1. Introduction
In daily life and work, multi-objective optimization problems (MOPs) have a wide range of applications, such as water distribution systems [
1], land use management problems [
2], automotive engine calibration problems [
3], and so on, which are all real-world applications of MOPs. All of these problems are needed to optimize two or more than two objectives simultaneously. Without a doubt, everyone wants to make all objectives achieve optimization. However, we cannot find a solution to achieve this goal, because all of the objectives are restricting each other. If one objective achieves the optimization, the other objectives must achieve more useless solutions, which the decision makers do not want to see. Due to the importance of MOPs, scholars have been trying to solve this effectively. In order to facilitate the study of MOPs, scholars summed up the general mathematical expression of the MOPs. Therefore, a multi-objective optimization problem (MOP) can be mathematically defined as follows:
where
is made up of
m real-valued objective functions,
is the decision (variable) space and
is called the objective space.
Given two objective vectors:
, vector
u is said to dominate
v, which means if and only if
for every
and there must exist at least one
satisfied with
. Additionally, if
dominates
, a solution
is said to dominate another solution
. A solution
is defined as a Pareto-optimal solution in the case that
is not dominated by any other solutions in the objective space. Then,
is called a Pareto-optimal objective vector. The set of all the Pareto-optimal solutions is known as the Pareto set (PS). In addition, the set of all of the Pareto-optimal objective vectors is the Pareto front (PF) [
4,
5]. Additionally, any improvement of one objective in the Pareto-optimal solutions is bound to the decline of at least one other objective.
In most real-world applications, because the objectives in (
1) conflict with each other, there is no solution that could minimize all of the objectives simultaneously. Because of the complexity of MOPs, the traditional mathematical methods will meet different levels of difficulty while solving the MOPs. Nevertheless, the evolutionary multi-objective optimization (EMO) algorithm based on natural evolution can solve the MOPs exceedingly well to some extent. Over the past twenty years, EMO algorithms and their applications came into being and developed rapidly, which has attracted a large number of researchers to study them [
6,
7,
8,
9,
10,
11,
12,
13].
Owing to the research of EMO, the evolutionary algorithm (EA) has some certain advantages in obtaining the multiple Pareto-optimal solutions; for example, it always can obtain more than one optimal solution in a single run. Therefore, it is very common to use multi-objective evolutionary algorithms (MOEAs) to solve MOPs. Many EMO algorithms did the fitness assignment through using Pareto dominance, which are called the domination-based algorithms. In these algorithms, they tried to find a set of solutions, which should be as approximate as possible to the true PF, and this is known as convergence. The allocation of the fitness scheme to solutions is based on the Pareto-dominance principle, and the convergence of the basic algorithm plays a pivotal role in this principle. On the other hand, these algorithms need an explicit diversity preservation scheme to maintain a diverse set of solutions. In this way, two of the most prevailing MOEAs are NSGA-II [
14] and SPEA2 (the improved version of strength Pareto evolutionary algorithm) [
15]. They have achieved remarkable results in solving MOPs. Although the dominance-based algorithms are prevailing, they also have their own limitations to overcome. One of the main drawbacks is that they are not very suitable for solving the many-objective optimization problems. Because in the face of the many-objective optimization problems, almost all of the solutions will become non-dominated with respect to each other in the population, this will reduce the selection pressure and hinder the process of evolution [
16,
17].
With the continuous in-depth study of scholars around the world, the recent well-known MOEA, the multi-objective evolutionary algorithm based on decomposition, named MOEA/D [
18], proposed by Zhang and Li in 2007, was dissimilar from the past algorithms. MOEA/D does not use the Pareto dominance, but uses the scalarization technique for fitness assignment to solve the multi-objective optimization problems. It uses scalarizing functions such as the weighted sum approach and the weighted Tchebycheff approach to decompose a MOP into a number of single subproblems and solves all of these subproblems in a single run (note that the description of the weighted sum approach and the weighted Tchebycheff will be shown in
Section 2.2). Each subproblem is relevant to a weighted scalarizing function and neighborhood relationship, which should be considered between any two sub-problems. These algorithms based on MOEA/D in solving continuous and combinatorial MOPs have already achieved extremely promising results [
19,
20,
21].
On the other hand, as an efficient and vigorous heuristic for the global optimization algorithm, differential evolution (DE) was proposed by Storn and Price [
22,
23]. As a prevalent EA, DE exhibits outstanding performance in solving a wide variety of problems in different fields. It employs crossover, mutation and selection operators to move its population toward the global optimum in each generation. DE as a successful EA is widely used to cope with many optimization problems, as well as it has good adaptability, so that it can be combined with other algorithms to solve MOPs at another level.
In the course of [
24], a simple DE scheme is combined with MOEA/D, called MOEA/D-DE, which solves a class of new MOPs that have complicated Pareto sets. In this version of MOEA/D, called MOEA/D-DE, mating parents are selected from the neighborhood and the whole population together. It also points out that the parameter setting in the DE scheme is very important for the performance of the MOEA/D-DE algorithm. The successful implementation of MOEA/D-DE not only shows the good performance of MOEA/D, but also shows the good adaptability of the DE algorithm. Therefore, we can make some effort following this means to attempt to solve more difficult MOPs.
Moreover, it is undoubted that (
1) is a multi-objective optimization problem and usually has two or three objectives. Nevertheless, in daily life, many real-world applications often involve four or more objectives for optimizing. Thus, we say that many-objective optimization problems are the class of MOPs that have four or more than four objectives. Because of its usefulness, it is not strange that the research on many-objective optimization problems has been one of the major research areas in the EMO community during recent years. To name only a few, in 2013, Tan et al. [
25] proposed an improved MOEA/D, named UMOEA/D (MOEA/D with uniform design). They used the uniform design method to set the weight vectors of MOEA/D for solving the many-objective problems and got some effective results. Qi et al. [
26] proposed an improved MOEA/D in the weight vector design method in 2014, called MOEA/D-AWA (MOEA/D with adaptive weight vector adjustment). They used a new weight vector initialization method and made the weight vectors adaptive. There were many experiments on MOPs and a small amount of experiments on the many-objective optimization problems, which certified how effective MOEA/D-AWA was. In 2014, Deb and Himanshu [
27] suggested a reference point-based NSGA-II for many-objective problems, similar to NSGA-II, called NSGA-III. NSGA-III still employed the Pareto non-dominated sorting method and added the decomposition concept to solve the many-objective optimization problems. In 2015, Li et al. [
28] proposed a new algorithm that exploited the merits from both the dominance- and decomposition-based approaches to balance the convergence and diversity of the evolutionary process to solve the many-objective optimization very well. From these points of view, while solving this kind of many-objective optimization problem, the original MOEA/D will meet some limitations, such as the distributions of weighted vectors not being very uniform, and it just uses a single approach to decompose the MOPs. All of these limitations are encouraging researchers to study it. This provides the major impetus for us to study how to improve the performance of MOEA/D on solving the many-objective optimization problems. Therefore, an improved MOEA/D with optimal DE schemes (MOEA/D-oDE) is proposed in this paper. Our purposes are to employ and use the advantages of different DE schemes. Firstly, MOEA/D-oDE uses the alterable decomposition approach. Besides, MOEA/D-oDE uses the optimal DE schemes. More precisely, the proposed algorithm MOEA/D-oDE combines the weighted sum approach and the Tchebycheff approach to produce a new scalarizing function to decompose the many-objective optimization problems. Additionally, we use the alterable DE’s trial vector operators to improve the performance of MOEA/D in solving the many-objective optimization problems.
The remaining part of this paper is arranged as follows.
Section 2 presents the preliminaries of our study, including the basic idea of MOEA/D, the basic decomposition approaches and a simple introduction to the DE’s trail vector design methods.
Section 3 presents our newly-proposed algorithm, named MOEA/D-oDE, which attaches importance to how to decompose the many-objective optimization problems and how to make the results of the DE operators perform well.
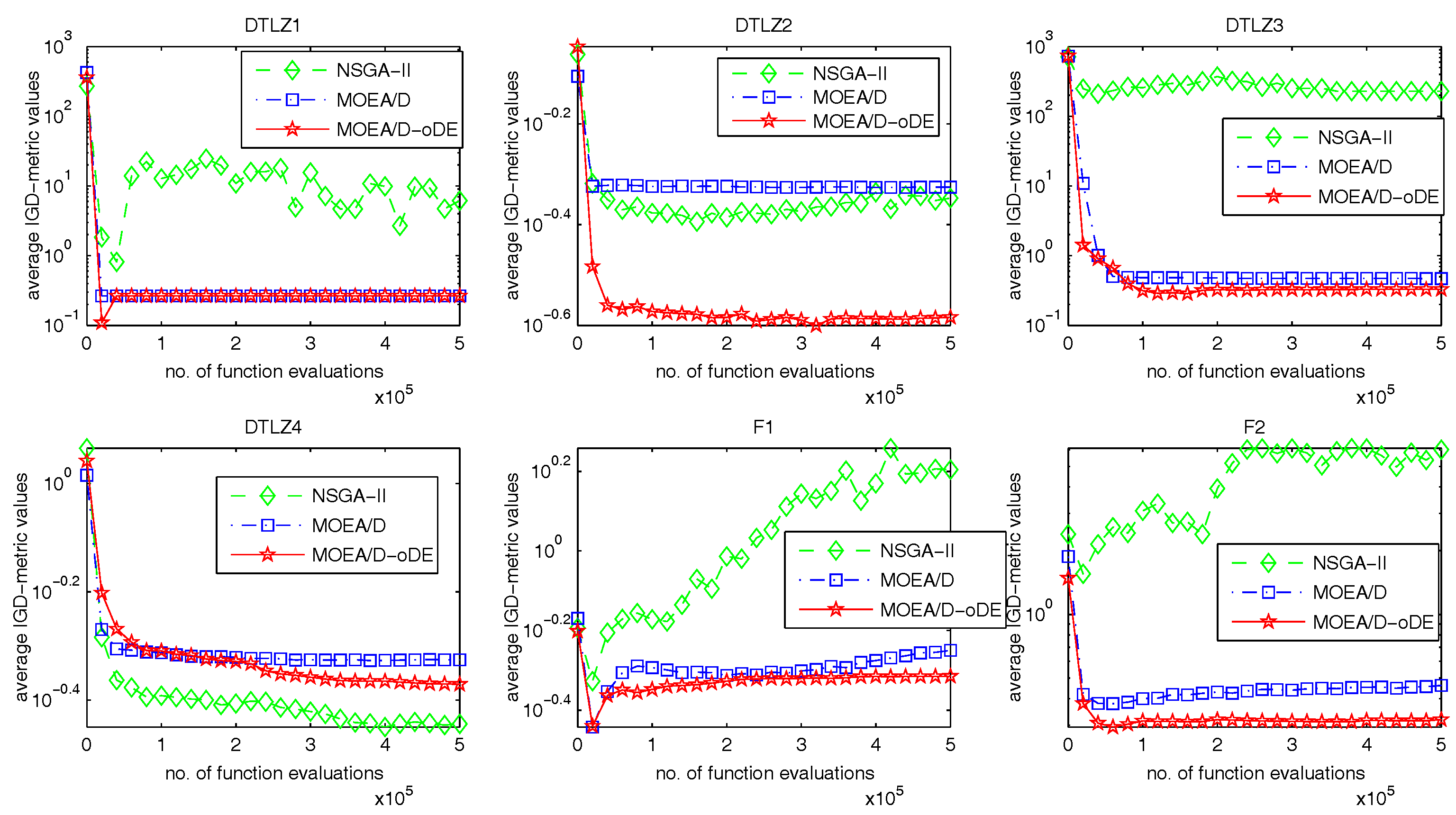
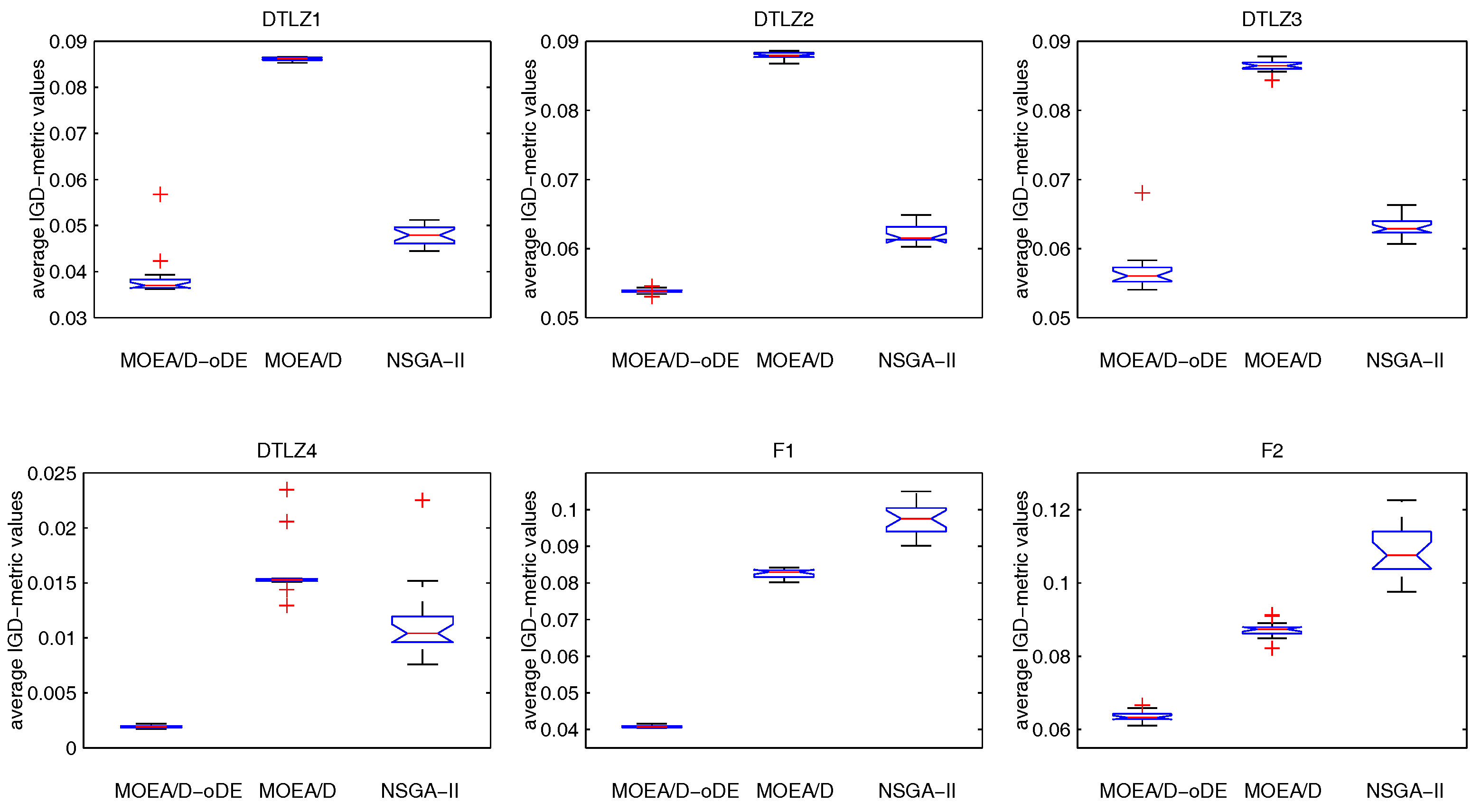
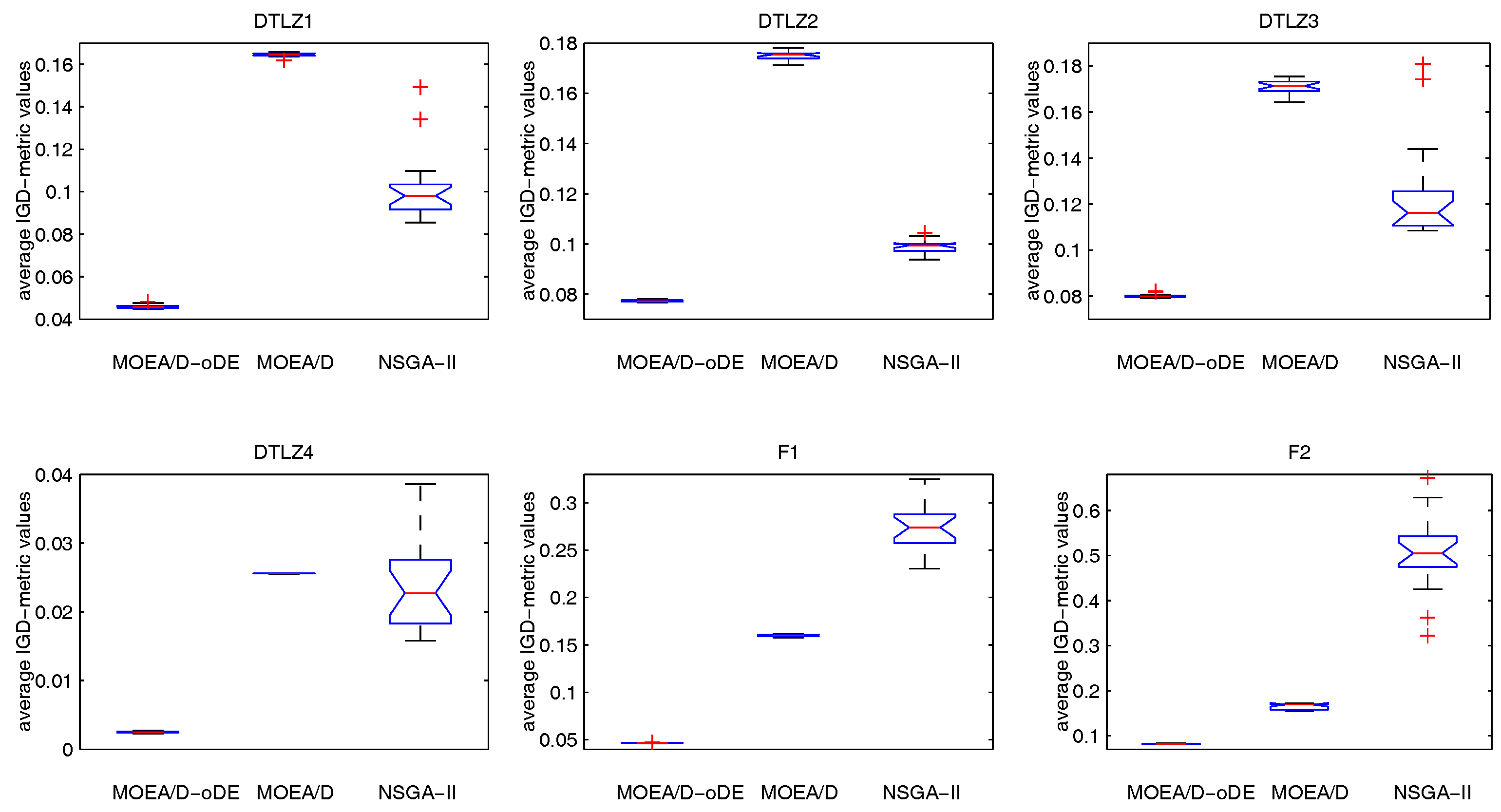
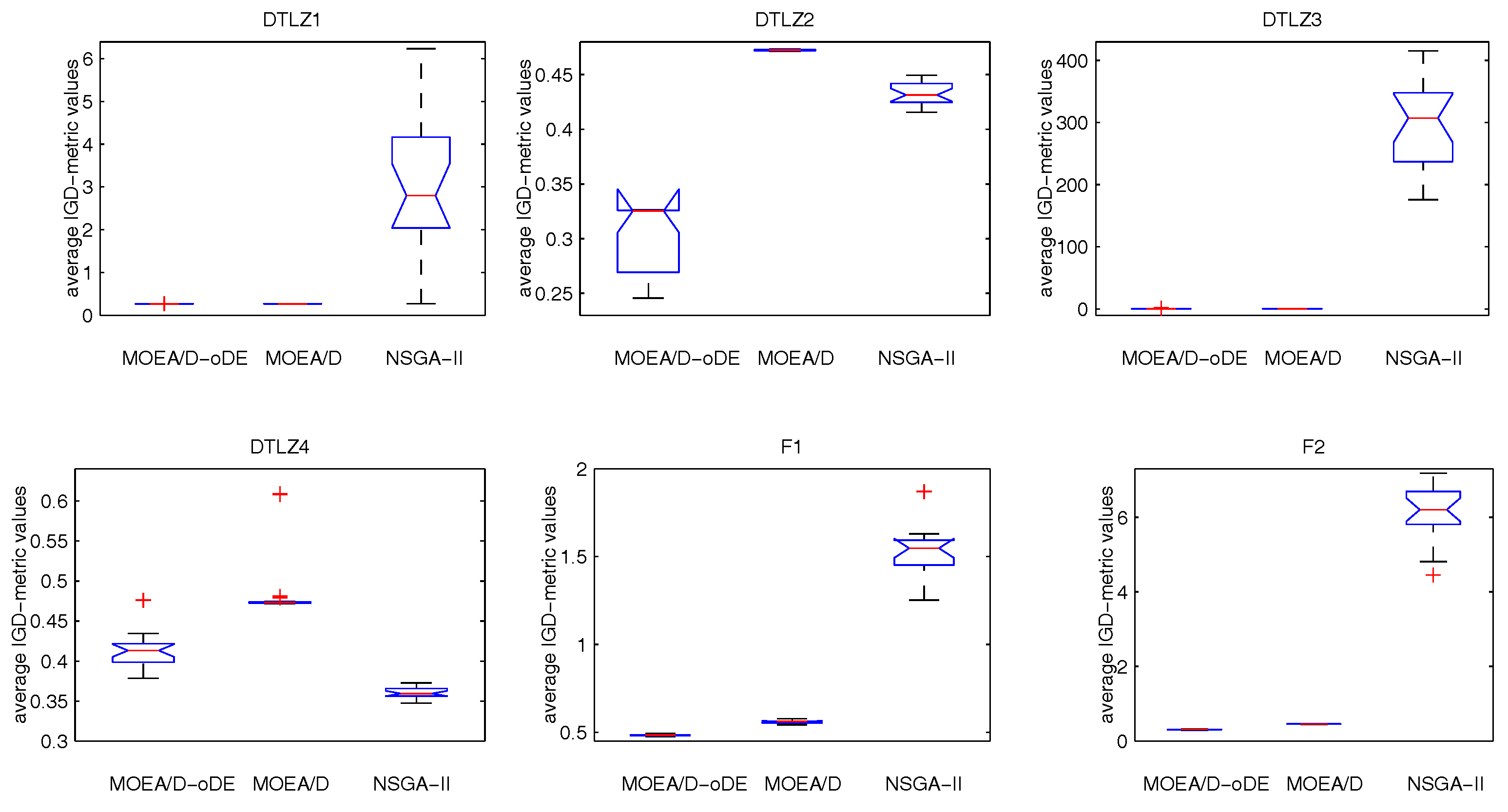
Section 4 presents the experimental studies on MOEA/D-oDE, comparing MOEA/D-oDE with MOEA/D and NSGA-II in solving the many-objective problems, and the experimental results demonstrate that MOEA/D-oDE outperforms or performs similarly to MOEA/D and NSGA-II. Finally,
Section 5 concludes this paper concisely.
2. Preliminaries
In this section, there is some basic knowledge that will be employed in this paper. First of all, the basic idea of MOEA/D is introduced in
Section 2.1, which presents briefly how MOEA/D works, but not providing the framework and details of MOEA/D. Thereafter, the decomposition approaches used in MOEA/D are introduced in
Section 2.2, which introduces the weighted sum approach, the Tchebycheff approach and the penalty-based boundary intersection approach, respectively. Eventually, how trail vectors of differential evolution are generated is interpreted in
Section 2.3 in detail.
2.1. Basic Idea of MOEA/D
MOEA/D is a representative algorithm based on decomposition, which was proposed by Zhang and Li. In addition, Zhang and Li had proven that it is superior to the other state-of-the-art MOEAs in 2007 [
18]. Moreover, a variant of MOEA/D, which is named MOEA/D-DRA (MOEA/D with dynamical resource allocation), had achieved first place at CEC2009 (2009 IEEE Congress on Evolutionary Computation) [
29]. The basic idea of MOEA/D is using some kind of aggregation function to decompose an MOP into some single objective optimization sub-problems and to use some other evolutionary algorithm to optimize them simultaneously.
In the general MOEA/D framework, let
N be the population size,
m be the number of the objectives, for all
, and
be a set of aggregation coefficient weight vectors, where
,
, and subject to
,
. With these weight vectors, MOEA/D employs a decomposition method (discussed in
Section 2.2) to decompose an MOP (
1) into single objective optimization subproblems and minimizes all of these
N subproblems in a single run. Each subproblem
i corresponding to vector
is optimized by using the information just from its neighborhood. The neighborhood of weight vector
is defined as a group of its
T closest weight vectors in the entire set {
}. Therefore, the neighborhood of the
i-th subproblem is composed of all of the subproblems whose weight vectors are from the neighborhood of
. The constantly-updated population consists of the best solution found up to now for each subproblem. Only the present solutions to these neighboring subproblems are utilized for optimizing a subproblem in the algorithm. For more details about MOEA/D, readers may refer to [
18].
2.2. Decomposition Approaches Used in MOEA/D
In the study of the original MOEA/D, a total of three kinds of decomposition approaches are introduced simply here. They are the weighted sum approach (WS), the Tchebycheff approach (TCH) and the penalty-based boundary intersection approach (PBI). A brief introduction of them is shown in the following:
- (1)
Weighted sum (WS) approach: The optimization problem of the WS approach is defined as:
where
is a set of weight vectors, for all
,
, and subject to
,
for all
. This approach could work well if the PF is convex (for minimization problems). Nevertheless, not every Pareto-optimal vector can be obtained through this approach if the PF is non-convex.
- (2)
The Tchebycheff (TCH) approach: The optimization problem of the TCH approach is defined as:
where
is the same as above in (
2), and
is the ideal reference point, i.e., for each
,
.
As we know, there must exist a weight vector
for every Pareto-optimal point
, such that
is the optimal solution of (
3). In addition, every optimal solution of (
3) should be a Pareto-optimal solution of (
1). Consequently, we can obtain different Pareto-optimal solutions by altering the weight vectors.
- (3)
Penalty-based boundary intersection (PBI) approach: The optimization problem of the PBI approach is defined as:
In (
4),
is the weight vector as defined in (
2),
is the ideal reference point as defined in (
3) and
is a penalty parameter. From the previous study, using the same distributed weighted vectors, the PBI approach has some advantages over the TCH approach when solving an MOP whose number of objectives is more than two. However, the benefits must come with a price, which means the
as a penalty parameter requires proper adjusting.
Some of these approaches have been successfully used in solving real-world problems. For example, in [
8], Tan et al. used the weighted sum approach to design a pattern reconfigurable array antenna and got some certain results. In [
20], Ke et al. used the Tchebycheff approach to solve the multi-objective traveling salesman problem (MTSP) and multiobjective 0-1 knapsack problem (MOKP) well.
2.3. Differential Evolution’s Trial Vectors
DE is a kind of algorithm that deals with continuous optimization problems. To illustrate the basic concepts of DE, suppose that the objective function for this part is minimizing the , , and the feasible solution region is . At generation , a random initial population {} is generated from the feasible solution region, where N is the population size. In the evolution of the DE algorithm, for each generation G of the current population, DE will create a mutation vector for each individual , which is called a target vector. Five kinds of widely-used DE mutation operators are shown as follows.
- (1)
- (2)
- (3)
- (4)
- (5)
In the above five equations, , , , and are the independent individuals randomly selected from the population size and are different from i. is the first-rate individual in the current population. Additionally, the parameters F, and are called the scaling factors, and F and are usually equal; all of them control the degree of mutation.
After mutation, DE employs a crossover operator on
and
to generate a trial vector
and
, described as follows:
where
,
,
is a random number uniformly distributed from zero to one, requiring to be generated for each
j. Additionally,
is called the control parameter for crossover. The number
is an integer in
, which is also chosen randomly. Using
, the trial vector
could always be different from the target vector
. More details about DE and the DE’s operator may be found in [
22,
23,
30].
3. MOEA/D with Optimal DE Schemes
In order to solve the many-objective problems well, this paper proposes an improved MOEA/D with optimal DE schemes, named MOEA/D-oDE. Our main purposes are to explore and employ the advantages of different DE schemes. Apart from this, a combined decomposition approach is introduced and adopted in the proposed MOEA/D-oDE. Therefore, the combined decomposition method is given in
Section 3.1, and the method of optimal DE schemes is given in
Section 3.2 to introduce them, respectively. The final subsection will give the framework of the proposed algorithm, MOEA/D-oDE, and interpret it briefly.
3.1. The Combined Decomposition Method
As shown in
Section 2.2, three decomposition approaches are introduced, on account of the friendly expansibility of the weighted sum approach and the Tchebycheff approach. We combine them in advance and propose a combined decomposition method, named the weighted sum
Tchebycheff (WST) approach. Here, we refer to a concept from [
31]: for subproblem
i, let
be the current solution in the decision space; the improvement region of
can be defined as:
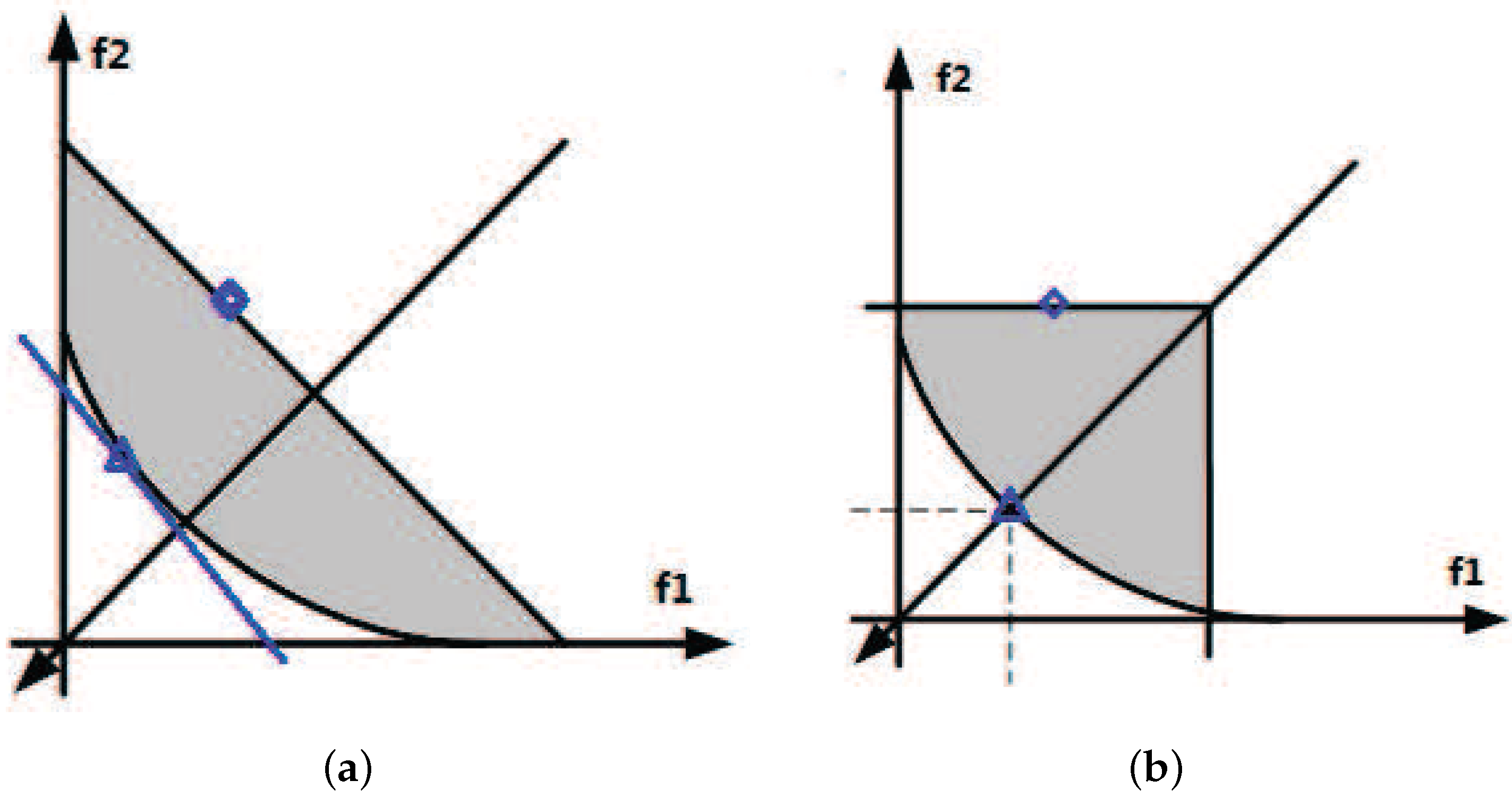
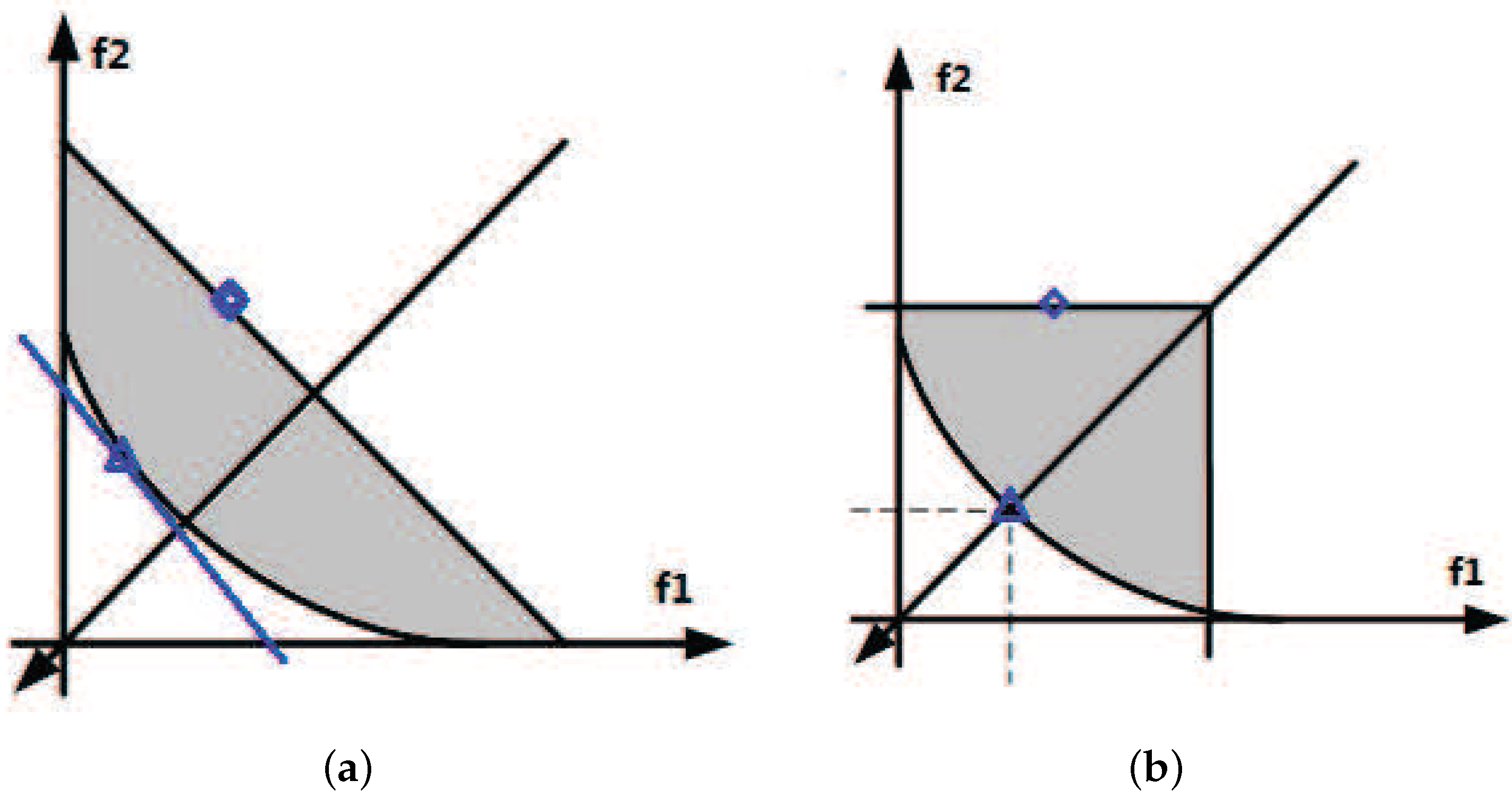
. As illustrated in
Figure 1, for two objective optimization as an example,
, the improvement regions of two commonly-used decomposition approaches, (a) the weighted sum approach and (b) weighted Tchebycheff approach, are shown. In each sub-figure, the grey area is the improvement region. The square point is the current solution of the subproblem
i with the direction vector and the triangle point being its optimal solution. Thereafter, the optimal target of the square point is to find its corresponding triangle point. As described in Equations (
2) and (
3) and from
Figure 1, we inform the reader that the weighted Tchebycheff approach barely gives priority to the salient objective, while on the contrary, the weighted sum approach attaches importance to all of the objectives. Therefore, we would like to combine these two approaches together by considering them on both a salient field and an entire field. A combined decomposition method, named the WST method, is introduced. The optimization problem of the WST approach is defined as:
where
m is the number of objectives,
is the weight vector as defined in (
2) and
is the reference points as defined in (
3). For each
,
.
Additionally, we would like to point out that the WST method combines the advantages of the weighted sum and the weighted Tchebycheff approach. It not only emphasizes one single aspect, but also pays attention to the entire direction of the objects. Our experimental results have proven its validity in the end.
3.2. The Optimal DE Schemes
As presented in
Section 2.3, there are five commonly-used DE mutation operators. In our algorithm, in order to make full use of DE operators and improve the search ability, due to the previous literature [
22,
32], and the fact that the value of
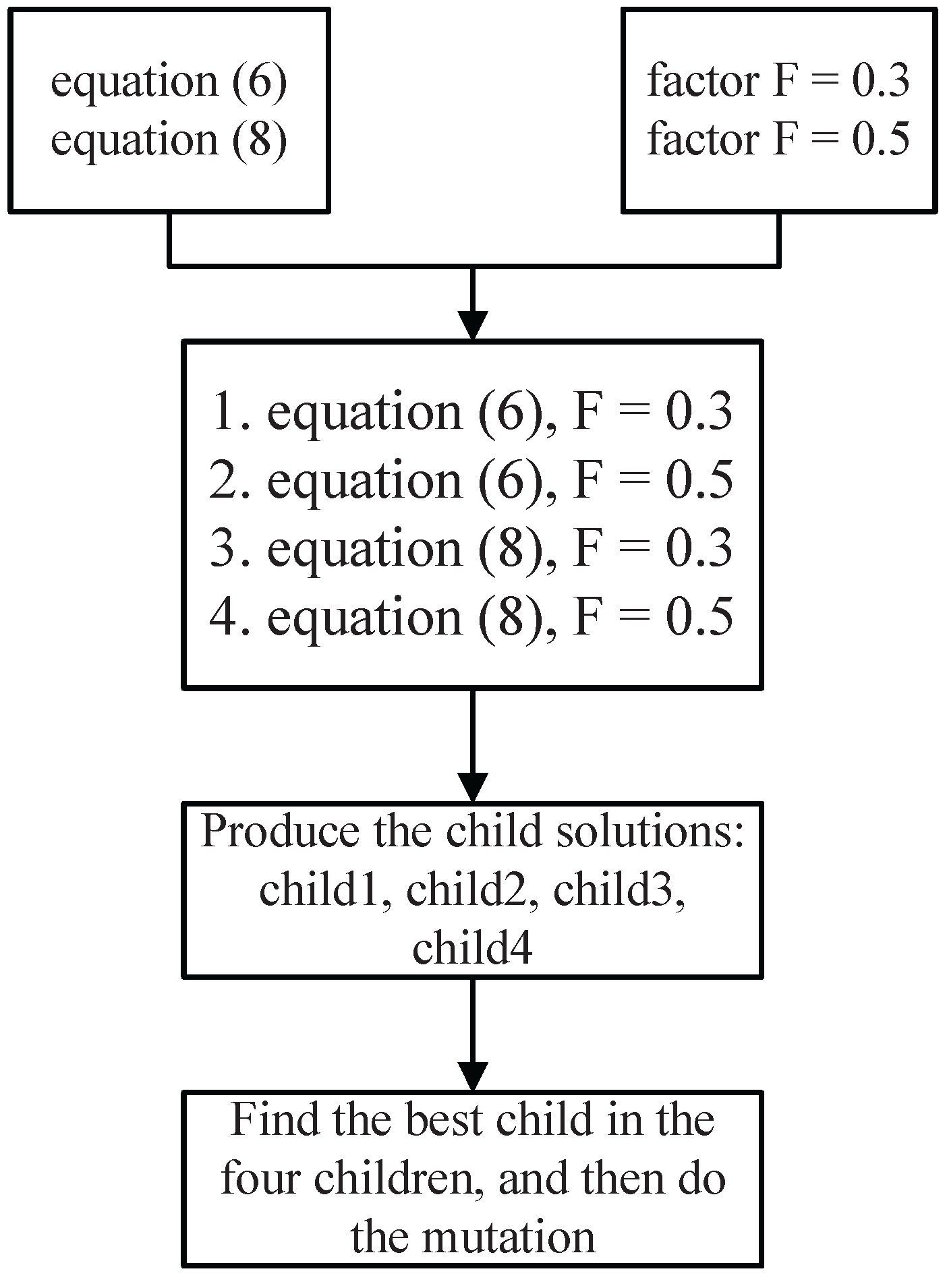
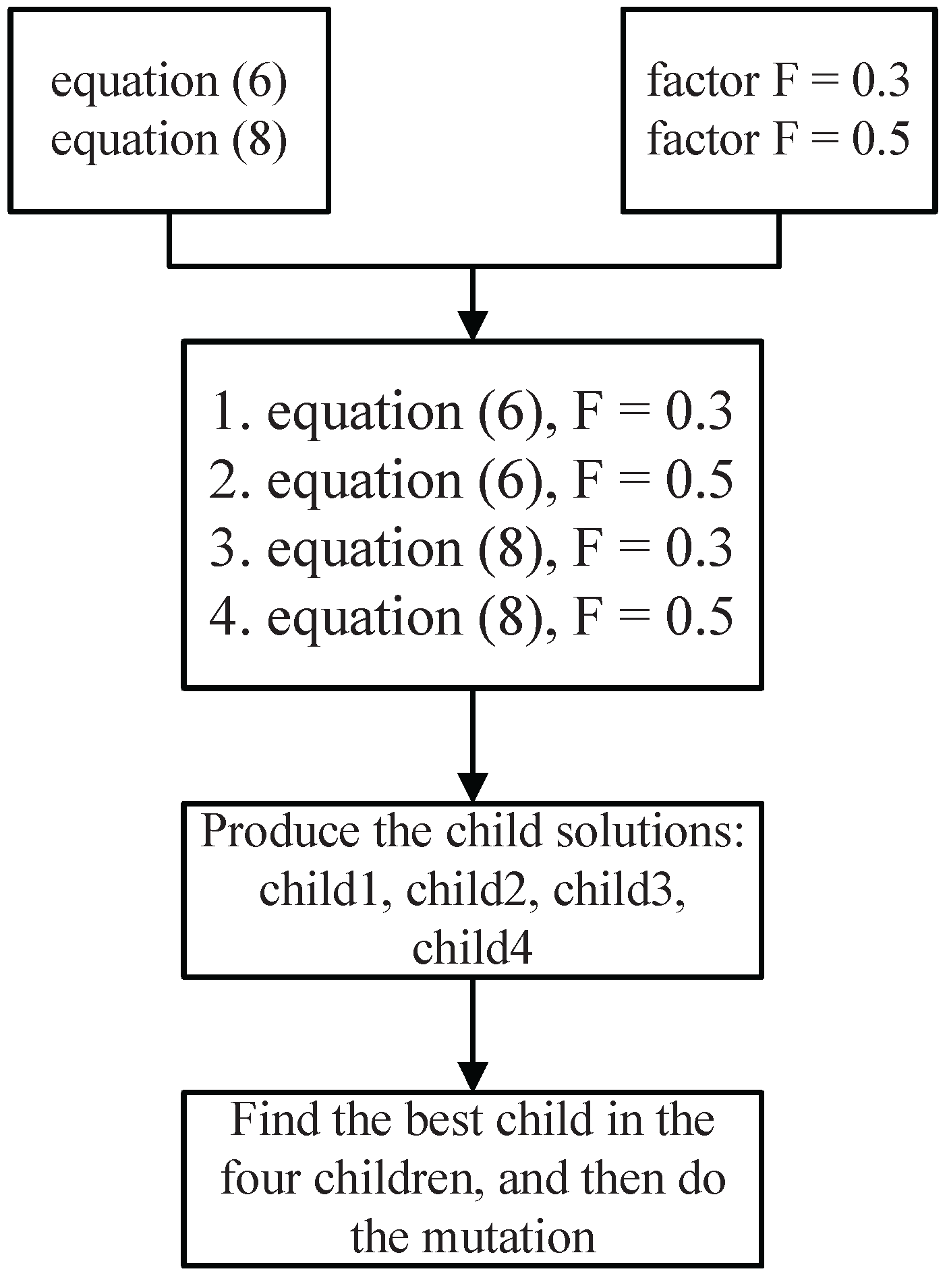
F could always be different for different problems, we decide to choose the set of Equations (
6) and (
8) and the scaling factors set of {0.3, 0.5} to generate trial vectors used in the later evolutionary computation to do our experiments. In this case, we could get four trial vectors (Operator (
6) with
, Operator (
6) with
, Operator (
8) with
and Operator (
8) with
) in a single run, and then, we would like to find and select the best child solution for the a posteriori evolution. Besides, for Formula (
8), the value of
is suggested to be a random number, which is uniformly distributed from zero to 0.5, which is beneficial for the convergence.
Figure 2 shows the flow chart of our method roughly. In the end, the experimental results have proven its effectiveness.
3.3. Framework of MOEA/D-oDE
MOEA/D-oDE decomposes a many-objective problem into a set of single objective problems and solves them in parallel. Each decomposed single objective problem is handled with optimal DE schemes. The framework of MOEA/D-oDE is based on MOEA/D. We would like to point out that there are two distinguishing points from MOEA/D: (1) we select the WST decomposition approach to decompose the many-objective optimization problems; (2) optimal DE schemes instead of single DE operator schemes are employed in our experiments.
Following the recounted methods, at each generation, MOEA/D-oDE with the WST approach maintains the following: (1) a population of N points , where is the present solution to the i-th subproblem; (2) reference ideal point , where is the best value for objective that is found up to now, and ; (3) the external population (EP), which is used to store the non-dominated solutions that have been found in the search process.
The pseudocodes of our proposed algorithm MOEA/D-oDE are shown in Algorithm 1. As shown in Algorithm 1, in the initialization procedure of MOEA/D-oDE (Lines 8–17), we dispose of the neighborhood structure
by computing the Euclidean distances between any two weight vectors and then arrange the
T closest weight vectors with respect to each weight vector firstly. Furthermore, we generate the initial population, and for
, evaluate
respectively, and mainly initialize
z by the condition:
in the end. In the update procedure of MOEA/D-oDE (Lines 19–27), if the stopping criteria are not satisfied, then go to Step 2.1 firstly, which does the reproduction by using optimal DE schemes, and then, the values that overstep the boundary should be repaired in Step 2.2. Secondly, we evaluate the function and update of
z by the new minimum evaluation. Finally, through the
, we renew the best solutions and obtain the final results.
| Algorithm 1: The pseudocode of MOEA/D-oDE. |
| 1 | Input: |
| 2 | MOP(1); |
| 3 | N: the number of the population size; |
| 4 | {}: a set of N improved uniformly-distributed weight vectors; |
| 5 |
T:the neighborhood size; |
| 6 | Output: |
| 7 | EP; |
| 8 | Step 1: Initialization |
| 9 |
Step 1.1
) Set ; |
| 10 |
Step 1.2) Compute the Euclidean distances between any two weight vectors, and then |
| 11 | dispose of the
T closest weight vectors with respect to each weight vector. For |
| 12 | each
, set , where , are the T |
| 13 | closest vectors to
; |
| 14 | Step 1.3) Generate the initial population randomly; |
| 15 |
Step 1.4) , evaluate ; |
| 16 |
Step 1.5) Initialize z: the original reference point generated by the |
| 17 | condition:
; |
| 18 | Step 2: Update |
| 19 |
Step 2.1) Reproduction: Randomly select two indexes k and l from , and generate a |
| 20 | child solution
from the parents and by using the optimal DE schemes; |
| 21 | Step 2.2) Repair: Repair by applying a problem-specific repair/improvement heuristic; |
| 22 |
Step 2.3) Function evaluation: Evaluate ; |
| 23 |
Step 2.4) Update of z: For each , if , then set ; |
| 24 |
Step 2.5) Replacement/update of solutions: For each index , if |
| 25 |
then set and ; |
| 26 |
Step 2.6) Remove from EP all of the vectors dominated by . Add to EP if no |
| 27 | vector in EP dominates
. |
| 28 | Step 3: Stopping criteria |
| 29 | If the stopping criteria is satisfied, then stop, and output EP. Otherwise, go to Step 2. |
5. Conclusions
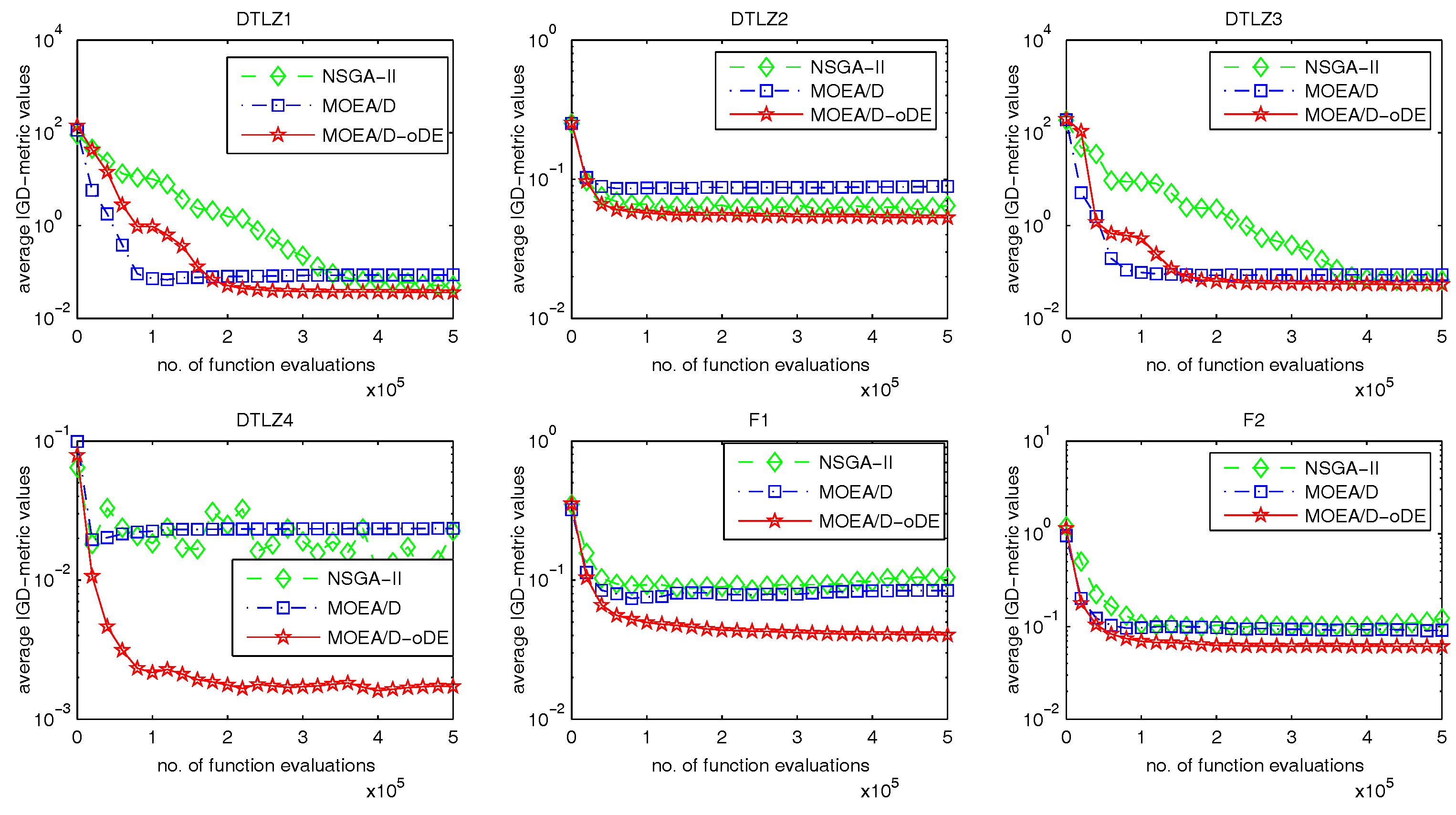
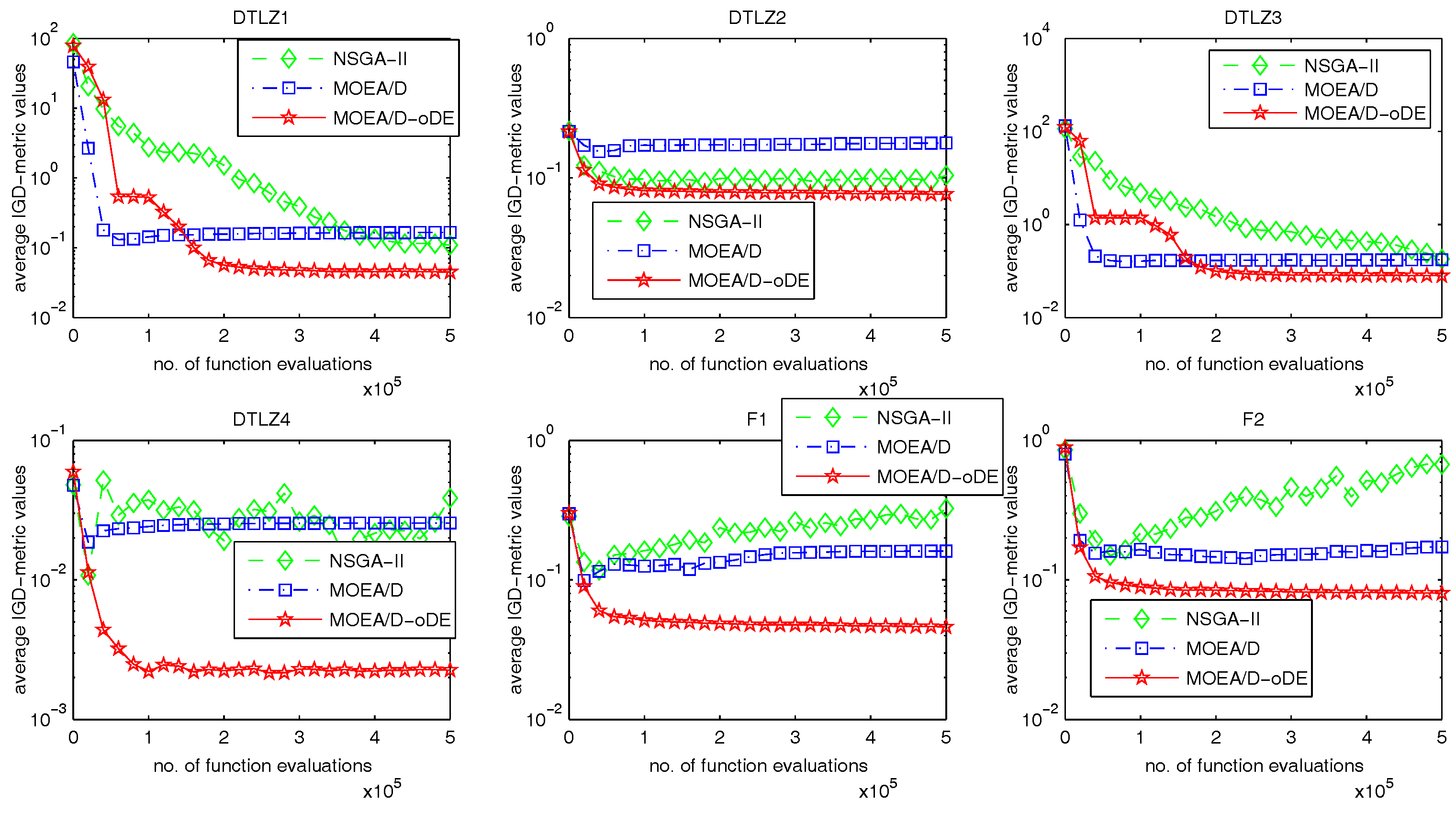
In order to solve the many-objective optimization problems well, an improved MOEA/D with optimal DE schemes, called MOEA/D-oDE, is proposed in this paper. MOEA/D-oDE under the framework of MOEA/D decomposes a many-objective problem into a set of single objective subproblems, and each subproblem is handled with evolutionary operators. All of these subproblems can be solved in parallel.
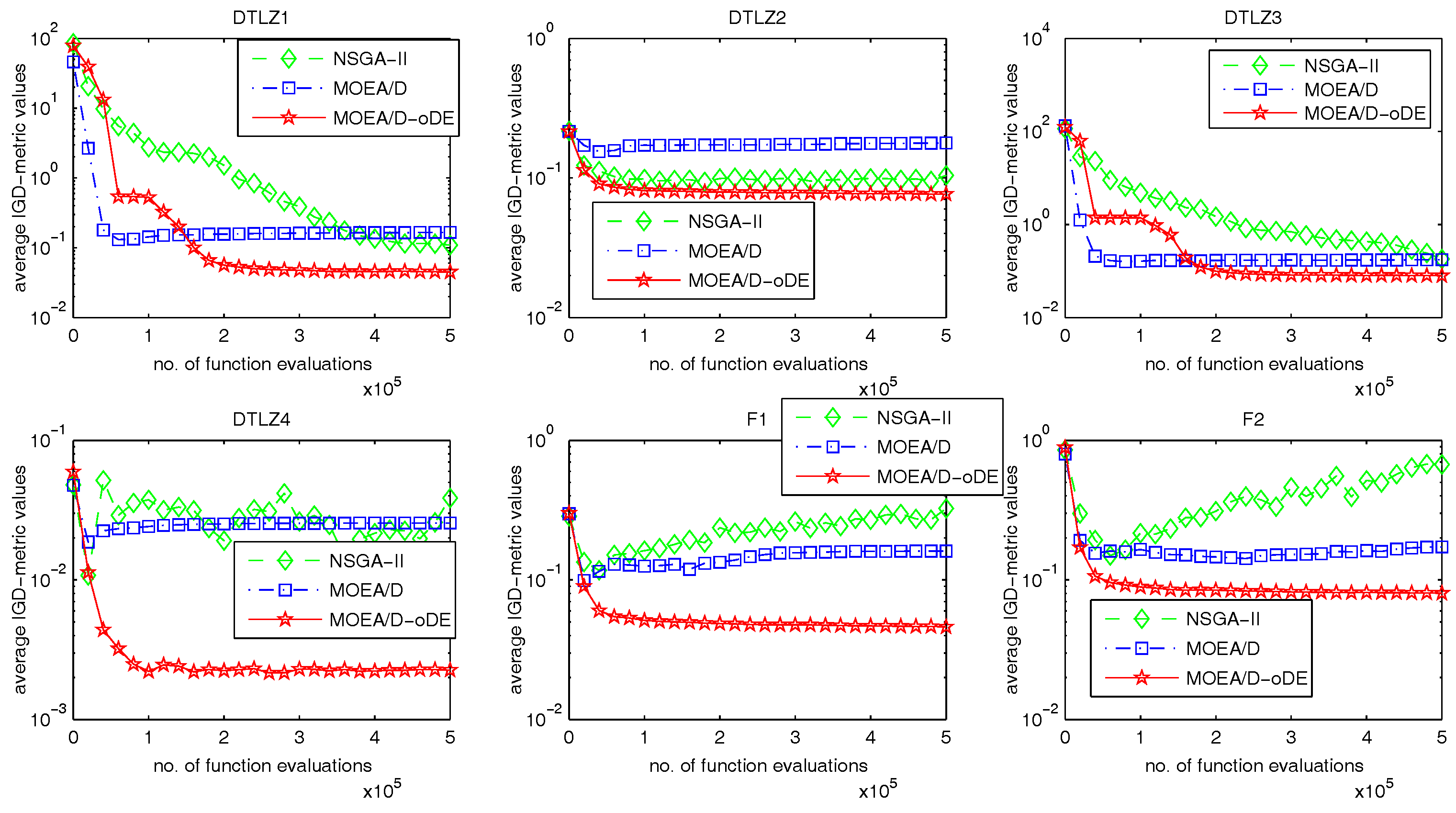
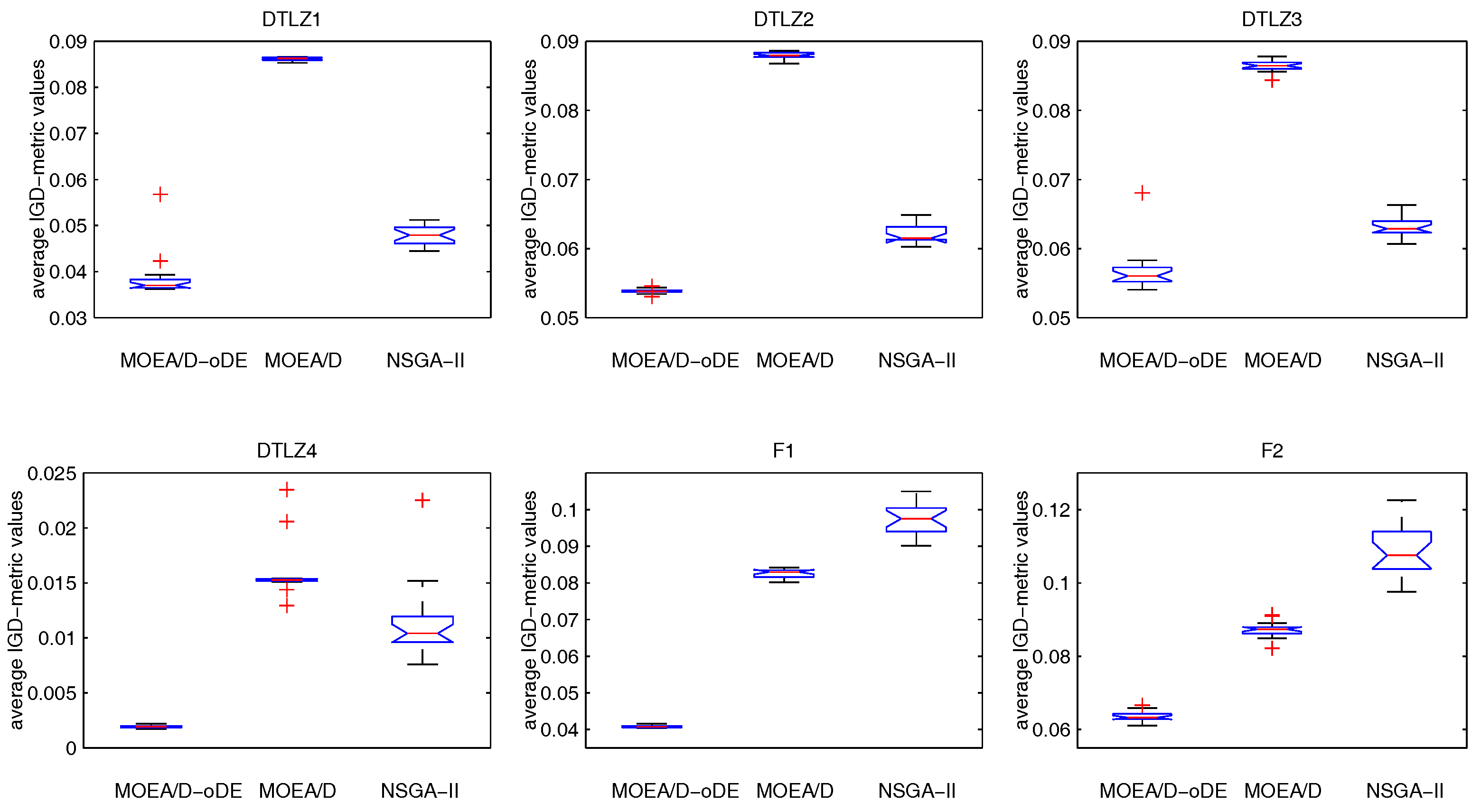
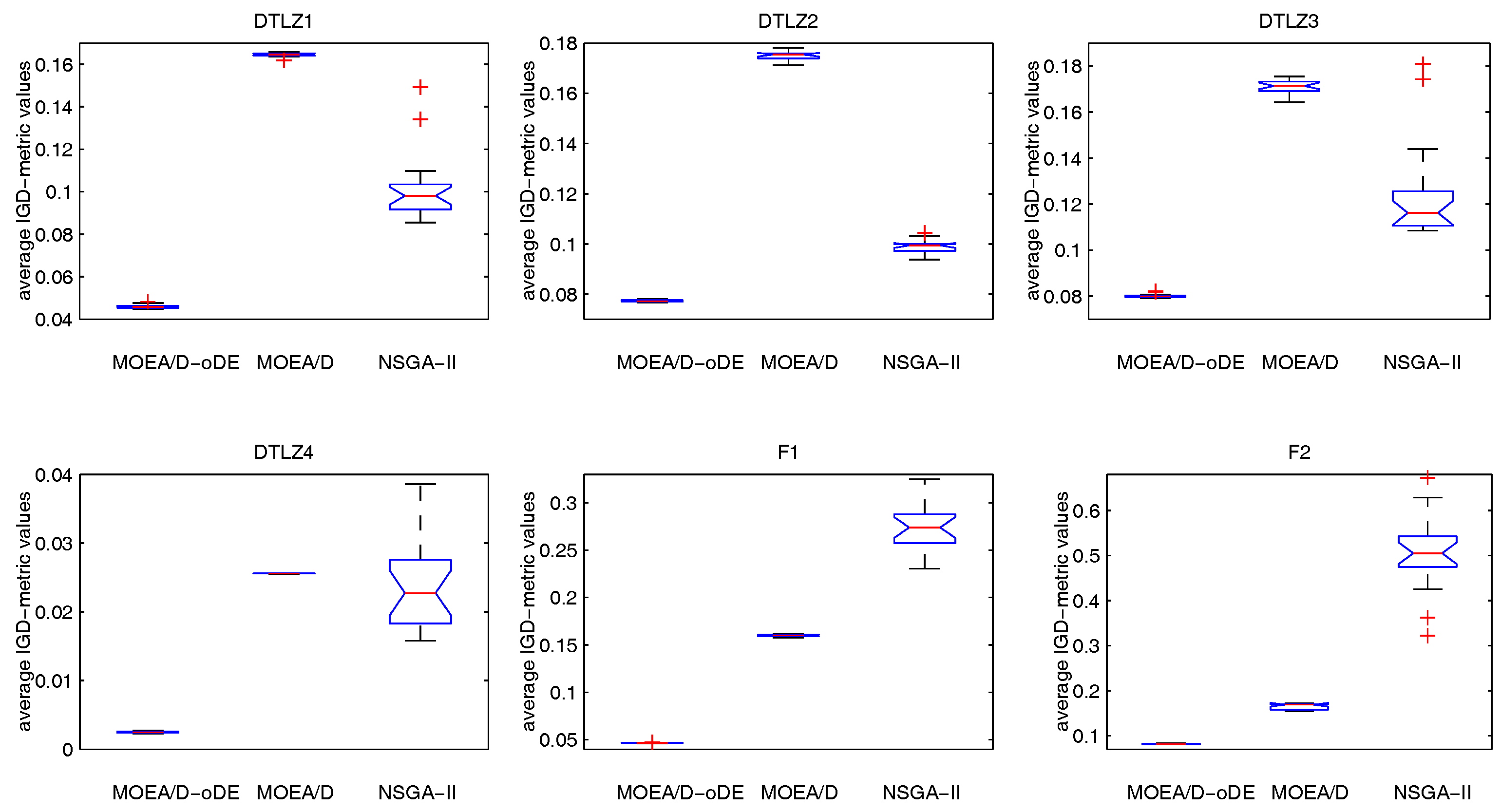
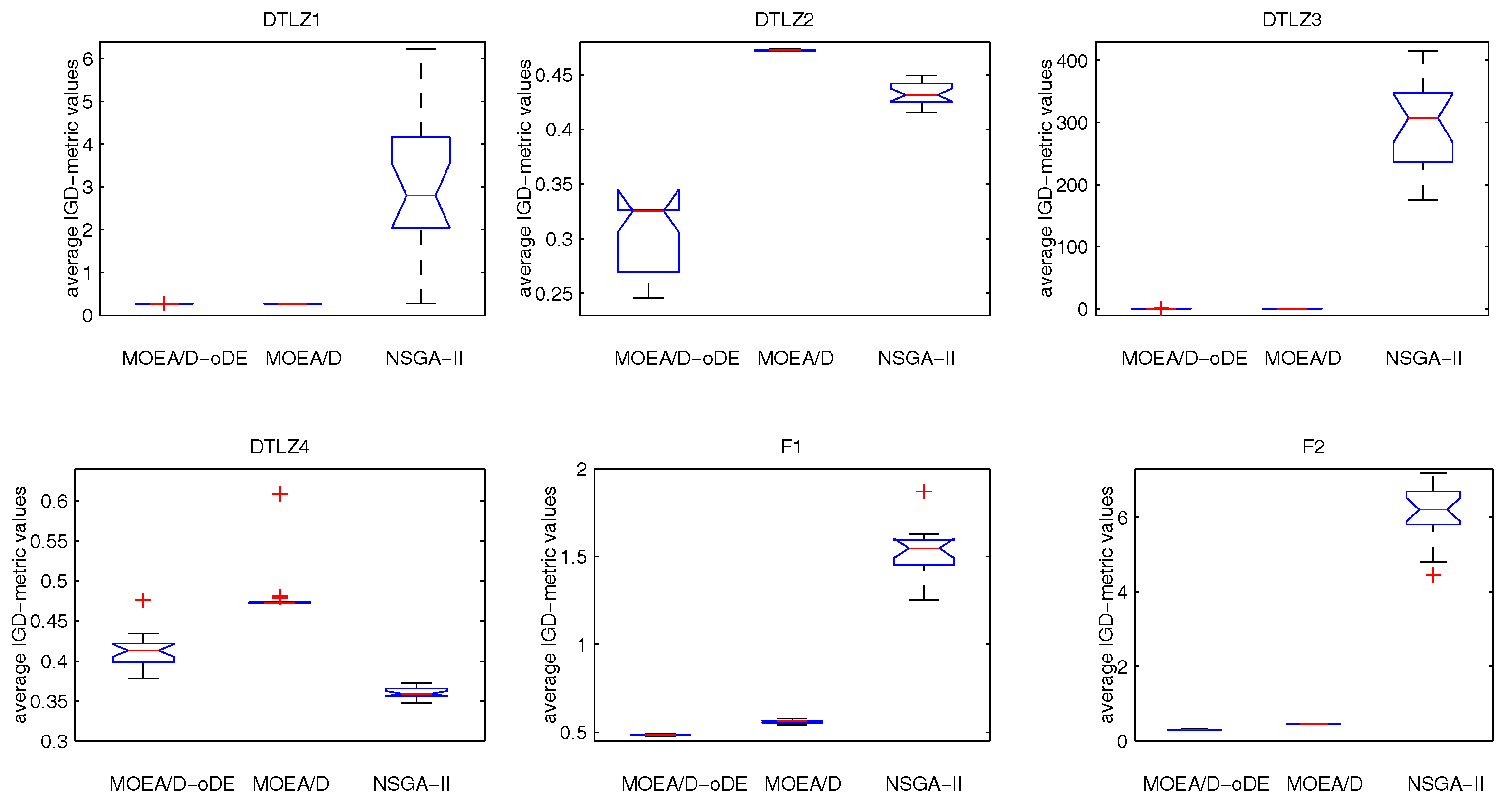
MOEA/D-oDE has two distinguishing points from MOEA/D. First, a new combined decomposition method named the WST approach is introduced and employed in MOEA/D-oDE. The WST approach combines the advantages of the weighted sum and the weighted Tchebycheff approach. It focuses not only on one single aspect, but also the entire direction of objectives. Second, we design an optimal DE scheme, which combines two DE crossover operators and two scaling factors F to generate and select the best child solution to do the a posteriori computing in each subproblem. In the experimental studies, MOEA/D with the WST method is compared with MOEA/D with the weighted sum approach and the Tchebycheff approach in DTLZ1–DTLZ4 with 4–6 objectives firstly, which reflects the effectiveness of the new decomposition method. Then, MOEA/D-oDE is tested on three sets of six continuous test instances with 4–6 objectives, and the results obtained by MOEA/D-oDE are compared with those obtained by MOEA/D and NSGA-II. Experimental results indicate that MOEA/D-oDE in solving the problems with a higher dimension of objectives outperforms MOEA/D and NSGA-II in most situations. In the end, the comparison with MOEA/DD and MOEA/D-AWA on DTLZ1–DTLZ4 with four objectives is made to reflect the performance of MOEA/D-oDE from another point of view. Additionally, several sets of parameter sensitivity experiments were carried out. In a word, to some extent, MOEA/D-oDE can solve the many-objective optimization problems well.
In the future, we plan to research how to make the DE’s trial vectors obtain the best child solutions dynamically. Additionally, the multi-objective discrete problems, such as the multi-objective TSP (travelling salesman problem) problems, are also our research targets. It is also worthwhile to research new methods to solve the many-objective optimization problems.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}