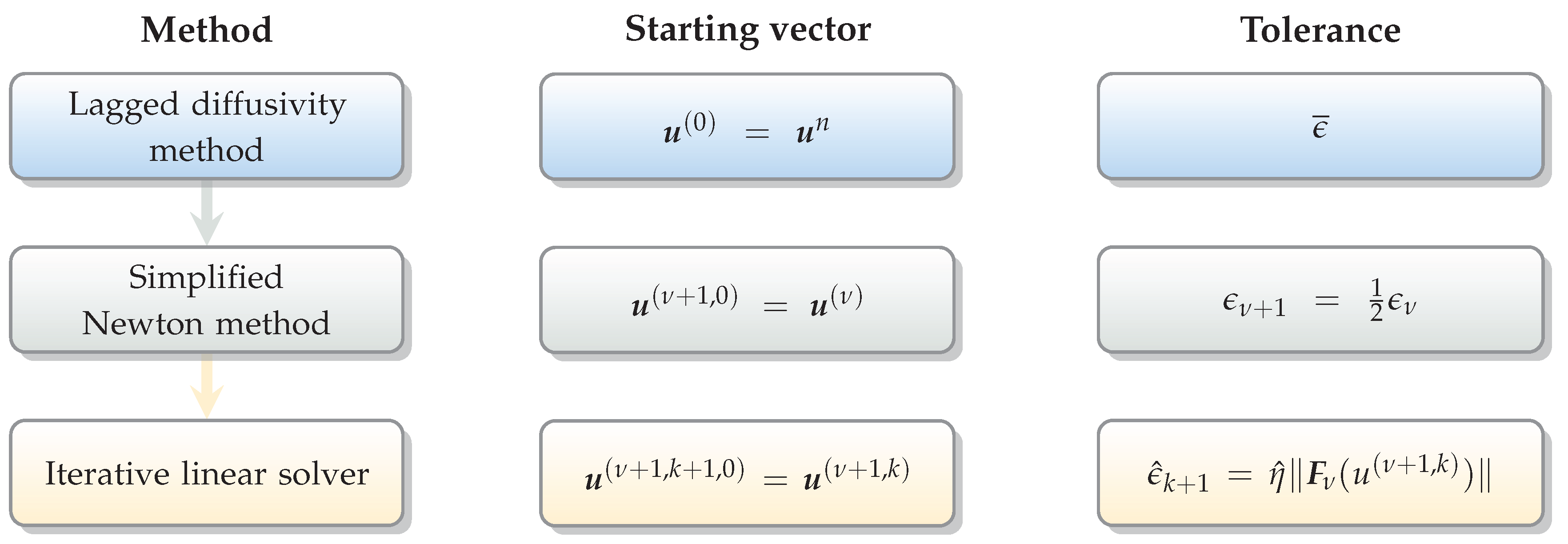
2.1. Space Discretization
For simplicity, let us assume
to be a 2D bounded rectangular domain. Let us superimpose a grid
to
. For simplicity, we use uniform mesh size
h along
x and
y. Thus,
is made of the mesh points
,
,
with:
Using this grid,
denotes the grid function which approximates the solution
at the mesh points
of
,
,
. This grid function satisfies the initial condition for
and
and the Dirichlet boundary conditions for
,
.
We can now approximate the derivatives of Equation (
1) by finite difference methods. In this regard, several choices are possible. In particular, it is interesting to analyze the space discretizations obtained by central finite differences and by the upwind scheme. Indeed, this choice influences the properties of the matrix of the discretized system, as we will see in the following. Regarding the upwind scheme, we consider, for instance, the case of positive
. If
<
0 the backward difference quotients which approximate the first-order derivatives are simply replaced by forward difference quotients.
Thus, denoting the forward finite differences (in x and in y respectively) by and , the backward finite differences by , and the central finite differences by , , we have:
Discretization by central finite differences (error
)
Discretization by upwind scheme (error
), case
>
0
In both cases, we can write the discretization in a more convenient way by defining
Then, setting
(analogously for
,
,
and
), the right hand-side of Equations (
2) and (
3) can be written formally in the same way as
In the following, we denote by for compactness of notation.
Finally, we use matrix notation to write the entire system of ordinary differential equations arising from the space discretization. In this regard, we use the row lexicographic ordering for mesh points and define
with
, for
,
. We can then write the vector
containing all the
at internal mesh points. Thus, the space discretization leads to
Again, we notice that formally this expression is valid both when the discretization is performed by central FD and when the upwind scheme is used. The following differences are however present:
The vector
in Equation (
6) derives from the Dirichlet boundary conditions
at points
. Considering the Dirichlet BCs in Equation (
1) and using, again, the row-lexicographic order, its components are
where the coefficients
L,
B,
R,
T depend on
at the inner point which is neighbor to the considered point of
. At corners, where the same inner point is neighbor to two boundary points, we then have two contributions: e.g.,
.
Defining
,
is the nonlinear mapping of components
, with
,
and
. It is, then, easy to notice that
is a diagonal mapping [
12] (p. 11).
Finally, contains the terms arising from the source term: with , and .
2.2. Time Discretization
We now consider time discretization. Let us introduce a time spacing , which defines a series of time levels: the n-th time level is defined by ,
The time derivatives of Equation (
6) can be approximated by several different schemes. We could use, for example, the well-known
method (e.g., see [
13]), which is completely implicit when
. An alternative, as noted in the Introduction, is given by IMEX methods, which have been employed to solve diffusion equations when convection or reaction terms can be treated explicitly.
For instance, let us apply the
-method. Denoting by
the approximation of
(with
solution of Equation (
6) at
) and by
, we get:
for
and with
.
By simple algebraic manipulations, we find that at each time level
the vector
is given by the solution of the nonlinear algebraic system
where
,
I is the
identity matrix and
is a vector containing the known terms, defined as
If we use an IMEX method, we similarly get a nonlinear algebraic system to solve at each time level. The difference is that some terms are treated explicitly. Thus, if, for instance, the reaction term is treated explicitly, at the time level the mapping is evaluated at time n; then becomes a known term which appears solely in the known vector .
Analogously, if the velocity is not linear, it could be useful to treat explicitly the convection term. In this case, the part of depending on would appear solely in the known vector .









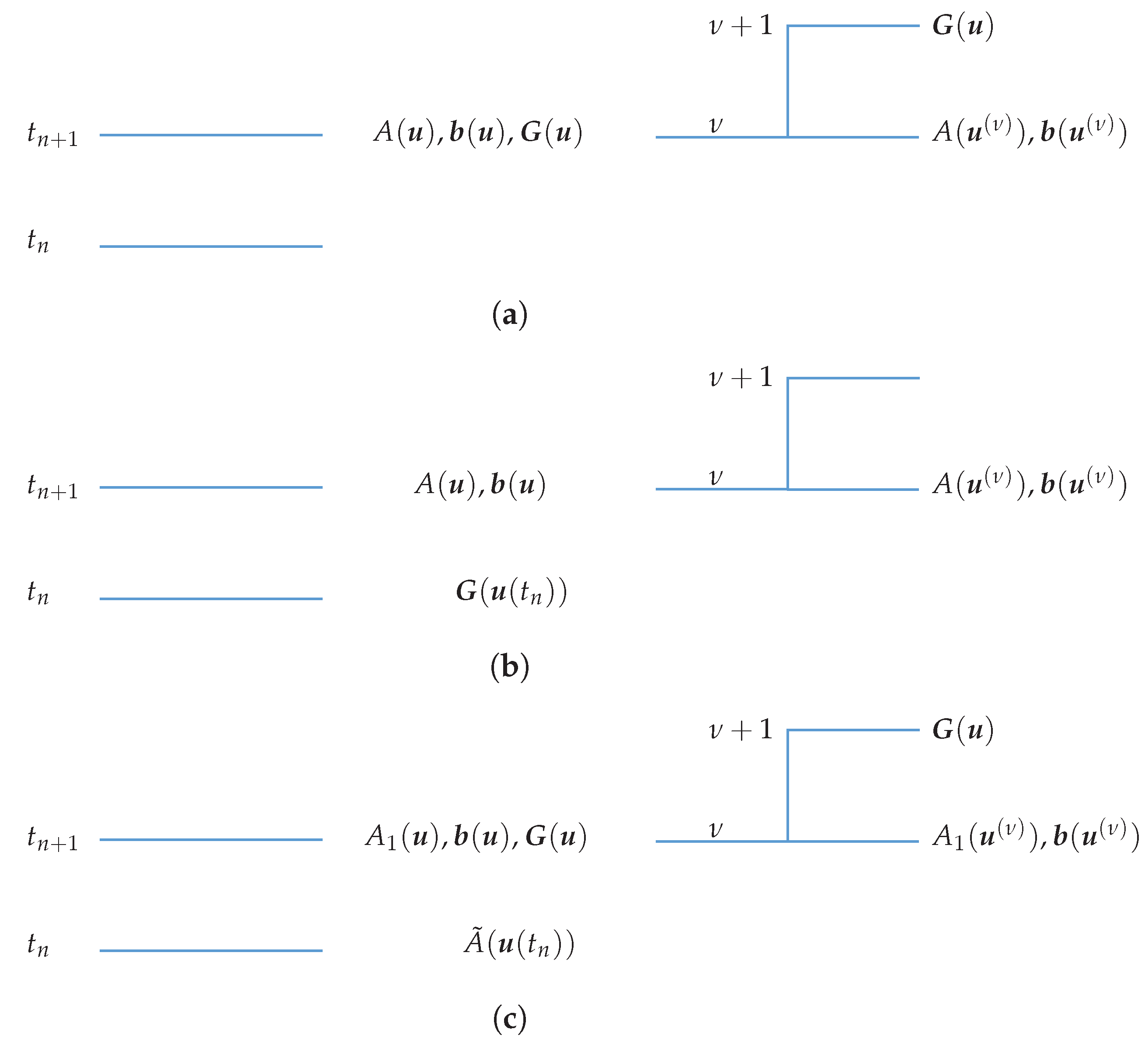{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}