1. Introduction
Transportation activities have an increasing economic, environmental, and social impact on our society [
1,
2]. Moreover, its contribution to the GDP and the number of people it employs are significant in most countries. On the one hand, optimizing logistics activities is essential for many enterprises to remain competitive. On the other hand, governments aim at improving citizens’ welfare by optimizing urban logistics, e.g., by limiting the maximum velocity they expect to reduce CO
emissions and noise, banning big trucks in the city center for safety reasons, etc. Promoting sustainable transportation activities, by using electric vehicles and making the distribution process more efficient, is becoming an important trend in most logistics and supply chain management projects [
3,
4]. Thus, for instance, some studies analyze best practices and key performance indicators related to sustainability in some supply chains [
5], while others propose methodological frameworks that help manufacturers to increase the sustainability of their industrial activities [
6]. All in all, optimization is a key factor for countries to achieve a smart and sustainable growth [
7].
During the last few years, the research community has been prolifically delivering new formulations and solving methods for the vehicle routing problem (VRP). Thus, review works on rich and real-life VRPs that can be found [
8]. Some of the most popular categories are: asymmetric cost matrix VRP, heterogeneous fleet VRP, multiple depots VRP, periodic delivery VRP, VRP with time windows [
9], VRP under dynamic conditions [
10], and green VRP including the use of electric vehicles in smart cities [
4], among others. However, there are plenty of open research lines in this field since most works tend to use strong assumptions in order to simplify the underlying optimization problem. In particular, a common assumption is that all the problem inputs are known in advance and that they do not change over time.
This paper, however, considers a more realistic scenario in which some of the optimization inputs (the traveling times in our case) are dynamic, and they depend on the structure of the emerging solution, i.e., they are influenced by the decisions made while constructing a routing plan. Since we are considering time-based costs, these costs will depend upon the specific values of these traveling times. Thus, in this work, we introduce a version of the dynamic VRP (DVRP) which considers the “state of the problem”. This state comprises a number of variables describing the particular configuration of the partial or complete solution, which includes the decisions made so far. Some examples are: the number of customers visited in a given route, the total cost or total demand in a route, and the load of a vehicle when visiting a given customer. The decisions of the planners may change the state of the problem and some inputs, which affect the quality of the solution. For instance, if a long route is designed, it may affect both the driver’s capabilities and the resting time required by them, resulting in a longer traveling time. Similarly, the vehicle load may change the traveling time between customers and the emissions released (i.e., the order in which the customers are visited might affect the total traveling time as well as the greenhouse gas emissions). Although it might not be possible to accurately compute the effect of each decision on the cost of the emerging solution, we assume that it might be possible to estimate this impact by using statistical learning methods.
The main challenge of our approach relies on being able to learn from new data (observations) obtained by checking our estimated cost with the real-life cost associated with our routing plan. Thus, we propose a hybrid approach integrating statistical learning [
11] into a metaheuristic-based framework [
12]. The metaheuristic component constructs new candidate solutions while the statistical learning component, based on the data gathered, makes predictions of the traveling time associated with each edge under the current system status. Some preliminary work can be found in [
13,
14], which offers a comprehensive review on this hybrid framework and presents it as a novel methodology. However, in their application, both components are not dependent but separate entities combined to solve a VRP where customers’ demands depend on the visiting order. In contrast, in our methodology, both components work together at each step while building solutions. This is done by generating data based on the decisions made so far, which is fed to the statistical learning model to make predictions regarding future decisions. Thus, we create an interdependence of both components to construct high-quality solutions.
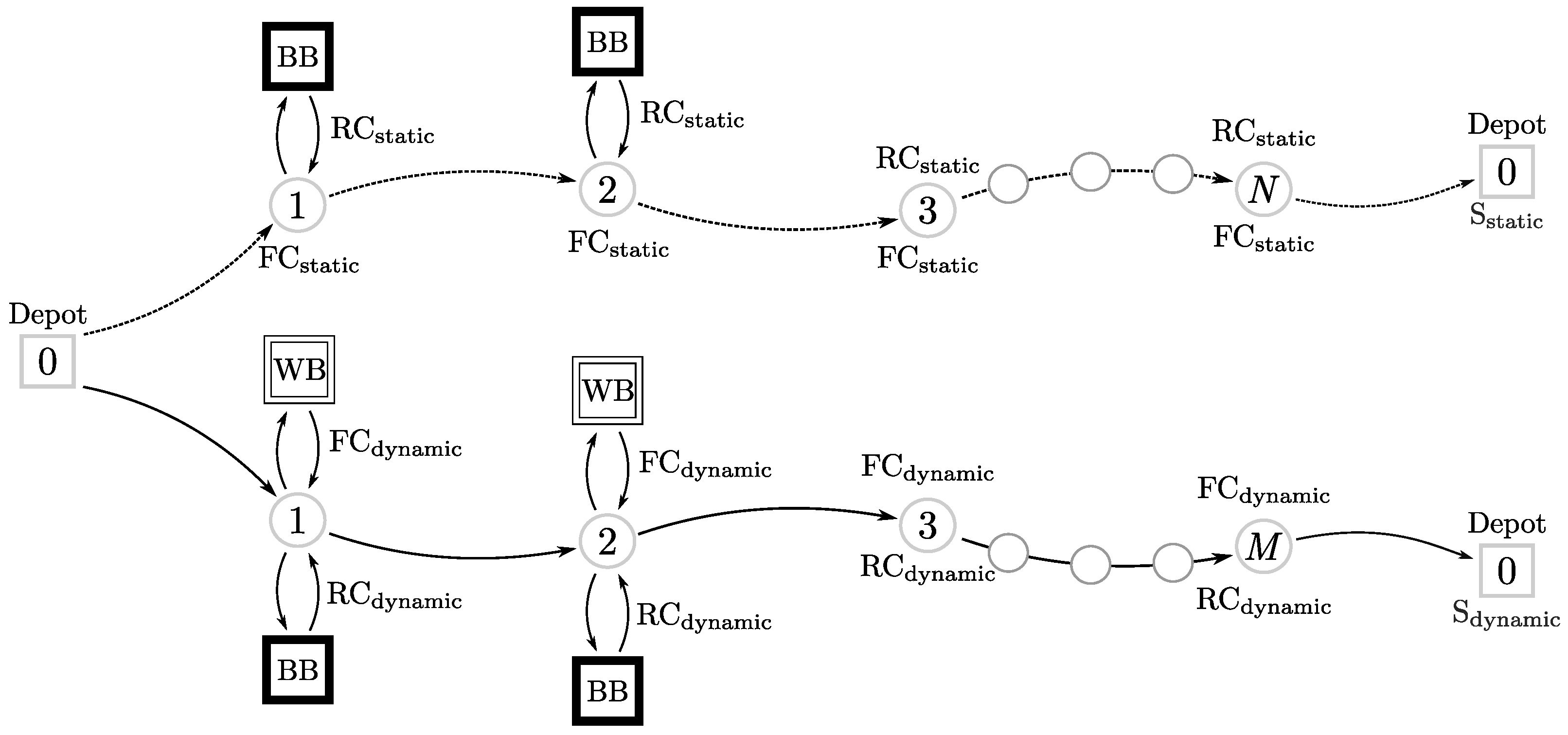
Figure 1 represents the basic idea behind the learnheuristics methodology applied to the dynamic VRP. In our approach, we will consider a ‘black box’ (BB) and a ‘white box’ (WB). The BB is an emulator of a real-life system that modifies the cost of a route based on its structure. The WB represents the statistical learning model, which aims at predicting the behavior of the BB.
Figure 1 illustrates two approaches considering dynamic inputs: (
i) the static approach (upper line), where the dynamism is ignored; and (
ii) the dynamic approach (solid line) where the WB is used to predict the inputs at each step of the constructive methodology for building a solution. In the static approach, the BB is used to compute the real cost (RC) of the solutions, but no predictions are made. Also in the static approach, the model for the forecasted cost (FC) considers that the cost does not change throughout the construction of the solution. On the contrary, in the dynamic approach, data from the system and the outputs provided by the BB are gathered to generate FCs with the WB. Given a WB able to reproduce the behavior of the BB, we will be able to plan near-optimal routes by considering accurate input estimates. The solutions for the static and the dynamic approaches may be different since the decision-maker receives different information in each case.
In this context, the main contributions of this work are: (i) to describe a more realistic version of the VRP, which includes dynamic traveling times; (ii) to introduce a hybrid solving methodology based on statistical learning techniques and a metaheuristic algorithm; and (iii) to build a set of benchmark instances, which allow other researchers to replicate our computational experiments and/or to compare their methodologies with ours.
The rest of this paper is organized as follows:
Section 2 provides a description of the problem addressed. Afterwards,
Section 3 reviews related works, considering works on dynamic VRPs, as well as works on hybridizing metaheuristics and statistical learning to deal with combinatorial optimization problems.
Section 4 presents the learnheuristics-based methodology proposed to solve the problem.
Section 5 explains the computational experiments carried out to illustrate both the problem and the approach, while
Section 6 analyzes the results obtained. Finally,
Section 7 draws some conclusions and identifies some potential lines for future research.
2. Problem Description
The VRP is a well-known NP-hard problem. Accordingly, metaheuristic solving approaches have been developed to solve large-scale instances in reasonable computing times. Consider a complete and undirected graph , where is a set of nodes composed of a depot 0 and n customers, and E is the set of edges connecting all nodes in V. Each customer i has a positive demand, . Traversing an edge in E has an associated fixed cost . There is a fleet of homogeneous vehicles, each with a capacity Q, with . A solution for this problem is a set of round-trip routes starting at the depot and connecting a set of customers. The total delivery in each route cannot exceed the capacity of each vehicle, Q. All the demands have to be satisfied and a customer may only be visited once. Typically, the objective function minimizes the total distribution costs.
The DVRP that we consider assumes that the costs are , where is the average cost associated with the edge , and S is the current state of the problem. A key aspect is that is unknown, and can only be computed once we have defined a state S. Thus, the costs are neither known in advance nor static. Indeed, they may depend on unpredictable factors (such as accidents) or predictable ones (such as the weather or the congestion level). We build a model (WB) that will estimate the behavior of f in order to generate accurate forecasts regarding the consequences of our decisions. This approach is based on online statistical learning since new data is progressively used to update the model.
For experimental purposes, the BB function
f, which is unknown for the solving approach, is defined as:
where
is the load of the vehicle at the moment of departure from node
i in route
k,
and
are parameters of the model, and
is an error term which follows a uniform distribution. We use this model as the BB, and each time the solving approach evaluates one candidate solution, it provides data of a realization (i.e., after completing these routes). The WB is progressively updated and improved with this new data. Notice that Equation (
1) represents the real-life (black box) dynamic behavior in our model. Thus, the real cost (e.g., traveling time) associated with traversing an edge is a function of the system status. For experimental purposes, we assume that this real-life cost can be modeled as a linear function of the vehicle load in the traversed edge. Of course, the exact value of this load will depend upon the customers already visited by the vehicle in its assigned route, i.e., these inputs are influenced by the decision variables.
4. Proposed Methodology
This section presents our hybrid approach for solving the DVRP. It is divided into three parts: (i) an overview of the metaheuristic-based framework; (ii) the description of the statistical learning model; and (iii) the hybridization of both methodologies.
4.1. Metaheuristic Algorithm
There are plenty of metaheuristics that may be applied to address the DVRP. We propose a multi-start method [
29], which is a highly popular and relatively simple-to-implement metaheuristic with a reduced number of parameters. It proposes to iteratively build solutions from scratch until a stopping criterion is satisfied, and then return the best one. The constructive heuristic of the proposed solving approach for building solutions is the Clarke and Wright’s Savings (CWS) heuristic [
30], which is a classical and fast heuristic for the VRP. In particular, the CWS is an iterative method that considers an initial base solution where each customer is served by a dedicated vehicle. Then, the heuristic starts an iterative process where route merges are applied so that vehicles can serve various customers. The merging criterion is based on the concept of savings. Given two customers, a savings value is assigned to the edge connecting them. This savings value represents the savings in cost generated by serving both customers with the same vehicle instead of using a dedicated vehicle for each customer. Thus, a list of edges ranked by their savings can be constructed. This is the so-called savings list. At each iteration of the process, the first edge on the list is taken as a candidate for merging the corresponding routes. There are two conditions that have to be satisfied to accept the merge: (
i) the nodes defining the edge are adjacent to the depot; and (
ii) the total demand of the customers in the new route does not exceed the capacity of the vehicle. The merging process continues until there are no more edges on the list to be considered, ending the heuristic method. The CWS heuristic usually provides good solutions for small and medium size problem instances [
31]. Authors in reference [
32] propose an improvement of the CWS heuristic. Their approach, biased randomized CWS (BR-CWS), introduces non-uniform randomness in the selection of edges to be considered from the savings list. While the classical heuristic considers iteratively each edge in the list (which is sorted from the edge with the highest savings to the one with the lowest savings), the BR-CWS algorithm reorders that list with a non-uniform or biased randomness. In particular, a random number is generated from a given probability distribution (either a theoretical or an empirical one). Then, the edge in the position of the random number is selected and deleted from the list of savings, and the merging of the corresponding routes is considered. Afterwards, a new random number is generated and the same steps are applied until the savings list is empty. A skewed probability distribution is required to follow the logic behind the CWS heuristic. In other words, the higher the savings associated with an edge, the higher its probability of being selected. By modifying the greedy behavior of the CWS heuristic, the randomized version may consider more solutions and return a better one. Obviously, building more solutions also means more computational time. However, since the CWS heuristic is fast, the BR-CWS heuristic may build hundreds or thousands of solutions in just a few seconds. Biased randomization techniques have been successfully applied to solve different VRPs [
33,
34,
35,
36], arc routing problems [
37], and even scheduling problems [
38,
39,
40]. For a complete review on biased-randomization techniques, the reader is referred to [
41].
4.2. Statistical Learning Model
Statistical learning tools have been gaining popularity over the last decades. There are plenty of methods to build predictive functions, which estimate the relationship between variables. The nature of the problem analyzed here requires making predictions. In particular, we predict the costs of an edge (dependent variable) for a given state of the problem (predictors), which is needed because the real costs are only revealed after the moment of realization.
It is crucial to select an appropriate method for a specific problem. Each statistical learning method represents a trade-off between performance, interpretability and computing time. Neural networks and support vector machines rank among the best performers due to their high flexibility. However, they also lack interpretability and require long computational times due to all the parameter tuning needed. Moreover, they are prone to overfitting (i.e., the model may capture the noise in the data). Linear regressions, despite being rigid methods, offer great interpretability and are faster to compute. Obviously, they tend to perform better in problems where the relationship between variables–or a transformation of these–is approximately linear.
We choose to employ a multiple linear regression model. As mentioned before, the solving approach relies on the WB, which aims to predict the behavior of the BB. The model is fed with the variables: load, number of nodes visited in a route, number of routes, and the capacity of the vehicle. Using multiple regression analysis [
42], and after analyzing the correlation matrix and the individual
p-values for the different variables, we found that the relevant variables are the load and the capacity of the vehicle. Thus, we build a linear regression model with just the load and the capacity of the vehicle, reducing the usage of memory and the computational time required.
4.3. Hybridization of the Metaheuristic Algorithm and the Statistical Learning Model
The pseudo-code of our approach for building a single solution is shown in Algorithm 1 and explained next. In the (static) VRP, the savings list is generated once at the beginning of the execution, and it remains constant throughout the resolution. The savings associated with an edge is the benefit from merging the corresponding routes. When two routes are merged, the total cost of the new route cannot be greater than the sum of the individual separated routes (i.e., the saving cannot be negative when the cost is based on the Euclidean-distance metric due to the triangle inequality). This statement is no longer true in general for dynamic inputs due to the change of the state of the problem. Thus, the savings must be computed with the total cost of the routes. In the DVRP, we know the current state of the problem and, as a consequence, the cost of the two separate routes to merge. However, we do not know the total cost of the merged route before actually merging it. Thus, it is needed to predict this cost based on historical data, and then recompute the savings (see pseudo-code of Algorithm 2).
The static approach for this problem does not present this nuance because the cost of a route is always known, while in our case it is only revealed once the merge is done. A key difference with respect to the static approach is the update of the savings list by means of the predictive model at each new state due to the dynamic nature of the problem. The hybridization of the metaheuristic and the statistical learning model is necessary to perform the task of keeping the list updated when new information is available. Generally, training a statistical learning model is an expensive task. The choice of implementing a multiple linear regression model was favored mainly for its fast execution times. Notice that the metaheuristic-based framework would not change if another statistical learning model was considered.
| Algorithm 1 Procedure to build a DVRP solution using the BR-CWS heuristic. |
1: procedure BuildDVRPsol(inputs)
2: solution ← generateBaseSolution(inputs) ▹inputs: coordinates, demands and vehicles’ capacity
3: savings ← computeSavings(solution, whiteBox) ▹ edges list decreasingly sorted by savings
4: while (savings is not empty) do
5: index ←generate random number ▹ given probability distribution
6: edge ← get edge from savings by index
7: savings ← delete edge from savings
8: if (mergeFeasible(edge)) then
9: route ← emptyRoute
10: route ← mergeRoutes(edge, solution)
11: realCost ← blackBox.getRealCost(route)
12: solution.update(realCost) ▹ update solution with the real cost of the route
13: whiteBox.update(route, realCost) ▹ update White Box
14: savings ← computeSavings(solution, whiteBox) ▹ update savings
15: end if
16: end while
17: return
18: end procedure |
| Algorithm 2 Procedure to compute the savings list. |
1: procedure ComputeSavings(solution, whiteBox)
2: savings ← emptyList
3: exteriorNodes ← getExteriorNodes(nodes)
4: for to exteriorNodes.size do
5: for to exteriorNodes.size do
6: iRoute ← getRoute(exteriorNodes(i)
7: jRoute ← getRoute(exteriorNodes(j))
8: mergedRoute ← mergeRoutes(iRoute, jRoute)
9: iRealCost ← getCost(iRoute) ▹ Black Box
10: jRealCost ← getCost(jRoute)
11: mergedPredictedCost ← whiteBox.predictCost(mergedRoute, solution)
▹ Based on the state of the problem
12: routeSavings ← iRealCost + jRealCost - mergedPredictedCost
13: add routeSavings to savings
14: end for
15: end for
16: savings.sort ▹ Sort in descending order
17: return savings
18: end procedure |
5. Computational Experiments
This section describes the computational experiments carried out to illustrate both the problem and the solving methodology, comparing different approaches. After introducing the experiments, we describe the instances and the parameters required, and summarize the results. A comprehensive analysis of the results is shown in the next section.
The algorithm described in this paper has been implemented as a Java application, and the Apache Commons Mathematics Library has been used to build the linear regression model. A standard personal computer, Intel® Core™ i5-8250U @ GHz and 8 GB of RAM has been used to execute the application.
The experiments compare two approaches to deal with the DVRP: (i) the static approach where the FCs are the cost of the edge using the Euclidean distance and do not change throughout the construction of the solution; and (ii) the dynamic approach where the FCs are predicted by the WB based on data from the BB. We compare the FC and the RC obtained with the static approach (called SFC and SRC, respectively) with the FC and the RC obtained with the dynamic approach (DFC and DRC, respectively). The comparison is done by computing the percentage gaps among them relative to the DRC. One should expect that ignoring the dynamism of the system will lead the static approach to generate suboptimal solutions. Thus, we expect the SRC to be greater than the DRC, at least on average. In addition, the SFC should be smaller than the DRC on the average, since the BB usually increases the cost of the routes. Lastly, one should expect the DFC to be similar in value to the DRC, since the WB should be able to make accurate predictions on the corrections of the BB.
5.1. Description of Instances
The set of instances that we employ to test our approach is a natural extension of the classical benchmark instances for the VRP, which are available at
http://vrp.atd-lab.inf.puc-rio.br/index.php/en/. This site provides a detailed description of each instance as well as a tool to visualize the distribution of the nodes. Each instance describes the capacity of the vehicle, the coordinates of each node and also its demand. Instances from different sets (A, B, E, M, F, and P) have been selected for the experiments. Instances with less than 24 nodes have been discarded because they can be easily solved by using exact methods. Instances from the sets A, E, and P have a homogeneously dispersed configuration of nodes, where the depot may be at the center or at any other location. The set F and some instances of E have a more heterogeneous density of nodes. Otherwise, sets B and M have several clusters of nodes and, in some cases, the depot belongs to one cluster. The name of the instances considered are listed along with the number of nodes and the capacity of the vehicles in the first columns of
Table 1.
In our experiments, these basic instances have been extended by incorporating different levels of dynamism in the traveling times. The specific level of dynamism employed is a design parameter. Hence, we should expect our results to converge to the best-known solutions for the original instances whenever the level of dynamism of travel times converges to zero. On the contrary, as this level grows, our results should diverge from the classical ones, and using the near-optimal solutions for the non-dynamic version in the dynamic scenario should lead to suboptimal results.
5.2. Parameters of the Algorithm and the Tests
Our methodology has a few parameters that need to be set before executing the algorithm. As in any other metaheuristic, the choice of these parameters could eventually affect the performance of our algorithm. First, the model for the BB has three parameters: the regression parameters
, and the error term
(see Equation (
1)). Our approach to fix them consists in: (
i) the BB should give corrections of reasonable order of magnitude; and (
ii) this order of magnitude should be the same for all instances. Considering these two statements, the BB is modeled as:
with
C being the capacity of the vehicle. In this way,
. Let us consider the extreme cases:
With this model, the corrections are bounded to
times the average cost of the edge for all instances. The extreme cases here are reasonable as the corrections do not change the average cost drastically. Using the capacity of the vehicle as a parameter allows us to generalize the corrections for all the instances, thus avoiding possible difficulties in using a general model for any type of problem configuration. The error term
is set in a range
, which is about two orders of magnitude smaller than the order of the corrections. As discussed in [
41], one effective way to transform a deterministic heuristic into a biased-randomized algorithm is by using a geometric probability distribution. This allows for assigning, during the solution-construction process, higher probabilities of being selected to those movements that are more promising according to the heuristic criterion. The geometric distribution has only one parameter
. Values of
p closer to 1 reproduce the greedy behavior of the original heuristic, while values of
p closer to 0 represent a uniform selection of candidates, which ignores the logic behind the heuristic. Values in between these extremes allow for considering this logic while, at the same time, do not follow a greedy deterministic behavior. After some initial tests, we noticed that the BR-CWS probabilistic algorithm was able to provide high-quality solutions when using values of
p inside the interval
.
In the iterative procedure, there is a lot of data generated by the BB. There is no need to use all of it to compute a predictive model that estimates, in an accurate way, the BB. In the preliminary tests we realized, it was observed that only around 500 instances of data were needed to build an accurate model. In this way, the computational time is reduced by not updating the predictive model at every iteration of the algorithm.
As is usual in the literature, the algorithm has been executed several times for each approach, each time with a different seed for the pseudo-random number generator. The same 30 seeds have been employed for both approaches. Only the best solutions have been stored. This reduces the options of obtaining a poor solution due to the effect of the seed [
43].
5.3. Computational Results
The results of our experiments comparing the static and dynamic approaches are summarized in
Table 1. It is structured as follows. The first three columns refer to the instance considered (name, number of nodes, and capacity of the vehicle). The next four columns describe the forecasted and the real costs for both approaches. Then, the number of routes for the solutions of each approach is revealed. Finally, the last three columns represent the gaps with respect to the DRC. The average values of each gap are shown in the last row.
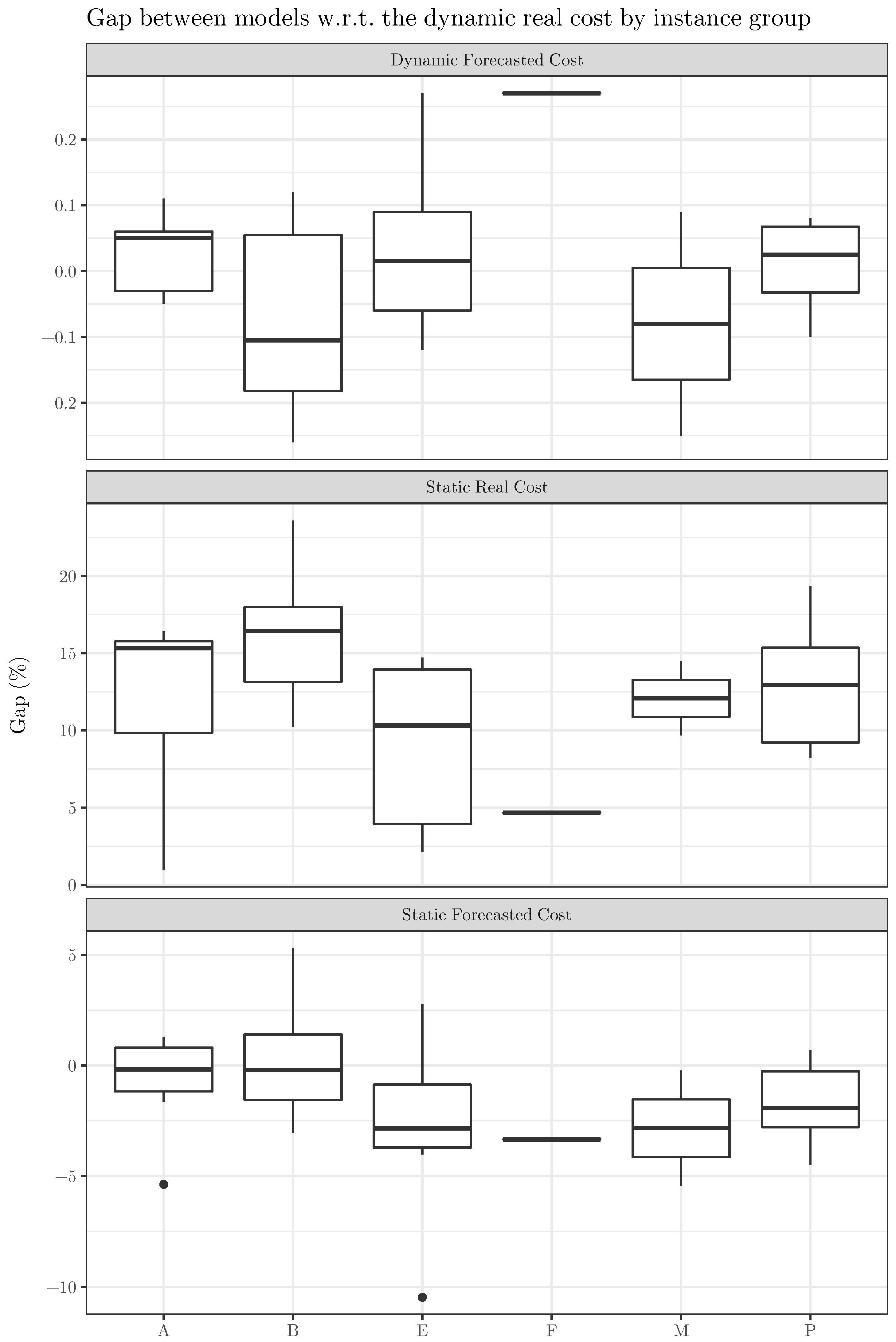
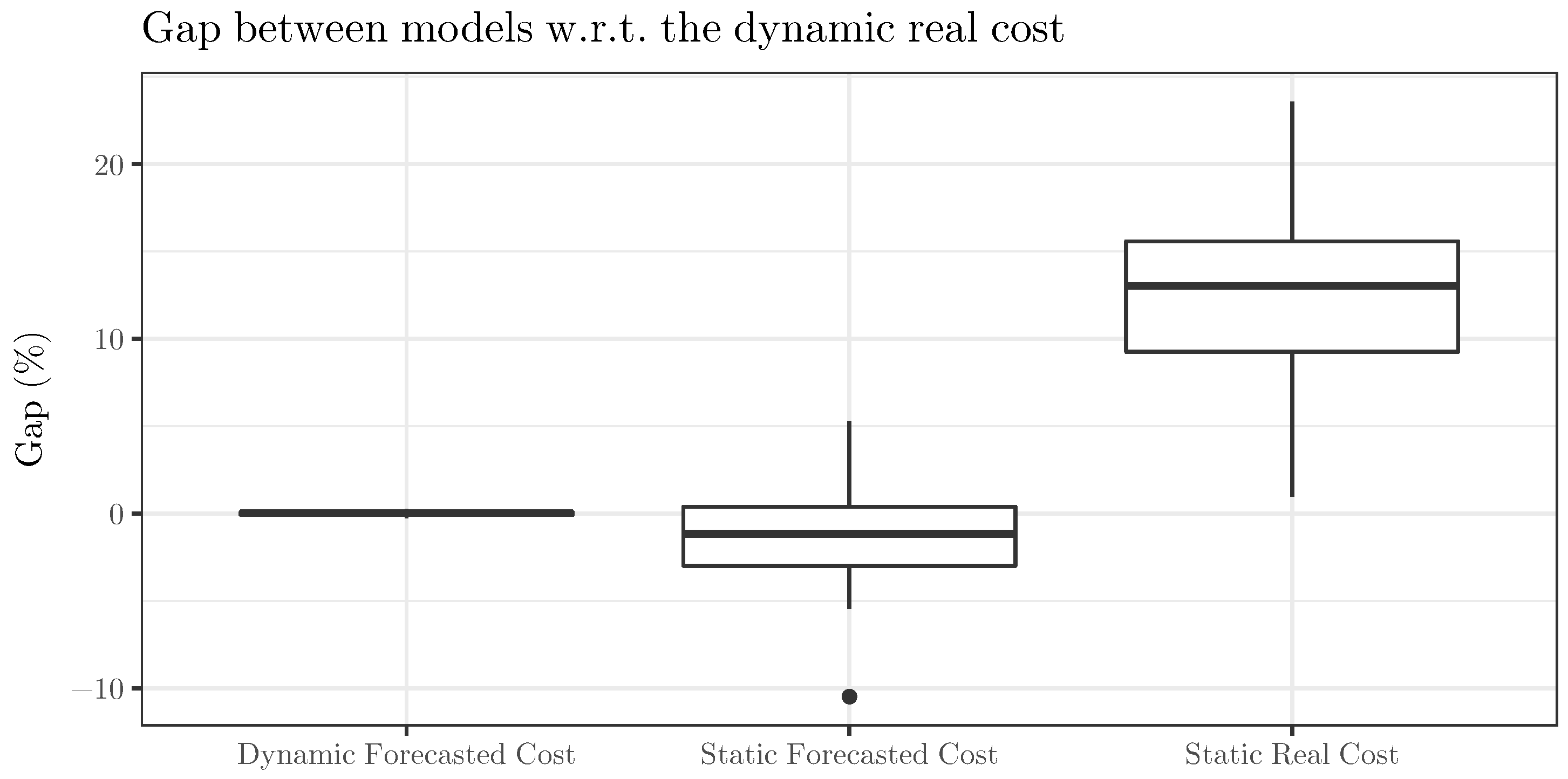
Figure 2 and
Figure 3 display the gaps using multiple boxplots. In particular, the first figure shows boxplots of each gap by instance set. In contrast, the second figure aggregates the gaps among all the sets and uses the same scale to represent the three resulting boxplots, which helps us to easily compare their magnitude.
6. Analysis of the Results
The columns of gaps in
Table 1 show the relative differences between the best solutions obtained with the static and dynamic approaches. The positive gaps between SRC and DRC proves the importance of considering the intrinsic dynamism of the system. Indeed, the maximum gap reaches a value of 23.58%, while the average gap is around
. All the gaps are strictly positive, thus the static approach does not outperform the dynamic one in any instance. Regarding the gaps between DFC and DRC, the amount is lower: the greater gap in terms of absolute values is 0.26%, and the mean is 0.00%. This is due to the fast learning of the linear regression model, which can be explained due to the fact that the BB model is linear and has a relatively small error term. Finally, there are positive and negative gaps between SFC and DRC, but SFC is, on average,
lower than DRC. Thus, when the dynamism is not considered, the forecast of real costs tends to be optimistic, misleading the planner. It is worth remarking that, while SFC and SRC are similar in some instances, the routes of those solutions are different. The planner may be deceived into thinking that ignoring dynamism leads to a solution with a similar performance to that of the optimal solution; however, once those routes are completed, SRC is greater than SFC.
Figure 2 represents graphically the gaps considering the different instance sets. Regarding the gaps between DFC and DRC (first raw of boxplots), we observe that the groups of instances have different distributions of gaps, but they tend to be relatively small. The distributions are relatively symmetric, except for sets A (negative skew) and F (no variability at all). There are no outliers. We focus now on the gaps between SRC and DRC. They range between almost 0% and 25%. The boxplots per group of instances share some similarities with the previous ones: symmetry except for sets A (positive skew) and F (no variability at all), there are no outliers, and the variability (either total range and interquartile range) depends on the set (higher for set E and lower for set M, for example). Finally, the last row displays the boxplot of the gaps between SFC and DR. They range between −10% and 5%, approximately. There are only two outliers, and the variability is also group-dependent: for sets B and E is higher than for F. There is also symmetry in this case. Since there is not any pair of sets with a similar distribution of gaps, it is difficult to link the main differences of the sets (described in
Section 5.1) to the boxplots.
Figure 3 aggregates the gaps by sets, and displays them using a unique scale, thus allowing a direct comparison. The gaps range between −10% and 25%, approximately. The boxplot for the gaps between DFC and DRC is a single line. Regarding the gaps between SFC and DRC, the boxplot represents a symmetric distribution with a negative outlier and a slightly negative median. Finally, the boxplot for the gaps between SRC and DRC shows a higher variability but is also symmetric. The first and third quartiles are close to 10% and 15%, respectively.
7. Conclusions
With an increasing concern for the environment, it is becoming a key aspect for governments to boost smart and sustainable transportation systems. While the literature on rich vehicle routing problems (VRPs) is extensive, some issues remain to be addressed. For example, most works assume that the traveling times between pairs of nodes are both known in advance and static. In contrast, this paper has focused on the dynamism characterizing many real-world routing applications, where traveling times are dynamic in nature.
Taking into account the high number of factors that might affect the traveling time (from accidents to the weather), we introduce the VRP with dynamic traveling times. In particular, these times vary dynamically as the routing plan is being generated. Therefore, they need to be re-evaluated dynamically during the optimization process. As far as we know, this is the first work addressing this version of the dynamic VRP. In order to deal with this problem, a hybrid solving approach has been presented. Our approach integrates a statistical learning technique into a multi-start framework. A comprehensive set of computational experiments have been carried out to quantify the differences between ignoring or not the dynamism in traveling times among many realistic scenarios. The results show an average gap around 12.02%, with all gaps being positive (i.e., it always pays off to take this dynamism into account while designing the routing plan).
Several lines of research stem from this work. For instance, we have employed a linear model as an emulator of a real system that provides data for building/updating our model. Thus, analyzing the convenience of building a more sophisticated emulator would be an interesting research line. If the function was not linear, it could make sense to apply and compare the performance of different statistical learning techniques. In case of requiring time-consuming techniques, the use of a distributed computing system could be tested. Finally, it would be interesting to model richer VRPs (heterogeneous fleet, multiple depots, etc) considering also dynamic traveling times influenced by the manager decisions.







{kind=link}
{kind=link}
{kind=link}