Linking and Cutting Spanning Trees

Abstract
:1. Introduction
- We present a new algorithm, which given a graph G, generates a spanning tree of G uniformly at random. The algorithm uses the link-cut tree data structure to compute randomizing operations in amortized time per operation. Hence, the overall algorithm takes time to obtain a uniform spanning tree of G, where is the mixing time of a Markov chain that is dependent on G. Theorem 1 summarizes this result.
- We propose a coupling to bound the mixing time . The analysis of the coupling yields a bound for cycle graphs (Theorem 2), and for graphs which consist of simple cycles connected by bridges or articulation points (Theorem 3). We also simulate this procedure experimentally to obtain bounds for other graphs. The link-cut tree data structure is also key in this process. Section 4.3 shows experimental results, including other classes of graphs.
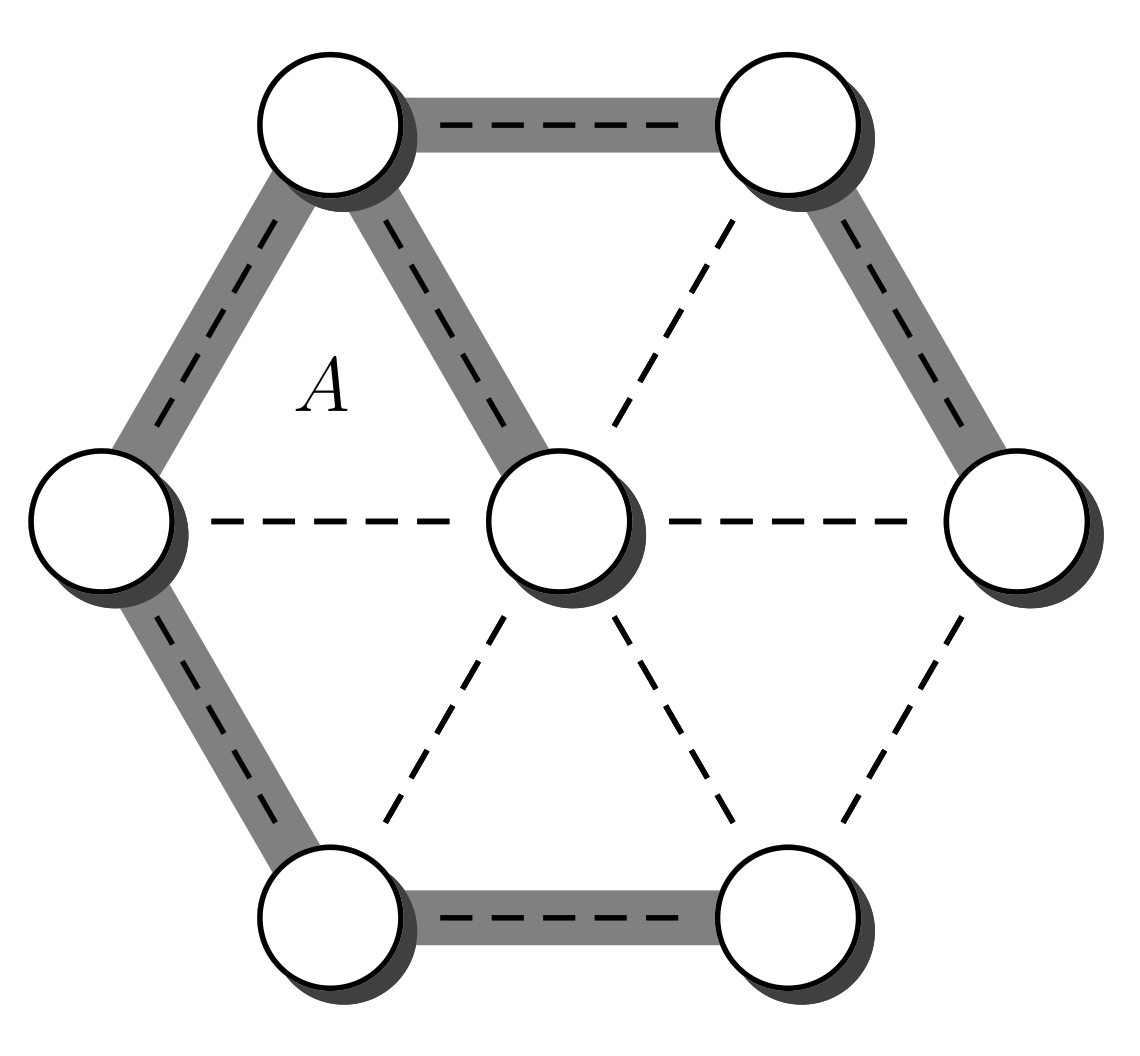
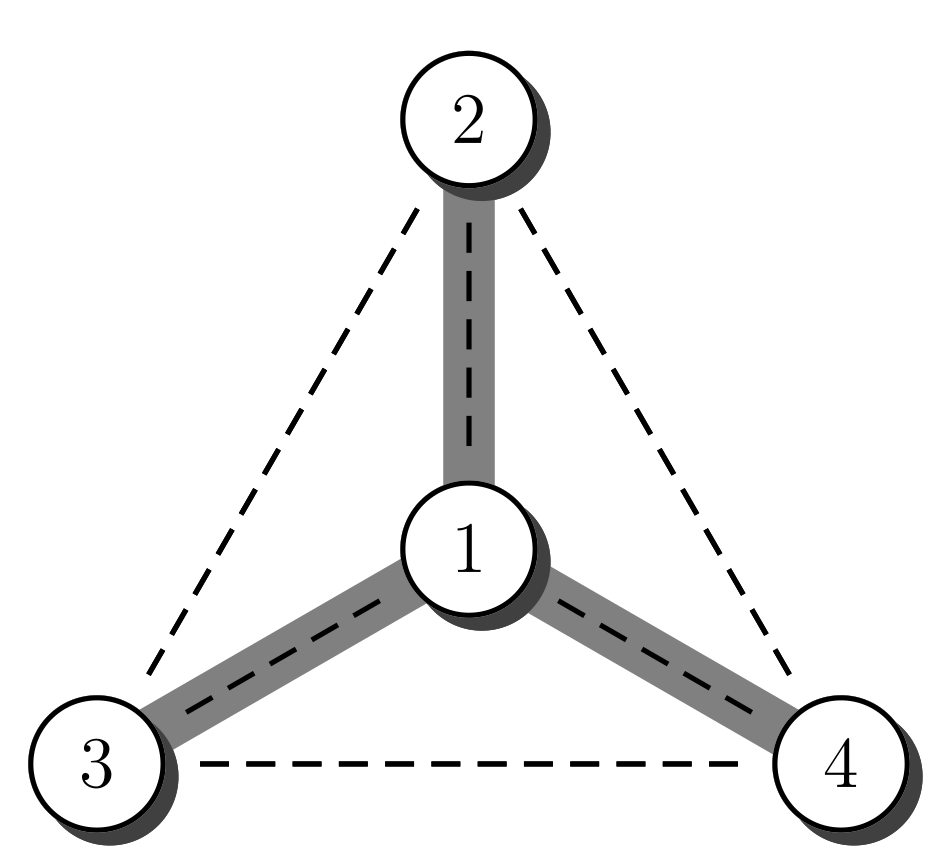
2. The Challenge
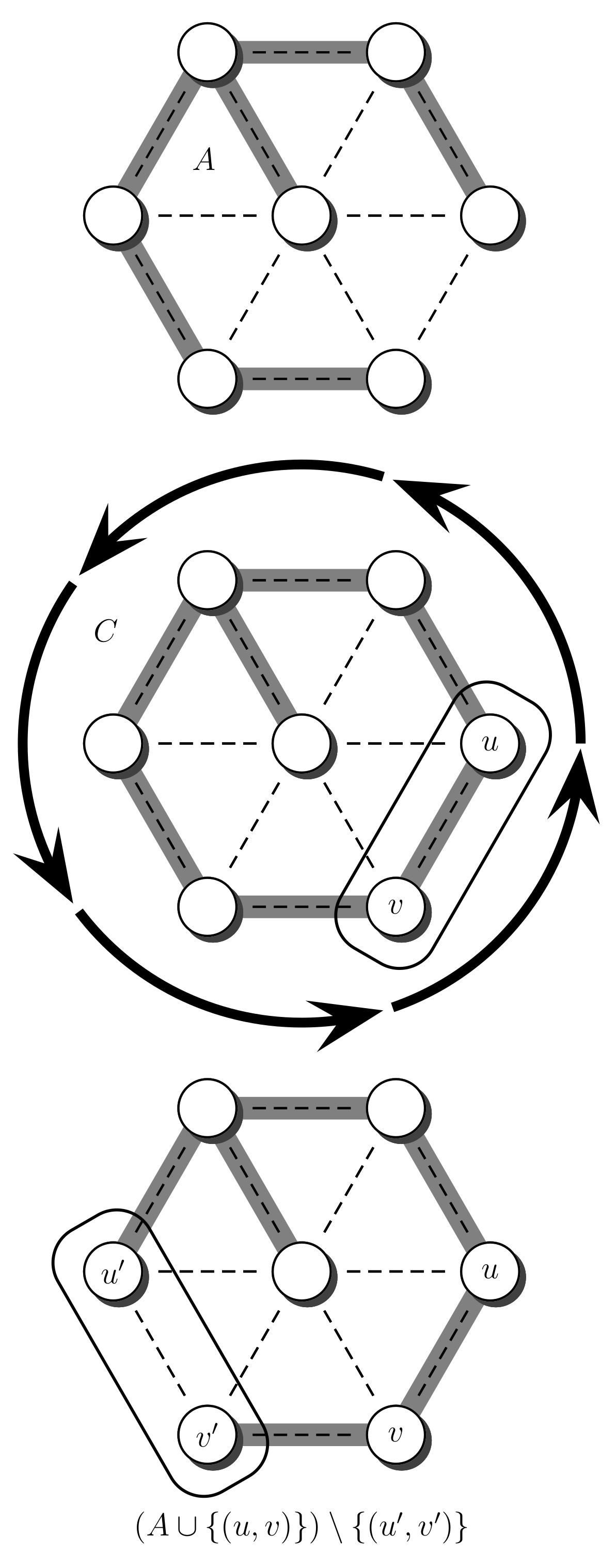
3. Main Idea
| Algorithm 1 Edge-swapping process | |
| 1: procedure EdgeSwap(A) | ▹A is an LCT representation of the current spanning tree |
| 2: Chosen uniformly at random from E | |
| 3: if then | ▹ time |
| 4: | ▹ Makes u the root of A |
| 5: | ▹ Obtains a representation of the path |
| 6: Chosen uniformly from | |
| 7: | ▹ Obtain the i-th edge from D |
| 8: | |
| 9: | |
| 10: end if | |
| 11: end procedure | |
4. The Details
4.1. Ergodic Analysis
- If we use a self-loop transition.
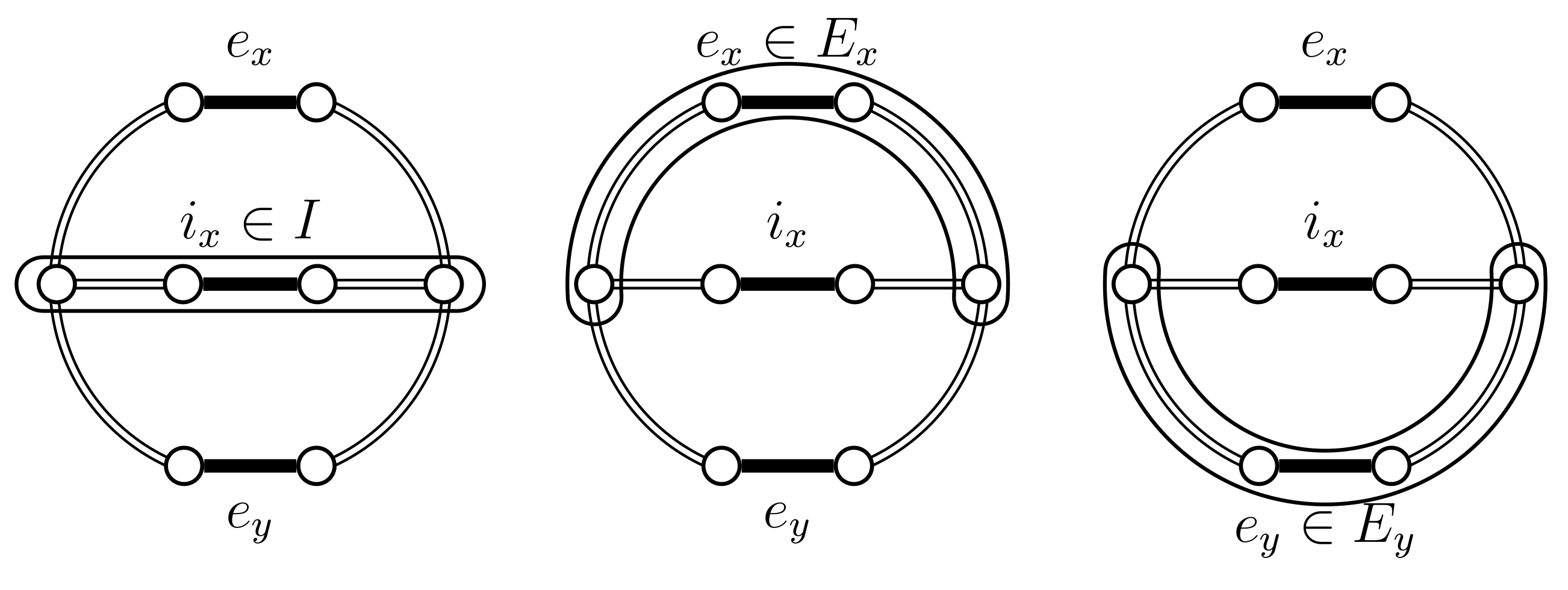
- Otherwise, when , it is possible to choose from , and from ; note that the set equality follows from the assumption that belongs to . For the last property, note that if no such exists then , which is a contradiction because is a tree and C is a cycle. As mentioned above, the probability of this transition is at least . After this step the resulting tree is not necessarily , but it is closer to that tree. More precisely is not necessarily , however the set is smaller than the original . Its size decreases by 1 because the edge exists on the second set but not on the first. Therefore, this process can be iterated until the resulting set is empty and therefore the resulting tree coincides with . The maximal size of is , because the size of is at most . This value occurs when and do not share edges. Multiplying all the probabilities in the process of transforming into we obtain a total probability of at least .
4.2. Coupling
4.2.1.
4.2.2.
- , ,
- , ,
- , , .
- If the chain loops (), because , then also loops and therefore . The set does not change, i.e., set .
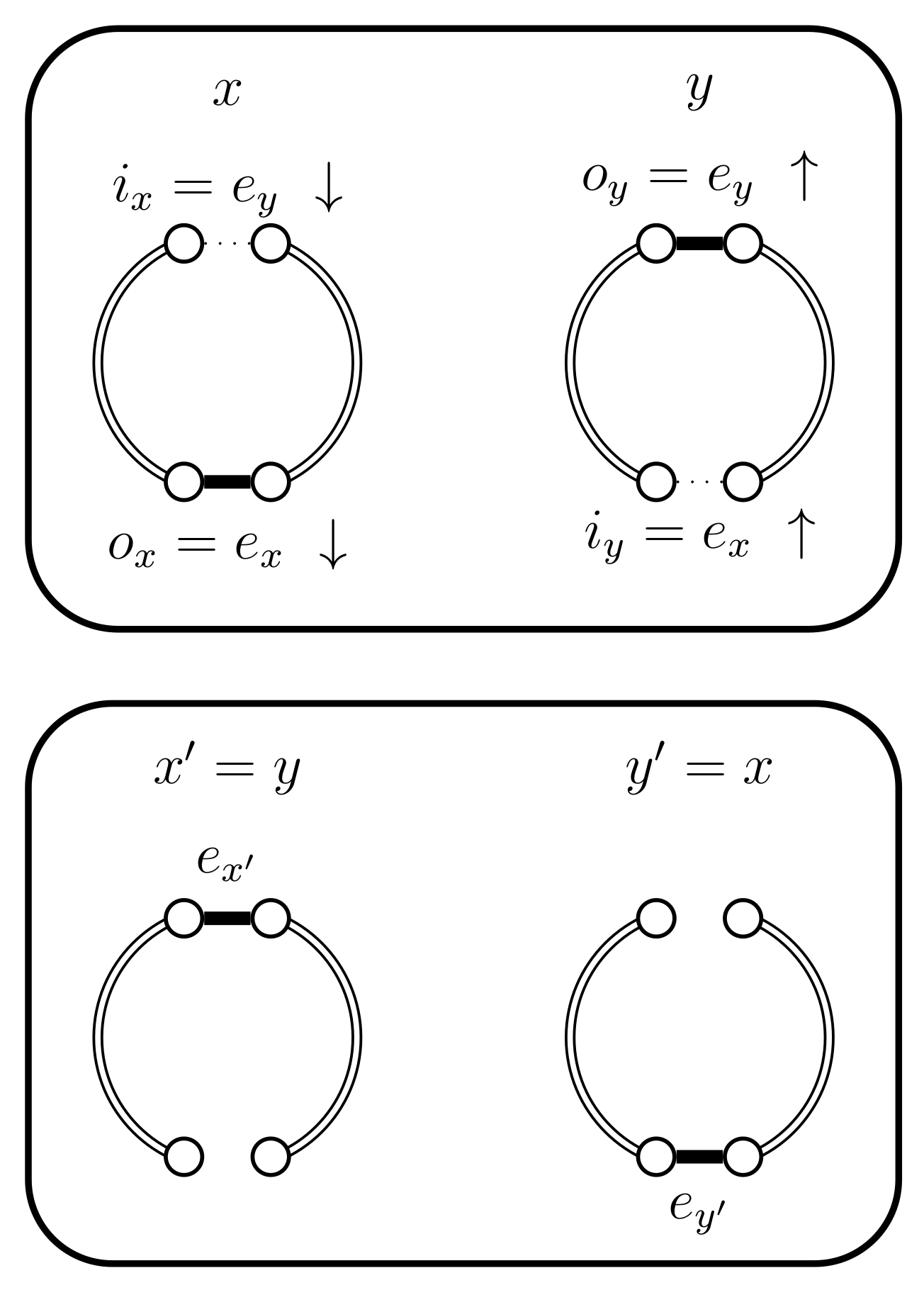
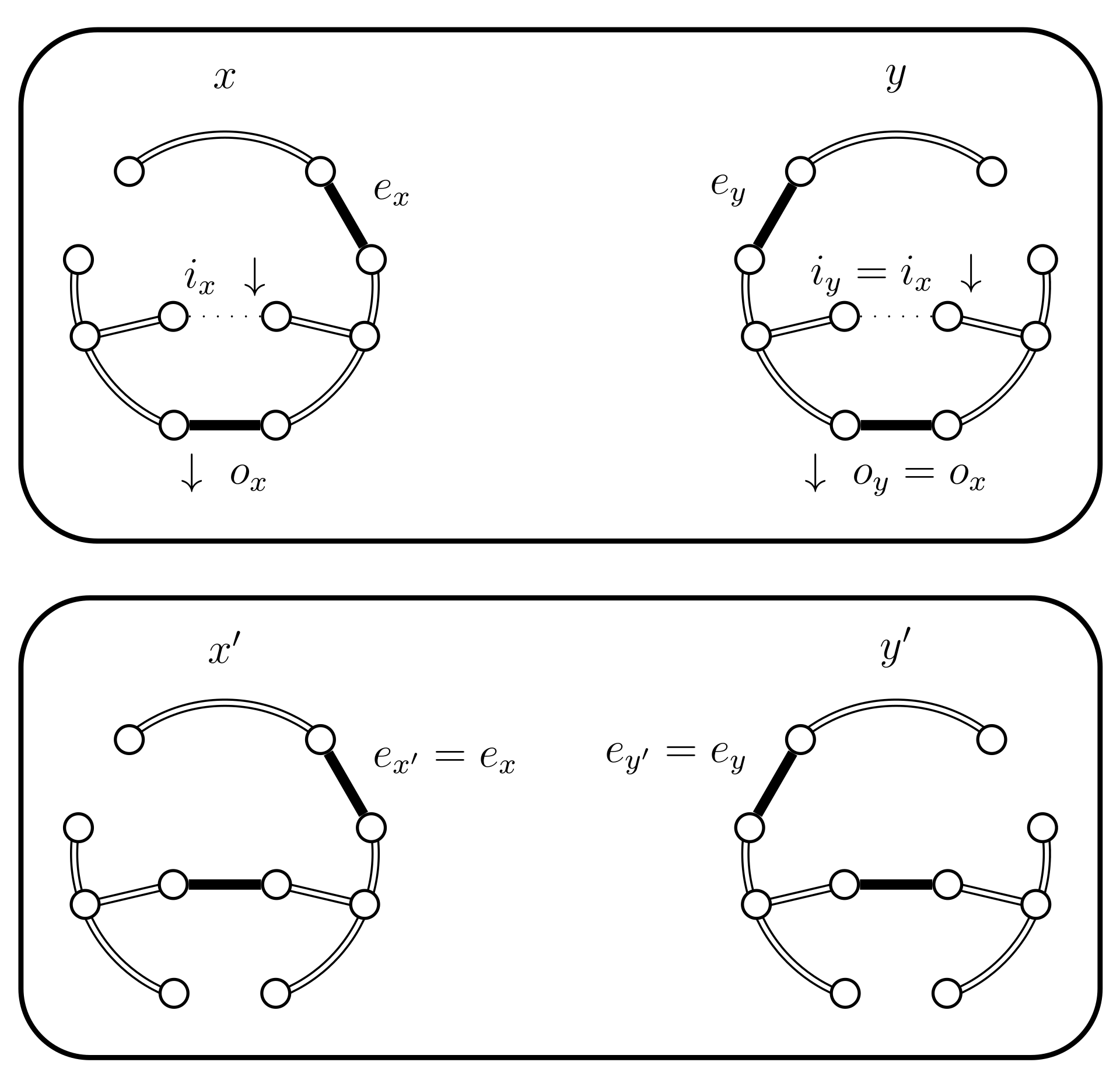
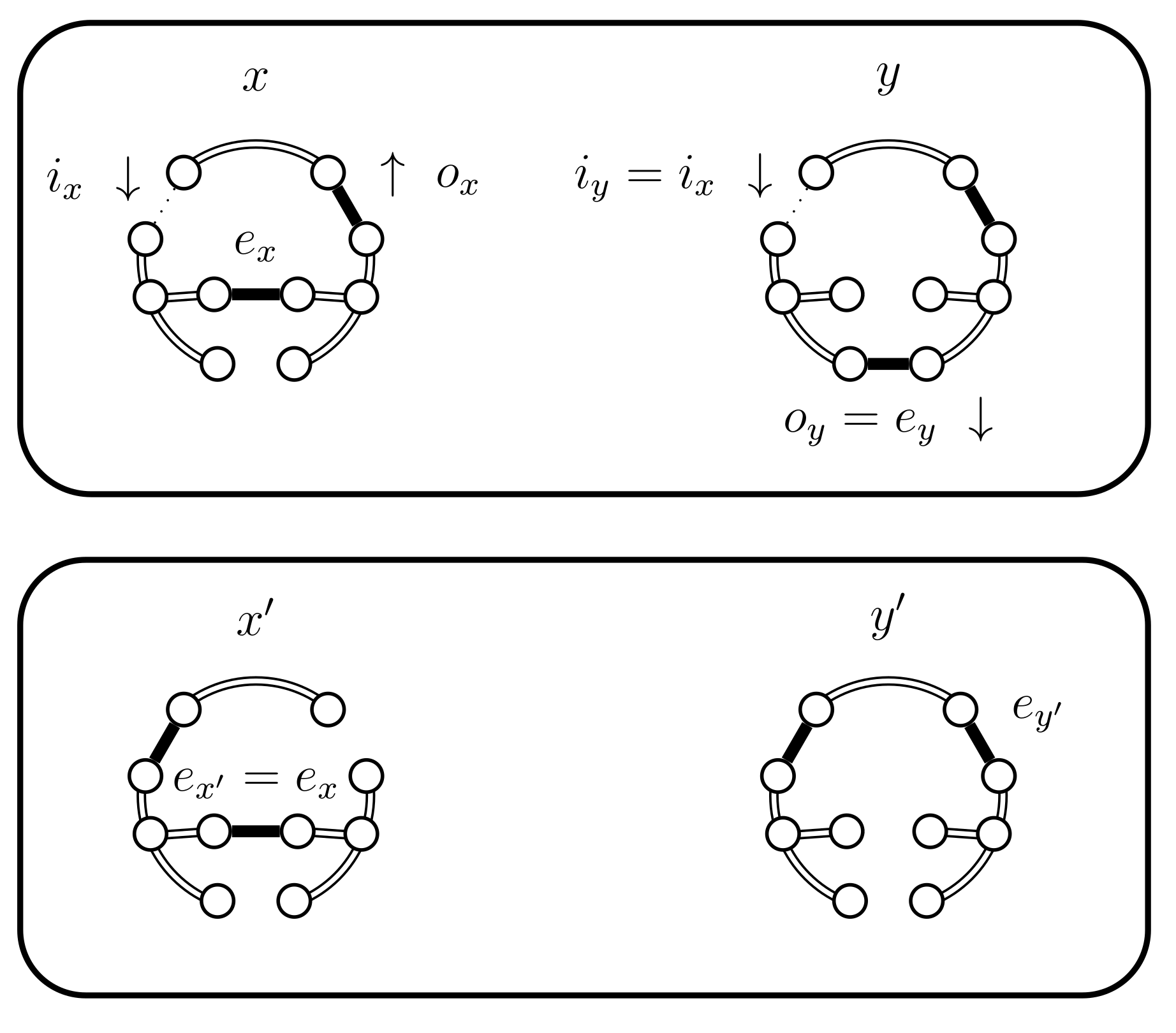
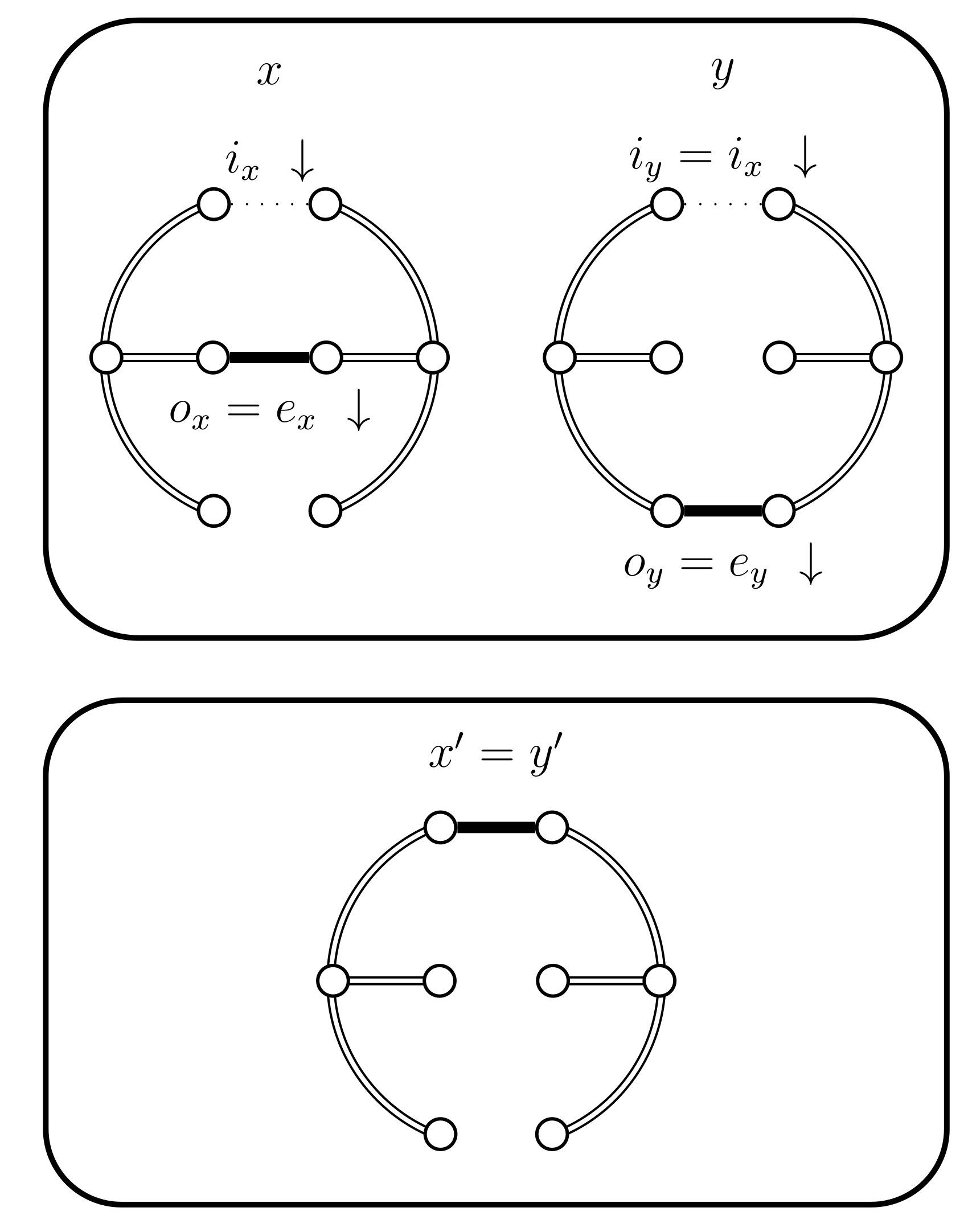
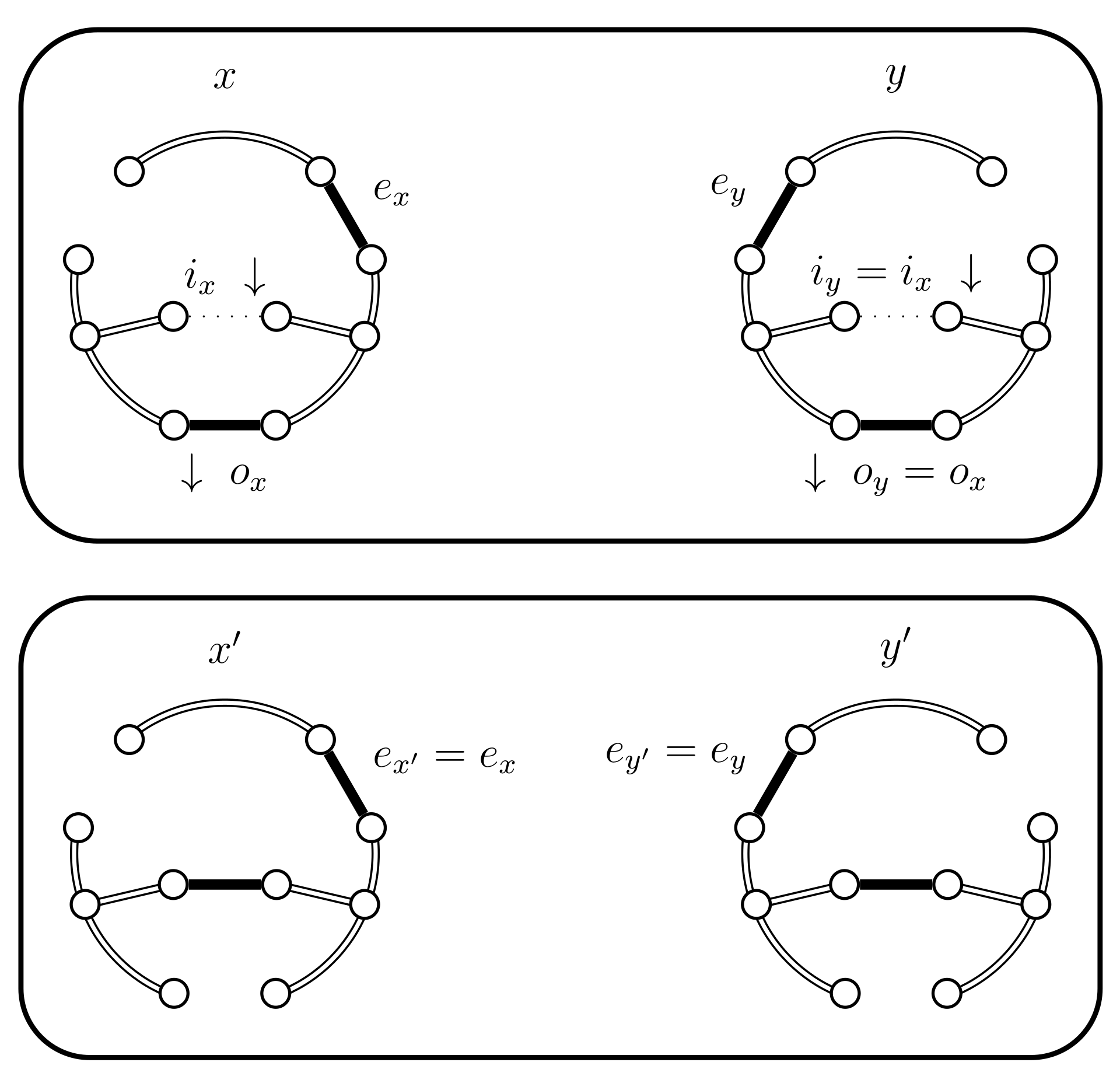
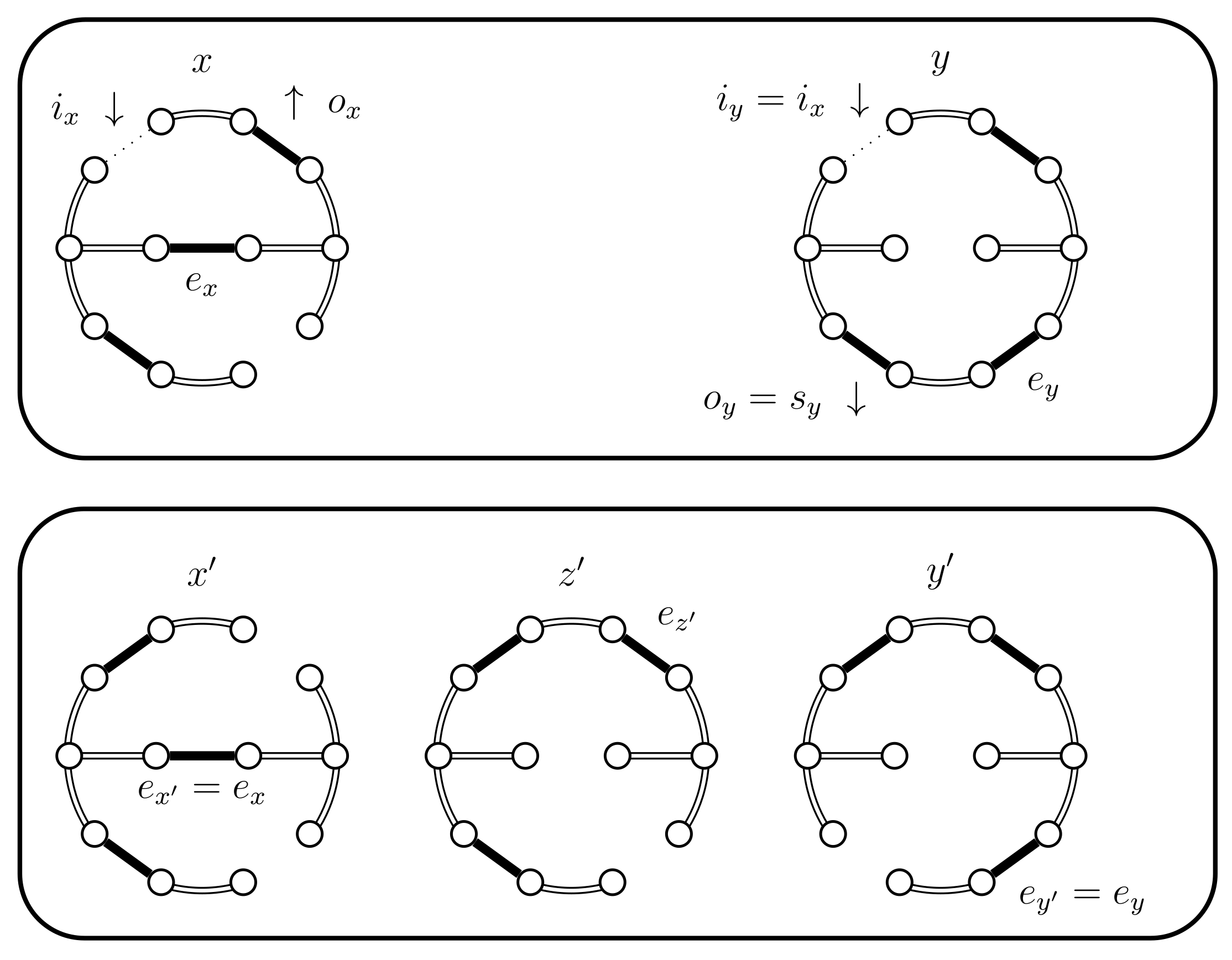
- If and then set and . In this case the chains do not coalesce; they swap states because and (see Figure 5). Set .
- If and then set and . In this case the chains coalesce, i.e., (see Figure 6). When the chains coalesce, the edges and no longer exist and the set is no longer relevant.
- If set . We now have three sub-cases, which are further sub-divided. These cases depend on whether , or . We start with which is simpler and establishes the basic situations. When or we use some Bernoulli random variables to balance out probabilities and whenever possible reduce to the cases considered for . When this is not possible we present the corresponding new situation.
- (a)
- If we have the following situations:
- (i)
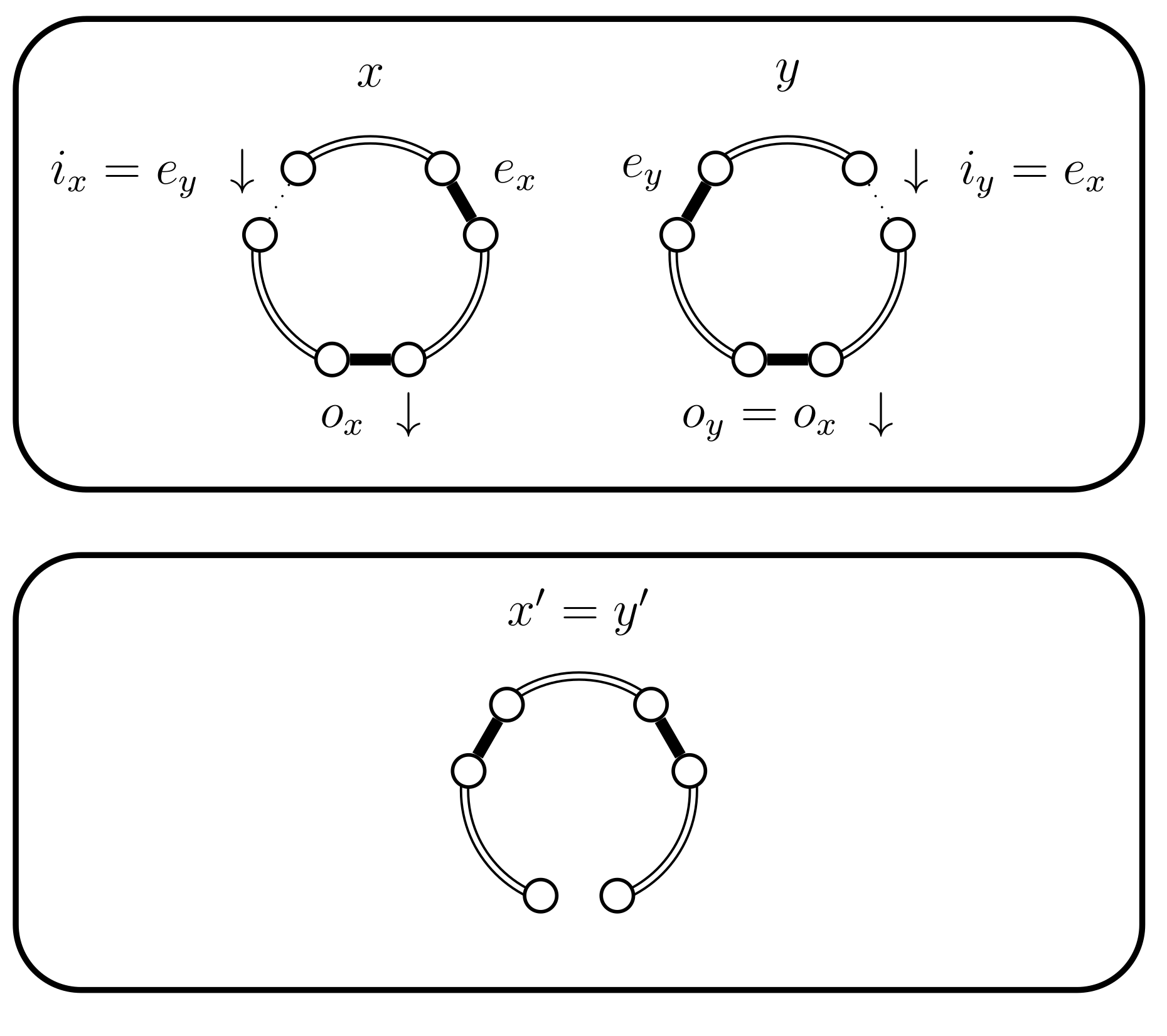
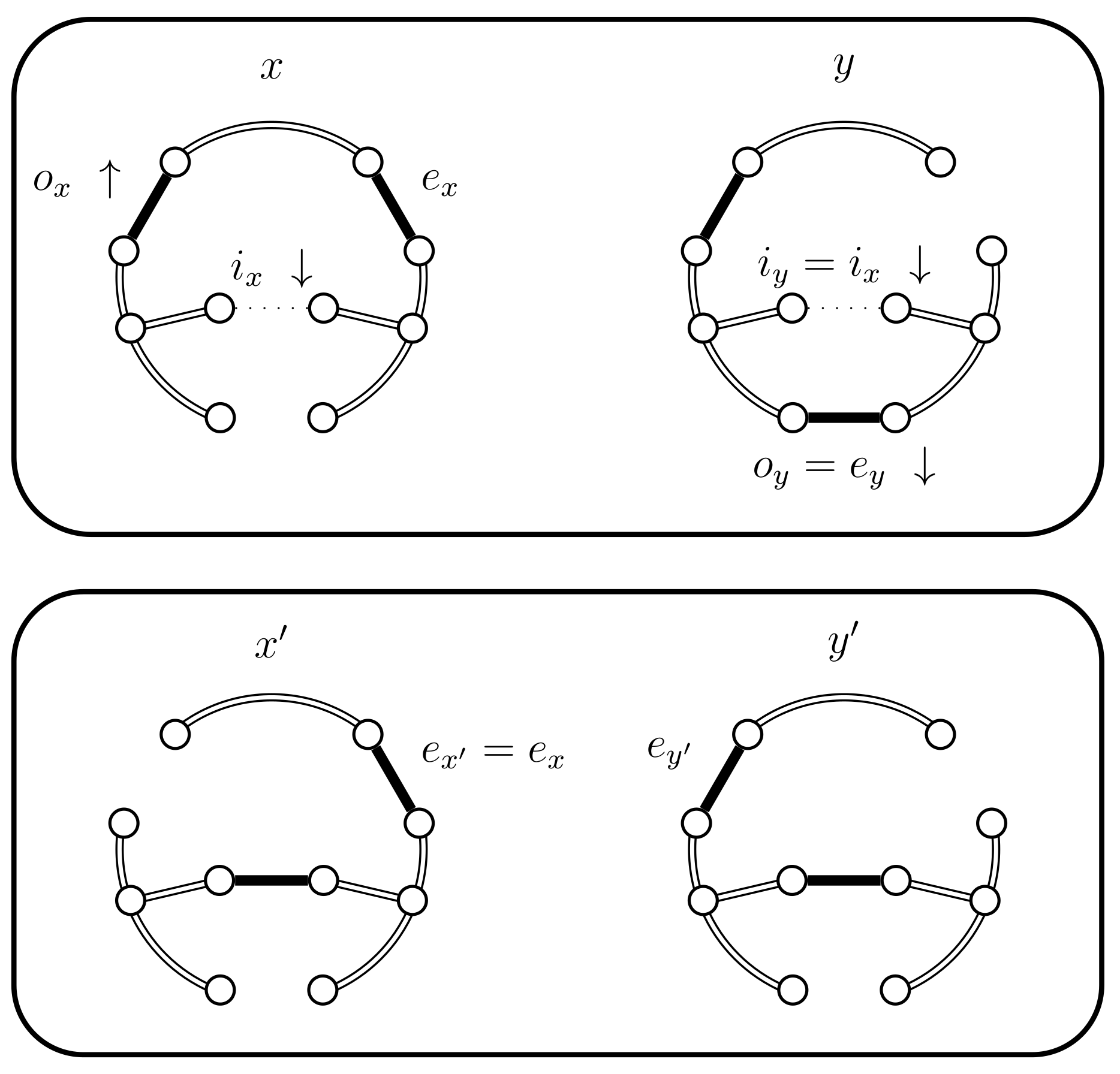
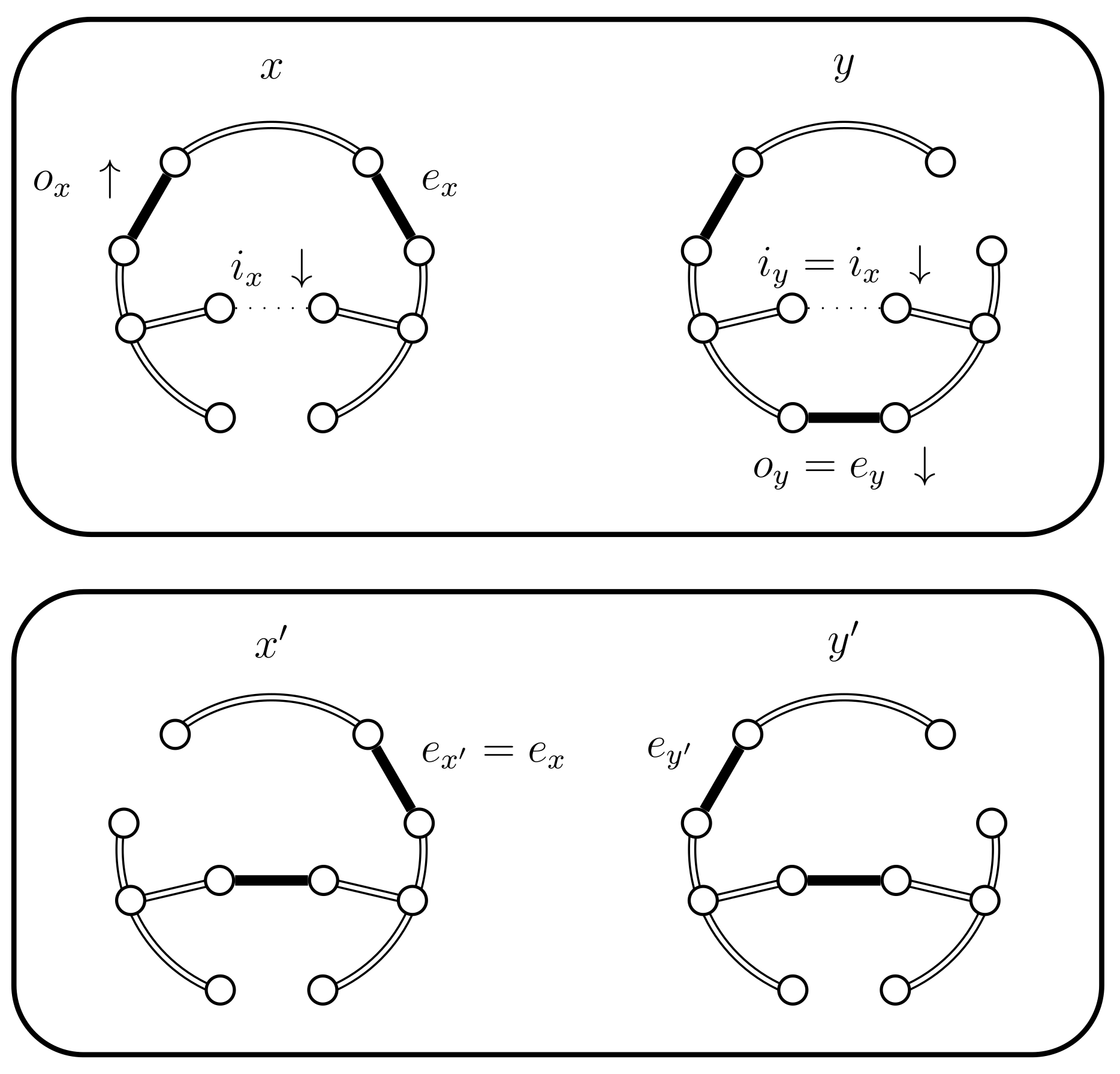
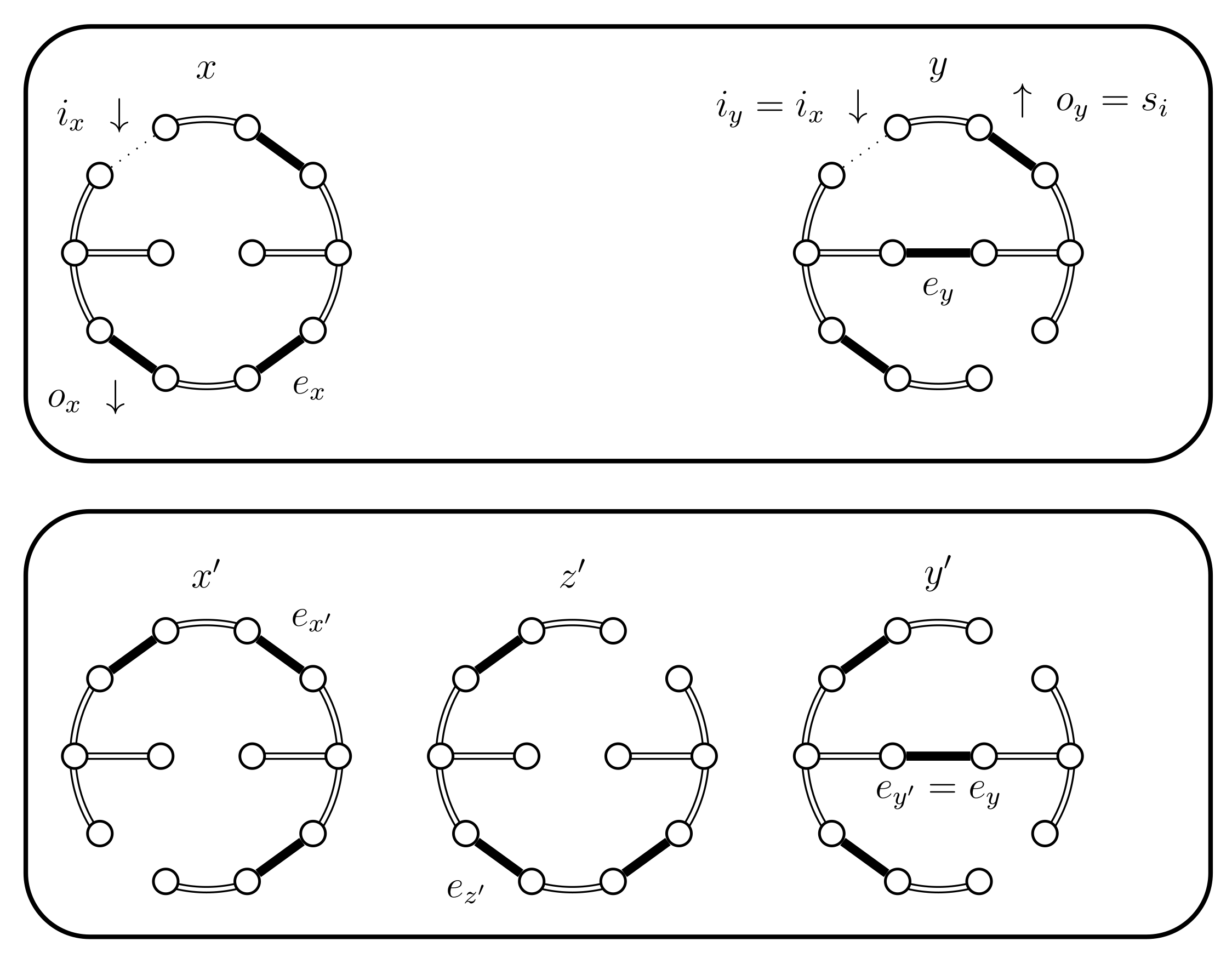
- If then set . In this case the chains coalesce (see Figure 7).
- (ii)
- (iii)
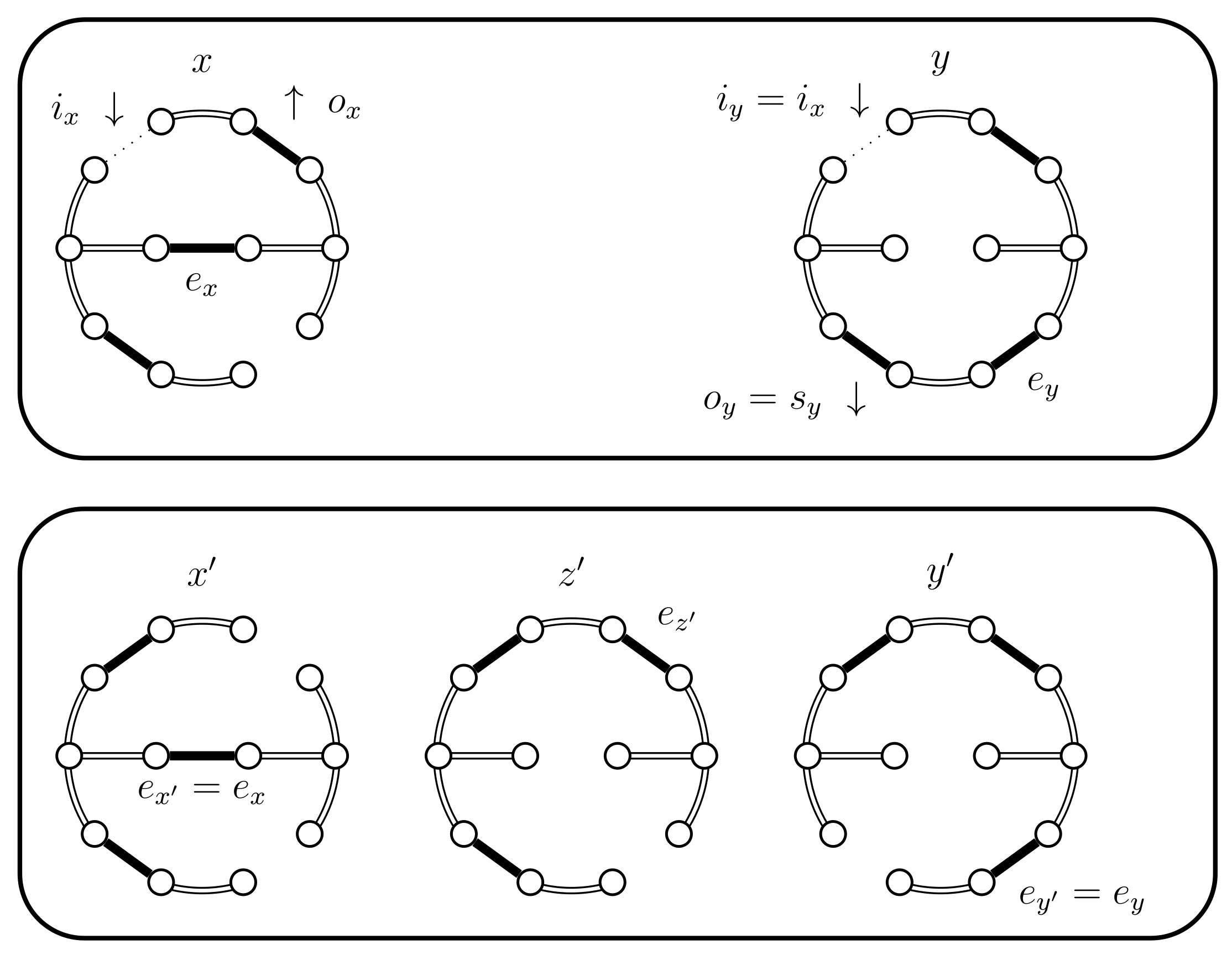
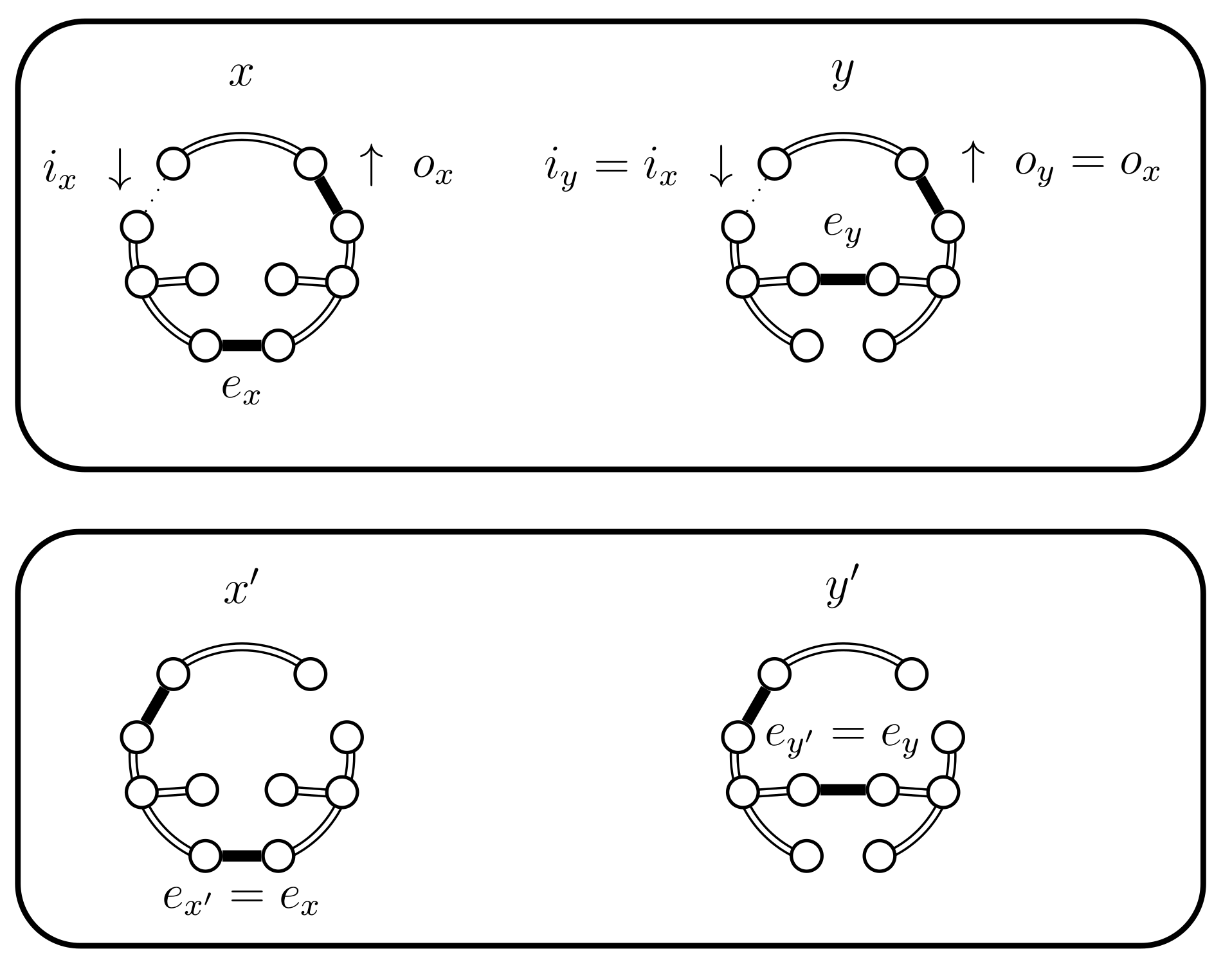
- If then select uniformly from . If then set (see Figure 10). In this case set . The alternative, when , is considered in the next case (4.a.iv).
- (iv)
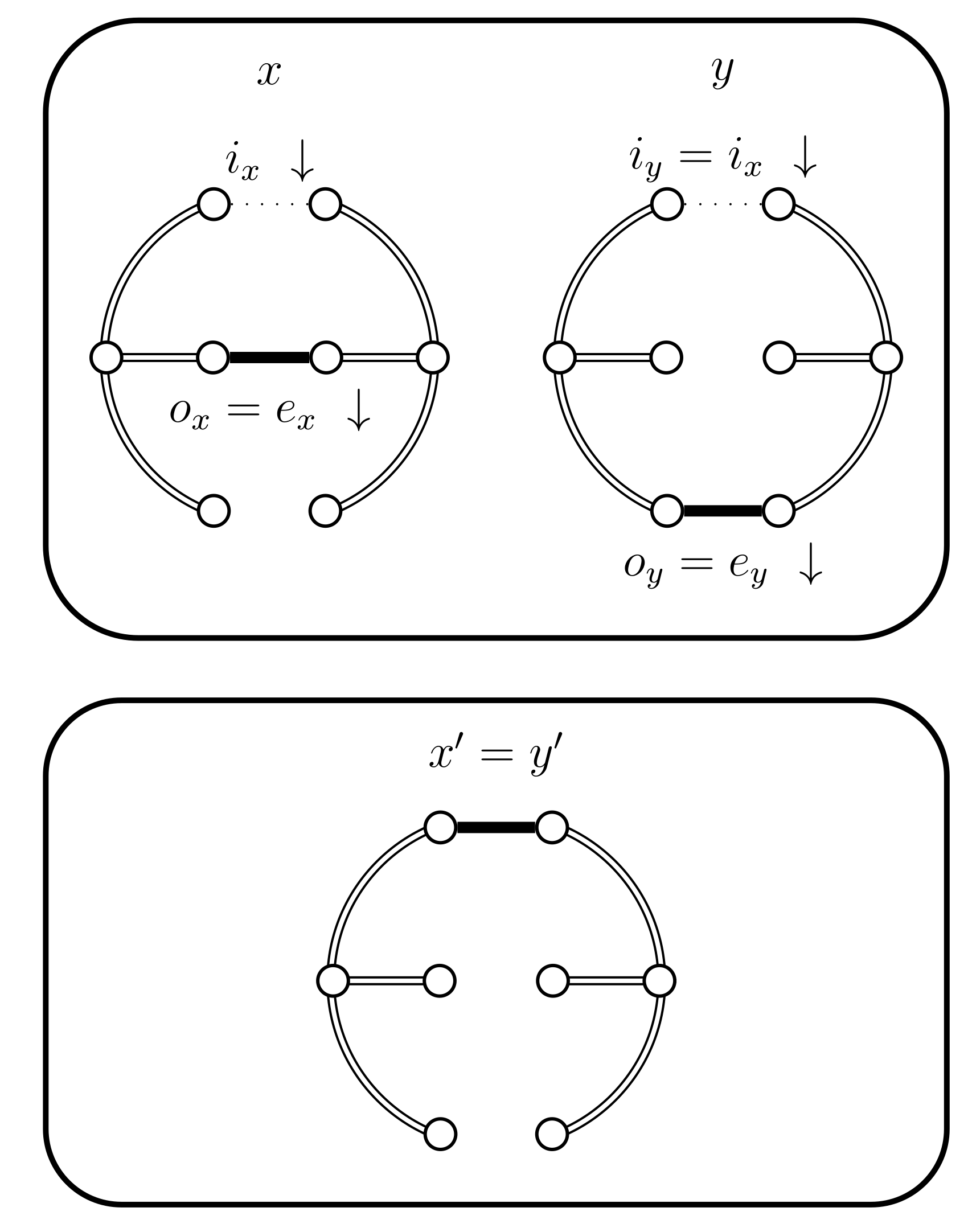
- If and , then set . This case is shown in Figure 11. In this case the distance of the coupled states increases, i.e., . Therefore we include a new state in between and and define to be the edge in ; the edge in ; and the edge in . The set should contain the edges that provide alternatives to . In this case set and .
- (b)
- If then will choose with a higher probability then what should. Therefore, we use a Bernoulli random variable B with a success probability p defined as follows:In Lemma 2 we prove that p properly balances the necessary probabilities. For now note that when the expression for p yields . This is coherent with the following cases, because when B yields true we use the choices defined for . The following situations are possible:
- (i)
- (ii)
- (iii)
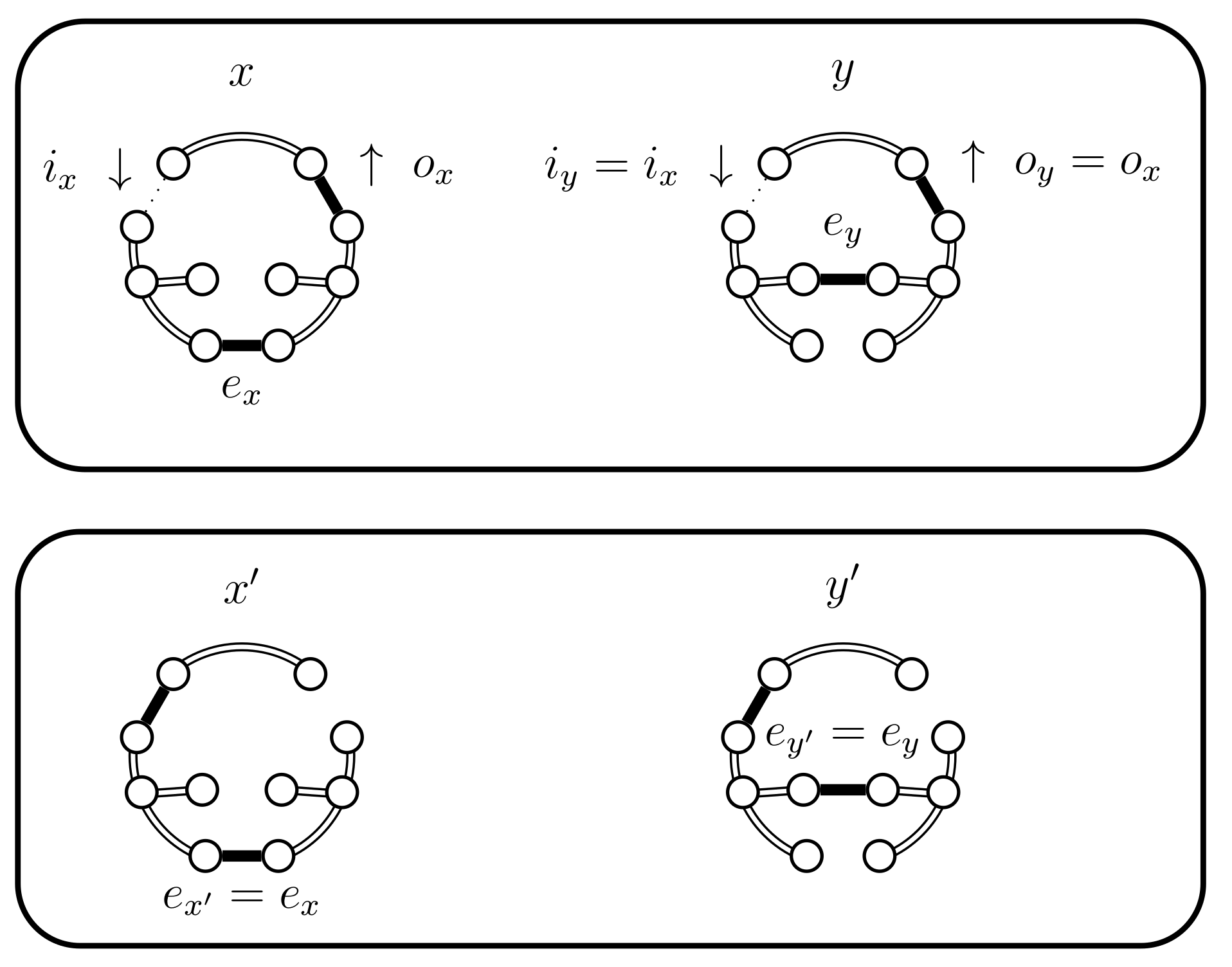
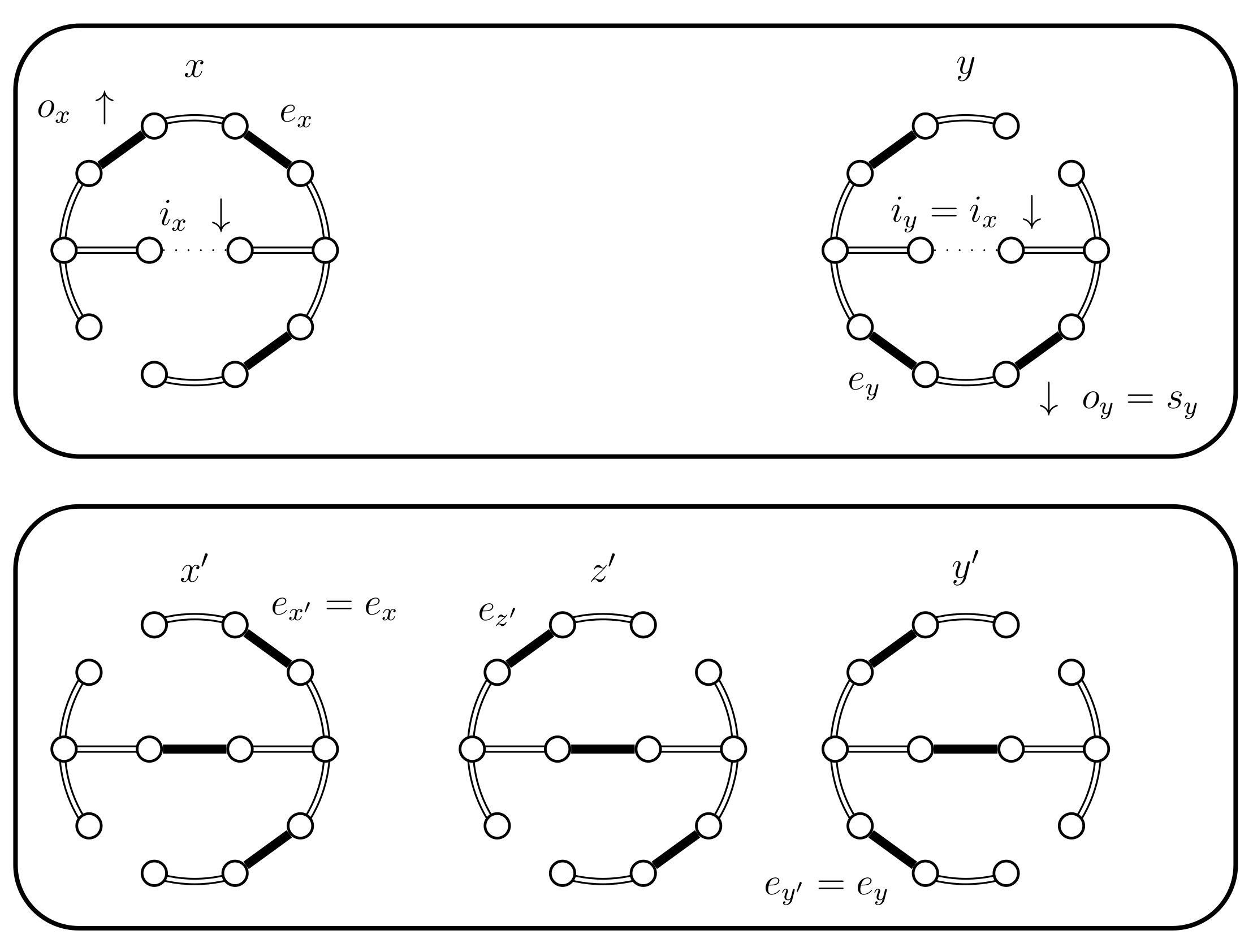
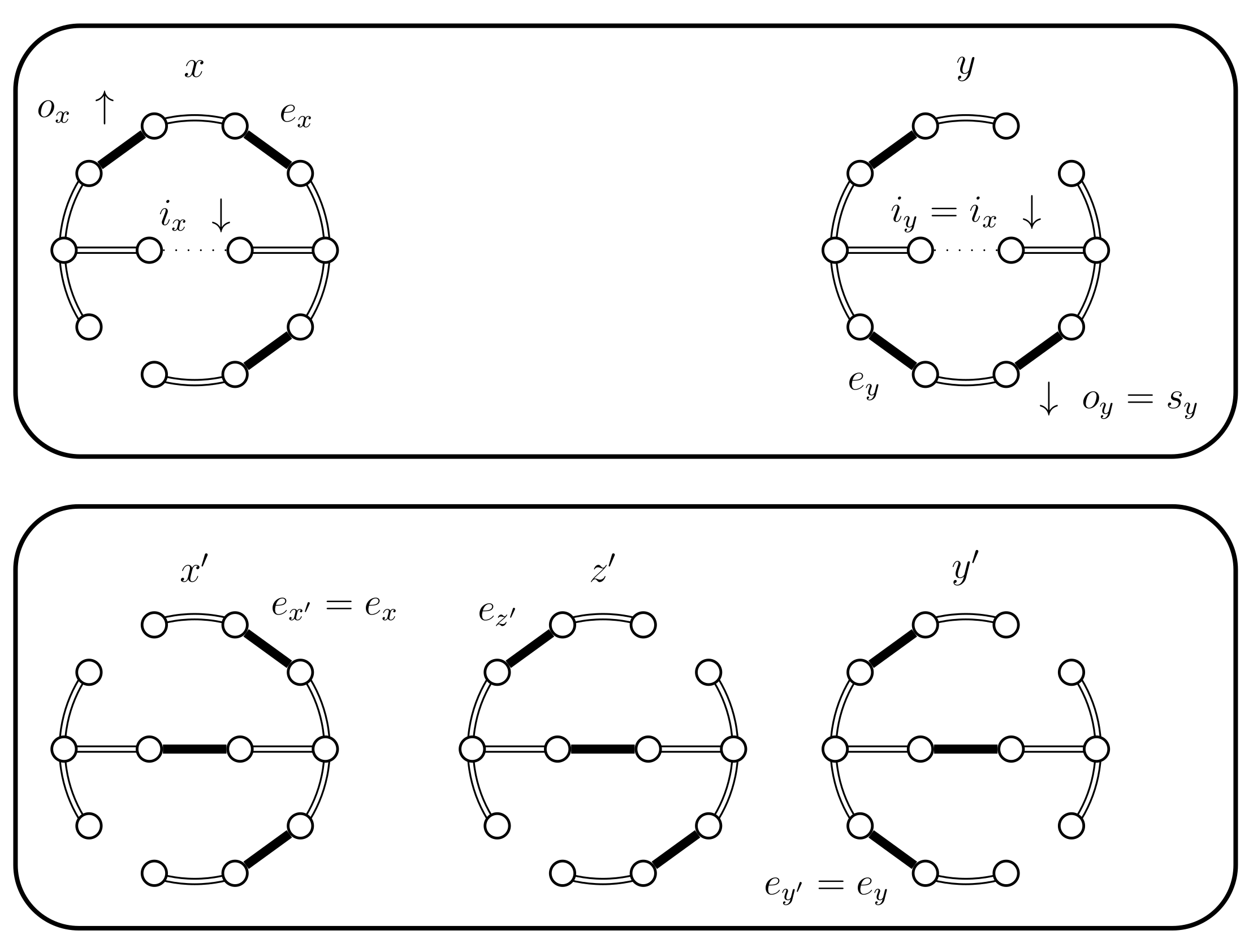
- If and B fails and . We have a new situation,;set . The distance increases, (see Figure 14). Set and .
- (iv)
- (c)
- If we have the following situations:
- (i)
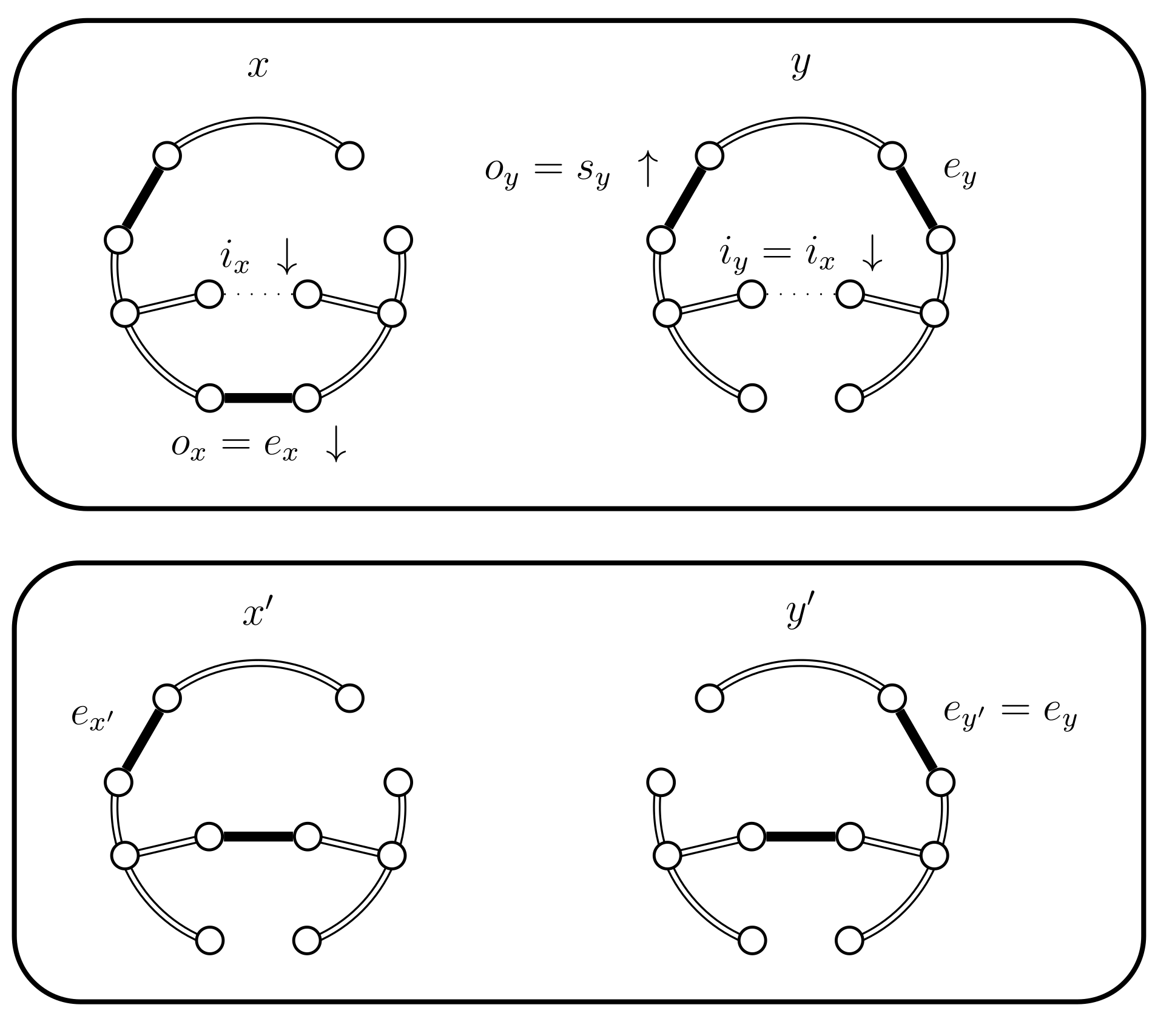
- If then use case 4.a.i and set (see Figure 7). The chains coalesce.
- (ii)
- (iii)
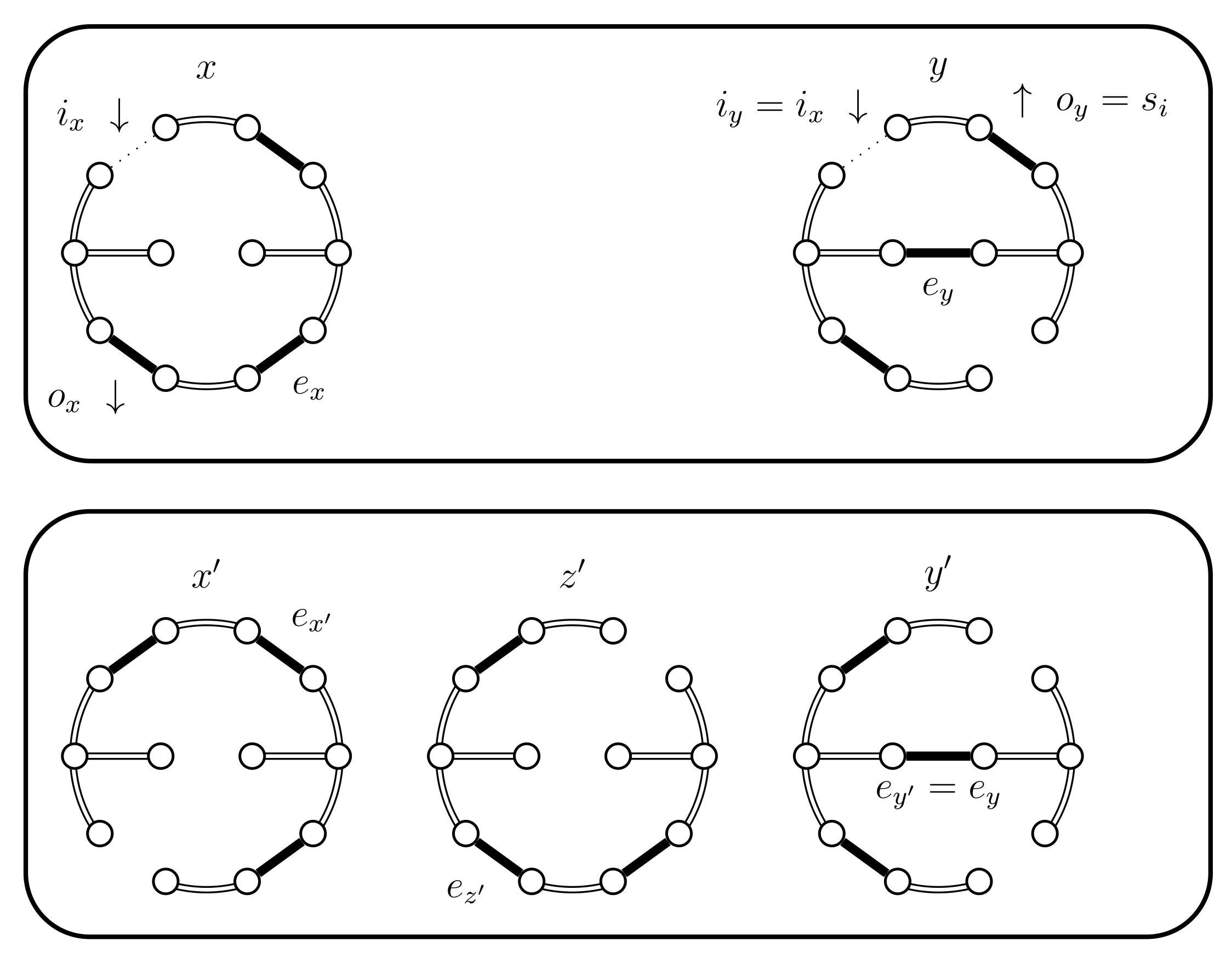
- If then we use a new Bernoulli random variable with a success probability defined as follows:In Lemma 2 we prove that properly balances the necessary probabilities. For now, note that when the expression for yields , because becomes 0. This is coherent because when returns false we will use the choices defined for . The case when fails is considered in the next case (4.c.iv).If is successful we have a new situation. Set , where is chosen uniformly from (see Figure 15). We have , , and .
- (iv)
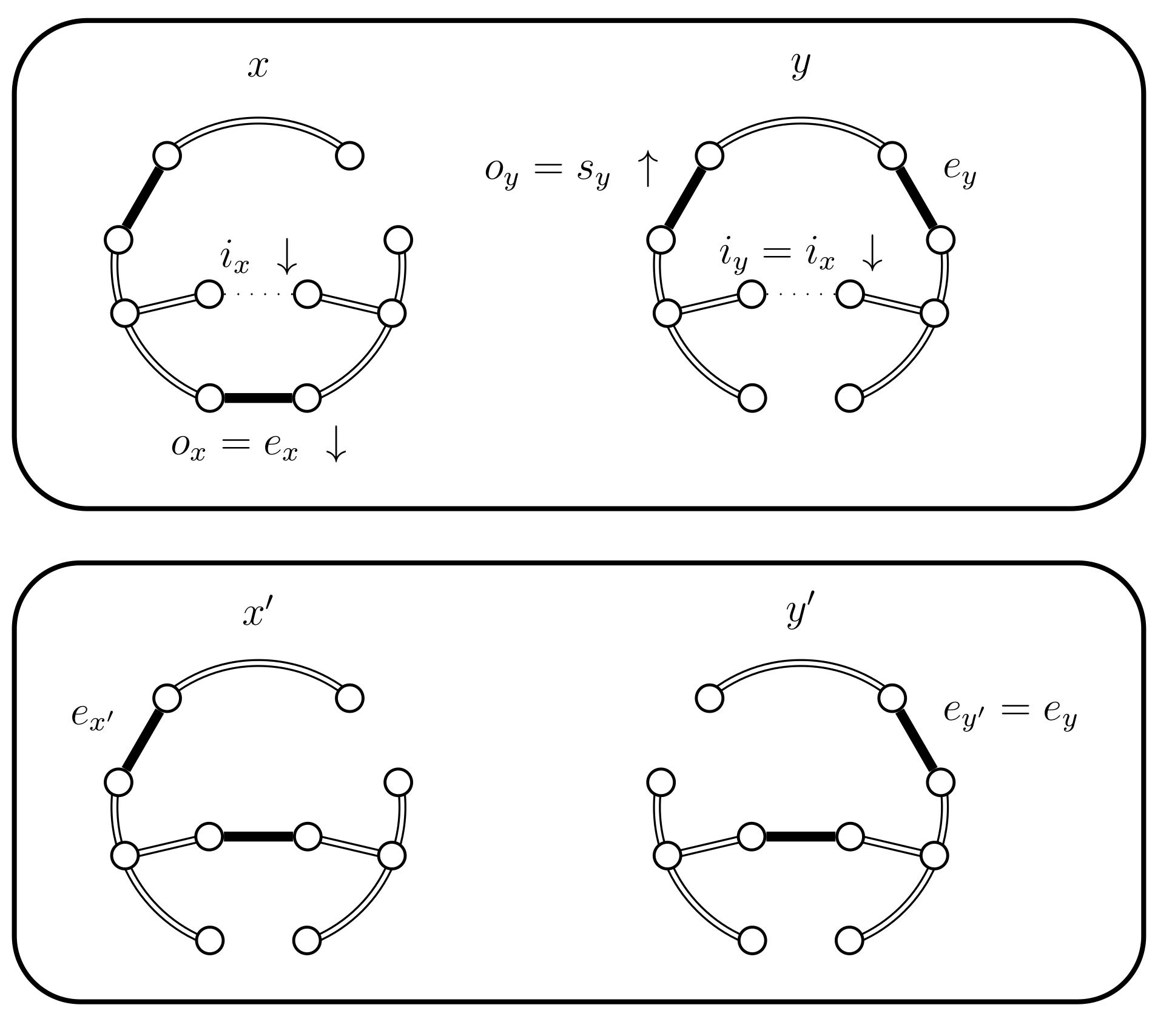
- If and fails we use another Bernoulli random variable with a success probability defined as follows:
- : this occurs only in case 1, when . It may be that ; this occurs when , in which case and this is the only case where . In this case . Otherwise, , in these cases , and therefore .
- : this occurs in cases 2 and 3, i.e., when , which is the decisive condition for this choice. Therefore .
- : this occurs in case 4. In this case so again we have that .
- Analysis of B. We need to have for p to be well defined. Any cycle must contain at least three edges; therefore and hence . This guarantees that the denominator is not 0. The same argument proves that , thus implying that , as both expressions are positive. We also establish that because of the hypothesis of case 4.b which guarantees and therefore .
- Analysis of . As in seen the analysis of B we have that and , therefore those denominators are not 0. Moreover we also need to prove that . In general we have that , because . Moreover, the hypothesis of case 4.c.iii is that and therefore , which is obtained by removing I from the both sides. This implies that and therefore , thus establishing that the last denominator is also not 0.Let us now establish that and . Note that can be simplified to the expression , where all the expressions in parenthesis are non-negative, so . For the second property we use the new expression for and simplify to . The deduction is straightforward using the equality that is obtained by removing I from the left side. The properties and establish the desired result.
- Analysis of . We established, in the analysis of B, that is non-zero. In the analysis of we also established that is non-zero. Note that case 4.c.iv also assumes the hypothesis that . Moreover, in the analysis of we also established that , which implies that and therefore the last denominator is also non-zero.Let us also establish that and . For the second property we instead prove that , where and all of the expressions in parenthesis are non-negative. We use the following deduction of equivalent inequalities to establish that :This last inequality is part of the hypothesis of case 4.c.iv.
- When the cycles are equal . This involves cases 2 and 3.
- : this occurs only in case 2 and it is determined by the fact that . Therefore, .
- : this occurs only in case 3 and it is determined by the fact that , in this case . Therefore .
- When the cycles have the same size (case 4.a). The possibilities for o are as follows:
- : this occurs only in the case 4.a.i. This case is determined by the fact that . Therefore, . Note that according to the Lemma’s hypothesis, case 4.a.iii never occurs.
- : this occurs only in case 4.a.ii. This case is determined by the fact that and sets . Therefore, .
- : this occurs only in case 4.a.iv. This case is determined by the fact that and moreover sets , which was uniformly selected from . We have the following deduction where we use the fact that the events are independent and that implies :
- When this involves case 4.b. The cases for o are as follows:
- : this occurs only in the case 4.b.i and when B is true. This case occurs when . We make the following deduction, that uses the fact that the events are independent and the success probability of B:
- : this occurs only in case 4.b.ii and when B is true. This case is determined by the fact that and sets . We make the following deduction, that uses the fact that the events are independent and the success probability of B:
- : this occurs in case 4.b.iv, but also in cases 4.b.iii and 4.b.i when B is false. We have the following deduction, that uses event independence, the fact that the cases are disjoint events, and the success probability of B:
- When , this concerns case 4.c. The cases for o are the following:
- : this occurs in the case 4.c.i and case 4.c.iv when is true. We use the following deduction:
- : this occurs in case 4.c.ii and case 4.c.iii when is true. We make the following deduction:
- : this occurs in case 4.c.iv when is false. We have the following deduction:
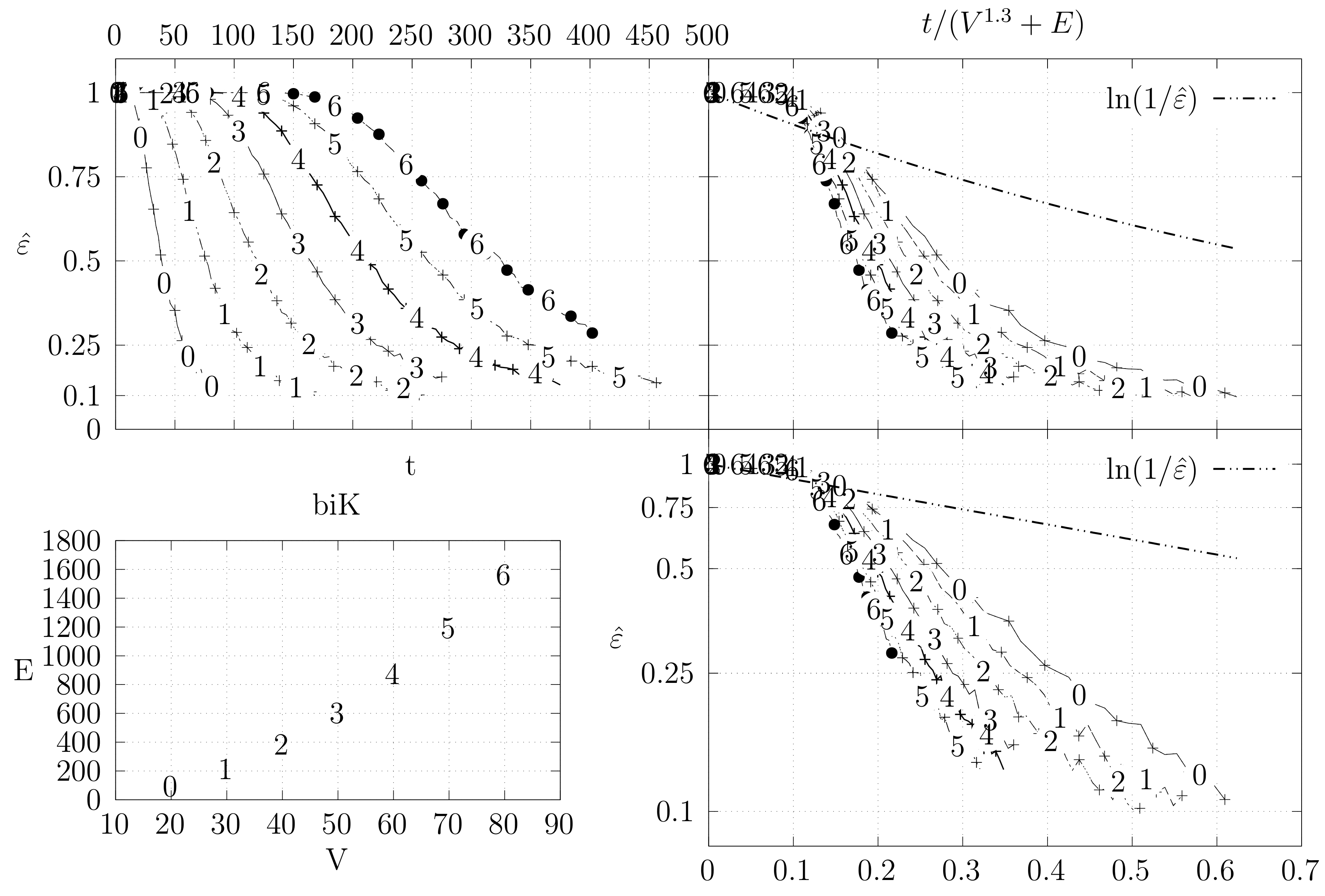
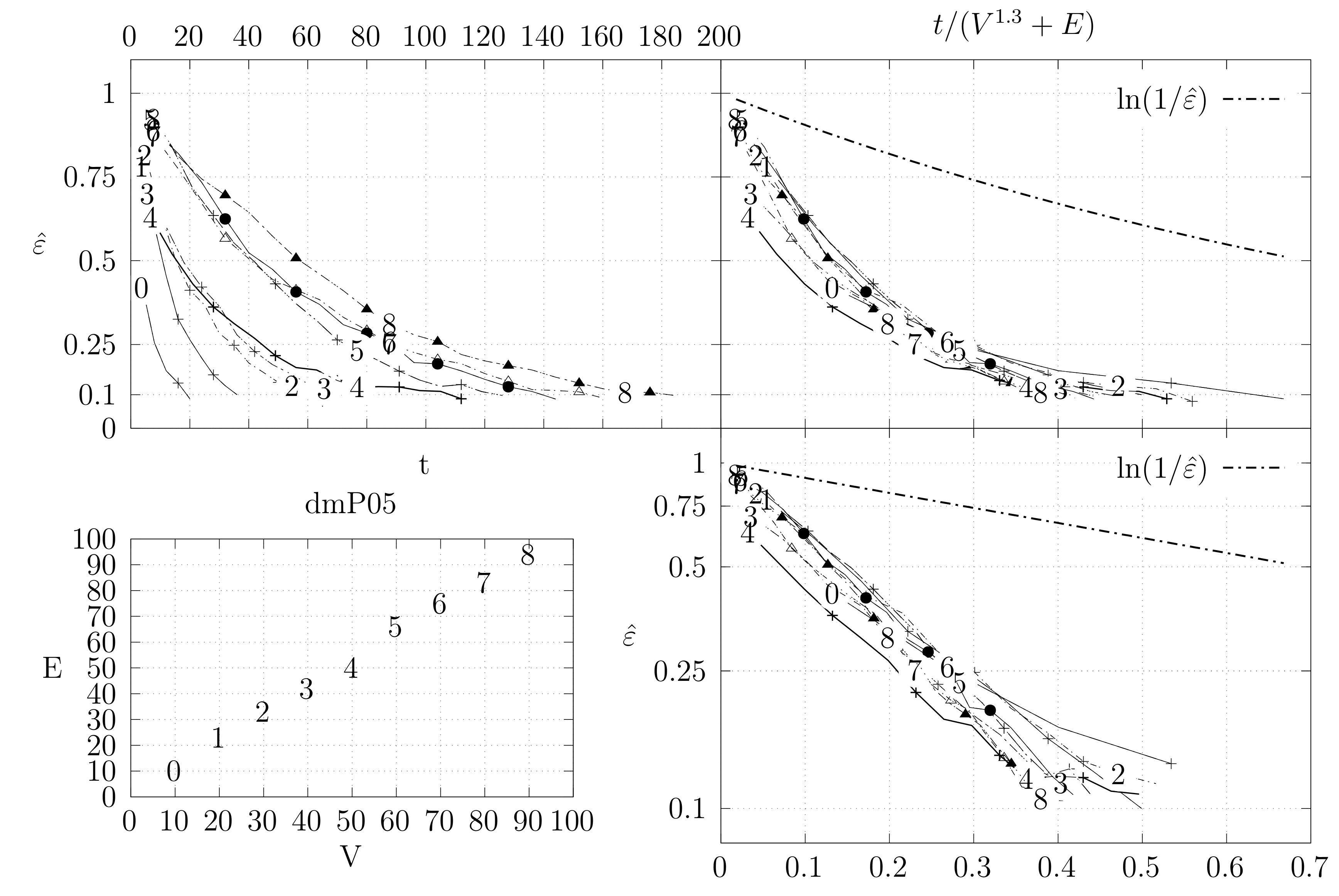
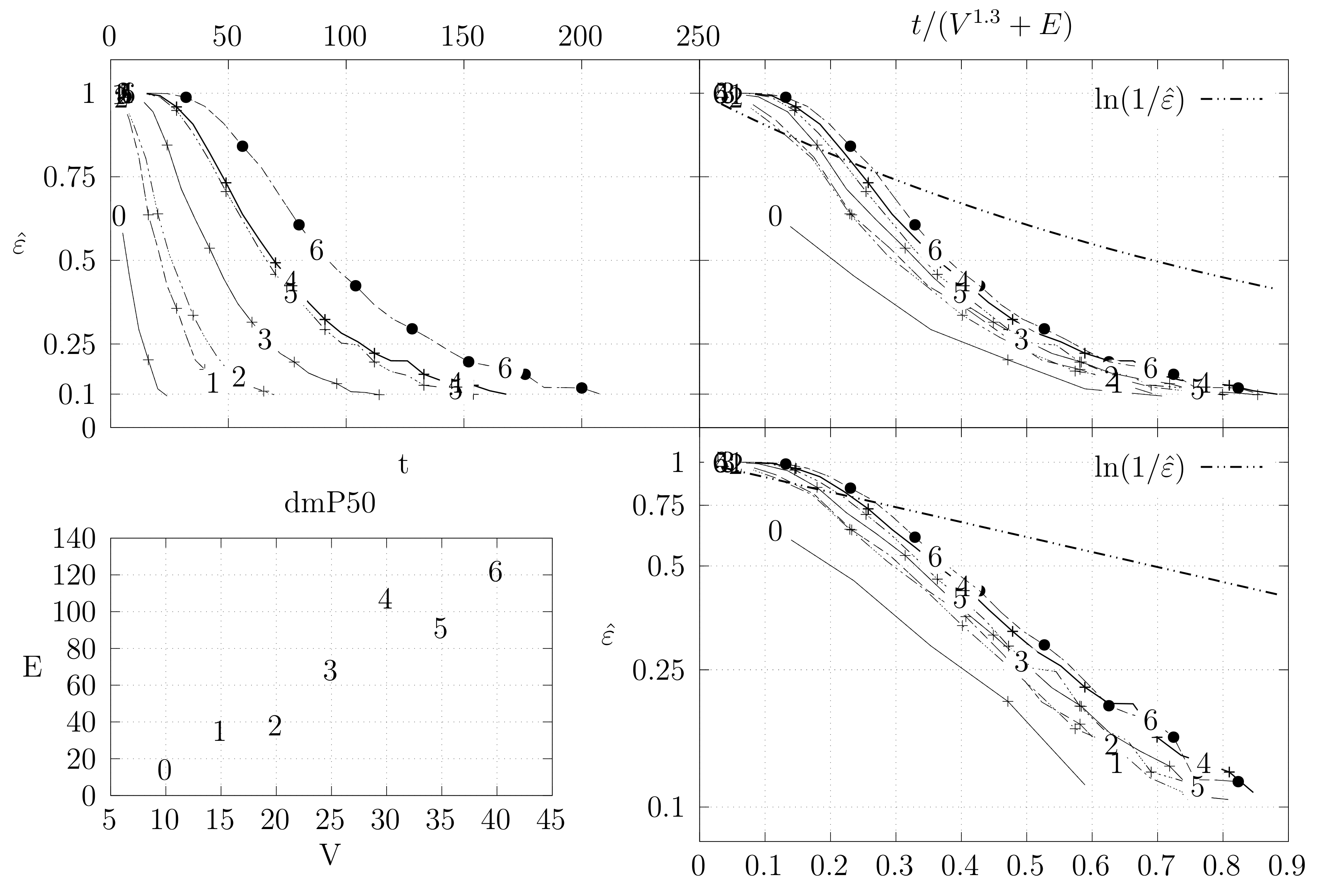
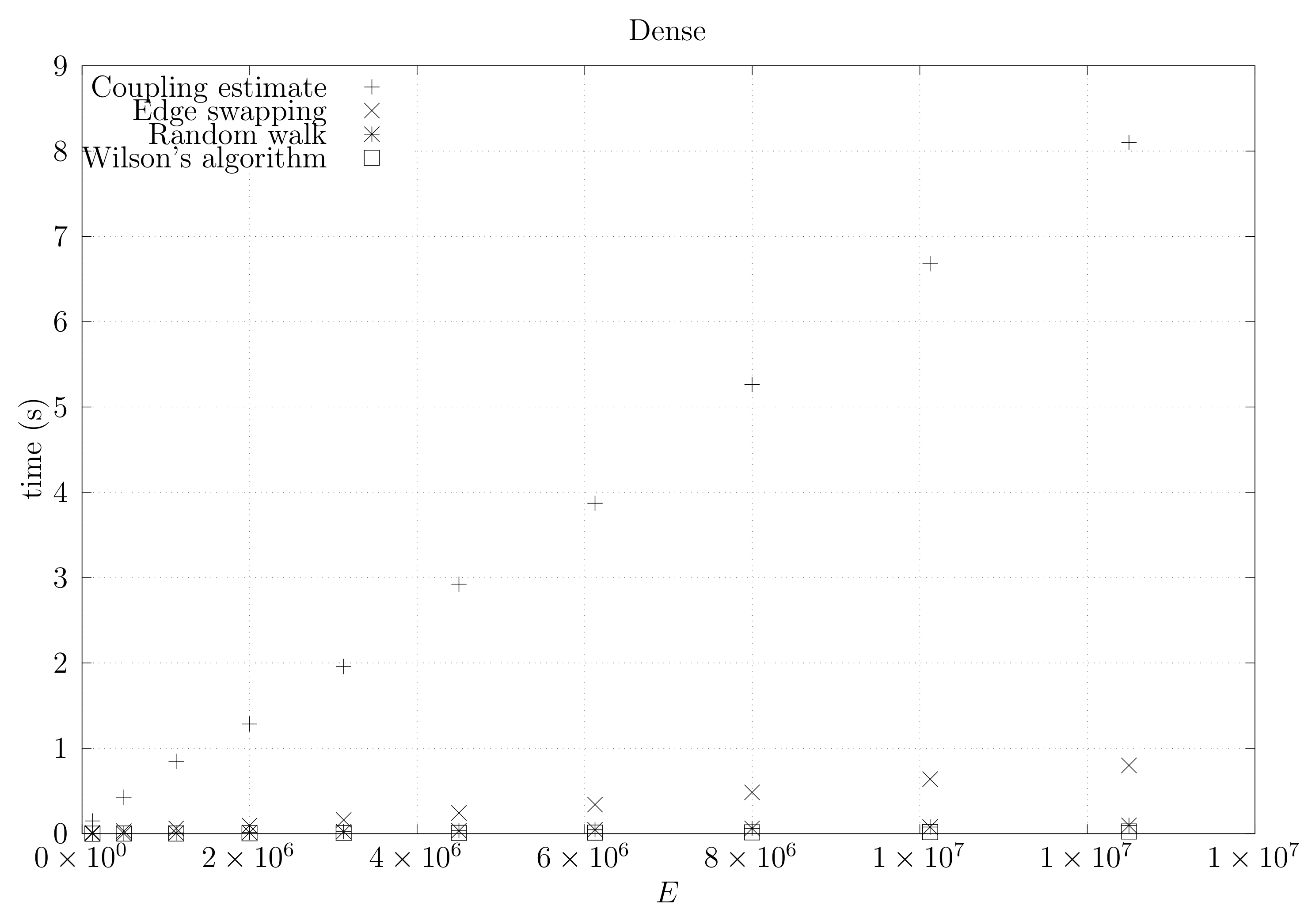
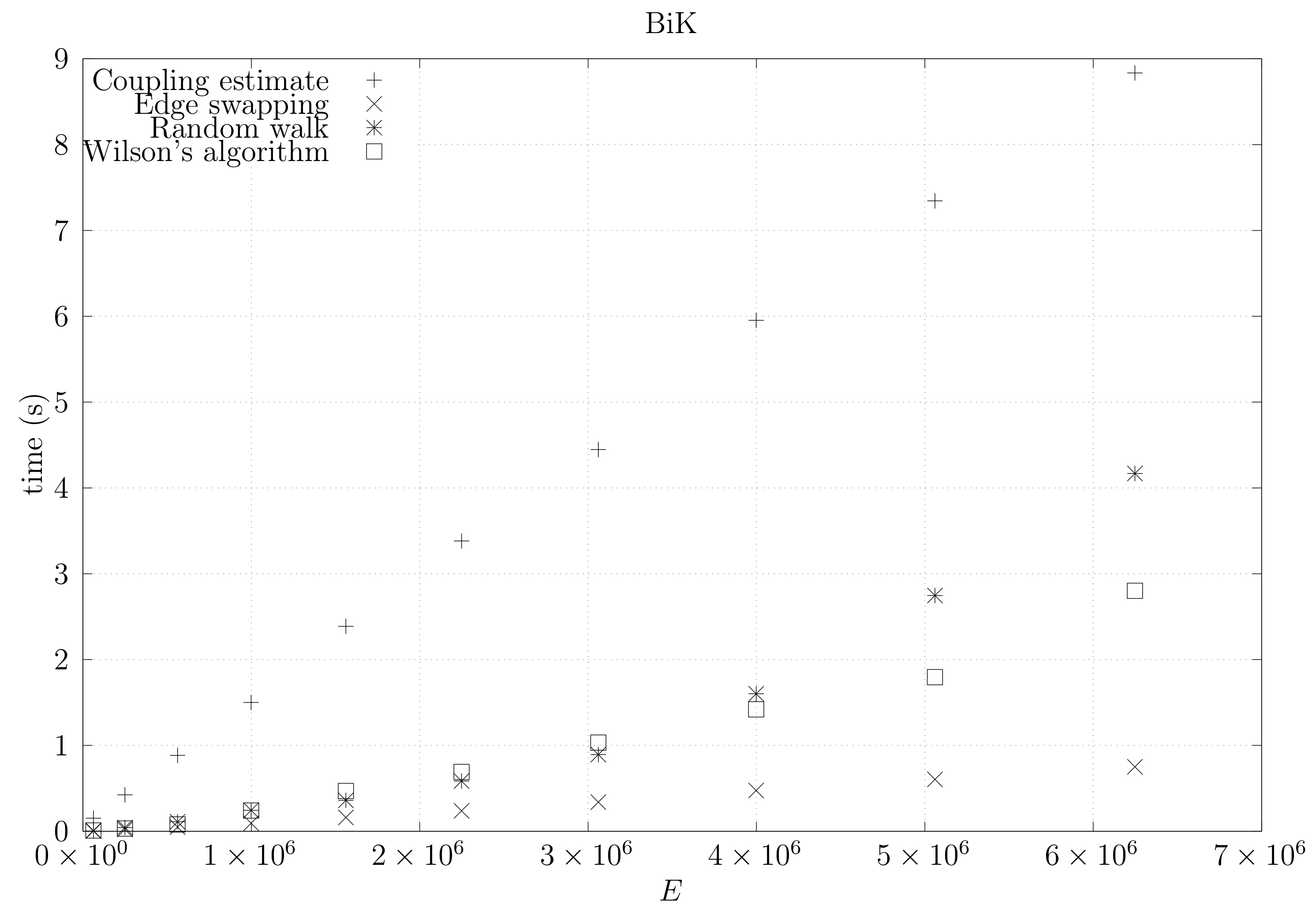
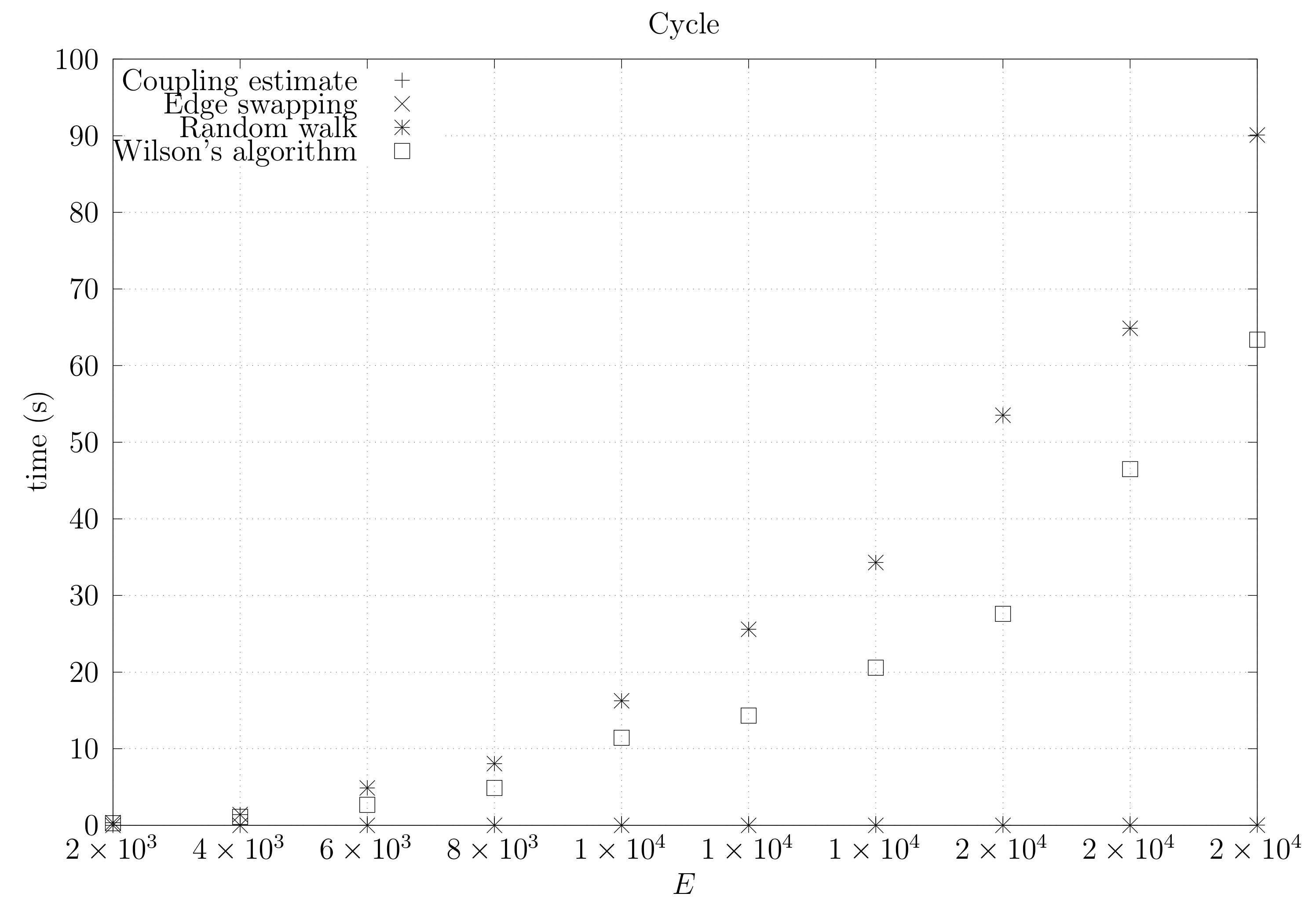
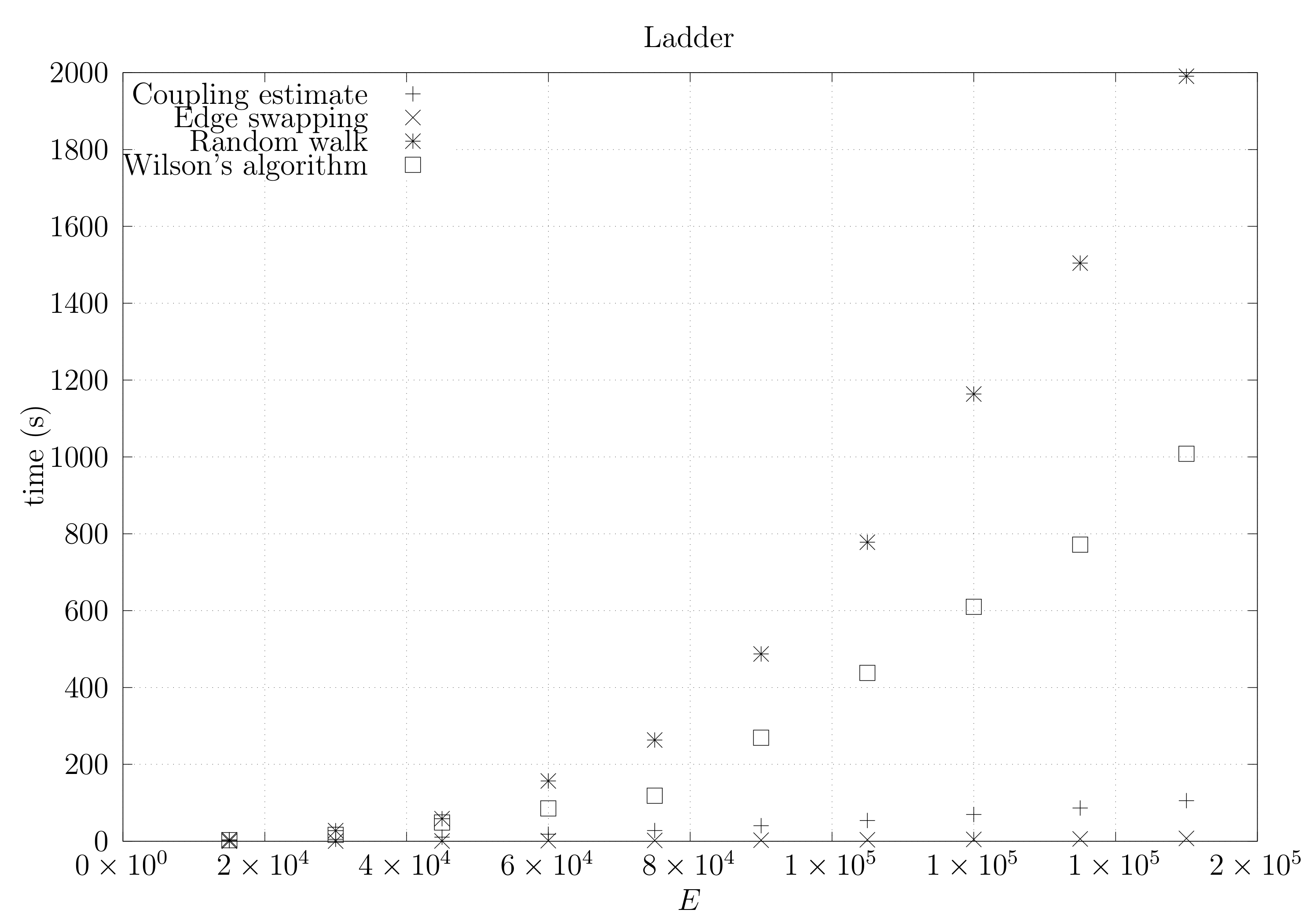
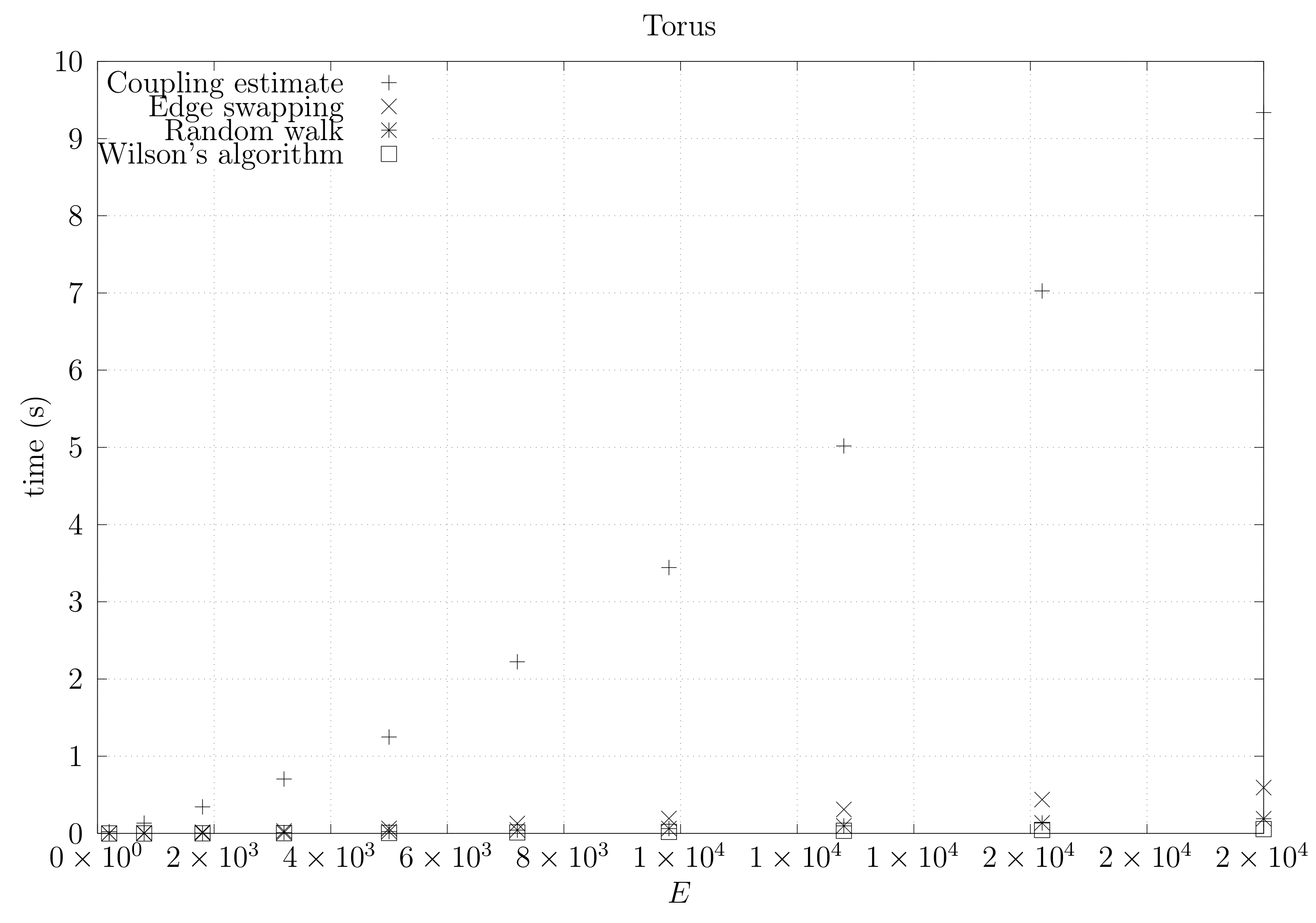
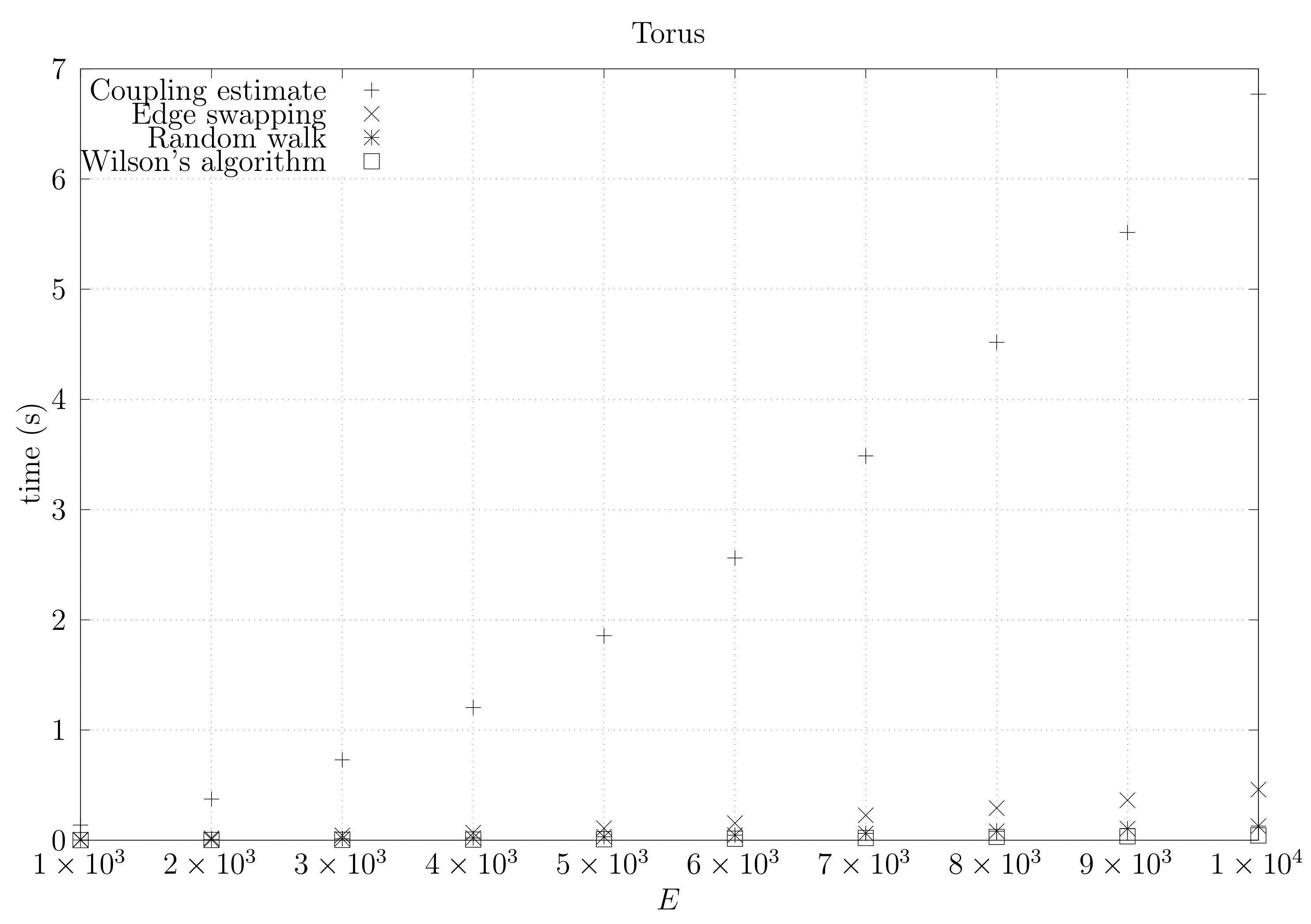
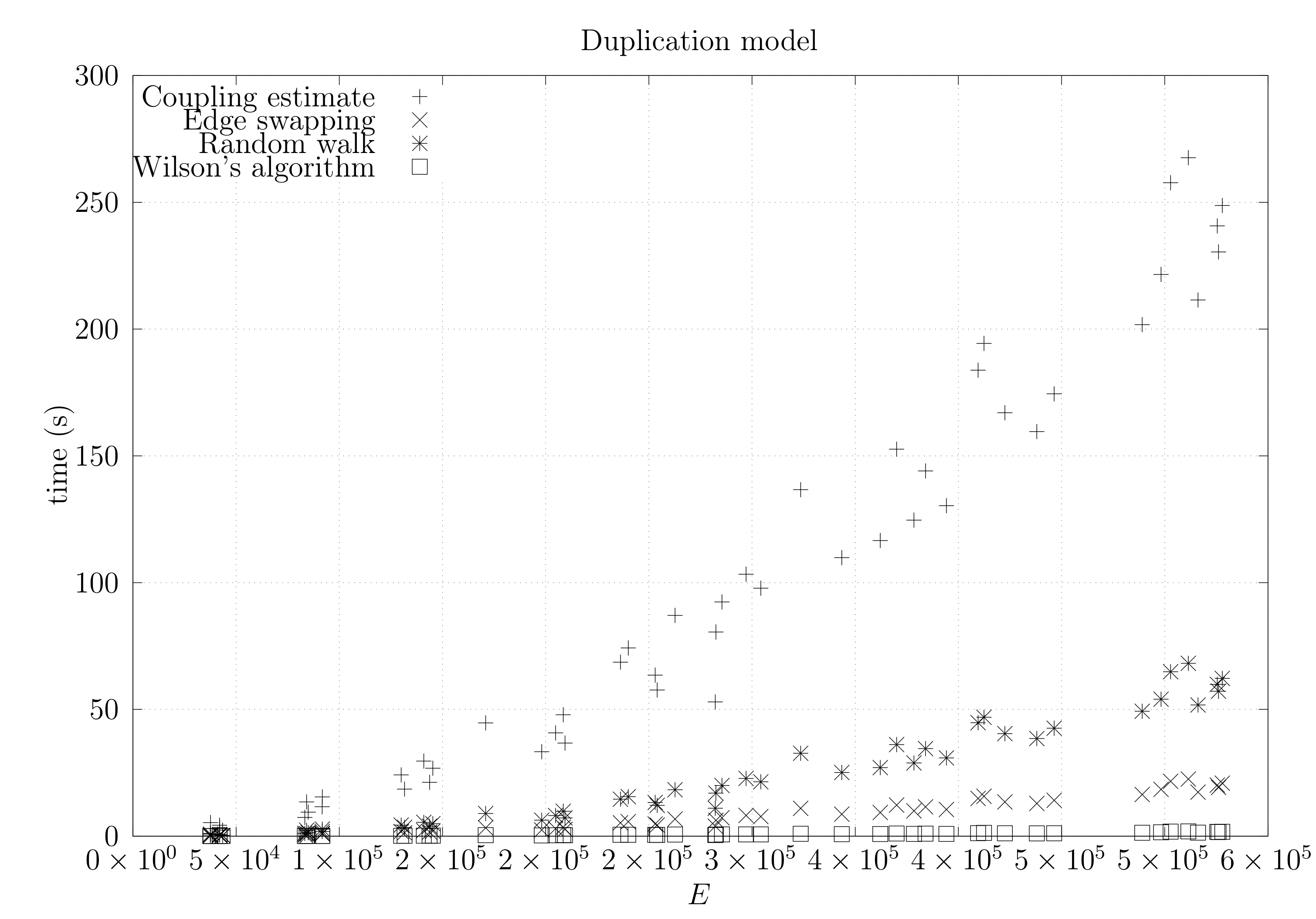
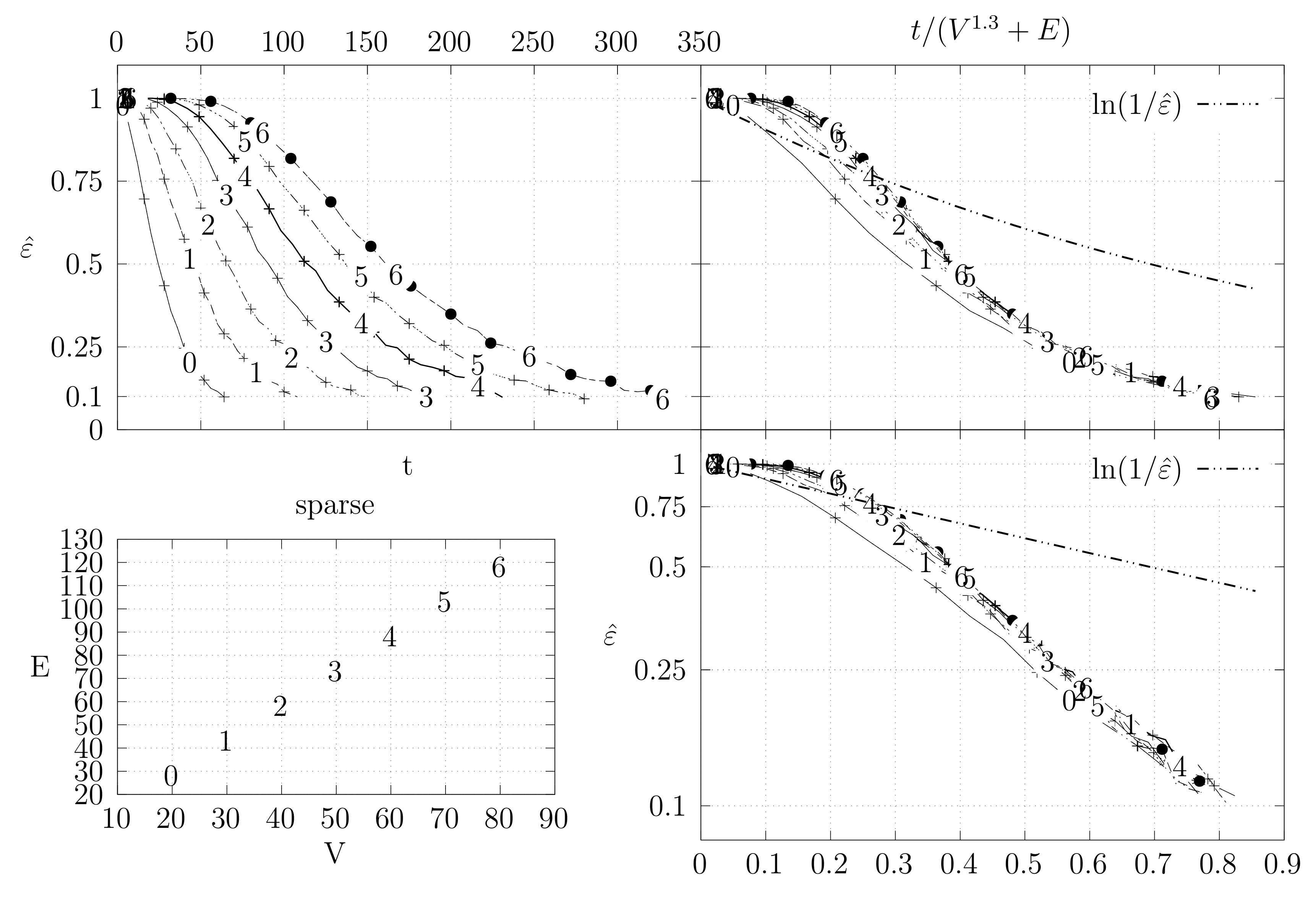
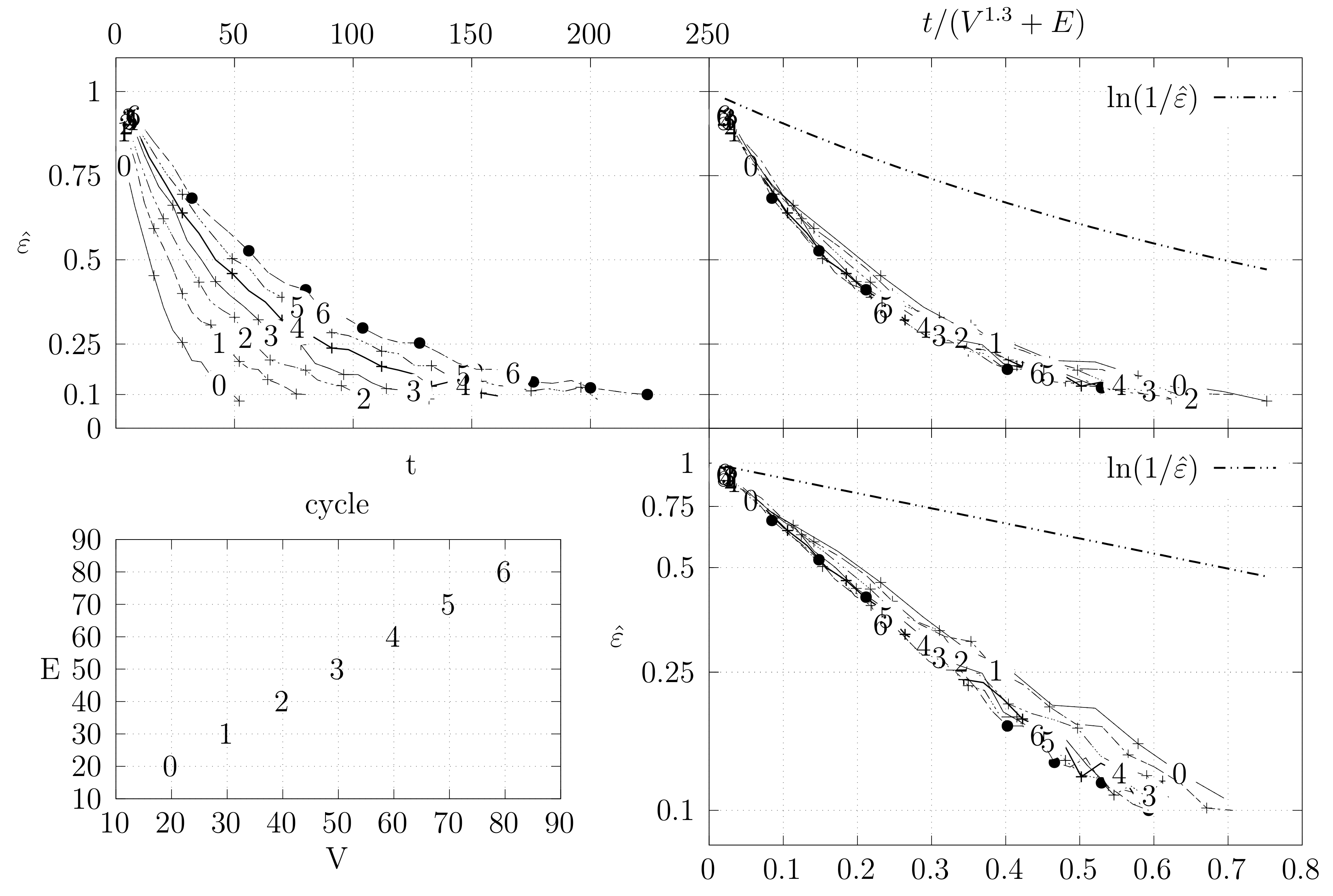
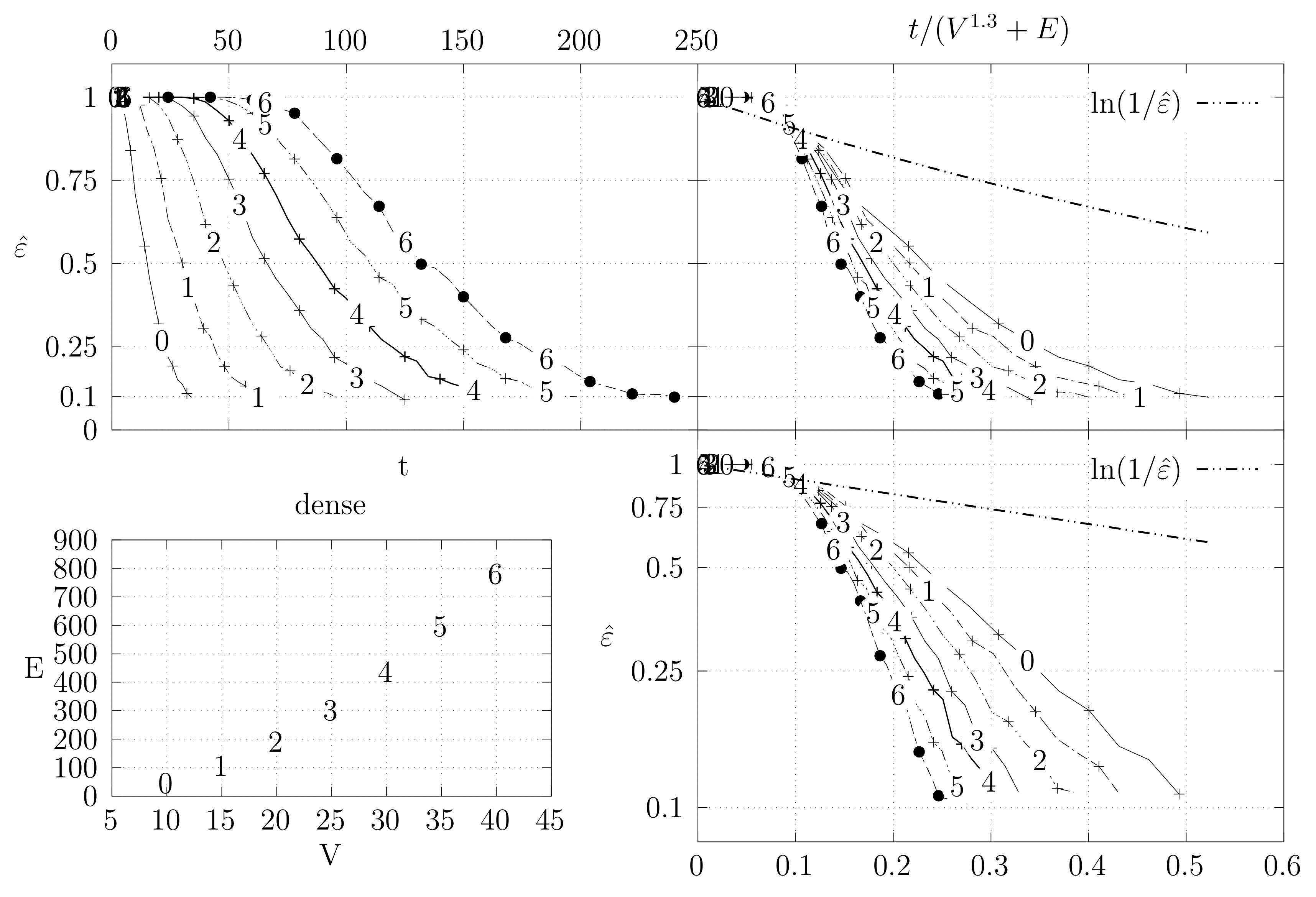
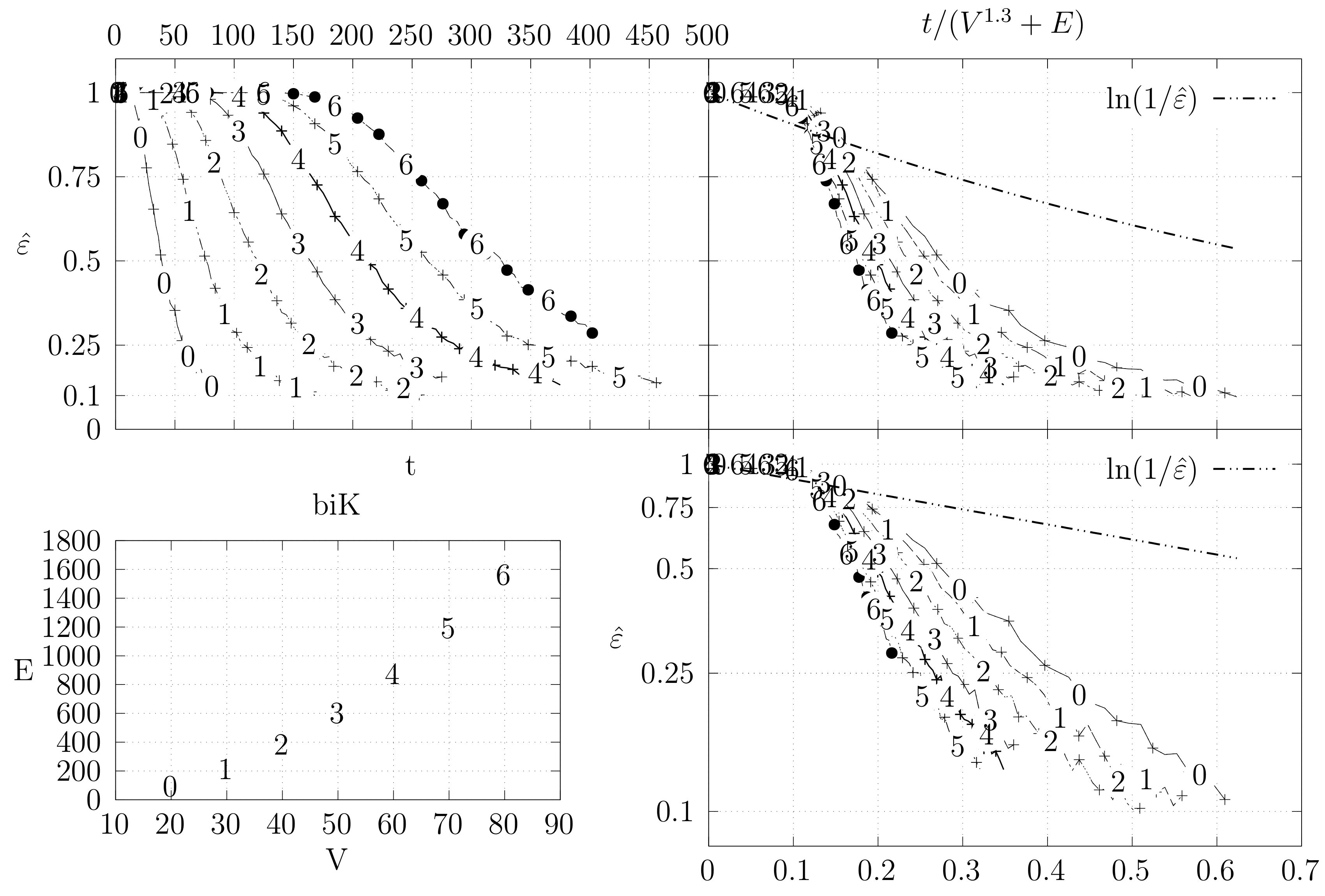
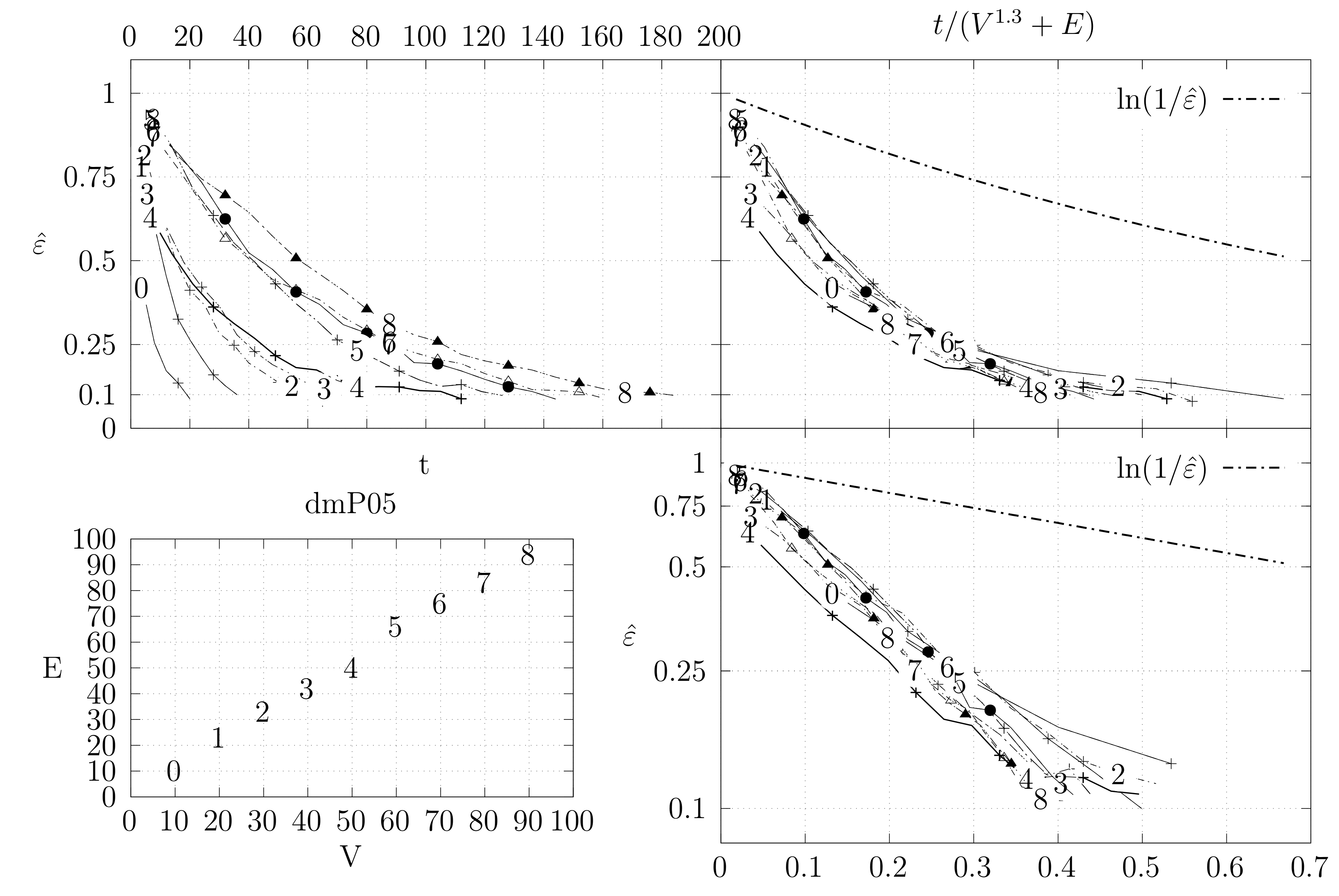
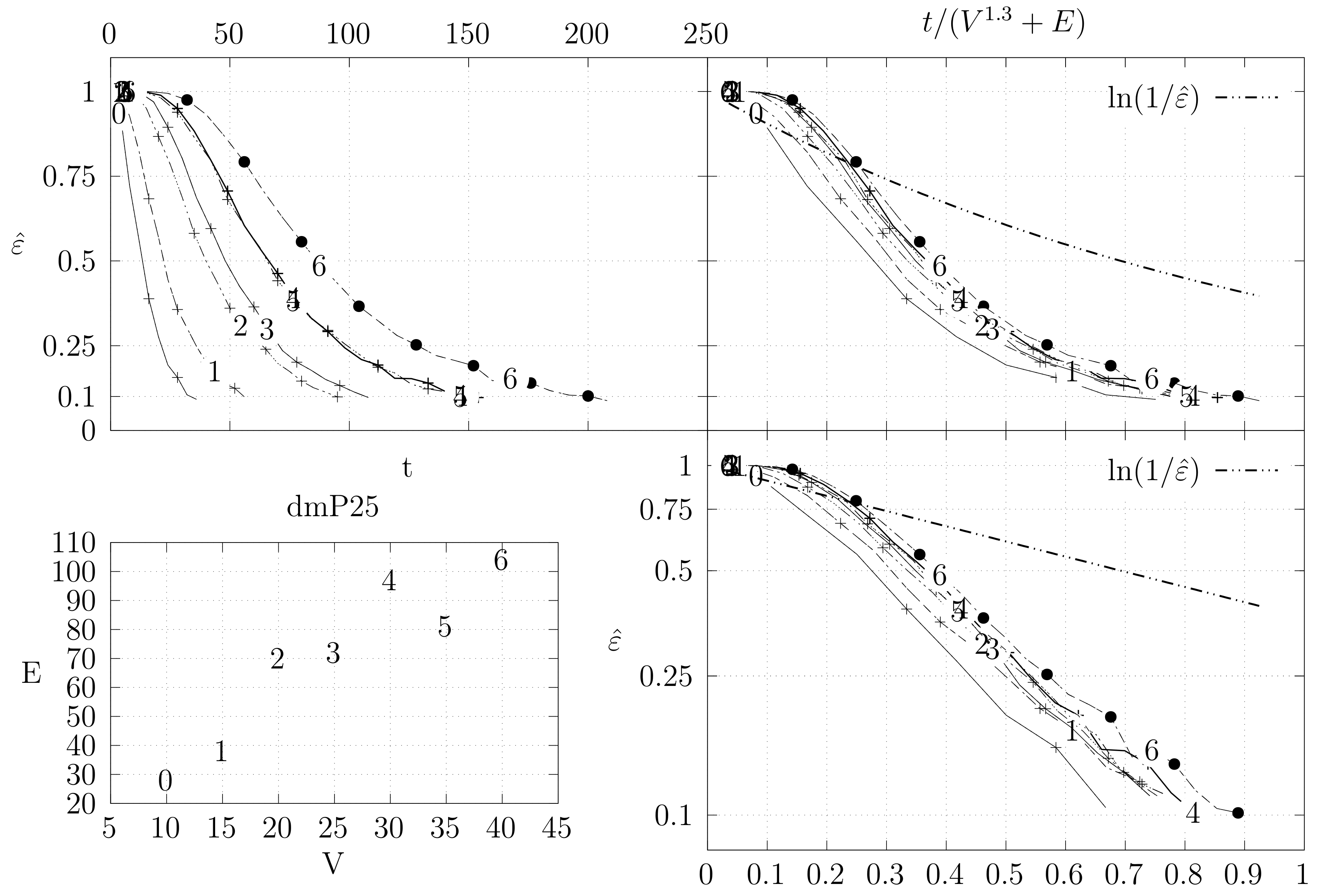
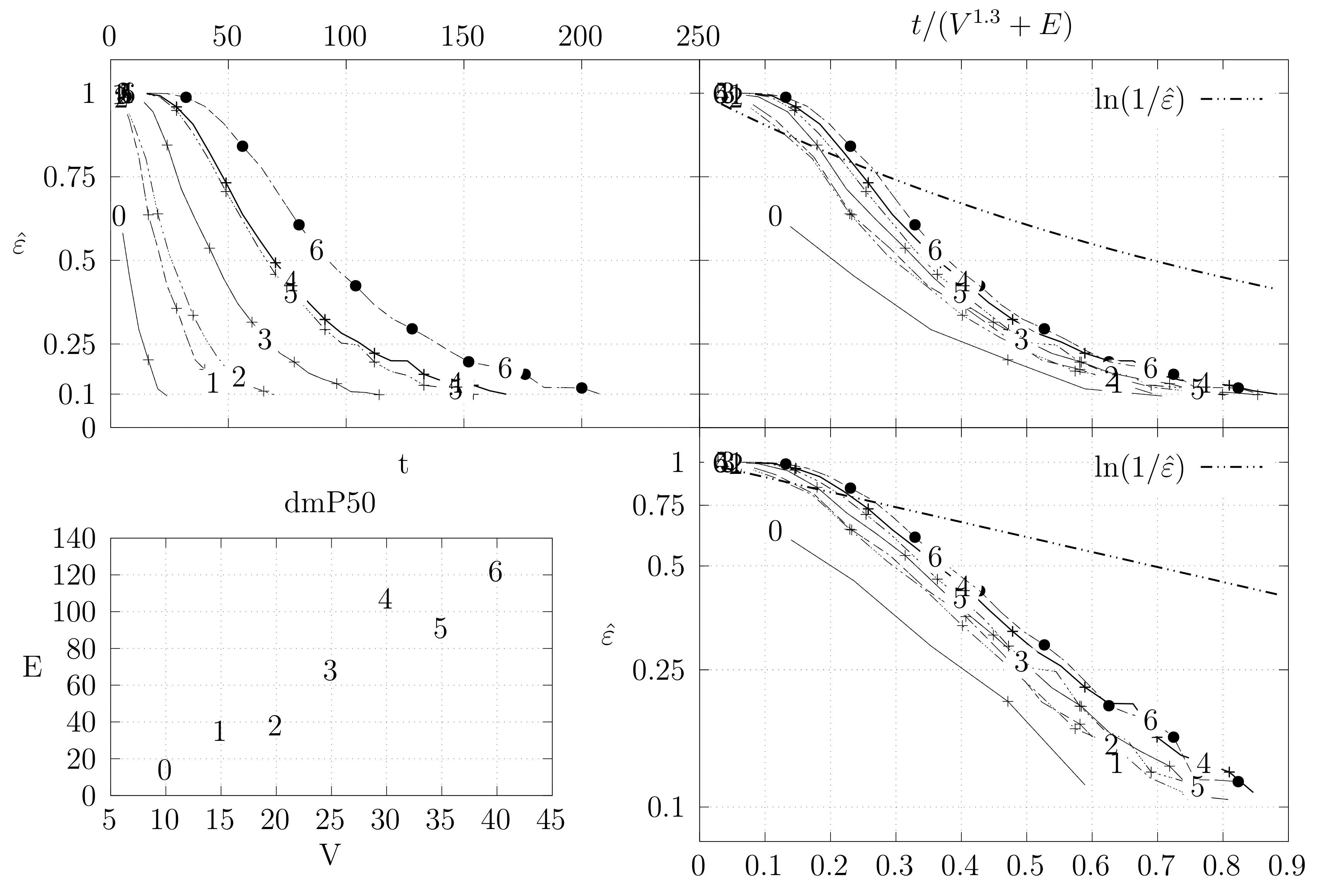
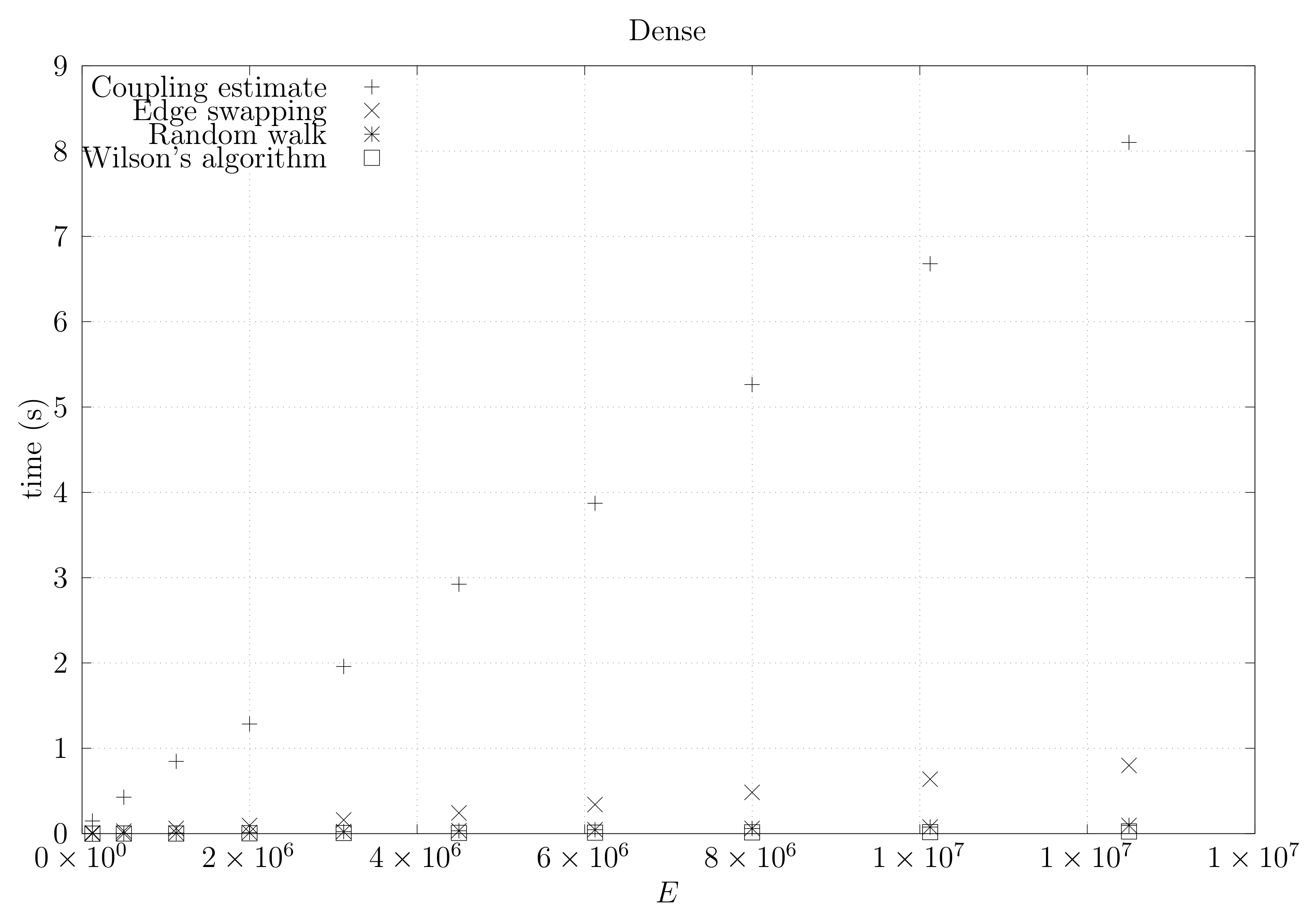
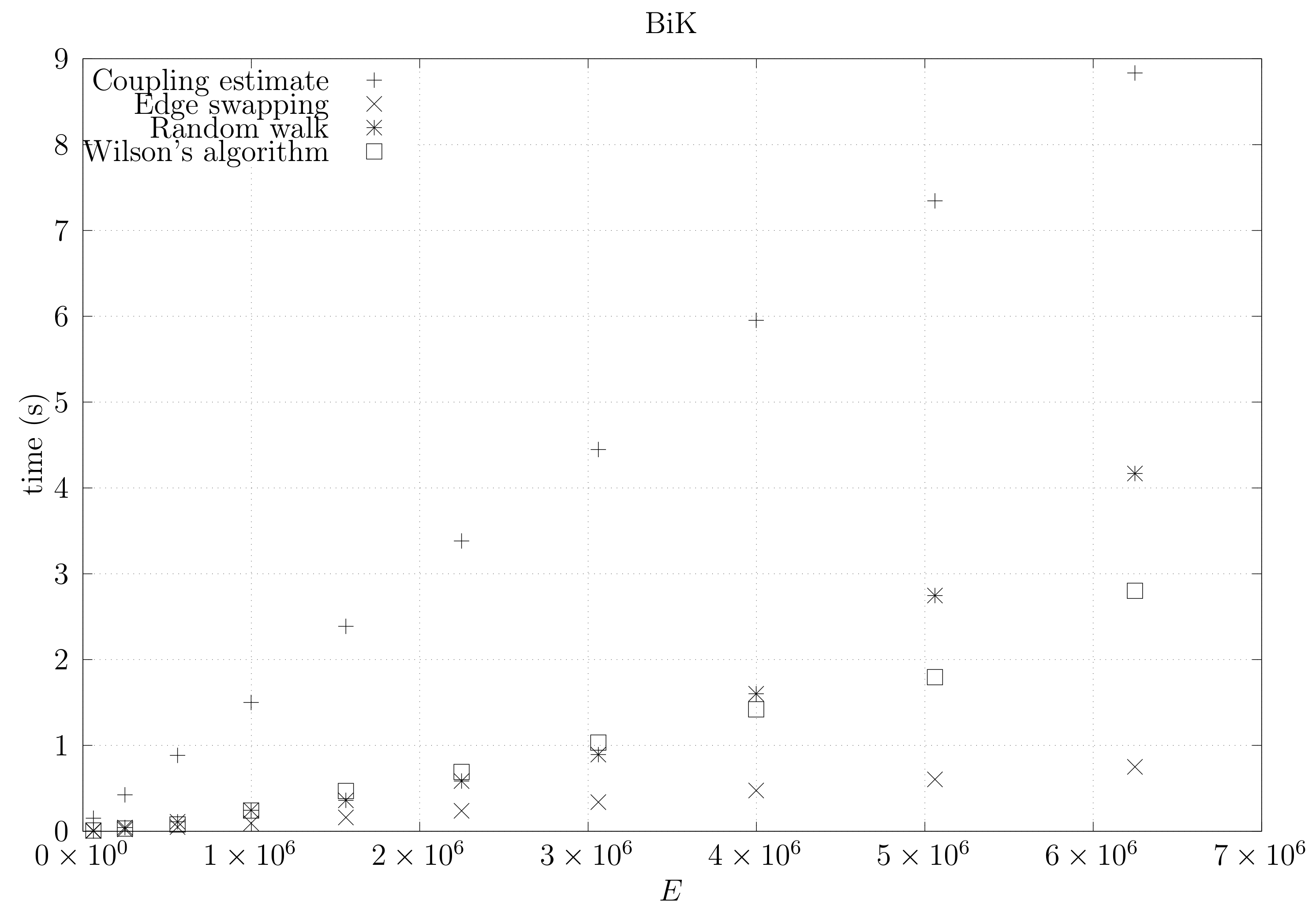
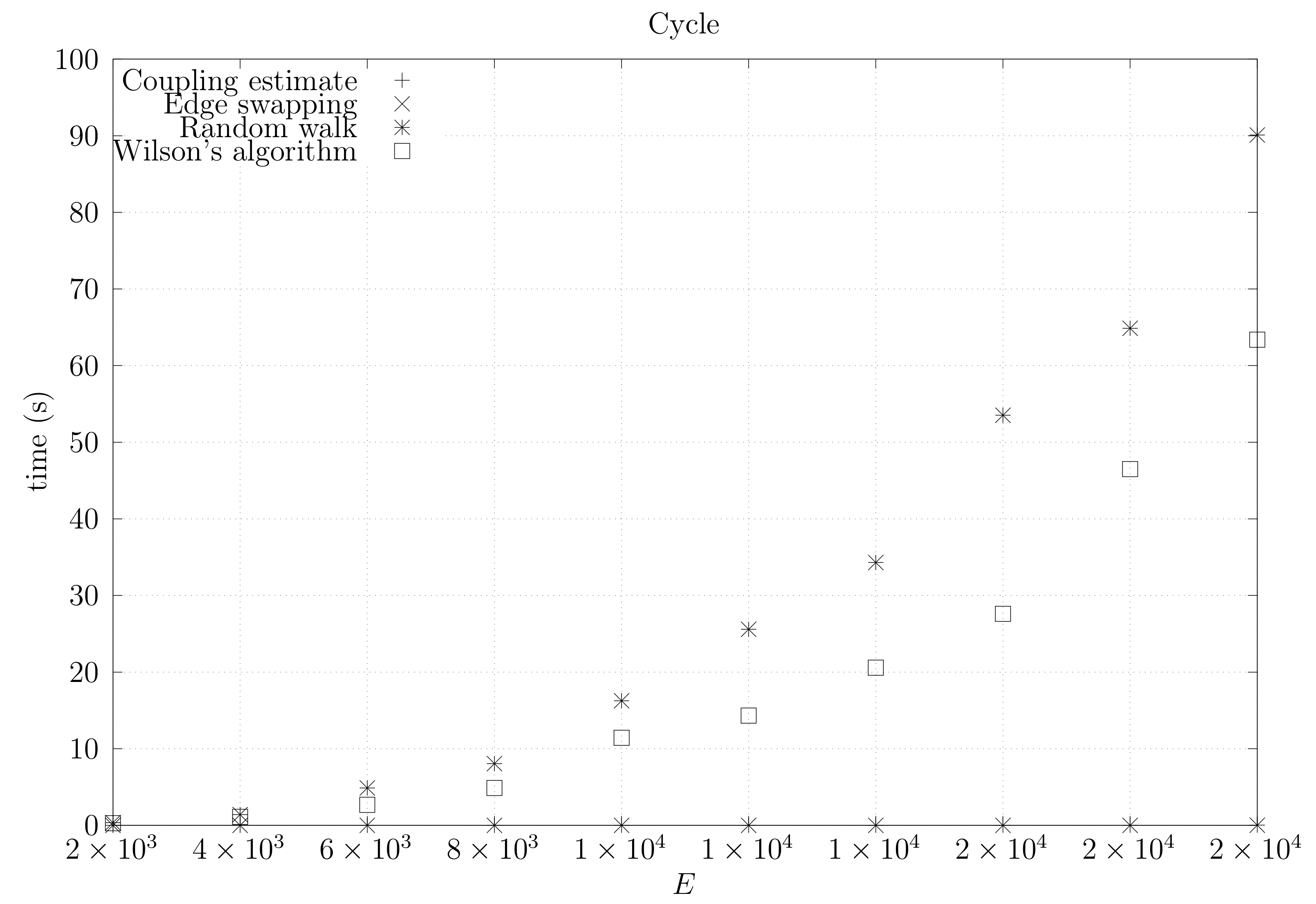
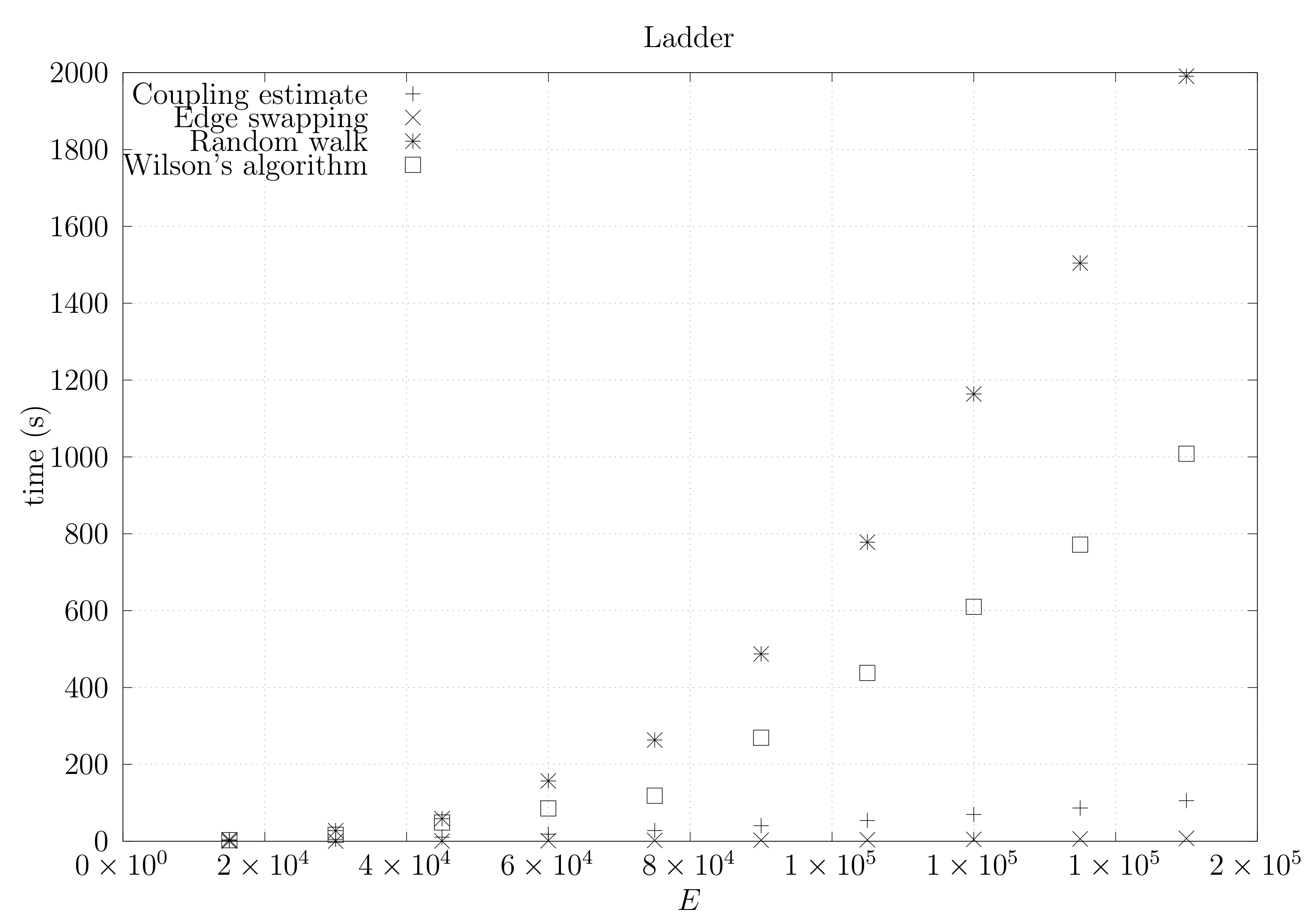
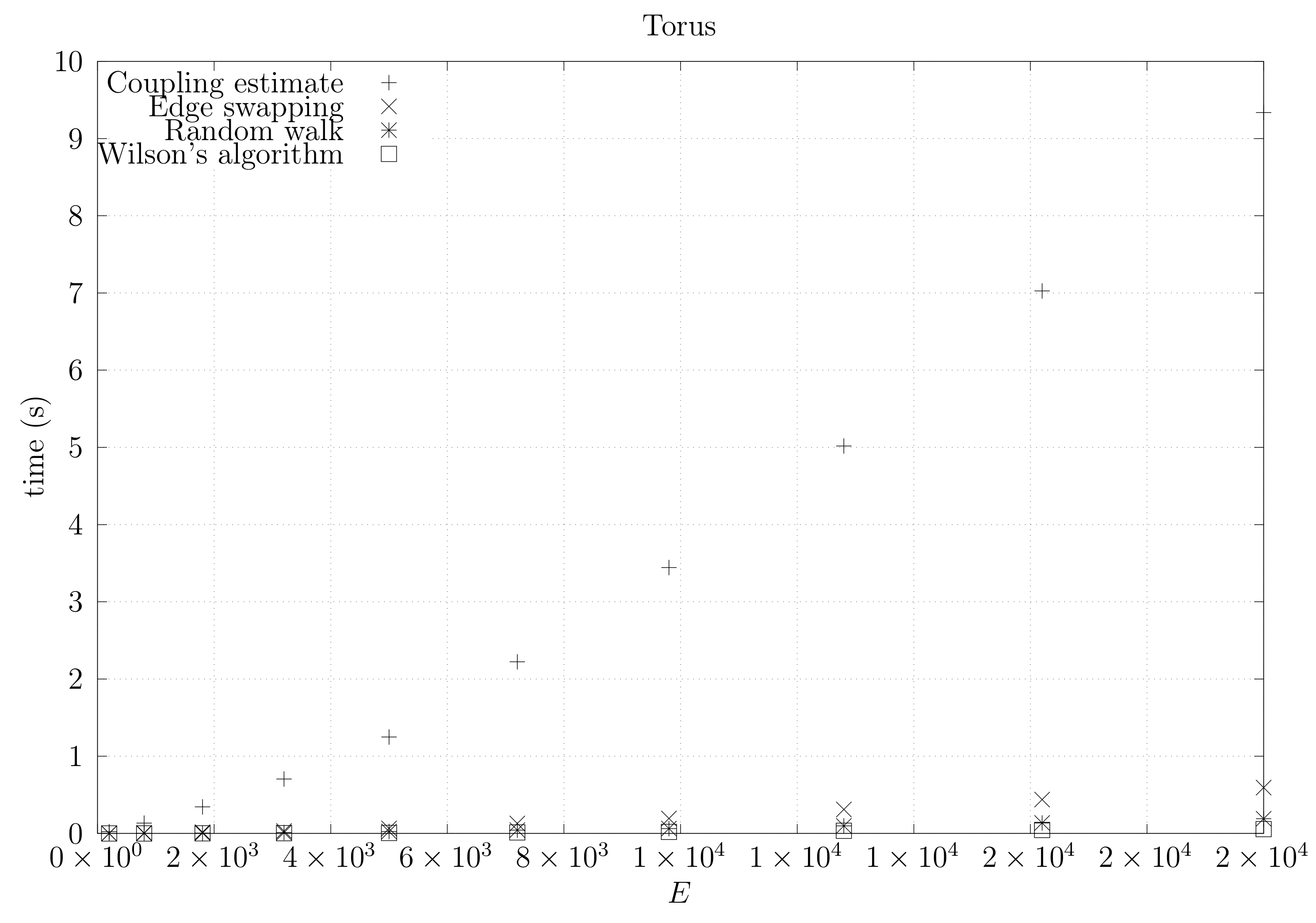
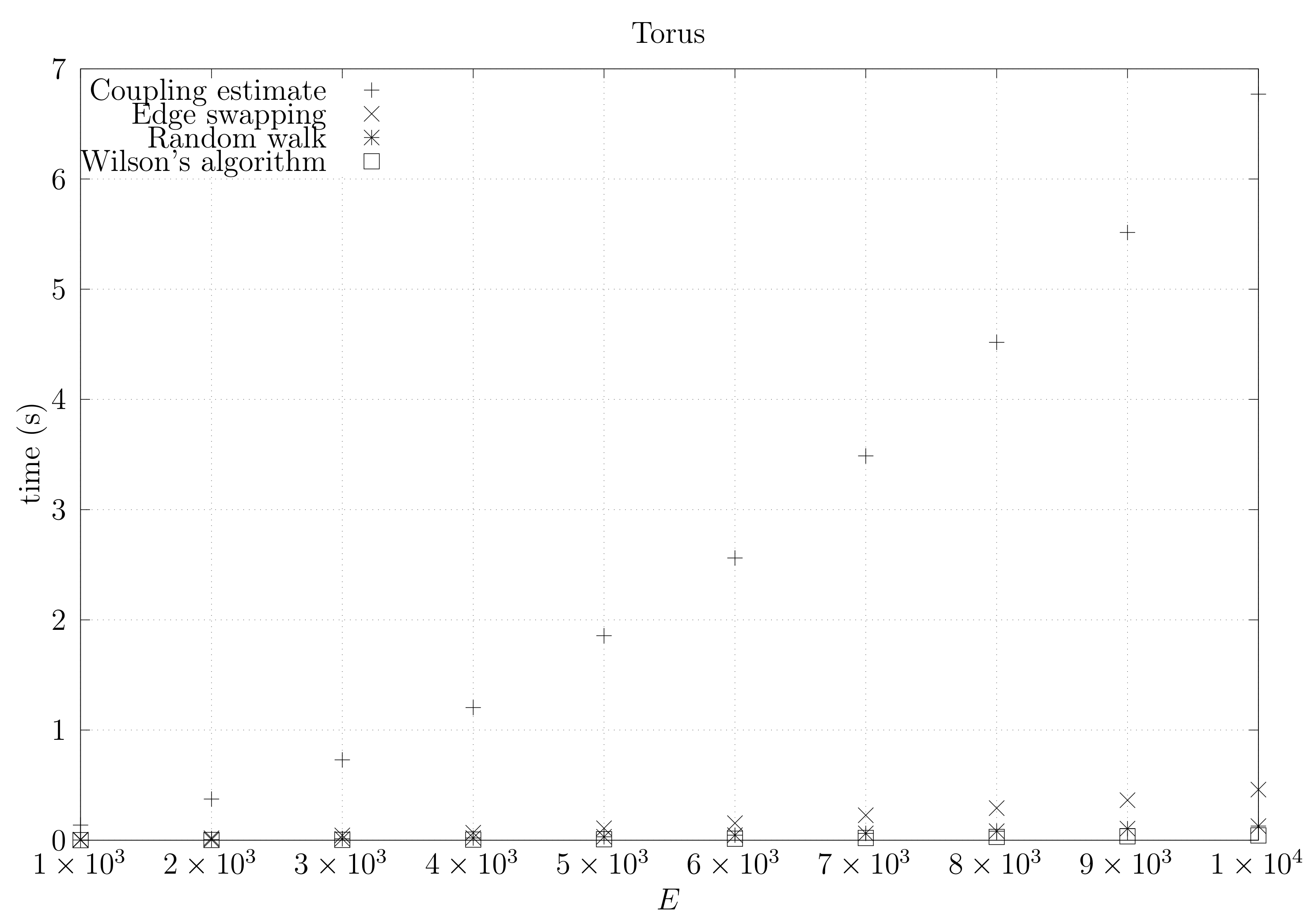
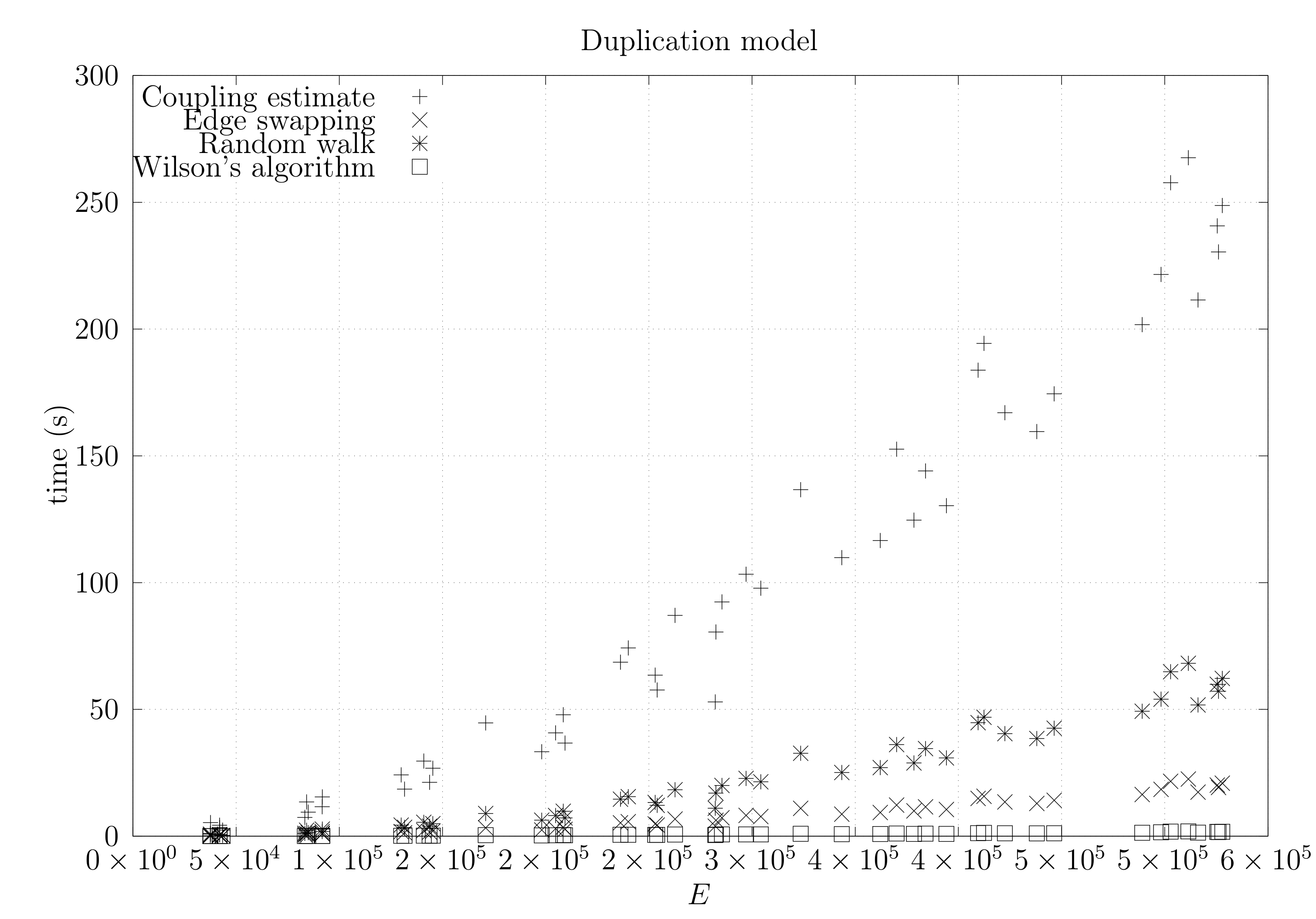
4.3. Experimental Results
4.3.1. Convergence Testing
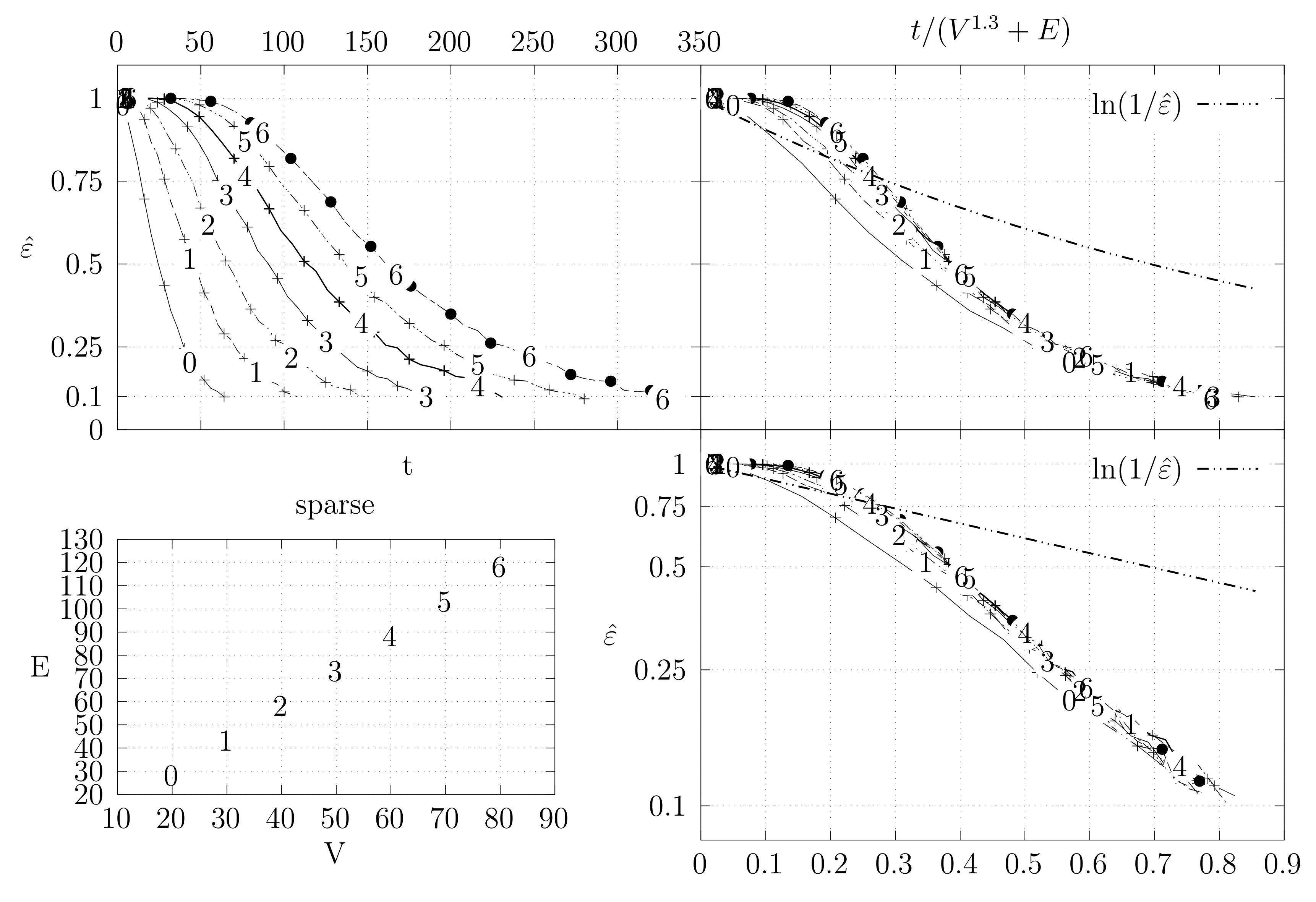
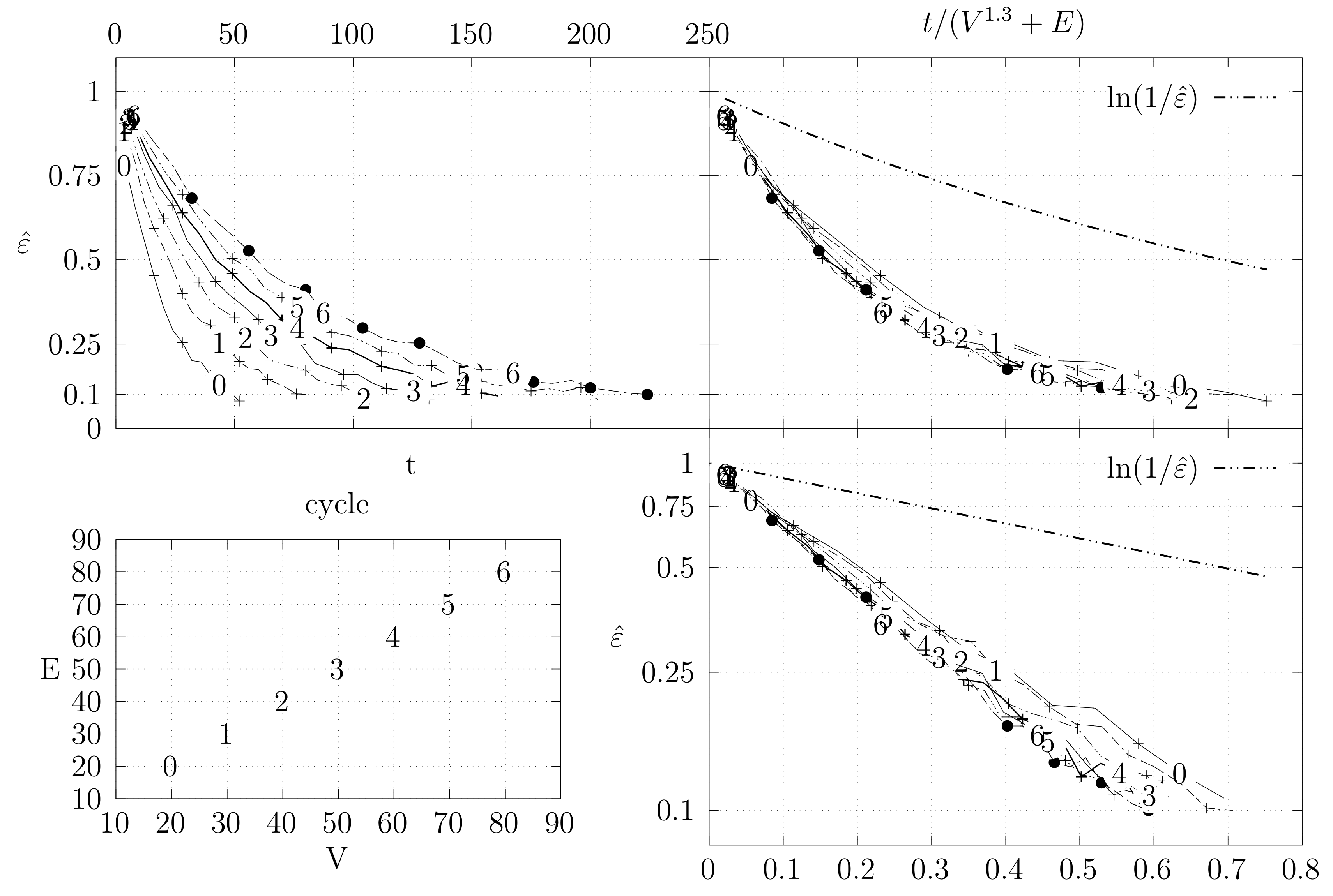
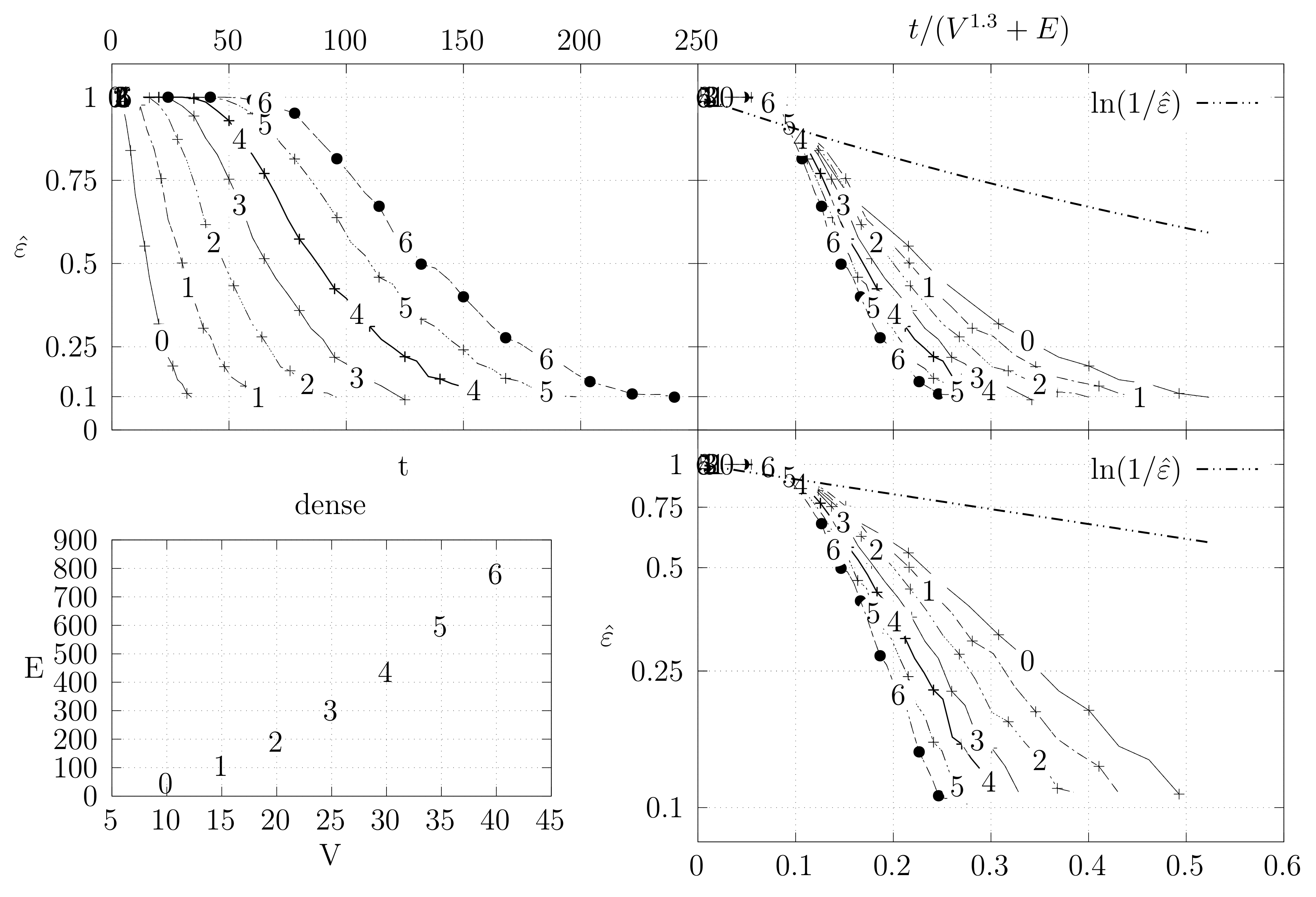
- The bottom left plot shows the graph properties, the number of vertices V in the x axis and the number edges E on the y axis. For the dense case graph 0 has 10 vertices and 45 edges. Moreover, graph 6 has 40 vertices and 780 edges. These graph indexes are used in the remaining plots.
- The top left plot shows the number of iterations t of the chain in the x axis and the estimated variation distance on the y axis, for all the different graphs.
- The top right plot is similar to the top left, but the x axis contains the number of iterations divided by . Besides the data this plot also shows a plot of for reference.
- The bottom right plot is the same as the top right plot, using a logarithmic scale on the y axis.
- Uniformly select a random vertex u of G.
- Add a new vertex v and an edge .
- For each neighbor w of u, add an edge with probability p.
4.3.2. Coupling Simulation
5. Related Work
6. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Aigner, M.; Ziegler, G.M.; Quarteroni, A. Proofs from the Book; Springer: Berlin/Heidelberg, Germany, 2010; Volume 274. [Google Scholar]
- Borchardt, C.W. Über Eine Interpolationsformel für Eine Art Symmetrischer Functionen und über Deren Anwendung; Math. Abh. der Akademie der Wissenschaften zu Berlin: Berlin, Germany, 1860; pp. 1–20. [Google Scholar]
- Cayley, A. A theorem on trees. Q. J. Math. 1889, 23, 376–378. [Google Scholar]
- Galler, B.A.; Fisher, M.J. An improved equivalence algorithm. Commun. ACM 1964, 7, 301–303. [Google Scholar] [CrossRef]
- Sleator, D.D.; Tarjan, R.E. Self-adjusting binary search trees. J. ACM 1985, 32, 652–686. [Google Scholar] [CrossRef]
- Mitzenmacher, M.; Upfal, E. Probability and Computing: Randomized Algorithms and Probabilistic Analysis; Cambridge University Press: New York, NY, USA, 2005. [Google Scholar]
- Levin, D.A.; Peres, Y. Markov Chains and Mixing Times; American Mathematical Society: Providence, RI, USA, 2017; Volume 107. [Google Scholar]
- Sinclair, A. Improved bounds for mixing rates of Markov chains and multicommodity flow. Comb. Probab. Comput. 1992, 1, 351–370. [Google Scholar] [CrossRef]
- Bubley, R.; Dyer, M. Path coupling: A technique for proving rapid mixing in Markov chains. In Proceedings of the 38th Annual Symposium on Foundations of Computer Science, Miami Beach, FL, USA, 20–22 October 1997; pp. 223–231. [Google Scholar]
- Kumar, V.S.A.; Ramesh, H. Markovian coupling vs. conductance for the Jerrum-Sinclair chain. In Proceedings of the 40th Annual Symposium on Foundations of Computer Science, New York, NY, USA, 17–19 October 1999; pp. 241–251. [Google Scholar]
- Jerrum, M.; Sinclair, A. Approximating the permanent. SIAM J. Comput. 1989, 18, 1149–1178. [Google Scholar] [CrossRef]
- Chung, F.R.K.; Lu, L.; Dewey, T.G.; Galas, D.J. Duplication models for biological networks. J. Comput. Biol. 2003, 10, 677–687. [Google Scholar] [CrossRef]
- Chung, F.R.; Lu, L. Complex Graphs and Networks; American Mathematical Society: Providence, RI, USA, 2006; No. 107. [Google Scholar]
- Lyons, R.; Peres, Y. Probability on Trees and Networks; Cambridge University Press: Cambridge, UK, 2016; Volume 42. [Google Scholar]
- Aldous, D.J. The random walk construction of uniform spanning trees and uniform labelled trees. SIAM J. Discret. Math. 1990, 3, 450–465. [Google Scholar] [CrossRef]
- Broader, A. Generating random spanning trees. In Proceedings of the IEEE Symposium on Fondations of Computer Science, Research Triangle Park, NC, USA, 30 October–1 November 1989; pp. 442–447. [Google Scholar]
- Aldous, D. A random tree model associated with random graphs. Random Struct. Algorithms 1990, 1, 383–402. [Google Scholar] [CrossRef]
- Wilson, D.B. Generating random spanning trees more quickly than the cover time. In Proceedings of the Twenty-Eighth Annual ACM Symposium on Theory of Computing (STOC ’96), Philadelphia, PA, USA, 22–24 May 1996; ACM: New York, NY, USA, 1996; pp. 296–303. [Google Scholar]
- Kirchhoff, G. Ueber die auflösung der gleichungen, auf welche man bei der untersuchung der linearen vertheilung galvanischer ströme geführt wird. Ann. Phys. 1847, 148, 497–508. [Google Scholar] [CrossRef]
- Guénoche, A. Random spanning tree. J. Algorithms 1983, 4, 214–220. [Google Scholar] [CrossRef]
- Kulkarni, V. Generating random combinatorial objects. J. Algorithms 1990, 11, 185–207. [Google Scholar] [CrossRef]
- Colbourn, C.J.; Day, R.P.J.; Nel, L.D. Unranking and ranking spanning trees of a graph. J. Algorithms 1989, 10, 271–286. [Google Scholar] [CrossRef]
- Colbourn, C.J.; Myrvold, W.J.; Neufeld, E. Two algorithms for unranking arborescences. J. Algorithms 1996, 20, 268–281. [Google Scholar] [CrossRef]
- Kelner, J.A.; Mądry, A. Faster generation of random spanning trees. In Proceedings of the 2009 50th Annual IEEE Symposium on Foundations of Computer Science, Atlanta, GA, USA, 24–27 October 2009; pp. 13–21. [Google Scholar]
- Mądry, A. From Graphs to Matrices, and Back: New Techniques For Graph Algorithms. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2011. [Google Scholar]
- Mądry, A.; Straszak, D.; Tarnawski, J. Fast generation of random spanning trees and the effective resistance metric. In Proceedings of the Twenty-Sixth Annual ACM-SIAM Symposium on Discrete Algorithms (SODA 2015), San Diego, CA, USA, 4–6 January 2015; Indyk, P., Ed.; pp. 2019–2036. [Google Scholar]
- Feder, T.; Mihail, M. Balanced matroids. In Proceedings of the Twenty-Fourth Annual ACM Symposium on Theory of Computing, Victoria, BC, Canada, 4–6 May 1992; ACM: New York, NY, USA, 1992; pp. 26–38. [Google Scholar]
- Jerrum, M.; Son, J.-B.; Tetali, P.; Vigoda, E. Elementary bounds on poincaré and log-sobolev constants for decomposable markov chains. Ann. Appl. Probab. 2004, 14, 1741–1765. [Google Scholar] [CrossRef]
- Mihail, M. Conductance and convergence of markov chains-a combinatorial treatment of expanders. In Proceedings of the 30th Annual Symposium on Foundations of Computer Science, Research Triangle Park, NC, USA, 30 October–1 November 1989; pp. 526–531. [Google Scholar]
- Jerrum, M.; Son, J.-B. Spectral gap and log-sobolev constant for balanced matroids. In Proceedings of the 43rd Annual IEEE Symposium on Foundations of Computer Science, Vancouver, BC, Canada, 19 November 2002; pp. 721–729. [Google Scholar]
- Sleator, D.D.; Tarjan, R.E. A data structure for dynamic trees. In Proceedings of the Thirteenth Annual ACM Symposium on Theory of Computing (STOC ’81), Milwaukee, WI, USA, 11–13 May 1981; ACM: New York, NY, USA, 1981; pp. 114–122. [Google Scholar]
- Goldberg, A.V.; Tarjan, R.E. Finding minimum-cost circulations by canceling negative cycles. J. ACM 1989, 36, 873–886. [Google Scholar] [CrossRef]
- Henzinger, M.R.; King, V. Randomized dynamic graph algorithms with polylogarithmic time per operation. In Proceedings of the Twenty-Seventh Annual ACM Symposium on Theory of Computing, Las Vegas, NV, USA, 29 May–1 June 1995; ACM: New York, NY, USA, 1995; pp. 519–527. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Graph | Median VD | Max VD | |
|---|---|---|---|
| dense | 0.060 | 0.194 | |
| biK | 0.065 | 0.190 | |
| cycle | 0.001 | 0.004 | |
| sparse | 0.053 | 0.110 | |
| torus | 0.094 | 0.383 | |
| dmP | 0.069 | 0.270 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Russo, L.M.S.; Teixeira, A.S.; Francisco, A.P. Linking and Cutting Spanning Trees. Algorithms 2018, 11, 53. https://doi.org/10.3390/a11040053
Russo LMS, Teixeira AS, Francisco AP. Linking and Cutting Spanning Trees. Algorithms. 2018; 11(4):53. https://doi.org/10.3390/a11040053
Chicago/Turabian StyleRusso, Luís M. S., Andreia Sofia Teixeira, and Alexandre P. Francisco. 2018. "Linking and Cutting Spanning Trees" Algorithms 11, no. 4: 53. https://doi.org/10.3390/a11040053
APA StyleRusso, L. M. S., Teixeira, A. S., & Francisco, A. P. (2018). Linking and Cutting Spanning Trees. Algorithms, 11(4), 53. https://doi.org/10.3390/a11040053