Short-Run Contexts and Imperfect Testing for Continuous Sampling Plans

Abstract
:1. Introduction
2. Background
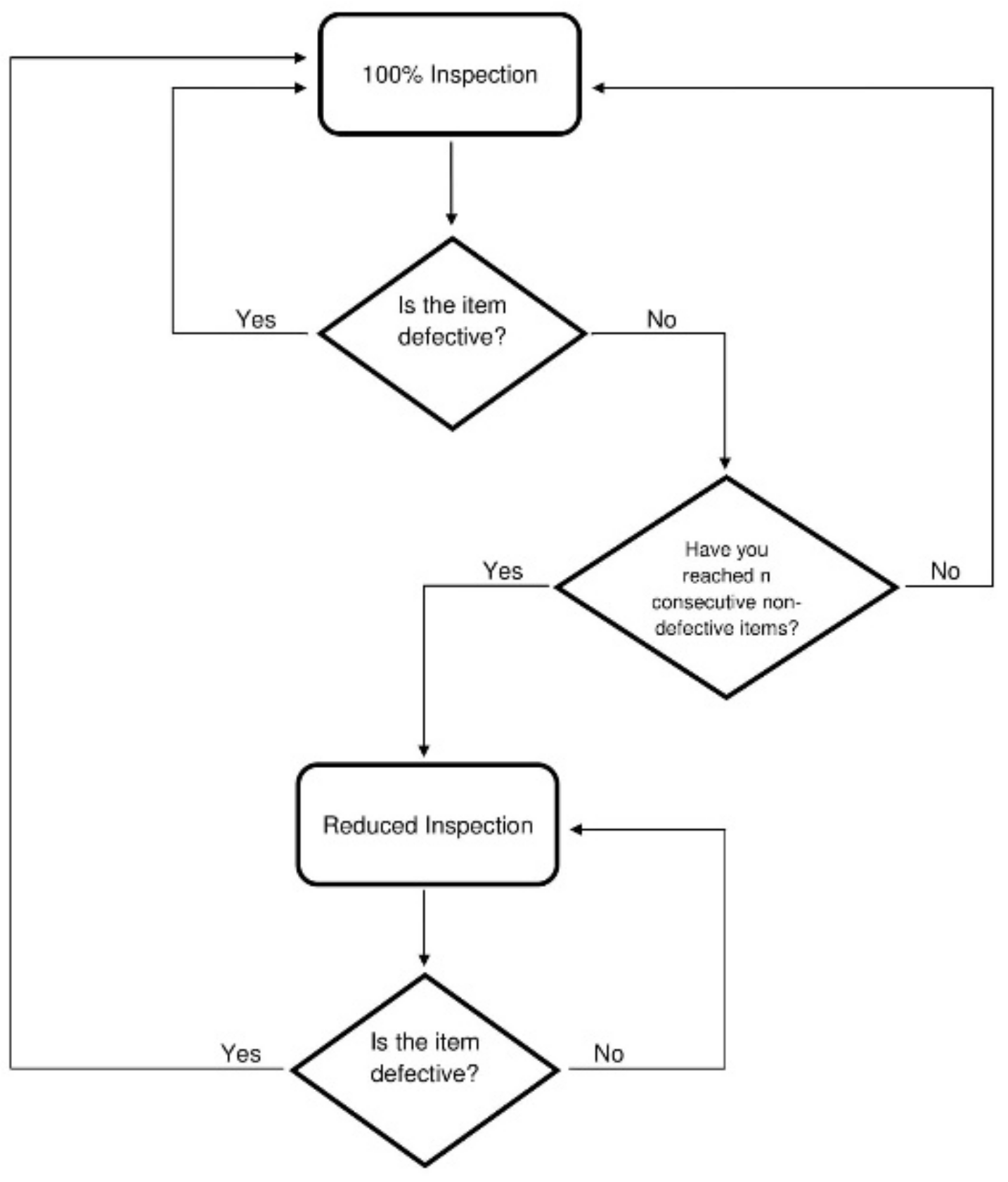
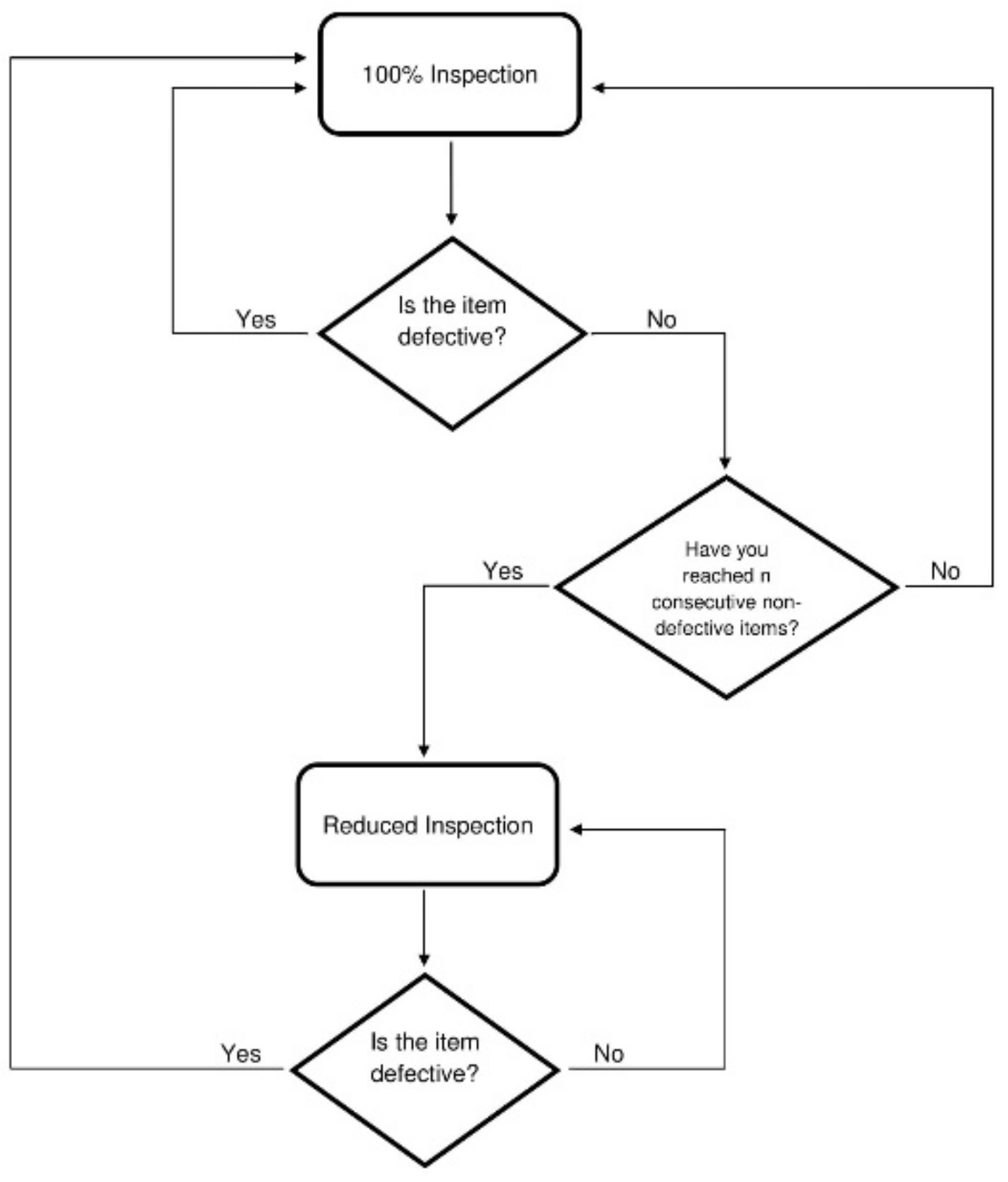
2.1. Continuous Sampling Plans
2.2. Operating Procedures for CSP-1
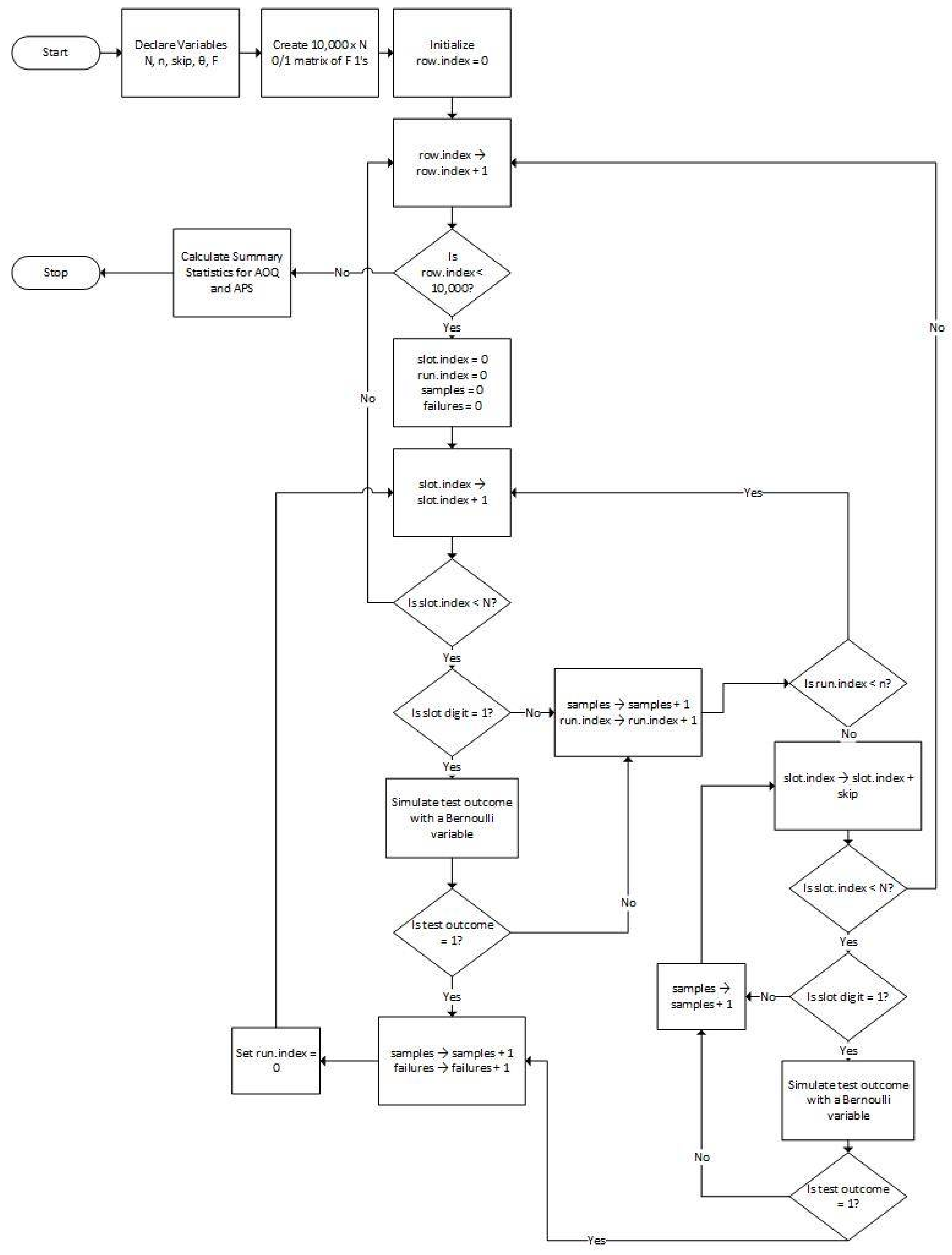
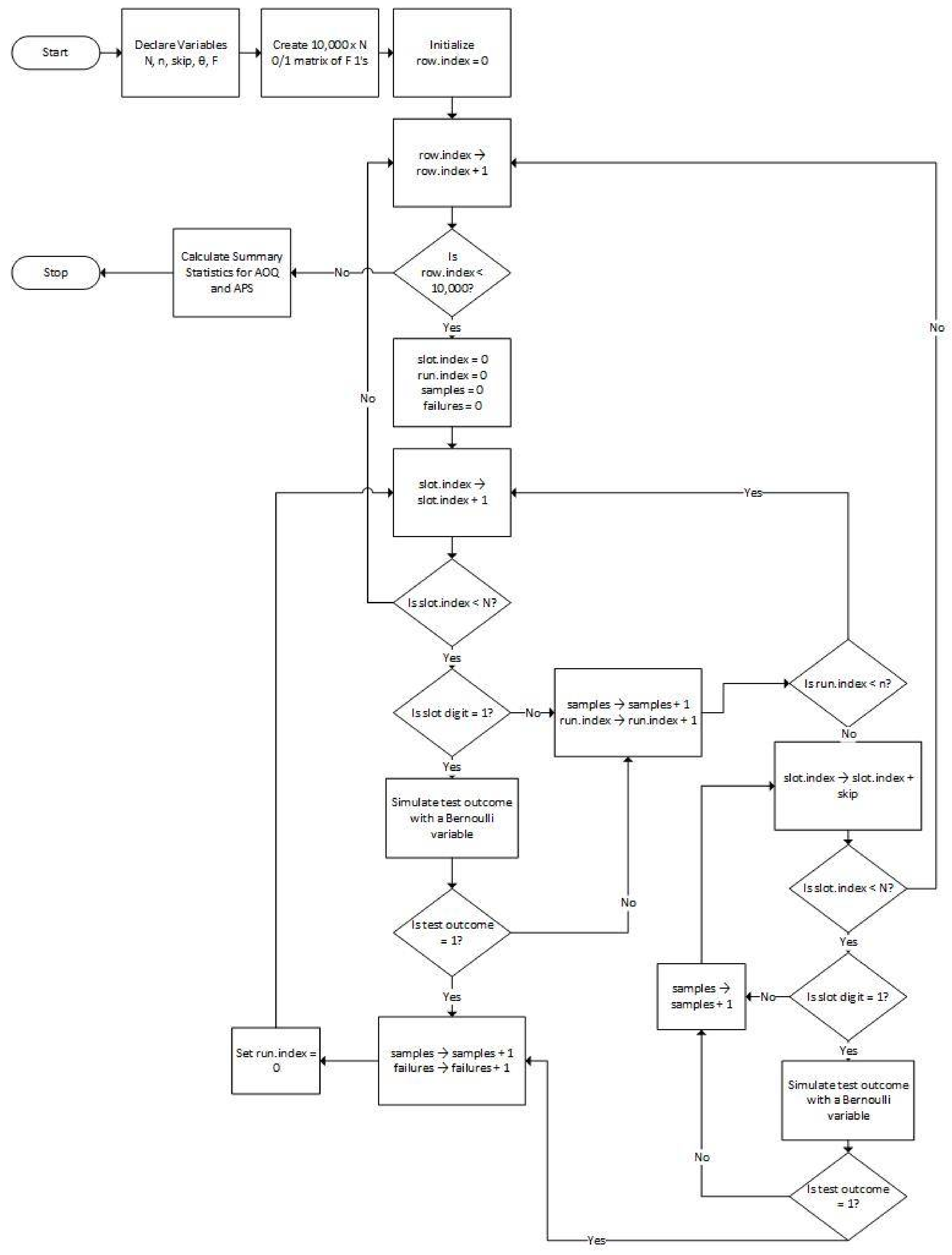
3. Simulation Algorithm
3.1. Inputs
3.2. Outputs
3.3. Algorithm Design
4. Navy Applications
4.1. Background
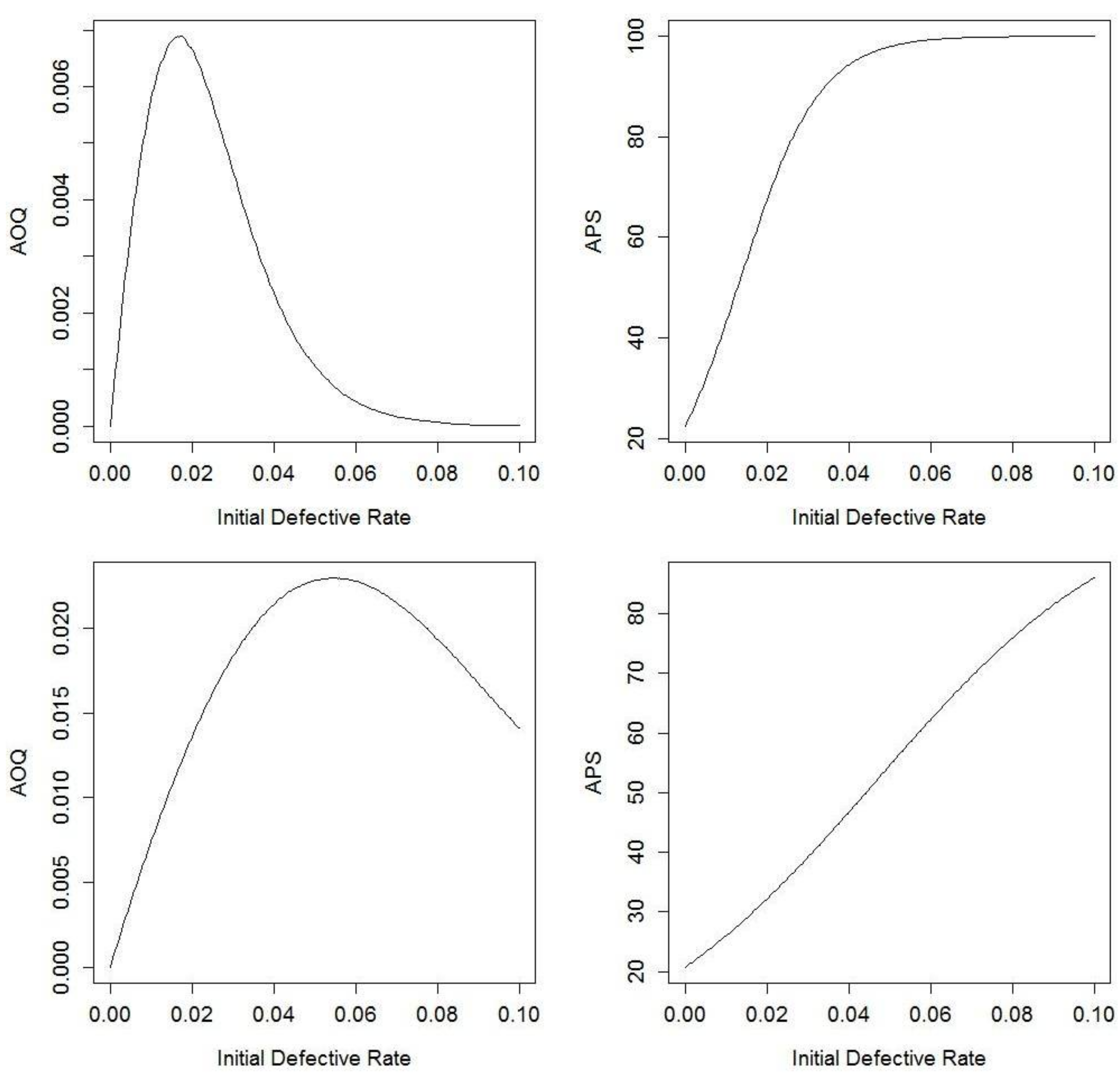
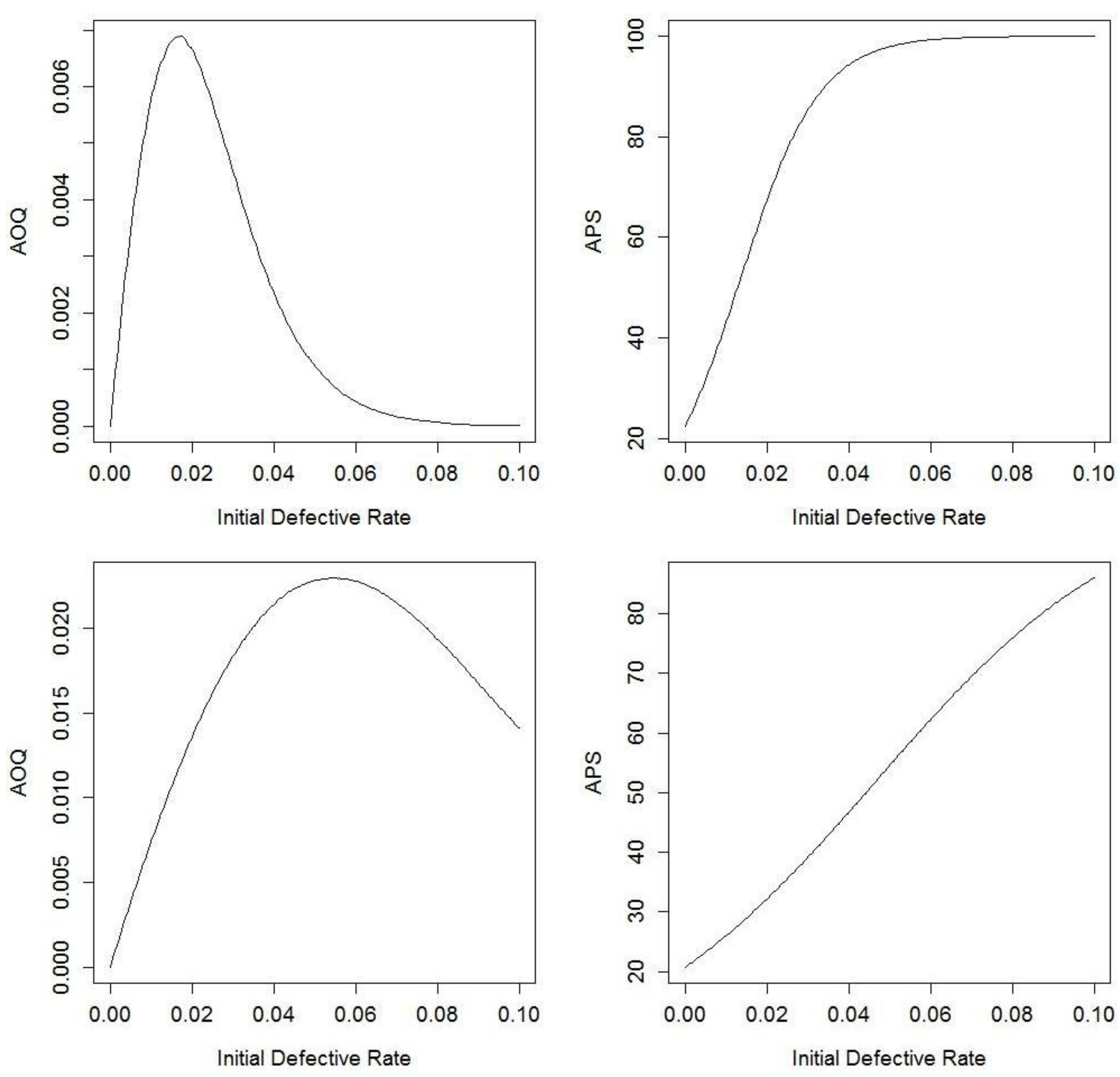
4.2. Perfect Testing
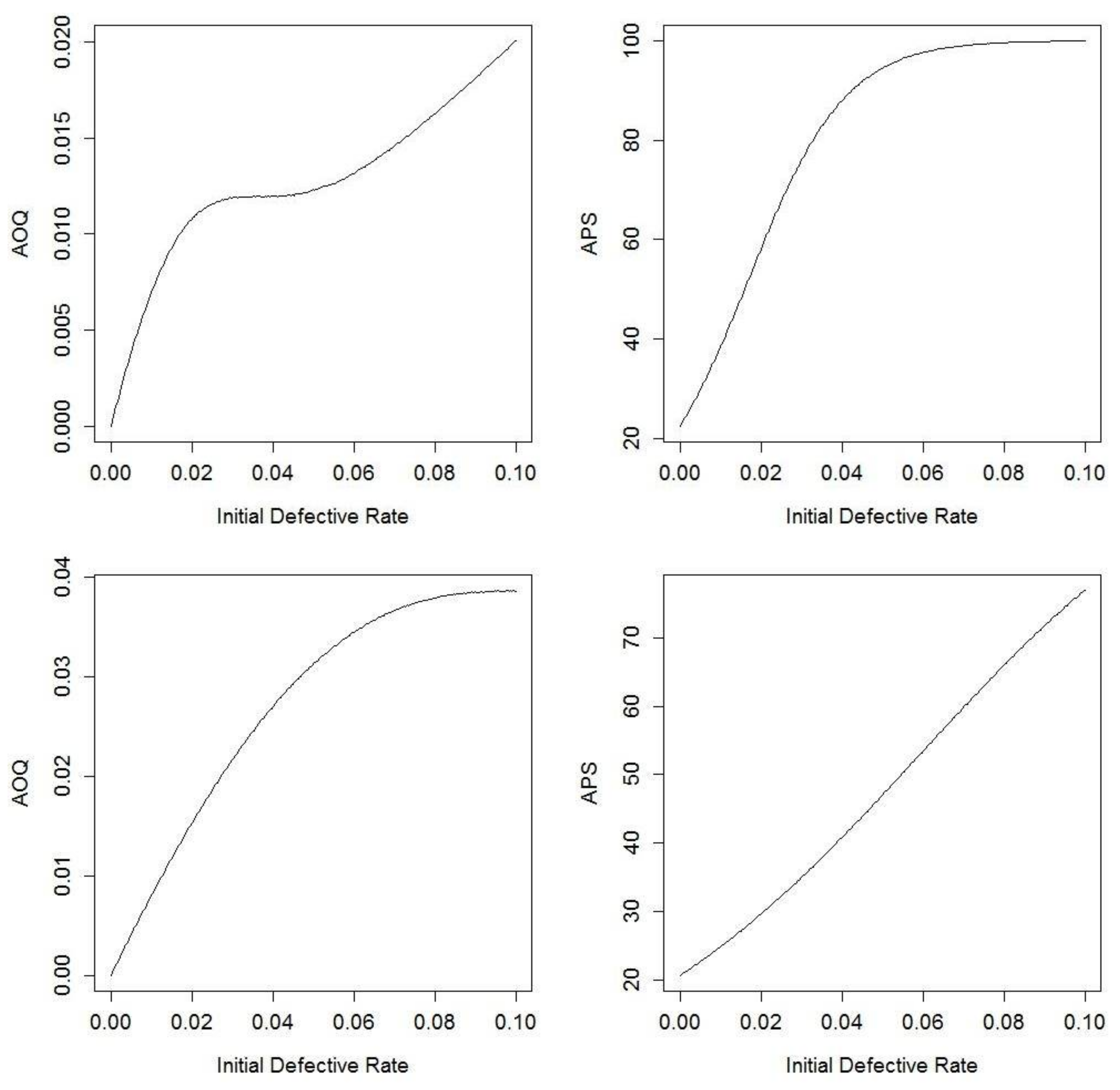
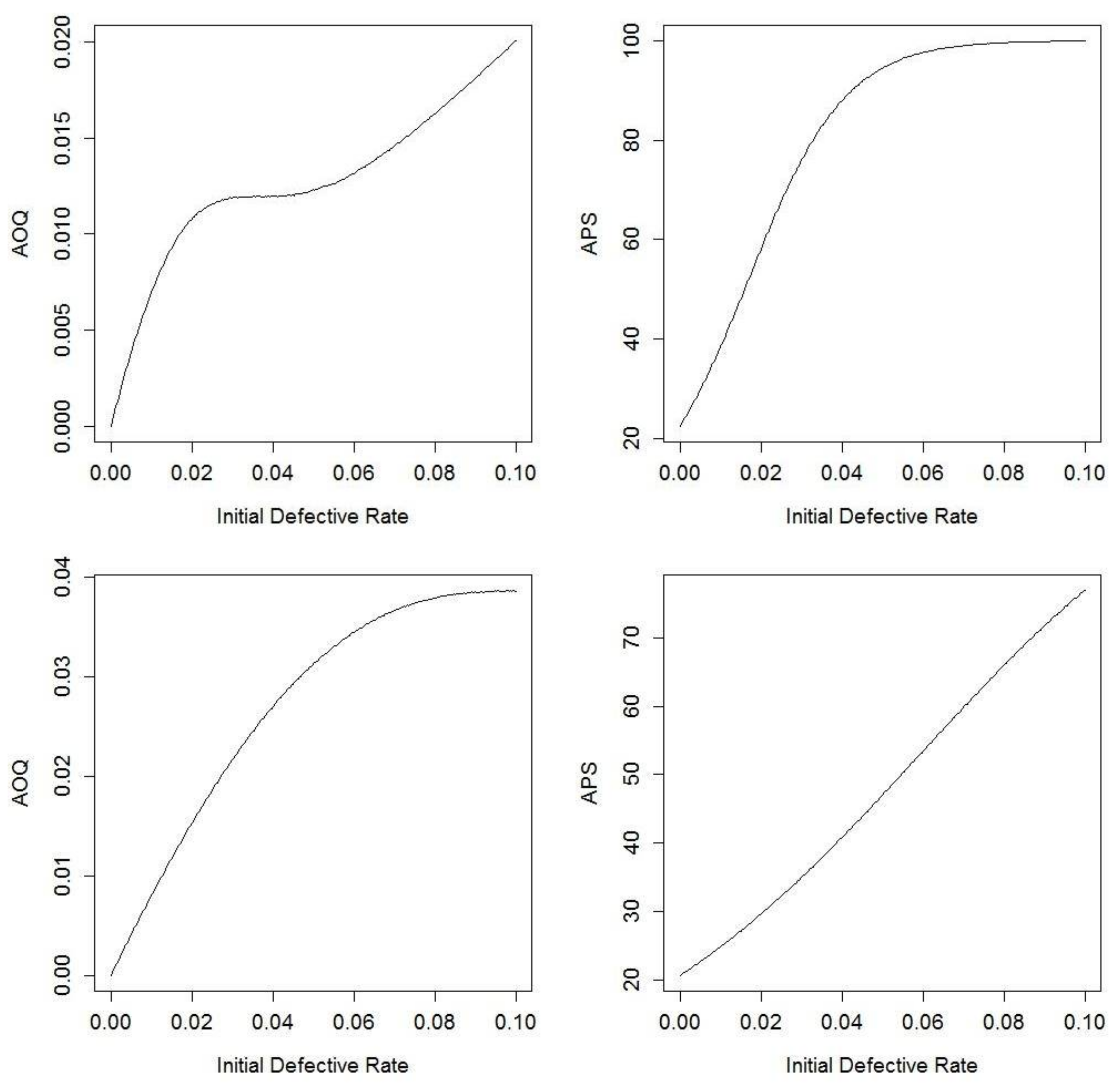
4.3. Imperfect Testing
5. Analytical Comparisons
5.1. Calibration
5.2. Illustrations
6. Summary
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. User Manual
Description
Usage
Arguments
| N | Total number of items |
| n | Failures among the N items |
| skip | Items to skip over in reduced inspection |
| θ | Test Effectiveness Parameter |
| F | Failures among N items |
Details
Example
Appendix B. R Code for the Implementation of the Simulation Algorithm
References
- Dodge, H.F. A Sampling Inspection Plan for Continuous Production. Ann. Math. Stat. 1943, 14, 264–279. [Google Scholar] [CrossRef]
- Case, K.E.; Bennett, G.K.; Schmidt, J.W. The Dodge CSP-1 Continuous Sampling Plan under Inspection Error. AIIE Trans. 1973, 5, 193–202. [Google Scholar] [CrossRef]
- Blackwell, M.T.R. The Effect of Short Production Runs on CSP-1. Technometrics 1977, 19, 259–262. [Google Scholar] [CrossRef]
- Chen, C.H. Average Outgoing Quality Limit for Short-Run CSP-1 Plan. Tamkang J. Sci. Eng. 2005, 8, 81–85. [Google Scholar]
- Wang, R.C.; Chen, C.H. Minimum Average Fraction Inspected for Short-Run CSP-1 Plan. J. Appl. Stat. 1998, 25, 733–738. [Google Scholar] [CrossRef]
- Yang, G.L. A Renewal-Process Approach to Continuous Sampling Plans. Technometrics 1993, 25, 59–67. [Google Scholar] [CrossRef]
- Liu, M.C.; Aldag, L. Computerized Continuous Sampling Plans with Finite Production. Comput. Ind. Eng. 1993, 25, 4345–4448. [Google Scholar] [CrossRef]
- Dodge, H.F.; Torrey, M.N. Additional Continuous Sampling Inspection Plans. Ind. Qual. Control 1951, 7, 7–12. [Google Scholar] [CrossRef]
- Suresh, K.K.; Nirmala, V. Comparison of Certain Types of Continuous Sampling Plans (CSPs) and its Operating Procedures—A Review. Int. J. Sci. Res. 2015, 4, 455–459. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description |
|---|---|
| N | Batch size |
| F | Failures in the batch |
| n | Required run under 100% inspection |
| skip | Items to skip over in reduced inspection |
| θ | Test effectiveness parameter |
| Variable | Description |
|---|---|
| AOQ | Average Outgoing Quality |
| APS | Average Percent Sampled |
| Metric | Simulation | Section 5.1 Approximation | Formulas in References [3,4] |
|---|---|---|---|
| AOQ | 0.66% | 0.69% | 0.65% |
| APS | 67.38% | 65.34% | 67.27% |
| Metric | Simulation | Formulas in Reference [2] |
|---|---|---|
| AOQ | 1.07% | 1.11% |
| APS | 58.15% | 55.6% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodriguez, M.; Jeske, D.R. Short-Run Contexts and Imperfect Testing for Continuous Sampling Plans. Algorithms 2018, 11, 46. https://doi.org/10.3390/a11040046
Rodriguez M, Jeske DR. Short-Run Contexts and Imperfect Testing for Continuous Sampling Plans. Algorithms. 2018; 11(4):46. https://doi.org/10.3390/a11040046
Chicago/Turabian StyleRodriguez, Mirella, and Daniel R. Jeske. 2018. "Short-Run Contexts and Imperfect Testing for Continuous Sampling Plans" Algorithms 11, no. 4: 46. https://doi.org/10.3390/a11040046
APA StyleRodriguez, M., & Jeske, D. R. (2018). Short-Run Contexts and Imperfect Testing for Continuous Sampling Plans. Algorithms, 11(4), 46. https://doi.org/10.3390/a11040046