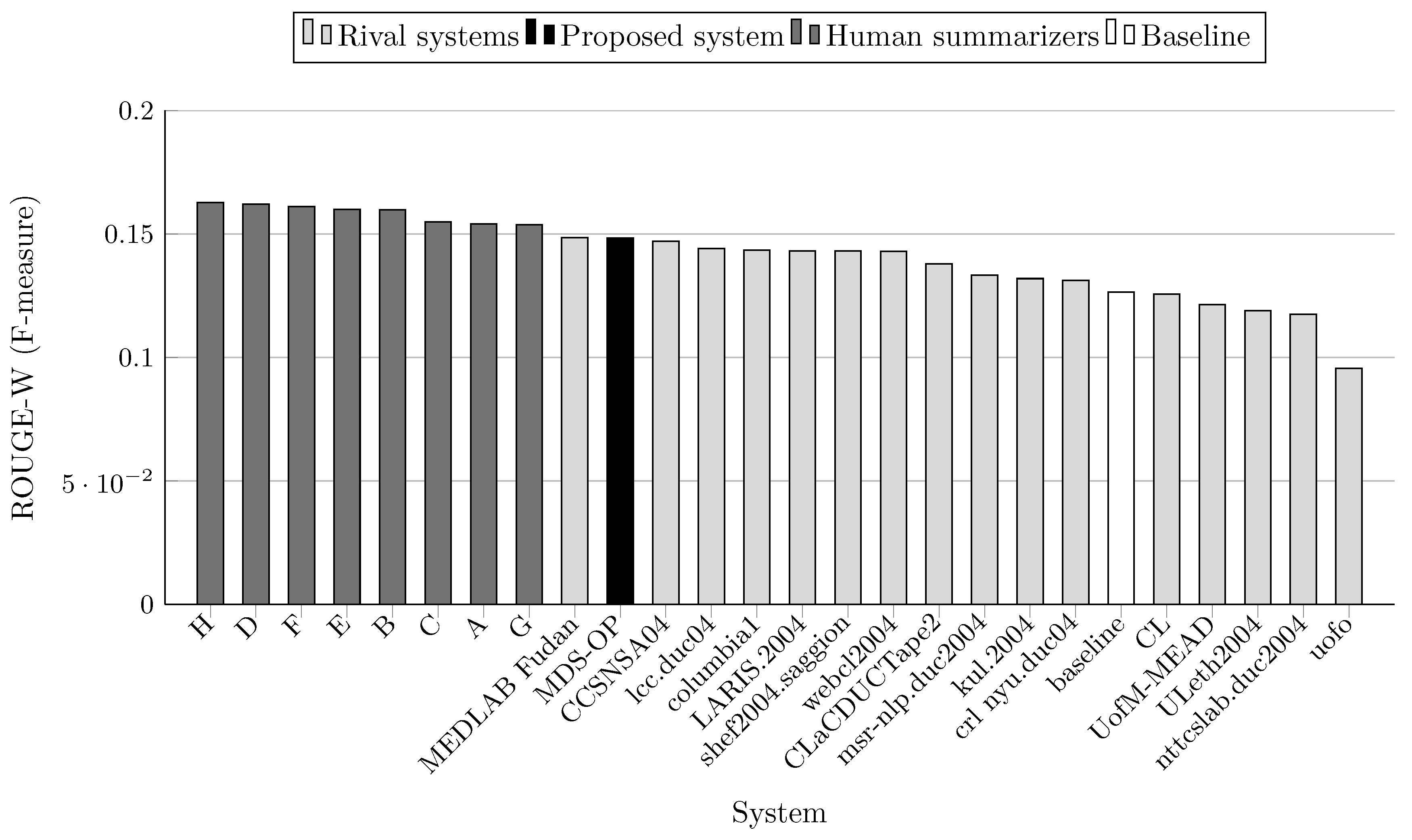
| System ID | R-1 | R-2 | R-3 | R-4 | R-L | R-W | Relative Improvement of | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MDS-OP (%) | ||||||||||||
| R-1 | R-2 | R-3 | R-4 | R-L | R-W | |||||||
| MDS-OP | 0.386142 | 0.08799 | 0.031144 | 0.013086 | 0.33438 | 0.15 | - | - | - | - | - | - |
| 2 (baseline) | 0.3212 | 0.06402 | 0.02011 | 0.00694 | 0.2847 | 0.12639 | +20.22 | +37.44 | +54.87 | +88.56 | +17.45 | +17.39 |
| CCSNSA04 | 0.37938 | 0.09215 | 0.03589 | 0.01689 | 0.32803 | 0.14707 | +1.78 * | −4.51 * | −13.22 * | −22.52 * | +1.94 | +0.88 |
| MEDLAB_Fudan | 0.37584 | 0.0839 | 0.02675 | 0.01068 | 0.3339 | 0.14853 | +2.74 | +4.87 | +16.43 | +22.53 | +0.14 * | −0.11 * |
| CL | 0.3319 | 0.07652 | 0.02762 | 0.01278 | 0.28452 | 0.12568 | +16.34 | + 14.99 | +12.76 | +2.39 | +17.52 | +18.05 |
| LARIS.2004 | 0.37422 | 0.08033 | 0.02555 | 0.01013 | 0.32356 | 0.14308 | +3.19 | +9.54 | +21.89 | +29.18 | +3.34 | +3.69 |
| ULeth2004 | 0.31238 | 0.0513 | 0.01364 | 0.00469 | 0.26949 | 0.11886 | +23.61 | +71.52 | +128.33 | +179.02 | +24.08 | +24.82 |
| columbia1 | 0.36282 | 0.07763 | 0.02637 | 0.01232 | 0.32299 | 0.14339 | +6.43 | +13.35 | +18.10 | +6.22 | +3.53 | +3.47 |
| CLaCDUCTape2 | 0.35387 | 0.07028 | 0.02047 | 0.00856 | 0.30801 | 0.13787 | +9.12 | +25.2 | +52.14 | +52.87 | +8.56 | +7.61 |
| webcl2004 | 0.3643 | 0.07987 | 0.02743 | 0.01253 | 0.31921 | 0.14298 | +6 | +10.17 | +13.54 | +4.44 | +4.75 | +3.77 |
| kul.2004 | 0.34142 | 0.07812 | 0.02599 | 0.01094 | 0.29622 | 0.13193 | +13.1 | +12.63 | +19.83 | +19.62 | +12.88 | +12.46 |
| lcc.duc04 | 0.37155 | 0.08528 | 0.02713 | 0.01073 | 0.32281 | 0.1441 | +3.93 | +3.18 | +14.8 | +21.96 | + 3.58 | +2.96 |
| uofo | 0.23412 | 0.01806 | 0.00265 | 0.00074 | 0.21411 | 0.09549 | +64.93 ⋆ | +387.21 ⋆ | +1075.25 ⋆ | +1668.38 ⋆ | +56.17 ⋆ | +55.37 ⋆ |
| msr-nlp.duc2004 | 0.33918 | 0.05853 | 0.01338 | 0.00377 | 0.30147 | 0.13339 | +13.85 | +50.338 | +132.77 | +247.11 | +10.92 | +11.23 |
| crl_nyu.duc04 | 0.34644 | 0.08608 | 0.03442 | 0.01635 | 0.29838 | 0.13124 | +11.46 | +2.22 | −9.52 | −19.96 | +12.07 | +13.05 |
| nttcslab.duc2004 | 0.31263 | 0.05376 | 0.014 | 0.00547 | 0.27008 | 0.11745 | +23.51 | +63.67 | +122.46 | +139.23 | +23.81 | +26.32 |
| shef2004.saggion | 0.36763 | 0.08255 | 0.02843 | 0.01212 | 0.31964 | 0.14306 | +5.04 | +6.59 | +9.55 | +7.97 | +4.61 | +3.71 |
| UofM-MEAD | 0.33962 | 0.07135 | 0.02342 | 0.01019 | 0.26726 | 0.12144 | +13.7 | +23.32 | +32.98 | +28.42 | +25.11 | +22.17 |
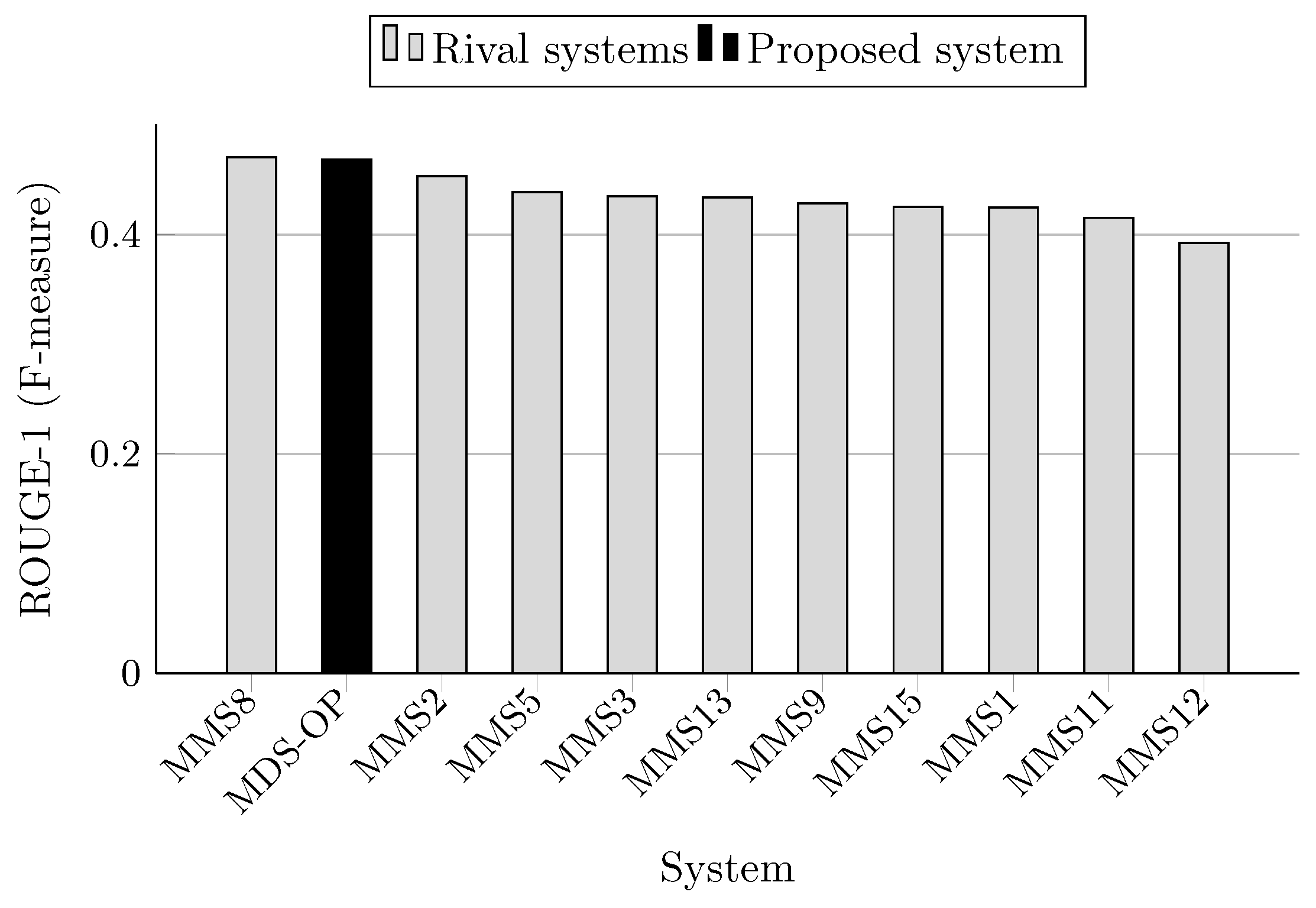
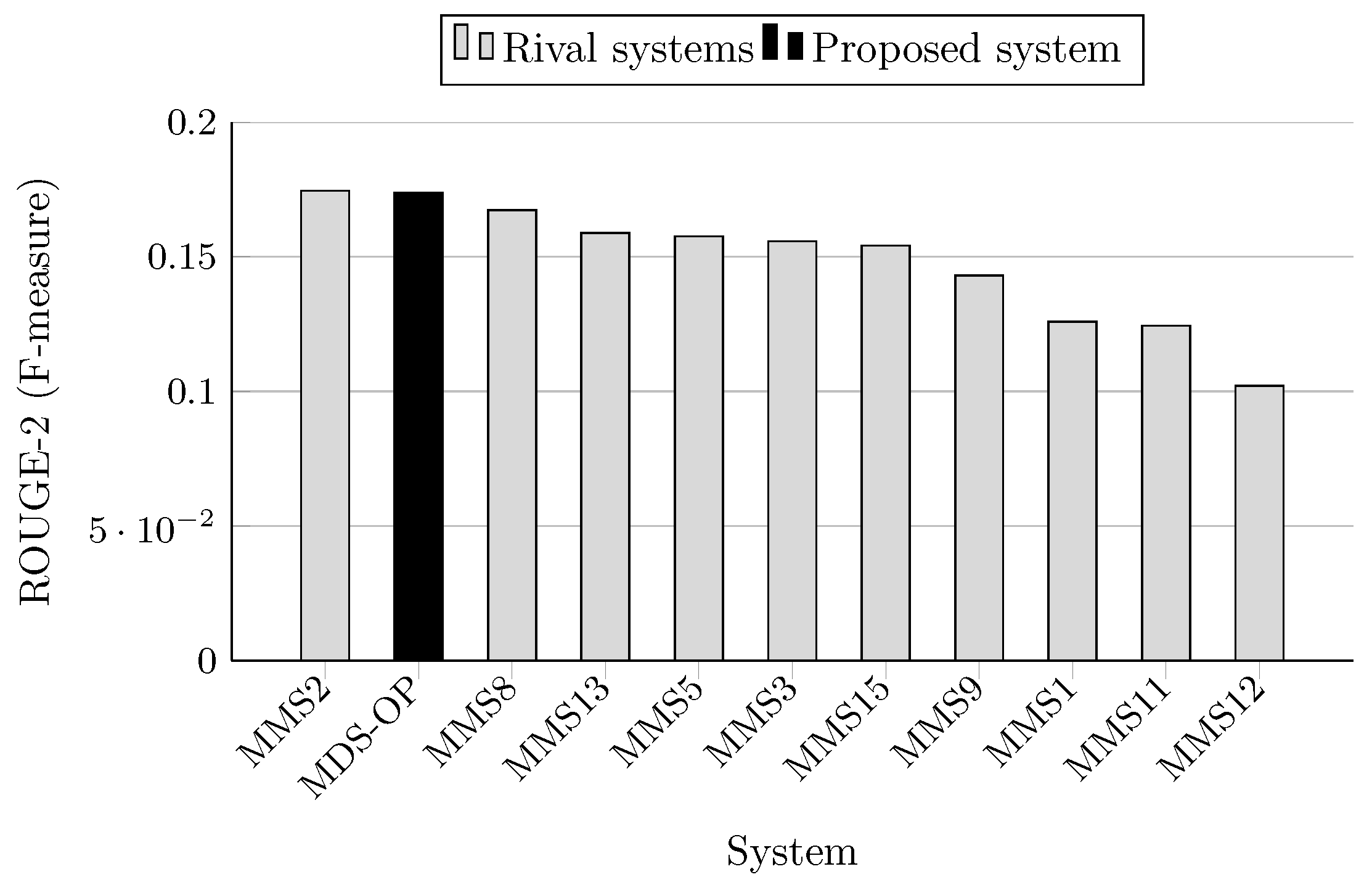
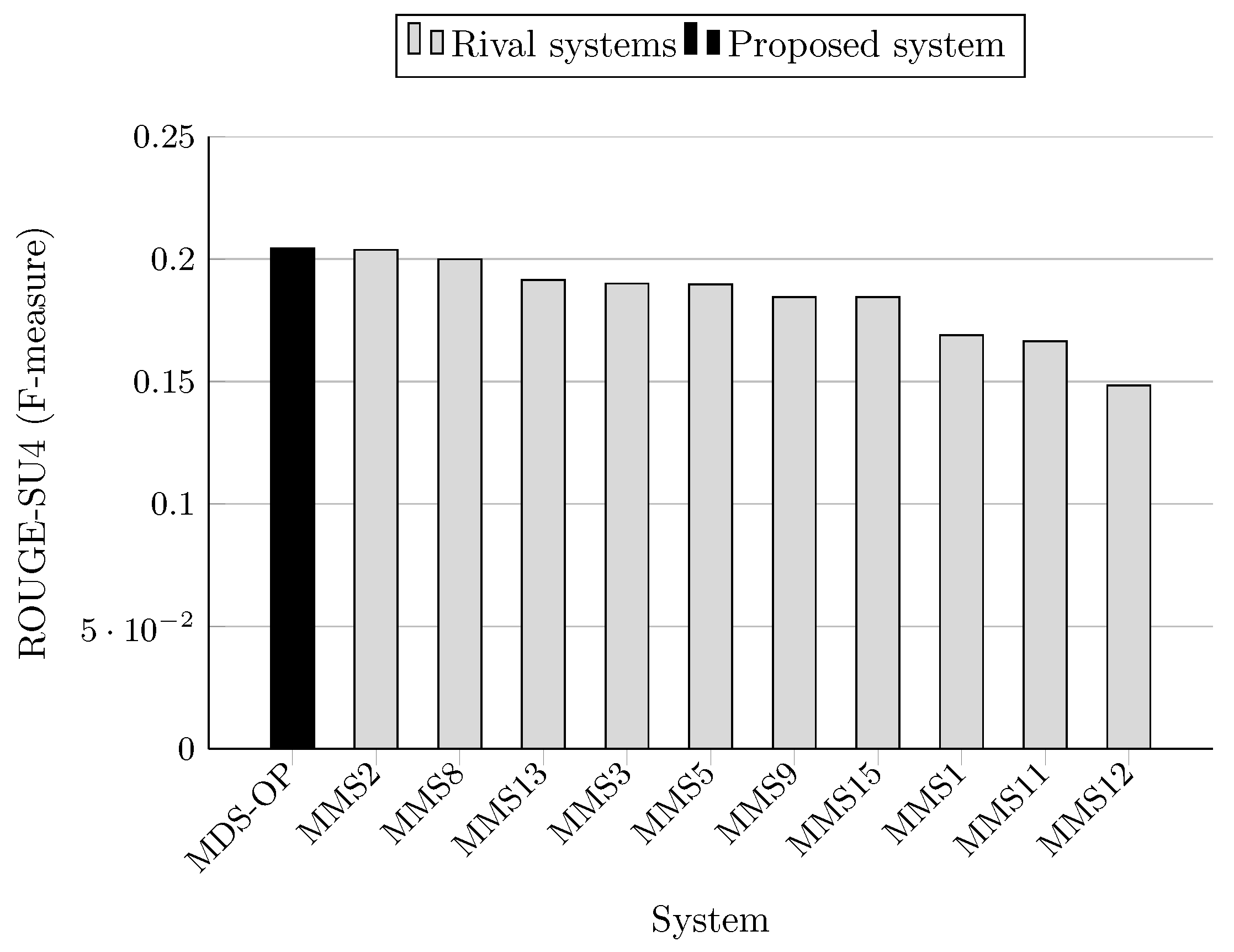
| System ID | R-1 | R-2 | R-SU4 | Relative Improvement of MDS-OP (%) | ||
|---|---|---|---|---|---|---|
| R-1 | R-2 | R-SU4 | ||||
| MDS-OP | 0.468276 | 0.173698 | 0.204328 | - | - | - |
| MMS1 | 0.42463 | 0.12593 | 0.16892 | +10.28 | +37.93 | +20.96 |
| MMS2 | 0.45302 | 0.17452 | 0.20371 | +3.37 | −0.47 * | +0.30 * |
| MMS3 | 0.43478 | 0.15572 | 0.19 | +7.7 | +11.55 | +7.54 |
| MMS5 | 0.43857 | 0.1576 | 0.18962 | +6.77 | +10.21 | +7.76 |
| MMS8 | 0.47035 | 0.1673 | 0.19989 | −0.44 * | +3.82 | +2.22 |
| MMS9 | 0.4281 | 0.14296 | 0.1844 | +9.38 | +21.50 | +10.81 |
| MMS11 | 0.41515 | 0.12438 | 0.1665 | +12.8 | +39.65 | +22.72 |
| MMS12 | 0.39243 | 0.10205 | 0.14846 | +19.33 ⋆ | +70.21 ⋆ | +37.63 ⋆ |
| MMS13 | 0.43376 | 0.15885 | 0.1914 | +7.96 | +9.35 | +6.75 |
| MMS15 | 0.42514 | 0.15414 | 0.18308 | +10.15 | +12.69 | +11.61 |
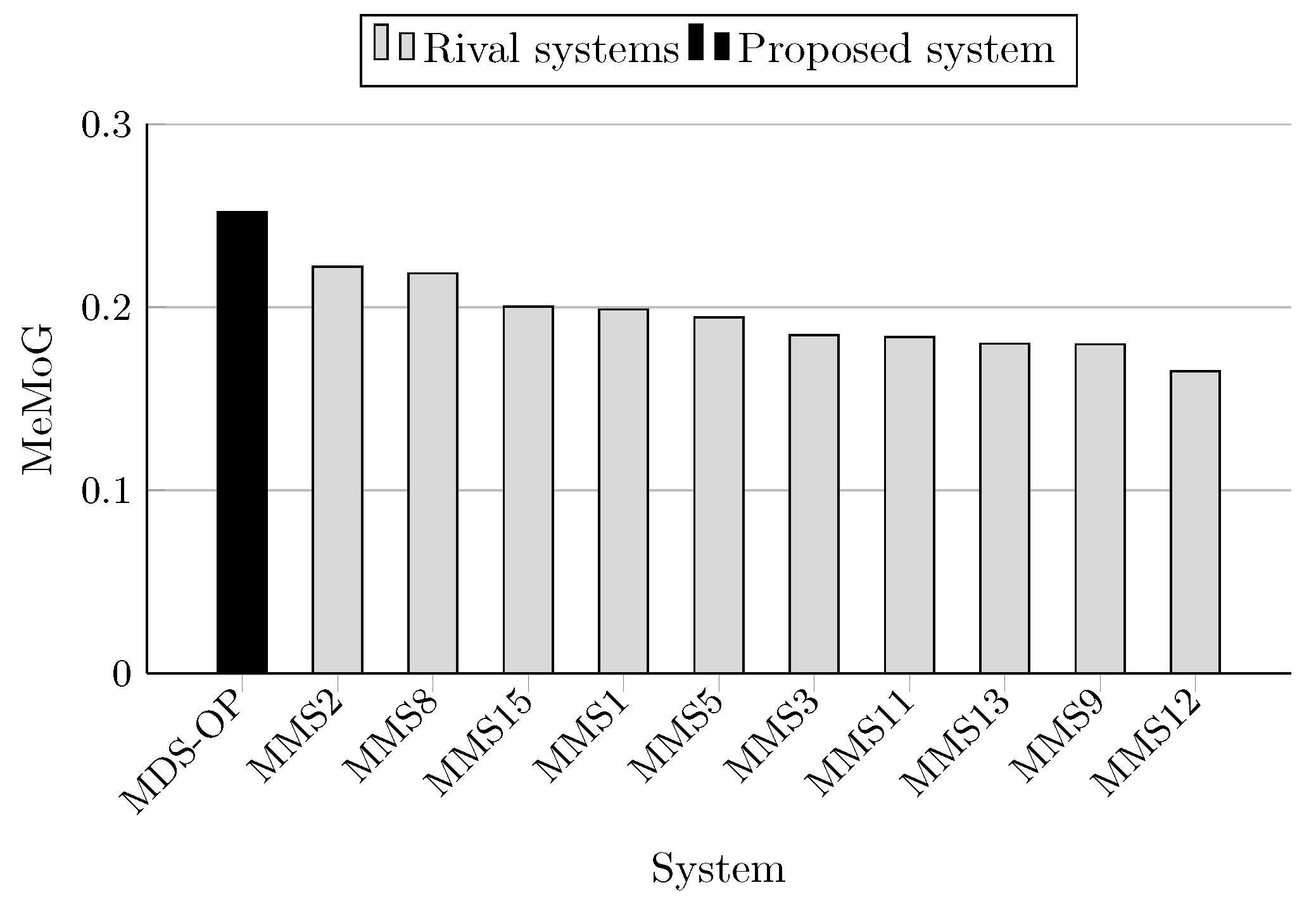
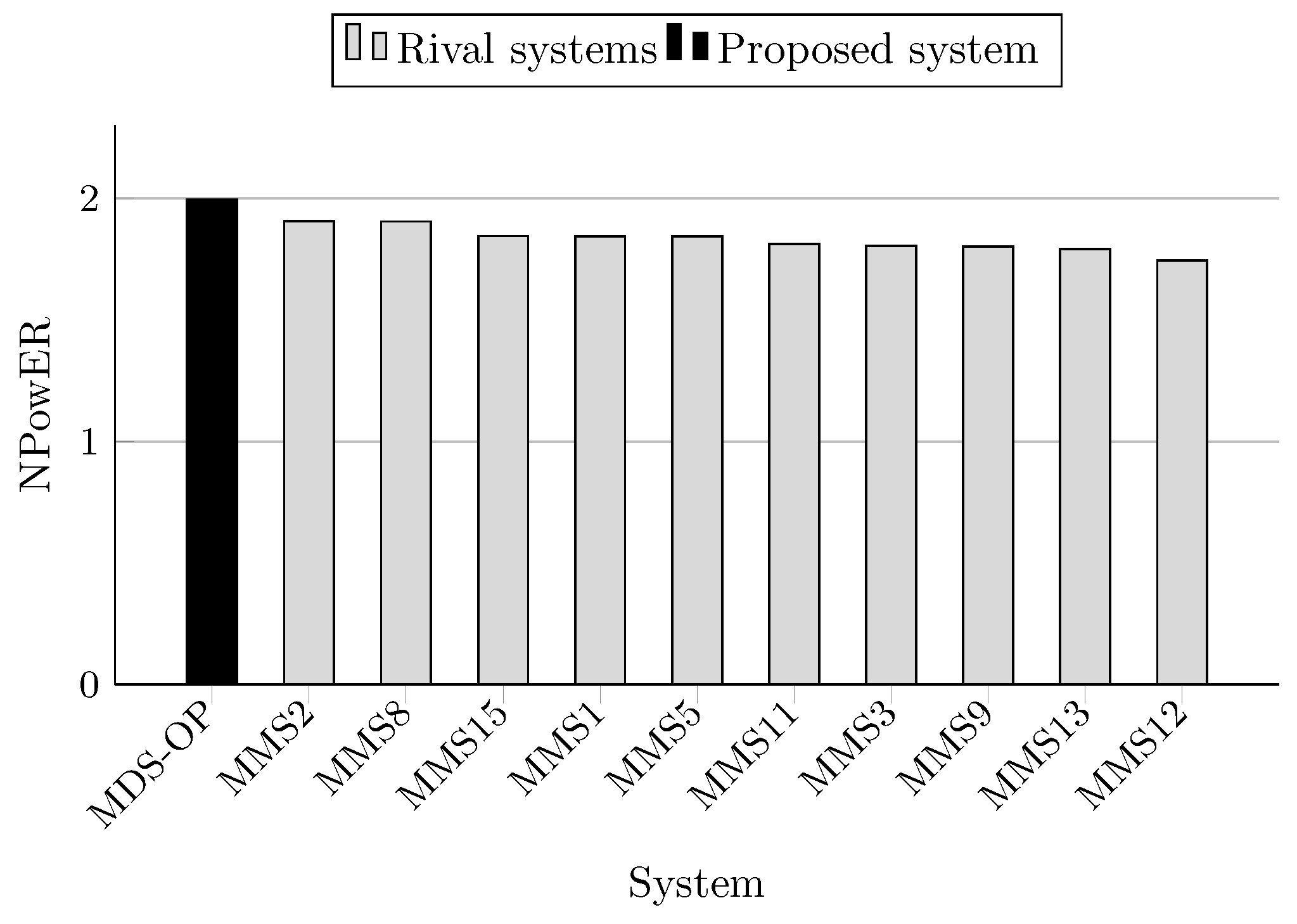
| System ID | AutoSummENG | MeMoG | NPowER | Relative Improvement of MDS-OP (%) | ||
|---|---|---|---|---|---|---|
| AutoSummENG | MeMoG | NPowER | ||||
| MDS-OP | 0.2157 | 0.2521 | 1.9942 | - | - | - |
| MMS1 | 0.1751 | 0.1988 | 1.8441 | +23.19 | +26.81 | +8.14 |
| MMS2 | 0.1909 | 0.222 | 1.9054 | +12.99 | +13.56 * | +4.66 * |
| MMS3 | 0.164 | 0.1848 | 1.8039 | +31.52 | +36.42 | +10.55 |
| MMS5 | 0.1778 | 0.1944 | 1.8436 | +21.32 | +29.68 | +8.17 |
| MMS8 | 0.1925 | 0.2185 | 1.9046 | +12.05 * | +15.38 | +4.7 |
| MMS9 | 0.1657 | 0.1797 | 1.8013 | +30.18 | +40.29 | +10.71 |
| MMS11 | 0.1688 | 0.1836 | 1.8125 | +27.78 | +37.31 | +10.02 |
| MMS12 | 0.1475 | 0.1651 | 1.7453 | +46.24 ⋆ | +52.7 ⋆ | +14.26 ⋆ |
| MMS13 | 0.1607 | 0.1801 | 1.7911 | +34.23 | +39.98 | +11.34 |
| MMS15 | 0.1744 | 0.2004 | 1.8446 | +23.68 | +25.8 | +8.11 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Saleh, A.; Menai, M.E.B. Solving Multi-Document Summarization as an Orienteering Problem. Algorithms 2018, 11, 96. https://doi.org/10.3390/a11070096
Al-Saleh A, Menai MEB. Solving Multi-Document Summarization as an Orienteering Problem. Algorithms. 2018; 11(7):96. https://doi.org/10.3390/a11070096
Chicago/Turabian StyleAl-Saleh, Asma, and Mohamed El Bachir Menai. 2018. "Solving Multi-Document Summarization as an Orienteering Problem" Algorithms 11, no. 7: 96. https://doi.org/10.3390/a11070096
APA StyleAl-Saleh, A., & Menai, M. E. B. (2018). Solving Multi-Document Summarization as an Orienteering Problem. Algorithms, 11(7), 96. https://doi.org/10.3390/a11070096